LLM 애플리케이션에서 오프라인·온라인·세미 온라인 워크로드를 구분하고, 각 워크로드가 요구하는 처리량·지연 시간·유연성을 충족하기 위한 인퍼런스 엔진 선택과 최적화 전략을 정리한다.
URL: https://modal.com/llm-almanac/workloads
우리는 이 진리를 자명한 것으로 믿는다: 모든 워크로드가 동일하게 만들어진 것은 아니다.
하지만 대규모 언어 모델(LLM)에서는 이 진리가 결코 보편적으로 인정되지 않는다. LLM 애플리케이션을 만드는 대부분의 조직은 API를 통해 AI를 사용하며, 이러한 API는 서로 다른 워크로드가 갖는 다양한 비용과 엔지니어링 트레이드오프를 그럴듯하게 평평한 토큰당 과금 뒤에 숨긴다.
그러나 진실은 결국 드러난다. 모델 API가 지배하는 시대는 끝나가고 있다. DeepSeek과 Alibaba Qwen이 오픈 소스 모델에서 훌륭한 작업을 해내며(오픈AI 같은 독점 모델 API의 이점을 잠식) vLLM과 SGLang 같은 오픈 소스 인퍼런스 엔진이 훌륭한 작업을 해내며(독점 인퍼런스 엔진으로 구동되는 ‘오픈 모델 API’의 이점을 잠식) 이 변화를 이끌고 있다.
이 기술적 변화를 활용하고자 하는 엔지니어라면, 시스템을 올바르게 설계하고 최적화하기 위해 자신의 워크로드를 더 자세히 이해해야 한다.
이 문서에서는 시장에서 우리가 관찰한 워크로드와 요구사항을, 프로덕션에서 대규모로 인퍼런스를 배포하는 선도 조직들과 함께 작업하며 얻은 경험을 바탕으로 살펴본다. 또한 이러한 워크로드를 위해 LLM 엔지니어가 맞닥뜨리는 과제와 그 해결 방법을 설명한다. 마지막으로, Modal의 클라우드 플랫폼에서 그 해결책을 어떻게 구현할 수 있는지도 일부 공유한다.
Gallia est omnis divisa in partes tres.
더 성숙한 데이터베이스 세계에서는 트랜잭션 처리(OLTP, “장바구니”를 떠올리면 됨)와 분석 처리(OLAP, “연말 결산(Year Wrapped)”을 떠올리면 됨) 사이의 잘 알려진 구분이 있다. 그리고 그 사이에는 두 특성을 모두 가진 하이브리드 워크로드(HTAP)가 있다.
비슷하게, LLM 워크로드를 정리하는 데 도움이 되는 세 가지 구분이 있다.
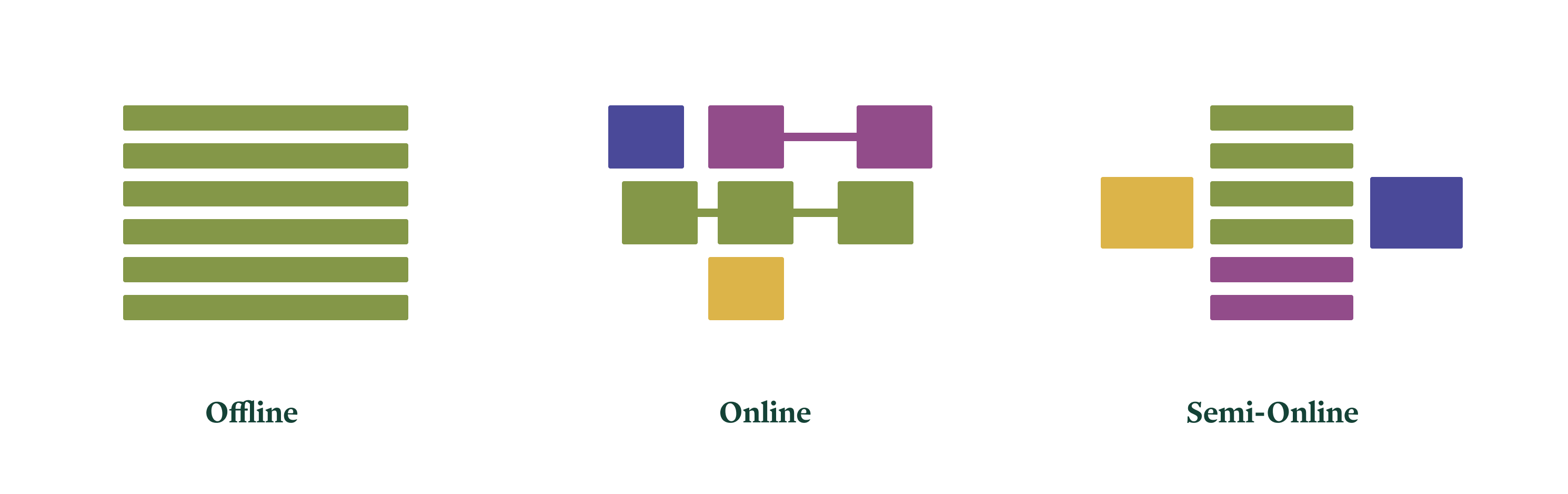
각 유형에 대한 우리의 권장 사항은 다음과 같다.
이 문서의 나머지 부분에서는, 우리 플랫폼에서 실제로 돌아가는 구체적인 애플리케이션과 워크로드, 그리고 여러분이 참고할 수 있는 샘플 코드에 근거해 이러한 권장 사항을 풀어 설명하고 정당화한다.
_수확체증의 법칙(law of increasing return)_은 다음과 같이 표현할 수 있다: 노동과 자본의 증가는 일반적으로 조직의 개선으로 이어지며, 이는 노동과 자본의 작업 효율을 증가시킨다.
Weaviate Transformation Agent는 각 행에 LLM을 적용해 전체 데이터셋을 보강(augment)하고 업데이트한다.
한 선도적인 비디오 전사(transcription) 서비스는, 나중에 검색 및 조회를 위해 대량의 녹화된 통화에 대해 LLM 요약을 생성해야 한다.
이 시스템들은 _오프라인_이다. 즉, 파일시스템이나 데이터베이스 같은 다른 컴퓨터 시스템에 장기 저장될 정보를 생성한다. 워크로드는 다수의 LLM 요청으로 구성된 대규모 “잡(job)” 형태로 제출된다. 비용 측면에서 전체 잡은 빠르게 완료되는 것이 좋지만, 개별 요청 하나하나가 즉시 처리될 필요는 없다. 잡의 규모는 상당한 병렬성을 드러내며, 이를 통해 규모의 경제를 얻을 수 있다.
오프라인 시스템은 일반적으로 설계가 더 쉽다. 컴퓨터 시스템이 오프라인 배치 처리 기계로 시작된 데에는 이유가 있다. 하지만 여전히 과제는 존재한다.
오프라인 배치 워크로드의 핵심 과제는, 배치 내부의 작업 병렬성을 활용해 비용을 통제하면서 처리량을 최대화하는 것이다.
근본적으로 이는 좋은 소식이다. LLM 인퍼런스를 실행하는 데 가장 대중적이고 쉽게 구할 수 있는 하드웨어인 GPU는 최대 처리량을 위해 설계되어 있다. 클럭 사이클당 컨텍스트 스위칭, 대규모 행렬 곱 유닛, 작업 병렬 프로그래밍 모델까지 모두 그렇다. 덕분에 연산 자원을 포화시키는 인퍼런스 커널을 작성하기가 비교적 쉽고, 오픈 소스 및 무료로 이용 가능한 커널도 충분히 만족스럽다. 더불어 LLM 및 다른 신경망의 학습은 오프라인 배치 워크로드이며, 학습 워크로드는 역사적으로 가장 많은, 그리고 가장 빠른 관심을 받아왔다. 예컨대 새로운 하드웨어가 시장에 등장할 때 그렇다.
하지만 오프라인 워크로드에서 병렬성을 활용하려면 커널만으로 충분하지 않다. 대표적 예로, 배치는 실행 중이거나 대기 중인 작업(=요청)들로부터 구성되어야 한다. 작업 내 LLM 인퍼런스는 두 단계로 나눌 수 있다: 프리필(prefill, 프롬프트 처리)과 디코드(decode, 생성). 프리필 작업은 더 작은 청크로도 나눌 수 있다. 주의를 기울이면 이러한 다양한 종류의 작업을 동일 배치에서 서로 다른 태스크들 사이에 섞어 스케줄링할 수 있다.

혼합 배칭에서는, 연산이 덜 집약적인 디코드 작업(얇은 선)이 더 연산 집약적인 프리필 작업(두꺼운 선)에 ‘얹혀’ 함께 처리될 수 있다. 색상은 서로 다른 태스크를 나타낸다. 자세한 내용은 SARATHI 논문을 참고하라.
vLLM 인퍼런스 엔진은 이러한 스케줄링 최적화를 더 잘 지원한다. 이런 이유로, 우리는 현재 처리량에 민감한 오프라인 워크로드에 vLLM을 권장한다.
오프라인 애플리케이션에서 (달러당) 처리량을 최적화하기 위해 다음 선택을 한다.
LLM 추상화 같은 오프라인 인터페이스에서 더 쉽다..spawn 또는 .spawn_map을 사용해 다수의 요청을 큐에 넣고, 나중에 결과를 회수하거나 저장한다.이 패턴들은 이 코드 샘플에서 자세히 시연하고 설명한다.
모델의 신뢰성이 높아지고 사용이 보편화됨에 따라, 점점 더 많은 배치 워크로드가 많은 기업의 백그라운드에서 조용히 돌아가게 될 것으로 예상한다. 이는 희귀하고 영웅적인 집계 작업(예: 인구조사)으로 시작했던 데이터 분석 잡이 이제는 평범한 필수 요소가 된 것과 유사하다.
GPU 가격에서 흥미로운 패턴도 관찰했다. 작성 시점의 Modal 현재 요금에서도 확인되는데, 달러당 FLOPs가 대략 일정하다. 따라서 온프레미스 배포에서 더 구하기 쉬운, 혹은 Modal 같은 플랫폼에서 더 많은 수량으로 제공되는 구형 GPU도, 초당 처리량보다 달러당 처리량을 더 중시하는 잡에 꽤 잘 맞는다.
컴퓨터와 사용자가 서로를 기다릴 필요가 없을 정도의 속도로 상호작용하면 생산성이 급상승하고, 컴퓨터로 수행한 작업의 비용이 급락하며, 직원들은 업무 만족도가 높아지고 품질도 개선되는 경향이 있다. 온라인 컴퓨터 시스템 중 이러한 균형을 이룬 경우는 드물다…
Decagon Voice로 구축된 에이전트는 지원을 요청하는 인간과의 전화 통화에 참여해야 한다.
한 선도적인 AI IDE 기업은, 인간 엔지니어가 다음에 어떤 코드를 쓸지 고민하는 짧은 순간에 “스마트” 자동완성을 제공해야 한다.
이 시스템들은 _온라인_이다. 사용자는 시스템과 상호작용하며, (다른 인간들과 마찬가지로) 반응 시간에 맞는 응답을 원한다. 대략 수백 밀리초 이내다. 인간 사용자는 반복적인 상호작용을 통해 멀티턴 컨텍스트를 만든다.
온라인 시스템은 구축이 극도로 어렵다. 성능 민감도가 매우 높으며, 성능은 추상화를 녹여버리고 분리된 관심사를 결합시킨다. 하지만 수반되는 과제를 해결할 수 있다면 구축할 수 있다.
온라인 워크로드의 1차 과제는 시스템이 수백 밀리초 안에 응답해야 한다는 것이다.
이는 먼저 파이썬 같은 인터프리터 언어를 사용할 때의 성능 손실이 중요해진다는 뜻이다. 주요 LLM 인퍼런스 엔진들은 빠른 개발을 위해 대부분 파이썬으로 작성되어 있으며, 따라서 CPU(호스트) 작업이 GPU 작업을 막아 “호스트 오버헤드(host overhead)”를 유발하지 않도록 신중하게 설계·구현되어야 한다. 인퍼런스 워크로드가 겪는 호스트 오버헤드의 유형과, 우리가 이를 해결하기 위해 인퍼런스 엔진에 기여한 내용은 이 블로그 글에 정리했다.
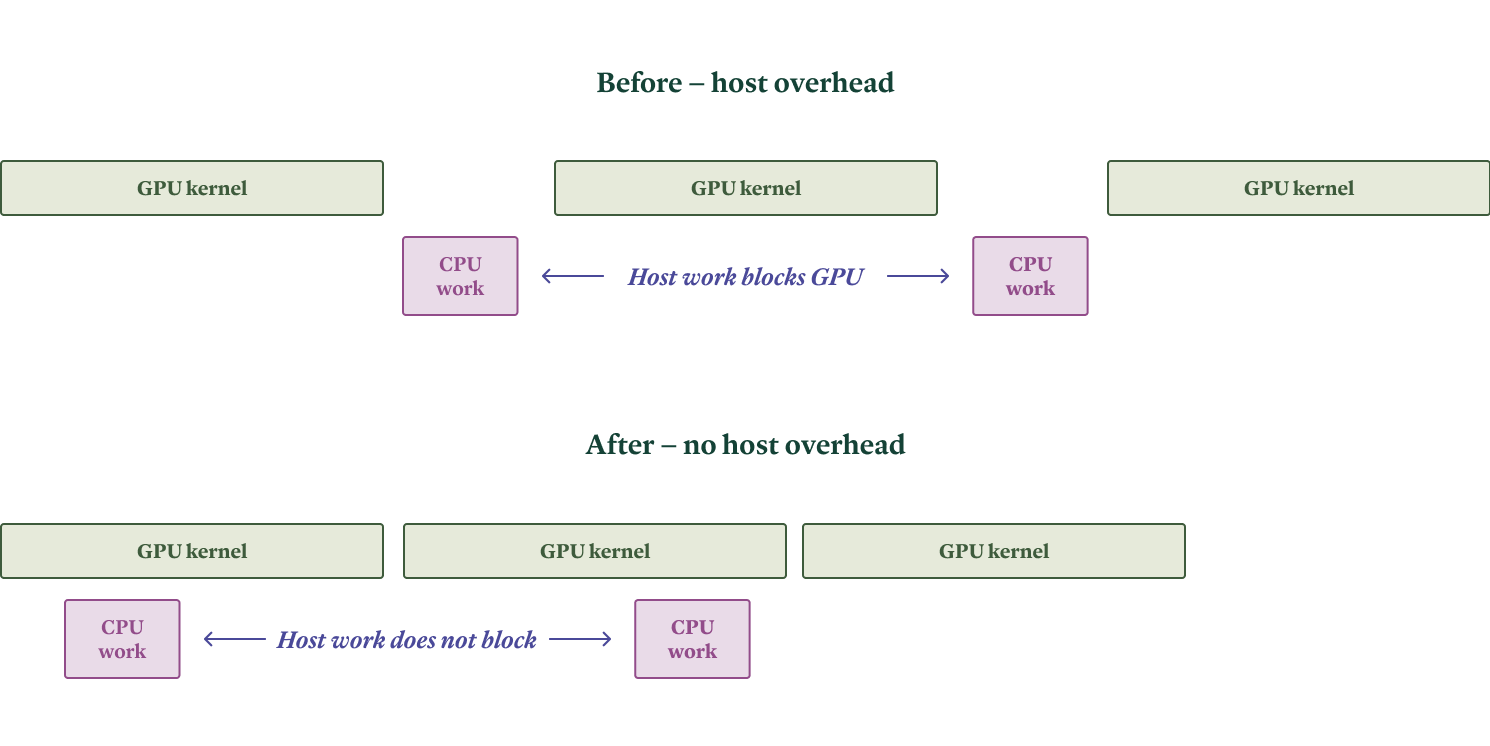
우리 경험상, SGLang 인퍼런스 엔진이 여기서 우위에 있다. 일반적으로 호스트 오버헤드가 더 낮기 때문이다.
반복하지만, 온라인 워크로드의 1차 과제는 수백 밀리초 안에 응답해야 한다는 것이다.
여기서는 로컬 애플리케이션이 아니라 LLM 인퍼런스 서비스를 고려하고 있으므로, 클라이언트와 시스템 간 통신은 이 시간 규모에서 눈에 띄는 지연을 도입할 수 있다. 특히 네트워크는 빛의 속도의 큰 비율로 동작하지만, 이는 (지구상에 있는) 클라이언트가 단일 지리적 위치에 구현된 시스템에 접속할 경우 수십~수백 밀리초의 지연을 의미한다.
해결책은 라우팅 프록시와 가속기 용량을 “엣지(edge)”—즉 클라이언트와 가까운 데이터센터—에 함께 배포하는 것이다. 순수 기술 문제를 떠나, 모든 클라우드 제공자가 모든 지역에 모든 GPU 유형의 가용 용량을 갖추고 있지 않기 때문에 시장 조건상 어려울 수 있다. Modal은 여러 클라우드의 용량을 집계하고, 지역화된 서비스 배포를 지원함으로써 이를 해결한다.
온라인 워크로드는 지연 시간 요구뿐 아니라 요청 패턴도 인터랙티브하다. 사용자는 시스템의 응답에 반응하고, 시스템은 다시 그에 응답해야 한다.
(명목상) 무상태(stateless) 프로토콜인 HTTP와 달리, 효율적인 멀티턴 LLM 인퍼런스는 상태(stateful)를 가진다. 클라이언트는 일반적으로 요청에 전체 대화 히스토리를 포함하므로 겉보기엔 무상태처럼 보일 수 있다. 그러나 트랜스포머 기반 모델은 대화 길이에 대해 계산 요구량이 제곱(quadric)으로 증가한다. 이를 선형(linear) 계산으로 바꿀 수 있는데, 대신 모델 활성값(activation)을 선형 크기만큼 저장해야 하며 이것이 “키-값 캐시(KV cache)”(원래는 더 설명적인 이름인 “past cache”로 불렸다)다.
해결책은 캐시를 채우는 데 사용된 정보에 기반해 요청을 인퍼런스 레플리카로 라우팅하는 것이다. 손실 없는 캐싱을 위해서는 요청의 접두어(prefix) 정보가 필요하다. 이러한 “접두어 인지(prefix-aware)” 라우팅은 대화별 스티키 세션처럼 단순할 수도 있으며(Modal은 이를 네이티브로 지원), 요청과 캐시 내용을 더 깊게 검사하는 방식일 수도 있다.
KV 캐싱을 사용하는 LLM 인퍼런스의 병목 연산은 산술 집약도(arithmetic intensity)가 낮아, 인퍼런스가 메모리 바운드된다.
직관적으로, 요청 하나당 포워드 패스 한 번으로 한두 개 토큰만 생성할 수 있지만, 모든 모델 가중치(보통 수십억 개)를 레지스터로 로드해야 한다. 사용자 관점에서 그 가중치는 대략 한 번의 덧셈과 한 번의 곱셈 정도에 사용되지만, GPU의 리지 포인트 산술 집약도는 바이트당 수백~수천 연산이다. 따라서 많은 산술 대역폭(arithmetic bandwidth)이 낭비된다. 또한 온라인 서비스의 지연 시간 요구와 요청 부하가 요청 간 배칭을 허용하더라도, 이런 워크로드에서는 요청별 접두어가 대체로 서로 달라 요청별로 서로 다른 KV 캐시 요소를 로드해야 한다. 캐시 내용은 처음에는 모델 가중치에 비해 미미하지만, 시퀀스 길이가 늘수록 커진다.
지금까지의 논리는 처리량에 초점을 맞췄지만, 지연 시간이 핵심인 온라인 워크로드에서는 상황이 더 나쁘다. 단일 가속기에서 배치에 대한 포워드 패스를 실행하려면 수십억 개의 모델 가중치를 로드해야 하며, 메모리 대역폭은 초당 수조 바이트 단위이므로 단일 가속기에서 포워드 패스는 필연적으로 밀리초 단위를 소요한다. 개별 사용자는 이보다 낮은 토큰당 지연 시간을 볼 수 없다. 자기회귀(autoregressive), 즉 순차 생성은 이러한 지연을 누적하며, 짧은 생성 시퀀스에서도 빠르게 지연 시간 예산을 잠식한다(애달픈 암달의 법칙의 또 다른 사례).
한 가지 해법은 시스템의 메모리 대역폭(구체적으로 모델 가중치+KV 캐시와 연산 유닛 사이의 메모리 대역폭)을 늘리는 것이다. 하드웨어 측면에서는 H100, B200 같은 최신 GPU를 사용하는 것으로, 과거 세대 대비 메모리 대역폭이 크게 개선됐다.
여러 GPU를 사용하면 집계 대역폭이 증가한다. 하지만 GPU를 더하는 것만으로는 지연 시간을 줄이기에 충분하지 않다. 소프트웨어 측면에서는 시스템이 태스크 내부 병렬성을 활용해 대역폭 수요를 가속기들에 분할해야 한다. 가장 흔한 접근은 텐서 병렬성(tensor parallelism)으로, 행렬 곱의 내재적 병렬성을 이용해 곱셈의 일부를 서로 다른 워커에 분할한다.
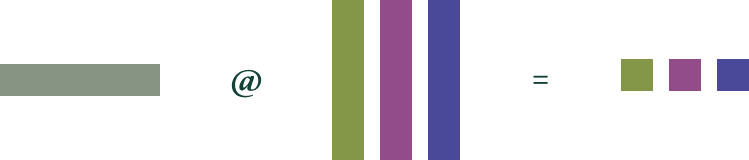
텐서 병렬성은 단일 행렬 곱(방정식의 좌변)을 GPU들(색으로 표시; 모든 GPU에 공유되는 데이터는 회색)로 분할한다.
이는 낮은 지연 시간과 높은 대역폭을 요구하므로 보통 백엔드/“스케일업(scale-up)” 네트워크 내부에서만 수행되며, GPU에서는 일반적으로 NVLink가 해당한다. 특정 태스크에 적용되는 유용한 오픈 소스 모델들 다수는 표준 8-가속기 NVLink 도메인만으로도 인터랙티브 지연 시간 목표를 달성할 만큼 충분한 메모리 대역폭을 제공하지만, 장차 NVSwitch가 제공하는 랙 스케일 NVLink 도메인이 필요해질 미래를 예상한다.
메모리 대역폭을 늘리는 것 외에도, 시스템은 (대개 모델 품질을 희생하면서) 메모리 요구량을 줄일 수 있다. 이 트레이드오프가 타당한지는 애플리케이션에 따라 다르다—자체 인퍼런스를 호스팅해야 하는 또 하나의 이유다.
첫 번째로 당길 수 있는 레버는 부동소수점 양자화(floating point quantization)다. 일반적으로 하드웨어가 양자화된 데이터 타입에 대해 네이티브 부동소수점 연산을 지원할수록 성능 이점이 크다: Hopper GPU는 8비트(FP8), Blackwell GPU는 4비트(FP4)다.
대략 700억 파라미터 이상의 모델에서는 4비트 양자화가 큰 번거로움 없이 잘 작동한다. 더 작은 모델(10억 파라미터까지 내려가는)에서는 8비트 양자화만이 충분한 품질을 유지한다—주목할 예외로 gpt-oss 20B가 있다.
마지막으로 덧붙이자면, 현대 아키텍처에서 피드포워드 레이어가 mixture-of-experts(MoE) 구조를 갖는 이유는 메모리 대역폭 수요를 줄이기 위해서다. 모델 간 비교로 메모리 요구량과 서빙 비용을 추정할 때는 총 파라미터 수뿐 아니라 활성 파라미터(active parameters)를 보라.
결국 메모리 바운드는 피할 수 없고, 지연 시간은 더 이상 줄일 수 없다. 시스템은 하드웨어의 은유적 “빛의 속도”에 도달한 것이다.
빛의 속도는 깰 수 없지만, ‘치팅’할 수는 있다.
메모리 바운드 인퍼런스를 위한 핵심 기법은 추측적 디코딩(speculative decoding)으로, 순진한 단일 토큰 자기회귀 인퍼런스에서 산술 대역폭의 여유분(slack)을 활용한다.
구체적으로, 더 단순한 언어 모델링 시스템(추측기, speculator)을 사용해 더 큰 타깃 시스템이 병렬로 평가할 여러 개의 연속 출력 토큰을 제안하게 한다. 인퍼런스가 메모리 바운드이므로, 추측기를 실행할 추가 FLOPs 여지가 있다. 또한 큰 모델은 입력의 각 토큰에 대한 확률을 이미 출력하므로, 엔진은 출력이 바뀌지 않도록(통계적 추론의 “거절 샘플링(rejection sampling)”을 떠올리면 됨) 쉽게 보장할 수 있다.

추측적 디코딩에서는, 추측기 모델이 “드래프트” 토큰(연두색)을 생성하고 타깃 모델이 이를 병렬로 검증한다. 타깃 모델 하에서 충분히 높은 확률을 가진 토큰은 채택되며(진초록, 오른쪽 아래), 처음 거절된 토큰은 타깃 모델의 생성(주황)으로 대체된다.
이 아이디어는 LLM 인퍼런스 기준으로는 오래-알려진 기법이지만, 비교적 최근까지는 더 정교한 드래프트 모델을 사용하는 것이 운영상의 어려움 때문에 제한적인 성능 향상을 상쇄해 왔다. 그 결과 “같은 부분 문자열이 반복될 것이다” 같은 매우 단순한 추측기(= n-그램 추측)가 주로 쓰였고, 이는 일반적으로 채택률이 낮아 가속 폭이 작다.
EAGLE-3 추측기 학습 방법은 우리에게 이를 바꿔놓았다. 오픈 소스 엔진에서 지원이 좋은 단순한 추측기를 만들 뿐만 아니라, 채택 길이(acceptance lengths)로 측정되는 품질도 매우 높다. 우리는 오픈 소스 인퍼런스 엔진을 통해 EAGLE-3를 추가하는 것만으로, 독점 인퍼런스 스택을 가진 모델 제공업체들이 달성한 성능과 맞먹는 수준에 도달할 수 있음을 확인했다. 작성 시점 기준으로 SGLang이 추측적 디코딩을 더 잘 지원하며, 이것이 저지연 애플리케이션에 SGLang을 권장하는 또 하나의 이유다.
온라인 애플리케이션에서 저지연을 최적화하기 위해 다음 선택을 한다.
modal.experimental.http_server 배포 데코레이터를 사용해 지역화된(regionalized), 초저오버헤드 웹 서버를 만들고 세션 기반 라우팅을 적용한다.동작 예시는 여기의 코드 샘플에서 볼 수 있다.
챗봇에 대한 막대한 투자와 관심 덕분에 이 워크로드는 이미 상당한 엔지니어링 작업을 받았고, 미래를 그리기에도 다소 수월하다.
우선, 가까운 미래에 “빛의 속도를 치팅”하는 더 많은 방법이 중요해질 것으로 예상한다. 특히 약간의 성능(정확도/품질)을 희생하고 큰 속도를 얻는 손실형(lossy) 최적화가 그렇다. 위에서 언급하지 않았지만 현재 연구의 주요 타깃인 기법들로는 근사 KV 캐싱, 레이어 스키핑(layer skipping), 프루닝(pruning), KV 캐시의 손실 압축, 손실 추측(lossy speculation)이 있다. 이러한 기법 중 다수는 다른 가속 기회가 제한적인 확산(diffusion) 모델 분야에서 이미 꽤 성숙했다(우리의 Flux 가속 블로그 글 참고).
이 최적화들은 “손실형”이므로 통계적 의미에서 호스팅되는 모델을 바꾼다. 아주 조금이라도 동작이 바뀌는 것이 보장된다. 이는 자체 호스팅의 경제적 이유가 된다. 여러분의 워크로드에 어떤 최적화가 효과적인지 직접 검증할 수 있기 때문이다.
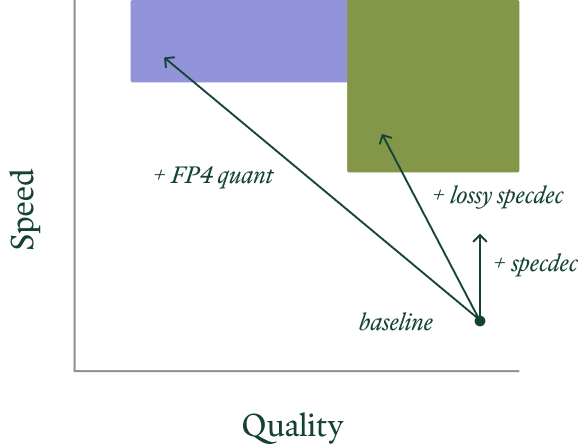
일부 워크로드에서는 추측적 디코딩 같은 완전 무손실 성능 개선만으로는 목표 지연 시간(수직 화살표)을 달성하기에 충분하지 않을 수 있다. 목표 속도와 지연 시간(색 영역)을 달성하기 위한 적절한 손실형 성능 개선(대각 화살표)은 워크로드(색으로 표시)마다 다르다.
기존 하드웨어 제공업체들의 투자와 인퍼런스 하드웨어 스타트업들의 등장으로 인해, 우리는 이러한 워크로드가 점점 더 ‘일반적인 워크스테이션’이나 ‘클라우드의 범용 고성능 머신’과는 더 멀어진, 더 이국적인(exotic) 하드웨어로 옮겨갈 것으로 예상한다.
Nvidia는 예컨대 “랙 스케일” NVL72/CPX Rubin 같은, 촘촘히 상호연결된 시스템에 크게 투자하고 있다. 이 아키텍처는 기존 시스템 대비 지나치게 이국적이지 않은 구성 요소(예: 시스템 메모리로 HBM 사용)를 이용해 낮은 지연 시간에서 거대한 메모리 대역폭을 달성할 수 있다. 같은 논리로, Google도 비슷한 아키텍처로 대형 TPU 시스템을 구축하고 있다. 더 나아가려면 실리콘 계층에서 더 깊은 혁신이 필요하며, 특정 모델 아키텍처에 맞춘 ASIC 형태가 유력하다. 예컨대 초당 10억 토큰에 도달하려면 스토리지와 연산을 매우 가깝게 공배치해야 하며, 아날로그 요소를 포함할 수도 있다.
이러한 시스템들이 수요가 없을 것이라 보진 않지만, 온라인/채팅 워크로드의 상대적 중요도는 시간이 지나며 감소할 것으로 본다. 현재의 관심은 LLM의 초기 “킬러 앱”인 OpenAI의 ChatGPT에 의해 촉발됐다. 이는 자본 제공자, 투자자, 창업자, 심지어 애플리케이션 개발자들 사이에서도 모방과 쏠림 행동을 낳았다.
하지만 우리는 이미 다른 “킬러 앱”이 떠오르는 조짐을 보고 있다—예를 들어 Claude Code 같은 장시간 실행되는 백그라운드 에이전트로, 인간이 아니라 기계의 인내심을 가진다. 이런 애플리케이션은 상당히 다른 워크로드를 만들어내며, 다음 섹션에서 이를 다룬다.
대체로 시스템의 비용은 (단기) 피크 트래픽에 비례해서 증가하지만, 대부분의 애플리케이션에서 시스템이 만들어내는 가치는 (장기) 평균 트래픽에 비례해 증가한다. “피크에 비용을 지불(pay for peak)”하는 것과 “평균에서 수익을 얻는(earn on average)” 것의 간극은 대규모 클라우드 시스템의 경제성이 전통적인 단일 테넌트 시스템과 어떻게 다른지 이해하는 데 핵심적이다.
Reducto의 문서 처리 플랫폼 사용자는 때로는 즉시 확인할 단일 양식을 업로드하고, 때로는 회사의 전체 문서 저장소를 한꺼번에 투입한다.
한 AI 뉴스 분석 에이전시는 속보에 대응해 뉴스 에이전트를 몇 분 내로 스케일업해야 하며, 다양한 출처를 크롤링해 종합 분석을 만든다. 또한 더 긴 주기로 “일간 신문”도 만들어야 한다.
이 시스템들은 _세미 온라인_이다. 어떤 때는 기다리는 인간에게 결과를 반환해야 하고, 다른 때는 파이프라인에서 다른 컴퓨터 시스템(다른 에이전트일 수도 있음)으로 결과를 넘긴다. 인간에게 직접 서비스를 제공하는 경우에도 그렇게 긴밀한 인터랙션이 필요하진 않다. 워크로드는 버스티하다—부하가 몇 분 또는 수십 분 동안 기준치의 수백 배까지 치솟기도 한다.
위 인용문에서 AWS의 Marc Brooker가 암시했듯이, 높은 피크-평균 비율은 이 워크로드를 서비스하는 시스템에 비용 딜레마를 만든다. 비용은 보통 피크 수요를 서비스하기 위한 요구사항에 의해 결정되지만, 수익은 평균 수요를 서비스하는 것으로부터 발생한다.

시스템 비용은 피크 수요를 위한 할당 자원(음영 영역)에 비례한다. 수익은 실현된 자원 수요(곡선 아래 면적)에 비례한다. 피크가 평균보다 훨씬 높을 때, 이 그림처럼 유연한 자원 할당이 없는 시스템은 비경제적이 된다.
Modal이 취한 해법은 AWS가 취한 것과 같다: 집계(aggregation)와 멀티테넌시(multitenancy)다. 즉, 상관관계가 낮은 피크들이 모여 하드웨어 수요가 시간적으로 더 매끄럽게 보이도록, 공유 하드웨어에서 다양한 워크로드를 서비스한다. 그 결과 피크-평균 비율이 감소한다.
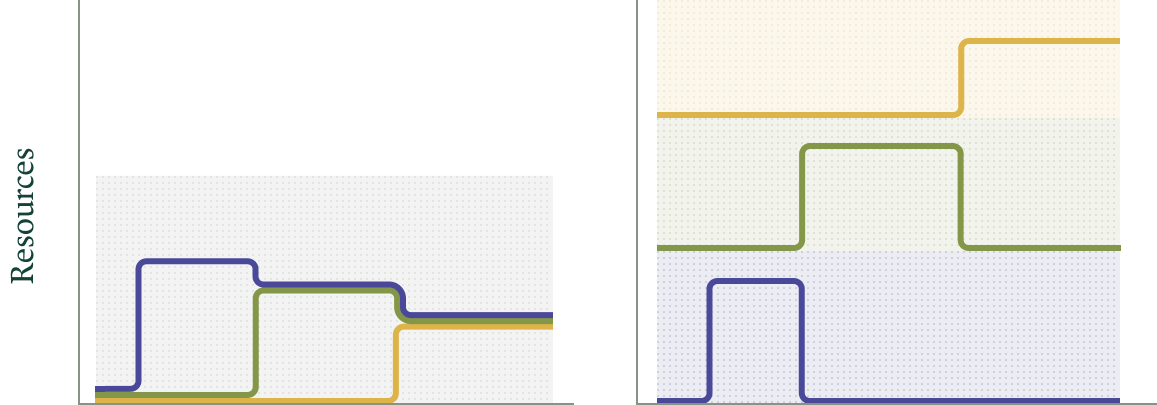
멀티테넌트 시스템(왼쪽, 테넌트 자원 수요는 색 선)에서는 피크 수요가 줄어 비용(음영 영역)이 감소한다. 단일 테넌트 시스템들의 그룹은 최악의 경우(오른쪽) 워크로드별 비용(각 음영 영역)이 멀티테넌트 시스템 전체 비용에 가깝게 된다.
그 후 우리는 평균이 변함에 따라 자원을 확보·해제하고, 즉시 자원 요청을 처리할 수 있을 만큼의 버퍼를 유지할 수 있다. 그 시스템에 대한 자세한 내용은 이 블로그 글을 참고하라.
멀티테넌트 컴퓨터 시스템에는 단점도 있는데, 그중 하나는 콜드 스타트 지연이 추가된다는 점이다. 즉, 서빙 자원 요청이 버퍼에서 처리되더라도, 그 자원을 구성해 요청 처리를 시작하도록 만드는 데 시간이 걸린다. 컨테이너나 VM이 부팅되어야 하고, 그 다음 인퍼런스 엔진이 시작되어야 한다.
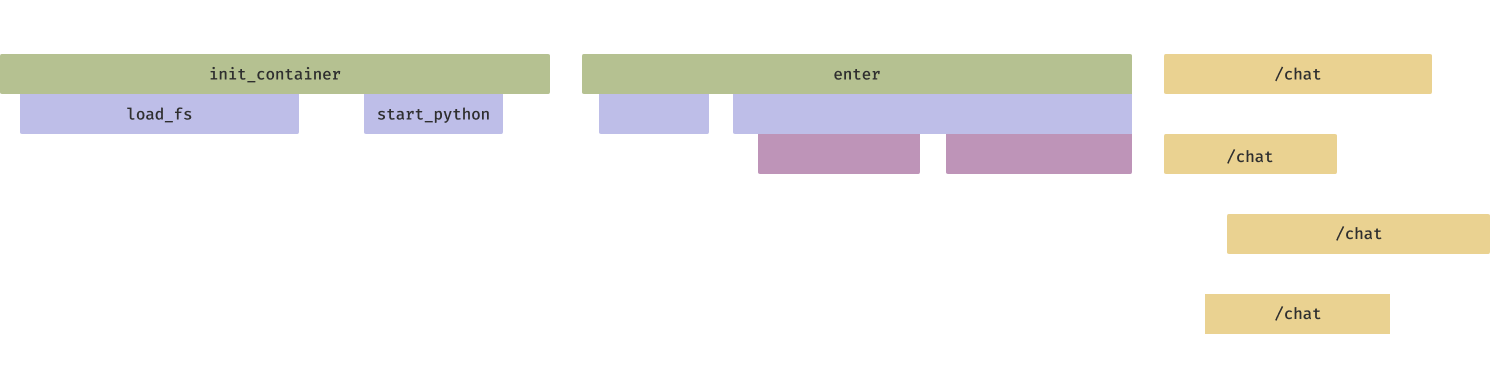
최적화가 없으면, 큰 컨테이너 이미지의 컨테이너 시작 시간은 몇 분까지 늘어날 수 있다.
Modal에서는 사용될 파일의 eager 프리패칭과 사용될 가능성이 낮은 파일의 lazy 로딩을 섞는 등, 컨테이너 시작 시간을 가속하는 기법에 크게 투자해왔다.
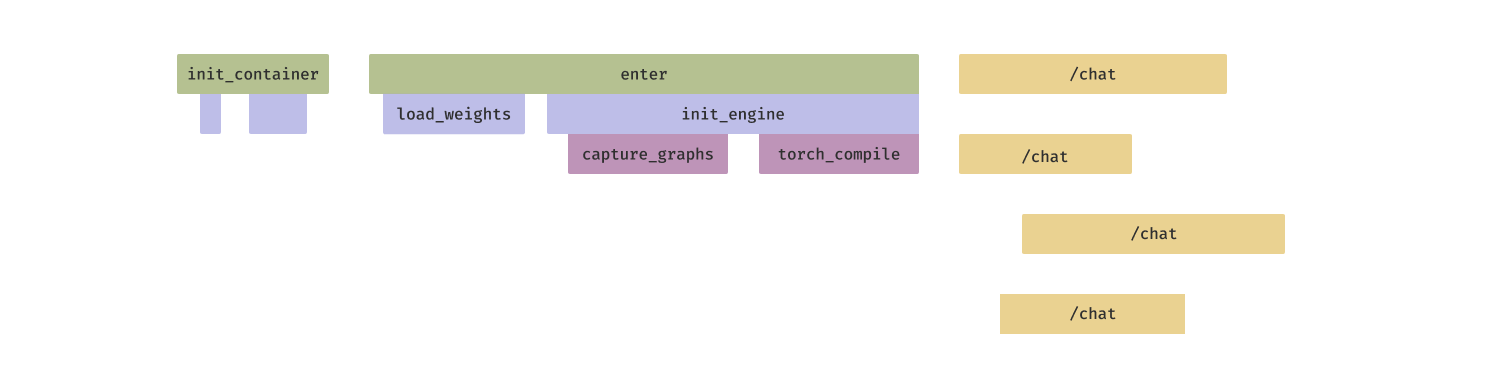
최적화 후 컨테이너 시작은 수 초로 줄일 수 있다. 하지만 엔진 초기화는 여전히 수십 초가 걸릴 수 있다.
예를 들어 Torch JIT 컴파일러는 인퍼런스 패스에 엄청난 속도 향상을 제공할 수 있지만, 실행에 몇 분이 걸릴 수 있다. 그 동안 인퍼런스 서버 레플리카는 요청을 처리할 수 없다.
우리의 해법은 GPU 메모리 스냅샷팅(memory snapshotting)이다. 인퍼런스 서버 레플리카가 요청을 처리할 준비가 되기 직전에, 프로그램 상태를 파일시스템에 덤프한다. 새 레플리카를 띄울 때는 파일시스템에서 곧바로 로드하여 Torch JIT 컴파일 같은 계산을 건너뛴다(또한 수많은 작은 파일 I/O를 하나의 큰 I/O로 바꿔, 스토리지 시스템에 더 잘 맞춘다).
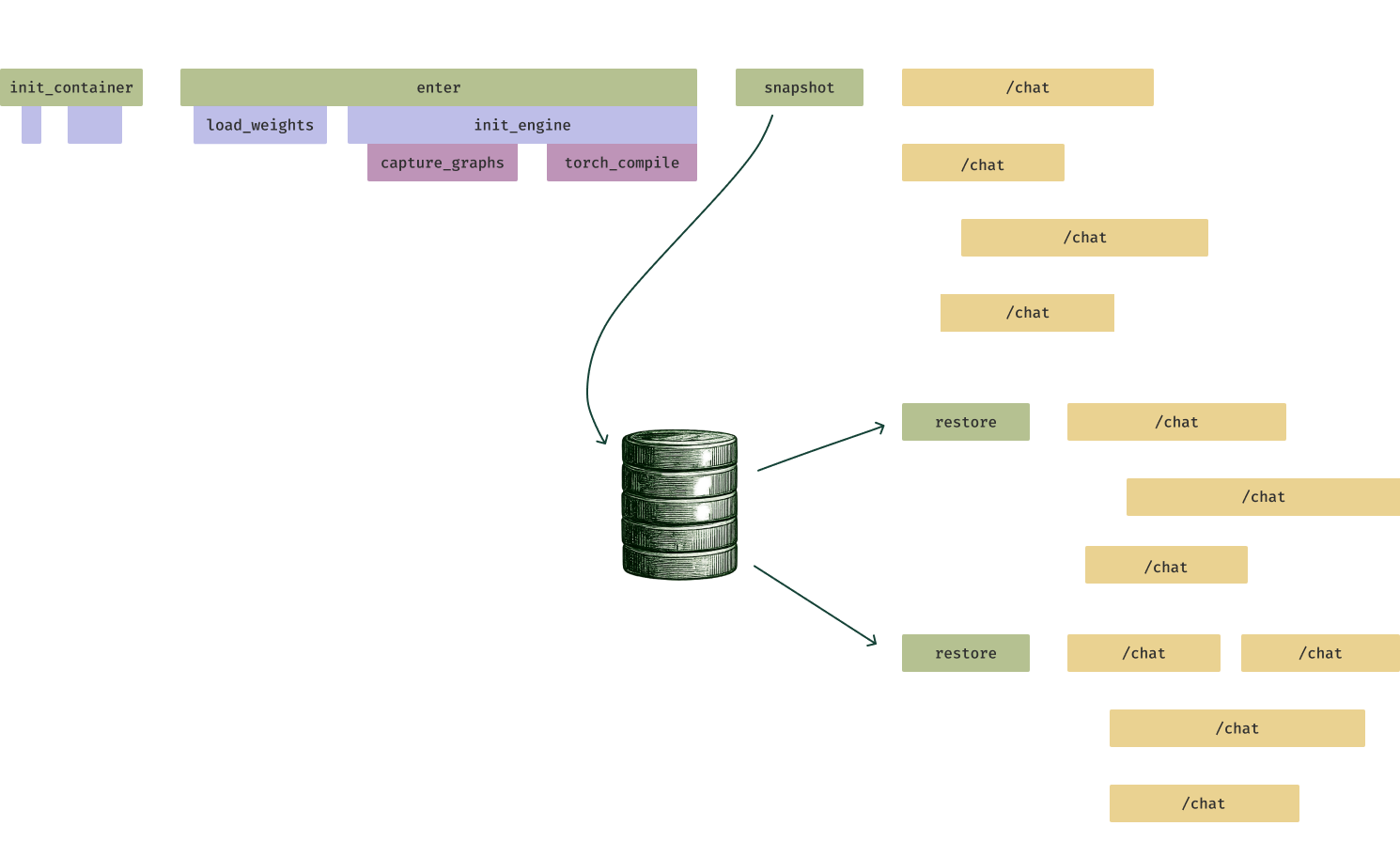
메모리 스냅샷팅은 인퍼런스 서버 시작 시간을 10배까지 단축할 수 있으며, 직렬화된 스냅샷 스토리지(북 아이콘)에서 서버를 restore하기만 하면 된다. 빠른 스케일업은 갑작스러운 부하 버스트(노란색 /chat/completions 요청)에서 응답 시간을 개선한다.
우리는 다양한 모델 클래스에서 GPU 스냅샷팅을 벤치마크했고, LLM 인퍼런스 서버 시작 시간을 분 단위에서 초 단위로 줄일 수 있음을 확인했다.
세미 온라인 애플리케이션에서 유연한 스케일링을 최적화하기 위해 다음 선택을 한다.
web_server 배포 데코레이터를 사용해 OpenAI 호환 서버를 노출하는 파이썬 프로그램을 웹 서비스로 전환한다.modal.concurrent 데코레이터에서 max_inputs를 target_inputs보다 높게 설정해 수행한다.이 워크로드를 SGLang으로 서빙하는 샘플 코드는 여기, vLLM으로 서빙하는 샘플 코드는 여기에서 찾을 수 있다.
분야가 성숙해짐에 따라 이러한 세미 온라인 애플리케이션이 더 많이 등장할 것으로 예상한다. 오프라인/분석과 온라인/트랜잭션 워크로드는 очевид한 선택이지만, 그 중간에는 두 특성을 결합한 과제가 훨씬 더 많다.
특히 인간이 아닌 컴퓨터 시스템의 인내심을 가진 장시간 실행 에이전트가 더 많은 일을 하게 되면서, 이러한 워크로드의 중요성이 커질 것으로 본다. 즉, 인간 사용자는 작은 대기 시간을 피하기 위해 큰 프리미엄을 지불할 것이며, 위에서 인용한 Doherty & Thadhani 같은 생산성 연구도 그 트레이드오프를 뒷받침한다. 하지만 장시간 실행 작업을 완료하기 위한 에이전트(또는 에이전트 시스템)를 설계하는 엔지니어는 일반적으로 그 반대의 트레이드오프를 선호할 것이다. 빌더와 엔지니어가 이런 워크로드를 발견하고 확장해 나감에 따라, 우리는 더 많은 워크로드를 서비스하게 되기를 기대한다.
LLM의 시대에 들어선 지 여러 해가 지났지만, 독점 모델 기업과 독점 인퍼런스 엔진이 기능(capabilities) 측면에서 얻은 선점 덕분에, 우리는 아직 LLM 엔지니어링 시대의 초입에 있다.
하지만 다른 도메인과 마찬가지로, 기반 기술은 충분히 확산되어 상품(commodity)이 되어가고 있다. 그러면 커스터마이징과 제어의 추가 이점이 점점 더 자체적으로 LLM 인퍼런스를 구축하는 쪽으로 균형을 기울게 만든다.
이는 추가적인 엔지니어링 노력이 필요하다—그리고 지식을 분산하고, 역량을 끌어올리며, 오픈 모델과 오픈 소스 소프트웨어를 만들어내기 위한 커뮤니티의 노력이 필요하다. Modal은 이 모든 것에 기여하게 되어 기쁘다. 자체 인퍼런스를 대규모로 배포하는 데 관심이 있다면, 연락해 달라.