AI가 형식 검증을 대중화하고 있지만, 자동 형식화·모델링·성능·피드백의 한계 때문에 테스트(특히 무작위 테스트)는 검증을 보완하며 앞으로도 핵심 역할을 한다.
AI는 형식 검증을 주류로 만들고 있다
AI가 형식 검증(formal verification)을 주류로 만들고 있다.
AI 보조 기계 증명 회사들이 10억 달러 규모의 밸류에이션으로 투자를 받고, 그 어느 때보다 많은 사람들이(대부분 Lean으로) 증명 보조기(proof assistant)를 시도하고 있다. 모델들은 IMO, ICPC, Putnam 같은, 이전에는 세상에서 가장 어려운 문제들이 포함되어 있다고 여겨졌던 대회들에서 흥미로운 성과를 내고 있고, 에르되시 문제(Erdös Problems) 같은 수학의 공개 난제에서도 결과를 내고 있다.
AI 보조 증명에 설레는 건 취미 수준의 사람들만이 아니다. Terry Tao부터 Martin Kleppman, Ilya Sergey까지, 전 세계의 저명한 연구자들이 그 효과에 기대를 걸고 있다.
먼저 논지의 개요를 빠르게 훑어보자.
형식 검증에는 복잡한 도전 과제가 여러 가지가 있다. 첫 번째는, 기술적으로 해결하기 매우 어려운 문제이기도 한데, 세상의 대부분의 소프트웨어에 형식 명세(formal specification)가 없다는 점이다. 형식 명세란 우리가 만드는 시스템을 더 단순한 수학적 언어로 기술한 것이다. 알고리즘에는 형식 명세가 있다. 자료구조, 프로토콜, 데이터 포맷, 안전 필수(safety-critical) 시스템은 보통 형식 명세를 가진다.
하지만 세상의 대다수 프로그램에는 형식 명세가 없다. 아니, 솔직히 말하면 대부분은 비형식(자연어) 명세조차 없다. 극단적으로(그리고 실제로 우리가 있는 지점이기도 하지만) 프로그램의 명세는 그 프로그램 자체이며, 구현이 곧 명세다. 형식 명세가 없으면 어떤 소프트웨어를 형식적으로 검증하기가 매우 어렵다. 대체 무엇을 검증한다는 말인가?
두 번째 문제는 증명 엔지니어링(proof engineering), 즉 시스템에 대한 정리들을 증명하는 실무가 매우 어렵다는 점이다. 증명에는 도메인 특화 요소가 매우 많다. 수학 정리의 증명과 프로그래밍 언어에 대한 증명은 완전히 다를 것이고, 프로그래밍 언어에 대한 증명은 그 언어가 기대는 이론적 프레임워크의 구성요소에 크게 좌우된다.
가장 널리 가르쳐지는 증명 엔지니어링 책은 Software Foundations인데, 각 장마다 증명 스타일이 다르다. Volume 2: Programming Language Foundations를 끝낸 사람도 Volume 6: Separation Logic Foundations의 문제들을 직관적이거나 자명하게 느끼지 못할 수 있다.
증명 자동화를 위한 도구, 증명의 취약성(brittleness), 재사용성 같은 다른 문제들도 있지만, 나는 이것들이 증명 엔지니어링 자체의 근본 문제라기보다는 현 세대의 문제라고 생각하므로 일단은 넘어가겠다.
LLM의 부상은 이 두 지점 모두에 큰 영향을 준다.
1번에 영향을 주는 이유는 AI 보조 프로그래밍이 명세 주도 개발(specification-driven development)과 매우 자연스럽게 잘 맞기 때문이다. AI 보조 프로그래밍은 “무엇을 구현할 수 있는가”에서 “무엇을 명세할 수 있는가, 무엇을 검증할 수 있는가”로 프로그래밍의 한계를 밀어붙인다. 이는 실행 가능한 명세(executable specification)를 작성할 강력한 유인이 된다. 그러면 LLM을 루프 안에 넣고, 어떤 수단을 쓰든 상관없이 목표를 달성할 때까지 반복시키면 되기 때문이다.
나는 예측한다—이것은 우리가 그 영역에서 일하는 방식에 변혁을 가져올 프로그램 최적화기와 번역기(program optimizer/translator)의 등장을 촉발할 것이다.
하지만 악명 높게도, 테스트는 불완전하다. 테스트는 버그를 찾는 데는 훌륭하다(사실 대부분의 경우 그렇게 훌륭하지도 않지만, 그건 다른 얘기다). 그러나 테스트는 버그가 없음을 증명할 수 없다. SQLite는 수백만 개의 테스트를 가진 것으로 유명하지만, 연구자들은 여전히 SQLite에서 버그를 찾아낸다. 비슷한 상황은 거의 모든 소프트웨어에서 벌어진다.
버그의 부재를 증명하는 유일한 방법은 형식 검증이며, 산업계에는 그 훌륭한 사례들이 있다. 널리 인용되는 형식 검증 프로젝트로 CompCert C 컴파일러가 있는데, 이를 GCC와 Clang에 대해 랜덤 테스트한 연구에서 GCC에서 79개, Clang에서 202개의 버그를 발견했지만, CompCert에서는 검증되지 않은 파서에서 2개의 버그만 발견했고, 검증된 컴파일 패스에서는 버그를 발견하지 못했다. 이는 형식 검증의 놀라운 승리다.
(A. Jesse Jiryu Davis가 알려줘서 알게 됐는데) 연구자들이 형식적으로 검증된 분산 시스템에서 실패의 원인을 연구했고, 검증되지 않은 부분에 대한 잘못된 가정이 유력한 원인이라는 결론을 내렸다고 한다.
이런 점 때문에 형식 검증은 AI 보조 프로그래밍의 주요 타깃이 된다. 형식 명세만 있다면, 기계를 몇 시간, 며칠, 심지어 몇 주 동안 헤매게 둘 수 있다. 그리고 해결책을 가져오면, 우리는 이른바 인공지능의 확률적 예측을 신뢰하는 것이 아니라, 해답을 검증해주는 기호적 증명 검사기(symbolic proof checker)를 신뢰하면 된다.
이 아이디어는 언제나 형식 검증의 핵심이었다. “불완전(unsound)한 증명 생성 + 건전(sound)한 증명 검사”의 조합은 복잡한 전술(tactic)과, 증명을 탐색으로 생성하는 알고리즘을 낳았고, 증명 엔지니어에게 엄청난 도움을 주었다.
좋은 소식은 여기서 끝나지 않는다. AI는 증명 작성에도 매우 능하다. 적어도 평균적인 소프트웨어 엔지니어보다는 훨씬 낫다. 완벽한 오라클이 있다면, 문제는 RLVR(Reinforcement Learning with Verifiable Rewards; 검증 가능한 보상을 활용한 강화학습)로도 바꿀 수 있다. 즉, 체스나 바둑 등에서 그랬듯 시간이 지날수록 모델이 더 좋아질 것을 기대할 수 있다.
이것이 10억 달러 밸류에이션 뒤에 있는 약속이다. 회사들은 인상적인 자동 형식화(autoformalization) 기법과 자동 증명기로 대회 문제나 공개 추측을 푸는 것에서 시작했지만, 진짜 산업적 가치는 “엔지니어가 자연어로 요구사항을 쓰면, 그것이 Lean 정리로 자동 형식화되고, 자동 증명기가 증명해서, 짠—완전히 신뢰할 수 있는 프로그램이 나오는” 소프트웨어 엔지니어링 자동화의 핵심에 있다.
…정말 그럴까?
나는 그 매력을 이해한다. 그 아이디어가 좋다. 이런 시스템을 만드는 연구자들을 신뢰한다. 하지만 거대한 약속(과장된 미래상)을 전적으로 좋아하진 않는다.
이 글은, 이미 다룬 좋은 점들과 이제부터 다룰 나쁜 점들을 함께 놓고, 합리적인 중간 지대를 만들려는 시도다. 그리고 마지막에는 이 분야에서, 그리고 미래에서 테스트가 차지할 위치를 다시 강조하며 마무리하려 한다.
이 글을 시작하며 “세상 대부분의 프로그램엔 형식 명세가 없다”고 했고, 이어서 AI가 명세 작성을 유인한다고 했으며, 자동 형식화는 그 명세를 가져와 형식(formal) 으로 만든다고 했다.
형식 검증에는 신뢰 기반(trusted computing base, TCB) 이라는 개념이 있다. TCB는 아킬레스건이다. 검증의 층이 층 위로 쌓일 때, 맨 아래에서 작은 핵심을 검증하지 않고 신뢰해야 한다. 어딘가에는 사다리의 바닥이 있어야 한다. 순환적인 검증 논증은 만들 수 없고, 시스템이 자기 자신을 검증할 수도 없다.
(내가 틀릴 수도 있으니, 혹시 잘못됐다면 팩트 체크 부탁한다.)
이 AI 보조 검증 프로그래밍 패러다임에서 자동 형식화는 TCB의 일부다. 자연어로 서술한 명세가 정말로 형식화된 명세와 일치하는지, 그 자체를 기계적으로 검증할 방법이 없기 때문이다.
사용 방식은 여러 가지가 있는데, 한 가지 문제는 건전성(soundness)이다. 자연어 명세가 거부해야 할 시나리오를 형식 모델이 받아들여서, 기계적으로는 “검증됨”이 될 수 있다. 또 다른 문제는 완전성(completeness)이다. 형식화된 모델이 우리의 설명에서 유효한 시나리오를 거부할 수도 있다.
자동 형식화는 이 검증 과정에서 중요한 실패 지점이므로, 특별한 주의가 필요하고 또 그럴 만한 가치가 있다.
증명 보조기의 1차 목표는 프로그램을 추론하고 검증을 쉽게 만드는 것이다. 예를 들어 증명 보조기는 전통적으로, 메모리의 워드에 담긴 우리가 익숙한 2의 보수 정수(two’s complement integer)를 쓰지 않는다. 대신 페아노 수(Peano number), 즉 자연수를 귀납적 데이터 구조로 인코딩한 것을 쓴다.
Inductive Nat : Type :=
| zero : Nat
| succ : Nat -> Nat.
이 인코딩에는 정수 오버플로라는 개념이 없다. 귀납 구조 덕분에, 워드에 들어갈 수 있는 값들에만 해당하는 정리가 아니라 모든 자연수에 대해 성립하는 정리를 만들 수 있다.
하지만 이는 끔찍하게 느리다. CPU에서 너무 빨라서 사실상 즉시 수행되는 a + b 같은 연산의 계산 복잡도가 O(a + b)가 된다. 즉 더해지는 값의 크기에 선형으로 비례한다(상수 시간이 아니다).
우리는 검증된 코드를 실제 워크로드에 올리고 싶다. 그러니 1M + 1M = 2M을 더하는 데 백만 사이클을 기다릴 수는 없다.
이 문제에는 두 가지 해결책이 있다.
첫 번째는, 증명 보조기 안에서 더 효율적인 인코딩을 만들고, “효율적이지만 추론하기 어려운 인코딩”이 “비효율적이지만 추론하기 쉬운 인코딩”과 동치임을 증명한 뒤, 계산에서는 효율적인 쪽을 쓰는 방법이다.
두 번째는 다시 한 번 공리화(axiomatization), 즉 TCB를 넓히는 것이다. 증명 보조기에는 추출(extraction) 이라는 메커니즘이 있어서, 증명 보조기 언어(예: Rocq)로 작성된 코드를 생산용 워크로드에 최적화된 더 큰 생태계의 언어(예: OCaml)로 추출할 수 있다.
추출의 많은 부분은 단순한 문법 변환을 통해 언어 간 1:1 대응을 이루지만, 이 추출을 가로채서(hijack) 우리 타입을 공리화할 수도 있다. Nat을 부호 없는 정수로 바꿔 Nat.add가 u64 + u64가 되게 만드는 식이다.
예컨대 Rocq에서는 Nat이 BigInt로 추출되는데, 의미론이 같아야 한다. 하지만 이 문장에서 “같아야 한다(should)”에 매우 무거운 의미가 실려 있다. 정당성에 대한 동반 증명이 없다면, 우리는 BigInt를 TCB에 집어넣는 셈이다.
TCB를 넓히지 않는다면, 증명 보조기의 속도는 귀납 타입 사용에서 자연스럽게 발생하는 대량의 포인터 추적(pointer chasing)과 트리 구조 특성 때문에 제한될 것이다.
속도가 그렇게 중요하지 않은 도메인도 많다. 하지만 나는 속도와 정확성 요구사항 사이에 긴장관계가 있다고도 생각한다. 더 빠른 코드는 보통 동시성(concurrency), 비트 조작, 메모리 레이아웃 인지 같은 더 복잡한 언어 구성요소를 요구하고, 이는 단순한 대응물보다 버그를 더 많이 만든다.
버그가 나기 쉬운 프로그램을 우리가 추론하지 못한다면, 우리는 전체 문제 중 얼마나 많은 부분을 वास्तवに(실제로) 다루고 있는 걸까?
시스템의 어떤 성질을 검증하려면, 그 시스템의 모델이 필요하다. 이런 모델은 나무에서 열리지 않는다. 도메인 전문가들이 수년에 걸쳐 공들여 만든다.
사람들은 포인터를 가진 프로그램(분리 논리, separation logic), 동시성이 있는 프로그램, 난수성이 있는 프로그램, 대수적 효과(algebraic effects)를 가진 프로그램 등을 위한 모델을 구축해 왔다(그리고 내가 들어보지도 못한 더 많은 것들이 있을 것이다).
시스템의 성질을 증명하려면 우리의 추론 과정에 기반이 필요하고, 이런 이론들이 각 도메인에 대한 기반을 제공한다.
하지만 좋은 모델이 없는 도메인도 많다. 예를 들어 런타임 성능(runtime performance)이 그렇다. 이는 컴퓨터 과학 커리큘럼에서도 논쟁적인 주제였는데, 점근적 복잡도(asymptotic complexity)는 실제 하드웨어에서의 프로그램 동작으로 그대로 번역되지 않는다.
현대 CPU에는 캐시 라인, 추측 실행(speculative execution), 분기 예측(branch prediction)이 있어서, 점근 분석에서 쓰는 낡은 추상 기계 모델은 많은 상황에서 무력해진다.
게다가 모델을 맞출 “단 하나의 하드웨어”조차 없다. 수십 가지 하드웨어 구성이 있고, 각각은 측정 결과를 다르게 만든다.
만약 어떤 코드가 특정 메모리/프로세서 조합에서 다른 코드보다 더 낫다는 것을 증명하려 한다면, 엄청난 일이 될 것이다. 나는 개인적으로 어디서부터 시작해야 할지도 모르겠다.
이를 테스트와 대비해 보라. 같은 알고리즘을 두 기계에서 돌리고, 벤치마크를 수행하면 된다. 그 결과가 최종적인 지상 진실(ground truth)이 된다.
테스트는 거의 보편적으로 형식 검증보다 열등하다고 여겨진다. 검증을 정당화할 자원이 없을 때 어쩔 수 없이 하는 것이 테스트이며, 시간을 쓸 수 있다면 버그의 부재나 시스템에 대한 보편적 사실을 증명하는 것이 단발적 측정 결과를 코드로 박제하는 것보다 훨씬 가치 있다고 믿기 때문이다.
나는 여기서 이렇게 말하고 싶다. 형식적으로는 검증할 수 없는 테스트도 쓸 수 있다. 왜냐하면 검증을 위한 기반 모델을 만드는 것이 어려울 수 있는 반면, 실제 하드웨어를 그대로 사용해 측정하는 건 훨씬 쉬울 수 있기 때문이다.
게임에서는 승자와 패자가 명확하다. 하지만 검증에서는, 정리가 맞다는 것을 증명할 수도 있고, 정리가 틀렸다는 것을 증명할 수도 있다. 그러나 어떤 정리에 대한 증명이 없다는 사실은 그 정리가 틀렸다는 뜻이 아니다. 단지 아직 증명을 못 찾았을 수도 있다.
즉, 증명을 쓰는 동안 받는 피드백은 제한적이다. 막혔다고 해서 그게 정리 자체에 문제가 있다는 신호로 믿을 수 없다. 문제는 당신일 수도 있다.
이것이, 유명한 Haskell의 QuickCheck에서 내려온(그리고 속성 기반 테스트(Property-Based Testing)를 세상에 소개한) 랜덤 테스트 도구 QuickChick이 Rocq 생태계에서 가장 인기 있는 패키지 3개 중 하나로 존재하는 이유다.
만약 검증이 테스트보다 엄밀히 우월했다면 QuickChick은 존재할 이유가 없었겠지만, QuickChick은 검증 과정에 매우 중요한 역할을 한다. 바로 반증(falsification) 이다.
나는 “증명이 없다고 정리가 틀린 것은 아니다”라고 했다. 하지만 정리를 위반하는 반례(witness)를 찾는다면, 그 정리가 틀렸다는 건 확실해진다.
랜덤 테스트는 그런 반례를 찾는 유력한 용의자다. 정리가 결국 틀렸기 때문에 증명이 존재하지 않는데도, 증명 탐색이 수많은 쓸모없는 길을 파고들다 포기하는 ‘토끼굴’을 방지해준다.
나는 형식 검증이 모델링할 수 없는 테스트의 예시를 들었고, 반대로 형식 검증 과정을 보완해 “헛되이 증명하려 하기” 대신 “거짓 정리를 빠르게 반증”하게 하는 테스트의 예시도 들었다.
테스트와 형식 검증의 시너지는 여기서 끝나지 않는다. 나는 검증-유도 개발(Verification-Guided Development, VGD)의 강력한 지지자다. VGD는 이 시너지를 활용하는 것뿐 아니라, 증명 보조기가 너무 느리다는 문제도 해결한다.
검증-유도 개발에서는 같은 시스템의 두 버전을 구현한다.
그리고 동일한 입력으로 둘을 실행해, 생산 시스템이 검증된 기준 구현(reference implementation)에 부합함을 테스트한다. 매번 결과가 같다고 주장(assert)하는 것이다.
VGD는 차등 무작위 테스트(differential random testing)를 활용해, 증명 보조기에서 만든 느린 구현의 ‘증명’을 생산 구현으로 들어 올린다(lift). 그 결과 정확하면서도 빠른, 두 마리 토끼를 잡는 시스템을 만들 수 있다.
아래 이미지는 (내가 알기로) VGD 개념을 도입한 논문에서 가져온 것으로, 그 워크플로를 설명한다.
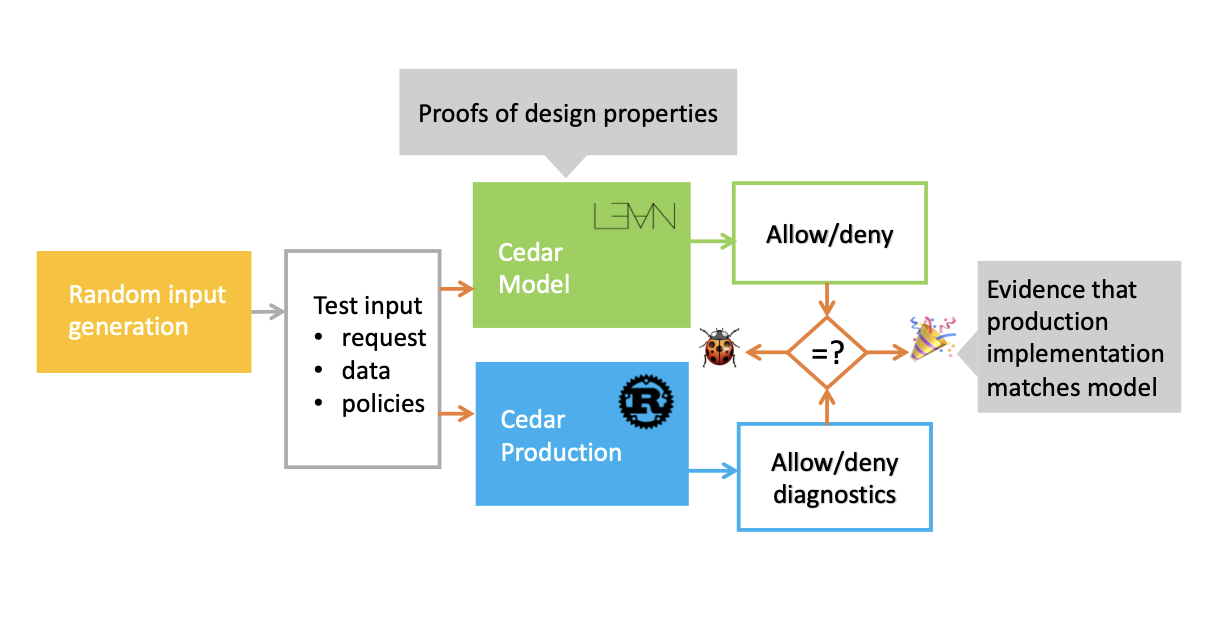
VGD가 내가 글의 나머지에서 언급하는 모든 문제를 해결하진 못한다. 하지만 ‘느림’이라는 문제는 혼합물에서 제거한다.
생산 구현이 있고 이를 충분히 테스트할 수 있으니, 검증의 범위를 벗어나지만 테스트의 영역에 속하는 온갖 종류의 측정을 할 수 있다. 이는 검증이 테스트를 활용할 때의 단점을 줄이면서, 검증된 컴퓨팅 세계와 검증되지 않은 세계 사이의 격차를 줄여준다.
모두를 위해 한 번 더 말하고 싶다.
나는 그 매력을 이해한다. 그 아이디어가 좋다. 이런 시스템을 만드는 연구자들을 신뢰한다. 하지만 거대한 약속을 전적으로 좋아하진 않는다. 이 글은 좋은 점과 나쁜 점을 함께 놓고 합리적인 중간 지대를 만들려는 시도이며, 마지막에는 이 분야에서, 그리고 미래에서 테스트가 차지할 위치를 다시 강조하며 마무리하려 한다.
나는 무작위 테스트가 미래의 소프트웨어 엔지니어링에서 형식 검증만큼 중요한 역할을 한다고 믿는다.
많은 도메인에서 우리는 마법처럼 형식적으로 완전히 검증된 시스템을 갖게 되진 않을 것이다. 그러나 자동 형식화 도구가 좋아질수록, 우리는 훨씬 더 많은 형식 명세를 갖게 될 것이다.
무작위 테스트는 이러한 형식 명세로부터, 형식 검증과는 다른 방식으로 혜택을 얻는다. 하지만 둘 다 자리가 있다. 증명 시스템은 동반하는 테스트 도구 없이 불완전할 것이고, 테스트 도구는 정확성 증명 없이 불완전할 것이다.
검증과 테스트의 어떤 조합을 통해서만, 우리는 미래 소프트웨어 엔지니어링의 이상에 도달할 수 있다. 버그가 규범이 아니라 이상(anomaly)으로 취급되는 세상, 정확성이 미덕인 세상, 그리고 우리 시스템의 버그가 우리가 치료해 과거로 밀어 넣은 질병들만큼 오래되고 잊힌 것이 되는 세상에서 살아갈 수 있다.