데이터센터에서 여러 작업을 한 머신에 공존시키며 SLA를 지키기 위해 Intel의 CAT(캐시 할당 기술) 같은 격리 메커니즘이 왜 필요해졌는지, Heracles 연구를 통해 설명한다.
전형적인 서버 활용률은 10%~50% 사이입니다. Google은 지연 시간 SLA에 영향을 주지 않으면서 90% 활용률을 달성했음을 보여줬습니다. Xkcd는 Google이 200만 대의 머신을 보유하고 있다고 추정했습니다. 머신 한 대당 연간 $4k의 감가상각된 총비용을 가정하면, 연간 $80억입니다. 이런 규모에서는 작은 개선도 큰 영향을 미치며, 이건 작은 개선이 아닙니다.
같은 하드웨어에서 어떻게 2배에서 9배 더 나은 활용률이 가능할까요? 전형적인 활용률 수치의 낮은 쪽은 수요가 변동적인 서비스에 고정된 머신 할당을 해두는 데서 옵니다. 예를 들어 Jenkins에 전용으로 100대의 머신을 붙여두었다고 해봅시다. 개발자들이 활동할 때는 머신들이 매우 바쁘겠지만, 새벽 3시에는 활용률이 2%일 수도 있습니다. 동적 할당(필요 없을 때 머신을 다른 작업으로 전환)은 전형적인 지연 시간 민감 서비스의 활용률을 대략 30%~70% 범위까지 끌어올릴 수 있습니다. 다양한 지연 시간 민감 워크로드에서 빡빡한 SLA를 유지한 채 이보다 더 잘하려면, 높은 우선순위 작업의 지연 시간을 건드리지 않으면서 같은 머신에 낮은 우선순위 작업을 스케줄링할 수 있는 방법이 필요합니다.
이게 가능하다는 건 자명하지 않습니다. 높은 우선순위와 낮은 우선순위 워크로드 모두가 마지막 단계 캐시(LLC), 메모리 대역폭, 디스크 대역폭, 네트워크 대역폭 같은 공유 자원을 독점해야 한다면, 우리는 방법이 없습니다. 일부 특수한 서비스를 제외하면 디스크나 네트워크를 꽉 채우는 경우는 드뭅니다. 하지만 캐시와 메모리는 어떨까요? 알고 보니 Ferdman et al.이 2012년에 이를 살펴봤고, 현대 서버 칩이 훨씬 큰 캐시를 갖고 있음에도 불구하고 전형적인 서버 워크로드는 4MB~6MB 이상의 LLC를 가져도 이득이 없다는 것을 발견했습니다.
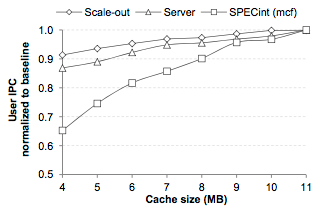
이 그래프에서 scale-out 워크로드는 분산 키-값 저장소, MapReduce류의 계산, 웹 검색, 웹 서빙 등입니다. SPECint(mcf)는 전통적인 워크스테이션 벤치마크입니다. “server”는 SPECweb, TPC 같은 올드스쿨 서버 벤치마크입니다. 4MB에서 11MB로 LLC를 늘리는 것은 전형적인 데이터센터 워크로드에는 작은 영향만 주지만, 이 전통적인 워크스테이션 벤치마크에는 큰 영향을 준다는 것을 볼 수 있습니다.
데이터센터 워크로드는 데이터셋이 너무 커서 한 대의 머신 RAM에 담는 것조차 종종 불가능하며, 하물며 캐시에 담는 건 더더욱 불가능합니다. 그래서 더 큰 LLC가 특별히 유용하지 않습니다. 이 결과는 Google의 워크로드를 본 Kanev et al.의 ISCA 2015 논문에서도 확인되었습니다. 이들은 또한 메모리 대역폭 활용이 평균적으로 꽤 낮다는 것도 보여줬습니다.
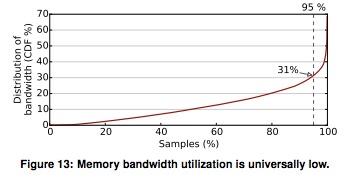
대역폭 활용이 낮은 이유가 워크로드가 연산 바운드라서 메모리 접근이 많지 않기 때문이라고 생각할 수도 있습니다. 하지만 저자들이 코어가 무엇을 하고 있는지 보니, 많은 시간이 캐시/메모리를 기다리며 stall 상태로 보내지고 있었습니다.
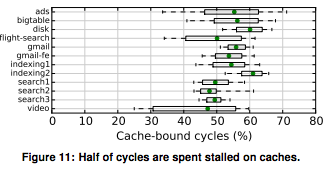
각 행은 Google 워크로드 하나입니다. 이런 전형적인 워크로드를 실행할 때 코어는 시간의 46%~61%를 캐시/메모리에 막혀 보냅니다. 캐시 적중률이 낮고, 캐시/메모리에서 stall로 보낸 시간이 많고, 대역폭 활용은 낮다는 점은 흥미롭습니다. 이는 워크로드가 어떤 의존성 때문에 독립적으로 실행할 수 없는 메모리 접근을 기다리느라 많은 시간을 보내고 있음을 시사합니다.
최상위 서버 칩의 LLC는 12MB에서 30MB 사이인데, 성능의 90%를 얻는 데는 4MB만 필요하고, 대역폭의 90% 분위(90%-ile) 활용률은 31%입니다. 이는 자원 낭비처럼 보입니다. 많은 자원이 놀고 있거나 효과적으로 쓰이지 않고 있습니다. 좋은 소식은 칩의 공유 자원 활용이 이렇게 낮기 때문에, 성능 저하 없이 한 머신에 여러 작업을 스케줄링할 수 있어야 한다는 점입니다.
좋습니다! 그렇다면 한 머신에 여러 작업을 스케줄링하면 어떤 일이 벌어질까요? 올해 ISCA의 Lo et al. Heracles 논문이 이를 아주 자세히 탐구합니다. Heracles의 목표는 같은 머신에 여러 작업을 공존(co-locate)시켜 머신 활용률을 높이는 것입니다.
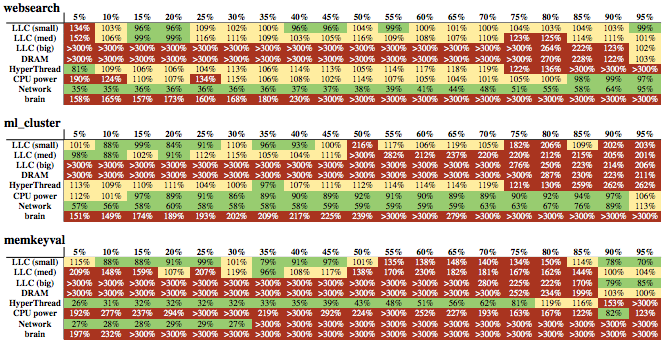
위 그림은 엄격한 SLA를 가진 세 가지 지연 시간 민감(LC) 워크로드를 보여줍니다. websearch는 Google 검색의 질의 서빙 서비스, ml_cluster는 실시간 텍스트 클러스터링, memkeyval은 memcached와 유사한 키-값 저장소입니다. 값은 SLA가 허용하는 최대치 대비 지연 시간 비율(퍼센트)입니다. 열은 서비스 부하를 나타내고, 행은 서로 다른 종류의 간섭(interference)을 나타냅니다. LLC, DRAM, Network는 말 그대로 그 자원을 놓고만 경쟁하도록 설계된 커스텀 작업입니다. HyperThread는 같은 코어의 다른 하이퍼스레드에서 돌아가는 스핀루프입니다(같은 하이퍼스레드에서 실행하는 경우는 OS 컨텍스트 스위치 비용이 너무 커서 고려조차 하지 않습니다). CPU power는 전력을 많이 쓰고 열 스로틀링을 유도하도록 설계된 작업입니다. Brain은 딥러닝입니다. 모든 간섭 작업은 낮은 우선순위의 컨테이너에서 실행됩니다.
이 그림에는 많은 정보가 담겨 있지만, 컨테이너 우선순위만 사용했을 때 우리가 스케줄링하고 싶은 best effort(BE) 작업은 어떤 LC 작업과도 공존할 수 없다는 점을 즉시 볼 수 있습니다. brain 행이 전부 빨간색이고, 낮은 활용률(맨 왼쪽 열)에서도 지연 시간이 SLA 지연 시간의 100%를 훨씬 넘습니다. 또한 서로 다른 LC 작업이 서로 다른 프로파일을 가지며 간섭 유형에 대한 내성이 다르다는 것도 분명합니다. 예를 들어 websearch와 ml_cluster는 네트워크나 연산 집약적이지 않아서 네트워크 및 전력 간섭을 잘 견딥니다. 하지만 memkeyval은 네트워크와 연산 모두 집약적이므로 네트워크나 전력 간섭 어느 쪽도 견디지 못합니다. 논문은 표의 세부사항에서 무엇을 추론할 수 있는지 더 많은 내용을 다룹니다. 저는 이것이 논문의 가장 흥미로운 부분 중 하나라고 생각합니다. 여기서는 건너뛰지만, 이런 종류의 내용에 관심이 있다면 논문을 읽어보길 권합니다.
저자들이 둔 단순화 가정은 이런 간섭 유형들이 기본적으로 서로 독립적이라는 것입니다. 이는 LC 작업을 각 개별 자원 종류마다 “과도한” 사용으로부터 격리하는 독립적인 메커니즘이 전체 간섭을 막기에 충분하다는 뜻입니다. 즉 자원 사용 유형마다 어떤 상한(cap)을 두고, 각 상한 아래에만 머무르면 됩니다. 하지만 이 가정은 정확히 참은 아닙니다. 예를 들어 저자들은 LLC 캐시 크기와 LC 작업에 할당된 코어 수의 관계를 보여주는 다음 그림을 제시합니다.
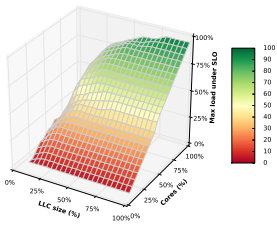
세로축은 특정 LLC와 코어 수를 할당했을 때 SLA를 위반하기 전까지 LC 작업이 처리할 수 있는 최대 부하입니다. 캐시와 코어 사이에 트레이드오프가 가능하다는 것을 볼 수 있는데, 이는 한 차원에서 자원 상한을 넘더라도 다른 자원을 덜 쓰는 방식으로 SLA를 유지할 수 있음을 의미합니다. 일반적인 경우에는 다른 자원들 사이에서도 트레이드오프가 가능할 수 있습니다. 하지만 각 자원을 독립적으로 다룰 수 있다는 가정은 복잡한 최적화 문제를 비교적 단순한 문제로 줄여줍니다.
이제 공유 자원 간섭의 각 유형과, Heracles가 SLA 위반 간섭을 방지하기 위해 자원을 어떻게 할당하는지 살펴보겠습니다.
LC와 BE 작업을 서로 다른 코어에 핀(pin)하는 것만으로도 같은 코어에서의 컨텍스트 스위칭 간섭과 하이퍼스레딩 간섭을 막기에 충분합니다. 이를 위해 Heracles는 cpuset을 사용했습니다. Cpuset은 프로세스(및 그 자식들)가 제한된 CPU 집합에서만 실행되도록 제한할 수 있습니다.
로컬 머신에서 Heracles는 qdisc를 사용해 쿼터를 강제했습니다. cpuset, qdisc, 그리고 다른 쿼터/파티셔닝 메커니즘에 대해 더 알아보려면 Neil Brown의 cgroups에 대한 LWN 연재가 시작점으로 좋습니다. Cgroups는 이미 많은 널리 쓰이는 소프트웨어(Docker, Kubernetes, Mesos 등)에서 사용되고 있으므로, 이 특정 응용에 관심이 없더라도 배워둘 가치는 아마 있을 겁니다.
Heracles는 전력을 추정하기 위해 Intel의 running average power limit을 사용합니다. 이는 Sandy Bridge(2009) 및 그 이후 프로세서에 있는 기능으로, 칩 내부 모니터링 하드웨어를 사용해 전력 사용량을 상당히 정확하게 추정합니다. 코어별 동적 전압 및 주파수 스케일링을 사용해 특정 코어의 전력 사용을 제한하여 예산을 넘지 않게 합니다.
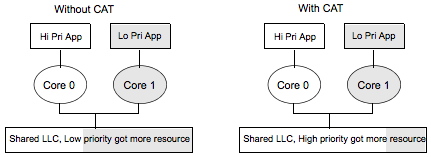
앞선 격리 메커니즘은 나온 지 오래됐지만, 이것은 Broadwell 칩(2015년 출시)에서 새로 등장했습니다. 문제는 BE 작업이 LLC 1MB를 필요로 하고 LC 작업이 LLC 4MB를 필요로 할 때, BE 작업의 한 번의 큰 할당이 공유된 LLC 전체를 마구 덮어써서 LC가 필요로 하는 4MB의 캐시된 데이터를 날려버릴 수 있다는 점입니다.
Intel의 “Cache Allocation Technology”(CAT)는 LLC에서 서로 다른 캐시 부분에 어떤 코어들이 접근할 수 있는지를 제한할 수 있게 해줍니다. 성능 민감 작업은 어차피 코어에 핀하고 싶은 경우가 많기 때문에, 이는 작업별로 캐시를 나눌 수 있게 해줍니다.
Intel의 2015년 4월 화이트페이퍼(그들이 Cache Allocation Technology, CAT라고 부르는 것)에는 CAT vs. no-CAT를 비교하는 간단한 벤치마크가 있습니다. 이 예에서는 다른 애플리케이션이 CPU-메모리 트래픽을 대량으로 발생시키는 동안 PCIe 인터럽트에 응답하는 지연 시간을 CAT on/off로 측정합니다.
| Condition | Min | Max | Avg |
|---|---|---|---|
| no CAT | 1.66 | 30.91 | 4.53 |
| CAT | 1.22 | 20.98 | 1.62 |
CAT를 쓰면 평균 지연 시간이 CAT 없이의 지연 시간의 36%입니다. 꼬리 지연(tail latency)은 그만큼 크게 개선되진 않지만, 그쪽도 상당한 개선이 있습니다. 흥미롭긴 하지만, 제게 더 흥미로운 질문은 실제 워크로드에서 얼마나 효과적인가 하는 점이며, 이는 이 모든 메커니즘을 함께 적용할 때 확인할 수 있습니다.
여기서 전혀 다루지 않을 CAT의 또 다른 용도는 타이밍 공격을 막는 것입니다. 예를 들어 LLC 간섭을 통해 VM 간에 RSA 키를 복구할 수 있는 이런 공격 같은 것 말입니다.
Broadwell 및 그 이후 Intel 칩에는 메모리 대역폭 모니터링은 있지만 제어 메커니즘은 없습니다. 이를 우회하기 위해 Heracles는 BE 작업이 대역폭을 너무 많이 써서 LC 작업을 방해한다면 BE 작업에 할당된 코어 수를 줄입니다. 이에 대한 거친(코arse-grained) 모니터링과 제어는 논문에 자세히 설명된 여러 비효율을 가지고 있지만, 그럼에도 비효율에도 불구하고 동작합니다. 하지만 코어별 대역폭 제한이 있다면 더 적은 노력으로 더 좋은 결과를 얻을 수 있을 겁니다.
이 그래프는 LC websearch의 SLA가 위반되지 않도록 충분한 여유를 두고 다른 BE 작업들을 함께 스케줄링했을 때, LC websearch의 유효 활용률을 보여줍니다.
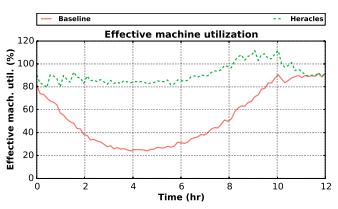
다른 회사 사람들과의 술자리 대화로는, 여기서의 베이스라인(빨간색)도 이미 꽤 좋아 보입니다. 피크 시간대 80% 활용률, 그리고 활용률이 50% 아래로 떨어지는 7시간의 골(trough)이 있습니다. Heracles를 쓰면 최악의 경우 활용률이 80%이고 평균은 90%입니다. 놀랍습니다.
유효 활용률은 100%를 넘을 수도 있다는 점에 유의하세요. 이는 100% 부하에서 단일 머신의 LC 작업 처리량에 더해, 100% 부하에서 단일 머신의 BE 작업 처리량까지 합한 것으로 측정되기 때문입니다. 예를 들어 한 작업이 DRAM 대역폭의 100%와 네트워크 대역폭의 0%를 필요로 하고, 다른 작업이 그 반대를 필요로 한다면, 두 작업은 같은 머신에 공존하여 200% 유효 활용률을 달성할 수 있습니다.
현실에서는 Heracles 같은 시스템에서 평균 활용률 90%를 “고작” 얻을지도 모릅니다. 큰 회사의 운영 비용 추정치 $40억을 떠올려보면, 그 회사가 이미 평균 활용률 75%라는 꽤 좋은 상태였더라도, 데이터센터 운영 비용에 대한 표준 모델을 사용하면 달러당 처리량이 15% 늘어날 것으로 예상할 수 있고, 이는 $6억의 공짜 컴퓨팅입니다. 규모가 커져가는 중인(연간 컴퓨팅에 $1천만~$1억 정도 쓰는) 더 작은 회사들과 이야기해보면, 이들은 활용률이 20% 정도인 경우가 흔합니다. 같은 총비용 모델을 다시 적용하면, 달러당 컴퓨팅이 300% 증가할 것으로 기대할 수 있고, 이는 규모에 따라 연간 $3천만~$3억의 공짜 컴퓨팅에 해당합니다1.
우리가 본 모든 논문에는 흥미로운 보석 같은 내용이 많습니다. 전부 다 다루진 않겠지만, 몇 가지는 특히 눈에 띄었습니다.
데이터센터 머신이 시간의 대략 절반을 메모리를 기다리며 stall 상태로 보낸다는 것은 오래전부터 알려져 있습니다. 더불어 서버 칩이 실제 워크로드에서 클럭당 실행할 수 있는 평균 명령어 수(IPC)는 꽤 낮습니다.
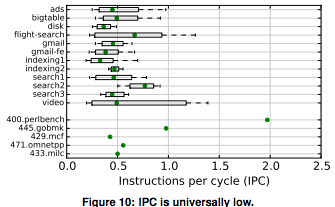
위쪽 행(수평 막대)은 Google 내부 워크로드, 아래쪽 행(초록 점)은 표준 벤치마크 스위트인 SPEC의 워크스테이션 벤치마크입니다. Google 워크로드는 평균적으로 클럭당 0.5개의 명령어 정도를 실행하는 게 고작이라는 것을 볼 수 있습니다. 그리고 앞서 이 워크로드들이 적어도 절반의 시간 동안 메모리에서 코어를 stall시키는 것도 봤습니다.
그런데 메모리를 기다리느라 대부분의 시간을 보내고 클럭당 반 개 정도의 명령어를 실행하는 데도, 실제 워크로드에서 고급 서버 칩은 Atom이나 ARM 칩보다 훨씬 더 잘합니다(Reddi et al., ToCS 2011). 이는 다소 역설적으로 들립니다. 칩이 어차피 메모리를 기다리고만 있다면 왜 고성능 칩이 필요할까요? 작은 ARM 칩도 똑같이 잘 기다릴 수 있습니다. 사실 기다리는 코어가 더 많으면 더 많은 대역폭을 쓸 수 있으니 기다리기에는 더 나을 수도 있습니다. 하지만 알고 보니 서버는 명령어 수준 병렬성(ILP)을 활용해 여러 명령을 동시에 실행하는 데에도 많은 시간을 씁니다.
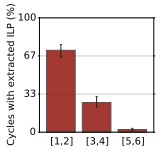
이는 동시에 몇 개의 실행 유닛이 바쁜지에 대한 그래프입니다. 거의 3분의 1의 시간은 3개 이상의 실행 유닛이 바쁘게 동작합니다. 메모리를 기다리는 긴 stall 사이사이에서, 고급 칩은 더 많은 계산을 해내고 다음 stall을 더 일찍 만나 기다리기 시작할 수 있습니다. 또 하나 흥미로운 점은 서버 워크로드가 전통적인 워크스테이션 워크로드보다 명령어 캐시 미스율이 훨씬 높다는 것입니다.
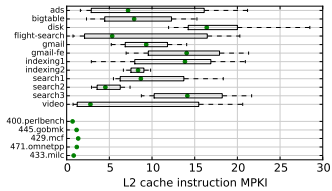
다시 말하지만, 위쪽 행(수평 막대)은 Google 내부 워크로드, 아래쪽 행(초록 점)은 SPEC의 워크스테이션 벤치마크입니다. 저자들은 명령어 미스 증가를 두 요인으로 설명합니다. 첫째, 명령어 캐시를 압도하는 큰 바이너리(100MB)를 배포하는 것이 일반적이라는 점. 둘째, 명령어가 캐시 공간을 놓고 훨씬 큰 데이터 스트림과 경쟁해야 해서 많은 명령어가 축출(evict)된다는 점입니다.
이 문제를 해결하기 위해 Intel은 “Code and Data Prioritization Technology”(CDP)라고 부르는 것을 도입했습니다. 이는 코어가 LLC의 어떤 부분집합에 명령어와 데이터가 각각 자리 잡을 수 있는지를 별도로 제한할 수 있게 해주는 CAT의 확장입니다. LLC(마지막 단계 캐시)를 대상으로 하므로, 위 그래프가 보여주는 L2 캐시 미스율 문제를 직접 해결하진 못합니다. 하지만 LLC에서 맞는 L2 캐시 미스의 비용은 Broadwell에서 대략 26ns이고, LLC에서도 미스가 나서 메인 메모리로 가야 하는 L2 미스는 86ns 정도로, 차이가 큽니다.
Kanev et al.은 한 단계 더 나아가 icache/dcache 계층을 분리한(split) 계층을 제안합니다. 이는 아주 급진적인 아이디어는 아닙니다. L1 캐시는 이미 분리되어 있으니, 나머지는 왜 안 되겠습니까? 제 추측으로는 Intel과 다른 주요 칩 벤더들이 이것이 달러당 성능을 개선하지 못한다는 시뮬레이션 결과를 갖고 있을 것 같지만, 누가 알겠습니까? 아마 분리된 L2 캐시를 곧 보게 될지도 모르죠.
더 일반적인 관찰로는, SPEC는 이제 벤치마크로서 사실상 무의미하다는 점입니다. 워크스테이션 벤치마크로도 다소 구식이고, 서버, 오피스 머신, 게이밍 머신, 덤 터미널, 노트북, 모바일 기기의 벤치마크로는 그냥 완전히 부적절합니다2. SPEC가 겨냥한 시장은 매년 줄어들고 있으며, SPEC는 그 시장조차 적어도 10년 전부터 제대로 대표하지 못했습니다. 그런데도 칩 업계에서는 여전히 가장 널리 쓰이는 벤치마크입니다.

이것은 Google에서의 검색 질의가 어떻게 생겼는지입니다. 질의 하나가 들어오면, 여러 머신 집합에 넓게 fanout되는 RPC들이 발행됩니다(첫 번째 행). 그 머신들도 RPC 묶음을 실행합니다(두 번째 행). 그 RPC들이 또 더 많은 RPC를 실행합니다(세 번째 행). 그리고 그래프에 너무 많은 일이 벌어져서 노이즈처럼 보이기 때문에 표시되지 않은 네 번째 행도 있습니다. 이것은 데이터센터에서 꽤 일반적인 워크로드 유형 중 하나이며, SPEC에는 이런 모습과 비슷한 것도 없습니다.
이 모든 논문에는 더 재미있는 자잘한 이야기들이 많고, 이 글에서 흥미로웠던 게 하나라도 있었다면 논문들을 읽어보길 권합니다. 이 글이 마음에 들었다면, 아마도 성능 및 프로파일링 관련 여러 주제를 다루는 Dick Sites의 이 강연, Intel의 새로운 CLWB 및 PCOMMIT 명령어에 대한 이 글, 그리고 다른 "새로운" CPU 기능들에 대한 이 글도 마음에 들 겁니다.
이 글에 대한 코멘트/수정에 도움을 준 Leah Hanson, David Kanter, Joe Wilder, Nico Erfurth, Jason Davies에게 감사드립니다.