Rust에서 어셈블리 없이(나이틀리 없이) SIMD 가속 코드를 작성하는 방법, CPU 기능 감지, 구현 선택, 자동 벡터화와 테스트 팁, 그리고 휴대용 SIMD의 미래를 소개한다.
URL: https://kerkour.com/introduction-rust-simd
최근에 AMD Zen 5 CPU(AWS의 m8a 인스턴스)를 잠깐 써봤는데… 와. GPU와 NPU 얘기를 꺼내기도 전에, 앞으로 5년의 CPU는 정말 흥미로울 것 같습니다!
잘 모르는 분들을 위해 설명하자면, Zen 5는 (AMD) CPU 중 최초로 완전한 512비트 데이터패스를 갖춘 세대입니다. 우리 같은 평범한 개발자 입장에서는, 처음으로 다운클록이나 기타 불쾌한 surprises를 걱정하지 않고 AVX-512 SIMD 명령어를 사용할 수 있다는 뜻입니다. 256비트 데이터패스인 Zen 4에서는 512비트 SIMD 명령이 “더블 펌프(double pumped)”로 처리되었습니다. 더 오래된 Intel CPU들은 AVX-512를 사용할 때 과도한 전력 소모(즉 열 발생) 때문에 주파수를 낮추곤 했고, 그 결과 AVX-512 가속을 쓰지 않을 때보다 성능이 더 나빠지는 경우도 있었습니다.
예를 들어 m8a.2xlarge 가상화 인스턴스에서 ChaCha12는 6.7 GB/s, ChaCha20은 5.1 GB/s, BLAKE3는 10.8 GB/s로 동작합니다. 나쁘지 않죠!
이 주제는 훌륭한 글인 Zen5's AVX512 Teardown과 Zen 5's AVX-512 Frequency Behavior에서 더 자세히 볼 수 있습니다.
대부분의 개발자들은 “오, 내 컴퓨터가 더 빨라졌네” 정도로만 생각할 수도 있지만, Rust 개발자에게는 아마도 연말 최고의 선물일 겁니다. 그것도 우리가 감히 꿈꾸지 못했던.
왜일까요?
Rust에서는 어셈블리를 다루지 않고도 핫 패스에 SIMD 가속을 붙이기가 정말 쉽습니다. SIMD 레지스터에 데이터를 로드하고, 마치 일반 변수처럼 코딩하면 됩니다! AVX-512 코드는 반나절 작업으로도 10배가 넘는 개선을 낼 수 있습니다.
그래서 여기서는 (나이틀리 필요 없이) 순수 Rust로 SIMD 가속 코드를 작성하는 방법을 소개하려고 합니다. 결국 소프트웨어가 더 빨라지면 우리 모두에게 이득이니까요.
x86, ARM64, WebAssembly용 SIMD 가속을 포함한 프로덕션 코드 예시는 GitHub에서 볼 수 있습니다: https://github.com/bloom42/chacha12-blake3
SIMD는 Single Instruction, Multiple Data의 약자로, 더 큰 데이터 벡터에 대해 동작할 수 있는 CPU 명령어를 뜻합니다.
CPU는 일반적으로 최대 64비트 값까지 처리하며, 이런 것들을 “스칼라(scalar) 명령어”라고 부릅니다. 반면 SIMD 명령어는 더 큰 값(예: amd64의 AVX-512는 최대 512비트)을 다룰 수 있게 해 줍니다. 이런 것들을 “벡터(vector) 명령어”라고 합니다.
다음은 4개의 uint64에 10을 더하고 싶은 상황을 가정한 의사코드 예시입니다:
// 이렇게 하는 대신:
let mut a = [1, 2, 3, 4];
for n in &a {
*n += 10;
}
// 이렇게 한다
let mut vector = u64x4::from_array([1, 2, 3, 4]); // 4개의 uint64로 이루어진 256비트 벡터
let x = u64x4::splat(10); // 4개의 uint64로 이루어진 256비트 벡터 생성: (10, 10, 10, 10)
let vector = vector + x;
// vector = u64x4(11, 12, 13, 4);
비용이 큰 루프를 생성하는 대신, 벡터화된 코드는 대략 3개의 명령어로 컴파일됩니다.
염두에 둘 만한 점 하나는, SIMD 명령이 스칼라 명령보다 전력을 더 많이 쓸 수 있다는 것입니다.
SIMD 명령어로 작업하는 방식은 일반적으로 다음 3단계로 정리할 수 있습니다:
load -> compute -> store
먼저 메모리에서 벡터 레지스터로 데이터를 로드(load) 합니다.
// 값 1을 갖는 int64를 8개 담은 512비트 벡터 로드
let v1 = _mm512_set1_epi64(1);
// (비정렬) int64 배열 8개 원소를 512비트 벡터로 로드
let v2 = _mm512_loadu_epi64([1, 2, 3, 4, 5, 6, 7, 8]);
그 다음 더하기/ xor/ 빼기 등 원하는 연산(compute) 을 수행합니다.
// 8개의 64비트 lane을 병렬로 더함
let v_result = _mm512_add_epi64(v1, v2);
// v_result = __m512i(2, 3, 4, 5, 6, 7, 8, 9)
마지막으로 결과를 메모리에 다시 저장(store) 합니다.
let result = [0i64, 8];
_mm512_storeu_epi64(result.as_mut_ptr(), v_result);
// result = [2, 3, 4, 5, 6, 7, 8, 9]
메모리에서/로 데이터를 로드/스토어하는 것은 (상대적으로) 지연(latency) 비용이 매우 크기 때문에 가능한 한 최소화해야 한다는 점을 이해하는 것이 중요합니다. 데이터는 SIMD 레지스터에 따뜻하게(즉, 계속 유지되도록) 두는 것이 더 좋습니다.
따라서 목표로 하는 명령어 집합에서 사용 가능한 SIMD 레지스터 수를 아는 것이 중요합니다. 예를 들어 arm64의 NEON은 128비트 레지스터 32개(v0~v31)를 제공합니다. 즉, “느린” 메모리를 건드리지 않고도 최대 32개의 128비트 벡터를 들고 연산을 수행할 수 있습니다.
SIMD 명령으로 알고리즘을 가속하는 방식은 보통 두 가지가 있습니다.
첫 번째는 알고리즘 내에서 병렬로 수행할 수 있는 연산을 찾아내는 방법입니다. 하지만 이는 알고리즘에 특화되어 있고 구현도 더 복잡한 경우가 많습니다.
두 번째는 더 일반적이고 구현이 쉬운 방법으로, 입력을 각각 X개의 데이터 블록을 담는 청크로 “쪼개는” 것입니다. 여기서 X는 사용 가능한 lane 수이며, 이를 통해 X개의 블록을 병렬로 계산할 수 있습니다.
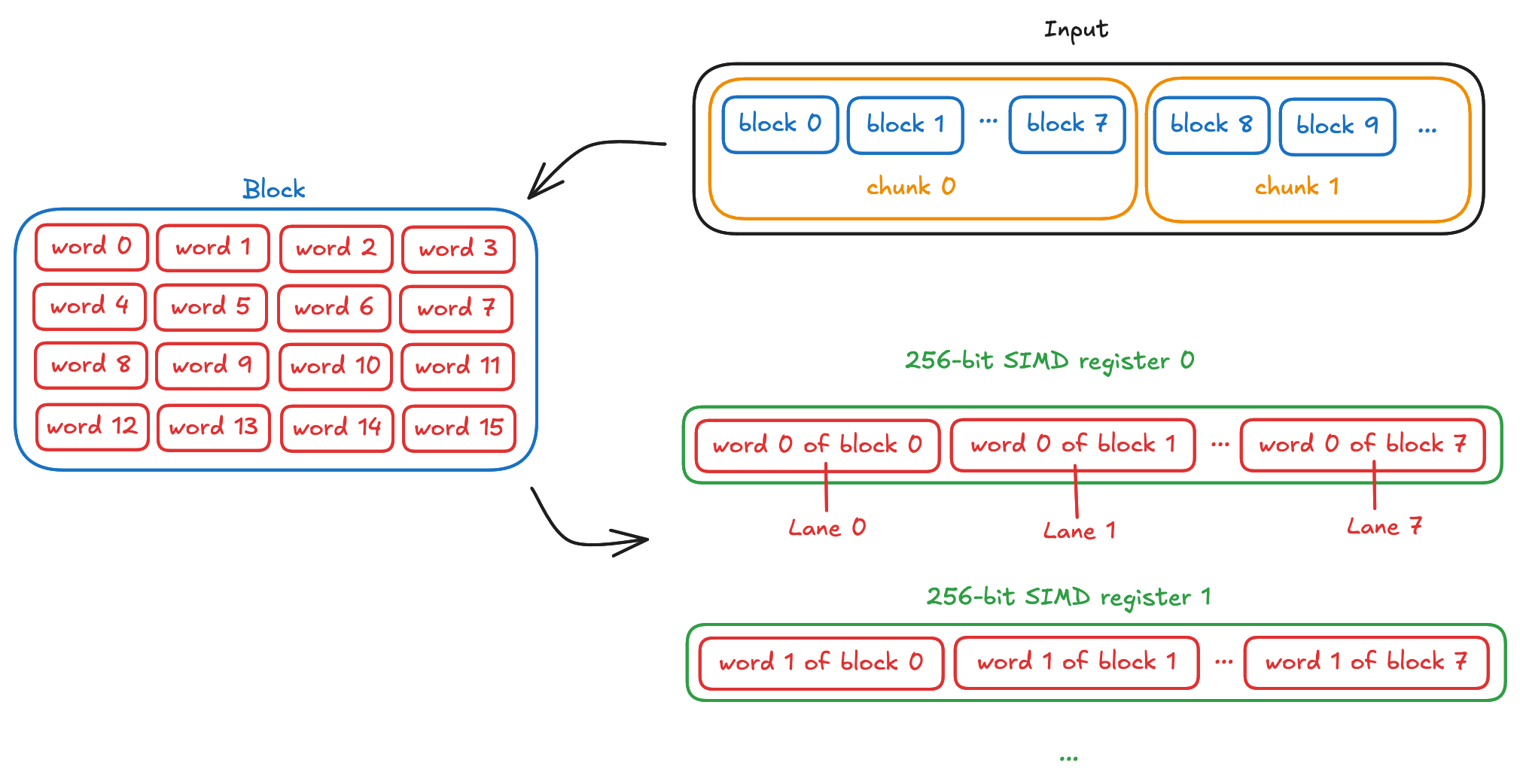
예를 들어 ChaCha20은 32비트(4바이트) 워드로 동작하며, 이들이 모여 512비트(64바이트) 블록을 구성합니다(16 * 32비트 = 512비트 = 64바이트).
따라서 256비트 벡터가 사용 가능하다면, 우리는 8개의 블록(lane)을 병렬로 처리하게 됩니다(256 / 32 = 8). 입력 데이터 청크는 8블록 길이가 되며, 입력이 8 * 64 = 512바이트 이상일 때 단일 코어 최대 속도에 도달합니다.
또 다른 예로 BLAKE3도 32비트 워드로 동작합니다. AVX-512가 있는 머신에서 BLAKE3는 입력이 16KiB 이상이면 단일 코어 최대 속도에 도달하는데, 입력을 1024바이트짜리 16개 블록(‘chunk’라 부름)으로 나눠 AVX-512로 16개 블록을 병렬 처리하며, 연산마다 상태(state)의 32비트 워드 16개를 계산합니다. AVX2(256비트 벡터)만 있는 머신에서는 256비트 벡터에 32비트 lane이 8개뿐이므로 입력이 8KiB 이상일 때 단일 코어 최대 속도에 도달합니다.
SIMD 가속 코드를 구현하는 데는 시간이 들고 유지보수 부담도 늘어납니다. 따라서 코드가 어디서 실행될지를 알고 그에 맞춰 노력을 집중해야 합니다.
코드가 고급 Intel/AMD 프로세서(예: 서버)에서만 실행된다면 AVX-512에 집중하는 것만으로도 충분할 수 있습니다.
반대로 소비자용 머신에서 주로 실행된다면 AVX2와 NEON에 집중하는 편이 최선일 가능성이 큽니다.
또한 요즘은 SSE2 SIMD를 구현하는 것은 의미가 거의 없습니다. 2015년 이후 생산된 대부분의 프로세서는 AVX2를 지원하기 때문입니다.
SIMD 가속 코드는 실행 중인 CPU에서 해당 명령어 집합이 사용 가능해야 합니다.
Rust에서 CPU 기능 감지를 제공하는 방법은 몇 가지가 있습니다.
첫 번째는 std::arch 모듈이 제공하는 매크로를 이용한 런타임 감지입니다:
fn foo() {
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
{
if is_x86_feature_detected!("avx2") {
return unsafe { foo_avx2() };
}
}
// AVX2를 사용하지 않는 폴백 구현
}
이 방법은 표준 라이브러리가 필요하며, 저수준 코드에서 항상 사용할 수 있는 것은 아닙니다.
두 번째는 컴파일 타임 기능 감지입니다:
#[cfg(all(target_arch = "x86_64", target_feature = "avx512f"))]
Cargo feature를 이용하는 등 좀 더 난해한 방법도 있지만, 특히 여러분의 패키지가 “의존성의 의존성의 의존성…” 같은 형태로 소비될 때 사용자들을 혼란스럽게 만들기 때문에 추천하지 않습니다.
런타임 감지는 표준 라이브러리에 의존하며(일부 프로젝트, 예: 임베디드 소프트웨어에서는 사용할 수 없음), 그래서 저는 기본으로는 런타임 감지를 제공하고, 패키지 사용자가 빌드 타임 전용 기능 감지를 선택할 수 있도록 Cargo feature를 제공하는 것을 추천합니다. 이렇게 하면 어떤 CPU를 정확히 타겟할지 사용자가 결정할 수 있습니다.
예를 들면:
Cargo.toml
[features]
default = ["std"]
# 지원 플랫폼에서 CPU 기능 감지를 위해 표준 라이브러리를 사용하도록 활성화
std = []
fn my_function() {
// 런타임 감지 사용
#[cfg(feature = "std")]
{
#[cfg(target_arch = "x86_64")]
if is_x86_feature_detected!("avx512f") {
return my_function_avx512();
}
#[cfg(any(target_arch = "x86", target_arch = "x86_64"))]
if is_x86_feature_detected!("avx2") {
return my_function_avx2();
}
}
// 컴파일 타임 감지 사용
#[cfg(not(feature = "std"))]
{
#[cfg(all(target_arch = "x86_64", target_feature = "avx512f"))]
return my_function_avx512();
#[cfg(all(any(target_arch = "x86", target_arch = "x86_64"), target_feature = "avx2"))]
return my_function_avx2()
}
// SIMD 가속을 사용할 수 없을 때의 스칼라 폴백
return my_function_generic();
}
순수 Rust에서 SIMD 명령어를 사용하는 방법은 몇 가지가 있습니다.
표준 라이브러리의 실험적 simd 모듈이 있습니다. 하지만 안타깝게도 현재는 Rust 나이틀리에서만 사용할 수 있습니다. 이 글 뒤쪽에서 이 모듈을 다룰 것입니다.
wide 크레이트는 stable Rust에서 simd 모듈을 재현한 서드파티 크레이트이지만, 현재 256비트 벡터로 제한됩니다. 저는 의존성이 너무 많이 딸려 와서 사용하지 못했습니다.
use wide::*;
fn main() {
let a = u32x4::splat(1);
let b = u32x4::from([1, 2, 3, 4]);
let result = a + b;
assert_eq!(result.to_array(), [2, 3, 4, 5]);
}
추가 의존성이 괜찮다면 이 방법을 추천합니다.
pulp 크레이트도 있는데, SIMD에 대한 고수준 추상화로, SIMD의 rayon이라고 생각하면 됩니다. wide와 마찬가지로 의존성이 너무 많아 저는 사용하지 못했습니다. 또한 현재 방식의 SIMD 런타임 감지는 no_std 타겟에서 사용할 수 없어서 그다지 선호하지 않습니다.
use pulp::Arch;
fn main() {
let mut v = (0..1000).map(|i| i as f64).collect::<Vec<_>>();
let arch = Arch::new();
arch.dispatch(|| {
for x in &mut v {
*x *= 2.0;
}
});
for (i, x) in v.into_iter().enumerate() {
assert_eq!(x, 2.0 * i as f64);
}
}
마지막으로 Rust 표준 라이브러리의 arch 모듈이 있습니다.
arch의 하위 모듈(x86, x86_64, aarch64 등)은 플랫폼별로 사용 가능한 로우 레벨 intrinsic(예: _mm512_add_epi32)과 벡터 레지스터 타입(예: __m512i)을 노출합니다.
이 방식은 가장 저수준이라 중복 코드가 더 생기지만, 현재 stable Rust에서 어떤 의존성도 없이 동작하는 유일한 방식이기도 합니다. 그래서 저는 제 구현에서 이 방식을 선택했습니다.
여기서 꼭 짚고 싶은 중요한 포인트가 하나 있습니다: LLVM이 수행하는 자동 벡터화(auto-vectorization) 입니다.
예를 들어, 몇 번 시도해 보더라도 두 버퍼를 XOR하는 더 빠른 방법을 기본적인 방식보다 구현하기가 매우 어렵습니다:
input_block
.iter_mut()
.zip(keystream)
.for_each(|(plaintext, keystream)| *plaintext ^= *keystream);
컴파일러는 이 패턴을 인식하고, 사용 가능한 명령어 집합에 맞춰 자동으로 벡터화된 구현을 생성합니다.
컴파일러가 더 많은 정보를 알수록(예: 청크/블록 크기 등) 자동 벡터화 같은 최적화를 더 잘 수행할 수 있습니다. 언제나 그렇듯 Rust의 똑똑한 컴파일러와 LLVM이 뒤를 봐주며 삶을 편하게 만들어줍니다.
제 조언은, 병목이라는 확실한 증거가 없다면 두 버퍼를 XOR/더하기 같은 흔한 연산을 위해 수동 SIMD 최적화를 굳이 구현하지 말라는 것입니다. 컴파일러가 아마 자동 벡터화해 주거나, 적어도 효율적인 코드를 출력해 줄 가능성이 큽니다.
각 SIMD 명령어 집합을 켰을 때/껐을 때 구현을 꼭 테스트하세요.
RUSTFLAGS 환경 변수를 사용하면 CPU 기능을 선택적으로 비활성화할 수 있습니다:
# generic(가속 없음) 코드 테스트 실행
RUSTFLAGS="-C target-cpu=native -C target-feature=-avx2,-avx512f" make test
# AVX2 코드 테스트 실행
RUSTFLAGS="-C target-cpu=native -C target-feature=-avx512f" make test
# AVX-512 코드 테스트 실행
make test
GitHub Actions는 현재 AVX-512를 지원하지 않으므로, AVX-512 테스트는 본인 머신에서 직접 실행해야 합니다.
휴대용 SIMD( Rust의 simd 모듈)는 현재 나이틀리에서 사용할 수 있는 Rust의 가장 흥미로운 기능 중 하나일지도 모릅니다.
이는 빠르고 효율적이면서도 유지보수 가능한 코드를 제공하려는 개발자들의 부담을 크게 줄여줄 것입니다.
u32x8 같은 고수준 코드로(예: 32비트 lane 8개로 이루어진 256비트 벡터를 조작) 벡터 크기별 알고리즘을 한 번만 구현해 두면, Rust 컴파일러가 컴파일 타임에 각 CPU 아키텍처에 맞는 구체적인 명령어를 선택해 주고, 스칼라 폴백도 자동으로 제공합니다.
코드는 wide와 비슷하지만, 서드파티 의존성이 없고 512비트까지의 벡터(반면 wide는 256비트까지)를 지원합니다.
fn main() {
// 128비트 레지스터를 지원하는 모든 플랫폼에서 동작하는 128비트 벡터
let a = u32x4::splat(1);
let b = u32x4::from([1, 2, 3, 4]);
let result = a + b;
assert_eq!(result.to_array(), [2, 3, 4, 5]);
}
이건 정말 놀랍습니다. 첫째로, 플랫폼/벡터 크기마다 다른 intrinsic 이름을 일일이 배우지 않아도 됩니다.
둘째로, 코드가 크게 단순해집니다. 예를 들어 저는 ChaCha20을 128비트 벡터로 2번 구현해야 했습니다. 한 번은 NEON(arm64)용, 한 번은 wasm32의 simd128용이었습니다. 코드는 거의 같고 타입과 intrinsic 이름만 바뀌기 때문에 어렵진 않았지만, 그래도 테스트/유지보수/문서화해야 할 코드가 늘어납니다.
휴대용 SIMD가 있다면 u32x4 타입(32비트 lane 4개로 이루어진 128비트 벡터) 위에서 한 번만 구현하면 되고, Rust가 128비트 벡터 명령을 지원하는 어떤 플랫폼에서든(arm64의 NEON, x86의 SSE2, wasm32의 simd128 등) 최적화된 코드로 컴파일해 줄 것입니다.
또한 SIMD 코드 테스트도 크게 쉬워집니다. u32x4 같은 플랫폼 비종속 구현은 128비트 벡터를 지원하는 어떤 플랫폼에서도 테스트할 수 있는 반면, std::arch 모듈은 테스트를 실행하려면 해당 하드웨어가 필요합니다.
이 기능이 Rust stable에 들어오는 날이 정말 기다려집니다!
Rust를 더 많이 사용할수록, 마이크로컨트롤러부터 대형 서버까지, WebAssembly, 로봇, 위성, 그리고 그 사이의 모든 것에 이르기까지 컴퓨팅 스택 전체를 결국 Rust가 먹어치우게 될 것임을 더 잘 이해하게 됩니다.
이전 글에서 언급했듯이, 암호화 라이브러리 취약점의 37% 이상이 메모리 안전성 문제입니다. 따라서 암호 코드는 디지털 시대의 가장 근본적인 구성 요소 중 하나인데, 이 영역에서 C와 어셈블리는 퇴장 수순에 있고, 그 대체로 의미 있는 선택지는 Rust뿐이라는 점이 꽤 분명합니다.
Rust로 백엔드 개발을 배우고 싶다면 Axum, SQLx, PostgreSQL로 중간 규모 웹 서비스를 설계·구현하기 글을 보세요. 임베디드 개발을 배우고 싶다면 Rust로 임베디드 개발 입문: 생태계 개요도 참고하세요.
응용 암호, 보안 엔지니어링, 안전하고 프로덕션 준비가 된 Rust 코드를 작성하는 방법 같은 “검은 마법사”급 일을 배우고 싶다면, 제 책 **Black Hat Rust**를 살펴보세요. 이 책에서는 (그 외에도) 종단 간 암호화된 Remote Access Tool, 익스플로잇, 그리고 Rust로 웹 서버를 구축하게 됩니다.