최근 AMD 및 Intel 프로세서의 AVX-512와 IFMA 명령을 활용해 64비트 정수를 매우 빠르게 10진 문자열로 변환하는 방법을 소개합니다.
64비트 정수를 10진 문자열 표현으로 변환하는 일은 흔하고도 평범한 작업입니다. 로깅, JSON 직렬화, CSV 출력, 디버그 출력 등 어디에나 등장합니다. C++에서는 std::to_chars, sprintf, 또는 어떤 라이브러리 루틴을 사용할 수 있습니다.
이 함수들은 어떻게 동작할까요? 높은 수준에서 보면, 이들은 10으로 반복해서 나눕니다. 정수 k에서 시작합니다. 이것을 10으로 나누고, 나머지를 마지막 자리 숫자로 사용합니다(값은 0 이상 9 이하입니다). 그런 다음 문자 0의 코드 포인트 값을 더해 ASCII 숫자를 얻습니다. 더 빠르게 하려면 100으로 나누고 조회 테이블을 사용하여 0 이상 99 이하의 값을 문자열에 대응시킬 수 있습니다.
지금까지는 좋습니다. 안타깝게도 이런 모든 최적화를 적용하더라도, 이 문자열 생성은 성능 병목이 될 수 있습니다. 더 잘할 수 있을까요?
최근 AMD 프로세서나 Intel 서버를 사용한다고 가정해 봅시다. 그러면 한 번에 8개의 64비트 정수를 곱할 수 있는 강력한 데이터 병렬 명령어(AVX-512)를 사용할 수 있습니다. 우리는 이런 명령어를 흔히 SIMD(single instruction multiple data)라고 부릅니다. 제 동료 Jaël Champagne Gareau와 저는 최근 바로 이 문제에 관한 새로운 논문을 발표했습니다. 제목이 모든 것을 말해 줍니다. Converting an Integer to a Decimal String in Under Two Nanoseconds.
코드에서 n / 100을 작성하면, 최적화 컴파일러는 이 연산을 곱셈 뒤의 시프트로 변환합니다. 이는 흔히 곱셈 역수로 설명됩니다. 일반적으로 n을 d로 나누는 연산은 역수를 근사하도록 고른 적절한 정수 c와 m에 대해 c/m ~= 1/d가 되도록 하여 c * n 또는 c * n + c를 m으로 나누는 연산으로 바꿀 수 있습니다. 우리는 종종 c * n + c를 fused multiply-add라고 부릅니다. m을 2의 거듭제곱으로 고르면 m으로의 나눗셈은 단순한 시프트가 됩니다. 그런 다음 m으로 나눈 나머지에 d를 곱하고 다시 m으로 나누면 원래 나눗셈의 나머지를 얻을 수 있는데, 이는 본질적으로 곱셈 뒤의 시프트입니다(Lemire et al., 2021).
최근 Intel 및 AMD 프로세서에서 제공되는 Integer Fused Multiply-Add(IFMA) 명령어를 이용하면 이를 매우 유용하게 활용할 수 있습니다. 이 명령어는 본질적으로 (c * n + c)/m의 8개 인스턴스를 한 명령으로 계산할 수 있게 해 줍니다. 식 (c * n + c)/m은 나눗셈 결과를 주지만, 우리에게는 나머지가 필요하므로 대신 (c * n + c)%m을 택하고, 여기에 제수를 곱해야 합니다.
AVX-512 명령어의 재미있는 점은 8개의 연산 각각에 대해 서로 다른 c와 서로 다른 제수를 사용할 수 있다는 것입니다. Intel intrinsic 함수를 사용하면 10^8보다 작은 값을 8자리 숫자로 변환하는 핵심 루틴은 다음과 같습니다:
__m512i to_string_avx512ifma_8digits(uint64_t n) {
__m512i bcstq_l = _mm512_set1_epi64(n);
constexpr uint64_t twoto52 = 0x10000000000000ULL; // 2^52
__m512i ifma_const = _mm512_setr_epi64(
twoto52 / 100000000, twoto52 / 10000000,
twoto52 / 1000000, twoto52 / 100000,
twoto52 / 10000, twoto52 / 1000,
twoto52 / 100, twoto52 / 10
);
__m512i zmmTen = _mm512_set1_epi64(10);
__m512i asciiZero = _mm512_set1_epi64('0');
__m512i lowbits_l = _mm512_madd52lo_epu64(ifma_const,
bcstq_l, ifma_const); // ifma_const * bcstq_l + ifma_const
__m512i highbits_l = _mm512_madd52hi_epu64(asciiZero,
zmmTen, lowbits_l);
return highbits_l;
}
이 코드는 두 개의 곱셈-덧셈 명령어 vpmadd52huq로 컴파일됩니다. 그게 전부입니다. 여덟 자리를 생성하는 데 명령어 두 개면 됩니다.
이는 n을 __m512i 벡터의 8개 64비트 레인 전체에 브로드캐스트하여(bcstq_l) 동작합니다. 그런 다음 10^8, 10^7, … 의 역수를 나타내는 신중하게 선택된 곱셈 역수 벡터(ifma_const)를 준비합니다. 핵심은 단일 _mm512_madd52lo_epu64 명령어에서 일어납니다. 이 명령어는 동시에 8개의 fused multiply-add를 수행합니다. 각 레인은 52비트 하위 절반 곱셈을 사용해 (ifma_const[i] * n + ifma_const[i])를 계산하고, 그 결과 해당 10의 거듭제곱으로 나눴을 때의 몫을 효과적으로 추출합니다. 이어서 두 번째 _mm512_madd52hi_epu64 명령어는(10의 벡터와 '0'의 벡터를 사용해) 숫자 값을 분리하고 상위 52비트에 ASCII '0' 오프셋을 더하여, 하나의 512비트 레지스터 안에 8개의 패킹된 숫자 문자를 만들어 냅니다.
모든 정수가 8자리를 필요로 한다면, 여기서 끝입니다. 하지만 일반적인 경우에는 이를 잘 활용하려면 약간의 노력이 필요합니다.
다행히 예를 들어 6자리만 필요하더라도 전체 8자리 계산을 수행한 다음, 6자리만 저장하고 남은 2자리는 무시하고 싶다면 masked store 를 사용할 수 있습니다. 즉, AVX-512 같은 명령어 집합은 메모리에 데이터 일부만 기록할 수 있게 해 주므로 매우 편리합니다.
우리에게는 두 가지 변형이 있습니다. 하나는 분기가 많은 방식으로, 균질한 데이터(자릿수 길이가 비슷한 수들)에서 잘 동작합니다. 다른 하나는 분기가 적은 방식으로, 혼합 워크로드에 더 적합합니다. 간단한 프로파일링 단계로 데이터셋에 맞는 쪽을 선택할 수 있습니다.
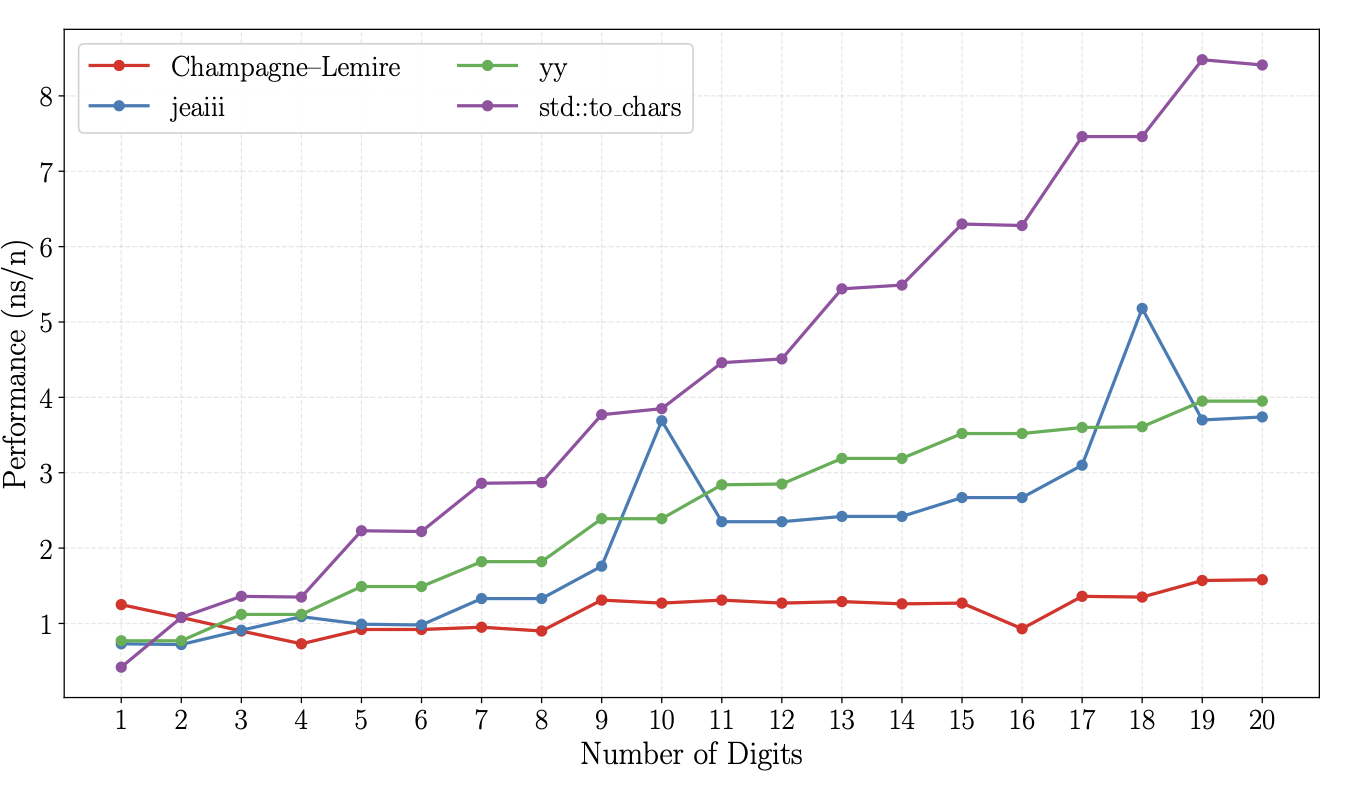
우리 구현은 다양한 입력 범위에서 최고의 경쟁자들보다 일관되게 1.4–2배 빠르며 std::to_chars보다 2–4배 빠릅니다. 제가 흥미롭다고 느끼는 점은 std::to_chars 구현이 전혀 순진하지 않음에도, 여러 방식으로 훨씬 더 나은 성능을 낼 수 있다는 것입니다. James Anhalt의 접근법(jeaiii) 역시 현대 하드웨어에서 상당히 빠릅니다.
추가 읽을거리
– 논문: doi:10.1002/spe.70079
– 벤치마크는 GitHub에 있습니다(완전히 재현 가능)
– 우리 논문이 온라인에 공개된 직후, Barend Erasmus가 우리가 제안한 접근법을 구현한 소프트웨어 라이브러리를 만들었습니다. Barend가 균질한 접근법과 이질적인 접근법을 모두 포함했는지는 저는 확실하지 않습니다.