LLVM 생태계의 MLIR을 소개하고, 현대 컴파일러 스택에서의 위치와 기본 개념, 설치 및 LLVM/MLIR 예제를 통해 파이프라인을 개관한다.

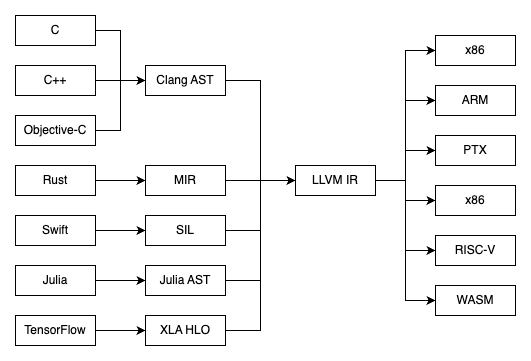
LLVM은 프로그래밍 언어와 도구를 만드는 방식을 혁신해 온 강력한 컴파일러 인프라 프로젝트입니다. 핵심적으로 LLVM은 어떤 프로그래밍 언어에 대해서도 프런트엔드 컴파일러를 개발하고, 다양한 타깃 아키텍처를 위해 최적화된 코드를 생성하는 데 사용할 수 있는 모듈식 컴파일러 및 툴체인 기술의 모음을 제공합니다.
MLIR은 LLVM 생태계 안의 비교적 새로운 프로젝트로, 현대의 하드웨어 가속기와 머신러닝 프레임워크가 던지는 과제들을 해결하기 위해 설계되었습니다. LLVM IR이 강력하긴 하지만, 비교적 낮은 수준에서 동작합니다. MLIR은 이런 개념을 확장해 여러 수준의 추상화를 지원합니다.
불행히도 현대 컴파일러 스택은 RFC, 논문, 메일링 리스트를 읽으면서 배워야 하는 경우가 많습니다. 이 튜토리얼에서는 현대 컴파일러 스택에 대한 간결한 개요, 그 안에서 MLIR이 어디에 들어맞는지, 그리고 이를 Python 머신러닝 생태계에 어떻게 통합하는지 설명하려고 합니다.
이 시리즈에서는 최종적으로 GPT2 트랜스포머 모델의 작은 버전을 효율적인 GPU 커널로 컴파일하는 것까지 이어지도록 다음 주제들을 다룰 것입니다.
이 튜토리얼은 C++와 고급 Python에 대한 약간의 지식, NVIDIA CUDA에 대한 기본적인 친숙함을 전제로 하지만, 그 외에는 자체 포함적으로 구성했습니다.
아마도 신경 쓰지 않아도 됩니다. 최적화 컴파일러를 작성하는 일은 아주 틈새 주제입니다. 다만 LLVM + MLIR 덕분에 불과 몇 년 전과 비교해 필요한 지식이 훨씬 적어졌습니다. 그래서 새로운 AI 프레임워크나 실험적 프로그래밍 언어를 만들고 싶다면 지금이 좋은 시기입니다. 반드시 배워야 하는 것은 아니지만, 다시 말해 인생의 많은 것들이 그렇기도 합니다.
MLIR은 전통적인 컴파일러(LLVM, GCC 등)의 한계를 해결하기 위해 설계되었습니다. 특히 현대 하드웨어 가속기와 AI 워크로드를 다룰 때의 한계를 겨냥합니다. LLVM은 전통적인 CPU 타깃에서는 뛰어나지만, AI와 머신러닝에서 등장하는 다양한 특화 아키텍처를 다루는 데는 어려움을 겪습니다.
현대 AI 시스템은 보통 CPU, GPU, TPU, 커스텀 ASIC의 혼합으로 이루어져 있습니다. MLIR의 유연한 아키텍처는 이런 서로 다른 플랫폼 전반에서 작업하기를 더 쉽게 만들어 주며, 이기종 하드웨어에 대한 견고한 지원을 제공합니다.
MLIR의 dialect 시스템은 고수준 ML 작업부터 하드웨어 특화 명령까지 다양한 수준에서 연산을 표현하고 최적화할 수 있습니다. 이는 특정 도메인에 맞춘 최적화를 구현할 수 있다는 뜻이며, AI 워크로드를 더 효율적으로 실행하도록 해줍니다.
가속기나 프레임워크의 종류마다 별도의 컴파일러가 필요한 대신, MLIR은 다양한 사용 사례에 맞게 확장 가능한 통합 인프라를 제공합니다. 전통적인 컴파일러는 AI를 염두에 두고 만들어지지 않았지만, MLIR은 텐서 연산, 신경망, 트랜스포머, 기타 ML 구성요소를 일급으로 지원합니다.
MLIR은 특화된 머신러닝 가속기를 위한 대표 기술이 되었고, 신호 처리, 양자 컴퓨팅, 동형암호, FPGA, 커스텀 실리콘 등에서도 활용되고 있습니다. 전통적인 CPU/GPU 틀에 맞지 않는 그런 “이상한 도메인”에서 도메인 특화 컴파일러를 만들 수 있다는 점은 판도를 바꿉니다. 게다가 다른 언어에 쉽게 임베드할 수 있어, 특정 작업을 위해 맞춤화된 도메인 특화 언어를 만들 수도 있습니다. 이 블로그에서 더 깊게 다뤄볼 내용입니다.
LLVM: LLVM의 핵심은 중간 표현(Intermediate Representation)입니다. 어셈블리와 비슷한 저수준 프로그래밍 언어이지만, 중요한 고수준 정보가 보존되어 있습니다. 이 IR은 소스 언어와 타깃 아키텍처 사이의 다리 역할을 합니다.
MLIR: MLIR은 더 표현력이 높은 새로운 “멀티 레벨” 중간 표현으로, 제어 흐름, 데이터 흐름, 병렬성과 같은 고수준 개념을 표현할 수 있으며 LLVM IR로 로워링될 수 있습니다.
최적화 패스: MLIR과 LLVM 모두 IR 수준에서 동작하는 방대한 최적화 패스 집합을 제공하며, LLVM을 사용하는 어떤 언어든 고도화된 최적화의 혜택을 누릴 수 있습니다. 대부분은 최신 컴파일러 최적화 연구를 바탕으로 대학원생과 박사들이 작성했습니다. 이것이 LLVM을 그렇게 강력한 도구로 만드는 요소입니다.
E-Graphs: Equality saturation은 e-그래프를 사용해 최적화 컴파일러를 구성하는 기법이며, 자동 정리 증명 세계에서 유래했습니다. e-matching을 사용한 재작성 집합을 적용해 e-그래프가 포화될 때까지 진행하고, 여러 중단 조건 중 하나가 충족될 때까지 포화 과정을 계속합니다. 재작성 단계 이후에는 비용 함수(보통 구문 트리 크기나 성능 고려와 관련됨)를 기반으로 e-그래프에서 최적 항을 추출합니다. 이를 통해 더 넓은 변환 후보 집합을 탐색하고 정의된 기준에 따라 최선의 변환을 선택함으로써 더 효율적인 최적화를 가능하게 합니다.
현대 컴파일러는 이런 구성요소들을 엮어 파이프라인을 구성합니다.
많은 프로그래밍 언어는 소스 언어와 LLVM 사이의 간극을 메우기 위해 “중간 수준” IR을 구현합니다. 예를 들어 Rust, Swift, Tensorflow 모두 이 패턴을 따릅니다. MLIR을 통해 같은 인프라를 재사용하고, LLVM이 많은 언어의 사실상 표준 백엔드가 된 것과 비슷한 방식으로 더 상호운용 가능한 새로운 세대의 언어와 프레임워크를 만들 수 있습니다.
MLIR 설치는 다소 고통스럽고, 먼저 몇 가지 의존성을 설치해야 합니다.
# MacOS
brew install cmake ninja ccache
# Linux
apt-get install cmake ninja-build ccache
그다음 LLVM 저장소를 클론하고 소스에서 MLIR을 빌드할 수 있습니다. 빌드에는 아주 오래 걸릴 수 있습니다. 우주에 엔트로피를 더하는 동안 차 한 잔을 권합니다.
git clone https://github.com/llvm/llvm-project
mkdir llvm-project/build
cd llvm-project/build
cmake -G Ninja ../llvm \
-DLLVM_ENABLE_PROJECTS=mlir \
-DLLVM_BUILD_EXAMPLES=ON \
-DLLVM_TARGETS_TO_BUILD="Native;ARM;X86" \
-DCMAKE_BUILD_TYPE=Release \
-DLLVM_ENABLE_ASSERTIONS=ON \
-DCMAKE_C_COMPILER=clang -DCMAKE_CXX_COMPILER=clang++ \
-DLLVM_CCACHE_BUILD=ON
cmake --build . --target check-mlir
cmake --build . --target install
설치된 MLIR 버전을 확인합니다. 이 튜토리얼은 21.0.0 버전을 사용합니다.
mlir-opt --version
LLVM (http://llvm.org/):
LLVM version 21.0.0git
Optimized build with assertions.
가까운 미래의 어느 시점에는 Homebrew의 LLVM 버전이 MLIR을 포함하도록 업데이트될 것이고, 그때는 훨씬 쉬워질 것입니다. 더 나은 미래의 어느 시점에 이 글을 읽고 있다면, 아래를 그냥 시도해보면 동작할지도 모릅니다.
brew install llvm
MLIR은 그 자체로 하나의 프로그래밍 언어입니다. 매우 저수준이지만, 다른 언어에서 볼 법한 핵심 프리미티브를 많이 포함합니다. 먼저 식별자 관례를 보겠습니다.
% 접두사: SSA 값(예: %result)@ 접두사: 함수(예: @fun)^ 접두사: 기본 블록(예: ^bb0)# 접두사: attribute 별칭(예: #map_1d_identity)x 구분자: shape 내부 및 shape과 타입 사이에 사용(예: 10xf32): 및 ->: 연산 또는 값의 타입을 표시하는 데 사용(예: %result: i32)! 접두사: 타입 별칭(예: !avx_m128 = vector<4 x f32>)() : 인자를 표현하는 데 사용(예: (%arg0, %arg1)){}: region을 표현하는 데 사용//: 주석에 사용<>: 타입 파라미터를 표시하는 데 사용(예: tensor<10xf32>)module {
// Operations
}
func.func @my_function(%arg0: i32, %arg1: i32) -> i32 {
// Operations
}
우리가 사용할 고수준 dialect는 다음과 같습니다.
* `tensor`: 다차원 배열(텐서)을 생성하고 조작하는 연산을 제공하며, 부작용 없는 방식으로 고수준 수학 표현과 변환을 가능하게 합니다.
* `linalg`: 선형대수(linalg) dialect는 선형대수 계산을 위해 특별히 설계된 연산 집합을 제공하여, 행렬 및 벡터 연산을 효율적으로 구현할 수 있게 합니다.
* `omp`: OpenMP(omp) dialect는 병렬 프로그래밍 모델을 지원하는 연산을 포함하며, OpenMP 표준과 호환되는 방식으로 병렬성을 표현할 수 있게 합니다.
* `affine`: affine dialect는 affine 연산과 분석을 표현하는 프레임워크를 제공하여, affine 표현의 예측 가능한 동작을 활용하는 최적화를 가능하게 합니다.
* `gpu`: GPU dialect는 GPU 프로그래밍에 특화되어 이기종 아키텍처에서의 병렬 실행을 위한 연산을 제공합니다.
저수준 dialect는 다음과 같습니다.
* `scf`: structured control flow(scf) dialect는 루프와 조건문 같은 구조화된 제어 흐름 구문을 나타내는 연산을 제공하여, 명확하고 유지보수 가능한 실행 흐름을 보장합니다.
* `func`: 함수 정의와 호출에 관련된 연산을 포함하여, 고수준 함수 추상화를 통해 코드의 조직화와 모듈화를 돕습니다.
* `memref`: memref dialect는 메모리 참조 연산에 전념하며, 성능이 중요한 애플리케이션에 필수적인 메모리 버퍼의 효율적 관리 및 조작을 가능하게 합니다.
* `index`: index dialect는 인덱스 계산을 다루는 연산에 특화되어 있으며, 특히 루프 반복 및 데이터 접근 패턴에서 배열과 텐서의 원소를 주소 지정하는 데 중요합니다.
* `arith`: 산술(arith) dialect는 정수 및 부동소수점 타입 모두에 대해 기본 수학 연산을 포함합니다. 기본 산술, 비트 연산, 비교 등을 제공하며 스칼라, 벡터, 텐서에 적용할 수 있습니다.
추가로 NVIDIA GPU를 타깃팅하기 위해 몇 가지 하드웨어 특화 dialect도 사용할 텐데, 이는 나중에 더 다루겠습니다.
// Example of an MLIR operation
%0 = "my_dialect.my_operation"(%arg0, %arg1) : (i32, i32) -> i32
이 예에서 my_dialect.my_operation은 my_dialect dialect에 정의된 연산이고, %arg0와 %arg1은 i32 타입의 인자입니다. 결과로 i32 타입을 반환하며 %0 변수에 바인딩됩니다.
구체적인 예로는 두 부동소수점 수를 더하는 arith.addf 연산이 있습니다.
%0 = arith.addf %arg0, %arg1 : f32
^bb1: // Label for the then block
%then_result = arith.muli %result, 2 : i32
return %then_result : i32
LLVM과 달리, 기본 블록은 이제 인자를 받을 수도 있으며, ^bb1(%result : i32) 구문을 통해 전달됩니다.
{} 블록으로 묶이며 인자를 받을 수 있습니다.{
^bb1(%result : i32):
%then_result = arith.muli %result, 2 : i32
return %then_result : i32
}
%result = arith.constant 1 : i32
편의를 위해 타입 동의어를 정의할 수도 있습니다.
!avx_m128 = vector<4 x f32>
이는 mlir-opt에 전달하여 MLIR을 변환할 수 있는 인자들이며, 가장 흔한 것들은 다음과 같습니다.
* `convert-func-to-llvm`: 함수 형태 연산을 LLVM dialect로 변환
* `convert-math-to-llvm`: math 연산을 LLVM dialect로 변환
* `convert-index-to-llvm`: index 연산을 LLVM dialect로 변환
* `convert-scf-to-cf`: structured control flow를 CF dialect로 변환
* `convert-cf-to-llvm`: control flow를 LLVM dialect로 변환
* `convert-arith-to-llvm`: 산술 연산을 LLVM dialect로 변환
* `reconcile-unrealized-casts`: unrealized cast 정합화
* `convert-memref-to-llvm`: memref 연산을 LLVM dialect로 변환
* `convert-tensor-to-llvm`: tensor 연산을 LLVM dialect로 변환
* `convert-linalg-to-scf`: linalg 연산을 `scf.for` 루프로 변환
* `convert-linalg-to-affine-loops`: linalg 연산을 `affine.for` 루프로 변환
* `convert-omp-to-llvm`: OpenMP 연산을 LLVM dialect로 변환
* `convert-vector-to-llvm`: vector 연산을 LLVM dialect로 변환
또한 MLRI에서 LLVM IR로 변환 가능한 모든 것을 변환하는 일반적인 -convert-to-llvm 패스도 있습니다. 실제로는 특정 dialect를 LLVM으로 변환하기 위해 더 세분화된 패스를 사용할 것입니다.
패스에 대한 더 세밀한 제어가 필요하다면, --pass-pipeline 문자열에 콤마로 구분한 목록으로 패스 이름을 지정할 수도 있습니다. 예: --pass-pipeline="builtin.module(pass1,pass2)". 패스들은 한 그룹 안에서 순차적으로 실행됩니다.
또한 패스 변환을 디버깅하기 위한 여러 플래그도 있습니다. --mlir-print-ir-after-all 플래그는 각 패스 이후의 IR을 출력하고, --mlir-print-ir-after-change 및 --mlir-print-ir-after-failure는 더 구체적인 출력을 제공합니다. --mlir-print-ir-tree-dir를 포함해 이런 print-ir 플래그들을 사용하면, 터미널 stdout을 훑고 싶지 않을 때 IR이 디렉터리 트리에 파일로 기록됩니다.
참고: 패스의 순서는 중요할 수 있습니다. 예를 들어 convert-scf-to-cf는 convert-cf-to-llvm보다 먼저 와야 합니다.
42를 종료 코드로 반환하는 간단한 LLVM 모듈을 만들고, 이를 공유 라이브러리로 컴파일한 다음 Python에서 사용하는 예제를 보겠습니다. 이 예제는 LLVM IR에서 사용 가능한 코드로 가는 전체 파이프라인을 보여줍니다.
먼저 simple.ll이라는 파일을 만들고 아래 LLVM IR을 넣습니다.
define i32 @main() {
ret i32 42
}
비유하자면 이 프로그램은 다음과 같습니다.
int main() {
return 42;
}
clang를 사용해 이 LLVM IR을 공유 오브젝트로 컴파일할 수 있습니다.
llc -filetype=obj --relocation-model=pic simple.ll -o simple.o
clang -shared -fPIC simple.o -o libsimple.so
clang simple.o -o simple # optionally create an executable
이제 실행 파일을 실행하면 종료 코드로 42가 반환되는 것을 볼 수 있습니다.
$ ./simple
$ echo $?
42
이제 ctypes를 사용해 Python에서 공유 라이브러리 libsimple.so를 사용할 수 있습니다.
import ctypes
module = ctypes.CDLL("./libsimple.so")
module.main.argtypes = []
module.main.restype = ctypes.c_int
print(module.main())
이를 실행하면 Python 로직이 공유 라이브러리를 성공적으로 호출하고 결과를 출력하는 것을 볼 수 있습니다.
$ python simple.py
42
42를 반환하는 함수만 놓고 보면 LLVM으로 작성하는 것은 충분히 간단합니다. 하지만 LLVM으로 비자명한 프로그램을 작성하는 것은 그렇게 간단하지 않습니다. 실제로 많은 응용에서 LLVM은 너무 “저수준”인 경우가 많고, 수년 동안 많은 사람들이 LLVM 위에 더 고수준의 추상화를 구축해 왔습니다.
예를 들어 LLVM에서 루프를 작성하는 것은 꽤 번거롭습니다. 기본적인 루프를 위해 블록, phi 노드 등을 수동으로 처리해야 합니다. MLIR은 고수준 구문을 직접 작성하고, 한 번의 패스로 LLVM으로 로워링할 수 있게 해줍니다.
먼저 simple.mlir 파일을 만들고 아래 MLIR을 넣습니다.
func.func @loop_add() -> (index) {
%init = index.constant 0
%lb = index.constant 0
%ub = index.constant 10
%step = index.constant 1
%sum = scf.for %iv = %lb to %ub step %step iter_args(%acc = %init) -> (index) {
%sum_next = arith.addi %acc, %iv : index
scf.yield %sum_next : index
}
return %sum : index
}
func.func @main() -> i32 {
%out = call @loop_add() : () -> index
%out_i32 = arith.index_cast %out : index to i32
func.return %out_i32 : i32
}
C로는 다음과 같습니다.
int loop_add(int lb, int ub, int step) {
int sum_0 = 0;
int sum = sum_0;
for (int iv = lb; iv < ub; iv += step) {
sum_next = sum + iv;
sum = sum_next;
}
return sum;
}
int main() {
int out = loop_add(0, 10, 1);
return out;
}
LLVM IR은 정적 단일 대입(Static Single Assignment)에 기반합니다. 즉 모든 변수는 정확히 한 번만 대입되며, 변수의 모든 사용은 그 정의에 의해 지배(dominated)되어야 합니다. SSA에서는 변수가 여러 번 재대입되는 대신, 각 새로운 “대입”이 변수의 새 버전을 만들며, 보통 %1, %2 같은 번호 접미사로 표기됩니다. 이런 성질은 정의와 사용 사이의 관계가 명시적이고 모호하지 않기 때문에, 많은 컴파일러 최적화를 더 단순하고 효과적으로 만듭니다.
예를 들어 LLVM IR에서는 다음과 같은 코드를 볼 수 있습니다.
%1 = add i32 %a, %b
%2 = mul i32 %1, %c
여기서 %1과 %2는 재대입될 수 없는 SSA 값입니다. 제어 흐름 때문에 어떤 경로를 택했는지에 따라 변수가 서로 다른 값을 가져야 할 때(예: if 문 이후), LLVM은 SSA 속성을 유지하면서 동적 프로그램 동작을 다루기 위해 특별한 “phi” 노드를 사용해 서로 다른 가능한 값들을 병합합니다.
LLVM에서 기본 블록은 제어 흐름의 기본 단위이며, 순차적으로 실행되는 명령들의 시퀀스입니다. 기본 블록은 하나의 진입점과 하나의 종료점을 가집니다.
Phi 노드는 SSA 기반 중간 표현에서 서로 다른 제어 흐름 경로로부터 올 수 있는 여러 잠재 값들을 하나의 값으로 해소하는 특별한 명령입니다. 본질적으로 제어 흐름을 인지하는 멀티플렉서로, 프로그램이 그 지점에 도달하기 위해 어떤 경로를 밟았는지에 따라 적절한 값을 선택합니다.
entry:
br i1 %cond, label %then, label %else
then:
%x.1 = add i32 1, 2
br label %merge
else:
%x.2 = mul i32 3, 4
br label %merge
merge:
%x.3 = phi i32 [ %x.1, %then ], [ %x.2, %else ]
ret i32 %x.3
이 예에서 phi 노드 %x.3는 제어 흐름이 then 블록에서 왔다면 %x.1 값(3)을 취하고, else 블록에서 왔다면 %x.2 값(12)을 취합니다. [ value, predecessor_block ] 구문은 어떤 블록이 직전에 실행되었는지에 따라 어떤 값을 사용할지를 지정합니다.
mlir-opt를 사용해 고수준 MLIR을 LLVM dialect로 로워링할 수 있습니다. 본질적으로 루프 구문을 블록에 대한 분기/조건 분기 문으로 줄이는 것입니다.
mlir-opt example.mlir \
--convert-func-to-llvm \
--convert-math-to-llvm \
--convert-index-to-llvm \
--convert-scf-to-cf \
--convert-cf-to-llvm \
--convert-arith-to-llvm \
--reconcile-unrealized-casts \
-o example_opt.mlir
그러면 다음 MLIR이 생성됩니다.
module {
llvm.func @loop_add() -> i64 {
%0 = llvm.mlir.constant(0 : i64) : i64
%1 = llvm.mlir.constant(0 : i64) : i64
%2 = llvm.mlir.constant(10 : i64) : i64
%3 = llvm.mlir.constant(1 : i64) : i64
llvm.br ^bb1(%1, %0 : i64, i64)
^bb1(%4: i64, %5: i64): // 2 preds: ^bb0, ^bb2
%6 = llvm.icmp "slt" %4, %2 : i64
llvm.cond_br %6, ^bb2, ^bb3
^bb2: // pred: ^bb1
%7 = llvm.add %5, %4 : i64
%8 = llvm.add %4, %3 : i64
llvm.br ^bb1(%8, %7 : i64, i64)
^bb3: // pred: ^bb1
llvm.return %5 : i64
}
llvm.func @main() -> i32 {
%0 = llvm.call @loop_add() : () -> i64
%1 = llvm.trunc %0 : i64 to i32
llvm.return %1 : i32
}
}
mlir-cpu-runner를 사용하면 MLIR 코드에서 main 함수를 직접 실행할 수 있습니다.
mlir-cpu-runner -e main -entry-point-result=i32 simple_opt.mlir
# To use the runner utils (e.g. for debug printing)
# mlir-cpu-runner -e main -entry-point-result=i32 -shared-libs=/opt/homebrew/opt/llvm/lib/libmlir_runner_utils.dylib simple_opt.mlir
그다음 mlir-translate로 MLIR을 LLVM IR로 직접 변환합니다. mlir-translate를 사용해 이 MLIR을 공유 오브젝트로 컴파일할 수 있습니다.
mlir-translate simple_opt.mlir -mlir-to-llvmir -o simple.ll
llc -filetype=obj --relocation-model=pic simple.ll -o simple.o
clang -shared -fPIC simple.o -o libsimple.so
그리고 LLVM은 어셈블리(이 경우 ARM64 어셈블리)로 컴파일됩니다.
_loop_add:
sub sp, sp, #0x30
mov x8, #0x0
mov x9, x8
str x9, [sp, #0x20]
str x8, [sp, #0x28]
b 0x100003f10
ldr x9, [sp, #0x20]
ldr x8, [sp, #0x28]
str x8, [sp, #0x8]
str x9, [sp, #0x10]
subs x9, x9, #0xa
str x8, [sp, #0x18]
b.ge 0x100003f4c
b 0x100003f30
ldr x9, [sp, #0x10]
ldr x8, [sp, #0x8]
add x8, x8, x9
add x9, x9, #0x1
str x9, [sp, #0x20]
str x8, [sp, #0x28]
b 0x100003f10
ldr x0, [sp, #0x18]
add sp, sp, #0x30
ret
llvmllvm dialect는 LLVM IR을 표현하는 dialect입니다. MLIR 계층에서 가장 저수준 dialect이며, LLVM IR로 직접 통과됩니다.
scf와 cf모든 고수준 scf 구조는 cf 구성요소로 컴파일됩니다.
cf.br - 기본 블록으로의 분기cf.cond_br - 기본 블록으로의 조건 분기cf.switch - 기본 블록으로의 switch 분기무조건 분기는 항상 같은 기본 블록으로 가는 분기입니다.
// A basic block
^bb0:
cf.br ^bb1
조건 분기는 조건 변수(여기서는 %c)에 따라 다른 기본 블록으로 가는 분기입니다.
// A conditional branch to a basic block
^bb0:
cf.cond_br %c, ^bb1, ^bb2
switch 분기는 switch 변수(여기서는 %i)에 따라 다른 기본 블록으로 가는 분기입니다.
// A switch to a basic block
^bb0:
cf.switch %i, ^bb1, ^bb2, ^bb3
예를 들어 이 구성요소들을 조합해, 불리언 플래그에 따라 두 값 중 하나를 선택하여 주어진 인자 중 하나를 반환하는 함수를 만들 수 있습니다.
func.func @select(%a: i32, %b: i32, %flag: i1) -> i32 {
cf.cond_br %flag, ^bb1(%a : i32), ^bb1(%b : i32)
^bb1(%x : i32) :
return %x : i32
}
가장 기본적인 structured control flow 구성요소는 scf.if입니다.
scf.if %b {
// true region
} else {
// false region
}
앞에서 했듯이 for 루프는 structured control flow 구성요소이며, 단일 진입점과 단일 종료점을 가집니다.
%lb = index.constant 0
%ub = index.constant 10
%step = index.constant 1
scf.for %iv = %lb to %ub step %step {
// loop region
}
이는 convert-scf-to-cf 패스를 통해 cf.br 및 cf.cond_br 연산들의 시퀀스로 로워링됩니다.
arith와 matharith dialect에는 다음과 같은 기본 연산이 포함됩니다.
addi, subi, muli, divsi(부호 있음), divui(부호 없음)addf, subf, mulf, divfcmpi(정수), cmpf(부동소수점)extsi(부호 확장), extui(0 확장), trunci, fptoui, fptosi, uitofp, sitofpandi, ori, xori산술 연산 예:
func.func @arithmetic_example(%a: i32, %b: f32) -> i32 {
// Integer addition
%1 = arith.constant 42 : i32
%2 = arith.addi %a, %1 : i32
// Float to integer conversion
%3 = arith.fptosi %b : f32 to i32
// Final addition
%4 = arith.addi %2, %3 : i32
return %4 : i32
}
math dialect는 더 복잡한 수학 연산을 제공합니다.
sin, cos, tanexp, exp2, log, log2, log10pow, sqrterf, atan2constantmath 연산 예:
func.func @math_example(%x: f32) -> f32 {
// Calculate sin(x) * sqrt(x)
%1 = math.sin %x : f32
%2 = math.sqrt %x : f32
%3 = arith.mulf %1, %2 : f32
return %3 : f32
}
-convert-math-to-llvm 및 -convert-arith-to-llvm 패스는 math 및 산술 연산을 기본 LLVM 연산의 동등물로 변환합니다.
indexindex dialect는 인덱스 계산을 다루는 데 특화되어 있으며, 배열/텐서 연산에서 특히 중요합니다. MLIR의 index 타입은 주소 지정과 루프 유도 변수에 사용되는 플랫폼 종속 크기의 정수입니다.
핵심 index 연산에는 다음이 포함됩니다.
index.constant: index 상수 생성index.add: 두 index 더하기index.sub: 두 index 빼기index.mul: 두 index 곱하기index.cmp: 두 index 비교index.divs: index의 부호 있는 나눗셈index.rems: index의 부호 있는 나머지index 연산은 배열에서 원소의 오프셋을 계산하는 데 사용됩니다. 예를 들어 다음 함수는 2D 배열에서 한 원소의 오프셋을 계산합니다. index는 항상 음수가 아니므로 자연수 연산처럼 다룰 수 있습니다.
func.func @compute_offset(%i: index, %j: index, %stride: index) -> index {
// Compute row-major array offset: i * stride + j
%1 = index.mul %i, %stride
%2 = index.add %1, %j
return %2 : index
}
-convert-index-to-llvm 패스는 index dialect를 LLVM dialect로 변환합니다.
index 타입은 텐서 및 메모리 레이아웃을 다룰 때 특히 유용합니다. 배열 인덱스와 차원을 표현하는 자연스러운 방법을 제공하기 때문입니다. 이는 배열 접근 패턴을 위해 memref 및 tensor dialect와 함께 사용됩니다. 다음에 이를 다루겠습니다.