단순한 “balls in bins” 모델을 CPU와 메모리라는 다차원 자원 모델로 확장하고, best-of-k(두 번의 무작위 선택의 힘) 알고리즘을 다양한 목적함수로 조정해 좌초(stranded) 자원과 실패 배치를 줄이는 방법을 시뮬레이션으로 살펴본다.
가입하기
앱 받기
가입하기

The Intuition Project ---------------------
· 발행물 팔로우
 복잡한 아이디어를 독자가 직관적으로 이해하도록 돕는 글을 위한 발행물
복잡한 아이디어를 독자가 직관적으로 이해하도록 돕는 글을 위한 발행물
발행물 팔로우

팔로우
8분 읽기
·
Nov 19, 2023
57
공유
로드 밸런싱에 관한 제 이전 글에서는 단순한 “balls in bins” 모델에 여러 기법을 적용했습니다. 단순한 모델은 이해하기 쉽고, 필요하면 수동으로 디버깅하기도 쉬워서 훌륭합니다. 하지만 이 주제에 대한 관심이 단순히 학술적인 수준을 넘어선다면, 현실과 더 잘 맞닿기 위해 더 높은 충실도의 모델로 ‘졸업’하고 싶어질 것입니다.
이번 글에서는 best-of-k의 무상태(stateless)·확장 가능한 아이디어를 현실 세계의 컴퓨트 플릿을 나타내는 다차원 모델에 맞게 확장하겠습니다. 이에 대한 제 경험은 AWS Lambda에서 이 기법들을 프로덕션에 배포해 대규모의 활용률(utilization) 개선을 이끌어낸 것에서 비롯됩니다. 어쩌면 더 인상적인 점은, 무상태라는 특성 덕분에 어떤 규모의 플릿에도 적용할 수 있다는 사실입니다. 즉, 플랫폼이 성장하더라도 중앙 알고리즘을 바꿀 필요가 없습니다.
Press enter or click to view image in full size
먼저 “balls in bins” 모델을 확장해, 워크로드에서 (대개) 가장 중요한 두 차원인 CPU와 메모리 사용률을 함께 고려하는 모델로 바꿔보겠습니다. 그러면 이전 모델에서는 풀 필요가 없었던 많은 새로운 문제가 생긴다는 것을 보게 될 것입니다. 그리고 앞서 좋아했던 알고리즘들을 이 추가 복잡도에 맞게 어떻게 조정할 수 있는지도 살펴보겠습니다.
이전과 마찬가지로 N 대의 워커 머신이 있다고 합시다. 각 워커는 매초 C 총 CPU 초를 쓸 수 있고, M 기가바이트의 RAM을 갖고 있습니다. 어떤 워크로드는 실행을 위해 매초 c 초의 CPU와 m 기가바이트의 RAM이 필요합니다. 워크로드는 단일 워커에서 실행되어야 하므로 당연히 m ≤ M 그리고 c ≤ C 입니다. 한 번 워커에 배치되면, 워크로드는 필요한 모든 자원을 한 번에 확보하고 영원히 계속 사용한다고 가정하겠습니다. 이 디테일들도 그리 현실적이지 않다는 건 분명하지만, 모든 복잡도를 한 번에 쌓아올릴 수는 없습니다.
이 문제를 시각화하는 한 가지 방법은 벡터를 쓰는 것입니다. 각 워크로드를 [c, m] 벡터로, 워커 자체를 [C, M] 이라는 큰 벡터로 생각해보세요. 워커에서 현재 실행 중인 모든 워크로드의 합이 사용률 벡터를 이룹니다. 이를 [Uc, Um] 라고 부르겠습니다. 다시 말해 Uc ≤ C 그리고 Um ≤ M 입니다.
Press enter or click to view image in full size
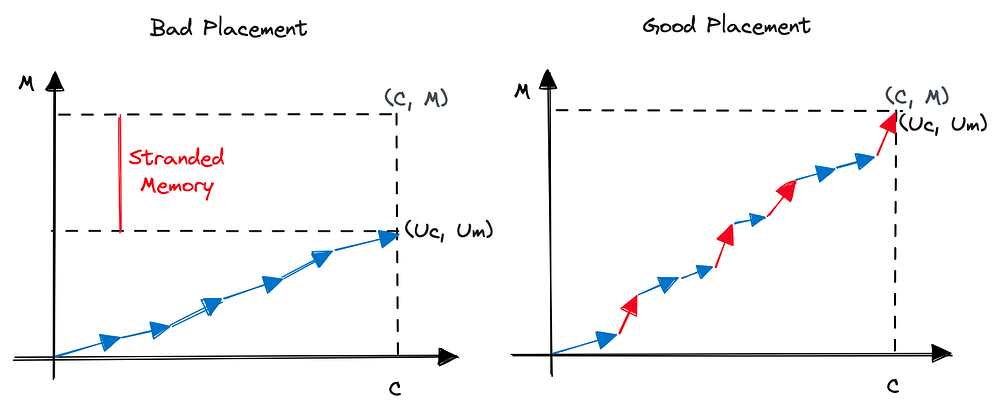
그림 1
CPU를 많이 먹는 워크로드를 한 워커에 너무 많이 채우면, 메모리가 많이 남아도는 상태에서 CPU가 고갈될 수 있고, 그 반대도 마찬가지입니다. 이렇게 남아도는 자원은 종종 좌초(stranded) 자원이라고 불립니다. 전역적으로 좌초 자원을 최소화하고 싶을 것입니다. 어떤 의미에서는, 이는 비용을 지불하고 있지만 대가를 받지 못하는 자원이기 때문입니다. 즉, 좌초가 많다면 전역 총합 워크로드(모든 c 와 m 의 합)를 처리하기 위해 모든 C 와 M 의 합보다 훨씬 큰 플릿이 필요하게 됩니다.
이번 시뮬레이션은 워크로드 데이터를 생성해야 하므로 조금 더 미묘합니다. 현실에서는 이것이 실제 트래픽입니다. 워크로드가 매우 동질적(homogeneous)이라면 로드 밸런싱 문제는 꽤 쉽습니다. “balls in bins” 모델과 비슷해지기 때문입니다(그 모델에서는 공의 모양과 크기가 다르다고 생각하지 않았죠). 이 경우에는 워커 크기(예: EC2 M, C, R 인스턴스 중)를 신중히 선택하기만 하면 됩니다. 하지만 모두가 이렇게 운이 좋은 건 아닙니다. 특히 제가 Lambda 시절에 그랬던 것처럼 3P 코드를 실행한다면, 매우 다양한 형태의 혼합을 다뤄야 하며 그중 일부는 병적으로 나쁠 수 있습니다. 이는 매우 흥미로운 배치 문제들을 만들어냅니다. 그중 일부는 이번 글에서 다루고, 일부는 다음으로 미루겠습니다.
Medium에 무료로 가입해 이 작성자의 업데이트를 받아보세요.
구독
구독
현실 세계에서는 실제 데이터에 분포를 피팅한 뒤, 시뮬레이션에서 그 분포를 사용합니다. 여기서는 그런 데이터가 없으니(여러분이 아는 그 CPU 열로) 공중에서 몇 가지 분포를 만들어내겠습니다. 제가 가장 익숙한 CPU와 메모리 분포는, 워크로드의 대다수가 낮은 사용률 구간에 몰려 있고 소수는 한 차원에서 훨씬 더 많은 자원을 사용하게 되는 형태입니다. 이것이 앞서 말한 병적 워크로드입니다. 감마 분포는 이런 워크로드를 모델링하는 데 아주 좋습니다. 사실 여러 현상을 모델링할 수 있어서, 저는 종종 기본 선택(go-to)으로 감마 분포를 씁니다. CPU와 메모리에 대해 다음 분포를 사용하겠습니다.
Press enter or click to view image in full size
그림 2
이제 100k 워크로드를 10k 워커에 배치할 준비가 됐습니다. 각 워커는 CPU 코어 50개(즉, 매초 50초의 CPU 시간을 지원)와 250GB 메모리를 가진다고 가정합니다. 먼저 무작위 배치를 사용하겠습니다. 임의의 워커를 하나 무작위로 뽑고 그 위에 배치해봅니다. 공간이 없으면 실패한 배치로 표시합니다.
Press enter or click to view image in full size
그림 3
약 6000번의 실패 시도가 있었습니다. CPU가 거의 꽉 찬 워커가 매우 많았고, 이는 대부분의 워커에 좌초된 메모리가 많다는 뜻입니다. 안타깝게도 좌초된 CPU가 있는 워커도 일부 있었습니다.
제 이전 글을 읽어본 분이라면 이 결과는 놀랍지 않을 것입니다. 무작위 배치는 자원 분포 관점에서 그다지 좋지 않습니다. 하지만 “두 번의 무작위 선택의 힘(power of two random choices)”은 모든 것을 고쳐주는 마법 같은 알고리즘이라고 알려져 있습니다. 그러니 이전처럼 여기에 적용해봅시다. 무작위로 워커 두 개를 보고, 워크로드 수가 더 적은 쪽을 고릅니다.
Press enter or click to view image in full size
그림 4
훨씬 낫네요! 메모리가 꽉 찬 워커가 없으니 CPU를 좌초시키지 않았습니다. 하지만 여전히 좌초된 메모리는 많습니다. CPU가 모두 소비된 워커가 500개 정도 있는데, 이전의 1100개에서 줄었으니 그래도 훨씬 좋아졌습니다. 실패 배치 수는 50% 줄었습니다.
따라서 두 번의 무작위 선택의 힘은 동작하긴 하지만, “balls into bins”에서처럼 강력하진 않습니다. “워크로드 수”와 다른 목적함수를 쓰면 고칠 수 있을까요? 워크로드가 균일하지 않기 때문에, 워크로드 수만으로는 전체 상황을 말해주지 못한다는 것이 이유입니다. 우리의 목적은 모든 워커가 동일한 수의 워크로드를 갖도록 하는 것이 아닙니다(그 일 자체는 그림 4의 세 번째 그래프를 보면 매우 잘 해냈습니다). 대신 두 자원 모두에서 워커가 균일하게 “채워지도록” 하고 싶습니다.
선형대수에서는 두 벡터가 서로 얼마나 떨어져 있는지 비교하기 위한 노름(norm)이라는 개념이 있습니다. 2-노름, 즉 L2 노름은 유클리드 거리와 같고, 지리·기하 문제에서 아주 흔히 쓰는 척도입니다. 이상적인 배치는 (Uc, Um) == (C, M) 일 때 일어난다는 것을 이미 알고 있으므로, (Uc, Um) 이 (C, M) 에 가까울수록 더 좋은 워커 배치라고 말할 수 있습니다. 이미 꽉 찬 플릿에 새로운 워커를 도입할 때의 몇 가지 주의사항이 있지만, 지금은 일단 넘어가겠습니다. 그러면 이 지식을 바탕으로 목적함수를 바꿔서, 이상적인 상태로부터의 사용률 거리가 더 큰 워커에 배치하도록 하겠습니다. 거기에 이 워크로드를 더하면 더 좋아질 것이라고 기대하는 것이죠. 사용률을 계산할 때는 반드시 퍼센트 같은 정규화된 형태로 해야 하며, 절대값으로 하면 안 됩니다.
Press enter or click to view image in full size
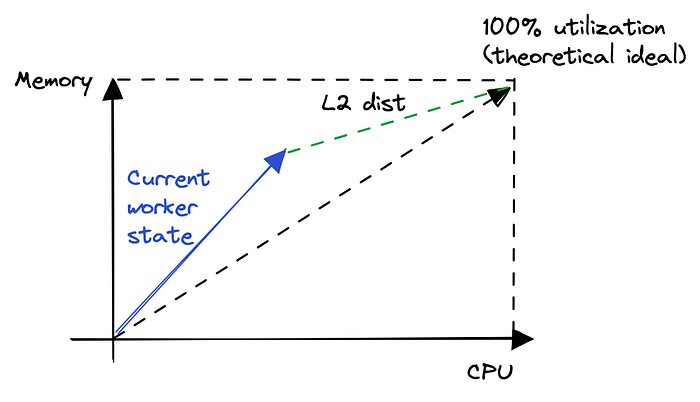
그림 5
Press enter or click to view image in full size
그림 6
훨씬 더 좋아졌습니다. 워커당 워크로드 분포는 더 넓어졌지만, CPU와 메모리 분포는 훨씬 좋아졌고 좌초 자원과 실패 배치를 줄였습니다.
주어진 워크로드가 얼마나 많은 자원을 필요로 할지 알 수 있는 방법이 있다고 가정해봅시다. 고객이 미리 지정해야 한다든지, 이전 값을 기억해두는 데이터 파이프라인이 있다든지 말이죠. 그런 경우라면 워커의 ‘빈 정도’를 단순 계산하는 대신, 워크로드를 배치했을 때의 빈 정도를 계산할 수 있습니다.
Press enter or click to view image in full size
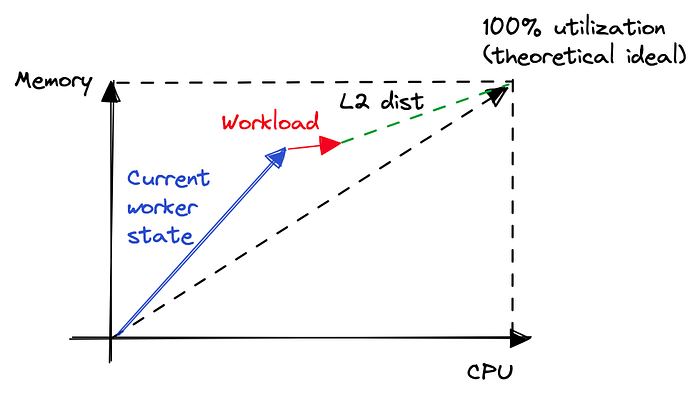
그림 7
Press enter or click to view image in full size
그림 8
훨씬 더 좋아졌습니다! 실패 배치 수가 1400에서 1100으로 내려갔고, CPU가 꽉 찬 워커 수도 약 350에서 약 220으로 내려갔습니다.
이전과 마찬가지로, 알고리즘을 튜닝할 수 있는 레버는 모두 여전히 있습니다. 예를 들어 여기서는 k=2 대신 k=5를 쓰면 다음과 같이 됩니다.
Press enter or click to view image in full size
그림 9
거의 다 왔지만, 더 좋은 것이 있을지도 모릅니다.
이제쯤이면, CPU를 좌초시키지 않는 것보다 메모리를 좌초시키지 않는 것이 훨씬 더 어렵다는 점이 분명해졌을 것입니다. 즉, 우리에게는 CPU가 더 균형 잡기 어려운 차원입니다. 그렇다면 CPU에만 모든 초점을 맞추고 메모리는 그냥 무시해보는 건 어떨까요? 기본적으로 목적함수를 “남은 메모리가 가장 적은 워커를 고르기”로 두고, best of 5 무작위 선택을 수행하겠습니다.
Press enter or click to view image in full size
그림 10
거의 다 됐습니다! 여기서는 메모리 좌초 문제를 사실상 해결했지만, 그 과정에서 CPU를 조금 좌초시키기 시작했습니다. 실패 배치도 더 줄었으니 전반적으로는 더 나은 결과라고 볼 수 있습니다.
다시 말하지만, 이런 급진적인 목적함수가 항상 통하는 것은 아닙니다. 그래서 실제로 프로덕션에 넣기 전에 데이터를 잘 이해하고 시뮬레이션하는 것이 중요합니다.
이번 글에서는 모델을 조금 확장해 다차원 배치에서 생기는 현실적인 문제들을 다뤘습니다. 또한 우리가 좋아하는 “두 번의 무작위 선택의 힘” 알고리즘을 더 나은 목적함수로 변형해보았습니다. 하지만 실제 알고리즘을 테스트하기 위한 좋은 모델이라는 관점에서는 이제 겨우 표면을 긁었을 뿐입니다. 다음 글들에서는 이 모델의 여러 측면을 덜 단순화하고, 새 요구사항을 만족하도록 전략을 업데이트해나가겠습니다.
57
57


팔로우
The Intuition Project에 게시됨 ----------------------------------
복잡한 아이디어를 독자가 직관적으로 이해하도록 돕는 글을 위한 발행물
팔로우


팔로우
Mihir Sathe 작성 ----------------------
저는 소프트웨어, 코딩, 대규모 시스템 구축을 좋아합니다. Snowflake의 소프트웨어 엔지니어입니다. 모든 의견은 제 개인 의견입니다. 제 Twitter: https://twitter.com/_mihir_sathe
팔로우
응답 작성
취소
응답

In
by
Jun 19, 2023
In
by
Apr 8, 2024
In
by
Jul 5, 2023

May 28, 2023
The Intuition Project의 글 모두 보기


In
by
Feb 23