μpack은 입력 메모리만 128개 요소 블록 크기에 맞춰 패딩하면 1~128개의 임의 길이 정수 시퀀스를 SIMD로 빠르게 비트패킹해, Stream VByte보다 높은 압축률과 초당 수십억 정수의 (역)압축 성능을 제공하는 라이브러리다.
효율적인 정수 압축은 어떤 검색 엔진, 컬럼형 파일 포맷, OLAP 워크로드 등에서든 핵심 구성 요소다. 또한 더 범용적인 LZ(Lempel–Ziv) 계열 데이터 압축기와 달리, SIMD 기반 최적화는 정수 압축 알고리즘을 한 자릿수 이상(orders of magnitude) 더 빠르게 만들 수 있는 경우가 많아, 단일 CPU 코어에서 초당 수십 GB의 정수 데이터를 압축/해제하기도 한다.
하지만 Daniel Lemire의 인기 라이브러리인 simdcomp 같은 기존 알고리즘은 SIMD 명령을 효율적으로 활용하기 위해 입력 정수들을 인터리브(interleave)하는 고정 크기 정수 블록을 요구한다. 그 결과, 고정 블록을 채우지 못하는 나머지 정수들에는 Google의 Varint-GB나 Daniel Lemire의 Stream VByte 같은 바이트 지향 압축 알고리즘이 흔히 사용되는데, 이들은 엄청나게 빠르긴 하지만 압축률이 상당히 떨어지는 경우가 많다.
여기서 μpack을 소개한다. μpack은 비트패킹(bitpacking) 라이브러리로, 입력 메모리만 128개 요소 블록 크기에 맞춰 패딩하면 되며, 1~128개 사이의 어떤 개수의 요소도 Stream VByte보다 더 효과적으로 압축하면서도 초당 수십억 개 정수를 (역)압축할 수 있다.
소스 코드와 예제: https://github.com/lnx-search/upack
순서를 유지한 채 정수를 단순하게(naively) 패킹하려고 하면, 루틴 성능과 그 안의 SIMD 연산을 최대화하면서 이를 구현하는 일이 쉽지 않다는 것을 바로 알게 된다.
simdcomp 라이브러리는 이 문제를 해결하기 위해 요소들을 수직으로 인터리브(vertically interleave)하는데, 이는 원래의 순서를 깨뜨리지만 SIMD 연산 효율을 크게 높인다.
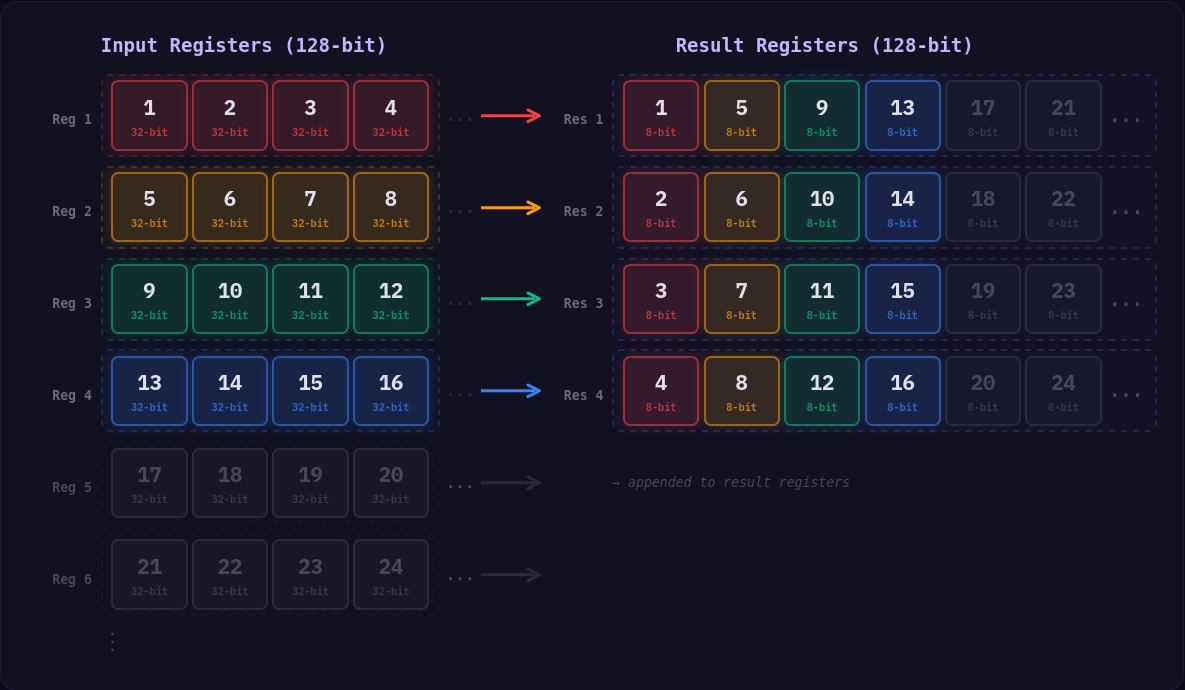
32비트 정수를 8비트 정수로 패킹할 때 simdcomp가 사용하는 수직 패킹(Vertical packing) 모습.
하지만 μpack에서는 패킹하려는 정수 개수가 가변적이기 때문에 조금 다른 접근이 필요하다. 이 기법을 쓰기 위해 패킹 전후로 모든 정수를 셔플(shuffle)하려고 하면, 추가 명령이 너무 많아져서 단순한 스칼라 구현보다 느려질 수 있다.
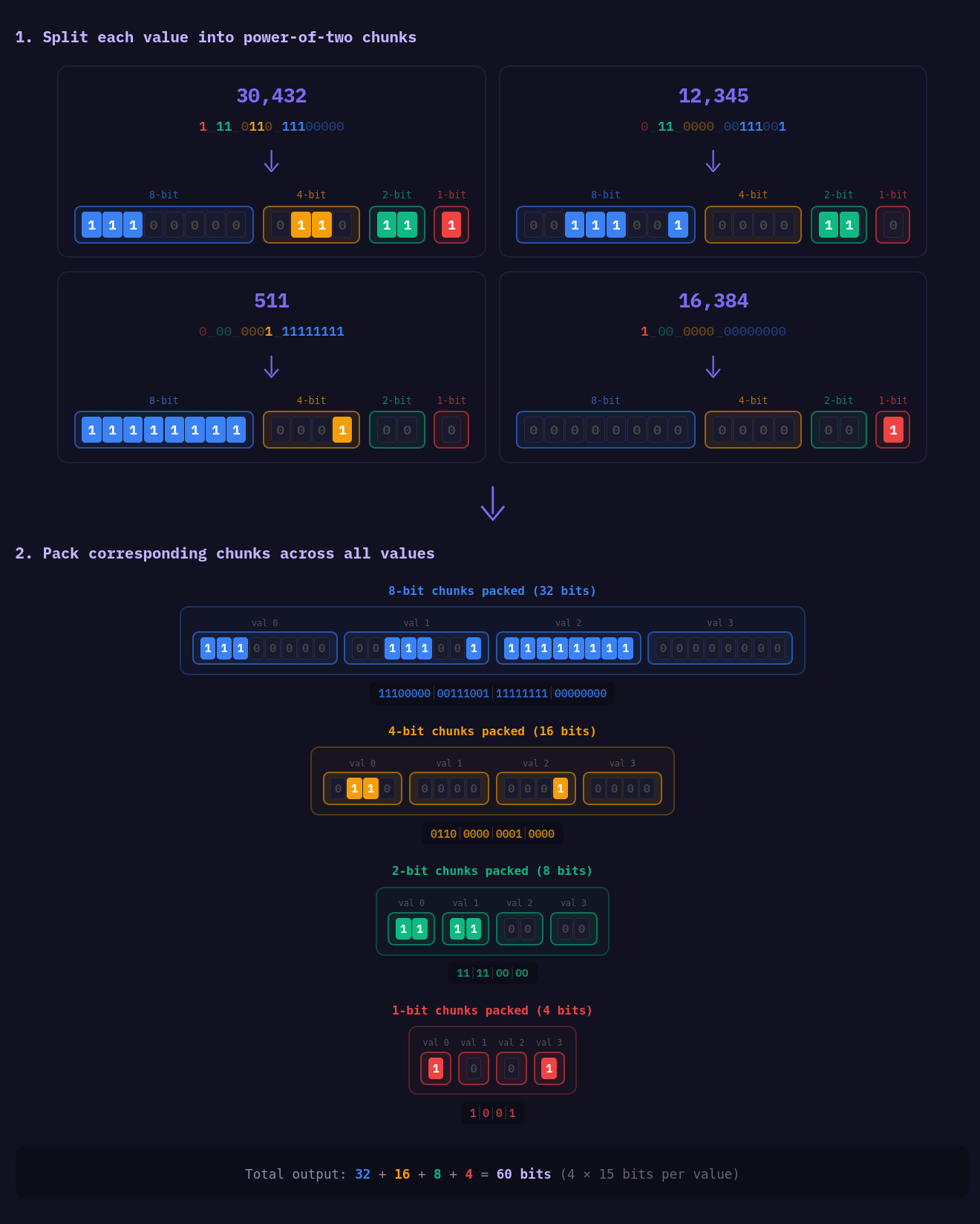
대신, 각 정수를 여러 “파트(part)”로 쪼개는데, 각 파트의 비트 수는 2의 거듭제곱(1, 2, 4, 8, 16, 32)이 되도록 한다. 우리가 지원하는 모든 SIMD ISA에는 이러한 비트 폭 간 변환을 효율적으로 수행하는 방법이 있기 때문이다. 예를 들어 AVX2에는 _mm256_packus_epi32가 있고, ARM의 Neon에는 vqmovun_s32가 있다. 이러한 명령들은 결과 레이아웃이 모두 동일하진 않지만(이는 뒤에서 다룬다), 핵심 파트로의 변환을 효율적으로 수행하는 데 쓸 수 있다.
예를 들어 입력 정수 30432의 이진 표현이
111_0110_1110_0000
라면, 다음과 같이 파트가 나뉜다.
1110_0000 - 정수의 첫 8비트0110 - 그 다음 4비트11 - 그 다음 2비트1 - 마지막으로 남은 1비트이 과정을 레지스터의 모든 레인(lane)에 적용한 다음, 각 레인의 동일 파트를 모아 압축 블록을 만든다. 이는 SIMD로 쉽게 할 수 있고, 무엇보다 결과 레지스터들 사이에 직접적인 데이터 의존성이 없이 수행할 수 있다.
아이디어 자체는 단순하지만, 실제 구현에서는 몇 가지 제약을 만나게 된다.
앞서 말한 제약 때문에, AVX2나 Neon에서는 128개의 32비트 정수를 한 번에 처리하면 레지스터가 부족해진다. 그래서 μpack은 정수들을 64개 단위의 서브블록(sub-block)으로 나눠 처리한다.
처음부터 64 블록이 계획이었던 건 아니다. 원래 구현을 만들 때 레지스터 제한을 깜빡했는데, AVX2 구현을 AVX512 머신(레지스터 32개 제공)에서 개발했기 때문이다.
또한 패킹 루틴을 두 가지 버전으로 구현한다. 하나는 전체(full) 블록 패킹, 다른 하나는 부분(partial) 블록 패킹이다. 이렇게 하면 요소 순서를 유지하는 오버헤드가 필요 없을 때 이를 제거할 수 있다.
그 결과, 명령어 세트(instruction set)별로 각 “파트”를 패킹하는 핵심 루틴이 12개 생긴다. 구현할 코드량은 늘어나지만, 전체 크기 블록의 성능을 희생하지 않고 유연성을 제공할 수 있다.
그 다음 128개 정수 블록 처리는 이 64개 서브블록 루틴들을 조합해 구현한다. 구체적으로:
64개 이하이면 pack_x64_partial 계열을 한 번 호출한다. 사용하지 않는 나머지 64개 요소에 대한 추가 처리를 없앤다.128보다 작으면 pack_x64_full 한 번과 pack_x64_partial 한 번을 호출한다. 최소 64개는 반드시 패킹해야 하므로 첫 서브블록은 절단(truncate)이 필요 없고, 뒤의 tail 서브블록만 순서 유지 상태에서 절단하면 된다.128이면 pack_x64_full을 두 번 호출한다.이 전략은 출력 블록에 패킹되는 정수 개수를 조정할 때 발생하는 성능 손실을 최소화한다.
정수의 특정 2의 거듭제곱 “파트”에 대한 압축 레이아웃은 비교적 단순하며 아키텍처나 ISA에 따라 바뀌지 않는다. 다만 “partial”과 “full” 서브블록, 그리고 각 파트의 비트 길이에 따라 달라진다.
Partial 서브블록은 요소의 순서를 유지하며, 이후 파트의 쓰기 오프셋(write offset)은 목표 정수 개수를 담는 데 필요한 마지막 바이트에서 시작한다.
이 방식은 정수 개수가 작을 때 각 파트가 “가장 가까운 전체 바이트 단위” 공간을 차지하기 때문에 압축 효율이 일부 손실될 수 있다.
예를 들어 32비트 정수 8191 하나를 13비트로 패킹하면 최적은 2바이트지만, 13비트 정수는 (8비트 + 4비트 + 1비트) 3개 파트로 쪼개지므로 3바이트가 소비된다.
Full 서브블록에서는 최적화를 위해 원래의 요소 순서를 유지하지 않고, 각 정수 “파트”에 대해 수직 패킹(vertical packing)을 수행한다.
기본적으로 AVX2/AVX512 등 하드웨어와 무관하게 512비트 연속 구간을 기준으로 정수 파트를 인터리브한다. 다만 작은 비트 길이는 약간 다르다.
⚠️
실제 구현은 정수 파트를 최종 비트 길이로 한 번에 줄이지 않고 단계적으로 줄인다. 그래서 실제 레이아웃은 약간 다르지만, 이 글에 다 담기에는 너무 길다. 코드(특히 유닛 테스트)를 읽어 기대 레이아웃을 확인하길 권한다.
출력에 포함되지 않을 정수들에 대해 연산량을 줄이긴 하지만, SIMD를 활용하면서 이 동작을 완전히 제거할 수는 없다. 따라서 제공된 배열에서 첫 번째 정수만 출력 블록에 포함하고 싶더라도, 최종 압축 블록에 담지 않는다고 해서 나머지 63개 정수 처리 비용이 완전히 사라지지는 않는다.
정확히 말하면, 이 구현의 효율은 대략 다음과 같다.
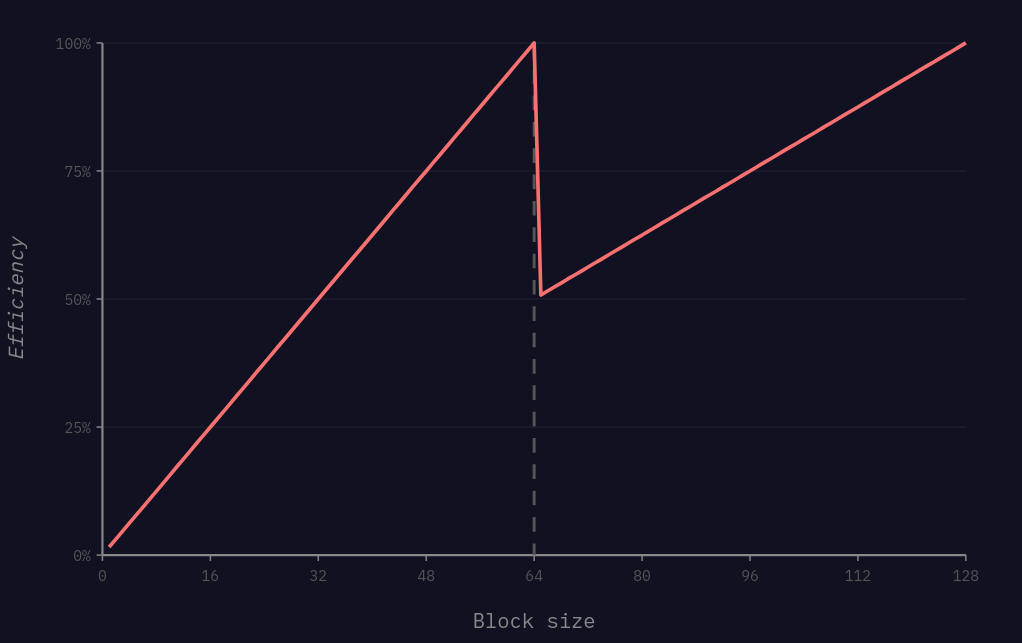
1~64개 정수 구간에서는 요소 수가 증가함에 따라 효율이 선형적으로 증가한다. 이는 고정 비용으로 계산되는 출력 중 더 큰 비율을 사용하게 되기 때문이다.
그리고 64개를 넘으면 시스템이 두 개의 서브블록 루틴을 디스패치하기 시작하면서 효율이 다시 한 번 떨어진다. 다만 이전 64개 서브블록은 full-block 루틴으로 처리되기 시작하고, 루틴 조회(lookup) 및 호출 자체의 고정 오버헤드가 있어 정확히 50% 감소는 아니다.
이 접근을 실제로 구현한 Rust 코드는 약 21,000줄이며, uint32 지원을 위해 Scalar, AVX2, AVX512, Neon 루틴을 포함한다. 또한 검색 엔진의 포스팅 리스트(posting lists)와 위치 데이터(positions)에서 흔히 쓰이는 delta 및 delta-1 변형도 제공한다.
서로 다른 ISA마다 적용되는 모든 최적화를 다 설명하기에는 글이 너무 길어지므로, 몇 가지 하이라이트만 짚겠다.
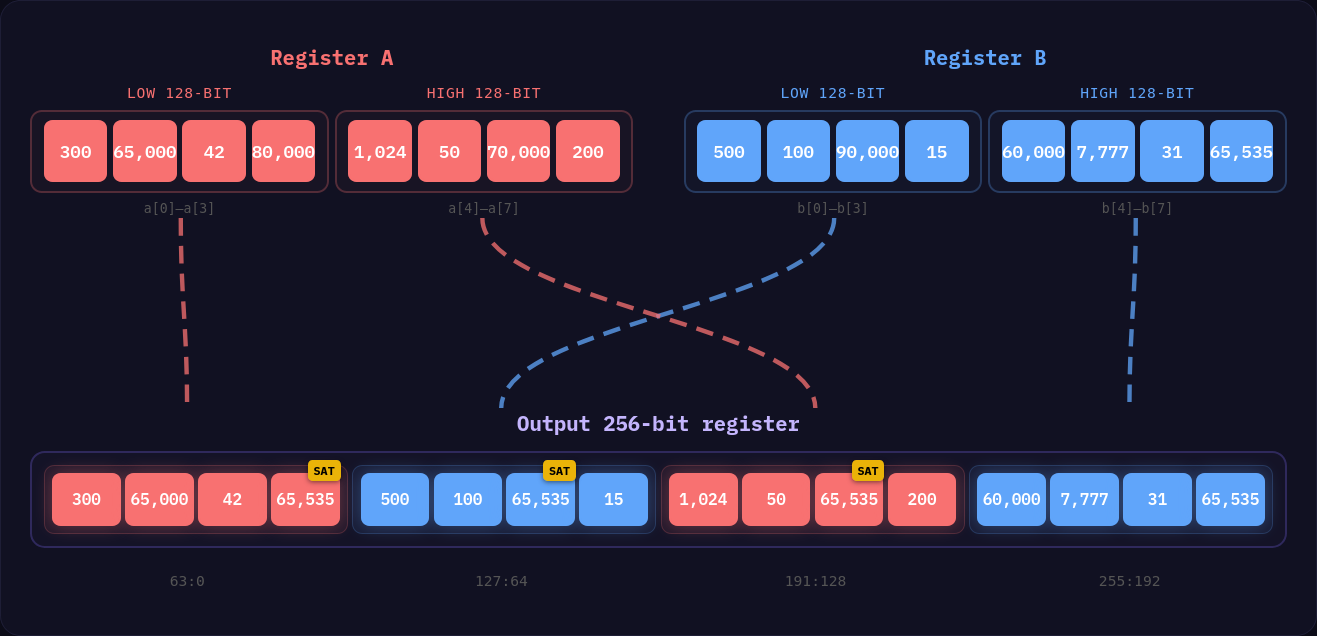
AVX2 또는 AVX512가 활성화된 x86 머신에서는 partial 루틴에서 pack 계열 명령을 활용한다. 이는 두 레지스터 세트를 하나의 레지스터로 패킹하며, 각 레인의 크기는 원래의 절반이 된다.
이 명령은 128비트 블록 단위로 동작하며, 출력에서 레지스터 A와 B의 결과가 번갈아 인터리브된다. 매우 효율적인 명령으로 셔플을 단순화한다. 예를 들어 32비트 정수를 8비트로 패킹할 때는 32비트 레인만 필요(128비트 -> 64비트 -> 32비트)하고, 16비트로 패킹할 때는 64비트 레인만 필요하다.
반면 Neon에는 이 명령의 직접적인 대응이 없지만, 더 작은 정수로 변환한 뒤 64비트 출력 레지스터를 다시 128비트로 결합하는 명령이 있어 결과 셔플을 피할 수 있다. 따라서 여기서 Neon과 AVX2의 성능 차이는(레지스터 폭이 작아 Neon 명령 수가 더 늘어나는 점을 제외하면) 크게 나지 않을 수도 있다.
#[target_feature(enable = "neon")]
/// 두 개의 [u32x8] 레지스터를 128비트 블록 단위로
/// 부호 없는 16비트 정수로 패킹
pub(super) fn _neon_pack_u32x8(a: u32x8, b: u32x8) -> u16x16 {
let a_lo = vmovn_u32(a[0]);
let a_hi = vmovn_u32(a[1]);
let b_lo = vmovn_u32(b[0]);
let b_hi = vmovn_u32(b[1]);
let r1 = vcombine_u16(a_lo, b_lo);
let r2 = vcombine_u16(a_hi, b_hi);
u16x16([r1, r2])
}요소 순서를 유지하면서 니블(4비트)을 패킹하는 일은 까다로울 수 있다. x86에서 요소들을 인터리브한 뒤 셔플로 복원하려 하면 매우 복잡하고 비싸지기 때문이다. 다행히 다음과 같은 트릭을 쓸 수 있다.
순서가 유지된 8비트 정수 집합이 있을 때, 이를 16비트 정수로 해석한 다음, _mm512_maddubs_epi16 (또는 AVX2의 _mm256 대응)와 0x1001 마스크를 결합하면, 인접한 니블 쌍을 하나의 16비트 정수로 합칠 수 있다. 이후 이를 8비트로 쉽게 변환하면 패킹된 니블을 얻는다.

이 마스크는 각 니블에 대한 시프트 연산처럼 동작한다.
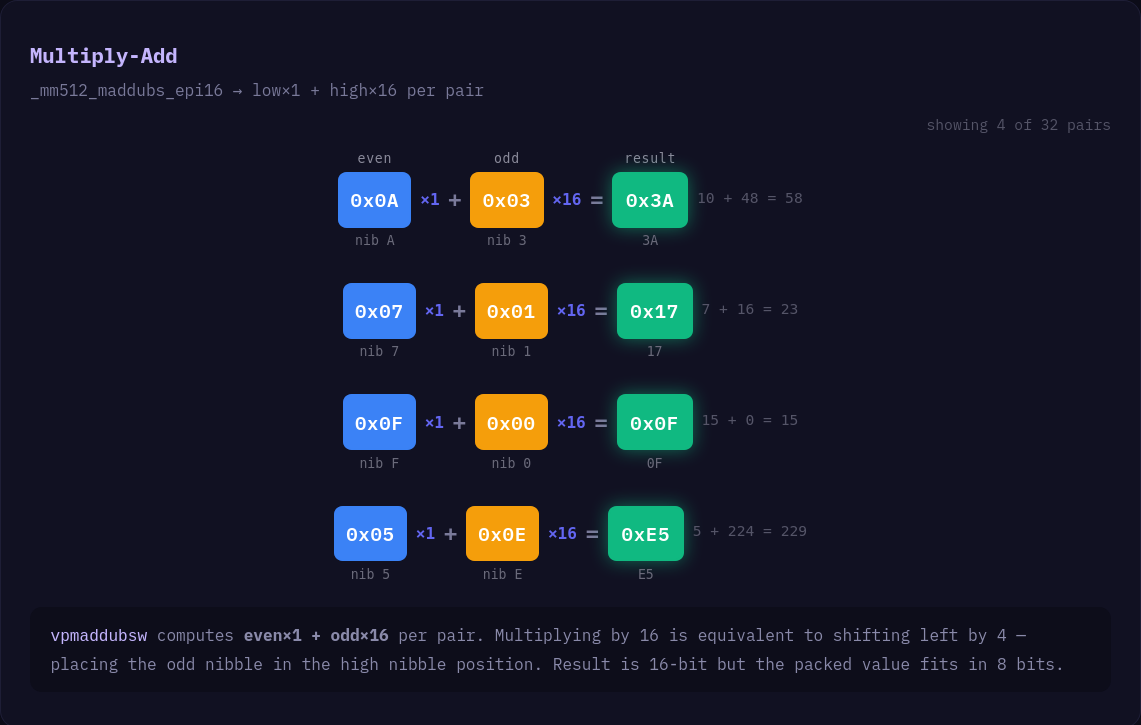
마스크를 사용하면 니블 쌍을 시프트하고 함께 패킹할 수 있다.
원래는 목표 비트 길이에 따라 패킹 함수를 선택하기 위해 다음과 같은 match 블록을 사용했다.
match nbits {
0 => unsafe { to_u0(output, input, n) },
1 => unsafe { to_u1(output, input, n) },
2 => unsafe { to_u2(output, input, n) },
...
}하지만 LLVM이 이를 그다지 잘 컴파일하지 못해, 결과 ASM은 nbits를 33번 검사하고 비교마다 점프 레이블을 추가했다. 이를 LUT로 바꾸자 하드웨어에 따라 약 15~20% 성능이 개선됐다.
const LUT: [unsafe fn(&mut [u8; X128_MAX_OUTPUT_LEN], &[u32; X128], usize); 33] = [
to_u0, to_u1, to_u2, to_u3, to_u4, to_u5, to_u6, to_u7, to_u8, to_u9, to_u10, to_u11,
to_u12, to_u13, to_u14, to_u15, to_u16, to_u17, to_u18, to_u19, to_u20, to_u21, to_u22,
to_u23, to_u24, to_u25, to_u26, to_u27, to_u28, to_u29, to_u30, to_u31, to_u32,
];
let func = unsafe { LUT.get_unchecked(nbits as usize) };
unsafe { func(out, block, pack_n) };이 방식의 부작용은 아래 ASM에서 보듯, 사실상 인라이닝 없이 점프가 강제된다는 점이다.
upack::uint32::avx512::pack_x128::to_nbits:
mov rax, rdi
lea r8, [rip + .Lanon.4cb93b769a4c3988e8fd210eaf9850ae.7]
mov rdi, rsi
mov rsi, rdx
mov rdx, rcx
jmp qword ptr [r8 + 8*rax]이 점은 64개 서브블록 설계로 옮기면서 문제가 됐다. 이전에는 128개 정수 블록마다 이 함수를 두 번 호출하면서 점프 비용을 두 번 지불했고, 이것이 전체 성능에 큰 영향을 줬다.
이 성능 회귀(regression)를 고치기 위한 방법은 안타깝게도 완벽하지 않았고, 언패커(unpacker)의 base, delta, delta-1 변형별로 별도의 LUT를 만들고, 이 점프가 수행된 이후에 partial/full 서브블록 패커 간 디스패치를 생성하는 작은 매크로를 사용해야 했다.
Neon/ARM은 내가 아주 익숙하거나 최적화에 능숙한 ISA가 아니라서, Discord에서 한 사용자가 Niles Selter의 블로그 글을 소개해준 것이 큰 도움이 됐다. 이 글은 특히 64개의 8비트 요소를 64비트 마스크로 옮기는 최적화에 대해 다루며, 다른 흥미로운 주제도 포함한다. 나는 그중 벡터->마스크, 마스크->벡터 알고리즘을 채택했다. 강력 추천: https://validark.dev/posts/interleaved-vectors-on-arm/
이 변경으로 μpack 알고리즘과 simdcomp 알고리즘 간 격차를 줄일 수 있었다. 여전히 느리긴 하지만, 놓친 다른 최적화가 더 있을 것이고 그 격차를 더 줄일 수 있을 것이라 본다.
각 ISA에 대해 64개 정수 서브블록을 패킹/언패킹하는 작은 SIMD 루틴이 132개 생기며, 실제 코드에서 uint32 패킹 구현은 528개의 개별 pack/unpack 루틴을 가진다.
예로, avx512f와 avx512bw를 사용해 64개의 32비트 정수를 한 번에 5비트 정수로 패킹하는 x86 어셈블리( partial 서브블록 전략)는 다음과 같다.
upack::uint32::avx512::pack_x64_partial::to_u5:
# 첫 16개 요소 로드, 다음 16개는 건너뛰고
# 그 다음 16개 요소 로드
vmovdqa64 zmm0, zmmword ptr [rsi]
vmovdqa64 zmm1, zmmword ptr [rsi + 128]
# 이후 패킹된 요소들의 순서를 보정하기 위한
# 퍼뮤테이션 마스크 로드
vmovdqa64 zmm2, zmmword ptr [rip + .LCPI239_0]
# 쓰기 오프셋 계산
mov rax, rdx
shr rax
# zmm0을 두 번째 16개 요소와, zmm1을 네 번째 16개 요소와
# 패킹하여 16비트 정수를 생성
vpackusdw zmm0, zmm0, zmmword ptr [rsi + 64]
vpackusdw zmm1, zmm1, zmmword ptr [rsi + 192]
# 추가 오프셋 계산
sub rdx, rax
# 생성된 zmm0/zmm1(16비트 정수)을 8비트 정수로 패킹
vpackuswb zmm0, zmm0, zmm1
# 앞에서 로드한 셔플 마스크 적용
vpermd zmm0, zmm2, zmm0
# zmm0의 하위 4비트만 선택해 zmm1에 저장
vpandd zmm1, zmm0, dword ptr [rip + .LCPI239_3]{1to16}
# maddubs 트릭으로 니블을 올바른 순서로 패킹
vpmaddubsw zmm1, zmm1, zmmword ptr [rip + .LCPI239_2]
# 8비트 정수에서 남은 1비트를 선택
vpsllw zmm0, zmm0, 3
# 최상위 비트(= 상위 1비트)를 결과 마스크로 이동
vpmovb2m k0, zmm0
# 16비트 -> 8비트(절단) 변환 후 니블 패킹 결과 저장
vpmovwb ymmword ptr [rdi], zmm1
# 1비트 마스크 저장
kmovq qword ptr [rdi + rdx], k0
vzeroupper
retcargo-show-asm으로 ASM을 얻은 뒤 코멘트를 추가했다.
코멘트를 제거하면, simdcomp처럼 더 큰 블록 크기를 요구하지 않으면서도 512비트 레지스터를 충분히 활용해 매우 컴팩트한 루틴이 된다는 것을 볼 수 있다.
upack::uint32::avx512::pack_x64_partial::to_u5:
vmovdqa64 zmm0, zmmword ptr [rsi]
vmovdqa64 zmm1, zmmword ptr [rsi + 128]
vmovdqa64 zmm2, zmmword ptr [rip + .LCPI239_0]
mov rax, rdx
shr rax
vpackusdw zmm0, zmm0, zmmword ptr [rsi + 64]
vpackusdw zmm1, zmm1, zmmword ptr [rsi + 192]
sub rdx, rax
vpackuswb zmm0, zmm0, zmm1
vpermd zmm0, zmm2, zmm0
vpandd zmm1, zmm0, dword ptr [rip + .LCPI239_3]{1to16}
vpmaddubsw zmm1, zmm1, zmmword ptr [rip + .LCPI239_2]
vpsllw zmm0, zmm0, 3
vpmovb2m k0, zmm0
vpmovwb ymmword ptr [rdi], zmm1
kmovq qword ptr [rdi + rdx], k0
vzeroupper
retμpack 저장소 안에 커스텀 벤치마크 러너가 있다: μpack repository 내. 이 러너는 데이터베이스나 검색 엔진을 구현할 때 마주치는 데이터에 좀 더 가까운 형태로 루틴을 측정하도록 설계됐다.
구체적으로 검색 엔진의 포스팅 리스트를 모사하는 입력 데이터를 생성한다. 초기 정수 값이 있고, 이어서 블록 내 doc ID가 단조 증가(monotonic increase)한다.
러너에서 설정 가능한 항목:
26인데, Lucene/Tantivy 세그먼트에서 단일 세그먼트가 가질 법한 현실적인 최대 doc ID(6,700만 문서)에 해당한다.언제나 그렇듯, 이 러너는 마이크로벤치마크보다는 정확하려고 하지만 여전히 합성 벤치마크다. 실제로 처리할 데이터로 비교해야 하며 결과는 참고 정도로만 받아들여야 한다.
Justfile 레시피 just bench로 실행할 수 있으며, 결과는 uint32 타입에 대한 것이다.
앞서 언급했듯 Neon 구현은 simdcomp보다 뒤처지는데, 이는 두 가지 이유라고 본다.
그럼에도, ARM 서버 CPU가 SVE2와 더 넓은 레지스터를 채택하면 이 알고리즘이 simdcomp를 따라잡고 앞설 수 있을 것이다. Google Cloud Platform과 Microsoft Azure에서도 이런 칩이 이미 보이기 시작했다.
전체적으로 x86에서는 AVX2를 지원하는 프로세서에서 모든 변형에 대해 평균적으로 소폭 개선을 보인다. Zen5 마이크로아키텍처의 AVX512 머신에서는 더 넓은 레지스터와 더 다재다능한 명령이 성능을 얼마나 끌어올릴 수 있는지 분명히 보인다.
안타깝게도 Apple Silicon의 Neon 구현에서는 꽤 큰 성능 손실이 있다. 다만 Apple Silicon은 서버에서 흔히 보는 Graviton/Ampere CPU보다 훨씬 강력하고, 더 약한 하드웨어에서는 격차가 조금 더 줄어드는 것을 볼 수 있다.
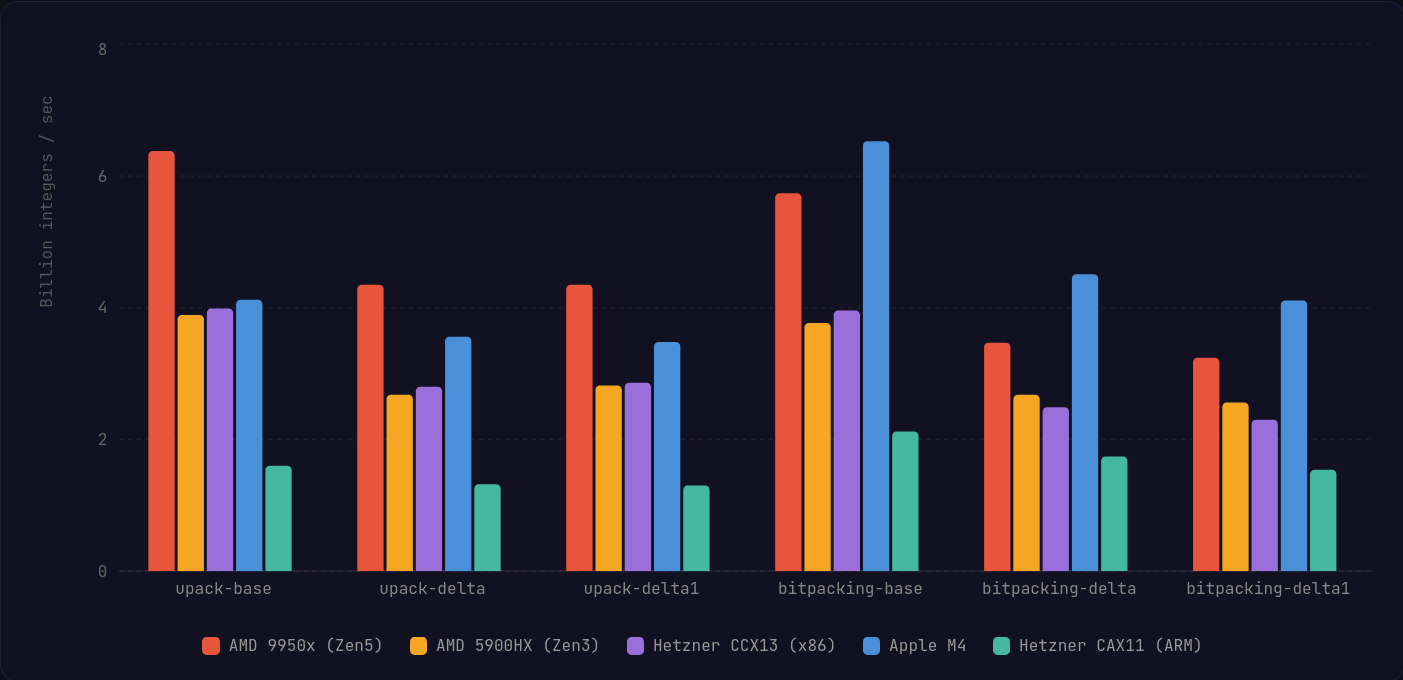
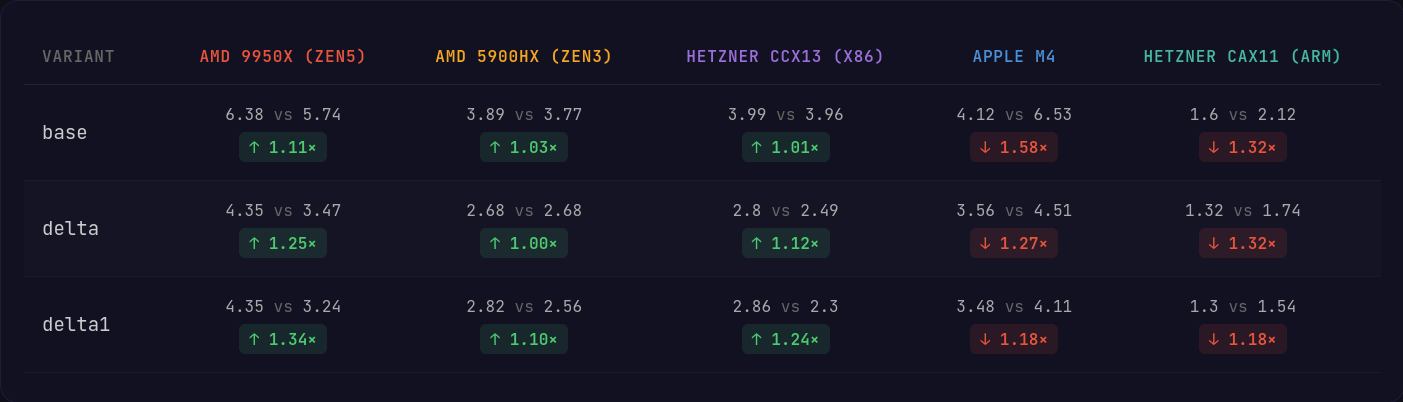
x86에서의 해제 성능이 가장 크게 개선되며, 특히 AVX512에서 두드러진다. AVX512는 비트마스크를 쉽게 채워진 레지스터로 캐스팅할 수 있고, 추가 셔플 없이 훨씬 적은 명령으로 블록 내 delta 인코딩된 정수들을 디코딩할 수 있다.
ARM 쪽에서는 Neon 구현이 격차를 크게 줄여 대부분의 애플리케이션에서 체감되지 않을 수준이라고 말할 수 있을 것 같다.
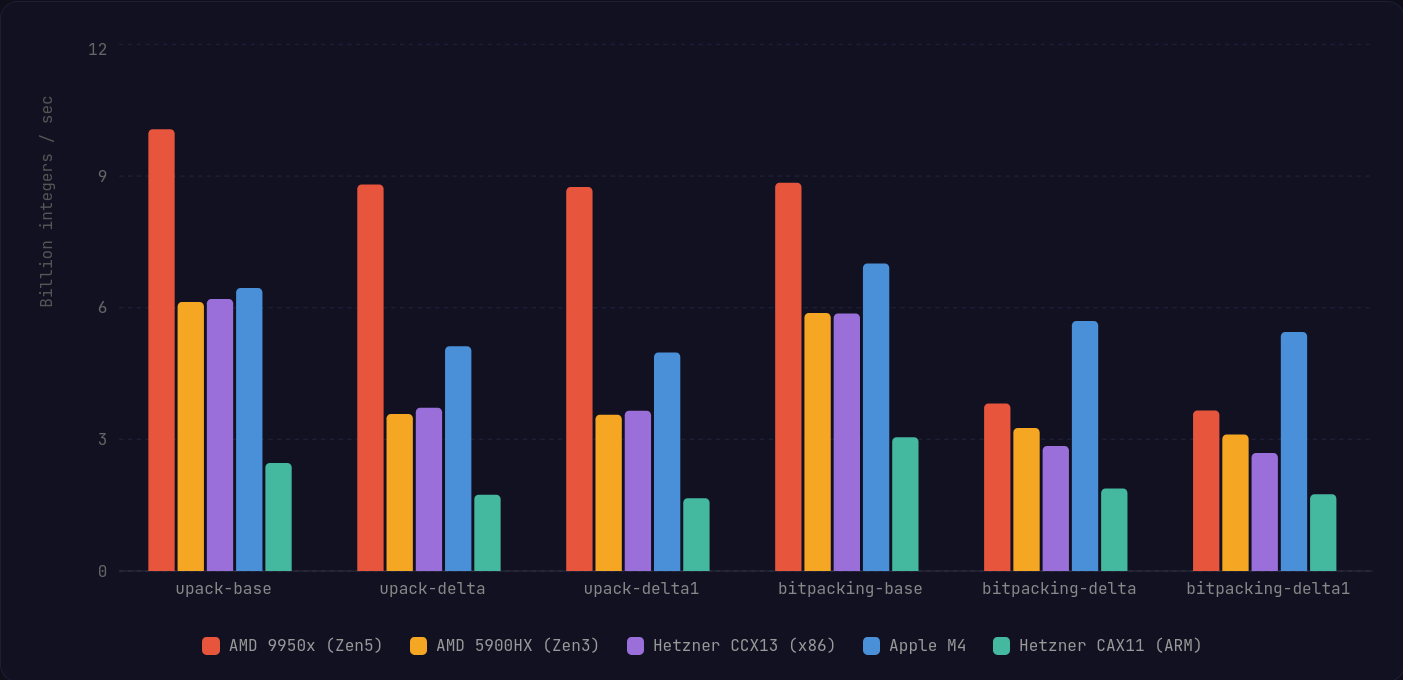
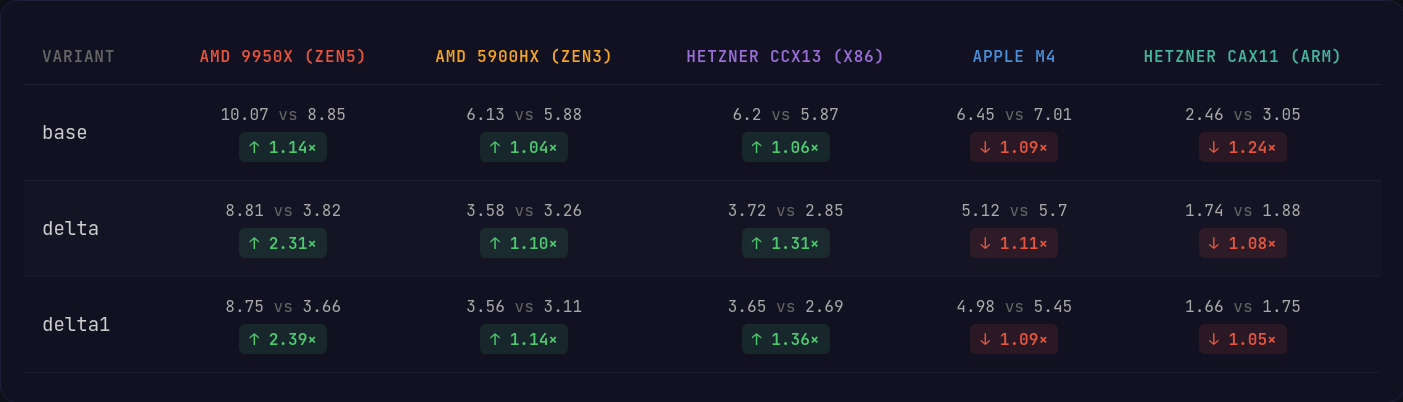
전반적으로 이 알고리즘은 성능 측면에서 수용 가능한 트레이드오프를 하면서도 더 큰 유연성을 제공한다고 생각한다. 즉, 정확한 블록 크기가 아닌 정수 블록에 대해 흔히 쓰이는 StreamVByte 같은 가변 바이트(variable-byte) 전략보다 더 높은 압축률을 구현자가 얻을 수 있다.
장기적으로 ARM 기반 CPU가 계속 발전하면, 성능 면에서 simdcomp를 따라잡고 넘어설 수 있을 것이다.
나는 이 성능 향상이 더 넓은 범위에서 어떤 영향을 주는지 시험하기 위해 Tantivy를 포크해 수정하기도 했다. 하지만 글을 쓰는 시점에는 Tantivy 포크가 세그먼트 병합(merging segments) 중 버그(μpack 자체와는 무관)를 도입해, 다른 사람들이 벤치마크를 신뢰성 있게 실행하기 어려웠다. 시간이 나면 Tantivy 포크를 수정한 뒤 별도로 공유할 계획이다.
이 라이브러리는 내가 작업 중인 두 개의 정수 압축 라이브러리 중 하나다. 두 번째 라이브러리는 유연한 블록 크기에 의존하므로, 이 라이브러리를 별도 크레이트(crate)로 분리해 따로 공개하는 것이 합리적이라 판단했다. 정수 압축 분야에서 또 다른 흥미로운 개선을 제공할 두 번째 알고리즘도 기대하고 있다.
읽어줘서 고맙다. 이 글이 어느 정도 흥미로웠고, simdcomp와 μpack이 어떻게 동작하는지에 대한 기본적인 이해를 얻었기를 바란다.
프로젝트에 기여하고 싶다면 소스 코드는 여기에서 볼 수 있다: https://github.com/lnx-search/upack. 데이터 레이아웃을 깨지 않고 재현 가능하다면 어떤 최적화든 환영한다.
가변 크기 출력 블록을 허용하는 이점 중 하나는 StreamVByte 같은 전통적인 바이트 단위 알고리즘과 비교했을 때 더 강한 압축률을 보인다는 점이다.
이게 글 맨 끝에 있는 이유가 궁금할 텐데, 내가 이 블로그에 사용하는 CMS인 Ghost가 임베디드 iframe을 렌더링할 때 모바일 뷰를 깨뜨리기 때문이다.