‘두 번의 무작위 선택의 힘(power of two random choices)’ 알고리즘이 왜 단순한 변화만으로도 로드 밸런싱에서 지수적 개선을 만들어내는지, 공-상자(balls-in-bins) 모델과 몬테카를로 시뮬레이션을 통해 직관적으로 설명한다.
가입하기
앱 받기
가입하기

The Intuition Project ---------------------
· 발행물 팔로우
 복잡한 아이디어를 독자들이 직관적으로 이해하도록 돕는 글을 싣는 발행물
복잡한 아이디어를 독자들이 직관적으로 이해하도록 돕는 글을 싣는 발행물
발행물 팔로우
1
1

팔로우
9분 읽기
·
Jun 19, 2023
343
5
공유
Enter를 누르거나 클릭하면 이미지를 원본 크기로 볼 수 있습니다
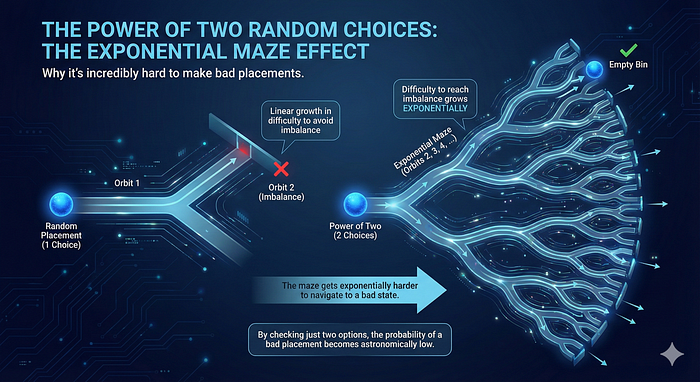
동적인 자원 할당과 로드 밸런싱에서, 가장 유명하면서도 매혹적인 알고리즘 중 하나는 이른바 “두 번의 무작위 선택의 힘(power of two random choices)”입니다. 이 알고리즘은 무작위 할당에 아주 단순한 변화를 주는 것만으로도 지수적인 개선을 얻을 수 있다고 말합니다. 저는 운 좋게도 AWS Lambda의 자원 활용도를 개선하기 위해 이 기법을 거대한 규모에서 직접 구현해볼 기회가 있었지만, 오랫동안 이를 직관적으로 “느끼기”가 어려웠습니다.
이 글에서는 이 알고리즘을 이해하기 위한 제 머릿속 모델을 공유하려 합니다. 이는 이 분야의 다른 여러 고급 기법들에 대한 좋은 직관을 쌓는 데도 도움이 됩니다.
업데이트: ‘balls in bins’보다 더 복잡한 모델에서 이 알고리즘을 적용하는 것을 보여주는 후속 글이 있습니다.
ChatGPT 같은 대규모 AI 봇 서비스를 운영한다고 해봅시다. 값비싼 GPU가 달린 서버 수천 대가 사용자 프롬프트에 기반해 텍스트를 생성합니다. 그런데 라우팅 알고리즘이 들어오는 요청의 약 80%를 서버의 20%에만 보낸다면, 그 20%의 서버는 매우 바빠질 것이고 그 서버로 들어간 요청은 GPU를 얻기까지 꽤 오래 기다려야 할 가능성이 큽니다. 반면 나머지 80%의 “차가운” 서버는 활용도가 낮아 귀중한 GPU 시간을 낭비합니다. 이것이 우리가 말하는 나쁜 로드 밸런싱입니다.
반대로 모든 서버가 대략 비슷한 부하를 받는다면, 요청을 거의 최적의 시간에 처리하면서도 자원에 과다 지출하지 않게 됩니다. 더 나아가 서버 풀의 “적정 규모(right size)”를 쉽게 맞출 수 있습니다. 응답 시간을 개선하려면 확장하고, 비용을 줄이려면 축소하면 됩니다.
로드 밸런싱을 생각하기 위한 단순화된 모델이 있습니다. 무한히 이어지는 공의 흐름(요청을 나타냄)과 N개의 상자(서버를 나타냄)가 있습니다. 여러분의 임무는 들어오는 공을 어떤 상자에 넣을지 정해서, 모든 상자에 대한 할당이 가능한 한 균등해지도록 하는 것입니다. 실제 문제는 이보다 훨씬 복잡하지만, 지금은 이 단순화로도 충분합니다.
공-상자(balls-in-bins)에서 가장 쉬운 전략 중 하나는 상자를 하나 골라 그 안에 공을 무작위로 넣는 것입니다. 균등한 무작위 선택을 쓰면 매번 모든 결과가 동일한 확률이므로, 모든 상자가 대략 비슷하게 채워질 것이라 기대할 수 있습니다.
다른 방법은 상자를 하나가 아니라 두 개를 무작위로 뽑고, 더 비어 있는 쪽에 공을 넣는 것입니다. 이것이 이른바 “두 번의 무작위 선택의 힘” 접근이며, 줄여서 “둘 중 더 나은 쪽(best of two)”이라고 부르겠습니다.
두 방법을 모두 사용해 1,000개의 상자에 100만 개의 공을 넣는 시뮬레이션을 돌려봅시다. 최종 상태의 최선은 모든 상자에 1,000개씩 들어가는 것입니다. 아래의 상자별 히스토그램을 보면 차이가 상당히 극적입니다.
Enter를 누르거나 클릭하면 이미지를 원본 크기로 볼 수 있습니다
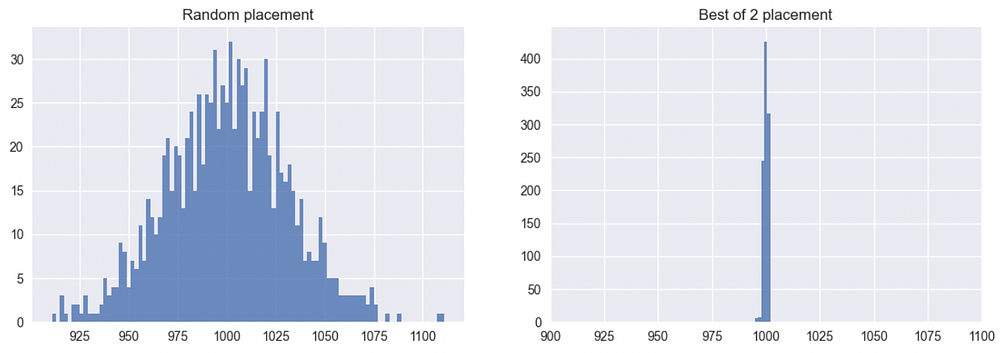
그림 1
무작위 배치는 대략 900개부터 1,200개까지 넓은 분포를 보이는 반면, 둘 중 더 나은 쪽 배치는 995에서 1,002 사이의 훨씬 더 촘촘한 분포를 만들어냅니다.
수학 수업에서 “중심극한정리(Central Limit Theorem)”를 들어본 적이 있을 것입니다. 이는 통계학의 기본으로, 어떤 임의 분포(우리의 균등 분포 같은 것)에서 독립적으로 뽑은 표본들의 합은 정규분포를 따른다는 취지의 내용입니다.
하지만 이를 더 직관적으로 “느껴” 봅시다. 상자 10개가 있고 처음에는 모두 비어 있습니다. 첫 번째 공을 두고 10면체 주사위를 굴렸더니 “1”이 나왔다고 합시다. 그러면 1번 상자에는 공이 하나 들어가고 나머지는 여전히 비어 있습니다. 이제 두 번째 공을 놓아야 합니다. 다시 주사위를 굴립니다. 이 주사위 굴림은 첫 번째 굴림과 완전히 독립이고 어떤 의미에서도 “기억”이 없기 때문에, 상자들이 이미 불균형해졌더라도 여전히 모든 결과는 동일한 확률로 발생합니다.
이제 1번 상자가 또 하나의 공을 받아서(다른 여러 상자가 비어 있는데도) 더 큰 문제가 되지 않게 하려면, 다음 9번의 시도 동안 주사위에서 “1”이 나오면 안 됩니다. 그 확률은 (9/10)⁹이고 이는 39%에 불과합니다. 즉, 1이 나오지 않을 확률보다 1이 한 번이라도 나올 확률이 더 큽니다. 그래서 우리는 더 불균형해지기 쉽습니다.
그렇다고 해도 공 100개를 상자 10개에 무작위로 넣는다면 상자당 개수의 기대값은 10입니다. 다만 이 시스템은 확률적이므로 “기대값”은 분포의 평균을 뜻합니다. 따라서 대부분의 상자는 10에 가깝지만, 어떤 상자는 눈에 띄게 덜 차고, 어떤 상자는 눈에 띄게 더 차서, 그림 1에서 보듯 대칭적인 정규분포 형태가 나타납니다.
이를 또 다른 방식으로 보면, 각 상자에 대한 배치 이력은 공의 흐름에서 X번째 공이 그 상자에 들어갔는지를 나타내는 X들의 목록으로 표현할 수 있습니다. 이 목록에서 연속된 X 사이의 차이는 10보다 작을 수도, 클 수도, 정확히 10일 수도 있습니다. 그 결과 목록의 길이는 10보다 작을 수도, 클 수도, 정확히 10일 수도 있습니다.
하지만 우리는 공을 100개만 놓았으므로, 세상에 “10보다 작음”이 아무리 많아도 그만큼의 “10보다 큼”이 반드시 존재해야 하며, 그 결과 평균적으로는 10을 중심으로 대칭적인 분포가 만들어집니다. 이런 도착 패턴은 기하분포(geometric distribution)라는 잘 알려진 분포를 따르기도 합니다.
Enter를 누르거나 클릭하면 이미지를 원본 크기로 볼 수 있습니다
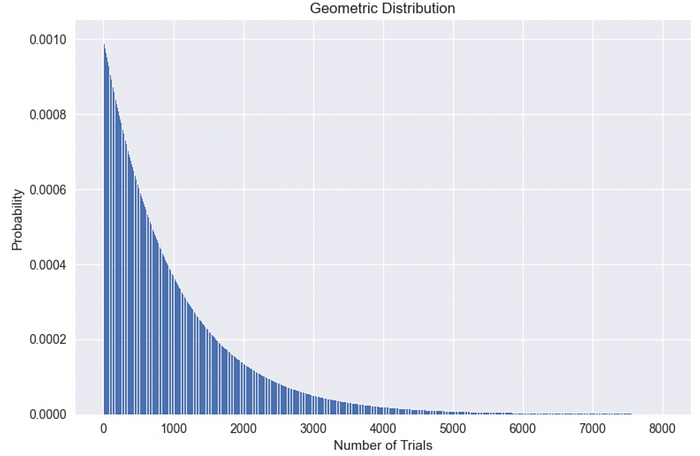
그림 2
그림 2의 플롯은 앞서 든 1,000개 상자에 100만 개 공을 넣는 예에서 기하분포의 형태를 보여줍니다. 기하분포는 긴 꼬리를 가진 분포로, [0, 평균] 구간에 확률이 더 많이 몰려 있지만, 뒤로 갈수록 평균보다 훨씬 큰 값도(확률은 낮지만) 발생합니다. 이 경우 평균은 1,000이지만, 같은 상자를 두 번 보기까지 무려 8,000번의 시도가 걸리는 경우도 있습니다!
최적화로 뛰어들기 전에, 좋은 배치에 대한 목적 함수를 정의해 봅시다. 실제로는 이것이 믿을 수 없을 만큼 복잡하지만, 이 장난감 예제에서는 비교적 쉽습니다. N개의 상자에 M개의 공을 놓고 싶다고 합시다. n번째 상자에 있는 공의 수를 Sn이라고 하겠습니다. 전체적으로, 가장 비어 있는 상자와 가장 꽉 찬 상자에 들어 있는 공의 수를 각각 Smin과 Smax라고 정의합니다.
처음에는 모든 상자의 Sn이 0이므로 Smin과 Smax도 0입니다. 어떤 상자에든 공 하나를 넣는 순간, 예를 들어 1번 상자에 넣으면 S1은 1, Smin은 0, Smax는 1이 됩니다. 이제 최적 배치라면 Smax는 결코 Smin + 1을 넘지 않아야 합니다.
Medium에 무료로 가입하고 이 작성자의 업데이트를 받아보세요.
구독
구독
예를 들어 n = 10이고 S1 = 1이며 S2부터 S10까지가 0이라면, 9개의 빈 상자에 먼저 넣지도 않고 S1을 2로 만들 이유가 전혀 없습니다. Smin = 1(모든 상자에 공이 하나씩 들어가면 그렇게 됩니다)이 되었을 때에야 최적 알고리즘은 Smax를 2로 올릴 것입니다. 따라서 Smax — Smin > 1은 나쁜 배치의 신호입니다. 이를 동심원 또는 궤도로 시각화할 수 있습니다. Smin이 중심이고, Smax는 궤도마다 1씩 증가합니다. 더 바깥 궤도일수록 배치가 더 나쁩니다.
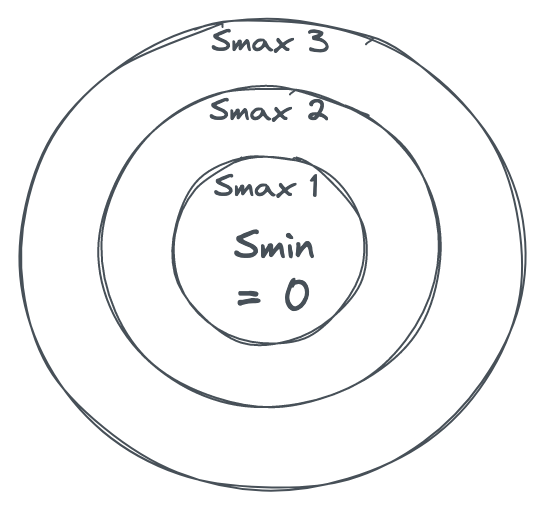
그림 3
즉, Smax가 Smin에서 여러 궤도만큼 멀어지기가 정말, 정말 어렵게 만드는 알고리즘이라면 좋은 배치 알고리즘입니다.
둘 중 더 나은 쪽 배치에 대한 제 머릿속 모델은, 그림 3의 궤도들 사이에 끔찍할 정도로 복잡한 미로를 만들어낸다는 것입니다. 그리고 더 높은 궤도로 올라가려 할수록 그 미로는 점점 더 복잡해집니다. 그 결과, 배치가 바람직하지 않은 상태에 도달하기가 매우 어려워집니다.
앞서의 예로 돌아가서, 비어 있는 상자 10개를 생각해 봅시다. 첫 번째 공이 “1”번 상자에 들어가서 우리는 1번 궤도에 있습니다. 무작위 배치에서는 2번 궤도(즉, 다시 “1”번 상자를 고르는 것)로 들어갈 확률이 10%입니다. 2번 궤도에 있을 때도 3번 궤도로 갈 확률은 여전히 10%입니다. 기본적으로 무작위 배치에서는 1/n의 확률로 배치를 1만큼 더 나쁘게 만들게 됩니다.
이제 둘 중 더 나은 쪽을 분석해봅시다. 1번 상자와 2번 상자에 각각 공이 하나씩 들어 있다고 합시다. 이제 2번 궤도로 올라갈 확률은 다음과 같습니다.
이 조건이 충족되면 우리는 2번 궤도로 강제로 들어가게 됩니다. 확률을 합치면 1/45, 즉 대략 0.02로, 무작위 배치의 0.1에 비해 작습니다. 좋긴 하지만 아직 감흥이 없으니, 3번 궤도로 가는 것을 생각해 봅시다.
무작위 배치에서는 2번 궤도로 가기 위해 “1”번 상자를 한 번 맞히고, 3번 궤도로 가기 위해 한 번 더 맞혀야 하므로 3번 궤도까지의 최단 경로 확률은 0.01입니다.
다시 둘 중 더 나은 쪽 알고리즘으로, “1”과 “2” 상자에 각각 공이 하나씩 들어 있는 상태에서 시작해봅시다. 다음 사건들은 3번 궤도로 가는 가장 빠른 경로를 나타냅니다.
이 확률들을 모두 곱하면 0.0000054가 나오며, 무작위 배치의 0.01과 비교됩니다. 이제 앞에서 말한 그 미로가 보이기 시작합니다. 이는 최단 경로의 확률이며, 더 길지만 더 높은 확률로 발생할 수 있는 다른 경로들도 있을 수 있습니다. 하지만 요지는 전달될 것입니다.
4번, 5번 궤도 등으로 가는 확률도 계속 보여주고 싶지만, 저는 수학 실력이 부족합니다. 결국 저는 그냥 프로그래머일 뿐이니까요. 저처럼 프로그래밍 실력이 수학 실력보다 훨씬 낫다면, 몬테카를로 시뮬레이션과 꼭 친해져야 합니다. 간단히 말해 몬테카를로 시뮬레이션은, 어떤 문제를 수학적으로 푸는 대신, 랜덤 입력을 사용해 컴퓨터에서 그 문제를 아주 많이 반복 실행하는 것입니다.
큰 수의 법칙 덕분에 표본이 충분히 크면, 결과는 수학적 결과에 꽤 가까워집니다. 주장을 입증하기엔 충분히 가까울 정도로 말이죠.
이 경우에는 확률을 직접 다루는 대신, 두 알고리즘 각각에 대해 10,000번의 실험을 실행해 평균적으로 2번, 3번…11번 궤도에 도달하기까지 몇 번의 배치가 필요한지 측정합니다.
Enter를 누르거나 클릭하면 이미지를 원본 크기로 볼 수 있습니다
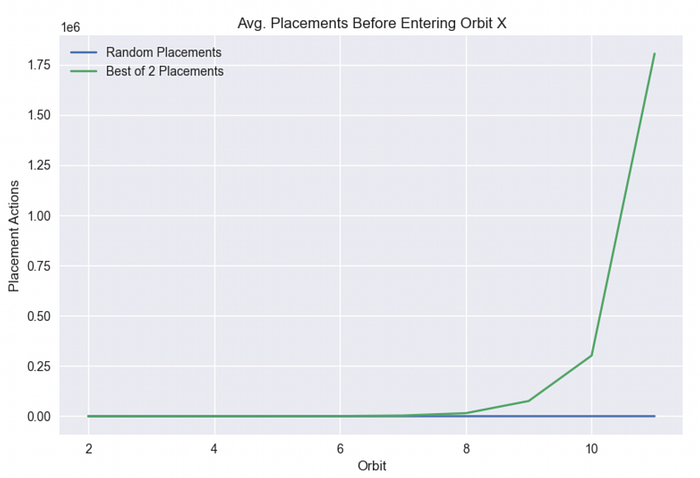
그림 4
지수 성장을 조금이라도 아는 사람이라면 위 차트의 모양을 알아볼 것입니다. 처음 몇 개의 궤도를 지나고 나면, 둘 중 더 나은 쪽에서는 난이도가 지수적으로 증가하기 때문에 더 높은 궤도로 가는 것이 엄청나게 어려워집니다. 반면 무작위 배치에서 난이도는 선형적으로 증가합니다.
성장 패턴을 비교하기 위해, 둘 중 더 나은 쪽은 로그 스케일로 그리고 무작위 배치는 선형 스케일로 유지해봅시다.
Enter를 누르거나 클릭하면 이미지를 원본 크기로 볼 수 있습니다
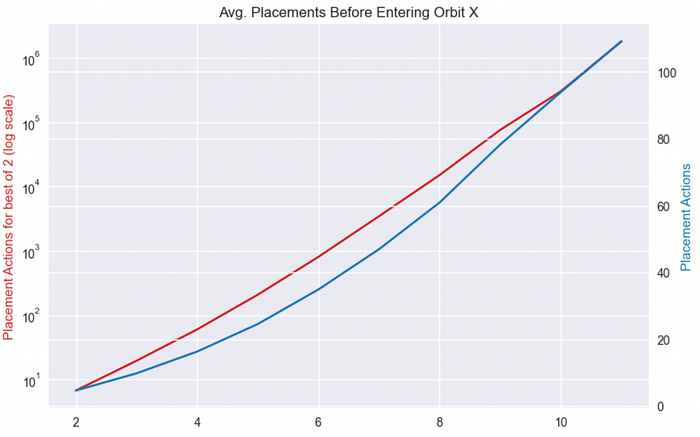
그림 5
이 글에서는 둘 중 더 나은 쪽(best of two) 무작위 선택 알고리즘이, 어떤 지점 이후로 나쁜 배치로 가는 것을 확률적으로 매우, 매우 어렵게 만들어 배치의 품질을 지수적으로 개선한다는 것을 살펴봤습니다.
그 과정에서 이 문제와 관련된 중심극한정리에 대한 직관도 함께 쌓았고, 몬테카를로 시뮬레이션이 약간의 프로그래밍과 많은 인내만 있으면 꽤 어려운 수학 문제의 해답을 얻는 데 어떻게 도움이 되는지도 배웠습니다.
이 글은 자원 할당의 기본 개념들에 대한 직관을 쌓는 데 목적이 있었습니다. 저는 이 주제를 정말 사랑합니다. 저는 이것뿐 아니라 더 고급 기법들도 큰 규모에서 구현해봤기 때문에, 앞으로의 글에서 더 많은 주제로 깊게 들어가 보고 싶습니다. 예를 들어 CPU/메모리 요구가 서로 다른 다차원 공이 있을 때 이 알고리즘을 일반화하는 방법을 쓸 수도 있겠죠. 상자들이 모두 동일하지 않은 경우도 있고, 상자들이 자주 교체되기도 합니다. 둘 중 더 나은 쪽을 k 중 최선(best of k)으로 일반화하려면 어떻게 해야 할까요? 좋은 k는 어떻게 찾을까요?
343
343
5


팔로우
The Intuition Project에 게시됨 ----------------------------------
복잡한 아이디어를 독자들이 직관적으로 이해하도록 돕는 글을 싣는 발행물
팔로우


팔로우
Mihir Sathe 작성 ----------------------
저는 소프트웨어, 코딩, 그리고 대규모 시스템 구축을 사랑합니다. 저는 Snowflake의 소프트웨어 엔지니어입니다. 모든 의견은 제 개인 의견입니다. 제 Twitter: https://twitter.com/_mihir_sathe
팔로우
응답 작성하기
취소
응답

정말 좋은 글입니다! 저는 2000년에 바로 같은 주제로 컴퓨터 과학 석사 논문을 썼습니다(https://www.cs.helsinki.fi/kirjasto/sarja-c.html 참고). 논문의 결론이 아직도 유효한 것 같네요.
답글
공-상자에서 가장 쉬운 전략 중 하나는 상자를 하나 골라 그 안에 공을 무작위로 넣는 것입니다.
상자를 무작위로 골라 그 상자에 공을 넣는다는 뜻인가요? 다시 말하면, 임의로 상자를 하나 선택하고 그 안에 넣는다는 뜻이죠? 지금 표현대로면 상자는 (어쩌면 결정적으로) 선택된 뒤에, 선택된 그 상자에 공을 넣는 행위 자체가 무작위인 것처럼 들립니다.
답글

그림 2
x축: 주어진 상자에 대해, 이 상자에 두 번째 공이 떨어지기 전까지의 시도 횟수 X.
y축: X번의 시도 이후 같은 상자에 두 번째 공이 두 번 떨어질 확률
주어진 상자에 대해 1000번째 시도가 이 상자에 떨어질 확률은 0.99 ^…더 보기
답글
모든 응답 보기

May 28, 2023

In
by
Nov 19, 2023
In
by
Jul 5, 2023
In
by
Apr 8, 2024
The Intuition Project의 모든 글 보기


In
by
Dec 28, 2025
In
by
Feb 16

In
by
Jan 29

Sep 14, 2025

In
by
Feb 17


In
by
Feb 13