SpacetimeDB 2.0의 벤치마크, 스토리지/내구성 설계, 그리고 그에 따른 트레이드오프와 사용 사례를 기술적으로 검토한다.
2026-02-26
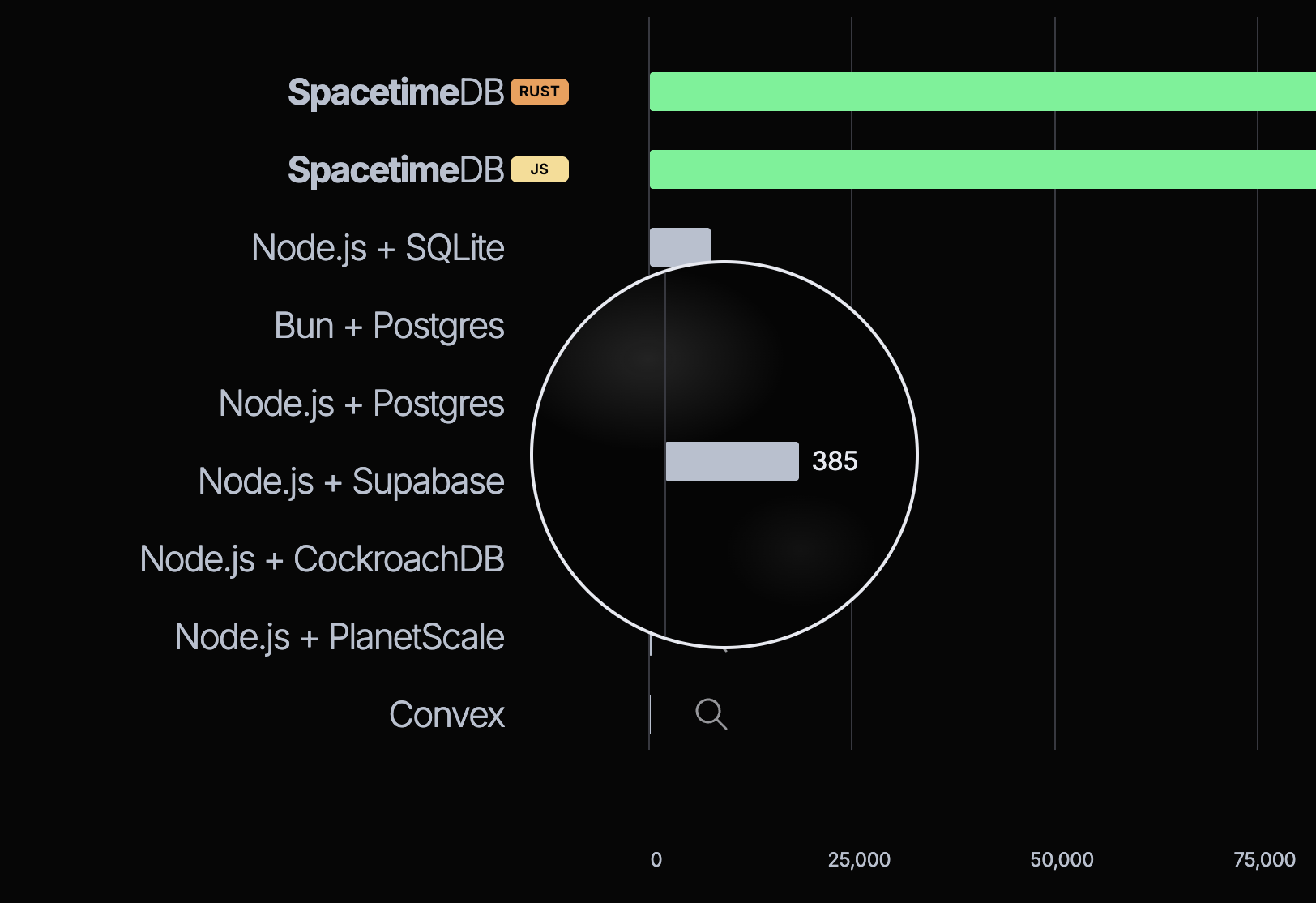
데이터베이스 시장은 가혹하며, 특히 신규 진입자에게 그렇습니다. 새로운 제품을 출시해 기존 강자들과 차별화하는 일은 매우 어렵습니다. 장기적인 모멘텀을 얻는 건 더 어렵죠. 이번 주 초 SpacetimeDB는 데이터베이스 2.0 버전을 공개했는데, —제가 알기론— 이전에 보지 못한 독특한 접근을 택했습니다. 경쟁사를 조롱하는(“경쟁사의 눈물”을 마신다) 다소 초현실적(밈스러운) 영상과, 사실이라고 믿기 어려울 정도로 좋은(실제로는 사실이 아닌) 벤치마크 세트를 내놓았고, 그 벤치마크 역시 다른 데이터베이스를 조롱합니다. 그 벤치마크의 큰 패배자 옆에 있는 귀여운 돋보기를 보세요. 얼마나 형편없는지 보려면 확대 해야 합니다! 참 좋네요.

먼저 솔직히 말하자면 저는 이게 불쾌하다고 느낍니다. 하지만 그럼에도 이 제품에는 흥미로운 아이디어가 있다고 생각하고, 가능한 한 공정하게 짧은 기술 리뷰를 해보고자 합니다.
데이터베이스 분야의 신규 진입자가 흔히 저지르는 실수 중 하나는 “최고의 성능”을 갖추면 이길 수 있다고 믿는 것입니다. 저는 실제로 그런 사례를 본 적이 없습니다. 지속 가능한 데이터베이스 비즈니스를 만든 (극소수의) 회사들은 스스로 서는 좋은, 정직한 기술적 작업을 제공함으로써 승리합니다. 물론 벤치마크는 거기에 확실히 도움이 됩니다. 하지만 그 벤치마크는 반드시 좋은, 정직한 기술적 작업이어야 합니다.
SpacetimeDB가 제공한 벤치마크는 그 어느 쪽도 아닙니다. 무엇을 측정하는지에 기술적 결함이 꽤 많습니다. SpacetimeDB가 경쟁사 대비 매우 좋지 않게 나오는 대체 벤치마크 세트는 여기에서 볼 수 있습니다.
그럼에도 이 벤치마크의 가장 근본적인 결함은 정직하지 않다는 점입니다. 그리고 그들이 어디서 오는지 이해는 합니다. 정말로요. 정직하지 않은 이유는, 그들의 데이터베이스가 경쟁사와는 아주 다른 무언가이기 때문이고, 그러면 저런 벤치마크를 쓰고 싶어지기 쉽습니다. 그들의 제품은 데이터베이스 시장 내에서 다른 세그먼트에 있고, 다른 트레이드오프를 하는 데이터베이스들과 자신을 비교하고 있습니다. 매력적인 비교이지만 공정하지는 않습니다.
제가 직접 겪었던 예를 하나 들어보겠습니다. 몇 년 전 PlanetScale에서 일할 때, 우리는 벡터 유사도 검색을 위한 MySQL 확장을 출시했습니다. 구현에는 매우 구체적인 목표가 있었고, 완전한 트랜잭션을 지원하며 벡터 데이터가 디스크에 저장되고 MySQL의 버퍼 풀로 관리된다는 점에서 다른 것들과 매우 달랐습니다. 이는 HNSW를 사용하고 유사도 그래프가 메모리에 들어가야 하는 pgvector 같은 더 단순한 접근과 대조적이죠. 완전히 다른 제품이었고 트레이드오프도 달랐습니다. 그리고 32GB RAM의 EC2 인스턴스에 64GB의 벡터 데이터를 우리 데이터베이스에 넣는 것은 엄청나게 유혹적이었습니다. 그 다음 Postgres 인스턴스와 pgvector로 똑같이 해보는 겁니다. 같은 머신, 같은 데이터셋! 같은 쿼리! 하지만 PlanetScale은 초당 수만 건을 처리하고, pgvector는 HNSW 그래프가 디스크에서 계속 페이징되며 단일 쿼리 하나를 끝내는 데 3초 이상 걸립니다.
그걸 벤치마크로 보여주는 건 정말 유혹적이었죠. “우리는 pgvector보다 10000배 빠르다!” 하지만 좀 봐주세요. 그건 정직하지 않습니다. 같은 머신, 같은 데이터셋, 같은 쿼리이긴 하지만 같은 것이 아닙니다. 우리는 그 벤치마크를 공개하지 않았습니다. 대신 불공정한 비교 없이 구현을 설명하는 기술 분석 글을 공개했고, 반응도 매우 좋았습니다.
여기서 이기기 위해 “미친 벤치마크”가 필요한 게 아닙니다. 탄탄한 기술 작업과, 제공하는 것의 트레이드오프와 한계를 설명하는 탄탄한 기술 글쓰기만 있으면 됩니다. Turbopuffer에서도 다른 예를 볼 수 있습니다. 그들의 벤치마크는, 특히 경쟁사와 비교했을 때, 인상적이지 않습니다. 문서에는 데이터베이스가 할 수 없는 일에 대한 줄 수가 할 수 있는 일보다 더 많습니다. 하지만 모두가 알고 있죠. 사용 사례가 그들의 제품에 맞기만 한다면, 검색 분야에서 그들이 시장 최고의 제품을 갖고 있다는 것을요. 경쟁사보다 수 마일 앞서 있습니다. 그들은 경쟁사의 눈물을 마시지 않습니다. 그냥 조용히 고객을 가져갈 뿐이죠.
어쨌든 SpacetimeDB와 그들의 벤치마크로 돌아가 봅시다. 그들은 경쟁사와 매우 다른 제품을 내놓고 있습니다! 데이터베이스 + 애플리케이션 서버 올인원으로, 데이터베이스 인스턴스를 배포하면 애플리케이션 코드가 데이터베이스 내부에서 실행 됩니다. 저는 이게 매우 흥미로운 아이디어라고 생각합니다. 관계형 데이터베이스의 저장 프로시저와 비슷하다고 말할 수도 있지만, 개발자 경험이 더 좋다—라고요. 그럴 수 있죠. 하지만 그걸로도 충분히 가능한 제품을 만들 수 있습니다!
다만, 자신이 벤치마킹 대상으로 삼는 멀티 리전, 고가용성 분산 데이터베이스들과는 관련이 거의 없다는 점을 인정해야 합니다. 애플리케이션 코드가 데이터베이스 안에서 실행되고, 경쟁사들은 각 쿼리마다 개별 네트워크 요청을 수행해야 하는 별도의 애플리케이션을 갖고 있다면, QPS를 측정하는 벤치마크에서 앞서는 게 당연합니다. 하지만 그게 정직한 벤치마크일까요? 잠재 고객이 기술적 제공을 평가할 때 보여주고 싶은 비교가 그것 일까요?
저는 강조하기에 그다지 좋은 포인트가 아니라고 봅니다. 메모리 내 데이터 접근은 네트워크越 접근보다 빠르고, 당신은 그걸 증명하는 벤치마크 하네스를 만든 셈입니다. 잠재 사용자 입장에서 저는 별로 인상적이지 않습니다. 마케팅 관점에서는, 메모리 내에서 데이터를 얼마나 빠르게 접근할 수 있는지를 보여준 뒤, 그 속도를 얻기 위해 어떤 트레이드오프를 했는지 설명 하는 편이 훨씬 흥미로울 겁니다.
제가 보기엔 그걸 설명하는 명확한 기술 분석이 웹사이트에 없습니다. 그래서 여기서 한번 해봅시다.
SpacetimeDB가 공개한 합성 벤치마크에서 매우 좋은 쓰기 성능을 보이는 데에는 몇 가지 이유가 있습니다. 당연히 가장 큰 이유는 애플리케이션 로직이 데이터베이스 옆에서 로컬로 실행되고, 그런 방식으로 데이터 저장소에 쓰면 극도로 효율적일 수 있다는 점입니다. 그들은 다른 트릭(예: 배치 쓰기)으로 이 효율을 더 끌어올리지만, 그들이 보여주는 성능 수치에 도달하려면 어딘가 에서 지름길을 택해야 합니다. 데이터 저장소가 인메모리이며, 이는 전통적인 RDBMS와는 매우 다릅니다.
자, 좋은 소식부터 말하자면 이 인메모리 저장소에 대한 쓰기는 linearizable 합니다. 하지만 나쁜 소식도 있습니다. 시스템의 linearizability를 증명하는 일은 보통 고된 작업입니다. 여기서는 TLA+를 꺼낼 필요도 없었습니다. 너무 자명하거든요. 왜냐하면 이 시스템은, 음, 앞에 락이 하나 달린 해시 테이블이기 때문입니다.

과장처럼 들릴 수 있지만, 믿어주세요. 이건 스토리지 엔진 설계를 꽤 정확하게 묘사한 것입니다. SpacetimeDB 인스턴스에서 데이터베이스 전체의 커밋된 상태는 단 하나의 Read-Write Mutex로 감싸져 있습니다. 모든 쓰기 작업은 순차적으로 일어나며, 따라서 linearizability 증명은 정말로 자명합니다. 두 쓰기는 동시에 일어날 수 없으니 충돌도 레이스도 없습니다. 하지만 읽기 와 쓰기 또한 동시에 일어날 수 없습니다!
쓰기가 너무 많으면 어떻게 될까요? 리더가 굶주리게 될까요? 읽기/쓰기 의미를 갖는 단일 전역 락 위에 데이터 저장소를 구축하는 것은 유효한 기술적 선택입니다. 다만 그걸 “데이터베이스”라고 마케팅하는 건 조금 의문스럽긴 합니다. 하지만 이 접근을 끝까지 밀어붙일 거라면, 즉 그 락이 데이터베이스 전체의 동시성 제어를 제공할 거라면, 어떤 워크로드에서도 서버가 응답성을 유지하도록 리더와 라이터의 우선순위를 명확하고 커스터마이즈 가능하게 정의할 필요가 있습니다.
여기서는 그 동작이 구현 디테일로 남아 있고, 어디에도 특별히 정의되거나 설명되어 있지 않습니다. 뮤텍스는 parking_lot 크레이트의 기성품 parking_lot::RWMutex입니다. 이 락은 eventual fairness를 제공하는데, 이는 쓰기 처리량이 높은 상황에서도 리더가 언젠가는 락을 획득한다는 뜻입니다. 다만 최대 0.5ms까지 랜덤하게 지연될 수 있습니다. parking_lot 크레이트는 WebKit의 원본 WTF::Lock를 Rust로 포팅한 것이고, 이 2024 changeset은 eventual fairness가 어떻게 구현됐는지 보여줍니다. 읽어보세요. 뮤텍스 경합에 대한 성능 인사이트가 아주 좋습니다. 이 블로그 글의 구강 세정제 같은 느낌으로요. 자, 다시 해시 테이블과 락으로 돌아갑시다.
그럼 이 시스템에서 쓰기 중에는 무슨 일이 일어날까요? 뭐든지 일어납니다. 정말 마법 같죠. 전역 락이 잡혀 있는 동안 Wasmtime 런타임이 “reducer”(임의의 사용자 코드, WebAssembly로 컴파일됨)를 실행합니다. reducer가 실행되는 동안 다른 reducer는 실행되어 데이터베이스에 쓸 수 없습니다. 다른 어떤 코드도 데이터베이스에서 읽을 수도 없습니다. 공식 문서에는 reducer가 “HTTP 요청을 수행할 수 없다”고 되어 있습니다. 네. 당연하죠. 이 데이터베이스에서 모든 쓰기의 크리티컬 섹션은 배타적이고 직렬화되어 있으며, 그 안에서 임의의 사용자 코드를 실행합니다. 그 한가운데서 HTTP 요청 같은 걸 하면 큰일입니다.
여기에는 약간의 탈출구가 있습니다. 서버에서 “Procedures”를 사용할 수 있거든요. 이번 주 릴리스 기준으로 여전히 Beta이며(문서에는 향후 API가 바뀔 수 있다고 경고합니다), 여기서는 HTTP 요청을 포함한 비용 큰 코드 실행이 가능하니 좋은 일입니다. procedure 안에서 트랜잭션을 열 수 있는데, 이때 다시 전역 뮤텍스를 획득하며 데이터베이스에 대한 다른 동시 쓰기 및 읽기를 허용하지 않으니, 반드시 아주아주 빨리 커밋해야 합니다. 그렇지 않으면 전체 시스템이 멈춥니다.
읽기도 이야기는 매우 비슷합니다. 읽기는 “Views”를 통해 일어나야 하는데, 이는 reducer의 읽기 전용 버전입니다. 전역 뮤텍스에 대한 reader 락을 획득하므로 여러 view를 동시에 실행할 수는 있지만, view가 실행되는 동안 데이터베이스에 쓸 수는 없습니다. reducer와 마찬가지로 view도 WebAssembly로 컴파일된 임의의 사용자 코드입니다.
데이터베이스에 단일 뮤텍스 설계를 적용하면 한 가지 뻔한 결과가 있습니다. 트랜잭션의 크리티컬 패스에서 가능한 한 적은 일을 해야 합니다. HTTP 요청은 물론 불가능합니다. 하지만 다른 RDBMS가 종종 하는 “비싼” 일도 할 수 없습니다. 예컨대, 아시다시피, 트랜잭션을 디스크에 영속화하는 일 같은 것 말이죠(히히).

이 완전한 인메모리 데이터베이스는 Write Ahead Log로 백업되긴 하지만, WAL은 쓰기 트랜잭션의 일부로 디스크에 커밋되지 않습니다. WAL은 비동기이며, 주기적으로 백그라운드에서 디스크로 플러시됩니다(기본값: 50ms마다).
이걸 완전히 일관되게 만들 수 있을까요? “단일 뮤텍스 설계”의 제약은 이를 복잡하게 만듭니다. WAL을 동기적으로 쓸 수가 없기 때문입니다(그렇게 하면 다른 모든 쓰기 그리고 읽기까지 완전히 멈춥니다). 시스템은 읽을 때 사용할 수 있는 옵션을 제공하긴 하는데, 의미가 좀 기묘합니다. withConfirmedReads 플래그를 사용하면 디스크에 동기화된 데이터만 읽기 결과로 반환하게 할 수 있는데, 서버가 잠들어 있다가 쿼리 결과에 해당하는 WAL 엔트리가 디스크로 플러시되는 것을 결국 관측하면 그때 깨어나는 방식입니다. 최대 50ms까지 슬립할 수 있는데, 요청 기준으로는 긴 시간입니다. 그다지 사용하기 편한 동작은 아니지만, 여기서는 “대부분 일시적인” 데이터를 위한 데이터베이스이며 평균적인 쿼리는 이런 강한 일관성 보장이 필요 없다는 가정을 깔고 있습니다.
이 모든 건 MongoDB-2011의 향수가 강하게 납니다. 여러 면에서요. Mongo 팀은 꽤 형편없는 데이터베이스를 매우 인상적인 벤치마크와 함께 출시했고, 결국 인터넷에서 두들겨 맞으며(참고: MongoDb is Web Scale) 제대로 된 스토리지 엔진을 구현하게 됐습니다. 그들은 WiredTiger를 인수했는데, 이건 정말로 제대로 된 스토리지 엔진입니다. 15년이 지나 Mongo는 진지하고 충분히 경쟁력 있는 데이터베이스 회사가 됐습니다. 그럼에도 초기 Mongo 시절을 기억하는 많은 기술자들이 여전히 프로덕션에서 사용하거나 추천하기를 거부합니다. 그들의 정보는 오래됐습니다. 현대의 Mongo는 잘 동작하는 진지한 데이터베이스입니다. 하지만 나쁜 기술적 평판은 남아 있고, 영원히 남을 겁니다.
여기서 큰 교훈이 하나 있습니다. 2026년에 제가 단일 락 하나가 달린 해시 테이블 같은 데이터베이스 제품을 출시한다면, 저는 조용히 할 겁니다. 데이터베이스 제품을 출시할 때 지름길을 택하는 것이 실현 가능한 접근임이 이미 증명됐기 때문입니다(저라면 안 하겠지만, MongoDB는 큰 성공을 거뒀죠). 하지만 제품이 주목을 받기 시작하면(만약 그렇다면) 기술 부채 그리고 평판 부채를 서둘러 갚아야 합니다. 레이저 빔과 “눈물 병”이 등장하는 마케팅 영상은 이를 훨씬 더 어렵게 만듭니다.
우리는 SpacetimeDB가 특정 벤치마크(즉, 애플리케이션이 얼마나 빨리 데이터베이스에 쓸 수 있는지 측정하는 벤치마크—애플리케이션이 곧 데이터베이스인 상황에서)에 매우 잘 나오게 하는 기술적 선택들을 봤습니다. 이런 선택들은 문서에서 처음부터 설명되지 않고, 안타깝게도 그 선택들이 수반하는 트레이드오프 역시 명시적으로 나열되어 있지 않습니다.
간단히 훑어보자면, 이것은 분산 시스템이 아니며 확장성이나 가용성에 매우 강한 한계가 있습니다. “SpacetimeDB 클러스터”를 배포할 수는 있는데, 이는 primary 인스턴스와 여러 follower를 두고 eventual consistent 복제를 한다는 뜻입니다(여기서 “eventual consistent”에 방점을 찍어야 합니다. WAL이 eventual consistent이고, 복제도 그렇고, 문제가 생길 여지가 매우 큽니다). 하지만 전체 시스템은 메인 SpacetimeDB 인스턴스가 배포된 머신의 CPU 그리고 RAM 용량에 의해 병목이 걸립니다. 데이터베이스가 모든 쿼리를 실행하기 위한 CPU가 필요할 뿐 아니라, 애플리케이션이 데이터베이스 안에서 살기 때문에 애플리케이션 로직을 실행할 CPU도 필요합니다. 데이터 전체를 메모리에 담을 RAM도 필요합니다. SpacetimeDB는 디스크 기반이 전혀 아닙니다. 디스크로 WAL을 플러시할 뿐이며(그리고 주기적으로 스냅샷을 떠서 재시작 시 WAL로부터의 복구를 더 빠르게 합니다). 데이터셋이 RAM보다 커지면 데이터베이스(그리고 동일한 것인 애플리케이션)는 페일오버할 것입니다. 여기서 확장성의 유일한 선택지는 수직 확장뿐입니다. 더 큰 머신을 사서 데이터베이스를 돌리는 거죠.
이런 트레이드오프는 다시 말하지만 완전히 유효합니다. 하지만 이는 SpacetimeDB를 “더 강력한 Redis” 로 포지셔닝하지, “더 성능 좋은 관계형 데이터베이스” 로 포지셔닝하지는 않습니다. 그런데도 후자의 기준으로 벤치마킹하기로 한 것이 매우 의아합니다.
SpacetimeDB의 초기 버전은 MMORPG의 백엔드로 개발되었습니다(실제로 지금 Steam에서 플레이할 수 있는 게임입니다). 제겐 납득이 됩니다. 데이터베이스의 모든 기술적 선택이 이 사용 사례에 맞습니다. xXxPussyHunter420xXx가 [Thunderfury, Blessed Blade of the Windseeker]를 루팅했다는 WAL 엔트리를 비동기로 디스크에 플러시해도 됩니다. 50ms 지연은 괜찮아요. 그 순간 인스턴스가 딱 맞춰 크래시 나면 화나겠지만, 곧 잊을 겁니다.
물론 요즘 MMORPG를 만드는 스튜디오는 많지 않고, 어떤 멀티플레이 게임이든 만드는 곳들은 대체로 자체 인하우스 백엔드를 선호합니다. 어쨌든 대형 스튜디오들이고, 이전에도 해봤으니까요. 그래서 SpacetimeDB v2를 더 폭넓은 매력의 무언가로 피벗하는 이유는 이해합니다.
이제 마케팅 페이지에는 “LLMs go much further”라고 적혀 있습니다. SpacetimeDB가 하나의 응집된 백엔드에서 영속성, 로직, 배포, 실시간 동기화를 모두 처리하기 때문이라는 거죠. 이것도 공정한 선택입니다. agentic coding이 지금 벌어지는 바로 그 일입니다. LLM을 타깃으로 하는 데이터베이스를 만든다는 건 좋은 아이디어처럼 보입니다. 하지만 솔직히 말하자면, 그들은 이 사용 사례에 대해 가능한 한 최악 의 기술적 선택을 했습니다.
SpacetimeDB의 핵심은 애플리케이션과 데이터베이스의 성능 그리고 가용성이, 부작용이나 스톨을 일으키는 연산을 할 수 없는 짧은 사용자 코드 구간에 의해 100% 지배된다는 점입니다. 왜냐하면 그 코드가 WebAssembly로 컴파일되어 가상 머신에 의해, 스토리지 백엔드에 대한 모든 쓰기 및 읽기를 직렬화하는 크리티컬 섹션 안에서 실행되기 때문입니다. 부작용이나 스톨의 부재는 타입 시스템으로 강제할 수 없고, 런타임에 JIT 컴파일러가 생성하는 특정 WASM 바이트코드에 달려 있습니다. 이 크리티컬 섹션 안에서의 어떤 실수든, 부하 하에서 스톨을 유발할 수 있는 어떤 연산이든, 아마 프로덕션에서나 보일 것이고 전체 애플리케이션의 성능을 떨어뜨릴 겁니다—대개 가용성 이슈를 일으킬 정도로요.
이건 LLM이 프로그래밍하기에 이상적인 환경이 아닙니다. lol
그렇다고 해도, 저는 여기에는 제품이 있고 배울 교훈도 있다고 생각합니다. 어쩌면 저자들은 결국 이를 SpacetimeDB v3에 적용해 더 견고하고 LLM 친화적인 데이터베이스를 출시할지도 모릅니다. 애플리케이션 코드가 격리 되어 필요한 만큼 오래 실행될 수 있고, 심각한 구현 버그가 있어도 로컬에서 실행되는 다른 애플리케이션 코드에 영향을 주지 않는; 트랜잭션이 필요한 만큼 오래 실행될 수 있고 다른 트랜잭션의 성능에 영향을 주지 않는; LLM이 최적의 쿼리 플랜을 내지 못했을 때 너무 오래 걸리는 트랜잭션이 암묵적으로 스로틀링되는—그런 시스템 말이죠. 장애에 훨씬 강하지만 “인상적인 성능”은 훨씬 덜한 시스템을 보게 될지도 모릅니다. AI 에이전트가 분산 시스템 자체를 계획하지 않아도 되게끔 시스템이 아주 쉽게 분산될지도 모르고요. 더 적은 엉터리 벤치마크와 더 많은 기술적 디테일과 함께 출시될지도 모릅니다.
그런 제품이라면 지켜볼 가치가 있겠죠.
Principal Systems Engineer
GitHub 2010-2020
PlanetScale 2020-2025
Cursor 2025-