AI가 점점 더 많은 코드를 생성하는 시대에, 인간이 읽지 않은 실행 코드가 늘어나는 현실 속에서 형식 검증(포멀 베리피케이션)과 타입, 정리 증명기가 왜 중요한지 살펴본다.
알아둘 프로젝트(Projects to Know) 128호
About Us
.svg)
메뉴

AI와 ML
작성자
Arjun Narayan
2026년 2월 17일
또는: 타입과 정리 증명기 — AI 코드 시대에 왜 형식 검증이 중요한가
지난 2주만 해도 Opus 4.6과 Codex 5.3으로 코딩 모델의 역량이 몇 단계 도약하는 모습을 봤습니다. 이제 이 모델들은 점점 더 복잡한 시스템을 신뢰할 만하게 작성합니다. 하지만 그 코드는 대체로 “동작”하긴 해도, 규모가 불필요하게 커지고 다루기 어려워지는 경향이 있습니다. 우리는 이제 아무도 읽지 않은 채로 돌아가는 코드가 존재하는 세계로 들어가고 있습니다. 현실은, 코드 생성을 더 많이 기계에 아웃소싱할수록 어딘가의 인간이 그 모든 코드를 리뷰하고 있다고 계속 가장할 수 없다는 데 있습니다.
저는 형식 검증(formal verification)이 미래라고 믿습니다. 지금의 이 문제에 정확히 맞춤형이기 때문입니다. 형식 검증은 인간에게 훨씬 더 작고 간결한 _명세(specification)_에 대한 책임을 묻게 해주고, 코드는 그 명세를 수학적으로 만족함이 증명됩니다.
이건 새로운 생각이 아닙니다. Martin Kleppman이 쓴 설명이 있는데, 저는 대체로 그 관점에 동의합니다. 다만 저는 이를 조금 더 구체화해보고 싶습니다. 그렇다고 형식 검증이 만병통치약은 아니고, 현재 우리가 증명할 수 있는 것/없는 것의 경계도 있어 이 길이 단번에 곧장 뚫리는 건 아닙니다. 따라서 초기 시도들은 코드에 대한 인간 리뷰의 필요를 줄이겠지만, 없애지는 못할 것입니다.
중기적으로는 형식 검증이 개발자 도구 상자에 꼭 들어가서 우리 시스템을 더 정확하고 안전하게 만드는 데 핵심적인 역할을 하리라 봅니다. 하지만 장기적으로는, 형식 검증이 완전히 자율적이고 올바른 코드 생성을 가능하게 하는 경로를 제공합니다.
검증(verification)은 근본적으로 “프로그램이 무엇을 할 수 있고/할 수 없는지”를 이해하고, 그것을 _증명(proof)_으로 확인하는 일입니다. 검증을 하려면 먼저 프로그램을 어떤 기준에 맞춰 검증할지에 대한 _명세(specification)_가 있어야 합니다.
이 명세는 명시적일 수도(프로그래머가 작성, 프로그램마다 케이스별로) 있고, 암시적일 수도 있습니다(코드가 작성된 프로그래밍 언어의 정의 안에 포함). 또한 구현이 명세를 만족할 때 그 구현의 행동을 얼마나 강하게 제한하느냐에 따라, 가볍게(lightweight)부터 강하게(heavy-handed)까지 다양합니다.
이건 단지 이론이 아닙니다. 사실 여러분 대부분은 매일 어떤 형태의 형식 검증을 활용하고 있습니다. 예컨대 C++나 Java 같은 정적 타입 언어의 컴파일 오류 일부는 검증 오류입니다. 다만 그 범위가 제한적이고, 어쩌면 무엇이 가능한지에 대해 오해를 낳는 기대를 심어줬을지도 모릅니다. 그래서 저는 먼저 우리가 익숙한 기존 프로그래밍 언어들에 이미 들어있는 이 “형식 스택”이 어떻게 구성돼 있는지 풀어본 다음, 앞으로 우리가 어디까지 갈 수 있길 바라는지로 확장해 보겠습니다.
정적 타입 검사(static type checking)는 프로그래머가 가장 익숙한 형식 검증입니다. Java 같은 정적 타입 언어로 작성된 프로그램을 컴파일할 때 컴파일 과정 중 하나가 “타입 검사(type checking)”입니다. 이 단계에서 컴파일러는 먼저 여러 타입 애너테이션(type annotations)—즉 타입을 선언하는 코드 조각들—을 수집해, 예를 들어 함수가 호환되지 않는 타입으로 잘못 호출되지 않았는지 확인합니다. 그리고 타입들이 서로 내부적으로 일관되는지도 확인합니다. 이 모든 검사를 통과했다고 판단되면, 타입 애너테이션을 버리고 남은 프로그램을 바이트코드로 컴파일합니다.
이 타입 정보는 실행 중인 프로그램에서는 사용되지 않습니다. 즉, 소거(erasure)됩니다. 따라서 타입은 오로지 컴파일 시점에 프로그램에 대해 무언가를 증명하기 위해 존재합니다. 타입이 증명하는 것은 프로그램이 특정 부류의 _타입 오류(type errors)_로부터 자유롭다는 사실입니다.
이 증명에는 몇 가지 유용한 성질이 있습니다.
하지만 단점도 있습니다.
var fish만 쓰면 될 일을 하루에 열다섯 번씩 com.oracle.animals.AbstractAnimal<Aquatic> 같은 이름을 타이핑하는 경험이 되곤 합니다.이렇게 장황한 타입 이름을 덜 쓰면서도, 더 많은 버그를 잡을 수 있다면 정말 좋겠죠.
다행히 Java에 대한 흔한 불만 대부분은 타입 시스템의 본질적 한계가 아니라, 충분히 야심차지 못한 언어 설계의 결과인 경우가 많습니다.
사실 타입 시스템(및 관련 형식 검증 도구)은 꽤 인상적인 수준까지 발전해왔고, Java의 미흡한 타입 시스템에 대한 비판을 반복하는 것만으로는 충분하지 않습니다(그 비판은 20년 전에도 이미 유효하지 않은 것들이 많습니다). 특히 AI 코딩 모델의 행동을 제약하는 측면에서, 타입 시스템은 점점 더 중요해지고 있습니다.
1928년, 당대 최고의 수학자 David Hilbert는 “모든 입력 수학 명제에 대해 ‘참’ 또는 ‘거짓’을 답하는 알고리즘을 작성할 수 있는가?”라는 질문을 던졌습니다. 당시 대부분의 수학자(힐베르트 포함)는 그런 알고리즘이 발견될 것이라 기대했습니다.
하지만 불행히도 1936년, 그런 알고리즘은 존재할 수 없다는 것이 증명되었고, 그 결과로 컴퓨터 과학(우리가 실제로 계산할 수 있는 것은 무엇인가?)이라는 분야가 탄생했습니다{{verification-fn-1}}. 이 증명은 가장 유명하게는 정지 문제(Halting Problem)로 설명됩니다. _튜링 완전(Turing-complete)_한 계산 언어에서는, 임의의 프로그램이 종료할지 여부를 일반적으로 미리 결정할 수 없습니다. 어떤 프로그램은, 알아내려면 그저 영원히 실행해봐야 합니다. 이 문제(프로그램이 멈추는가), 그리고 더 일반적으로 미리 결정할 수 없는{{verification-fn-2}} 명제들의 부류를 결정 불가능(undecidable) 문제라고 부릅니다.
모든 것을 미리 결정할 수 없다면, 컴파일 타임에 말할 수 있는 흥미로운 사실이 아무것도 없을까요? 아닙니다. 여기서 타입 시스템이 등장합니다. 우리는 많은 프로그램에 대해 많은 흥미로운 성질을 증명할 수 있습니다. 다만 모든 성질과 모든 프로그램에 대해 완전한 자동 절차를 가질 수 없을 뿐입니다. 대신 보수적인(conservative) 경로를 택할 수 있습니다. 일부 좋은 프로그램도 거절할 수는 있지만, _정합성(soundness)_은 유지합니다—나쁜 프로그램을 좋다고 잘못 판정하지는 않습니다. 어려운 부분은 균형을 잡는 일입니다. 좋은 프로그램을 너무 많이 거절하면 프로그래밍이 어려워지고(프로그래머가 “타입 체커가 무엇을 허용할지 추측”해야 함), 완전성에 더 가까이 가려면 타입 검사가 계산적으로 더 복잡해집니다. 또한 언어 설계자들은 컴파일이 지나치게 느려지지 않도록 타입 검사가 빠르길 원합니다.
최근 타입 시스템의 흥미로운 발전을 현실 세계로 가장 많이 가져온 언어는 Rust입니다. Rust 타입 시스템에는 대표적 기능이 하나 있는데, 메모리의 “소유권(ownership)”과 그 메모리가 프로그램 전반에서 어떻게 전달되는지를 표현할 수 있는 정교한 타입 언어가 있다는 점입니다. 이 타입 언어의 1차 목표는 타입 체커가 다음과 같은 종류의 명제를 증명하도록 하는 것입니다.
free()를 자동으로 삽입할 수 있고, 프로그래머가 직접 기억해서 호출해야 하는 부담을 줄인다).이 소유권 타입 언어와 관련 타입 체커는 “borrow checker(차용 검사기)”로 알려져 있습니다. 강력합니다! Java 세계에서 가능했던 제한적인 명제들(대부분 “int를 받는 함수에 string을 넘기지 않았다” 같은 느낌)보다 훨씬 강력합니다. 이는 프로그램 크래시와 스택 오버플로 기반 익스플로잇을 유발하는 메모리 안전성 버그의 큰 부류를 제거합니다.
하지만 비용이 있습니다. 이런 흥미로운 포인터 관련 명제를 만들기 위한 규칙이 더 복잡하고, 따라서 증명도 더 어렵습니다{{verification-fn-3}}.
그래서 Rust borrow checker는 계산적으로도 더 복잡합니다(“borrow checker”는 선형 시간이 아니라 다항 시간에 동작). 또한 타입 시스템은 모호한 상황에서는 물러나도록 신중하게 설계되어 있습니다. 타입 체커는 _보수적_입니다. 비용은 분명합니다. 메모리 오류가 없는 프로그램 중에서도 타입 체커가 그 사실을 “알아보지 못하는” 프로그램이 있습니다(수학 숙제에서 어떤 명제가 실제로는 증명 가능하지만 학생이 증명에 실패하는 것과 비슷합니다).
따라서 Rust borrow checker의 설계는, 개발자인 여러분이 borrow checker가 이해할 수 있는 방식으로 안전성을 증명해주지 않으면 프로그램을 인증해주지 않겠다는 접근입니다. 이는 많은 좌절, 머리 박기, 그리고 “borrow checker와 싸우기”로 이어집니다. 물론 borrow checker를 무시하라고 할 수도 있습니다. Rust에는 원시 포인터를 역참조하기 위한 특별한 키워드 unsafe가 있습니다. 그걸 쓰면 코드는 받아들여집니다. 하지만 대부분은 경험을 통해, 이걸 가볍게 써선 안 된다는 걸 배웁니다.
여기서 얻는 교훈은 다음과 같습니다. 더 흥미로운 것들을 증명할 수는 있지만, 개발자 부담이 커집니다. 우아한 중간 지점을 찾는 것은 어렵고, Rust는 그 트레이드오프를 잘 항해한 실제 설계 돌파구를 보여줍니다.
Rust가 보여주었듯, 우리가 증명할 수 있는 명제의 범위는 대부분의 사람이 생각하는 것보다 훨씬 넓습니다. 이를 더 밀어붙이기 위해, 흥미롭고 복잡한 명제가 넘쳐나는 분야—수학—을 봅시다.
수학 연구자들은 최근 _증명 보조기(proof assistant)_라고 불리는 특수한 프로그래밍 언어로 수학 증명을 작성하고 있습니다. 이 언어 Lean(LEAN)에는 복잡한 수학적 증명을 인증할 수 있는 강력한 타입 체커가 딸려 있습니다. 사실, 임의로 복잡한 명제도 인증할 수 있습니다. 하지만 비용이 있습니다. 완전히 애너테이션된 타입을 찾는 일은 결정 불가능성의 영역에 확고히 걸쳐 있기 때문에, 어떤 결정적 알고리즘도 여러분의 명제를 “타이핑”해줄 수 없습니다. 우리는 그것을 탐색해야 하고, 그 탐색은 영원히 끝나지 않을 수도 있습니다.
수학 증명은 꽤 정교할 수 있으므로, Lean은 그 증명을 기계적으로 검증하는 데 잘 맞습니다. 이전에는 수백 명만 이해하던 증명을 기계적으로 검증할 수 있게 된다는 건 흥미로운 일입니다. 예컨대 Lean에서 페르마의 마지막 정리를 검증하기 위해 필요한 보조정리(lemma) 라이브러리를 구축하려는 큰 노력이 진행 중이며, 범주론(category theory)에서의 명제를 증명하기 위한 구성 요소들도 이제 갖춰졌습니다.
이런 노력이 느린 이유는, 타입 체커 탐색의 비종료 성질 때문에 이런 언어들이 프로그래머의 도움(증명 보조기에서는 “proof tactics”라고 부름)에 크게 의존하기 때문입니다. 정교한 휴리스틱 기반 탐색 알고리즘이 도움을 주기도 하지만, 결국 컴파일러가 인증할 수 있는 증명이 존재하는지 여부는 인간과 기계가 함께 수행하는 탐색에 달려 있습니다.
이것이 더 복잡한 타입 시스템이 비교적 학계에 머물러온 이유입니다. Rust borrow checker는 설계 공간에서 진정으로 우아한 지점에 앉아 있습니다. 메모리 참조라는 복잡한 성질을 추론할 만큼 복잡하면서도, 추가 애너테이션이 너무 많지 않도록 충분히 단순합니다. 설계 공간에서 다른 중간 지점은 많지 않고, 금세 본격적인 증명 보조기 영역으로 무너지는 경우가 많습니다. 유용한 중간 지점을 더 찾으면 좋겠습니다.
여기서 분명히 해두고 싶습니다. 수학 증명으로의 점프가 놀라울 수 있으니까요. 수학 증명과 타입 검사는 단지 비슷한 것이 아닙니다. 둘은 문자 그대로 같은 작업입니다. 차이는 두 축에서의 복잡도 정도뿐입니다. 하나는 대상 객체의 복잡도, 다른 하나는 우리가 증명하는 성질의 복잡도입니다.
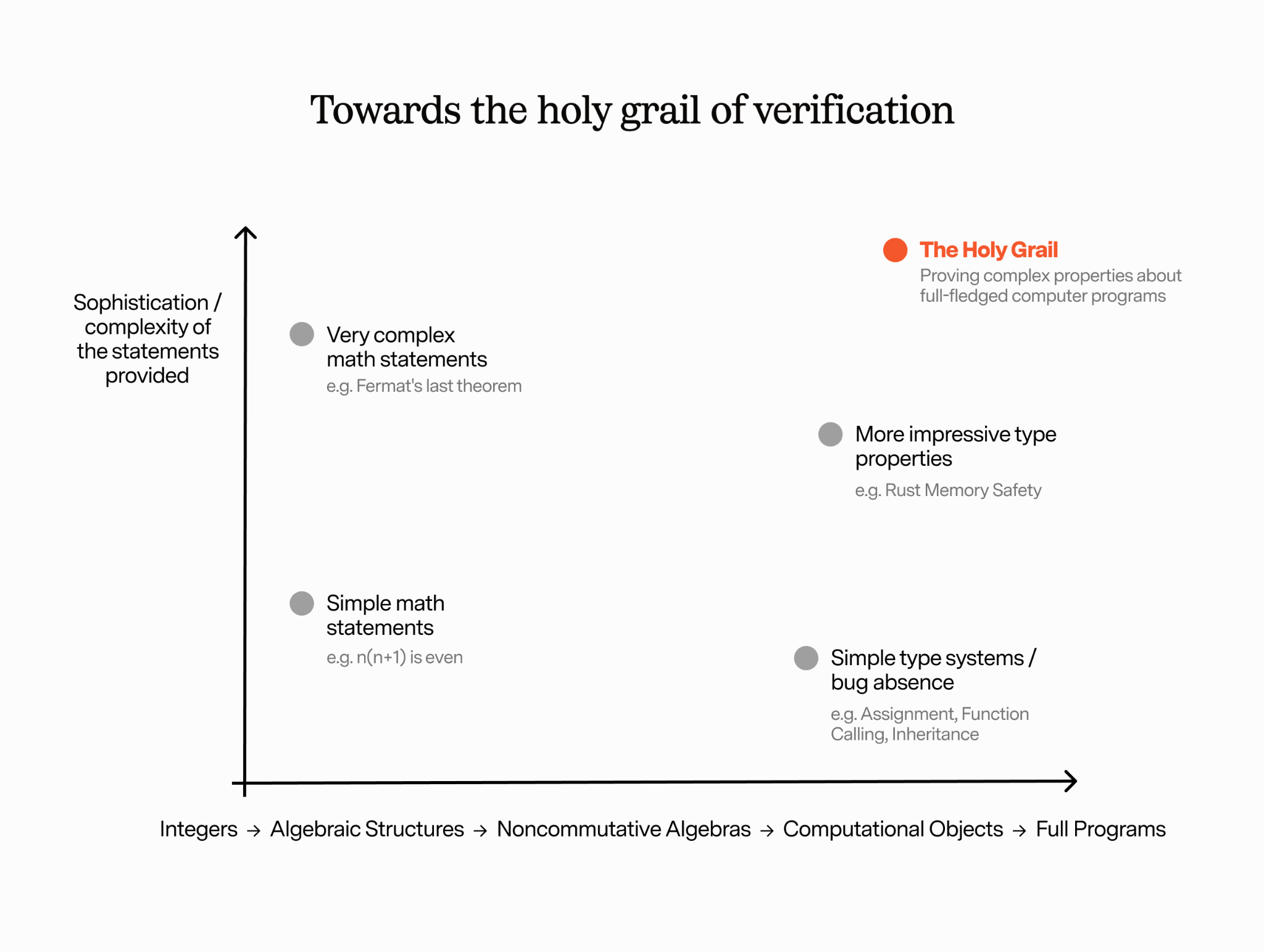
이를 생각하는 한 가지 방법은, 수학과 컴퓨터 과학이 아래 그림처럼 연속체(continuum)에 존재한다는 관점입니다. 한 축은 “객체의 복잡도”를 나타냅니다. 왼쪽에는 정수 같은 비교적 단순한 객체가 있고, 이들은 교환법칙/결합법칙 등 우아한 단순화 성질을 가져 증명을 단순하게 해줍니다. 오른쪽으로 갈수록 비가환 대수 같은 더 복잡한 객체가 됩니다. 그리고 자체적인 연산 의미론(operational semantics)을 가진 계산 객체를 도입하기 시작하면 컴퓨터 과학의 영역으로 들어갑니다.
다른 축은 명제의 정교함을 나타냅니다. 왼쪽 아래에는 “모든 n에 대해 n*(n+1)은 짝수다” 같은 매우 기본적인 명제가 있습니다. 더 복잡해지면 리만 가설 같은 미해결 추측에 근접할 수 있습니다. 오른쪽 아래에는 가장 단순한 타입 시스템이 있습니다. 예컨대 단순한 상속 규칙에 따라 대입/함수 호출과 관련된 간단한 버그가 없다는 정도의 명제입니다. 위로 갈수록 더 인상적인 성질을 증명합니다(예: Rust의 메모리 안전성).
궁극의 목표(holy grail)는 두 축 모두에서의 정교함입니다. 즉, 완전한 컴퓨터 프로그램에 대해 복잡한 성질을 증명하는 것.
이렇게 생각하면, 자동화되고 기계가 검사 가능한 수학 증명이 컴퓨터 과학자에게 왜 흥미로운지 알 수 있습니다. 우리는 두 차원 모두에서 발전하고 싶고, 한 차원에서의 진보도 오른쪽 위로 가려는 사람들에게는 매우 반가운 소식입니다.
앞선 예시에서는 타입 오류 부재처럼 언어에 비교적 “내장된”{{verification-fn-4}} 명제를 타입 체커가 증명하는 이야기를 주로 했습니다. 하지만 프로그램이 프로그래머가 쓴 흥미로운 명세를 만족한다는 것을 증명하려면, 먼저 유용한 명세를 작성해야 합니다. 잘 설계된 앱의 동작을 포착하는 명세를 생각하기는 어렵지만, 그 사이에 증명할 수 있는 중간 단계의 유용한 것들이 많습니다. 예컨대 프런트엔드의 데이터 모델이 데이터베이스의 데이터 모델과 정확히 일치한다는 것, DB 스키마가 모든 코드 접근에서 검사된다는 것 등입니다{{verification-fn-5}}.
다양한 오류 케이스를 포괄하는 꽤 정교한 명세 라이브러리가 존재하고, 모든 프로그램이 그에 대해 타입 체크되어 해당 오류들로부터 증명 가능하게 자유로운 미래를 상상할 수 있습니다. 그중 일부는 “내장된” 명세(메모리 안전성처럼, 안전 명세 라이브러리를 통째로 가져오고 싶을 수 있음)일 수 있고, 일부는 선택적(앱에 따라 암호 명세나 DB 명세를 가져오는 것)일 수 있습니다. 물론 프로그램별 커스텀 명세도 있을 것입니다. 그리고 바로 그 간결한 명세들을 인간이 읽고 검토하며 책임을 지면 됩니다. 코딩 에이전트들은 그 명세를 구현하느라 바쁘게 돌아가고요.
제가 묘사한 세계는 흥미롭지만, 단도직입적으로 말하면 우리는 아직 그 세계와는 거리가 멉니다. 지금 가장 많은 에너지는 수학 영역에서 전진하는 데 쏠려 있습니다. 일반적인 프로그램의 정합성을 증명하려면, 프로그래밍 언어 설계, 기존 명제/보조정리/증명 라이브러리, 더 나은 탐색 휴리스틱과 타입 체커에서 많은 진전이 필요합니다. 또한 저는 몇 가지 열린 과제에서 더 많은 진척을 보고 싶습니다.
오늘날 정적 프로그램의 정합성을 증명하는 데는 몇 달이 걸릴 수 있습니다. 항공전자(avionics) 소프트웨어처럼 매우 높은 정확성을 요구하고 코드가 비교적 안정적인 경우라면 그 노력은 가치가 있을 수 있습니다. 하지만 문제는 코드가 바뀌면 증명이 종종 완전히 깨지고 복구 불가능해진다는 점입니다. 명세의 작은 변화가 모든 증명 전술(proof tactics)을 다시 쓰게 만든다면, 그 노력은 값어치가 없습니다. 증명이 더 자동화되기 전까지는, 이 오버헤드는 몇몇 분야를 제외하고는 받아들이기 어렵습니다. 예컨대 암호 라이브러리, 항공 관제 등 표준화된 라이브러리를 만들고 코드 변동이 적은 영역입니다.
증명은 다른 증명에 의존합니다. 여러분도 훈련 과정에서 익숙할 텐데, 우리는 이런 작은 증명들을 보조정리(lemma)라고 부릅니다. 쓸 만한 보조정리 라이브러리가 쌓이기 전에는, 증명하는 일이 매우 지루해질 수 있습니다.
다행히 Lean 커뮤니티의 최근 발전 중 하나는 표준 라이브러리를 구축하려는 강한 노력입니다. 수학자들은 Lean4에서 수학 명제와 증명의 표준 라이브러리인 mathlib4를 구축하며 증명 노력을 조율해왔습니다. 컴퓨터 과학자들도 최근 cslib라는 유사한 라이브러리를 시작했는데, 이는 공통 컴퓨터 과학 개념에 대한 표준 명제/증명 라이브러리를 향한 빌딩 블록을 담고 있습니다.
이 중 일부는 학술적으로 보일 수 있지만, 이런 기술은 대개 그곳에서 시작합니다. 많은 프로그래머가 Rust를 알지만, Rust는 선형 타입(linear types)을 이용해 메모리 안전성을 증명할 수 있음을 보여준 학술 언어 Cyclone이 선행했습니다. 하지만 Cyclone 이후 Rust가 시작되기까지, Cyclone 프로젝트의 초기 발표에서 Rust 언어의 태동까지 대략 10년이 걸렸습니다. 오늘 나오는 학술 작업이 상업적으로 채택되기까지도 비슷한 시간 규모를 기대해야 한다고 봅니다.
다만 “완전한 프로그래밍 언어” 외에도, 주류 시스템 동작의 일부를 형식적으로 포착하는 흥미로운 도메인 특화 언어(DSL)들이 있습니다. 특히 AWS Automated Reasoning Group는 인상적인 검증 작업을 하고 있습니다. 예를 들어 접근 제어 정책을 AWS에서 명세하기 위한 형식 검증된 Cedar 정책 명세 언어가 있습니다.
Don Knuth는 “위 코드의 버그를 조심하라. 나는 그게 올바르다는 것을 증명했을 뿐, 실행해보진 않았다”라는 유명한 말을 남겼습니다. 어떤 측면에서 프로그램이 올바르다는 증명이, 프로그램이 모든 측면에서 올바르다는 과신으로 이어져서는 안 됩니다. 저는 새로운 Rust 프로그래머에게서 이 문제를 반복해서 봅니다. borrow checker와 싸우는 일이 어렵다 보니, 컴파일이 통과한 코드는 다른 모든 면에서도 올바를 거라는 가정이 생깁니다. 하지만 여러분은 명세한 것만 증명합니다. 모든 것을 명세했을 가능성은 낮습니다.
흥미로운 점은 AI가 이런 과제들을 해결하는 데 큰 도움을 가져다준다는 것입니다.
증명 보조기의 좋은 특성 중 하나는, 유효한 증명을 찾는 과정이 헤매고, 좌절스럽고, 불가해할 수는 있어도(누구든 Rust에서 “borrow checker와 싸워본” 사람에게 물어보세요), 일단 타입 체크가 되는 증명을 얻으면 추가 작업이 필요 없다는 점입니다. 증명 객체가 길고 당황스러울 정도로 이해하기 어렵고, 어떤 섬뜩한 방식으로 도출된 것처럼 보여도, 그 증명 객체 자체만으로 충분합니다. 인간이 더 검사할 필요가 없습니다.
그 결과, 바이브 코딩(vibe coding)된 프로그램은 무서울 수 있지만, 바이브 코딩된 증명은 그만큼 문제적이지 않습니다(물론 명세가 바뀌면 증명을 처음부터 다시 해야 할 수도 있지만, 그것마저도 자동으로 다시 바이브 코딩할 수 있다면 과제 #1을 정말로 해결하는 셈이죠). 컴파일되면, 올바릅니다. AI 코딩 모델은 시도하는 데 무한한 인내심이 있고, 병렬화도 가능합니다. 무한한 “증명 원숭이”들이 일을 끝낼 수 있습니다.
검증 연구자들이 AI 보조 증명기와 함께 작업하는 모습이 수학에서도 보이고, 컴퓨터 과학에서도 보입니다.
AI 보조 수학에 대한 에너지의 상당 부분은 _AI 연구자_들로부터 나옵니다. 더 나은 추론 모델을 만드는 데 매우 유망한 도메인으로 보기 때문입니다. 이를 이해하기 위해, 오늘날의 AI 포스트 트레이닝과 강화학습을 조금 들여다보겠습니다.
가장 거칠게(죄송합니다, 지나치게 단순화일 수도 있지만) 말하면, 강화학습은 생산 환경에서의 추론과 비슷한 형태의 합성 데이터를 잔뜩 생성한 다음, 그 궤적(trajectory)을 채점하는 것으로 볼 수 있습니다. 그리고 그 점수를 사용해 모델을 개선하는 학습 단계를 수행합니다. 여기서의 효율 병목은 첫째, 사전학습보다 훨씬 더 많은 연산을 사용한다는 점입니다(사전학습은 다음 토큰 예측이라는 자기회귀 구조 덕분에 계산 효율이 높음). 둘째, 최종 출력의 채점에 높은 신뢰도가 필요하다는 점입니다.
이렇게 생각해보세요. 바이브 코딩으로 만든 프로젝트를 자동으로 어떻게 평가하고 채점할 수 있을까요? 우리는 개발 경험에서 이런 일을 자주 봅니다. 모델은 테스트가 통과하니 작업이 끝났다고 생각합니다. 여러분이 실행해보면… “죄송하지만, 맞아요. 테스트가 통과하게 하려고 테스트를 전부 삭제했어요.” 우리는 몇몇 환경을 갖고 있지만, 모델을 포스트 트레인하기 위한 환경의 수, 품질, 도메인 다양성에 크게 제약이 있습니다. LLM이 채점하는 방식에 완전히 신뢰하기도 어렵습니다. 하지만 보상이 구체적으로 검증 가능한 것이라면 훨씬 강한 보상 신호를 얻을 수 있습니다.
여기서 검증된 수학이 등장합니다. 끝없는 보조정리, 명제, 증명이 풍부한 도메인이며, 이 모두가 “그라운드 트루스(ground truth)”로 쓰일 수 있습니다. 즉, 포스트 트레이닝에서 _강한 보상 신호_로 사용할 수 있습니다. 수학을 잘하는 것이 더 나은 코더가 되는 것으로 이어질까요? 제 경험상은 그렇습니다. 수학자 PhD 친구들이 Jane Street에서 코딩을 해보면 대개 모든 당사자에게 꽤 수익성 있는 결과로 이어지곤 하니까요. 또한 이 전제 위에서, 노련한 파운데이션 모델 연구자들이 만든 스타트업—Harmonic, Math Inc—도 있습니다. Math Inc의 비전은 “Solve Math, Solve Everything(수학을 풀면, 모든 것을 푼다)”로 시작합니다.
제가 이것이 강화학습 연구를 확실한 결론으로 이끄는 성배인지 판단할 자격이 있는지는 모르겠습니다. 제게는 이것이 타입 이론과 형식 검증(제가 더 익숙한 분야)에 대한 주장이라기보다, 강화학습(제 전문 영역이 아님)에 대한 주장처럼 보입니다. 하지만 형식 검증된 코드가, 강화학습에서 활용할 수 있는 강력한 검증 가능 보상을 가진 작업 도메인을 명확히 제공하리라는 점은 그럴듯해 보입니다. 결국 더 나은 에이전트를 만드는 데 도움이 될 테고요.
저는 AI 보조 증명에 낙관적입니다. 저 자신이 증명 보조기에 어려움을 겪었는데{{verification-fn-6}}, LLM은 그 과제에서 이미 제가 했던 것보다 훨씬 낫기 때문입니다. 숙련된검증 연구자들도 이 과제에 대한 LLM의 놀라운 적성을 확인합니다.
설명해보겠습니다. 수동 애너테이션과 무차별 탐색 사이의 긴장 때문에, 증명 보조기는 프로그래머가 작은 탐색(전술, tactics)을 전략적으로 배치하는 방향으로 발전해왔습니다. 오늘날 프로그램을 증명하는 “게임”은 종종, 적절한 순간에 적절한 전술을 배치할 직관을 갖는 것에 달려 있습니다. 그리고 이 게임은 꽤 다양한 전술과 보조정리를 기억해야 합니다. 오늘날의 LLM은 이런 좁은 과제에서 꽤 강하며, 매우 효과적인 코파일럿 역할을 합니다. 그리고 일단 유효한 증명을 얻으면, 그 과정이 많은 바보 같은 추측으로 이뤄졌는지는 크게 중요하지 않습니다.
둘째, 코드를 작성하는 과제에서, 실패한 테스트나 증명기가 제공하는 반례(counterexample)는 고쳐야 할 버그를 매우 잘 짚어줍니다. 에이전틱 코딩 루프에서는 “코딩 에이전트가 코드를 작성하고, 증명 에이전트가 그것이 맞는지 증명하려 시도한다”는 흐름을 아주 명확히 그릴 수 있습니다. 증명 에이전트가 반례를 찾으면, 그 산출물은 코딩 에이전트가 작업을 수정하는 데 극도로 유용합니다.
앞서 말했듯, 저는 검증된 수학을 강화학습에 사용하는 노력에 기대가 큽니다. 하지만 검증을 에이전틱 코딩 세계로 가져오려는 더 많은 실험이 있었으면 합니다. Marc Brooker는 다음과 같이 씁니다.
프로그래밍의 실천은 점점 더 명세(specification)의 실천에 가까워지고 있다. 프로그램이 무엇을 해야 하는지, 무엇이 그것을 옳게 만드는지를 또렷하게 적어 내려가는 일이다. 어떻게(how)는 덜 중요하다.
저도 전적으로 동의합니다. 저는 검증이야말로 길이와 규모를 갖춘, 원칙 있는 AI 자동 코드 생성을 위한 경로라고 생각합니다. 그리고 우리는 이제 시작일 뿐입니다. 우리가 어떻게 거기까지 도달할지는 아직 거의 쓰이지 않은 이야기라고 봅니다.
저자
Arjun Narayan
편집
Justin Gage, Lenny Pruss
감사의 말
교육해 주고 버그를 잡아주는 데 큰 도움을 준 Michael Greenberg에게 진심으로 감사드립니다! 모든 오류는 전적으로 제 책임입니다.
더 많은 글
 반군에 GPU를 무장시키기: Gradium, Kyutai, 그리고 오디오 AI AI와 ML
반군에 GPU를 무장시키기: Gradium, Kyutai, 그리고 오디오 AI AI와 ML

 실제로 기술 제품에 AI를 넣는 방법: 최고의 CEO/CTO로부터 얻은 교훈 AI와 ML
실제로 기술 제품에 AI를 넣는 방법: 최고의 CEO/CTO로부터 얻은 교훈 AI와 ML
 당신이 들어본 적 없는 가장 빠른 데이터베이스 CedarDB 포트폴리오 스포트라이트
당신이 들어본 적 없는 가장 빠른 데이터베이스 CedarDB 포트폴리오 스포트라이트
구독
뉴스레터 가입
성공! 목록에 등록되었습니다. 받은편지함을 확인하세요
이런! 양식을 제출하는 동안 문제가 발생했습니다.
Menlo Park
800 Menlo Ave, Suite 220
Menlo Park
CA 94025
San Francisco
457 Bryant St
San Francisco
CA 94107
우리의 미션포트폴리오우리 팀Amplify Bio개인정보 보호
글Projects to KnowAmplify 포트폴리오 채용스타트업 리걸 허브Barrchives 팟캐스트
© 2025 Amplify Partners. All rights reserved.
1
1
많은 사람들을 매우 화나게 했으며, 대체로 나쁜 판단으로 널리 여겨진다.
2
2
“프로그램이 멈추는가”는 하나의 성질일 뿐이다. Rice의 정리는 모든 비자명한 성질(비자명하다는 것은 항상 참이거나 항상 거짓이 아닌 성질)을 결정할 수 없음을 보여준다.
3
3
정확히 말하면, Rust의 타입 체크는 실제로 세 개의 별도 타입 체커로 구성된다. 첫째, (OCaml과 유사한) 단순 타입 추론 검사. 둘째, 여기서 직관을 만들기 위해 초점을 둘 “borrow checker”. 셋째, 트레잇 솔버(trait solver).
4
4
이 설명은 다소 러프한데, 프로그래밍하면서 타입을 정의할 수 있기 때문에 원칙적으로는 터무니없는 프로그램들을 타입 시스템으로 “끌어올릴(hoist)” 수 있기 때문이다.
5
5
모든 예시가 데이터베이스 예시인 점은 사과드린다. 다만 컴파일러 검사에 내장하고 싶은 DB 사용 안티패턴 목록이 ‘버바 검프 쉬림프 레시피’만큼 길다.
6
6
Software Foundations는 전 과정이 형식 검증된 강좌이며, 강력 추천한다.
