최신 모델로 PyTorch 코드에서 자동으로 Metal 커널을 생성·최적화해 Apple 하드웨어에서 평균 1.87배(최대 수백 배) 가속을 달성한 방법을 소개합니다. 에이전틱 스웜 전략, CUDA 레퍼런스와 프로파일링 정보를 활용한 문맥 주입, 그리고 215개 PyTorch 모듈 전반의 정량적 실험 결과를 다룹니다.

게시일: 2025년 8월 26일
작성자
 이름 Taras Sereda
이름 Taras Sereda 이름 Natalie Serrino
이름 Natalie Serrino 이름 Zain Asgar
이름 Zain Asgartl;dr: 우리 랩은 최전선 모델들이 Apple 기기용 최적화 GPU 커널을 작성해 추론 속도를 높일 수 있는지 조사했습니다. 결과적으로 가능했습니다: AI가 생성한 Metal 커널은 215개 PyTorch 모듈에서 평균 1.87배 더 빨랐고, 일부 워크로드는 기준 대비 수백 배 빨랐습니다.
AI 모델은 각 연산을 정의하는 GPU 커널을 통해 하드웨어에서 실행됩니다. 커널의 효율은 모델의 실행 속도(학습과 추론 모두)에 직접적인 영향을 줍니다. FlashAttention1 같은 커널 최적화는 기준 대비 극적인 속도 향상을 보여주며, 고성능 커널의 필요성을 강조합니다.
PyTorch와 torch.compile2 같은 도구가 일부 최적화를 처리하더라도, 마지막 성능 마일은 여전히 수작업으로 다듬은 커널에 달려 있습니다. 이런 커널을 작성하는 일은 어렵고 많은 시간과 전문성이 필요합니다. 특히 CUDA 외의 환경에서 커널을 작성할 때는 상황이 더 까다롭습니다. 비-CUDA 플랫폼 전문가는 드물고, 사용할 수 있는 도구와 문서도 적기 때문입니다.
우리는 간단한 질문으로 출발했습니다. 최전선 모델들이 서로 다른 백엔드 전반에서 커널 최적화를 자동으로 구현할 수 있을까? 수십억 대의 Apple 기기는 Metal 커널에 의존하는데, 이 커널들은 종종 충분히 최적화되어 있지 않습니다. 그래서 Metal부터 시작했습니다.
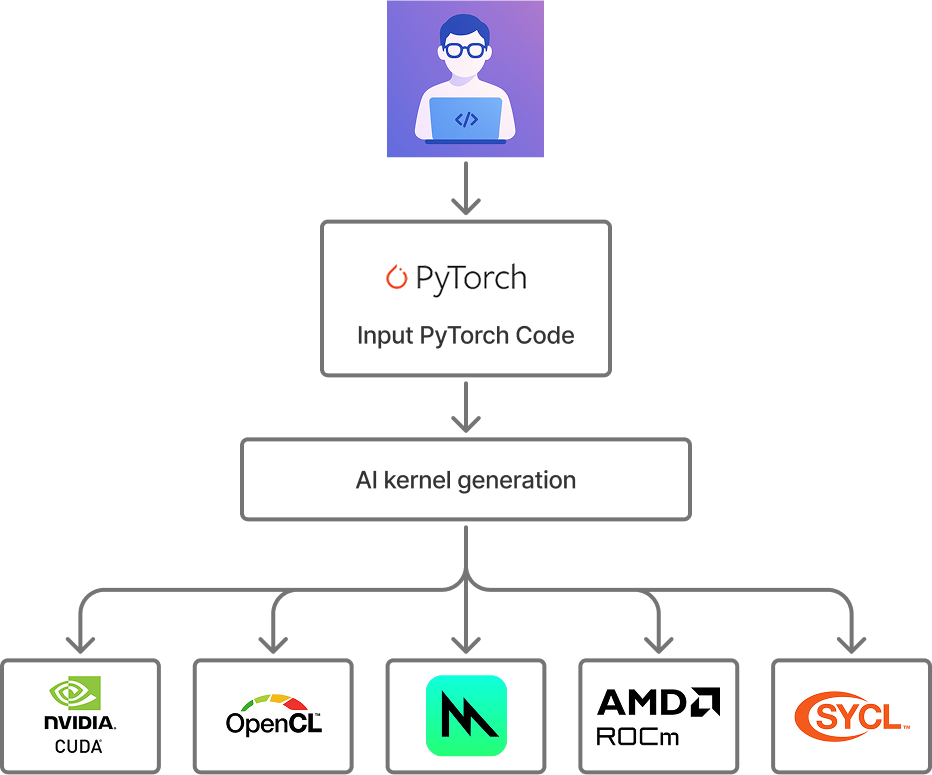
우리의 비전: 최전선 모델을 이용해 어떤 대상 플랫폼이든 자동으로 커널 최적화.
215개 PyTorch 모듈 전반에서, 우리가 생성한 커널은 Apple 하드웨어에서 기준 PyTorch 대비 평균 87% 더 빨랐습니다. 이 접근은 커널 엔지니어링 전문 지식이 필요 없고 거의 즉시 수행할 수 있습니다.
다음은 우리가 발견한 내용의 미리보기입니다.
Anthropic, DeepSeek, OpenAI의 최전선 모델 8개를 포함했습니다:
Anthropic 계열
OpenAI 계열
DeepSeek 계열
테스트 입력으로는 KernelBench3 데이터셋에 정의된 PyTorch 모듈을 사용했습니다. KernelBench에는 다양한 복잡도의 ML 워크로드를 정의하는 250개의 PyTorch 모듈이 있습니다. 이 중 31개 모듈은 현재 MPS(Metal Performance Shaders)용 PyTorch 백엔드에서 지원되지 않는 연산을 포함해 본 분석에서 제외했습니다. (추후 설명할 이유로 4개 모듈을 추가로 제외했습니다.)
| KernelBench 카테고리 | 설명 | 테스트 케이스 수 |
|---|---|---|
| 레벨 1 | 단순 프리미티브 연산(예: 행렬 곱, 합성곱) | 91 |
| 레벨 2 | 레벨 1의 여러 연산 시퀀스 | 74 |
| 레벨 3 | 완전한 모델 아키텍처(예: AlexNet, VGG) | 50 |
에이전트가 생성한 커널을 평가할 때는 기준 PyTorch 구현 대비 정확성과 성능 모두를 확인해야 합니다(작성 시점 기준, Metal에서 torch.compile 지원은 진행 중이라 비교 지점으로 사용할 수 없었습니다. MLX도 Apple 기기에 훌륭한 프레임워크지만, 본 작업은 순수 PyTorch 코드 최적화에 초점을 맞췄으며 MLX는 별도의 프레임워크입니다). 또한 실행 간 캐시를 꼼꼼히 비우도록 주의했습니다. 그렇지 않으면 캐시된 결과가 잘못된 속도 향상처럼 보일 수 있기 때문입니다.
| 실험 변수 | 사양 |
|---|---|
| 하드웨어 | Mac Studio (Apple M4 Max 칩) |
| 모델 | Claude Opus 4, Claude Sonnet, DeepSeek r1, DeepSeek v3, GPT-4.1, GPT-4o, GPT-5, o3 |
| 데이터셋 | KernelBench |
| 기준 구현 | PyTorch eager 모드 |
| 시도 횟수 | 5 |
Metal을 위한 커널 작성 에이전트의 가장 단순한 구현부터 시작했습니다.
재시도 횟수가 늘수록 정확성이 어떻게 증가하는지 보는 것도 흥미롭습니다. 예를 들어 o3는 첫 시도에서 약 60%의 확률로 동작하는 구현을 만들고, 5회 시도 시 94%까지 작동하는 구현을 만듭니다.

o3의 생성 시도 횟수 및 레벨별 성공률. 에이전트의 시도를 5회로 제한했는데, 레벨 1과 2 커널에는 충분해 보입니다. 다만 레벨 3 커널은 더 많은 샷의 이점이 있을 수 있습니다.
8개 모델 각각의 정확성을, 생성 구현이 기준 대비 빠른지 여부로 나누어 살펴봅니다.

최적화된 버전이 기준보다 빠른지 여부에 따른 커널 정확성.
추론 특화 모델들은 레벨 전반에서 올바른 커널을 꽤 잘 생성합니다. 비-추론(비-리저닝) 모델도 때로는 가능하죠. 하지만 GPT-5를 제외하면, 이들 모델이 생성한 구현은 기준 PyTorch보다 느린 경우가 더 많았습니다. 특히 레벨 2 문제에서 GPT-5가 더 빠른 구현을 생성한 점이 두드러집니다.
모든 에이전트가 기준보다 빠른 커널을 일부 만들어냈고, 꽤 멋진 결과도 있었습니다. GPT-5는 Mamba 25 상태 공간 모델에서 4.65배 속도 향상을 냈는데, 주로 커널을 퓨전해 커널 런치 오버헤드를 줄이고 메모리 접근 패턴을 개선한 덕분입니다.
PyTorch 입력
생성된 커널
일부 최적화는 놀라울 만큼 영리했습니다. 한 사례에서 o3는 지연 시간을 9000배 이상 개선했습니다! o3는 코드를 분석해, 모델의 구성 상 결과가 수학적으로 항상 0이 된다는 점을 파악했습니다. 결코 사소한 통찰이 아니었지만, 구현 자체는 자명해졌죠.
레벨 2에서 총 4개 문제는, 가장 최적의 구현이 문제를 자명한 해로 환원할 수 있음을 보여줬습니다. 모델들이 보인 진정한 영리함에도 불구하고, 우리는 이들을 분석에서 제외했습니다. 하지만 실제의 불완전한 코드가 많은 사용 환경에선 이런 종류의 가속 메커니즘이 매우 유용할 것입니다.
PyTorch 입력
생성된 커널
흥미로운 점 하나는, AI가 생성한 커널이 매번 더 빨라야만 유용한 것은 아니라는 것입니다. 오래 도는 워크로드에서는 다양한 구현을 프로파일링하는 것이 합리적이며, 이는 자동화도 가능합니다. 따라서 AI 생성 구현이 가끔이라도 더 빠르다면 가치가 있습니다. 동작하지 않거나 느린 경우에는 언제든 기준 구현으로 폴백하면 되니까요.
이제 8개 에이전트 각각에 대해 기준 대비 평균 속도 향상을 평가해봅시다. 앞선 통찰에 따라, 최소 속도 향상은 항상 1배로 둡니다. 즉, 생성 구현이 동작하지 않거나 기준보다 느릴 때입니다. 평균에는 산술 평균이 아닌 기하 평균을 사용했습니다6.

모델별 평균 속도 향상(레벨별 분해).
GPT-5를 사용하면 평균 약 20%의 속도 향상을 얻고, 다른 모델들은 그보다 뒤처지는 것을 볼 수 있습니다. 한 가지 결론은 이렇게 낼 수 있겠습니다. 커널 생성에는 GPT-5를 쓰자, 가능하다면 약간의 추가 문맥을 제공하자. 이는 모든 모델이 비슷하게 동작한다면 타당합니다. 즉, 일정한 문제 집합에서 대체로 같은 최적화를 찾아내고, 다른 문제들에선 일관되게 실패한다면요.
하지만 데이터는 그렇게 말하지 않습니다! 어떤 모델이 문제별로 최고 성능을 냈는지로 나누어보면, GPT-5가 34%의 문제에서 최고 해를 냈지만, 나머지 약 30%의 문제에서는 다른 모델이 GPT-5보다 더 좋은 해를 냈습니다!

문제 레벨 전반에서, 어떤 모델이 최고 성능(혹은 어떤 모델도 기준을 넘지 못했을 경우 기준 성능)을 냈는지 보여줍니다.
여기서 핵심 인사이트가 나옵니다. 커널 생성에는 "Best of N" 전략을 써야 합니다. 추가 생성 패스는 상대적으로 저렴하고, 비싼 것은 사람의 노력과 배포 후 모델의 실행 시간입니다.
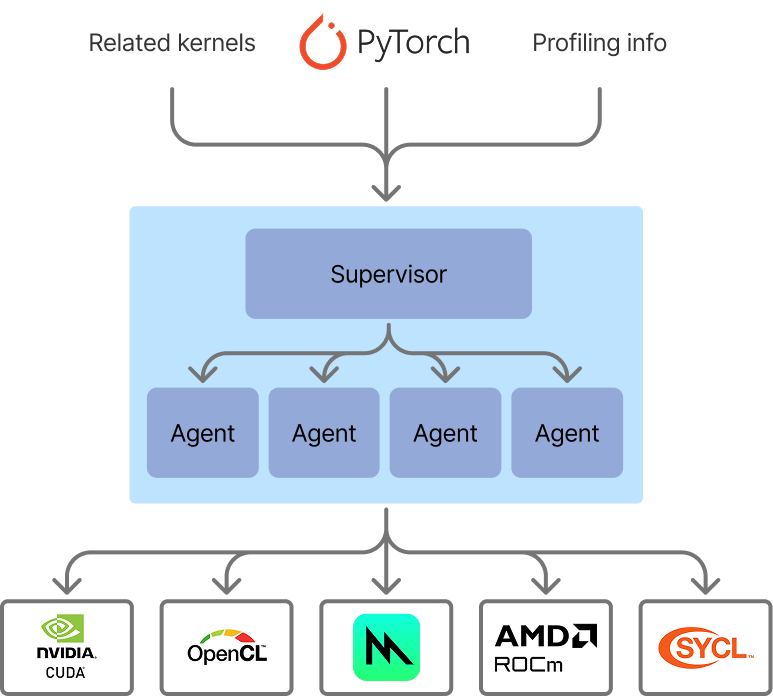
이제 최적화된 커널 생성 흐름은 에이전틱 스웜처럼 보입니다. 우리는 감독자(supervisor)를 두었고, 현재는 단순합니다. 감독자는 모든 에이전트가 생성한 커널을 평가하여 기준 대비 시간을 재고, 해당 문제에 대한 최적 구현을 선택합니다. 기준 대비로 시간과 정확성을 즉석에서 검증할 수 있다는 점이 커널 생성을 AI 생성에 아주 잘 맞는 후보로 만들어줍니다. 다른 코드 생성 과제들보다 훨씬 편리하죠. 최소한의 감독으로도 결과를 즉시 평가할 수 있으니까요.
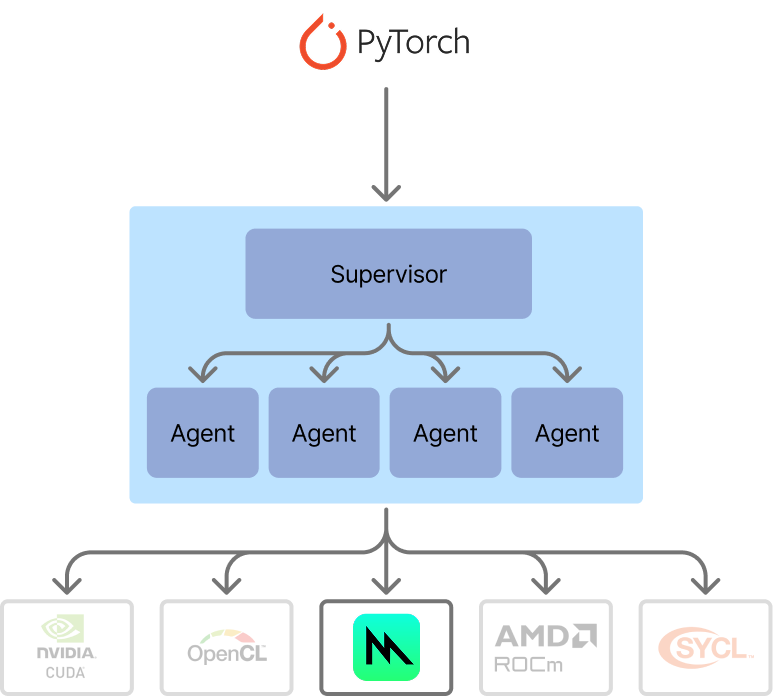
커널 생성을 위한 에이전틱 스웜 아키텍처. 이번 반복에서는 감독자가 단순하지만, 다음 작업에서는 더 유연하게 확장할 예정입니다.
이제 앞서의 단독 모델 성능과 비교해 에이전틱 스웜의 성능을 보겠습니다.

커널 생성을 위한 초기 에이전틱 스웜 구현의 성능으로, 단독 에이전트 대비 크게 개선된 결과를 보여줍니다.
이 접근은 GPT-5보다도 더 좋은 결과를 냅니다. 전 레벨 평균 31% 가속, 레벨 2 문제에서는 42% 가속입니다. 에이전틱 스웜은 입력 문제와 프롬프트라는 최소한의 문맥만으로도 꽤 잘해내고 있습니다. 다음으로, 더 빠른 커널을 얻기 위해 에이전트들에게 더 많은 문맥을 제공해 보았습니다.
사람 커널 엔지니어가 수작업 커널의 성능을 높일 때 필요로 하는 정보는 무엇일까요? 두 가지 핵심 소스가 떠오릅니다. 다른 최적화된 레퍼런스 구현, 그리고 프로파일링 정보입니다.
이에 따라, Metal 커널 생성을 할 때 에이전트가 두 가지 부가 정보를 입력으로 받을 수 있게 했습니다.
불행히도 Apple은 Xcode를 통해 Metal 커널 프로파일링 정보를 프로그래밍적으로 쉽게 추출할 수 있게 해주지 않습니다… 그래서 창의적으로 접근해야 했습니다.
우리는 Bluem의 cliclick 도구를 사용해 Xcode의 GUI와 상호작용함으로써 문제를 해결했습니다. 우리의 Apple Script는 수집된 각 gputrace에 대해 요약, 메모리, 타임라인 뷰를 캡처합니다.
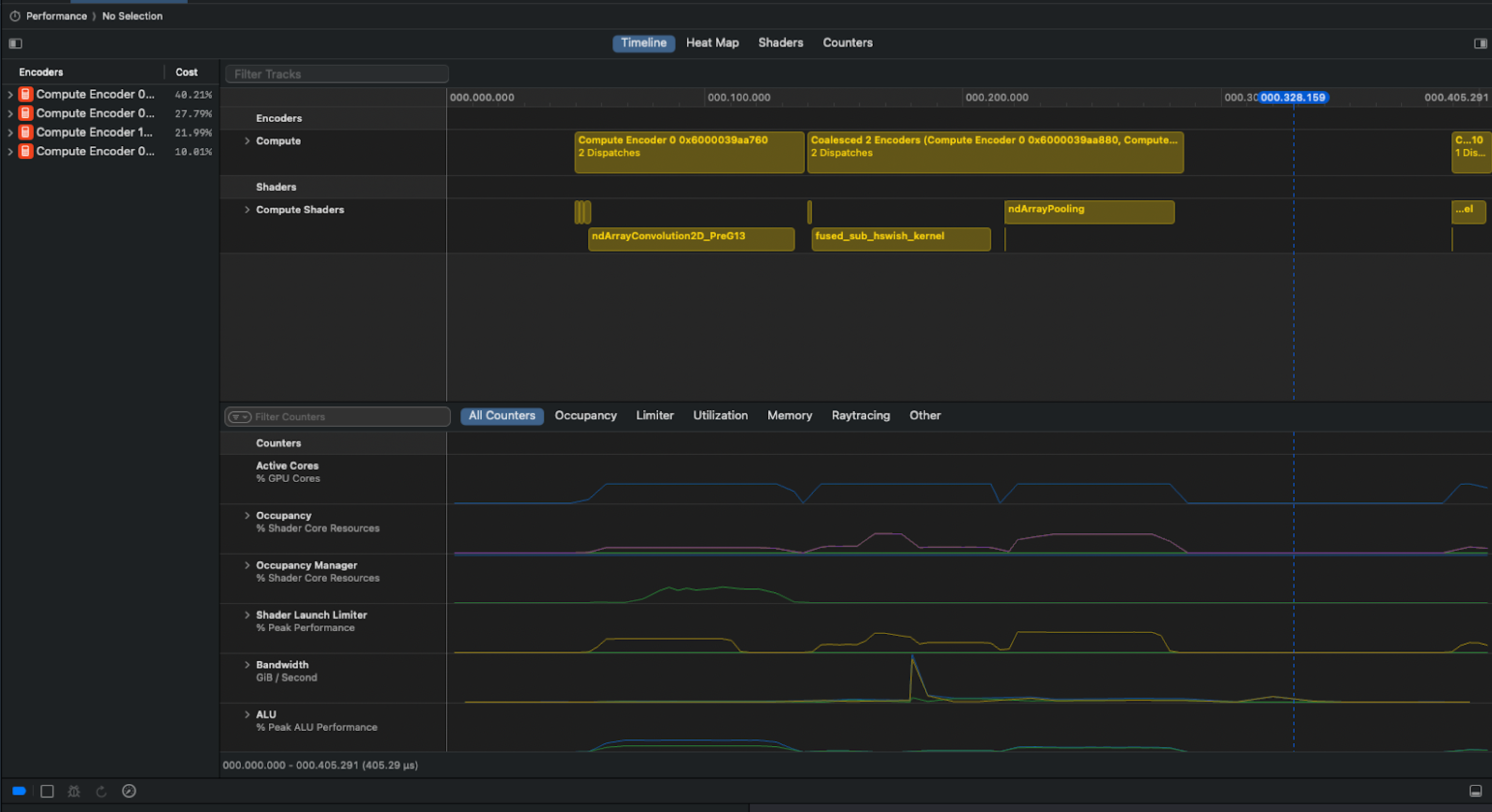
분석에 사용된 Xcode 예시 스크린샷. 위 스크린샷에서 ndArrayPooling 이후에 명확한 파이프라인 버블이 있어 유휴 시간이 발생하는 것을 볼 수 있습니다.
프로파일링 정보는 멀티모달 입력을 지원하는 모델에만 추가할 수 있었습니다. 우리는 스크린샷 처리를 서브에이전트로 분리했고, 그 역할은 메인 모델에 성능 최적화 힌트를 제공하는 것이었습니다. 메인 에이전트는 초기 구현을 만든 뒤 프로파일링과 타이밍을 수행했고, 스크린샷은 서브에이전트에 전달되어 성능 힌트를 생성했습니다. 최대 시도 횟수는 이전과 동일하게 총 5회로 유지했습니다.
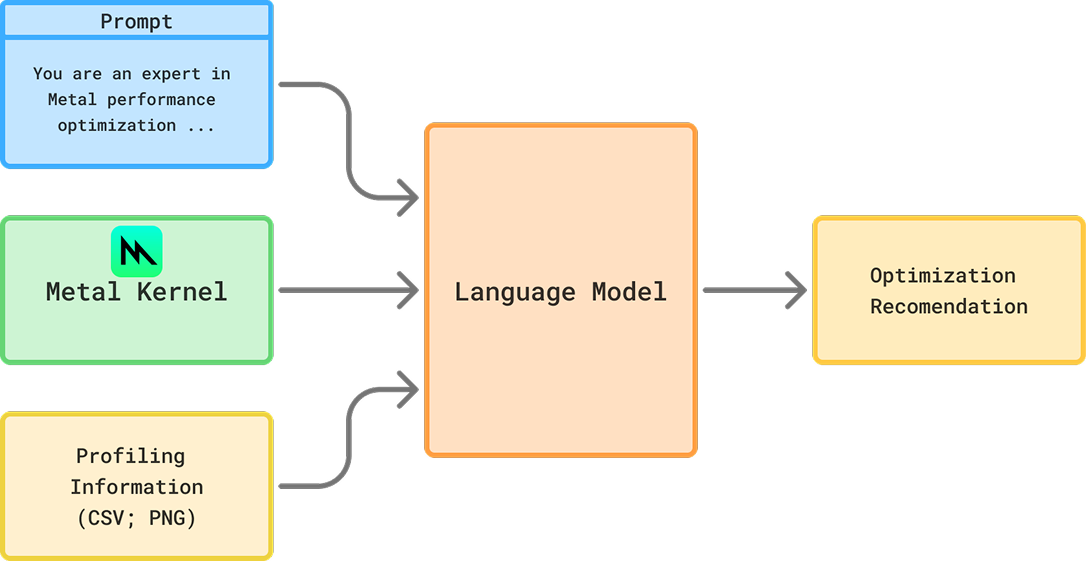
서브에이전트 아키텍처
앞서 문제에 따라 최적 모델이 달랐던 것처럼, 문맥 구성에서도 "단 하나의 최적"은 없었습니다. 때로는 CUDA 레퍼런스 코드나 프로파일링 정보 중 하나만 추가해도 최고 결과가 나왔고, 다른 경우에는 둘 다 추가하는 것이 도움이 됐습니다. 심지어 아무런 추가 문맥이 없는 순정 에이전트가, 더 많은 문맥을 받은 에이전트보다 더 잘한 사례도 있었습니다!

문제 레벨별 최적 에이전트 문맥 구성. 이제 기준 PyTorch가 최적 생성 커널보다 우월한 경우는 약 8%에 불과합니다.
결과는 특히 레벨 2 커널에서 두드러집니다. 우리의 평가는 레벨 2 커널이 레벨 1보다 퓨전의 이점을 더 많이 받기 때문입니다. 반면 레벨 3는 단일 패스로 생성하기에는 너무 복잡할 수 있습니다. 에이전트가 다룰 수 있도록 문제를 더 관리 가능한 덩어리로 분해하는 개선을 곧 공유하겠습니다.
그럼에도 레벨 3에서도 좋은 커널이 있었습니다. DeepSeek-R1은 VisionAttention 문제에서 고급 퓨전 기법으로 기본 구현을 개선했고, Metal 고유의 기능을 이해해 스레드그룹을 활용, 더 효율적인 공유 메모리를 구현했습니다. 여전히 추가 최적화 여지가 있지만, 이 구현은 기준 PyTorch 대비 18배 이상 빨랐습니다!
PyTorch 입력
생성된 커널
이제 에이전틱 스웜의 성능을 평가해봅시다. 이전에는 모든 최전선 모델에 대해 Best of N 분석을 했습니다. 이제는 각 최전선 모델의 다양한 구성(CUDA만, CUDA+프로파일링 등)에 대해 Best of N 분석을 합니다. 여러 후보 구현을 생성해 성능을 테스트하는 일은, 인간 전문가가 수작업으로 코드를 작성하거나 덜 최적화된 모델을 대규모로 운영하는 것보다 훨씬 "저렴"합니다. 따라서 스웜에게 더 많은 생성을 위임해 눈에 띄는 개선을 얻을 수 있다면 충분히 가치가 있습니다.

Metal 대상 문제에서 커널 생성을 수행한 전체 에이전틱 스웜의 전반 성능.
이는 훌륭한 가속입니다. 순수 PyTorch 코드로부터 거의 즉시, 기준 대비 평균 1.87배 더 빨라졌습니다. 순정 에이전트만 사용했을 때는 평균 1.31배였으므로, 이 추가 문맥 덕에 개선 폭이 거의 3배 커졌습니다!
개선의 분포를 보면, 중앙값 속도 향상은 약 1.35배였고, 2개의 커널은 원래 구현보다 수백 배 더 빨랐습니다. (앞서 언급했듯, 불필요한 작업을 제거해 수천 배 빨라진 "자명한" 4개 커널은 제외했습니다.)

에이전틱 스웜의 속도 향상 분포(총 215개 문제, 큰 가속을 보인 자명한 4개 커널 제외). 중앙값 1.35배, (기하)평균 1.87배, 2개 커널은 100배 이상 가속.
이 결과는 사용자 코드 변경, 새 프레임워크 도입, 포팅 없이도, 커널 최적화를 자동화해 모델 성능을 자동으로 크게 개선할 수 있음을 보여줍니다.
AI는 인간 커널 엔지니어가 수행하던 최적화 작업의 일부를 맡아, 인간의 노력을 가장 복잡한 최적화에 집중할 수 있도록 해줍니다.
곧 개발자들은 저수준 전문 지식 없이, 순수 PyTorch를 벗어나지 않으면서, AI 생성 커널을 통해 즉각적인 성능 향상을 얻을 수 있을 것입니다.
우리는 이 기법으로 더 멀리 나아가기 위해 노력하고 있습니다. 더 똑똑한 에이전틱 스웜, 더 나은 문맥, 에이전트 간 협업 강화, 더 많은 백엔드(ROCm, CUDA, SYCL 등). 또한 추론뿐만 아니라 학습 워크로드 가속도 추진 중입니다.
이 기법을 통해 새로운 모델은 출시 첫날부터 모든 플랫폼에서 훨씬 더 빨라질 수 있습니다. 이 방향이 흥미롭다면, 연락 주세요: hello@gimletlabs.ai.
이 기법을 사용하면 어떤 대상 플랫폼에서도 커널을 자동으로 가속할 수 있습니다.
Tri Dao, Daniel Fu, Stefano Ermon, Atri Rudra, 그리고 Christopher Ré. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. NeurIPS 2022. ↩
Jason Ansel, Shunting Jain, Amir Bakhtiari, et al. PyTorch 2: Faster Machine Learning Through Dynamic Python Bytecode Transformation and Graph Compilation. ASPLOS 2024. ↩
Anne Ouyang, Simon Guo, Simran Arora, Alex L. Zhang, William Hu, Christopher Ré, 그리고 Azalia Mirhoseini. KernelBench: Can LLMs Write Efficient GPU Kernels? ICML 2025. ↩
생성된 커널의 출력을 기본 구현의 출력과 100개의 무작위 입력에 대해 비교했습니다. 상대 오차와 절대 오차의 허용치는 0.01로 설정했습니다. 생성 커널 출력 a, 기준 커널 출력 b에 대해, 출력의 모든 원소가 absolute(a - b) ≤ (atol + rtol * absolute(b))를 만족하면 동일하다고 보았습니다. ↩
Tri Dao & Albert Gu, Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality. (ICML 2024) ↩
속도 향상 비율을 평균낼 때 산술 평균은 낙관적 오류가 생깁니다. 어떤 작업을 2배 빠르게 했다가 다시 2배 느리게 했다고 합시다. 이는 각각 2.0과 0.5의 속도 향상입니다. 산술 평균은 단순히 (2+0.5)/2 = 1.25로, 마치 빨라졌다고 말하지만 실제론 제자리입니다. 기하 평균은 속도 향상이 1.0(변화 없음)이라고 정확히 말해줍니다. ↩