NVIDIA CuTe(CUDA Template) 라이브러리의 핵심인 레이아웃 대수를 소개하고, 레이아웃의 정의·타일링·합성(컴포지션)과 이를 바탕으로 벡터화/비동기/스위즐 복사 커널을 구성하는 방법을 설명한다.
파트 1/2 — 개념적 기초부터 효율적인 메모리 연산까지
시리즈 개요: 이 글은 NVIDIA의 CuTe(CUDA Template) 라이브러리를 다루는 2부작 시리즈의 1편이다. 이번 글에서는 레이아웃 대수, CuTe API, 그리고 효율적인 copy 연산을 만드는 방법 등 기본기를 다룬다. 다음 주에 올라올 Part 2에서는 이 개념들을 적용해 특정 행렬 크기에서 cuBLAS를 능가하는 GEMM 커널을 만든다.
TL;DR: CuTe는 커스텀 레이아웃(또는 텐서)을 임의로 분할(partition)하고 이를 극도로 간결한 형태로 표현할 수 있게 해준다. 이 글에서는 이러한 Layout이 어떻게 동작하는지 이해하고, 고성능 GPU 알고리즘의 기반이 되는 효율적인 copy 커널을 구축한다.

CuTe에서 SM80 타입 MMA 연산의 예시 레이아웃.
면책 조항: 이 글은 NVIDIA 문서를 그대로 재현하려는 것도 아니고, 모든 내용을 완벽하게 다룬다고 주장하지도 않는다. CuTe 레이아웃이 어떻게 동작하는지와 이를 어떻게 적용할 수 있는지를 전반적으로 보여주고 싶다. 정말 화려한 대수(algebra)에 대해서는 직접 연습문제를 풀어보는 것을 추천한다.
최근 CuTe 레이아웃은 점점 더 많은 주목을 받고 있다(FA3, CuTiles, CuTe). 왜 모두가 이 레이아웃을 사랑하는 것처럼 보이는지, 그리고 NVIDIA가 왜 이를 강하게 밀고 있는지 이해해보고 싶었다. 처음 감을 잡는 것은 쉬웠지만, 단순한 행렬 대수 이상을 다루는 중급 수준의 블로그 글은 부족하다. 코드가 조금 있긴 하지만 꽤 고급이고, 단계별 가이드는 거의 없다. 이 글은 그 간극을 메우고, 내가 학습해나간 여정을 함께 따라오도록 구성했다.
CuTe는 CUTLASS 3.0에서 도입된 확장이다. 레이아웃과 그 대수는 CuTe의 핵심 혁신이다. 이는 프로그래머에게 타일링(tiling)을 표현하고, 출력 계산에 쓰일 자원과 매칭하는 새로운 방식을 제공한다. 커널에서 이러한 매칭은 자연스럽게 드러나며, CuTe 형식으로 더 쉽게 표현할 수 있어 코드 가독성이 좋아진다. 그 결과 (1) 유지보수가 쉬워지고 (2) 인덱싱/커널 코딩 실수가 줄어든다.
근본적으로 CuTe는 두 가지 문제를 해결한다:
새로운 것을 배울 때는 다양한 추상화 레벨을 사용할 수 있다. 이 글은 가능한 한 많은 것을 추상화하되, 커널을 설계할 때 프로그래머로서 최대한의 유연성을 유지하도록 한다. 그래서 CUTLASS의 고수준 API만 쓰지 않고, 저수준 내부 CuTe 함수도 사용할 것이다.
언제 CUTLASS를 써야 할까? 표준 선형대수 문제라면 cuBLAS나 cuDNN 같은 라이브러리를 사용하라. 매우 최적화되어 있다. 하지만 이들은 데이터 이동(data movement)이나 커널 퓨전(kernel fusion)을 쉽게 커스터마이즈할 수 없다. cuBLASLT가 일부 퓨전 기능을 제공하긴 하지만, 종종 충분치 않아 더 낮은 레벨의 제어가 필요하다. 새로운 아키텍처(예: 새로운 attention 변형이나 Mamba류 모델) 또는 커스텀 fused 커널을 구현한다면, 표준 cuBLAS 라이브러리는 필요한 특화 최적화가 부족한 경우가 많다.
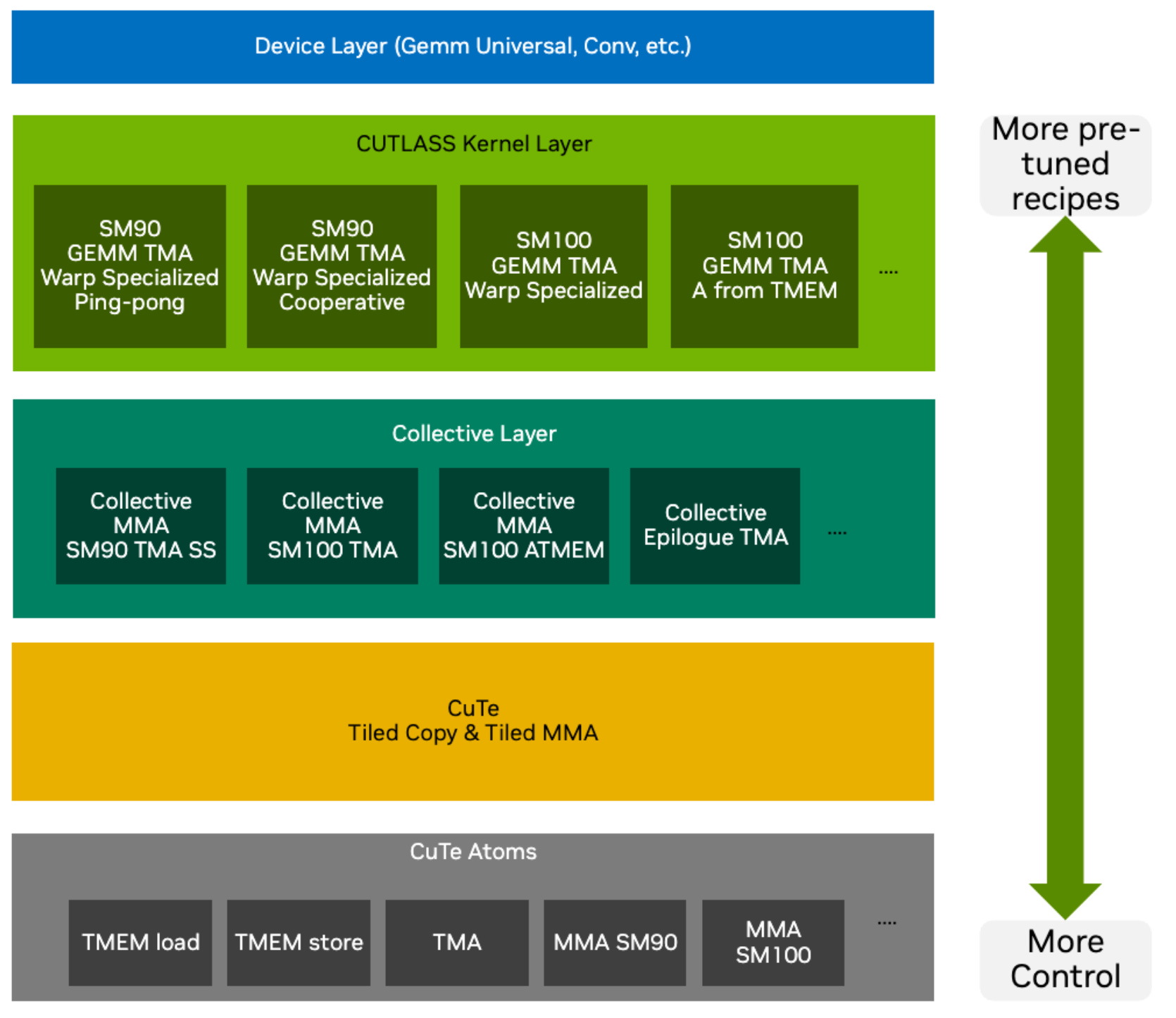
그림 1: 가장 낮은 레벨(제어가 가장 큼)부터 더 높은 추상화(연산이 미리 튜닝됨)까지의 NVIDIA 프로그래밍 스택. Cris Cecka, GPUMode Lecture 57
핵심적으로 CUTLASS는 텐서(Tensor) 위에서 동작한다. CuTe 세계에서 Tensor는 단 두 가지의 조합이다:
여기서 주인공은 Layout이다. Layout은 Shape(논리적 차원)와 Stride(요소 간 물리적 거리)로 구성된다. 이러한 Layout을 조작하면, 커널 코드를 다시 쓰지 않고도 복잡한 타일링/파티셔닝 패턴을 기술할 수 있다.
CuTe의 언어를 말하려면 먼저 알파벳, 즉 타입(Type)을 이해해야 한다.
타입 문서 CuTe는 C++ 템플릿 메타프로그래밍을 강하게 활용해 zero-overhead 추상화를 보장한다. 레이아웃을 기술하려면 정수와 이를 재귀적으로 중첩할 수 있는 방법이 필요하다. 그래서 CuTe는 다음 타입만 필요하다: 정수, 튜플(묶기), IntTuple(임의의 재귀적 중첩).
정수(Integer) 는 두 버전이 있다:
튜플(Tuple) 은 0개 이상의 원소를 갖는 유한한 순서 리스트로 정의되며, std::tuple의 CUDA 호환 버전(디바이스/호스트에서 동작, 단순화된 명령 집합)을 제공한다.
CuTe는 IntTuple 개념을 “정수 또는 IntTuple의 튜플”로 정의한다. 즉 임의의 재귀적 중첩이 가능하다. 예: 2, Int<3>{}, (2,3), (42,(1,3),17) 는 모두 IntTuple이다. IntTuple은 다음과 같은 핵심 연산을 지원한다:
CuTe에서 IntTuple은 Shape, Stride, Step, Coordinates 등 거의 모든 것을 표현한다.
문서 이제 레이아웃을 정식화할 수 있다. Shape와 Stride가 모두 IntTuple이므로 둘을 결합하면 된다.
Layout은 (Shape, Stride)의 튜플이다. 의미적으로 Layout은 논리적 Coordinate를 물리적 Index(오프셋)로 매핑하는 함수다.
Layout은 포인터나 배열 같은 데이터와 합성되어 Tensor를 만든다. Layout이 생성한 인덱스는 이터레이터를 subscript하여 올바른 데이터를 가져오는 데 쓰인다.
예를 들어 M×N 크기의 column-major 행렬에서 (i,j)의 메모리 인덱스는 index = i + j×M 이다. 여기서 i는 row 인덱스(0..M−1), j는 column 인덱스(0..N−1)다. 3D는 (i,j,k)↦ i + j×M + k×M×N 이고, 허용 좌표는 i,j,k∈[0,M−1]×[0,N−1]×[0,K−1]이다.
따라서 이 매핑은 내적 (i,j,k)⋅(1,M,MN) 로 볼 수 있다. 두 번째 벡터는 stride, 각 차원의 크기는 shape (M,N,K)로 생각할 수 있다. CuTe는 이를 다음 형식으로 쓴다.
(원문에는 수식/표기 이미지가 포함되어 있으나 여기서는 텍스트만 제공됨)
이는 일반화되어 다음과 같다.
(원문에는 수식/표기 이미지가 포함되어 있으나 여기서는 텍스트만 제공됨)
정리하자: 레이아웃의 첫 부분은 허용 입력(좌표 공간), 두 번째 부분은 좌표에서 메모리 오프셋으로 가는 방법(스트라이드)을 설명한다. 각 방향의 stride는 한 스텝 이동이 오프셋을 얼마나 증가시키는지로 볼 수 있다. 예를 들어 (4,3):(3,1)은 그림 2 좌상단의 행렬을 만든다.
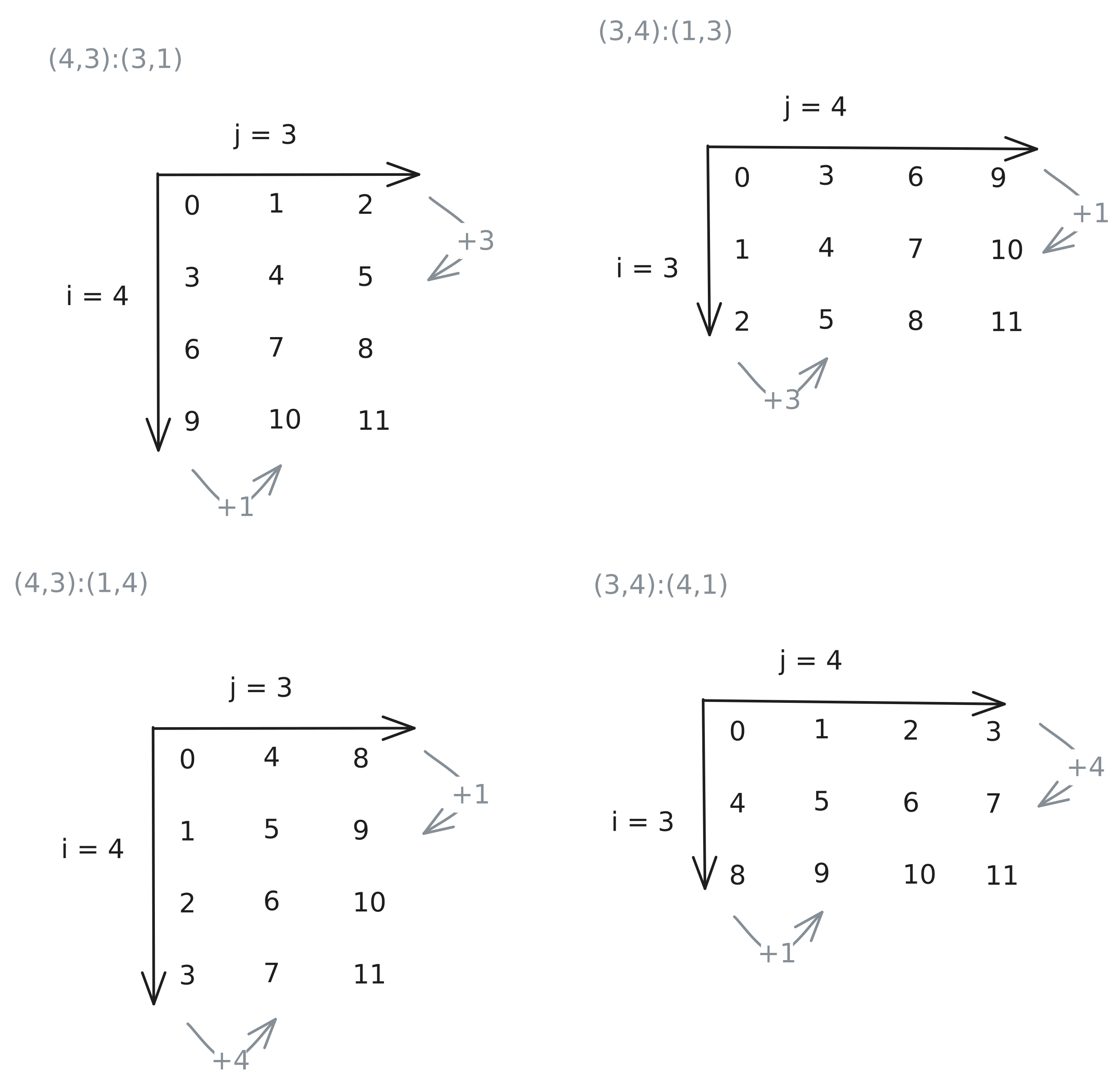
그림 2: CuTe 레이아웃과 인덱싱 패턴 — column/row major 4x3 및 그 전치 3x4.
이제 전치(transpose)가 어떻게 보이는지 확인할 수 있다. 전치 행렬에서는, 전치하는 축에 대해 shape와 stride를 모두 swap해야 한다(그림 2 우상단). 완전성을 위해 그림 하단 행은 상단과 같은 shape이지만 stride 패턴이 반대인 경우를 보여준다. 여기서 큰 stride는 N에서 M으로 바뀐다.
CuTe는 두 가지 기본 stride 패턴을 제공한다.
여기까지는 직관적이다. 하지만 CuTe는 레이아웃을 중첩(nest)할 수 있으며, 이때 표현력이 폭발한다. 중첩 구조(예: ((M_m, M_n),N):((a,b), M))를 원한다면, 좌표도 같은 중첩을 가져야 한다. CuTe에서는 이를 congruent라 부른다.
중첩 레이아웃의 가장 단순한 사용법은 동일한 stride 패턴의 타일을 만드는 것이다. 더 큰 행렬 T 안에 작은 서브타일이 있는 예를 그림 3으로 시작하자.
(원문에는 그림 3에 대한 서술이 이어지지만, 이 구간 역시 수식/도식 의존이 있어 텍스트 중심으로 번역을 이어간다.)
작은 타일 텐서는 같은 stride 패턴을 가지되 shape와 시작 포인터만 다르다(오프셋 (om,on)은 om+on×M). Layout(T)=(M,N):(1,M)이고 Layout(t)=(m,n):(1,M)이다.
레이아웃을 좌표→오프셋 함수로 볼 수 있으므로, 이를 합성(composition)해 전체 타일드 텐서 Ttiled = T∘t 를 기술할 수 있다. 결과 레이아웃은 어떻게 생겼을까? 단계적으로 유도해보자. 핵심 아이디어는 원래 각 차원이 두 개의 서브차원으로 쪼개진다는 것이다: 타일 내부 위치와 어떤 타일인지.
이 레이아웃을 이해하려면 shape (2,2)를 ((2,1),(2,1)) (크기 2의 타일 1개)로 생각해, 저수준(내부)에서 고수준(외부) 추상화로 올라간다고 보면 된다. 행(row) 차원을 생각해보자. 원래 M개의 row가 있고, 높이 m 타일로 타일링하면:
열(column) 차원도 동일하다(N개의 column, 폭 n 타일):
이를 합치면 타일드 레이아웃은 다음과 같다.
(원문 수식 생략)
오프셋 공식은 다음이 된다.
(원문 수식 생략)
여기서 ((m,n),(j,k)):((a,b),(c,d))는 (m,n,j,k):(a,b,c,d)와 같은 인덱싱 패턴을 만든다.
예로 (6,20):(20,1)을 (2,4) 타일로 타일링하면 i방향 3개, j방향 5개의 타일이 된다. 메모리는 column-major로 배치되어야 한다.
CuTe에서 이 타일링 연산은 논리적 나눗셈 연산자 ⊘에 해당한다. “차원(dimension)” 대신 “모드(mode)”로 생각을 바꾸자. shape은 (mode0, mode1)이고, 각 modex는 추가로 분할될 수 있다.
논리적 나눗셈은 첫 모드가 divisor(제수)가 되도록 새로운 shape을 만든다. 따라서:
이는 깊은(내부)→높은(외부) 순서를 보존한다.
(A,B,C)⊘(a,b,c)=((a,b,c),(A/a,B/b,C/c))
divisor가 모든 모드를 나누지 못하면, 빠진 모드는 1로 취급한다. 타일러(tiler)는 위치 기반으로 매칭된다: tiler의 0번째는 레이아웃 모드0을, 1번째는 모드1을… 나눈다. tiler의 rank를 넘는 레이아웃 모드는 나누지 않는다. 예를 들어 (a,b)는 (a,b,1)로 취급된다. 만약 mode-1을 건너뛰고 mode 0과 2만 나누고 싶다면 <a, _, c> 같은 placeholder를 명시해야 한다. 따라서 “빠진” 모드는 결과의 두 번째 부분에 남는다: (A,B,C)⊘(a,b)=((a,b),(A/a,B/b,C)).
Stride는 어떻게 될까? 레이아웃 (A,B,C):(1,A,AB)를 (a,b,c)로 나누면 결과는?
앞서 말했듯 타일 내부 stride(Stile)는 원 텐서와 동일하다. 외부 stride(Souter)는 원래 stride에 기반하지만 인덱스가 타일 크기(a,b,c)만큼 이동한다. 따라서 새 레이아웃은 다음과 같다.
(원문 수식 생략)
타일링을 이해했으니 또 다른 기본 연산인 합성(composition)을 보자.
레이아웃 합성은 중요한 대수 연산이다. A∘B↦R는 먼저 B를 적용하고 그 다음 A를 적용하는 것으로 볼 수 있다. R(c)=A(B(C)). 여기서 R의 레이아웃은 B와 같은 shape을 가져야 하므로 compatible 해야 한다. 정의는 단순하지만 실제로는 꽤 번거로워질 수 있다. 우선 몇 가지 규칙을 소개한다.
언제 합성을 쓰는가? 예를 들어 입력 텐서에 적용하고 싶은 접근 패턴(B)이 있다. 그런데 입력 텐서 자체가 이상한 접근 패턴(예: 매 두 번째 원소만 취함)을 가진다면, 합성을 통해 이전에 정의한 최적 접근 패턴 B를 각 입력 텐서에 그대로 적용할 수 있고, 복잡한 결과 인덱싱을 명시적으로 다시 표현할 필요가 없다.
대표적 사용처는 swizzling이다. bank conflict를 피하기 위해 레이아웃을 permutation(재배열)하고 싶을 때, swizzle 변환을 별도로 정의한 뒤 레이아웃에 적용한다. 코드는 다음처럼 생길 수 있다:
// Swizzled shared memory layout
auto sA = composition(
Swizzle<2,3,3>{}, // the swizzle transform
make_layout(make_shape(Int<BM>{}, Int<BK>{}), // the base (row-major) layout
make_stride(Int<BK>{}, Int<1>{}))
);이 swizzle 예시는 아래의 Example::Copying::Swizzle 섹션에서 가져온 것이며 거기서 설명한다.
이 레이아웃 대수를 바탕으로 이제 CuTe API와 레이아웃 사용법을 보자.
완전성을 위해 cute/layout.hpp와 cute/tensor.hpp에 있는 CuTe 핵심 API를 요약한다.
CuTe API는 대체로 다음 논리 그룹으로 구성된다:
copy, gemm 같은 고수준 연산(텐서를 받아 루프 로직을 처리)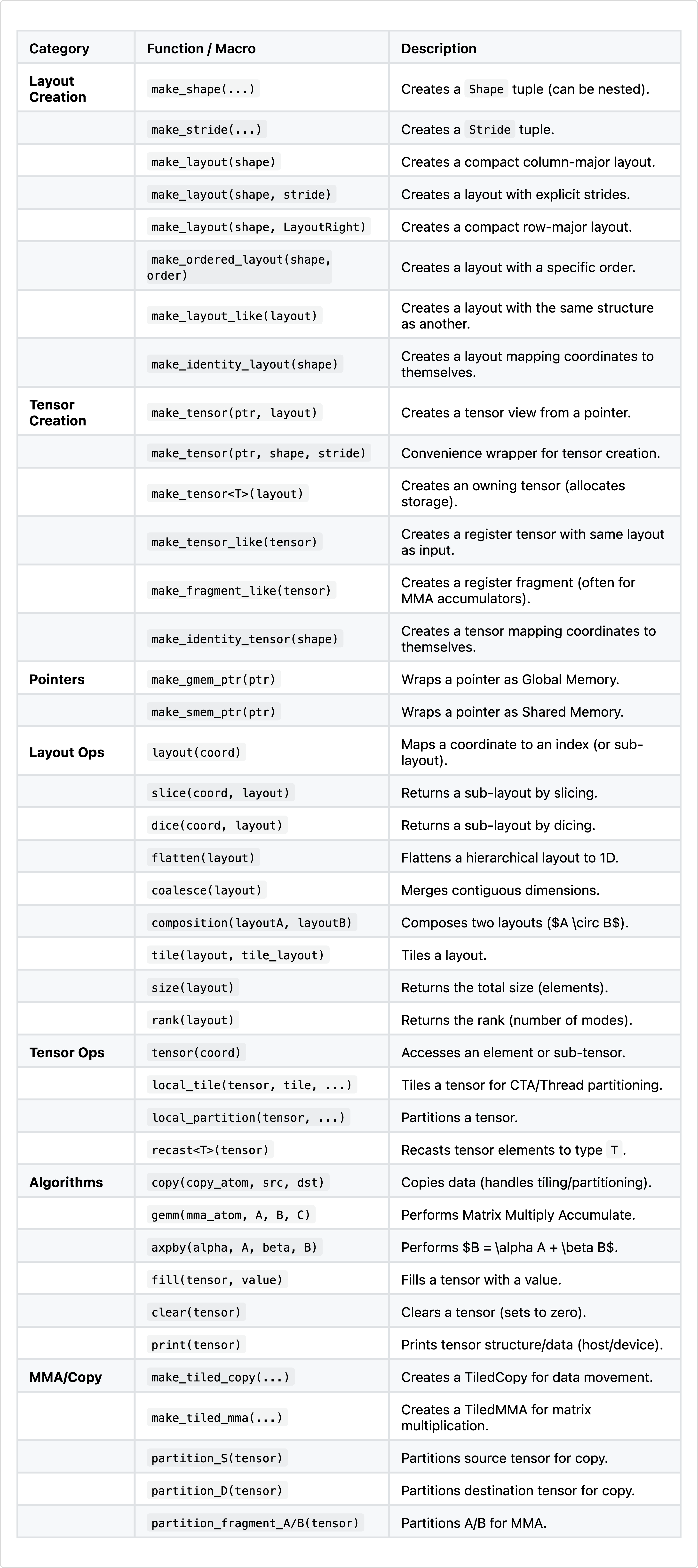
표 1: CuTe의 핵심 API(C++).
목록은 길지만, 핵심 워크플로는 “Layout Creation”과 “Layout Ops”에 집중된다.
make_layout(shape, stride): 데이터의 초기 구조를 정의하는 기본 생성자tile(layout, tile_layout): 앞서 논의한 타일링 연산자에 해당, 레이아웃을 중첩composition(A, B): A∘B 합성에 해당, 레이아웃 변환을 체인으로 연결이 연산들은 조합 가능하도록 설계되었다. 보통 make_layout으로 베이스 레이아웃을 만들고, tile(논리적 나눗셈)이나 composition으로 하드웨어 계층(예: 워프 타일링, 공유메모리 bank 등)에 맞춰 정제(refine)한다.
API를 알았으니, 이제 CuTe가 이 추상화를 이용해 알고리즘을 구현하는 방식을 보자.
CuTe 알고리즘은 본질적으로 제네릭 템플릿이다. 예를 들어 copy는 텐서를 순회하며 src에서 dst로 복사하면 된다:
copy(Tensor const& src, Tensor& dst){
for (int i=0; i< size(dst); i++){
dst(i) = src(i);
}
}참고: shape가 컴파일타임에 알려져 있다면(고정 타일링을 쓰기 때문에 흔함) 루프는 언롤(unroll)될 수 있고 오프셋도 정적으로 계산되어 copy가 최적화된다.
또한 copy 알고리즘으로 전체 텐서를 복사하는 형태로 더 단순화할 수도 있다.
copy(Tensor const& src, Tensor& dst){
copy(src, dst);
}실제로 copy는 단순 복사 이상의 일을 할 수 있다. 전치(transpose), 집계(aggregate), 캐스팅(cast)도 가능하다. 예를 들어 브로드캐스팅은 “항상 0 위치를 가리키는 레이아웃”에서 “stride >= 1인 레이아웃”으로의 copy로 볼 수 있다. 아래 표에서 더 많은 아이디어를 얻을 수 있다.
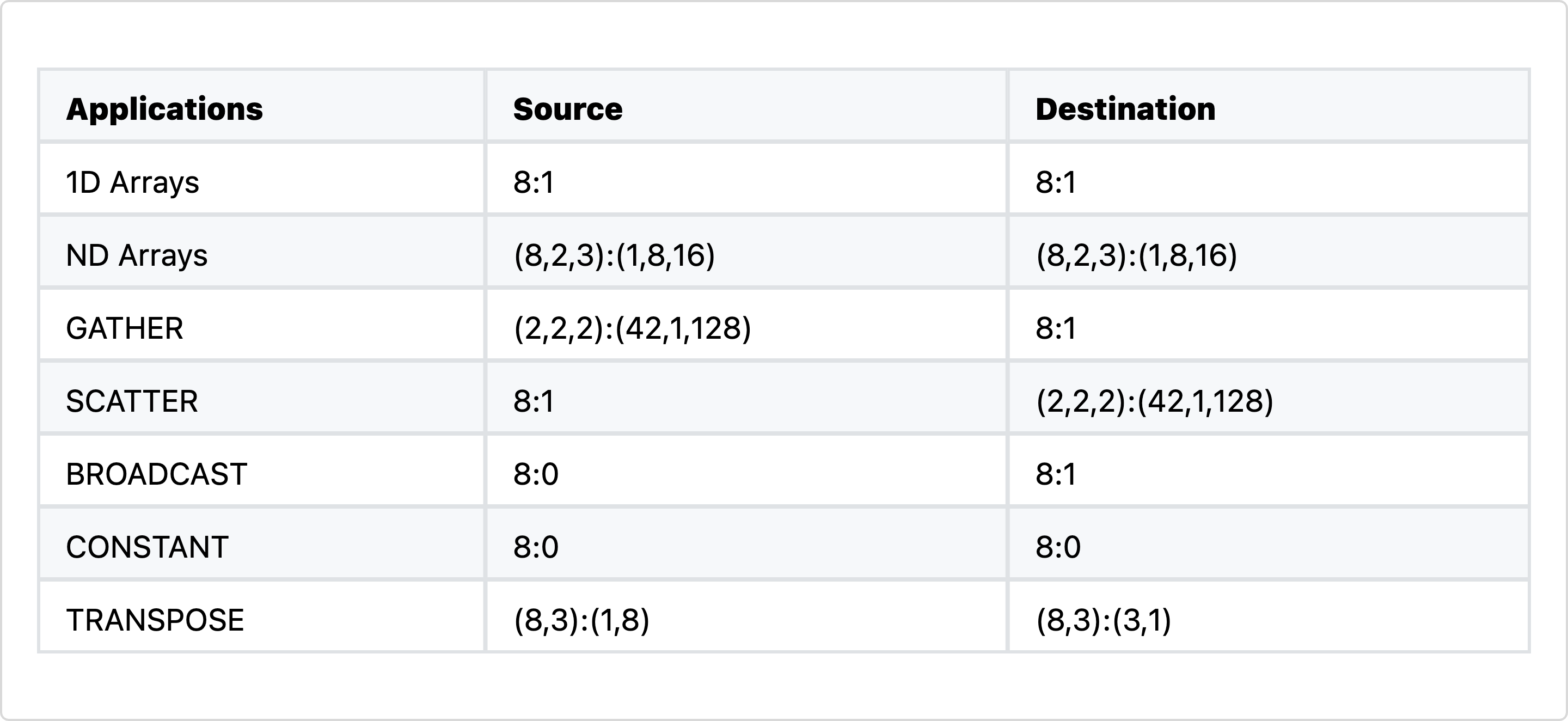
표 2: 입력/출력 레이아웃을 바꾸면 copy는 단순 직접 복사 이상의 연산을 수행할 수 있다. Cris Cecka, GPUMode Lecture 57
GEMM도 유사하게 단순한 형태로 표현할 수 있다. 예를 들어 rank 3 텐서라면 대략 다음과 같다.
gemm(Tensor const& A, Tensor const& B, Tensor& C){
for (int i=0; i< size(dst); i++){
for (int j=0; j< size(dst); j++){
for (int k=0; k< size(dst); k++){
C(j,k) += A(j,i) * B(k,i);
}}}
}그리고 shape/stride를 바꾸는 것만으로도, 단순 GEMM이 그림 4처럼 컨볼루션을 포함한 다양한 알고리즘을 구현할 수 있다.
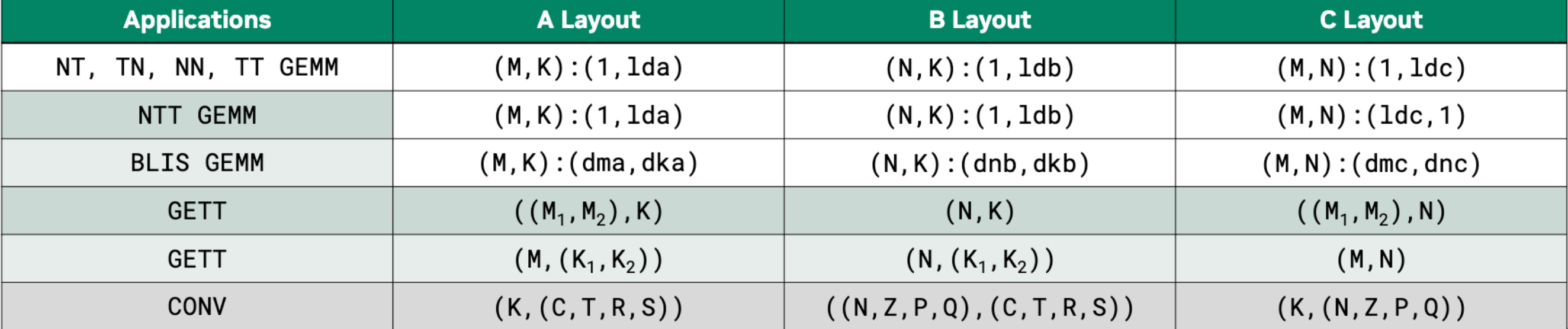
그림 4: 입력/출력 레이아웃을 바꾸면 행렬곱은 단순 직접 MMA 이상의 연산을 할 수 있다. Cris Cecka, GPUMode Lecture 57
이 제네릭 루프들은 어떤 레이아웃에서도 동작하지만, 최고 성능에 필요한 특수 하드웨어 명령(텐서코어, 벡터화/비동기 copy, TMA 등)을 활용하지 못한다. 논리 레이아웃과 하드웨어 명령 사이의 간극을 메우기 위해 CuTe는 Atom을 도입한다.
앞서 본 것처럼 CuTe의 copy(Tensor A, Tensor B)로 데이터 이동을 할 수 있다. 더 구체적으로 “어떻게 copy할지”를 추가로 기술할 수 있는데, CuTe에서 TiledCopy는 스레드가 협력해서 타일을 메모리 공간(예: global→shared, shared→registers) 사이로 복사하는 방식을 컴파일타임에 기술한다. 즉 누가 무엇을 복사하는지를 정의한다. 예를 들어:
TiledCopy copyA = make_tiled_copy(
Copy_Atom<AutoVectorizingCopy, bf16>{}, // 각 스레드가 수행하는 연산(아톰)
Layout<Shape<_4,_8>,Stride<_8,_1>>{}, // thread layout: 4 x 8 threads = 32 threads (warp)
Layout<Shape<_1,_8>>{} // per-thread tile shape: 각 스레드가 1 x 8 원소 복사
);첫 인자는 각 원자적 copy(스레드 1개가 수행)가 bf16 원소를 벡터 명령으로 복사하며 128바이트 정렬을 가정한다는 뜻이다. 더 많은 copy 명령은 cutlass/include/cute/arch/copy.hpp에서 찾을 수 있다. 두 번째 인자는 thread layout(협력 copy 시 스레드의 논리적 배치)이며, 마지막 인자는 per-thread copy tile shape(각 스레드가 복사하는 원소 수)을 선언한다.
이 예에서는 4×8 스레드 타일(워프 1개)을 row-major로 조직하고, 각 스레드는 1행×8 연속 column을 복사한다. 즉 워프 전체가 4×64 BF16 타일을 한 메모리 공간에서 다른 공간으로 복사한다.
copy atom의 전체 목록은 아래 표에 있다.
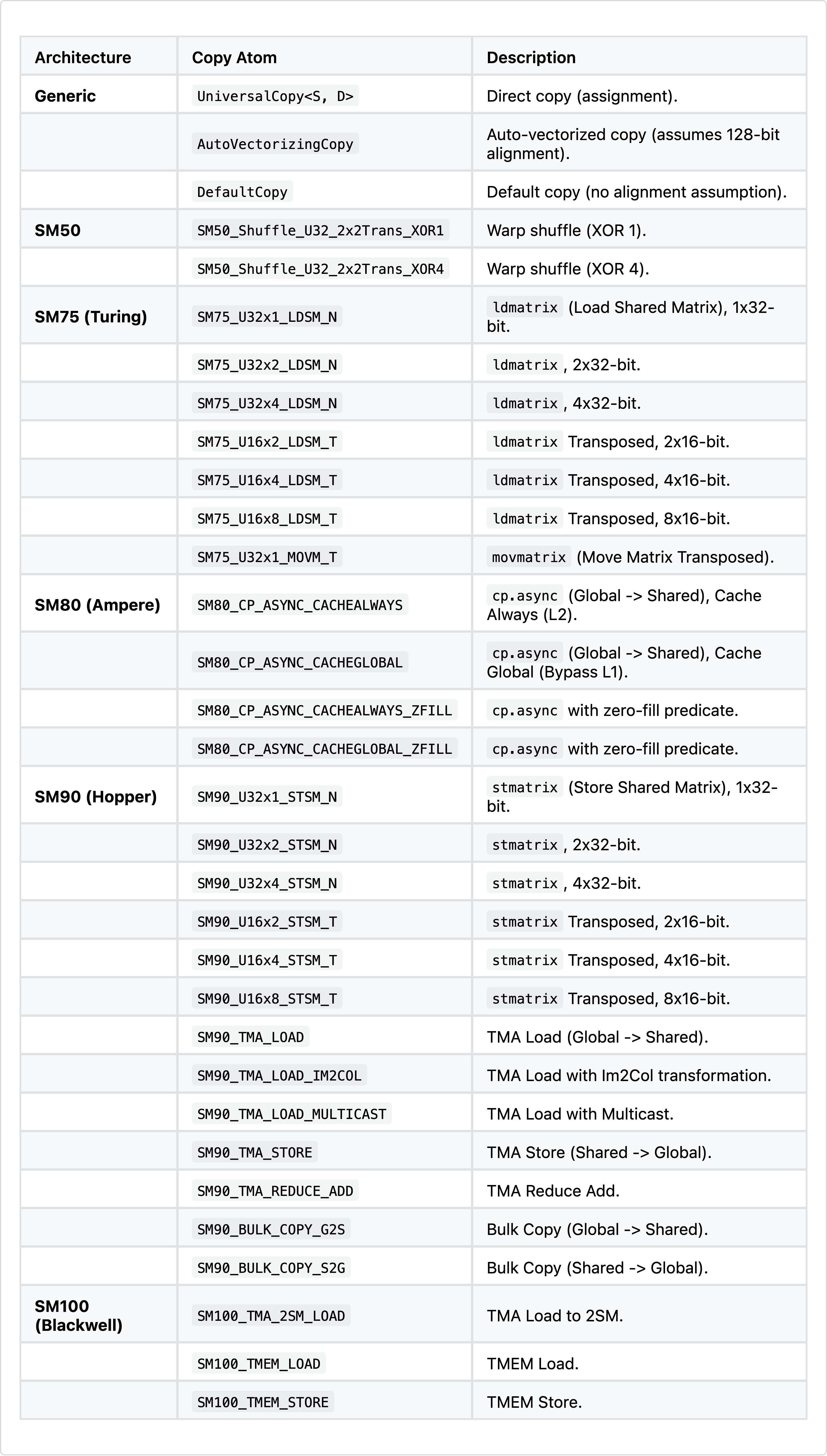
표 3: CuTe의 주요 copy 명령(C++).
효율적으로 copy할 수 있으면, 텐서코어 연산도 효율적으로 하고 싶다.
예시로 Volta FP16 16x8x8 MMA 텐서코어 명령은 그림 5처럼 CuTe shape로 레이아웃을 표현할 수 있다.

그림 5: 우: Volta SM80 16x8x8 MMA 텐서코어 명령의 일러스트, 좌: 대응하는 C++ 템플릿. Cris Cecka, GPUMode Lecture 57
이를 다른 하드웨어 유닛에도 확장할 수 있다. 연산과 traits(메타정보)를 결합하면 MMA Atom이 된다. MMA Atom을 이용해 다음처럼 예쁜 그림을 출력할 수 있다.
MMA_Atom mma = MMA_Atom<SM90_16x8x4_F64F64F64F64_TN>{};
print_latex(mma)또한 입력 행렬 타입도 체크할 수 있다.
CuTe 레이아웃의 매력은 atom도 확장 가능하다는 점이다. TiledMMA를 사용하면 atom을 반복해 더 큰 shape를 만들 수 있고, 텐서코어 연산에서 다른 stride를 사용할 수도 있어 공유메모리 접근 패턴에 도움이 될 수 있다.
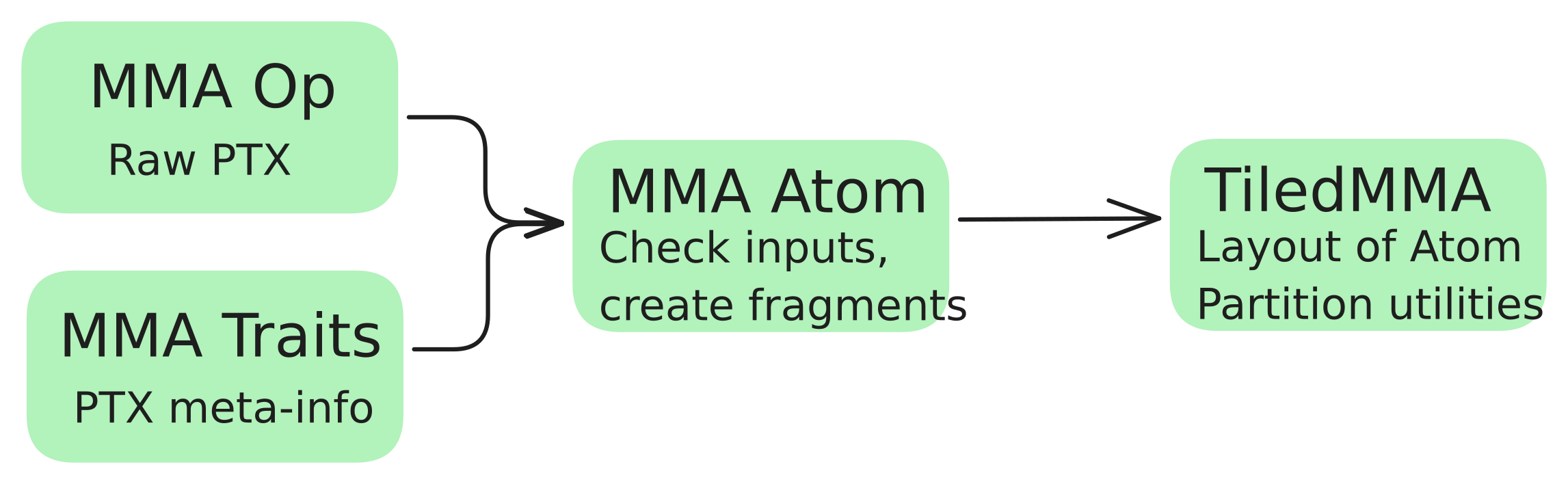
그림 6: MMA atom은 MMA 연산(PTX 명령)과 traits(요구 입력 shape)를 결합한 것이다. TiledMMA는 이를 중첩해 임의의 MMA 연산을 가능케 한다. Cris Cecka의 GPUMode Lecture 57에서 영감을 받음.
일반적인 CuTe GEMM 커널은 3단계로 구성된다: (1) 스레드에 작업 분배, (2) 공유메모리로 copy, (3) MMA로 계산. 각 스레드는 다음으로 자신의 타일을 얻을 수 있다.
ThrMMA thr_mma = tiled_mma.get_slice(threadIdx.x);이후 각 스레드에서 MMA를 실행한다. CuTe에서 MMA를 사용하는 메인 GEMM 루프는 대략 다음과 같다.
// Partition the threads by telling which thread moves what
// [...]
for (int k = 0; k < (K + BK - 1) / BK; k += 1) {
// Async copy from global to shared
copy(copyA, tAgA(_,_,_,k), tAsA);
copy(copyB, tBgB(_,_,_,k), tBsB);
// [...]
// Load fragments from shared memory to registers
copy(copyS2R_A, tXsA, tXrA);
copy(copyS2R_B, tXsB, tXrB);
// MMA operation
gemm(mma, tCrA, tCrB, tCrC);
// [...]
}아래 표 4에는 MMA atom의 일부 목록이 있다. 패턴을 보면, MMA atom은 타일 shape 및 입출력 quantization으로 정의된다.
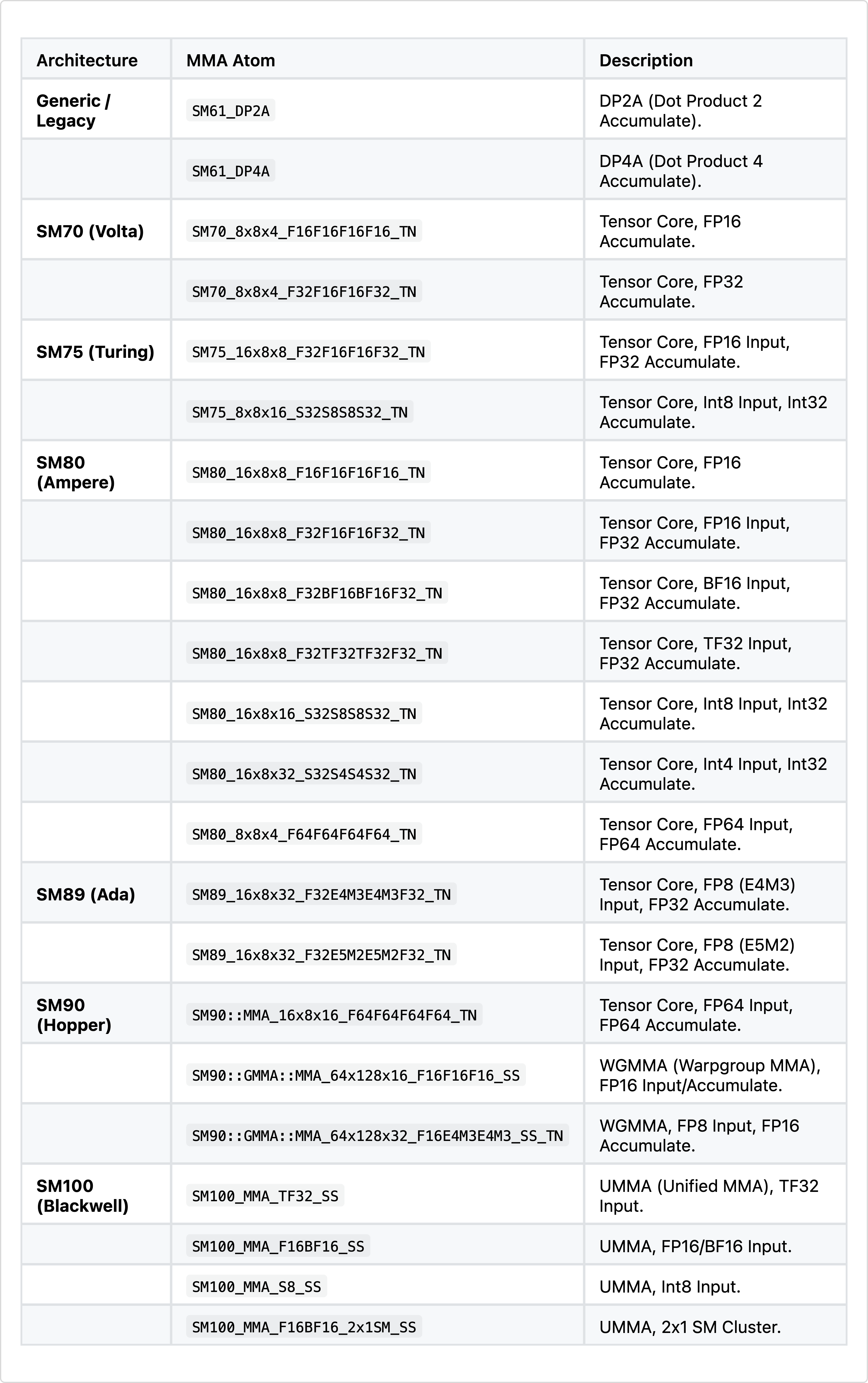
표 4: CuTe의 주요 mma 명령(C++).
이제 이 정보를 바탕으로 커널을 작성할 수 있다. 몇 가지 예시를 보자.
CUTLASS 레포의 cutlass/examples/cute 아래에 CuTe 예시가 있긴 하지만, 꽤 복잡하다. 그래서 다음 섹션에서는 완전한 GEMM 예제로 점진적으로 빌드업한다. 내 예시는 A100(80GB)에서 코딩했다. 레거시 CUDA 코드보다 Hopper나 Blackwell 명령을 사용하도록 커널을 업데이트하는 것이 훨씬 쉬워질 것이다.
현대 GPU의 GEMM에서는 텐서코어를 사용해야 하고, 텐서코어는 매우 ‘배고프다’. 따라서 어떤 GEMM 커널이든 일반 아이디어는 텐서코어를 최대한 바쁘게 만들고 잘 ‘먹이는’ 것이다. 즉 효율적인 copy가 중요하다. CuTe 템플릿 기반 copy가 실험을 쉽게 만드는 방식을 보자.
모든 예시는 이 레포에서 전체 코드를 볼 수 있다. 목표는 최고 성능을 찍는 것이 아니라 CuTe 레이아웃이 어떻게 쓰이며 해석에 도움이 되는지 보여주는 것이다. 합리적 제약(블록 크기 최적화 없음; 데모지만 128x128x64는 꽤 괜찮을 것; 정렬이 좋고 충분히 큰 행렬) 하에서 가능한 빠르게 만들려고 했다.
역사적 노트: CuTe에서는 threadblock을 CTA(Cooperative Thread Arrays)라고 부르곤 한다. 이는 CUDA 용어로 threadblock을 의미한다.
GEMM 예제로 가기 위해, 타일을 smem으로 옮겼다가 다시 global로 되돌려야 한다. 이후 m128n128k64 타일 shape를 쓸 것이다. 따라서 이 장의 예시는 A 행렬(128×64, BF16)의 타일을 공유메모리로 옮기고 다시 global로 복사하는 방법을 보여준다.
CuTe는 문제→계산 매핑을 ‘전역적으로’ 기술한다는 점에서 CUDA의 로컬 관점과 대비된다. 즉 전체 문제 레이아웃을 먼저 선언하고, 이를 CTA로 타일링한 뒤(CUDA의 thread-block에 매핑), 마지막으로 타일 내부에서 연산한다. copy 예제에서 복사할 행렬은 row-major로 메모리에 놓이며, K를 순회할 때 가장 빠르게 움직인다.
// Problem shape and strides
auto prob_shape = make_shape(M, K);
auto dA = make_stride(K, Int<1>{});그다음 연산할 threadblock 크기를 정의한다. Int<...>{}는 정적 타입(컴파일타임 계산)이라 런타임을 줄여준다. 여기서 BM과 BK가 constexpr이기 때문에 가능하다.
// Block tiling sizes
auto cta_tiler = make_shape(Int<BM>{}, Int<BK>{});마지막으로 커널 런치 전에 공유메모리 타일 레이아웃을 정의할 수 있다.
// Create shared memory layouts
auto sA = make_layout(make_shape(Int<BM>{}, Int<BK>{}), make_stride(Int<BK>{}, Int<1>{}));지금은 타일 shape를 우리가 수행할 copy와 동일하게 두자. 즉 BM=128, BK=64.
커널 런치는 표준 CUDA와 동일하다. 인자 copyA는 TiledCopy 타입이며 스레드가 copy에 어떻게 참여하는지 기술한다. 각 커널은 조금씩 다르게 정의한다. 여기서는 생략하고 이후 하위 섹션에서 보여준다.
kernelCuteBasicCopy<<<dimGrid, dimBlock, smem_bytes>>>(
prob_shape,
cta_tiler,
In, dA, sA, copyA,
Out, M, K
);각 copy 커널 내부에서는 3단계를 수행한다:
먼저 필요한 공유메모리를 만들고, 이를 기술하는 CuTe 텐서를 만든다(여기서는 CPU 코드에서 정의한 레이아웃을 사용). 입력/출력 GMem 행렬에 대한 텐서도 만든다. 텐서 초기화의 또 다른 방법을 보여주기 위해, shape와 stride를 먼저 layout에 담지 않고도 만들 수 있음을 보여준다(둘 다 가능).
// Create SMem tensor
int smem_a_elems = int(size(a_smem_layout));
extern __shared__ bf16 smem[];
Tensor sA = make_tensor(make_smem_ptr<bf16>(smem), a_smem_layout);
// Create a tensor view of global memory A
Tensor gIn = make_tensor(make_gmem_ptr(In), make_shape(M, K), a_stride);
Tensor gOut = make_tensor(make_gmem_ptr(Out), make_shape(M, K), a_stride);다음으로 threadblock이 작업할 메모리 타일을 얻는다.
// Define the tile to copy (use the shared-memory layout’s shape)
auto tile_shape = shape(a_smem_layout);
auto gIn_tile = local_tile(gIn, tile_shape, make_coord(blockIdx.x, blockIdx.y));
auto gOut_tile = local_tile(gOut, tile_shape, make_coord(blockIdx.x, blockIdx.y));여기서 shape(a_smem_layout)으로 레이아웃의 shape를 얻을 수 있고, stride(a_smem_layout)도 마찬가지다. 따라서 레이아웃은 문제를 전체적으로 선언하기에 매우 유용하다.
마지막으로 copyA라는 선언적 copy 명령을 사용해 copy를 수행한다. copy() 함수는 선언적 copy 없이도 쓸 수 있지만, 그 경우 기본 copy로 폴백한다.
// Copy global memory A → shared memory sA using CuTe copy
copy(copyA, gIn_tile, sA);
__syncthreads();
copy(copyA, sA, gOut_tile); // Copy back to global memory for verification
__syncthreads();이 커널은 상당히 단순화되었다. 메모리 배열에 대한 인덱싱을 직접 신경 쓸 필요가 없어서 실수하기 쉬운 단계를 제거한다. 마법은 TiledCopy에 있다. 여기서 스레드가 값에 어떻게 매핑되는지, 그리고 어떤 copy 명령을 쓸지 정의한다. 즉 copy 수행 방식을 조향할 수 있다. tiled copy의 형태는 다음이다.
TiledCopy copyA = make_tiled_copy(
Copy_Atom, // Copy Atom
Layout, // Thread Layout
Layout); // Value LayoutCopy_Atom은 어떤 명령을 쓸지 선언한다. 예: Copy_Atom<DefaultCopy, bf16>{}는 BF16 값을 하나씩 복사한다.
thread layout은 스레드가 메모리 레이아웃에 어떻게 매핑되는지, 그리고 몇 개가 copy에 참여하는지 정한다. 예를 들어 Layout<Shape<_16, _2>, Stride<_2, _1>>{}는 워프 전체에서 16개 스레드가 M방향에 매핑되고, 각 M에 대해 2개 스레드가 K방향에 매핑된다. stride가 row-major이므로 thread 0과 1이 (0,0), (0,1), thread 2가 (1,0)… 순이다.
마지막으로 value layout은 각 스레드가 어떤 값들을 다룰지 기술한다. thread/value layout을 합치면 복사할 메모리의 크기와 shape가 정해진다. 예를 들어 Layout<Shape<_1,_1>>{}이면 16x2를 복사하고, Layout<Shape<_1,_8>>{}이면 16x16을 복사한다. 후자에서는 각 스레드가 연속된 값 8개를 복사한다. thread 0은 (0,0:8), thread 1은 (0,8:16), thread 2는 (1,0:8)…
즉 네 줄로 임의의 copy 연산을 정의할 수 있다는 점이 보일 것이다.
또한 print_latex(tiled_copy);로 정의한 copy 명령을 시각화할 수 있다. 더 이상 손으로 그림을 그릴 필요가 없다.
간단한 베이스라인으로 기본 copy(각 스레드가 BF16 하나)를 수행해보자. 입력을 coalescing하려면 연속 스레드가 메모리상 연속 값에 매핑되어야 한다. 타일 크기 때문에 최대 64까지 가능하다. 가장 단순한 레이아웃은 K방향 coalesced를 위해 row-major인 1x32 스레드 레이아웃이며, 각 스레드는 1개 값을 복사하고 M방향으로 span한다. 더 나아가 128B 캐시라인을 최대 활용하기 위해 2워프를 사용해 1x64 스레드 레이아웃을 쓸 수 있다.
TiledCopy copyA =make_tiled_copy(
Copy_Atom<DefaultCopy, bf16>{},
Layout<Shape<_1, _64>, Stride<_64, _1>>{}, // ThrLayout
Layout<Shape<_1, _1>>{}); // ValLayoutprint_latex(tiled_copy);의 출력으로 의도대로 동작하는지 검증할 수 있으며, 결과는 그림 7에 있다.

그림 7: 기본 copy 예제에서 print_latex(tiled_copy); 출력.
이 copy 명령을 실행하면 이미 1.33 TB/s 정도의 메모리 처리량을 얻는다.
메모리 처리량을 더 올리려면 벡터 명령을 사용해 한 명령으로 여러 값을 로드한다. 메모리 버스팅 관점에서 인덱스 계산/룩업 사이클이 줄어 더 빠르다. 벡터 명령을 쓰려면 원소가 메모리에서 128비트 정렬이어야 한다. A100에서 가장 큰 벡터 copy는 16바이트(.global.load.v4)이므로, K차원에 8개 스레드를 두고 각 스레드가 연속 8값을 처리하면 캐시라인을 최대 활용할 수 있다. 이 연속 8값이 16바이트 벡터 명령 1개가 된다. 워프의 나머지 스레드로 row들을 채운다.
TiledCopy copyA = make_tiled_copy(
Copy_Atom<AutoVectorizingCopyWithAssumedAlignment<128>, bf16>{},
Layout<Shape<_4,_8>, Stride<_8,_1>>{}, // thread layout
Layout<Shape<_1,_8>>{}); // per-thread: 8 contiguous elements이 벡터화 copy는 1.42 TB/s 처리량을 준다.
우리는 GMem→SMem→GMem을 하고 싶으므로 레지스터를 건드리지 않는 것이 이상적이다(낭비). 그런데 NCU의 메모리 차트(그림 8)를 보면 데이터 경로가 GMem→캐시→레지스터→SMem으로 간다.
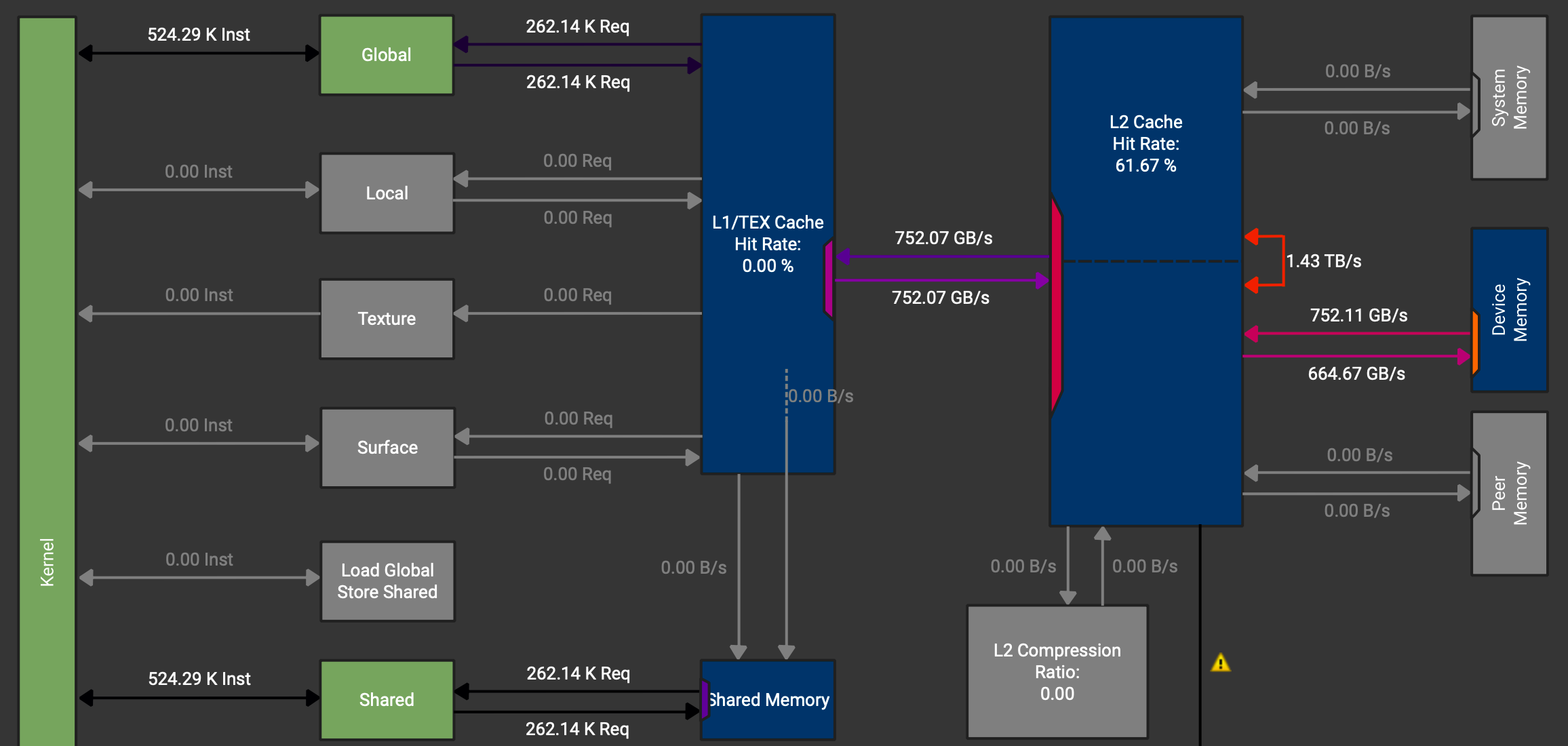
그림 8: 벡터화 copy 예제의 NCU 메모리 차트.
또한 SMem으로 직접 로드하는(Load Global Store Shared) 명령이 존재하지만 사용되지 않는 것도 보인다. A100에서는 async copy를 사용하면 이를 활성화할 수 있다.
A100은 레지스터를 거치지 않고 GMem→SMem async copy를 수행하는 특수 하드웨어가 있다. 하지만 이는 로드에만 해당하고, 저장(store)은 다른 명령이 필요하다. 따라서 로드는 CuTe atom SM80_CP_ASYNC_CACHEGLOBAL을 쓰고, store는 다시 벡터 명령을 쓴다. 두 개의 copy 명령을 쓰기 위해 코드를 약간 수정해야 한다.
로드 쪽은 128비트 폭(=16바이트=BF16 8개)의 async copy를 쓸 수 있으며, 스레드→값 매핑은 초기 벡터화 예제와 같다.
// Simple async copy that works
TiledCopy copyA = make_tiled_copy(
Copy_Atom<SM80_CP_ASYNC_CACHEGLOBAL<uint128_t>, bf16>{},
Layout<Shape<_4, _8>, Stride<_8, _1>>{}, // 32 threads
Layout<Shape<_1,_8>>{}); // Each copies 8 BF16store 쪽은 동일한 벡터화 copy를 쓴다. 이 데이터 경로에서는 L2 캐싱이 없으므로 스레드당 8개/16개는 큰 차이가 없다.
// Regular copy for shared → global (Async not available)
TiledCopy copyOut = make_tiled_copy(
Copy_Atom<AutoVectorizingCopyWithAssumedAlignment<128>, bf16>{},
Layout<Shape<_4,_8>, Stride<_8,_1>>{},
Layout<Shape<_1,_8>>{});마지막으로 첫 copy가 끝나기를 기다린 뒤 store를 수행해야 한다.
cp_async_fence();
cp_async_wait<0>();
__syncthreads();async copy로 1.47 TB/s로 소폭 개선되며, 로드 경로가 더 이상 레지스터를 지나지 않는 것을 확인할 수 있다.
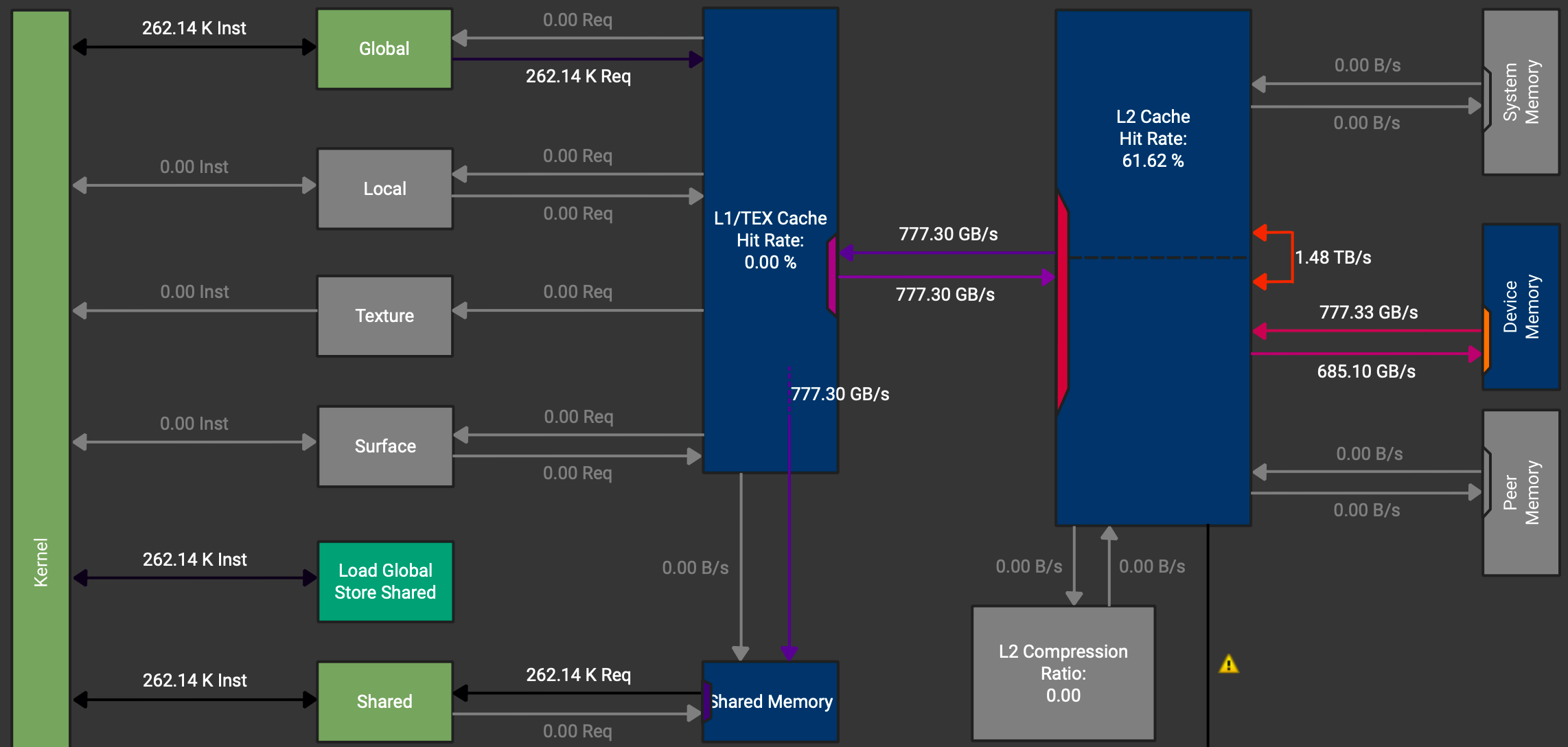
그림 9: async copy 예제의 NCU 메모리 차트 — SMem으로 직접 로드.
다음 단계는 보통 공유메모리 로드에서 bank conflict를 제거하는 것이다. 예시를 위해 이 커널을 보여주지만, 이 커널은 GMem bandwidth가 병목이므로 런타임 개선은 없을 수 있다.
CUDA 디바이스에서 공유메모리는 “bank”라 불리는 동일 크기 메모리 모듈로 나뉘며 동시에 접근할 수 있다. bank conflict는 워프 내 여러 스레드가 같은 클럭 사이클에 같은 bank에 매핑되는 서로 다른 주소를 접근할 때 발생한다. 이 경우 접근이 직렬화되어 성능이 크게 떨어진다. 각 bank가 물리적으로 인접한 4바이트를 저장하므로, 연속 스레드가 연속 주소를 접근하면 conflict가 생길 수 있다. N-D 배열은 메모리에 직렬화되므로 row-major라도 column 방향으로 conflict가 날 수 있다.
swizzling은 어떻게 해결하는가? swizzling은 보통 XOR 같은 비트 조작으로 메모리 내 데이터 배치를 재배열해 주소를 서로 다른 bank에 분산시킨다. 핵심은 conflict가 나던 스레드들이 이제 다른 bank에 접근하도록 주소 패턴을 변환하는 것이다.
(추가로 Alex Armbruster의 GEMM 튜토리얼을 추천한다. bank conflict와 swizzling을 멋진 그림으로 설명한다.)
현재 공유메모리 bank를 그리면 대략 다음과 같다.
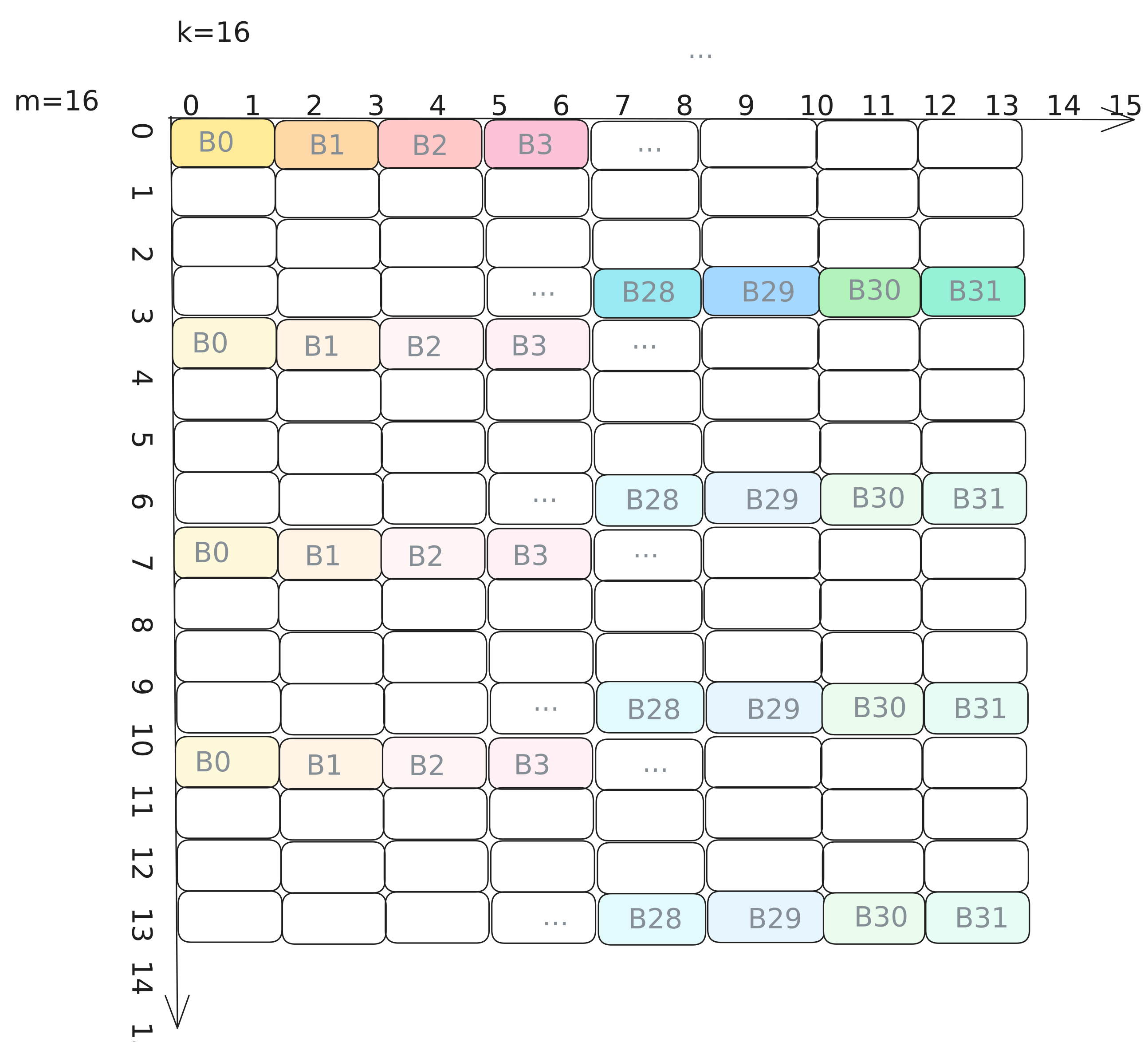
그림 10: swizzle 적용 전, 행렬 값→메모리 bank 매핑.
copy 예제에서는 HBM bandwidth가 주로 중요하므로 bank 관리의 영향이 작다. 하지만 GEMM에서는 SMem에서 데이터를 더 자주 가져와 재사용하므로 영향이 훨씬 크다.
swizzling 패턴은 다양하지만, 여기서는 128바이트 폭 타일을 완벽히 swizzle하도록 설계된 표준 128-bit swizzle 패턴을 사용할 수 있다.
swizzling을 실제로 구현하는 것은 보통 번거롭고 많은 사고가 필요하다. 그러나 CuTe에서는 변화가 최소다. 공유메모리 레이아웃에 swizzle 패턴을 composition으로 추가하기만 하면 된다.
// Swizzled shared memory layout
auto sA = composition(
Swizzle<2,3,3>{}, // the swizzle transform
make_layout(make_shape(Int<BM>{}, Int<BK>{}), // the base (row-major) layout
make_stride(Int<BK>{}, Int<1>{})));좋은 swizzle 패턴을 정의하려면, 나중에 사용할 mma 연산 mma.sync.aligned.m16n8k16.row.col.f32.bf16.bf16.f32과 그에 대응하는 thread layout 및 관련 matrix load 명령을 봐야 한다. 다음 이미지는 PTX 문서에서 가져왔다. 또는 해당 MMA atom을 출력해도 된다.
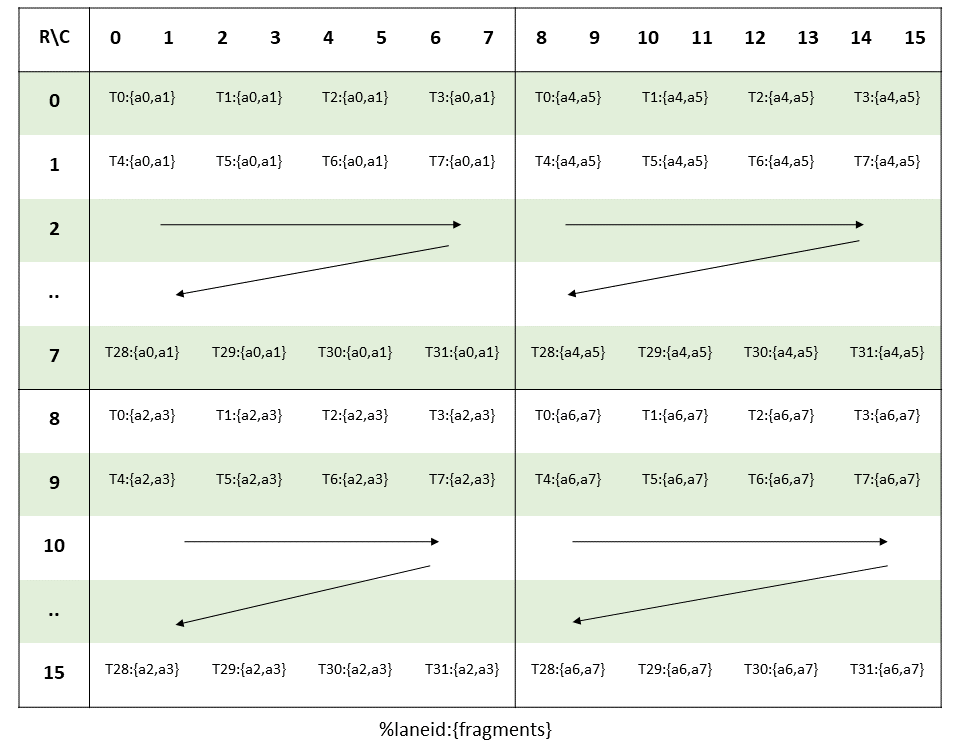
그림 11: 16x8x16 BF16 mma 명령 일러스트. 출처
이 MMA의 입력 행렬을 로드하려면 ldmatrix.x4 또는 CuTe의 SM75_U32x4_LDSM_N copy atom을 사용할 수 있다. 이 명령은 공유메모리에서 16x16 타일을 로드하며, 이는 텐서코어 명령에서 사용하는 타일 크기와 정확히 같다.
Swizzle는 3개의 파라미터로 정의된다(Swizzle<BBits,MBase,SShift>{}):
각 스레드가 8x8 서브타일(4x8 스레드)에서 연속된 4바이트를 로드하므로, 이 서브타일들을 swizzle해야 한다. 한 row 안에서는 모든 스레드가 서로 다른 bank에 닿으므로 row 내부 순서는 유지해도 된다. 따라서 MBase = 3비트로 둘 수 있다.
BBits는 8x8 서브타일의 8 row를 다루기 위해 3비트로 둔다. 공유메모리는 32 bank이고 4바이트 bank width를 사용하며 bank 인덱싱에 비트 [6:2]를 사용하므로, 3비트를 XOR해 8개의 서로 다른 패턴(2³=8)을 만들면 8개 row가 서로 다른 bank 집합에 매핑되도록 할 수 있다. 이는 워프의 32 스레드가 서로 다른 row에서 동시에 로드할 때 bank conflict를 방지한다.
마지막으로 SShift = 3은 XOR하기 전에 얼마나 쉬프트할지 지정한다. 서브타일의 각 row는 16바이트 폭(8 BF16 × 2바이트)이고, row 정보(8바이트 경계 위의 비트)를 bank 비트와 XOR해야 한다. MBase=3이 하위 3비트를 담당하므로, 추가로 3만큼 쉬프트하면 비트 [5:3](서브타일 내 row를 인코딩)을 비트 [8:6] 이상의 비트와 XOR하게 된다. 그 결과 연속 row가 서로 다른 bank를 접근하게 되어 워프 전체에서 conflict-free 로드를 달성한다.
이렇게 Swizzle<3,3,3>{}는 표준 128-bit swizzle 패턴을 구성하며, ldmatrix.x4가 로드하는 16×16 타일을 공유메모리 bank 전반에 분산해 bank conflict를 제거한다.
이 간단한 swizzle 소개를 마쳤으니, copy 섹션을 마무리하고 GEMM으로 넘어가자.
Hopper부터는 TMAs(Tensor Memory Accelerators)를 만들어 비동기 copy의 비중이 더 커졌다. TMA를 사용하면 GMem과 SMem 사이에서 타일을 직접 복사할 수 있다. CuTe에서 설정은 유사하지만 일반 copy atom보다 약간 확장된다. 공식 예시는 다음을 포함한다.
make_tma_atom(SM90_TMA_LOAD{}, A, As(_,_,0), make_shape(bM,bK));
추가 정보는 CUTLASS 레포의 cutlass/include/cute/arch/copy_sm90_tma.hpp 및 copy_sm100_tma.hpp에서 찾을 수 있다.
이번 1편에서는 CuTe 레이아웃 대수의 탄탄한 기반을 쌓았다:
기본 copy(1.33 TB/s)에서 벡터화/async copy, 그리고 더 큰 타일에 대한 swizzled 레이아웃(1.48 TB/s)까지 진행하면서도, 코드는 선언적이고 유지보수 가능하게 유지했다.
하지만 아직 겉만 훑었다. 진짜 장점은 이 개념들을 GEMM 커널에 적용할 때 드러난다.
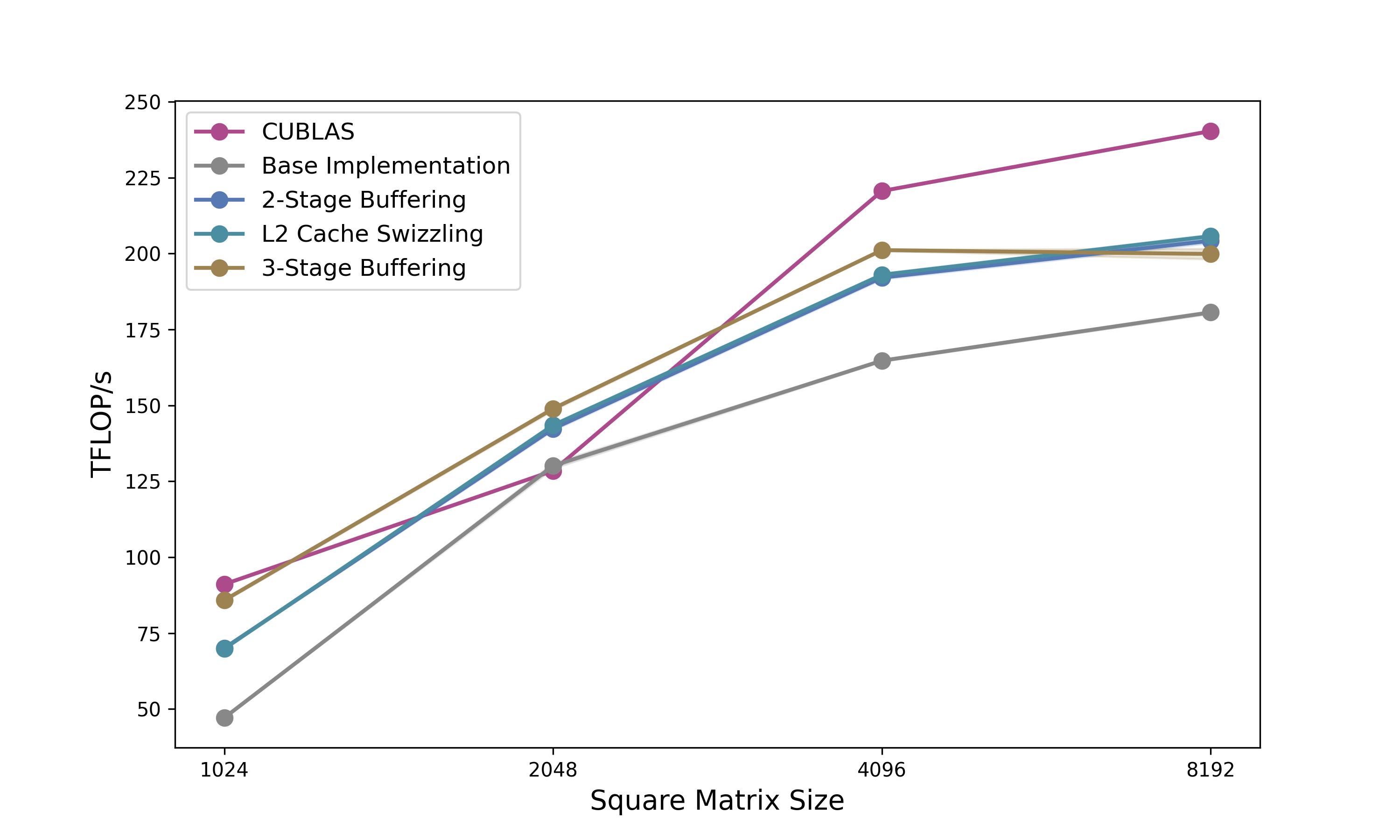
그림 13 (미리보기): Part 2에서는 2-stage 파이프라이닝, L2 swizzling, 3-stage 파이프라이닝을 통해 cuBLAS 대비 102%에서 116%까지 점진적으로 개선되는 GEMM 커널을 만든다.
Part 2: CuTe로 고성능 GEMM 만들기에서는:
이 글을 위해 컴퓨팅 자원을 제공해준 Verda와 Paul, 벤치마크를 제대로 하는 방법에 대한 교정/가이드를 해준 Szymon, 코드의 바보 같은 버그를 고치도록 도와준 Lukas에게 큰 감사를 전한다.