SpacetimeDB 전송 처리량 벤치마크와 경쟁 제품에 대한 비판에 대응하며, 방법론과 상세 수치, 그리고 주요 주장들을 검토합니다.
3월에 저희는 SpacetimeDB 2.0을 발표하면서, SpacetimeDB가 초당 100,000건이 넘는 종단 간 전송 트랜잭션을 처리할 수 있다고 주장한 벤치마크를 함께 공개했습니다. 그 영상과 소셜 미디어 게시물들은 큰 주목을 받았고, 경우에 따라서는 오해를 부를 수 있는 벤치마킹이라는 비판도 받았습니다. 특히 저희 테스트에서 좋은 성능을 내지 못한 경쟁사들로부터 그런 비판이 나왔습니다.
최근 저희는 SpacetimeDB의 몇 가지문제를 발견하고 수정했습니다. 안타깝게도 이 문제들은 당시 저희가 공개한 벤치마크 수치를 실제로 오해의 소지가 있게 만들었고, 이에 대해 사과드립니다. 다만 문제는 여러분이 예상하는 방식이 아니었습니다. 문제는 벤치마크가 아니라 SpacetimeDB 자체에 있었습니다. 당시의 SpacetimeDB는 자기 본래의 잠재력을 충분히 발휘하지 못하고 있었습니다.
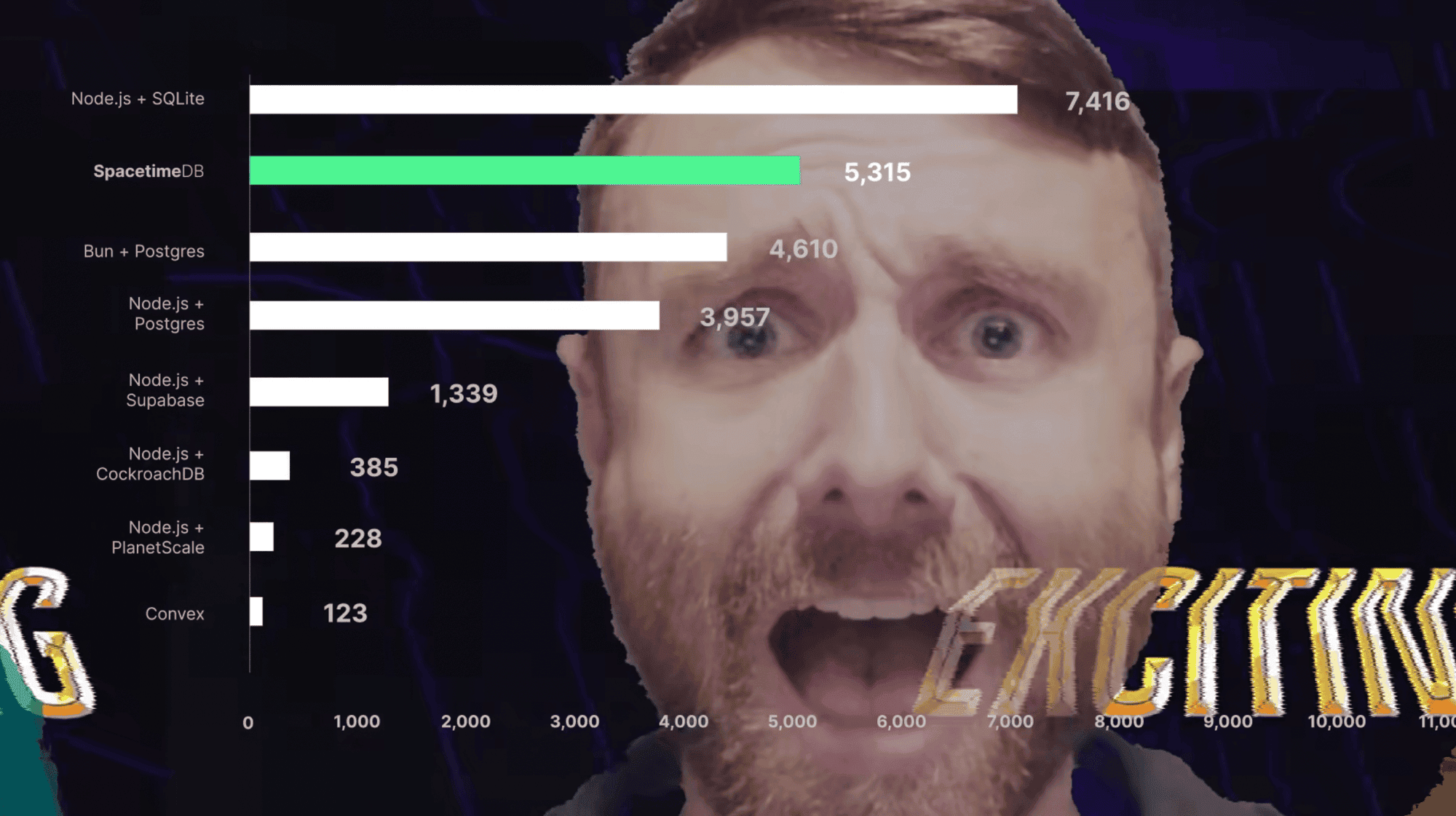
특히 V8 스레딩 모델을 개선한 이후, SpacetimeDB는 이제 TypeScript 벤치마크에서 초당 303,920 ± 4,712건의 트랜잭션을 처리할 수 있습니다. 이는 원래 벤치마크 수치인 초당 약 100,000건과 비교해 거의 200%의 향상 입니다. 저희가 주로 V8 성능에 집중했기 때문에, 이제는 TypeScript가 Rust보다도 더 빠르며, Rust는 같은 벤치마크에서 단지 265,541 ± 940건의 트랜잭션만 처리합니다.
물론 이에 맞춰 홈페이지의 그래프도 업데이트했습니다!
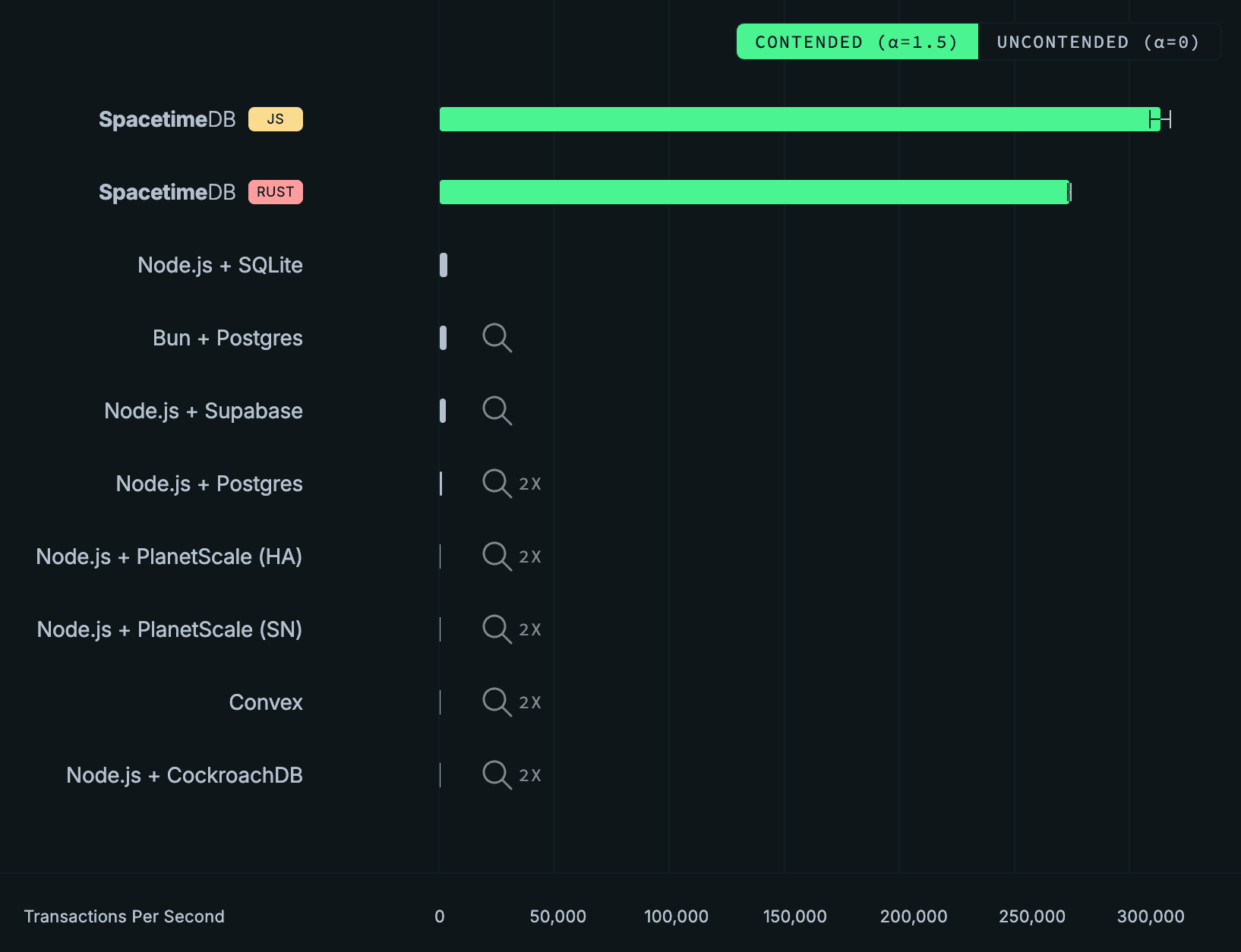
심지어 오차 막대도 추가했습니다! 경쟁 백엔드들에도 오차 막대를 추가하고 싶었지만, 픽셀이 충분하지 않았습니다. 사실 Convex, PlanetScale, CockroachDB의 전체 처리량은 1080p 화면에서는 거의 보이지도 않아서, 오늘은 새로운 기능도 소개합니다…
2배 확대!
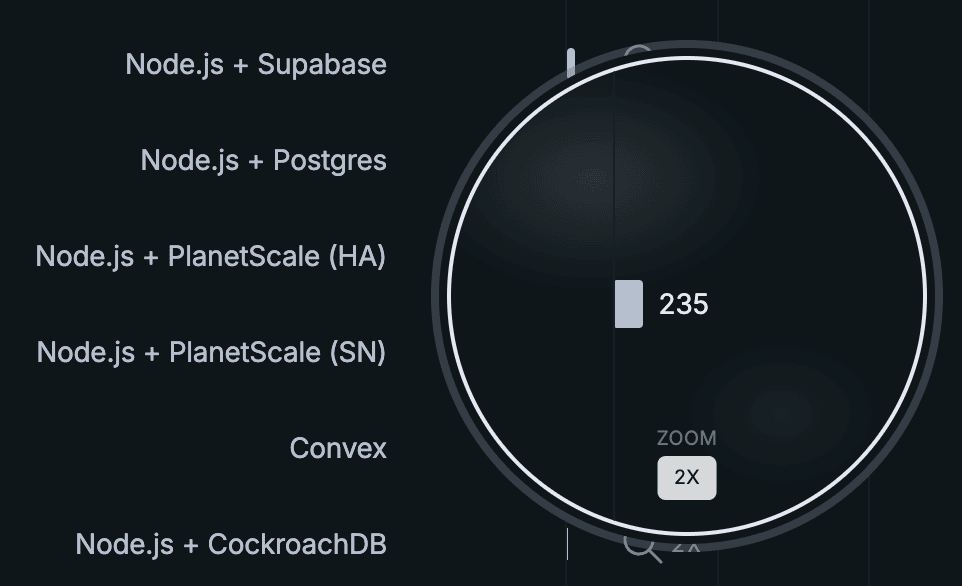
저희는 화면 해상도와 상관없이 모든 사용자가 벤치마킹 결과를 볼 수 있도록 하고 싶습니다.
저도 남들만큼 Twitter에서의 좋은 말싸움을 좋아합니다. 하지만 2.0을 발표한 이후 저와 팀은 “goons”, “liars”, “morons”, “dishonest”, “deceptive”라는 말을 들었고, 저희 데이터베이스는 “just Redis”라거나 “doesn’t offer replication”, “doesn’t provide ACID guarantees”, 저희 벤치마크는 “comparative”하지도 않고 “apples-to-apples”도 아니며, SpacetimeDB는 “not a very good database”라는 말까지 들었습니다. 물론 이 모든 말은 사실이 아닙니다. 이런 주장 중 상당수는 스스로 “technical diligence” 를 자랑한다고 말하는 PlanetScale에서 나왔습니다. 하지만 그들은 저희 제품에 대해 광범위하고 단정적이며 잘못된 기술적 주장을 하기 전에 사실상 아무런 검증도 하지 않았습니다. 제 생각에는 썩 좋아 보이진 않습니다.
저희는 아직 이 모든 문제를 한 곳에서 다루지 않았습니다. 사실 원래 영상을 공개한 이후로는 대체로 침묵을 지켜 왔습니다.
“technical diligence”라는 정신에 따라, 저희는 지난 몇 주 동안 제기된 비판을 신중하게 검토하는 데 시간을 쓰고자 했습니다. 이제 наконец truth와 lies를 가려내고, 왜 이 벤치마크를 선택했는지, 왜 이것이 중요한 벤치마크라고 믿는지, 그리고 왜 SpacetimeDB가 이 벤치마크에서 이렇게 좋은 성능을 보이는지 살펴보겠습니다. 스포일러를 하자면, 일반적인 추정과 달리 이것은 “in-memory” 데이터베이스이기 때문이 아닙니다.
먼저 이 벤치마크와 비판을 이해해 봅시다.
SpacetimeDB란 무엇인가?
SpacetimeDB에 익숙하지 않다면, 이것은 서버 로직을 데이터베이스와 같은 프로세스 안에서 실행하는 백엔드 프레임워크입니다. 핵심 아이디어는 서버와 데이터베이스를 하나의 통합된 시스템으로 결합하는 것입니다. 이것은 코드를 극적으로 단순화할 뿐 아니라 성능도 극적으로 향상시킵니다. 사실 이 아이디어는 매우 오래되었습니다. 바로 stored procedures입니다. 예를 들어 SpacetimeDB의 stored procedure와 Postgres의 stored procedure의 차이는 사용성과 사용자 경험에 있습니다. SpacetimeDB는 stored procedure를 데이터베이스의 일급 기능으로 끌어올립니다. 여러분은 스키마, 함수, 타입을 정의하는 모든 서버 로직을 하나의 모듈로 업로드합니다. 앱 개발자는 원하는 범용 프로그래밍 언어로 코드를 작성하고, 저희는 Wasm과 JS를 사용해 그것을 데이터베이스 내부에서 실행합니다.
벤치마크
저희 벤치마크에서는, 2.0 발표 영상에서 크게 소개된 것처럼, 사용자가 계정 간 잔액 이체를 수행할 수 있는 단순화된 은행 또는 회계 애플리케이션을 가정합니다. 벤치마크는 전송 처리량, 즉 특정 백엔드 스택이 초당 처리할 수 있는 전송 트랜잭션 수를 측정합니다. 처리량은 애플리케이션 클라이언트 기준으로, 일정 시간 창 안에서 성공한 전송 트랜잭션 수를 측정하는 방식으로 계산됩니다. 또한 이것은 완전한 종단 간 벤치마크이기도 합니다. 즉 웹 서버와 데이터베이스를 함께 포함한 전체 백엔드 스택의 성능을 측정합니다. SpacetimeDB와 Convex는 둘 다 서버와 데이터베이스를 하나의 플랫폼으로 결합합니다. 다른 스택들의 경우에는 백엔드 런타임과 데이터베이스 관리 시스템을 모두 명시합니다.
참고로, 서버 측 transfer 엔드포인트의 SpacetimeDB 구현 전체는 다음과 같습니다.
export const transfer = spacetimedb.reducer(
{ from: t.u32(), to: t.u32(), amount: t.i64() },
(ctx, { from, to, amount }) => {
if (from === to) throw new SenderError('same_account');
if (amount <= 0) throw new SenderError('non_positive_amount');
const fromRow = ctx.db.accounts.id.find(from);
const toRow = ctx.db.accounts.id.find(to);
if (fromRow === null || toRow === null) throw new SenderError('account_missing');
if (fromRow.balance < amount) throw new SenderError('insufficient_funds');
ctx.db.accounts.id.update({
id: from,
balance: fromRow.balance - amount,
});
ctx.db.accounts.id.update({
id: to,
balance: toRow.balance + amount,
});
}
);
현실 세계의 워크로드를 표현하기 위해, 저희는 멱법칙에 따라 전송에 포함할 계정을 선택합니다. 이는 일부 계정이 다른 계정보다 훨씬 더 많은 전송을 수행하고, 전체 계정 중 작은 비율이 대부분의 전송을 담당한다는 뜻입니다. Ethereum의 계정 전송은 정확히 이 법칙을 따른다고 알려져 있고, X와 같은 소셜 네트워크 역시 이런 활동 분포를 보입니다.
방법론
저희는 PlanetScale이 최근 On Benchmarking 블로그 글에서 권장한 방법론이 전반적으로 좋은 벤치마킹 관행을 잘 설명한다고 생각합니다.
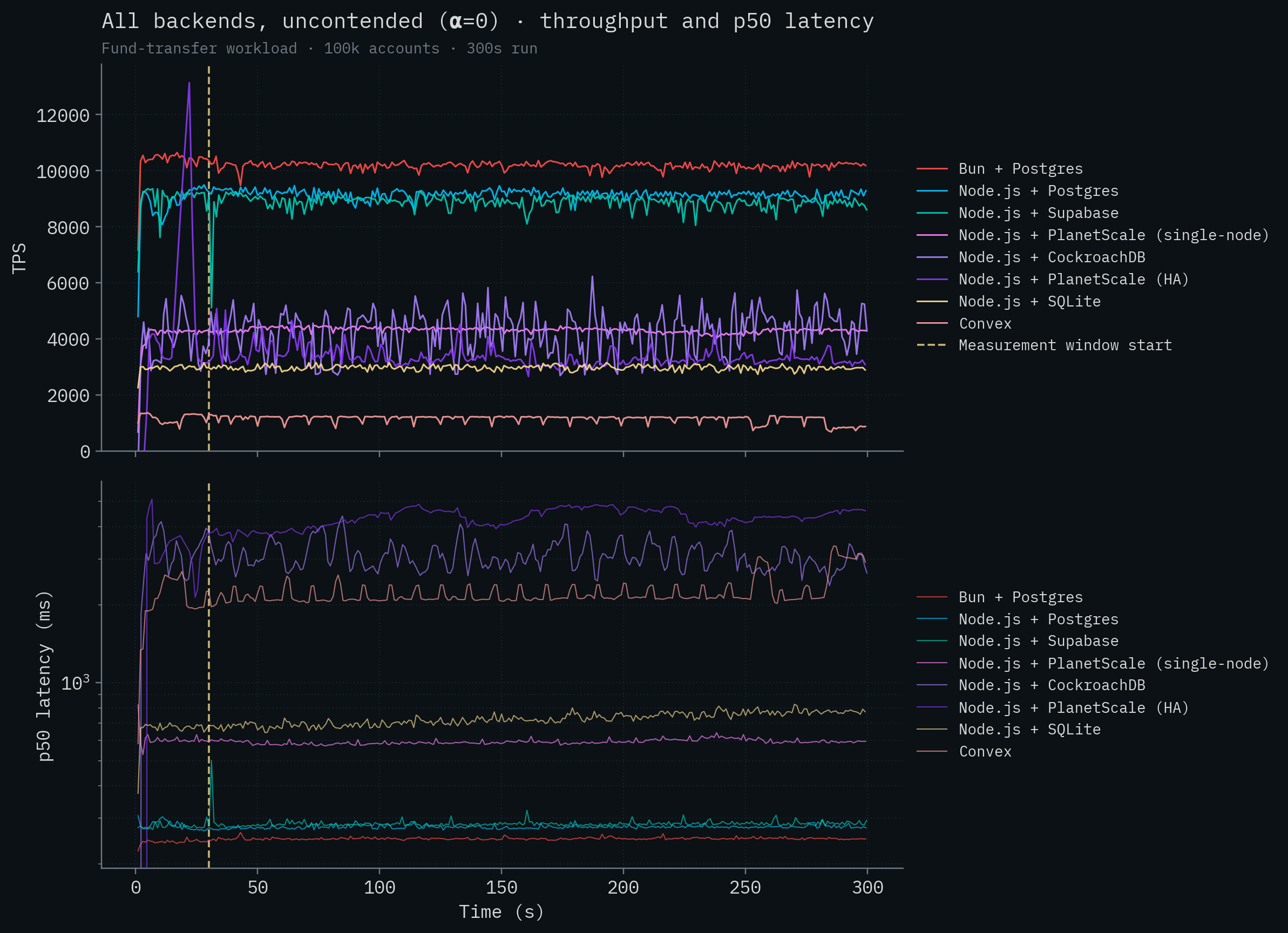
저희는 원래의 벤치마크와 방법론을 여전히 지지하지만, 이 더 심층적인 블로그 글을 위해 SpacetimeDB와 모든 경쟁 제품에 대해 동일한 transfer 벤치마크를 다시 실행하여 5분 동안의 처리량과 지연 시간 데이터를 모두 수집하고 보고했습니다. 이때 처음 30초는 워밍업 기간으로 두었고, 이 기간 동안의 처리량 및 지연 시간 측정은 무시했습니다. 모든 시계열 차트에는 측정 창 시작 시점이 수직 표시선으로 나타납니다.
Postgres 배포의 경우, Postgres 모범 사례에 맞춰 Drizzle의 최대 connection pool 크기를 데이터베이스 머신의 CPU 코어 수의 2배로 설정했습니다. 또한 Postgres에서는 기본 설정값을 사용했고, CockroachDB와 PlanetScale의 경우에는 플랫폼 기본값을 사용했습니다. Postgres 테스트에서는 서버를 PGBouncer 없이 Postgres에 직접 연결했습니다(아래 참고).
Convex의 경우 기본 설정을 사용했습니다. Pro 티어의 클라우드 배포와 self-host 배포를 모두 테스트했으며 결과는 비슷했습니다. 다른 사람들이 결과를 쉽게 재현할 수 있도록 self-host 결과만 공개합니다.
SQLite의 경우 기본 설정을 사용했습니다.
CockroachDB의 경우, 모두 동일한 리전과 availability zone 안에 있는 5노드 클러스터를 구성했습니다. 기본 설정을 사용했습니다. 특히 CockroachDB에서는 max_connections가 기본적으로 무제한입니다. 서버 측에서는 최대 connection pool 크기를 클러스터 내 모든 머신의 총 코어 수로 설정했습니다.
Bun, Node.js, Drizzle의 경우, 위에서 설명한 최대 connection pool 크기를 제외하면 모두 기본 설정을 사용했습니다.
모든 테스트에서 저희는 N개의 클라이언트를 실행했는데, 여기서 N은 테스트에 사용된 데이터베이스 머신의 CPU 수의 2배입니다. 이 수를 선택한 이유는 Postgres 배포에서 최적의 처리량을 보장하기 위해서입니다. 연결 수가 Postgres 질의의 최대 병렬성을 결정하고, 최대 connection pool 크기도 CPU 코어 수의 2배이기 때문입니다. 중요한 점은 클라이언트 수와 연결 수가 같기 때문에 PGBouncer가 필요 없다는 것입니다. PGBouncer는 Postgres 질의의 처리량이나 병렬성을 높일 수 없으며, 오히려 지연 시간에 부정적인 영향을 줄 수 있어서 의도적으로 제외했습니다.
클라이언트는 실제 워크로드처럼 백엔드에 개별 요청을 보냅니다. 요청을 배치하지는 않습니다. 단, SpacetimeDB에 대해서만 클라이언트가 응답을 기다리지 않고 서버에 최대 40개의 요청을 제출할 수 있도록 했습니다. 목적은 단일 머신에서 쉽게 실행하기 어려운 더 많은 수의 클라이언트, 구체적으로는 2,560명의 클라이언트를 시뮬레이션하여 결과를 쉽게 재현할 수 있게 하기 위함입니다. 이것이 불공정하다고 생각한다면 Claim 9를 보시면 됩니다. 스포일러를 하자면, 저희는 경쟁 제품에서도 이것을 테스트했고 그들은 따라오지 못했습니다.
아래는 각 백엔드의 설정 요약입니다.
| Backend | Clients | Pipelining | Drizzle pool | DB max_connections | DB worker procs |
|---|---|---|---|---|---|
| SpacetimeDB | 64 | 40 | N/A | N/A | N/A |
| Node.js + SQLite | 64 | off | N/A | N/A | N/A |
| Node.js + Supabase | 64 | off | 64 | 100 | 8 |
| Bun + Postgres | 64 | off | 64 | 100 | 8 |
| Node.js + Postgres | 64 | off | 64 | 100 | 8 |
| Node.js + PlanetScale (SN) | 64 | off | 64 | 600 | 25 |
| Node.js + PlanetScale (HA) | 384 | off | 384 | 600 | 155 |
| Convex | 64 | off | N/A | N/A | N/A |
| Node.js + CockroachDB (5 node) | 320 | off | 320 | unlimited | N/A |
전체 세부 사항은 벤치마크 README and code에서 확인할 수 있습니다.
Note
SpacetimeDB는 replication을 지원하지만(Claim 7 참고), 이 글의 모든 SpacetimeDB 수치는 replicated SpacetimeDB Cloud 변형이 아니라 GitHub에서 제공되는 SpacetimeDB Standalone의 단일 노드 배포에서 측정한 것입니다. 이렇게 하면 다른 단일 노드 데이터베이스들과 apples-to-apples 비교가 가능하며, 누구나 공개 소프트웨어만으로 결과를 재현할 수 있습니다.
세부 수치
저희는 두 가지 워크로드를 보고합니다.
먼저 contention이 있는 경우, 그다음 contention이 없는 경우를, 모든 경쟁 백엔드를 같은 차트에 겹쳐 보겠습니다. 처리량은 선형 축이고, 지연 시간은 로그 축입니다. 이렇게 해야 네 자릿수 규모 차이가 나는 백엔드도 같은 축을 공유할 수 있습니다.
Note
벤치마크 코드(모든 백엔드, 모든 워크로드, 모든 connector 설정)는 github.com/clockworklabs/SpacetimeDB/tree/master/templates/keynote-2에 있습니다. 이 글의 모든 수치는
pnpm run bench test-1 --seconds 300 --connectors <backend>명령으로 재현할 수 있습니다. Intel 14900K가 있다면 같은 CPU에서도 실행할 수 있습니다.
처리량 그래프를 봅시다.
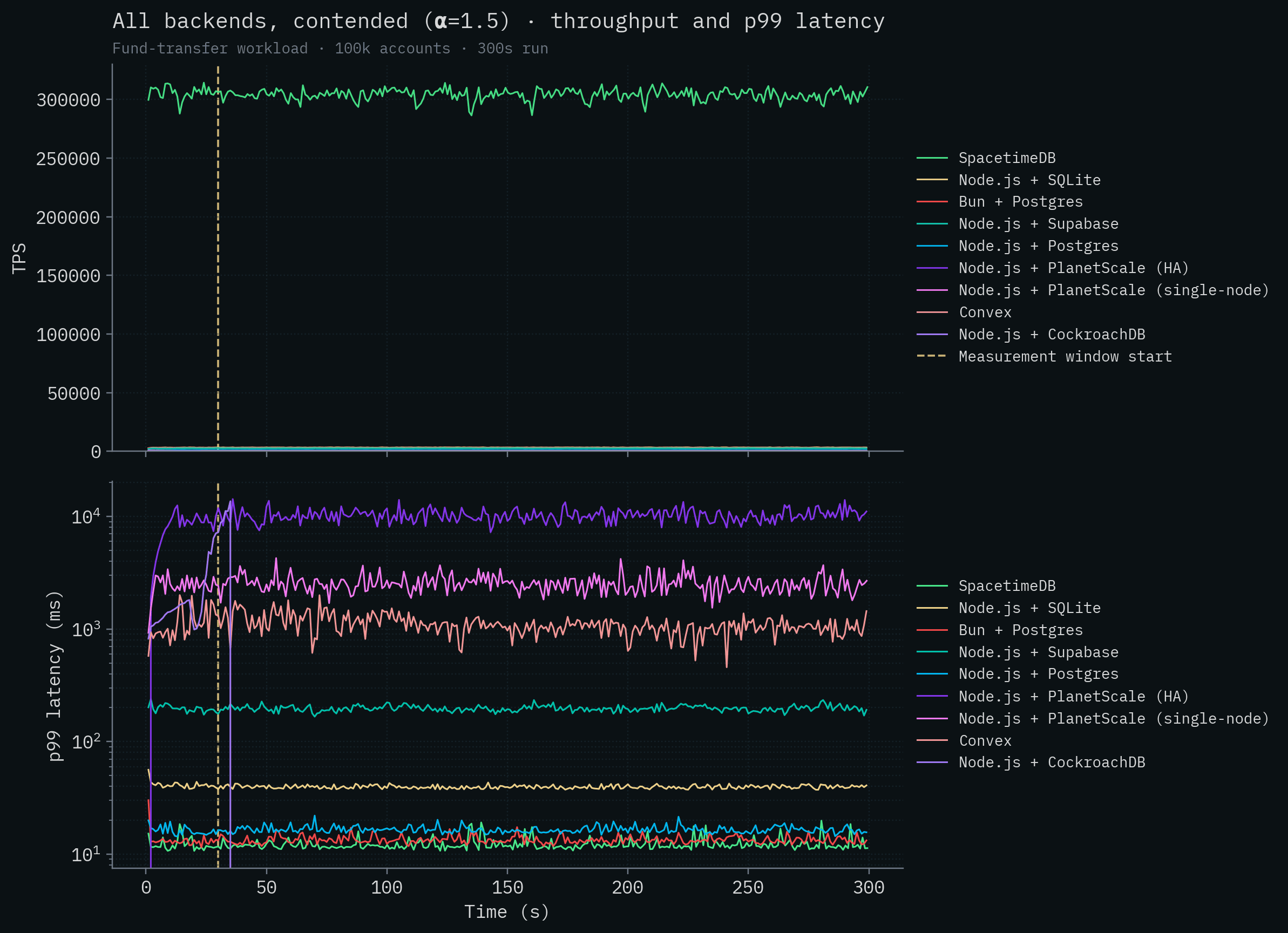
잠깐만요, 실수라도 있는 것처럼 보입니다. SpacetimeDB만 나오네요. 이게 X축인가요, 아니면 경쟁 제품들인가요?
SpacetimeDB 선은 약 279k–304k TPS 수준에 위치하며, 어떤 경쟁 제품보다도 두 자릿수 이상 높은 수준입니다. 경쟁 백엔드들의 처리량 변화를 시각화할 수 있도록 SpacetimeDB를 제거해 봅시다. Node.js + SQLite가 초당 약 3,200건으로 가장 좋은 경쟁 제품 성능을 보입니다. 분산 트랜잭션을 사용하는 CockroachDB는 contention 상황에서 완전히 무너져 테스트를 끝내지 못합니다. Convex는 대체로 초당 100건 미만에서 동작합니다. PlanetScale의 두 배포 모두 300 TPS를 넘지 못합니다.
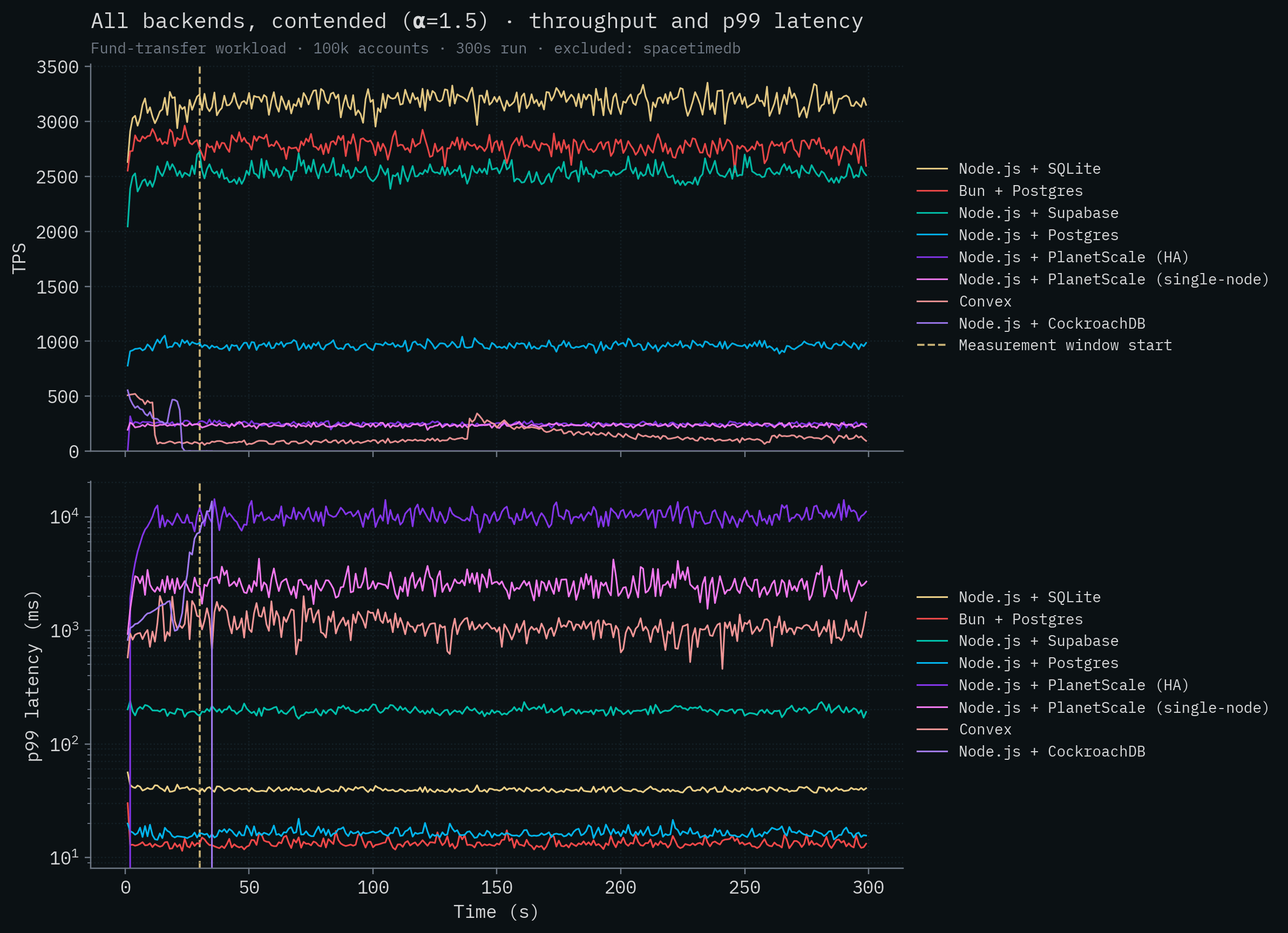
또 한 가지 주목할 점은, SpacetimeDB가 초당 300,000건이 넘는 트랜잭션을 처리하면서도 지연 시간이 꽤 낮다는 것입니다. 다만 로컬 Postgres 배포와 비슷한 범위에 있습니다. 이는 예상된 결과입니다. 다른 fsync 기반 데이터베이스와 같은 durability 보장을 제공하면서, 처리량을 늘리는 것만큼 극적으로 지연 시간을 줄일 수 있는 마법 같은 방법은 없습니다. 디스크는 디스크이고, 빛의 속도는 빛의 속도입니다.
다음으로 row contention이 거의 없는 테스트를 봅시다. 이 경우 inflight 트랜잭션들이 같은 계정을 동시에 수정할 가능성이 훨씬 낮습니다. 여기서 경쟁 백엔드들은 병렬화와 multi-version concurrency control의 장점을 최대한 활용할 수 있습니다. 모든 백엔드에서 처리량이 확실히 증가하는 것이 보이지만, 안타깝게도 겨우 X축에서 조금 떠오르는 정도에 그칩니다.
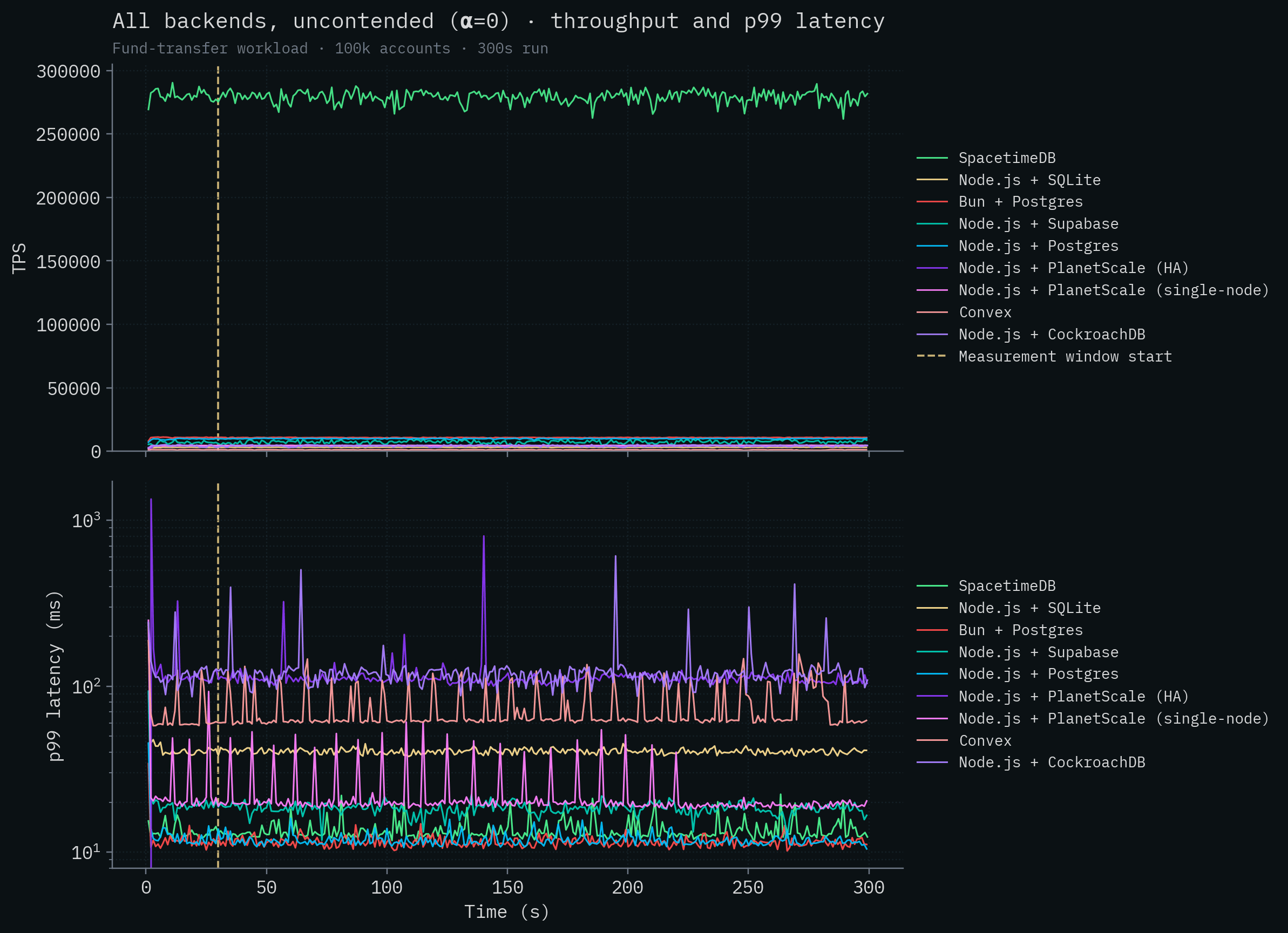
코어가 부족해서 그런 것도 아닙니다. 저희는 PlanetScale HA 테스트를 총 512 vCPU와 기본 설정을 갖춘 그들의 $67,349 / monthPlanetScale Metal M-15630 클러스터에서 수행했습니다. 테스트를 실행하는 데만도 거의 500달러가 들었습니다!
다시 그래프에서 SpacetimeDB를 제거하면, 그 클러스터가 저희 테스트에서 어느 정도였는지 볼 수 있습니다.
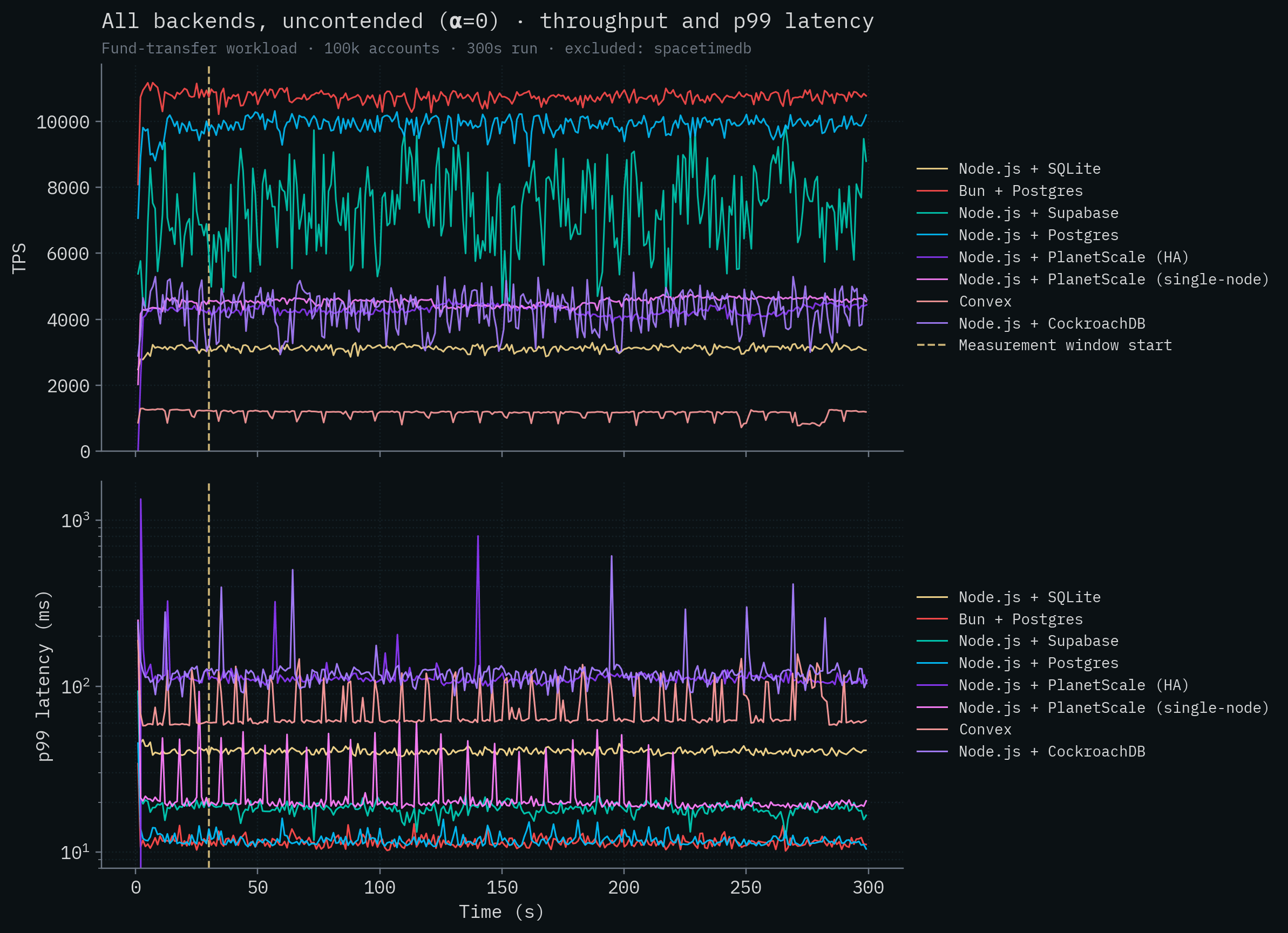
일반적인 vanilla Postgres 배포는 여기서 꽤 잘 나옵니다(SpacetimeDB 제외). Bun + Postgres는 초당 10k가 넘는 트랜잭션으로 경쟁 제품 중 가장 높은 처리량을 보였고, Node.js + Postgres가 그 뒤를 바짝 따르며, Supabase도 7k 이상으로 비슷한 범위에 있습니다. 이는 서버와 데이터베이스가 같은 머신에서 실행되고, Postgres가 여러 트랜잭션을 병렬로 처리할 수 있기 때문입니다. 32 vCPU를 가진 PlanetScale 단일 노드 배포, CockroachDB의 5노드 클러스터, PlanetScale의 HA 클러스터는 모두 4–4.5k TPS 수준에 머뭅니다. 거대한 vCPU 수와 384개의 데이터베이스 연결을 가졌음에도(PlanetScale의 경우) 같은 위치에 배치된 Postgres 백엔드보다 훨씬 낮습니다. 이들은 서버 <-> 데이터베이스 지연 시간을 극복할 수 없습니다(Claim 1 및 Claim 9 참고). SQLite의 처리량은 이 테스트에서도 대략 3k 수준에 머물고, Convex는 약 1k TPS로 맨 뒤를 차지합니다.
Note
솔직히 말하면 PlanetScale Metal HA 결과는 다소 놀랍습니다. 서버와 데이터베이스 사이의 지연 시간, 더 낮은 contention, 머신 크기, 설정된 연결 수를 고려하면 이론적 최대치인 약 77,000 TPS에 더 가까운 처리량을 예상했을 것입니다(Claim 9에 전체 계산이 있습니다). replication 문제일 수도 있고, 높은 서버 <-> 데이터베이스 지연 시간과 결합된 어떤 contention이든 처리량을 망가뜨리고 있는 것일 수도 있습니다. 하지만 이 클러스터에서 읽기 전용, 비경합 질의에서도 비슷한 처리량 문제를 보았습니다(대략 9,000 TPS). 저희는 며칠 동안 튜닝했지만 어떤 설정에서도 로컬 Postgres를 이기지 못했습니다. PlanetScale과의 협력 없이 저희는 다른 고객과 마찬가지로 그들의 클라우드 서비스만 사용할 수 있고, 그러면 내부 가시성이 매우 제한됩니다.
아래에 요약된 전체 결과는 측정 창 동안의 평균 처리량과 지연 시간을 ± 표준편차 1개와 함께 보고합니다.
Throughput (contended throughput, α=1.5 기준 정렬; 백엔드를 클릭하면 실행별 차트를 볼 수 있습니다)
| Backend | α=0 (TPS) | α=1.5 (TPS) |
|---|---|---|
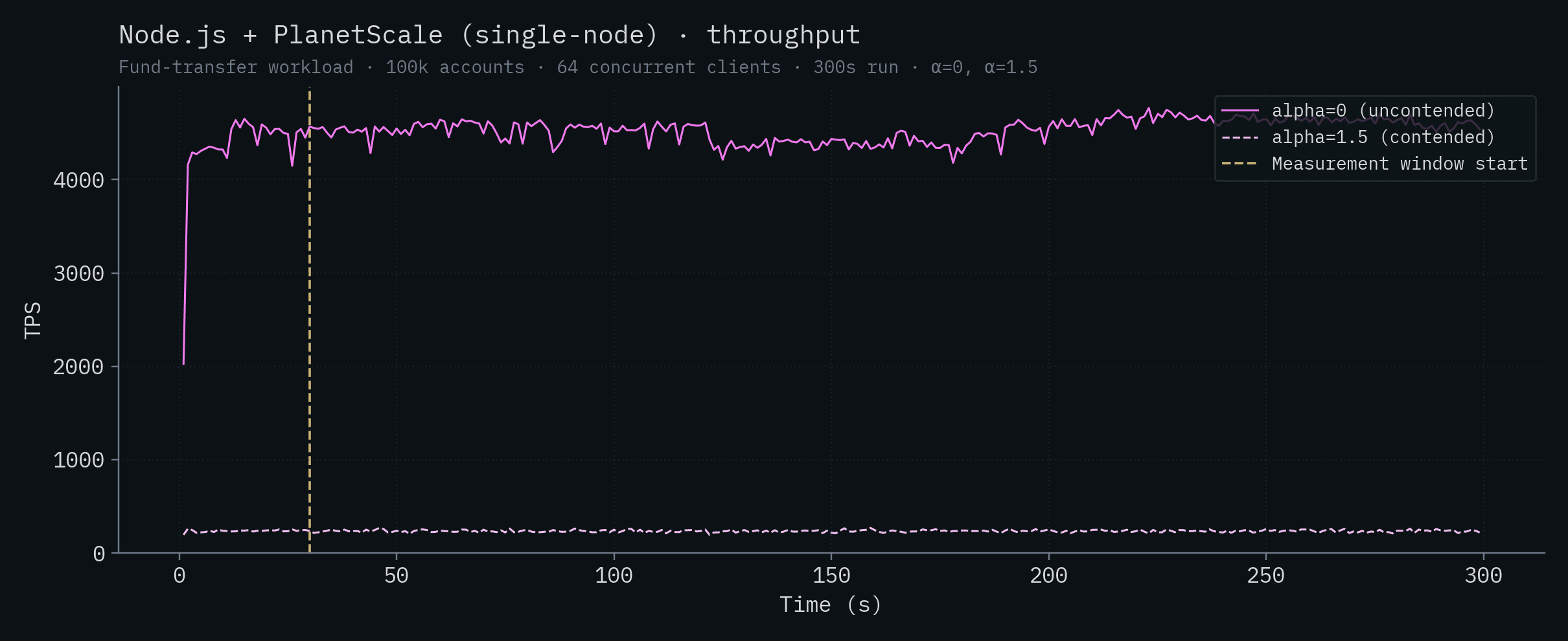
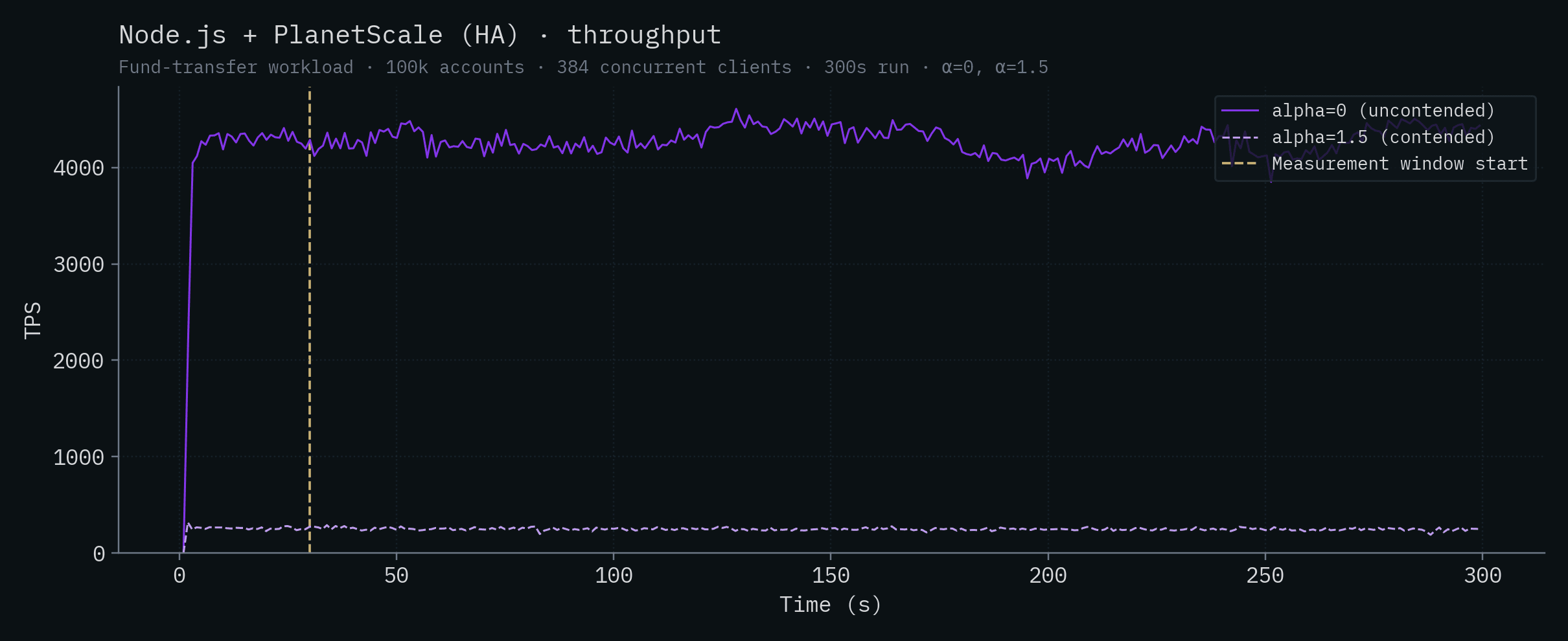
| SpacetimeDB (Standalone) | 279,025 ± 4,763 | 303,920 ± 4,712 |
| Node.js + SQLite | 3,122 ± 81 | 3,188 ± 73 |
| Bun + Postgres | 10,730 ± 146 | 2,773 ± 61 |
| Node.js + Supabase | 7,362 ± 1,179 | 2,534 ± 57 |
| Node.js + Postgres | 9,905 ± 224 | 961 ± 26 |
| Node.js + PlanetScale (HA) | 4,275 ± 135 | 248 ± 13 |
| Node.js + PlanetScale (SN) | 4,535 ± 117 | 235 ± 12 |
| Convex | 1,140 ± 118 | 127 ± 53 |
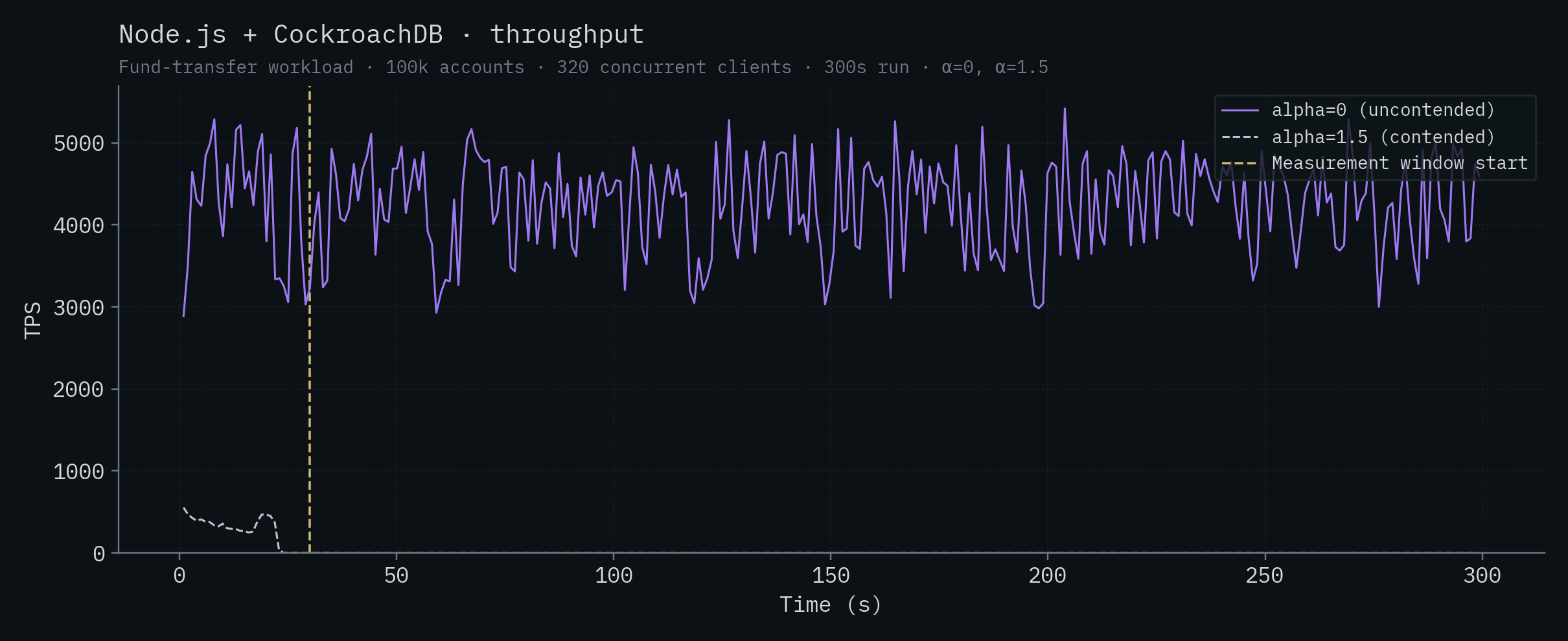
| Node.js + CockroachDB | 4,253 ± 561 | did not complete |
Latency
| Backend | α=0 p50 (ms) | α=0 p99 (ms) | α=1.5 p50 (ms) | α=1.5 p99 (ms) |
|---|---|---|---|---|
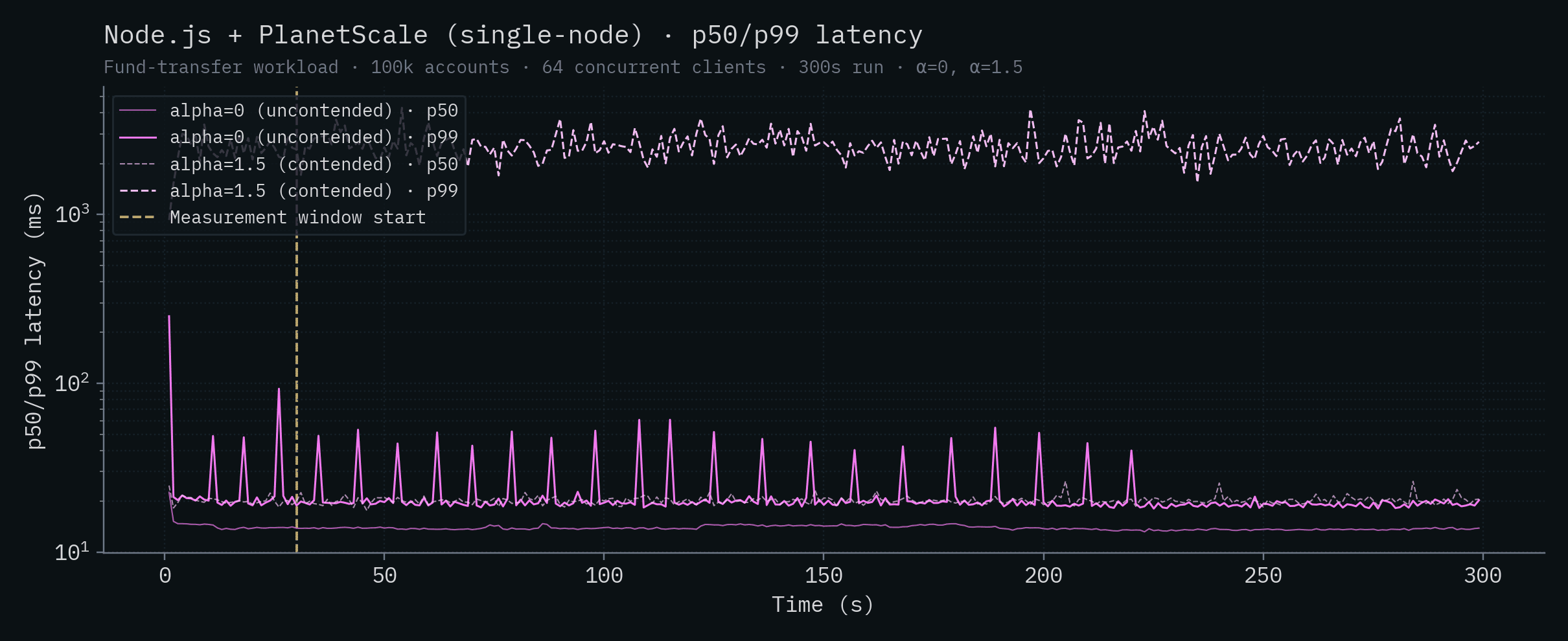
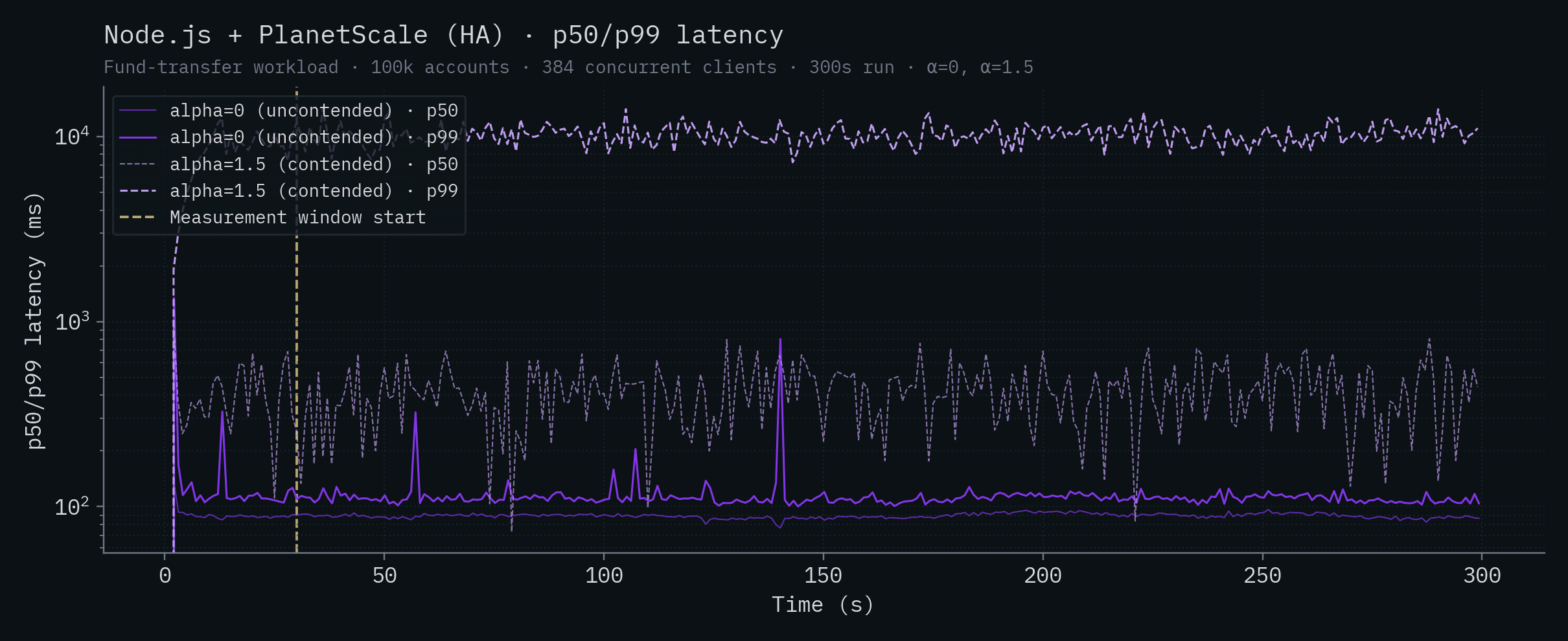
| SpacetimeDB (Standalone) | 8.08 | 12.9 | 7.39 | 11.7 |
| Node.js + SQLite | 19.3 | 40.5 | 18.9 | 39.4 |
| Bun + Postgres | 5.66 | 11.4 | 7.85 | 13.2 |
| Node.js + Supabase | 6.68 | 18.3 | 2.60 | 197 |
| Node.js + Postgres | 6.16 | 11.6 | 10.3 | 16.3 |
| Node.js + PlanetScale (HA) | 89.1 | 110 | 416 | 10,121 |
| Node.js + PlanetScale (SN) | 13.8 | 19.5 | 20.2 | 2,504 |
| Convex | 53.7 | 62.2 | 20.2 | 1,082 |
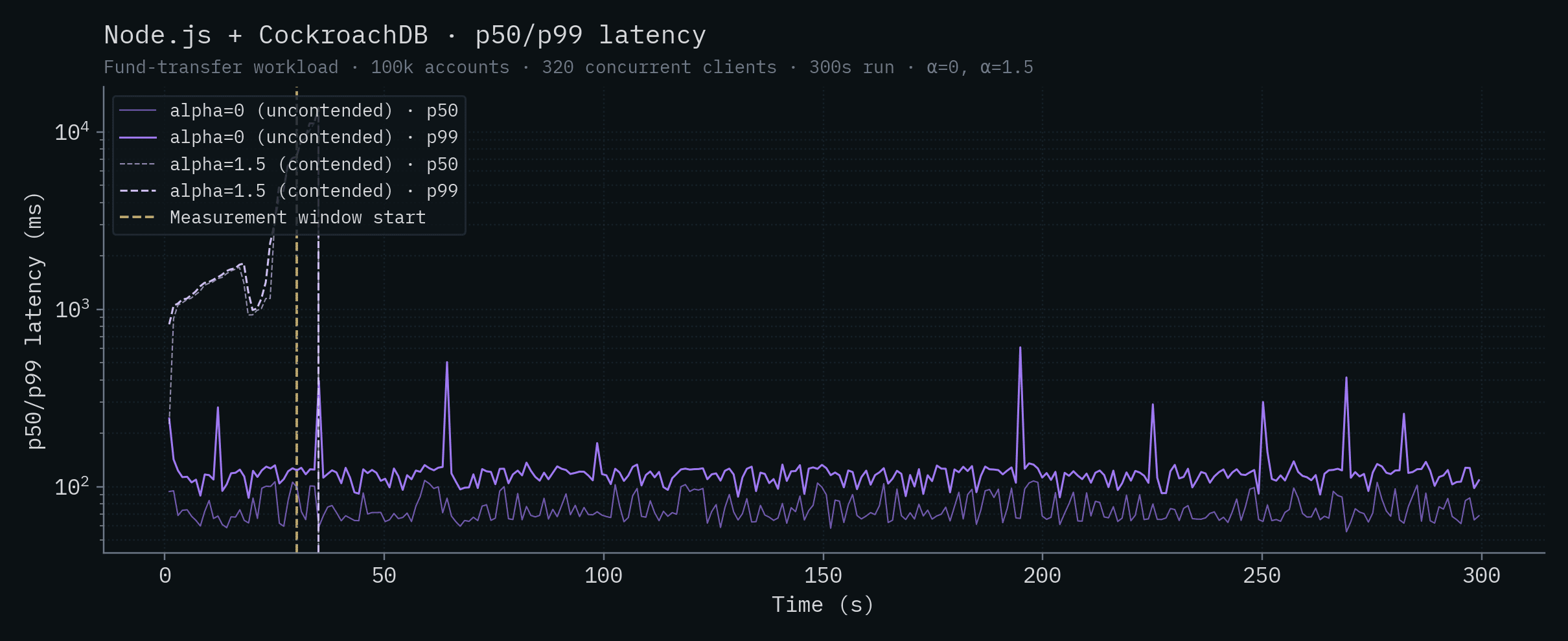
| Node.js + CockroachDB | 71.0 | 120 | 990 | 9,695 |
천 TPS당 월 비용 (α=0 기준 가격 대비 성능 순 정렬)
| Deployment | Hardware | $ / month | TPS (α=0) | $/month per kTPS |
|---|---|---|---|---|
| SpacetimeDB (Standalone) | 1× Intel 14900K (24 vCPU) | ~$1,000 | 279,025 | ~$3.6 |
| Bun + Postgres | 1× Intel 14900K (24 vCPU) | ~$1,000 | 10,730 | ~$93 |
| Node.js + Postgres | 1× Intel 14900K (24 vCPU) | ~$1,000 | 9,905 | ~$101 |
| Node.js + Supabase | 1× Intel 14900K (24 vCPU) | ~$1,000 | 7,362 | ~$136 |
| Node.js + CockroachDB | 5× Intel 14900K (24 vCPU) | ~$5,000 | 4,253 | ~$1,176 |
| Node.js + SQLite | 1× Intel 14900K (24 vCPU) | ~$1,000 | 3,122 | ~$320 |
| Node.js + PlanetScale (SN) | PS-2560, 32 vCPU | $1,510 | 4,535 | $333 |
| Convex | 1× Intel 14900K (24 vCPU) | ~$1,000 | 1,140 | ~$877 |
| Node.js + PlanetScale (HA) | M-15360 cluster, 192 vCPU | $67,349 | 4,275 | ~$15.8k |
$1,000/month는 SpacetimeDB와 동급의 전용 머신(Intel 14900K와 동일 CPU)의 넉넉한 추정치입니다. Hetzner에서는 이보다 훨씬 저렴하고, 클라우드 동급인 m7i.8xlarge는 이 가격에 가깝습니다. 저희 벤치마크에서 로컬에 함께 배치된 모든 백엔드는 동일한 하드웨어를 공유하므로, 이 표에서 동일한 월 비용 줄을 공유합니다. PlanetScale만 유일하게 함께 배치할 수 없었기 때문에 실제 클라우드 가격을 반영했습니다.
표 데이터를 보면 몇 가지가 눈에 띕니다. contention 상황에서 CockroachDB의 5노드 클러스터는 완전히 붕괴하며, 실행 36초 시점 이후부터는 트랜잭션을 완료하지 못하고 나머지 측정 창 동안 사실상 트래픽을 처리하지 못합니다. 분산 트랜잭션이 hot row와 상호작용하는 방식을 생각하면 이는 대체로 예상 가능한 결과입니다. PlanetScale의 단일 노드 처리량은 uncontended에서 contended로 가면서 약 19배 감소하고, HA 클러스터는 약 17배 감소합니다. PlanetScale의 두 배포 모두 contention 아래에서 tail latency가 수 초 단위까지 치솟습니다. Convex의 처리량은 약 9배 감소해 겨우 100 TPS를 조금 넘는 수준이 되고, α=1.5의 tail은 1초를 넘깁니다. Postgres 계열 백엔드(Bun, Node.js + Postgres, Supabase)는 contention에서 3–10배 감소하여 대략 비슷한 처리량에 수렴합니다. SQLite는 SpacetimeDB를 제외하면 contention 아래에서 처리량이 사실상 변하지 않고, 오히려 약간 증가하는 유일한 백엔드입니다. 이것은 single-writer 설계의 특성이며, 별도의 논의가 필요합니다(Claim 12 참고).
Note
SQLite 백엔드가 이 벤치마크에서 저희가 원래 공개한 벤치마크보다 훨씬 나쁜 성능을 낸 것을 눈치채셨을 수 있습니다. 이는 원래 벤치마킹 코드의 실수로 SQLite 수치가 부풀려졌기 때문입니다. 이 문제는 아래 Claim 12와 Claim 13에서 설명합니다.
각 시스템별 백엔드 처리량과 지연 시간 차트(두 α 값을 함께 표시)는 이 글 마지막의 appendix에서 확인할 수 있습니다.
저희 벤치마크의 결과가 매우 극적이었기 때문에, 경쟁사들과 다른 이들은 SpacetimeDB와 벤치마크에 대해 다양한 주장을 했습니다. 이런 주장들은 대체로 이 벤치마크와 그 결과를 गंभीर하게 받아들일 필요가 없다는 변명처럼 제시되었습니다. 논리는 이런 것이었습니다. SpacetimeDB의 성능이 이렇게 극단적이라면, 분명 어딘가에서 편법을 쓰거나 뭔가를 왜곡하고 있을 것 아닌가? 아래에서 설명하겠지만, 실제로는 그렇지 않습니다. 각각의 주장은 상당한 혼란을 불러왔기 때문에, 벤치마크가 실제로 무엇을 측정하는지부터 시작해 하나씩 체계적으로 다뤄보겠습니다.
일부 사람들은 저희가 표준 데이터베이스 벤치마크를 사용하지 않았다는 이유만으로 결과를 일축했습니다(Claim 4 참고). 하지만 저희 벤치마크는 애초에 데이터베이스 벤치마크가 아니며, 따라서 표준 데이터베이스 벤치마크는 적합하지 않습니다.
문제는 일반적인 데이터베이스 벤치마크가 데이터베이스 자체의 성능은 측정하지만, 전체 백엔드 스택의 성능은 측정하지 않는다는 점입니다. 다시 말해, 대부분의 웹 애플리케이션 스택에서 가장 큰 병목인 데이터베이스 <-> 서버 통신을 가린다는 것입니다.
“Are we benchmarking databases or network latencies?” - Ben Dicken, Head of Developer Education at PlanetScale
이것이야말로 정말로 답해야 하는 핵심 질문이며, Ben이 최근 On Benchmarking 글의 앞부분에서 깊이 있게 다룬 문제이기도 합니다.
그의 예시와 도표를 사용해 보겠습니다. 이 상황을 아주 잘 설명한다고 생각합니다.
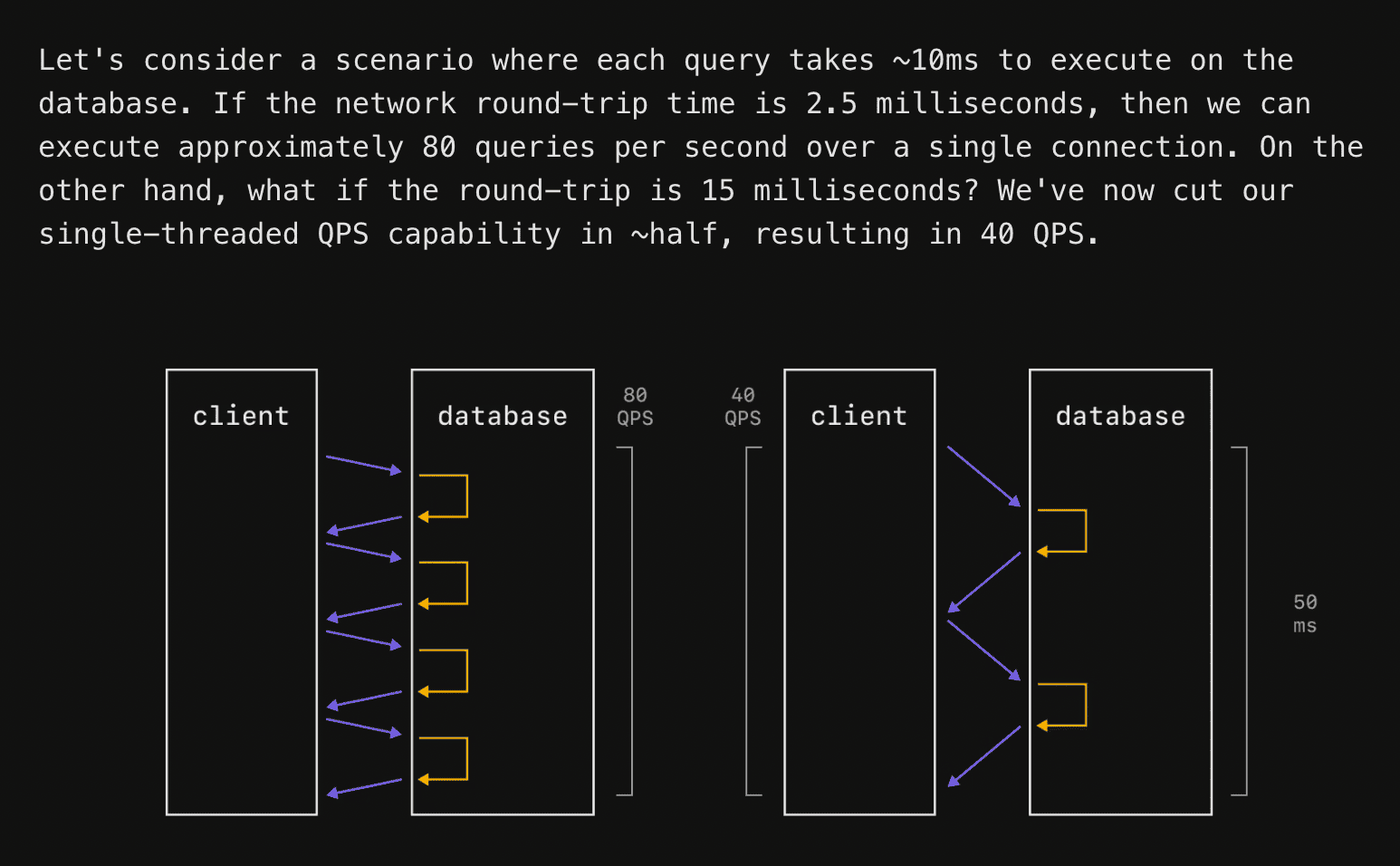
일반적인 웹 앱 아키텍처는 다음과 같습니다.
HTTP 애플리케이션 서버(예: Node.js, Bun, Django, Actix 등)
애플리케이션 서버 타입을 매핑하는 ORM(예: Drizzle, TypeORM 등)
데이터베이스(예: Postgres, MySQL, MongoDB 등)
이 설정에서 “client”라고 표시된 사각형은 전통적인 웹 백엔드 스택에서는 보통 여러분의 서버에 해당합니다.
핵심은 단일 데이터베이스 연결 또는 “client”에 대해, “client”와 데이터베이스 사이의 지연 시간이 증가하면 트랜잭션 지연 시간도 증가하고 처리량(초당 트랜잭션 수도)도 감소한다는 점입니다. Ben이 아래 인용문에서 말한 것처럼, 트랜잭션을 병렬로 처리하면 이 영향을 어느 정도 완화할 수 있습니다.
“This latency variation will always have an impact on latency measurements. It can also impact throughput. We often don't run benchmarks on a single connection. We'll do 10, 50, or 100 simultaneous connections to best utilize the parallelism of the machine and database. But if we have a fixed connection count, and are not making it dynamic to account for round-trip latency, we can end up allowing the elevated latency to hurt throughput.”
이는 어느 시점이 되면 서버와 클라이언트 사이의 지연 시간이 처리량에 영향을 주기 시작한다는 뜻이며, 그 근본적인 이유는 두 가지입니다.
약간 계산을 해보겠습니다.
서버에서 db.transaction()으로 여는 트랜잭션은 커밋되거나 중단되기 전에 데이터베이스와 여러 번 왕복할 수 있습니다(예: 사용자 조회, 그 친구들 조회, 친구들의 게시물 조회, 그리고 사용자를 다시 데이터베이스에 기록). 서버 <-> 데이터베이스 왕복 시간이 2.5 ms라면, 트랜잭션이 정기적으로 10ms 이상 열린 채로 유지된다는 뜻일 수 있습니다.
데이터베이스가 의미 있는 작업을 전혀 하지 않는다고 해도, 트랜잭션은 최소한 다음만큼 열려 있습니다.
4 round trips × 2.5 ms RTT = 10 ms
이제 PostgreSQL에 이 워크로드를 위한 백엔드 연결이 100개 있다고 가정해 보겠습니다. 각 연결은 한 번에 최대 하나의 활성 트랜잭션만 가질 수 있으므로, contention이 전혀 없을 때의 이론적 상한은 다음과 같습니다.
100 concurrent transactions / 10 ms per transaction
= 100 / 0.010
= 10,000 transactions per second
이것이 2.5ms 네트워크 지연 시간에서의 최선의 경우, 즉 빛의 속도 한계입니다. 여기에는 lock contention도, CPU 병목도, WAL 병목도, connection-pool 대기열도, 재시도도, 의미 있는 질의 실행 시간도 포함되지 않습니다.
4 round trips → 10.0 ms transaction duration → 10,000 TPS
8 round trips → 20.0 ms transaction duration → 5,000 TPS
12 round trips → 30.0 ms transaction duration → 3,333 TPS
20 round trips → 50.0 ms transaction duration → 2,000 TPS
이제 contention 상황에서 무슨 일이 일어나는지 보여주기 위해, 모든 트랜잭션이 같은 row를 업데이트하는 극단적인 경우를 생각해 봅시다.
UPDATE counters
SET value = value + 1
WHERE id = 1;
Note
저희는 수학을 쉽게 하기 위해 이 극단적인 예시를 사용하고 있지만, 실제로도 the pareto principle, the birthday paradox, Amdahl’s Law가 모두 함께 작용해 여러분에게 불리하게 작용하기 때문에, 실전에서 예상할 수 있는 상황과 놀랄 만큼 가깝습니다.
한 번에 오직 하나의 트랜잭션만 그 row에 대한 row lock을 가질 수 있습니다. 트랜잭션이 row lock을 획득한 뒤 commit 전에 추가 왕복이 더 필요하다면, 워크로드의 경합 구간은 직렬화됩니다.
락이 네 번의 왕복 동안 유지된다면, lock-hold time은 다음과 같습니다.
4 × 2.5 ms = 10 ms
이제 이론적 상한은 더 이상 10,000 TPS가 아닙니다. 대신 다음과 같습니다.
1 / 0.010 = 100 TPS
와, 엄청난 확장성입니다. 정말 빠르네요. 참고로 이건 어떤 현실적인 문제도 고려하기 전입니다. 이 한계를 우회하려면 애플리케이션 전체를 다시 설계해야 하고, 그렇지 않으면 사용자들은 형편없는 성능을 받아들여야 합니다.
이제 다시 질문으로 돌아가 봅시다. 우리는 지연 시간을 테스트하는 걸까요, 아니면 데이터베이스를 테스트하는 걸까요?
답은 둘 다 아닙니다. 저희가 테스트하는 것은 실제로 중요한 유일한 것, 즉 사용자가 경험하는 것입니다. 이 벤치마크의 목적은 전체 웹 스택의 종단 간 성능을 측정하는 것입니다. 왜냐하면 사용자가 실제로 느끼는 것이 바로 그것이기 때문입니다. 이 벤치마크는 여러 일반적인 웹 앱 백엔드가, 데이터베이스가 아니라, SpacetimeDB와 비교해 어떻게 동작하는지를 측정합니다.
저희는 이 목표를 발표 영상과 벤치마크 코드 자체에서 최대한 분명하게 하려고 했지만, 안타깝게도 많은 이들이 그 목표를 오해한 것 같습니다.
SpacetimeDB가 다른 백엔드보다 빠른 가장 큰 이유는, 유일한 이유는 아니지만, 여러분의 서버와 데이터베이스 사이 왕복 시간을 최소 99.95% 줄였기 때문입니다. SpacetimeDB에서는 애플리케이션 서버, ORM, 데이터베이스가 하나의 시스템으로 합쳐져 있어 이 셋이 모두 같은 프로세스 안에서 실행됩니다. 이는 서버에서 데이터베이스로의 왕복 시간을 없애며, 절대적인 최선의 경우인 200마이크로초(저희 2.0 발표 영상과 Ben Dicken의 유명한 balls benchmark에서 제시된 수치)에서 대략 100나노초 수준으로 낮춥니다. 2000배의 속도 향상입니다!
지연 시간을 줄이는 것이 바로 핵심입니다! 병렬성이 연결 수나 contention에 의해 제한된다면, 지연 시간은 언제나 데이터베이스 처리량에 영향을 줍니다. 애플리케이션 성능에 대한 이 지연 시간의 영향은 PlanetScale도 분명 잘 알고 있을 것입니다. 그들은 it. all. the. time. 라고 계속 이야기하니까요.
SpacetimeDB가 빠른 이유는 단지 “in-memory” 데이터베이스이기 때문인가?
“You are not going to believe the results of my groundbreaking research. RAM is faster than disk.” - Sam Lambert, CEO of PlanetScale
이에 답하기 전에 오해 하나를 바로잡겠습니다. in-memory 데이터베이스란 런타임 시점에 테이블 데이터가 전부 DRAM에 상주하는 데이터베이스를 뜻합니다. 그렇다고 데이터가 디스크에 영속화되지 않는다 는 뜻은 아닙니다. 이 점이 중요합니다. 데이터베이스는 보통… 아시다시피… 데이터를 영속 저장하니까요.
이 주장은 소프트웨어가 왜 빠른지에 대한 오해입니다. SpacetimeDB가 빠른 주된 이유는 위에서 논의한 왕복 시간 때문입니다. 부차적인 이유는, 저희가 SpacetimeDB를 극도로 데이터 효율적이고 캐시 효율적으로 만들기 위해 많은 시간과 노력을 들여 최적화했기 때문입니다.
현대 하드웨어에서는 캐시가 왕입니다. Postgres 같은 데이터베이스가 30년 전에 설계될 당시에는 그렇지 않았습니다. Postgres의 핵심 아키텍처와 메모리 레이아웃은 Pentium II가 출시되던 무렵에 설계되었습니다. Postgres 개발자들도 지금이라면 그때와는 다른 선택을 했을 것이라고 생각하지만, 미래를 내다보지 못했다고 비난할 수는 없습니다.
지금 당장은 SpacetimeDB 테이블이 런타임에서 완전히 RAM에 상주하는 것이 사실이지만, 이것은 아키텍처의 본질적인 제약은 아니며, 가까운 시일 안에 사용자에게 더 크고 더 저렴한 저장 공간을 제공하기 위해 이를 변경할 계획입니다. 대부분의 경우 디스크 테이블도 메모리 전용 테이블과 유사한 성능을 낼 것으로 기대합니다. 개념적으로 저희는 DRAM을 테이블 데이터의 L4 캐시, 드라이브 스토리지를 L5 캐시로 봅니다. L5는 더 크고, 더 느리며, 더 저렴합니다.
“we would never do it. we go to great lengths to produce a fair benchmark, they made no effort to do so.” - Sam Lambert, CEO of PlanetScale
이 주장은 아마 가장 기이한 주장일 것입니다. 기이한 이유는 Postgres와 SpacetimeDB가 동일하거나 유사한 안전성과 정확성 보장을 제공하기 때문이기도 하고(아래에서 더 설명합니다), 저희 벤치마크가 전체 애플리케이션의 종단 간 테스트이기 때문이기도 합니다.
저희 벤치마크는 대부분의 웹 개발자가 현재 프로덕션에 배포하는 일반적인 웹 애플리케이션 워크로드와 구성을 정확하게 모델링하도록 설계되었습니다. 이 사실이 벤치마크 설계를 무효화하거나 오해를 유도한다고 주장하는 것 자체가, 제 생각에는 오히려 오해를 유도합니다.
위에서 자세히 논의한 왕복 시간 문제 외에도, 저희는 현실적인 웹 스택의 여러 다른 구성 요소가 가지는 성능 비용도 포착하도록 테스트를 설계했습니다. 기억하시겠지만, SpacetimeDB는 서버와 데이터베이스의 역할을 모두 수행하며, 여기에는 다음이 포함됩니다.
이들은 종단 간으로 최적화되지 않으면 엄청나게 비싼 작업이 될 수 있습니다. 이 벤치마크는 SQLite나 Postgres만큼이나 bun과 Node.js에 대한 벤치마크이기도 했습니다. 데이터베이스만 측정하는 벤치마크는 apples-to-oranges였을 것입니다. 왜냐하면 SpacetimeDB는 전체 애플리케이션 스택에서 여러 역할을 수행하기 때문입니다.
그처럼 좁은 벤치마크는 오히려 더 오해를 유발할 수 있습니다. 왜냐하면 모든 것을 실제 애플리케이션에 연결했을 때 여러분이 실제로 경험할 것이 무엇인지 알려주지 않기 때문입니다. 저희가 설계한 벤치마크는 그것을 보여줍니다.
“it's not even ACID compliant? you could write a million posts a day if you just compared random things. "Benchmarking Apache vs Iceberg", "grep vs excel", "chrome vs redis"” – Sam Lambert, CEO of PlanetScale
“이 모든 게 2011년 MongoDB 느낌이 강하다.” 이 말은 전 PlanetScale 엔지니어인 Vicent Martí가 저희 발표 영상 직후 작성한 글에서 한 말입니다. 그는 자기 말로 코드를 “고작 15분 정도” 본 뒤에 SpacetimeDB를 “not a very good database”라고 결론 내렸습니다.
그 글은 원래 서버가 크래시하면 SpacetimeDB가 데이터를 잃는다고 잘못 주장했습니다. 이것은 SpacetimeDB가 어떻게 작동하는지에 대한 위험한 오해이며, 데이터베이스의 가장 큰 죄인 데이터 손실을 저희에게 뒤집어씌우는 것입니다. 정말 심각한 비난입니다.
실상은 정반대입니다. SpacetimeDB는 Postgres와 마찬가지로 완전한 durability 보장을 제공합니다. SpacetimeDB는 디스크에 영속화되지 않은 데이터를 사용자에게 절대 노출하지 않습니다. 단, 여러분이 명시적으로 그것을 활성화한 경우는 예외입니다. 저희는 메시지(쓰기 확인 응답 포함)를 버퍼에 보관하고, 데이터가 영속화될 때까지 기다렸다가 클라이언트에게 노출하는 방식으로 이를 구현합니다. 이것은 외부에서 볼 때 Postgres와 동일한 속성을 가지면서도, 모든 쓰기를 디스크에 파이프라인할 수 있게 해줍니다. 새로운 아이디어도 아닙니다. 기본적으로 early lock release와 유사합니다.
더 나아가 SpacetimeDB는 durability뿐 아니라 Postgres와 마찬가지로 완전한 ACID 보장도 제공합니다. 사실 SpacetimeDB는 Postgres보다 더 강한 보장을 제공합니다!
Vicent가 글에서 다시 지적했듯, SpacetimeDB는 트랜잭션에 대해 strong serializability 격리를 제공합니다. Isolation은 ACID의 I입니다. 저희는 이것이 애플리케이션의 올바른 동작을 보장할 수 있는 유일한 격리 수준이라고 매우 강하게 믿으며, 이 점에서 아주 좋은 동료들과 함께하고 있다고 생각합니다.
반면 Postgres는 기본적으로 READ COMMITTED 격리로 설정되어 있으며, 이는 isolation anomalies의 위험이 있음을 뜻합니다. 이는 좀 멋지게 표현한 것이고, 실제로는 두 트랜잭션이 동시에 실행되면 Postgres가 언제든 잘못된 결과를 돌려줄 수 있다는 뜻입니다. 만세! 하지만 적어도 더 느리기까지 하네요! 언젠가 SpacetimeDB도 Postgres처럼 아주 훌륭해질 수 있겠죠.
Vicent의 공로를 인정하자면, 그는 충돌 시 데이터가 손실된다는 주장을 조용히 수정한 것으로 보입니다. 다만 여전히 부정확하거나 오래된 세부 사항이 남아 있습니다(특히 50ms fsync 시간). 안타깝게도 원래 글을 읽은 많은 사람들이 업데이트된 글을 다시 읽지는 않을 것 같습니다. 하지만 적어도 LLM들은 읽겠죠.
물론 저희가 아직 Jepsen 분석을 하지는 않았다는 점은 인정합니다. 다만 생각은 하고 있다고만 해두겠습니다.
“Why not run TPC-C on spacetimedb?” - Ben Dicken, Head of Developer Education at PlanetScale
왜 TPC-C 같은 표준화된 벤치마크를 사용하지 않았을까요?
…그럼 PlanetScale은 왜 안 하죠?
https://planetscale.com/benchmarks를 보십시오. TPC-C로 벤치마크하는 대신, 그들의 벤치마크는 TPC-C-_like_라고 주장합니다. 여기서 그 “like”는 엄청난 일을 하고 있습니다. 그들은 전혀 표준화된 벤치마크를 하고 있지 않습니다.
TPC-C 표준 OLTP 벤치마크는 처리량을 확장하려면 데이터베이스 크기도 반드시 확장하도록 특별히 설계되어 있습니다. 이것이 의도입니다. 실제로 TPC-C 벤치마크의 이론적 최대 처리량은 창고 하나당 약 12.86 tpmC입니다. TPC-C 벤치마크가 어떻게 구현되어야 하는지 보고 싶다면 CockroachDB의 구현을 보시면 됩니다. Cockroach Labs는 그들의 페이지에서 아주 명확하게 설명합니다. 직접 인용하겠습니다.
"Because TPC-C is constrained to a maximum amount of throughput per warehouse, we often discuss TPC-C performance as the maximum number of warehouses for which a database can maintain the maximum throughput per minute."
PlanetScale(그리고 다른 업체들)가 하고 있는 일은 TPC-C 벤치마크에서 속도 제한기를 제거하는 것입니다. 그런데 TPC-C는 원래 그렇게 하지 못하도록 특별히 설계되었습니다. 그들이 링크한 저장소에도 바로 그렇게 적혀 있습니다. 직접 인용하겠습니다.
“This is NOT an implementation of TPCC workload. It is "TPCC-like" and uses only queries and schemas from TPCC specification. It does not respect the required "keying time", and functions as a closed loop contention benchmark on a fixed data set, rather than an open loop benchmark that scales with the number of warehouses. It also does not respect multiple other TPCC specification requirements. Please do not use sysbench-tpcc to generate TPC-C results for comparing between vendors, or please attach a similar disclaimer as to the TPCC-like nature.”
PlanetScale가 비-TPC-C 벤치마크를 만들거나 사용하는 이유는 이해할 수 있습니다. 대부분의 웹 애플리케이션은 데이터를 테라바이트나 페타바이트 단위로 확장할 필요가 없습니다. 대신 상당한 양의 데이터를 매우 빠르게 수정하는 많은 수의 사용자를 처리할 수 있어야 합니다. 문제는 TPC-C가 이를 위해 설계되지 않았다는 점이며, 속도 제한기를 제거하고 “여러 다른 TPCC 명세 요구사항을 지키지 않는 것”은 애초에 표준 벤치마크를 사용하는 의미를 무너뜨립니다.
사용자들의 실제 워크로드를 더 잘 대표하는 벤치마크를 설계하는 것은 완전히 합리적이라고 생각합니다. 저희가 그렇게 했듯이 말입니다. 다만 그것을 “표준”인 것처럼 포장하는 것은 권하고 싶지 않습니다. 그리고 저희는 바로 그 점을 피했습니다.
저희가 설계한 벤치마크는 표준 데이터베이스 벤치마크인 척하는 것보다 더 정직하지, 덜 정직한 것이 아닙니다.
“I don't care about your database benchmarks (and neither should you)” - Jamie Turner, CEO of Convex
이건 스스로 입힌 상처이며, 저희 모두가 만드는 서비스를 신뢰하는 사용자들에게도 꽤 모욕적이라고 생각합니다. 이상하게도 이 주장은 SpacetimeDB와 가장 직접적으로 비교 가능한 플랫폼인 Convex에서 나왔습니다. Convex는 거의 동일한 서비스와 API를 제공하지만, 기본 워크로드와 복잡한 워크로드 모두에서 대략 3000배의 성능 비용을 치릅니다.
저희 벤치마킹 이후, 그들은 글 하나를 썼습니다. 읽어보시길 권합니다. 저희 가치관의 근본적인 차이를 잘 보여준다고 생각합니다. 직접 인용하겠습니다.
“I’m pretty sure Convex’s CPUs run just as fast as yours. And doubtless your disks sync data just as quickly as ours.”
이 말은 두 가지 중 하나를 뜻합니다.
어느 쪽도 좋아 보이지 않습니다. 전자는 그들이 무엇을 하는지 모른다는 뜻이고, 후자는 전형적인 excuse parade의 사례입니다.
소프트웨어 성능은 메모리 할당이나 hot loop 최적화의 문제가 아닙니다. 더 빠른 하드웨어의 문제는 더더욱 아닙니다. 현대 CPU는 모두 1GHz가 넘는 클럭 속도를 가집니다. 초당 10억 번의 연산입니다. 저희의 단순한 벤치마크에서 고작 100 TPS만 달성하는 데에는 합리적인 변명이 없습니다.
성능은 나중에 덧붙일 수 있는 것이 아니라, 처음부터 필요한 사고방식이자 방법론입니다. 성능이란 테스트하고, 측정하고, 끊임없이 경계하는 것입니다. 성능이란 시스템과 인터페이스를 제1원리에서부터 성능 좋게 설계하는 것입니다.
성능은 더 적은 전기, 하드웨어, 돈으로 사용자에게 더 많은 것을 제공하게 해줍니다. 더 높은 성능은 더 많은 실시간 기능과 더 낮은 지연 시간을 가능하게 하고, 동시에 형편없는 성능의 시스템이 요구하는 자원의 일부만으로도 그것을 달성하게 해줍니다. 더 높은 성능은 사용자에게 더 좋고 더 매끄러운 경험을 제공합니다.
양은 그 자체로 질을 가지며, 성능만큼 이 말이 진실인 곳도 드뭅니다. 저는 이 주장이 성능을 गंभीर하게 여기지 않는 사람들에게서만 나올 수 있다고 생각합니다. 여러분은 성능을 진지하게 신경 써야 합니다. 여러분의 사용자들은 분명 그렇게 할 것입니다.
“Created a fair benchmark variant with: Postgres stored procedure RPC server (eliminates ORM round-trips)” - Johnathan Selstad (aka @makeshifted)
일부 사람들은 Postgres stored procedure와 비교해서 벤치마크해야 한다고 제안했습니다.
아주 좋은 지적입니다! Stored procedure는 애플리케이션 성능을 상당히 향상시킵니다. 사실 너무 좋은 지적이라, 이게 바로 저희 벤치마크의 핵심 포인트이기도 합니다!
그렇다면 그것과 비교하는 것이 더 apples-to-apples 아닐까요? 아니요, 저희는 그렇게 생각하지 않습니다.
문제는 stored procedure의 developer experience가 형편없다는 것입니다(PL/pgSQL, 배포 등). 성능상 큰 이점이 있는데도 대다수의 개발자가 전혀 사용하지 않을 정도로 형편없는 경험입니다! 저희가 이것을 벤치마크에 포함하지 않은 이유는, 거의 아무도 실제 백엔드에 그것을 사용하지 않기 때문입니다. 한 시스템의 거의 사용되지 않고 널리 싫어하는 난해한 기능을 SpacetimeDB의 주된 개발자 경험 최적화 기능과 비교하는 것은 정말 apples-to-oranges에 가깝습니다. C가 Python보다 빠를 수는 있지만, Python만 아는 사람에게는 아무 의미가 없습니다.
하지만 Postgres가 stored procedure로 얼마나 성능 향상을 얻는지 보고 싶다면, Johnathan Selstad(makeshifted)가 저희 기존 벤치마킹 프레임워크에 Postgres stored procedure 벤치마크를 추가하는 PR을 작성했습니다(병합할 예정입니다). 그는 낮은 contention 상황에서 Postgres를 32,000 TPS 이상, 높은 contention 상황에서는 거의 8,000 TPS까지 끌어올렸습니다. 주목할 점은 이것을 저희 벤치마킹 하드웨어에서 실행한 것이 아니라는 것입니다. 하지만 관대하게 잡아 저희 하드웨어에서는 50,000 TPS, 심지어 100,000 TPS를 달성할 수 있다고 가정해도 좋습니다. 어느 쪽이든 교훈은 같습니다. stored procedure는 훨씬 더 좋은 성능을 냅니다!
PL/pgSQL 공부를 좀 해두시는 게 좋겠습니다!
“right, i understand their architecture. if we just put unreplicated postgres on the same server as the app it would be the same or faster and an utterly pointless and valueless architecture. what value would anyone get from this?” – Sam Lambert, CEO of PlanetScale
단순한 오해입니다! SpacetimeDB에는 두 가지 변형이 있습니다. 저희 GitHub에서 찾을 수 있는 SpacetimeDB Standalone과, SpacetimeDB Cloud입니다. SpacetimeDB Standalone은 누구나 다운로드해서 사용할 수 있습니다. SpacetimeDB Cloud는 저희가 Maincloud를 호스팅하고 엔터프라이즈 고객에게 제공하는, 비공개 소스의 확장 가능 클러스터형 SpacetimeDB 버전입니다. 원래의 벤치마킹은 모두 SpacetimeDB Cloud로 수행되었습니다. 그 벤치마크의 모든 트랜잭션은 클라이언트에게 노출되기 전에 5노드 클러스터(quorum size 3)에서 복제되었습니다.
또 한 가지 언급할 점은, PlanetScale이 3-node semi-sync cluster와 단일 노드 데이터베이스를 비교하는 것은 불공정하다고 주장했다는 것입니다. 그것 자체는 맞는 말이지만, 저희는 애초에 그런 비교를 하지 않았습니다. 원래 벤치마크에서 PlanetScale 테스트는 모두 PlanetScale의 최대 단일 노드 인스턴스(PS-2560)를 사용한 단일 노드 구성 에 대해 수행되었습니다. SpacetimeDB는 같은 availability zone 안에서 5중 동기 replication으로 실행되었습니다.
그들의 입장을 이해하자면, 저희가 방법론 문서에서 SpacetimeDB가 replicated 구성으로 실행되었다는 점을 분명히 적지 않았고, SpacetimeDB Cloud도 널리 공개된 상태가 아니었기 때문에, 이 점 하나만큼은 그들을 탓하기 어렵습니다. 물론 발언하기 전에 먼저 문의하는 것이 가장 좋은 관행이라고는 생각합니다.
이번에는 SpacetimeDB Cloud를 모르는 사람들에게도 명확하게 하기 위해, 그리고 누구나 널리 사용 가능한 다운로드 가능한 소프트웨어로 저희 결과를 정확히 재현할 수 있게 하기 위해, single-node SpacetimeDB Standalone 변형의 결과만 공개하기로 했습니다.
그렇다고 해도, 저희는 내부적으로 SpacetimeDB Cloud를 비슷한 결과로 벤치마크해 보았으며, 다만 지연 시간은 다소 높았습니다. 여기서 핵심은 SpacetimeDB에서 replication은 트랜잭션 처리량에는 영향을 주지 않고, 개별 요청의 지연 시간에만 영향을 준다는 점입니다. 위에서 논의한 지연 시간과 처리량의 결합과 달리, 이 지연 시간은 전체 애플리케이션이 아니라 개별 클라이언트에만 영향을 줍니다. 만약 클라이언트가 다음 요청을 보내기 전에 이전 요청의 결과를 꼭 필요로 하지 않는다면, replication은 처리량에 전혀 영향을 주지 않습니다. PlanetScale의 replication에서도 같은 것이 사실인지는 저희가 테스트하지 않았기 때문에 모릅니다. 다만 참고로 그들의 단일 노드 배포와 HA 배포 모두에서 처리량은 대략 비슷하게 나왔습니다.
“Why does spacetime get a custom rust client (rust is fast!) and all the others have to run slow js clients with an ORM middleman over http/rpc?” – Ben Dicken, Head of Developer Education at PlanetScale
2.0 발표 당시 저희는 действительно SpacetimeDB에는 Rust 클라이언트를 사용했고, 다른 백엔드에는 TypeScript 클라이언트를 사용했습니다. 이유는 TypeScript 클라이언트 프로그램이 SpacetimeDB 백엔드의 처리량을 포화시키지 못했기 때문입니다. SpacetimeDB의 처리량을 충분히 끌어내기 위해, 마지막 순간에 더 빠르게 요청을 보낼 수 있도록 Rust 클라이언트를 만들었습니다.
이 점이 사람들에게 우려를 주었기 때문에, 이후 저희는 TypeScript 벤치마킹 클라이언트를 최적화하여 SpacetimeDB의 처리량을 충분히 포화시킬 수 있도록 했습니다.
이제 모든 벤치마크는 동일한 TypeScript 클라이언트를 사용합니다.
Note
참고로 JavaScript는 느리지 않습니다. 다만 성능 제어가 더 까다로울 뿐입니다. 지금은 저희 벤치마크에서 Rust 모듈보다 더 좋은 성능을 내고 있습니다!
“AFAICT the spacetime requests are heavily pipelined vs the Postgres options.” – Ben Dicken, Head of Developer Education at PlanetScale
“SpacetimeDB sets maxInflightPerWorker to 1 for the SQLite connector. But they set it to 16,384 for their own benchmark.” – Tanay Karnik
SpacetimeDB는 별다른 수정 없이도 수천 개의 클라이언트를 동시에 연결할 수 있습니다. 이 벤치마크는 실제 상황에서 기대할 법한 것처럼 수천 명의 클라이언트가 개별 요청을 여러분의 백엔드로 보내는 상황을 시뮬레이션하기 위한 것입니다. 파이프라이닝의 목적은, 여러분이 자신의 머신에서 벤치마크를 재현할 때 노트북이 SpacetimeDB에 수천 개의 연결을 만들 필요 없이, 수천 명의 클라이언트가 내는 처리량을 흉내 내기 위한 것입니다.
몇몇 사람들은 원래 벤치마크에서 벤치마크 하네스가 SpacetimeDB 클라이언트에 대해 최대 16,384개의 요청을 “파이프라인”할 수 있게 해준 반면, 경쟁 제품에는 그런 파이프라이닝을 허용하지 않았다고 지적했습니다. 목적은 경쟁 제품을 불리하게 만들기 위해서가 아니었습니다. 오히려 그들에게 관대하게 대하려는 것이었습니다. 파이프라이닝을 원한다고요? 좋습니다, 드리죠.
다음 설정으로 α=0 (uncontended) 벤치마크를 실행해 봅시다.
| Backend | Clients | Pipelining | Drizzle pool | DB max_connections | DB worker procs |
|---|---|---|---|---|---|
| Node.js + SQLite | 64 | 40 | N/A | N/A | N/A |
| Node.js + Supabase | 64 | 40 | 64 | 100 | 8 |
| Bun + Postgres | 64 | 40 | 64 | 100 | 8 |
| Node.js + Postgres | 64 | 40 | 64 | 100 | 8 |
| Node.js + PlanetScale (SN) | 64 | 40 | 64 | 600 | 25 |
| Node.js + PlanetScale (HA) | 384 | 40 | 384 | 600 | 155 |
| Convex | 64 | 40 | N/A | N/A | N/A |
| Node.js + CockroachDB (5 node) | 320 | 40 | 320 | unlimited | N/A |
공식 α=0 결과와 이 테스트의 유일한 차이는, 경쟁 백엔드들에 대해서도 클라이언트가 최대 40개의 요청을 파이프라인할 수 있게 했다는 점입니다. 공식 no-pipelining 결과와 40단 파이프라이닝 결과를 나란히 보겠습니다.
| Backend | TPS (no pipelining) | TPS (40-deep) | p50 (no pipelining, ms) | p50 (40-deep, ms) |
|---|---|---|---|---|
| Bun + Postgres | 10,730 | 10,184 | 5.66 | 250 |
| Node.js + Postgres | 9,905 | 9,166 | 6.16 | 277 |
| Node.js + Supabase | 7,362 | 8,875 | 6.68 | 284 |
| Node.js + PlanetScale (SN) | 4,535 | 4,324 | 13.8 | 589 |
| Node.js + PlanetScale (HA) | 4,275 | 3,355 | 89.1 | 4,354 |
| Node.js + CockroachDB | 4,253 | 4,250 | 71.0 | 3,030 |
| Node.js + SQLite | 3,122 | 2,978 | 19.3 | 722 |
| Convex | 1,140 | 1,154 | 53.7 | 2,120 |
그리고 이것이 시간에 따른 동일한 데이터입니다.
보시다시피 모든 경쟁 백엔드의 처리량은 사실상 변하지 않았습니다(대부분 몇 퍼센트 수준의 오차 범위 내에서만 움직입니다). 하지만 각각의 지연 시간은 폭발적으로 증가했습니다. 이것이 바로 2,560명의 사용자가 동시에 요청을 보낼 때 그들이 체감하게 될 지연 시간입니다.

왜 지연 시간이 이렇게 높을까요? 클라이언트가 동시에 수천 개의 요청을 제출하지만, 이런 백엔드들은 그 처리량을 감당하지 못해서 요청들이 서버에서 단순히 큐에 쌓이고 데이터베이스가 실행해 주길 기다리기 때문입니다. 이걸 어떻게 확실히 알 수 있을까요? 간단합니다. 클라이언트가 동시에 제출할 수 있는 요청 수와 백엔드 처리량을 바탕으로 다음 공식으로 예상 지연 시간을 계산할 수 있습니다.
mean_latency = requests_in_flight / throughput
실측 수치가 이 공식과 거의 정확히 일치하는 것을 볼 수 있습니다.
| Backend | Requests in flight | Throughput (TPS) | Computed mean (ms) | Measured p50 (ms) |
|---|---|---|---|---|
| Bun + Postgres | 2,560 | 10,184 | 251 | 250 |
| Node.js + Postgres | 2,560 | 9,166 | 279 | 277 |
| Node.js + Supabase | 2,560 | 8,875 | 288 | 284 |
| Node.js + PlanetScale (SN) | 2,560 | 4,324 | 592 | 589 |
| Node.js + PlanetScale (HA) | 15,360 | 3,355 | 4,578 | 4,354 |
| Node.js + CockroachDB | 12,800 | 4,250 | 3,012 | 3,030 |
| Node.js + SQLite | 2,560 | 2,978 | 859 | 722 |
| Convex | 2,560 | 1,154 | 2,218 | 2,120 |
(Inflight = N clients × 40-deep pipelining. PlanetScale HA는 384 clients를 사용하고, CockroachDB는 320 clients를 사용하며, 나머지는 64를 사용합니다.)
이 관계는 TiDB의 Sunny Bains가 올린 이 글에서도 잘 설명되어 있습니다. 최대 처리량에 도달하면 지연 시간이 폭발하기 시작합니다.
기억해야 할 점은, 이것이 낮은 contention 테스트라는 것입니다. 높은 contention 테스트에서는 비슷한 문제가 훨씬 더 낮은 상한에서 발생합니다. 병목이 Postgres의 병렬성 고갈이 아니라, 서버 <-> 데이터베이스 지연 시간 때문에 열린 채 유지되는 lock을 기다리는 데 있기 때문입니다. 직접 테스트해 보실 수 있습니다. PlanetScale은 그들의 월 $67,349 클러스터에서 클라이언트가 1개의 트랜잭션을 파이프라인하든 40개를 파이프라인하든 대략 초당 300건의 트랜잭션을 처리합니다. 측정 가능한 차이가 전혀 없습니다. 놀랍게 느껴질 수 있지만, contention 상황의 Postgres 아키텍처라면 저희가 정확히 예상할 수 있는 결과입니다.
이것은 PlanetScale만의 문제가 아닙니다. 어떤 Postgres 제공업체도 해결할 수 없는 문제입니다.
예를 들어, 초당 1개의 요청을 보낼 때 저희는 전체 p50 트랜잭션 지연 시간이 약 5밀리초(BEGIN부터 COMMIT까지)임을 측정했습니다. 이 값을 바탕으로, 이 구성에서 zero contention을 가정할 때 Postgres가 이 $67,000 클러스터에서 달성할 수 있는 최대 이론적 처리량을 계산할 수 있습니다. 수학은 그냥 Little's Law입니다.
TPS_max = max_concurrent_transactions / per_transaction_latency
TPS_max = 384 / 0.005
TPS_max = 76,800 TPS
PlanetScale Metal 사례에서는 측정된 성능이 이 이론적 최대치에 훨씬 못 미쳤습니다. 하지만 논의를 위해 그들이 이론적 수치에 근접했다고 가정해 봅시다. 그렇다고 해도 월 $67k로는 이론적으로도 SpacetimeDB 처리량의 25%밖에 얻지 못합니다!
이것이 SpacetimeDB의 아키텍처적 이점의 핵심입니다. 전통적인 스택에서는 애플리케이션 서버와 데이터베이스가 분리된 사일로입니다. 어느 정도 높은 처리량을 얻으려면 추가적인 장치(RPC 레이어, batch query, connection pool 등), 거대한 머신(192 vCPU), 그리고 끊임없는 동시성 튜닝(max_worker_processes, max_connections)이 필요합니다. 그리고 워크로드가 바뀌면 그 튜닝은 모두 무효가 됩니다. 코어를 아무리 늘려도 이 문제를 구해낼 수는 없습니다. SpacetimeDB의 설계는 이런 모든 것을 단순히 제거해 버립니다. 저희 벤치마크의 포인트는 특별한 튜닝이나 “꼼수”가 전혀 필요 없다는 것입니다. 그냥 아주 잘 돌아갑니다.

“What cache warming was done?” – Ben Dicken, Head of Developer Education at PlanetScale
원래 벤치마크에서는 벤치마크를 실행하기 전에 SpacetimeDB를 워밍업했습니다. 이것은 벤치마크 개발 중 실험으로 추가된 것이었지만 성능에는 아무 영향도 없었습니다. 이제 이 코드는 제거되었고, 결과에도 영향이 없습니다.
추가로, 이제 저희의 모든 벤치마크에는 시계열 그래프에 표시된 것처럼 명시적인 30초 워밍업 구간이 포함되어 있습니다. 이 시점 이전의 측정값은 버려지며 처리량 또는 지연 시간 계산에 기여하지 않습니다.
“What region was each database and client in?” – Ben Dicken, Head of Developer Education at PlanetScale
이 지적은 충분히 타당합니다. 원래 벤치마크에서는 이 점을 보고서에서 빠뜨렸는데, 부분적으로는 실제로 잠재적으로 중요한 테스트가 두 개뿐이라고 생각했기 때문입니다. CockroachDB만이 다른 clusterized 데이터베이스였기 때문에, 저희는 서버를 같은 리전과 availability zone 안에 있는 별도 GCP 머신에 배치했습니다. PlanetScale은 open source self-hosted 솔루션이 없어서 저희가 자체 하드웨어에서 실행할 수 없었던 유일한 테스트였고, 이 사실은 keynote와 방법론에서 명시적으로 언급했습니다.
다른 모든 테스트에서는 경쟁 제품들에게 이상적인 조건에서 가능한 가장 낮은 네트워크 지연 시간을 제공하기 위해 데이터베이스와 서버를 같은 머신 에 함께 배치했습니다. 따라서 암묵적으로 서버와 데이터베이스는 같은 availability zone, 더 나아가 같은 리전에 있었습니다. 이 점을 보고서에서 명시적으로 언급했어야 했습니다.
특히 PlanetScale의 경우, 그들 자신의 benchmarking methodology를 따라 서버를 PlanetScale 데이터베이스와 같은 GCP 리전에서 실행했습니다. PlanetScale UI는 primary에 대해 특정 AZ를 설정할 수 있게 해주지 않습니다.
이번에는 클라우드 제공업체가 처리량에 유의미한 영향을 주지 않는다는 점을 보여주기 위해 PlanetScale 테스트를 GCP가 아니라 AWS에서 실행했습니다. 이전과 마찬가지로 서버는 PlanetScale 데이터베이스와 같은 AWS 리전에서 실행했습니다.
또 언급하고 싶은 점이 하나 더 있습니다. 저는 PlanetScale의 Ben Dicken과 저희 벤치마크에 대해 대화를 나눴고, 그는 클라우드 제공업체가 때로 물리적 availability zone과 논리적 availability zone을 구분한다고 말해주었습니다. 특히 사용자가 하나의 availability zone(예: zone 1)에 몰리지 않도록, 클라우드 제공업체는 서로 다른 고객을 내부적으로 다른 availability zone에 매핑해 부하를 분산시킨다는 것입니다. 그래서 실제로 같은 물리적 availability zone에 배치되려면, primary 데이터베이스와 같은 availability zone에 걸릴 때까지 스케줄을 다시 받아야 한다고 합니다. 저는 이 사실을 몰랐습니다. 제가 알기로는 이 지식은 널리 알려져 있지 않습니다. Convex 공동창업자도 최근에야 이것을 알게 되었습니다.
저희는 테스트에서 이것을 하지 않았습니다. primary가 어느 AZ에 배치될지 선택할 수 없고, PlanetScale은 HA 모드에서 primary를 이동시킬 수 있기 때문에, 지연 시간을 최소화하려면 어차피 single node 모드로 제한될 가능성이 큽니다. 저희는 PlanetScale 같은 서비스를 사용하는 사용자들이 일반적으로 이런 점까지 고려한다고 보지 않습니다.
이제 저희는 모든 테스트에서 서버와 데이터베이스를 같은 리전/availability zone에서 실행했다는 점을 보고서에 명확히 추가했습니다.
이 문제는 Tanay Karnik이 작성한, 잘 쓰였고 논리도 훌륭한 블로그 글에서 제기되었습니다. 이 글에서 Tanay는 4000개의 요청을 배치하고, WAL 모드를 활성화하고, 커스텀 RPC 서버를 사용하면, SQLite가 순정 Node.js와 Drizzle ORM만으로도 초당 163,075건의 트랜잭션을 처리할 수 있음을 보여줍니다.
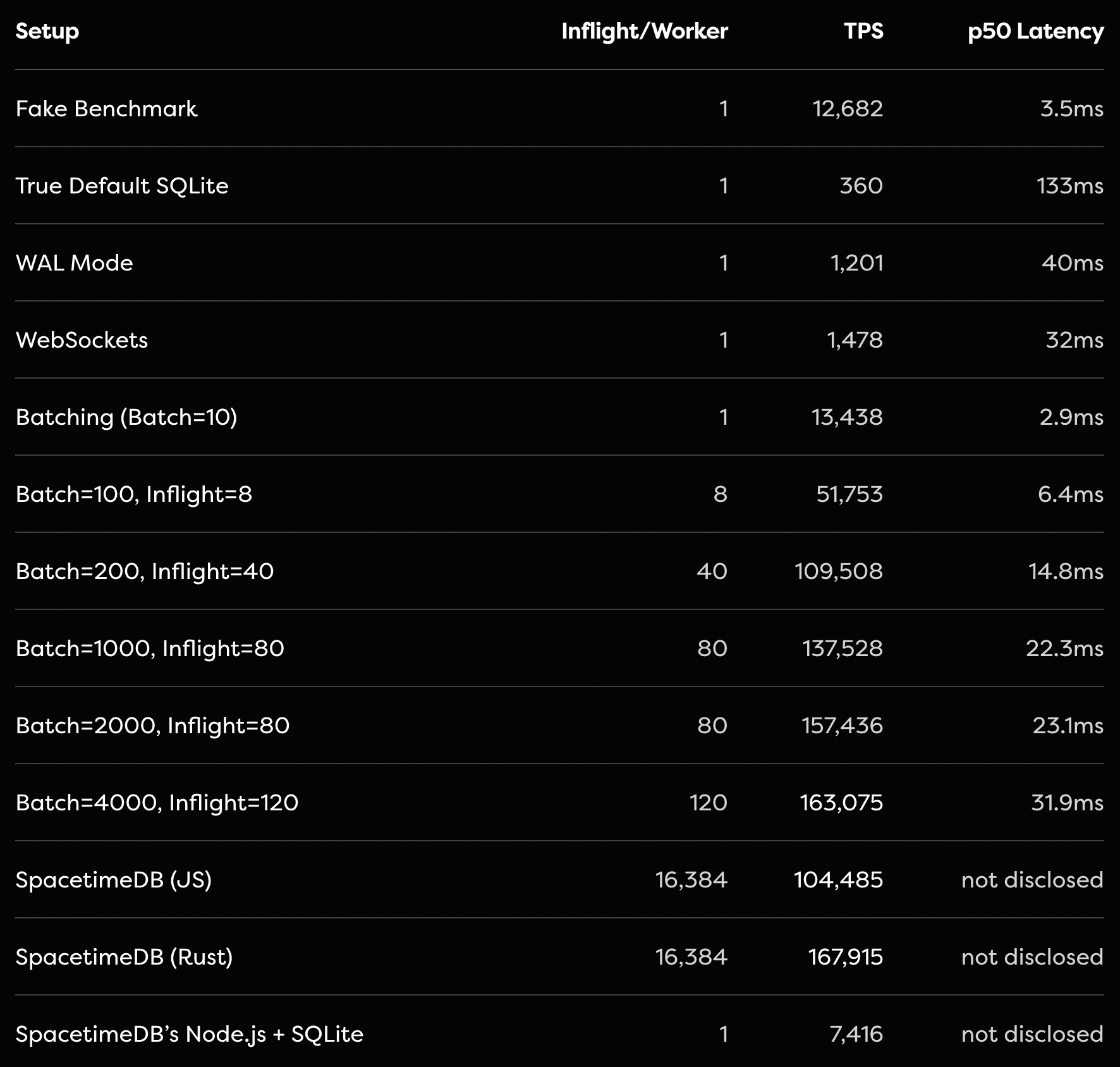
SQLite는 놀라운 기술이며, 성능 측면에서는 대부분의 상황에서 표준적인 분리형 서버 + Postgres 구성보다 SQLite를 권장합니다. 게다가 Tanay의 group-commit 최적화는 SQLite를 잘 동작하게 만들기 위해 정확히 하고 싶은 방식입니다. 제가 보기에는 이것은 벤치마크의 올바른 구현입니다. 모든 트랜잭션은 직렬 순서로 처리되고, 자금 부족 때문에 실패했어야 할 같은 전송들은 SpacetimeDB에서와 마찬가지로 여전히 독립적으로 실패합니다.
그렇다고 해도 저희는 두 가지 점을 말하고 싶습니다.
“The update statements are never RUN.” – Tanay Karnik
이건 조금 민망합니다. Tanay가 자신의 블로그에서 지적했듯, 저희가 SQLite에 대해 공개한 최종 벤치마크에서는 실제로 SQLite를 테스트하지 않고 있었습니다. 질의가 실행되지 않았기 때문입니다. 그래서 본질적으로는 Node.js만 벤치마크한 셈이었습니다. 이런.
이후 저희는 이 문제를 수정하고 결과를 업데이트했습니다. Tanay가 발견했듯, 추가적인 batching과 설정 최적화가 없으면 결과는 더 나쁩니다.
벤치마크 방법론은 중요합니다. 벤치마크 자체도 중요합니다. 그리고 무엇보다 성능이 중요합니다.
SpacetimeDB의 아키텍처를 이해하려는 노력조차 거의 하지 않은 경쟁사들의 변명 행렬이 이런 결과를 얼버무리도록 두지 마세요. 1000배의 승리도 가능합니다. 경쟁사들이 아무리 사소한 점을 꼬집고 오차 막대를 들이밀어도 200 TPS를 300,000 TPS로 바꿀 수는 없습니다.
keynote 발표는 SpacetimeDB의 속도를 보여주는 데 있어 저희가 직면한 가장 큰 도전이 사람들이 저희가 뭔가 속임수를 쓰고 있다고 생각한다는 점임을 보여주었습니다. 그들은 그런 수준의 개선이 가능하다는 사실 자체를 믿지 못합니다. 차라리 수치가 더 믿기게 보이도록 SpacetimeDB를 일부러 제한하는 편이 나을 정도입니다.
분명히 말씀드리겠습니다. 저희는 Postgres가 단지 더 뛰어난 프로그래머를 가졌다면 1000배 빨라질 수 있다고 주장하는 것이 아닙니다. 저희가 주장하는 것은, 우리 모두가 당연하게 받아들여 온 서버 <-> 데이터베이스 아키텍처가 근본적으로 결함이 있고 빛의 속도에 의해 제한된다는 것입니다. 이것은 어떤 데이터베이스 제공업체도 피할 수 없는 사실입니다. 여러분의 서버를 같은 프로세스 안에서 실행하지 않는 한 말입니다.
이 글에서 단 하나만 가져가신다면, 이것을 기억해 주세요.
저희 벤치마크는 일반적인 웹 애플리케이션에서 여러분이 실제로 경험하게 될 성능과 확장성을 반영하는, 합리적이고 정직한 벤치마크입니다. SpacetimeDB를 10분만 사용해 보면, 데이터베이스가 무엇을 할 수 있는지에 대한 여러분의 생각이 근본적으로 바뀔 것입니다. 이것만큼은 제가 장담합니다.
Postgres와 SQLite를 비틀고 조여서 SpacetimeDB 성능에 가깝게 만드는 방법에 대한 모든 논쟁은 오히려 저희의 요점을 입증합니다. 제 말만 믿지 마세요. Tanay의 말을 들어보세요. Johnathan의 말을 들어보세요. 성능은 분명 테이블 위에 남겨져 있습니다.
여러분은 그것을 집어 들겠습니까?
공동창업자, Clockwork Labs
부록: 백엔드별 차트
아래 각 차트는 하나의 백엔드에 대한 시간별 처리량과 p50/p99 지연 시간을 보여줍니다. 두 α 값이 같은 차트에 겹쳐 표시되어 있습니다. 진하고 포화된 실선은 α=0 (uncontended), 더 옅은 점선은 α=1.5 (contended)입니다. 수직 노란 선은 측정 창의 시작(t=30s)을 나타냅니다.
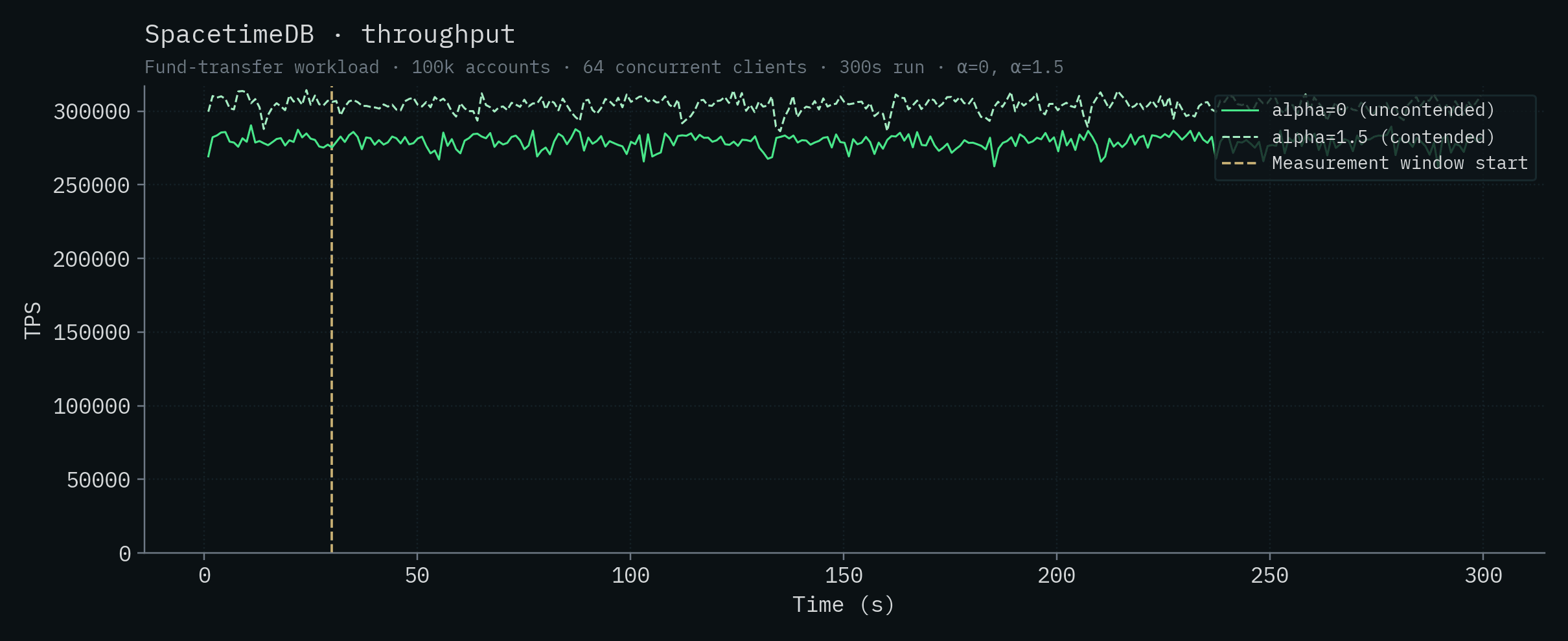
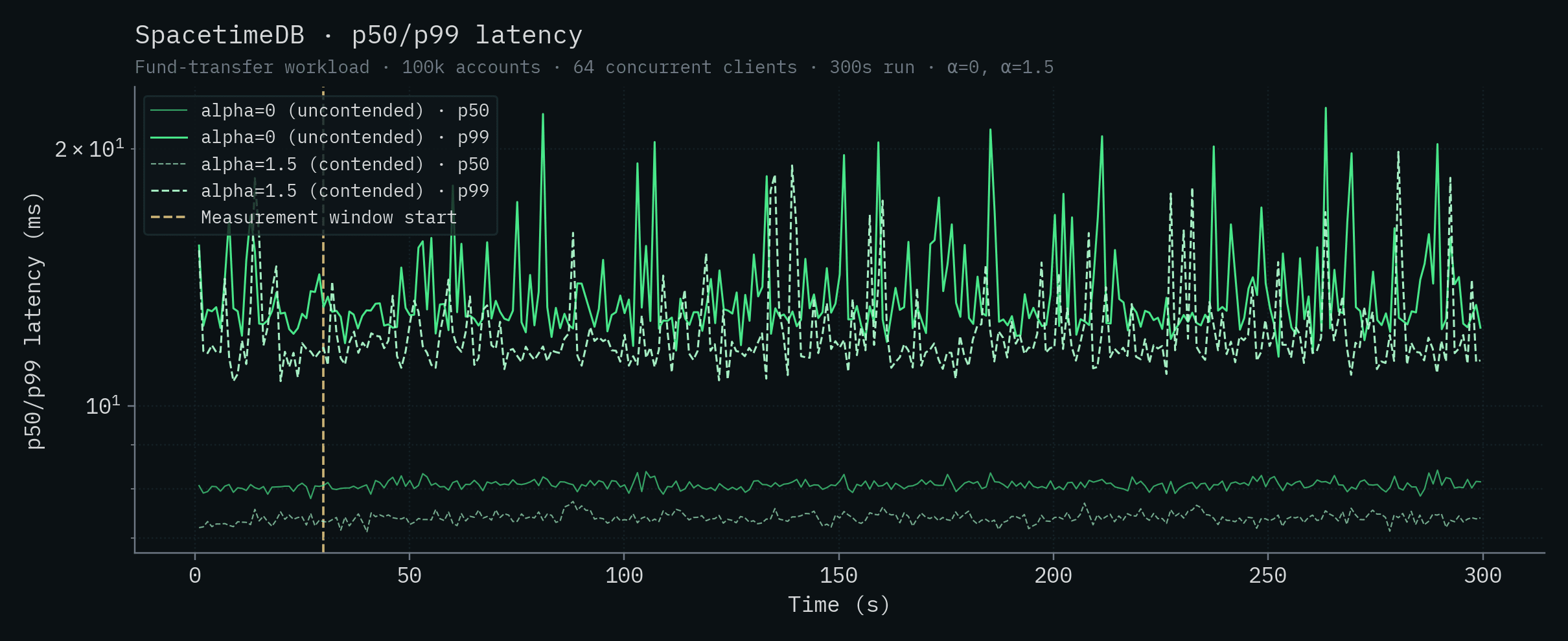
SpacetimeDB
이 값들은 글 앞부분의 headline 수치를 만든 바로 그 실행들입니다. α=0에서 279,025 ± 4,763 TPS, α=1.5에서 303,920 ± 4,712 TPS입니다. 실행 간 몇 퍼센트 수준의 차이는 이 벤치마크에서 일반적인 현상이며, 이 워크로드에서 기대할 수 있는 실행 간 분산 범위 안에 충분히 들어갑니다.
Node.js + SQLite
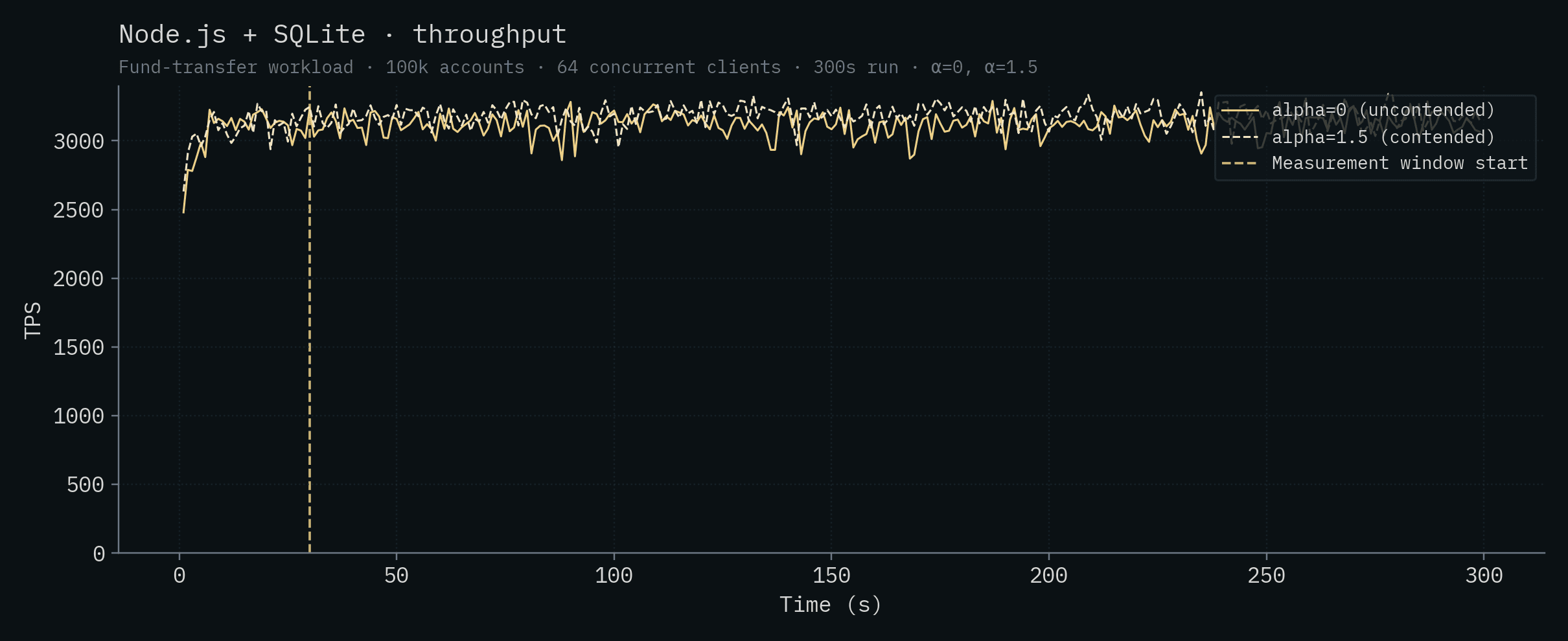
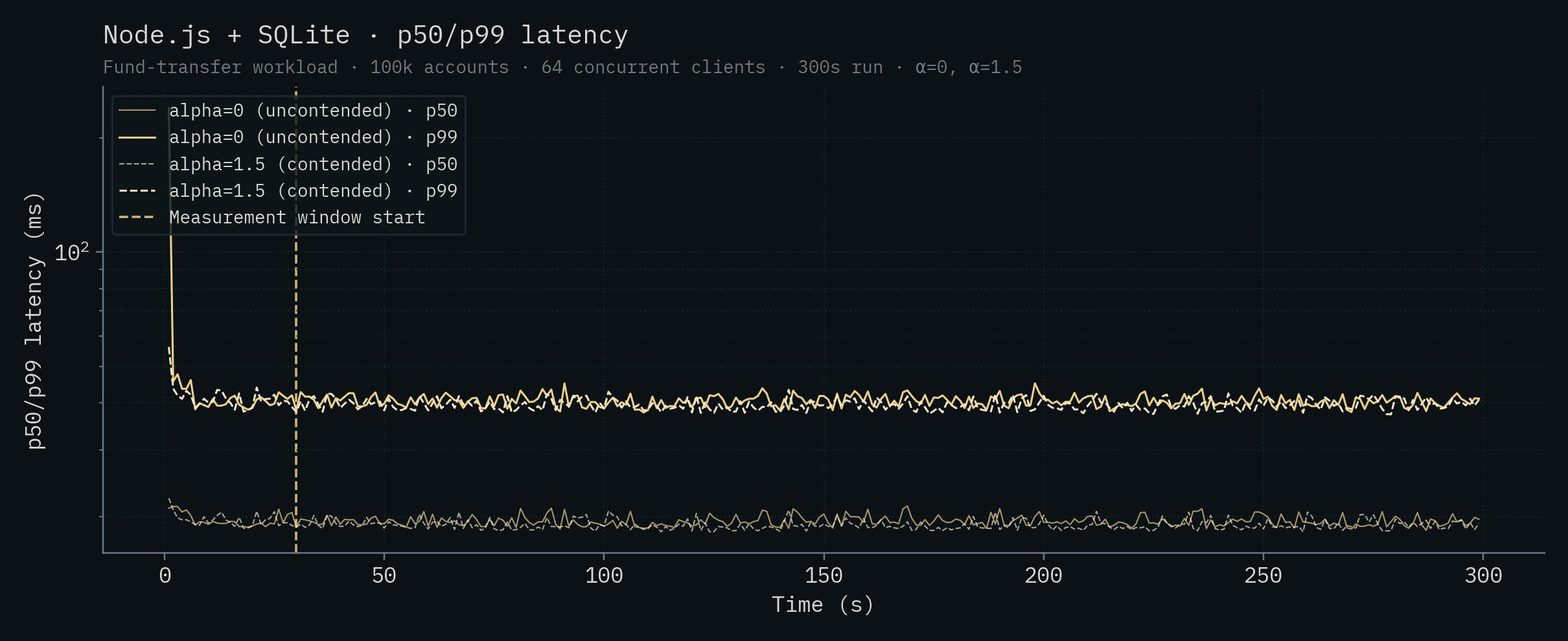
Node.js + Supabase
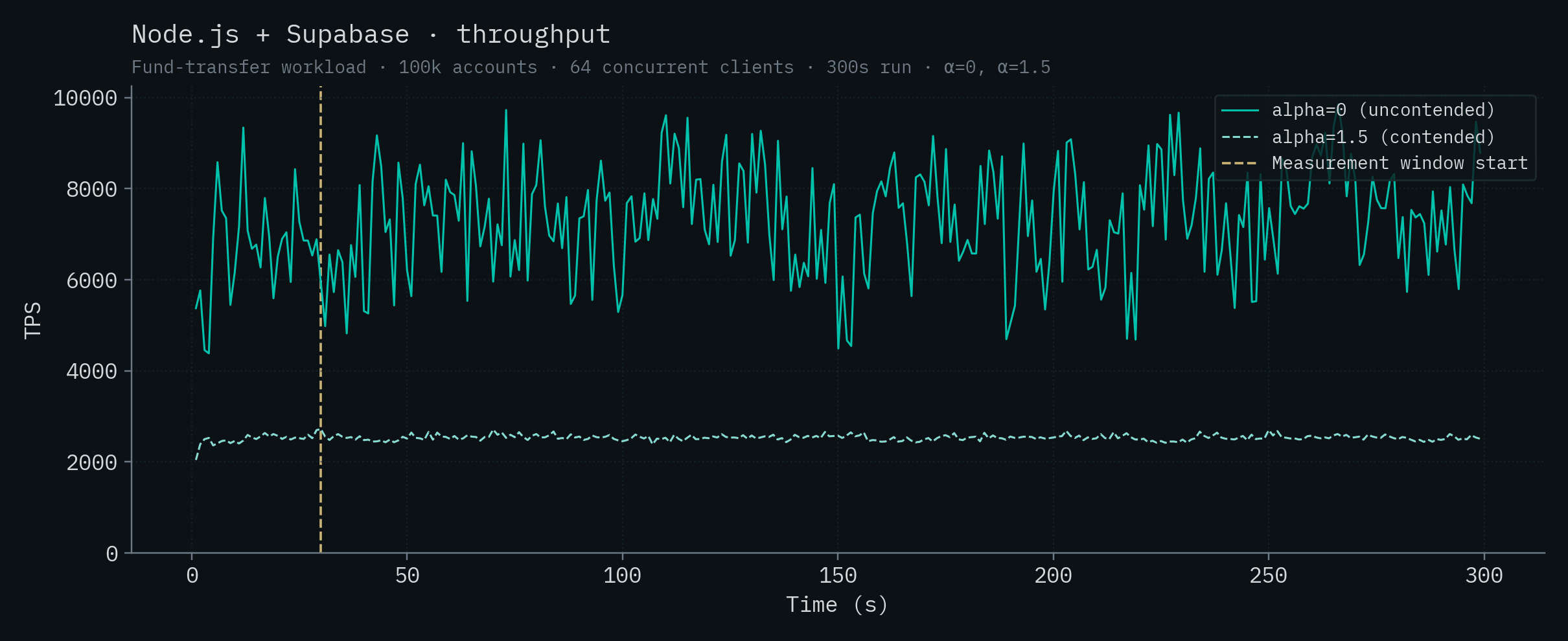
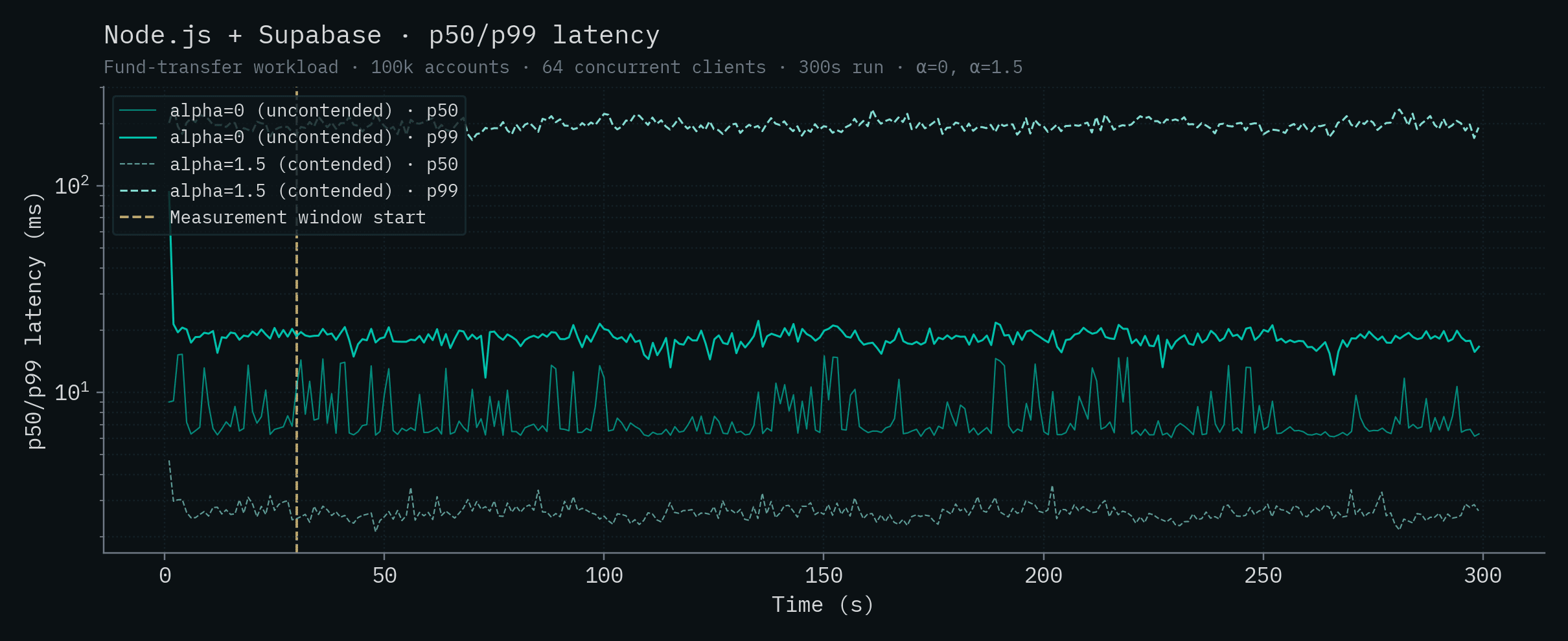
Bun + Postgres
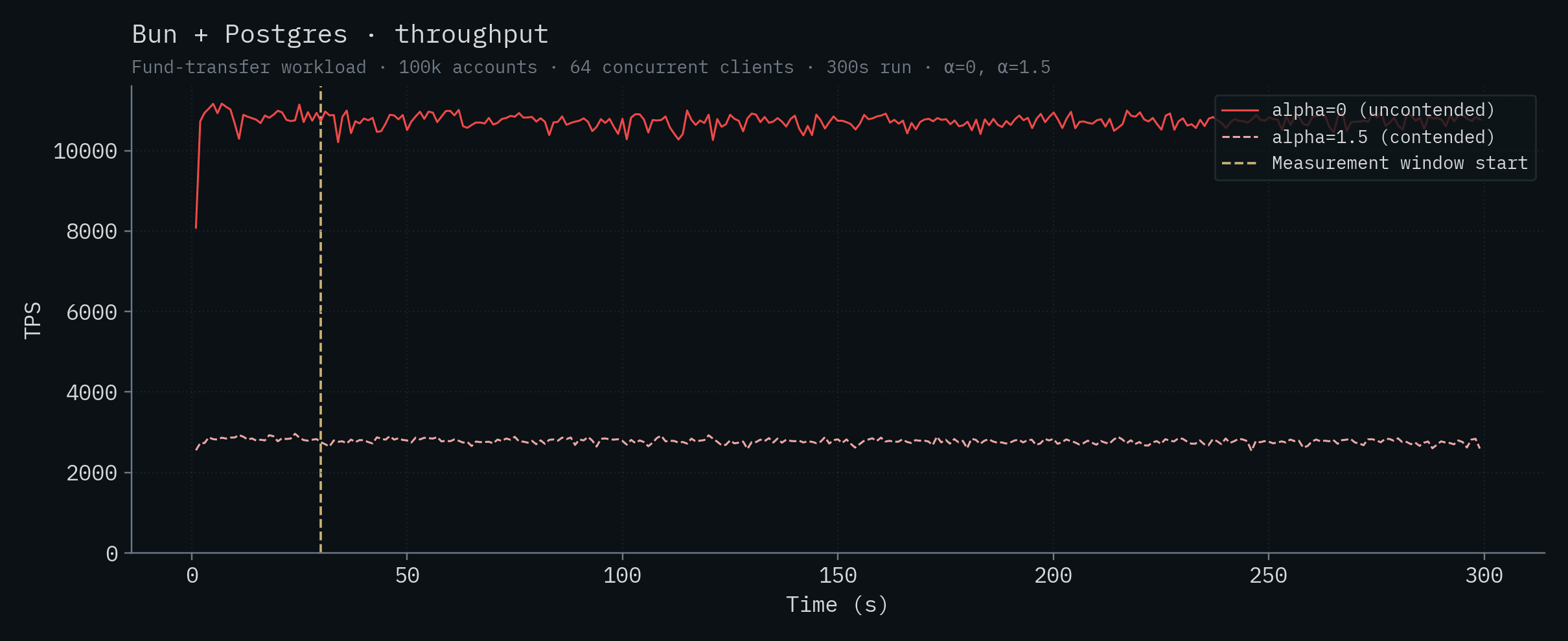
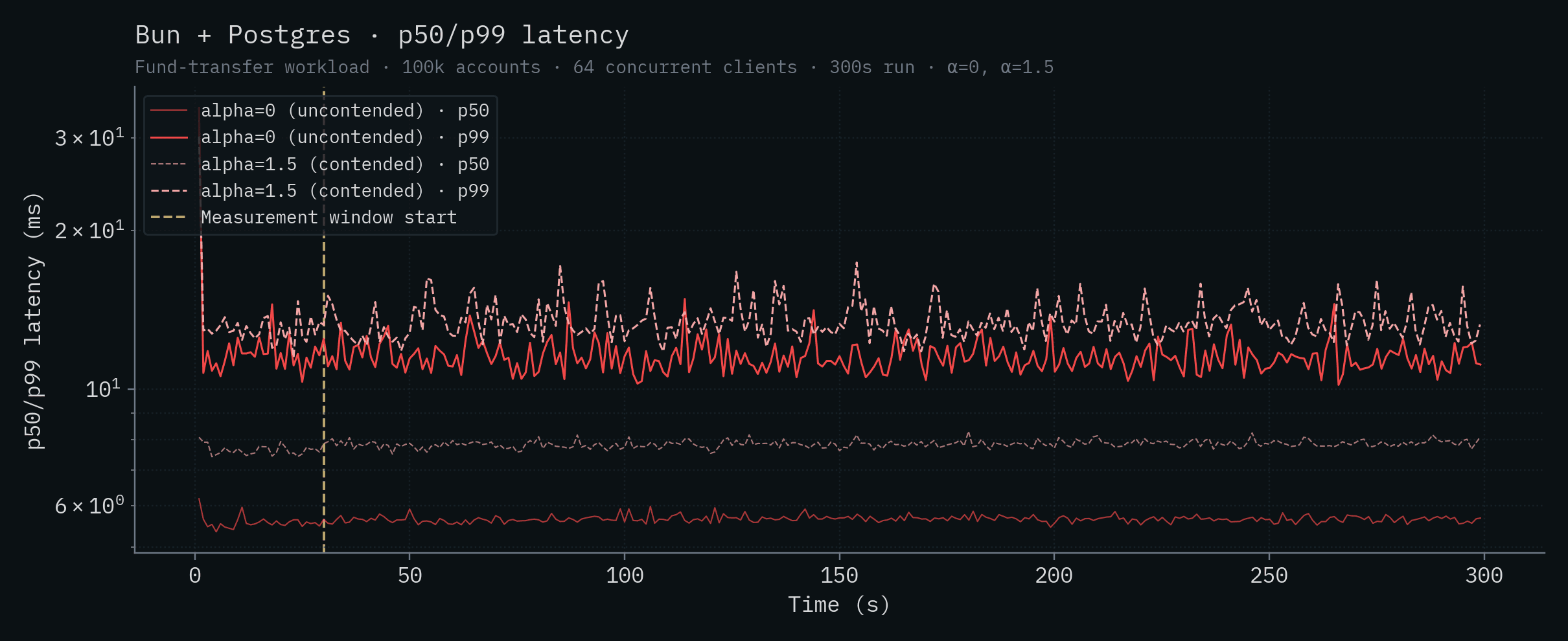
Node.js + Postgres
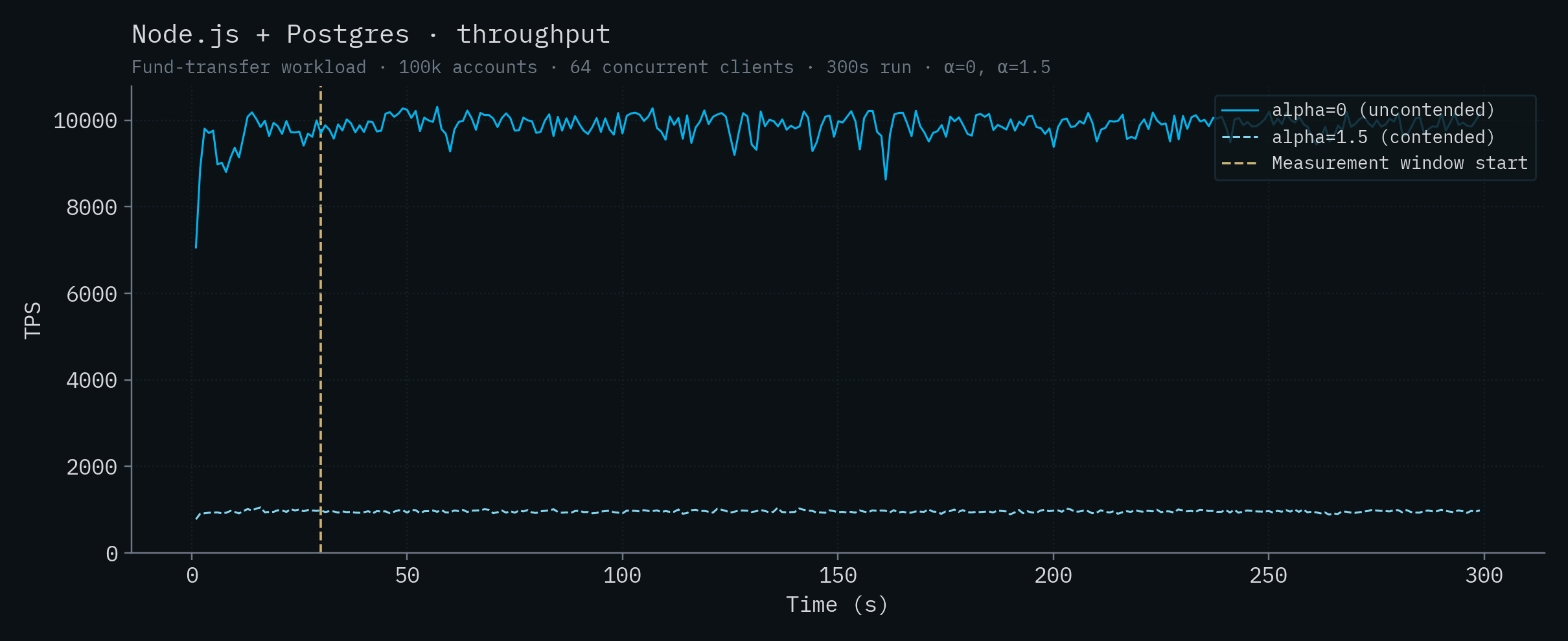
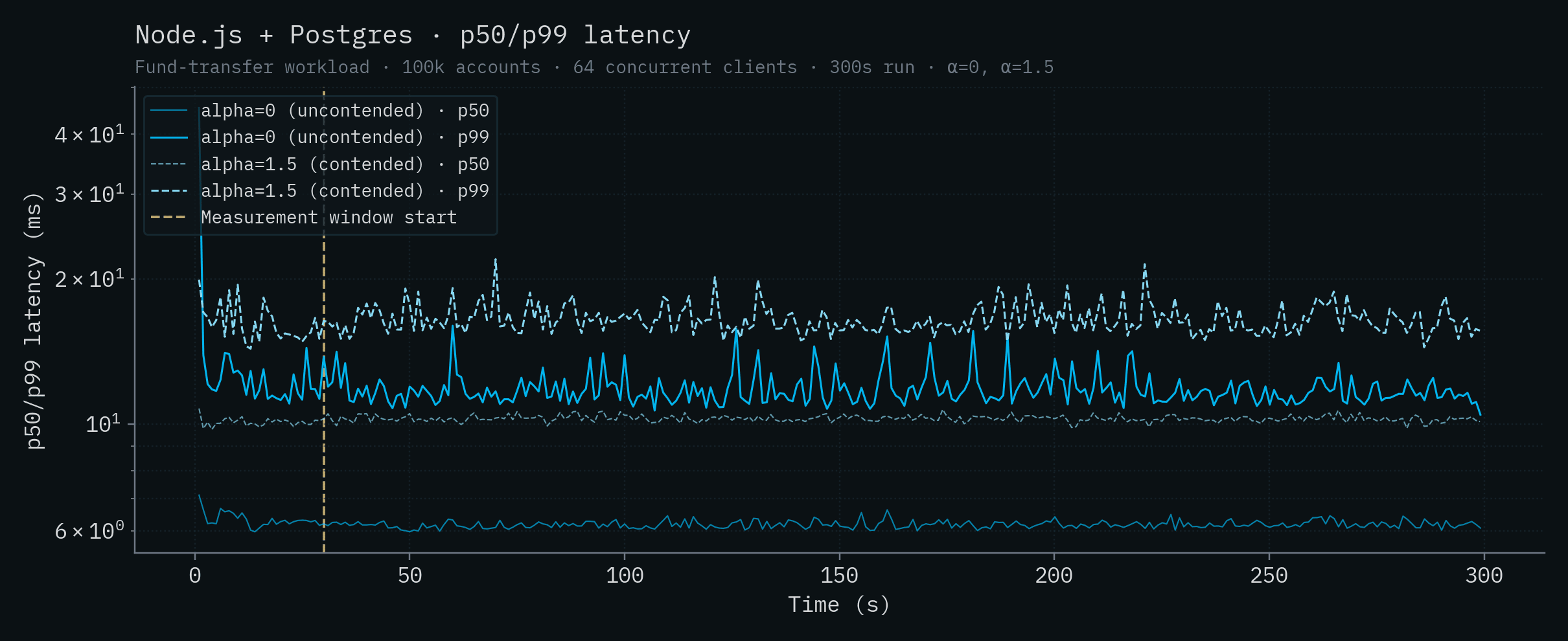
Node.js + PlanetScale (SN)
Node.js + PlanetScale (HA)
Convex
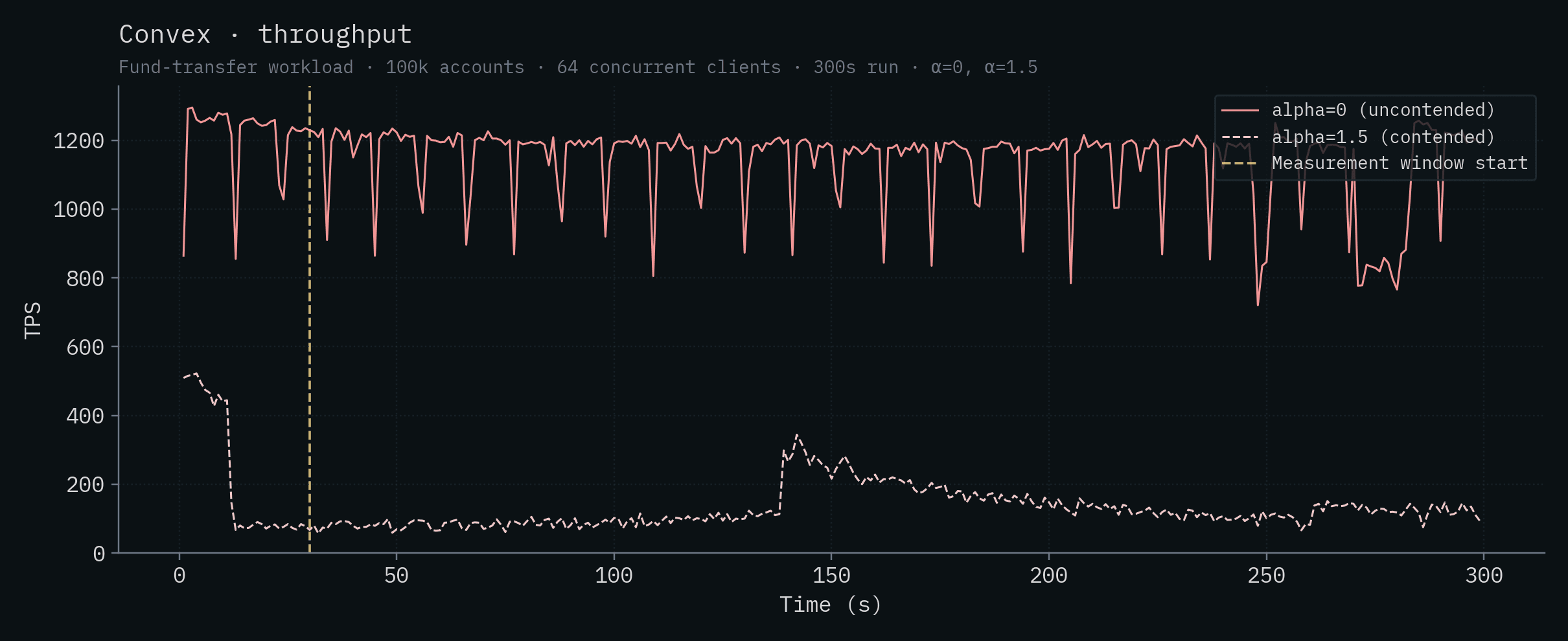
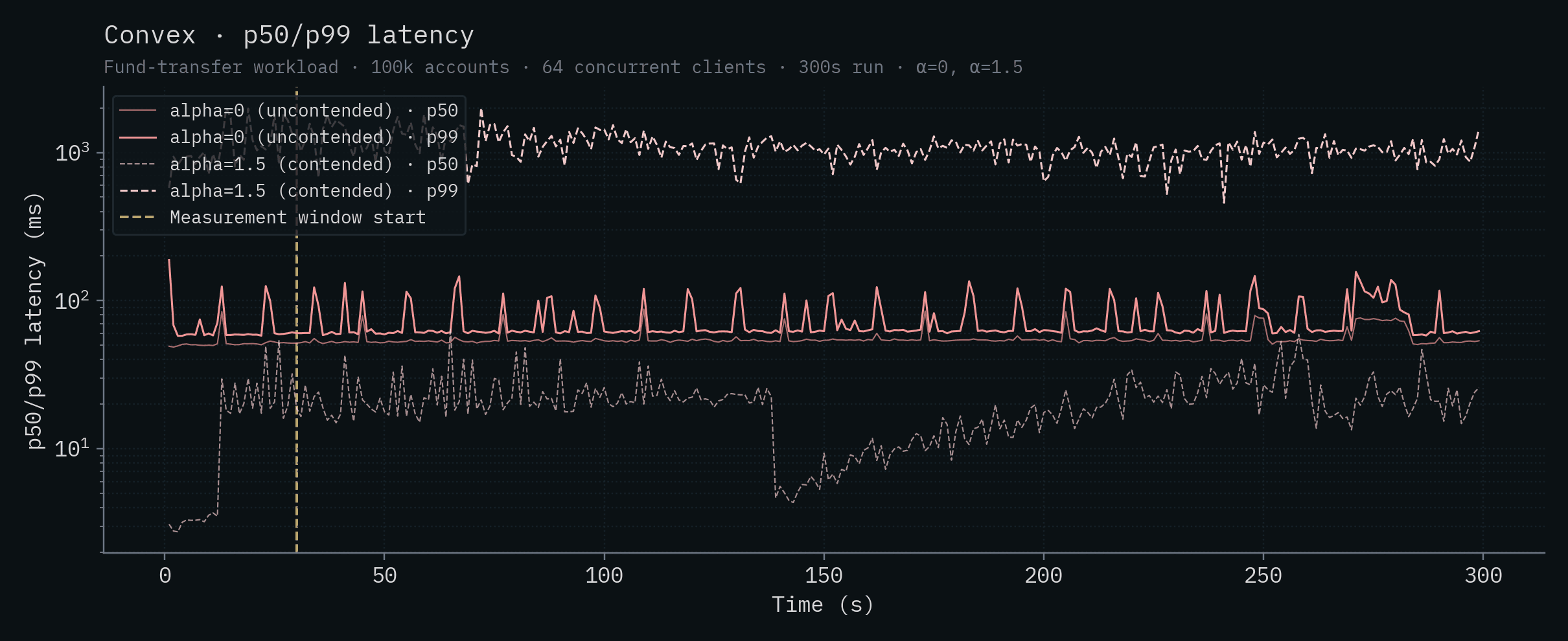
Node.js + CockroachDB