Autocomp가 AWS Neuron 팀의 conv1d_depthwise_default 커널을 단계적으로 최적화해 최종적으로 17.37배의 속도 향상을 달성한 방법을 프로파일과 함께 설명합니다.
UC Berkeley
conv1d_depthwise_default 커널을 어떻게 최적화하여 최종 구현에서 17.37배 속도를 달성했는지 자세히 살펴봅니다.conv1d 소개1D 합성곱(conv1d)은 필터의 높이가 1로 고정된 표준 2D 합성곱의 특수한 경우입니다. conv2d에 익숙하다면, conv1d는 하나의 공간 차원 위에서 좁은 필터를 수평으로 미끄러뜨리는 작업이라고 생각하면 됩니다.
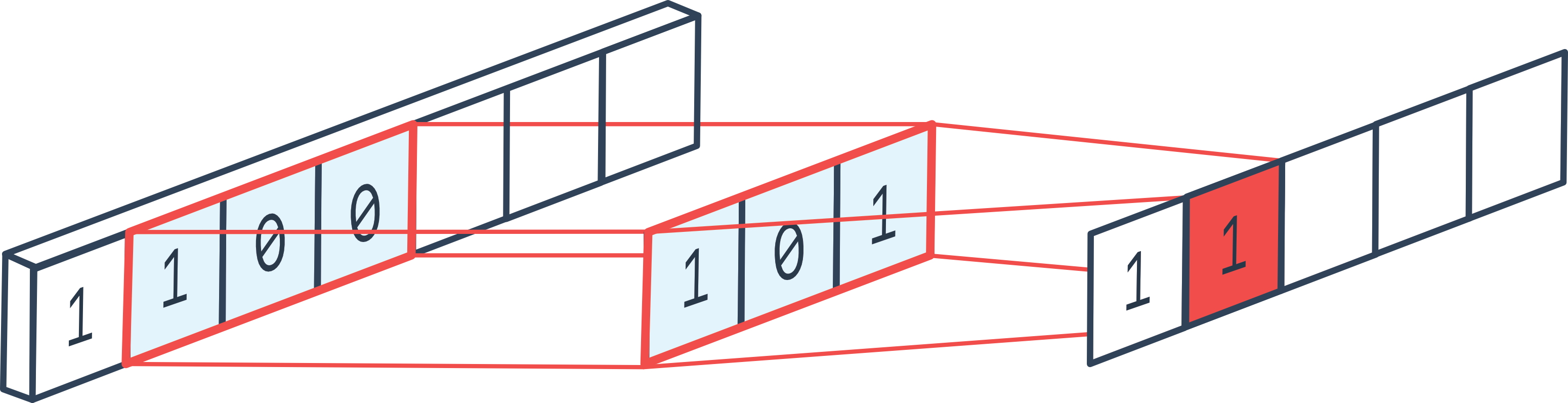
출처: Stack Exchange.
이번 사례에서 커널은 depthwise 1D 합성곱을 수행합니다. 즉, 각 입력 채널이 고유한 필터로 독립적으로 합성곱되며(in_channel = out_channel).
원래 커널의 대략적인 의사코드는 다음과 같습니다:
def conv1d_depthwise_default(img, filters, output):
"""
입력 텐서 형태: [N, C_in, 1, W]
필터 텐서 형태: [C_out, 1, 1, W_f]
출력 텐서 형태: [N, C_out, 1, W]
"""
# 1. 입력을 Trainium의 스크래치패드(SBUF)로 가져오기
img_local_prefetch_raw = nl.array(...)
for n in range(N):
for c_tiled in range(C_in // 128):
img_local_prefetch_raw[n, [c_tiled+:128], :, :] = nl.load(...)
# 2. 필터를 Trainium의 스크래치패드(SBUF)로 가져오기
filter_local = nl.array(...)
for c_tiled in range(C_out // 128):
filter_local[[c_tiled+:128], :, :, :] = nl.load(...)
# 3. Trainium의 스크래치패드(SBUF)에 임시 출력 버퍼 할당
out_sb = nl.array(...)
# 4. depthwise 합성곱 수행
for n in range(N):
for c_tiled in range(C_in // 128):
for w in range(W):
prod = nl.multiply(img_local_prefetch_raw[n, [c_tiled+:128], :, [w+:W_f]], filter_local[[c_tiled+:128], :, :, :])
out_sb[n, [c_tiled+:128], :, w] = nl.sum(prod)
# 5. 결과를 HBM의 출력으로 저장
for n in range(N):
for c_tiled in range(C_out // 128):
nl.store(output[...], out_sb[...])
출력 너비는 input_width − filter_width + 1이 아니라 입력 너비와 동일합니다. 이는 출력 크기를 입력과 동일하게 유지하기 위해 입력의 양쪽에 zero-padding을 적용하기 때문입니다.
이번 사례에서 사용한 설정은 N = 8, in_channel = out_channel = 512, image_width = 2048, filter_width = 3 입니다. Autocomp의 속도 향상 일부는 이 형태에 특화된 최적화를 활용한 데서 나옵니다.
마지막으로, Trainium의 128채널 그룹 최적화 실행을 활용하기 위해 in_channel(그리고 동일하므로 out_channel도)을 128 단위로 타일링합니다. 이 메모리/계산 배치는 높은 성능을 얻는 데 핵심이며, 최적화 단계를 따라가며 Autocomp가 이 구조를 점진적으로 활용해 커널을 Trainium의 잠재력에 더 가깝게 밀어붙이는 과정을 보게 됩니다.
먼저 커널을 전처리하여 Autocomp로 넘기기 쉽게 만듭니다. 스타일 변경과, 커널 외부에 선언되어 있던 헬퍼 함수를 인라인하는 것 외에, 기능적으로 주목할 만한 변경은 출력 텐서를 인자로 받아 제자리에서 수정하는 대신 커널 내부에서 명시적으로 할당하고 리턴하도록 바꾼 점입니다. 이는 NKI 컴파일러 요구사항을 충족하고 커널을 독립적으로 실행하기 위해 필요합니다.
def optimize_0(img, filters):
# 인라인된 헬퍼 함수
def div_ceil():
def create_indices():
# 출력 텐서를 인자로 받는 대신 HBM에 명시적으로 할당
out_hbm = nl.array(...)
# ... (이전과 동일)
return out_hbm
지연 시간(10회 측정 중 최저 nc_latency, 워ーム업 2회 포함): 8.007 ms
Autocomp는 루프 불변인 filter_local[c_tile, i_p_a, i_f_a] 타일의 인덱싱을 가장 안쪽 합성곱 루프 밖으로 이동시키는(호이스팅) 최적화를 시도하고, 그 결과를 새 변수 filt_tile에 할당합니다. 다만 SBUF를 인덱싱할 때의 인덱싱은 실제 계산이나 데이터 이동을 증가시키지 않는 논리 연산이므로, 지연 시간은 변하지 않습니다.
def optimize_1(img, filters):
# ... (이전과 동일)
# 4. depthwise 합성곱 수행
for n in range(N):
for c_tiled in range(C_in // 128):
# HOISTED: 모든 w에 대해 동일한 필터 서브타일 재사용
filt_tile = filter_local[[c_tiled+:128], :, :, :]
for w in range(W):
prod = nl.multiply(img_local_prefetch_raw[n, [c_tiled+:128], :, [w+:W_f]], filt_tile)
out_sb[n, [c_tiled+:128], :, w] = nl.sum(prod)
# ... (이전과 동일)
지연 시간: 8.007 ms (베이스라인과 동일)
커널은 인덱스 매핑을 위한 브로드캐스트 가능한 배열을 생성하기 위해 헬퍼 함수 create_indices를 사용합니다(NumPy의 ogrid와 유사). 이 함수가 사용되는 위치 중 하나는 커널 마지막 단계에서 결과를 HBM으로 저장할 때입니다. Autocomp는 저장(store) 명령어의 수를 줄이기 위해 “스토어 집계(aggregate stores)”를 시도하면서 create_indices를 제거했지만, 변환된 코드는 의미상 원본과 동일합니다. 결과적으로 저장 동작은 바뀌지 않고 지연 시간도 사실상 동일합니다.
참고로 초기 두 번의 최적화 반복 동안에는 탐색을 장려하기 위해 지연 시간이 소폭 증가하는 것을 허용합니다.
[의사코드 생략]
지연 시간: 8.010 ms (0.99x 속도 향상)
Autocomp가 눈에 띄는 개선을 시작합니다. “메모리 버퍼 할당 최적화”라는 이름으로 여러 최적화가 적용됩니다:
nl.load를 nisa.dma_copy로 대체합니다.create_indices 사용을 완전히 제거합니다.def optimize_3(img, filters):
# 모든 것을 하나의 글로벌 루프로 퓨전
out_hbm = nl.array(...)
for n in range(N):
for c_tiled in range(C_in // 128):
# 각 반복에 필요한 부분만 할당/로딩하여 SBUF 압력 감소
img_tile = nl.array(...)
filt_tile = nl.array(...)
out_tile = nl.array(...)
# nl.load를 nisa.dma_copy로 대체(의미적 차이 없음)
nisa.dma_copy(img_tile, img[n, [c_tiled+:128], :, :])
nisa.dma_copy(filt_tile, filters[[c_tiled+:128], :, :, :])
for w in range(W):
# 의사코드에서는 생략; 더 이상 create_indices에 의존하지 않음
prod = nl.multiply(img_tile[:, :, :, [w+:W_f]], filt_tile)
out_tile[:, :, :, w] = nl.sum(prod)
# 결과가 준비되는 즉시 HBM으로 기록
nl.store(out_hbm[n, [c_tiled+:128], :, :], out_tile)
return out_hbm
지연 시간: 7.934 ms (1.01x)
Autocomp는 PSUM을 활용해 메모리 트래픽을 줄입니다. 각 합성곱에서 모든 출력 원소를 곧바로 SBUF에 저장하는 대신, 먼저 PSUM에 저장한 뒤 nisa.tensor_copy를 사용해 PSUM → SBUF 전송을 한 번만 수행하는 방식입니다. 이때 PSUM 버퍼가 자유 차원(free-dimension) 제한을 넘지 않도록, 커널은 합성곱을 F_BLK = min(out_image_size, nl.tile_size.psum_fmax) 크기의 블록으로 나눕니다.
def optimize_4(img, filters):
# ... (이전과 동일)
# W를 512 묶음으로 그룹화
F_BLK = min(W, nl.tile_size.psum_fmax) # nl.tile_size.psum_fmax = 512
for w_tiled in range(W // F_BLK):
out_psum = nl.array(...) # shape: [128, F_BLK]
blk_base = F_BLK * w_tiled # W 내 시작 인덱스
# 합성곱을 수행하고, 해당 자유 차원의 PSUM으로 누적
for f in range(F_BLK):
prod = nl.multiply(img_tile[:, :, :, [blk_base+:W_f]], filt_tile)
out_psum += nl.sum(prod)
# PSUM 데이터를 SBUF로 복사
out_sbuf_blk = nisa.tensor_copy(out_psum)
# 복사된 블록을 HBM에 기록
nl.store(out_hbm[n, [c_tiled+:128], :, blk_base+:F_BLK], out_sbuf_blk)
return out_hbm
이제 Trainium의 neuron_profile 도구로 이 최적화 전후의 차이를 자세히 살펴봅니다. Step 4 최적화 적용 전(즉, optimize_3)의 프로파일 뷰어는 다음과 같습니다:
 그리고 적용 후(
그리고 적용 후(optimize_4):
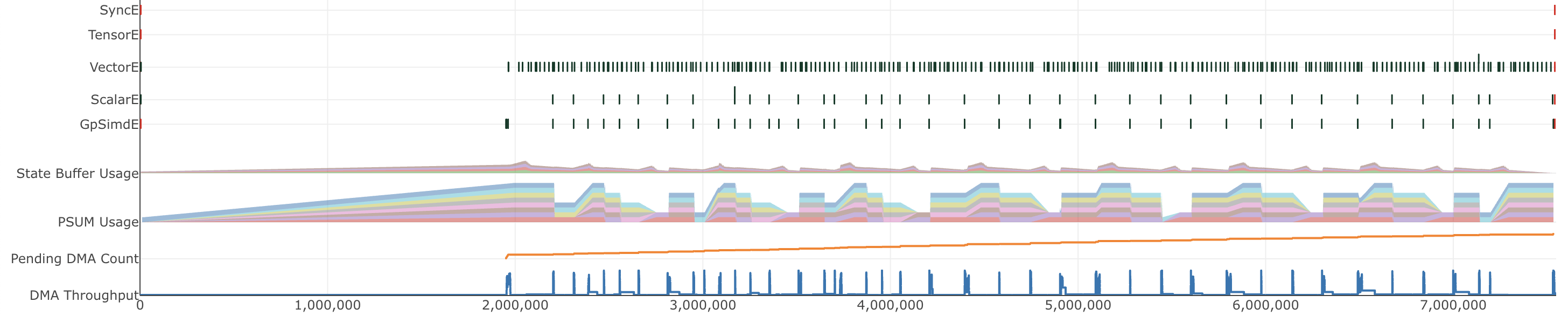 PSUM을 활용하자 SBUF 압력이 감소했고 필터 가중치 접근이 빨라져 전체 처리량이 높아지고 지연 시간이 줄어듭니다.
PSUM을 활용하자 SBUF 압력이 감소했고 필터 가중치 접근이 빨라져 전체 처리량이 높아지고 지연 시간이 줄어듭니다.
지연 시간: 5.602 ms (1.43x)
Autocomp는 루프 순서를 바꾸어 로드한 필터 가중치를 재사용합니다. 즉, 바깥쪽 루프 순서를 “이미지별 → 입력 채널별”에서 “입력 채널별 → 이미지별”로 교환하여 동일한 필터 가중치를 여러 이미지에 걸쳐 재사용합니다.
동시에, Autocomp는 Step 4에서 nl.multiply 연산 가속을 위해 사용하던 PSUM 활용을 버리고, 대신 재사용 가능한 필터 가중치를 PSUM에 저장합니다. PSUM 용량이 제한되어 있고 재충전(reload)을 피하고자 하므로, 필터를 PSUM에 우선 배치하는 전략을 택한 것입니다. 이 전략은 이전 최적화보다 더 큰 속도 향상을 가져왔습니다.
def optimize_5(img, filters):
out_hbm = nl.array(...)
# 가장 바깥/그 다음 바깥 루프 순서 교환
for c_tiled in range(C_in // 128):
# 재사용할 필터를 가져와 PSUM에 저장
filt_sbuf = nl.load(filters[[c_tiled+:128], :, :, :])
filt_psum = nisa.tensor_copy(filt_sbuf)
for n in range(N):
img_tile = nl.load(img[n, [c_tiled+:128], :, :])
out_tile = nl.array(...)
for w in range(W):
prod = nl.multiply(img_tile[:, :, :, [w+:W_f]], filt_psum)
out_tile[:, :, :, w] = nl.sum(prod)
nl.store(out_hbm[n, [c_tiled+:128], :, :], out_tile)
return out_hbm
지연 시간: 4.955 ms (1.62x)
합성곱 루프 내부에서, Autocomp는 출력 너비 차원을 64 단위 그룹으로 타일링합니다.
for w in range(W):
for w_out_tile in range(W // 64):
for w_in_tile in range(64):
w = w_out_tile * 64 + w_in_tile
흥미로운 점은 이 변환이 문법적 변화에 그친다는 것입니다. 즉, 코드 상에서 64개 요소 그룹을 하나의 결합된 연산으로 실제로 처리하도록 nl.multiply(실제로는 tensor_tensor로 구현)나 nl.sum(실제로는 tensor_reduce로 구현) 호출을 수동으로 병합하는 것은 아닙니다. 하지만 이런 재구성이 컴파일러에 작업을 묶을 수 있음을 신호로 전달하기에 충분했고, 결과적으로 컴파일러가 64개 출력을 마치 함께 처리하는 것처럼 공격적으로 스케줄링·최적화할 수 있게 했습니다.
Autocomp가 더 직관적으로 보이는 128 대신 타일 크기를 64로 택한 이유는 완전히 명확하지 않습니다. 다만 값이 128에 가까운 크기(예: 32 또는 64)로 타일링해도 컴파일러가 128 배수로 자체 그룹화를 수행하는 듯 보입니다. 아래에서 제시하는 연산 개수에서도 이를 확인할 수 있습니다.
def optimize_6(img, filters):
# ... (이전과 동일)
NUM_FULL_BLOCKS = W // 64
for w_out_tile in range(NUM_FULL_BLOCKS):
base_out = w_out_tile * 64
for w_in_tile in range(64):
prod = nl.multiply(img_tile[:, :, :, [(base_out + w_in_tile)+:W_f]], filt_psum)
out_tile[:, :, :, base_out + w_in_tile] = nl.sum(prod)
nl.store(out_hbm[n, [c_tiled+:128], :, :], out_tile)
return out_hbm
참고로, Step 6 최적화 전(optimize_5)의 프로파일 뷰어는 다음과 같습니다:

 그리고 최적화 적용 후(
그리고 최적화 적용 후(optimize_6):

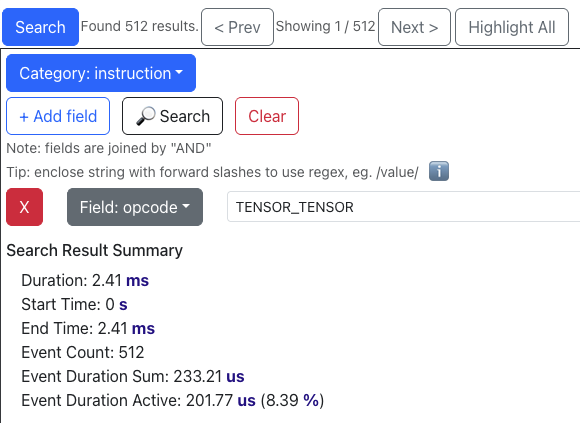
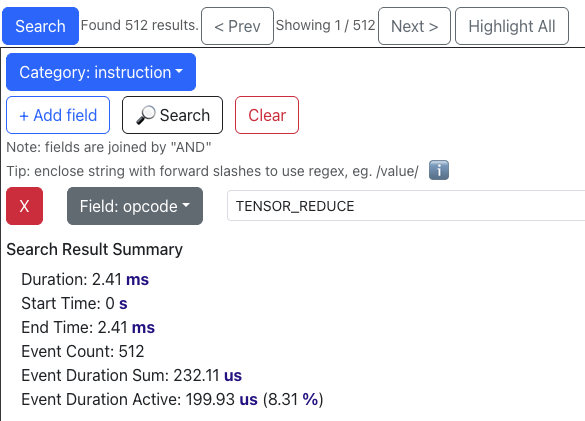
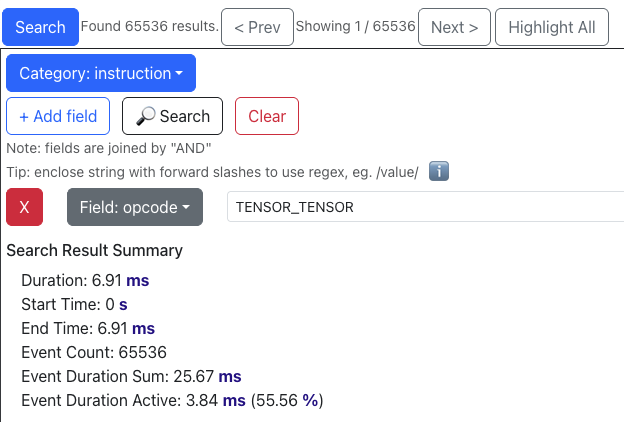
Before: optimize_5에서는 tensor_tensor 연산이 N * (C_in / 128) * W = 65536회, tensor_reduce 연산이 65536 / 4 = 16384회 발생합니다. 이는 루프 내 tensor_reduce 총 호출 횟수를 컴파일 타임에 알 수 없을 때, NKI 컴파일러가 네 개의 파티션 타일씩 적극적으로 tensor_reduce를 융합(fuse)하는 것처럼 보입니다. Trainium 전문가분들께서 확인해 주실 수 있다면 알려주세요!
이 두 종류의 명령어가 합쳐서 전체 프로파일 시간의 약 70%(55.56% + 14.85%)를 차지하므로, Amdahl의 법칙 관점에서 최적화의 주요 대상이 됩니다.
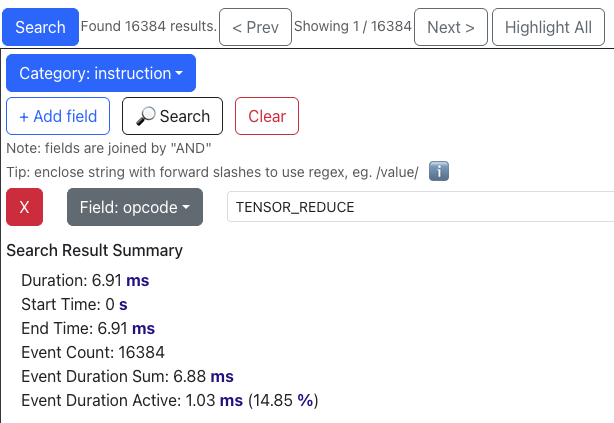
After: optimize_6에서는 tensor_tensor와 tensor_reduce 연산 수가 모두 512(= 65536 / 128)로 감소합니다. 이는 두 연산 모두 이제 128개의 파티션 타일에 걸쳐 융합되고 있음을 시사합니다. 실행 시간은 3.84 → 0.2ms, 1.03 → 0.2ms로 줄었고, 이제 프로파일 전체의 17%(8.39% + 8.31%)만을 차지합니다. 커널이 주로 이 두 연산에서 연산 바운드였으므로, 이러한 감소는 전체적인 큰 속도 향상으로 이어졌습니다.
지연 시간: 0.461 ms (17.37x)
속도 향상 요약:
| 최적화 | 지연 시간 (ms) | 속도 향상 |
|---|---|---|
| 베이스라인 | 8.007 | 1.00x |
| 필터 인덱싱 호이스팅 | 8.007 | 1.00x |
create_indices 제거 | 8.010 | 0.99x |
| 루프 퓨전 + 메모리 버퍼 최적화 | 7.934 | 1.01x |
| PSUM 버퍼 할당 | 5.602 | 1.43x |
| 루프 순서 교환 | 4.955 | 1.62x |
| 타일 힌트 | 0.461 | 17.37x |
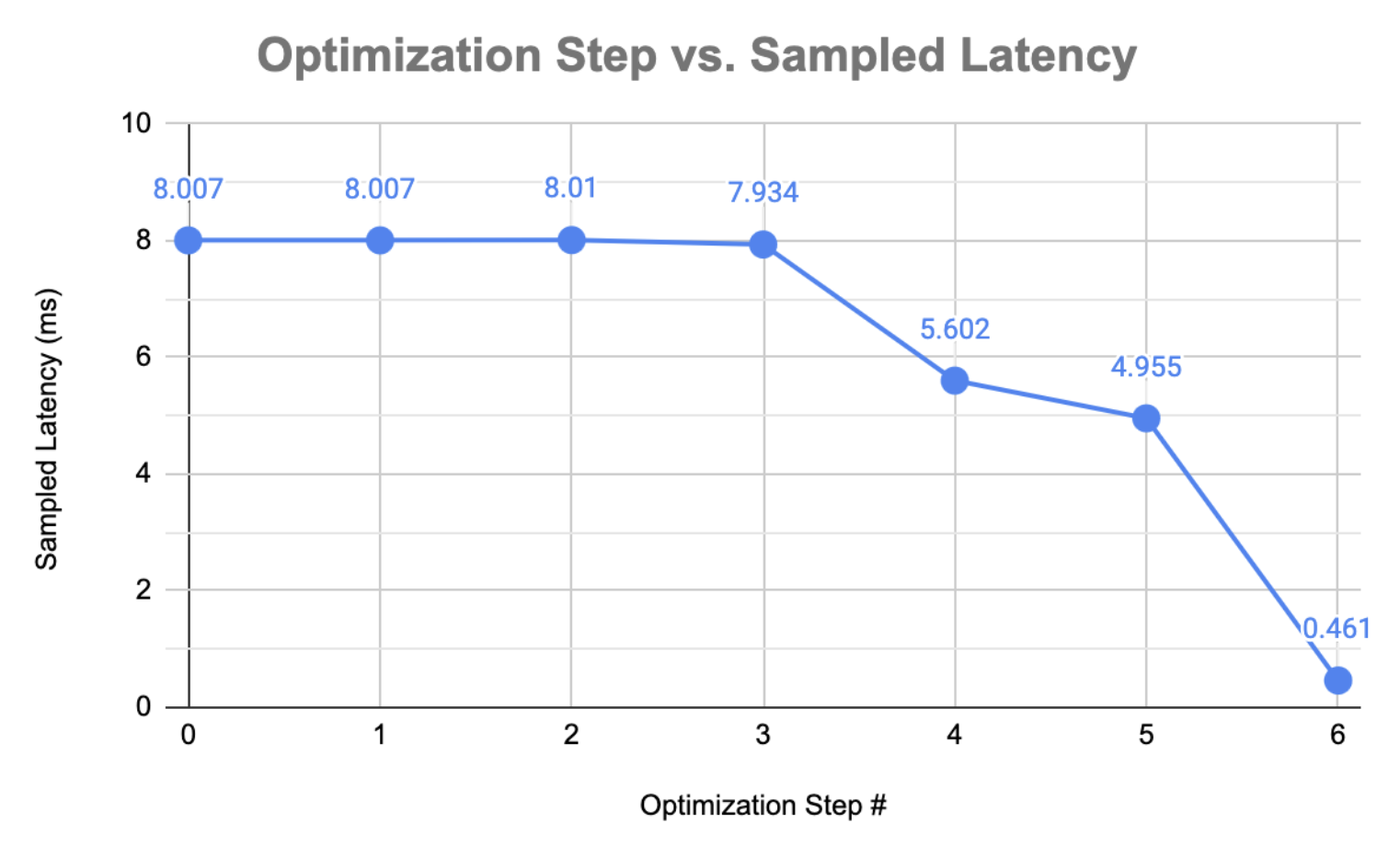 |
속도 향상 요약 차트.
이 사례 연구에서는 Autocomp가 AWS Neuron 팀이 제공한 conv1d 커널을 개선하기 위해 다양한 커널 최적화 기법을 어떻게 적용했는지 살펴보았습니다. 전통적인 메모리 트래픽 최적화부터 NKI 특이적 동작에 이르기까지, Autocomp는 코드를 체계적으로 변환하며 사람 커널 작성자가 쉽게 떠올리기 어려운 설계 공간과 엣지 케이스를 탐색했습니다. 앞으로도 Autocomp 활용 범위를 넓혀 더 많은 애플리케이션에서 어떤 최적화를 달성할 수 있을지 기대합니다.
감사 인사: SLICE Lab에서 함께하는 뛰어난 학부 연구원 Huijae An에게 이 글의 집필을 주도해 준 데 대해 감사드리며, Neuron Science 팀의 Haozheng Fan에게 피드백과 인사이트를 제공해 주신 점에 감사드립니다.