Fully Sharded Data Parallel(FSDP)의 동작 원리를 4개 GPU 예제로 단계별로 추적하고, PyTorch FSDP2와 Ray Train으로 ViT 학습 및 Qwen3-TTS(1.7B) 음성 클로닝 파인튜닝까지 구현한다.
몇 달 전, 저는 분산 학습(distributed training)에 대해 정리한 내용을 이 글에 적었습니다. 그 글에서는 단일 GPU 병목부터 데이터 병렬성(Data Parallelism), 그리고 ZeRO 최적화 단계까지 기본기를 다뤘습니다. 또한 메모리 제약이 단일 GPU에서 학습 가능한 모델 크기를 어떻게 제한하는지, 그리고 샤딩(sharding) 전략이 이러한 한계를 어떻게 극복하는지 살펴봤습니다.
이번 글에서는 Fully Sharded Data Parallelism(FSDP) 를 깊게 파고들어 보겠습니다. 4개의 GPU를 사용하는 구체적인 예시로, 한 번의 학습 이터레이션(훈련 반복)을 단계별로 따라가며 각 단계에서 모델 파라미터, 그라디언트, 옵티마이저 상태가 정확히 어떻게 변하는지 추적합니다. 글을 다 읽고 나면, FSDP가 어떻게 놀라운 메모리 효율을 달성하는지에 대한 선명한 멘탈 모델을 갖게 될 것입니다.
FSDP 내부를 제대로 이해한 다음에는, PyTorch의 FSDP와 Ray Train을 사용해 이를 실제로 적용해 보겠습니다. 먼저 FashionMNIST에서 Vision Transformer를 학습하고, 이후 알리바바가 최근 공개했고 Hugging Face에서도 제공되는 17억(1.7B) 파라미터의 Qwen3-TTS 모델을 파인튜닝하여, 내 목소리를 클로닝(voice cloning)하는 과정까지 진행합니다.
Note Prerequisites
이 글은 이전의 분산 학습 글에서 다룬 개념을 바탕으로 합니다. 다음 항목들에 익숙해야 합니다.
ZeRO-1, ZeRO-2, ZeRO-3 샤딩 전략All-Reduce, All-Gather, Reduce-Scatter낯선 개념이 있다면 먼저 분산 학습 기초 글을 읽는 것을 권합니다.
이전 글에서 ZeRO(Zero Redundancy Optimizer) 가 GPU들 사이에 모델 상태를 점진적으로 샤딩하는 방식을 살펴봤습니다.
| Strategy | What’s Sharded | Memory per GPU |
|---|---|---|
| DDP | 없음(각 GPU에 전체 모델 복사본) | |
| ZeRO-1 | 옵티마이저 상태 | |
| ZeRO-2 | 옵티마이저 상태 + 그라디언트 | |
| ZeRO-3 / FSDP | 옵티마이저 상태 + 그라디언트 + 파라미터 |
FSDP 는 PyTorch의 네이티브 fully sharded data parallel 학습 구현으로, ZeRO-3 단계와 매우 유사합니다. FSDP는 parameters, gradients, optimizer states로 구성된 모든 모델 상태를 데이터 병렬 워커들 전체에 걸쳐 샤딩하여, 이 텐서들에 대해 이론적으로 가능한 GPU당 최소 메모리 사용량을 달성합니다.
그런데 실제로는 어떻게 동작 할까요? parameters가 여러 GPU로 흩어져 있을 때, 각 GPU는 어떻게 forward pass를 수행할 수 있을까요? FSDP로 들어가기 전에, 여러 GPU에 큰 모델을 나누어 올리는 “당연해 보이는” 해결책이 왜 실패하는지 먼저 이해해 봅시다.
모델이 단일 GPU에는 안 들어가지만 4개 GPU에 나누면 들어간다고 합시다. 순진한 접근은 파이프라인 스타일의 순차 실행입니다. 예를 들어 Transformer 계열 12개 레이어 모델에서 레이어 1-3은 GPU0, 4-6은 GPU1, 7-9는 GPU2, 10-12는 GPU3에 두는 방식입니다. 그러면 forward와 backward 파이프라인은 다음과 같습니다.
단일 배치에 대해 forward pass 동안(T1~T4) 한 번에 한 GPU만 활성화되고 나머지는 놀게 됩니다.
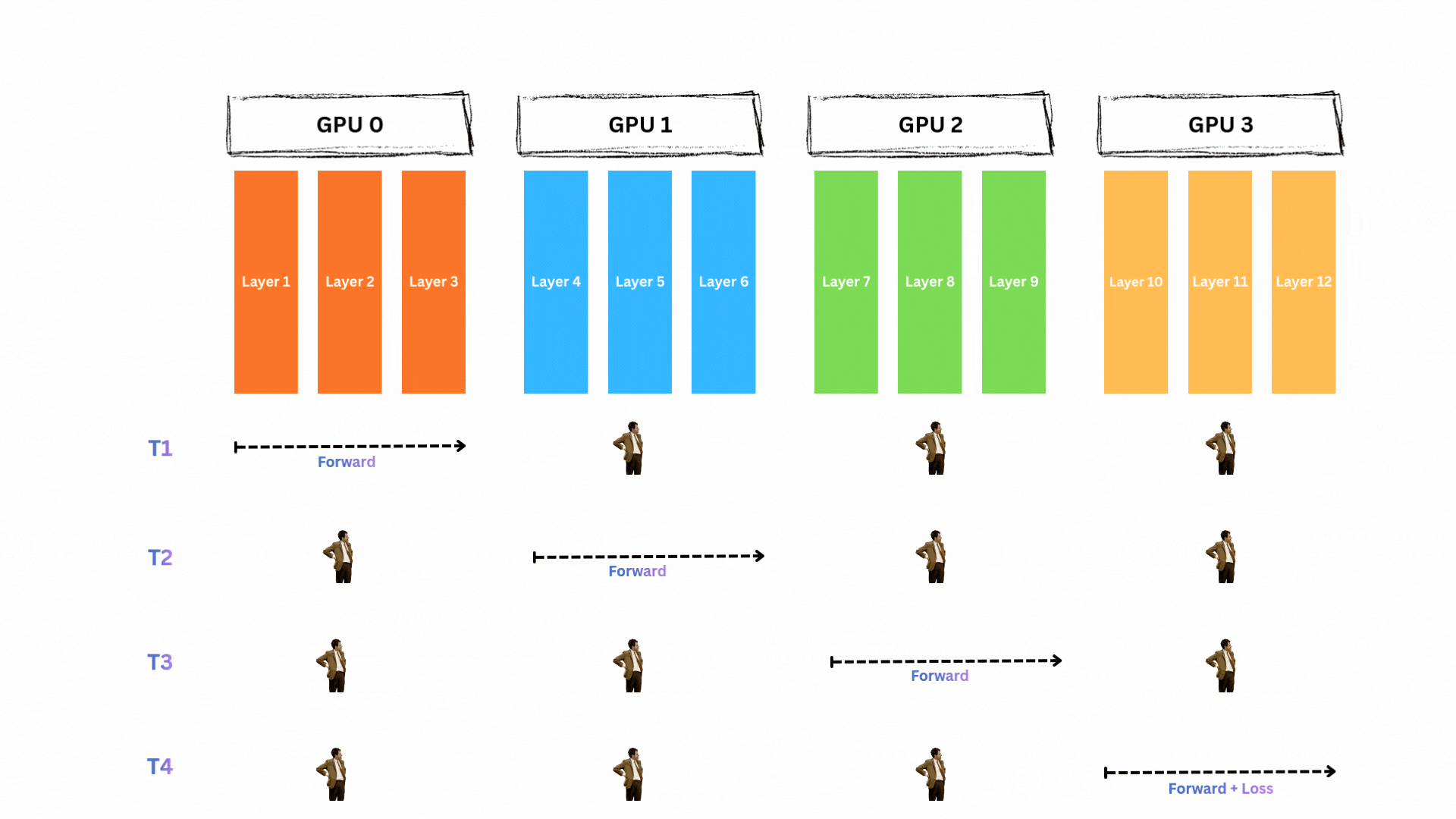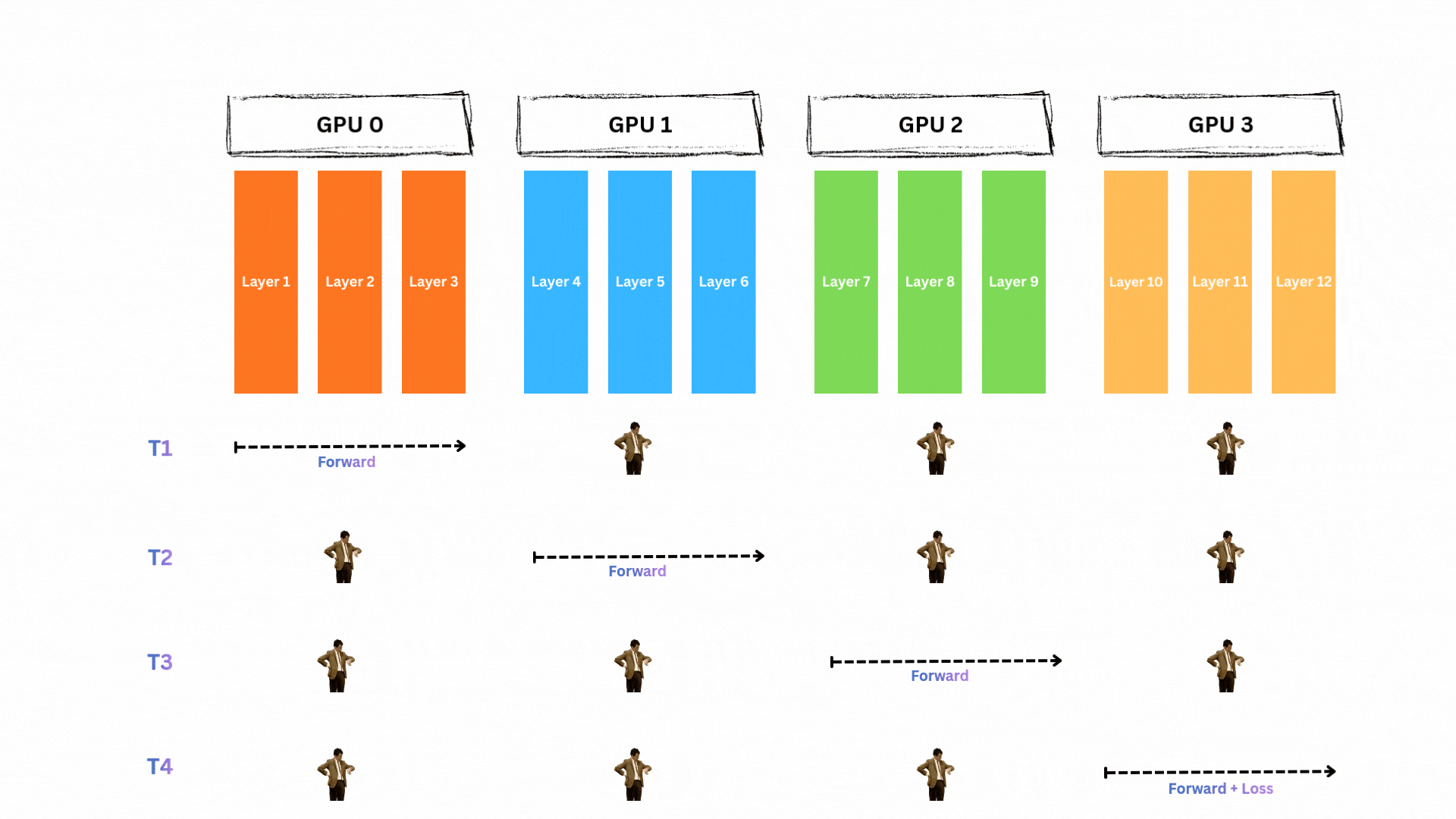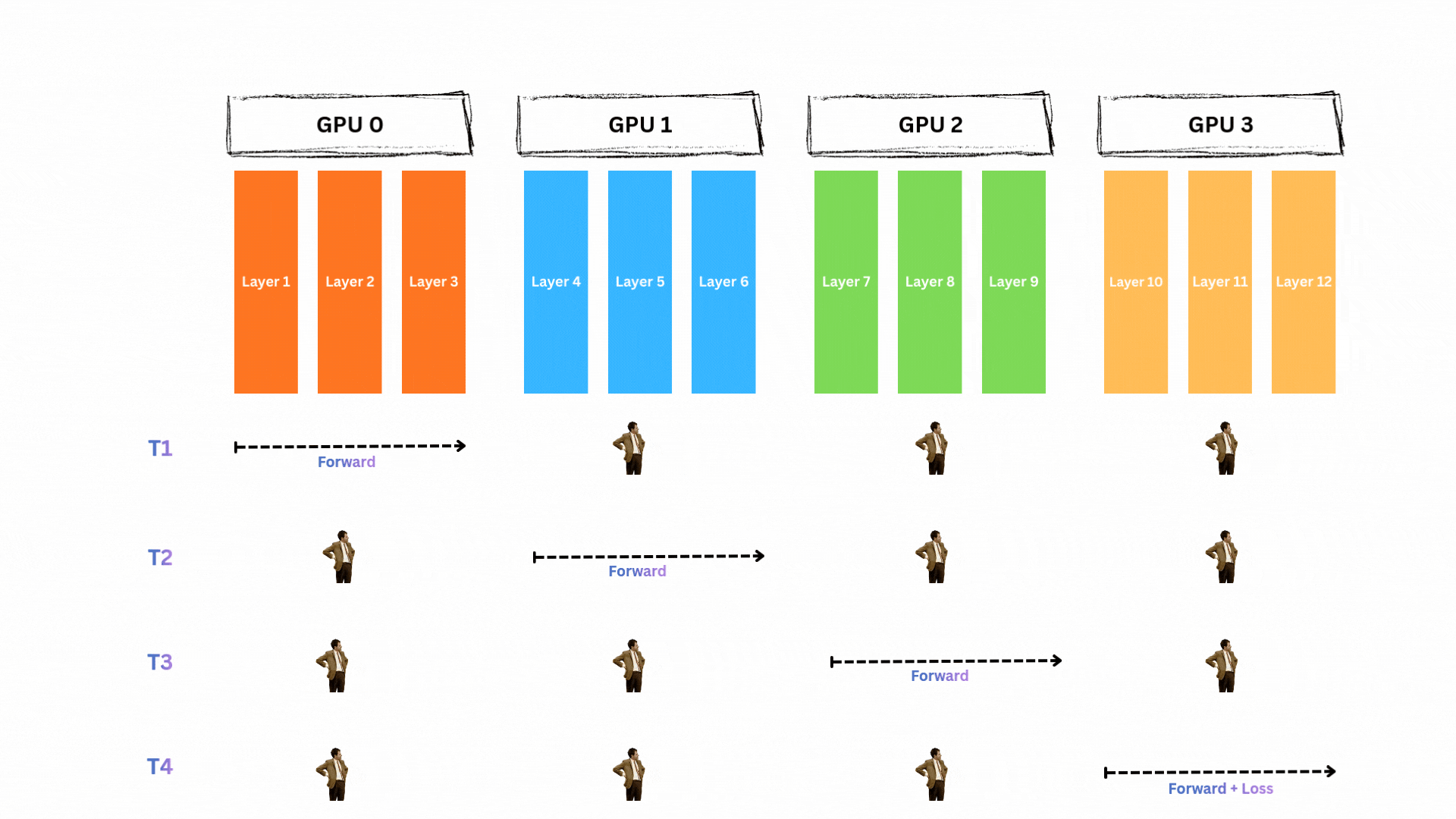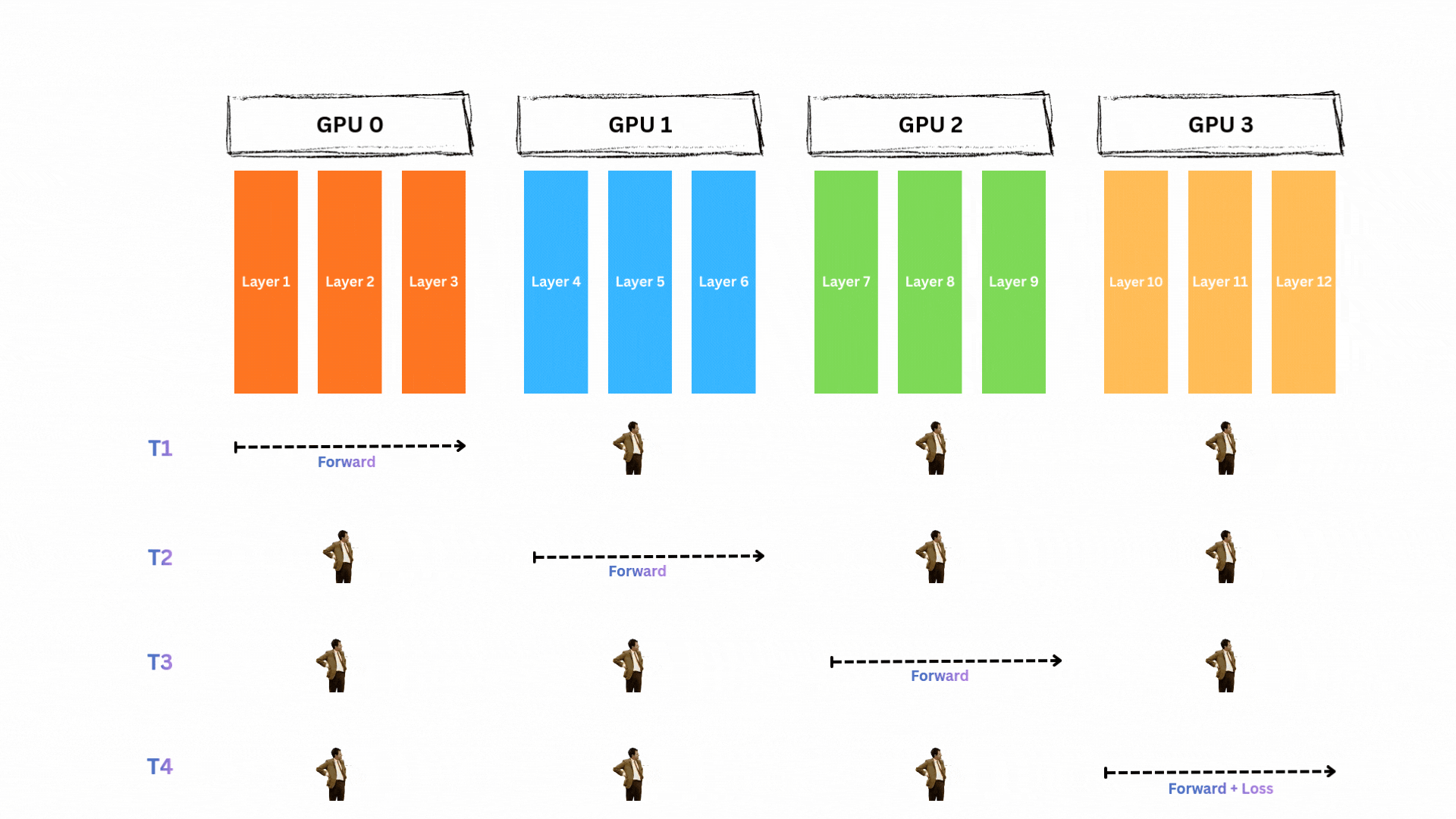
backward pass도 동일합니다(T5~T8).
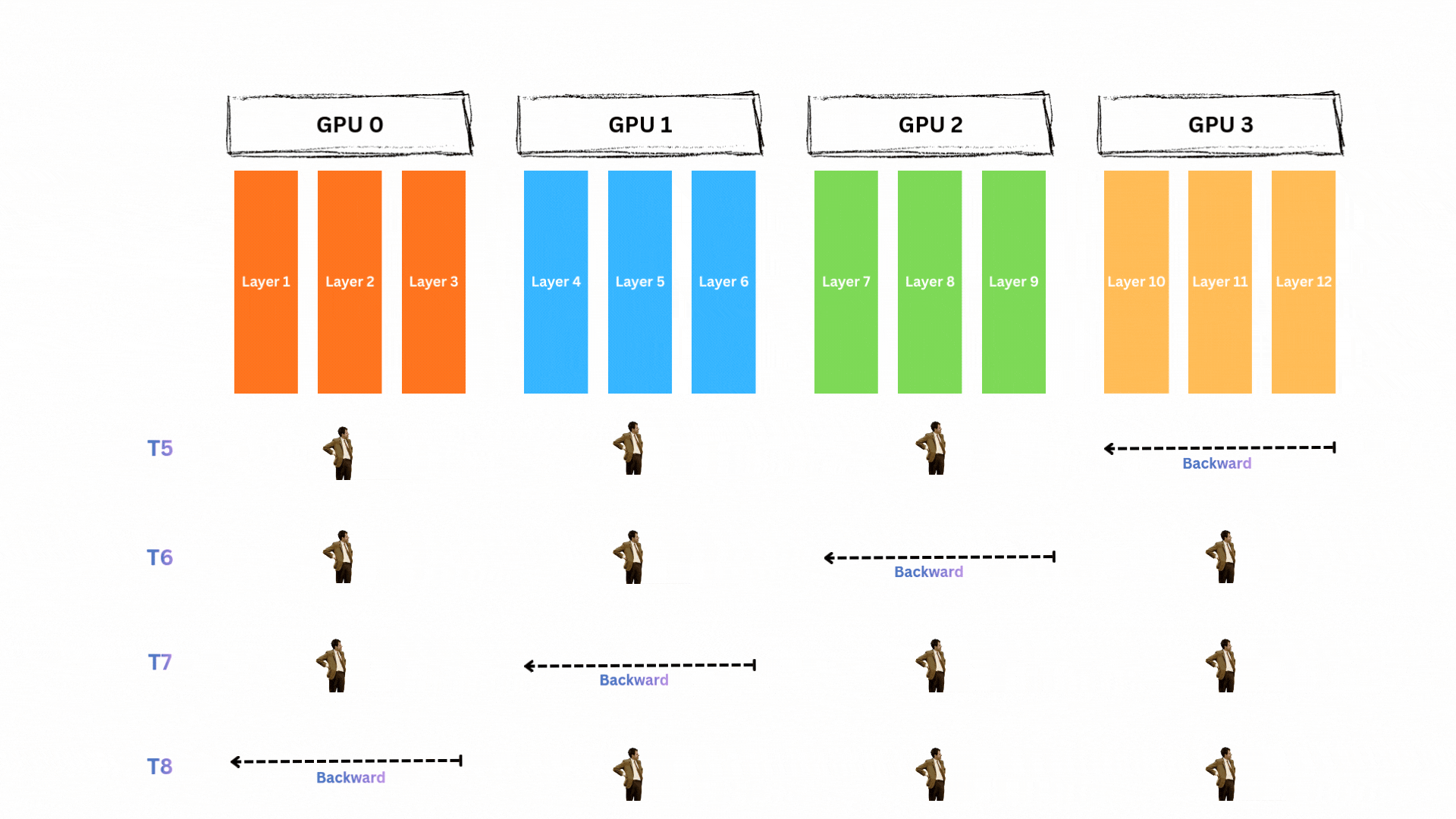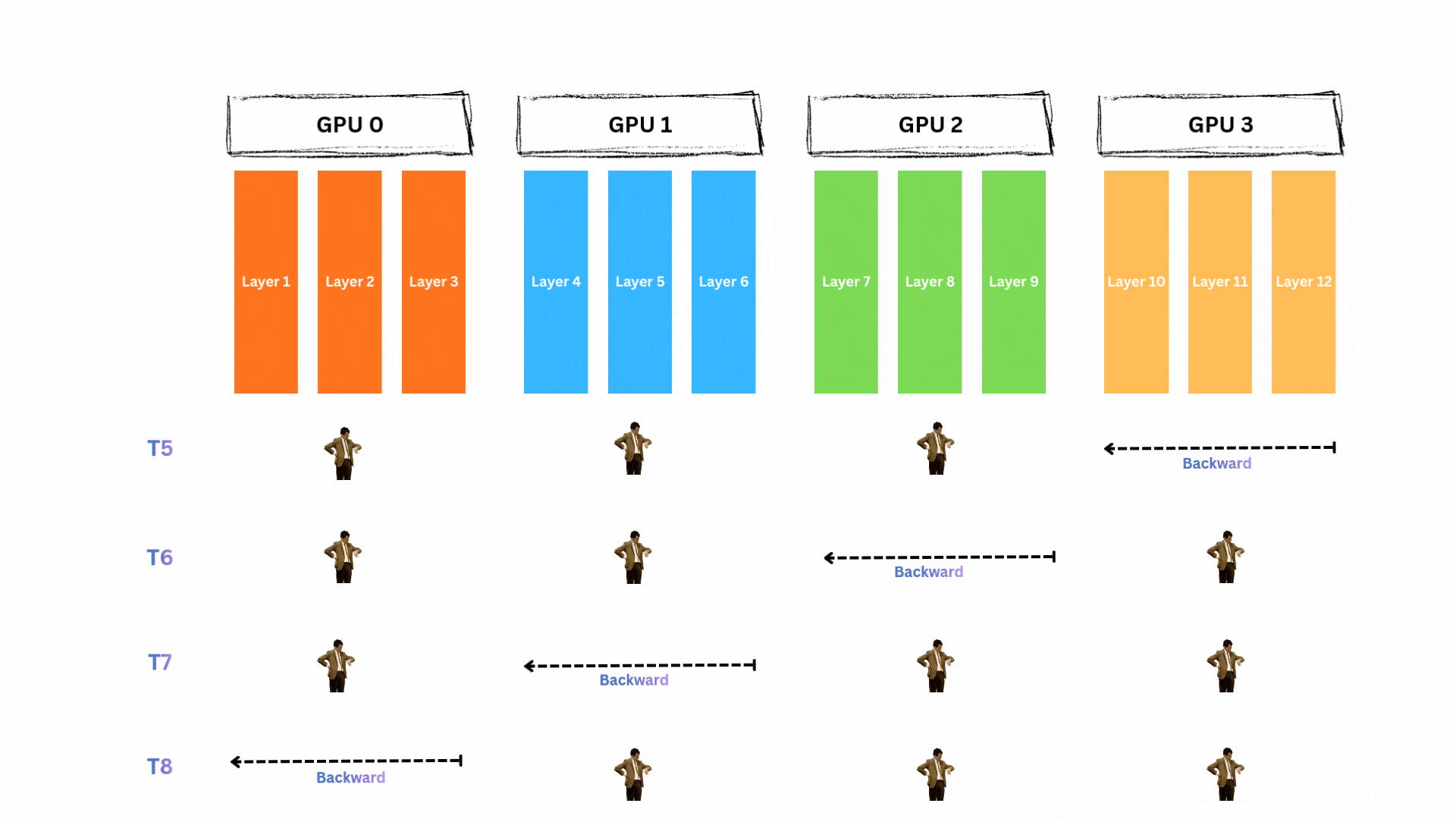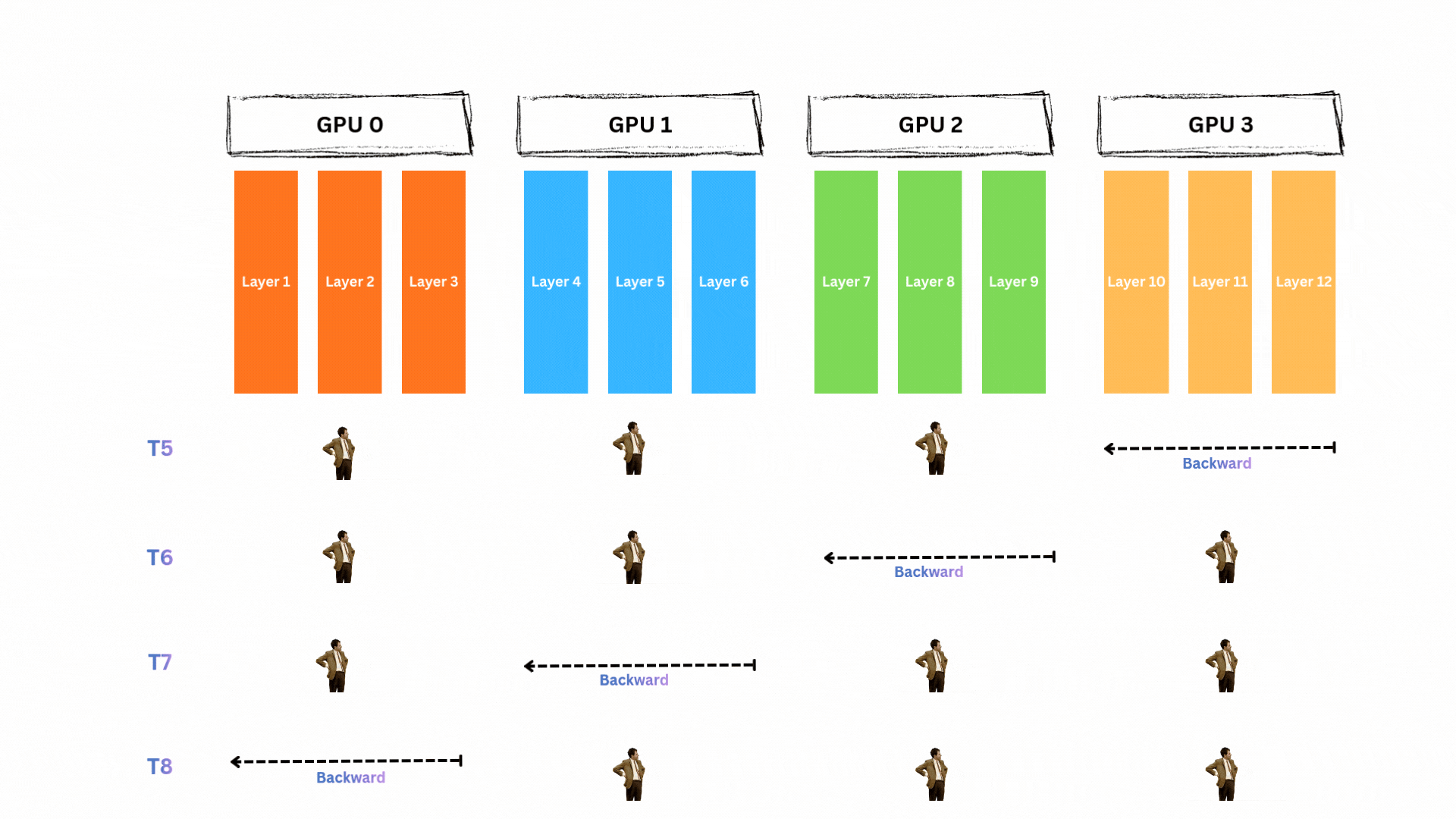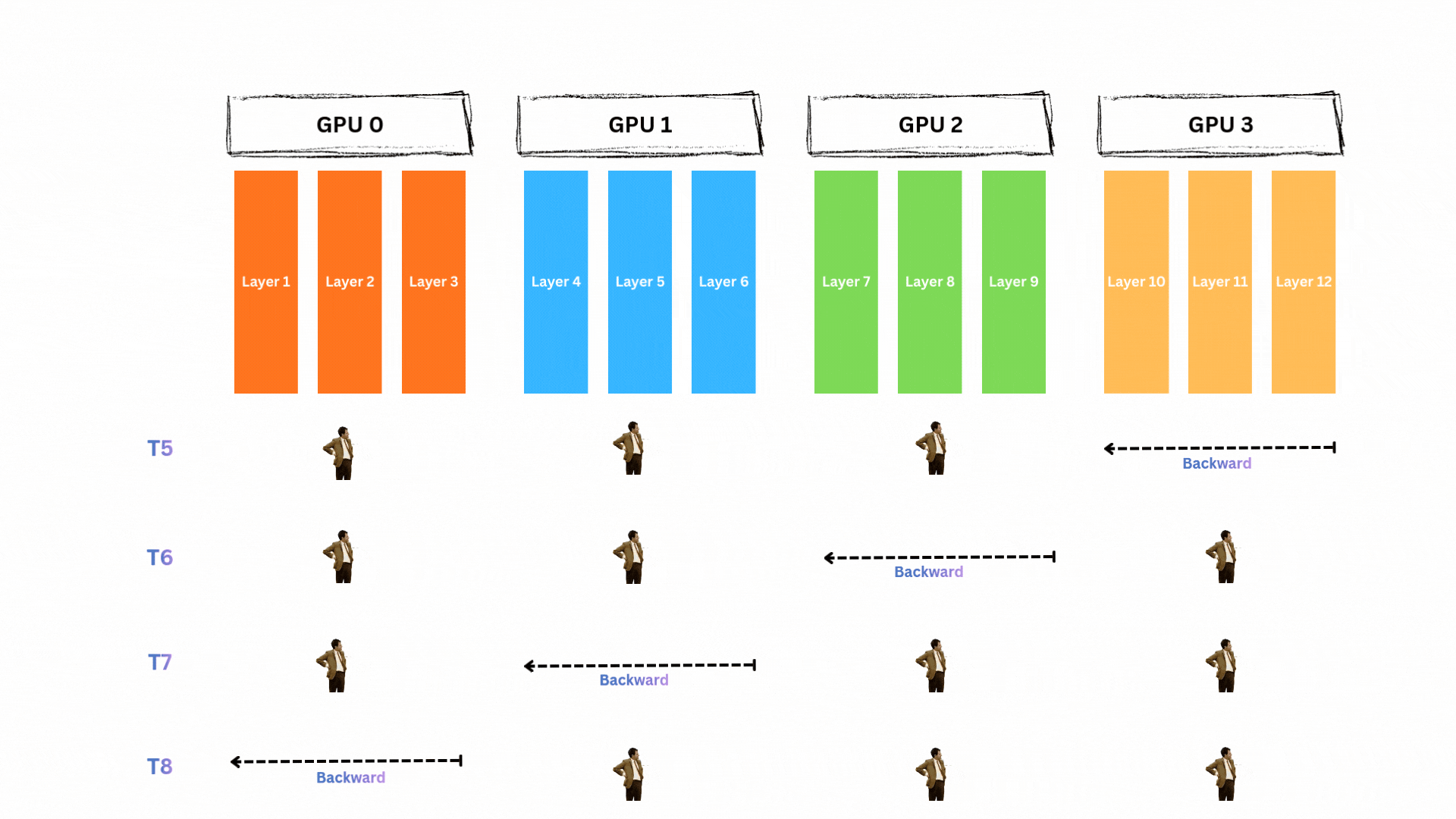
막대한 GPU 유휴 시간
자세히 보면 GPU0는 무려 6 타임스텝 동안 기다리기만 합니다! 각 GPU는 대략 75%의 시간 동안 놀게 됩니다. 모델을 GPU들에 나눠 놓기는 했지만 대부분의 시간에 각 GPU는 아무 것도 하지 않고 대기합니다. 이는 계산 자원의 엄청난 낭비입니다.
Note
“Batch 1이 진행되는 동안 Batch 2의 forward를 시작하면 되지 않나요?”라고 생각할 수 있습니다.
불행히도, 안 됩니다. 현재 배치의 가중치가 업데이트되기 전에는 다음 forward pass를 시작할 수 없습니다. GPU0는 다음 배치를 처리하기 전에 전체 forward-backward 사이클이 끝날 때까지 기다려야 합니다.
FSDP는 이 문제를 우아하게 해결하여, 하나의 일관된 모델을 학습하면서도 모든 GPU가 서로 다른 배치를 동시에 처리하게 만듭니다. FSDP는 메모리 효율과 GPU 활용률을 모두 확보하기 위해 서로 직교하는 두 가지 분할 전략을 결합합니다.
units로 구성parameters, gradients, optimizer states를 모든 GPU에 걸쳐 샤딩이제 글 전체에서 계속 추적할 구체적인 시나리오를 설정해 보겠습니다. 여기서의 초점은 모델 학습 자체나 정확도가 아니라, FSDP 내부 동작을 이해하는 것입니다.
12 layers의 간단한 Transformer-style 모델과 4 GPUs를 사용하고, 각 GPU는 16 GB 메모리를 갖습니다.
모델의 메모리 요구량은 대략 다음과 같습니다.
| Component | Memory Required |
|---|---|
| Model Parameters (MP) | 8 GB |
| Gradients (GRD) | 8 GB |
| Optimizer State (OS) | 16 GB |
| Total Static Memory | 32 GB |
Note Why 16 GB for Optimizer State?
여기서는 Adam 옵티마이저를 가정합니다. 옵티마이저 상태(OS)는 각 파라미터에 대해 FP32 텐서 2개(1차 모멘트, 2차 모멘트)를 유지합니다. FP32 파라미터가 8GB이면 옵티마이저 상태는 대략 16GB가 됩니다.
4개의 GPU가 있고, 각 GPU는 16 GB 메모리를 갖습니다.
문제는 명확합니다: 정적 메모리만 32GB가 필요하니 어떤 단일 16GB GPU에도 들어가지 않습니다. 하지만 4개 GPU를 합치면 총 64GB이므로, 효과적으로 분산만 할 수 있다면 충분합니다.
따라서 어떻게든 4개 GPU로 이 모델을 학습할 수 있어야 합니다(효과적인 분산만 찾으면).
그리고 여기서는 활성화값(activations)을 고려하지 않고 있습니다. 활성화값은 보통 파라미터와 그라디언트보다 훨씬 커서 동적 메모리 제약(Dynamic Memory Constraints)에 해당합니다.
맥락상, 이 글의 나머지 부분에서 입력 데이터도 활성화값으로 취급해도 됩니다. 단지 1번째 레이어의 활성화값을 input이라고 부르는 것뿐입니다.
이제 4개 GPU에서 모델 학습을 효율적으로 수행하도록 분산하는 방법을 봅시다. GPU에서 메모리를 가장 많이 먹는 것은 파라미터와 활성화값(입력 포함)입니다. 그래서 먼저 데이터셋을 처리하겠습니다.
훈련 데이터를 GPU별로 하나씩, 4개의 서로 다른 미니배치로 나눕니다.
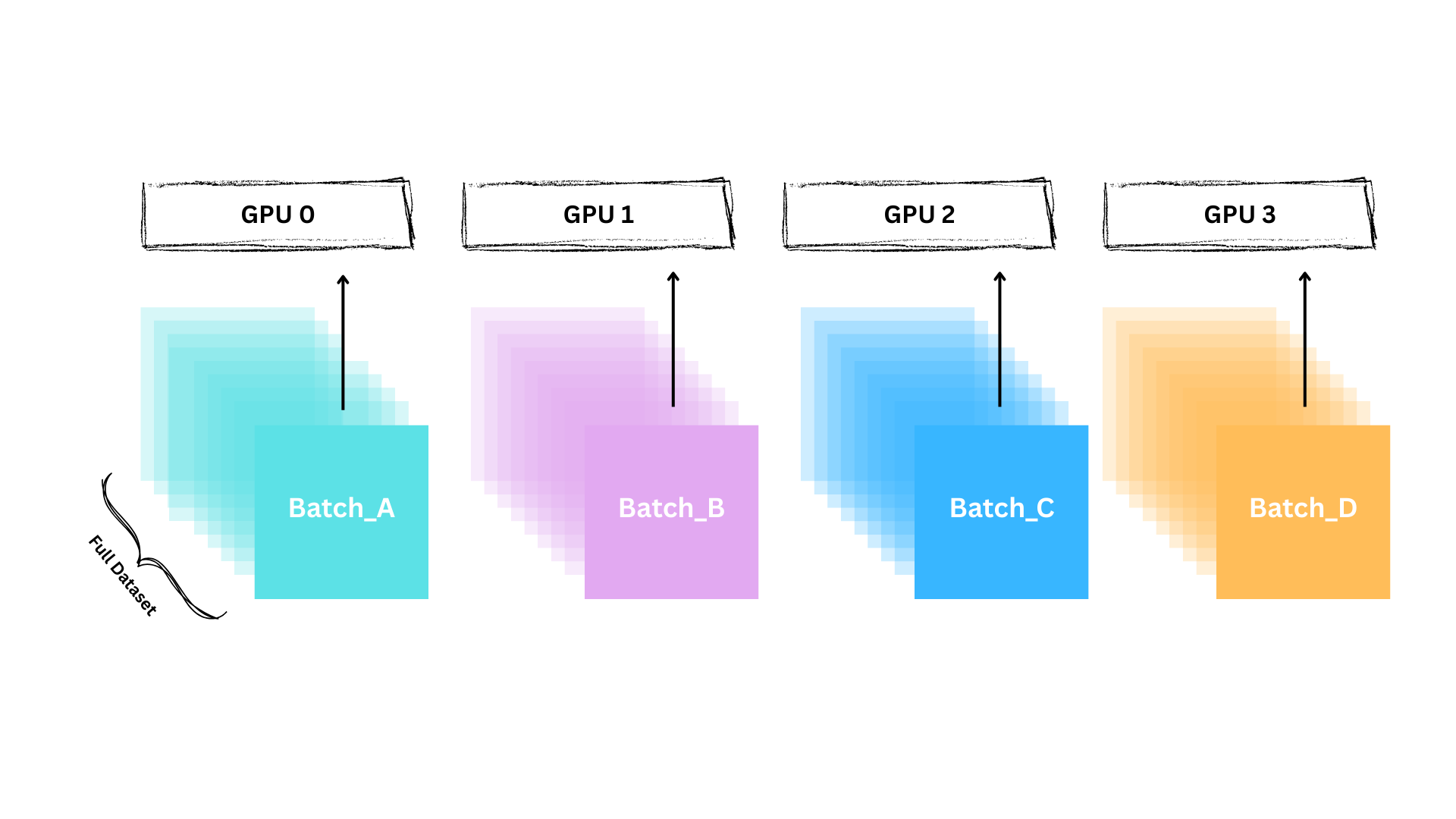
각 GPU는 동시에 자신의 배치를 처리하며, 같은 모델 가중치를 사용합니다. 여전히 본질은 데이터 병렬성이지만, 차이는 가중치를 저장/관리하는 방식입니다.
FSDP는 메모리 효율과 GPU 활용률을 모두 얻기 위해 서로 직교하는 두 가지 분할 전략을 결합합니다.
모델 레이어를 unit으로 묶습니다. 모델이 12개 레이어이므로, 3개 레이어씩 관리하는 4개 unit으로 구성할 수 있습니다.
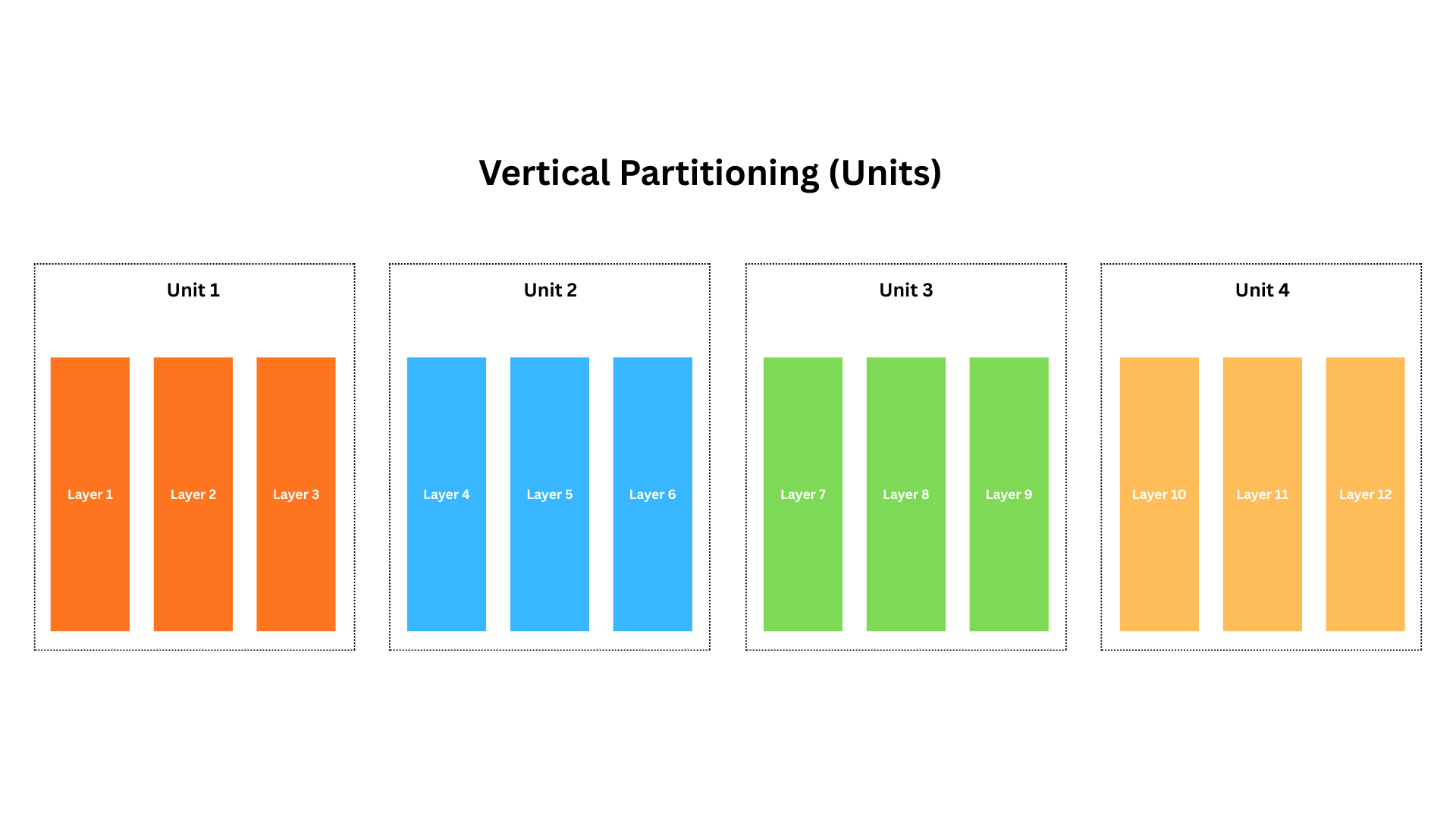
이는 순전히 조직(organizational)적인 개념으로, 계산 중에 FSDP가 파라미터를 gather하고 다시 해제(release)하는 단위의 세밀함(granularity) 을 결정합니다. 모델 크기와 GPU 수에 따라 unit을 더 많이/적게 선택할 수 있습니다.
Note Units ≠ GPUs
FSDP에서 unit(레이어의 수직 파티션)을 정의하는 것은 파라미터 로딩, 체크포인팅, 샤딩 granularity를 제어하기 위한 모델링 선택입니다. GPU 개수와 일치할 필요가 없고, 실제로도 종종 일치하지 않습니다. unit의 개수나 경계가 디바이스 토폴로지와 대응해야 할 기술적 요구사항은 없습니다.
unit은 파라미터 관리를 위한 논리적 그룹일 뿐이며, 파라미터를 GPU에 어떻게 샤딩할지는 별도의 “수평 샤딩”이 담당합니다. 따라서 GPU 수와 무관하게 어떤 개수의 unit도 구성할 수 있습니다.
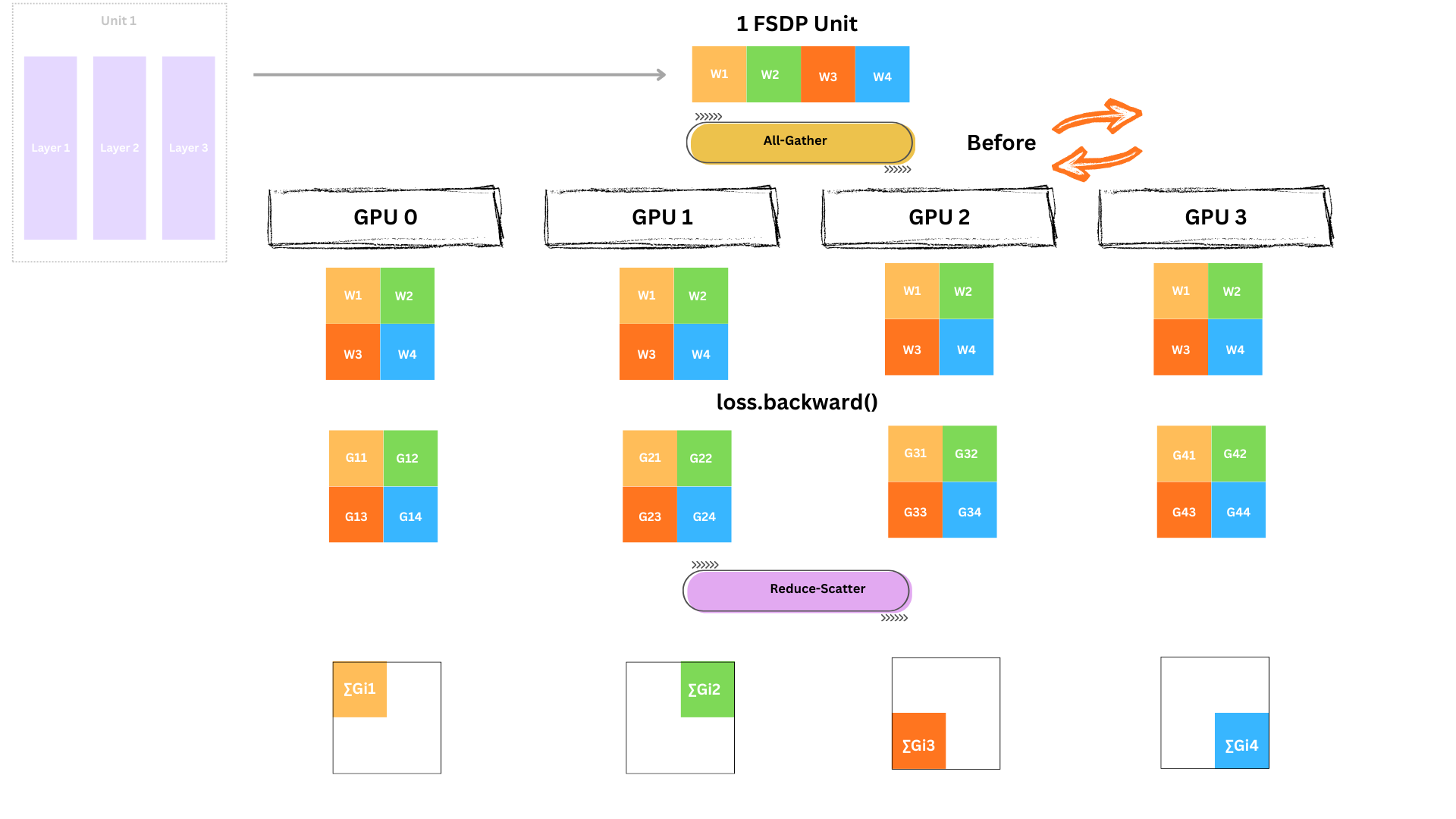
여기서 FSDP는 순진한 접근과 근본적으로 달라집니다. 서로 다른 레이어를 서로 다른 GPU에 할당하는 대신, 각 엔티티(파라미터, 그라디언트, 옵티마이저 상태)를 모든 GPU에 걸쳐 수평으로 샤딩합니다.
샤딩 전(GPU당 32GB 필요):

샤딩 후(GPU당 8GB만):
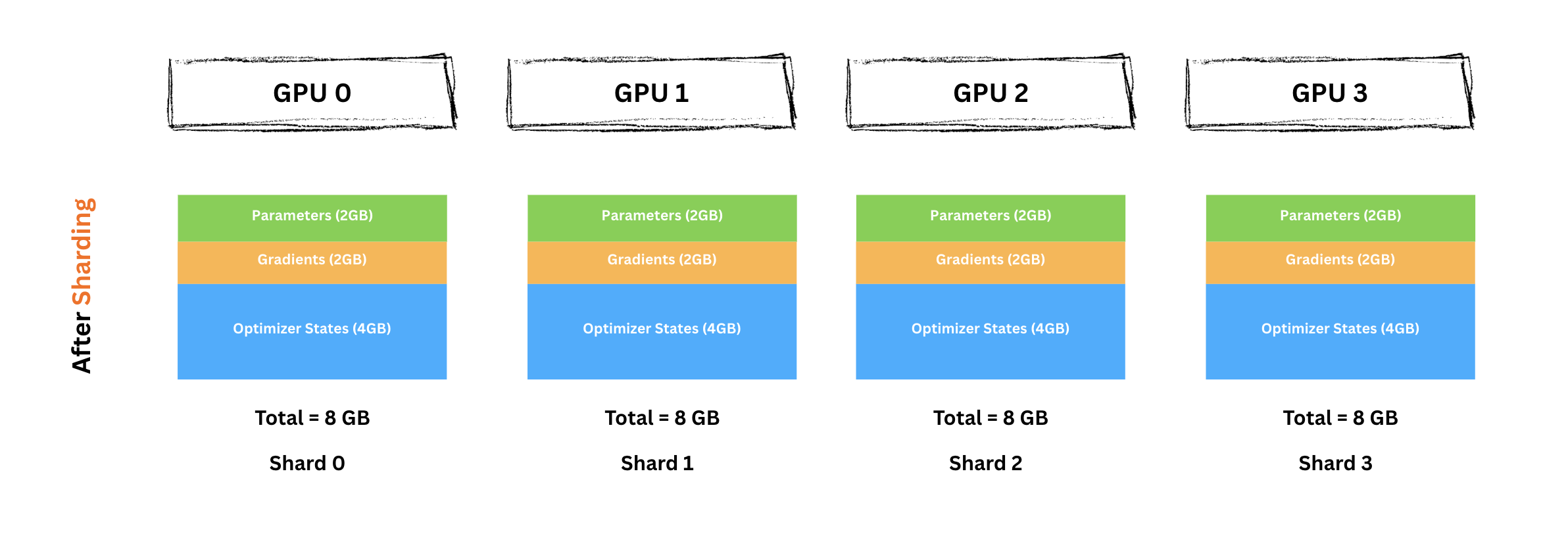
Important Critical Insight
각 shard는 특정 레이어 묶음이 아니라, 모든 레이어에서의 수평 슬라이스를 포함합니다.
예를 들어 GPU0의 shard에는 레이어 1~12 전체에서 파라미터의 앞 1/4씩이 들어 있습니다. 이는 GPU0가 레이어 1-3의 전체 파라미터만 갖는 순진한 접근과는 완전히 다릅니다.
이 수평 샤딩 덕분에 모든 GPU가 모델의 모든 레이어 처리에 참여할 수 있습니다.
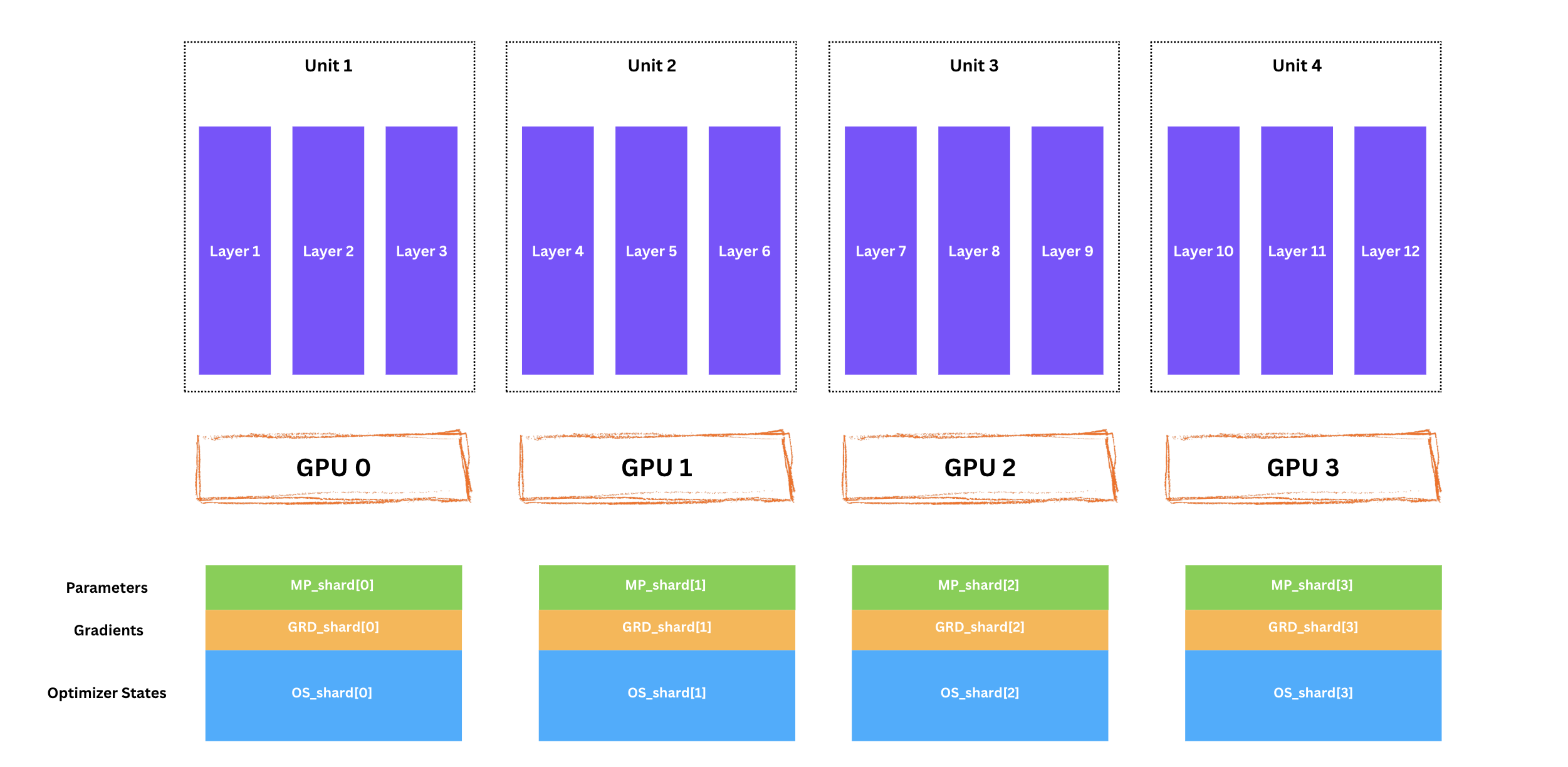
이제 FSDP가 모델을 수직(unit)과 수평(GPU 간)으로 분할하는 것을 봤으니, 중요한 질문을 정리해야 합니다. 우리는 실제로 무엇을 샤딩하고 있을까요?
FSDP의 기본이자 가장 메모리 효율적인 모드인 FULL_SHARD에서는 세 가지 엔티티(모델 파라미터, 그라디언트, 옵티마이저 상태) 모두를 모든 GPU에 걸쳐 샤딩합니다. 이것이 단일 디바이스에 절대 들어가지 못할 정도로 큰 모델로 확장할 수 있게 해주는 핵심 차이입니다.
이후 설명에서 사용할 표기 규칙은 다음과 같습니다.
기초가 준비됐으니, 이제 FSDP가 실제로 어떻게 동작하는지 단계별로 보겠습니다.
이제 한 번의 완전한 학습 이터레이션(Forward + Backward)을 따라가 보겠습니다.
학습 시작 전 FSDP는 두 가지 설정 작업을 합니다.
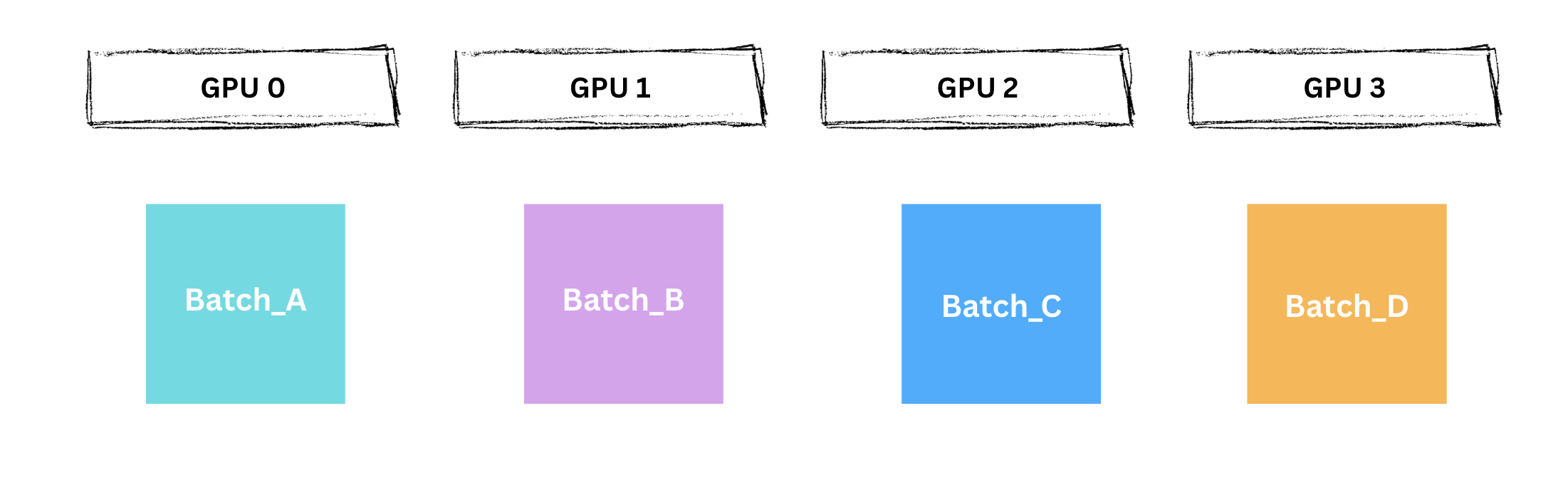
Step 0.1: 데이터셋 분할
각 GPU에 서로 다른 미니배치를 할당합니다.
Step 0.2: 모델 샤딩
앞서 본 것처럼 각 엔티티를 4개 shard로 나눠 분배합니다.
샤딩 직후 초기 상태:
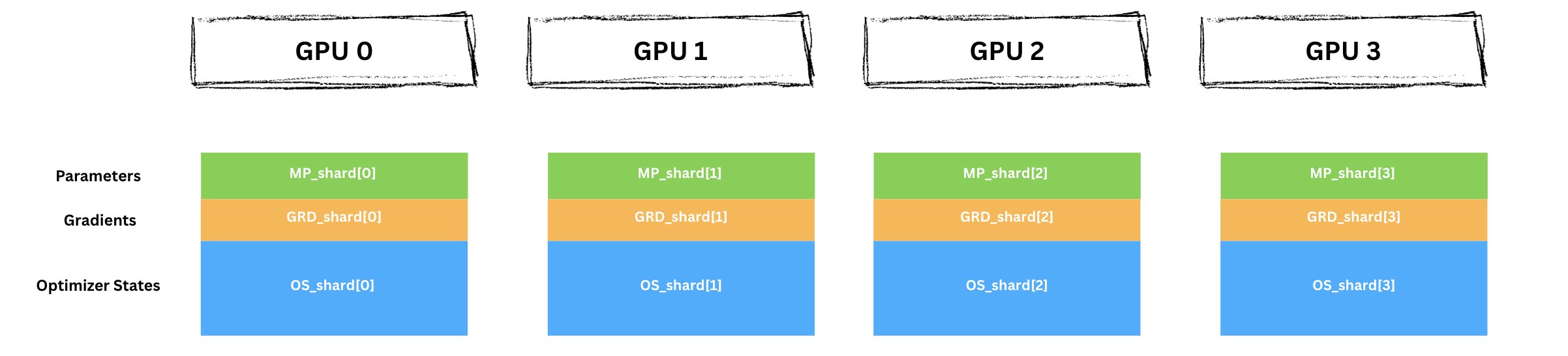
Note
이 시점에서 GRD(그라디언트) shard는 단지 플레이스홀더입니다. 각 GPU에 메모리만 할당되어 있을 뿐, 아직 의미 있는 값은 없습니다.
forward/backward가 시작되지 않았기 때문에 그라디언트는 아직 계산되지 않았습니다. 실제 그라디언트 값은 backward에서 loss가 네트워크를 거꾸로 전파할 때 계산되어 채워집니다.
“unit”은 앞서 수직 분할로 만든 레이어의 논리적 그룹입니다. forward pass에서는 unit을 순차적으로 처리하지만, 각 unit의 차례에서 4개 GPU는 각자의 미니배치에 대해 병렬로 동작합니다. 이제 각 GPU에는 다음이 있습니다.
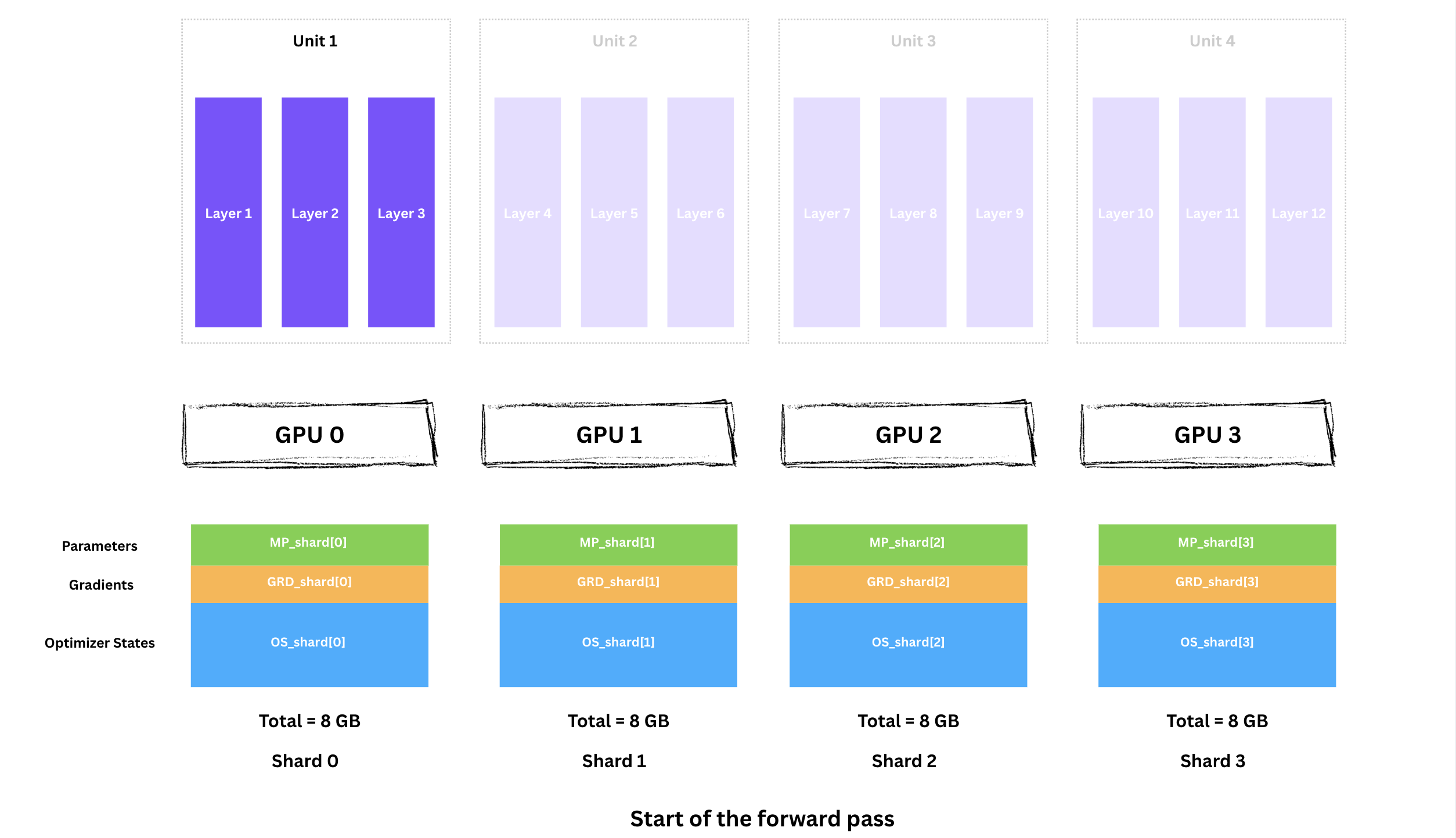
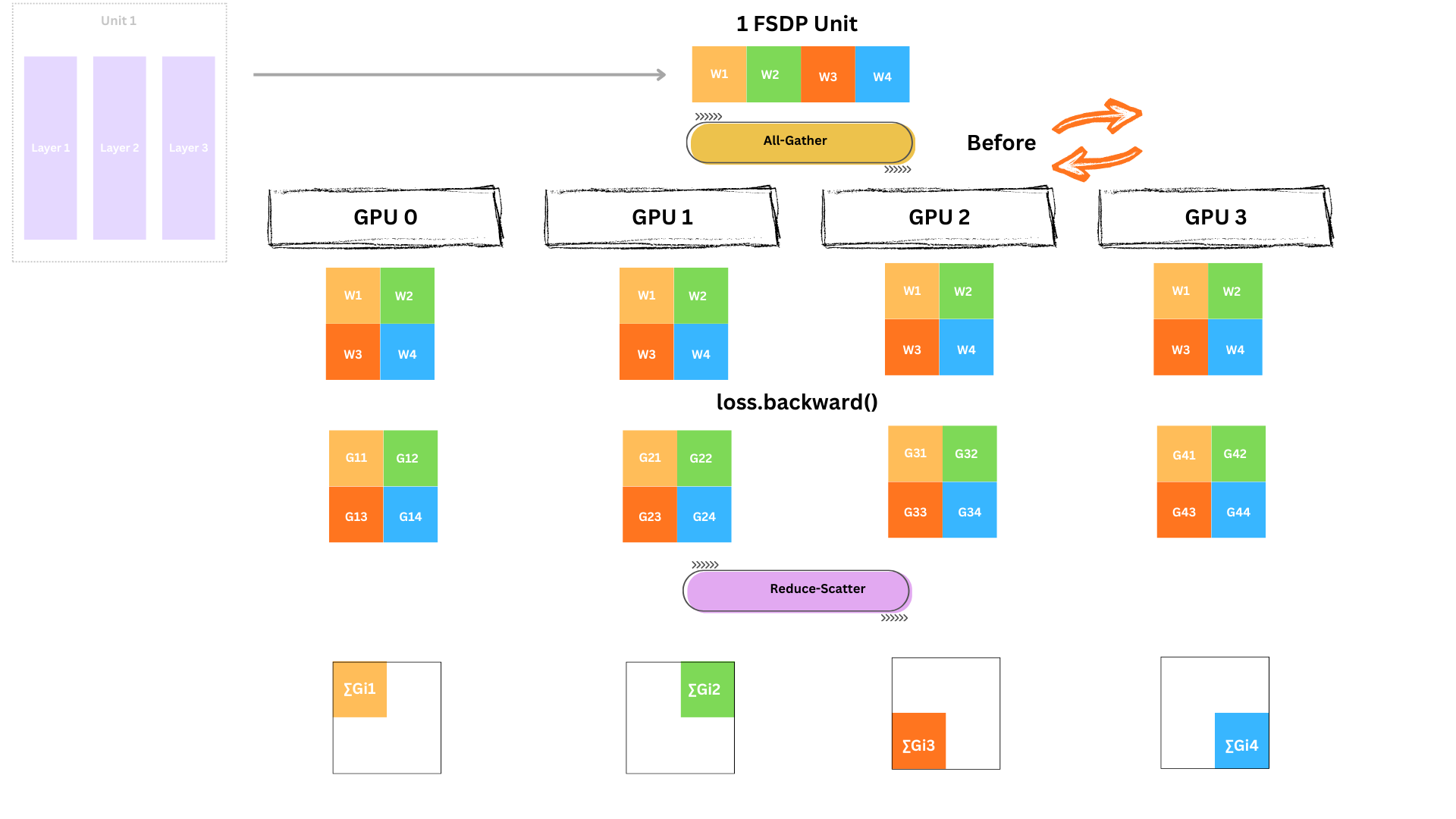
레이어 1-3을 실행하려면 각 GPU가 Unit 1의 전체 파라미터를 가져야 합니다. 파라미터는 GPU 전체에 샤딩되어 있으므로 All-Gather를 수행합니다.
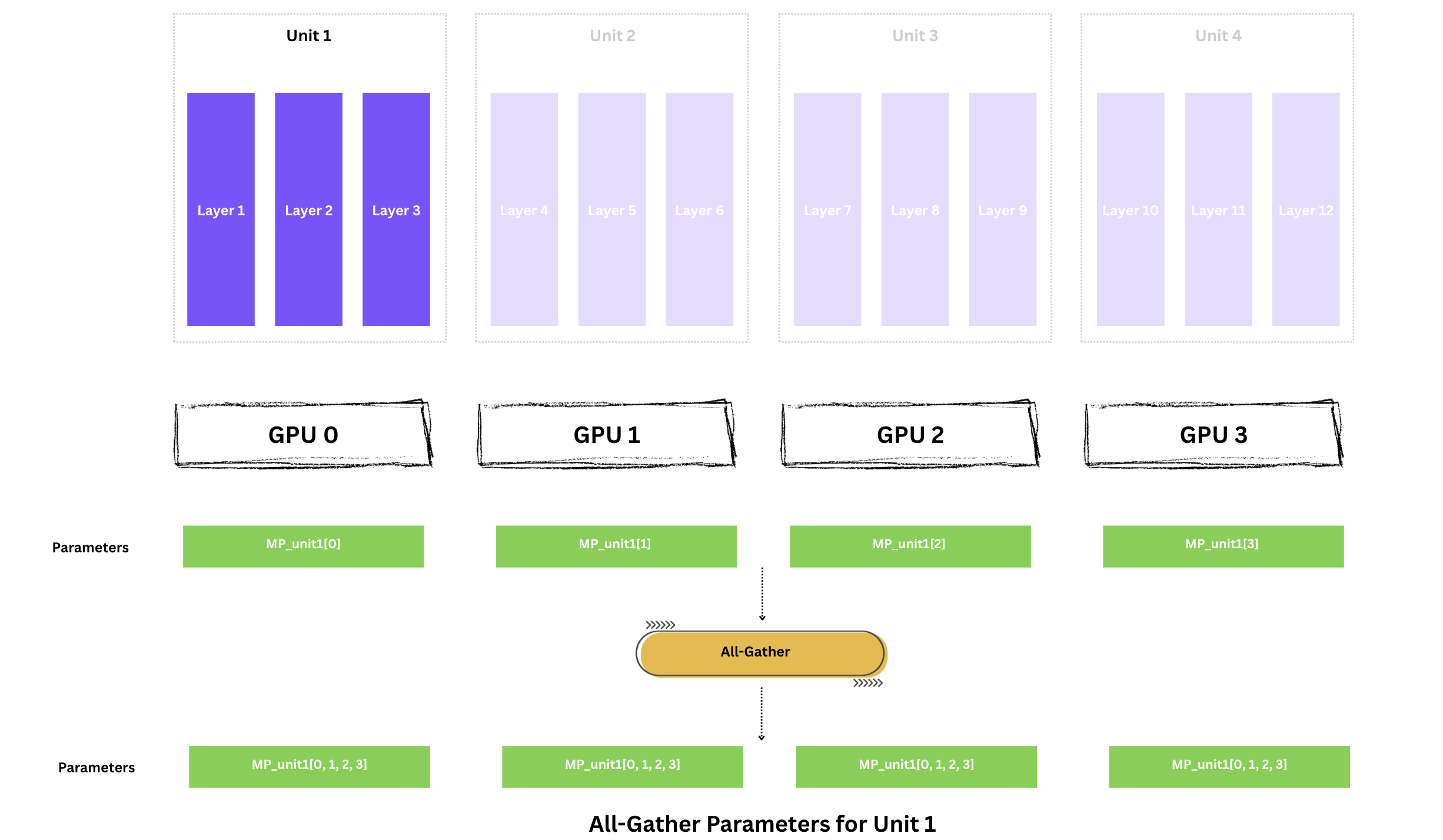
이제 각 GPU는 Unit 1 파라미터 전체를 일시적으로 보유합니다. 중요한 단어는 일시적으로이며, 사용 후 빌려온 shard는 버립니다.
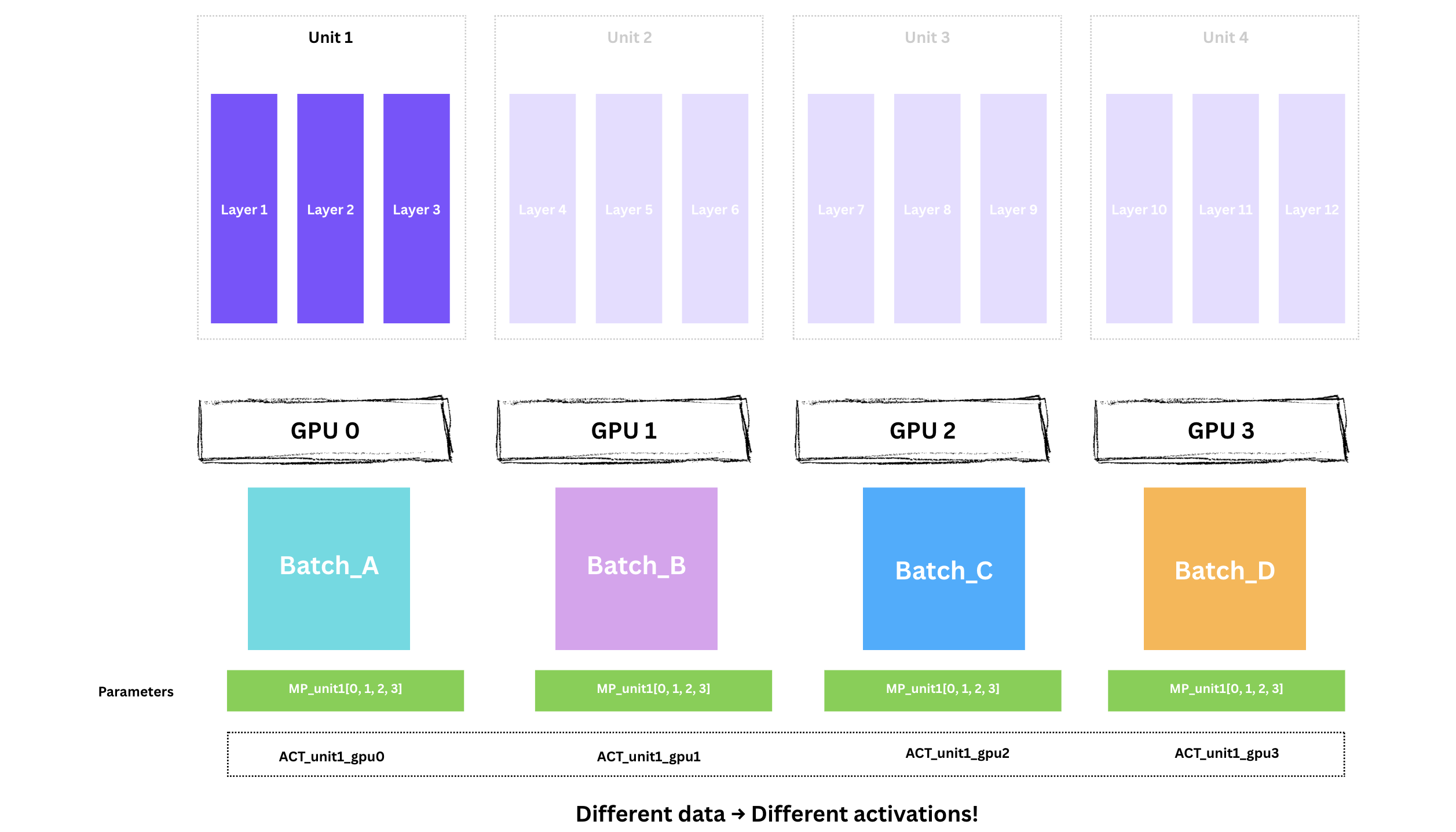
이제 4개 GPU 모두가 동시에 Unit 1(레이어 1-3)에 대해 forward를 실행합니다. 각자 다른 미니배치를 사용하지만 모델 가중치는 동일합니다.
Tip This is the magic of FSDP
4개 GPU가 동시에 일합니다. 같은 model weights, 다른 data, 다른 activations.
각 GPU는 계산한 활성화값을 저장합니다. backward에서 그라디언트를 계산할 때 필요합니다.
Unit 1의 forward가 끝났으므로, GPU 메모리를 확보하기 위해 빌려온 파라미터 shard를 삭제하고, 자기 shard만 유지합니다.
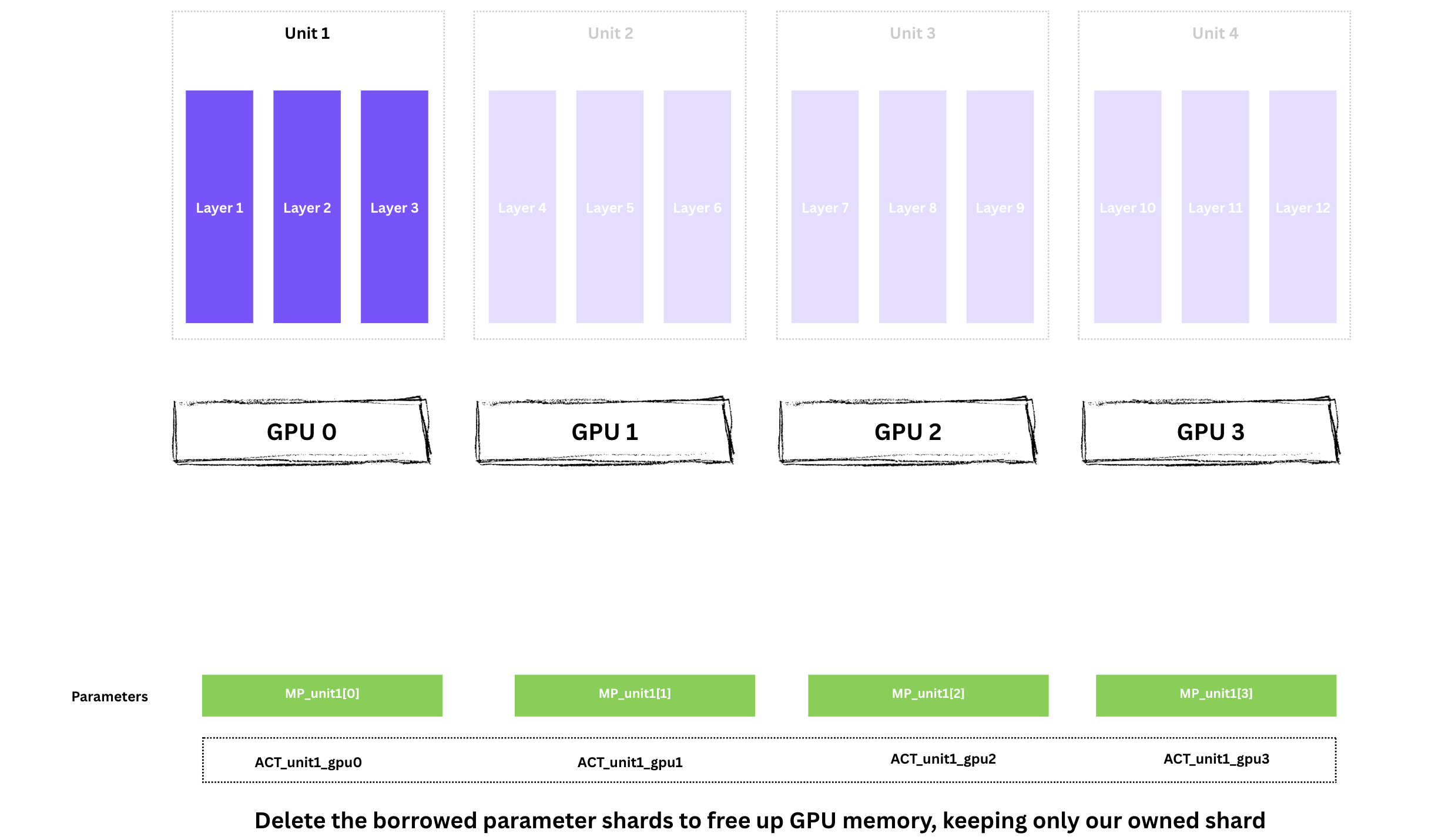
메모리 사용량은 다시 내려가지만, backward에 필요한 activations는 유지됩니다.
남은 units(Unit 2, 3, 4)에 대해 동일한 사이클을 반복합니다.
All-Gather → Forward → ACT 저장 → Reshard
각 GPU는 자신의 미니배치에 대해 loss를 계산합니다.
Forward 종료 시 상태:
이 시점에서 각 GPU가 보유한 것은:
1/4 shardACT_unit1~ACT_unit4)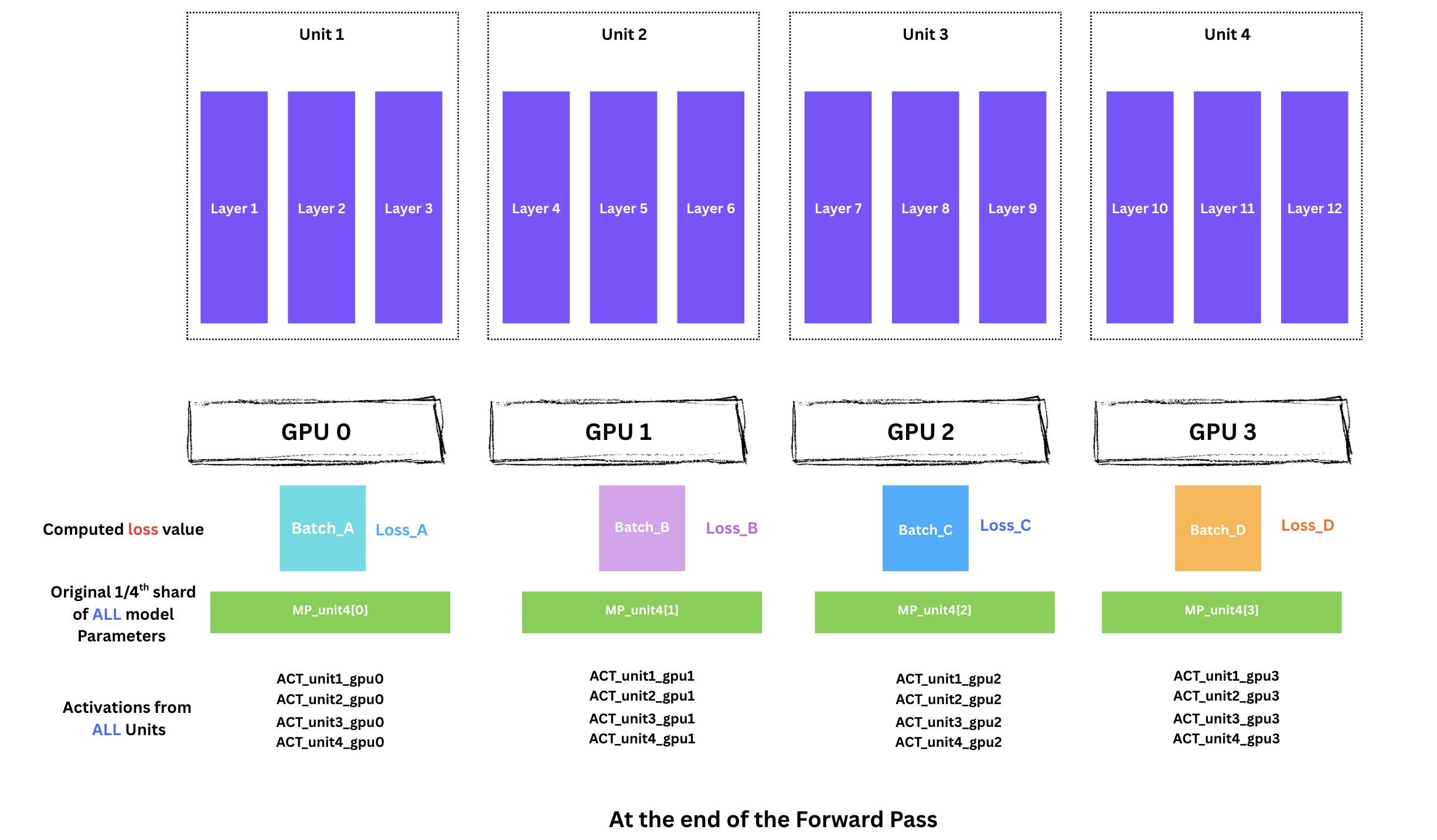
이제 역방향으로 진행하며 그라디언트를 계산해 네트워크를 통해 전달합니다. 마지막 레이어 묶음(Unit 4)부터 시작해서 첫 묶음(Unit 1)까지 거꾸로 진행합니다.
backward를 시작하기 전에, forward 때처럼 Unit 4의 전체 파라미터를 다시 모아야 합니다.
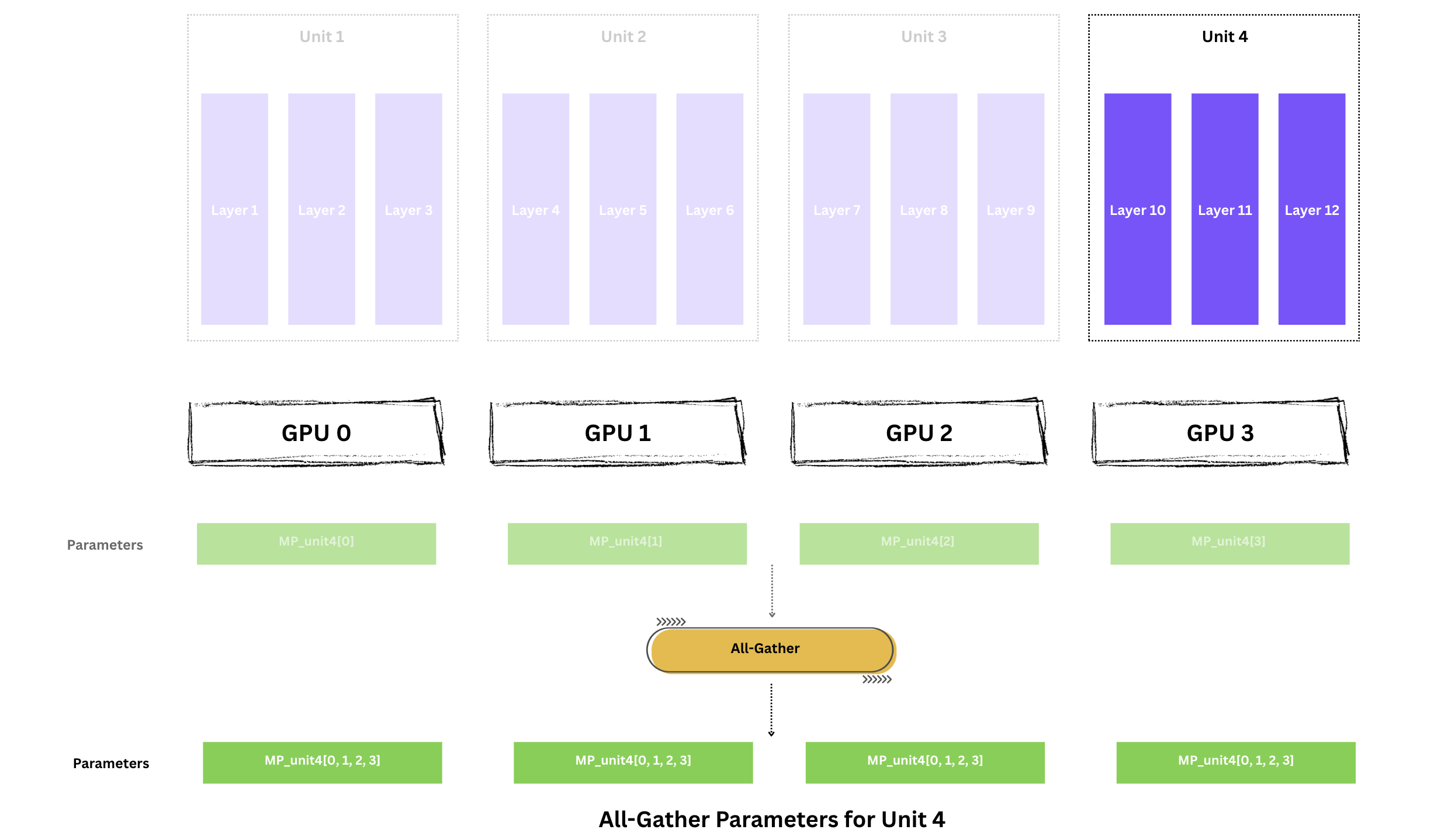
Note No Need to All-Gather for Unit 4
좋은 소식: Unit 4는 forward 직후에 모든 GPU가 이미 전체 파라미터(MP_unit4)를 보유하고 있으므로, 이 단계에서 새로 할 일이 없습니다.
하지만 더 앞쪽 unit(Unit 3, Unit 2, Unit 1)으로 이동하면, 메모리 절약을 위해 각 단계 후 보통 다시 reshard하기 때문에, forward에서 했던 것처럼 All-Gather로 전체 파라미터를 다시 조립해야 합니다.
각 GPU는 자신의 배치 loss와 자신이 저장한 활성화값을 바탕으로 그라디언트를 계산합니다.
이 시점의 그라디언트는 각 GPU 데이터에 대한 로컬 그라디언트입니다.
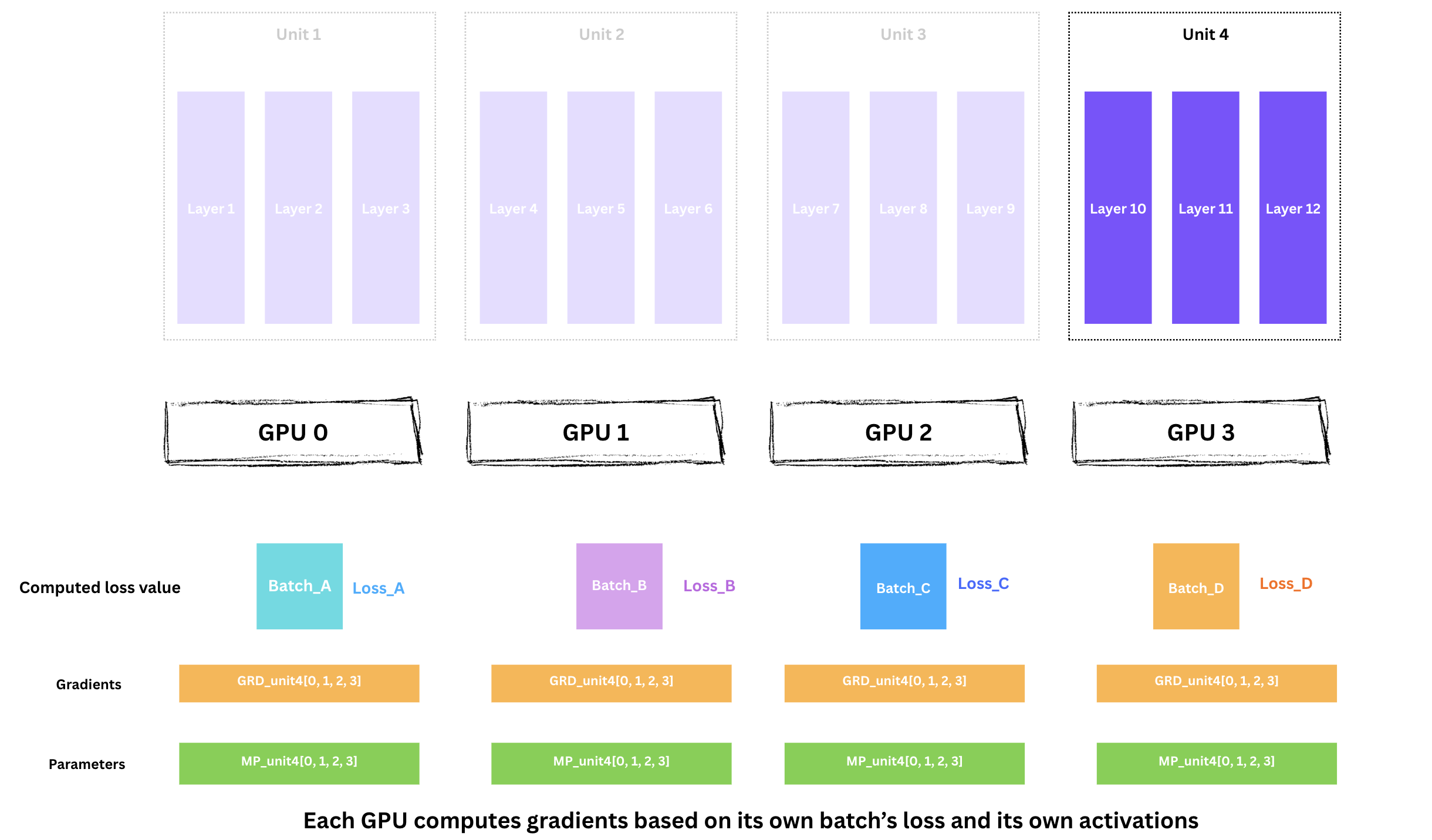
하지만 최적화를 위해서는 모든 로컬 그라디언트를 합친 글로벌 그라디언트가 필요합니다. 따라서 GPU 간 그라디언트를 reduce해야 합니다.
여기서 핵심이 나옵니다. Reduce-Scatter로 다음을 동시에 수행합니다.
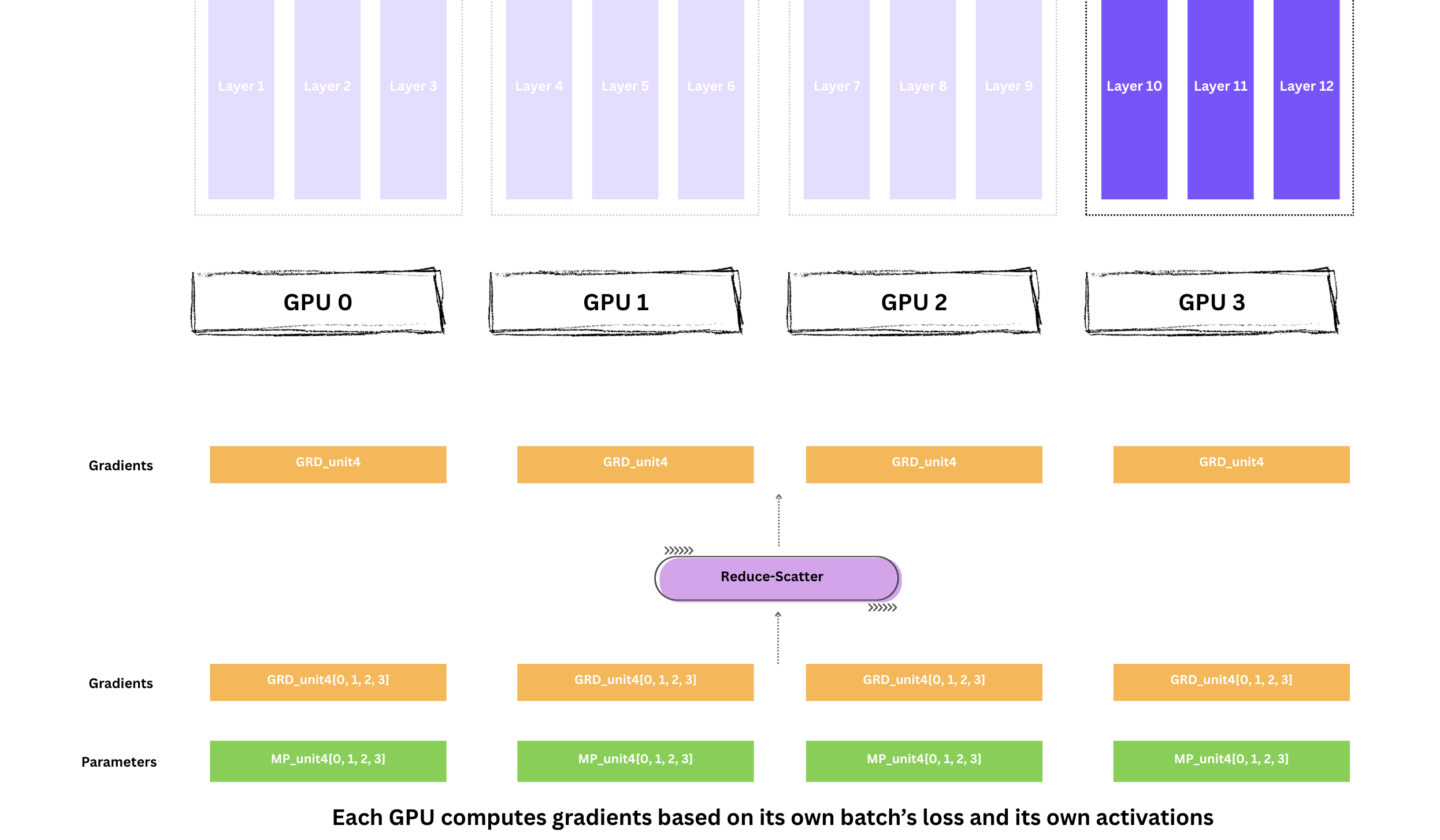
Note Why Reduce-Scatter instead of All-Reduce?
DDP에서는 All-Reduce로 모든 GPU가 합산된 그라디언트의 전체 를 받습니다. 하지만 FSDP에서는 각 GPU가 자신이 소유한 파라미터에 대한 그라디언트만 있으면 됩니다.
Reduce-Scatter는 같은 합(sum)을 만들면서 결과를 분배하므로, 메모리와 통신 대역폭을 모두 절약합니다.
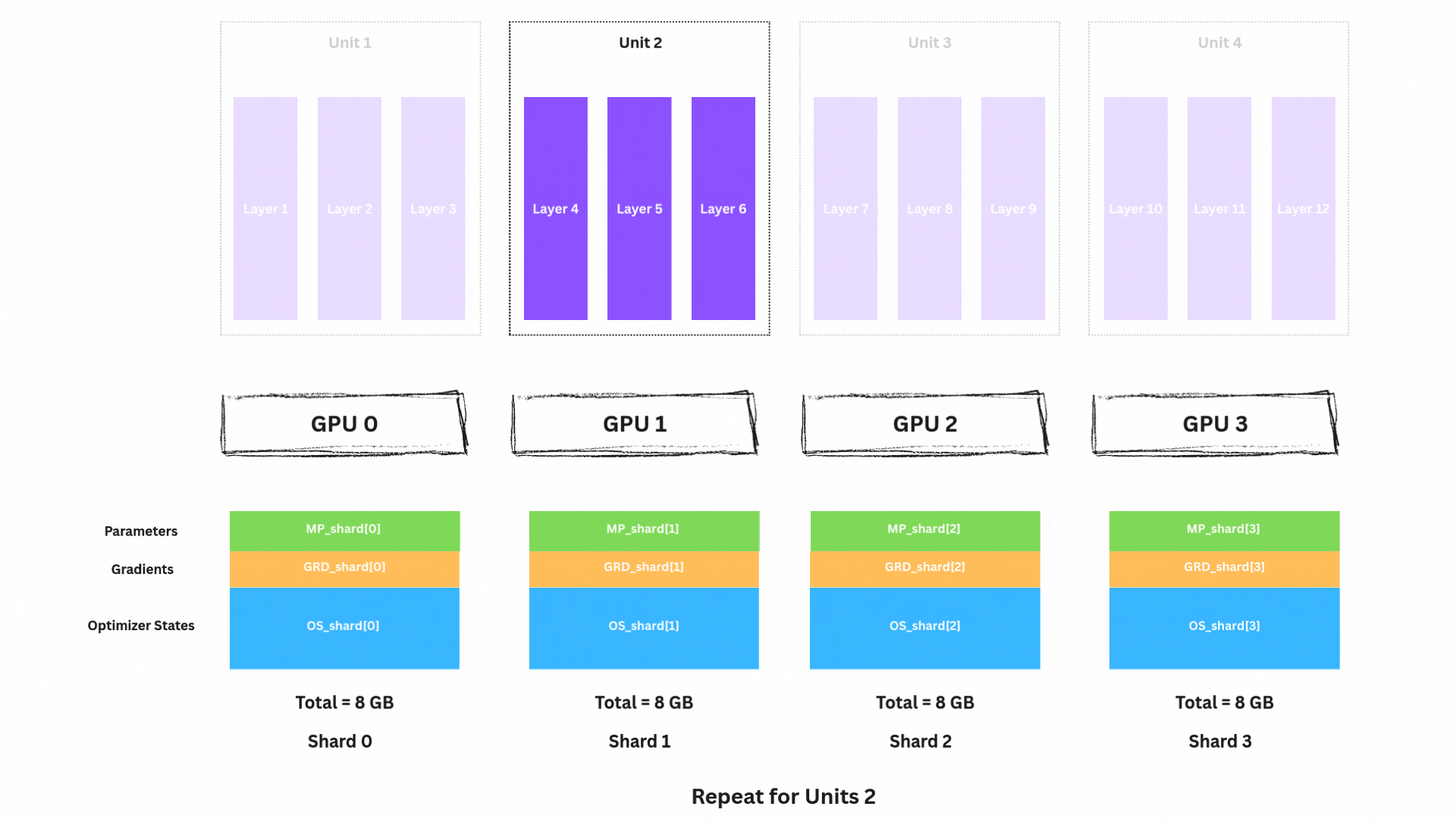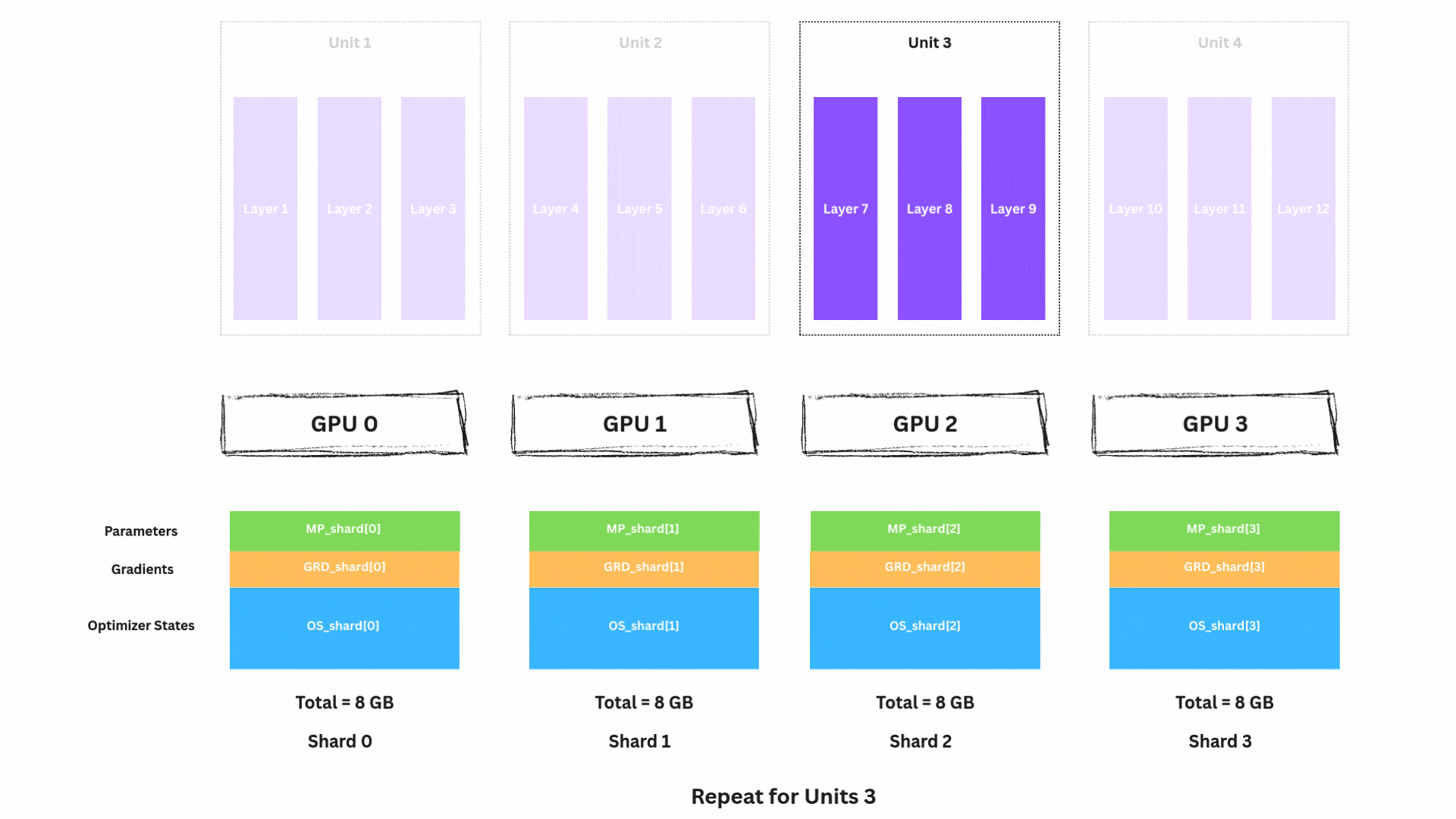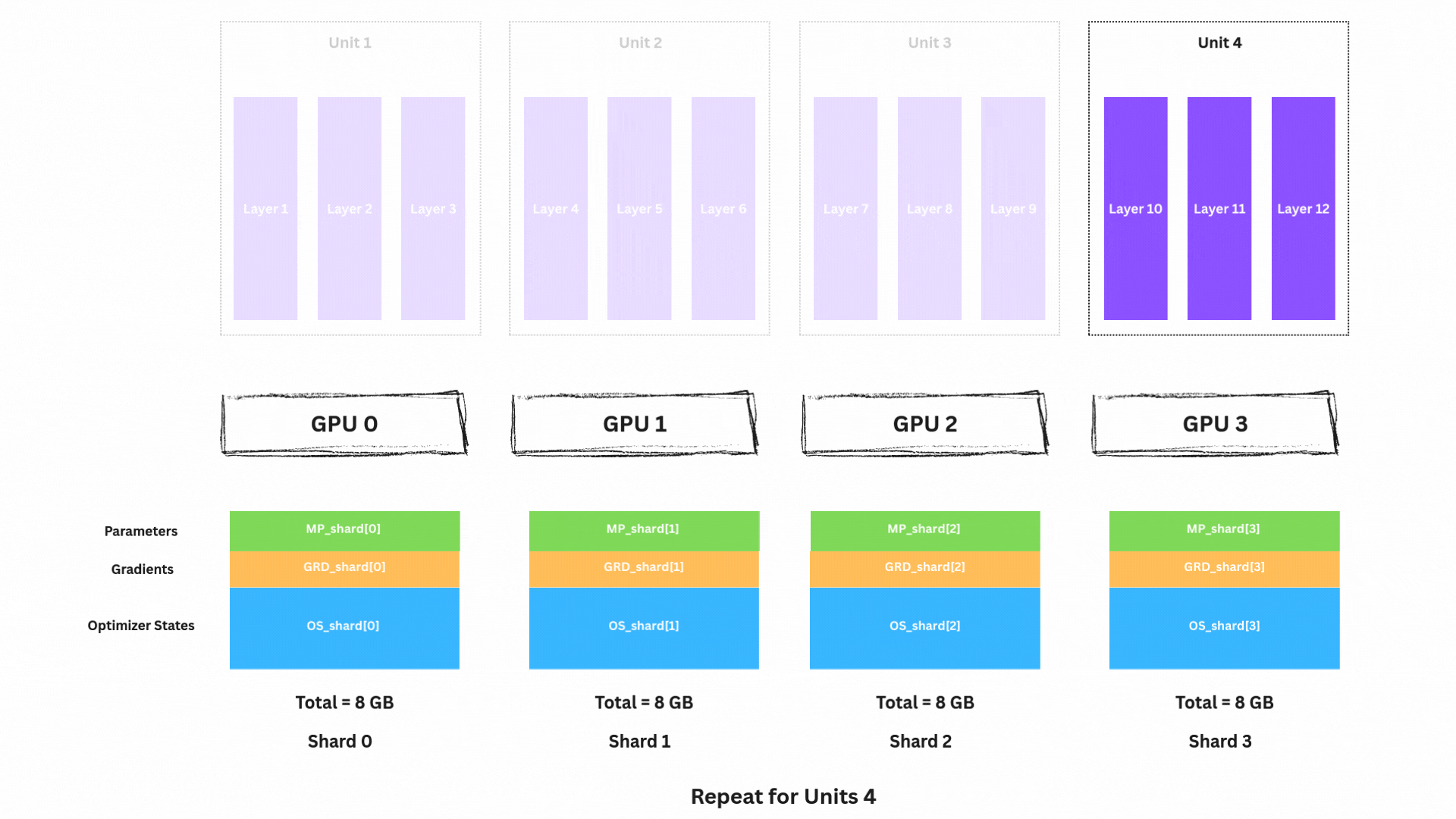
reduce-scatter 이후 다음을 해제할 수 있습니다.
MP_unit4(자기 shard만 남김)ACT_unit4(더 이상 필요 없음)네트워크를 거꾸로 진행하며 남은 unit들(Unit 3, 2, 1)에 대해 다음을 반복합니다.
MP_unit3 → Backward → Reduce-Scatter GRD → Free ACT_unit3MP_unit2 → Backward → Reduce-Scatter GRD → Free ACT_unit2MP_unit1 → Backward → Reduce-Scatter GRD → Free ACT_unit1Backward 종료 시 상태:
각 GPU는 이제 다음을 보유합니다.
1/4 shard(MP_shard)1/4 shard(GRD_shard) ← 최적화 준비 완료1/4 shard(OS_shard)이제 아름다운 부분입니다. 각 GPU는 독립적으로 파라미터를 업데이트할 수 있습니다.
각 GPU는 자신의 모델 조각을 업데이트하는 데 필요한 모든 것을 이미 가지고 있습니다.
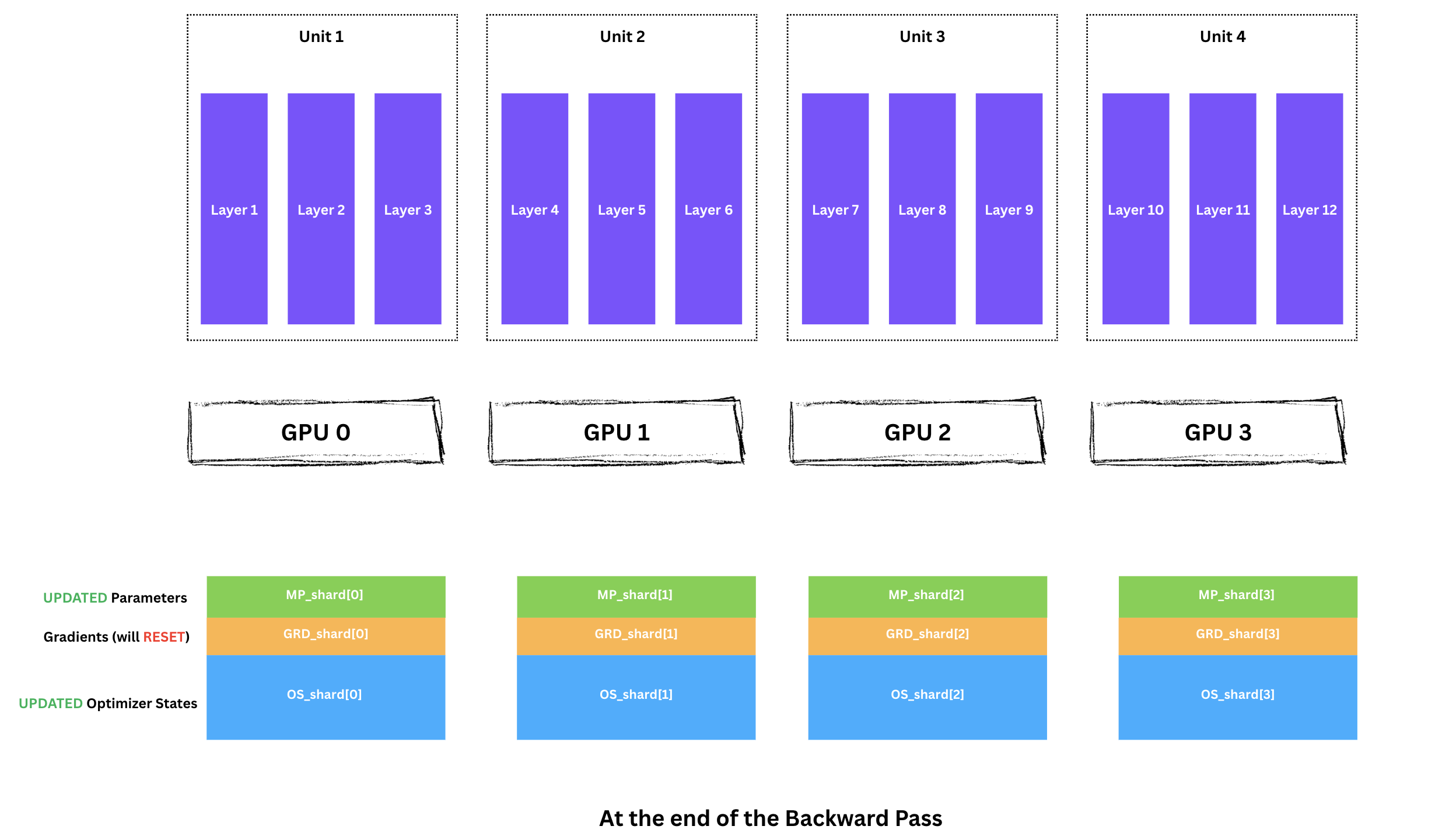
Tip No Communication Needed!
각 GPU는 이미 가진 데이터만으로 자기 shard를 업데이트하므로, GPU 간 통신이 전혀 필요 없습니다.
업데이트된 파라미터를 가진 채로 초기 상태로 돌아오며, 다음 배치를 가져올 수 있습니다.
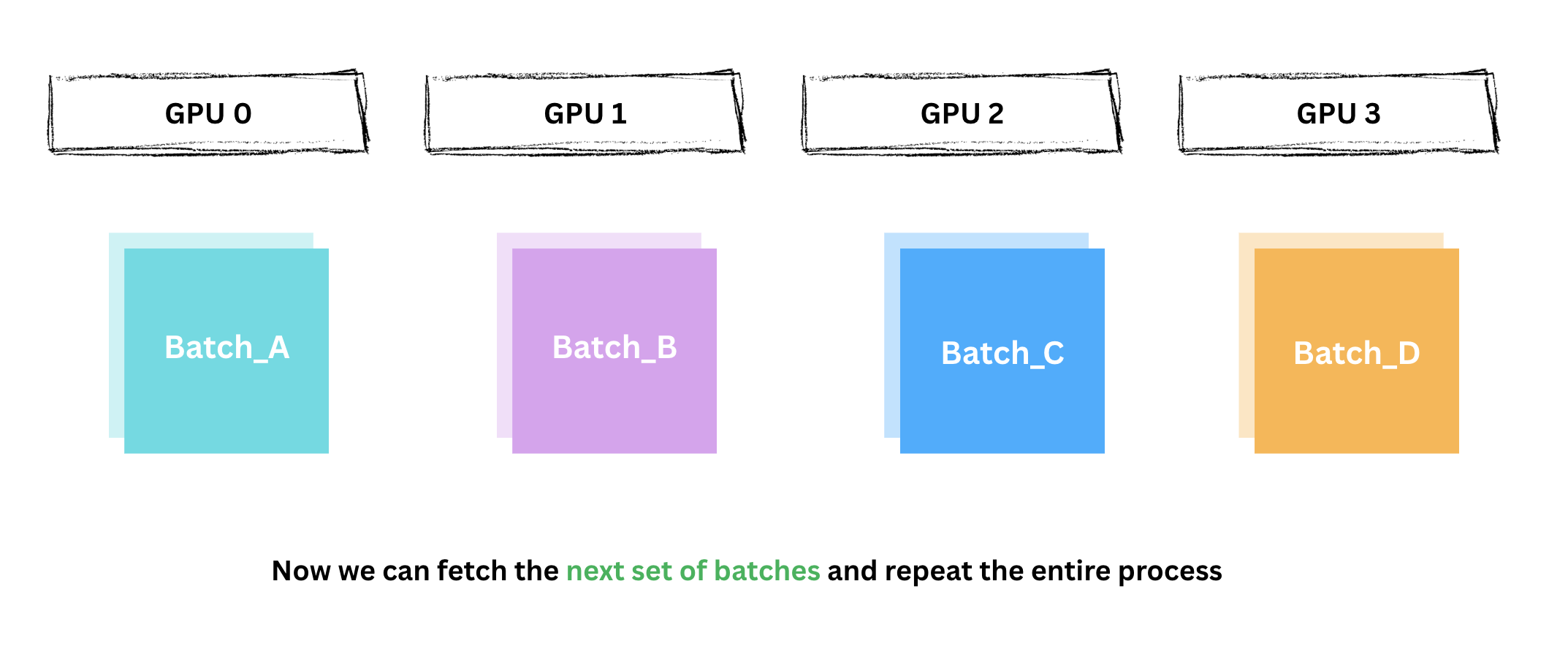
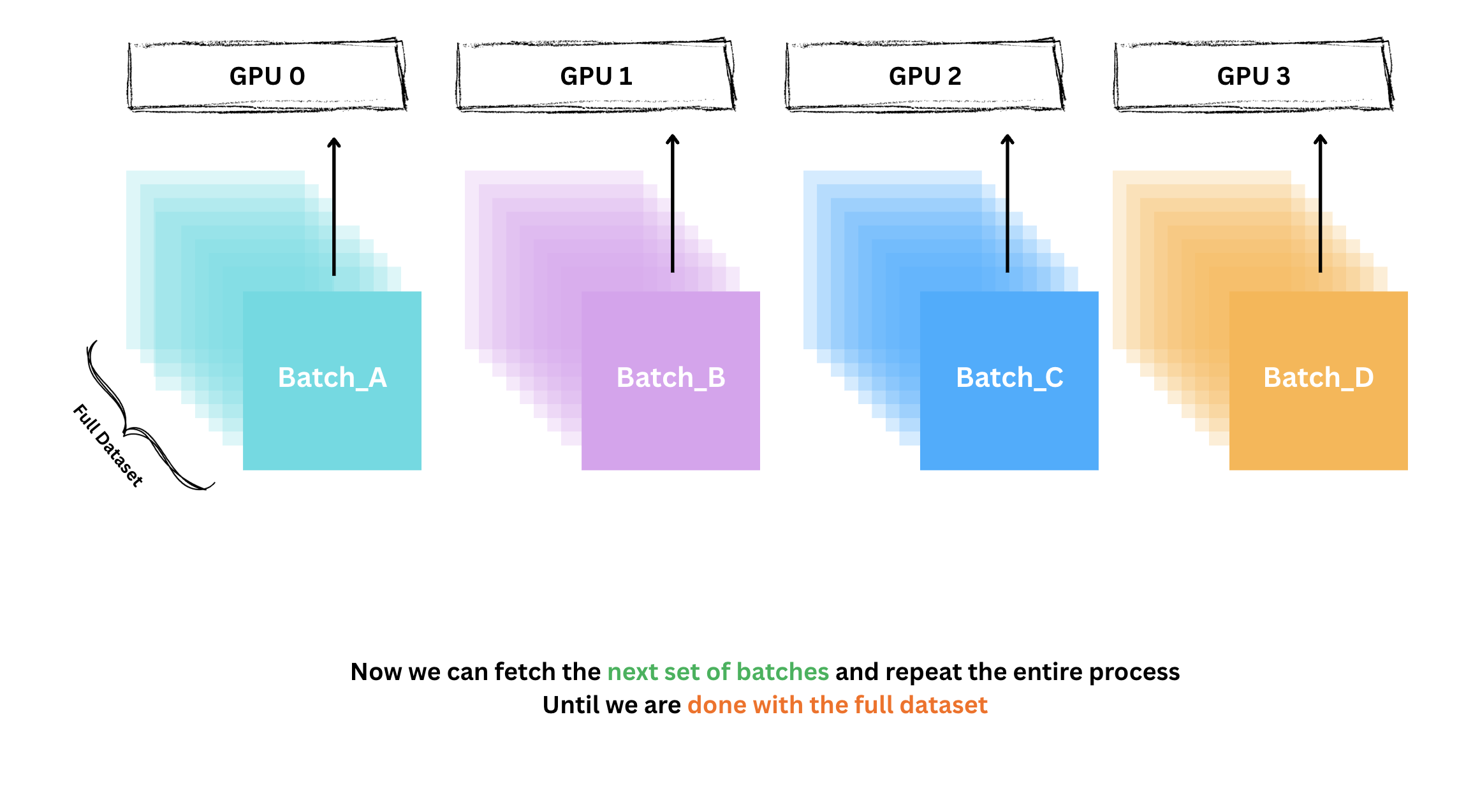
이 과정을 데이터셋의 모든 배치에 대해 반복합니다.
요약하면, FSDP로 한 번의 학습 이터레이션에서 일어나는 일은 다음과 같습니다.
4-GPU 예시로 실제 숫자를 계산해 FSDP의 메모리 효율 효과를 확인해 봅시다.
클래식 데이터 병렬(DDP)에서는 각 GPU가 모델, 그라디언트, 옵티마이저 상태의 전체 복사본을 보유합니다.
여기서:
따라서 각 GPU는 32GB가 필요합니다.
결과: 16GB GPU에는 들어가지 않습니다. 대부분의 컨슈머 GPU 및 많은 데이터센터 GPU에서 즉시 OOM이 납니다.
FSDP에서는 parameters, gradients, optimizer states가 모든 GPU에 걸쳐 샤딩되어 메모리 요구량이 크게 줄어듭니다.
각 GPU가 필요로 하는 메모리는:
여기서 는 GPU 개수입니다.
각 GPU는 어느 시점이든 파라미터/그라디언트/옵티마이저 상태의 1/4만 저장합니다.
결과: 16GB GPU에서도 충분히 들어갑니다. 같은 하드웨어에서 2배 큰 모델을 학습하거나, 같은 모델로 더 큰 배치 크기를 사용할 수 있습니다.
하지만 공짜 점심은 없습니다. 통신 오버헤드를 지불해야 합니다.
학습 이터레이션마다:
| Phase | Operation | Data Volume |
|---|---|---|
| Forward (per unit) | All-Gather MP | |
| Backward (per unit) | All-Gather MP | |
| Backward (per unit) | Reduce-Scatter GRD |
이터레이션당 총 통신량은 대략 (전체 파라미터 크기 기준)입니다.
Tip Prefetching Optimization
실제로 FSDP는 통신과 계산을 겹쳐(overlap) 수행합니다. Unit 의 forward를 계산하는 동안 백그라운드에서 Unit 의 all-gather를 시작할 수 있어, 실효 통신 오버헤드가 크게 줄어듭니다.
이제 FSDP가 어떻게 동작하는지 이해했으니 구현해 봅시다. 구현은 비교적 간단합니다.
PyTorch FSDP2 와 Ray Train 을 사용해 FashionMNIST에서 Vision Transformer를 학습하겠습니다.
Ray Train이 처음이라면, 제 이전 글의 이 섹션을 참고하세요.
PyTorch의 Fully Sharded Data Parallel(FSDP)은 두 번째 메이저 버전(FSDP2)에서 큰 진화를 겪었습니다. 기존 설계는 이후 FSDP1이라고도 부릅니다.
주요 개선점은 다음과 같습니다.
| Aspect | FSDP1 | FSDP2 |
|---|---|---|
| Parameter Storage | 큰 FlatParameter 텐서(그룹별 파라미터를 concat해서 샤딩) | 각 파라미터가 랭크들 사이에서 독립적으로 샤딩(파라미터 단위 샤딩) |
| Sharding Unit | 평탄화된 파라미터 그룹(명시적 그룹핑 필요) | 개별 파라미터(어떤 파라미터 텐서에도 자연스러운 granularity) |
| DTensor Support | 실험적/제한적, 네이티브로 노출되지 않음 | DTensor 네이티브 통합(다차원/하이브리드 샤딩) |
| State Dict Handling | 전체 텐서 재구성을 위해 워커 간 통신이 필요한 경우가 많음 | 집단 통신 없이 fully sharded state dict 저장/로드 가능(병렬 체크/리스토어 및 스트리밍 지원) |
| Frozen Parameters | 관리가 까다로움(레이어 freeze 시 그룹 업데이트 필요) | freeze된 파라미터는 자연스럽게 스킵(추가 그룹핑 불필요) |
| Selective Wrapping and Nested Structure | 경직/에러 발생 가능, 임의 모듈 경계에서 래핑 어려움 | 어떤 모듈/서브모듈/파라미터 레벨에서도 세밀하고 쉬운 래핑 |
FSDP2의 핵심 아이디어는 각 파라미터 텐서를(보통 첫 번째 차원 dim-0 기준으로) 분할하여 모든 GPU(rank)에 분산하는 것입니다. 이를 통해 샤딩 그룹마다 파라미터를 flatten/concat하는 복잡성이 사라지고, 다양한 모델에 대한 호환성이 좋아지며, 다른 샤딩 전략과의 결합도 쉬워집니다.
코드로 들어가기 전에 Ray 클러스터가 필요합니다. GPU 워커를 가진 Ray 클러스터를 쉽게 띄우고 관리할 수 있으므로 Anyscale 사용을 강력히 권합니다.
자세한 방법은 GitHub Repository 또는 Anyscale 문서를 참고하세요.
요약하면 다음과 같습니다.
Anyscale 계정 생성
먼저 https://www.anyscale.com/에서 가입합니다.
Anyscale에서 Ray 클러스터 프로비저닝
Workspace 열기
Workspace 버튼으로 워크스페이스를 엽니다.git clone https://github.com/debnsuma/vhol-ray-train.git
cd vhol-ray-train
pip install -r requirements.txtimport os
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
import tempfile
import uuid
import torch
import ray
print(f"PyTorch version: {torch.__version__}")
print(f"Ray version: {ray.__version__}")PyTorch version: 2.10.0+cu128
Ray version: 2.53.0이 튜토리얼에서는 Vision Transformer(ViT) 를 사용합니다. ViT는 반복적인 transformer encoder block 구조를 가지므로, 이론 파트의 unit 개념과 잘 맞습니다. 물론 원하는 어떤 모델을 사용해도 됩니다.
from torchvision.models import VisionTransformer
from torchvision.datasets import FashionMNIST
from torchvision.transforms import ToTensor, Normalize, Compose
def init_model():
"""FashionMNIST(28x28 grayscale, 10 classes)용 Vision Transformer 초기화"""
model = VisionTransformer(
image_size=28, patch_size=7, num_layers=10, num_heads=2,
hidden_dim=128, mlp_dim=128, num_classes=10,
)
# grayscale 입력을 위해 수정
model.conv_proj = torch.nn.Conv2d(1, 128, kernel_size=7, stride=7)
return model
# 모델 확인
test_model = init_model()
print(f"Model parameters: {sum(p.numel() for p in test_model.parameters()):,}")
del test_modelModel parameters: 1,006,090
이제 앞서 논의한 샤딩 전략을 구현합니다. 각 encoder block을 개별 unit으로 만들고 각각 샤딩합니다.
from torch.distributed.fsdp import fully_shard
from torch.distributed.device_mesh import init_device_mesh
import ray.train
def shard_model(model):
"""모델에 FSDP2 샤딩 적용"""
world_size = ray.train.get_context().get_world_size()
# 데이터 병렬을 위한 device mesh 생성
mesh = init_device_mesh("cuda", (world_size,), mesh_dim_names=("dp",))
# 각 encoder block을 개별적으로 샤딩
for block in model.encoder.layers.children():
fully_shard(block, mesh=mesh, reshard_after_forward=True)
# 루트 모델 샤딩
fully_shard(model, mesh=mesh, reshard_after_forward=True)Note reshard_after_forward Trade-off
reshard_after_forward=True로 설정하면, 앞에서 설명한 메모리 최적화(즉 forward 후 파라미터를 해제하고 backward에서 다시 gather)를 적용합니다. 피크 메모리는 줄지만 통신은 늘어납니다.
Tip Optional: Advanced Policies
메모리가 더 부족한 경우 다음을 추가할 수 있습니다.
CPUOffloadPolicy() - 사용하지 않는 파라미터를 CPU로 오프로딩MixedPrecisionPolicy(param_dtype=torch.float16) - FP16으로 메모리 감소. 최신 GPU(A100, H100)에서는 FP16보다 BF16을 권장합니다. BF16은 FP32와 같은 지수 범위를 가지므로 overflow/underflow가 줄고 대부분 loss scaling이 필요 없습니다.from torch.distributed.fsdp import CPUOffloadPolicy, MixedPrecisionPolicy
fully_shard(block,
mesh=mesh,
reshard_after_forward=True,
offload_policy=CPUOffloadPolicy(),
mp_policy=MixedPrecisionPolicy(param_dtype=torch.float16))이제 샤딩된 모델에서 체크포인팅을 다뤄봅시다. 기존 방식(예: torch.save(model.state_dict()))은 rank 0에 전체 파라미터를 모아야 하므로, 큰 샤딩 모델에서는 메모리/통신 비용 때문에 비현실적입니다.
PyTorch Distributed Checkpoint(DCP)는 워커 전체에 걸친 효율적/확장 가능한 체크포인팅을 제공합니다.
아래 클래스는 DCP로 모델과 옵티마이저 상태를 함께 저장/로드하기 위한 래퍼입니다.
from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict, get_model_state_dict, StateDictOptions
from torch.distributed.checkpoint.stateful import Stateful
import torch.distributed.checkpoint as dcp
class AppState(Stateful):
"""DCP 체크포인팅을 위한 래퍼"""
def __init__(self, model, optimizer=None, epoch=None):
self.model, self.optimizer, self.epoch = model, optimizer, epoch
def state_dict(self):
model_sd, optim_sd = get_state_dict(self.model, self.optimizer)
return {"model": model_sd, "optim": optim_sd, "epoch": self.epoch}
def load_state_dict(self, state_dict):
set_state_dict(self.model, self.optimizer,
model_state_dict=state_dict["model"],
optim_state_dict=state_dict["optim"])
self.epoch = state_dict.get("epoch")이 함수는 DCP 체크포인트를 로드하여 모델/옵티마이저/epoch를 복원하며, DCP의 자동 resharding을 활용합니다.
def load_checkpoint(model, optimizer, ckpt):
"""FSDP 체크포인트 로드(resharding 자동 처리)"""
with ckpt.as_directory() as ckpt_dir:
app_state = AppState(model, optimizer)
dcp.load(state_dict={"app": app_state}, checkpoint_id=ckpt_dir)
return app_state.epoch이 함수는 모델과 옵티마이저 상태를 분산 체크포인트로 저장하고, Ray에 메트릭을 보고합니다.
def save_checkpoint(model, optimizer, metrics, epoch):
"""FSDP 체크포인트 저장 및 메트릭 보고"""
with tempfile.TemporaryDirectory() as tmp_dir:
dcp.save(state_dict={"app": AppState(model, optimizer, epoch)}, checkpoint_id=tmp_dir)
ray.train.report(metrics, checkpoint=ray.train.Checkpoint.from_directory(tmp_dir))이 함수는 샤딩된 모델 가중치를 rank 0에 모아, 추론용으로 전체 PyTorch 모델 체크포인트를 저장합니다.
def save_model_for_inference(model, world_rank):
"""추론을 위해 샤딩 모델을 통합(rank 0이 전체 모델 저장)"""
with tempfile.TemporaryDirectory() as tmp_dir:
model_sd = get_model_state_dict(model, options=StateDictOptions(full_state_dict=True, cpu_offload=True))
ckpt = None
if world_rank == 0:
torch.save(model_sd, os.path.join(tmp_dir, "full-model.pt"))
ckpt = ray.train.Checkpoint.from_directory(tmp_dir)
ray.train.report({}, checkpoint=ckpt, checkpoint_dir_name="full_model")Note Model Consolidation for Inference
save_model_for_inference는 rank 0에서 all-gather로 가중치를 모아 표준 PyTorch 체크포인트로 저장합니다. 이 통합 모델은 추론 시 FSDP 없이도 로드할 수 있습니다.
이제 학습 함수를 구현합니다. 이 함수는 각 Ray 워커에서 실행되며, FSDP 학습 라이프사이클 전체를 오케스트레이션합니다.
특히 다음을 주의 깊게 보세요.
shard_model(model) 호출로 FSDP 래핑 준비ray.train.torch.prepare_data_loader로 샘플 샤딩/분배를 효율화import ray.train.torch
from torch.nn import CrossEntropyLoss
from torch.optim import Adam
from torch.utils.data import DataLoader
def train_func(config):
"""FSDP2 학습 함수"""
# 모델 설정
model = init_model()
device = ray.train.torch.get_device()
torch.cuda.set_device(device)
model.to(device)
shard_model(model) # FSDP 샤딩 및 분산 실행 준비
# 학습 설정
criterion = CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=config.get('lr', 0.001))
# 체크포인트가 있으면 재개
start_epoch = 0
if ray.train.get_checkpoint():
# 체크포인트 로딩은 재개/장애 복구에 필수
start_epoch = load_checkpoint(model, optimizer, ray.train.get_checkpoint()) + 1
# 데이터 로딩
transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])
train_data = FashionMNIST(root=tempfile.gettempdir(), train=True, download=True, transform=transform)
train_loader = DataLoader(train_data, batch_size=config.get('batch_size', 64), shuffle=True)
train_loader = ray.train.torch.prepare_data_loader(train_loader) # 분산 샤딩 보장
# 컨텍스트
world_rank = ray.train.get_context().get_world_rank()
# 학습 루프
for epoch in range(start_epoch, config.get('epochs', 1)):
# 분산 환경에서 epoch별 셔플 품질 보장
if ray.train.get_context().get_world_size() > 1:
train_loader.sampler.set_epoch(epoch)
total_loss, num_batches = 0.0, 0
for images, labels in train_loader:
outputs = model(images)
loss = criterion(outputs, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
num_batches += 1
avg_loss = total_loss / num_batches
# 체크포인트 저장은 Ray의 fault tolerance와 진행 추적의 핵심
save_checkpoint(model, optimizer, {"loss": avg_loss, "epoch": epoch}, epoch)
if world_rank == 0:
print(f"Epoch {epoch}: loss={avg_loss:.4f}")
# 다운스트림 추론을 위한 전체 모델 통합 저장(rank 0에서만)
save_model_for_inference(model, world_rank)이제 분산 학습을 실행합니다.
Ray Train의 TorchTrainer가 워커 생성, 프로세스 그룹 초기화, 체크포인트 조정을 처리합니다.
특히 다음을 확인하세요.
import ray.train.torch
import uuid
# 설정
experiment_name = f"fsdp_{uuid.uuid4().hex[:8]}"
scaling_config = ray.train.ScalingConfig(num_workers=2, use_gpu=True)
run_config = ray.train.RunConfig(storage_path="/mnt/cluster_storage/", name=experiment_name)
train_config = {"epochs": 1, "lr": 0.001, "batch_size": 64}
print(f"Experiment: {experiment_name}")학습을 실행합니다.
# 트레이너 생성 및 실행
trainer = ray.train.torch.TorchTrainer(
train_loop_per_worker=train_func,
scaling_config=scaling_config,
train_loop_config=train_config,
run_config=run_config,
)
result = trainer.fit()
print(f"Training complete! Checkpoint: {result.checkpoint}")학습 출력:
Experiment: fsdp_b2f564ce
(RayTrainWorker) Epoch 0: loss=0.7410
Training complete! Checkpoint: Checkpoint(filesystem=local, path=/mnt/cluster_storage/fsdp_b2f564ce/full_model)Note Parameter-Efficient Fine-Tuning
이 예시에서는 전체 모델을 완전 파라미터 업데이트로 파인튜닝했습니다. LoRA나 QLoRA 같은 파라미터 효율 파인튜닝을 쓰고 싶다면 여기에도 쉽게 통합할 수 있습니다. 모델/옵티마이저/학습 루프를 필요한 방식으로 감싸거나 수정하면 되고, Ray Train 파이프라인은 대부분 동일하게 유지됩니다.
다음 단계로 넘어가기 전에 아티팩트를 확인해 봅시다.
checkpoint_*/ - 분산 shard가 포함된 epoch 체크포인트full_model/ - 추론용 통합 모델# 아티팩트 나열
storage_path = f"/mnt/cluster_storage/{experiment_name}/"
print(f"Artifacts in {storage_path}:")
for item in sorted(os.listdir(storage_path)):
print(f" {item}/" if os.path.isdir(os.path.join(storage_path, item)) else f" {item}")Artifacts in /mnt/cluster_storage/fsdp_b2f564ce/:
.validate_storage_marker
checkpoint_2026-02-02_06-52-14.180406/
checkpoint_manager_snapshot.json
full_model/이제 추론용으로 모델을 로드합니다. 통합 모델(full-model.pt)은 표준 PyTorch 체크포인트이므로 FSDP2 없이도 동작합니다.
# 추론용 모델 로드
model_path = f"/mnt/cluster_storage/{experiment_name}/full_model/full-model.pt"
inference_model = init_model()
inference_model.load_state_dict(torch.load(model_path, map_location='cpu', weights_only=True))
inference_model.eval()
print("Model loaded.")# 추론 테스트
test_data = FashionMNIST(root="/tmp", train=False, download=True,
transform=Compose([ToTensor(), Normalize((0.5,), (0.5,))]))
with torch.no_grad():
sample = test_data.data[0].reshape(1, 1, 28, 28).float()
output = inference_model(sample)
print(f"Inference output shape: {output.shape}")Inference output shape: torch.Size([1, 10])
대규모 모델 학습에서는 여러 GPU/노드에 계산과 메모리를 효율적으로 분산하는 다양한 전략이 있습니다. 마이크로소프트가 개발한 오픈소스 라이브러리 DeepSpeed는 초대형 모델을 빠르고 확장 가능하며 쉽게 분산 학습하도록 설계되었습니다.
DeepSpeed는 ZeRO, 고급 옵티마이저, mixed precision 등 효율적인 최적화들을 제공하여, 그렇지 않으면 GPU 메모리에 들어가지 않는 모델도 학습 가능하게 해줍니다.
FSDP2가 PyTorch 네이티브 샤딩 솔루션이라면, DeepSpeed는 또 하나의 인기 있고 기능이 풍부한 분산 학습 프레임워크입니다. 간단히 소개하고 비교해 보겠습니다.
| Aspect | FSDP2 | DeepSpeed |
|---|---|---|
| Setup | fully_shard(model, ...) | deepspeed.initialize(model, config) |
| Optimizer | 사용자가 별도로 생성 | DeepSpeed가 관리 |
| Backward | loss.backward() | model.backward(loss) |
| Config | Python API | JSON/dict 설정 |
ZeRO 단계는 이전 글에서 이미 논의했습니다. DeepSpeed는 FSDP2와 같은 ZeRO 단계를 구현하지만, 간단한 설정 파일로 쉽게 구성할 수 있도록 돕습니다.
DeepSpeed는 표준 PyTorch 학습 루프의 플러그인 대체재로 설계되어, 대부분의 PyTorch 사용자에게 접근성이 좋습니다.
FSDP2가 전부 Python API인 반면, DeepSpeed는 분산 동작과 최적화 전략을 정의하기 위해 사용자 친화적인 설정 파일을 의도적으로 사용합니다. 아래는 코드로 구성한 간단한 예시입니다(원하면 JSON으로도 작성 가능).
def get_deepspeed_config(batch_size=64, lr=0.001):
"""최소 DeepSpeed ZeRO Stage 2 설정"""
return {
"optimizer": {
"type": "Adam",
"params": {"lr": lr, "betas": [0.9, 0.999], "eps": 1e-8},
},
"fp16": {"enabled": False}, # mixed precision을 쓰려면 True
"zero_optimization": {
"stage": 2, # ZeRO Stage 2: 옵티마이저+그라디언트 상태 파티셔닝
"allgather_bucket_size": 2e8,
"reduce_bucket_size": 2e8,
"overlap_comm": True,
"contiguous_gradients": True,
},
"train_micro_batch_size_per_gpu": batch_size,
"gradient_accumulation_steps": 1,
"gradient_clipping": 1.0,
"steps_per_print": 1000,
}이 딕셔너리(또는 JSON 경로)를 DeepSpeed에 넘기기만 하면 됩니다. mixed precision, NVMe 오프로딩 같은 고급 기능을 원하면 설정 키를 추가하면 됩니다. 더 많은 내용은 DeepSpeed Getting Started guide를 참고하세요.
DeepSpeed 시작 방법은 PyTorch와 매우 유사합니다. 주요 단계는 두 가지입니다.
DeepSpeed로 모델 초기화
모델을 model engine으로 감싸 분산 병렬, 메모리 최적화(ZeRO), 옵티마이저 상태, LR 스케줄 등을 처리합니다.
학습 루프에서 DeepSpeed 엔진 사용
model_engine.backward(loss)가 loss.backward()를 대체model_engine.step()가 optimizer.step()를 대체학습 함수는 다음과 같습니다.
def train_func(config):
"""DeepSpeed 학습 함수(Python은 비슷하지만 스케일링이 쉬움)."""
import deepspeed
# 모델 및 DeepSpeed 엔진 설정
model = init_model()
ds_config = get_deepspeed_config(batch_size=config.get('batch_size', 64), lr=config.get('lr', 0.001))
model_engine, optimizer, _, _ = deepspeed.initialize(
model=model, config=ds_config, model_parameters=model.parameters()
)
device = model_engine.device
criterion = CrossEntropyLoss()
# 분산 sampler 및 dataloader(PyTorch DDP와 유사)
transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])
train_data = FashionMNIST(root=tempfile.gettempdir(), train=True, download=True, transform=transform)
sampler = torch.utils.data.DistributedSampler(
train_data,
num_replicas=ray.train.get_context().get_world_size(),
rank=ray.train.get_context().get_world_rank(),
shuffle=True,
)
train_loader = DataLoader(train_data, batch_size=config.get('batch_size', 64), sampler=sampler)
# 학습 루프
for epoch in range(config.get('epochs', 1)):
sampler.set_epoch(epoch)
total_loss, num_batches = 0.0, 0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
# forward/backward/step을 DeepSpeed가 처리
outputs = model_engine(images)
loss = criterion(outputs, labels)
model_engine.backward(loss)
model_engine.step()
total_loss += loss.item()
num_batches += 1
avg_loss = total_loss / num_batches
print(f"Epoch {epoch}: loss={avg_loss:.4f}")이제 FSDP와 분산 학습 개념을 실제로 흥미로운 애플리케이션에 적용해 봅시다. 17억(1.7B) 파라미터의 TTS 모델을 파인튜닝하여 내 목소리를 클로닝하는 것입니다.
이 섹션에서는 알리바바의 Qwen3-TTS를 사용해, 우리가 배운 FSDP와 Ray Train 기법으로 음성 클로닝 시스템을 구축하는 과정을 다룹니다.
Qwen3-TTS는 1.7B 파라미터의 오픈소스 텍스트-투-스피치 모델이며, 다음과 같은 독특한 아키텍처를 사용합니다.
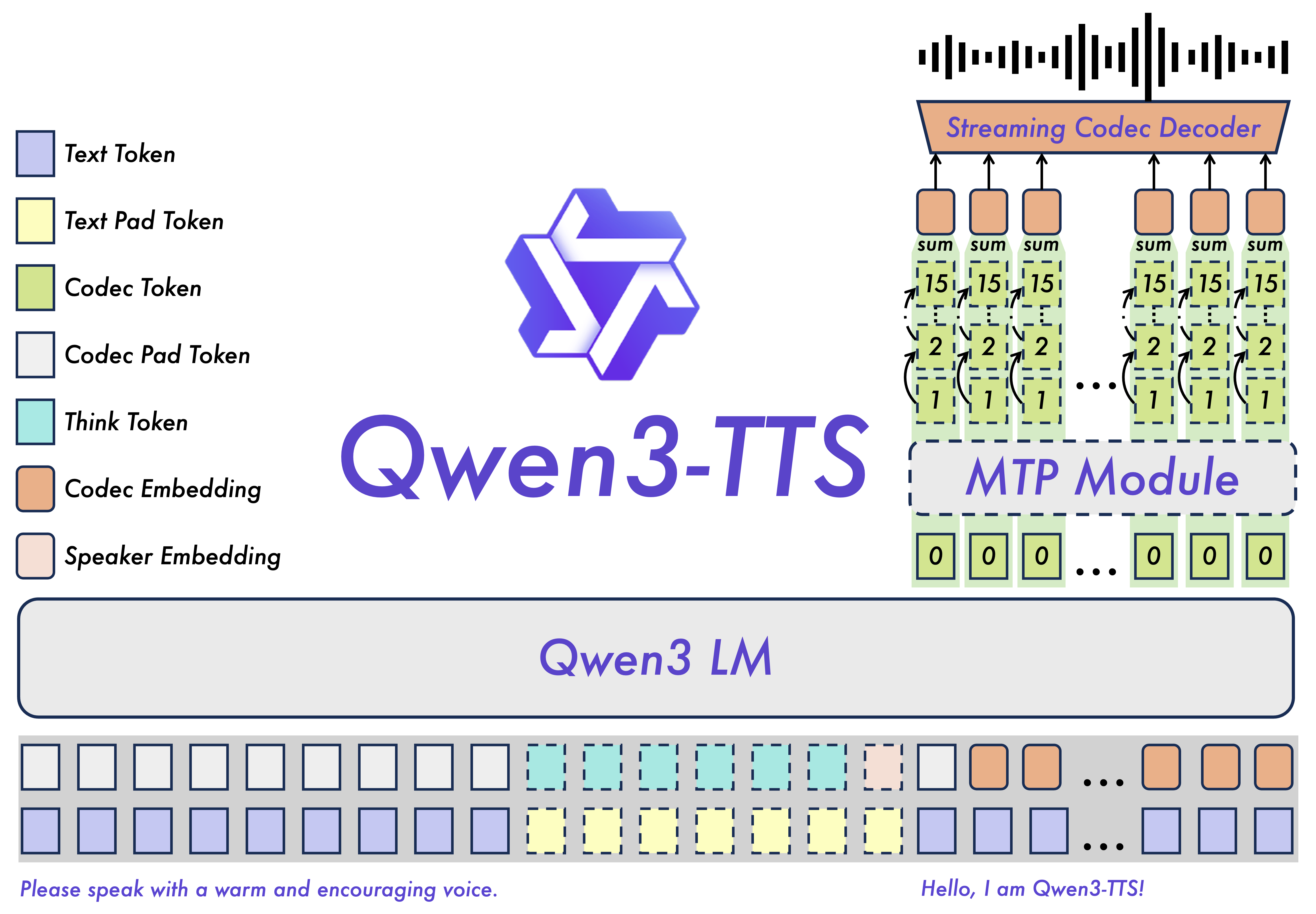
이 모델은 참조 오디오 샘플 하나만으로 제로샷 음성 클로닝이 가능하지만, 파인튜닝을 하면 특정 목소리 매칭을 훨씬 더 잘 할 수 있습니다.
이 프로젝트는 Ray Train을 이용한 분산 학습으로 Qwen3-TTS를 커스텀 보이스로 만드는 방법을 보여줍니다. 목표는 내 음성 녹음을 사용해 Qwen3-TTS-12Hz-1.7B-Base 모델을 적응시켜, 나만의 목소리를 클로닝하는 것입니다. 제 경우에는 제 목소리를 클로닝했습니다 :) 3~4시간 분량의 음성 녹음을 다운로드한 뒤 Whisper로 전사했습니다.
Goal: 내 음성 샘플로 Qwen3-TTS를 파인튜닝하여 개인화된 고품질 보이스 클론 생성.
워크플로우는 다음 단계들로 구성됩니다.
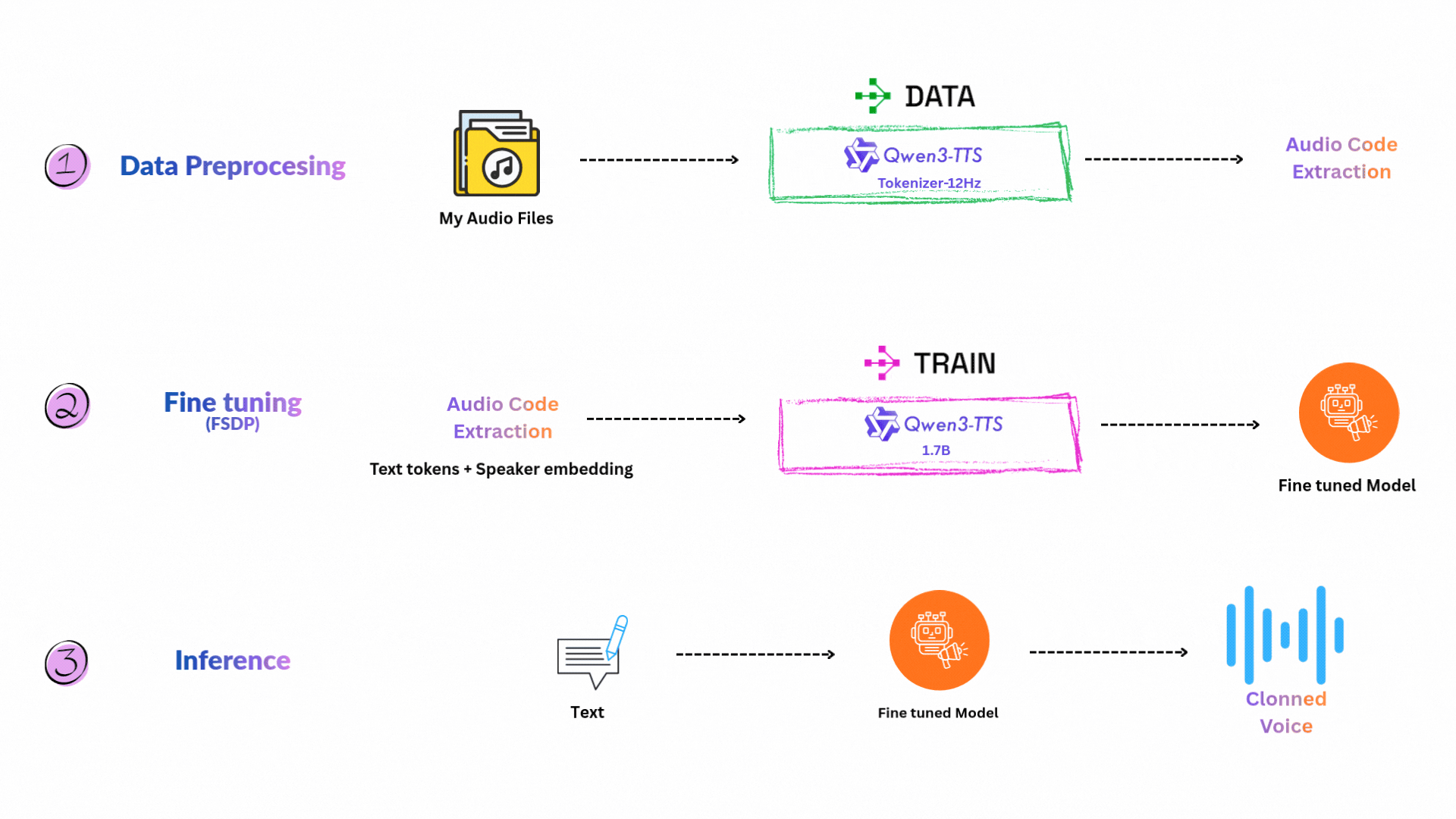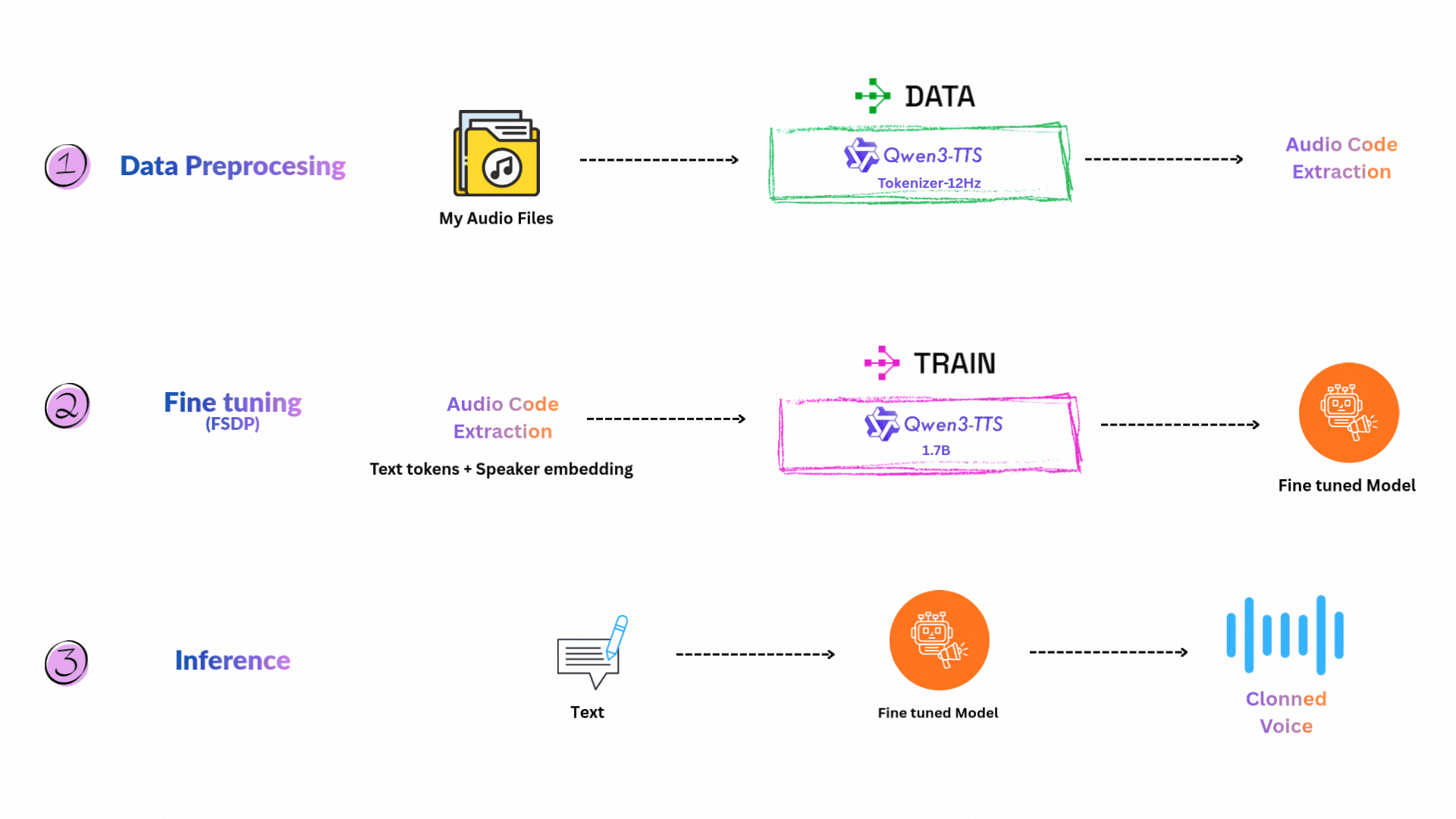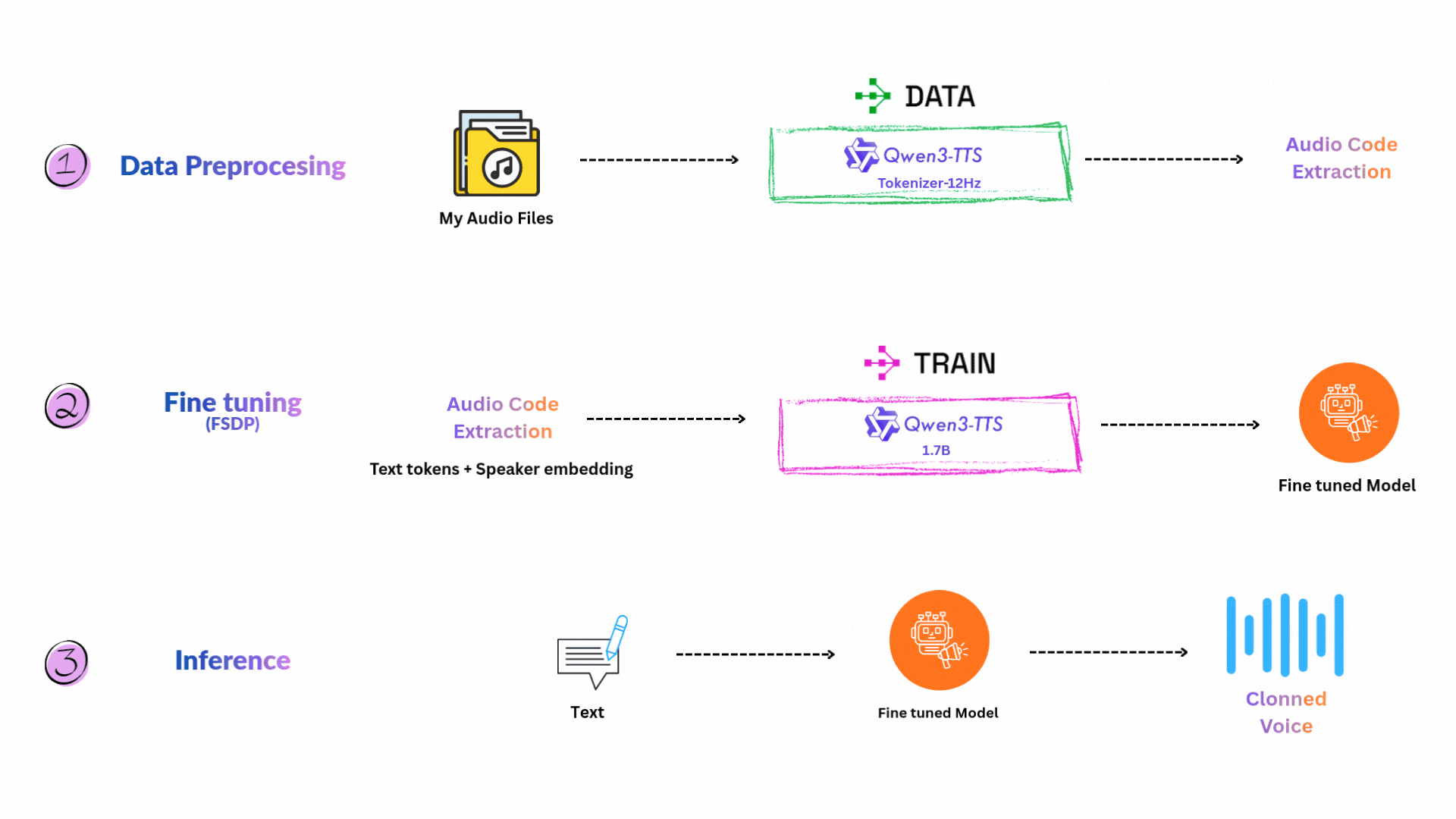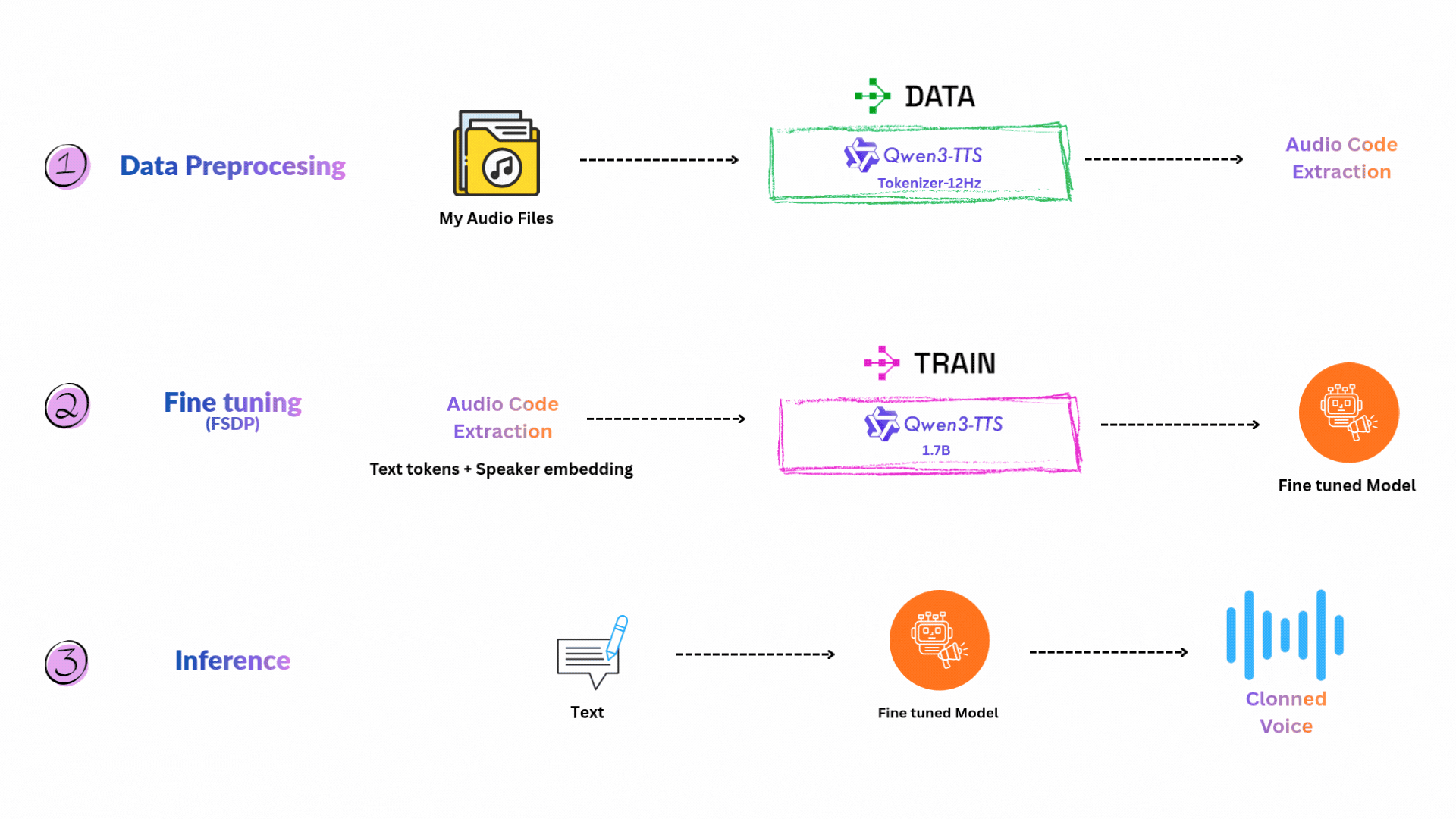
먼저 녹음 파일을 학습에 쓸 수 있는 세그먼트로 변환하고, Ray로 작업을 분산합니다.
import ray
import whisper
import numpy as np
@ray.remote(num_gpus=0.5) # Whisper에 GPU 사용
def process_audio_ray(audio_path: str, output_dir: str, config: dict):
"""Ray 워커에서 단일 오디오 파일 처리"""
import soundfile as sf
# Whisper 전사를 위해 16kHz로 오디오 로드
audio_16k, _ = sf.read(audio_path)
# Whisper로 전사
model = whisper.load_model("base")
result = model.transcribe(audio_16k, language="en", word_timestamps=True)
# Whisper 세그먼트를 기반으로 분절
segments = []
for seg in result["segments"]:
if 1.0 < (seg["end"] - seg["start"]) < 15.0: # 1~15초 세그먼트 유지
segments.append({
"audio": audio_16k[int(seg["start"]*16000):int(seg["end"]*16000)],
"text": seg["text"].strip()
})
# 개별 WAV로 저장
results = []
for i, seg in enumerate(segments):
seg_path = f"{output_dir}/{Path(audio_path).stem}_seg{i:04d}.wav"
sf.write(seg_path, seg["audio"], 24000) # Qwen3-TTS는 24kHz 기대
results.append({"audio": seg_path, "text": seg["text"]})
return results이제 각 WAV 파일을 process_audio_ray에 넘겨 Ray로 병렬 처리할 수 있습니다.
# 모든 오디오 파일을 병렬 처리
audio_files = list(Path("data/").glob("*.wav"))
futures = [process_audio_ray.remote(str(f), "output/wav/", config) for f in audio_files]
all_segments = ray.get(futures)출력은 각 줄에 audio 경로와 text 전사가 들어 있는 JSONL입니다.
{"audio": "output/wav/recording_seg0001.wav", "text": "Hello, this is my voice."}
{"audio": "output/wav/recording_seg0002.wav", "text": "I'm recording samples for training."}다음은 각 Ray 워커에서 실행되는 핵심 학습 함수입니다. 여기서 FSDP 지식이 모두 합쳐집니다.
import ray.train.torch
from ray import train as ray_train
def train_func(config: dict):
"""speaker embedding conditioning을 사용하는 Qwen3-TTS 파인튜닝"""
import torch
from qwen_tts import Qwen3TTSModel
from torch.utils.data import DataLoader, DistributedSampler
# 분산 컨텍스트 설정
rank = ray_train.get_context().get_world_rank()
world_size = ray_train.get_context().get_world_size()
local_rank = ray_train.get_context().get_local_rank()
device = torch.device(f"cuda:{local_rank}")
torch.cuda.set_device(device)
print(f"Worker {rank}/{world_size} starting on {device}")
# 사전학습 모델 로드
wrapper = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map=f"cuda:{local_rank}",
dtype=torch.bfloat16,
)
model = wrapper.model
talker = model.talker
# 대부분의 파라미터를 freeze, talker(audio generation)만 학습
for param in model.parameters():
param.requires_grad = False
for param in talker.parameters():
param.requires_grad = True
trainable = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Trainable parameters: {trainable:,}")
# 참조 오디오에서 speaker embedding(목소리 시그니처) 추출
import librosa
ref_audio, sr = librosa.load(config["ref_audio"], sr=24000, mono=True)
with torch.no_grad():
speaker_embedding = model.extract_speaker_embedding(ref_audio, sr=24000)
speaker_embedding = speaker_embedding.to(device).to(torch.bfloat16)
# DistributedSampler로 데이터 로딩
dataset = TTSDataset(config["train_jsonl"])
sampler = DistributedSampler(dataset, num_replicas=world_size, rank=rank)
dataloader = DataLoader(dataset, batch_size=config["batch_size"], sampler=sampler)
# 코사인 스케줄과 함께 AdamW
optimizer = torch.optim.AdamW(
[p for p in model.parameters() if p.requires_grad],
lr=config["learning_rate"],
weight_decay=0.01,
)
# 학습 루프
for epoch in range(config["num_epochs"]):
sampler.set_epoch(epoch)
epoch_loss = 0.0
for batch_idx, batch in enumerate(dataloader):
# 텍스트 토크나이즈
text_inputs = wrapper.processor.tokenizer(
batch["text"], padding=True, return_tensors="pt"
).to(device)
# 오디오 코드 [batch, time, 16]
audio_codes = torch.tensor(batch["audio_codes"]).to(device)
# 텍스트 임베딩 및 speaker conditioning 추가
with torch.no_grad():
text_embeds = talker.get_text_embeddings()(text_inputs["input_ids"])
text_embeds = talker.text_projection(text_embeds)
# speaker-conditioned hidden states로 forward
loss = torch.tensor(0.0, device=device)
for t in range(min(audio_codes.shape[1], 100)):
codec_ids = audio_codes[:, t, :]
# speaker embedding으로 컨디셔닝
text_hidden = text_embeds[:, min(t, text_embeds.shape[1]-1), :]
talker_hidden = text_hidden + 0.1 * speaker_embedding
# 오디오 코드 예측에 대한 loss
_, step_loss = talker.forward_sub_talker_finetune(
codec_ids=codec_ids,
talker_hidden_states=talker_hidden.to(torch.bfloat16)
)
if step_loss is not None:
loss = loss + step_loss
# backward
loss = loss / config["gradient_accumulation_steps"]
loss.backward()
if (batch_idx + 1) % config["gradient_accumulation_steps"] == 0:
torch.nn.utils.clip_grad_norm_(
[p for p in model.parameters() if p.requires_grad], 1.0
)
optimizer.step()
optimizer.zero_grad()
epoch_loss += loss.item()
# Ray Train에 메트릭 리포트
avg_loss = epoch_loss / len(dataloader)
ray_train.report({"loss": avg_loss, "epoch": epoch})
if rank == 0:
print(f"Epoch {epoch}: loss={avg_loss:.4f}")Note Speaker Embedding Conditioning
음성 클로닝의 핵심은 speaker embedding입니다. 참조 오디오에서 x-vector를 추출해 목소리의 고유 특성(피치, 음색, 말투 등)을 담습니다.
학습 중에는 이 임베딩을 텍스트 히든 상태에 더해, 모델이 내 목소리처럼 들리는 오디오 코드를 생성하도록 학습시킵니다.
이전 예시처럼 Ray Train으로 여러 GPU에서 학습을 실행합니다.
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig, RunConfig
# 학습 설정
train_config = {
"train_jsonl": "output/train_with_codes.jsonl",
"ref_audio": "output/wav/reference.wav",
"batch_size": 2,
"learning_rate": 1e-5,
"num_epochs": 10,
"gradient_accumulation_steps": 4,
}
# 4 GPU로 스케일
scaling_config = ScalingConfig(
num_workers=4,
use_gpu=True,
resources_per_worker={"CPU": 4, "GPU": 1}
)
run_config = RunConfig(
name="qwen_tts_voice_clone",
storage_path="/mnt/cluster_storage/",
)
# 학습 실행
trainer = TorchTrainer(
train_func,
train_loop_config=train_config,
scaling_config=scaling_config,
run_config=run_config,
)
print("Starting voice cloning training...")
result = trainer.fit()
print(f"Training complete! Checkpoint: {result.checkpoint}")예상 출력:
Worker 0/4 starting on cuda:0
Worker 1/4 starting on cuda:1
Worker 2/4 starting on cuda:2
Worker 3/4 starting on cuda:3
Trainable parameters: 847,234,560
Epoch 0: loss=2.4521
Epoch 1: loss=1.8734
Epoch 2: loss=1.5289
...
Epoch 9: loss=0.8142
Training complete!학습 후에는 클로닝된 목소리로 음성을 생성할 수 있습니다.
import torch
from qwen_tts import Qwen3TTSModel
# 베이스 모델 로드
wrapper = Qwen3TTSModel.from_pretrained(
"Qwen/Qwen3-TTS-12Hz-1.7B-Base",
device_map="cuda:0",
dtype=torch.bfloat16,
)
# 파인튜닝된 가중치 로드
checkpoint = torch.load("final_model/model.pt", map_location="cuda:0")
wrapper.model.load_state_dict(checkpoint["model_state_dict"], strict=False)
wrapper.model.eval()
# 음성 생성
text = "Hello! This is my cloned voice speaking. Pretty cool, right?"
with torch.no_grad():
wavs, sr = wrapper.generate_voice_clone(
text=text,
language="english",
ref_audio=("reference.wav", 24000),
x_vector_only_mode=True,
)
# 저장
import soundfile as sf
sf.write("my_voice_output.wav", wavs[0].cpu().numpy(), sr)
print("Generated speech saved to my_voice_output.wav")다음은 파인튜닝된 모델이 생성한 샘플 중 하나입니다(오디오 처음 10초).
이 글에서는 Fully Sharded Data Parallel(FSDP)을 깊이 있게 살펴보고, Ray Train과 함께 사용하여 대규모 딥러닝의 어려움을 해결하는 방법을 탐구했습니다. 먼저 전통적인 순차적 학습 접근이 GPU 자원을 충분히 활용하지 못하고, 모델이 커질수록 빠르게 비현실적이 되는 이유를 확인했습니다. 이후 FSDP가 모델 파라미터를 수직(unit)과 수평(GPU 간)으로 분할하여, 스마트한 샤딩과 통신을 통해 거대한 모델을 효율적으로 학습하는 방식을 이해했습니다.
또한 FSDP로 한 번의 학습 이터레이션에서 실제로 어떤 일이 일어나는지(계산을 위해 파라미터를 all-gather하고, 다시 reshard한 뒤, 분산 backprop과 옵티마이저 스텝을 수행하는 과정)를 단계별로 분해했습니다. 그리고 이를 실제 코드로 구현했습니다. 먼저 프로덕션 품질의 분산 코드로 ViT를 학습했고, 이어서 17억 파라미터 TTS 모델을 파인튜닝하여 특정 목소리를 클로닝하는 실제 애플리케이션으로 확장했습니다.
FSDP는 중요한 트레이드오프를 합니다. 파라미터를 샤딩해 메모리 사용량을 줄이는 대신, 디바이스 간 통신이 늘어납니다. 하지만 계산-통신 오버랩 같은 기법 덕분에 이 오버헤드는 관리 가능하며, 이전보다 훨씬 큰 모델을 학습할 수 있습니다.
FSDP와 Ray Train 같은 분산 학습 엔진은, 최근까지 거대 연구소만 가능했던 역량을 더 넓은 사용자에게 열어줍니다. 우리가 만든 보이스 클로닝 파인튜닝 모델은 대규모 학습의 실용적 파워를 보여줍니다. 비록 오늘날 기준으로 “엄청 큰” 모델은 아닐지라도, 분산 학습과 FSDP의 기본을 이해하기 위한 좋은 출발점이었습니다.
Anyscale and Ray
Distributed Training
GPU/System Engineering
LLM and Advance Deep Learning
Ray, PyTorch and DeepSpeed