AWS Aurora DSQL의 설계 여정과 Rust 도입을 통해 서버리스 확장성과 엔지니어링 효율을 이뤄낸 실제 사례, 그리고 그 과정에서 얻은 교훈을 공유합니다.
2025년 5월 27일 • 3404 단어

re:Invent에서 Aurora DSQL을 발표한 후, 많은 빌더들과 이 기술이 데이터베이스 엔지니어링에 의미하는 바에 대해 이야기를 나눴습니다. 이 기술 자체도 흥미롭지만, 그 여정, 즉 우리가 어떻게, 왜 여기에 이르렀는지도 중요합니다. 오랫동안 이 이야기를 더 깊이 들여다보고, DSQL 개발의 '무엇' 뿐 아니라 '어떻게', '왜'를 공유하고 싶었죠. 그러던 중, 몇 주 전 사내 개발자 컨퍼런스 DevCon에서 두 분 수석 엔지니어가 처음엔 100% JVM에서 시작해 100% Rust로 끝난 DSQL 구축기를 강연하셨습니다. 발표 후, Niko Matsakis와 Marc Bowes에게 그들의 인사이트를 더 심도 있게 풀어 써보자는 제안에 흔쾌히 협조해주셨고, 기술적으로 복잡한 부분까지 설명을 도왔습니다.
아래 블로그에서는 Niko와 Marc가 Rust와 DSQL 빌드에 어떻게 활용했는지, 왜 과거의 결정도 의심해야 하는지에 대한 심도 있는 기술 인사이트를 제공합니다. 이는 엔지니어링 효율을 추구하는 여정이자, '비판적 사고'의 중요성을 일깨워주는 사례이기도 합니다.
저자 노트
이 프로젝트는 스토리지부터 제어 플레인까지 방대한 전문 지식이 필요한 대담한 도전이었습니다. 본문에는 DSQL을 만든 많은 수석 엔지니어들의 지혜와 배움을 녹여 넣었습니다. 읽으시면서 저와 마찬가지로 즐거움과 통찰을 얻으시길 바랍니다.
특별 감사: Marc Brooker, Marc Bowes, Niko Matsakis, James Morle, Mike Hershey, Zak van der Merwe, Gourav Roy, Matthys Strydom.
AWS 초창기부터 고객의 요구는 더 다양해졌고, 때로는 더 긴급해졌습니다. 2009년 Amazon RDS 출시는 전통적 관계형 데이터베이스의 관리 편의성을 높이는 데서 시작했으나, 곧 목적별 옵션으로 확장되었습니다: 인터넷 규모 NoSQL 작업용 DynamoDB, 대규모 데이터셋 분석 쿼리용 Redshift, 복잡하고 비싼 상용 DB를 벗어나고 싶었던 고객을 위한 Aurora까지. 이들은 단순한 기능 추가가 아니라, 고객이 실제 마주한 제약의 해법이었습니다. 성공의 열쇠는 천재적 번뜩임이 아니라, 고객의 목소리에 귀를 기울이며 반복적으로, 때론 고객과 함께 개발한 데 있었습니다.
속도와 확장성만이 전부는 아닙니다. ElastiCache는 관계형 DB에서 더 많은 처리량을 원했던 개발자 니즈에서 탄생했고, Neptune은 그래프 기반 워크로드와 관계 중심 애플리케이션이 기존 DB의 한계를 넘어서면서 등장했습니다. 돌아보면, 제품군이 어떻게 성장했는지만이 아니라, 서버리스·엣지·실시간 분석 등 새로운 컴퓨팅 패턴과 나란히 성장했다는 점이 인상적입니다. 혁신은 거의 언제나 점진적 진화의 산물입니다. 성공 위에 쌓고, 실패에서 배움을 얻으며, 도전을 두려워하지 않는 팀에서 탄생했습니다.
각 DB 서비스가 중요한 문제를 해결했지만, 우리는 늘 반복해 마주치는 도전이 있었습니다: 인프라 관리는 전혀 필요 없으면서 자동 확장되는 관계형 DB, 즉 SQL의 익숙함과 파워, 서버리스 확장성, 멀티리전 배포, 운영 부담이 제로인 DB를 어떻게 만들 것인가? 과거의 시도들은 매번 목표에 가까워졌으나, 진정한 혁신적 도약이 필요했습니다. 기능을 추가하거나 성능만 개선하는 게 아니라, 클라우드 DB의 본질을 재정의하는 것이었습니다.
드디어 Aurora DSQL이 탄생하게 됩니다.
Aurora DSQL은 데이터베이스를 작은, 명확한 인터페이스와 계약을 가진 컴포넌트로 분해하는 것이 목표입니다. 각 요소는 유닉스 철학(한 가지를 잘 하라)을 따르면서, 함께 협력해 트랜잭션, 내구성, 쿼리, 격리성, 일관성, 복구, 동시성, 성능, 로깅 등 사용자가 기대하는 모든 DB 기능을 제공합니다.
DSQL의 고수준 아키텍처는 다음과 같습니다.
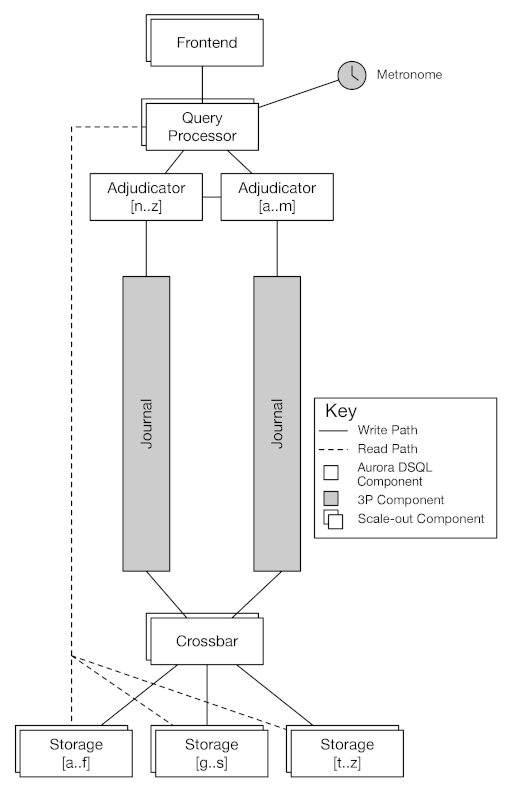
2021년에 이미 읽기 처리 경로는 풀었으나, 쓰기 처리를 수평적으로 확장하는 좋은 방법이 없었습니다. 전통적으로 데이터베이스 쓰기 확장은 2단계 커밋(2PC)이 해법입니다. 각 저널이 특정 행을 담당하고, 이는 스토리지와 비슷합니다. 트랜잭션이 근처 행들만 수정한다면 문제없지만, 여러 저널에 걸쳐 수정하는 경우 복잡성이 급증합니다. 검사, 잠금, 원자적 커밋까지의 복잡한 과정을 거치는데, 이상적 경로는 잘 작동해도 현실은 다릅니다. 타임아웃, 라이브니스, 롤백, 코디네이터 장애 처리 등 운영적 복잡성이 기하급수적으로 늘어납니다. DSQL에서는 하중이 걸려도 가용성과 지연을 보장하는 완전히 새로운 접근이 필요했습니다.
행을 저널에 미리 할당하지 않고, 커밋 전체를 단일 저널에 기록하는 방식을 채택했습니다. (수정 행이 몇 개든 상관없음) 이는 ACID의 원자성, 내구성 요구를 단박에 해결했습니다. 이제 쓰기 경로 확장이 단순해졌습니다. 하지만 읽기 경로는 훨씬 복잡해졌습니다. 각 행의 최신 값을 알기 위해선 모든 저널을 조사해야 했죠. 업데이트는 어디든 올 수 있으니, 스토리지는 각 저널과 연결을 유지해야 했고, 저널 수가 늘면 네트워크 대역폭 한계에 부딪힙니다.
해결책이 바로 Crossbar입니다. Crossbar는 읽기와 쓰기 경로의 확장을 분리합니다. 구독 API를 통해, 각 스토리지 노드는 특정 키 범위의 업데이트만 구독합니다. 트랜잭션이 들어오면, Crossbar가 해당 업데이트를 해당 노드로 라우팅합니다. 개념은 단순하나, 효율적으로 구현하긴 쉽지 않습니다. 각 저널은 트랜잭션 시간순으로 정렬되고, Crossbar는 이들을 따라가며 전체 순서를 만듭니다.
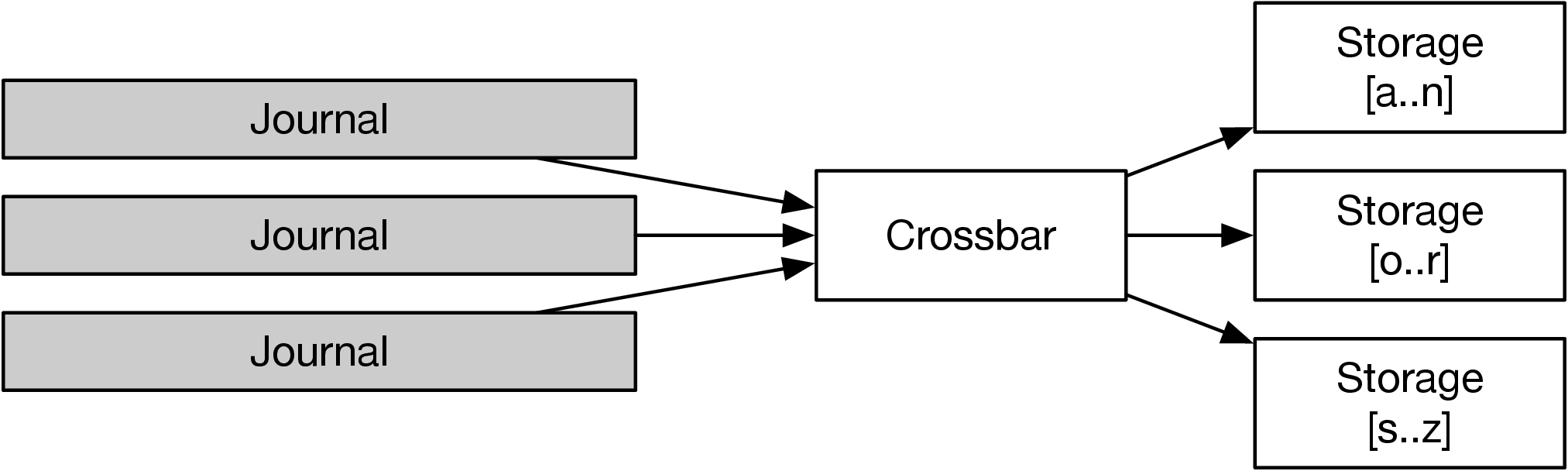
여기에 고도 fanning out이 필요하며, 현실에서는 구독자가 뒤처질 수 있어 다양한 버퍼링 로직이 필요해졌습니다. 이런 구조상 GC(가비지 컬렉션)과 그로 인한 일시정지(GC pause)가 큰 걱정거리가 되었습니다.
분산 시스템의 현실은 냉혹합니다. 모든 저널의 데이터를 모아야만 전체 순서 제공이 가능한 구조에서는, 호스트 중 단 한 곳에서 tail latency(꼬리 지연) 이벤트가 발생할 확률이 급격히 1에 가까워집니다 – Marc Brooker가 쓴 글도 참고해보세요.
이에 대한 우려를 검증하고자, 40개의 호스트에서 초당 100만 TPS를 기대했던 crossbar 시뮬레이션을 실행했습니다(1초간의 간헐적 지연도 포함해). 결과는 충격적이었습니다. TPS는 약 6000에 그쳤고, tail latency가 1초에서 10초까지 치솟았습니다. 이런 현상은 단지 드문 경우가 아니라, 아키텍처 근본적 문제임이 드러났습니다. 트랜잭션마다 여러 호스트를 읽어야 하다 보니, 규모가 커질수록 어느 한 호스트에서라도 GC stop이 발생할 확률이 100%에 가까워졌던 거죠. 즉, 대규모로 갈수록 거의 모든 트랜잭션이 시스템 내 최악 지연에 의해 영향을 받게 됩니다.
분기점에 섰습니다. GC, 처리량, 지연은 실제적이고 시급한 문제였습니다. JVM 최적화에 몰두해 GC 생성을 줄이는 길, C/C++로 전환(그러나 메모리 안전성 상실), 아니면 Rust를 시도하는 선택이 있었고, Rust를 택했습니다. Rust는 GC 오버헤드 없이 예측 가능한 성능과, 메모리 안정성, 그리고 비용 없는 추상화 덕분에 고수준 코드를 효율적으로 만들 수 있었습니다.
언어를 바꾼다는 건 큰 결정입니다. 대부분 One-way door – 한번 코드베이스가 커지면 되돌리기 어렵죠. 이 결정이 프로젝트의 성공/실패를 가릅니다. 당장 팀 뿐만 아니라, 조직의 협업, 모범사례 공유, 프로젝트 간 이동성까지 좌우합니다.
Crossbar 같은 복잡한 컴포넌트 대신, 비교적 단순한 Adjudicator 컴포넌트(충돌 시 트랜잭션 하나만 승리하도록 보장)를 먼저 Rust로 옮겼습니다. Rust 클라이언트는 이미 있었고, 기존 JVM(Kotlin) 구현과 성능 비교가 가능했습니다. 20년 가까운 AWS 엔지니어링의 원칙, 즉 작게 시작하고, 빨리 배우고, 데이터를 보고 교정하는 실용적 태도를 따랐죠.
두 명의 엔지니어가 배정됐지만, 둘 다 C/C++/Rust 경험이 없었습니다. Rust에서 흔히 쓰는 말 — "Rust는 숙취가 먼저 온다"(참고) — 처럼, 컴파일러와 여러 번 싸웠습니다.

(이미지: Lee Baillie)
하지만 몇 주 만에 컴파일이 되었고, 결과는 충격적이었습니다. 러스트 버전은 JVM(Kotlin)에서 2~3천 TPS까지 세심하게 튜닝했던 것을 뛰어넘어, 3만 TPS를 기록했습니다(고작 Java 개발자가 Rust를 처음 써서 얻은 성과임에도!).
이 짧은 학습 기간 대비 성능 이득이 너무 커, "Rust를 쓸까?"가 아니라 "어디까지 Rust를 쓰면 문제를 더 풀 수 있나?"로 질문이 바뀌었습니다.
결론은 데이터 플레인 전체를 Rust로 재작성, 컨트롤 플레인은 기존 Kotlin 유지였습니다. 고수준 로직은 GC 기반 언어로, 지연에 민감한 부분만 Rust로 — 당시엔 최고의 조합으로 보였습니다만, 현실은 달랐습니다. 이건 뒷부분에서 더 다룹니다.
데이터 플레인에 Rust를 적용하는 결정은 시작에 불과했습니다. 내부 토론 끝에 PostgreSQL(이하 Postgres) 위에 구축하기로 했습니다. Postgres의 모듈성/확장성 덕에 쿼리 처리(파서·플래너)는 Postgres에 맡기고, 복제, 동시성 제어, 내구성, 스토리지, 트랜잭션 세션 관리는 새로 구현할 수 있었습니다.
그런데 1986년 시작, 100만줄 C 코드, 수천 기여자, 계속되는 변경… 과연 어떻게 커스텀을 해야 할까요? 하드포크는 장기적으로 새로운 기능·성능 개선을 잃게 된다는 경험이 있었습니다.
Postgres는 처음부터 확장성을 염두에 둔 DB입니다. 확장 포인트들은 Postgres의 퍼블릭 API의 일부로, 핵심 코드를 건드리지 않고 행동을 바꿀 수 있게 해줍니다. 별도 파일 및 패키지로 관리 가능해, 업스트림과의 동기화도 용이합니다.
문제는, 확장도 C로 쓸 것인가 Rust로 쓸 것인가였습니다. 처음엔 기존 Postgres의 C 코드를 이해해야 했으니 C에 손이 갈 수밖에 없었습니다. 실제 작업을 하다 보니, 새로운 C 코드는 언제든 메모리 오류 가능성이 있음을 깨달았습니다. 단순 데이터 구조에서도 여러 memory safety issue가 발견됐습니다. Rust였다면 proven, safe한 Crates.io의 구현을 쓰면 됐을 겁니다.
최근 Android 팀의 리서치도 같은 결과를 보여줍니다. 새 코드에서 거의 모든 메모리 버그가 유입된다는 것이죠.
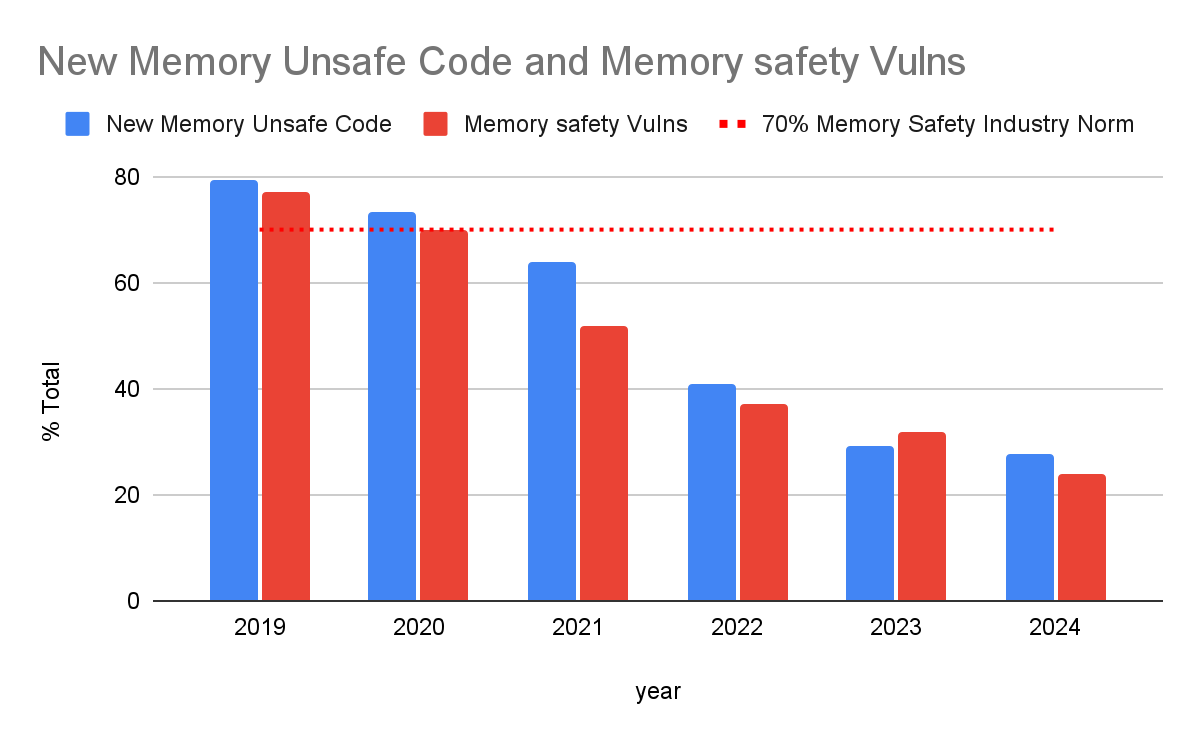
(Android팀 연구: 새 코드가 거의 모든 취약점의 원인. 즉, 메모리 안전 언어를 고르면 메모리 버그 자체가 사라짐)
그래서 Rust로 확장 구현을 전환했습니다. Rust가 Postgres와 C API로 밀접히 맞닿아있더라도, Rust 특유의 추상화 레이어를 두어 메모리 안전성 패턴을 강제할 수 있습니다. 예를 들어, C에서는 char*와 len을 함께 안전하게 다뤄야 하는데, Rust에서는 String 타입이 이를 안전하게 래핑합니다. Postgres 코드베이스에도 안전한 struct 사용법을 헤더 파일에서 매번 주석으로 설명하지만, Rust에서는 타입 시스템에 규칙을 녹여 실수 자체를 막습니다.
확장 추상화 코드는 신중하게 다뤄야 했지만, 나머지 코드는 안전한 타입만 사용하면 실수가 일어나지 않았습니다.
확장성과 보안, 회복성 관련 결정은 쉽지 않더라도 반드시 우선해야 합니다. 새로운 언어 습득 비용은 메모리 결함을 고치는 장기 리스크에 비하면 미미합니다.
컨트롤 플레인은 Kotlin으로 썼는데, 이는 Aurora/RDS등의 컨트롤 플레인에 JVM 계열 언어가 매우 검증된 선택지였기 때문입니다. Rust에서 확인한 처리량, 지연, 메모리 안전성이 컨트롤 계층엔 그다지 중요하지 않았고, 내부 라이브러리 지원도 Kotlin 쪽이 강했습니다. 당시엔 올바른 의사결정처럼 보였으나, 이 선택은 결과적으로 잘못된 것으로 드러났습니다.
처음엔 데이터/컨트롤 플레인 개별적으로 잘 동작했습니다. 하지만 통합 후 문제가 드러났습니다. DSQL 컨트롤플레인은 CRUD 그 이상을 수행하며, 무중단 자동 운영과 확장을 감지·조정하는 두뇌입니다. 데이터 플레인과 많은 로직을 공유해야 최적이지만, 언어가 달라 코드 공유가 어렵고, 테스트도 따로 해야 했고, 문서화/화이트보드 세션 의존도가 높아졌으며, 사소한 오해도 큰 디버깅 비용을 유발했습니다.
시뮬레이션 툴을 Rust/Kotlin 양쪽에서 쓸지, 아니면 컨트롤플레인도 Rust로 옮길지 택해야 했습니다.
이번에는 선택이 쉬웠습니다. 1년 만에 Rust의 2021 에디션이 단점을 많이 상쇄했고, 내부 라이브러리도 풍부해졌으며, 여러 통합은 API Gateway, Lambda로 이동해 구조가 단순해졌습니다.
무엇보다 놀라웠던 건 엔지니어 반응이었습니다. Kotlin 개발자들은 "해야 합니까?"가 아니라 "언제 시작하죠?" 였습니다. 동료들의 Rust 개발 경험을 지켜보았기 때문입니다.
이런 분위기는 '학습과 성장'에 대한 조직의 문화에서 비롯했습니다. Marc Brooker가 쓴 “The DSQL Book”(사내 설계·철학·의사결정 가이드), 매주 분산컴퓨팅/논문 리뷰/아키텍처 심층 토론, Niko 등 Rust 전문가 영입 등 학습환경이 팀에 자신감을 심어주었습니다.
종합하면, 정답은 Rust였습니다. 컨트롤/데이터 플레인을 시뮬에서 같이 돌려야 했고, 비즈니스 로직을 양쪽에 따로 유지할 수 없었습니다. Rust 전체 시스템의 crossbar 처리량이 뛰어났고, tail latency가 매우 일관적이었습니다. p99 latency가 p50 median과 거의 일치해, 가장 느린 동작도 예측가능, 프로덕션 퀄러티를 확보했습니다.
Rust는 DSQL에 딱 맞았습니다. 시스템 핵심의 tail latency 회피, C 기반 Postgres 연동, 컨트롤플레인 생산성을 모두 충족했고, 웹 오퍼레이션 페이지도 Rust(WebAssembly 경유)로 구현했습니다.
Rust가 Java 대비 생산성이 낮을 거라 생각했지만, 사실이 아니었습니다. 러닝커브는 있었지만, 팀이 적응하자 생산성 차이는 없었습니다.
Rust가 만능은 아닙니다. JDK21 등 현대 Java 역시 충분히 고성능입니다. 중요한 건 여러분이 가진 요구사항, 팀 환경, 운영 환경에 근거해 기술을 결정하는 것입니다. tail latency가 치명적인 서비스라면 Rust가 답일 수 있습니다. 그러나 Java 단일 표준 조직에서 고립된다면, 비용/이점 저울질이 필요합니다. 중요한 건 심사숙고해 결정을 내릴 수 있도록 지원하고, 학습·도전을 장려할 환경을 만드는 일입니다. 그게 장기적 성공의 비결입니다.
이제 여러분도 빌드하세요!
DSQL 및 그 설계적 배경에 대해 더 알고 싶으시다면, Marc Brooker의 'DSQL Vignettes' 시리즈를 강력 추천합니다: