Rust에서 데이터베이스 버퍼 풀과 페이지 레이아웃을 제로-카피로 설계하며 `O_DIRECT`, borrowed view, lifetime, 그리고 읽기/쓰기 경로 분리를 통해 불필요한 복사를 제거하는 방법을 살펴봅니다.
프로젝트의 소스 코드는 여기에서 찾을 수 있습니다.
제로-카피는 커널과 사용자 공간 버퍼 사이의 CPU 복사를 생략하는 방법으로, 데이터베이스 엔진처럼 높은 처리량이 필요한 애플리케이션에서 특히 유용합니다. 특히 작업 집합이 더 이상 캐시에 상주하지 않을 때 높은 부하 상황에서 성능 차이를 크게 만들어 냅니다.
전형적인 데이터베이스 엔진은 다음과 같이 생겼습니다. 이 글에서는 두 개의 복사 경계에 집중하겠습니다. 하나는 OS 경계이고, 다른 하나는 버퍼 풀에서 그 위 계층으로 올라가는 경로입니다.
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Execution Engine │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Transaction Manager │
└──────────┬─────────────┴─────────────────┬──────────────┘
│ │
┌──────────▼──────────┐ ┌────────────▼────────────┐
│ Lock Manager │ │ Log Manager │
└─────────────────────┘ └─────────────────────────┘
│ 상위 계층으로의 새로운 복사
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
└────────────────────────┬────────────────────────────────┘
│ OS 경계에서의 복사
┌────────────────────────▼────────────────────────────────┐
│ Disk │
└─────────────────────────────────────────────────────────┘
고성능 엔진을 만들려면 가능한 한 쓸모없는 작업을 제거해야 하며, 데이터 복사는 그 범주에 정확히 들어맞습니다.
각 복사 연산을 memcpy()와 동등하다고 생각해 보세요.memcpy()는 실제로 pipeline stall을 유발할 수 있는데, 이는 고성능 애플리케이션에서 피하고 싶은 일입니다. CPU는 소스에서 데이터를 읽어 목적지에 써야 합니다. 즉, 본질적이지 않은 작업에 사이클을 소비하고 있으며, 이 과정은 CPU 캐시에서 뜨거운 데이터를 밀어내는 원인이 될 수 있습니다.
전형적인 읽기 또는 쓰기 연산이 거치는 수명주기를 보여 주는 훌륭한 예시는 여기에 있습니다. 저 모든 CPU 복사는 사이클만 태우는 쓸모없는 작업입니다.
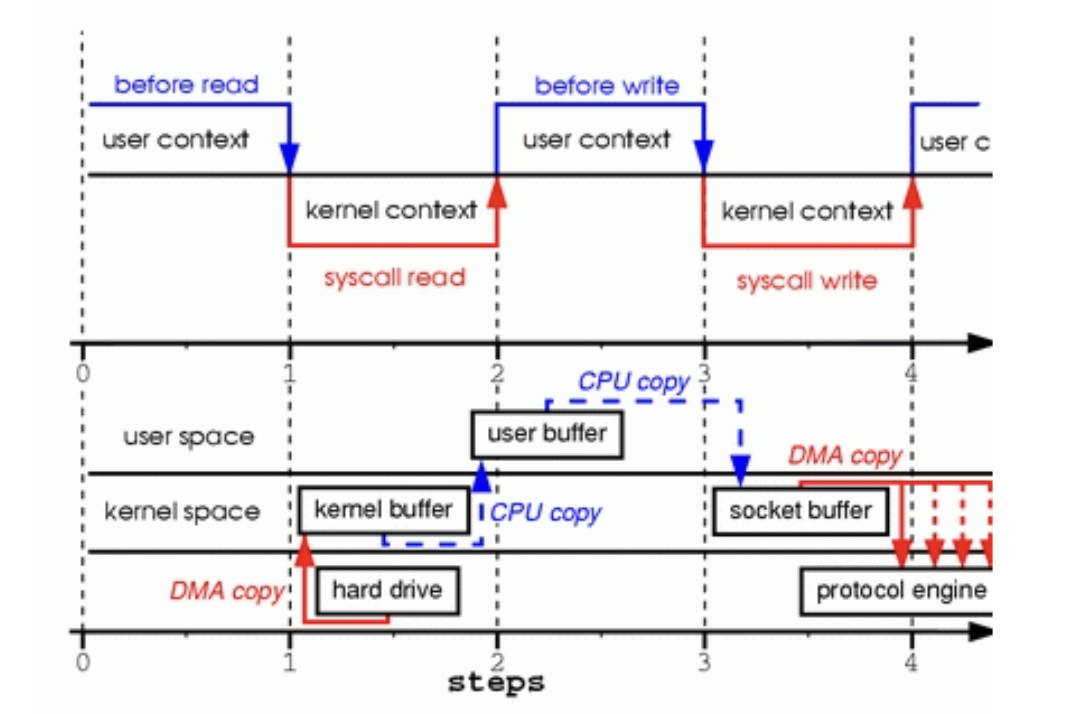 |
|---|
| 이미지는 https://www.linuxjournal.com/article/6345 에서 가져옴 |
이제 먼저 버퍼 풀과 디스크 사이 계층에서의 복사를 제거하는 데 집중해 봅시다.
⊕ direct IO 인터페이스에 대한 Linus Torvalds의 유명한 독설은 여기에서 볼 수 있습니다. 그는 데이터베이스 개발자를 좋아하지 않습니다.
버퍼 풀은 open() 시스템 콜로 파일 디스크립터를 열고 저장합니다. 이 파일 디스크립터들에 대해 read()와 write()를 호출하면, 앞에서 본 사용자 공간, 커널, DMA 사이의 복사를 포함한 전체 주기를 거치게 됩니다.
여기서 쉽게 얻을 수 있는 이득은 O_DIRECT 플래그와 함께 direct IO를 사용하는 것입니다. 많은 현대 데이터베이스가 이 접근을 사용하지만, Postgres처럼 그렇지 않은 경우도 있습니다. 이렇게 하면 애플리케이션은 OS 페이지 캐시를 우회하게 됩니다. 이는 64-bit DMA 가능 하드웨어를 가정합니다. 32-bit DMA 장치가 있는 시스템이나 confidential computing VM(AMD SEV, Intel TDX)에서는 커널이 조용히 SWIOTLB bounce buffer를 도입해 CPU 복사를 다시 끼워 넣을 수 있습니다. 자세한 내용은 Linux 커널 문서의 swiotlb를 보세요.
O_DIRECT는 제출되는 버퍼의 포인터 정렬뿐 아니라 I/O 길이와 파일 오프셋도 정렬되어 있기를 요구합니다. Rust에서는 페이지를 담는 버퍼에 #[repr(align(4096))]를 붙여 전자를 보장하고, 페이지 크기인 4 KiB 단위의 읽기/쓰기를 페이지 정렬된 오프셋에서 수행해 나머지 조건을 만족시킵니다. 그렇지 않으면 O_DIRECT 읽기나 쓰기는 흔히 EINVAL로 실패합니다. 이를 C로 보여 주는 gist도 있습니다. 첫 번째 프로그램은 malloc을 사용해 4096 정렬이 아니므로 쓰기에 실패하고, 두 번째는 posix_memalign을 사용해 성공합니다.
커널 페이지 캐시를 우회하므로 readahead나 write coalescing 같은 유용한 향상은 얻지 못합니다. 하지만 바로 이것이 데이터베이스에서 버퍼 풀이 중요한 이유입니다.
버퍼 풀은 특정 워크로드를 염두에 두고 설계된 OS 페이지 캐시의 대체물입니다. 이를 생각할 때는 항상 메커니즘 + 정책의 관점이 도움이 됩니다.
메커니즘: 위 계층의 페이지 요청을 처리하고 다른 페이지를 위한 공간을 만들기 위해 일부 페이지를 축출하는 고정 크기 페이지 테이블
정책: 어떤 페이지를 축출할지 결정하는 방법(축출 정책)
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
│ │
│ TableScan / IndexScan / BTreeScan │
│ (iterates rows, calls next(), get_value()) │
└────────────────────────┬────────────────────────────────┘
│ uses
┌────────────────────────▼────────────────────────────────┐
│ Transaction │
│ │
│ tx_id | ConcurrencyManager | RecoveryManager │
└────────────────────────┬────────────────────────────────┘
│ pin() / unpin()
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
│ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Frame 0 │ │ Frame 1 │ │ Frame 2 │ ... │
│ │ │ │ │ │ │ │
│ │ file:3 │ │ file:7 │ │ empty │ │
│ │ pins: 1 │ │ pins: 0 │ │ pins: 0 │ │
│ │ │ │ │ │ │ │
│ │ 4KB data │ │ 4KB data │ │ │ │
│ └──────────┘ └──────────┘ └──────────┘ │
│ │
│ policy: LRU | CLOCK | SIEVE │
└────────────────────────┬────────────────────────────────┘
│
│
┌────────────────────────▼────────────────────────────────┐
│ Disk │
│ │
│ [ file:1 ] [ file:3 ] [ file:7 ] [ file:9 ] │
└─────────────────────────────────────────────────────────┘
시스템에 맞는 정책을 선택하는 일은 워크로드의 특성에 달려 있지만, 대부분의 시스템은 LRU 근사치인 CLOCK을 사용합니다. 버퍼 풀에서 사용되는 교체 정책들의 비포괄적 목록은 여기에 있습니다.
O_DIRECT는 OS 경계에서의 복사를 제거합니다. 다음 문제는 페이지가 이미 버퍼 풀에 있을 때 새로운 복사를 피하는 것입니다.
지금까지 제로-카피는 커널과 버퍼 풀 사이의 복사를 없애는 것을 의미했습니다. 이제부터는 의미를 조금 넓혀서, 엔진 내부의 중복 복사도 제거하는 것으로 보겠습니다.
Rust에는 데이터 복사를 다루지 않게 해 주는 훌륭하면서도 끔찍한 방법이 있습니다. 바로 참조입니다. 훌륭한 이유는 단 한 글자(&)이기 때문이고, 끔찍한 이유는 이제 lifetime을 배워 다뤄야 하기 때문입니다.
lifetime을 이해하는 가장 단순한 방법은, 타입 A가 들고 있는 어떤 참조도 그것이 가리키는 데이터보다 오래 살지 않는다는 사실을 컴파일러에게 증명하는 것이라고 생각하는 것입니다.
먼저 단일 페이지의 원시 바이트를 이렇게 정의해 봅시다.
pub struct PageBytes {
bytes: [u8; PAGE_SIZE_BYTES as usize],
}
이제 단일 버퍼 풀 프레임 안에 들어 있는 데이터를 정의하겠습니다. 여기서 RwLock<T> 타입은 페이지 래치입니다.
#[derive(Debug)]
pub struct BufferFrame {
page: RwLock<PageBytes>,
}
이제 이 프레임의 데이터를 PageReadGuard 안에 저장해 보겠습니다.
// 예제를 작게 유지하기 위해, 다음 타입은 문자 그대로의 구현이 아니라 개략적인 형태입니다.
// 이것은 `RwLockReadGuard`의 정확한 구현 세부사항이 아니라
// 소유권상의 절충을 보여 주기 위한 것입니다.
/// 고정된 페이지에 대한 공유 접근을 제공하는 읽기 가드.
pub struct PageReadGuard {
page: PageBytes,
}
이 버전은 모델링하기는 단순하지만, 설계 자체에 복사를 박아 넣습니다. 상위 계층의 각 페이지 객체가 자기만의 PageBytes를 소유한다면, 버퍼 풀 저장소로부터 그런 객체를 구성하는 일은 새로운 소유 값을 실제로 만들어 내는 것을 의미합니다.
우리가 वास्तव로 원하는 것은 소유권이 아니라, 이미 다른 어딘가에 존재하는 바이트에 대한 borrowed view입니다. 이를 lifetime을 도입해 모델링할 수 있습니다.
pub struct PageReadGuard<'a> {
page: &'a PageBytes,
}
이 lifetime 표기를 통해 우리는 PageReadGuard가 PageBytes보다 오래 살지 않는다는 점을 컴파일러에 증명합니다. 이는 상위 계층 페이지 객체가 소유된 복사본이 아니라 기존 바이트에 대한 view가 될 수 있음을 뜻합니다.
실제 구현에서 이 필드는 &'a PageBytes가 아니라 RwLockReadGuard<'a, PageBytes>입니다. 하지만 소유권에 대한 이야기는 같습니다. 가드는 페이지 바이트를 소유하지 않고 빌리며, 우리의 래퍼는 그 borrow를 계속 앞으로 전달합니다.
pub struct PageReadGuard<'a> {
page: RwLockReadGuard<'a, PageBytes>
}
전형적인 데이터베이스 엔진에는 두 가지 핵심 페이지 타입이 있습니다. heap 페이지와 btree 페이지입니다. 그러니 전자에 집중해 봅시다. 페이지 구조는 표준적인 slotted page 레이아웃이 될 것입니다.
이 시점에서 바이트는 이미 PageReadGuard<'a>를 통해 빌려진 상태입니다. 이제 문제는 가드를 어디에 두고, 페이지 내부로 파싱된 참조들을 어디에 둘 것인가입니다.
가장 자연스러운 시도는 모든 것을 하나의 struct 안에 넣는 것입니다.
struct HeapPage<'a> {
guard: PageReadGuard<'a>,
header: &'a [u8],
line_pointers: &'a [u8],
record_space: &'a [u8],
}
이렇게 하면 Rust에서 포인터 무효화를 매우 어렵게 만드는 고전적인 self-referential struct 문제에 부딪힙니다. 잠시 상상해 봅시다. 어떤 struct가 있고 두 필드 A와 B가 있으며, B는 A를 가리킵니다. 그런데 struct A가 이동합니다. 그러면 B는 무엇을 가리킬까요? A가 원래 있던 곳을 계속 가리키게 되지만, 그것은 무효이며 UB로 이어질 수 있습니다. Rust에서는 Pin, unsafe raw pointer, Arc 포인터, ouroboros 같은 외부 크레이트로 이를 우회하는 방법이 있습니다. 하지만 이들 모두는 그에 따른 오버헤드를 갖습니다.
그래서 다음으로 시도할 일은 가드의 소유권과 페이지에 대한 파싱된 view를 분리하는 것입니다.
pub struct HeapPage<'a> {
guard: PageReadGuard<'a>,
}
pub struct HeapPageView<'a> {
header: &'a [u8],
line_pointers: &'a [u8],
record_space: &'a [u8],
layout: &'a Layout,
}
let page = HeapPage::new(guard);
let view = HeapPageView::new(&'a page, layout); // page에서 borrow하고, page는 스택에서 살아 있음
이 방식은 동작하지만, 바이트를 변경하고 싶을 때 문제가 생깁니다. heap 페이지에 레코드를 삽입하고 싶다고 해 봅시다. 그러려면 record_space를 변경해야 하고 line_pointers도 변경해야 합니다. 이제 둘의 경계가 모두 바뀌었을 수 있으므로 struct 안의 참조는 낡아 버립니다. struct를 버리고 다시 만들어야 합니다. 비용은 작지만, 이는 새는 추상화입니다.
더 나은 형태는 다음과 같습니다.
pub struct HeapPage<'a> {
guard: PageReadGuard<'a>,
}
pub struct HeapPageView<'a> {
header: &'a [u8],
body_bytes: &'a [u8],
layout: &'a Layout,
}
let page = HeapPage::new(guard);
let view = HeapPageView::new(&'a page, layout); // page에서 borrow하고, page는 스택에서 살아 있음
slotted page에서는 헤더 크기가 고정되어 있고, 어떤 연산을 수행하든 헤더의 정보를 사용해 body 바이트를 다시 파싱함으로써 바이트에 대한 정확한 view를 얻습니다.
하지만 위 방식은 page와 view를 스택에 계속 살아 있게 유지해야 하며, 구현 세부사항을 query layer까지 새어 나가게 만듭니다. 다시 말해 새는 추상화입니다.
제가 택한 버전은 이 관계를 뒤집습니다. 옛날 컴퓨터 과학식 수법이죠. “컴퓨터 과학의 모든 문제는 한 단계 더 많은 간접화를 통해 해결할 수 있다”. 이를 구체적으로 말하면, slotted page는 헤더, line pointer, record space로 나뉘므로, 파싱된 참조는 HeapPage에 저장하고 PageReadGuard는 HeapPageView에 둡니다.
pub struct HeapHeaderRef<'a> {
bytes: &'a [u8],
}
struct LinePtrBytes<'a> {
bytes: &'a [u8],
}
struct LinePtrArray<'a> {
bytes: LinePtrBytes<'a>,
len: usize,
capacity: usize,
}
struct HeapRecordSpace<'a> {
bytes: &'a [u8],
base_offset: usize,
}
struct HeapPage<'a> {
header: HeapHeaderRef<'a>,
line_pointers: LinePtrArray<'a>,
record_space: HeapRecordSpace<'a>,
}
pub struct HeapPageView<'a> {
guard: PageReadGuard<'a>,
layout: &'a Layout,
}
이들은 모두 정확히 동일한 'a lifetime을 공유합니다. 즉, 어떤 다른 타입이 이 참조들 중 하나를 들고 있더라도 그 타입보다 오래 살지 않는다는 뜻입니다.
그리고 이 모든 타입은 BufferFrame의 PageBytes가 들고 있는 정확히 동일한 바이트 집합에 대한 참조입니다.
PageBytes (BufferFrame이 소유)
┌─────────────────────────────────────────────────────┐
│ Header (34 bytes) │
│ page_type | slot_count | free_lower | free_upper .. │
├─────────────────────────────────────────────────────┤
│ Line Pointers (grows →) │
│ [ slot 0 ] [ slot 1 ] [ slot 2 ] ... │
├─────────────────────────────────────────────────────┤
│ Free Space │
├─────────────────────────────────────────────────────┤
│ Record Space (grows ←) │
│ ... [ tuple 2 ] [ tuple 1 ] [ tuple 0 ] │
└─────────────────────────────────────────────────────┘
│ │ │
HeapHeaderRef<'a> LinePtrArray<'a> HeapRecordSpace<'a>
│ │ │
└───────────────┴────────────────────┘
│
HeapPage<'a> ←─────────────────────────┐
│
built from
│
HeapPageView<'a>
┌──────────────────────────┐
│ guard: PageReadGuard<'a> │
│ layout: &'a Layout │
└──────────────────────────┘
│
owns the lock on
│
BufferFrame의 PageBytes
이 둘을 연결하는 것은 HeapPageView 위의 메서드이며, 페이지 바이트에 대한 해석된 view가 필요할 때마다 HeapPage를 구성합니다.
impl<'a> HeapPageView<'a> {
fn build_page(&'a self) -> HeapPage<'a> {
HeapPage::new(self.guard.bytes()).unwrap()
}
pub fn row(&self, slot: SlotId) -> Option<LogicalRow<'_>> {
let view = self.build_page();
let mut current = slot;
loop {
match view.tuple_ref(current)? {
// 단순화를 위해 코드 생략
}
}
}
}
impl<'a> HeapPage<'a> {
fn new(bytes: &'a [u8]) -> SimpleDBResult<Self> {
// PageKind trait의 공유 파싱 로직 사용
let layout = Self::parse_layout(bytes)?;
let header = HeapHeaderRef::new(layout.header);
// heap 전용 추가 검증
let free_upper = header.free_upper() as usize;
let page_size = PAGE_SIZE_BYTES as usize;
if free_upper < header.free_lower() as usize || free_upper > page_size {
return Err("heap page free_upper out of bounds".into());
}
let page = Self::from_parts(header, layout.line_ptrs, layout.records, layout.base_offset);
assert_eq!(
page.slot_count(),
header.slot_count() as usize,
"slot directory length must match header slot_count"
);
Ok(page)
}
}
query layer가 데이터 페이지로부터 무언가를 읽고자 할 때 HeapPageView를 받게 되며, 논리적 데이터 구간에 대한 접근이 필요한 HeapPageView의 모든 연산은 페이지 위의 바이트가 어떻게 배치되어 있는지 이해하는 HeapPage를 구성합니다.
이제 아마 매번 HeapPage를 다시 구성하는 비용이 궁금할 것입니다. 실제로는 매우 저렴합니다. 이 타입은 전적으로 산술 연산으로 이루어져 있고, 몇몇 불변식이 깨졌을 때를 위한 panic이 약간 섞여 있을 뿐입니다. 그리고 산술 연산은 CPU가 수행하기에 엄청나게 저렴하며, 특히 memcpy() 연산과 비교하면 더욱 그렇습니다.
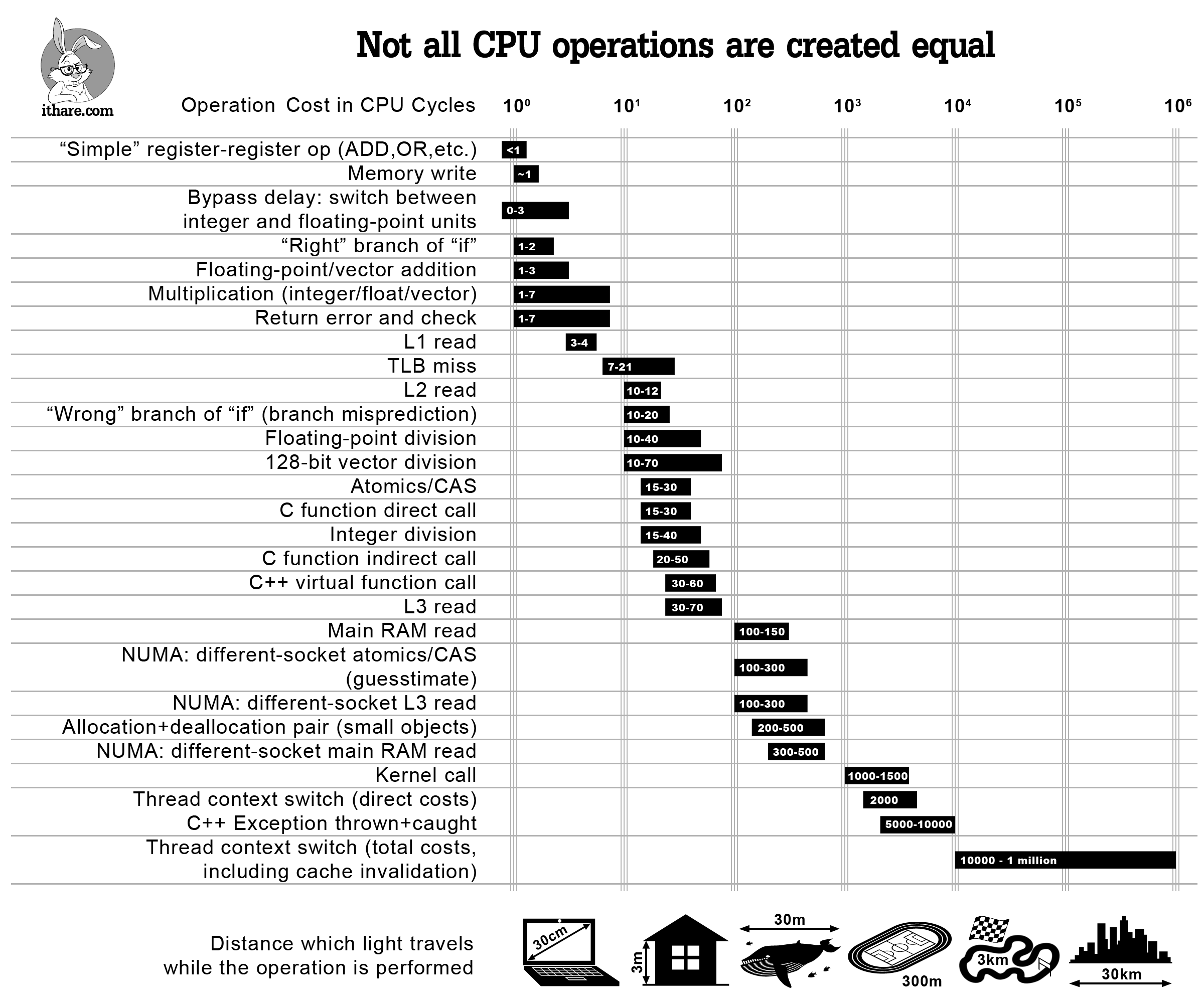 |
|---|
| 모든 CPU 연산의 비용이 같은 것은 아닙니다. 출처: ithare.com, Andrew Kelley의 Data Oriented Design 강연 경유 |
앞 절에서는 PageReadGuard, HeapPage, HeapPageView를 살펴보았고, 이들은 함께 페이지의 읽기 측 경로를 이룹니다. 하지만 Rust에는 aliasing XOR mutability 원칙이 있습니다. 이는 여러 개의 &T 또는 하나의 &mut T 중 하나만 가능하다는 뜻입니다. 지금까지 본 모든 것은 &T 경로에 있었고, 이제 &mut T 경로가 필요합니다.
/// 고정된 페이지에 대한 배타적 접근을 제공하는 쓰기 가드.
pub struct PageWriteGuard<'a> {
page: RwLockWriteGuard<'a, PageBytes>,
}
pub struct HeapPageMut<'a> {
header: HeapHeaderMut<'a>,
body_bytes: &'a mut [u8],
}
pub struct HeapPageViewMut<'a> {
guard: PageWriteGuard<'a>,
layout: &'a Layout,
}
impl<'a> HeapPageViewMut<'a> {
fn build_mut_page(&mut self) -> SimpleDBResult<HeapPageMut<'_>> {
HeapPageMut::new(self.guard.bytes_mut())
}
pub fn insert_tuple(&mut self, tuple: &[u8]) -> SimpleDBResult<SlotId> {
let mut page = self.build_mut_page()?;
page.insert(tuple)
}
}
이제 Rust의 aliasing 규칙을 따르게 되며, BufferFrame이 있다면 read 래치를 여러 번 획득해 읽기 경로를 만들 수도 있고, write 래치를 획득해 쓰기 경로를 만들 수도 있습니다.
BufferFrame
RwLock<PageBytes>
│
┌──────────┴──────────┐
│ │
read_page() write_page()
│ │
RwLockReadGuard RwLockWriteGuard
(shared, N readers) (exclusive, 1 writer)
│ │
PageReadGuard PageWriteGuard
&'a [u8] &'a mut [u8]
│ │
HeapPage HeapPageMut
(borrows &'a [u8]) (borrows &'a mut [u8])
│ │
HeapPageView<'a> HeapPageViewMut<'a>
물론 Rust의 borrow checker는 use-after-unpin을 런타임 위험이 아니라 컴파일 오류로 만들어 줍니다.
여기서 주목할 만한 비대칭이 하나 더 있습니다. HeapPage는 바이트를 세 필드(헤더, line pointer, record space)로 분할합니다. 읽기는 idempotent하고, 그 경계가 절대 변하지 않기 때문입니다.
하지만 HeapPageMut는 그렇게 할 수 없습니다. 단 한 번의 insert만으로도 free_lower와 free_upper가 모두 움직이기 때문에, 미리 분할해 둔 참조는 즉시 낡아 버립니다. 그래서 HeapPageMut는 단일한 body_bytes: &mut [u8]만 유지하고, 각 연산마다 헤더로부터 하위 영역을 다시 도출합니다. Rust는 alias된 mutable access를 막아 주지만, 분할 지점이 항상 헤더와 일치해야 한다는 더 깊은 불변식은 설계를 통해 강제해야 합니다.
눈치챘겠지만, 지금까지 우리는 'a라는 단 하나의 lifetime만 사용해 왔습니다. 모든 것을 동일한 기반 바이트 집합으로부터 빌려 왔으니 당연합니다.
하지만 실제로는 다소 부정확하게 설명했고, 컴파일러가 귀찮은 일을 일부 대신 처리해 주었습니다. 지금까지의 borrow 체인은 다음과 같았습니다.
PageBytes → RwLock{Read,Write}Guard<'a> → Page{Read,Write}Guard<'a> → HeapPage[Mut]<'a> → HeapPageView[Mut]<'a>
각 successive borrow는 이전 것 안에 중첩되지만, 컴파일러는 lifetime variance 덕분에 이 모든 것을 단일 lifetime으로 표현하도록 허용합니다.
lifetime variance의 핵심은 공유 참조는 공변이고 배타적 참조는 불변이라는 점입니다. 이를 흔히 &T는 'a에 대해 공변이고 &mut T는 'a에 대해 불변이라고 표현합니다.
공변 lifetime의 경우, Rust는 더 오래 사는 &T를 필요할 때 더 짧게 사는 &T로 줄일 수 있습니다. 그래서 우리는 중첩된 lifetime을 생략하고, 중간 lifetime은 컴파일러가 추론하도록 둘 수 있습니다.
mutable borrow는 덜 관대합니다. 변경 가능성이 이런 강제를 훨씬 엄격하게 만들기 때문입니다. &mut T에 대해 Rust는 내부 lifetime에 대해 그렇게 유연할 수 없습니다. 더 짧게 사는 참조가 더 오래 살아야 한다고 약속한 장소에 써 넣어지는 위험이 생길 수 있기 때문입니다.
이 비대칭을 보여 주는 구체적 예제를 보겠습니다. 두 개의 lifetime을 가진 struct를 정의하고, 함수 안에서 하나를 줄이려 해 봅니다.
struct Inner<'a> {
data: &'a [u8],
}
struct Outer<'short, 'long> {
inner: &'short Inner<'long>,
}
fn shorten<'long, 'short>(outer: Outer<'short, 'long>) -> Outer<'short, 'short> { outer }
이 코드는 컴파일됩니다. &T가 'long에 대해 공변이기 때문입니다. 함수는 데이터가 borrow보다 더 오래 사는 참조를 더 짧은 lifetime 쪽으로 강제 변환할 수 있습니다.
이제 바깥 참조를 mutable로 바꿔 봅시다.
struct Outer<'short, 'long> {
inner: &'short mut Inner<'long>,
}
fn shorten<'long, 'short>(outer: Outer<'short, 'long>) -> Outer<'short, 'short> { outer }
이 코드는 컴파일되지 않습니다. &mut T는 자신의 lifetime 매개변수에 대해 불변입니다. 데이터가 borrow보다 더 오래 살아도 줄일 수 없습니다. lifetime이 정확히 일치해야 합니다.
이것이 HeapPageViewMut::row_mut()와 LogicalRowMut의 구성에서 정확히 일어나는 일입니다.
pub struct LogicalRowMut<'row, 'page: 'row> {
view: &'row mut HeapPageViewMut<'page>,
}
impl<'a> HeapPageViewMut<'a> {
/// `slot`에 있는 live tuple을 편집 가능한 `LogicalRowMut`로 디코딩합니다.
/// 반환된 값이 drop될 때 변경 사항은 자동으로 페이지에 다시 기록됩니다.
pub fn row_mut<'row>(
&'row mut self,
slot: SlotId,
) -> SimpleDBResult<Option<LogicalRowMut<'row, 'a>>> {
// 단순화를 위해 코드 생략
Ok(Some(LogicalRowMut {
view: self,
slot,
values,
layout,
dirty: false,
}))
}
}
'page는 기반이 되는 페이지 view의 lifetime이며, 이 view는 이미 고정된 페이지 바이트를 빌리고 있습니다. 'row는 그 view 위에서 수행되는 하나의 배타적 편집 세션에 대한 더 짧은 lifetime입니다. 'page: 'row라는 관계는 mutable row editor가 그것을 빌리고 있는 동안 최소한 그 기간만큼 페이지 view가 유효해야 함을 뜻합니다.
BufferFrame 안의 페이지 바이트
┌─────────────────────────────────────────────────────────────┐
│ header │ line pointers │ free space │ tuple 2 │ tuple 1 │… │
└─────────────────────────────────────────────────────────────┘
<---------------------- 'page 동안 borrow됨 ---------------------->
row_mut() 한 번 호출
│
▼
LogicalRowMut<'row, 'page>
┌─────────────────────────┐
│ 하나의 논리적 row를 편집 │
└─────────────────────────┘
<---- 'row 동안 borrow됨 --->
Constraint: 'page : 'row
읽기 타입과 쓰기 타입을 별도로 나누는 것은 실제로 사용성 비용을 가집니다. HeapPageViewMut는 HeapPageView의 읽기 메서드를 자동으로 얻지 못합니다. Rust 표준 라이브러리에서는 &mut Vec<T>가 Deref를 통해 자동으로 &Vec<T>로 강제 변환되므로, mutable reference는 모든 immutable 메서드를 공짜로 얻습니다.
이것이 가능한 이유는 Vec<T>가 내부적으로 단일 raw pointer를 기반으로 하기 때문입니다. Deref<Target=[T]>와 DerefMut<Target=[T]>를 구현해 &[T] 또는 &mut [T]를 제공합니다. 하나의 포인터로부터, borrow checker는 호출 지점에서 그것을 어떻게 빌렸는지에 따라 공유 슬라이스를 줄지 배타적 슬라이스를 줄지 결정합니다. unsafe는 Vec 내부에 있으며, 한 번 감사되면 호출자에게는 보이지 않습니다.
pub struct Vec<T, #[unstable(feature = "allocator_api", issue = "32838")] A: Allocator = Global> {
buf: RawVec<T, A>,
len: usize,
}
#[stable(feature = "rust1", since = "1.0.0")]
impl<T, A: Allocator> ops::Deref for Vec<T, A> {
type Target = [T];
#[inline]
fn deref(&self) -> &[T] {
self.as_slice()
}
}
pub const fn as_slice(&self) -> &[T] {
unsafe { slice::from_raw_parts(self.as_ptr(), self.len) }
}
우리의 설계는 이 방식을 사용할 수 없습니다. PageReadGuard와 PageWriteGuard는 본질적으로 서로 다른 타입인 RwLockReadGuard와 RwLockWriteGuard를 들고 있으며, 이 둘은 하나의 raw pointer로 통합할 수 없습니다. RwLock이 런타임에서 읽기/쓰기를 구분해 강제하기 때문에, 컴파일 타임에서도 서로 다른 두 타입으로 반영되어야 합니다. HeapPageViewMut에 원하는 읽기 메서드는 무엇이든 명시적으로 작성해야 합니다.
이것이 Rust API 설계의 절충점입니다. unsafe는 없고, 능력의 분리는 명확하지만, unsafe 기반 타입이 공짜로 얻는 사용성만큼 매끄럽지는 않습니다.
결국 경로는 다음과 더 비슷해집니다.
┌─────────────────────────────────────────────────────────┐
│ Query Layer │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Execution Engine │
└────────────────────────┬────────────────────────────────┘
│
┌────────────────────────▼────────────────────────────────┐
│ Transaction Manager │
└──────────┬─────────────┴─────────────────┬──────────────┘
│ │
┌──────────▼──────────┐ ┌────────────▼────────────┐
│ Lock Manager │ │ Log Manager │
└─────────────────────┘ └─────────────────────────┘
│ 페이지 바이트에 대한 borrowed view
┌────────────────────────▼────────────────────────────────┐
│ Buffer Pool │
└────────────────────────┬────────────────────────────────┘
│ `O_DIRECT`가 이 복사를 제거함
┌────────────────────────▼────────────────────────────────┐
│ Disk │
└─────────────────────────────────────────────────────────┘
O_DIRECT는 디스크와 버퍼 풀 사이의 복사를 제거하고, 페이지/view 설계는 상위 계층의 페이지 객체를 이미 메모리에 고정된 바이트에 대한 borrowed view로 바꿈으로써 버퍼 풀 위에서의 새로운 복사를 제거합니다.
제게 이 설계에서 흥미로운 부분은 소유권을 버퍼 풀이라는 한 곳으로 이동시킨다는 점입니다. 그 위의 모든 것은 동일한 바이트 집합에 대한 view에 관한 이야기입니다. 물론 그 대가로 API 사용성은 떨어집니다. 컴파일러가 내가 신경 쓰는 동일한 불변식을 볼 수 있도록 제로-카피 페이지 접근 방식을 구조화해야 했습니다. 그 결과 코드 곳곳에 lifetime 표기가 흩어지지만, 특정 종류의 버그를 제거하고 중복된 데이터 이동을 피할 수 있습니다.