C#으로 ACID 데이터베이스 엔진 Typhon을 만드는 이유와, 현대 C#이 GC, 메모리 배치, JIT, SIMD, unsafe 코드로 고성능 시스템 프로그래밍을 어떻게 가능하게 하는지 설명합니다.
2026년 3월 28일 - 읽는 데 16분
태그: csharpdotnetdatabaseperformancetyphon
💡Typhon은 .NET으로 작성된 임베디드형 영속 ACID 데이터베이스 엔진으로, 게임 서버와 실시간 시뮬레이션의 모국어인 엔티티, 컴포넌트, 시스템을 이해합니다.
캐시 라인을 고려한 저장소, zero-copy 접근, 설정 가능한 내구성을 바탕으로, 서브마이크로초 지연 시간에서 MVCC 스냅샷 격리를 포함한 완전한 트랜잭션 안전성을 제공합니다.
시리즈: 게임 엔진처럼 사고하는 데이터베이스
- 왜 나는 C#으로 데이터베이스 엔진을 만들고 있는가(이 글)
- 데이터베이스가 잊어버린 데이터에 대해 게임 엔진이 알고 있는 것
- 관리형 언어에서의 마이크로초 지연 시간 (곧 공개)
내가 C#으로 ACID 데이터베이스 엔진을 만들고 있다고 말하면, 사람들의 첫 반응은 언제나 같다. “그런데 GC 일시 정지는 어떻게 하려고?”
충분히 타당한 질문이다. .NET으로 고성능 데이터베이스 엔진을 만드는 사람은 없다. 이런 부류의 소프트웨어에는 C, C++, Rust가 필요하다는 가정, 관리형 언어는 본질적으로 마이크로초 지연 시간 클럽에 들어갈 자격이 없다는 가정이 깔려 있다.
30년 동안 실시간 3D 엔진과 시스템 소프트웨어를 만들어 온 끝에, 나는 그래도 C#을 선택했다. 프로젝트 이름은 Typhon이다. 목표는 1–2 마이크로초 트랜잭션 커밋을 겨냥한 임베디드 ACID 데이터베이스 엔진이다. 그리고 그 선택의 이유는 C#이 무엇을 할 수 있는지에 대한 당신의 생각을 바꿔 놓을지도 모른다.
내 주장을 하기 전에, 왜 여기서 C#을 선택하면 안 되는지에 대한 모든 논거를 솔직하게 정리해 보겠다. 이것들은 허수아비 논증이 아니라 실제 우려다.
GC는 비결정적이다. 원할 때마다 모든 스레드를 멈출 수 있다. 마이크로초 지연 시간을 약속하는 데이터베이스 엔진에서 10ms Gen2 수집은 치명적이다 — 이는 지연 시간 예산의 10,000배다.
메모리 배치를 제어할 수 없다. 관리 힙이 객체의 위치를 결정한다. GC는 압축 중에 객체를 이리저리 옮길 수 있다. B+Tree 노드가 캐시 라인 경계에 놓이도록 보장할 수도 없고, 페이지 캐시 버퍼가 트랜잭션 도중 재배치되지 않는다고 보장할 수도 없다.
JIT 워밍업은 실제 문제다. 어떤 메서드든 첫 호출은 컴파일 비용을 치른다. 데이터베이스 엔진이라면 시작 직후 첫 트랜잭션이 정상 상태보다 100배 느려서는 안 된다.
가상 디스패치와 경계 검사에는 오버헤드가 있다. 모든 배열 접근에는 숨겨진 경계 검사가 있다. 모든 인터페이스 호출은 vtable을 거친다. 수백만 개의 엔티티를 처리하는 핫 루프에서는 이런 나노초 단위 비용이 누적된다.
이것들은 모두 정당한 문제다. 그렇지 않다고 가장하지는 않겠다. 하지만 대부분이 놓치는 것이 있다: 현대 C#은 이 모든 문제 각각에 대한 해답을 갖고 있다.
대부분의 개발자가 아는 C# — 클래스, 가비지 컬렉션, LINQ — 은 언어의 절반에 불과하다. .NET 런타임 팀이 지난 10년 동안 조용히 구축해 온 또 다른 측면이 있고, 그것은 당신이 예상하는 모습과 전혀 다르다.
**```plaintext unsafe
는 C 수준의 제어를 준다.** 로우 포인터, 포인터 산술,
```plaintext
stackalloc
를 이용한 스택 버퍼,
fixed크기 배열 — JIT는 C에서 얻는 것과 동일한
mov/
cmp/
jne명령어를 생성한다. “C에 가깝다”가 아니다. 같은 명령어다.
**```plaintext GCHandle.Alloc(Pinned)
는 중요한 곳에서는 GC를 무의미하게 만든다.** 바이트 배열을 고정하면 GC가 절대 움직이지 못하게 할 수 있다. Typhon의 전체 페이지 캐시는 pinned memory다 — GC는 건드리지도, 스캔하지도, 이동시키지도 않는다. 고정 주소에 있는 그저 로우 바이트일 뿐이며, C의
```plaintext
malloc
와 정확히 같다.
plaintext ref struct 는 핫 패스에서 힙 할당을 제거한다.
ref struct는 절대로 힙으로 탈출할 수 없다. 스택에 살고, 스코프가 끝나면 사라지며, GC는 그것이 존재했는지도 모른다. Typhon의 엔티티 접근자(
EntityRef)는 96바이트짜리
ref struct다 — 할당 0, GC 압력 0.
제약된 제네릭은 진정한 모노모피제이션을 제공한다.
where T : unmanaged를 쓰면, JIT는 각 타입 매개변수마다 별도의 네이티브 코드 경로를 생성한다.
sizeof(T)는 상수가 된다. 죽은 분기는 제거된다. Rust가 제네릭에서 얻는 것과 같은 최적화다 — 런타임 디스패치가 아니라 컴파일 타임 특수화다.
하드웨어 인트린식은 일급 시민이다. plaintext System.Runtime.Intrinsics 는
Vector256,
Sse42.Crc32,
BitOperations.TrailingZeroCount를 제공한다 — C/C++에서 사용 가능한 것과 같은 SIMD 명령어를, 같은 성능으로, 그리고 런타임 기능 감지를 통해 우아하게 폴백할 수 있게 해 준다.
**```plaintext [StructLayout(Explicit)]
는 정확한 메모리 배치를 제공한다.** 필드 오프셋, 패딩, 크기 — 모든 바이트를 당신이 제어한다. 캐시 라인 정렬, false sharing 방지, 비트 패킹 — 전부 가능하다.
이것은 “C#이 C가 되려고 애쓰는 것”이 아니다. 최고 수준의 관리형 생태계 위에 진짜 시스템 프로그래밍 계층을 제공하는 C#이다.
## Typhon은 실제로 어떤 모습인가
[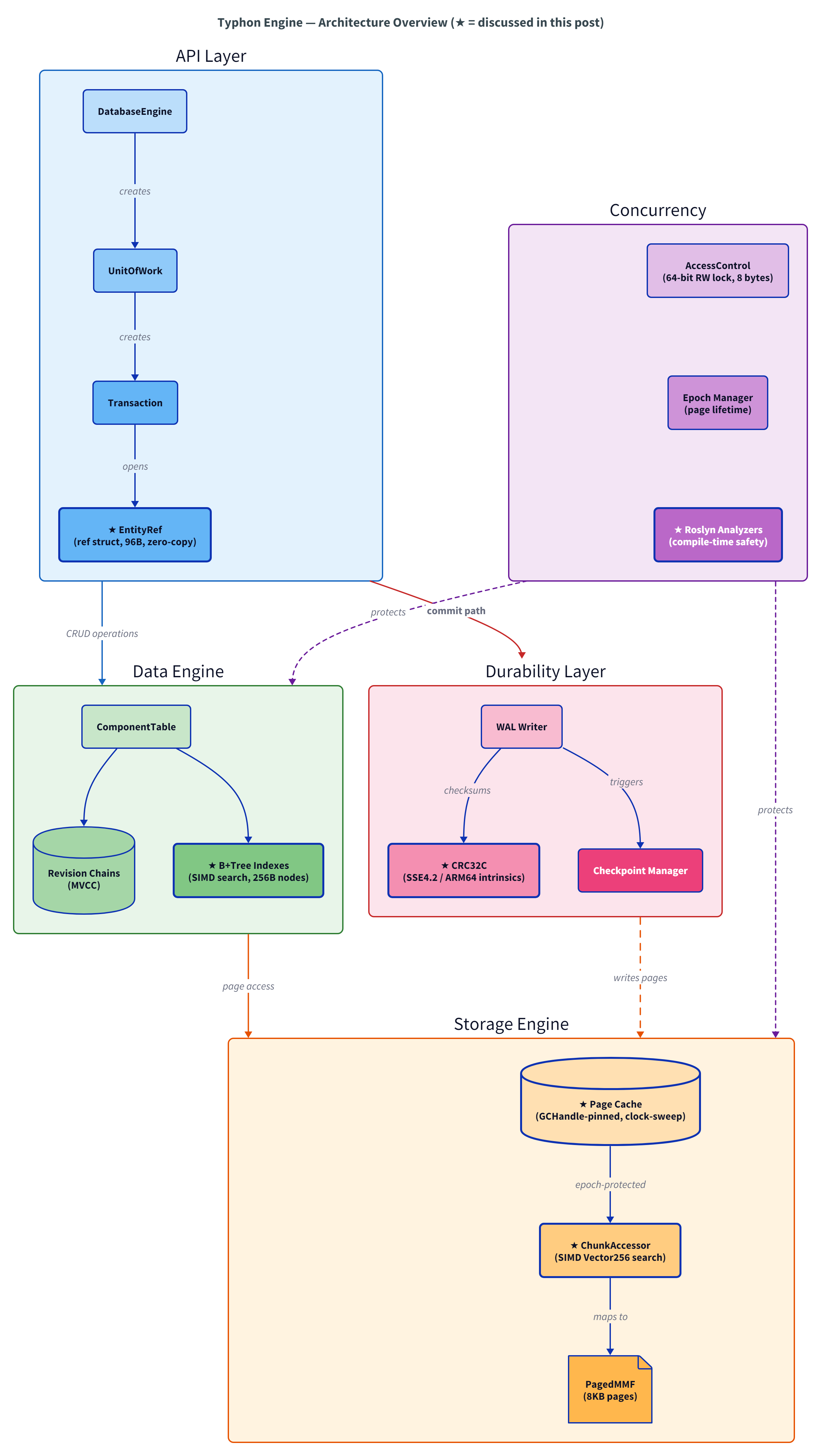](https://nockawa.github.io/assets/posts/typhon-blog-architecture.svg)
이론은 좋다. 이제 실제 코드를 보자.
### 하드웨어 가속 WAL 체크섬
Write-Ahead Log에 기록되는 모든 페이지에는 CRC32C 체크섬이 필요하다. C#에서 이것이 어떻게 보이는지 보자 — CPU 명령어를 이름으로 직접 호출한다:
private static uint ComputePartial(uint crc, ReadOnlySpan<byte> data) { if (Sse42.X64.IsSupported) return ComputeSse42X64(crc, data); if (Sse42.IsSupported) return ComputeSse42X32(crc, data); if (ArmCrc32.Arm64.IsSupported) return ComputeArm64(crc, data); return ComputeSoftware(crc, data); }
private static uint ComputeSse42X64(uint crc, ReadOnlySpan<byte> data) { ulong crc64 = crc; ref byte ptr = ref MemoryMarshal.GetReference(data); int offset = 0; int aligned = data.Length & ~7;
while (offset < aligned)
{
crc64 = Sse42.X64.Crc32(crc64, Unsafe.ReadUnaligned<ulong>(ref Unsafe.Add(ref ptr, offset)));
offset += 8;
}
uint crc32 = (uint)crc64;
while (offset < data.Length)
{
crc32 = Sse42.Crc32(crc32, Unsafe.Add(ref ptr, offset));
offset++;
}
return crc32;
}
```plaintext
Sse42.X64.Crc32()
는 단일 x86
crc32명령어로 컴파일된다. 런타임이 CPU 기능을 감지하고, JIT가 죽은 분기를 제거하며, 실제로 실행되는 것은 C 프로그래머가 작성할 코드와 동일하다 — 다만 SSE4.2가 없는 플랫폼에서는 자동 폴백이 된다. 결과: 8 KB 페이지당 약 1.3 µs.
이것은 Typhon 페이지 캐시의 핫 패스다 — 16슬롯 캐시가 세 단계 중 하나에서 당신의 데이터를 찾는다:
// === ULTRA FAST PATH: MRU check ===
var mru = _mruSlot;
if (_pageIndices[mru] == pageIndex)
{
var headerOffset = pageIndex == 0 ? _rootHeaderOffset : _otherHeaderOffset;
return (byte*)_baseAddresses[mru] + headerOffset + offset * _stride;
}
// === FAST PATH: SIMD search through all 16 cached slots ===
fixed (int* indices = _pageIndices)
{
var target = Vector256.Create(pageIndex);
var v0 = Vector256.Load(indices);
var mask0 = Vector256.Equals(v0, target).ExtractMostSignificantBits();
if (mask0 != 0)
{
var slot = BitOperations.TrailingZeroCount(mask0);
return GetFromSlot(slot, pageIndex, offset, dirty);
}
var v1 = Vector256.Load(indices + 8);
var mask1 = Vector256.Equals(v1, target).ExtractMostSignificantBits();
if (mask1 != 0)
{
var slot = 8 + BitOperations.TrailingZeroCount(mask1);
return GetFromSlot(slot, pageIndex, offset, dirty);
}
}
_pageIndices배열은
fixed int[16]이다 — 64바이트, 캐시 라인 하나, SIMD에 맞게 패킹되어 있다.
Vector256.Equals한 번이면 8개의 페이지 인덱스를 단일 명령어로 비교한다. MRU 초고속 경로는 흔한 경우(같은 페이지에 대한 반복 접근)를 단일 분기로 처리한다 — 분기 예측기에 친화적이고, 비용은 거의 0에 가깝다.
EntityRef는
ref struct다 — 스택 전용, 96바이트, 컴포넌트 위치를 캐시하는 인라인 고정 배열을 가진다:
public unsafe ref struct EntityRef
{
internal readonly EntityId _id;
internal readonly ArchetypeMetadata _archetype;
internal readonly ArchetypeEngineState _engineState;
internal readonly Transaction _tx;
internal ushort _enabledBits;
internal readonly bool _writable;
private fixed int _locations[16]; // inline component chunk IDs
[MethodImpl(MethodImplOptions.AggressiveInlining)]
public ref readonly T Read<T>(Comp<T> comp) where T : unmanaged
{
byte slot = _archetype.GetSlot(comp._componentTypeId);
int chunkId = _locations[slot];
var table = _engineState.SlotToComponentTable[slot];
return ref _tx.ReadEcsComponentData<T>(table, chunkId);
}
}
이
Read<T>호출은 메서드 호출 → 슬롯 조회 → 청크 ID → 페이지 캐시 → 포인터 산술 → pinned memory 페이지를 직접 가리키는
ref readonly T까지 이어진다. 복사 0. 할당 0. GC 개입 0.
where T : unmanaged제약 덕분에 JIT는 정확한 배치를 알고 있다 — 포인터 산술로 컴파일될 뿐, 그 이상은 없다.
해시 함수조차 JIT를 활용한다.
sizeof(TKey)는 제약된 제네릭에서는 컴파일 타임 상수이므로, 죽은 분기가 사라진다:
[MethodImpl(MethodImplOptions.AggressiveInlining)]
internal static uint ComputeHash<TKey>(TKey key) where TKey : unmanaged
{
if (sizeof(TKey) == 4) return FastHash32(Unsafe.As<TKey, uint>(ref key));
if (sizeof(TKey) == 8) return XxHash32_8Bytes(Unsafe.As<TKey, long>(ref key));
return XxHash32_Bytes((byte*)Unsafe.AsPointer(ref key), sizeof(TKey));
}
ComputeHash<int>(42)를 호출하면, JIT는 4바이트 경로만 생성한다. 나머지 두 분기는 완전히 제거된다. 이것은 런타임 디스패치가 아니라 진짜 모노모피제이션이다.
데이터베이스 엔진은 핫 패스만으로 이루어지지 않는다. 코어 엔진 주변에는 인프라라는 큰 외곽이 있다: 설정 관리, 구조화된 로깅, 텔레메트리, 의존성 주입, 테스트, 벤치마킹.
C나 Rust에서는 이 중 많은 부분을 직접 만들거나, 품질이 제각각인 crate나 라이브러리를 이어 붙여야 한다. .NET에서는 이것들이 프로덕션급이며 무료다: 관측 가능성을 위한
ILogger와 OpenTelemetry, 엄격한 마이크로벤치마크를 위한 BenchmarkDotNet, 테스트를 위한 NUnit, 설정을 위한
IConfiguration. 모두 문서화가 잘 되어 있고, 서로 잘 맞물리며, Microsoft 또는 실전에서 검증된 OSS 커뮤니티가 유지한다.
혼자서 데이터베이스 엔진을 만드는 개발자에게 이것은 진짜 경쟁 우위다. 나는 로깅 프레임워크를 다시 만드는 데 시간을 쓰는 대신, 동시성 프리미티브와 페이지 캐시 축출에 시간을 쓴다.
실시간 3D 엔진을 만들며 배운 통찰은 이것이다: 데이터베이스 엔진의 병목은 명령어 처리량이 아니라 메모리 접근 패턴이다.
Ryzen 7950X에서 DRAM 캐시 미스 하나의 비용은 61–73 나노초다. 이는 데이터를 기다리며 아무것도 하지 않는 약 250 CPU 사이클이다. L1에 적중하는 CAS 연산은 1.4 나노초다. 비율은 50:1이다.
당신의 데이터 구조가 캐시 미스를 유발한다면, 언어에서 제공하는 어떤 “zero-cost abstraction”도 당신을 구해 주지 못한다. 반대로 데이터 배치가 캐시 친화적이라면 — 연속적이고, 정렬되어 있고, 접근 패턴이 예측 가능하다면 — 언어는 거의 중요하지 않다. C#의
unsafe는 핫 패스에서 C와 동일한 머신 코드를 생성한다. JIT는 그 정도로 훌륭하다.
중요한 것은 다음이다:
어떤 언어로 쓰느냐보다 어떤 메모리 배치를 설계하느냐가 훨씬 더 중요하다.
모든 측정은 Ryzen 9 7950X, .NET 10.0, BenchmarkDotNet, 릴리스 구성에서 수행했다.
| 연산 | 지연 시간 | 처리량 |
|---|---|---|
| CRUD 라이프사이클 MVCC (생성, 읽기, 갱신, 삭제, 커밋) | 1.2 µs | 830K ops/sec |
| 90회 읽기/10회 갱신 워크로드 (트랜잭션당 100회 연산, MVCC) | 22 µs | ~4.5M entity-ops/sec |
| B+Tree 조회 (적중) | 267 ns | 3.7M ops/sec |
| B+Tree 순차 스캔 (키당) | 2.1 ns | 479M keys/sec |
| 경합 없는 락 획득 | 7.8 ns | 128M ops/sec |
| 페이지 캐시 적중 | 5.3 ns | — |
맥락을 보자: Zen4에서 경합 없는 CAS는 1.4 ns가 든다. DRAM 왕복은 61–73 ns가 든다. Typhon의 락 획득(7.8 ns)은 대략 CAS 5회 수준이다 — 대기자 추적과 공유/배타 중재까지 처리한다는 점을 생각하면 촘촘한 수치다. 267 ns의 B+Tree 조회는 6–7회의 메모리 접근을 암시하며, 이는 L2/L3 캐시를 통과하는 트리 순회와 일치한다.
이 수치들은 초기 알파 단계의 수치다. 개선할 여지는 있다. 하지만 핵심 논지를 검증해 준다: 병목은 C#이 아니다.
비용 없는 선택은 없다. 같은 길을 고려하는 사람에게 나는 이렇게 말할 것이다.
메모리 안전성은 당신 책임이다.
unsafe블록 안에서는 메모리를 손상시키고, 잘못된 포인터를 역참조하고, 버퍼를 넘치게 만들 수 있다 — 컴파일러는 당신을 구해 주지 않는다. plaintext Span<T> 는 약간 더 느리지만 완전히 안전한 대안이다.
GC는 지금까지 문제가 아니었지만 — 문제가 될 수는 있다. 페이지 캐시를 pinned memory로 만들고 핫 패스에서
ref struct를 사용함으로써, Gen2 수집은 드물고 저렴하다. 하지만 이것이 보장된다고 가장하지는 않겠다. 트랜잭션 사이에 관리 코드에서 할당을 많이 하는 워크로드라면 여전히 일시 정지를 볼 수 있다. 해답은 규율이다: 핫 패스에서는 할당하지 말라. 언어는 그것을 가능하게 해 주지만, 강제하지는 않는다.
“하지만 Rust라면 컴파일 타임 안전성을 주잖아.” 맞다 — borrow checker는
unsafeC#이 잡지 못하는 소유권과 생애주기 버그를 잡아낸다. 하지만 C#에는 Rust에 없는 묘수가 있다: Roslyn analyzers. 나는 도메인 특화 안전 규칙을 컴파일러 오류로 강제하는 커스텀 analyzer 모음(TYPHON001–007)을 작성했다:
[NoCopy]
속성 + analyzer:
```plaintext
ChunkAccessor
같은 성능 민감 struct는 값으로 전달될 수 없다 —
ref를 빼먹으면 컴파일러 오류가 난다. 이것은 Rust의 borrow checker가 이동 의미론에 대해 주는 보장과 같은 종류지만, 실제로 중요한 타입들에 한정되어 있다.
ChunkAccessor나
Transaction을 생성하고 dispose하지 않으면, 그것은 컴파일러 오류다 — 런타임 누수가 아니다. analyzer는 대입, 반환,
ref/
out매개변수를 통한 소유권 이전을 추적하며, 메서드의
[return: TransfersOwnership]는 analyzer가 그에 맞게 동작하도록 소유권 이전을 표현하는 데 도움을 준다.
Dispose()메서드에서 그것을 빠뜨리거나, 그것을 건너뛰는 조기 반환이 있다면 — 컴파일러 오류다.
// 이것은 Typhon에서 컴파일 타임 오류다 — TYPHON001
void Process(ChunkAccessor accessor) { ... } // ✗ Error: must be passed by ref
void Process(ref ChunkAccessor accessor) { ... } // ✓ OK
C#에서 Rust의 안전성을 공짜로 얻을 수는 없다. 하지만 당신에게 필요한 정확한 부분집합을, 도메인에 맞춰진 컴파일러 오류로 구축할 수 있다. 그리고 Rust의 borrow checker와 달리, 이런 규칙들은 진단 메시지에 도메인 맥락을 담을 수 있다: “value moved here”보다 “페이지 캐시 데드락을 유발함”이 더 행동 가능하다.
주변 인프라(로깅, DI, 설정, 테스트)를 위한 Rust 생태계도 .NET만큼 성숙하지 않으며, 혼자 개발하는 내게는 개발 속도가 중요하다. 나는 더 빨리 출하할 수 있는 언어를 선택했다.
JIT 워밍업은 실제지만 관리 가능하다. 콜드 스타트 직후 처음 몇 개 트랜잭션은 더 느리다. 임베디드 엔진(별도의 서버 프로세스가 없음)에서는 이것이 허용 가능하다 — 호스트 애플리케이션은 보통 자체 워밍업을 갖고 있기 때문이다. 서버형 데이터베이스라면 tiered compilation이나 AOT를 원할 것이다.
다음 글에서는 왜 ACID 데이터베이스 엔진이 저장소 아키텍처를 게임 엔진에서, 구체적으로는 Entity-Component-System 패턴에서 빌려오는지 설명할 것이다. 게임 엔진과 데이터베이스는 근본적으로 같은 문제를 해결하고 있다: 극단적인 성능 제약 아래에서 구조화된 데이터를 관리하는 것. 단지 완전히 다른 해법으로 진화했을 뿐이다.
계속 따라오고 싶다면, 가장 좋은 방법은 리포지토리에 star를 누르거나 RSS 피드를 구독하는 것이다.
Loïc Baumann 작성
테마 portfolYOU