NVIDIA H100에서 기본적인 FP32 GEMM 커널부터 공유 메모리, 레지스터 타일링, 벡터화, 워프 타일링, 그리고 Hopper의 Tensor Core, TMA, WGMMA까지 단계적으로 적용하며 cuBLAS에 가까운 성능을 추적하는 최적화 워크로그입니다.
2026년 1월 12일
🚧 작업 진행 중입니다. 실수를 발견하시면 LinkedIn으로 연락 부탁드립니다.
행렬 곱셈은 현대 딥러닝의 핵심에 자리 잡고 있습니다. 트랜스포머, CNN, 혹은 단순한 MLP이든 결국 모든 것은 GEMM으로 귀결됩니다. GPU는 이 연산을 대규모로 수행하도록 설계되어 있으며, cuBLAS 같은 라이브러리는 마지막 명령어 하나까지 조율된 커널로 성능의 기준을 세웁니다.
이 블로그에서는 NVIDIA H100 위에서 그 경로를 바닥부터 다시 구축해 봅니다. 가장 기본적인 커널에서 시작해서 공유 메모리 타일링, 레지스터 블로킹, 벡터화, 워프 타일링, 그리고 Tensor Core, Tensor Memory Accelerator 같은 Hopper 전용 기능까지 최적화를 점진적으로 쌓아 올립니다. 이 프로젝트는 Pranjal Shankhdhar와 Simon Boehm의 훌륭한 작업에서 영감을 받았고, 여기에 제 기여를 더해 전체 최적화 경로를 탐구하면서 결과를 재현할 수 있는 일관되고 재현 가능한 저장소를 제공하려고 합니다. 첫 일곱 개 커널에서는 FP32 정밀도만 사용합니다. 이 단계에서는 GEMM 성능 튜닝의 기반이 되는, 그리고 대체로 아키텍처에 독립적인 근본적인 최적화 기법에 집중하고 싶었습니다. FP32를 사용하면 Nsight Compute로 디버깅하기가 더 쉬워지고 PTX와 SASS를 깔끔하게 살펴볼 수 있습니다. 두 번째 단계로 들어가 Tensor Core와 H100 전용 기능을 활용하기 시작하면 혼합 정밀도로 전환합니다. 그 시점부터 모든 벤치마크는 Tensor Core가 활성화된 cuBLAS와 비교하게 되며, 반면 이 첫 단계에서는 순수 FP32 모드로 동작하는 cuBLAS와 비교합니다. (다만 저장소에는 혼합 정밀도 구현도 포함되어 있습니다.)
목표는 단순히 순수한 속도만이 아닙니다. 각 변경이 실제로 무엇을 가져다주는지, 프로파일러가 매 단계에서 무엇을 말해주는지, 그리고 커널이 순진한 구현에서 고도로 튜닝된 형태로 어떻게 진화하는지를 보는 것입니다. 마지막에는 손수 작성한 CUDA가 cuBLAS에 얼마나 가까이 갈 수 있는지, 그리고 고정된 행렬 크기에서는 오히려 그것을 앞지를 수 있는지도 측정해 볼 것입니다.
전체 코드는 제 GitHub에 있습니다. 모든 코드는 FP32와 BF16+FP32 혼합 정밀도를 지원하는 제 GitHub에서 확인할 수 있습니다.
시작해봅시다.
코드로 들어가기 전에, GPU 내부 하드웨어 구성 요소에 대한 명확한 정신 모델을 먼저 세우는 것이 도움이 됩니다. GPU 내부의 메모리 계층 구조, 온칩 메모리와 오프칩 메모리의 크기 및 지연 시간 차이, 그리고 Hopper 아키텍처 계열에서 새롭게 도입된 구성 요소를 이해하면 이후 내용을 훨씬 쉽게 추론할 수 있습니다. 이 절에서는 아직 CUDA 프로그래밍 모델을 다루지 않을 것입니다. 대신 커널을 따라가면서 개념을 점진적으로 소개하겠습니다. 저는 이것을 일종의 워크로그로 생각하는 편이기 때문입니다. 따라서 이 절은 일종의 입문서 역할을 합니다. 아래 그림은 Aleksa의 글을 바탕으로 확장한 것으로, 전체 아키텍처를 자세히 보여줍니다.

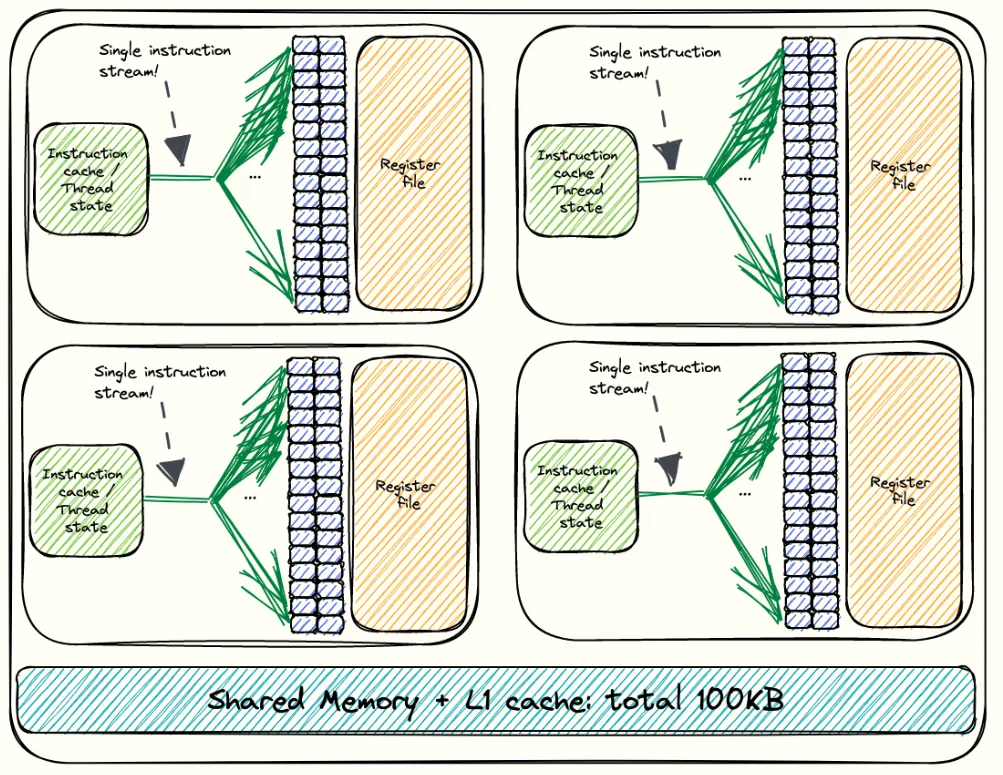
최상위 수준에서 H100은 여러 개의 Graphics Processing Cluster(GPC)로 구성되며, 총 8개의 GPC가 있고 각 GPC는 18개의 Streaming Multiprocessor(SM)를 포함합니다. 각 네 개의 GPC는 하나의 L2 파티션에 직접 연결되고, 나머지 네 개는 두 번째 파티션에 연결됩니다. 이 SM들에는 칩의 주요 연산 유닛과 몇몇 “온칩” 메모리 구성 요소가 들어 있습니다. H100의 SXM 버전은 132개의 SM을 가지며(여기서 제가 사용하는 버전입니다), PCIe 버전은 114개를 가집니다. 사실 8 * 18 = 144이므로 132개보다 많아야 할 것처럼 보입니다. 하지만 144는 전체 GH100 다이에 해당합니다. 실제로는 일부 SM이 비활성화되어 SXM 변종에서는 132개의 SM만 동작합니다. H100 같은 현대 GPU는 매우 거대하고 극도로 복잡한 실리콘이기 때문에 결함 없이 제조하는 것은 거의 불가능합니다. 단 하나의 불량 SM만 있어도 칩 전체를 사용할 수 없게 됩니다. 이런 낭비를 피하기 위해 NVIDIA는 결함이 있거나 부분적으로 결함이 있는 SM을 비활성화하여, 더 적은 수의 SM으로도 칩이 정상 동작하도록 만듭니다. 이 과정은 제조 수율을 높입니다. 아래는 SM 내부를 더 자세히 본 모습입니다.
SM 내부에는 위 그림과 같이 네 개의 파티션이 있습니다. 각 SM은 다음과 같은 핵심 자원을 포함합니다.
CUDA 코어: 표준 부동소수점 연산(FLOPS)과 정수 연산(IOPS)을 처리합니다.
4세대 Tensor Core: 각 SM에는 4개의 특수 연산 유닛이 포함됩니다. 이들은 고처리량 행렬 곱셈-누산 연산을 위해 설계되었으며, 현대 GPU 워크로드에서 최고 성능을 달성하는 데 필수적입니다.
Load/Store (LD/ST) 유닛: SM과 메모리 계층 간에 데이터를 이동시키는 역할을 합니다.
SFU 유닛: sin, cos, sqrt, exp 같은 복잡한 수학 연산을 처리하여 CUDA 코어의 부담을 덜어줍니다. 각 SM 파티션은 자체 SFU를 가지므로 이런 연산은 일반 산술 연산과 병렬로 실행될 수 있습니다. SASS 명령어 중 MUFU로 시작하는 것들(예: MUFU.SQRT, MUFU.EX2)은 SFU에서 실행됩니다.
디스패치 유닛: 워프 스케줄러와 실행 파이프라인 사이의 다리 역할을 합니다. 워프 스케줄러가 워프와 그 다음 명령어를 선택하면, 디스패치 유닛이 그 명령어를 SM 내부의 적절한 기능 유닛으로 보냅니다. 각 SM 파티션은 자체 디스패치 유닛을 가지므로 서로 다른 워프의 여러 명령어를 서로 다른 실행 유닛으로 동시에 발행할 수 있습니다.
워프 스케줄러: 각 SM에는 네 개의 워프 스케줄러가 있습니다(파티션당 하나). 각 스케줄러는 32개 스레드로 이루어진 워프에 명령어를 발행합니다(이건 조금 뒤에 더 설명하겠습니다!). 워프 스케줄러는 클록 사이클당 단 하나의 워프에 대해 하나의 명령어만 발행할 수 있습니다. 따라서 네 파티션 전체를 합치면, 하나의 SM은 사이클당 최대 네 개의 워프 명령어를 발행할 수 있으며, 이는 어느 시점에서든 128개 스레드가 병렬 실행될 수 있음을 의미합니다. 모든 스케줄러를 완전히 활용하려면, 블록당 충분한 활성 워프가 있어야 하며 어떤 스케줄러도 놀지 않도록 해야 합니다. 그래서 일반적으로 블록당 128개 미만의 스레드를 발사하는 것을 피하는데, 이렇게 해야 모든 스케줄러가 작업할 워프를 갖게 됩니다. 실제로는 하나의 SM이 여러 스레드 블록을 수용할 수 있고 필요하면 다른 블록에서 워프를 가져올 수 있지만, SM이 우연히 단 하나의 블록만 수용할 자원만 가진 경우를 생각하면 여전히 유용한 경험칙입니다.
이제 메모리 계층 구조를 살펴봅시다. 각 메모리 유형이 GPU 내부 어디에 물리적으로 위치하는지, 그리고 접근 지연 시간 측면에서 어떻게 다른지를 보겠습니다. 다시 한번 Aleksa의 글에 있는 피라미드 그림을 바탕으로 설명하겠습니다.
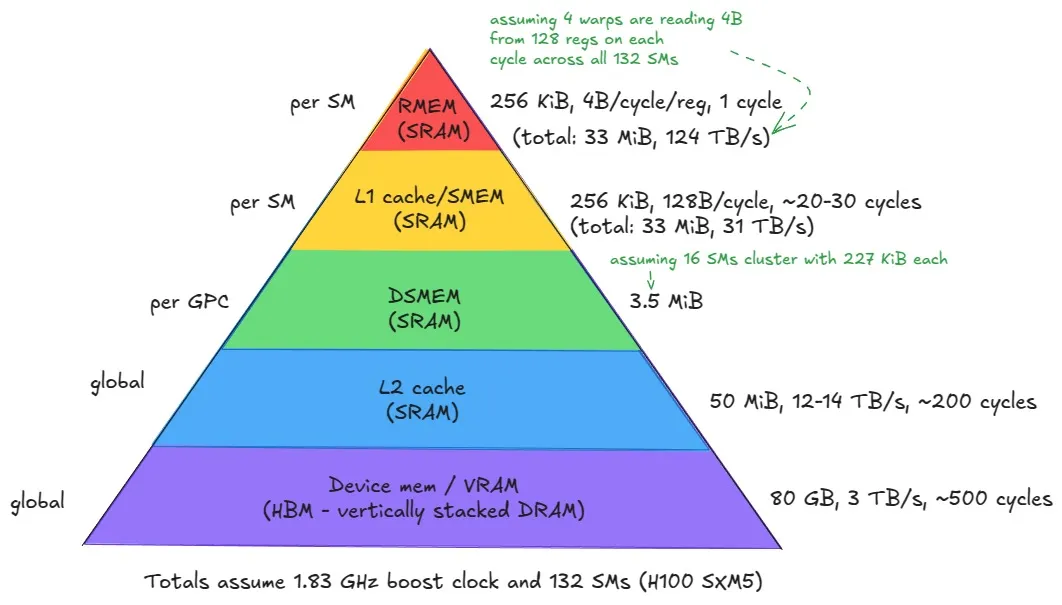
계층 구조의 맨 아래부터 시작해 위로 올라가 보겠습니다. 즉, 가장 크고 느린 메모리에서 가장 작고 빠른 메모리로 이동합니다.

L2 캐시: 전역 메모리 위에는 L2 캐시가 있습니다. 이는 모든 SM이 공유하는 큰 온칩 캐시(SRAM으로 구성됨)입니다. 연산 코어와 더 느린 오프칩 HBM 사이의 주요 다리 역할을 하며, 최근 접근한 데이터를 캐싱해 지연 시간을 줄입니다. 물리적으로는 두 개 파티션으로 나뉘며, 각 SM은 하나의 파티션에 직접 연결되고 다른 하나에는 크로스바를 통해 간접적으로 연결됩니다.
분산 공유 메모리(Distributed Shared Memory, DSMEM): 메모리 계층에 새롭게 추가된 요소입니다. DSMEM은 같은 GPC 안의 여러 SM에 걸쳐 여러 스레드 블록이 직접 데이터를 공유할 수 있게 합니다. 이는 전통적인 공유 메모리를 단일 SM 너머로 확장해, 스레드 블록 클러스터 내 최대 16개 블록 간 협업을 가능하게 합니다. 지연 시간은 L2보다 낮지만, SM 단위 공유 메모리 및 L1보다는 높습니다.
공유 메모리(SMEM) & L1 캐시: 이 둘은 동일한 물리적 온칩 저장소 위에 공존하므로 함께 묶어 설명하겠습니다. 역시 SRAM 셀로 만들어져 피라미드 아래쪽의 다른 메모리보다 훨씬 빠르고, 지연 시간은 더 낮으며 대역폭은 더 높습니다. 총 최대 크기는 256 KiB이고 메모리 대역폭은 31 TB/s입니다. L1 데이터 캐시는 SM의 LD/ST 유닛이 접근합니다. 이 256 KiB는 구성 가능하며, 더 큰 공유 메모리를 위해 더 작은 L1 캐시를 선택하거나 그 반대도 가능합니다. 다만 공유 메모리로 할당할 수 있는 최대치는 228 KiB 정도인데, L1 캐시를 위해서도 충분한 메모리를 남겨 두어야 하기 때문입니다. 사실 위 H100 아키텍처 그림에서 보이듯 228 KiB도 정확한 값은 아닙니다. 블록당 1 KiB의 SMEM은 어차피 시스템 용도로 사용되므로, 실질적으로는 최대 구성 가능 크기가 228 − num_blocks * 1 KiB가 됩니다.
레지스터 메모리(Register Memory, RMEM): 메모리 계층의 최하위이자 피라미드의 최상단에는 레지스터가 있습니다. 이는 단일 스레드가 조작하는 값을 저장합니다. 레지스터는 각 스레드에 사적이지만 예외가 하나 있습니다. 같은 워프 안에 있는 스레드끼리는 다른 스레드의 레지스터를 읽을 수 있습니다. 이는 warp level shuffle primitives를 통해 이루어집니다. 예를 들어 reduction 커널에서 자주 볼 수 있는데, 스레드 간 매우 빠른 통신을 가능하게 해줍니다. 레지스터는 매우 빠르며, 유효 대역폭은 124 TB/s 수준이고 지연 시간은 대략 한 클록 사이클입니다. 스레드의 레지스터 사용량이 가용 레지스터 파일을 초과하면 컴파일러는 값을 로컬 메모리로 스필하는데, 로컬 메모리는 전역 메모리에 위치하므로 훨씬 느립니다. CPU 프로그래밍과 마찬가지로, 레지스터는 CUDA C/C++ 수준에서 직접 조작되지 않습니다. PTX에서만 보이고 궁극적으로는 컴파일 시 ptxas가 할당합니다(아래의 Compilation Story 참고). 컴파일러의 목표 중 하나는 스레드당 레지스터 사용량을 충분히 낮게 유지해서 더 많은 스레드 블록이 동시에 하나의 SM에 상주할 수 있게 하는 것입니다. 높은 레지스터 압력은 occupancy를 낮추기 때문입니다.
Tensor Memory Accelerator (TMA): Hopper 아키텍처에서 도입되었습니다. 전역 메모리와 공유 메모리 사이, 그리고 스레드 블록 클러스터 내 공유 메모리들 사이에서 비동기 데이터 전송을 가능하게 합니다. 또한 공유 메모리 bank conflict를 막기 위해 자동으로 swizzling도 수행하여, 이전에는 개발자가 수동으로 관리해야 했던 복잡한 데이터 이동 및 레이아웃 패턴을 추상화합니다.
📖 Compilation Story
CUDA 프로그램이 소스 코드에서 최종 실행까지 도달하는 과정은 NVCC 컴파일러 드라이버가 조정하는 다단계 컴파일 과정을 거칩니다. NVCC 컴파일러 드라이버는 프로그램을 호스트 코드(CPU)와 디바이스 코드(GPU)로 분리해 과정을 관리합니다.
디바이스 코드는 먼저 PTX(Parallel Thread Execution, 저는 “피티엑스”라고 읽습니다 :))로 컴파일됩니다. PTX는 NVIDIA의 가상 ISA(Instruction Set Architecture)이며, 아키텍처 독립적인 중간 표현(IR)을 제공합니다. 이후 ptxas 어셈블러가 PTX 코드를 받아 필요한 최적화를 수행하고, 이를 SASS(Streaming ASSembler)라는 네이티브 ISA로 변환합니다. 이것이 사람이 읽을 수 있는 코드로 작성 가능한 가장 낮은 수준의 형식입니다. SASS 코드와 기타 메타데이터는 특정 GPU 아키텍처용 실행 컨테이너인 CUBIN(CUDA Binary)에 패키징됩니다. 마지막으로 NVCC는 하나 이상의 CUBIN과 원본 PTX를 Fat Binary로 묶고, 이를 CPU 바이너리 코드와 함께 최종 실행 파일에 포함시킵니다.
PTX를 포함하는 것은 전방 호환성에 매우 중요합니다. Fat Binary가 미래의 GPU에서 실행되는데 거기에 맞는 CUBIN이 없다면, 런타임은 포함된 PTX를 사용해 Just-In-Time(JIT) 컴파일을 수행하여 필요한 SASS를 생성하고 실행을 보장합니다. 커널 2와 5에서는 PTX와 SASS를 분석해 왜 이것들이 유용한지 보겠습니다.
이제 충분히 탄탄한 정신 모델을 세웠으니, 지금까지 이야기한 모든 것을 하나의 시각화로 묶어 H100 아키텍처 전체를 다시 바라보며 이 절을 마무리하겠습니다.

CUDA 프로그래밍 모델에서 계산은 2단계 계층으로 구성됩니다. CUDA 커널을 한 번 호출하면 새로운 grid가 만들어지고, 이 grid는 여러 block으로 이루어집니다. 각 block 안에는 스레드가 1D, 2D, 3D로 배열되었는지와 상관없이 총 최대 1024개까지 들어갈 수 있습니다. 즉, blockDim.x * blockDim.y * blockDim.z <= 1024입니다. grid 안의 모든 스레드는 같은 커널 함수를 실행하지만, 자신을 구분하고 처리할 데이터의 적절한 부분을 식별하기 위해 스레드 인덱스에 의존합니다. 일반적으로는 하드웨어 효율을 위해 스레드 블록의 각 차원 스레드 수를 32의 배수로 두는 것이 권장됩니다. 이것은 곧 소개할 워프라는 개념과 정렬되기 때문입니다. 지금은 워프가 32개 스레드의 묶음이라는 점만 기억해두면 됩니다. 커널은 SIMT(Single Instruction, Multiple Threads) 실행 모델에 따라 단일 스레드의 관점에서 작성됩니다. 따라서 CUDA 프로그래밍은 SPMD(Single Program, Multiple Data) 패러다임의 한 예입니다.
커널 내부의 스레드가 __device__ 함수를 호출하면, 그 스레드 자신이 그 함수를 실행합니다. 그 함수는 오직 자신을 호출한 스레드만 알고 있습니다. 기본적으로는 C++의 일반 함수와 같지만, 단 하나의 GPU 스레드 내부에서 일어난다고 보면 됩니다. 그리고 이런 함수 인스턴스 수천 개가 병렬로 실행된다고 상상하면 됩니다.
__global__ 함수는 커널입니다. GPU 실행용으로 컴파일되지만 CPU(호스트)에서 실행됩니다. 커널을 실행하면 블록들의 grid가 만들어지고, 그 블록 내부의 각 스레드는 독립적으로 커널 코드를 실행하기 시작합니다.
모든 스레드 블록은 입력의 서로 다른 부분에서 작동하므로 임의의 순서로 실행될 수 있습니다. 따라서 블록의 실행 순서나, 블록 내부에서 어떤 스레드가 먼저 실행될지에 대해 절대 가정해서는 안 됩니다.

새로 이해한 CUDA 프로그래밍 모델을 하부 하드웨어에 대한 정신 모델과 연결하면, 다음 그림은 하나의 스레드 관점에서 그것이 커널과 하드웨어 내부 어디에 위치하는지, 서로 다른 메모리 공간과 어떻게 상호작용하는지, 그리고 전체 grid 구조 속에서 어떻게 들어맞는지를 보여줍니다. L1과 L2 캐시는 하드웨어가 관리하고 우리가 직접 제어하지 않으므로 의도적으로 제외했습니다.

이 첫 번째 커널에서는 grid 안의 block에 있는 각 스레드가 C의 정확히 하나의 원소를 계산하도록 할당합니다. 각 스레드는 자신의 좌표를 가져와 공유 차원 N에 걸쳐 A의 해당 행을 순회합니다(공식 자료 대부분은 여기서 K를 사용하지만, 저는 모든 커널에서 이미 N으로 통일해두었기 때문에 일관성을 위해 그대로 쓰겠습니다). 동시에 그 스레드는 B의 맞는 열을 따라 내려가면서 곱을 누적합니다. 루프가 끝나면 결과를 같은 좌표의 C에 다시 씁니다.
스포일러: 이런 식으로 스레드 결과를 출력 원소와 1:1 대응시키는 방식은 사실 가장 효율적인 방법이 아닙니다(그렇게 짐작하셨다면 맞습니다). 이후 커널에서는 하나의 스레드가 출력의 여러 원소를 계산하게 할 것이지만, 일단은 여기까지로 두겠습니다.
아래는 이 동작 방식에 대한 간단한 시각화이며, 단일 스레드 관점에서의 예시도 포함되어 있습니다.

CUDA 프로그래밍 모델이 2D 좌표(x, y)를 지원하더라도, 여기서는 block을 여전히 1D로 실행한다는 점에 주목하세요. Simon의 작업(Kernel 2)에서는 2D launch를 1D launch와 remapping으로 바꾸면 전역 메모리 접근이 coalesced되도록 도울 수 있다고 언급합니다. 아이디어는 1D block을 실행한 뒤 threadIdx.x를 %와 /를 사용해 2D 좌표로 재해석하는 것입니다.
하지만 제가 두 접근법, 즉 remapping을 사용하는 1D launch와 일반적인 2D launch를 모두 테스트해봤을 때 성능은 동일했습니다. 처음에는 Simon의 버전에서는 속도 향상이 있었기 때문에 이 점이 꽤 헷갈렸습니다. 핵심 차이는 Simon의 순진한 커널이 A 행렬을 열 방향으로 접근했다는 점인데, 이건 coalesced되지 않은 패턴입니다. 반면 그의 coalesced 커널은 blockIdx.x와 threadIdx.x가 열이 아니라 행에 대응하도록 하여 A를 행 방향으로 접근합니다. 이는 제가 제 버전에서 하는 방식과 반대입니다. 제 구현에서는 순진한 커널조차 이미 A를 coalesced된 row-major 방식으로 접근하고 있기 때문에, 두 버전 모두 자연스럽게 같은 효율을 냅니다. 웃기게도 이건 아마도 매우 기본적인 내용이었겠지만, 저는 처음에 coalescing이 remapping 기법에서 오는 줄 알았기 때문에 한동안 꽤 혼란스러웠습니다.
즉 Simon의 속도 향상은 실제로는 1D 대 2D block 레이아웃 자체에서 오는 것이 아니라, 메모리 접근 패턴을 바로잡은 데서 옵니다. 제 순진한 커널은 이미 coalesced load를 사용하므로, launch 구성은 차이를 만들지 않습니다. 그래도 저는 여기서 1D launch + remapping 접근을 계속 사용할 텐데, 이것이 memory coalescing을 설명할 자연스러운 시점을 주기 때문이고, 또한 Simon의 방식이 어떻게 non-coalesced 패턴으로 이어지는지도 보여주고 싶기 때문입니다. 먼저 워프가 무엇인지 정의해봅시다.
각 SM은 스레드 블록 안의 스레드를 워프라는 묶음으로 그룹화하는데, 워프는 32개 스레드의 집합입니다. 워프는 워프 스케줄러가 한 번에 명령어를 발행할 수 있는 스케줄링 단위이며, 워프 안의 32개 스레드는 모두 같은 명령어를 lockstep으로 실행합니다. 블록은 먼저 1D 배열로 선형화되고(row-major 순서), 그 다음 연속된 32개 스레드 묶음으로 나뉩니다. 즉 warp 0은 스레드 0–31, warp 1은 32–63 등을 실행합니다.

이 커널의 코드는 다음과 같습니다.
template <const uint BLOCK_SIZE>
__global__ void sgemm_coalesced(const float* __restrict__ A, const float* __restrict__ B, float* __restrict__ C,
int M, int N, int K, float alpha, float beta) {
// flattened IDs remapping
uint row = blockIdx.y * BLOCK_SIZE + (threadIdx.x / BLOCK_SIZE);
uint column = blockIdx.x * BLOCK_SIZE + (threadIdx.x % BLOCK_SIZE);
if (row < M && column < K) {
float cumulative_sum = 0.0f;
for (int n = 0; n < N; n++) {
cumulative_sum += A[row * N + n] * B[n * K + column];
}
C[row * K + column] = (alpha * cumulative_sum) + (beta * (C[row * K + column]));
}
}
제가 언급한 remapping은 여기서 일어납니다. 만약 block을 2차원으로 실행했다면 threadIdx.x % BLOCK_SIZE와 threadIdx.x / BLOCK_SIZE를 통해 값을 계산하는 대신 그냥 threadIdx.x와 threadIdx.y를 직접 사용하면 됩니다. 저는 이 remapping을 영화관 좌석 번호를 받았지만 몇 행 몇 번째 좌석인지 듣지 못한 경우처럼 시각화하는 걸 좋아합니다. 예를 들어 각 줄에 여섯 좌석이 있고 제가 7번 좌석을 받았다고 합시다. 제 그림은 1부터 시작하는 번호를 쓰므로, 먼저 1을 빼서 0부터 시작하는 체계로 바꿉니다:
저는 이 remapping을 영화관 좌석 번호를 받았지만 몇 행 몇 번째 좌석인지 듣지 못한 경우처럼 시각화하는 걸 좋아합니다. 예를 들어 각 줄에 여섯 좌석이 있고 제가 7번 좌석을 받았다고 합시다. 제 그림은 1부터 시작하는 번호를 쓰므로, 먼저 1을 빼서 0부터 시작하는 체계로 바꿉니다: 6 = 7 - 1. 한 줄당 좌석 수로 나누면 행 인덱스가 나옵니다: 6 / 6 = 1, 이는 1부터 세는 기준으로는 2번째 줄입니다. 나머지는 그 줄 안에서의 좌석 위치를 알려줍니다: 6 % 6 = 0, 이는 1부터 세면 1번째 좌석이 됩니다. 그래서 7번 좌석은 두 번째 줄의 첫 번째 좌석입니다. 한 줄당 좌석 수로 나누면 몇 줄을 완전히 건너뛰는지 알 수 있고, 나머지는 그 줄 안에서의 좌석 위치를 줍니다.
uint row = blockIdx.y * BLOCK_SIZE + (threadIdx.x / BLOCK_SIZE);
uint column = blockIdx.x * BLOCK_SIZE + (threadIdx.x % BLOCK_SIZE);
32개 스레드로 이루어진 각 워프는 다음과 같이 전역 메모리 load를 병렬로 실행합니다.
cumulative_sum += A[row * N + n] * B[n * K + column];
메모리 명령어(전역이든 공유든)는 워프 안의 주소 분포에 따라 재발행이 필요할 수 있습니다. 아직 공유 메모리를 프로그래밍 측면에서 소개하지 않았으니, 지금은 전역 메모리에 집중하겠습니다.
워프가 load를 실행하면 하드웨어는 32개 스레드가 연속된 메모리 위치에 접근하는지 확인합니다. 가장 좋은 경우는 모든 스레드가 연속된 주소를 읽는 경우이며, 이때 하드웨어는 32개의 요청을 하나의 transaction으로 coalesce할 수 있습니다.
전역 메모리는 디바이스 DRAM에 있고, DRAM은 32, 64, 128바이트 단위 청크로 접근됩니다. transaction 수가 적을수록 효율이 높습니다. 여기서는 FP32 load(스레드당 4바이트) 기준으로 설명하겠습니다. 만약 각 스레드의 4바이트 load가 각각 별도의 32바이트 transaction을 필요로 한다면, 처리량은 8배나 떨어지게 됩니다.
예를 들어:
이제 이 coalesced 커널의 전역 메모리 접근 패턴과, non-coalesced 커널이 어떻게 보일지를 비교해봅시다.

이 커널을 실행하면 4.2 TFLOP/s의 처리량이 나오며, 이는 FP32 cuBLAS 커널 성능 대비 약 **8.2%**입니다. 우리는 아직 하드웨어가 이론적으로 제공할 수 있는 수준, 흔히 Speed of Light(SoL)라고 부르는 것과는 거리가 멉니다. Speed of Light는 물리와 칩 설계만을 기준으로 했을 때 GPU가 낼 수 있는 계산 처리량의 이론적 상한을 뜻합니다. Tensor Core 워크로드의 경우 이 상한은 perf = freq_clk_max * num_tc * flop_per_tc_per_clk로 주어집니다(H100 SXM5에서 BF16 Tensor Core 피크 989 TFLOP/s, FP32 피크 66.9 TFLOP/s).
이 숫자는 보통 고정된 값처럼 제시되지만, 실제로는 전혀 상수가 아닙니다. GPU가 실제로 유지할 수 있는 클록 주파수에 따라 움직이며, 그 주파수 자체도 전력과 열 제한 아래에서 변합니다. GPU가 전력 한계에 가까워질수록 전압 조정기는 전압을 낮추고, 클록 속도는 떨어지며, 유효 SoL도 함께 감소합니다. 이런 동작을 **전력 스로틀링(power throttling)**이라고 합니다.
Horace He는 간단한 matmul 벤치마크를 통해 이를 아주 잘 보여주었습니다. PyTorch에서 큰 matmul은 약 258 TFLOPs를 냈지만, 같은 연산을 CUTLASS profiler 안에서 실행하면 약 288 TFLOPs로 10–11% 더 빨랐습니다. 얼핏 보면 진짜 커널 수준 속도 향상처럼 보입니다. 하지만 같은 CUTLASS 커널을 Python에 바인딩해서 같은 입력으로 실행하면 그 이득은 사라졌습니다. 유일한 차이는 CUTLASS profiler는 텐서를 정수로 초기화하고, PyTorch는 난수를 사용한다는 점이었습니다.
왜 이게 중요한가는 칩의 전력 소비 방식에 뿌리를 두고 있습니다. 정적 전력은 트랜지스터를 켜 둔 상태로 유지하는 데 쓰이고, 동적 전력은 트랜지스터가 상태를 바꿀 때마다 소모됩니다. 난수는 수십억 개의 트랜지스터에서 혼란스러운 비트 전환을 일으켜 동적 전력을 높이고 스로틀링을 유발합니다. 반면 0이나 단순한 정수 패턴 같은 예측 가능한 값은 훨씬 적은 비트만 전환시키므로 동적 전력을 낮게 유지하고 GPU가 더 높은 클록을 유지할 수 있게 합니다. 다시 말해, 커널이 더 “빠르게” 보이는 것은 코드가 더 효율적이어서가 아니라 하드웨어가 전기적으로 덜 스트레스를 받기 때문입니다.
이것이 실제 커널이 광고된 피크 TFLOP/s에 거의 도달하지 못하는 이유입니다. 이론적 SoL은 최대 클록 주파수를 가정하지만, 실제 워크로드는 끊임없이 전력 및 열 제약에 부딪힙니다. 진짜 상한은 전압, 클록 속도, 온도, 심지어 입력 데이터의 랜덤성에 따라 달라집니다.
. 이는 당연한 결과입니다. 우리는 아직 매우 초기 단계이고, 가장 명백한 병목 중 하나는 루프의 매 반복마다 전역 메모리까지 나가야 한다는 사실입니다. 앞서 언급했듯이 GMEM 접근은 대략 500사이클이 들지만, 공유 메모리(SMEM) 접근은 대략 20~30사이클입니다. 다음 커널에서는 계산을 수행하기 전에 스레드들이 협력해서 GMEM의 값을 먼저 SMEM으로 로드하게 하여 성능을 개선할 것입니다. 타일이 SMEM에 올라오면, 스레드들은 반복적으로 GMEM에 가지 않고 그곳에서 피연산자를 가져올 수 있습니다. 이것은 속도를 크게 높여주며 더 높은 처리량에 가까워지도록 도와줍니다.
이 커널의 로직은 다음과 같습니다. A와 B의 타일을 로드하기 위한 공유 메모리 공간 sharedA와 sharedB를 각각 할당합니다. 각 타일의 원소 수는 TILE_SIZE * TILE_SIZE가 되며, 이는 grid를 dim3 blockDim(32 * 32)로 실행할 때 각 block의 스레드 수와 일치합니다. 즉, 이전과 마찬가지로 각 스레드는 출력의 단일 원소 하나를 계산합니다. 거기에 더해, 각 스레드는 타일 반복마다 A에서 하나, B에서 하나, 총 두 개의 값을 공유 메모리에 로드합니다.
이 점을 짚는 이유는 이후에는 각 스레드가 하나보다 많은 원소를 로드하는 커널도 등장하기 때문입니다. 그 경우 스레드가 공유 메모리 안의 어디에 써야 하는지 판단하기 위한 추가 인덱싱 로직이 필요합니다. 하지만 이 커널에서는 아직 그럴 필요가 없습니다. 각 스레드가 각 행렬에서 정확히 한 원소씩만 로드하므로 ty와 tx만 알면 충분하기 때문입니다.
이건 말보다 그림으로 보는 편이 훨씬 쉽기 때문에, 먼저 4 x 4 행렬 A와 B를 사용하는 작은 예제로 아이디어를 설명한 뒤, 실제 커널 안에서 같은 로직이 어떻게 보이는지 보여드리겠습니다.

이 로직을 합쳐 실제 실행 구성에 적용하면, 커널은 이제 다음과 같이 됩니다.

전체 코드는 다음과 같습니다.
template <const uint TILE_SIZE>
__global__ void sgemm_tiled_shared(const float* __restrict__ A, const float* __restrict__ B, float* __restrict__ C,
int M, int N, int K, float alpha, float beta) {
// Allocate shared memory
__shared__ float sharedA[TILE_SIZE * TILE_SIZE];
__shared__ float sharedB[TILE_SIZE * TILE_SIZE];
// Identify the tile of C this thread block is responsible for (We assume tiles are same size as block)
const uint block_row = blockIdx.y;
const uint block_column = blockIdx.x;
// Calculate position of thread within tile (Remapping from 1-D to 2-D)
const uint ty = threadIdx.x / TILE_SIZE; // (0, TILE_SIZE-1)
const uint tx = threadIdx.x % TILE_SIZE; // (0, TILE_SIZE-1)
// Move pointers from A[0], B[0] and C[0] to the starting positions of the tile
A += block_row * TILE_SIZE * N; // Move pointer (block_row * TILE_SIZE) rows down
B += block_column * TILE_SIZE; // Move pointer (block_column * TILE_SIZE) columns to the right
C += (block_row * TILE_SIZE * K) + (block_column * TILE_SIZE); // Move pointer (block_row * TILE_SIZE * K) rows down then (block_column * TILE_SIZE) columns to the right
// Calculate how many tiles we have
const uint num_tiles = CEIL_DIV(N, TILE_SIZE);
float cumulative_sum = 0.0f;
// Iterate over tiles (Phase 1: Loading data)
for (int t = 0; t < num_tiles; t++) {
sharedA[ty * TILE_SIZE + tx] = A[ty * N + tx];
sharedB[ty * TILE_SIZE + tx] = B[ty * K + tx];
__syncthreads();
// Phase 2: Compute partial results iteratively
for (int i = 0; i < TILE_SIZE; i++) {
cumulative_sum += sharedA[ty * TILE_SIZE + i] * sharedB[i * TILE_SIZE + tx];
}
__syncthreads();
// Move all pointers to the starting positions of the next tile
A += TILE_SIZE; // Move right
B += TILE_SIZE * K; // Move down
}
// Write results back to C
C[ty * K + tx] = (alpha * cumulative_sum) + (beta * C[ty * K + tx]);
}
이 커널은 이전 커널보다 대략 1.7× 처리량 향상을 달성하여 이제 cuBLAS(FP32) 대비 **13.9%**에 도달하지만, Nvidia의 Nsight Compute로 프로파일링해보면 몇 가지 핵심 문제가 드러납니다.
먼저 프로파일러의 Speed of Light 섹션을 보면 흥미로운 점이 있습니다. Compute throughput은 76.63%, Memory throughput은 91.13%입니다. 이것들은 하드웨어 FP32 SoL 대비 비율입니다. 얼핏 보면 76.63% compute throughput은 꽤 괜찮아 보일 수 있지만, 이 커널은 비교적 기초적인 GEMM 커널이므로 그럴 리가 없습니다.
백분율 기준의 병목을 보여주는 throughput breakdown을 보면, 오해가 즉시 풀립니다. SM: Inst Executed Pipe Lsu = 76.63%(개요에 표시된 값과 같은 수치인데, 개요는 단순히 instruction breakdown 중 가장 높은 비율을 보여주기 때문입니다). Pipe LSU는 load/store unit입니다. 프로파일러 설명에 따르면 그 역할은 다음과 같습니다.
"The LSU pipeline issues load, store, atomic, and reduction instructions to the L1TEX unit for global, local, and shared memory. It also issues special register reads (S2R), shuffles, and CTA level arrive or wait barrier instructions to the L1TEX unit."
그다음으로 많이 발행된 명령어는 SM: Mio Inst Issued = 40.08%인데, 이는 memory input/output unit입니다. 즉 명령어 발행이 LSU 연산과 비메모리 연산 사이에 거의 반반으로 나뉘어 있으며, 역시 메모리 쪽이 지배적인 힘이라는 뜻입니다.
그럼 실제 FP32 계산을 수행하는 명령어 수는 어떨까요? SM: Pipe FMA Cycles Active = 14.81%입니다. 우리가 진짜 관심 있는 숫자는 이것입니다. 왜냐하면 이 값은 FP32 FMA 실행 파이프가 활성 SM 사이클 중 실제로 얼마만큼 일하고 있었는지를 보여주기 때문입니다. 이 초기 단계에서 FP32 하드웨어 능력을 전혀 활용하지 못하고 있다는 뜻이며, 이것이 바로 우리가 예상해야 할 상황입니다. 좋은 GEMM이라면 이 숫자가 매우 높기를 바랍니다(예를 들어 60~80%+). GEMM은 거의 전부 FMA이기 때문입니다. 스포일러: 커널 6에서 이 숫자를 어떻게 62%까지 끌어올리는지 보게 됩니다.
따라서 개요의 compute throughput 수치(최댓값으로 선택된 그 값)는 조금 오해를 불러일으켰습니다. 전체 값은 SM에서 실행된 모든 명령어(ALU, FMA, SFU, LSU 등)를 고려하기 때문입니다. 유용한 다른 지표들도 있지만 지금은 무시하겠습니다. 자세히 보고 싶으시다면 모든 프로파일링 리포트를 다운로드 가능한 .ncu-rep 형식으로 GitHub 저장소에 올려두었습니다. Nsight Compute에서 열어 자세히 살펴볼 수 있습니다. 지금은 메모리 throughput breakdown으로 시선을 돌려봅시다.
상위 세 지표는 L1: Data Pipe Lsu Wavefronts = 91.13%, L1: Lsu Writeback Active = 87.07%, L1: Lsuin Requests = 76.63%입니다. 이 시점에서는 우리가 공유 메모리로부터, 그리고 공유 메모리로 향하는 엄청난 양의 load/store 요청으로 그것을 압도하고 있다는 것이 분명합니다.
프로파일러에서 이 현상을 바라볼 수 있는 흥미로운 지표와 관점이 더 있으므로, 아래 그림은 주석이 달린 세 가지 다른 프로파일러 화면을 보여줍니다. SASS 코드는 프로파일러의 source 섹션이나 이 GoodBolt 링크에서 전체를 볼 수 있습니다.

제가 roofline plot에서 지적했듯이 산술 집약도는 커널에서의 산술 연산 수 대비 메모리 연산 수의 비율입니다. , 우리는 산술 집약도를 높이고 싶습니다. 즉 시각적으로는 그래프에서 오른쪽으로 이동하고 싶습니다. 현대 GPU에서는 산술 대역폭과 메모리 대역폭 사이의 비율이 매우 크기 때문에, 가장 효율적인 커널은 높은 산술 집약도를 가집니다. 이는 메모리 병목을 해결할 때 종종 작업을 메모리 서브시스템에서 계산 서브시스템으로 옮겨, 메모리 대역폭을 절약하면서 산술 유닛의 부하를 늘릴 수 있음을 뜻합니다.
산술 집약도는 커널에서의 산술 연산 수 대비 메모리 연산 수의 비율입니다. , 우리는 산술 집약도를 높이고 싶습니다. 즉 시각적으로는 그래프에서 오른쪽으로 이동하고 싶습니다. 현대 GPU에서는 산술 대역폭과 메모리 대역폭 사이의 비율이 매우 크기 때문에, 가장 효율적인 커널은 높은 산술 집약도를 가집니다. 이는 메모리 병목을 해결할 때 종종 작업을 메모리 서브시스템에서 계산 서브시스템으로 옮겨, 메모리 대역폭을 절약하면서 산술 유닛의 부하를 늘릴 수 있음을 뜻합니다.
따라서 다음 커널에서는 각 스레드가 출력 행렬의 단 하나의 원소 결과만 계산하도록 두는 대신, 여러 원소를 계산하게 할 것입니다. 각 스레드는 여러 결과를 자신의 레지스터에 부분 누적하고, 계산이 완전히 끝났을 때만 레지스터의 최종 값을 C에 저장하게 됩니다.
작성 중입니다. 모든 커널 코드는 GitHub에서 확인할 수 있습니다.

우리 커널의 산술 집약도를 조금 더 끌어올리기 위해 이제 각 스레드가 단일 출력 원소보다 더 많은 것을 계산하게 합니다. 아래 그림처럼, 하나의 스레드 블록이 출력 행렬의 한 타일을 덮고, 그 타일 안에서 각 스레드는 자신만의 작은 2D 패치를 담당해 ROWS_PER_THREAD * COLS_PER_THREAD개의 결과를 계산합니다.
이제 공유 메모리 타일의 원소 수보다 적은 수의 스레드를 실행하므로, 각 스레드는 stride를 사용해 전역 메모리의 여러 원소를 공유 메모리에 로드해야 하며, 모든 타일 원소가 겹침 없이 채워지도록 해야 합니다. A와 B의 공유 메모리 타일이 완전히 채워지면, 각 스레드는 자신에게 필요한 A와 B 조각을 공유 메모리에서 레지스터로 반복적으로 가져와 부분 외적 갱신을 수행하고, 최종 ROWS_PER_THREAD * COLS_PER_THREAD 크기의 C 블록이 완성될 때까지 로컬 레지스터에 누적합니다.
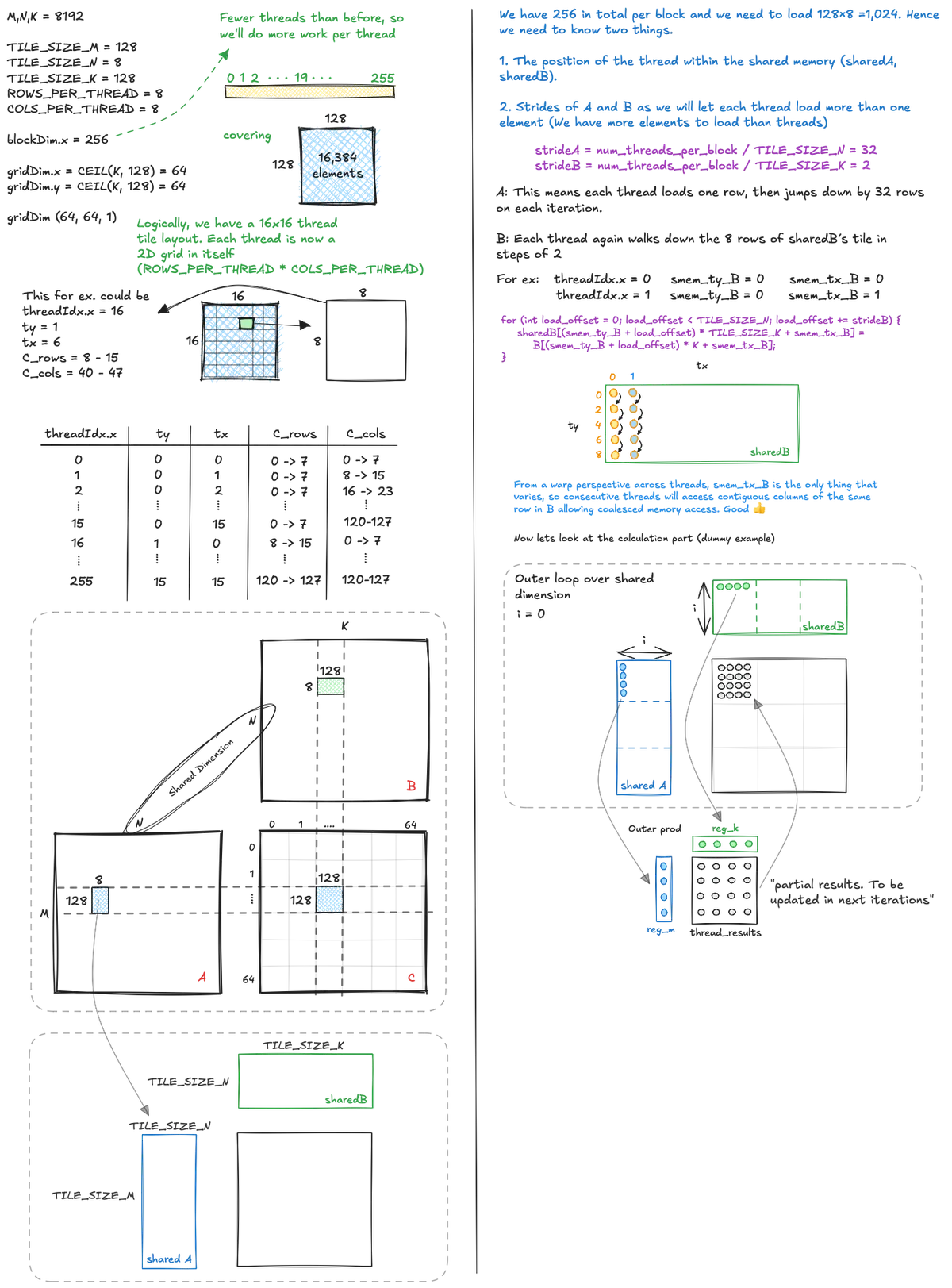 이 커널의 코드는 다음과 같습니다.
이 커널의 코드는 다음과 같습니다.
template <const uint TILE_SIZE_M, const uint TILE_SIZE_N, const uint TILE_SIZE_K, const uint ROWS_PER_THREAD>
__global__ void sgemm_1D_registertiling(const float* __restrict__ A, const float* __restrict__ B, float* __restrict__ C,
int M, int N, int K, float alpha, float beta) {
// Allocate shared memory
__shared__ float sharedA[TILE_SIZE_M * TILE_SIZE_N];
__shared__ float sharedB[TILE_SIZE_N * TILE_SIZE_K];
// Identify the tile of C this thread block is responsible for
const uint block_row = blockIdx.y;
const uint block_column = blockIdx.x;
// Calculate position of thread within tile (Remapping from 1-D to 2-D)
const uint ty = threadIdx.x / TILE_SIZE_K;
const uint tx = threadIdx.x % TILE_SIZE_K;
// Move pointers from A[0], B[0] and C[0] to the starting positions of the tile
A += block_row * TILE_SIZE_M * N;
B += block_column * TILE_SIZE_K;
C += (block_row * TILE_SIZE_M * K) + (block_column * TILE_SIZE_K);
// Calculate position of thread within shared memory tile
const uint smem_ty_A = threadIdx.x / TILE_SIZE_N;
const uint smem_tx_A = threadIdx.x % TILE_SIZE_N;
const uint smem_ty_B = threadIdx.x / TILE_SIZE_K;
const uint smem_tx_B = threadIdx.x % TILE_SIZE_K;
// Calculate number of tiles
const uint num_tiles = CEIL_DIV(N, TILE_SIZE_N);
// Initialise thread-local results in registers
float thread_results[ROWS_PER_THREAD] = {0.0f};
// Iterate over tiles
for (int t = 0; t < num_tiles; t++) {
sharedA[smem_ty_A * TILE_SIZE_N + smem_tx_A] =
A[smem_ty_A * N + smem_tx_A];
sharedB[smem_ty_B * TILE_SIZE_K + smem_tx_B] =
B[smem_ty_B * K + smem_tx_B];
__syncthreads();
// Inner computation loop
for (int i = 0; i < TILE_SIZE_N; i++) {
float fixed_B = sharedB[i * TILE_SIZE_K + tx];
for (int row = 0; row < ROWS_PER_THREAD; row++) {
uint global_row_idx = ty * ROWS_PER_THREAD + row;
thread_results[row] +=
sharedA[global_row_idx * TILE_SIZE_N + i] *
fixed_B;
}
}
__syncthreads();
// Move to next tile
A += TILE_SIZE_N;
B += TILE_SIZE_N * K;
}
// Write results back to C
for (int row = 0; row < ROWS_PER_THREAD; row++) {
uint global_row_idx = ty * ROWS_PER_THREAD + row;
C[global_row_idx * K + tx] =
(alpha * thread_results[row]) +
(beta * C[global_row_idx * K + tx]);
}
}
이전 커널은 메모리 IO stall을 줄였지만, 출력 하나당 스레드가 여전히 너무 많은 공유 메모리 읽기를 수행하고 있었습니다.
이 커널에서는 이제 각 스레드가 수직 스트립만이 아니라 행과 열로 이루어진 타일을 계산합니다. 그 결과 다음과 같이 줄었습니다.
이는 출력당 SMEM load 트래픽이 4.5배 감소하고, GMEM은 2× 감소한 것이며, 동시에 각 스레드가 계산하는 결과 수는 8× 늘어났습니다.
이 커널을 프로파일링해보면 H100의 FP32 피크의 38%에 도달하는데, 이는 즉시 이 커널이 compute-bound가 아님을 알려줍니다. 전역 메모리도 포화 상태와는 거리가 멉니다. DRAM 대역폭의 2.90%, L2의 약 10.13%만 사용하며, GEMM 워크로드치고는 둘 다 매우 낮습니다. 따라서 전역 대역폭도, L2 트래픽도 제한 요인이 아닙니다.
처음으로 의미 있는 신호는 Speed of Light 섹션에서 나타납니다.
프로파일러는 심지어 병목 방향까지 직접 알려줍니다.
“The kernel is utilising greater than 80% of the available compute or memory performance. To further improve performance, work will likely need to be shifted from the most utilised unit to another. Start by analysing L1 in the Memory Workload Analysis section.”
DRAM과 L2는 거의 건드리지 않는데 L1/TEX는 90% 가까이 활용되고 있으므로, 압력은 분명 온칩 메모리 계층에 집중되어 있습니다. 즉 이건 전혀 DRAM 문제가 아닙니다. 제한 요인은 L1 캐시/SMEM 경로의 대역폭과 지연 시간입니다.
이 그림은 스케줄러 지표로도 강화됩니다. SM Issue Active는 55.50%로, 워프 스케줄러가 전체 사이클 중 절반 조금 넘는 시간에만 명령어를 발행하고 있음을 뜻합니다. 나머지 약 45% 사이클은 보통 DRAM이나 L2가 아니라 L1/SMEM을 통한 데이터 이동을 기다리며 stall 상태로 소비됩니다.
스케줄러 통계를 보면 다음과 같습니다.
"Every scheduler is capable of issuing one instruction per cycle, but for this kernel each scheduler only issues an instruction every 1.8 cycles. This might leave hardware resources underutilized and may lead to less optimal performance."
Stall MIO throttle도 0.59로 나타나며, 우리는 이것을 줄이고 싶습니다. 종합하면, 극히 낮은 DRAM 사용량, 극히 낮은 L2 사용량, 높은 L1/TEX 활용도(∼88%), 그리고 중간 수준의 50%대 SM issue는 모두 같은 결론을 가리킵니다. 이
커널은 L1-bound 혹은 SMEM-bound입니다. compute-bound도 아니고, 확실히 GMEM-bound도 아닙니다. 병목은 레지스터, 공유 메모리, L1/TEX 경로 사이의 온칩 데이터 이동입니다. 다음 최적화에서는 L1/SMEM 파이프라인 내부의 instruction overhead를 줄여야 하며, 이를 통해 1.8 cycles per instruction 문제를 직접 해결하고 워프 스케줄러가 SM Issue Active를 더 높일 수 있게 해야 합니다.
이 한계에도 불구하고, 우리는 이전 커널 대비 1.40× 향상을 얻었습니다. 12.2 TFLOPs에서 19.1 TFLOPs로 올라가며 cuBLAS 대비 **36.8%**까지 도달했습니다.
지금까지 이전 모든 커널에서는 스칼라당 하나의 load instruction을 발행했습니다. 우리가 최적화한 coalescing 때문에 실제로 스칼라당 하나씩 load를 하는 것이 아니라는 인상을 받을 수도 있어 약간 헷갈릴 수 있습니다. 여기서 빠진 디테일은 다음 두 가지 사이에 중요한 차이가 있다는 것입니다.
coalescing은 첫 번째만 도와줍니다. 여러 스레드가 요청한 데이터를 하드웨어가 하나의 연속된 메모리 transaction으로 합칠 수 있게 해줍니다. 하지만 두 번째는 전혀 바꾸지 않습니다. 각 스칼라 load는 여전히 별도의 instruction으로 존재하고, 각각이 워프 스케줄러에 의해 발행되어 load/store 파이프라인을 통과해야 합니다.
이를 확인하기 위해 이전 커널의 SASS를, 특히 GMEM에서 SMEM으로 로드하는 부분을 보면 실제로 루프 반복마다 스레드당 별도 instruction issue가 생성되는 것을 확인할 수 있습니다. 예를 들어 B에 대한 접근이 coalesced되어 있고, 이는 메모리 컨트롤러 수준에서 제 역할을 하지만, 하드웨어는 여전히 스레드당 네 번의 개별 instruction issue를 필요로 합니다. coalescing은 컴파일 시점에 일어나는 것이 아닙니다. 실제 주소가 알려진 런타임에 하드웨어가 동적으로 수행합니다. 이는 타당합니다. 행렬 포인터는 함수 인자로 전달되므로 컴파일러가 정렬이나 레이아웃을 가정할 수 없기 때문입니다. 이제 이것을 워프 전체로 확장해봅시다. 커널이 이 구간을 한 번 통과할 때마다 워프 스케줄러는 총 32 threads * 4 loads/thread = 128개의 별도 load instruction을 발행해야 합니다. 메모리 컨트롤러는 이 128개의 스칼라 요청을 몇 개의 크고 효율적인 메모리 transaction으로 합칠 수 있을지라도, 파이프라인의 병목은 여전히 프런트엔드에 남습니다. 워프 스케줄러는 과로 상태이고, load/store 파이프라인은 반복적인 요청으로 포화되어 실제 계산 유닛에서 값진 클록 사이클을 빼앗습니다.

instruction 압력을 해결하는 유일한 방법은 컴파일러가 데이터 전송을 바라보는 방식을 근본적으로 바꾸는 것입니다. 하나의 load 요청을 보았을 때 여러 스칼라를 한 번에 가져오라고 컴파일러에 알려야 합니다. CUDA는 이런 instruction 압력을 줄이기 위해 벡터화 변수를 제공합니다. 이는 float2나 float4 같은 더 넓은 자료형을 뜻합니다. 일반 float는 32비트(4바이트)이고, float4는 128비트(16바이트)입니다. float*를 float4*로 캐스팅하고 한 번의 load를 발행하면 하나의 128비트 전역 메모리 instruction이 트리거됩니다. SASS에서는 이것이 LDG.E.128 또는 때때로 LDG.E.CI.128으로 나타납니다. 이렇게 하면 load instruction 수를 극적으로 줄이고 하드웨어 메모리 경로를 더 효율적으로 사용할 수 있습니다.
그럼 다음 커널을 보겠습니다. 전체 구조는 동일하고, 유일한 차이는 sharedA를 전치한다는 점입니다. 즉 GMEM에서 한 행을 로드한 뒤 sharedA에서는 그것을 열로 저장합니다. 이렇게 하는 이유는 벡터화된 load를 사용할 수 있게 하기 위해서입니다. 벡터화된 load instruction을 발행하려면 주소가 물리적으로 연속되어 있어야 하기 때문입니다.
핵심 로직은 행렬 A의 접근 패턴에 있습니다. 각 스레드는 계산에 필요한 ROWS_PER_THREAD개의 원소(열을 따라가는 형태)를 로드해야 하므로, 기본 메모리 접근은 stride를 가집니다. 이 열 데이터를 전치하면 그것은 sharedA 안에서 물리적으로 연속된 행으로 저장됩니다. 그러면 나중에 SMEM에서 reg_m으로 데이터를 옮길 때 float4 load를 발행할 수 있습니다.
같은 접근을 sharedB에도 적용할 수 있지만, 그쪽은 전치하지 않을 것입니다. 이전 커널에서 기억하듯 각 스레드는 COLS_PER_THREAD를 reg_k로 로드하며, 이 원소들은 이미 같은 행에서 서로 붙어 있기 때문에 전치가 필요 없습니다.
이렇게 하면 스칼라 + offset 접근을 완전히 버릴 수 있고, 따라서 GMEM에서 SMEM으로 로드할 때 stride를 두고 반복하는 루프가 필요 없어집니다. 또한 레지스터로 로드할 때 float4를 발행할 수 있고, ROWS_PER_THREAD와 COLS_PER_THREAD가 모두 8이므로 여전히 루프 안에서 로드하되 이제는 4씩 건너뛰게 됩니다. 이 모든 설명이 여전히 조금 헷갈릴 수 있으니, 늘 그렇듯 시각적으로 그려보겠습니다.


이제 이 커널의 SASS를 살펴보고 이전 버전과 비교한 뒤, 프로파일러가 무엇을 말해주는지 보겠습니다.

우리 접근법을 통해 스레드당 발행되는 instruction 수가 8개에서 단 2개로 줄었다는 것을 볼 수 있습니다. 위 그림은 LDG.E.CI.128을 사용하는 GMEM 로딩 단계만 보여주지만, 마찬가지로 SMEM에서 RMEM(Register Memory)으로 읽을 때의 instruction 수도 줄였습니다. 너무 길어져서 여기 넣지는 않겠지만, SASS에서 LDS.U.128 instruction이 여전히 분명히 보이므로 공유 메모리 읽기도 벡터화에 성공했음을 확인할 수 있습니다. 더 자세히 보고 싶다면 이 커널의 전체 SASS/PTX도 볼 수 있습니다.
이 커널을 실행하면 또 한 번 약 2배 속도 향상을 얻고, 이제 37.2 TFLOP/s로 cuBLAS 성능의 **72%**에 도달합니다. 좋습니다, 점점 가까워지고 있습니다(FP32 경로만 기준입니다! Tensor Core를 사용하는 cuBLAS를 이기기까지는 아직 멀었습니다)
프로파일러를 보면 이 커널이 이제 GPU를 꽤 잘 활용하고 있음을 알 수 있습니다. compute throughput은 피크 대비 약 66%, memory throughput은 약 85%, 장치 FP32 roofline의 56%에 도달합니다.
참고로 cuBLAS는 대략 85% 수준에 있으며, 실제 워크로드가 하드웨어의 이론적 피크 100%에 도달하는 일은 사실상 없습니다.
이제 이전에 발견한 문제들과 이 커널의 새로운 프로파일링 결과를 비교해봅시다.
SM Issue Active: 55.50%에서 66.05%로 증가(계산에 더 많은 시간이 쓰입니다. 스케줄러가 약 ∼19% 더 바빠졌습니다)SM Pipe Fma Cycles Active: 42.00%에서 56.73%로 증가(더 많은 계산이 수행됩니다)SM Inst Executed Pipe Lsu(Load Store Unit): 28.78%에서 17.09%로 감소(instruction 수가 줄었다는 증거)SM Mio Inst Issued: 14.99%에서 9.21%로 감소Stall MIO Throttle: 0.59에서 0.02로 감소또한 스케줄러가 instruction당 1.8사이클마다 한 번만 발행한다는 경고도 이제 사라졌습니다. 큰 개선이지만, 아직 손볼 부분은 남아 있습니다.
자세히 보면 현재 성능을 갉아먹고 더 높은 compute throughput 달성을 막는 몇 가지 미묘한 핵심 지표가 있습니다.
가장 치명적인 것은 공유 메모리 접근에서 심한 bank conflict가 보인다는 점입니다. load에는 약 5-way conflict, store에는 2.6-way conflict가 있으며, 전체 공유 메모리 wavefront의 40% 이상이 직렬화로 낭비되고 있습니다.
Nsight Compute에서 wavefront는 공유 메모리 요청을 한 사이클에 처리할 수 있는 하드웨어 청크를 뜻합니다. bank conflict가 발생하면 요청은 여러 wavefront로 쪼개져 순차적으로 처리되어 stall을 유발합니다.
우리는 지금까지 커널에서 bank conflict를 제대로 고려하지 않았으므로, 지금이 이 개념을 소개하기 좋은 시점입니다.

이를 더 잘 시각화하려고 공유 메모리 구조를 그려봤지만, 핵심 개념은 NVIDIA GPU(H100 포함)의 공유 메모리가 32개의 bank로 나뉘어 있고, 각 bank는 사이클당 하나의 4바이트 word를 처리할 수 있다는 점입니다. 저는 이를 슈퍼마켓의 서른두 개 계산대에 비유하는 편인데, 각 계산대가 사이클당 고객 한 명을 처리한다고 생각하면 됩니다. 여기서 “word”는 기본 저장 단위를 뜻하며 4바이트입니다(예를 들어 float 하나).
그러면 bank index는 흔한 modulo 기법으로 간단히 계산할 수 있습니다.
bank_index = word_index % 32
이제 32개 스레드의 워프가 공유 메모리 접근을 발행할 때:
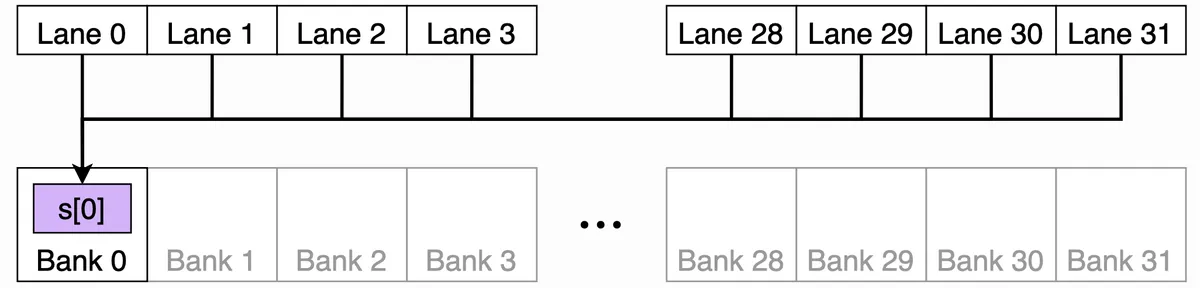 이 그림에서는 32개 lane이 모두 같은 banked word에서 읽을 수 있습니다. 하드웨어가 값을 효율적으로 broadcast하기 때문에 conflict가 발생하지 않습니다.
이 그림에서는 32개 lane이 모두 같은 banked word에서 읽을 수 있습니다. 하드웨어가 값을 효율적으로 broadcast하기 때문에 conflict가 발생하지 않습니다.

먼저 store conflict부터 봅시다. 코드에서 store 측의 약 2.6 conflict는 전치된 타일로 sharedA를 채울 때 나타납니다.
// Populate smem using vector loads
float4 tempA = reinterpret_cast<const float4*>(&A[smem_ty_A * N + smem_tx_A*4])[0]; // [0] dereference issues one ld.global.nc.v4.f32
// Transpose A (instead of 128x8 previously for ex, now it will be 8x128)
sharedA[(smem_tx_A * 4 + 0) * TILE_SIZE_M + smem_ty_A] = tempA.x;
sharedA[(smem_tx_A * 4 + 1) * TILE_SIZE_M + smem_ty_A] = tempA.y;
sharedA[(smem_tx_A * 4 + 2) * TILE_SIZE_M + smem_ty_A] = tempA.z;
sharedA[(smem_tx_A * 4 + 3) * TILE_SIZE_M + smem_ty_A] = tempA.w;
smem_ty_A는 전치된 sharedA의 열을 따라 바뀌고, smem_tx_A는 이 커널 구성에서는 0 또는 1입니다. 각 스칼라 store의 word index는 다음과 같습니다.
word_index = (smem_tx_A*4 + q) * TILE_SIZE_M + smem_ty_A → q in {0,1,2,3}bank = word_index % 32TILE_SIZE_M = 128이면 leading stride가 32개 bank로 정확히 나누어집니다. 128 % 32 = 0이므로, bank는 stride 항이 아니라 계산 후 남는 offset에만 의존하게 됩니다.
실제로 bank는 smem_tx_A 값(행 인덱스)이 아니라 smem_ty_A 값(열 offset)에만 의존하게 됩니다. 각 두 스레드가 같은 smem_ty_A 값을 공유하므로, 네 개의 스칼라 store 각각에 대해 같은 bank를 겨냥하게 됩니다. 이것이 바로 프로파일러가 지적한 2-way store conflict 패턴입니다.
leading stride가 32 word의 배수일 때 이런 종류의 conflict를 피하는 일반적인 기법 중 하나는 padding입니다.
// Allocate shared memory. Use padded leading strides that keep float4 alignment
constexpr uint STRIDE_A = (TILE_SIZE_M % 32u == 0u) ? (TILE_SIZE_M + 4u) : TILE_SIZE_M;
constexpr uint STRIDE_B = (TILE_SIZE_K % 32u == 0u) ? (TILE_SIZE_K + 4u) : TILE_SIZE_K;
static_assert((STRIDE_A % 4u) == 0u, "STRIDE_A must keep float4 alignment");
static_assert((STRIDE_B % 4u) == 0u, "STRIDE_B must keep float4 alignment");
leading stride를 132 word로 padding하고, sharedA를 건드리는 모든 곳(전치해서 쓸 때와 나중에 읽을 때 모두)에서 그 padded stride를 사용하면, 이제 행을 나타내는 smem_tx_A가 bank에 영향을 주게 됩니다. 이전에 충돌하던 두 lane은 16개 bank 간격으로 분리되고, x, y, z, w에 대한 네 개의 스칼라 store도 하나의 bank에 몰리지 않고 bank들 사이를 순환하게 됩니다. 이를 증명하기 위해 padding 후 커널을 프로파일링해봤고, store conflict가 제거되었다는 결과를 얻었습니다.

이제 더 큰 문제인 load에서의 5-way bank conflict가 남아 있습니다. 이 conflict는 주로 sharedB에서 로드할 때, 특히 다음 코드에서 발생합니다.
for (int col = 0; col < COLS_PER_THREAD; col += 4) {
uint global_smem_col_idx = tx * COLS_PER_THREAD + col;
float4 temp_shared_B =
reinterpret_cast<float4*>(&sharedB[i * TILE_SIZE_K + global_smem_col_idx])[0];
reg_k[col + 0] = temp_shared_B.x;
reg_k[col + 1] = temp_shared_B.y;
reg_k[col + 2] = temp_shared_B.z;
reg_k[col + 3] = temp_shared_B.w;
}
lane 0..15에서는 ty는 여전히 0이고 tx만 0..15로 움직입니다. 단순화를 위해 col = 0으로 고정하면, 각 lane의 float4 첫 word에 대한 bank는 다음과 같습니다.
bank = (i* 128 + 8 * tx) % 32 = (8 * tx) % 32여기서 우리는 벡터화된 float4 load를 하고 있으므로, 한 lane은 연속된 네 개 bank에 걸칩니다. 따라서 시작 bank가 0인 lane은 {0,1,2,3}, 8인 lane은 {8,9,10,11}, 16인 lane은 {16,17,18,19}, 24인 lane은 {24,25,26,27}을 건드립니다.
패턴이 네 lane마다 반복되므로, 네 개 lane이 동시에 {0..3} bank를 원하고, 또 다른 네 개 lane이 {8..11}을 원하는 식이 됩니다. 이것이 이 instruction에서 4-way conflict가 발생하는 이유입니다.
sharedA load는 다릅니다. 반 워프 내에서 lane별로 변하는 것은 tx지만, 주소에는 tx가 나타나지 않습니다. 한 반 워프 안에서는 ty가 상수입니다. 고정된 i와 row에 대해 모든 lane이 같은 주소를 계산합니다. 따라서 반 워프의 열여섯 lane은 그 단계에서 sharedA의 같은 네 word를 읽습니다. 앞서 말했듯 이것은 broadcast될 수 있으므로, load 관점에서는 conflict-free입니다.

여기서 중요한 점은 padding이 이 load conflict를 해결하지 못한다는 것입니다. padding은 주소의 가변 부분이 32 word의 배수인 stride와 곱해질 때 도움을 줍니다. 위 sharedB load에서는 가변 부분이 tx * COLS_PER_THREAD + col인데, 이 부분은 padded stride와 곱해지지 않습니다. 따라서 STRIDE_B = 132로 설정해도 반 워프 내부 lane들은 여전히 같은 네 개 bank 그룹으로 뭉치게 됩니다. 즉 padding은 store 쪽은 해결했지만, sharedB load conflict는 다른 접근이 필요합니다.
padding이 적용된 최종 벡터화 2D 레지스터 타일링 커널 코드는 다음과 같습니다.
template <const uint TILE_SIZE_M, const uint TILE_SIZE_N, const uint TILE_SIZE_K, const uint ROWS_PER_THREAD, const uint COLS_PER_THREAD>
__global__ void sgemm_vectorised(const float *__restrict__ A, const float *__restrict__ B, float *__restrict__ C,
int M, int N, int K, float alpha, float beta)
{
// Allocate shared memory. Use padded leading strides that keep float4 alignment
constexpr uint STRIDE_A = (TILE_SIZE_M % 32u == 0u) ? (TILE_SIZE_M + 4u) : TILE_SIZE_M;
constexpr uint STRIDE_B = (TILE_SIZE_K % 32u == 0u) ? (TILE_SIZE_K + 4u) : TILE_SIZE_K;
static_assert((STRIDE_A % 4u) == 0u, "STRIDE_A must keep float4 alignment");
static_assert((STRIDE_B % 4u) == 0u, "STRIDE_B must keep float4 alignment");
// Allocate shared memory
__shared__ float sharedA[STRIDE_A * TILE_SIZE_N];
__shared__ float sharedB[TILE_SIZE_N * STRIDE_B];
// Identify the tile of C this thread block is responsible for
const uint block_row = blockIdx.y;
const uint block_column = blockIdx.x;
// Calculate position of thread within tile (Remapping from 1-D to 2-D)
const uint ty = threadIdx.x / (TILE_SIZE_K / COLS_PER_THREAD);
const uint tx = threadIdx.x % (TILE_SIZE_K / COLS_PER_THREAD);
// Move pointers from A, B, C to tile starts
A += block_row * TILE_SIZE_M * N;
B += block_column * TILE_SIZE_K;
C += (block_row * TILE_SIZE_M * K) + (block_column * TILE_SIZE_K);
// Map each thread to one 4-float chunk
const uint smem_ty_A = threadIdx.x / (TILE_SIZE_N / 4);
const uint smem_tx_A = threadIdx.x % (TILE_SIZE_N / 4);
const uint smem_ty_B = threadIdx.x / (TILE_SIZE_K / 4);
const uint smem_tx_B = threadIdx.x % (TILE_SIZE_K / 4);
// Tile count
const uint num_tiles = CEIL_DIV(N, TILE_SIZE_N);
float thread_results[ROWS_PER_THREAD * COLS_PER_THREAD] = {0.0f};
float reg_m[ROWS_PER_THREAD] = {0.0f};
float reg_k[COLS_PER_THREAD] = {0.0f};
// Outer loop iterate over tiles
for (int t = 0; t < num_tiles; t++)
{
// Populate smem using vector loads
float4 tempA = reinterpret_cast<const float4 *>(&A[smem_ty_A * N + smem_tx_A * 4])[0];
sharedA[(smem_tx_A * 4 + 0) * STRIDE_A + smem_ty_A] = tempA.x;
sharedA[(smem_tx_A * 4 + 1) * STRIDE_A + smem_ty_A] = tempA.y;
sharedA[(smem_tx_A * 4 + 2) * STRIDE_A + smem_ty_A] = tempA.z;
sharedA[(smem_tx_A * 4 + 3) * STRIDE_A + smem_ty_A] = tempA.w;
float4 tempB = reinterpret_cast<const float4 *>(&B[smem_ty_B * K + smem_tx_B * 4])[0];
reinterpret_cast<float4 *>(&sharedB[smem_ty_B * STRIDE_B + smem_tx_B * 4])[0] = tempB;
__syncthreads();
// Outer loop over shared dimension N
for (int i = 0; i < TILE_SIZE_N; i++)
{
// Load regs from sharedA
for (int row = 0; row < ROWS_PER_THREAD; row += 4)
{
uint global_smem_row_idx = ty * ROWS_PER_THREAD + row;
float4 temp_shared_A = reinterpret_cast<float4 *>(&sharedA[i * STRIDE_A + global_smem_row_idx])[0];
reg_m[row + 0] = temp_shared_A.x;
reg_m[row + 1] = temp_shared_A.y;
reg_m[row + 2] = temp_shared_A.z;
reg_m[row + 3] = temp_shared_A.w;
}
// Load regs from sharedB
for (int col = 0; col < COLS_PER_THREAD; col += 4)
{
uint global_smem_col_idx = tx * COLS_PER_THREAD + col;
float4 temp_shared_B = reinterpret_cast<float4 *>(&sharedB[i * STRIDE_B + global_smem_col_idx])[0];
reg_k[col + 0] = temp_shared_B.x;
reg_k[col + 1] = temp_shared_B.y;
reg_k[col + 2] = temp_shared_B.z;
reg_k[col + 3] = temp_shared_B.w;
}
// Outer product
for (uint m = 0; m < ROWS_PER_THREAD; m++)
for (uint k = 0; k < COLS_PER_THREAD; k++)
thread_results[m * COLS_PER_THREAD + k] += reg_m[m] * reg_k[k];
}
__syncthreads();
A += TILE_SIZE_N;
B += TILE_SIZE_N * K;
}
// Write results back
for (uint row = 0; row < ROWS_PER_THREAD; row++)
for (uint col = 0; col < COLS_PER_THREAD; col += 4)
{
uint global_row_idx = ty * ROWS_PER_THREAD + row;
uint global_col_idx = tx * COLS_PER_THREAD + col;
float4 tempC = reinterpret_cast<float4 *>(&C[global_row_idx * K + global_col_idx])[0];
tempC.x = (alpha * thread_results[row * COLS_PER_THREAD + col]) + (beta * tempC.x);
tempC.y = (alpha * thread_results[row * COLS_PER_THREAD + col + 1]) + (beta * tempC.y);
tempC.z = (alpha * thread_results[row * COLS_PER_THREAD + col + 2]) + (beta * tempC.z);
tempC.w = (alpha * thread_results[row * COLS_PER_THREAD + col + 3]) + (beta * tempC.w);
reinterpret_cast<float4 *>(&C[global_row_idx * K + global_col_idx])[0] = tempC;
}
}
지금까지 우리는 두 수준의 병렬성을 활용했습니다.
(ROWS_PER_THREAD × COLS_PER_THREAD)을 전부 레지스터 안에서 계산하여, 결과를 전역 메모리에 쓰기 전에 데이터 재사용을 극대화했습니다.이번 커널에서는 블록 타일링과 스레드 타일링 사이에 새로운 타일링 수준 하나를 더 도입할 것입니다. 그것이 바로 워프 타일링입니다.
워프 타일링은 최적화 계층에서 블록 타일링과 스레드 타일링 사이에 위치합니다. 블록 안의 모든 스레드가 하나의 큰 타일에서 협력하는 대신, 그 타일을 더 작은 서브타일로 나누어 각각을 하나의 워프에 할당합니다. 이렇게 하면 워프가 중간 수준의 계산 단위가 됩니다. 블록은 여전히 C의 128 × 128 패치를 덮지만, 이를 64 × 64 서브타일 네 개로 나눕니다. M 방향으로 두 워프, K 방향으로 두 워프이므로 블록당 총 네 개 워프가 됩니다.
TILE_SIZE_M = 128
TILE_SIZE_N = 16
TILE_SIZE_K = 128
WARP_TILE_M = 64
WARP_TILE_K = 64
WARP_STEPS_K = 4
ROWS_PER_THREAD = 8
COLS_PER_THREAD = 4
NUM_THREADS = 128 // four warps per block
블록은 여전히 이전 커널의 벡터화, padding, transpose 기법을 사용해 GMEM에서 SMEM으로 데이터를 협력적으로 로드합니다. 데이터가 온칩에 올라오면 스레드들은 네 개 워프로 나뉘고, 각 워프는 warp_row와 warp_col로 식별되는 출력 행렬의 한 사분면에 대한 독점적 소유권을 가집니다.
워프 내부의 32개 스레드는 자신의 세부 서브인덱스(ty, tx, 8×4 스레드 서브그리드에서 유도됨)를 사용해 할당된 64×64 영역을 공략합니다. 워프는 수직 차원은 한 번에 처리하므로 WARP_STEPS_M = 1이지만, 수평 방향으로는 WARP_STEPS_K=4번 반복해야 합니다(물론 이것들은 구성 가능하지만 신중히 선택해야 합니다!). 부분 결과 누적은 TILE_SIZE_N 공유 차원을 반복하는 루프(i 루프) 안에서 일어납니다. 계산 루프에서 이 설계는 스레드가 sharedA에서 reg_m 조각을 한 번 로드한 뒤 네 개의 수평 step에 걸쳐 재사용할 수 있게 해주며, 그 사이 sharedB에서 새로운 reg_k 데이터를 매 step마다 로드해 외적(reg_m과 reg_k 사이)의 결과를 큰 thread_results 배열에 더해 최종 결과를 모든 i 반복에 걸쳐 누적합니다.
먼저 워프 타일링이 새로운 계층 수준으로 어떻게 통합되는지, 커널의 상위 구조부터 보여드리겠습니다. 그 다음에는 몇 가지 더미 파라미터를 사용해 단일 스레드 관점으로 내려가, 이 스레드의 전체 생애를 시각화할 것입니다. 계산이 어디서 일어나고, 정확히 어디서 load와 store를 수행하는지 말입니다.

이제 단일 스레드 관점에서 계산 흐름을 시각화합니다.

이 추가 타일링 수준은 여러 이점을 제공합니다.
워프는 NVIDIA GPU의 기본 실행 단위입니다. 각 워프에 출력의 자체 서브타일을 주면, 작업 분할이 하드웨어가 실제로 명령어를 스케줄링하는 방식과 잘 맞아떨어집니다.
이렇게 하면 각 워프는 독립적으로 실행될 수 있습니다. 어떤 워프가 메모리에서 stall되더라도 다른 워프가 계속 실행될 수 있어, 워프 스케줄러 슬롯을 채운 상태로 유지하고 유휴 사이클을 줄일 수 있습니다.
 Simon의 블로그에서 가져옴
Simon의 블로그에서 가져옴
워프 타일은 각 워프의 footprint를 작게 유지하고 lane별 stride를 단순하고 반복 가능하게 만듭니다. 이는 bank-friendly 레이아웃을 설계하기 쉽게 해줍니다. 스포일러를 하자면, 그래서 이 커널에서는 SMEM load conflict가 나타나지 않았습니다.
각 Streaming Multiprocessor 내부의 register file(RF)은 스레드별 변수를 저장합니다. Hopper에서는 이것 역시 여러 개의 단일 포트 bank로 나뉘어 있습니다(SMEM bank와 비슷합니다!). 하나의 bank는 사이클당 하나의 접근만 처리할 수 있습니다. 같은 워프 내 두 스레드가 같은 사이클에 같은 bank에서 읽으려 하면 접근이 직렬화됩니다. 이것도 일종의 bank conflict지만 레지스터에 대한 것이며, instruction의 피연산자를 가져오는 시간을 늘립니다. 불행히도 NVIDIA의 프로파일링 도구는 이런 conflict에 대한 지표를 제공하지 않아서, 이 커널에서 실제로 개선되었는지 확인하기가 어렵습니다.
RF와 실행 유닛 사이에는 Operand Collector Unit(OCU)이 있습니다. 논문: BOW Breathing Operand Windows to Exploit Bypassing in GPUs. 각 OCU는 레지스터 bank에서 source operand를 가져와 작은 버퍼에 저장하는데, 128바이트 엔트리 세 개를 담을 공간이 있습니다. 피연산자가 곧 다시 필요하다면 메인 RF로 돌아가지 않고 이 버퍼에서 직접 제공될 수 있습니다. 이렇게 하면 bank conflict와 추가 RF 트래픽을 모두 피할 수 있습니다.
워프 타일링은 각 워프가 출력 행렬의 작고 고정된 서브타일에서 작업하므로 내부 루프에서 같은 레지스터를 반복해서 재사용하는 경향이 있다는 점에서 도움이 됩니다. 이는 bank conflict 가능성을 줄이고, 피연산자가 OCU 버퍼에서 직접 재사용될 확률을 높입니다.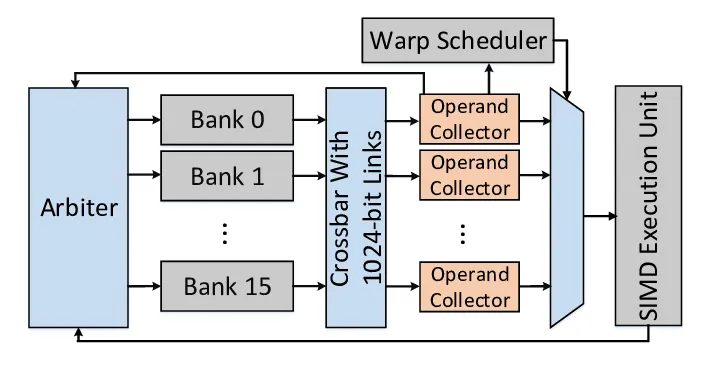
다시 말하지만 이건 추측입니다. 실제로 차이를 만드는지는 저도 잘 모르겠지만, 그럴듯해 보입니다.
변경된 코드의 주요 부분은 다음과 같습니다.
// Iterate over the shared dimension of the SMEM tiles
for (int i = 0; i < TILE_SIZE_N; i++)
{
// Load slice at current i iteration in sharedA's register
for (int wSubRow = 0; wSubRow < WARP_STEPS_M; wSubRow++)
{
uint base_row =
(warp_row * WARP_TILE_M) +
(wSubRow * WARP_SUB_M) +
(ty * ROWS_PER_THREAD);
// Each thread loads ROWS_PER_THREAD into the register
#pragma unroll
for (int row = 0; row < ROWS_PER_THREAD; row += 4)
{
const float4 va =
reinterpret_cast<const float4*>(
&sharedA[i * STRIDE_A + base_row + row])[0];
reg_m[wSubRow * ROWS_PER_THREAD + row + 0] = va.x;
reg_m[wSubRow * ROWS_PER_THREAD + row + 1] = va.y;
reg_m[wSubRow * ROWS_PER_THREAD + row + 2] = va.z;
reg_m[wSubRow * ROWS_PER_THREAD + row + 3] = va.w;
}
for (int wSubCol = 0; wSubCol < WARP_STEPS_K; wSubCol++)
{
uint col_base =
(warp_col * WARP_TILE_K) +
(wSubCol * WARP_SUB_K) +
(tx * COLS_PER_THREAD);
// Each thread loads COLS_PER_THREAD into the register x 4 times in our case since WARP_STEPS_K = 4
#pragma unroll
for (int col = 0; col < COLS_PER_THREAD; col += 4)
{
const float4 vb =
reinterpret_cast<const float4*>(
&sharedB[i * STRIDE_B + col_base + col])[0];
reg_k[wSubCol * COLS_PER_THREAD + col + 0] = vb.x;
reg_k[wSubCol * COLS_PER_THREAD + col + 1] = vb.y;
reg_k[wSubCol * COLS_PER_THREAD + col + 2] = vb.z;
reg_k[wSubCol * COLS_PER_THREAD + col + 3] = vb.w;
}
}
// Compute outer product
for (int wSubRow = 0; wSubRow < WARP_STEPS_M; wSubRow++)
{
for (int wSubCol = 0; wSubCol < WARP_STEPS_K; wSubCol++)
{
#pragma unroll
for (int im = 0; im < ROWS_PER_THREAD; im++)
{
float fixed_temp =
reg_m[wSubRow * ROWS_PER_THREAD + im];
#pragma unroll
for (int ik = 0; ik < COLS_PER_THREAD; ik++)
{
float out =
fixed_temp * reg_k[wSubCol * COLS_PER_THREAD + ik];
int out_idx =
(wSubRow * ROWS_PER_THREAD + im) *
(WARP_STEPS_K * COLS_PER_THREAD) +
(wSubCol * COLS_PER_THREAD + ik);
thread_results[out_idx] += out;
}
}
}
}
}
}
__syncthreads();
A += TILE_SIZE_N; // Move right
B += TILE_SIZE_N * K; // Move down
이 커널을 padding 전후로 테스트해봤습니다.
정리하자면, 이 워프 타일링 커널에서 padding은 주로 store 경로(sharedA에 전치해 쓰는 부분)에 도움을 주었고, 이는 store-conflict counter가 약 4.0에서 약 2.5-way로 떨어진 것과 일치합니다. 이전 벡터화 커널과 달리, 여기서는 load conflict가 문제가 아니었습니다. load 쪽에서는 우리가 특별한 일을 하지 않았는데도 두 가지가 은근히 도움이 되었습니다. COLS_PER_THREAD = 4를 사용해 sharedB lane이 더 많은 bank 그룹에 퍼졌고, 워프 로컬 서브타일이 lane 패턴의 aliasing을 덜하게 만들었습니다. 이 둘이 합쳐져 unpadded run과 padded run 모두에서 shared-load conflict가 프로파일러에 잡히지 않은 이유입니다.
우리를 여전히 붙잡고 있는 것은 다른 곳입니다. 레지스터 압력 때문에 achieved occupancy가 ~18% 수준에 머무르고, 이는 “not selected” scheduler stall로 나타납니다. 그리고 우리는 여전히 대체로 compute-bound 상태입니다(FMA busy가 60% 후반대) 반면 memory는 ~52% 수준이므로, 몇 GB/s를 더 짜내는 것은 복사와 계산을 겹치게 하거나 레지스터를 줄여 상주 워프 하나를 더 얻는 것만큼 큰 효과를 주지 못합니다.
📝 중요한 참고: 이 커널부터는 차원 표기법을 바꾸어
A = MxK,B=KxN으로 사용합니다. 이유는 이후 Tensor Core 명령어들이 이 형식의 행렬을 기대하기 때문입니다. 이전 커널들의 로직은 모두 동일하고 단지 명명 규칙만 바뀝니다. 앞으로는 일관성을 위해 위쪽의 모든 코드와 그림도 수정할 예정입니다.
도입부에서 H100의 Tensor Core 구성 요소를 잠깐 언급했습니다. 이제 그것이 어떻게 동작하는지, 그리고 이를 사용해 성능을 얼마나 크게 끌어올릴 수 있는지 자세히 보겠습니다. 이 커널이 끝날 즈음에는 성능이 급상승할 것이니, 기대해 봅시다.
NVIDIA의 최근 GPU 아키텍처에서 가장 중요한 발전 중 하나는 Tensor Core의 도입과 진화입니다. 진지한 병렬 계산을 위해 고급 GPU를 구매하는 가장 큰 이유이기도 합니다. 이것은 항상 존재했던 것은 아니며, Volta 아키텍처(V100)에서 처음 도입되었습니다. 즉, 표준 CUDA 코어에 맞춰 최적화한 이전 모든 커널은 Volta 이전 아키텍처에서의 최첨단 상태를 대표합니다.
Tensor Core는 GPU의 계산 모델을 근본적으로 바꿉니다. 이들은 **행렬 곱셈 및 누산(MMA)**을 가속하기 위해 특별히 설계된 특수 엔진입니다.
a @ b + c 같은 단순한 스칼라 명령어를 실행하는 CUDA Core와 달리, Tensor Core는 D = A @ B + C 같은 전체 행렬 연산을 수행하는 단일 명령어를 실행합니다. 이런 구조는 흔히 CISC(Complex Instruction Set Computer)에 비유됩니다. 단일 CISC 명령어는 메모리에서 값을 로드하고, 산술 계산을 수행하고, 결과를 다시 메모리에 쓰는 등 여러 저수준 작업을 한 번에 처리할 수 있습니다. 반면 RISC 아키텍처는 각 명령어가 한 번에 하나의 기본 작업만 수행하는 매우 단순한 명령어를 사용합니다.
Power Density: 이런 CISC 유사 접근은 엄청난 속도의 핵심입니다. 명령어당 큰 데이터 블록을 처리하면 명령어 디코딩 같은 연산당 오버헤드가 극적으로 줄어듭니다.
예를 들어:
나중에 사용할 Warp Group Matrix Multiply and Accumulate (WGMMA) 명령어는 wgmma.mma_async.sync.aligned.m64n64k16.f32.bf16.bf16처럼 작성됩니다. 여기의 m64n64k16은 행렬 차원을 뜻합니다. 바깥 차원은 m과 n이고 앞과 뒤에 오며, 누산을 위한 공통 내부 차원 k는 가운데에 있습니다. 이 복합 명령어는 행렬 A, B, 누산기 C에 대해 D = A @ B + C를 계산합니다(C는 종종 물리적으로 D와 같은 행렬입니다). 이것을 곱해보면 이 명령어 하나가 64 * 16 * 64 = 65,536개의 multiply-accumulate(MAC) 연산을 수행한다는 것을 알 수 있습니다.
이를 CUDA 코어만 사용하는 워프 타일링 커널과 비교해봅시다.
float out = fixed_temp * reg_k[...]; // multiplication
thread_results[out_idx] += out; // addition (accumulation)
우리는 instruction당 1 MAC(FMA)만 수행했습니다. 같은 작업을 완료하려면 CUDA Core는 65,536개의 FMA instruction을 실행해야 합니다. 반면 WGMMA에서는 하나의 warp group(128 스레드)이 하나의 WGMMA instruction으로 이 65,536 MAC 전체를 수행합니다.
여기서 잠시 멈춰 방금 도입한 두 가지 새로운 개념인 WGMMA와 warp-group을 짚고 넘어갑시다. 이 개념들은 Hopper 아키텍처에만 존재하며 이전 GPU에는 없었습니다. 왜 이것들이 중요한지, 그리고 왜 이 커널에서 WGMMA에 의존하게 되는지 이해하려면, Hopper 이전에는 Tensor Core를 어떻게 프로그래밍했는지, 그리고 프로그래밍 모델이 어떻게 여기까지 진화했는지를 짧게 보는 것이 도움이 됩니다.
Hopper 이전에는 Tensor Core를 프로그래밍하는 일반적인 방법이 WMMA API(Warp Matrix Multiply Accumulate)였습니다. 이 인터페이스는 Volta에서 도입되어 Turing과 Ampere까지 nvcuda::wmma로 이어졌습니다. Tensor Core를 활용하기 위한 고수준 추상화를 제공했고, API가 내부 세부사항 대부분을 처리했습니다.
이후 NVIDIA는 하부 Tensor Core 명령어를 직접 노출했습니다. 그 결과 Turing과 Ampere의 MMA PTX 명령어가 도입되었습니다. 이것들 역시 워프 수준에서 동작하며, 32개 스레드가 협력해 더 작은 MMA 연산을 수행합니다. 이 명령어들에 올바르게 데이터를 공급하기 위해 아키텍처에는 ldmatrix라는 특별한 warp-wide load instruction도 추가되었는데, 이것이 공유 메모리에서 필요한 packed fragment를 레지스터로 가져옵니다. 이 시점에서 전형적인 Tensor Core 커널은 각 워프 내부에서 명확한 패턴을 따랐습니다. ldmatrix로 SMEM에서 A와 B fragment를 로드하고, 하나 이상의 mma.sync instruction을 발행한 뒤, 누적 결과를 써내는 방식입니다.
Hopper에서는 tensor 연산이 워프 수준에서 warp group 수준으로 확장됩니다. 여기서는 **128 (32*4)**개의 스레드가 하나의 훨씬 더 큰 MMA에 협력합니다. 이 명령어들은 더 이상 작은 워프 크기 타일을 다루지 않고, 공유 메모리에 이미 존재해야 하는 훨씬 더 큰 A와 B 블록을 대상으로 합니다. 그런데 WGMMA는 이 타일들이 특정한 swizzled 레이아웃으로 배치되어 있기를 기대합니다. 그래서 자연스럽게 이런 질문이 생깁니다.
WGMMA가 기대하는 정확한 형식으로 필요한 행렬 타일을 공유 메모리에 어떻게 배치하고, 또 Tensor Core가 절대 놀지 않을 만큼 빠르게 그렇게 할 수 있을까?
이 부분에서 도입부에서 이야기한 **Tensor Memory Accelerator (TMA)**가 등장합니다.
H100에서 TMA는 전용 병렬 복사 엔진으로 작동하며 데이터 병목을 해결합니다.
Bulk Loading: 단 하나의 하드웨어 명령만으로 A와 B의 전체 2D 타일을 GMEM에서 SMEM으로 이동시킵니다.
Asynchronous Transfer: 더 중요한 점은 이 전송이 백그라운드에서 실행된다는 것입니다. 덕분에 Tensor Core는 현재 데이터를 계산하는 동안, TMA는 이미 다음 반복을 위한 다음 2D 타일을 가져오고 있을 수 있습니다.
“bulk loading”이라는 말 뒤에는 과거에 프로그래머가 직접 떠안아야 했던 많은 복잡성이 숨어 있습니다. 이전 커널에서는 각 스레드가 정확히 어떤 원소를 가져와야 하는지 지루한 코드를 통해 직접 지정해야 했습니다. 이제는 그 수동 인덱싱이 하드웨어로 넘어갑니다. 우리는 더 이상 특정 원소를 GMEM에서 SMEM으로 로드하도록 스레드를 미세하게 통제할 필요가 없습니다.
또한 이전처럼 SMEM bank conflict를 피하기 위해 padding을 수동으로 처리할 필요도 없어집니다. 하드웨어가 Swizzling이라고 불리는 것을 자동으로 적용합니다. 이 레이아웃은 손으로 코딩하기 복잡하므로, 다행히도 NVIDIA가 이런 패턴을 TMA 안에 직접 구현했습니다. 우리가 알아야 할 것은 bank conflict가 사실상 “공짜로” 처리된다는 점입니다. swizzling 패턴의 내부 동작에 대해 더 자세히 알고 싶다면 Aleksa의 글이 아주 깊이 다룹니다. 그가 사용한, SMEM으로의 swizzled copy가 상위 수준에서 어떻게 보이는지 보여주는 그림은 다음과 같습니다.
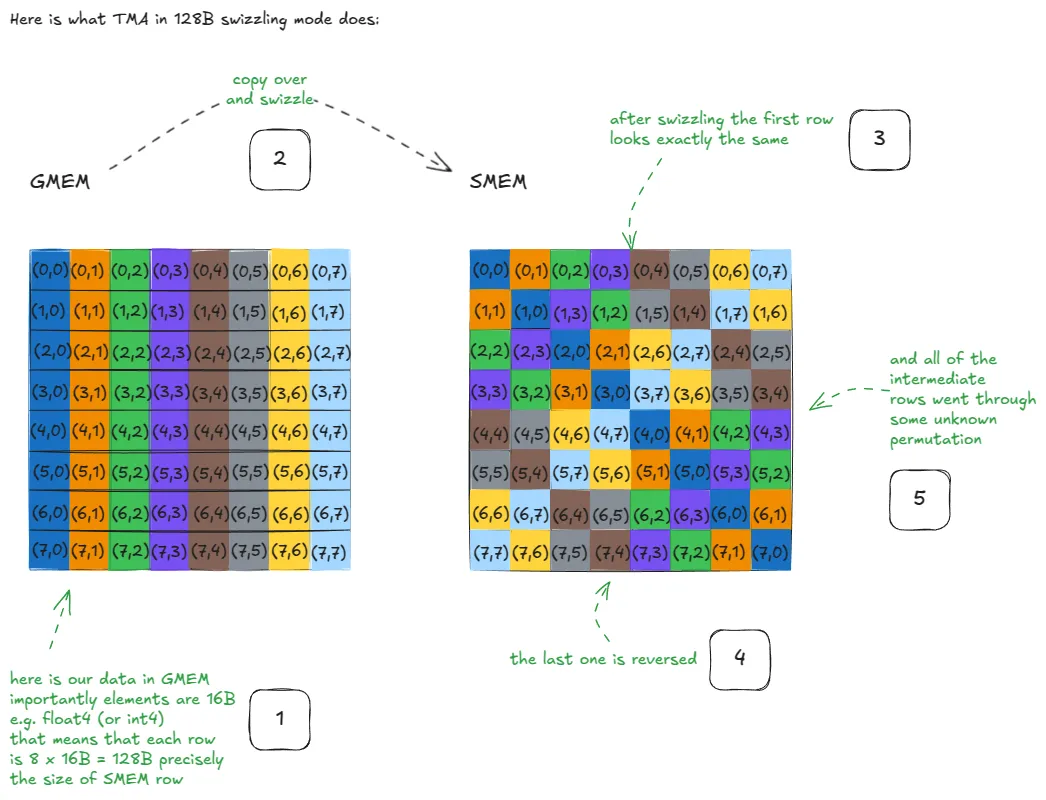
TMA를 사용하려면 세 가지 주요 단계를 거쳐야 합니다.
A와 B에 대한 tensor map을 구성합니다(호스트에서).Tensor Map은 하드웨어가 이해할 수 있는 descriptor입니다. 메모리 안의 텐서의 shape, layout, stride를 기술하여, TMA가 스레드 수준의 주소 계산 없이 다차원 타일 전체를 이동할 수 있게 합니다.
이전 커널과 달리, 우리는 const float* A 같은 raw pointer를 커널 인자로 넘기지 않습니다. 대신 CUtensorMap descriptor에 대한 포인터를 넘깁니다. 이것은 CUDA Driver가 정의하는 구조체로, 행렬의 전체 메타데이터(shape, stride, swizzle pattern)를 담고 있어 하드웨어가 타일을 직접 가져올 수 있게 합니다.
이 map을 만들기 위해 우리는 CUDA Driver API의 cuTensorMapEncodeTiled 함수를 사용합니다. 이 그림은 CUDA 소프트웨어 플랫폼을 이루는 여러 구성 요소를 보여주며, 무엇이 호스트에서 호출되어야 하고 무엇이 디바이스에서 가능한지 이해하는 데 중요합니다.
스택의 맨 아래에는 CUDA Driver API가 있습니다. 가장 세밀한 GPU 제어를 제공하지만, 더 장황하고 복잡합니다. tensor map 생성 같은 저수준 연산은 이 레벨에서 명시적으로 노출됩니다.
이 그림은 CUDA 소프트웨어 플랫폼을 이루는 여러 구성 요소를 보여주며, 무엇이 호스트에서 호출되어야 하고 무엇이 디바이스에서 가능한지 이해하는 데 중요합니다.
스택의 맨 아래에는 CUDA Driver API가 있습니다. 가장 세밀한 GPU 제어를 제공하지만, 더 장황하고 복잡합니다. tensor map 생성 같은 저수준 연산은 이 레벨에서 명시적으로 노출됩니다.
Driver API 위에는 CUDA Runtime API가 있습니다. 이는 많은 기능을 감싸고 더 높은 수준의 인터페이스를 제공합니다. 예를 들어 runtime API의 cudaMalloc은 driver API의 cuMemAlloc을 얇게 감싼 래퍼입니다.
그리고 이 두 API 위에는 선형대수용 cuBLAS, 딥러닝용 cuDNN 같은 일반 및 도메인 특화 워크로드용으로 고도로 최적화된 CUDA 라이브러리들이 있습니다. 실전 코드 대부분은 runtime API를 사용하지만, TMA tensor map 같은 일부 Hopper 기능은 현재 Driver API로만 노출됩니다.
. 이 함수는 우리가 설명한 행렬 정보를 받아 TMA 엔진이 이해할 수 있는 128B 하드웨어 descriptor로 포장합니다. TMA 하드웨어는 매우 특수화되어 있기 때문에, 이 128B 객체는 메모리에서 반드시 128B 경계에 정렬되어 있어야 하며, 그렇지 않으면 하드웨어가 읽을 수조차 없습니다!
과정은 다음과 같습니다.
cudaMalloc으로 디바이스에 tensor map 메모리를 할당합니다.cudaMemcpy를 사용해 map을 호스트에서 디바이스로 복사합니다.다음 코드 스니펫은 이 단계를 다음과 같이 수행합니다.
template <const uint BlockMajorSize, const uint BlockMinorSize>
__host__ static inline CUtensorMap *
create_and_allocate_tensor_map(bf16 *tensor_ptr, uint blocks_height, uint blocks_width) {
CUtensorMap *tensor_map;
// Allocate device memory for the tensor map descriptor.
CUDA_CHECK(cudaMalloc((void **)&tensor_map, sizeof(CUtensorMap)));
// Register the tensorMap in our device memory pointers
// resources.add_device_ptr(tensor_map);
// Create on host
CUtensorMap tensor_map_host;
create_tensor_map<BlockMajorSize, BlockMinorSize>(&tensor_map_host, tensor_ptr, blocks_height, blocks_width);
// Copy descriptor to device
CUDA_CHECK(cudaMemcpy(tensor_map, &tensor_map_host, sizeof(CUtensorMap), cudaMemcpyHostToDevice));
return tensor_map;
}
그리고 tensor의 메타데이터를 인코딩해 실제로 tensor map을 만드는 함수는 다음과 같습니다.
template <const uint BlockMajorSize, const uint BlockMinorSize>
void create_tensor_map(CUtensorMap *tensor_map, bf16 *tensor_ptr, uint blocks_height, uint blocks_width) {
// Starting address of memory region described by tensor (casting to void
// as the tensor map descriptor is type-agnostic.)
void *gmem_address = static_cast<void *>(tensor_ptr);
uint num_tiles_major = blocks_height;
uint num_tiles_minor = blocks_width;
// full size of the tensor in global memory (API expects the 5D supported
// tensor ranks to be defined)
uint64_t global_dim[5] = {
static_cast<uint64_t>(BlockMinorSize * num_tiles_minor),
static_cast<uint64_t>(BlockMajorSize * num_tiles_major),
1, 1, 1};
// Define the tensor strides (in bytes) along each of the tensor ranks dims - 1
uint64_t global_strides[5] = {
sizeof(bf16),
sizeof(bf16) * BlockMinorSize * num_tiles_minor,
0, 0, 0};
// Define the shape of the "box_size" -> the tile shapes a TMA ops will load
uint32_t box_dim[5] = {
static_cast<uint32_t>(BlockMinorSize),
static_cast<uint32_t>(BlockMajorSize),
1, 1, 1};
uint32_t elem_strides[5] = {1, 1, 1, 1, 1};
// Create tensor map
CU_CHECK(cuTensorMapEncodeTiled(
tensor_map, CU_TENSOR_MAP_DATA_TYPE_BFLOAT16, 2, gmem_address,
global_dim, global_strides + 1, box_dim, elem_strides,
CU_TENSOR_MAP_INTERLEAVE_NONE, CU_TENSOR_MAP_SWIZZLE_128B,
CU_TENSOR_MAP_L2_PROMOTION_NONE, CU_TENSOR_MAP_FLOAT_OOB_FILL_NONE));
}
다음으로 WGMMA instruction을 이야기해봅시다. WGMMA instruction은 우리가 이전 모든 커널에서 했던 것처럼 raw byte address를 직접 사용하지 않습니다. 대신 행렬이 공유 메모리 어디에 있고 어떤 레이아웃으로 배치되어 있는지를 하드웨어에 알려주는 packed 64-bit matrix descriptor를 받습니다.
matrix descriptor의 형식은 문서에 다음과 같이 설명되어 있습니다.

원래 주소는 byte address입니다. 예를 들어 16384바이트 주소는 16진수로 0x4000입니다. 만약 descriptor가 이런 raw byte address를 직접 저장해야 한다면, 비트가 금방 고갈되어 표현 가능한 주소 범위가 심각하게 제한될 것입니다.
대신 하드웨어는 중요한 성질 하나를 이용합니다. WGMMA가 사용하는 SMEM operand는 항상 최소 16B 정렬을 만족합니다. 이는 유효한 주소의 하위 4비트가 항상 0이며 어떤 유용한 정보도 담고 있지 않음을 뜻합니다.
그래서 descriptor는 byte address를 저장하는 대신 16B 단위의 주소를 저장합니다. 같은 인코딩은 base address뿐 아니라 leading dimension과 stride offset에도 적용되며, 위 표에서 볼 수 있습니다. 이렇게 하면 descriptor는 훨씬 더 큰 SMEM 영역을 표현할 수 있으면서도 필요한 메타데이터를 모두 단일 64-bit 값 안에 담을 수 있고, 하드웨어는 이를 warp group 전체에 효율적으로 broadcast하고 decode할 수 있습니다.
이 인코딩이 어떻게 일어나는지에 대한 개념적 예시는 다음과 같습니다.
![Image 36: matrix-desc-encoding]](https://bear-images.sfo2.cdn.digitaloceanspaces.com/testing-inf1/excalidraw-52.svg)
이 인코딩 로직과 descriptor 구성은 WGMMA matrix descriptor가 커널 내부에서 만들어지므로 디바이스에서 실행되어야 합니다. 우리는 make_smem_descriptor 함수에서 matrix descriptor를 구성합니다.
또한 인코딩 전에 일반 포인터 bf16*를 __cvta_generic_to_shared를 사용해 shared-memory address로 변환해야 합니다. 이 단계는 미묘하지만 필수적입니다. WGMMA는 C++ 추상이 아니라, 매우 특정한 형식의 SMEM byte address를 기대하는 저수준 하드웨어 instruction입니다. 일반 CUDA C++ 포인터는 자신이 어떤 주소 공간(예: Global, Shared 등)에 속하는지 명시적으로 인코딩하지 않으므로, 직접 사용하거나 인코딩할 수 없습니다. 따라서 먼저 그 포인터를 하드웨어가 이해할 수 있는 구체적인 SMEM 주소로 변환한 뒤, 그 값을 압축해 matrix descriptor에 넣어야 합니다. CUDA C++ 포인터는 generic이므로 전역 메모리나 공유 메모리 객체를 가리킬 수 있지만 주소 공간 자체를 명시적으로 담지 않습니다. 이 추상화는 일반 C++ load/store에는 잘 맞지만, PTX instruction이나 WGMMA 같은 하드웨어 인터페이스와 직접 상호작용할 때는 깨집니다. 이런 인터페이스는 특정 메모리 공간을 명시하는 주소를 요구합니다. 이를 연결하기 위해 CUDA는 __cvta_generic_to_shared 같은 address-space conversion intrinsic을 제공하며, 이것이 generic pointer를 PTX instruction 및 하드웨어 descriptor가 사용할 수 있는 shared-memory address로 바꿉니다. 두 함수의 코드는 다음과 같습니다.
__device__ static inline uint64_t matrix_descriptor_encode(uint64_t x) {
return ((x) & 0x3FFFF) >> 4;
}
__device__ uint64_t make_smem_desc(bf16* ptr) {
uint32_t address = static_cast<uint32_t>(__cvta_generic_to_shared(ptr));
// Initialise an empty 64 bit descriptor
uint64_t desc = 0x0000000000000000;
// bitwise OR
// sets bits [13:0] encoded matrix start address
desc |= matrix_descriptor_encode(address);
// sets bits [29:16] leading dimension byte offset
desc |= matrix_descriptor_encode(static_cast<uint64_t>(16)) << 16;
// sets bits [45: 32] stride dimension byte offset
desc |= matrix_descriptor_encode(static_cast<uint64_t>(1024)) << 32;
// sets bits [62: 63] swizzle mode
desc |= 1llu << 62;
return desc;
}
make_smem_desc 함수에서는 먼저 빈 64-bit descriptor를 초기화하고, 이후 위의 matrix descriptor 레이아웃에 따라 필드를 하나씩 채워 나갑니다.
먼저 matrix 시작 주소를 인코딩해서 descriptor의 bits [13:0]에 넣습니다. 이것은 shared memory 안에서의 행렬 base address를 나타내며, 16바이트 단위로 인코딩됩니다. 다음으로 leading dimension byte offset을 인코딩해 bits [29:16]에 넣습니다. 이는 행렬의 leading dimension을 따라 이동할 때 하드웨어가 몇 바이트를 건너뛰어야 하는지를 설명합니다.
세 번째 필드는 stride dimension byte offset이며, bits [45:32]에 들어갑니다. 문서에서 설명하듯이:

개념적으로 이 필드는 다음 질문에 답합니다.
“K 차원을 따라 columns 0–7에서 columns 8–15로 가려면 몇 바이트를 이동해야 하는가?”
아직 정확한 타일 모양을 소개하진 않았지만, 스포일러를 하자면 sharedA는 64 × 64 행렬이 될 것입니다. 각 열은 64개의 bf16 원소를 포함하고, bf16 하나는 2바이트이므로, 하나의 열은 128바이트 폭을 가집니다. 따라서 K 방향으로 8개 열을 건너뛰려면 8 × 128 bytes = 1024 bytes가 필요합니다. 그래서 stride dimension byte offset을 1024로 인코딩합니다.
마지막 필드는 swizzling mode이며 bits [63:62]에 저장됩니다. 우리는 128-byte swizzling을 사용하므로 이 필드를 1로 설정합니다. 이 필드는 byte offset이 아니라 고정된 열거형 값이므로 인코딩 함수를 거치지 않습니다.
이제 본론으로 들어가 커널 자체에 대해 이야기하며 모든 조각을 함께 맞춰봅시다. 다만 한 가지 주의할 점은, 지금은 WGMMA instruction 자체를 어떻게 정의하는지는 자세히 들어가지 않을 것입니다. 이야기의 흐름을 위해 일단 블랙박스로 두고, 이후 다시 자세히 돌아오겠습니다.
커널 코드를 보기 전에 먼저 상위 수준의 커널 흐름 구조를 배치하고, 그것이 시각적으로 어떻게 보일지부터 보여드리고 싶습니다.
A와 B의 전체 2D 타일을 GMEM에서 SMEM으로 로드합니다.K 반복마다 네 번의 m64n64k16 WGMMA instruction을 발행한다는 뜻입니다.K 타일이 처리될 때까지 이것을 반복하며, 결과는 레지스터에 누적됩니다.
그림에서 보이듯 각 tensor core MMA 동안 우리는 sharedA의 서브타일과 sharedB의 서브타일의 외적을 취해 크기 TILE_SIZE_M(64) × TILE_SIZE_N(64)의 accumulator 타일을 갱신합니다.
operand 배치 규칙은 다음과 같습니다.
sharedA는 레지스터나 공유 메모리에 있을 수 있습니다.sharedB는 반드시 공유 메모리에 있어야 합니다.D는 반드시 레지스터에 있어야 합니다(그림의 C's tile에 해당).분명히 단일 스레드가 64 × 64 accumulator 전체를 들고 있을 수는 없습니다. 대신 accumulator는 warp group 전체에 분산됩니다. 우리 경우 warp group은 128개 스레드로 이루어져 있고, 이 128개 스레드가 각각의 m64n64k16 WGMMA instruction을 협력해서 실행합니다. 하나의 K 반복 안에서 warp group은 여러 WGMMA instruction을 연속으로 발행하며, 각 instruction은 K 차원의 다른 slice(그림의 2.1, 2.2 등)를 대상으로 하되 같은 스레드별 accumulator 레지스터에 누적합니다. 이 instruction들이 합쳐져 전체 64 × 64 출력 타일을 만들어냅니다.
이 레이아웃은 우리가 수동으로 선택하는 것이 아닙니다. 하드웨어가 고정해 둔 것이며, PTX 문서의 9.7.15.5.1.1. 절에 기술되어 있습니다. 거기서는 m64n64k16에 대한 레지스터 fragment 레이아웃과 accumulator 타일이 warp group 전체에 어떻게 분산되는지를 설명합니다.
코드에서는 이것이 스레드별 accumulator 레지스터를 초기화할 때 나타납니다.
// Initialise thread's accumilator
// d[4][8] = 32 floats per thread
float d[WGMMA_N / 16][8];
memset(d, 0, sizeof(d));
각 스레드는 정확히 32개의 부동소수점 accumulator 값을 소유하며, 이들이 합쳐져 그 스레드가 전체 64 × 64 출력 타일 안에서 담당하는 fragment를 이룹니다. 각 WGMMA step 동안 이 레지스터들은 그 자리에서 갱신됩니다. 다음으로 sharedA와 sharedB에 대한 쓰기를 동기화하기 위해 두 개의 SMEM barrier를 만들고 초기화합니다. 두 barrier 모두 warp group의 128개 스레드 전체로 초기화됩니다.
// SMEM barriers for A and B
__shared__ barrier barA;
__shared__ barrier barB;
if (threadIdx.x == 0) {
init(&barA, blockDim.x);
init(&barB, blockDim.x);
cde::fence_proxy_async_shared_cta();
}
__syncthreads();
여기서 cuda::barrier<cuda::thread_scope_block> API(barrier는 alias로 사용됨)를 사용하면서도 여전히 __syncthreads()를 한 번 쓰는 점에 주목하세요. 이유는 일종의 부트스트래핑 문제 때문입니다.
문서에 따르면, 스레드들이 이런 barrier를 사용해 동기화를 시작하기 전에 barrier 자체를 먼저 커널 내부에서 초기화해야 합니다. 그런데 그러면 초기화하기 위해 스레드들은 무엇으로 서로를 동기화해야 할까요?
그래서 __syncthreads()를 여전히 사용합니다. barrier를 안전하게 사용하기 전에, barrier 초기화가 끝난 뒤 모든 스레드를 동기화하기 위해 단 한 번만 이전 세대의 동기화 primitive로 돌아가는 것입니다(앞선 커널들에서 보았듯 __syncthreads()는 초기화가 필요 없습니다). 이 일회성 bootstrap 이후에는 커널의 나머지 구간에서 cuda::barrier를 정상적으로 사용할 수 있습니다.
이제 이전 커널들처럼 num_blocks_k(공유 차원)를 반복하는 바깥 루프를 시작하고, TMA를 사용한 bulk load를 발행하기 시작합니다.
barrier::arrival_token tokenA, tokenB;
for (int block_k_iter = 0; block_k_iter < num_blocks_k; block_k_iter++) {
// Async loads (Only 1 thread launches the TMA op)
if (threadIdx.x == 0) {
// Thread 0 launches async bulk tensor copy operations for both matrices
cde::cp_async_bulk_tensor_2d_global_to_shared(&sharedA[0], tensorMapA, block_k_iter * TILE_SIZE_K, num_block_m * TILE_SIZE_M, barA);
// Signal barrier and wait for both loads to complete
tokenA = cuda::device::barrier_arrive_tx(barA, 1, sizeof(sharedA));
cde::cp_async_bulk_tensor_2d_global_to_shared(&sharedB[0], tensorMapB, block_k_iter * TILE_SIZE_K, num_block_n * TILE_SIZE_N, barB);
tokenB = cuda::device::barrier_arrive_tx(barB, 1, sizeof(sharedB));
}
else {
// Other threads arrive at barrier to synchronise data loads
tokenA = barA.arrive();
tokenB = barB.arrive();
}
// All threads wait for async loads to complete
barA.wait(std::move(tokenA));
barB.wait(std::move(tokenB));
__syncthreads();
}
K 차원을 반복하는 각 단계에서 블록 안의 단 하나의 스레드(thread 0)가 cp_async_bulk_tensor_2d_global_to_shared를 사용해 행렬 A와 B 모두에 대한 TMA load를 발행하는 책임을 집니다. 이 instruction들은 앞에서 만든 tensor map을 바탕으로 GMEM에서 SMEM으로 전체 2D 타일을 옮기는 비동기 bulk copy를 큐에 넣습니다. 각 copy를 발행한 직후 thread 0은 barrier_arrive_tx를 호출하는데, 이 함수는 두 가지 일을 합니다. barrier에 도착했다는 신호를 보내고, 비동기 copy에 의해 몇 바이트가 쓰일 예정인지를 barrier에 알려줍니다. 블록의 다른 모든 스레드는 단순히 bar.arrive()를 호출해 도착만 기여하고, 데이터 전송은 연결하지 않습니다. 마지막으로 모든 스레드는 bar.wait(token)으로 barrier를 기다립니다(문서 참고). 이 wait는 블록의 모든 스레드가 barrier에 도착하고, TMA 엔진이 SMEM에 전체 타일을 다 써 넣었을 때에만 완료됩니다.
그 시점이 되면 SMEM 타일이 완전히 채워졌고 모든 스레드에서 볼 수 있다는 것이 보장되며, WGMMA 계산 단계로 넘어가도 안전합니다. 여기서 warp group이 실제 MMA를 수행하는 WGMMA instruction을 실행합니다. 계산 단계는 다음 순서를 따릅니다.
wgmma.fence.sync.aligned를 발행합니다. 개념적으로는 warp group 전체에 걸쳐 관련된 모든 레지스터 및 SMEM 쓰기가 완료되어 보이게 되었고, WGMMA instruction 발행을 시작할 준비가 되었음을 뜻합니다.wgmma.mma_async를 사용해 여러 비동기 WGMMA 연산을 순차적으로 발행합니다. 코드에서 wgmma64는 단일 wgmma.mma_async.m64n64k16 instruction을 감싼 얇은 래퍼이며, 지금은 의도적으로 블랙박스로 취급하고 다음에 자세히 볼 것입니다. 각 WGMMA instruction은 64 × 64 × 16 행렬 곱을 계산하고 같은 스레드별 accumulator 레지스터에 누적합니다. 네 번의 호출을 통해 우리는 사실상 K 차원의 서로 다른 slice를 지나가며 동일한 64 × 64 출력 타일에 누적하고 있습니다. 이 wgmma.mma_async instruction들은 비동기적입니다. 발행했다고 해서 즉시 완료된다는 뜻이 아닙니다. 대신 하드웨어가 나중에 실행하도록 큐에 넣습니다.wgmma.commit_group 연산을 사용해 앞서 발행된 outstanding wgmma.mma_async 연산들을 하나의 wgmma-group으로 묶고 commit합니다.wgmma.wait_group.wgmma.mma_async 연산이 실행된 것이고, 누적 결과가 레지스터에서 안전하게 사용 가능해집니다. 이 시점에서 커널은 다음 K 타일로 넘어가거나 store 단계로 진행할 수 있습니다.// Compute phase using WGMMA tensor cores
warpgroup_arrive(); // asm volatile("wgmma.fence.sync.aligned;\n" ::: "memory");
wgmma64<1, 1, 1, 0, 0>(d, &sharedA[0], &sharedB[0]);
wgmma64<1, 1, 1, 0, 0>(d, &sharedA[WGMMA_K], &sharedB[WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sharedA[2 * WGMMA_K], &sharedB[2 * WGMMA_K]);
wgmma64<1, 1, 1, 0, 0>(d, &sharedA[3 * WGMMA_K], &sharedB[3 * WGMMA_K]);
warpgroup_commit_batch(); // asm volatile("wgmma.commit_group.sync.aligned;\n" ::: "memory");
warpgroup_wait<0>(); // asm volatile("wgmma.wait_group.sync.aligned %0;\n" ::"n"(N) : "memory");
마지막으로 남은 조각은 WGMMA instruction 자체입니다. 위에서는 의도적으로 먼저 전체 커널 구조에 초점을 맞췄습니다. 즉 타일을 TMA로 어떻게 로드하는지, 동기화는 어떻게 동작하는지, 계산 단계는 어떻게 조직되는지를 먼저 봤습니다. 계산 단계에서 wgmma64 함수가 호출되는 것도 이미 보았지만, 지금까지는 블랙박스로 다뤘습니다. 이제 드디어 그것을 열어볼 수 있습니다.
wgmma64 함수는 인라인 PTX instruction wgmma.mma_async.m64n64k16.f32.bf16.bf16를 얇게 감싼 래퍼입니다. 함수의 전체 모양과 시그니처는 하드웨어 인터페이스가 결정합니다.
template <int ScaleD, int ScaleA, int ScaleB, int TransA, int TransB>
__device__ void wgmma64(float d[4][8], bf16 *sharedA, bf16 *sharedB)
{
uint64_t desc_a = make_smem_desc(&sharedA[0]);
uint64_t desc_b = make_smem_desc(&sharedB[0]);
각 호출은 행렬 A와 B 각각에 대해 두 개의 matrix descriptor를 만드는 것부터 시작합니다. 이 descriptor는 행렬이 SMEM 어디에 있고 어떤 레이아웃인지 인코딩합니다. 앞서 논의했듯 WGMMA는 raw pointer를 받지 않으며, 대신 이런 packed 64-bit descriptor를 소비합니다.
함수의 핵심은 인라인 PTX 블록입니다.
asm volatile(
"{\n"
"wgmma.mma_async.sync.aligned.m64n64k16.f32.bf16.bf16 "
"{%0, %1, %2, %3, %4, %5, %6, %7, "
" %8, %9, %10, %11, %12, %13, %14, %15, "
" %16, %17, %18, %19, %20, %21, %22, %23, "
" %24, %25, %26, %27, %28, %29, %30, %31},""
" %32,"
" %33,"
" %34, %35, %36, %37, %38;\n"
"}\n"
: "+f"(d[0][0]), "+f"(d[0][1]), "+f"(d[0][2]), "+f"(d[0][3]), "+f"(d[0][4]), "+f"(d[0][5]),
"+f"(d[0][6]), "+f"(d[0][7]), "+f"(d[1][0]), "+f"(d[1][1]), "+f"(d[1][2]), "+f"(d[1][3]),
"+f"(d[1][4]), "+f"(d[1][5]), "+f"(d[1][6]), "+f"(d[1][7]), "+f"(d[2][0]), "+f"(d[2][1]),
"+f"(d[2][2]), "+f"(d[2][3]), "+f"(d[2][4]), "+f"(d[2][5]), "+f"(d[2][6]), "+f"(d[2][7]),
"+f"(d[3][0]), "+f"(d[3][1]), "+f"(d[3][2]), "+f"(d[3][3]), "+f"(d[3][4]), "+f"(d[3][5]),
"+f"(d[3][6]), "+f"(d[3][7])
: "l"(desc_a), "l"(desc_b), "n"(int32_t(ScaleD)), "n"(int32_t(ScaleA)),
"n"(int32_t(ScaleB)), "n"(int32_t(TransA)), "n"(int32_t(TransB)));
긴 목록 {%0 … %31}은 호출한 스레드가 소유한 accumulator 레지스터를 의미합니다. 이 레지스터들은 입력이자 출력이므로, operand 목록에서 "+f"로 표시됩니다. 각 WGMMA instruction은 이 레지스터들의 현재 값을 읽고, MMA를 수행한 뒤, 갱신된 결과를 같은 레지스터에 다시 씁니다.
그다음 두 operand %32와 %33은 SMEM에 있는 A와 B의 matrix descriptor입니다. 마지막 operand들은 scaling 및 transpose flag를 인코딩하며, template parameter이기 때문에 컴파일 타임 상수로 직접 instruction 안에 박힐 수 있습니다.
주어진 K 반복에 대해 모든 WGMMA instruction이 발행되고 완료되면, accumulator 레지스터에는 출력 타일의 최종 결과가 담기게 됩니다. 마지막 단계는 이 값을 전역 메모리에 쓰는 것입니다.
먼저 store를 담당하는 코드 스니펫을 보여드리겠습니다. 그 다음 문서에 정의된 accumulator D(우리 코드에서는 C에 해당)의 전체 레지스터 fragment 레이아웃으로 다시 돌아오겠습니다. 다만 warp-group 레이아웃 전체를 한 번에 해석하려고 하기보다, 단일 스레드(특히 thread 0)에 초점을 맞춰 설명하겠습니다. 하나의 스레드의 레지스터 fragment가 출력 원소에 어떻게 매핑되는지를 이해하면, 전체 레이아웃도 자연스럽게 보입니다.
for (int m_it = 0; m_it < TILE_SIZE_M / WGMMA_M; ++m_it) {
for (int n_it = 0; n_it < TILE_SIZE_N / WGMMA_N; ++n_it) {
for (int w = 0; w < WGMMA_N / 16; ++w) { // w = {0, 1, 2, 3}
// (16 * w) selects the base col of the 16 col block
int col = 16 * w + 2 * (tid % 4);
#define IDX(i, j) ((j + n_it * WGMMA_N) * M + ((i) + m_it * WGMMA_M))
// Apply alpha scaling to accumulator results and add beta*C
block_C[IDX(row, col)] = __float2bfloat16(alpha * d[w][0] + beta * __bfloat162float(block_C[IDX(row, col)]));
block_C[IDX(row, col + 1)] = __float2bfloat16(alpha * d[w][1] + beta * __bfloat162float(block_C[IDX(row, col + 1)]));
block_C[IDX(row + 8, col)] = __float2bfloat16(alpha * d[w][2] + beta * __bfloat162float(block_C[IDX(row + 8, col)]));
block_C[IDX(row + 8, col + 1)] = __float2bfloat16(alpha * d[w][3] + beta * __bfloat162float(block_C[IDX(row + 8, col + 1)]));
block_C[IDX(row, col + 8)] = __float2bfloat16(alpha * d[w][4] + beta * __bfloat162float(block_C[IDX(row, col + 8)]));
block_C[IDX(row, col + 9)] = __float2bfloat16(alpha * d[w][5] + beta * __bfloat162float(block_C[IDX(row, col + 9)]));
block_C[IDX(row + 8, col + 8)] = __float2bfloat16(alpha * d[w][6] + beta * __bfloat162float(block_C[IDX(row + 8, col + 8)]));
block_C[IDX(row + 8, col + 9)] = __float2bfloat16(alpha * d[w][7] + beta * __bfloat162float(block_C[IDX(row + 8, col + 9)]));
#undef IDX
}
}
}
여기서 각 스레드는 warp와 lane을 기반으로 자신이 담당할 row 인덱스를 계산합니다. 그 뒤의 중첩 루프는 M과 N 차원의 논리 타일과 내부 fragment 구조를 반복합니다. 각 반복에서 스레드는 accumulator 레지스터의 해당 원소를 GMEM의 정확한 위치에 써 넣습니다.
모든 스레드에 대한 레지스터 fragment 레이아웃은 다음과 같으며, 예시로 thread 0에만 초점을 맞춥니다.

이제 우리는 코드 관점과 하부 하드웨어 실행 모델 관점 모두에서 이 커널 전체를 처음부터 끝까지 살펴보았습니다. 모든 조각이 갖춰졌으니, 다음 단계는 커널을 벤치마킹하고 성능 결과를 보는 것입니다.
우리는 280.4 TFLOP/s의 처리량을 달성하며, 이는 전체 FP32 경로에서 41.4, 혼합 정밀도에서 31.5만 달성했던 이전 커널에 비해 엄청난 향상입니다. 완전히 다른 게임입니다.
전체 FP32 cuBLAS 벤치마크와 비교하면 성능은 이제 **약 544%**이지만, 당연히 이제부터 이 비교는 “공정한” 비교가 아닙니다. 이 cuBLAS 버전은 Tensor Core를 사용하지 않기 때문입니다. 단지 차이를 함께 보고 싶어서 나란히 두었습니다.
이제부터 우리의 진짜 벤치마크는 bf16과 Tensor Core가 활성화된 cuBLAS입니다. 그 기준에서는 **37.8%**를 달성합니다. (참고로, 앞선 커널들에서는 FP32 기준 상대 성능을 보고했지만, 혼합 정밀도로도 Tensor Core cuBLAS와 비교해 보았고, 워프 타일링은 고작 **4.3%**만 달성했었습니다. 그러니까 기술적으로는 4.3%에서 37.8%로, 거의 9배 점프한 셈입니다.)
지금까지 우리는 단 하나의 WGMMA shape인 m64n64k16만 실험했습니다. 전통적인 CUDA 커널에서는 수학적으로만 맞으면 거의 임의의 타일 크기를 실험할 수 있지만, Tensor Core MMA 연산은 훨씬 더 제약이 많습니다. NVIDIA는 operand A, B, accumulator C에 대해 제한된 고정 행렬 shape만 지원하며, 이는 PTX ISA 명세에 문서화되어 있습니다(아래 표 참고).
지원되는 각 MMA shape는 특정 하드웨어 instruction에 대응하며, 단일 WGMMA 연산이 생성하는 출력 타일의 크기를 결정합니다. 어떤 shape는 자연스럽게 더 큰 accumulator 타일을 만들고, 다른 shape는 더 작은 타일을 만듭니다. 이는 warp group이 instruction당 얼마만큼의 일을 하는지, 나아가 커널 구조를 그 주변에 어떻게 설계해야 하는지에 직접적인 영향을 줍니다.
자연스럽게도, warp group이 instruction당 더 많은 출력 원소를 생산하게 해주는 MMA shape를 선택할 수 있다면, 발행된 WGMMA당 더 많은 산술 작업이 수행되므로 더 높은 성능을 기대할 수 있습니다. 물론 이는 레지스터 압력 같은 다른 요인에 발목 잡히지 않는 한에서만 성립하며, 레지스터 압력은 다시 occupancy 감소로 이어질 수 있습니다.
이 커널의 목표는 서로 다른 WGMMA 구성을 탐색하고, 어떤 shape가 H100 아키텍처에 가장 잘 맞는지 평가하는 것입니다. 가능한 모든 옵션을 완전히 탐색하기보다는, bf16을 지원하는 소수의 대표적인 shape에 집중해 성능에 미치는 영향을 비교하겠습니다.
아래는 하드웨어가 지원하는 bf16 WGMMA shape들입니다. 이 목록에서 몇 가지 대표 후보를 골라 실험하고 더 분석해보겠습니다.
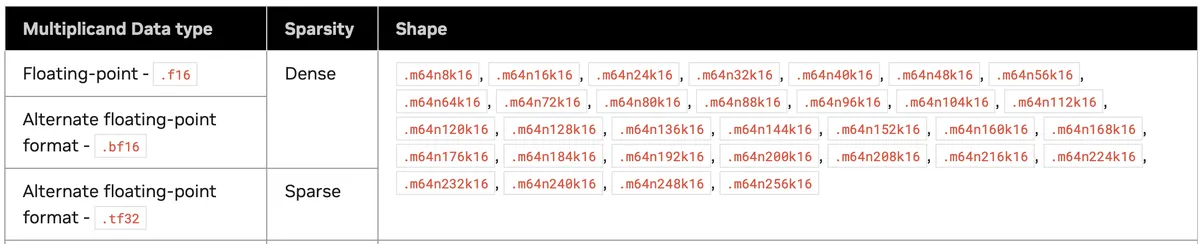
N차원만 바뀝니다.M은 64로 고정이고,K도 이 bf16 dense shape들에서는 16으로 고정입니다.
시각적으로 이 커널은 이전 것과 거의 동일합니다. 핵심 차이는 더 큰 TILE_SIZE_M을 커버할 수 있도록 바깥 루프를 도입했다는 점입니다. 이를 구체적으로 만들기 위해, TILE_SIZE_M을 64에서 128로 늘리는 상황을 상상해 보면, 하나의 block 안에서 이제 M 타일 두 개를 순회하게 된다는 것을 볼 수 있습니다.

TILE_SIZE_M = 128, TILE_SIZE_N = 128, TILE_SIZE_K = 64이고, WGMMA shape 표에서 WGMMA_K가 16으로 고정이라는 것을 알고 있으므로 K 차원은 여전히 네 개의 수직 panel로 나뉘며, 이는 이전 커널과 정확히 같습니다.
바뀌는 것은 TILE_SIZE_M 차원입니다. WGMMA shape 표는 WGMMA_M이 64로 고정임을 알려주므로, 단일 WGMMA 연산은 한 번에 64행의 출력만 만들 수 있습니다. 이제 블록이 128행을 덮기 때문에, 전체 출력 타일을 커버하려면 TILE_SIZE_M 차원을 명시적으로 루프 돌며 첫 64행용 한 번, 두 번째 64행용 한 번, 총 두 번 WGMMA를 호출해야 합니다.
따라서 이 커널의 구조는 다음과 같습니다.
WGMMA_N = TILE_SIZE_N을 선택해 block 폭 전체를 하나의 instruction으로 커버합니다.m_it를 루프 돌며 TILE_SIZE_M을 커버합니다.k_it를 루프 돌며 TILE_SIZE_K를 커버합니다.그 외에는 TMA load, SMEM 레이아웃, store 측면에서 논리적으로 동일하며, 핵심 차이는 계산 단계가 WGMMA instruction shape를 중심으로 어떻게 구성되는가에 있습니다. 예를 들어 m64n128k16 shape를 사용하고 TILE_SIZE_M = 128로 늘렸다면, 새 커널의 계산 단계는 아래처럼 보일 것입니다.
이 커널의 핵심인 계산 단계는 따라서 다음과 같습니다.
// 2. Compute phase using WGMMA tensor cores instructions
warpgroup_arrive();
// Outer loop over TILE_SIZE_M in WGMMA_M steps
// If we have two warp groups, we let each work on a different partition of TILE_SIZE_M
// @example:
#pragma unroll
for (int m_iter = 0; m_iter < rows_per_warp_group / WGMMA_M; m_iter++) {
bf16* sharedA_wgmma_tile_base = sharedA + ((warp_group_idx * rows_per_warp_group) + (m_iter * WGMMA_M)) * TILE_SIZE_K;
// Inner loop iterating over TILE_SIZE_K in WGMMA_K steps
#pragma unroll
for (int k_iter = 0; k_iter < TILE_SIZE_K / WGMMA_K; k_iter++) {
wgmma<WGMMA_N, 1, 1, 1, 0, 0>(d[m_iter], &sharedA_wgmma_tile_base[k_iter * WGMMA_K], &sharedB[k_iter * WGMMA_K]);
}
}
warpgroup_commit_batch(); // asm volatile("wgmma.commit_group.sync.aligned;\n" ::: "memory");
warpgroup_wait<0>(); // asm volatile("wgmma.wait_group.sync.aligned %0;\n" ::"n"(N) : "memory");
}
| WGMMA_N | TFLOP/s | cuBLAS 대비 성능 % |
|---|---|---|
| 32 | 230.2 | 31.7% |
| 128 | 407.7 | 56.9% |
| 256 | 70.3 | 9.7% |
몇 가지 다른 WGMMA_N shape를 실험해보면, 앞서 암시했던 예상된 동작을 확인할 수 있습니다. 128이 instruction 효율과 메모리 재사용 사이에서 가장 좋은 균형을 제공하고, 64는 그 뒤를 바짝 따라 이전 커널과 비슷한 수준을 냅니다. 32는 Tensor Core를 충분히 활용하지 못하고, 256은 레지스터 압력을 폭발시켜 성능을 무너뜨립니다. 전체적으로 이는 이전 커널 대비 약 1.5× 향상을 주며, 이제 cuBLAS 성능의 **56.9%**에 도달합니다. 즉 대략 절반 정도 온 셈입니다.
이전 커널 절의 시작에서 우리는 이런 질문을 던졌습니다.
“WGMMA가 기대하는 정확한 형식으로 필요한 행렬 타일을 공유 메모리에 어떻게 배치하고, Tensor Core가 절대 놀지 않을 만큼 충분히 빠르게 그렇게 할 수 있을까?”
첫 번째 질문에는 답했지만, 이 커널의 프로파일링 결과를 보면 두 번째 질문에는 아직 답하지 못했다는 것이 분명합니다.
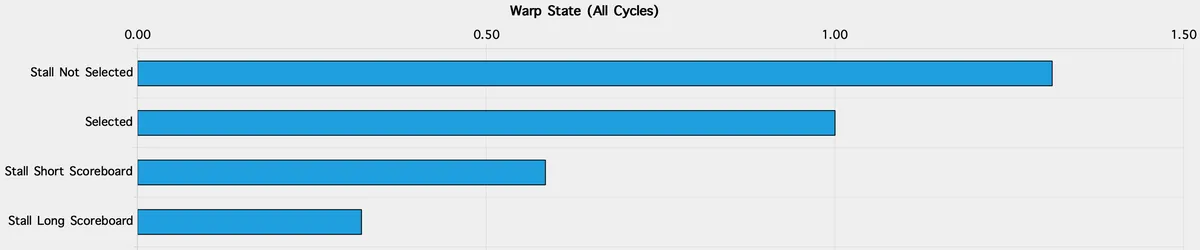
먼저 SoL 섹션의 compute throughput breakdown을 보면 tensor pipeline이 크게 미활용되고 있습니다. SM: Pipe Tensor Cycles Active 지표는 지속 가능한 피크의 **51.17%**에 불과하여, tensor MMA 유닛이 커널 실행 시간의 거의 절반 동안 놀고 있다는 것을 뜻합니다. 동시에 어떤 메모리 시스템도 이론적 피크에 근접하지 않으므로, 이 커널은 memory bound가 아니라 scheduling bound라는 강한 신호를 줍니다. 왜 그런지 이해하기 위해 이제 스케줄러와 warp 통계를 보겠습니다.
스케줄러 통계를 보면 다음과 같습니다.
이는 각 스케줄러마다 여러 워프가 상주하고 있음에도, 어떤 사이클에서든 실제로 실행 가능한 워프는 거의 없다는 뜻입니다. 다시 말해 스케줄러는 자주 작업을 발행하고 싶어 하지만, 선택할 eligible warp가 없습니다. 이것은 정의상 scheduling 및 dependency 문제입니다.
처음에는 NUM_THREADS를 256으로 늘려 각 block이 두 개의 warp group을 갖게 해보았습니다. 직관적으로는 occupancy와 active warp 수가 증가해 지연 시간을 숨기는 데 도움이 될 것 같았습니다. 실제로 occupancy와 active warp는 증가했지만, 성능은 나아지지 않았고 오히려 약간 나빠졌습니다. 이유는 occupancy 자체가 eligible warp를 만들어내지 않기 때문입니다. 이 경우 scheduler당 eligible warp는 0.19에서 0.23으로 아주 조금만 증가했는데, 이는 scheduling 동작을 의미 있게 바꾸기엔 턱없이 작습니다.
🔎 아래는 128-thread 커널(기준선)과 256-thread 커널(현재)의 scheduler 및 warp 통계 비교입니다. active warp는 확실히 증가했지만, warp들이 비슷한 stall 문제를 여전히 겪고 있기 때문에 개선으로 이어지지 않았음을 보여줍니다(지표를 명확히 보려면 확대해 주세요):
스레드 수를 늘리면 occupancy는 높아질 수 있지만, 그 워프들이 여전히 barrier, wait, dependency chain에 막혀 있다면 스케줄러가 실제로 발행할 유용한 작업은 여전히 거의 없습니다. 그래서 원래 128-thread 커널의 warp state 통계를 더 자세히 볼 필요가 생깁니다.
가장 지배적인 stall 이유는 Long Scoreboard = 10.73입니다. 이는 워프가 실행 및 메모리 파이프라인을 흐르는 outstanding dependency 때문에 자주 막힌다는 뜻입니다. 이 커널에서 이런 dependency의 주된 원천은 누산 루프 자체입니다. 각 WGMMA instruction은 같은 accumulator 레지스터를 읽고 다시 쓰기 때문에, 연속된 WGMMA 연산은 본질적으로 서로 의존적입니다. accumulation loop 내부의 이 직렬 dependency는 GEMM 알고리즘에 본질적이며 변하지 않습니다.
Barrier와 Wait stall도 상당합니다. K 차원의 각 반복은 항상 같은 엄격한 직렬 패턴을 따릅니다. TMA load가 발행되고, 커널은 그 load가 완료될 때까지 기다리고, CTA를 동기화하고, WGMMA 계산을 실행한 뒤, 마지막으로 모든 outstanding WGMMA 작업을 비워낸 다음에야 다음 반복으로 넘어갑니다. scheduler당 eligible warp가 너무 적기 때문에 이런 지연을 숨길 수 없고, tensor pipeline은 실행 시간의 상당 부분 동안 유휴 상태가 됩니다.
결과적으로 이 커널은 반복 수준에서 큰 pipeline bubble을 보입니다. WGMMA 계산 단계 동안 메모리 시스템은 놀고 있습니다. TMA load와 동기화 단계 동안 Tensor Core는 놀고 있습니다. 이런 패턴이 128개의 모든 K 반복에서 동일하게 반복되기 때문에, 이런 유휴 구간이 누적되어 큰 효율 손실이 되고, 이는 프로파일링에서 관측된 낮은 tensor pipe 활용도를 직접 설명합니다.
아래는 코드에서 이런 stall이 발생하는 위치입니다.
// TMA launch on one thread
if (threadIdx.x == 0) {
cde::cp_async_bulk_tensor_2d_global_to_shared(..., barA);
tokenA = cuda::device::barrier_arrive_tx(barA, 1, sizeof(s.A));
cde::cp_async_bulk_tensor_2d_global_to_shared(..., barB);
tokenB = cuda::device::barrier_arrive_tx(barB, 1, sizeof(s.B));
}
else {
tokenA = barA.arrive();
tokenB = barB.arrive();
}
// Stall Barrier: arrival skew (other warps reach arrive/wait earlier than thread 0)
// Stall Wait: arrive_tx ties barrier completion to async copy bytes landing
barA.wait(std::move(tokenA));
barB.wait(std::move(tokenB));
// Stall Wait: waiting for TMA transaction completion (bytes written to SMEM)
// Stall Barrier: waiting for all warps to arrive at the barrier phase
__syncthreads();
// Stall Barrier: explicit CTA barrier each K-iteration (often redundant here)
for (int k_iter = 0; k_iter < TILE_SIZE_K / WGMMA_K; k_iter++) {
wgmma(...)(d[m_iter], ...);
// Stall Long Scoreboard: dependency chain on d[m_iter] registers
// each WGMMA reads+writes d, next WGMMA needs updated d
}
warpgroup_wait<0>();
// Stall Wait: explicit drain of all WGMMA work before next iteration
시각적으로 이것은 각 스레드의 파이프라인이 다음과 같다는 뜻입니다.

이전 커널에서 식별한 파이프라인 직렬화를 고려할 때, 다음 단계는 커널을 producer-consumer 패턴으로 재구성하는 것입니다. 이 설계에서는 하나의 warp group이 producer 역할을 맡아 주로 TMA load를 발행하고, 나머지 warp group(들)은 consumer로서 WGMMA를 사용한 Tensor Core 계산을 수행합니다.
중요한 점은 이 역할들이 병렬로 동작한다는 것입니다. consumer warp group이 현재 K 타일에 대해 WGMMA를 실행하는 동안, producer warp group은 이미 다음 타일을 위한 비동기 TMA load를 발행할 수 있습니다. 이는 TMA 전송이 Tensor Core 파이프라인과 독립적으로 실행된다는 사실을 활용합니다.
이 커널의 목표는 WGMMA 내부의 직렬 누산 dependency를 없애는 것이 아닙니다. 그것은 GEMM에 본질적이며 제거할 수 없습니다. 대신 목적은 K 반복 사이에서 TMA load와 Tensor Core 계산을 겹치게 하여 load 및 동기화 지연을 숨기는 것입니다. 이를 통해 (1) pipeline bubble을 줄이고, (2) Tensor Core pipe 활용도를 높이며, (3) eligible warp 수를 늘려 scheduler 동작을 개선하고, (4) long scoreboard stall을 줄이는 것을 목표로 합니다.
구현에 들어가기 전에, 아래 그림은 우리가 시각적으로 어떤 실행 모델을 목표로 하는지 보여줍니다.

이 커널의 핵심은 다음과 같습니다.
#pragma nv_diag_suppress static_var_with_dynamic_init
__shared__ barrier full[NUM_STAGES]; // Signals data is ready
__shared__ barrier empty[NUM_STAGES]; // Signals slot is available
if (threadIdx.x == 0) {
for (int i = 0; i < NUM_STAGES; i++) {
init(&full[i], num_consumer_groups * 128 + 1); // consumers + producer thread 0
init(&empty[i], num_consumer_groups * 128 + 1);
}
cde::fence_proxy_async_shared_cta();
}
__syncthreads();
if (is_producer) {
// Producer warp group: Issues TMA loads
if (threadIdx.x == 0) {
// Fill the pipeline
for (int stage = 0; stage < NUM_STAGES && stage < num_blocks_k; stage++) {
int block_k_iter = stage;
// Wait for empty slot (initially all are empty, so this passes immediately)
empty[stage].wait(empty[stage].arrive());
// Get pointers for this stage in the flat arrays
bf16* A_stage = s.A + (stage * A_stage_size);
bf16* B_stage = s.B + (stage * B_stage_size);
// TMA loads for A and B
cde::cp_async_bulk_tensor_2d_global_to_shared(A_stage, tensorMapA, block_k_iter * TILE_SIZE_K, num_block_m * TILE_SIZE_M, full[stage]);
cde::cp_async_bulk_tensor_2d_global_to_shared(B_stage, tensorMapB, block_k_iter * TILE_SIZE_K, num_block_n * TILE_SIZE_N, full[stage]);
// Signal data is ready
barrier::arrival_token token = cuda::device::barrier_arrive_tx(full[stage], 1, A_stage_size * sizeof(bf16) + B_stage_size * sizeof(bf16));
}
// Main loop: Continue issuing loads
for (int block_k_iter = NUM_STAGES; block_k_iter < num_blocks_k; block_k_iter++) {
int stage = block_k_iter % NUM_STAGES;
// Wait for this stage to be empty before overwriting
empty[stage].wait(empty[stage].arrive());
// Get pointers for this stage in the flat arrays
bf16* A_stage = s.A + (stage * A_stage_size);
bf16* B_stage = s.B + (stage * B_stage_size);
// Issue next TMA loads
cde::cp_async_bulk_tensor_2d_global_to_shared(A_stage, tensorMapA, block_k_iter * TILE_SIZE_K, num_block_m * TILE_SIZE_M, full[stage]);
cde::cp_async_bulk_tensor_2d_global_to_shared(B_stage, tensorMapB, block_k_iter * TILE_SIZE_K, num_block_n * TILE_SIZE_N, full[stage]);
// Signal data is ready
barrier::arrival_token token = cuda::device::barrier_arrive_tx(full[stage], 1, A_stage_size * sizeof(bf16) + B_stage_size * sizeof(bf16));
}
}
} else {
// Consumer warp groups: Execute WGMMA compute
// Accumulator registers - declared inside consumer branch only so
// ptxas doesn't allocate them for the producer warp group
float d[TILE_SIZE_M / WGMMA_M / num_consumer_groups][WGMMA_N / 16][8];
memset(d, 0, sizeof(d));
// Initially signal all empty slots are available
for (int i = 0; i < NUM_STAGES; i++) {
barrier::arrival_token token = empty[i].arrive();
}
// Main compute loop
for (int block_k_iter = 0; block_k_iter < num_blocks_k; block_k_iter++) {
int stage = block_k_iter % NUM_STAGES;
// Get pointers for this stage in the flat arrays
bf16* A_stage = s.A + (stage * A_stage_size);
bf16* B_stage = s.B + (stage * B_stage_size);
// Wait for data to be ready
full[stage].arrive_and_wait();
// Compute phase using WGMMA
warpgroup_arrive();
#pragma unroll
for (int m_iter = 0; m_iter < rows_per_consumer_warp_group / WGMMA_M; m_iter++) {
bf16* sharedA_wgmma_tile_base = A_stage + ((consumer_warp_group_idx * rows_per_consumer_warp_group) + (m_iter * WGMMA_M)) * TILE_SIZE_K;
#pragma unroll
for (int k_iter = 0; k_iter < TILE_SIZE_K / WGMMA_K; k_iter++) {
wgmma<WGMMA_N, 1, 1, 1, 0, 0>(d[m_iter], &sharedA_wgmma_tile_base[k_iter * WGMMA_K], &B_stage[k_iter * WGMMA_K]);
}
}
warpgroup_commit_batch();
warpgroup_wait<0>();
// Signal this slot is now empty and can be reused
barrier::arrival_token empty_token = empty[stage].arrive();
}
}
파이프라인을 올바르게 조정하기 위해 각 파이프라인 stage마다 두 개의 공유 메모리 barrier 배열을 할당합니다. empty[stage]는 “이 stage 버퍼에 써도 된다”는 뜻이고, full[stage]는 “이 stage 버퍼에 유효한 A와 B 타일이 들어 있다”는 뜻입니다. thread 0이 모든 barrier를 예상 참가자 수로 초기화한 뒤, barrier가 준비되도록 모든 스레드가 한 번 동기화합니다. 그 뒤 producer(역시 thread 0이 주도)는 먼저 파이프라인을 “예열”합니다. 처음 몇 개 K 타일에 대해 루프를 돌며 각 stage가 비어 있기를 기다리고, 그 stage의 s.A와 s.B slice에 두 개의 TMA load를 발행한 뒤, transaction arrive를 통해 full[stage]를 signal해서 consumer가 바이트가 도착하면 깨어날 수 있게 합니다. 파이프라인이 채워지면 producer는 정상 상태에 들어갑니다. 새 K 타일마다 stage = block_k_iter % NUM_STAGES를 재사용하고, consumer가 그 stage를 empty로 표시할 때까지 기다렸다가, 다음 TMA load로 덮어쓰고 다시 full을 signal합니다. 그와 동시에 각 consumer warpgroup은 레지스터에 accumulator fragment d를 할당하고, producer가 즉시 시작할 수 있도록 모든 stage를 처음에는 empty로 표시한 뒤, 같은 순환 stage를 택하는 K 루프를 실행합니다. full[stage]를 기다려 producer가 그 stage 로드를 끝냈는지 확인한 뒤, 자신이 소유한 A 서브타일과 해당 stage의 B 타일에 대해 WGMMA 마이크로루프를 실행하고, WGMMA batch를 commit하고 기다린 다음, 그 stage를 다시 empty[stage]로 표시하여 다음 사이클에서 producer가 재사용할 수 있게 넘겨줍니다.
다음 시각화는 producer와 consumer가 어떻게 협력하는지 더 분명하게 보여줄 것입니다.
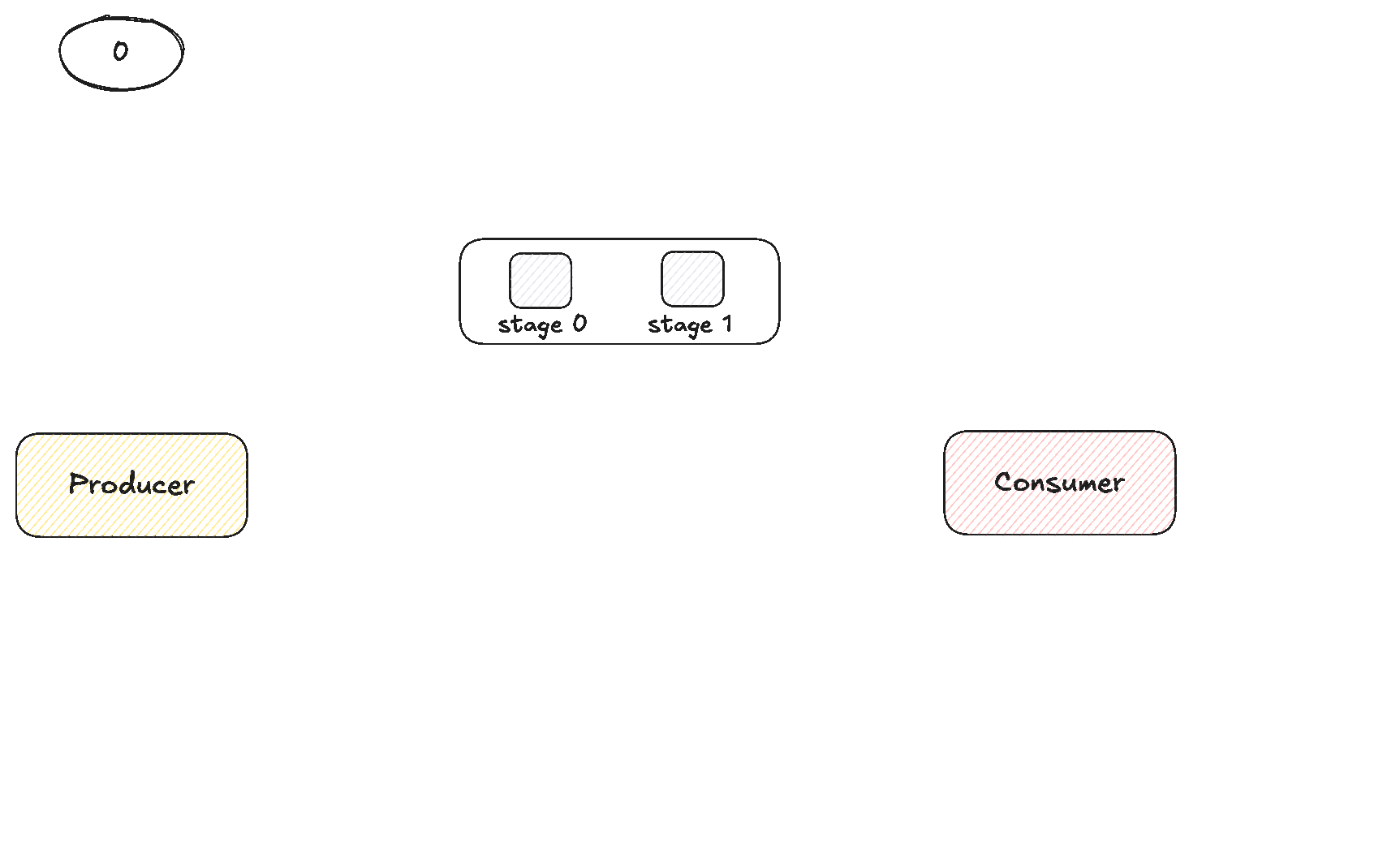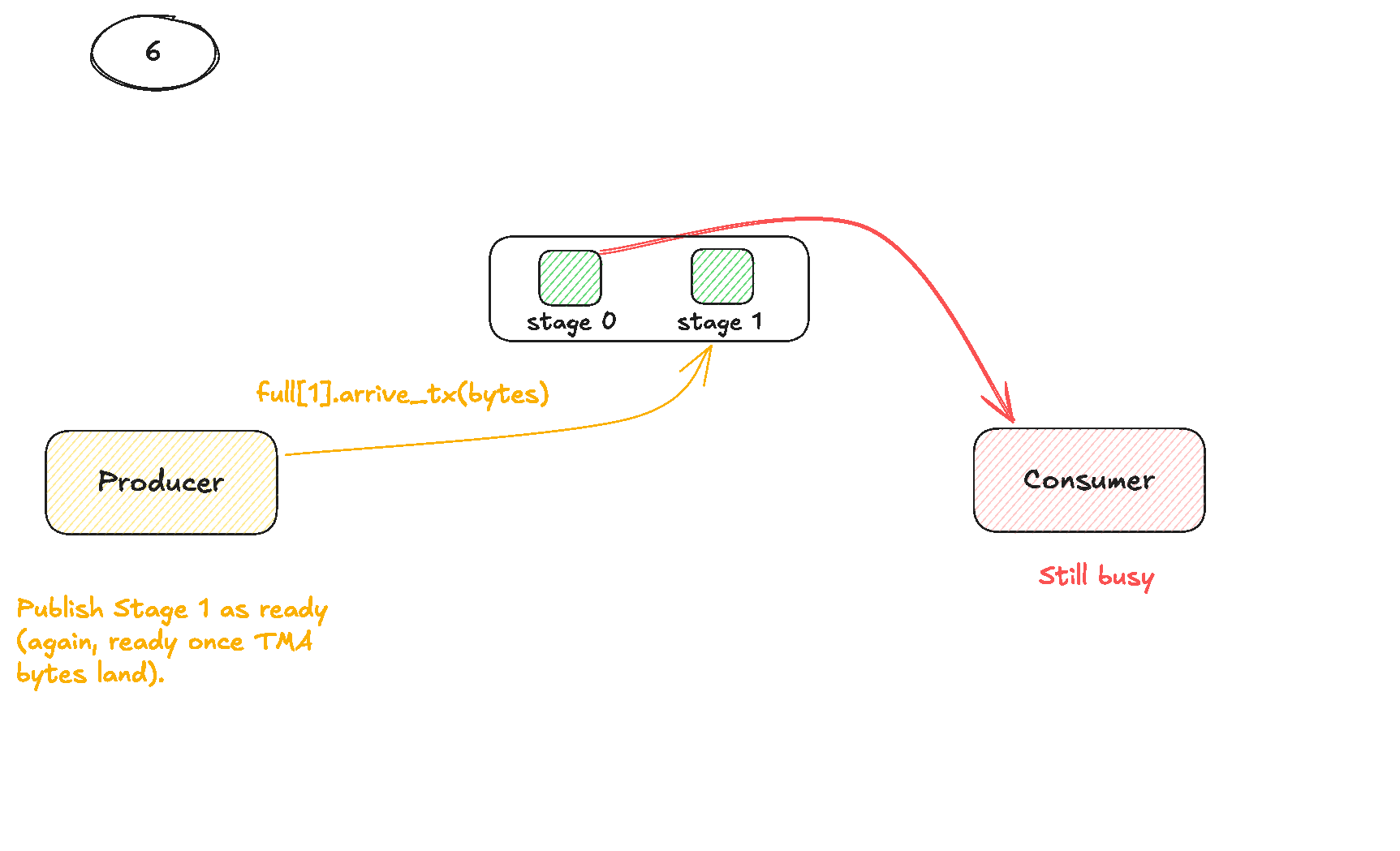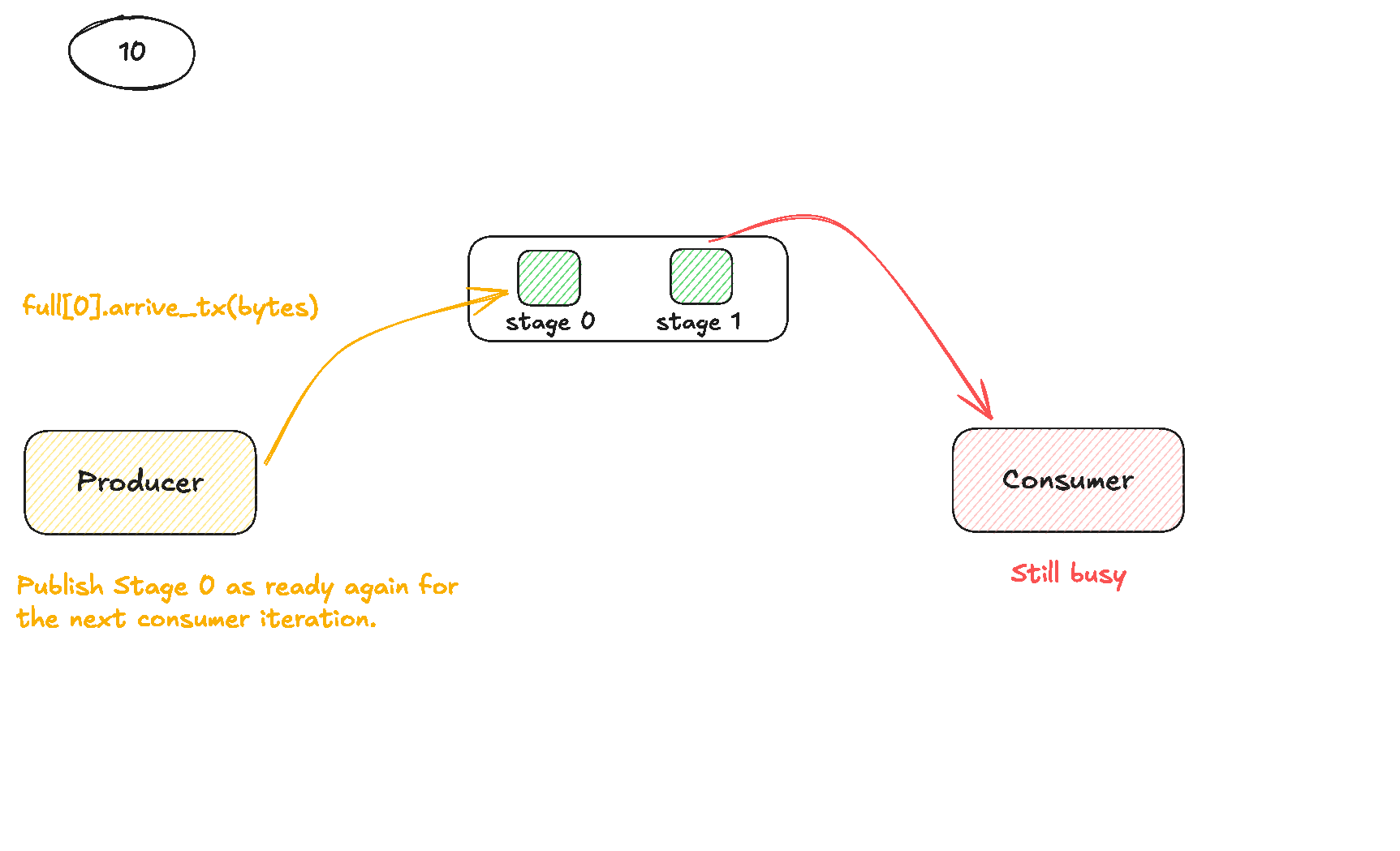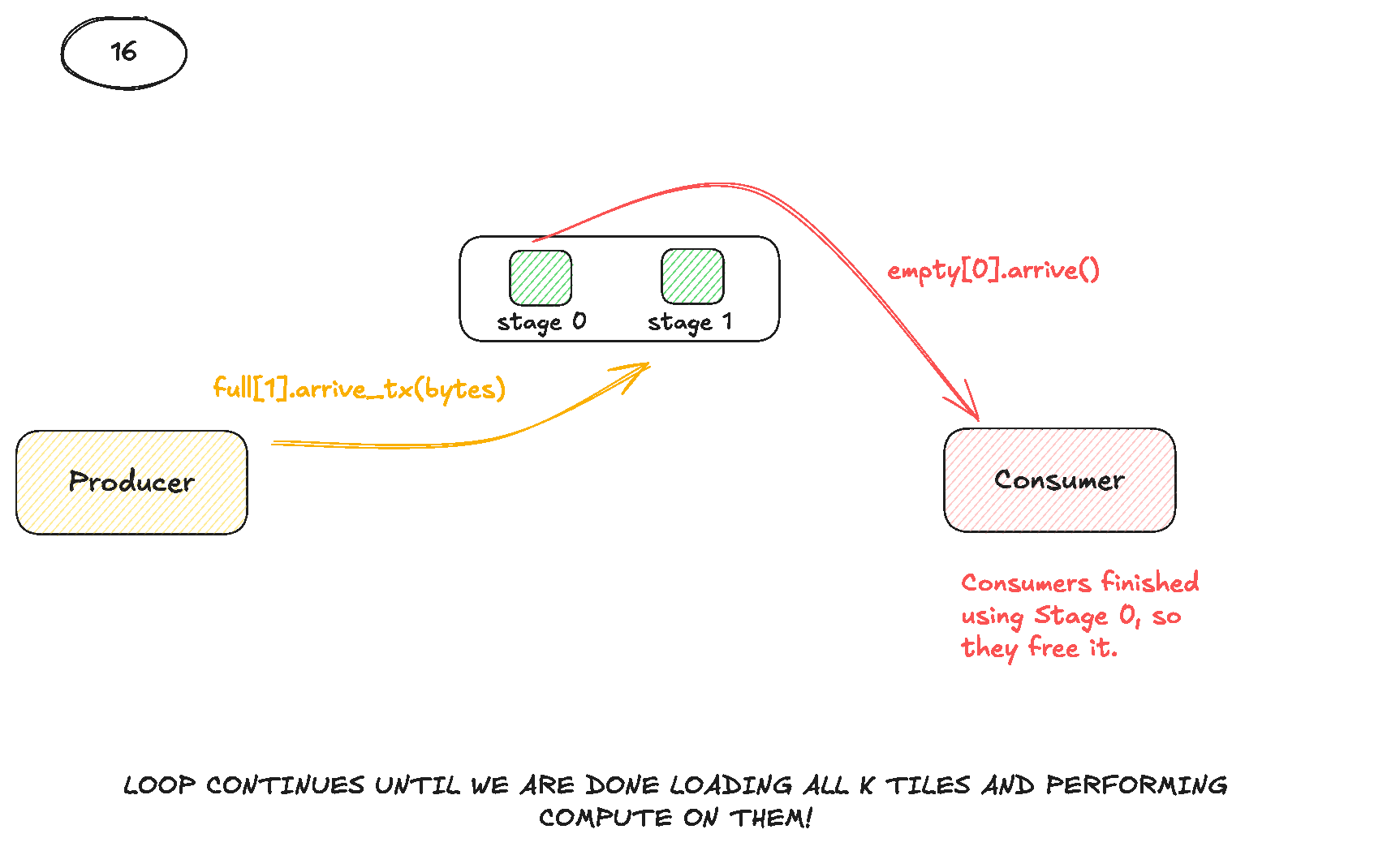
이 커널을 구현한 뒤, Pranjal의 구현이 보여준 것과 같은 성능 향상을 기대했습니다. 이전 커널은 이미 그의 성능과 거의 정확히 맞먹었기 때문에 비교는 공정했습니다. 그의 커널이 파이프라인 추가로 큰 향상을 보였다면, 제 커널도 비슷한 이득을 보여야 했습니다. 하지만 그렇지 않았습니다. 이는 곧바로 두 가지 가능성을 시사했습니다. 제 구현이 구조적으로 달라서 overlap이 제대로 일어나지 않았거나, 혹은 더 근본적인 무언가가 파이프라인 효과를 제한하고 있다는 뜻이었습니다. 저는 producer 쪽을 약간 재구성하여 prefill 단계와 steady state를 별도 루프로 나누고 stage 주소 계산도 다시 짰습니다. 이 변경들은 의미론적으로는 맞았지만, 그의 구현 구조와는 달랐기 때문에 문제가 어디서 비롯됐는지 더 불분명해졌습니다.
무엇이 잘못되었는지 확인하는 데에는 여러 번의 표적 실험을 통한 프로파일링이 핵심이었습니다. 모든 프로파일링 리포트는 저장소의 h100_gemm/profiling_reports/producer-consumer-pipeline에서 확인할 수 있습니다.
핵심 통찰은 구현 차이와 무관하게 output scaling의 효과를 독립적으로 분리해 보는 것이었습니다. 저는 Pranjal의 구현 자체를 두 가지 구성으로 직접 프로파일링했습니다.
이 실험 설계가 중요했습니다. scaling이 적용된 참조 커널에서도 제가 관찰한 것과 같은 성능 하락이 나타난다면, 문제는 제 파이프라인 구조가 아니라 epilogue scaling 자체에 있다는 뜻이기 때문입니다.
기준선(Scaling 없음): 기준선 커널은 잘 튜닝된 파이프라인이 보여야 할 특성을 보여주었습니다.
Nsight Compute는 “평균적으로 sector당 전송된 32바이트 중 16바이트만 활용된다”는 비효율 경고를 전역 store에 대해 표시했지만, 이 경고는 성능 병목으로 이어지지는 않았습니다.
Scaling 적용(알파와 베타 scaling을 포함한 epilogue): epilogue에 scaling을 추가하자 성능 프로파일이 근본적으로 바뀌었습니다. 기준선 대비 처리량 저하는 다음과 같았습니다.
메모리 동작:
C를 load하고, scaling하고, 다시 store하므로 예상 가능한 결과)이 42% 메모리 트래픽 증가는 특히 많은 것을 말해주었습니다. scaling된 epilogue는 추가 메모리 연산을 도입했을 뿐 아니라, 그것을 비효율적으로 수행하고 있었습니다.
결정적인 발견은 scaling된 참조 커널이 이제 제 구현과 거의 동일한 성능 특성을 보인다는 점이었습니다. 처리량 감소, 메모리 트래픽 증가, compute activity 감소(Pipe Tensor Cycles Active [%] 지표로 확인 가능)가 두 커널 모두에서 나타났습니다. 이로써 초기 가설, 즉 문제가 제 커널 구조나 심지어 스레드당 레지스터 수 때문이라는 생각은 배제할 수 있었습니다. 우리는 로컬 메모리 스필조차 없었기 때문입니다. 이 성능 저하는 scaling이 추가되면 참조 구현 자체에서도 재현되었습니다. 파이프라인 구조는 건전했고, 병목은 epilogue로 이동한 것이었습니다.
이 관찰을 더 구체적인 수치로 뒷받침하기 위해, 지금까지 이 작업 전반에서 일관되게 사용해온 문제 크기에서 제 정확한 파이프라인 커널을 두 구성으로 벤치마크했습니다. (참고로 코드는 512, 1024, 2048, 4096, 8192 크기를 모두 벤치마크하지만, 지금까지는 8192 결과를 주로 보고해 왔습니다.)
M=N=K= 8192에서 alpha와 beta scaling이 없고, shared memory epilogue staging도 없는 파이프라인 커널은 436.7 TFLOPs를 달성하며, 이는 cuBLAS의 **58.4%**에 해당합니다. 반면 alpha와 beta scaling 전체와 shared memory staged epilogue를 포함한 버전은 356 TFLOPs, 즉 cuBLAS의 **49.5%**를 기록합니다.
M=N=K= 4096에서는 scaling 없는 변형이 cuBLAS의 **73.8%**에 도달하며, 그 크기에서 Pranjal이 보고한 파이프라인 성능을 약간 앞섭니다. 하지만 cuBLAS는 더 큰 문제 크기에서 더 효율적으로 확장되므로, 이 이점은 8192에서는 줄어들어 상대 성능이 58.4%까지 떨어집니다.
따라서 효과는 분명합니다. scaling을 도입하면 8192에서 대략 80 TFLOPs를 잃습니다. 이 회귀는 주로 producer–consumer 파이프라인 자체 때문이 아니라, mainloop가 충분히 효율적이 되면 read–modify–write epilogue가 지배적인 제한 요소로 떠오른다는 사실에서 비롯됩니다.
이 성능 차이는 두 epilogue 변형이 메모리와 상호작용하는 방식에서 옵니다. scaling이 없으면 우리는 C = accumulator라는 write-only 경로를 가집니다. 각 스레드는 전역 store 하나만 수행합니다. 접근 패턴은 완벽하게 coalesced되지는 않지만(그래서 sector utilisation 경고가 나옵니다), 커널은 여전히 compute-bound입니다. Tensor Core가 충분히 포화되어 이 메모리 비효율이 실행 시간을 지배하지 못합니다.
scaling이 있으면 C = α × accumulator + β × C라는 read-modify-write 경로가 됩니다. 이제 epilogue는 다음을 필요로 합니다.
β × Cα × accumulator + (β × C)핵심 변화는 전역 load 스트림이 도입된다는 점입니다. 스레드별 접근 패턴이 완전히 coalesced되지 않는다면, 그리고 프로파일러는 실제로 그렇다고 확인해주고 있으며, 우리는 이제 그 비효율 비용을 두 번 치르게 됩니다. 한 번은 load 경로에서, 또 한 번은 store 경로에서입니다.
그러면 질문은 이렇게 바뀝니다. 이전 커널에서도 scaling이 있었는데 왜 거기서는 이 문제가 보이지 않았을까? 이것은 추론하기가 꽤 어려웠지만, 제 추측으로는 파이프라인이 TMA load와 WGMMA compute를 성공적으로 overlap시켰고, 그 결과 커널을 피크 compute throughput에 더 가깝게 밀어 붙이면서 epilogue 메모리 접근 패턴이 새로운 지배 병목으로 드러난 것입니다. epilogue 메모리 접근 패턴은 두 경우 모두 비효율적이었지만, 순차 커널에서는 그 비효율이 다른 stall 뒤에 가려져 있었습니다.
제가 또 궁금했던 질문 하나는 이것이었습니다. epilogue가 문제이고 compute 뒤에 실행된다면, Tensor Core 활용도는 여전히 높게 보여야 하지 않나?
핵심은 프로파일러 지표가 커널 전체 실행 시간에 대해 평균된다는 점입니다. overlap 덕분에 mainloop가 빨라지면 epilogue는 전체 런타임에서 더 큰 비중을 차지하게 됩니다. 그 시간 동안 Tensor Core는 놀고 있으므로 전체 tensor pipe activity가 떨어집니다. 순차 커널에서는 compute phase가 더 길고 원래부터 stall도 많았기 때문에, 비효율적인 epilogue가 상대적으로 덜 눈에 띄었을 뿐입니다.
이제 epilogue가 병목이라는 것이 확인되었으니, 다음 질문은 **왜 메모리 접근 패턴이 비효율적인가?**였습니다.
스레드들은 Kernel 7에서 봤던 것처럼 WGMMA 실행에 효율적인 형태로 정리된 register fragment에 결과를 누적합니다. 그러나 전역 메모리는 하드웨어 소개와 이전 커널들에서 논의했듯 최적의 처리량을 위해 coalesced된 128-byte sector access를 요구합니다. 이 두 레이아웃은 자연스럽게 서로 호환되지 않습니다.
하지만 현재 epilogue는 레지스터에서 전역 메모리로 직접 써 버립니다. 이 때문에 레이아웃을 화해시키는 단계가 빠지고, 결과적으로 sector utilisation이 나빠집니다.

CUTLASS의 실전 GEMM 커널은 레지스터에서 전역 메모리로 직접 쓰지 않습니다. 대신 epilogue는 단계형 접근을 따릅니다.
전형적인 epilogue 구조는 다음과 같습니다.
CUTLASS는 epilogue에 SMEM swizzle을 적용하는 것 같지만, 저는 padding을 사용하고 이후 bank conflict가 여전히 존재하는지 확인해 보겠습니다.
따라서 epilogue는 다음과 같아집니다.
int tid = threadIdx.x % 128;
int lane = tid % 32;
int warp = tid / 32;
uint32_t row = warp * 16 + lane / 4;
// @note C is column-major
bf16* block_C = C + (num_block_n * TILE_SIZE_N * M) + (num_block_m * TILE_SIZE_M);
constexpr int TILE_M_PAD = TILE_SIZE_M + 8;
#define IDX_GMEM(r, c) ((c) * M + (r))
#define IDX_SMEM(r, c) ((c) * TILE_M_PAD + (r))
// Phase 1: alpha-scaled accumulators -> shared staging tile
for (int m_iter = 0; m_iter < rows_per_consumer_warp_group / WGMMA_M; m_iter++) {
int row_tile_base_C = (consumer_warp_group_idx * rows_per_consumer_warp_group) + (m_iter * WGMMA_M);
for (int w = 0; w < WGMMA_N / 16; w++) {
int col = 16 * w + 2 * (tid % 4);
s.C_epi[IDX_SMEM(row + row_tile_base_C, col)] = __float2bfloat16(alpha * d[m_iter][w][0]);
s.C_epi[IDX_SMEM(row + row_tile_base_C, col + 1)] = __float2bfloat16(alpha * d[m_iter][w][1]);
s.C_epi[IDX_SMEM(row + 8 + row_tile_base_C, col)] = __float2bfloat16(alpha * d[m_iter][w][2]);
s.C_epi[IDX_SMEM(row + 8 + row_tile_base_C, col + 1)] = __float2bfloat16(alpha * d[m_iter][w][3]);
s.C_epi[IDX_SMEM(row + row_tile_base_C, col + 8)] = __float2bfloat16(alpha * d[m_iter][w][4]);
s.C_epi[IDX_SMEM(row + row_tile_base_C, col + 9)] = __float2bfloat16(alpha * d[m_iter][w][5]);
s.C_epi[IDX_SMEM(row + 8 + row_tile_base_C, col + 8)] = __float2bfloat16(alpha * d[m_iter][w][6]);
s.C_epi[IDX_SMEM(row + 8 + row_tile_base_C, col + 9)] = __float2bfloat16(alpha * d[m_iter][w][7]);
}
}
__syncthreads();
// Phase 2: coalesced write to GMEM (alpha*D + beta*C)
int row4_in_group = lane * 4;
int group_base_row = consumer_warp_group_idx * rows_per_consumer_warp_group;
if (row4_in_group < rows_per_consumer_warp_group) {
int r0 = group_base_row + row4_in_group;
for (int c = warp; c < TILE_SIZE_N; c += 4) {
block_C[IDX_GMEM(r0 + 0, c)] = __float2bfloat16(__bfloat162float(s.C_epi[IDX_SMEM(r0 + 0, c)]) + beta * __bfloat162float(block_C[IDX_GMEM(r0 + 0, c)]));
block_C[IDX_GMEM(r0 + 1, c)] = __float2bfloat16(__bfloat162float(s.C_epi[IDX_SMEM(r0 + 1, c)]) + beta * __bfloat162float(block_C[IDX_GMEM(r0 + 1, c)]));
block_C[IDX_GMEM(r0 + 2, c)] = __float2bfloat16(__bfloat162float(s.C_epi[IDX_SMEM(r0 + 2, c)]) + beta * __bfloat162float(block_C[IDX_GMEM(r0 + 2, c)]));
block_C[IDX_GMEM(r0 + 3, c)] = __float2bfloat16(__bfloat162float(s.C_epi[IDX_SMEM(r0 + 3, c)]) + beta * __bfloat162float(block_C[IDX_GMEM(r0 + 3, c)]));
}
}
#undef IDX_GMEM
#undef IDX_SMEM
이 커널을 프로파일링하면 분명한 개선이 보입니다. Tensor Core activity가 거의 32% 증가하고, L1/TEX, L2, DRAM 처리량도 모두 상승하며, 커널 실행 시간은 줄고 전체 처리량은 개선됩니다. 또한 전역 메모리 load/store의 uncoalesced access 경고도 사라집니다. 여기서의 비교 대상은 초기 파이프라이닝 버전입니다.
하지만 producer–consumer 파이프라인이 제대로 동작하고, staged epilogue가 메모리 접근 비효율을 해결했음에도 불구하고, 이 커널은 여전히 Kernel 8을 넘어서지 못합니다. Tensor Core 활용도도 기대만큼 높지 않습니다.
파이프라인이 의도대로 작동하는지 검증하기 위해 Nsight Systems로 커널을 프로파일링했습니다. trace를 보면 TMA 전송과 WGMMA 실행이 직렬이 아니라 실제로 시간상 겹쳐서 수행됩니다. 이는 producer–consumer 메커니즘이 load latency를 제대로 숨기고 있음을 뜻합니다. 그럼에도 불구하고, 수많은 실험과 Nsight Compute 지표에 대한 꼼꼼한 검토 후에도, 왜 이 커널이 이전 커널보다 빠르지 않은지에 대해 저는 아직 완전히 만족스러운 설명을 갖고 있지 못합니다. 따라서 이 부분은 추가 조사의 여지가 있습니다. 이 동작에 대한 통찰이 있으시다면 꼭 연락 부탁드립니다.

따라서 남아 있는 성능 격차는 파이프라인이 깨졌기 때문이라기보다, 각 파이프라인 stage에서 고정 오버헤드(barrier phase, warpgroup fencing, stage handoff, epilogue 등)에 비해 우리가 얼마나 많은 유용한 계산을 뽑아내는가의 문제로 보입니다.
자연스러운 다음 단계는 더 큰 WGMMA_N을 사용하고 추가 consumer warpgroup을 도입해 출력 타일 폭을 넓히는 것입니다. 이렇게 하면 각 K 타일당 수행되는 계산량이 늘어나고, 이미 overlap이 달성된 상황에서 원하는 바로 그 tradeoff, 즉 더 많은 산술 위에 파이프라인 오버헤드를 더 잘 상쇄하게 됩니다.
이 변화를 구현해 보면, 특히 WGMMA_N을 256으로 늘리고 두 개의 consumer warpgroup으로 실행했을 때 성능은 더 올라갑니다. M=N=K= 8192에서 이 커널은 이제 463.9 TFLOPs, 즉 cuBLAS의 **63.1%**에 도달합니다. 4096에서는 70.5% 상대 성능을 달성합니다.
이것은 우리의 직관을 확인해줍니다. 메모리와 계산이 올바르게 overlap된 이후에는, 각 파이프라인 stage에서 더 많은 일을 끌어내는 것이 효과적인 레버입니다. 각 stage의 산술 집약도를 높이고 producer와 consumer warpgoup 간에 레지스터 자원을 더 의도적으로 배분함으로써, Tensor Core 파이프라인 포화에 더 가까이 다가갈 수 있습니다.
그럼에도 불구하고, 아직도 상당한 성능이 남아 있으며, 특히 epilogue가 도입한 회귀를 완화하는 부분에 큰 여지가 남아 있습니다.

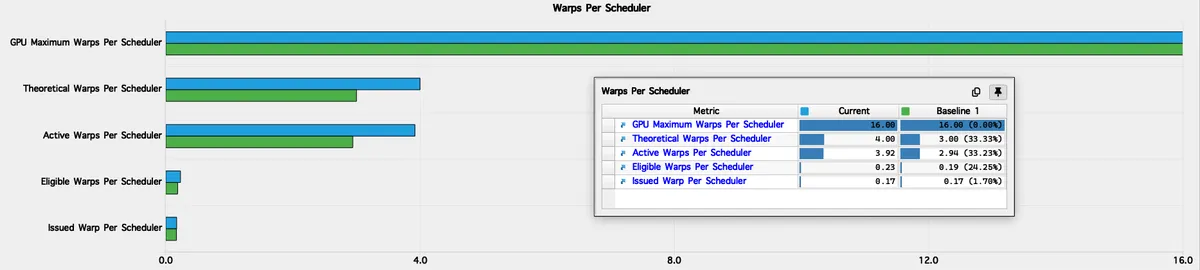
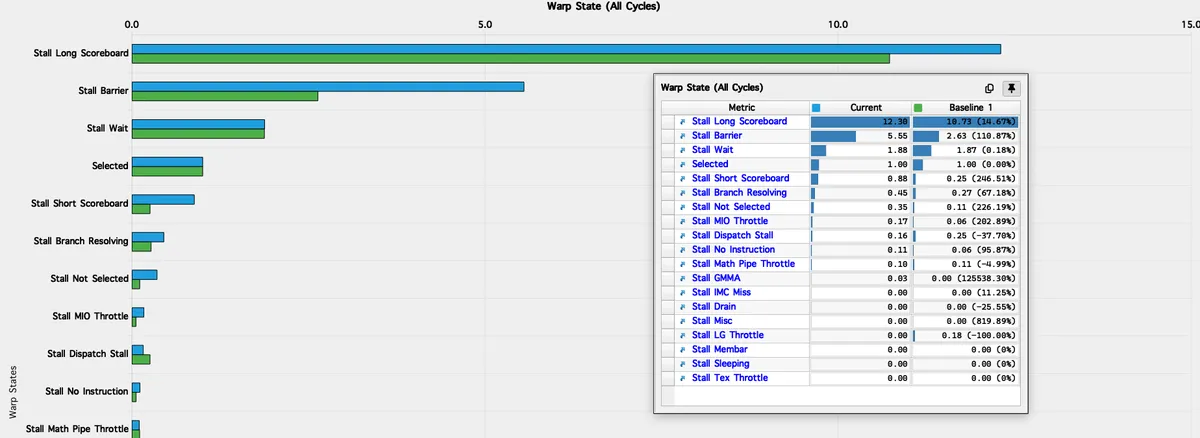
{kind=link}