MLIR과 현대 컴파일러 기술의 관점에서 신경망의 기초(그래디언트, 자동 미분, 역전파)를 순수 Python으로 구현하고, 이후 MLIR로 CUDA 커널 최적화로 이어지는 흐름을 설명한다.

MLIR과 현대 컴파일러 기술을 따라가는 여정에서 우리는 수치 계산을 위한 효율적인 시스템을 어떻게 구축하는지 살펴봤다. 이제 우리는 이러한 시스템의 가장 중요한 응용 중 하나인 딥러닝에 주목한다. MLIR이 신경망 계산을 어떻게 최적화할 수 있는지로 들어가기 전에, 신경망이 1원리에서 어떻게 동작하는지 이해하는 것이 중요하다.
이 절에서는 순수 Python으로 신경망 라이브러리를 바닥부터 구현한다. 이 구현은 성능보다 명확성을 우선하지만, MLIR이 제공할 수 있는 최적화를 이해하기 위한 훌륭한 토대가 된다. 모든 것을 처음부터 만들어 봄으로써 우리는 다음에 대해 깊은 통찰을 얻게 된다:
이후 절들에서는 이 단순한 구현을 MLIR을 사용해 고도로 최적화된 CUDA 커널로 변환할 것이다. 명확하지만 순진한 구현에서 고성능 컴파일 버전으로 이어지는 이 진행은 딥러닝에서 현대 컴파일러 기술의 힘을 보여줄 것이다.
이 절의 전체 소스 코드는 참고를 위해 별도 리포지토리에서 확인할 수 있다.
요즘 신경망은 어디에나 있다. 왜 유용한지에 대해서는 많이 설명하지 않겠지만, Jax, PyTorch, TensorFlow 같은 대중적인 라이브러리를 써 봤다면 복잡한 모델을 만들고 학습시키는 것이 얼마나 쉬운지 알고 있을 것이다. 이 프레임워크들이 내부에서 어떻게 동작하는지 이해하는 것은 매우 가치가 있다. 이 절에서는 1원리에서 출발해 아주 최소한의 신경망 라이브러리를 만들어 보며, 현대 딥러닝을 구동하는 핵심 메커니즘에 대한 통찰을 제공한다.
신경망 학습의 핵심에는 그래디언트(gradient) 개념이 있다. 그래디언트는 함수가 가장 가파르게 증가하는 방향을 가리키는 나침반이라고 생각할 수 있다. 여러 입력을 갖는 함수 f(x 1,x 2,...,x n)에 대해, 그래디언트 ∇f는 각 방향에서의 변화율을 담은 벡터다:
∇f=[∂f∂x 1∂f∂x 2⋮∂f∂x n]
각 성분 ∂f∂x i는 다른 입력을 고정한 채 그 입력을 약간 조정했을 때 함수가 얼마나 변하는지 알려준다. 이 정보는 신경망을 학습시키는 데 결정적으로 중요하다.
신경망 학습에서는 모델이 얼마나 잘 동작하는지 측정하는 손실 함수 L(θ)를 최소화하고자 한다. 파라미터 θ에는 네트워크의 모든 가중치와 바이어스가 포함되며, 종종 수천 또는 수백만 개의 값이 된다. 그래디언트 ∇L(θ)는 손실을 줄이기 위해 각 파라미터를 어떻게 조정해야 하는지 알려준다:
θ t+1=θ t−α∇L(θ t)
이것이 바로 경사 하강법(gradient descent)이다. 우리는 그래디언트의 반대 방향으로(학습률 α가 제어하는) 작은 스텝을 반복적으로 내딛으며, 점차 손실을 최소화하는 파라미터 값을 찾아간다.
이 그래디언트를 효율적으로 계산하는 것이 중요하다. 수치적 근사로도 계산할 수 있지만:
∂f∂x i≈f(x+h e i)−f(x)h
여기서 h는 작은 수이고 e i는 i 방향의 단위 벡터인데, 이 방법은 느릴 뿐 아니라 수치적으로도 불안정하다. 대신 우리는 자동 미분(automatic differentiation)을 사용한다. 자동 미분은 계산 그래프를 따라 연쇄 법칙을 체계적으로 적용하여 정확한 그래디언트를 계산한다.
연쇄 법칙은 합성 함수에 대해 도함수가 곱으로 연결된다고 말한다:
d d x(f(g(x)))=f′(g(x))⋅g′(x)
고차원에서는 다음과 같이 된다:
∂f∂x i=∑j∂f∂y j∂y j∂x i
여기서 y j는 계산 과정의 중간 값들이다. 이것이 우리가 신경망 라이브러리에서 구현할 역전파(backpropagation)의 기반이다.
신경망은 본질적으로 입력을 출력으로 매핑하는 함수를, 조정 가능한 변환들의 연쇄를 통해 학습하는 것이다. 기본 구성 요소는 인공 뉴런(artificial neuron)으로, 생물학적 뉴런이 정보를 처리하는 방식을 모사한다:
수학적으로는 다음과 같이 표현된다:
z=∑i=1 n w i x i+b
a=σ(z)
여기서 z는 가중합(흔히 pre-activation이라 부름)이고, a는 뉴런의 출력(activation)이다.
여러 뉴런은 층(layer)으로 구성되고, 층들이 쌓여 네트워크를 이룬다. 완전 연결(feed-forward) 신경망에서는 각 뉴런이 다음 층의 모든 뉴런과 연결된다. l번째 층을 행렬 형태로 간단히 쓰면 다음과 같다:
Z[l]=W[l]A[l−1]+b[l]
A[l]=σ(Z[l])
여기서:
활성화 함수의 선택은 비선형성을 도입한다는 점에서 결정적으로 중요하며, 이 비선형성 덕분에 네트워크가 복잡한 패턴을 학습할 수 있다. 비선형성이 없다면, 층의 수와 무관하게 신경망은 선형 모델처럼 행동한다. 이는 선형 함수들의 합성이 여전히 선형 함수이기 때문이다. 비선형 활성화 함수는 네트워크가 복잡한 함수를 근사하고 데이터의 정교한 관계를 포착할 수 있게 한다. 또한 오류로부터 학습하고 더 다양한 함수들을 표현할 수 있도록 가중치를 조정하게 해 준다. 흔히 쓰이는 활성화 함수는 다음과 같다:
* 단순하고 계산적으로 효율적
* 그래디언트 소실을 방지하는 데 도움
* 현대 네트워크에서 가장 널리 사용
2. Sigmoid: σ(z)=1 1+e−z
* 값을 [0,1] 범위로 압축
* 역사적으로는 популяр했지만 그래디언트 소실에 취약
* 이진 분류에 여전히 유용
3. Tanh: σ(z)=tanh(z)=e z−e−z e z+e−z
* Sigmoid와 비슷하지만 범위가 [-1,1]
* 종종 sigmoid보다 성능이 좋음
* 여전히 그래디언트 소실 문제가 있을 수 있음
4. SwiGLU: σ(z)=ReLU(z W 1+b 1)V+b 2
* GLU (Gated Linear Unit) 계열에서 도입
* Transformer 아키텍처에서 자주 사용
* 비선형성과 계산 효율 사이의 균형 제공
SwiGLU는 많은 현대 네트워크에서 기본 선택이 되었다. 여기서는 GLU 계열의 자세한 내용은 다루지 않겠지만, 더 알고 싶다면 GLU 논문을 확인해 보길 권한다. 우리의 목적상 더 단순하기 때문에 활성화 함수로 ReLU를 사용할 것이다.
자동 미분은 신경망 학습을 구동하는 엔진이다. 수치 미분(도함수 근사)이나 기호 미분(수식 조작)과 달리, 자동 미분은 계산 그래프에서 연산을 추적하여 정확한 도함수를 계산한다.
우리 구현의 중심은 스칼라 값을 감싸고 그 위에서 수행된 연산들을 기록하는 Value 클래스다:
class Value:
def __init__(self, data, _children=(), _op="", label=""):
self.data = data
self.grad = 0.0
self.label = label
self._backward = lambda: None
self._prev = set(_children)
self._op = _op
각 연산(예: 덧셈, 곱셈)은 새로운 Value를 만들고, 그래디언트가 어떻게 역방향으로 흐를지 정의한다. 예를 들어 덧셈은 다음처럼 동작한다:
def __add__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data + other.data, (self, other), "+")
def _backward():
# The gradient flows equally to both inputs
self.grad += out.grad
other.grad += out.grad
out._backward = _backward
return out
곱셈에서는 그래디언트가 곱의 미분 법칙(product rule)을 따른다. 각 입력의 그래디언트는 다른 입력 값에 의해 스케일된다:
def __mul__(self, other):
other = other if isinstance(other, Value) else Value(other)
out = Value(self.data * other.data, (self, other), "*")
def _backward():
# Each input's gradient is scaled by the other's value
self.grad += other.data * out.grad
other.grad += self.data * out.grad
out._backward = _backward
return out
역전파는 backward()를 호출함으로써 시작되며, 이는:
def backward(self):
# Sort nodes in topological order
topo = []
visited = set()
def topo_sort(v):
if v not in visited:
visited.add(v)
for child in v._prev:
topo_sort(child)
topo.append(v)
topo_sort(self)
# Backpropagate gradients
self.grad = 1
for v in reversed(topo):
v._backward()
이를 실제로 확인하기 위해, relu(a * b + c) 표현식에 대한 간단한 계산 그래프를 만들어 보자:
# Create input values
a = Value(2.0, label="a")
b = Value(-3.0, label="b")
c = Value(10.0, label="c")
# Build computation graph
d = a * b
d.label = "d"
e = d + c
e.label = "e"
f = e.relu()
f.label = "f"
이제 각 입력에 대한 출력의 그래디언트를 계산할 수 있다:
print("Gradients after backward pass:")
print(f"a.grad = {a.grad}")
print(f"b.grad = {b.grad}")
print(f"c.grad = {c.grad}")
print(f"d.grad = {d.grad}")
print(f"e.grad = {e.grad}")
print(f"f.grad = {f.grad}")
결과 계산 그래프는 그림 1에 나와 있다. 각 노드는 하나의 값을 나타내고, 에지는 연산을 통해 값들이 어떻게 결합되는지 보여준다. f.backward()를 호출하면, 그래디언트가 이 그래프를 따라 역방향으로 흐르며 각 입력이 최종 출력에 어떤 영향을 주는지 계산할 수 있게 된다.

그림 1: 연산들이 어떻게 연결되고 그래디언트가 역방향으로 흐르는지 보여주는 계산 그래프 시각화.
역전파(backpropagation)는 손실 함수에 대한 네트워크 파라미터의 그래디언트를 효율적으로 계산함으로써 신경망이 데이터에서 학습할 수 있게 하는 알고리즘이다. 출력층에서 입력층으로, 네트워크를 거꾸로 따라가며 오차 그래디언트를 전파하기 위해 미적분의 연쇄 법칙을 적용한다.
과정은 먼저 순전파(forward pass)로 시작한다. 입력 데이터가 네트워크를 통과해 예측을 만들고, 손실 함수 L이 예측과 실제 타깃 값의 차이를 정량화한다. 평균 제곱 오차 손실(mean squared error)에서는 다음과 같다:
L=1 n∑i=1 n(y i−y^i)2
여기서 y i는 실제 값이고 y^i는 예측 값이다.
학습의 목표는 네트워크 파라미터(가중치와 바이어스)를 조정하여 이 손실을 최소화하는 것이다. 이를 위해 각 파라미터에 대한 손실의 그래디언트를 계산해야 한다:
∂L∂w i j[l]and∂L∂b i[l]
이는 l번째 층의 각 가중치 w i j[l]와 바이어스 b i[l]에 대해 계산된다.
역전파는 네트워크를 뒤에서부터 거슬러 올라가며 이러한 그래디언트를 효율적으로 계산한다. 출력층 L에 대해 먼저 오차 항(error term)을 계산한다:
δ[L]=∇a L⊙σ′(z[L])
여기서 ∇a L은 출력 activation에 대한 손실의 그래디언트이고, σ′(z[L])는 pre-activation 값 z[L]에서 평가한 활성화 함수의 도함수이며, ⊙는 원소별 곱(element-wise multiplication)을 뜻한다.
은닉층에서는 오차 항이 재귀적으로 계산된다:
δ[l]=((w[l+1])T δ[l+1])⊙σ′(z[l])
여기서 (w[l+1])T는 l+1번째 층의 가중치 행렬의 전치(transpose)이다.
마지막으로 파라미터에 대한 손실의 그래디언트는 다음과 같다:
∂L∂w i j[l]=a j[l−1]δ i[l]
∂L∂b i[l]=δ i[l]
여기서 a j[l−1]는 l−1번째 층에서 j 뉴런의 activation이다.
우리 구현에서는 이러한 계산이 Value 클래스와 그 연산들에 의해 자동으로 처리된다. loss.backward()를 호출하면 그래디언트가 계산되어 각 파라미터의 grad 속성에 저장된다.
자동 미분 엔진이 준비되었으니 신경망 구성 요소를 만들 수 있다. Module 클래스는 모든 신경망 모듈의 기반이 된다:
class Module:
"""Base class for all neural network modules."""
def zero_grad(self):
"""Sets gradients of all parameters to zero."""
for p in self.parameters():
p.grad = 0
def parameters(self):
"""Returns a list of all parameters in the module."""
return []
Neuron 클래스는 여러 입력의 가중합에 바이어스를 더한 뒤, 선택적으로 비선형 활성화 함수를 적용하는 단일 뉴런을 구현한다:
class Neuron(Module):
"""A single neuron with multiple inputs and one output."""
def __init__(self, nin, nonlin=True):
self.w = [Value(random.uniform(-1, 1)) for _ in range(nin)]
self.b = Value(0)
self.nonlin = nonlin
def __call__(self, x):
act = sum((wi * xi for wi, xi in zip(self.w, x)), self.b)
return act.relu() if self.nonlin else act
def parameters(self):
return self.w + [self.b]
Layer 클래스는 뉴런들을 묶어 입력을 병렬로 처리한다:
class Layer(Module):
"""A layer of neurons, where each neuron has the same number of inputs."""
def __init__(self, nin, nout, **kwargs):
self.neurons = [Neuron(nin, **kwargs) for _ in range(nout)]
def __call__(self, x):
out = [n(x) for n in self.neurons]
return out[0] if len(out) == 1 else out
def parameters(self):
return [p for n in self.neurons for p in n.parameters()]
마지막으로 MLP(Multi-Layer Perceptron) 클래스는 층들을 결합해 완전한 네트워크를 만든다:
class MLP(Module):
"""Multi-layer perceptron (fully connected feed-forward neural network)."""
def __init__(self, nin, nouts):
sz = [nin] + nouts
self.layers = [
Layer(sz[i], sz[i + 1], nonlin=i != len(nouts) - 1)
for i in range(len(nouts))
]
def __call__(self, x):
for layer in self.layers:
x = layer(x)
return x
def parameters(self):
return [p for layer in self.layers for p in layer.parameters()]
이 모듈식 설계 덕분에 어떤 크기의 네트워크든 쉽게 만들 수 있다. 예를 들어 이진 분류를 위한 작은 네트워크는 다음과 같이 만들 수 있다:
# Create a network with:
# - 2 input features
# - 8 neurons in first hidden layer
# - 8 neurons in second hidden layer
# - 1 output neuron
model = MLP(nin=2, nouts=[8, 8, 1])
아키텍처는 그림 2에서 시각화되어 있으며, 뉴런이 층으로 조직되고 층들이 연결되어 전체 네트워크를 이루는 방식을 보여준다.
그림 2: 여러 층의 뉴런으로 구성된 우리의 신경망 아키텍처 시각화.
그림 3처럼 더 많은 층을 추가하면 더 깊은 네트워크를 만들 수 있다. 각 추가 층은 네트워크가 더 복잡한 특징을 학습할 수 있게 한다. 초기 층은 보통 단순한 패턴(예: 이미지의 에지)을 학습하고, 더 깊은 층은 이를 결합해 더 복잡한 패턴(예: 물체나 개념)을 인식한다.
그림 3: 여러 은닉층을 가진 더 깊은 신경망으로, 모델 용량을 늘리기 위해 층을 어떻게 쌓을 수 있는지 보여준다.
신경망을 학습시키려면 그래디언트에 기반해 파라미터를 업데이트하는 최적화기가 필요하다. 우리의 SGD(Stochastic Gradient Descent) 최적화기는 놀랄 만큼 단순하다:
class SGD:
"""
Stochastic Gradient Descent optimizer.
"""
def __init__(self, parameters, lr=0.01):
self.parameters = parameters
self.lr = lr
def zero_grad(self):
"""Set all parameter gradients to zero."""
for p in self.parameters:
p.grad = 0
def step(self):
"""
Updates each parameter as: p = p - lr * p.grad
"""
for p in self.parameters:
p.data -= self.lr * p.grad
이 최적화기는 모델 파라미터에 대한 참조를 저장하고, 각 순전파 전에 그래디언트를 0으로 만드는 메서드를 제공하며, 경사 하강법 규칙으로 파라미터를 업데이트한다:
θ t+1=θ t−α∇θ L(θ t)
여기서 θ는 파라미터, α는 학습률, ∇θ L(θ t)는 파라미터에 대한 손실 함수의 그래디언트이다.
Adam이나 RMSProp 같은 더 정교한 최적화기는 과거의 그래디언트 정보를 바탕으로 각 파라미터의 학습률을 적응적으로 조절해 더 나은 수렴 특성을 제공하지만, SGD는 그래디언트 기반 최적화의 핵심 원리를 잘 보여준다.
학습 과정은 Trainer 클래스에 캡슐화되어 있으며, 데이터 배치 처리, 순전파/역전파, 파라미터 업데이트, 메트릭 추적을 담당한다:
import random
import matplotlib.pyplot as plt
from tinynn.engine import Value
class Trainer:
def __init__(self, model, optimizer, loss_fn=None):
self.model = model
self.optimizer = optimizer
self.loss_fn = loss_fn or self._mse_loss
# Training history
self.losses = []
self.accuracies = []
def _mse_loss(self, pred, target):
"""Mean squared error loss function."""
return (pred - target) * (pred - target)
def train(
self, X, y, n_epochs=100, batch_size=32, verbose=True, early_stopping=True
):
"""
Train the model on the given dataset.
Args:
X: Features (list or numpy array)
y: Target values (list or numpy array)
n_epochs: Number of training epochs
batch_size: Mini-batch size
verbose: Whether to print progress
early_stopping: Whether to stop early on perfect accuracy
Returns:
Dictionary containing training history
"""
print("Training neural network...")
for epoch in range(n_epochs):
# Track metrics for this epoch
total_loss = 0.0
correct = 0
# Shuffle the data
indices = list(range(len(X)))
random.shuffle(indices)
# Mini-batch training
for start_idx in range(0, len(X), batch_size):
end_idx = min(start_idx + batch_size, len(X))
batch_indices = indices[start_idx:end_idx]
# Zero gradients
self.optimizer.zero_grad()
# Accumulate loss and accuracy over the batch
batch_loss = Value(0.0)
for idx in batch_indices:
# Convert numpy features to Value objects
x_vals = [Value(X[idx][0]), Value(X[idx][1])]
# Forward pass
pred = self.model(x_vals)
pred_value = pred[0] if isinstance(pred, list) else pred
# Binary cross-entropy loss with tanh activation
target = 1.0 if y[idx] == 1 else -1.0 # Use -1/1 targets for tanh
# Calculate loss
loss = self.loss_fn(pred_value, target)
# Accumulate loss
batch_loss = batch_loss + loss
# Check accuracy
pred_class = 1 if pred_value.data > 0 else 0
if pred_class == y[idx]:
correct += 1
# Scale loss by batch size
batch_loss = batch_loss * (1.0 / len(batch_indices))
# Backward pass
batch_loss.backward()
# Update parameters
self.optimizer.step()
# Track total loss
total_loss += batch_loss.data
# Record metrics
avg_loss = total_loss / max(1, (len(X) // batch_size))
accuracy = correct / len(X)
self.losses.append(avg_loss)
self.accuracies.append(accuracy)
# Print progress every 10 epochs
if verbose and (epoch + 1) % 10 == 0:
print(
f"Epoch {epoch+1}/{n_epochs}: Loss={avg_loss:.4f}, Accuracy={accuracy:.4f}"
)
# Early stopping if we reach perfect accuracy
if early_stopping and accuracy == 1.0 and avg_loss < 0.01:
print(f"Early stopping at epoch {epoch+1} with 100% accuracy!")
break
print("Training complete!")
print(f"Final accuracy: {self.accuracies[-1]:.4f}")
return {"losses": self.losses, "accuracies": self.accuracies}
def plot_training_progress(self, save_path="output/training_progress.png"):
"""Plot and save the training progress."""
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(self.losses)
plt.title("Training Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.subplot(1, 2, 2)
plt.plot(self.accuracies)
plt.title("Training Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.tight_layout()
plt.savefig(save_path)
plt.close()
각 epoch마다 트레이너는 데이터를 섞고, 미니배치를 처리하며, 손실과 그래디언트를 계산하고, 파라미터를 업데이트하고, 손실과 정확도 같은 메트릭을 추적한다. 이러한 구조화된 학습 접근은 일관된 학습 절차를 유지하면서도 다양한 모델과 데이터셋을 쉽게 실험할 수 있게 해준다.
정규화(regularization) 기법은 모델이 학습 데이터에서는 잘 작동하지만 보지 못한 데이터에서는 성능이 떨어지는 과적합(overfitting)을 방지하기 위해 머신러닝에서 필수적이다. L2 정규화(L2 regularization)는 **가중치 감쇠(weight decay)**라고도 불리며, 신경망에서 가장 흔한 정규화 방법 중 하나다.
L2 정규화의 핵심 아이디어는 큰 가중치를 억제하는 패널티 항을 손실 함수에 추가하는 것이다:
L r e g u l a r i z e d=L o r i g i n a l+λ∑w∈weights w 2
여기서 λ는 정규화 강도이며, 학습 데이터에 맞추는 것과 가중치를 작게 유지하는 것 사이의 트레이드오프를 조절하는 하이퍼파라미터다.
이 정규화 항을 각 가중치에 대해 미분한 그래디언트는 다음과 같다:
∂∂w(λ w 2)=2 λ w
즉, 가중치 업데이트 단계에서 각 가중치는 원래 손실의 그래디언트에 따라 조정될 뿐 아니라, 그 크기에 비례해 추가로 줄어든다:
w t+1=w t−α(∂L o r i g i n a l∂w t+2 λ w t)=(1−2 α λ)w t−α∂L o r i g i n a l∂w t
이는 데이터로부터 가중치가 커야 한다는 강한 증거가 없는 한, 가중치를 0 쪽으로 밀어내는 효과를 가진다. 그 결과 더 단순한 모델이 되어 과적합 가능성이 줄어든다.
우리 프레임워크에서 L2 정규화를 구현하는 것은 간단하다. 손실 함수에 정규화 항을 포함하도록 수정하면 된다:
def _mse_loss_with_l2(self, pred, target, lambda_reg=0.01):
"""Mean squared error loss function with L2 regularization."""
# Original MSE loss
mse_loss = (pred - target) * (pred - target)
# L2 regularization term
l2_reg = Value(0.0)
for p in self.model.parameters():
l2_reg = l2_reg + p * p
l2_reg = l2_reg * lambda_reg
# Combined loss
return mse_loss + l2_reg
또는 가중치 업데이트 규칙을 수정해 최적화기에서 직접 L2 정규화를 구현할 수도 있다:
def step(self, lambda_reg=0.01):
"""Updates each parameter with L2 regularization."""
for p in self.parameters:
# L2 regularization: weight decay
p.data -= self.lr * (p.grad + 2 * lambda_reg * p.data)
L2 정규화는 여러 장점이 있다:
정규화 강도 λ는 튜닝이 필요한 하이퍼파라미터다. λ가 너무 작으면 정규화 효과가 미미하고, 너무 크면 모델이 과소적합(underfit)할 수 있다. 보통 교차 검증(cross-validation)을 통해 λ의 최적 값을 찾는다.
라이브러리가 실제로 어떻게 동작하는지 보여주기 위해, scikit-learn의 "moons" 데이터셋에서 신경망을 학습시켜 보자. 이 데이터셋은 서로 맞물린 두 개의 반원으로 이루어져 있어, 클래스를 분리하려면 비선형 결정 경계가 필요하다:
from sklearn.datasets import make_moons
import numpy as np
import matplotlib.pyplot as plt
from tinynn.engine import Value
from tinynn.nn import MLP
from tinynn.optim import SGD
from tinynn.trainer import Trainer
# Generate the dataset
X, y = make_moons(n_samples=100, noise=0.1, random_state=42)
# Create a neural network: 2 inputs -> 32 -> 32 -> 16 -> 1 output
model = MLP(nin=2, nouts=[32, 32, 16, 1])
# Create an optimizer
optimizer = SGD(model.parameters(), lr=0.005)
# Create trainer
trainer = Trainer(model, optimizer)
# Train the model
trainer.train(X, y, n_epochs=500, batch_size=10, verbose=True)
핵심 학습 개념:
배치 크기(Batch Size): 각 순전파/역전파에서 함께 처리되는 학습 예제 수를 결정한다. 더 작은 배치는 그래디언트 업데이트에 더 많은 노이즈를 도입(이는 국소 최소에서 벗어나는 데 도움이 될 수 있음)하지만 수렴이 더 느릴 수 있다. 더 큰 배치는 더 안정적인 업데이트를 제공하지만 최적이 아닌 해에 갇힐 수도 있다.
에폭(Epochs): 학습 데이터셋 전체를 한 번 완전히 통과하는 것. 모델이 효과적으로 학습하려면 여러 에폭이 필요하다. 최적의 에폭 수는 데이터셋 크기, 모델 복잡도, 최적화 파라미터 등에 따라 달라진다.
학습 손실(Training Loss): 모델의 예측이 실제 값과 얼마나 일치하는지 측정한다. 우리는 평균 제곱 오차(MSE)를 사용한다:
M S E=1 n∑i=1 n(y p r e d i−y t a r g e t i)2
MSE가 우리의 이진 분류 작업에 특히 적합한 이유는 다음과 같다:
정확도(Accuracy): 올바른 예측의 비율. 직관적이지만, 불균형 데이터셋에서는 오해를 낳을 수 있으므로 다른 메트릭과 함께 고려해야 한다.
학습 진행은 그림 4에 나와 있으며, 시간이 지남에 따라 손실이 감소하고 정확도가 향상되는 것을 볼 수 있다:
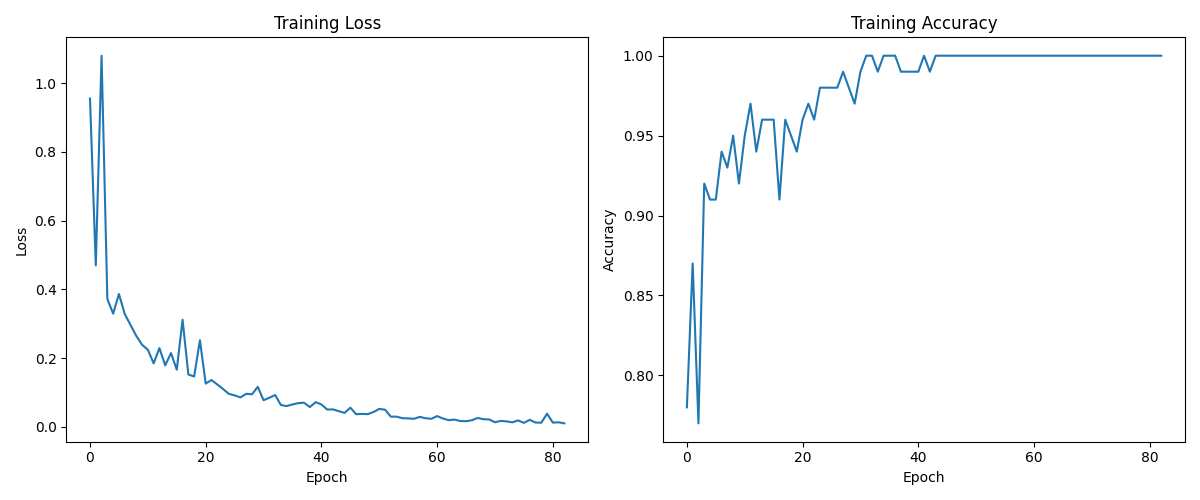
그림 4: 모델이 학습함에 따라 손실이 감소하고 정확도가 향상되는 학습 진행 상황.
우리의 단순한 모델은 그림 5의 결정 경계 시각화에서 보이듯 두 클래스를 효과적으로 분리하는 법을 학습한다:
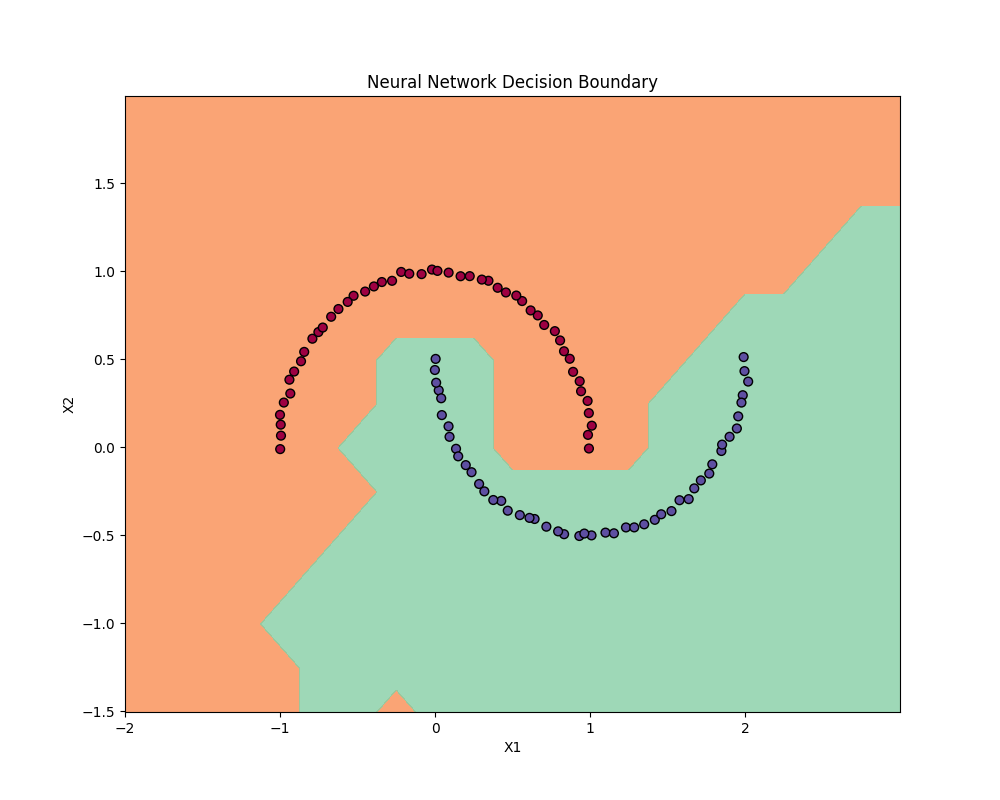
그림 5: 학습된 결정 경계는 모델이 비선형 경계로 두 클래스를 어떻게 분리하는지 보여준다.
신경망 학습에는 여러 차원에서 병렬화 기회가 풍부하다. 가장 눈에 띄는 것은 배치 병렬성으로, 여러 학습 예제를 네트워크를 통해 동시에 처리할 수 있다. 배치 내 각 예제는 순전파 동안 독립적으로 계산할 수 있고, 역전파 동안에는 그래디언트를 병렬로 누적할 수 있다. 또한 각 층 내부에서는 행렬 곱과 원소별 연산을 뉴런 차원과 특성 차원에 걸쳐 병렬화할 수 있어, 현대 하드웨어가 활용할 수 있는 풍부한 병렬 계산 계층을 만든다.
이러한 내재적 병렬성은 현대 GPU를 딥러닝 워크로드에 이상적으로 만든다. 복잡한 제어 흐름을 가진 순차 처리에 최적화된 CPU와 달리, GPU는 병렬 산술 연산을 위해 설계된 수천 개의 더 단순한 코어를 포함한다. 이 아키텍처는 신경망 계산과 완벽하게 맞아떨어진다. 행렬 곱, 컨볼루션, 원소별 연산은 모두 이러한 코어들에 분산될 수 있어 CPU 구현과 비교해 자릿수 단위의 속도 향상을 제공한다. 현대 GPU는 또한 딥러닝에서 흔한 혼합 정밀도 행렬 연산을 가속하는 특수 텐서 코어(tensor core)도 갖추고 있다.
GPU의 메모리 계층 구조는 딥러닝 성능에 또 다른 중요한 요인이다. 높은 대역폭 메모리와 정교한 캐싱 메커니즘은 많은 처리 코어에 데이터를 효율적으로 공급할 수 있게 하고, 공유 메모리는 동일한 계산을 수행하는 스레드 간의 빠른 통신을 가능하게 한다. 이는 메모리 접근 패턴이 예측 가능하고 규칙적인 딥러닝에서 특히 중요하며, 메모리 서브시스템을 최적으로 활용할 수 있게 해준다. 이러한 메모리 특성과 막대한 병렬 처리 능력이 결합되어 GPU는 현대 딥러닝 인프라의 중추가 되었고, 점점 더 크고 복잡한 모델의 학습을 가능하게 한다. 다음은 그쪽으로 넘어가 보자.