CoreML을 우회해 M4 Apple Neural Engine에 직접 접근하기 위해 소프트웨어 스택을 역분석하고, MIL→E5 컴파일 경로와 바이너리 형식, 큐 심도, IOSurface 기반 I/O 및 전력/성능 특성을 밝혀낸 과정.

“우리(we)”에 대한 메모:
이 시리즈 전반에서 _“우리”_는 maderix(사람)와 Claude Opus 4.6(Anthropic)을 한 쌍으로 일한 것을 뜻합니다. 리버스 엔지니어링, 벤치마킹, 학습 코드는 협업으로 개발되었습니다 — 탐색은 인간의 직관이 이끌고, AI는 데이터로부터 추론하고 분석을 작성하며 코드를 썼습니다. 우리는 이런 인간–AI 협업이 시스템 연구를 하는 새롭고 자연스러운 방식이라고 생각합니다. 한 파트너는 직관을 가진 **설계자(architect)**로, 다른 파트너는 코드 작성과 실험 설계를 맡는 **엔지니어(engineer)**로요.
이 모든 건 아주 단순한 질문에서 시작했습니다: Apple의 Neural Engine에서 모델을 학습(train)할 수 있을까?
Apple은 당신이 그 답을 알길 원하지 않습니다. 그들은 ANE의 ISA를 공개하지 않습니다. 내부 아키텍처도 문서화하지 않습니다. 심지어 직접 프로그래밍할 방법도 주지 않습니다 — 모든 것은 CoreML을 통해서만 이뤄지는데, CoreML은 여러 추상화 계층, 최적화 패스, 오버헤드를 더해 하드웨어가 실제로 무엇을 하고 있는지 이해하기가 거의 불가능해집니다.
그래서 우리는 리버스 엔지니어링했습니다.
며칠에 걸쳐 CoreML에서 IOKit 커널 드라이버까지 전체 소프트웨어 스택을 매핑했고, CoreML 없이도 ANE에서 프로그램을 컴파일하고 실행하는 방법을 찾아냈으며, 바이너리 포맷을 해독했고, 진짜 피크 성능을 측정했으며(스포일러: Apple의 “38 TOPS” 숫자는 오해의 소지가 있습니다), 결국 추론 전용으로 설계된 칩에서 신경망을 _학습_시키는 데 성공했습니다.
이 글은 3부작 시리즈의 1부입니다. 여기서는 리버스 엔지니어링 — 즉 M4 Neural Engine이 실제로 무엇이며, 어떻게 그와 직접 통신하는지 이해하기 위해 우리가 계층을 어떻게 벗겨냈는지를 다룹니다.
ANE는 GPU가 아닙니다. CPU도 아닙니다. ANE는 **그래프 실행 엔진(graph execution engine)**입니다 — 컴파일된 신경망 그래프를 받아 전체를 하나의 원자적(atomic) 연산으로 실행하는 고정 기능 가속기입니다. 개별 MAC(multiply-accumulate) 명령을 발행하는 방식이 아닙니다. 전체 계산 그래프를 기술하는 컴파일된 프로그램을 제출하면, 하드웨어가 이를 끝에서 끝까지 실행합니다.
Apple은 A11(2017)에서 2코어 설계로 Neural Engine을 도입했습니다. 세대가 거듭될수록 규모를 키웠습니다:
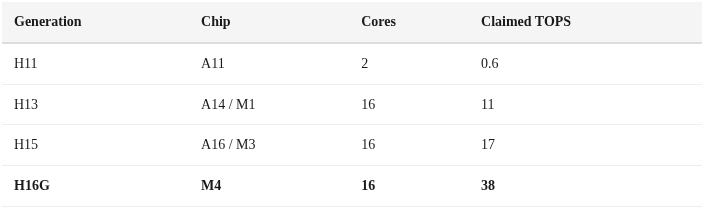
우리가 다루는 대상은 M4의 ANE(코드네임 H16G)입니다. 16코어, 평가 요청(evaluation request) 큐 심도 127, 독립적인 DVFS(dynamic voltage/frequency scaling), 그리고 유휴 시 정확히 0mW로 떨어뜨리는 강력한 전력 게이팅을 갖고 있습니다.
ANE 내부를 건드려 본 사람이 우리가 처음은 아닙니다.
hollance/neural-engine — Matthijs Hollemans가 정리한 ANE 동작, 성능 특성, 지원 연산에 대한 포괄적인 커뮤니티 문서. ANE에 관한 기존 자료 중 단연 최고.
mdaiter/ane — ANECompiler 프레임워크와 IOKit 디스패치를 문서화하고, 동작하는 Python/Objective-C 샘플을 포함한 초기 리버스 엔지니어링.
eiln/ane — ANE용 리버스 엔지니어링된 Linux 드라이버(Asahi Linux 프로젝트)로, 커널 수준 인터페이스에 대한 통찰을 제공.
apple/ml-ane-transformers — ANE에 최적화된 transformer에 대한 Apple의 레퍼런스 구현으로, 채널-퍼스트 레이아웃과 1×1 conv 선호 같은 설계 패턴을 확인해 줌.
하지만 우리가 아는 한, 이전에는 아무도 다음을 해내지 못했습니다: (a) M4에서 CoreML 없이 직접 _ANEClient API에 접근, (b) 메모리 내(in-memory) MIL 컴파일 경로 해독, (c) CoreML 오버헤드를 우회해 진짜 피크 처리량 측정, (d) ANE에서 모델 학습.
우리의 접근은 여러 기법을 결합했습니다:
AppleNeuralEngine.framework에서 dyld_info -objc로 클래스 탐색 — 모든 Objective-C 클래스와 메서드를 덤프
CoreML의 프라이빗 ANE 프레임워크 호출을 가로채기 위한 메서드 스위즐링(method swizzling)
신경 프로그램 포맷을 이해하기 위한 컴파일된 E5 번들의 바이너리 분석
하드웨어 토폴로지를 추론하기 위해 행렬 크기, 그래프 깊이, 채널 수를 바꿔가며 하는 스케일링 분석
우리는 AppleNeuralEngine.framework에서 _ANEClient, _ANEModel, _ANERequest, _ANEIOSurfaceObject, _ANEInMemoryModel 등을 포함해 40개 이상의 프라이빗 클래스를 발견했습니다.
다음은 공개 CoreML API부터 하드웨어까지 내려가는 전체 ANE 소프트웨어 스택의 모습입니다:
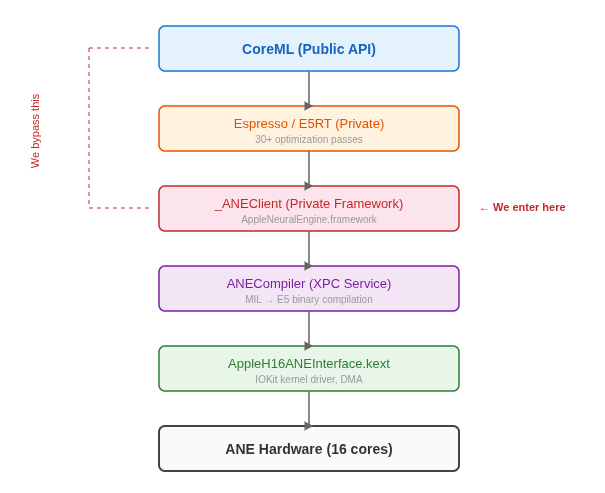
핵심 통찰: CoreML은 유일한 진입로가 아닙니다. AppleNeuralEngine.framework의 _ANEClient 클래스는 컴파일 → 로드 → 평가 파이프라인에 대한 직접 접근을 제공합니다. CoreML은 그 위에 얹힌 편의 레이어일 뿐입니다.
다음은 CoreML 없이 ANE에서 프로그램을 컴파일하고 실행하는 전체 시퀀스입니다:
I/O는 GPU 텍스처에도 쓰이는 동일한 공유 메모리 메커니즘인 IOSurface를 사용합니다. 이는 같은 IOSurfaceRef를 공유한다면 GPU와 ANE 사이의 제로-카피 전송이 이론적으로 가능하다는 뜻입니다.
핵심 발견: ANE는 큐 심도 127을 지원합니다 — 동시에 최대 127개의 평가 요청을 인-플라이트 상태로 둘 수 있습니다. 이는 대부분의 가속기 큐보다 훨씬 깊으며, 하드웨어가 고처리량 스트리밍 추론을 위해 설계되었음을 시사합니다.
CoreML은 신경망을 ONNX나 protobuf 포맷으로 ANE에 보내지 않습니다. 대신 MIL — Machine Learning Intermediate Language — 을 사용합니다. MIL은 다음처럼 보이는, 타입이 있는 SSA(Static Single Assignment) 표현입니다:
MIL은 놀랍도록 읽기 쉽습니다. 모든 값에 정밀도와 형태(shape)가 함께 타입으로 붙습니다. 연산은 이름을 갖고 키워드 인자를 받습니다. 함수 시그니처는 입력 텐서를 명시적 차원으로 선언합니다.
텐서 레이아웃은 ANE의 네이티브 NCDHW + Interleave 포맷을 따릅니다: [Batch, Channels, Depth, Height, Width]. 1024×1024 행렬의 경우 4D에서 [1, 1024, 1, 1024]가 됩니다.
ANECompiler가 MIL 프로그램을 처리하면 E5 바이너리를 생성합니다 — 다음 섹션들로 구성된 FlatBuffer 구조의 파일입니다:
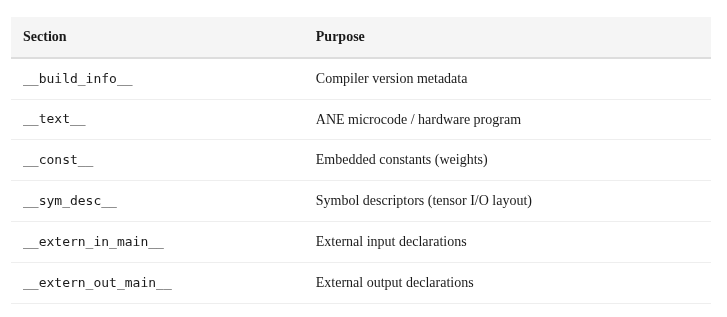
여기서 정말 흥미로운 부분이 나옵니다. 1024×1024 matmul은 2,688 bytes로 컴파일됩니다. 128×128 matmul도 2,680 bytes로 컴파일됩니다. 거의 동일합니다. E5 바이너리는 행렬 곱 알고리즘을 인코딩하고 있는 게 아니라, 런타임에서 텐서 디스크립터로 동작이 제어되는 _파라미터화된 프로그램_을 인코딩합니다. 이 “마이크로코드”는 전통적인 머신 코드라기보다 설정(configuration)에 가깝습니다.
함의: ANE 하드웨어에는 (convolution, matrix multiply, elementwise 같은) 고정된 소수의 연산 프리미티브가 있고, 이들이 텐서 형태 디스크립터에 의해 파라미터화되는 것으로 보입니다. E5 바이너리는 연산 자체가 아니라, 어떤 프리미티브를 어떤 순서로 체인하고 어떻게 연결할지를 기술합니다.
파일 기반 컴파일 경로는 동작하지만 문제가 있습니다. MIL 텍스트를 디스크에 쓰고, 디렉터리 구조를 만들고, 컴파일러가 그걸 보게 해야 합니다. 학습에서는 몇 스텝마다 업데이트된 가중치로 재컴파일해야 하는데, 이런 파일시스템 왕복은 용납하기 어렵습니다.
우리는 MIL 텍스트를 메모리에서 직접 받는 _ANEInMemoryModelDescriptor를 발견했습니다:
이걸 동작시키려면 며칠을 잡아먹은 디버깅 끝에 세 가지 함정을 해결해야 했습니다:
NSString가 아니라 NSData: milText 파라미터는 NSString*가 아니라 UTF-8 바이트를 담은 NSData*를 원합니다. 문자열을 넘기면 조용히 실패합니다.
NSData가 아니라 NSDictionary: weights 파라미터는 단일 데이터 버퍼가 아니라, 가중치 이름을 NSData 블롭에 매핑하는 딕셔너리입니다.
임시 디렉터리 우회: “인메모리” 경로도 내부적으로는 temp 디렉터리에 씁니다. 기본 위치에 대한 쓰기 권한이 없으면 컴파일이 불투명한 오류로 실패합니다. 쓰기 가능한 temp 경로가 있도록 보장해야 했습니다.
그리고 한 가지 유쾌한 발견: Apple 내부 코드가 클래스 이름 중 하나에서 Desctiptor(오타)를 참조합니다. Apple 엔지니어들도 프라이빗 API에서 오타를 냅니다. :)
IOKit 프로빙, 스케일링 분석, 전력 측정을 통해 우리는 M4 ANE에 대해 이런 프로파일을 구축했습니다:
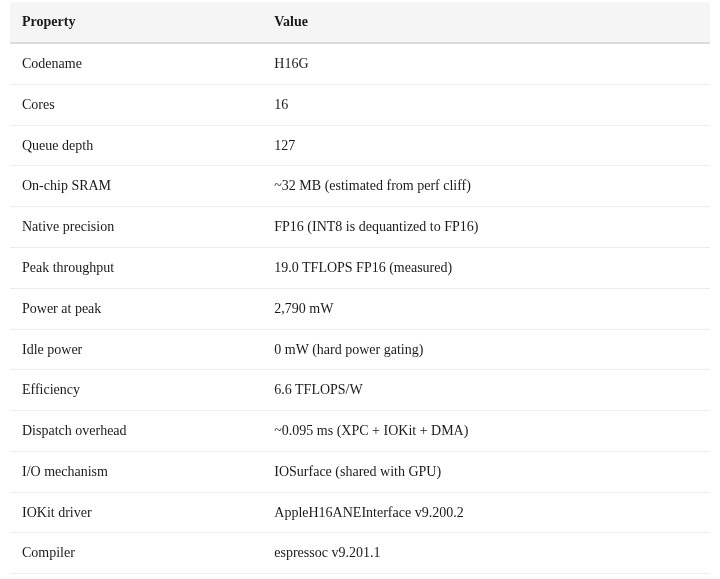
IOKit의 IOReportLegend는 ANE가 적응형 클로킹, 디더링, 그리고 다수의 하드웨어/소프트웨어 트리거를 갖춘 독립적인 전력 관리를 가지고 있음을 보여줍니다:
이 정도 수준의 DVFS 정교함은 ANE가 워크로드 특성에 따라 CPU 및 GPU 전력 도메인과 별개로 독립적으로 주파수와 전압을 스케일링할 수 있음을 시사합니다.
ANECompiler.framework의 export를 보면, ANE는 네이티브로 다음을 지원합니다:

특히 Conv가 ANE의 주요 계산 프리미티브로 보입니다. 2부에서 보여주겠지만, matmul을 1×1 convolution으로 표현하면 처리량을 크게 더 끌어올릴 수 있습니다.
ANE로의 모든 데이터 전송은 IOSurface를 사용합니다. 프로토콜은 간단합니다:
IOSurface는 GPU 텍스처 공유에도 쓰이는 동일한 메커니즘이므로, 이는 두 가속기가 같은 메모리에서 작업하는 제로-카피 GPU↔ANE 파이프라인 가능성을 열어 줍니다.
ANE 컴파일러는 재컴파일을 피하기 위해 E5 바이너리를 디스크에 캐시합니다:
첫 컴파일은 약 20–40ms가 걸립니다. 캐시 히트는 사실상 공짜입니다. 이는 추론(한 번 컴파일하고 계속 실행)에서는 중요하지만, 매 스텝마다 가중치가 바뀌는 학습에서는 과제를 만듭니다.
발견한 클래스 중 일부는 아직 탐색하지 않았고, 테스트해 보지 않은 기능을 암시합니다:
_ANEChainingRequest — 여러 컴파일된 모델을 단일 디스패치에서 체이닝할 수 있게 해줄지도
_ANESharedEvents / _ANESharedSignalEvent / _ANESharedWaitEvent — GPU↔ANE 동기화를 위한 Metal 스타일의 펜스/시그널 프리미티브
_ANEPerformanceStats — 하드웨어 성능 카운터일 가능성
_ANEVirtualClient — 가상화된 ANE 접근(프로세스 간 공유용일 수도)
그리고 우리가 정말로 모르는 것들도 있습니다:
ANE 코어의 정확한 마이크로아키텍처와 ISA
그래프 내부에서 연산에 코어가 어떻게 할당되는지
ANE 클록 주파수(DVFS 때문에 동적)
하드웨어 성능 카운터에 접근 가능한지 여부
SRAM의 정확한 토폴로지(뱅크드? 유니파이드? 코어별?)
이제 ANE에 직접 접근할 수 있으니, 실제로 무엇을 할 수 있는지 측정할 수 있습니다. 2부, 에서는 matmul 스케일링, SRAM 성능 절벽, convolution이 matmul보다 3배 빠른 이유, Apple의 “38 TOPS” 주장이 왜 오해의 소지가 있는지, 그리고 CoreML을 우회하면 처리량이 2–4배 늘어나는 이유까지 전부 벤치마크할 것입니다.
3부에서는 Apple이 안 된다고 말하는 일을 할 겁니다: Neural Engine에서 신경망을 학습시키는 것.
모든 코드는 github.com/maderix/ANE의
ane/디렉터리에 있습니다. M4 Mac Mini, macOS 15.x에서 테스트했습니다.