PyTorch로 분산 학습의 기초(메모리 병목, 체크포인팅, 그래디언트 누적, 데이터 병렬, ZeRO 1~3)를 직접 구현 관점에서 이해하고, Ray Train과 PyTorch FSDP로 멀티 GPU/멀티 노드 학습을 확장하는 과정을 정리한다.
Title: PyTorch와 Ray로 분산 학습을 실전으로 파헤쳐 보기 – 내 블로그
딥러닝 모델은 날이 갈수록 더 커지고 더 복잡해지고 있으며, 학습 시 마주치는 도전 과제도 함께 커지고 있습니다. 저도 사실 분산 학습은 아직 초보에 가깝고, 여러 형태의 병렬성을 활용해 여러 GPU, 나아가 여러 대의 머신으로 학습을 확장하는 방법을 지금도 파악해 가는 중입니다.
제가 빠르게 깨달은 건, 더 큰 난관은 학습 알고리즘 자체가 아니라 분산 시스템이 어떻게 동작하는지 이해하고, 자원(GPU/CPU)을 효율적으로 관리하는 것이라는 점이었습니다!
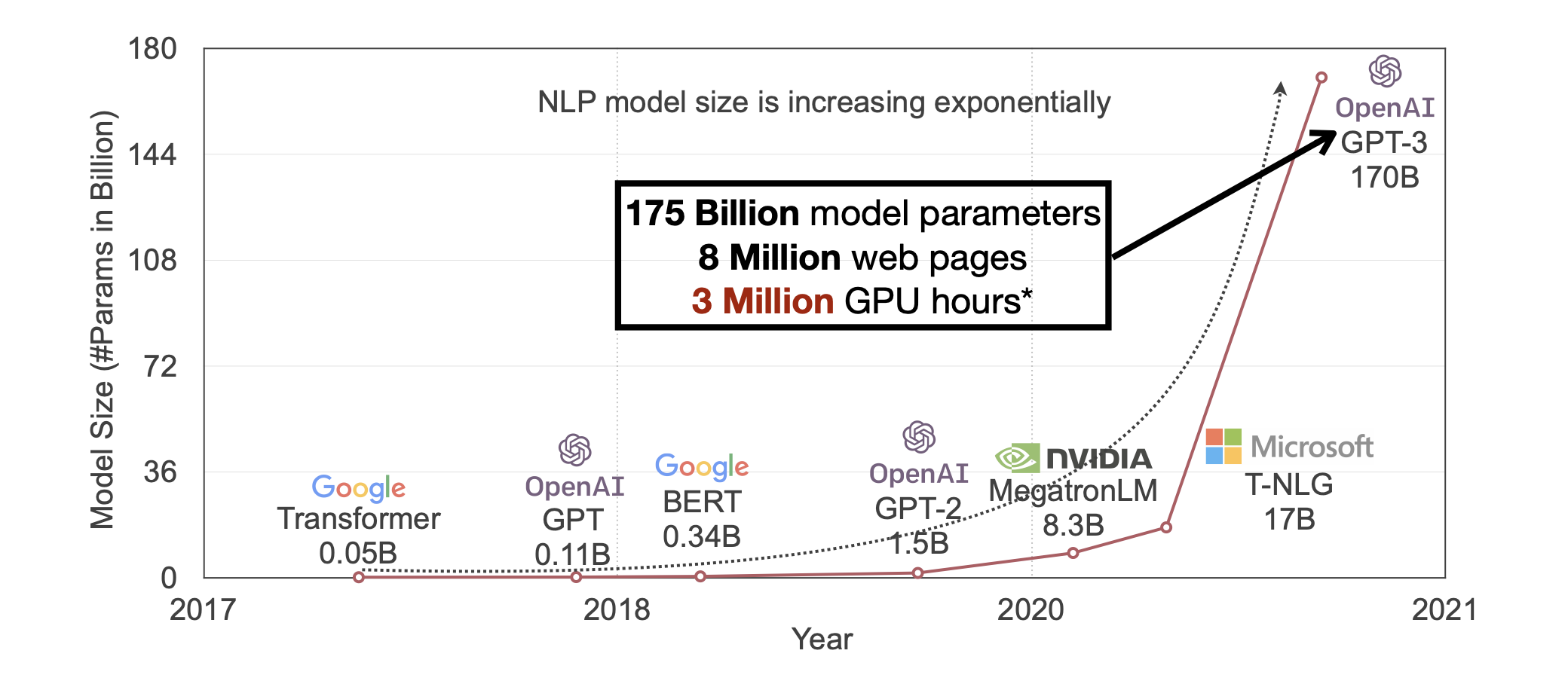
모델이 커질수록 학습 시간은 폭발적으로 증가하며, 단일 GPU에서 한 에폭(epoch)만 도는 데도 며칠, 몇 주, 심지어 몇 달이 걸리기도 합니다.
| Model | Parameters (Millions) | Training Time on A100 (GPU Hours) |
|---|---|---|
| ResNet-50 | 26 | 31 |
| ResNet-101 | 45 | 44 |
| BERT-Base | 108 | 84 |
| Turing-NLG 17B | 17,000 | TBA |
| GPT-3 175B | 175,000 | 3,100,000 |
이 표를 보면 파라미터 수와 학습 시간이 모두 급격히 증가하는 것을 확인할 수 있습니다.
Note
만약 GPT-3를 단일 GPU에서 학습하려고 한다면 완료까지 대략 355년이 걸립니다. 모델 크기와 학습 시간 요구가 치솟는 지금, 분산 학습은 유용한 수준을 넘어 절대적으로 필수입니다.
그런데 왜 이런 일이 생길까요?
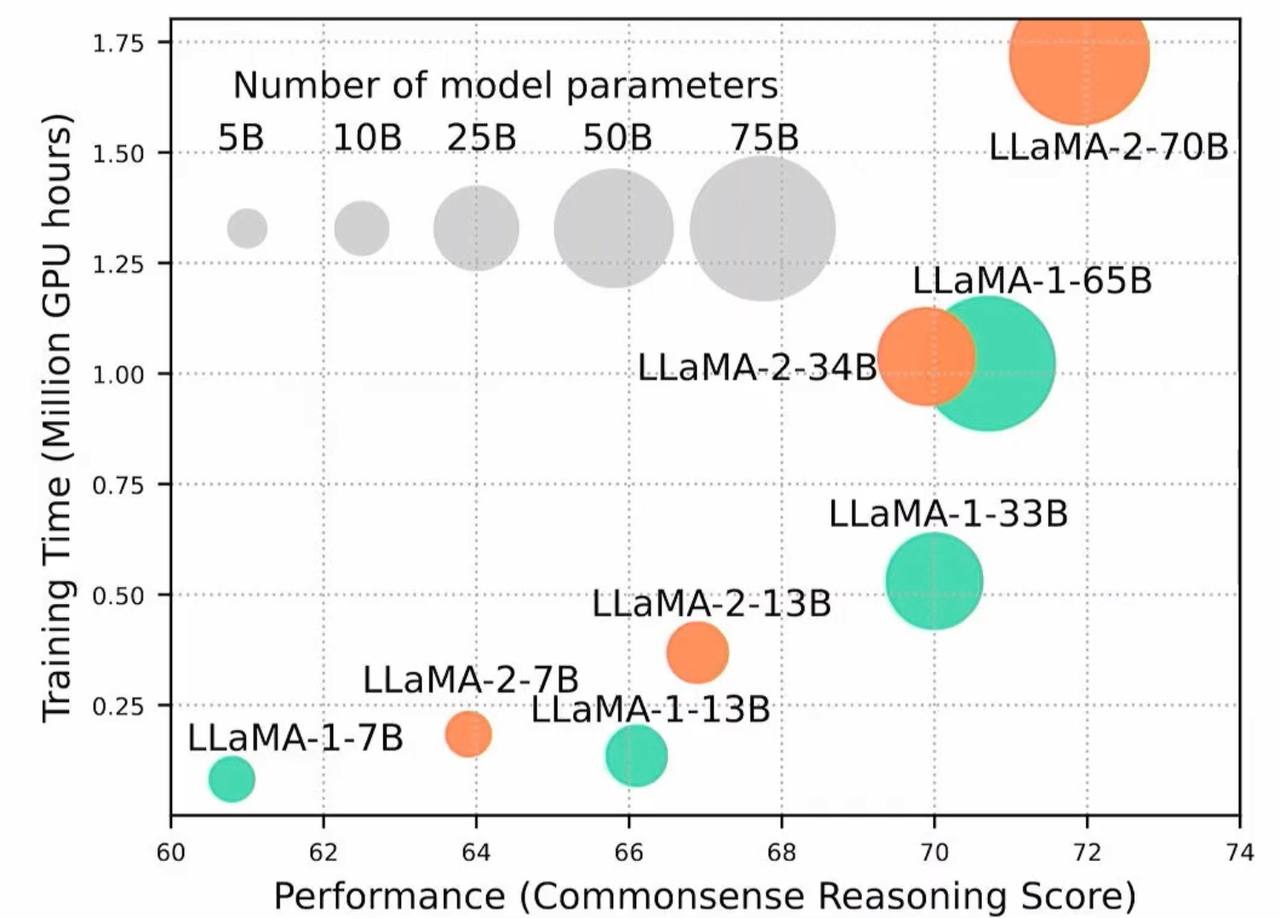
예로 LLaMA 모델 패밀리를 보겠습니다. 아래 그래프는 모델 크기(원 지름)가 커질수록 성능은 좋아지지만, 학습 시간도 더 필요해지는 모습을 보여줍니다. y축을 보면 수백만 GPU 시간입니다! 이런 거대 모델을 단일 GPU에서 학습하는 것은 느린 수준을 넘어 사실상 불가능에 가깝습니다.
이 글에서는 분산 학습을 바닥부터 탐구해 보면서, 다양한 병렬화 기법으로 딥러닝을 여러 GPU/머신으로 확장하는 방법을 살펴봅니다. 먼저 PyTorch로 이러한 전략을 바닥부터 구현해 보고, 이후 Ray를 사용해 확장 가능한 학습으로 레벨업해 보겠습니다.
말했듯이 저는 분산 학습 여정의 아직 첫 에폭을 달리는 중입니다! 배우는 대로 이 글도 계속 업데이트할 예정입니다.
들어가기 전에, 함께 도움을 준 훌륭한 분들께 감사 인사를 전하고 싶습니다: Prof.Tanmoy Chakraborty, Dr.Yatin Nandwani, Prof.Song Han, 멘토이자 선생님인 Rohan Shravan(수년간 뛰어난 가르침과 가이드에 감사드립니다), 그리고 친구/동료 Dipankar Ranjan Baisya, Chris Fregly, Zachary Mueller, Ram Mohan, Debanjan Saha, Siddhant Gupta.
이 글의 대부분의 내용은 그분들의 작업, 강의, 조언에서 영감을 받았습니다. 모든 참고자료와 리소스는 글 마지막에 정리했습니다.
확장에 들어가기 전에, 간단한 다층 퍼셉트론(MLP) 같은 표준 학습 루프를 빠르게 복습해 보겠습니다.
1 model = MLP().to(device)
2 optimizer = Adam(model.parameters())
3 criterion = CrossEntropyLoss()
4 data_loader = DataLoader(dataset)
5
6 for epoch in range(num_epochs):
7 model.train()
8 for inputs, targets in data_loader:
9 # 1. Move batch to GPU
10 inputs, targets = inputs.to(device), targets.to(device)
11
12 # 2. Clear gradients
13 optimizer.zero_grad()
14
15 # 3. Forward pass
16 outputs = model(inputs)
17 loss = criterion(outputs, targets)
18
19 # 4. Backpropagation
20 loss.backward()
21
22 # 5. Optimization
23 optimizer.step()
각 에폭에서 무엇이 일어나나요?
line 6-8).line 9-10).line 12-13).line 15-17).line 18-19).line 20-21).
이 패턴이 대부분의 딥러닝 학습 루프의 핵심입니다(사실 어떤 머신러닝 학습 루틴의 핵심이기도 합니다).
단일 GPU에서 딥러닝 모델을 학습할 때, 고대역폭 메모리(HBM)를 잡아먹는 큰 요소는 네 가지입니다.
모델이 학습하는 가중치들입니다. 2. 파라미터 그래디언트 ():
역전파 중 계산되는 그래디언트로, 파라미터 업데이트에 사용됩니다. 3. 옵티마이저 상태(optimizer states) ():
Adam의 모멘텀/분산 같은 옵티마이저가 추가로 필요로 하는 변수들입니다.
4. 활성값(activations) ():
각 레이어의 중간 출력으로, 역전파에서 그래디언트 계산에 필요합니다.
처음 세 가지(파라미터, 그래디언트, 옵티마이저 상태)는 **정적(static)**입니다. 모델 아키텍처가 정하는 고정 메모리 풋프린트를 구성합니다.
반면 활성값은 **동적(dynamic)**으로, 배치/시퀀스 길이에 따라 달라지며 대규모 학습에서 종종 가장 큰 병목이 됩니다.
학습 루프를 다시 보면 optimizer.step() 전까지는 모든 것이 메모리에 유지되어야 합니다. 이후에는 활성값과 그래디언트를 버릴 수 있지만, 모델 파라미터와 옵티마이저 상태는 계속 남습니다.
가 전체 파라미터 개수일 때, Adam을 사용한 정적 메모리()는 깔끔하게 바이트입니다.
| Component | Precision | Size ( Bytes) | Details |
|---|---|---|---|
| Model Parameters | BF32 (4 bytes) | Used for fwd/back passes | |
| Parameter Gradients | BF32 (4 bytes) | For backpropagation | |
| Optimizer States (Adam) | FP32 (4+4 bytes) | 1st and 2nd moment estimates | |
| Total Static Memory | Absolute minimum for static storage |
Note Adam 옵티마이저가 파라미터당 바이트를 쓰는 이유
Adam은 각 파라미터에 대해 FP32(4바이트) 텐서 두 개를 추가로 유지합니다: 1차 모멘트(그래디언트 평균, )와 2차 모멘트(비중심 분산, )입니다. 따라서 파라미터당 바이트(용) + 바이트(용)로 합계 바이트가 됩니다.
대형 모델을 최적화할 때 메모리 관리는 예술입니다. 현대 LLM 학습은 보통 **혼합 정밀도(mixed precision)**를 사용하며, 빠른 연산을 위해 BF16(2바이트)을 쓰되 정확도를 위해 가중치와 옵티마이저 상태는 FP32(4바이트) 복사본을 유지합니다.
Tip Mixed Precision Training
혼합 정밀도 학습은 16비트(BF16/FP16)와 32비트(FP32) 부동소수 연산을 결합해 딥러닝을 가속하고 메모리 사용을 줄입니다.
마스터(master) 복사본을 유지합니다.혼합 정밀도에서 메모리 사용은 아래와 같습니다.
| Component | Precision | Size ( Bytes) | Details |
|---|---|---|---|
| Model Parameters | BF16 (2 bytes) | For forward/backward passes | |
| Parameter Gradients | BF16 (2 bytes) | Backpropagation | |
| Master Weights | FP32 (4 bytes) | For weight updates | |
| Optimizer States (Adam) | FP32 (4+4 bytes) | 1st/2nd moment estimates | |
| Total Static Memory | Unchanged overall |
총 정적 메모리가 여전히 바이트인 것을 볼 수 있습니다. 그럼 혼합 정밀도의 이점은 무엇일까요?
정적 풋프린트는 줄지 않더라도 학습이 더 빨라지고, 더 큰 동적 활성값을 넣을 수 있어 GPU를 최대한 활용할 수 있습니다.
하지만 냉정한 현실이 있습니다. 70B 파라미터 모델은 정적 메모리만 해도 대략 이며, 이는 A100 80GB 단일 GPU로는 턱없이 부족합니다. 활성값은 아직 계산도 안 했는데 말이죠!
동적 메모리, 특히 활성값은 입력에 완전히 의존하며 보통 메모리 문제의 주범입니다.
활성값: 각 레이어의 출력입니다. 그래디언트를 계산하려면 **역전파(backward pass)**까지 저장해야 합니다.
활성값 메모리 추정식: 혼합 정밀도에서 활성값 총 메모리()는 다음 식으로 대략 추정할 수 있습니다.
Where:
* : 레이어 수
* : 시퀀스 길이
* : 배치 크기(샘플 수)
* : 히든 차원
* : 어텐션 헤드 수

활성값 메모리는 모델만으로 고정되지 않고 다음과 같이 커집니다.
선형 증가제곱 증가이 제곱 증가(어텐션 행렬 덕분이죠!) 때문에 배치나 시퀀스 길이를 키우면 활성값 메모리가 통제 불능으로 불어납니다.
예상했겠지만 시퀀스가 길수록 활성값이 많아지고 메모리도 더 필요합니다. 실제로 긴 시퀀스 하나만으로도 50GB를 넘길 수 있습니다! 큰 모델을 학습한다면 이는 매우 큰 제약입니다.
Note Global Batch Size
LLM 사전학습에서 배치 크기는 보통 시퀀스 개수가 아니라 토큰 수를 의미합니다. 토큰 배치 크기는 시퀀스 길이 × 마이크로 배치 크기입니다.
현업 사전학습은 매우 큰 글로벌 배치(종종 수백만 토큰)를 사용합니다. 실무에서는 작은 배치로 시작(노이즈가 많아 빠르게 진행)한 뒤, 수렴에 가까워질수록 안정성과 정확도를 위해 배치를 키웁니다.

스케일을 체감하기 위해 Llama 3.1( 8B, 13B, 70B)의 메모리 사용을 보겠습니다.
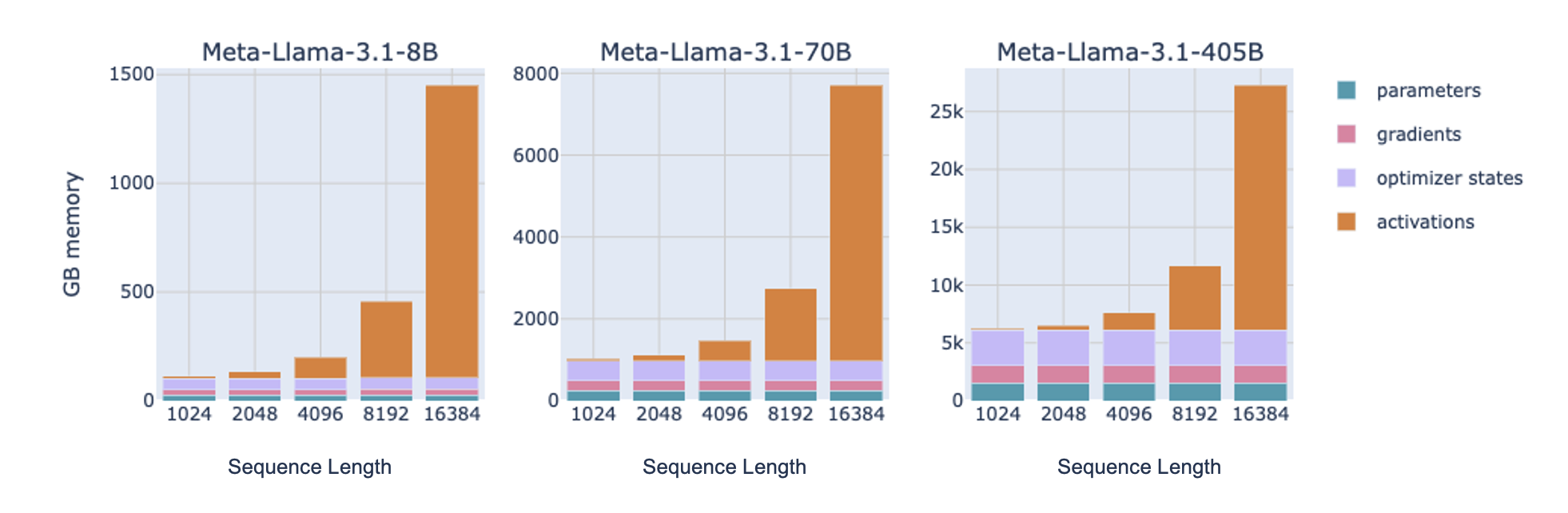
이 그래프에서 짧은 시퀀스(또는 작은 배치)에서는 활성값 메모리가 거의 무시할 수준이지만, 대략 4K~16K 토큰부터는 크게 증가합니다(앞서 말한 시퀀스 길이의 제곱 스케일링 때문). 반면 파라미터/그래디언트/옵티마이저 상태 메모리는 시퀀스 길이나 배치 크기와 거의 무관합니다.
이 activation explosion(활성값 폭발) 문제를 어떻게 풀 수 있을까요? 모든 활성값을 저장하지 않도록 할 수 있을까요?
왜 모든 활성값을 저장할까요? 역전파에서 파라미터 그래디언트를 계산하려면 필요하기 때문입니다. 그렇다면 모든 활성값을 메모리에 들고 있지 않도록 할 수 있을까요?
이를 수행하는 기법이 그래디언트 체크포인팅(gradient checkpointing), 또는 **활성값 재계산(activation recomputation)**입니다. 순전파 중 일부 활성값만 저장하고, 역전파 때 누락된 것들을 즉석(on-the-fly)에서 다시 계산합니다. 메모리는 절약하지만, 계산량이 늘어납니다!
보통은 학습 가능한 연산(FFN, LayerNorm 등) 사이의 모든 히든 상태를 저장해 역전파에 씁니다. 활성값 재계산에서는 특정 체크포인트의 활성값만 저장하고, 나머지는 역전파 중에 다시 계산합니다. 이렇게 하면 대형 모델 학습에서 메모리를 관리할 수 있습니다.
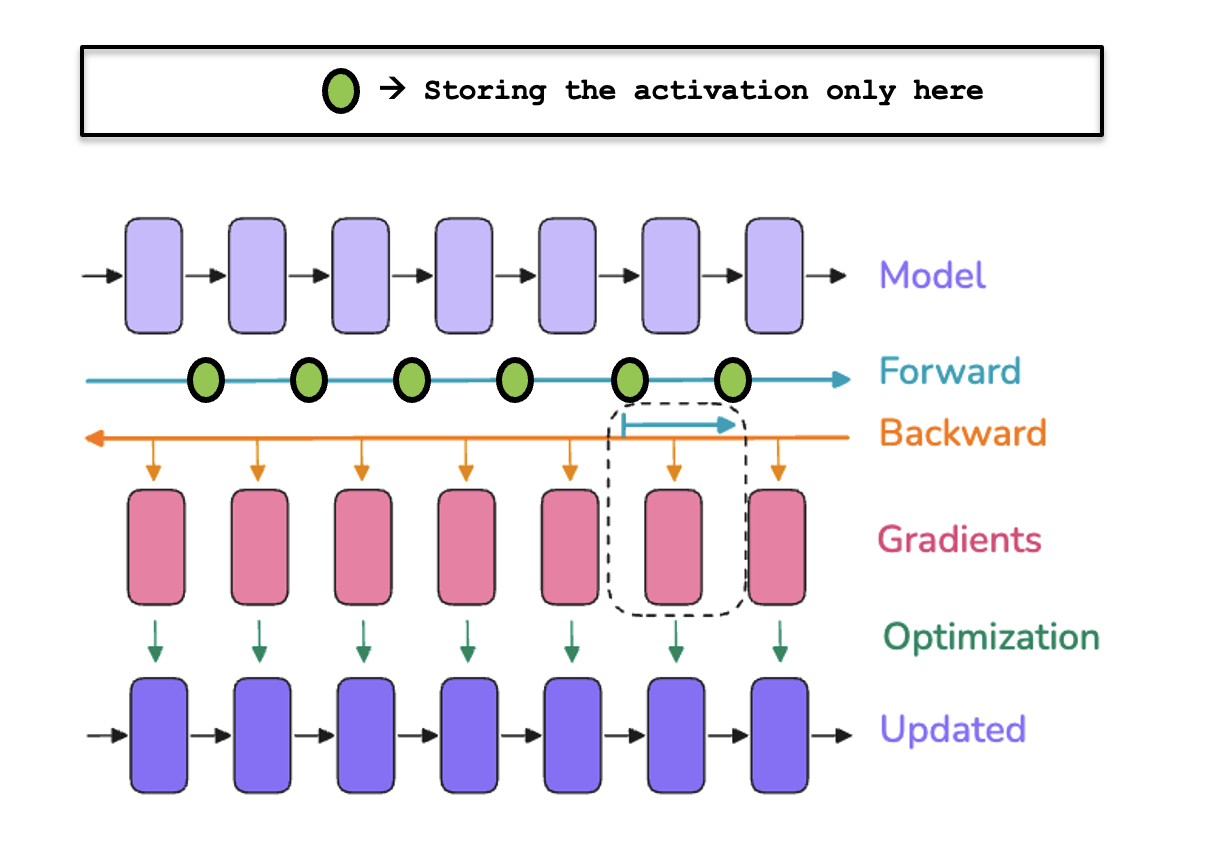
물론 공짜 점심은 없습니다. 메모리는 줄지만 역전파 동안 활성값을 재생성하느라 추가 연산이 필요합니다. 체크포인팅에는 여러 방식이 있고, 각 방식은 메모리/연산 트레이드오프가 다릅니다.
가장 공격적인 방식은 Full Activation Checkpointing으로, 각 레이어 끝의 활성값만 저장합니다(중간 활성값은 저장하지 않음). 메모리 관점에서는 매우 좋지만, 역전파에서 거의 모든 것을 재계산해야 해서 연산 시간이 30~40% 늘어날 수 있습니다.
그런데 정말 모델의 모든 부분을 같은 방식으로 다뤄야 할까요? 프로파일링을 해 보면 메모리의 주범은 시퀀스 길이에 대해 제곱 스케일링하는 **Multi-Headed Attention(MHA)**의 활성값입니다.
그래서 보다 균형 잡힌 전략인 Selective Checkpointing이 등장합니다. 무거운 MHA 레이어의 활성값만 저장을 생략하고, 비교적 가벼운 MLP 레이어는 저장합니다. 효과는 인상적입니다. 약 2.7% 추가 연산으로 최대 70% 메모리를 절약할 수 있습니다.
Note Llama 3.1 8B에서의 Activation Checkpointing
아래 그래프를 보면 8B 파라미터 모델에서 배치 1, 시퀀스 길이 4096일 때 체크포인팅이 없으면 활성값 메모리가 97GB까지 치솟아 대부분의 GPU를 터뜨릴 수 있습니다. selective activation checkpointing을 쓰면 17GB로 줄고, full checkpointing은 극단적으로 1GB까지도 내려갑니다!

이제 재계산을 알게 되었으니 앞선 그래프에서 본 활성값 메모리 사용을 어느 정도 제어할 수 있습니다.
하지만 활성값은 배치 크기에 선형으로 의존하므로 배치를 키우면 다시 문제가 될 수 있습니다. 그럼 배치를 어떻게 늘릴 수 있을까요?
이를 위해 다음 도구인 **그래디언트 누적(gradient accumulation)**을 살펴보겠습니다.
그래디언트 누적은 여러 마이크로 배치(micro-batch)에 대해 그래디언트를 누적한 뒤, 한 번의 전역 최적화 스텝을 수행하는 기법입니다. 큰 배치 크기를 원하지만 메모리 부족이 걱정될 때 특히 유용합니다.
아이디어는 배치를 더 작은 마이크로 배치(예: 3개)로 쪼개서 하나씩 처리하는 것입니다. 각 마이크로 배치에서 그래디언트를 계산해 누적하고(각 마이크로 배치마다 optimizer.step()을 하지 않습니다), 모두 처리한 뒤 한 번만 전역 최적화 스텝을 수행합니다.
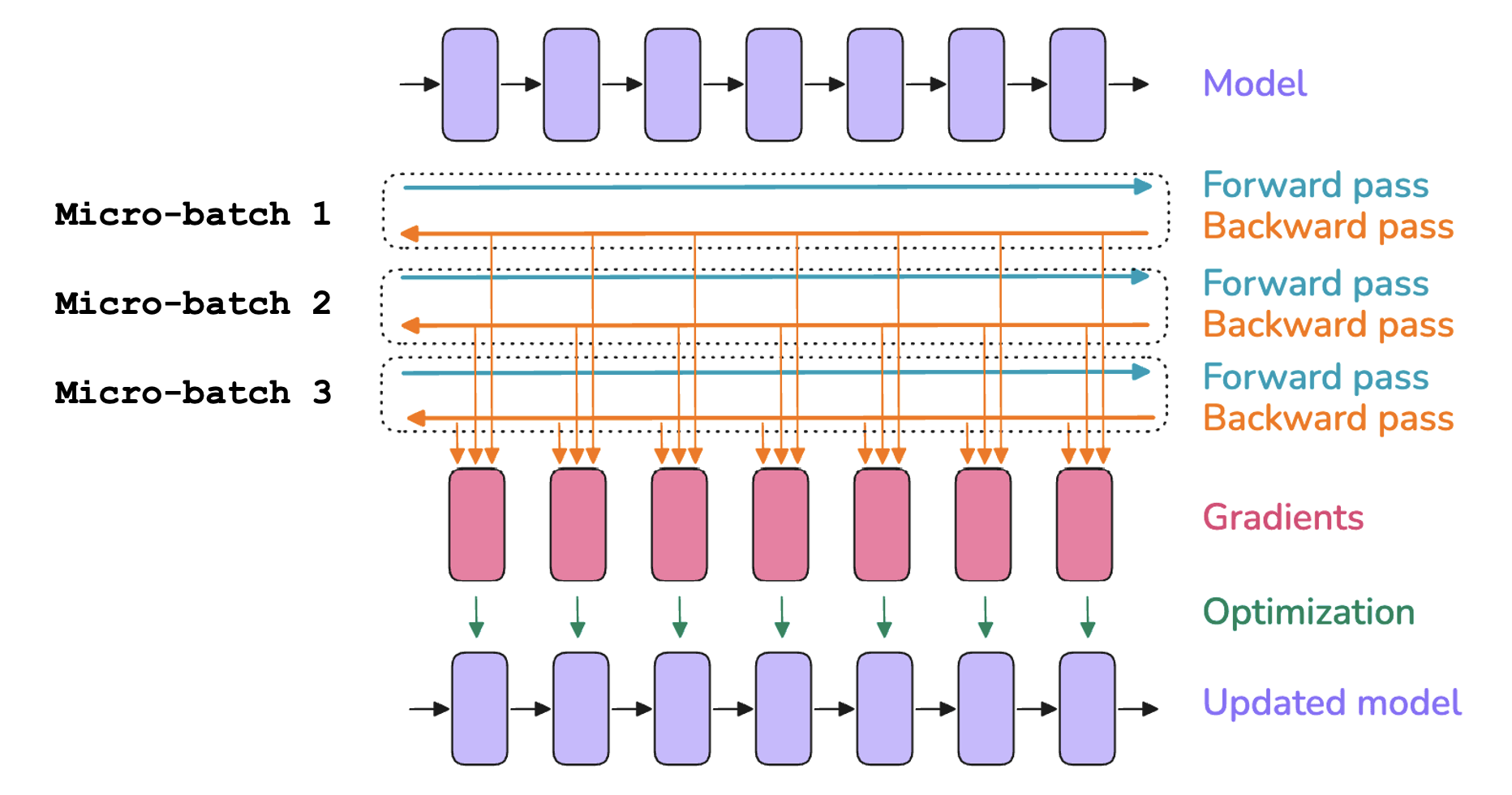
간단한 선형 회귀 예시로 보겠습니다. 두 변수로 학생의 시험 점수를 예측한다고 합시다.
공부 시간 ()전날 수면 시간 ()입력과 출력 점수 사이에 선형 관계를 가정합니다: 목표는 확률적 경사하강법으로 , , 를 찾아 MSE를 최소화하는 것입니다: 그래디언트 누적이 없다면 매 배치마다 파라미터를 업데이트합니다.
1 def train_no_accumulate(params: ModelParameters,
2 num_epochs: int = 10,
3 learning_rate: float = 1e-3):
4 for epoch in range(1, num_epochs + 1):
5 for (x1, x2), y_target in training_data:
6
7 # Calculate the output of the model
8 z1 = x1 * params.w1
9 z2 = x2 * params.w2
10 y_pred = z1 + z2 + params.b
11 loss = (y_pred - y_target) ** 2
12
13 # Calculate the gradients of the loss w.r.t. the parameters
14 loss.backward()
15
16 # Update the parameters (at each iteration)
17 with torch.no_grad():
18 # Equivalent to calling optimizer.step()
19 params.w1 -= learning_rate * params.w1.grad
20 params.w2 -= learning_rate * params.w2.grad
21 params.b -= learning_rate * params.b.grad
22
23 # Reset the gradients to zero
24 # Equivalent to calling optimizer.zero_grad()
25 params.w1.grad.zero_()
26 params.w2.grad.zero_()
27 params.b.grad.zero_()
그래디언트 누적을 쓰면 배치마다 업데이트하지 않고, 여러 마이크로 배치(micro_batch_size = 3)에 걸쳐 그래디언트를 누적한 뒤 한 번에 업데이트합니다.
메모리가 제한되어도 더 큰 유효 배치 크기로 학습할 수 있습니다.
1 def train_accumulate(params: ModelParameters,
2 num_epochs: int = 10,
3 learning_rate: float = 1e-3,
4 micro_batch_size: int = 3):
5
6 for epoch in range(1, num_epochs + 1):
7 for index, ((x1, x2), y_target) in enumerate(training_data):
8
9 # Calculate the output of the model
10 z1 = x1 * params.w1
11 z2 = x2 * params.w2
12 y_pred = z1 + z2 + params.b
13 loss = (y_pred - y_target) ** 2
14
15 # Accumulate gradients
16 loss.backward()
17
18 # If we have processed 3 micro-batches OR reached the end of the dataset
19 if (index + 1) % micro_batch_size == 0 or index == len(training_data) - 1:
20 with torch.no_grad():
21 # Equivalent to optimizer.step()
22 params.w1 -= learning_rate * params.w1.grad
23 params.w2 -= learning_rate * params.w2.grad
24 params.b -= learning_rate * params.b.grad
25
26 # Reset the gradients = optimizer.zero_grad()
27 params.w1.grad.zero_()
28 params.w2.grad.zero_()
29 params.b.grad.zero_()
그래디언트 누적은 배치 크기에 선형으로 증가하는 활성값 메모리를 줄입니다. 더 작은 마이크로 배치를 순차적으로 처리하므로 한 번에 메모리에 유지해야 하는 활성값이 마이크로 배치 하나 분량이면 됩니다. 따라서 전체 활성값 풋프린트를 줄이는 데 도움이 됩니다.
여기에도 트레이드오프가 있습니다. 옵티마이저 스텝 전까지 더 많은 순전파/역전파를 수행하므로 계산량이 증가해 학습이 느려질 수 있습니다. 하지만 제한된 하드웨어에서 훨씬 큰 유효 배치 크기를 가능하게 합니다.
지금까지 gradient checkpointing과 gradient accumulation으로 활성값으로 인한 동적 메모리 폭증을 다루는 방법을 보았습니다.
둘 다 단일 GPU에서 더 큰 모델이나 배치를 넣을 수 있게 해 주지만, 대부분 순차 처리로 인해 학습 속도를 늦춥니다. 또한 파라미터/그래디언트/옵티마이저 상태에 필요한 정적 메모리를 해결하지 못하며, (GPU가 여러 개 있다고 가정할 때) 하드웨어도 충분히 활용하지 못합니다.
이를 해결하기 위해 여러 GPU로 학습을 확장하는 **데이터 병렬(Data Parallelism)**을 사용할 수 있습니다. 마이크로 배치를 쪼개 여러 GPU에서 동시에 처리함으로써 메모리와 연산 병목을 함께 완화할 수 있습니다.
그래디언트 누적에서는 **마이크로 배치(MBS)**를 순차적으로 처리했습니다. 마이크로 배치들은 서로 독립적이므로, 서로 다른 GPU에서 병렬 처리할 수 있습니다.
아래 그림처럼 말이죠. 이제 micro-batches를 여러 GPU에서 병렬로 처리합니다. 그래디언트 누적에서는 단일 GPU에서 순차로 처리했던 것과 대비됩니다. 이것이 데이터 병렬(DP)입니다.
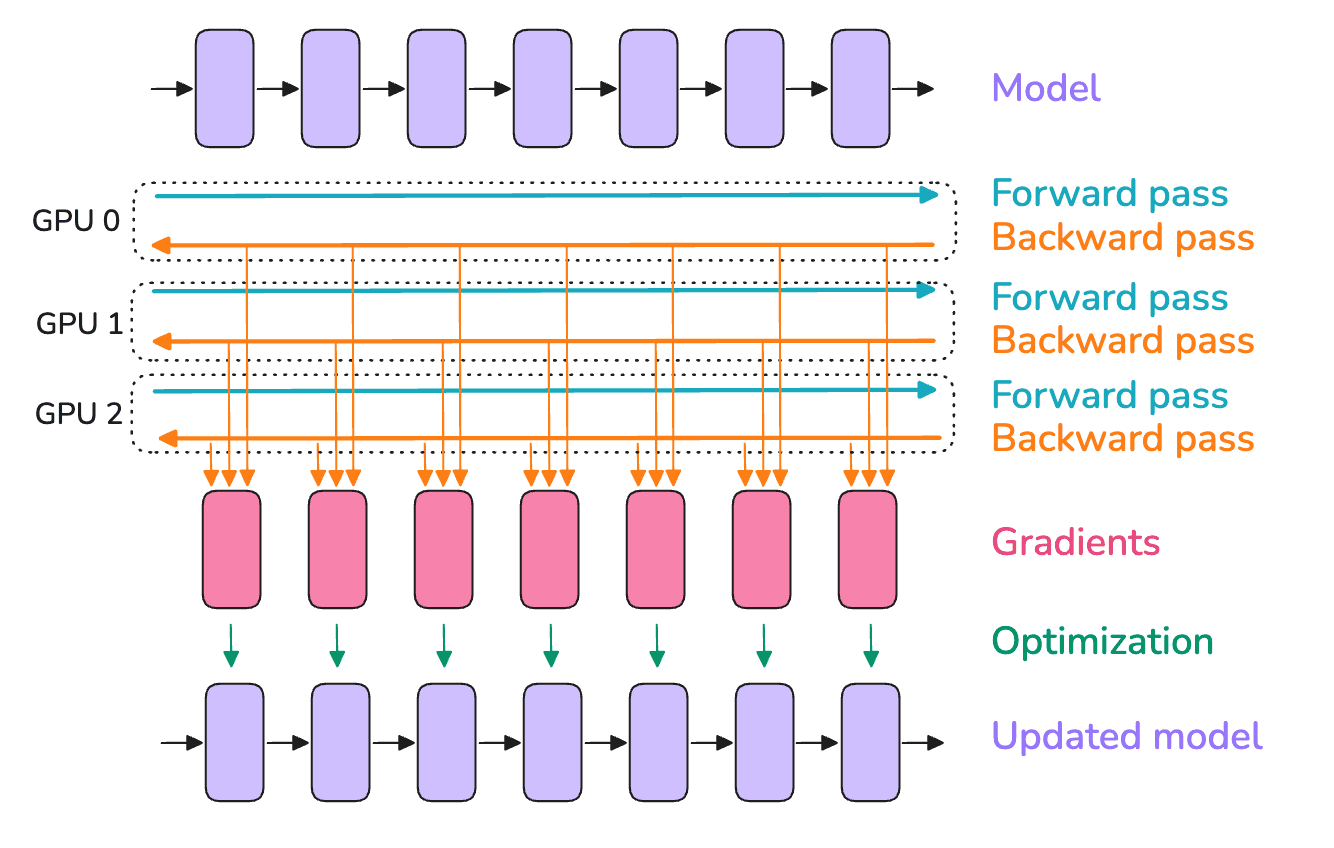
데이터 병렬에서는 데이터를 여러 GPU에 나누어 주되, 각 GPU마다 모델 파라미터, 그래디언트, 옵티마이저 상태의 완전한(중복) 복제본을 유지합니다.
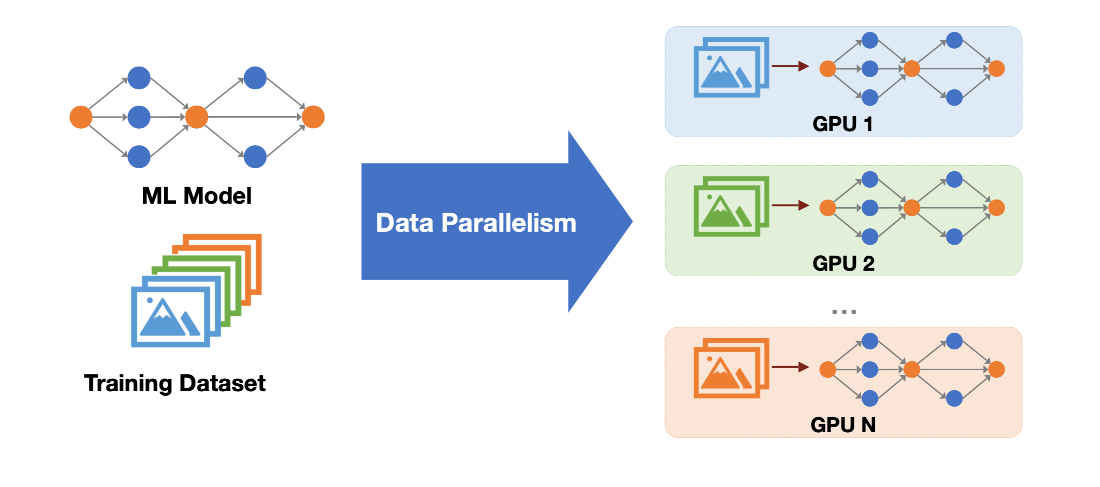
SIMD(Single Instruction Multiple Data)라고도 부릅니다.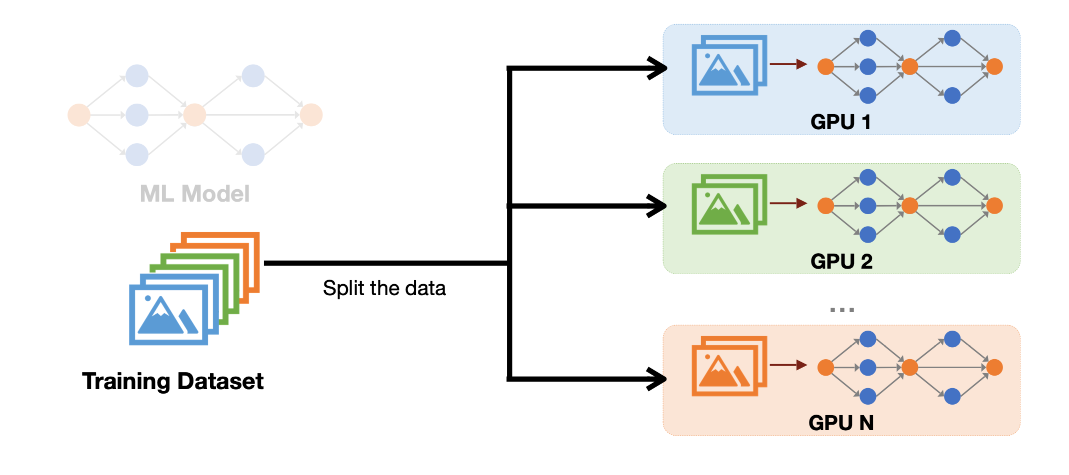
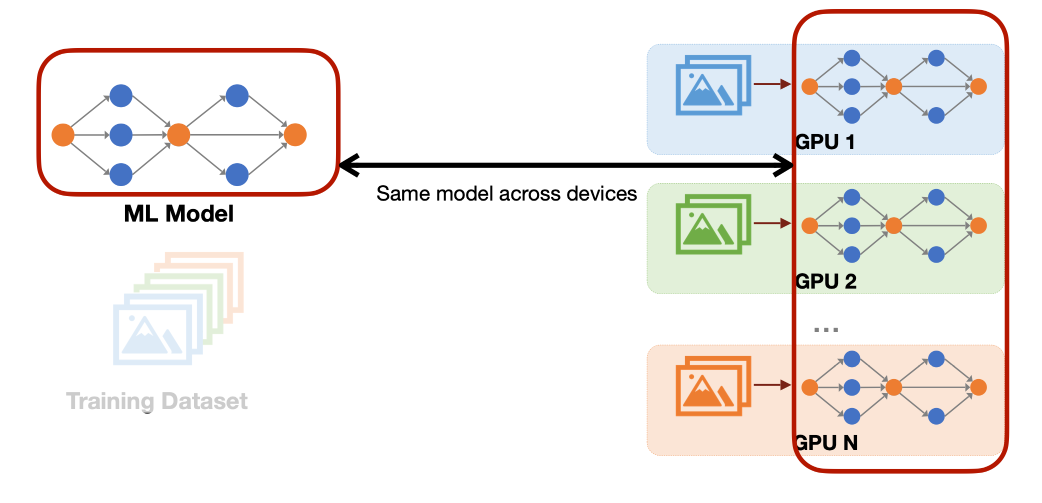
자세히 보면 순전파와 역전파는 여러 GPU에서 병렬로 수행할 수 있습니다. 하지만 옵티마이저 스텝과 파라미터 업데이트를 각 GPU에서 독립적으로 해서는 안 됩니다. 그렇게 하면 GPU마다 서로 다른 N개의 모델을 학습하는 셈이 되기 때문입니다.
따라서 역전파 후에는 GPU 간 그래디언트를 동기화해야 합니다. 이를 위해 All-Reduce 프리미티브를 사용합니다.
All-Reduce를 보기 전에, NVIDIA는 분산 학습 생태계의 일환으로 NCCL(NVIDIA collective communication library) 같은 풍부한 통신 프리미티브를 제공합니다. 이 프리미티브들은 멀티 GPU/멀티 노드 통신을 단순화하고 가속하여 대규모 학습에 필요한 동기화와 샤딩(sharding)을 효율적으로 수행하게 해 줍니다.
Note 분산 학습의 통신 프리미티브
All-Reduce는 그중 하나로, 표준 데이터 병렬 학습에서 각 역전파 끝에 GPU들 사이의 그래디언트를 동기화하는 데 사용됩니다. 하지만 All-Gather, Reduce-Scatter, Broadcast 등 다른 통신 패턴/병렬성에 맞춘 프리미티브도 여럿 있습니다.
이 글의 후반에서 더 고급 병렬화(예: ZeRO, 모델 샤딩, 텐서 병렬)를 다룰 때 이러한 프리미티브들도 만나게 될 것입니다.
지금은 DP에서 그래디언트를 동기화하는 데 꼭 필요한 All-Reduce만 자세히 보겠습니다.
각 GPU는 자신의 마이크로 배치로부터 그래디언트를 계산하므로, 최적화 스텝 전에 전역 그래디언트를 얻기 위해 더해야 합니다. 필요한 통신 연산이 All-Reduce입니다.
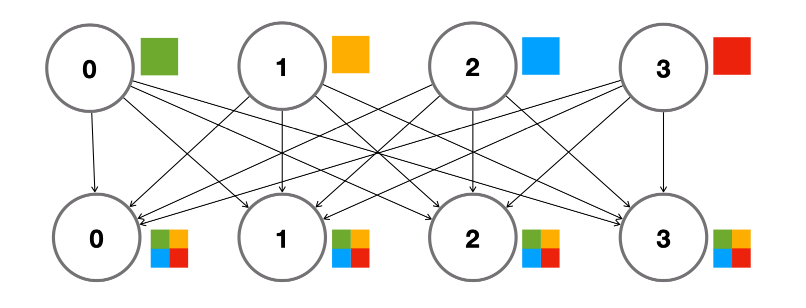
각 노드가 전역 그래디언트를 받으면, 각자 **optimizer.step()**을 수행해 모델 복제본이 동기(synced) 상태를 유지합니다. 이런 집합 연산은 torch.distributed API로 제공됩니다.
여기서는 4개의 T4 GPU가 있는 머신을 사용합니다.
ray@ip-10-0-69-225:code$ nvidia-smi -L
GPU 0: Tesla T4 (UUID: GPU-31a1b562-c769-c7f1-ede1-48847cec8d53)
GPU 1: Tesla T4 (UUID: GPU-1beaf204-f6f7-182d-67f8-aee6c58128df)
GPU 2: Tesla T4 (UUID: GPU-934ca246-df7e-2c7f-4bdd-b07859e46b2d)
GPU 3: Tesla T4 (UUID: GPU-141171cb-db62-b770-97ff-955f8c7f2265)
이제 4개 GPU 각각에 텐서를 만들고 All-Reduce를 수행하는 간단한 예시를 보겠습니다.
import torch
import torch.distributed as dist
def init_process():
# Initializes the process group using the efficient nccl backend
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank())
def example_all_reduce():
tensor = torch.tensor([dist.get_rank() + 1] * 3, dtype=torch.float32).cuda()
print(f"Before all_reduce on rank {dist.get_rank()}: {tensor}")
dist.all_reduce(tensor, op=dist.ReduceOp.SUM)
print(f"After all_reduce on rank {dist.get_rank()}: {tensor}")
# Initialize the process group and set the device, create a tensor on each GPU and perform the All-Reduce operation on them.
init_process()
example_all_reduce()
torchrun으로 4개 GPU에서 실행할 수 있습니다.
torchrun --nproc_per_node=4 dist_all_reduce.py
출력은 다음과 같습니다.
Before all_reduce on rank 3: tensor([4., 4., 4.], device='cuda:3')
Before all_reduce on rank 0: tensor([1., 1., 1.], device='cuda:0')
Before all_reduce on rank 2: tensor([3., 3., 3.], device='cuda:2')
Before all_reduce on rank 1: tensor([2., 2., 2.], device='cuda:1')
After all_reduce on rank 3: tensor([10., 10., 10.], device='cuda:3')
After all_reduce on rank 0: tensor([10., 10., 10.], device='cuda:0')
After all_reduce on rank 2: tensor([10., 10., 10.], device='cuda:2')
After all_reduce on rank 1: tensor([10., 10., 10.], device='cuda:1')
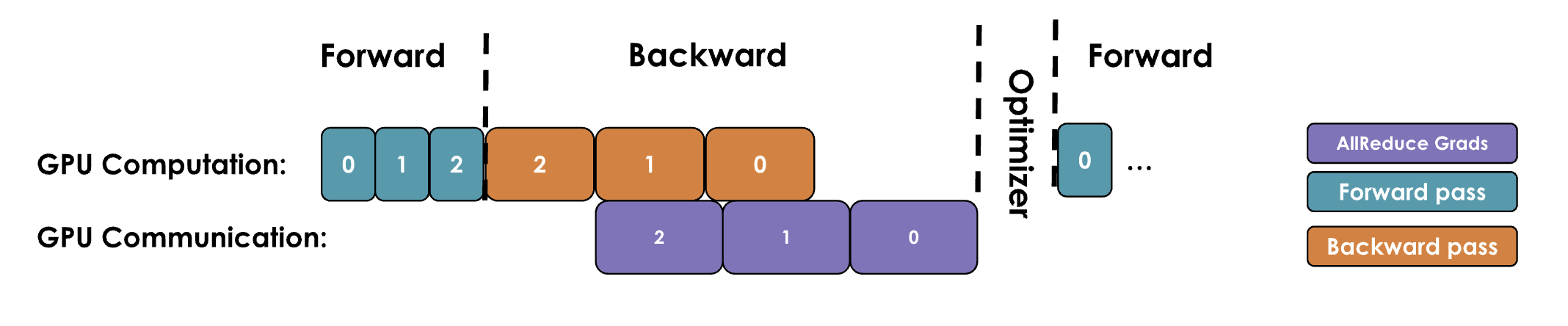
단순한(바닐라) DP 구현에서는 통신 단계에서 GPU들이 유휴(idle) 상태가 됩니다. All-Reduce는 역전파에서 모든 그래디언트가 계산된 뒤에야 시작되기 때문입니다. 이는 비효율적입니다.
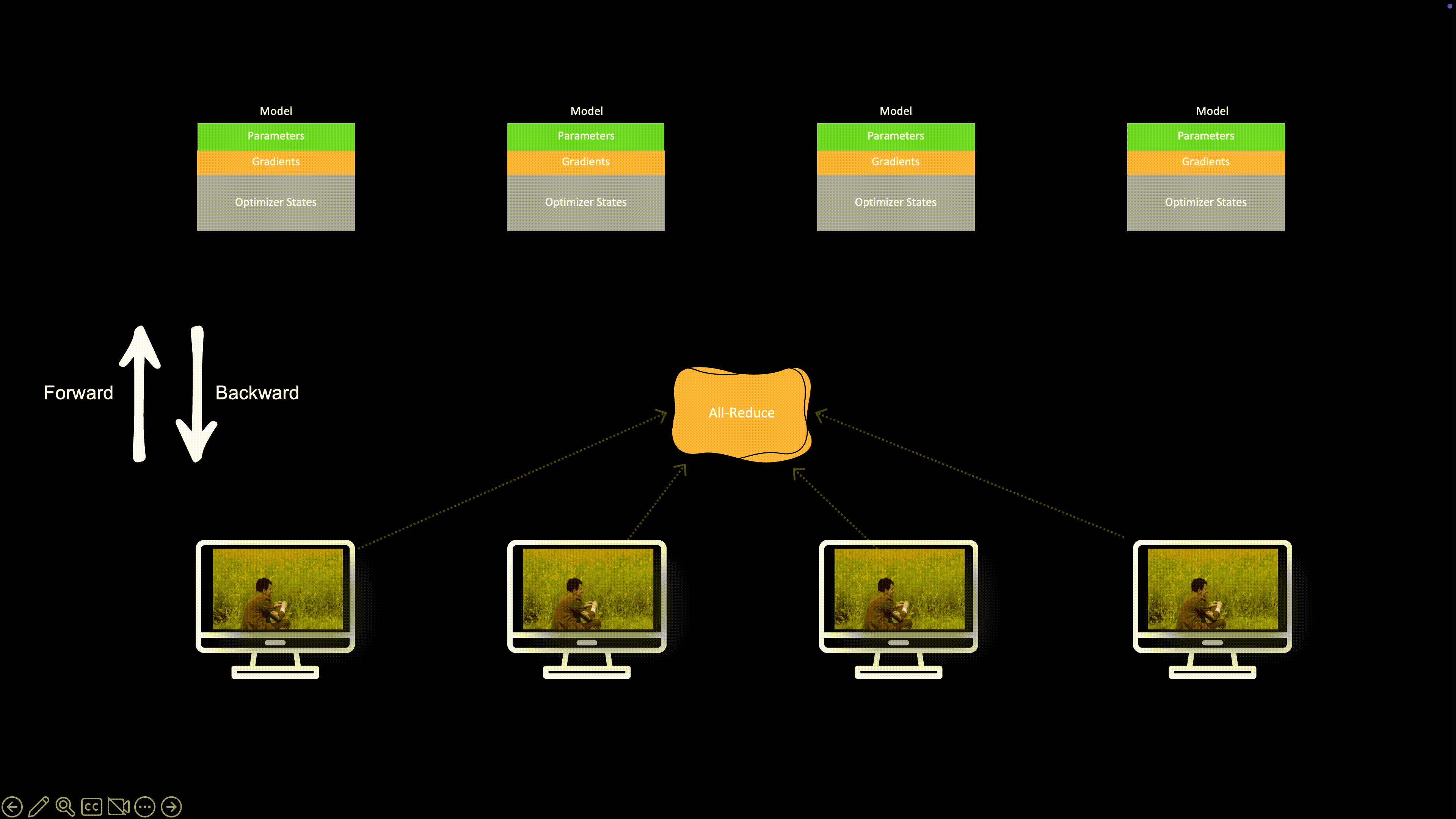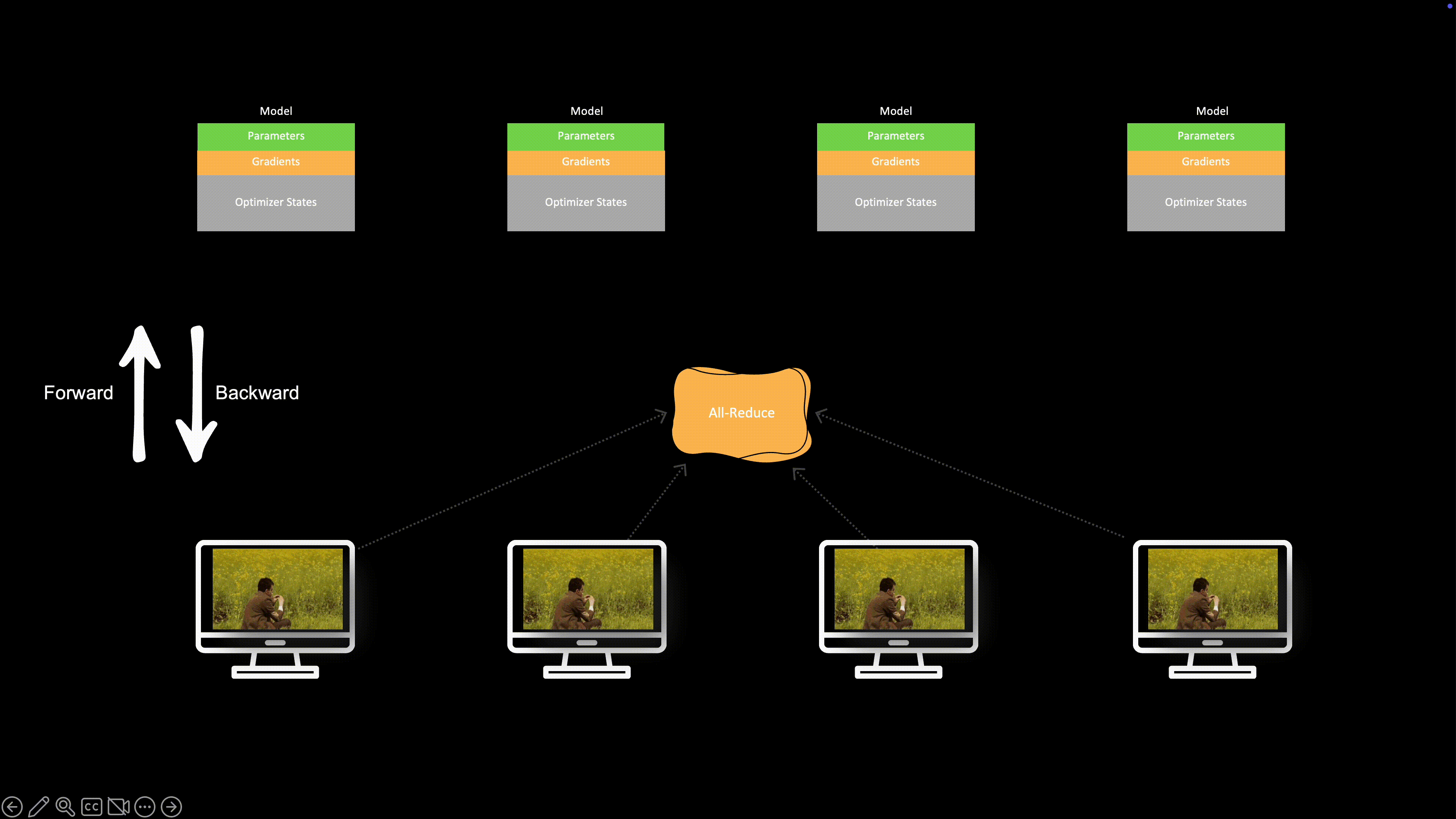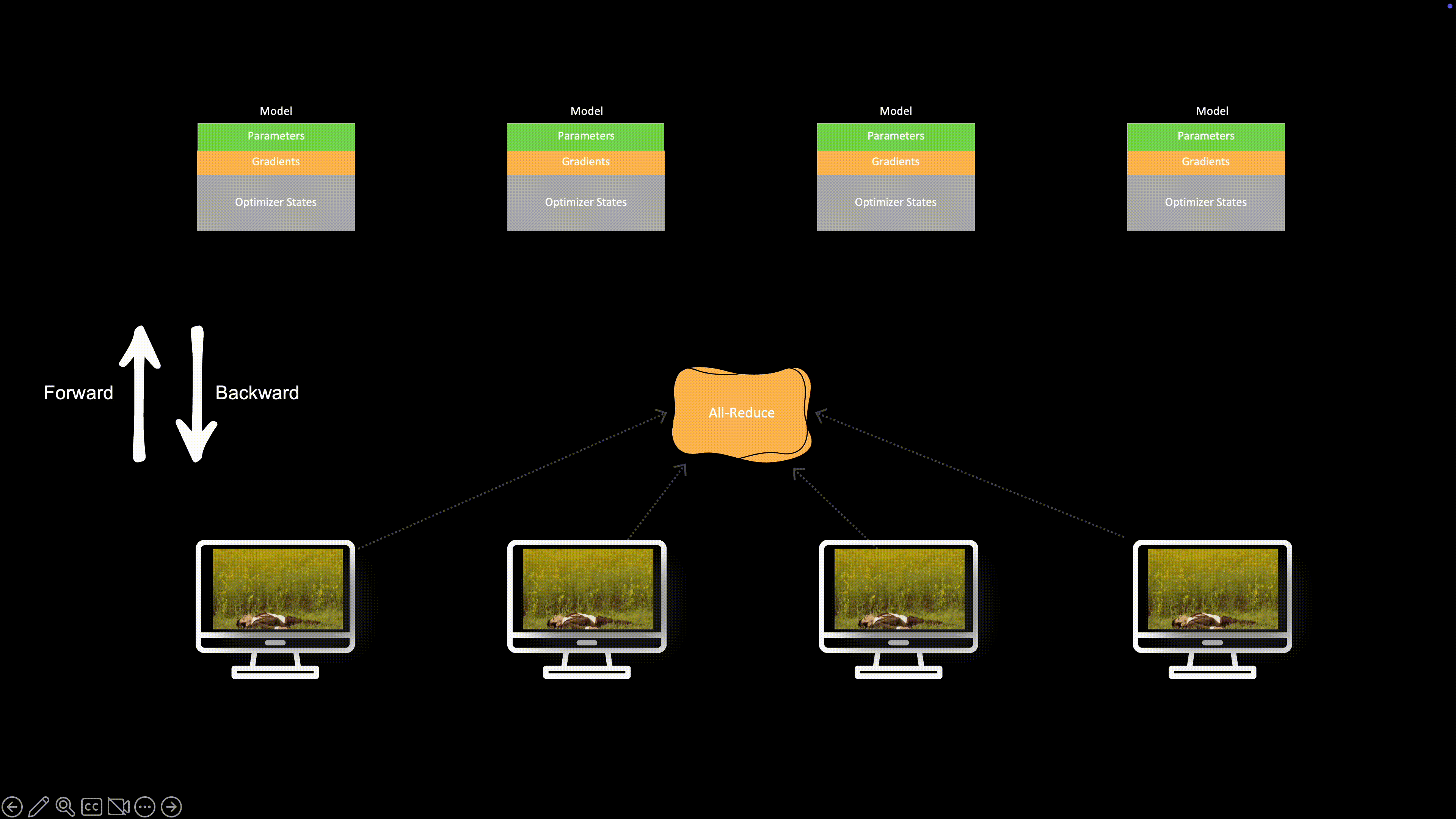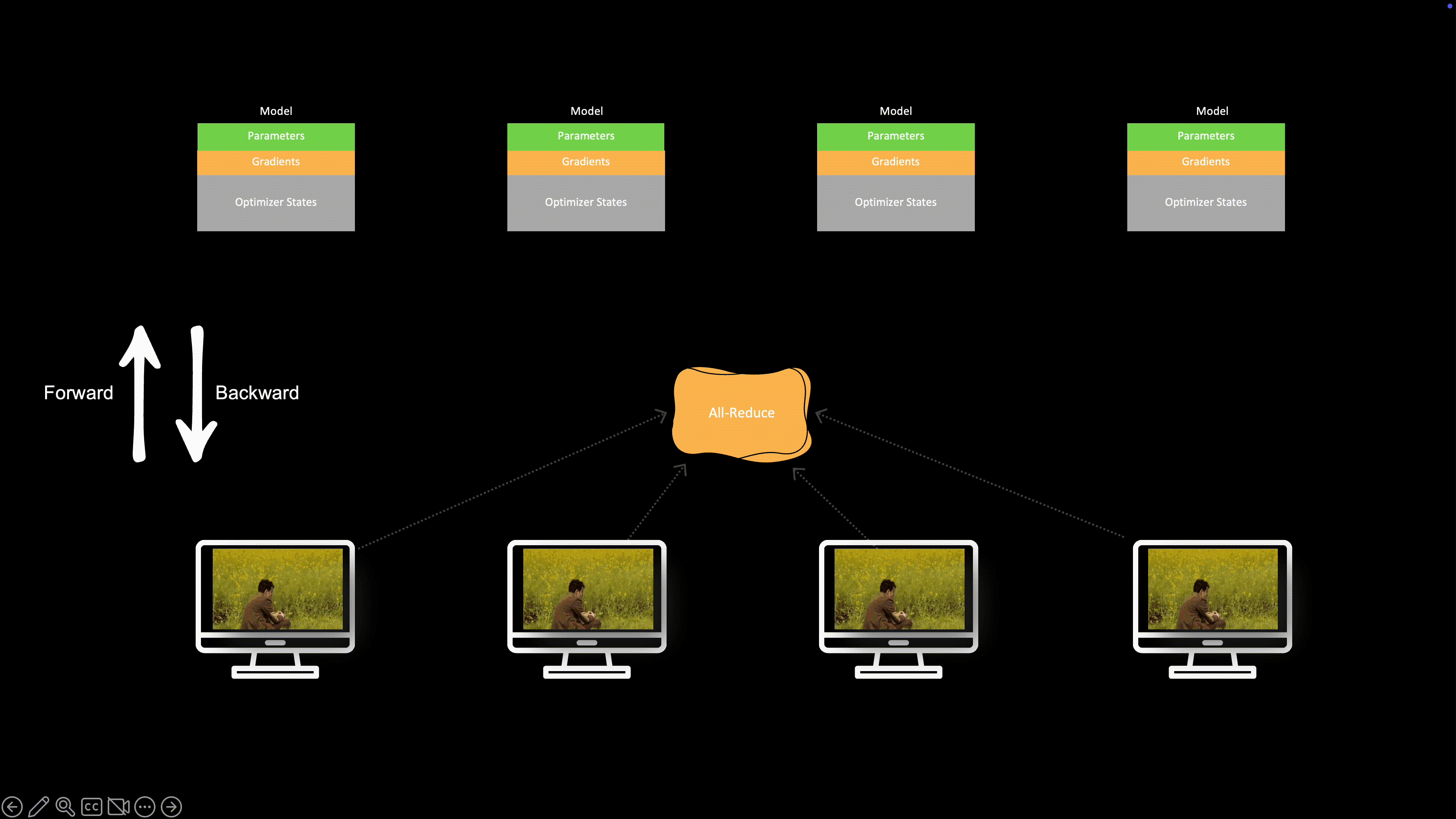
이 유휴 시간을 없애기 위해 통신과 연산을 최대한 겹치도록(overlap) 합니다.
방법: 역전파 중 특정 레이어의 그래디언트가 계산되자마자(예: ), 그 그래디언트에 대한 All-Reduce를 백그라운드에서 즉시 실행합니다.
근거: 다음 레이어의 그래디언트 계산()은 이전 레이어 그래디언트 통신()과 독립적입니다.
구현: PyTorch의 hook(예: post_accumulate_grad_hook())으로 구현할 수 있습니다. 각 파라미터에 all-reduce hook function을 붙여 다음 연산을 진행하는 동안 통신이 동시 실행되게 하여 처리량을 크게 높입니다. 이 방식은 더 자주 통신하지만 패킷은 더 작습니다.
def register_backward_hook(self, hook):
"""
Registers a backward hook for all parameters of the model that
require gradients.
"""
for p in self.module.parameters():
if p.requires_grad is True:
p.register_post_accumulate_grad_hook(hook)
이전에는 통신이 일어나는 동안 역전파에서 모든 그래디언트가 계산될 때까지 기다려야 했습니다.
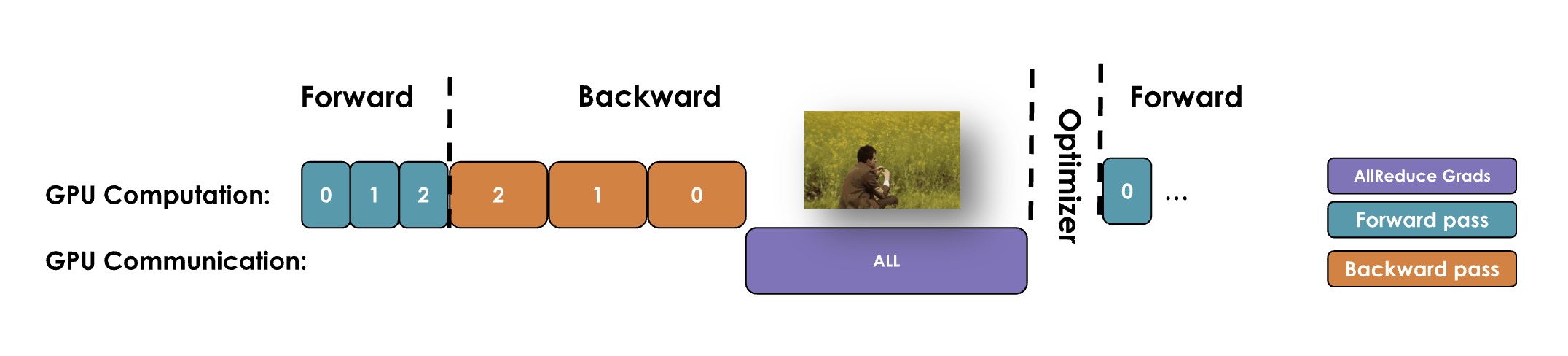
하지만 이제 통신과 연산을 겹치므로, 모든 그래디언트 계산을 기다릴 필요가 없습니다. 이전 레이어 그래디언트 통신이 진행되는 동안 다음 레이어 그래디언트를 계산할 수 있습니다.
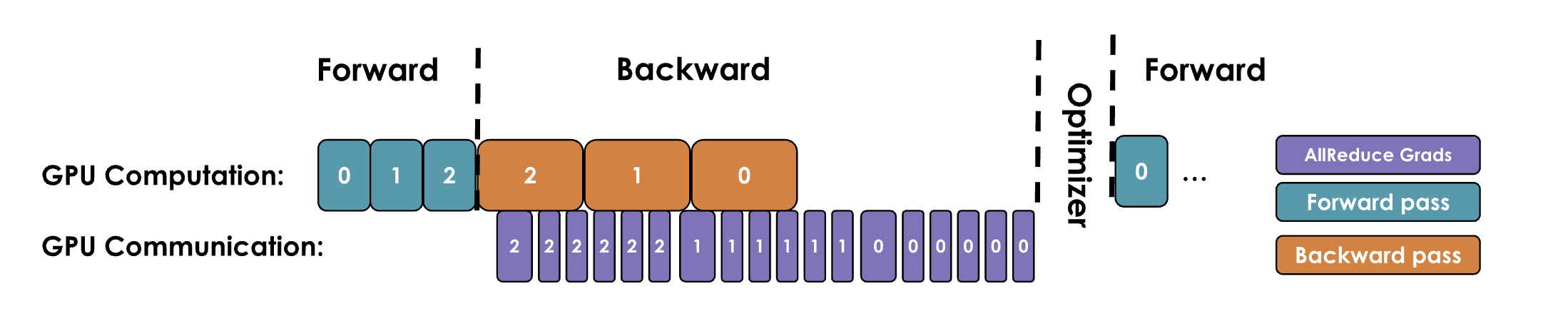
더 나아가 그래디언트를 큰 버킷(bucket)으로 묶어 그 버킷 단위로 All-Reduce하면 통신 효율이 더 좋아집니다.
마치 배송 전 물건을 박스에 포장하는 것과 같습니다. (아마존 주문할 때 여러 물건을 한 박스로 묶어 보내 배송비를 줄이는 것과 비슷하죠. 여기서는 그래디언트를 그렇게 하는 겁니다.)
이렇게 하면 통신 오버헤드를 크게 줄여 연산을 가속할 수 있습니다.
데이터 병렬로 멀티 GPU 학습을 확장하는 방법을 보았으니 자연스러운 질문이 생깁니다. GPU를 늘리면 완벽한 선형 성능 향상이 생길까요? 즉 GPU를 추가할수록 처리량이 비례해서 증가할까요?
현실은 더 미묘합니다. 데이터 병렬은 all-reduce 동기화를 역전파 계산과 겹치게 해 효율을 올리지만, GPU 수가 수백/수천으로 늘어나면 조정 비용과 네트워크 요구가 급격히 증가합니다. 결국 GPU를 추가할수록 처리량 개선이 점점 줄어들고 전체 시스템 효율도 떨어집니다.
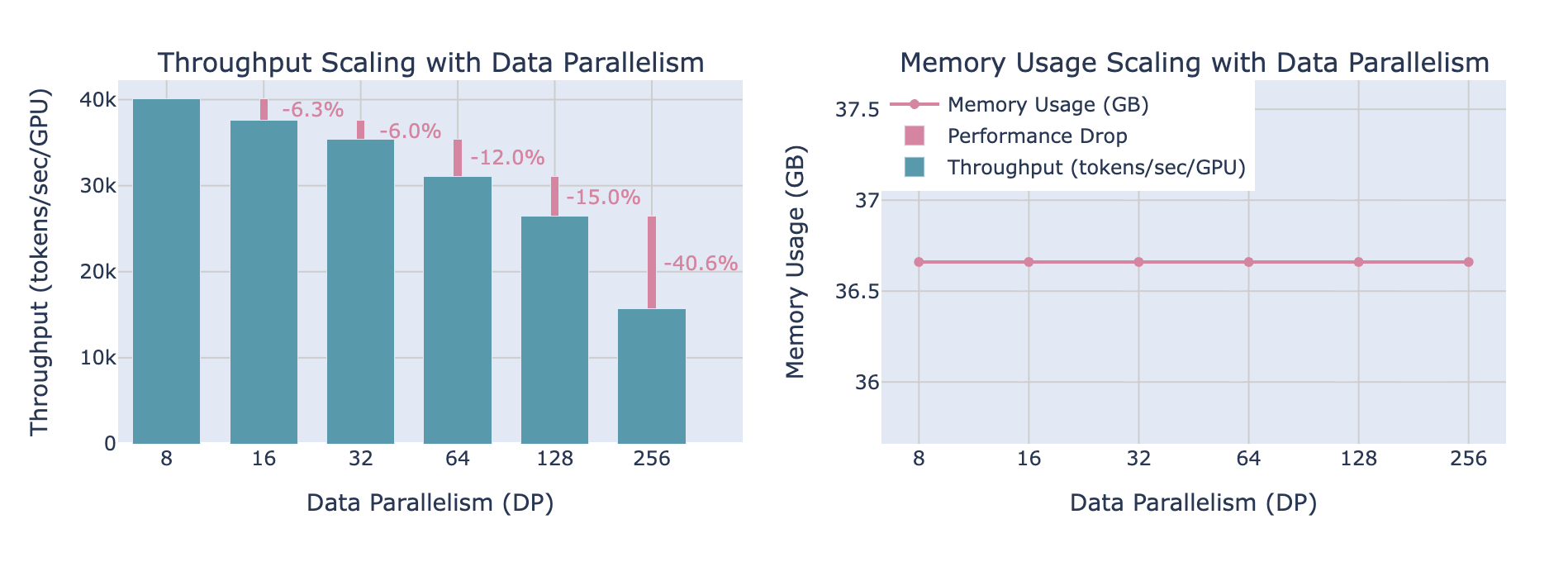
위 차트는 GPU를 추가할수록 처리량이 눈에 띄게 저하되는 모습을 보여줍니다. 반면 DP 워커 수와 무관하게 GPU당 메모리 사용량은 변하지 않습니다.
데이터 병렬은 여러 GPU로 학습을 확장하는 첫 번째(가장 단순한) 전략이었습니다.
하지만 지금까지는 모델 전체가 단일 GPU 메모리에 들어간다고 가정했습니다. 그런데 GPT-3(175B)처럼 너무 커서 단일 GPU(A100 80GB)에 들어가지 않는다면 어떻게 될까요?
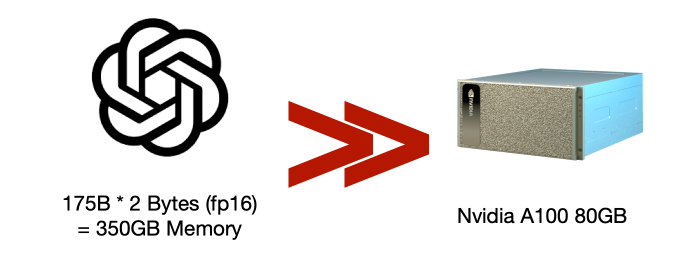
모델이 커지면 단일 GPU가 파라미터/옵티마이저 상태/그래디언트 전체를 담지 못하는 일이 흔해집니다. 따라서 단순 DP를 넘어, 단일 GPU에 들어가지 않는 모델을 학습할 수 있게 하는 더 많은 확장 방법이 필요합니다.
그리고 다음 섹션에서 다룰 것이 바로 **ZeRO(Zero Redundancy Optimizer)**입니다.
ZeRO(Zero Redundancy Optimizer)는 단일 GPU에서 parameters, gradients, optimizer states 같은 정적 메모리 제약을 해결하는 기법 패밀리입니다. ZeRO는 정적 메모리 구성 요소를 여러 GPU에 **샤딩(sharding)**하여 단일 GPU에 들어가지 않는 모델도 학습할 수 있게 합니다.
세 단계로 구성됩니다.
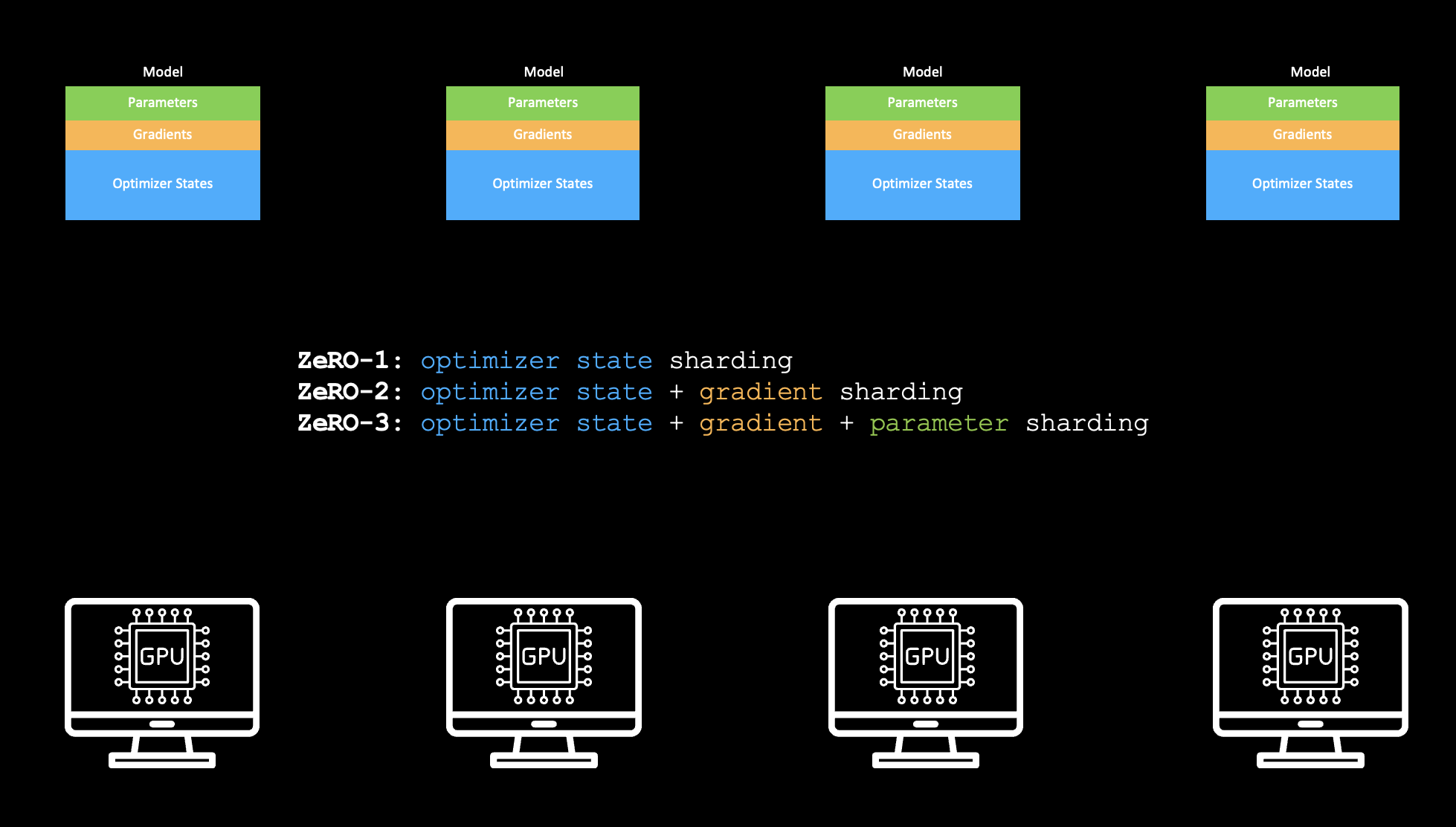
여기까지만 봐도 이 접근은 GPU 사이에 많은 통신이 필요하다는 것을 짐작할 수 있습니다.
하지만 앞에서 본 것처럼 통신과 연산을 어느 정도 오버랩할 수 있으므로, 오버헤드를 줄일 수 있습니다.
각 기법을 ZeRO-1부터 자세히 살펴보겠습니다.
Optimizer States 샤딩앞서 논의한 혼합 정밀도(BF16 + FP32)에서 GPU당 정적 메모리 풋프린트를 다시 보겠습니다.
| Memory Component | Precision | Size ( Bytes) | Description |
|---|---|---|---|
| Model Parameters | BF16 (2 bytes) | Used for forward and backward passes | |
| Parameter Gradients | BF16 (2 bytes) | Used in backpropagation | |
| Master Weights | FP32 (4 bytes) | Full precision copy for the update step | |
| Optimizer States (Adam) | FP32 (4+4 bytes) | Stores 1st and 2nd moment estimates ( each) | |
| Total Static Memory (with Mixed Precision) | The absolute floor for static storage |
정적 메모리에서 가장 큰 부분은 보통 옵티마이저 상태입니다. 특히 Adam처럼 1/2차 모멘트 통계를 유지하는 옵티마이저에서 더 큽니다.
DP에서는 이 모든 구성 요소가 데이터 병렬 그룹의 모든 GPU에 중복 저장되므로, 각 디바이스가 이 텐서들의 전체 비용()을 부담합니다(활성값은 일단 제외).
Note 중요한 주의사항: 마스터 가중치는 옵티마이저 상태 샤딩에 포함됩니다
ZeRO에서 옵티마이저 상태 샤딩을 말할 때는, 옵티마이저 업데이트에 사용하는 **마스터 가중치(FP32 복사본)**도 샤딩 계산에 포함해야 합니다. 옵티마이저 상태와 마스터 가중치는 모두 FP32로 저장되며 ZeRO-1에서 함께 샤딩됩니다.
따라서 현대 혼합 정밀도 학습에서 optimizer state sharding이라는 표현은 암묵적으로 마스터 가중치를 포함합니다.
ZeRO-1의 목표는 각 GPU에 FP32 옵티마이저 상태와 FP32 마스터 가중치를 전부 저장하는 대신, 개 GPU에 걸쳐 샤딩하는 것입니다.
optimizer states()와 master weights()의 중 만큼만 저장합니다.parameters와 gradients(BF16)는 순전파/역전파 호환성을 위해 각 GPU에 완전 복제된 상태로 남습니다.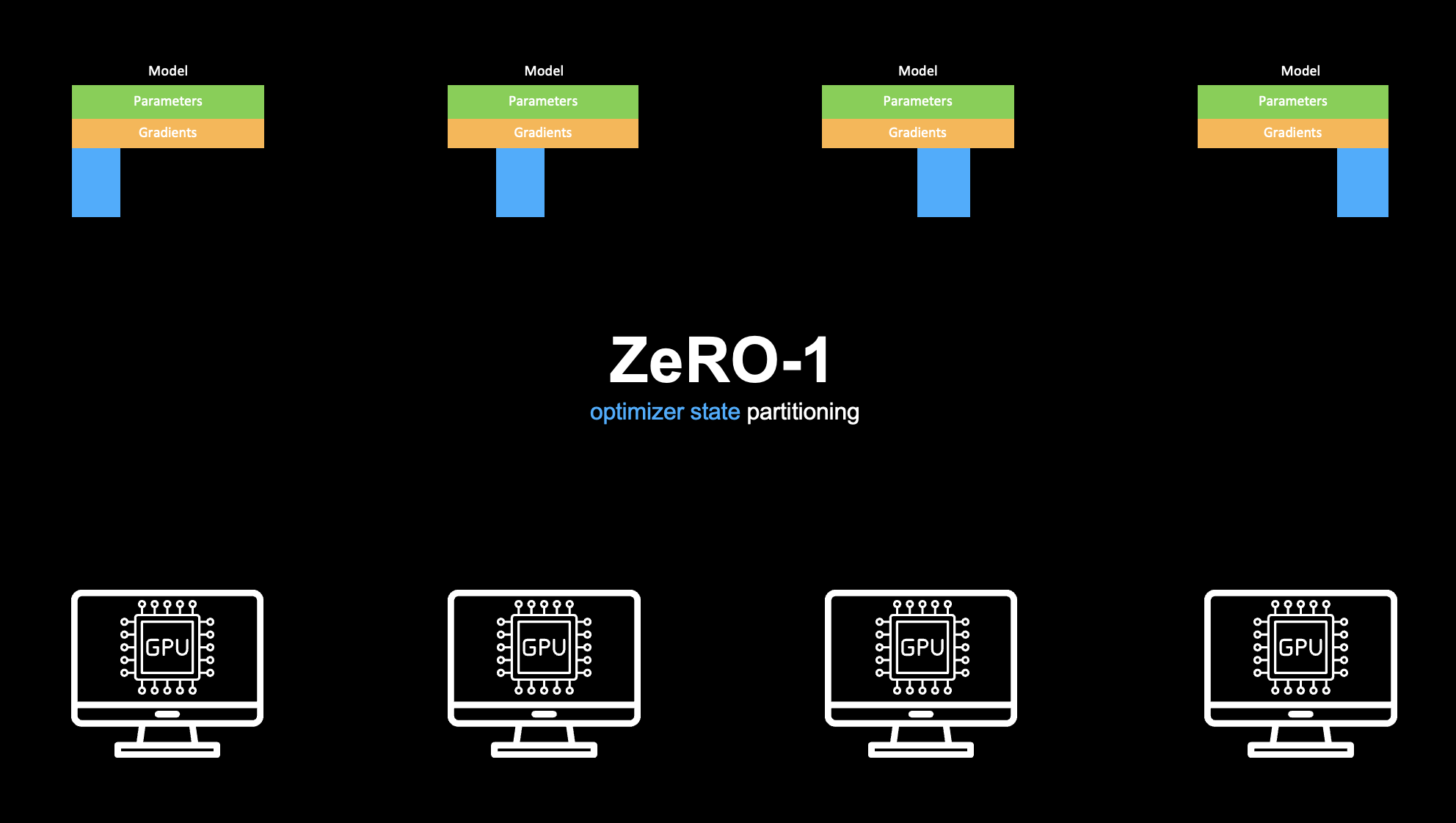
결과적으로 ZeRO-1에서 GPU당 정적 메모리는 다음과 같습니다.
좀 더 구체적인 수치를 보겠습니다. 80GB 메모리의 A100/H100 GPU가 있다고 합시다. DP에서 들어갈 수 있는 최대 모델은 대략:
하지만 ZeRO-1을 64 GPU()로 적용하면 옵티마이저 상태와 마스터 가중치가 GPU당 작은 샤드로 줄어듭니다.
따라서 같은 80GB GPU에서 학습할 수 있는 최대 모델이 다음으로 점프합니다.
큰 모델을 같은 하드웨어에서 학습할 수 있다는 건 좋지만, 이 접근에서의 통신 오버헤드도 봐야 합니다.
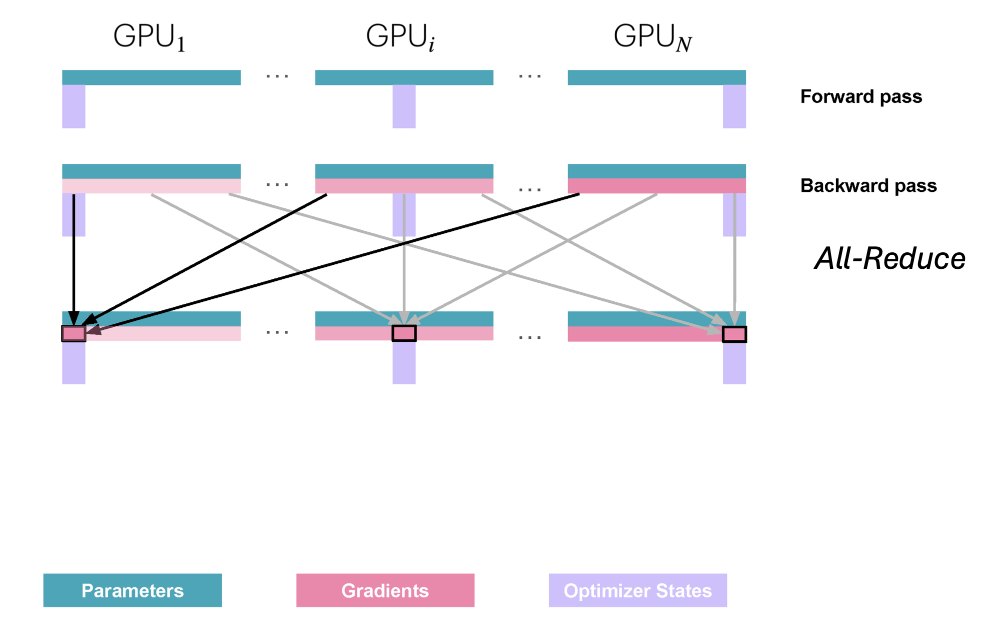
forward pass에서는 각 GPU가 파라미터 전체를 갖고 있으므로 통신이 필요 없습니다.

backward pass에서는 각 GPU가 모든 파라미터에 대한 그래디언트를 계산하므로, 모든 GPU가 그래디언트를 완전히 갖고 있습니다. 이를 동기화하기 위해 All-Reduce를 수행합니다. 그 후 모든 GPU는 동일한(동기화된) 그래디언트를 갖습니다.
이제 각 GPU는 자신이 보유한 옵티마이저 상태에 해당하는 그래디언트만 남기고 나머지는 버릴 수 있습니다.
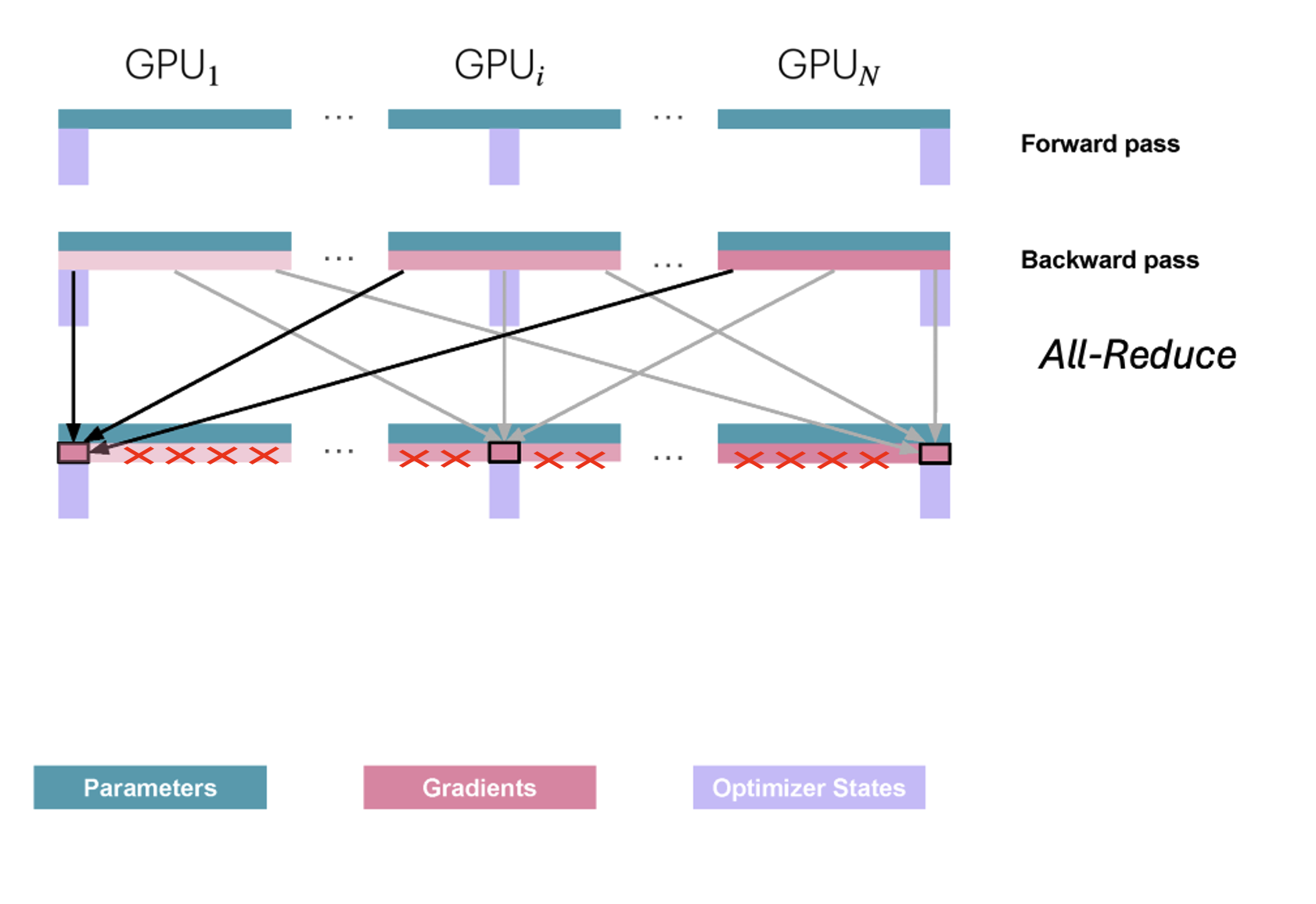
이후 각 GPU는 자신의 옵티마이저 상태 샤드와 그래디언트 샤드로 해당 파라미터를 _업데이트_할 수 있습니다.
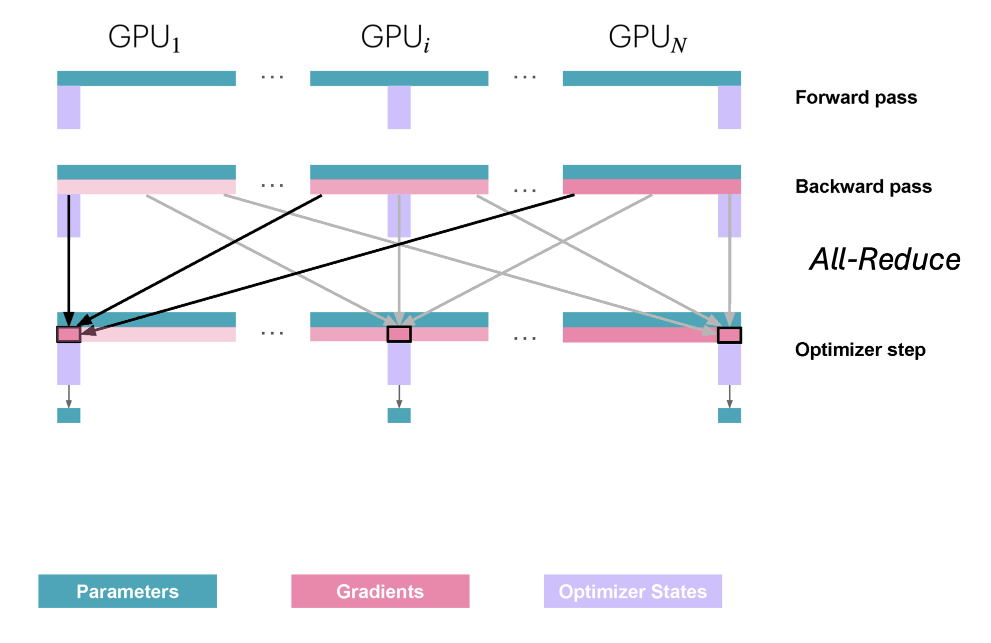
그런데 이 시점에 다시 통신이 필요합니다. 업데이트 후 각 GPU는 자기 샤드에 해당하는 업데이트된 파라미터만 가지고 있기 때문입니다.
그럼 어떤 통신이 필요할까요?
각 GPU는 다른 GPU들로부터 업데이트된 파라미터를 모아야(gather) 합니다. 이를 위해 All-Gather 연산을 사용합니다. 이는 All-Reduce와 유사한 또 다른 통신 프리미티브입니다.
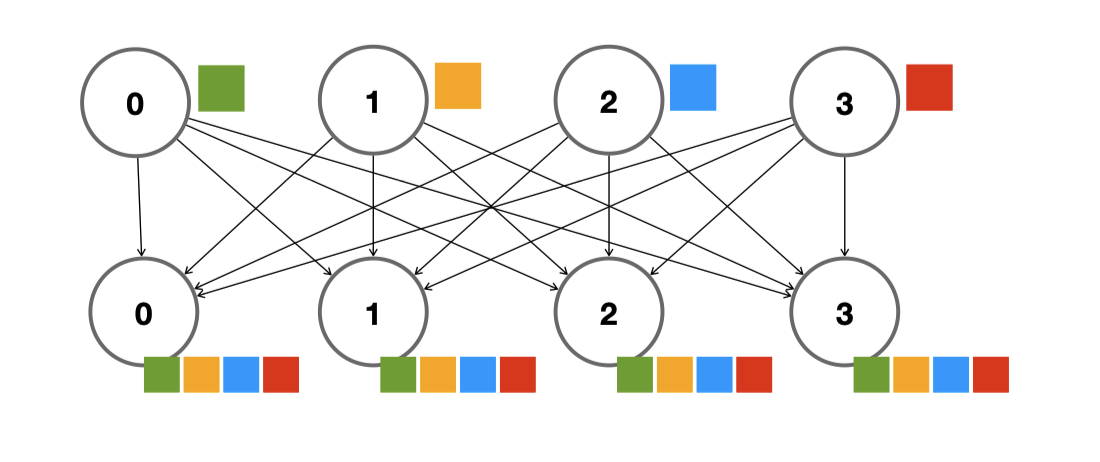
torch.distributed.all_gather()로 이를 수행하는 예시를 보겠습니다. 각 GPU에 텐서를 만들고 All-Gather를 수행합니다.
import torch
import torch.distributed as dist
def init_process():
# Initializes the process group using the efficient nccl backend
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank())
def example_all_gather():
tensor = torch.tensor([dist.get_rank() + 1] * 3, dtype=torch.float32).cuda()
# Prepare an output list of tensors for all_gather
world_size = dist.get_world_size()
gathered = [torch.zeros_like(tensor) for _ in range(world_size)]
print(f"Before all_gather on rank {dist.get_rank()}: {tensor}")
dist.all_gather(gathered, tensor)
print(f"After all_gather on rank {dist.get_rank()}: {[t.cpu().tolist() for t in gathered]}")
# Initialize the process group and set the device, create a tensor on each GPU and perform the All-Gather operation on them.
init_process()
example_all_gather()
4개 GPU에서 torchrun으로 실행합니다.
torchrun --nproc_per_node=4 dist_all_gather.py
출력은 다음과 같습니다.
Before all_gather on rank 2: tensor([3., 3., 3.], device='cuda:2')
Before all_gather on rank 0: tensor([1., 1., 1.], device='cuda:0')
Before all_gather on rank 1: tensor([2., 2., 2.], device='cuda:1')
Before all_gather on rank 3: tensor([4., 4., 4.], device='cuda:3')
After all_gather on rank 0: [[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0], [4.0, 4.0, 4.0]]
After all_gather on rank 1: [[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0], [4.0, 4.0, 4.0]]
After all_gather on rank 2: [[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0], [4.0, 4.0, 4.0]]
After all_gather on rank 3: [[1.0, 1.0, 1.0], [2.0, 2.0, 2.0], [3.0, 3.0, 3.0], [4.0, 4.0, 4.0]]
이로써 각 GPU는 업데이트된 모델 파라미터 전체를 갖게 되고, 다음 배치의 순전파를 업데이트된 파라미터로 수행하며 학습을 계속할 수 있습니다.

이것이 ZeRO-1의 동작 방식입니다.
ZeRO-1에서 All-Reduce 이후를 다시 보면, 각 GPU는 다른 그래디언트를 버리고, 자신이 가진 옵티마이저 상태에 해당하는 그래디언트만 유지했습니다.
그렇다면 처음부터 왜 모든 GPU에 모든 그래디언트를 유지해야 할까요? 옵티마이저 상태와 함께 그래디언트도 샤딩할 수는 없을까요? 이것이 바로 ZeRO-2입니다.
Gradients 샤딩ZeRO-2에서는 optimizer states와 함께 gradients도 샤딩합니다. 따라서 각 GPU는 자신이 가진 옵티마이저 상태 샤드에 해당하는 그래디언트 샤드만 저장하면 됩니다.
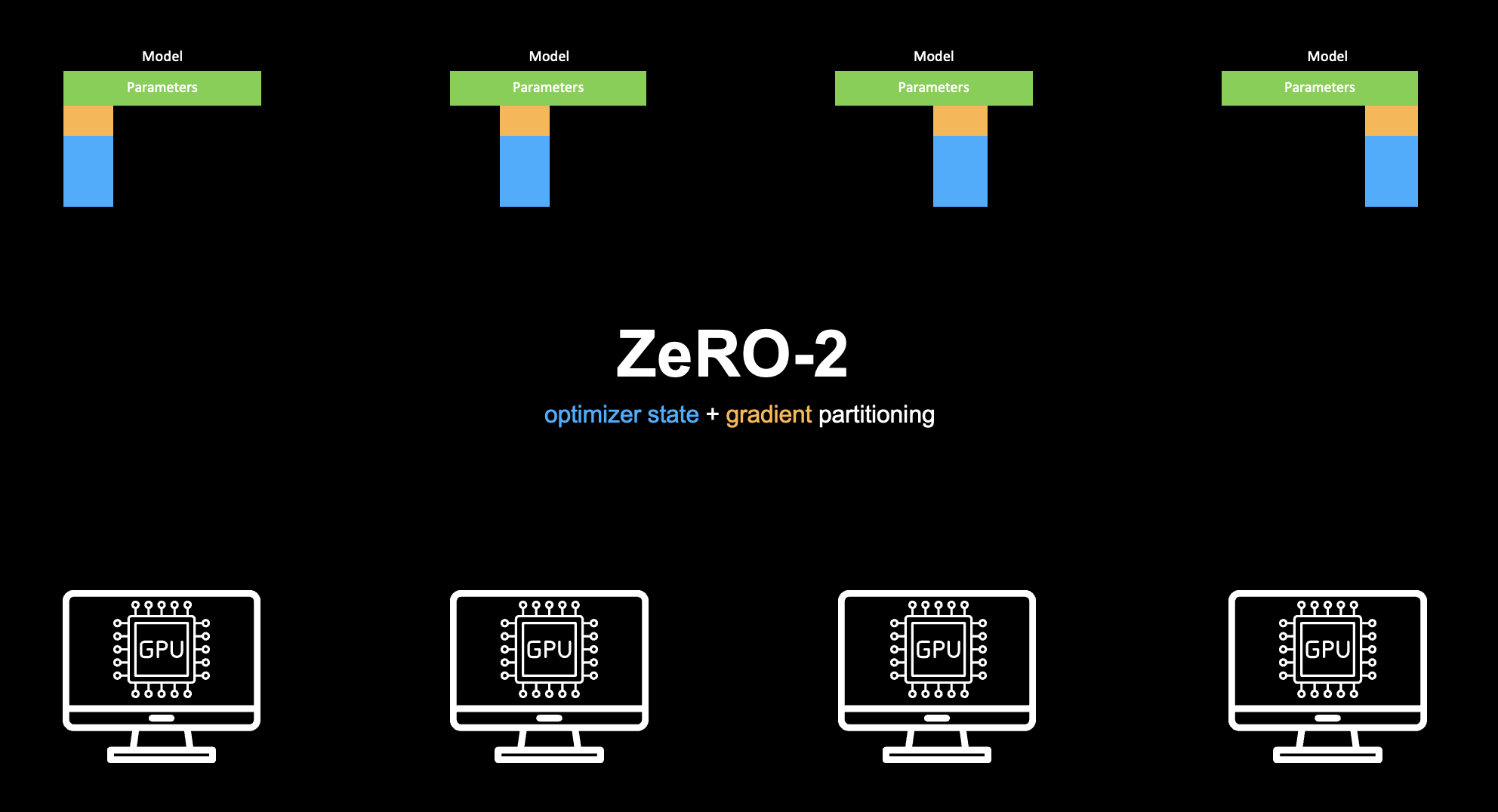
ZeRO-2에서 GPU당 메모리는 다음과 같습니다.
80GB A100/H100과 GPUs라면 학습 가능한 최대 모델은:
이를 비교해 보면:
| Strategy | Effective Bytes/Param | Max Model on 80GB GPU |
|---|---|---|
| DP | 16 | ~5B |
| ZeRO-1 | 4.2 | ~19B |
| ZeRO-2 | 2.2 | ~36B |
ZeRO-2는 ZeRO-1 대비 거의 2배, 바닐라 DP 대비 7배 이상 큰 모델을 학습할 수 있게 합니다. 그럼 통신 오버헤드는 어떻게 달라질까요?
forward pass에서는(ZeRO-1과 동일하게) 파라미터 전체를 각 GPU가 갖고 있으므로 통신이 필요 없습니다.
backward pass에서는 그래디언트에 대해 All-Reduce 대신 Reduce-Scatter를 수행합니다. 이는 All-Reduce/All-Gather와 유사한 또 다른 통신 프리미티브입니다.
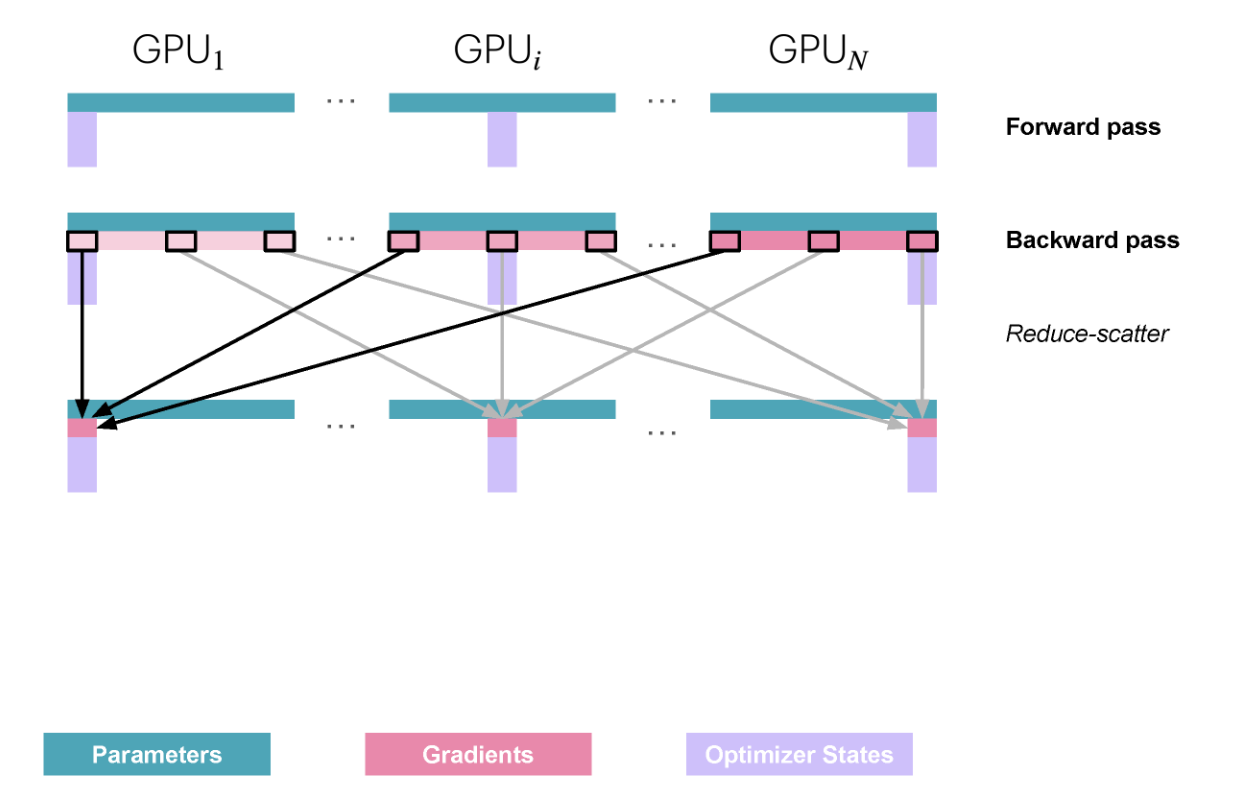
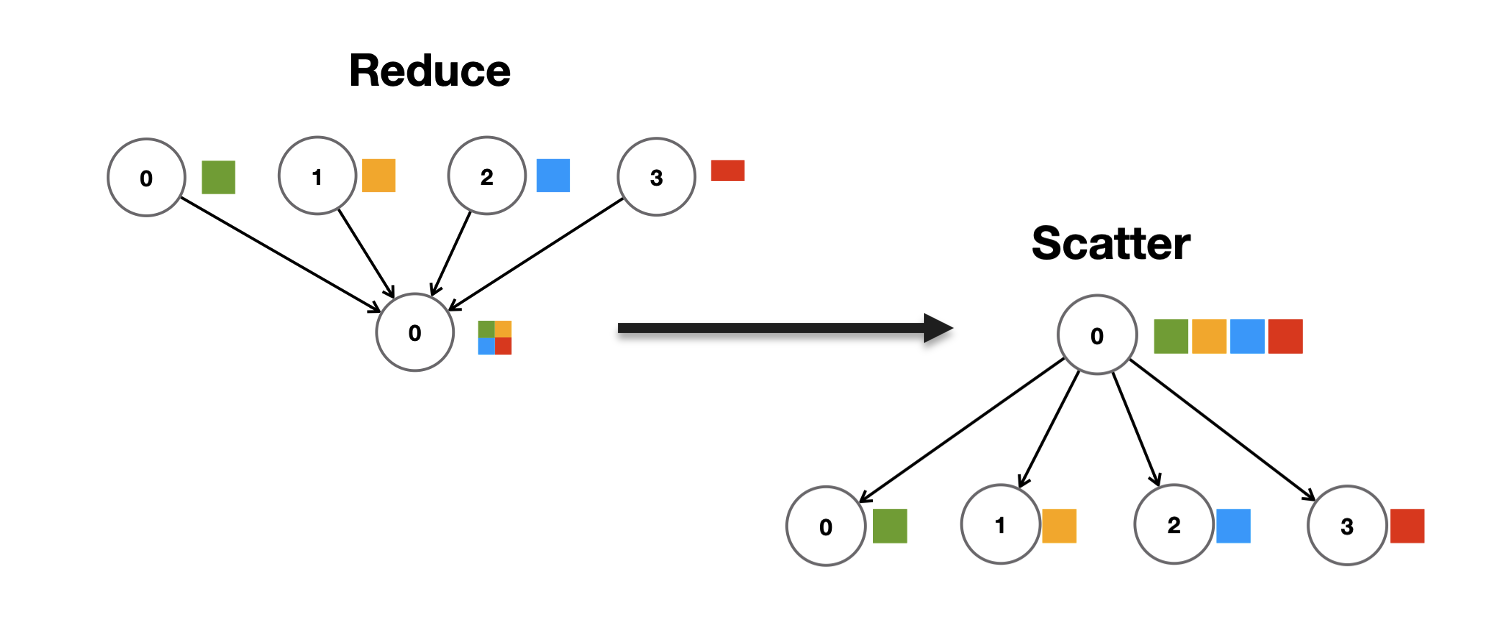
Reduce-Scatter는 내부적으로 먼저 그래디언트를 모든 GPU에서 reduce(합)한 다음, 그 결과를 필요한 GPU들에게 scatter하여 그래디언트 샤드로 나눠줍니다.
Note 연산-통신 타임라인
reduce-scatter, FP32 파라미터 복사본에는 **all-gather**를 사용.예시로 확인해 보겠습니다.
import torch
import torch.distributed as dist
def init_process():
# Initializes the process group using the efficient nccl backend
dist.init_process_group(backend='nccl')
torch.cuda.set_device(dist.get_rank())
def example_reduce_scatter():
rank = dist.get_rank()
world_size = dist.get_world_size()
# Construct a single input tensor, then split into equal chunks (one for each rank)
input_tensor = torch.arange(1, world_size * 3 + 1, dtype=torch.float32).cuda()
input_list = list(torch.chunk(input_tensor, world_size))
output_tensor = torch.zeros(3, dtype=torch.float32).cuda()
print(f"Before reduce_scatter on rank {rank}: {[t.cpu().tolist() for t in input_list]}")
dist.reduce_scatter(output_tensor, input_list, op=dist.ReduceOp.SUM)
print(f"After reduce_scatter on rank {rank}: {output_tensor.cpu().tolist()}")
# Initialize the process group and set device, then perform Reduce-Scatter
init_process()
example_reduce_scatter()
4개 GPU에서 torchrun으로 실행합니다.
torchrun --nproc_per_node=4 dist_reduce_scatter.py
출력:
Before reduce_scatter on rank 0: [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]
Before reduce_scatter on rank 1: [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]
Before reduce_scatter on rank 2: [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]
Before reduce_scatter on rank 3: [[1.0, 2.0, 3.0], [4.0, 5.0, 6.0], [7.0, 8.0, 9.0], [10.0, 11.0, 12.0]]
After reduce_scatter on rank 0: [4.0, 8.0, 12.0]
After reduce_scatter on rank 1: [16.0, 20.0, 24.0]
After reduce_scatter on rank 2: [28.0, 32.0, 36.0]
After reduce_scatter on rank 3: [40.0, 44.0, 48.0]
각 GPU는 동일한 입력 청크를 시작으로 갖고 있다가, reduce_scatter 후에는 모든 GPU의 합(전역 합)에서 _i번째 청크_의 결과를 각자 받아 갖게 됩니다. 즉 GPU0은 청크0 합, GPU1은 청크1 합을 받는 식입니다.
Reduce-Scatter 후 각 GPU는 자신의 옵티마이저 상태 샤드에 해당하는 그래디언트 샤드를 갖게 되며, 이를 사용해 해당 파라미터를 업데이트할 수 있습니다.
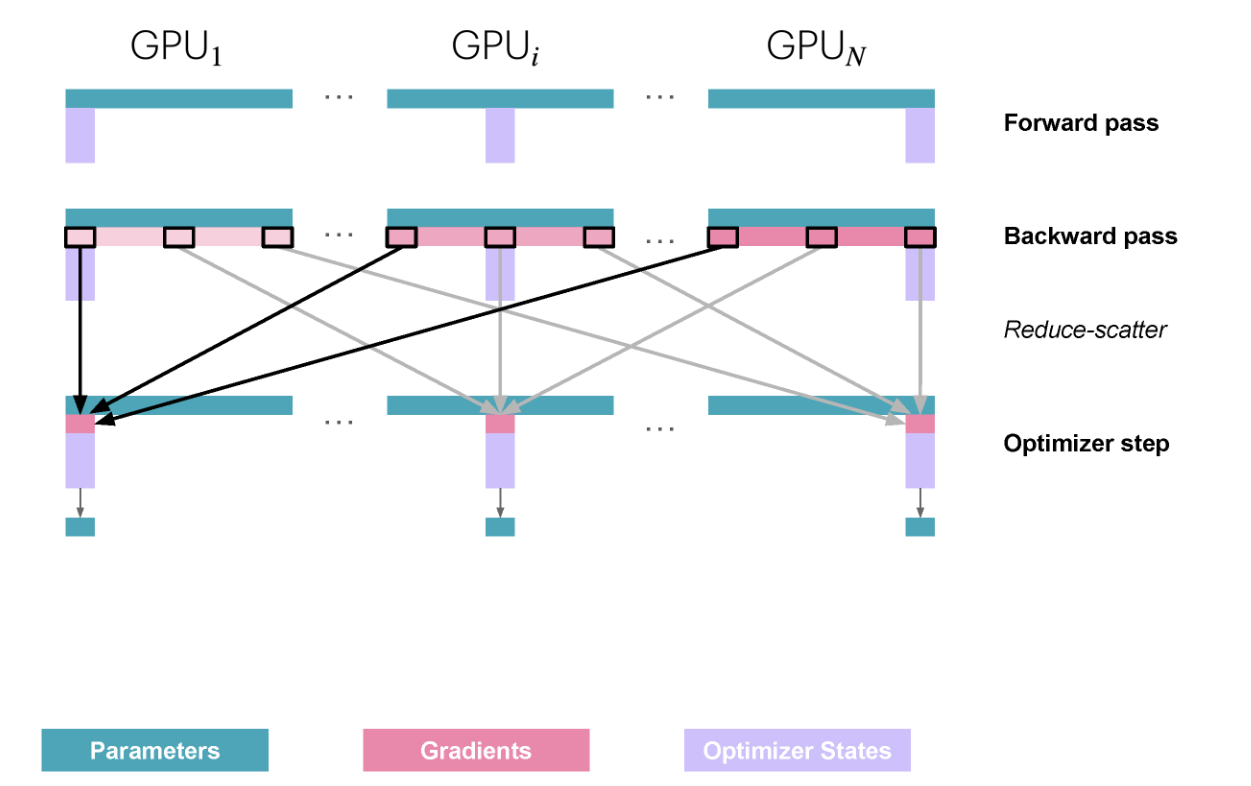
그 다음, 업데이트된 파라미터를 모든 GPU에 공유하기 위해 다시 통신이 필요합니다. 로컬 업데이트 후 각 GPU는 자신 샤드의 업데이트된 파라미터만 갖고 있기 때문입니다.
이것이 ZeRO-2입니다.
바닐라 DP에서 ZeRO-2까지 오면서 메모리 풋프린트를 크게 줄였습니다. 더 확장할 수 있을까요? 물론 가능합니다. 그것이 ZeRO-3입니다.
Parameters 샤딩ZeRO-3는 가장 공격적인 형태로, parameters, gradients, optimizer states 모든 정적 구성 요소를 샤딩합니다.
따라서 각 GPU는 자신의 옵티마이저 상태 샤드에 해당하는 파라미터 샤드만 저장하면 됩니다.
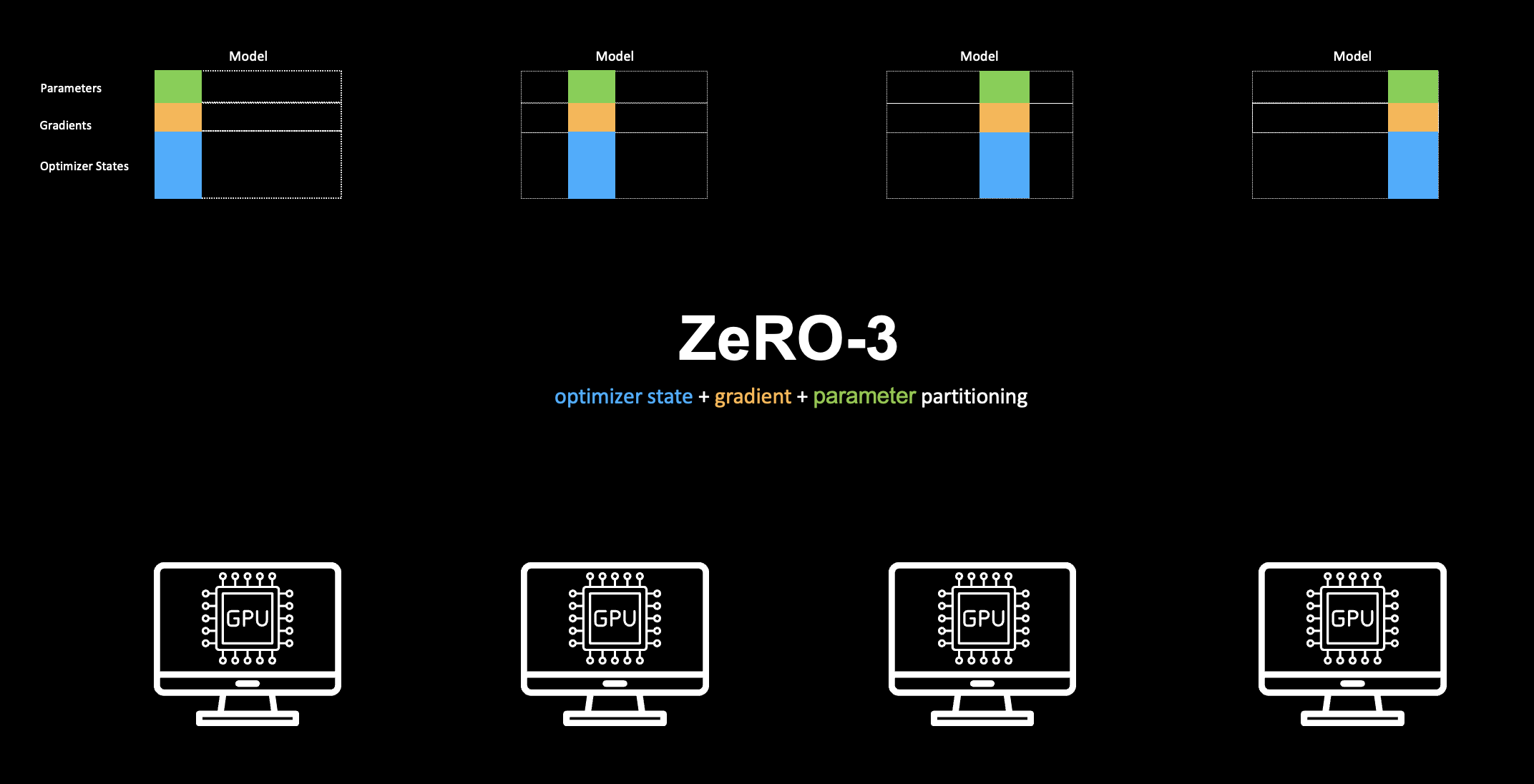
Note ZeRO-3 vs. FSDP
문헌/블로그/PyTorch 문서에서 ZeRO-3와 **FSDP(Fully Sharded Data Parallel)**가 거의 같은 의미로 쓰이는 것을 보았을 것입니다. 전략이 동일하기 때문입니다. 파라미터/그래디언트/옵티마이저 상태를 GPU들에 샤딩해 디바이스당 메모리 사용을 최소화합니다.
ZeRO-3에서 GPU당 메모리는 다음과 같습니다.
80GB A100/H100과 GPUs에서 학습 가능한 최대 모델:
비교표는 다음과 같습니다.
| Strategy | Effective Bytes/Param | Max Model on 80GB GPU |
|---|---|---|
| DP | 16 | ~5B |
| ZeRO-1 | 4.2 | ~19B |
| ZeRO-2 | 2.2 | ~36B |
| ZeRO-3 | 0.25 | ~320B |
ZeRO-3/FSDP는 ZeRO-2 대비 10배, 바닐라 DP 대비 60배 이상 큰 모델을 학습할 수 있게 합니다.
그럼 ZeRO-3에서 통신 오버헤드는 어떻게 바뀔까요?
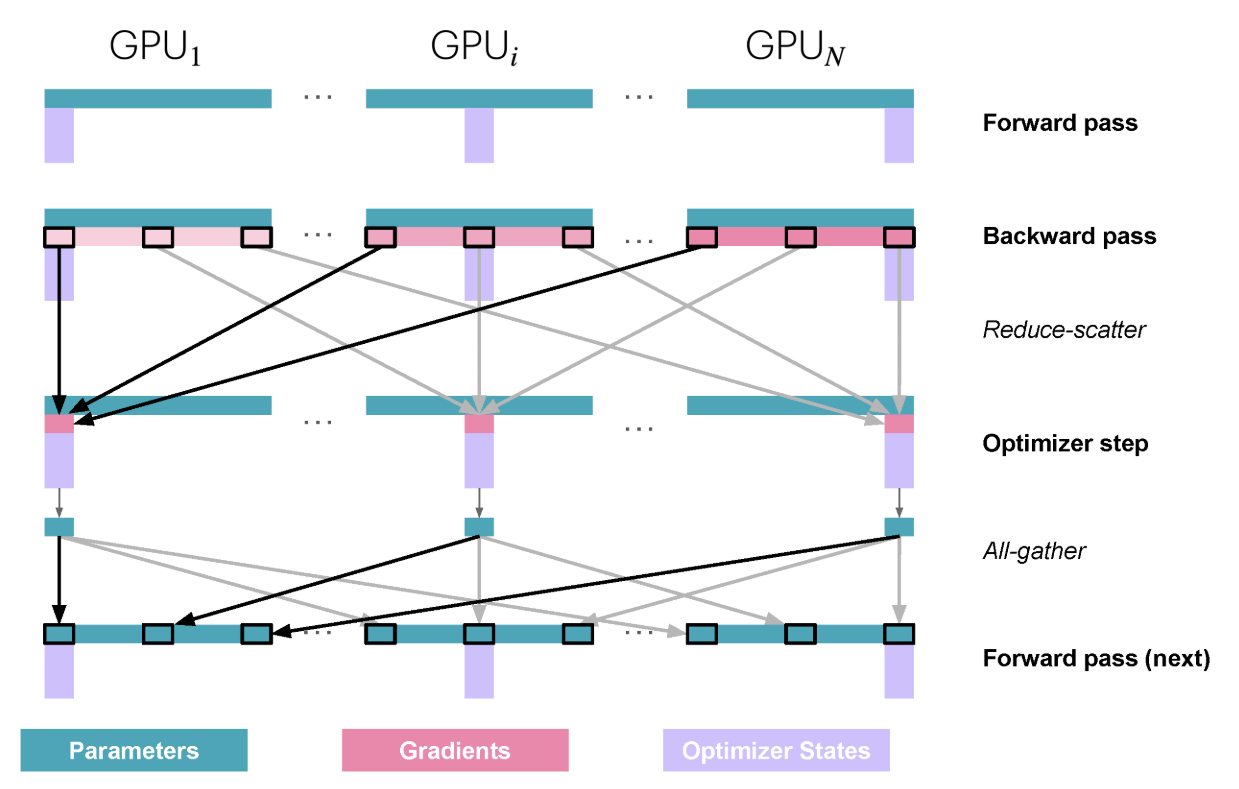
파라미터가 샤딩되어 있으므로, 통신 없이 forward pass를 할 수 없습니다. 먼저 All-Gather로 모든 GPU에서 완전한 파라미터를 모아야 합니다.
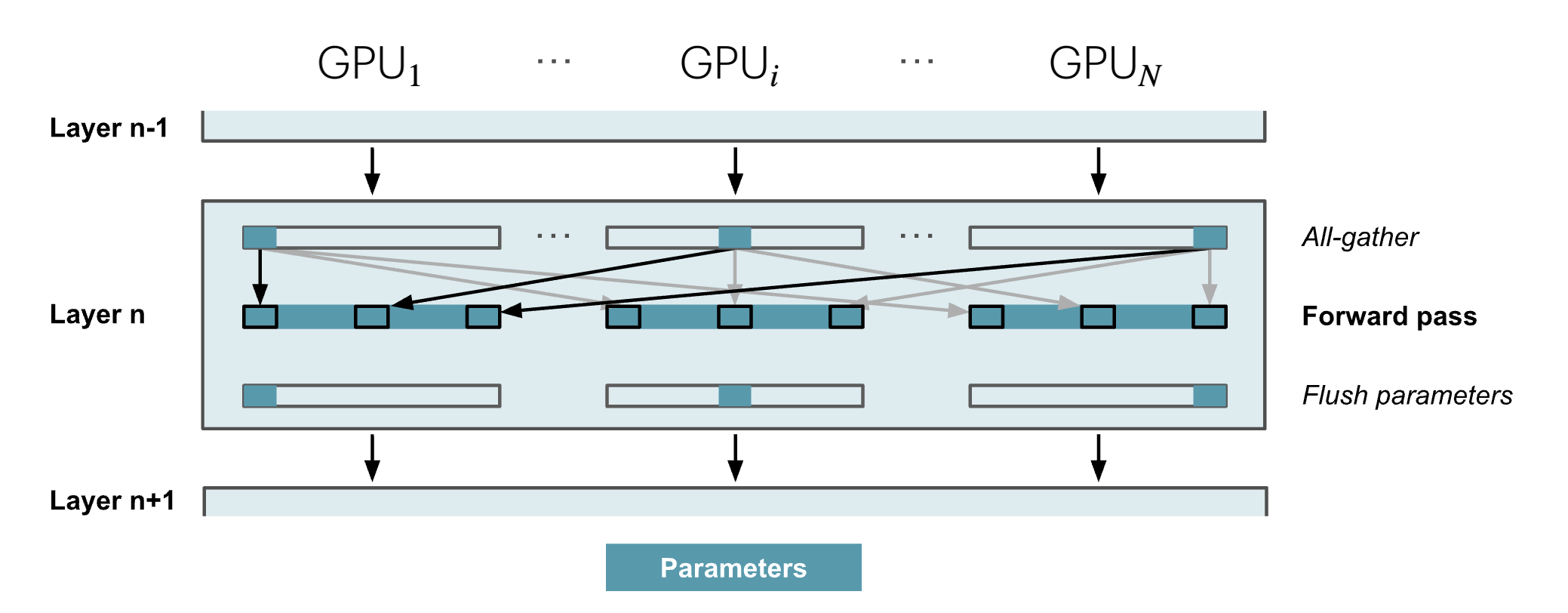
하지만 forward pass 이후에는 현재 순전파에 더 이상 필요 없으므로 파라미터를 메모리에서 _flush_할 수 있습니다(위 그림). 메모리는 줄지만 통신 오버헤드가 생깁니다.
backward pass에서도 필요한 순간에 All-Gather로 파라미터를 모아오고, ZeRO-2와 같이 Reduce-Scatter로 그래디언트 샤드를 얻습니다.
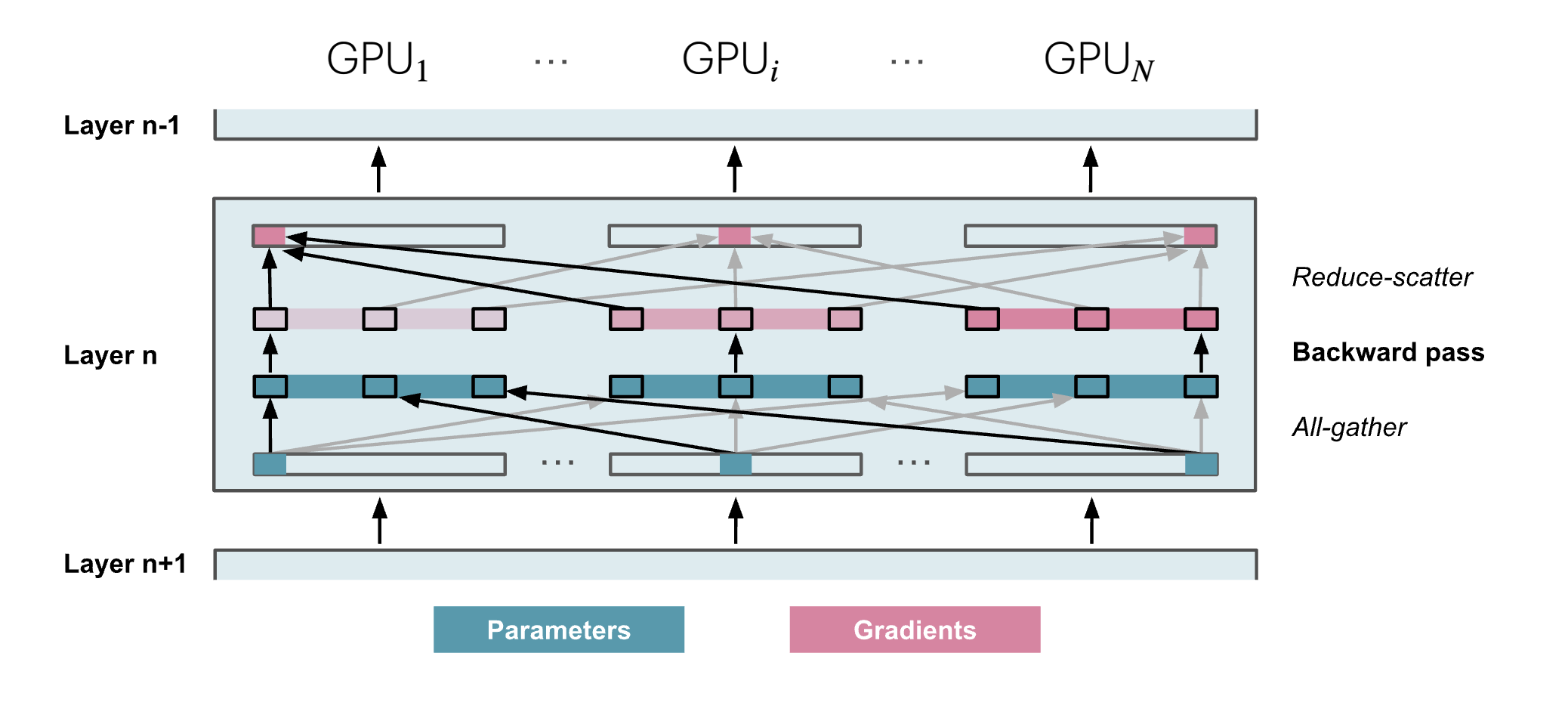
Note ZeRO-3의 통신/메모리 요약
ZeRO-3에서 통신과 메모리를 정리해 보겠습니다.
forward pass에서는 파라미터가 완전 샤딩되어 있으므로, 필요할 때마다 가중치를 all-gather해야 하며 통신 비용은 입니다. 파라미터는 순전파에서 사용 직후 메모리에서 해제할 수 있으므로, backward pass에서도 필요할 때 다시 all-gather를 해야 하고, 결과적으로 이 “세금”을 두 번 냅니다.
그리고 ZeRO-2처럼 backward pass 끝에 그래디언트에 대해 reduce-scatter가 필요해 또 통신 비용이 듭니다. 따라서 이터레이션당 총 통신 비용은 로, ZeRO-2의 보다 약간 더 큽니다.
종이 위에서는 데이터 이동이 커 보이지만, 실전에서는 prefetching으로 all-gather를 계산과 겹칠 수 있어 크게 무섭지 않습니다.
보통 레이어 의 순전파를 수행하는 동안 레이어 의 파라미터를 병렬로 all-gather할 수 있고, backward pass에서도 다음에 필요한 가중치를 미리 가져올 수 있습니다. DP 규모를 너무 크게만 하지 않으면(대략 DP 512 정도는 안전한 가이드라인) 이런 오버랩으로 충분히 효율적입니다.
메모리 관점에서 모든 것을 샤딩하면 공식이 가장 компакт해집니다.
DP 그룹 크기를 늘릴수록 GPU당 모델 메모리는 계속 줄지만, 활성값 메모리는 여전히 체크포인팅/그래디언트 누적 같은 트릭이 필요합니다.
처음엔 헷갈릴 수 있는 중요한 포인트가 하나 있습니다. ZeRO-1/2/3는 모두 모델을 샤딩하지만, 여전히 DP의 한 형태입니다.
각 GPU는 바닐라 DP처럼 자기 배치 데이터에 대해 모델 전체의 순전파/역전파를 수행합니다. 차이는 ZeRO가 모델의 parameters와 관련 텐서를 GPU들에 어떻게 저장/관리하는지 바꾼다는 점이며, 이것이 메모리를 크게 줄이지만 DP의 핵심 아이디어는 바꾸지 않습니다.

Unified AI Compute Engine이제 ZeRO 단계와 데이터 병렬 전략을 살펴봤으니, Ray와 PyTorch로 이 기법들을 실제로 어떻게 적용하는지, 그리고 Ray가 왜 실무 대규모 분산 학습에 잘 맞는지 살펴보겠습니다.
지금까지는 주로 단일 머신 내 여러 GPU를 활용하는 데 집중했습니다. 하지만 현대 딥러닝을 스케일업하려면 여러 GPU뿐 아니라 여러 대의 머신에 걸쳐 학습 작업을 분산해야 하는 경우가 많습니다.
이때 클러스터 실행/설정, 모니터링, 장애 처리, 스케일 조절 시의 엔지니어링 오버헤드 최소화 등 새로운 과제가 생깁니다.
대규모 분산 학습에서는 실무적으로 아래 요구사항과 도전이 등장합니다.
Ray는 이 요구사항(그리고 더 많은 것들)에 대한 해법을 제공하여 대규모 분산 딥러닝을 위한 매력적인 선택지입니다.
이후 섹션에서 Ray가 PyTorch 학습을 얼마나 쉽게 스케일시키는지(간단한 데이터 병렬부터 고급 ZeRO/FSDP까지) 코드와 레시피로 보겠습니다. 그 전에 Ray가 무엇이며 어떻게 동작하는지 이해해 봅시다.
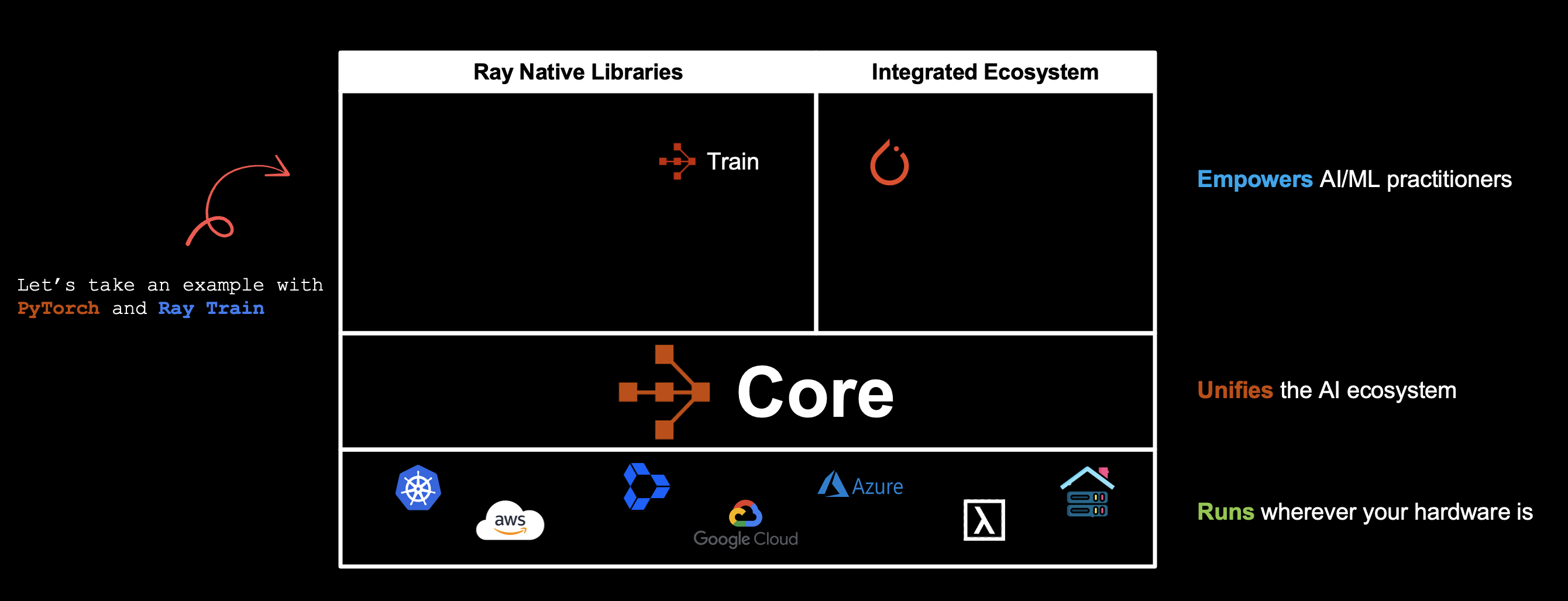
Ray는 오픈소스 통합 AI 컴퓨트 엔진으로, 특히 AI/ML 워크로드를 단일 머신에서 수천 대 규모 클러스터까지 최소한의 코드 변경으로 확장하도록 설계되었습니다.
Ray의 핵심은 Ray Core이며, 단순하고 파이썬다운 API로 어떤 분산 애플리케이션이든 만들고 확장할 수 있는 저수준 분산 컴퓨팅 프레임워크입니다.

Ray Core는 일반 파이썬 코드를 거의 마찰 없이 분산 코드로 업그레이드할 수 있는 최소하지만 강력한 프리미티브를 제공합니다.

Note Ray Compute Engine
Ray는 작업 스케줄링, 노드 장애, 데이터 전송 등 어려운 부분을 뒤에서 처리해 줍니다. ML 엔지니어/연구자는 모델/알고리즘/데이터에 집중하고, Ray가 분산 시스템의 복잡성을 맡습니다.
Stateless Tasks (Tasks)Ray의 핵심 프리미티브인 tasks와 actors를 예시로 이해해 보겠습니다. 예를 들어 이미지 배치를 간단한 변환(색 반전)으로 처리해야 하는 앱을 만든다고 합시다.
처음에는 for-loop로 순차 처리합니다. 동작은 하지만 매우 느리고, 머신에 8코어가 있어도 CPU 코어 1개만 씁니다. 수백/수천 장이면 어떨까요? 여기서 Ray가 등장하며 즉각적인 확장의 세계가 열립니다.
아래에서는 고통스러운 순차 파이썬 함수에서 출발해, Ray Tasks로 병렬 파워하우스로 바뀌고, 마지막으로 Ray Actors로 상태를 공유하는 병렬 처리까지 단계별로 살펴봅니다.
각 이미지는 1초 필터를 거치며 순서대로 처리됩니다. 이미지 8장이면 총 8초가 걸립니다.
# sequential_process.py
import time
import numpy as np
def process_image(image: np.ndarray) -> np.ndarray:
"""Simulates a slow 1-second filter."""
time.sleep(1)
return 255 - image
images = [np.random.randint(0, 255, (10, 10, 3)) for _ in range(8)]
start_time = time.time()
# Sequential: 8 images × 1 sec/image = 8 seconds
results = [process_image(img) for img in images]
end_time = time.time()
print(f"Processed {len(results)} images in {end_time - start_time:.2f} seconds.")
코드는 동작하지만 코어 하나만 써서 나머지는 놀고 있습니다. 좋지 않죠. Ray Tasks로 병렬화해 보겠습니다.
이제 Ray로 이미지 처리를 병렬화합니다.
Ray의 @ray.remote 데코레이터를 붙이면 함수가 병렬로 실행됩니다. 사용 가능한 CPU 코어 수만큼 복제되어 동작합니다.
# parallel_process.py
import ray
import time
import numpy as np
# 1. Initialize Ray - autodetects & uses all available CPU cores
ray.init()
# 2. Decorate the function as a remote Ray task
@ray.remote
def process_image(image: np.ndarray) -> np.ndarray:
"""Simulates a slow 1-second filter."""
time.sleep(1)
return 255 - image
images = [np.random.randint(0, 255, (10, 10, 3)) for _ in range(8)]
start_time = time.time()
# 3. Launch tasks in parallel; returns list of ObjectRefs (futures)
result_refs = [process_image.remote(img) for img in images]
# 4. Wait for and retrieve finished results via ray.get()
results = ray.get(result_refs)
end_time = time.time()
# On an 8-core machine: ~1 second total runtime!
print(f"Processed {len(results)} images in {end_time - start_time:.2f} seconds.")
ray.shutdown()
무엇이 달라졌나요?
@ray.remote 데코레이터로 함수를 원격 태스크로 만들었습니다..remote()로 호출하여 원격 태스크를 실행했습니다.remote 호출이 반환하는 ObjectRef에 대해 ray.get()을 호출해 결과를 기다렸습니다.ObjectRef입니다. 각 .remote()가 백그라운드에서 작업을 던지고, 메인 코드는 계속 진행합니다. ray.get(result_refs)를 호출하면 Ray가 준비된 결과들을 모아 줍니다.Tip Ray Speed-Up
@ray.remote, .remote(), ray.get()만 추가하면, 8코어에서 거의 8배 속도 향상을 얻을 수 있습니다.
Stateful Tasks (Actors)Ray의 장점은 단순 병렬화에 그치지 않고, 병렬 작업 간 상태(state) 공유에 맞는 도구도 제공한다는 점입니다. 예를 들어 모든 이미지에서 처리된 픽셀 수를 합산하는 누적 카운터(총 픽셀 수)를 원한다고 합시다. 하지만 각 병렬 작업은 격리되어 실행되므로 전역 변수를 쓸 수 없습니다.
사실 원하는 것은 서비스입니다. 즉 모든 작업이 실시간으로 업데이트할 수 있는 _살아 있는 원격 카운터_죠. Ray에서는 이를 Actor라고 부릅니다. 클러스터 어딘가에 살아 있으며 자체적으로 지속 상태를 갖는 클래스입니다.
이제 stateful 작업을 위한 Actor 생성/사용 방법을 보겠습니다.
# actor_counter.py
import ray
import numpy as np
import time
ray.init()
# 1. Define the stateful service as a Python Class
@ray.remote
class PixelCounter:
# The internal state is defined in __init__
def __init__(self):
self.total_pixels = 0
# A method to mutate (update) the internal state
def add(self, num_pixels: int):
self.total_pixels += num_pixels
# A method to retrieve the internal state
def get_total(self) -> int:
return self.total_pixels
# 2. Modify the Task to use the Actor Handle
@ray.remote
def process_image_with_actor(image: np.ndarray, counter_actor: "ActorHandle"):
# This task calls the Actor's add method remotely
counter_actor.add.remote(image.size)
time.sleep(1)
# The image processing logic is here, but omitted for simplicity
# --- Main Script ---
images = [np.random.randint(0, 255, (10, 10, 3)) for _ in range(8)]
image_size = images[0].size
expected_total = image_size * len(images) # 8 * 300 = 2400
# 3. Create a single instance (the Actor Handle)
counter = PixelCounter.remote()
# 4. Launch 8 parallel tasks, passing the Actor Handle to each
task_refs = [process_image_with_actor.remote(img, counter) for img in images]
# Wait for all the image processing tasks to complete
ray.get(task_refs)
# 5. Retrieve the final state from the Actor
final_total_ref = counter.get_total.remote()
final_total = ray.get(final_total_ref)
print(f"Expected total pixels: {expected_total}")
print(f"Actual total from actor: {final_total}")
ray.shutdown()
무엇이 달라졌나요?
stateless) 독립적으로 이미지를 처리했습니다. 이제 Actor(원격 PixelCounter 클래스)를 사용해 각 태스크가 처리한 픽셀 수를 안전하게 누적할 수 있습니다.@ray.remote 클래스를 정의하고, 그 핸들을 태스크에 넘겨 태스크가 add.remote()로 공유 상태를 업데이트한다는 것입니다.이처럼 Ray Tasks(함수처럼 stateless한 독립 작업)와 Ray Actors(클래스처럼 stateful한 작업)를 조합하는 패턴은, 실무 애플리케이션(꼭 AI뿐 아니라)에서 확장 가능한 파이프라인을 만드는 기반입니다.
Ray의 프리미티브는 스레드/프로세스를 직접 관리하거나 모든 코드를 다시 쓰지 않고도, 확장 가능하고 신뢰할 수 있으며 유지보수 가능한 분산 애플리케이션을 구축할 수 있게 해 줍니다.
Ray Core가 분산 애플리케이션을 만들기 위한 저수준 프리미티브를 제공하지만, 특히 특화된 AI 워크로드에서는 더 높은 수준의 추상화가 더 적합할 때가 많습니다.
Ray는 데이터 처리, 학습, 하이퍼파라미터 탐색, 강화학습(RL), 서빙 같은 작업을 위한 고수준 라이브러리도 제공합니다.
| Ray Library | Purpose | Key Features / Benefits |
|---|---|---|
Ray Data | 확장 가능한 데이터 수집/처리/추론 | 대규모 데이터셋을 손쉽게 샤딩/전처리; CPU(ETL)와 GPU(학습/추론) 사이를 효율적으로 스트리밍해 하드웨어 사용률을 극대화. |
Ray Train | 분산 학습 및 파인튜닝 | PyTorch, TensorFlow 등에 대해 멀티 노드/GPU 오케스트레이션과 동기화를 추상화; 보일러플레이트나 수동 sync 없이 동작. |
Ray Tune | 확장 가능한 하이퍼파라미터 탐색 | 클러스터 전체에서 실험(trial)을 조율/관리(탐색, 조기 종료, 스케줄링); 실험 추적 및 베스트 모델 선택 포함. |
Ray Serve | 빠르고 프로그래머블한 모델 서빙 | 자동 확장 가능한 마이크로서비스로 모델/로직 배포; 모델 합성, 트래픽 분할, 버저닝 등 지원. |
Ray RLlib | 확장 가능한 강화학습 | RL 알고리즘을 학습/평가하기 위한 포괄적 라이브러리 제공. |
이 라이브러리들은 Ray Core 위에 구축되어, 분산 애플리케이션을 더 사용자 친화적으로 만들 수 있게 합니다.
Tip 왜 고수준 Ray 라이브러리를 쓰나요?
Ray Core의 Tasks/Actors가 이렇게 강력한데, 왜 Ray Train/Ray Data 같은 고수준 라이브러리를 써야 할까요?
답은 추상화와 특화입니다. Ray Core만으로도 분산 학습 파이프라인을 만들 수는 있지만, 그러면 데이터 샤딩, PyTorch DDP 동기화, 분산 체크포인팅, 장애 내성, 재개 처리, 하이퍼파라미터 탐색 등을 모두 직접 구현해야 합니다. 보일러플레이트와 위험이 큽니다.
또한 Ray는 PyTorch, vLLM, Hugging Face 등과의 강한 통합도 제공합니다.
이 통합 생태계는 end-to-end 분산 AI 워크플로를 구축할 수 있게 해 줍니다.
Warning 왜 PyTorch Distributed만 쓰지 않을까요?
**PyTorch Distributed(DDP 등)**는 멀티 GPU 학습에 매우 훌륭한 내장 솔루션이지만, 주로 단일 노드 또는 _균질하고 강하게 결합된 클러스터_에 최적화되어 있습니다. 한 머신에서 여러 GPU로 확장하는 정도면 PyTorch 도구만으로도 충분할 때가 많고, torchrun으로 실행할 수 있습니다.
하지만 여러 대의 머신으로 확장하거나 복잡한 워크플로를 오케스트레이션하려고 하면 난이도가 급격히 올라갑니다. 예를 들어:
이런 것들은 PyTorch 기본 도구만으로는 고통스럽고 복잡합니다.
바로 이런 곳에서 Ray가 빛납니다.
Ray는 대규모 분산 워크로드를 위한 저수준 엔지니어링을 추상화합니다. 예를 들어 Ray Train과 Ray Data를 사용하면 멀티 GPU/멀티 노드 오케스트레이션, CPU-GPU 통합 파이프라인, 복원력/확장성을 손쉽게 얻을 수 있습니다. 덕분에 인프라 대신 알고리즘과 모델에 집중할 수 있습니다.
이제 Ray의 기본을 이해했으니, Ray Train과 PyTorch로 분산 학습을 깊게 들어가 보겠습니다.
분산 학습에 들어가기 전, 단일 GPU 학습 루프를 기준선으로 보겠습니다. 이후 분산으로 마이그레이션할 때 무엇이 바뀌어야 하는지 이해하는 데 도움이 됩니다.
Vision Transformer(torchvision.models.VisionTransformer)와 CIFAR-10 데이터셋을 사용합니다. 이 코드는 CPU, GPU(CUDA), Apple MPS에서 동작하지만, 완전히 일반적인(분산이 아닌) PyTorch 코드입니다.
PyTorch로 단일 머신/Colab에서 학습해 본 적이 있다면 아래와 비슷한 루프를 봤을 겁니다.
dataset 다운로드 및 준비
* data loader 설정
model 정의
* 모델을 사용 가능한 디바이스(GPU/MPS/CPU)로 이동
optimizer와 loss 설정
training loop 실행
* 학습 데이터를 순회하며 가중치 업데이트
* 검증 데이터 정확도 확인
선택적으로 마지막에 checkpoint 저장
단일 GPU/단일 머신에는 잘 동작하지만 자동으로 확장되진 않습니다. 곧 Ray Train으로 마이그레이션하는 방법을 보겠지만, 우선 기본 셋업을 보겠습니다.
이 함수는 CIFAR-10의 train/test split을 위한 DataLoader를 설정합니다.
from torchvision import datasets, transforms
from torchvision.transforms import Normalize, ToTensor
from torch.utils.data import DataLoader
from filelock import FileLock
import os
def get_dataloaders(batch_size):
"""
Create standard PyTorch DataLoaders.
No distributed code, just vanilla PyTorch.
"""
transform = transforms.Compose([
ToTensor(),
Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
with FileLock(os.path.expanduser("~/data.lock")):
train_data = datasets.CIFAR10(
root="~/data", train=True, download=True, transform=transform,
)
test_data = datasets.CIFAR10(
root="~/data", train=False, download=True, transform=transform,
)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size)
return train_loader, test_loader
Tip 왜 FileLock을 쓰나요?
데이터셋 다운로드가 동시에 발생할 때 생기는 동시성 문제를 피하기 위해 FileLock을 사용합니다.
torchvision.models.VisionTransformer를 쓰는 표준 PyTorch 학습 루프입니다.
from torchvision.models import VisionTransformer
from torch import nn
import torch
from tqdm import tqdm
def train_func(lr=1e-3, epochs=10, batch_size=512):
"""
Main training function: single machine, single GPU.
"""
# Get data loaders
train_loader, val_loader = get_dataloaders(batch_size=batch_size)
# Create the model
model = VisionTransformer(
image_size=32, # CIFAR-10 images are 32x32
patch_size=4, # Reasonable patch size for CIFAR-10
num_layers=12, # Transformer layers
num_heads=8, # Attention heads
hidden_dim=384, # Model width
mlp_dim=768, # Transformer MLP dim
num_classes=10 # CIFAR-10
)
# Move model to correct device (GPU/MPS/CPU)
device = torch.device('cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu')
print(f"Using device: {device}")
model.to(device)
# Set up loss and optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
# Training loop
for epoch in range(epochs):
print(f"\nEpoch {epoch + 1}/{epochs}")
# Training phase
model.train()
train_loss = 0.0
for X, y in tqdm(train_loader, desc=f"Train Epoch {epoch + 1}"):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss /= len(train_loader)
# Validation phase
model.eval()
val_loss, num_correct, num_total = 0, 0, 0
with torch.no_grad():
for X, y in tqdm(val_loader, desc=f"Valid Epoch {epoch + 1}"):
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
val_loss += loss.item()
num_total += y.shape[0]
num_correct += (pred.argmax(1) == y).sum().item()
val_loss /= len(val_loader)
accuracy = num_correct / num_total
print(f" Train Loss: {train_loss:.4f} | Valid Loss: {val_loss:.4f} | Accuracy: {accuracy:.4f} ({100 * accuracy:.2f}%)")
# Optional: Save checkpoint
checkpoint = {
'epoch': epochs,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'accuracy': accuracy,
}
torch.save(checkpoint, 'checkpoint_single_machine.pth')
print(f"\nTraining completed! Final accuracy: {100 * accuracy:.2f}%\nCheckpoint saved to checkpoint_single_machine.pth")
단일 GPU에서 모델을 학습해 보겠습니다.
train_func(lr=1e-3, epochs=10, batch_size=512)

보시다시피 단일 GPU만 사용되고 나머지 GPU는 유휴 상태입니다.
이 스크립트는 분산 로직이나 Ray가 없는 바닐라 PyTorch입니다. get_dataloaders 함수와 train_func 구조 같은 핵심 로직은, Ray Train으로 마이그레이션해도 대부분 동일하게 유지됩니다.
이제 여러 머신/여러 GPU로 클러스터에서 스케일 학습을 해 보겠습니다.
이제 single-machine, single-GPU 학습 루프를 Ray Train과 PyTorch로 multiple machines, multiple GPUs에서 distributed training으로 마이그레이션해 보겠습니다.
Your browser does not support the video tag.
Distributed Training with Ray Train Key Concepts.
Ray Train 아키텍처는 다음 구성요소로 이루어집니다.
학습 워커를 스케줄링하고 에러를 처리하며 체크포인트를 관리하는 Ray Train Controller/Driver
학습 코드를 실행하는 Ray Train Workers
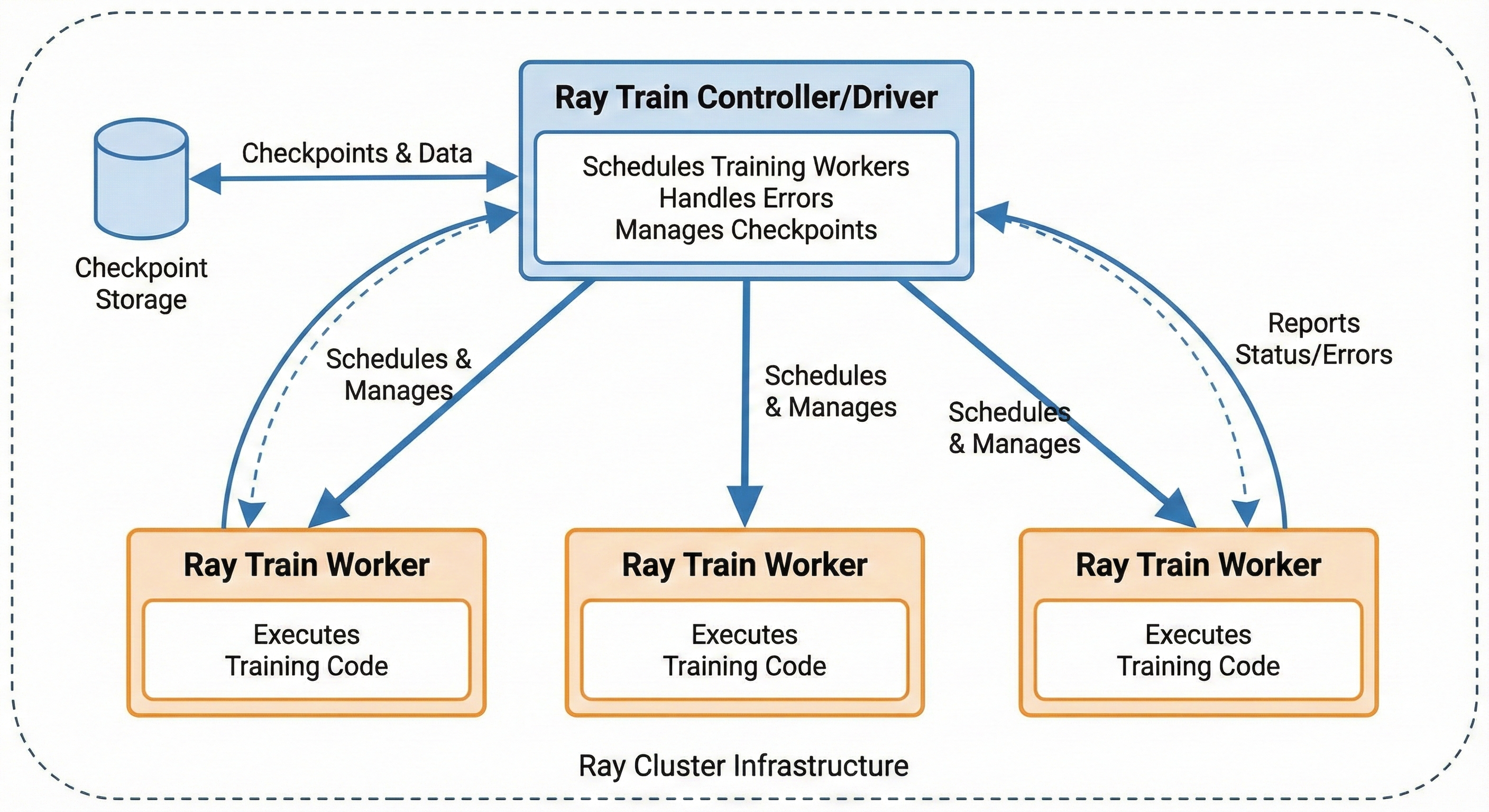
Ray Train의 주요 API 개념은 다음과 같습니다.
train_loop_per_worker: 모델 학습 로직이 들어가는 핵심 함수
ScalingConfig: 워커 수와 자원(CPU/GPU/TPU) 지정
Trainer: 학습 프로세스 관리
Trainer.fit(): 분산 학습 작업 시작
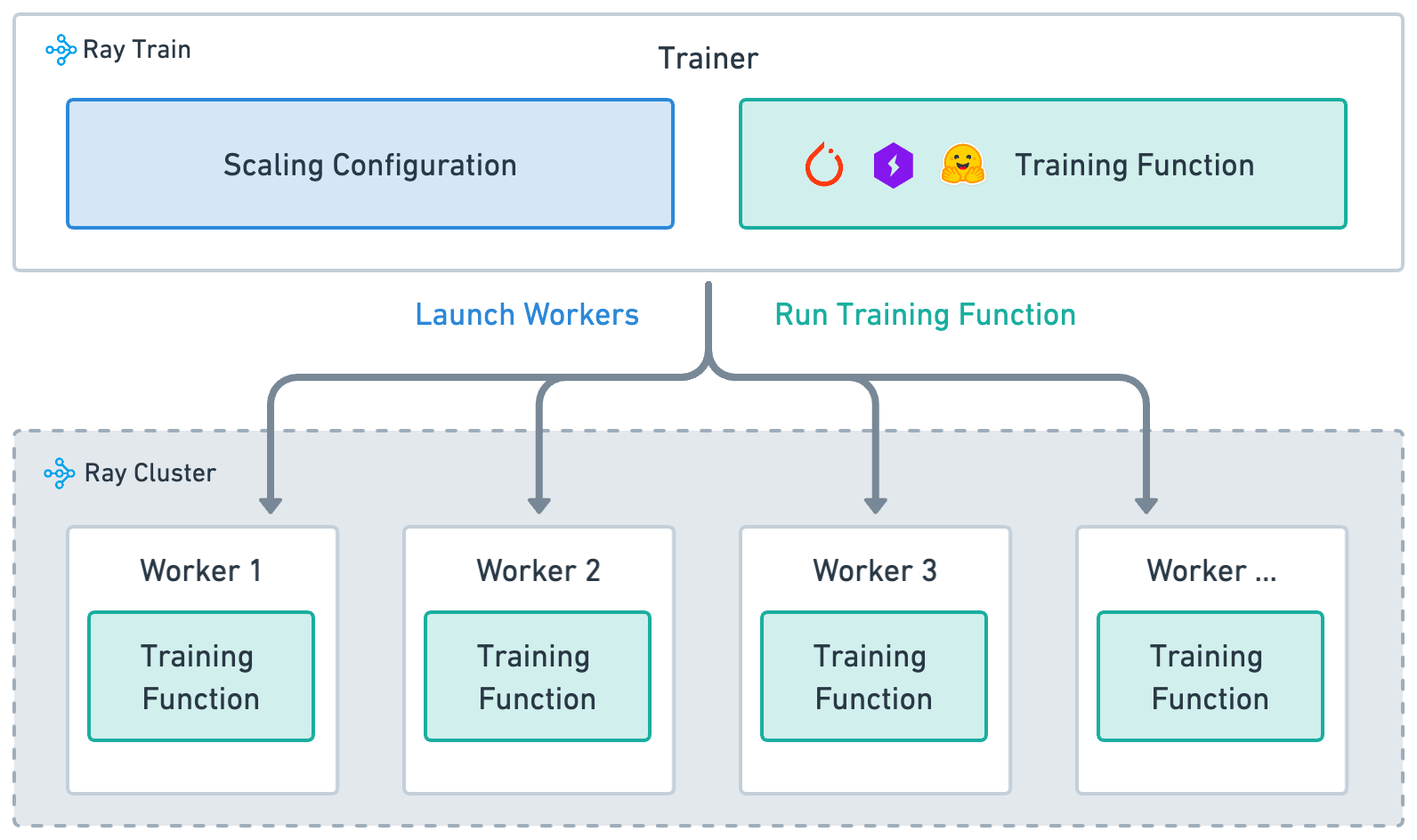
다음은 Ray Data와 Ray Train의 통합 다이어그램입니다.
이 글에서는 Ray Data와 Ray Train 통합을 자세히 다루지는 않습니다. 더 알고 싶다면 Ray Data 문서를 참고하세요.
학습을 시작하기 전, Ray 클러스터에 사용 가능한 GPU/CPU가 얼마나 있는지 확인해 보겠습니다.
import ray
import torch
def check_cluster_gpus():
"""Check GPU count in the entire Ray cluster."""
# Initialize Ray if not already initialized
if not ray.is_initialized():
ray.init()
# Get cluster resources (total GPUs in cluster)
cluster_resources = ray.cluster_resources()
total_gpus = cluster_resources.get("GPU", 0)
# Get available resources (currently available GPUs)
available_resources = ray.available_resources()
available_gpus = available_resources.get("GPU", 0)
# Get local GPU count (GPUs on this node only)
local_gpus = torch.cuda.device_count() if torch.cuda.is_available() else 0
# Print results
print("\n" + "="*60)
print("Ray Cluster GPU Information")
print("="*60)
print(f"Total GPUs in cluster: {int(total_gpus)}")
print(f"Available GPUs in cluster: {int(available_gpus)}")
print(f"Local GPUs (head node): {local_gpus}")
print("="*60)
# Additional cluster info
print("\nCluster Resources:")
print(f" CPUs (total): {int(cluster_resources.get('CPU', 0))}")
print(f" CPUs (available): {int(available_resources.get('CPU', 0))}")
# Show node details if available
try:
nodes = ray.nodes()
print(f"\nCluster Nodes: {len(nodes)}")
for i, node in enumerate(nodes):
node_resources = node.get('Resources', {})
node_gpus = node_resources.get('GPU', 0)
print(f" Node {i+1}: {int(node_gpus)} GPU(s)")
except Exception as e:
print(f"\nNote: Could not retrieve node details: {e}")
print()
return {
'total_gpus': int(total_gpus),
'available_gpus': int(available_gpus),
'local_gpus': local_gpus
}
if __name__ == '__main__':
check_cluster_gpus()
제가 가진 클러스터는 총 8 GPU입니다. 헤드 노드 1개와 워커 노드 2개로 구성되며, 각 워커 노드는 4 GPU를 갖습니다.
============================================================
Ray Cluster GPU Information
============================================================
Total GPUs in cluster: 8
Available GPUs in cluster: 8
Local GPUs (head node): 0
============================================================
Cluster Resources:
CPUs (total): 96
CPUs (available): 96
Cluster Nodes: 3
Node 1: 0 GPU(s)
Node 2: 4 GPU(s)
Node 3: 4 GPU(s)
이제 Ray Train 기본을 이해했고, Ray 클러스터도 준비되었습니다. 이제 Ray Train과 PyTorch FSDP로 분산 학습을 해 보겠습니다.
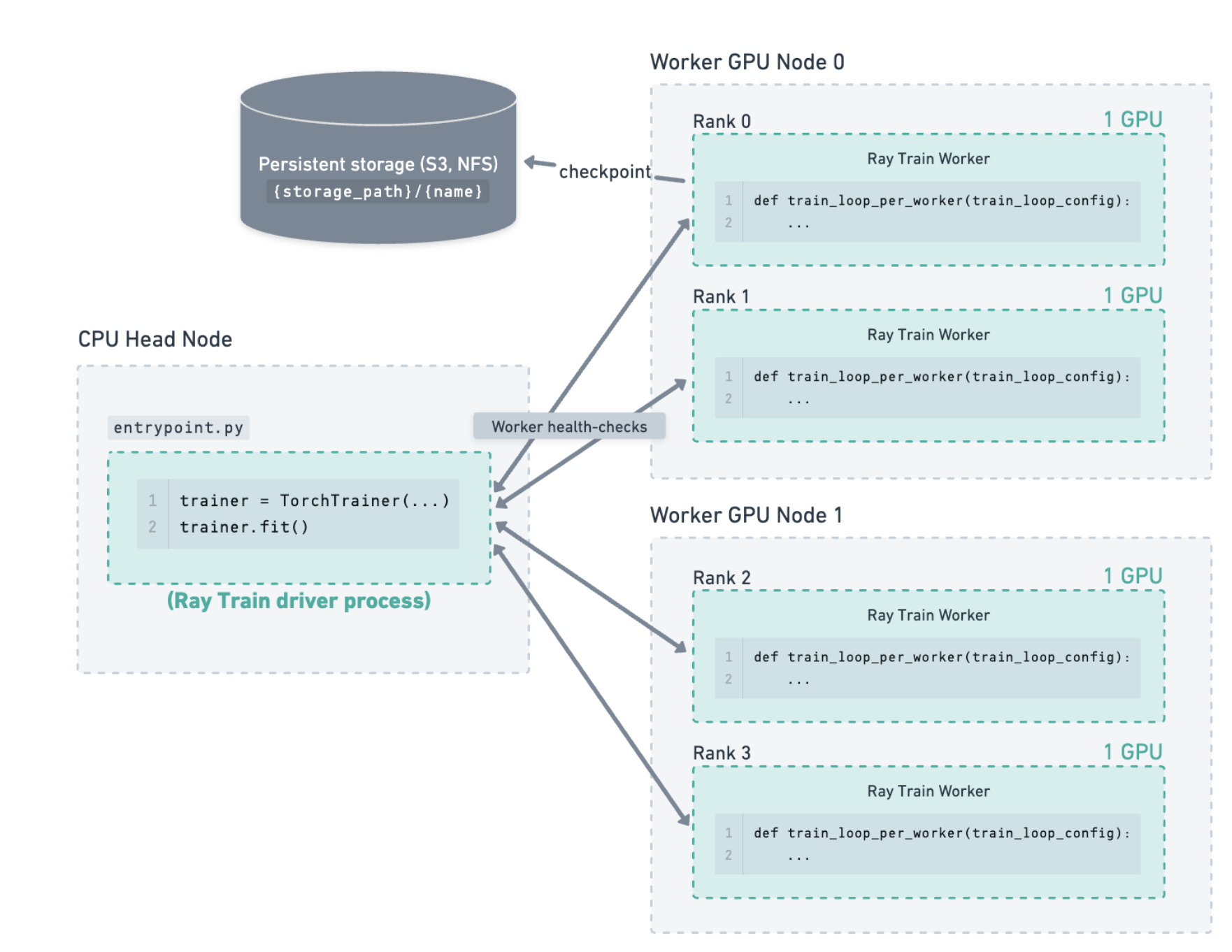
먼저 몇 개의 Ray 워커(프로세스)가 참여할지 정합니다. 보통 GPU당 1워커입니다. 8 GPU 클러스터라면:
scaling_config = ScalingConfig(
num_workers=8, # e.g., 8 GPUs in our cluster
use_gpu=True,
resources_per_worker={"CPU": 2, "GPU": 1},
)
데이터 준비는 일반 PyTorch/DDP와 동일합니다. 기존 transform/DataLoader 로직을 그대로 사용합니다.
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from filelock import FileLock
import os
def get_dataloaders(batch_size):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
with FileLock(os.path.expanduser("~/data.lock")):
train_ds = datasets.CIFAR10("~/data", train=True, download=True, transform=transform)
valid_ds = datasets.CIFAR10("~/data", train=False, download=True, transform=transform)
return (
DataLoader(train_ds, batch_size=batch_size, shuffle=True),
DataLoader(valid_ds, batch_size=batch_size),
)
이 단계에서는 FSDP에 대한 특별한 고려가 필요 없습니다.
다음으로 Ray Train 워커에서 실행될 학습 함수를 정의합니다.
모델이 FSDP에 맞게 준비되어야 하므로 prepare_model을 사용합니다.
def train_func_per_worker(config):
lr = config["lr"]
epochs = config["epochs"]
batch_size = config["batch_size_per_worker"]
ctx = ray.train.get_context()
rank = ctx.get_world_rank()
world_size = ctx.get_world_size()
if rank == 0:
print(f"Training with FSDP across {world_size} workers...")
# Prepare DataLoaders for distributed training
train_dl, valid_dl = get_dataloaders(batch_size)
train_dl = ray.train.torch.prepare_data_loader(train_dl)
valid_dl = ray.train.torch.prepare_data_loader(valid_dl)
# Define the model
model = VisionTransformer(
image_size=32, patch_size=4,
num_layers=12, num_heads=8, hidden_dim=384, mlp_dim=768, num_classes=10,
)
# Prepare the model for FSDP
model = ray.train.torch.prepare_model(model, parallel_strategy="fsdp")
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
for epoch in range(epochs):
model.train()
total_loss, sample_cnt = 0.0, 0
for X, y in train_dl:
pred = model(X)
loss = criterion(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item() * X.shape[0]
sample_cnt += X.shape[0]
train_loss = total_loss / sample_cnt
# Validation loop
model.eval()
valid_loss, correct, total = 0.0, 0, 0
with torch.no_grad():
for X, y in valid_dl:
pred = model(X)
valid_loss += criterion(pred, y).item() * X.shape[0]
total += y.shape[0]
correct += (pred.argmax(dim=1) == y).sum().item()
valid_loss /= total
acc = correct / total
if rank == 0:
print(f"Epoch {epoch+1}: Train Loss={train_loss:.4f} Valid Loss={valid_loss:.4f} Acc={acc:.3%}")
metrics = {"epoch": epoch+1, "train_loss": train_loss, "valid_loss": valid_loss, "accuracy": acc}
# Checkpoint every 5 epochs
if (epoch + 1) % 5 == 0:
with tempfile.TemporaryDirectory() as ckpt_dir:
torch.save(model.module.state_dict(), os.path.join(ckpt_dir, "model.pt"))
ray.train.report(metrics, checkpoint=ray.train.Checkpoint.from_directory(ckpt_dir))
else:
ray.train.report(metrics)
Note 병렬 전략을 DDP로 바꾸기
DDP로 바꾸려면 파라미터를 "ddp"로 바꾸면 됩니다.
model = ray.train.torch.prepare_model(model, parallel_strategy="fsdp")
이제 Ray 체크포인팅 유틸리티로 베스트 결과와 복구 가능한 상태를 저장합니다.
from ray.train import RunConfig, CheckpointConfig
checkpoint_config = CheckpointConfig(
num_to_keep=2,
checkpoint_score_attribute="accuracy",
checkpoint_score_order="max",
)
run_config = RunConfig(
name="cifar10_fsdp_example",
storage_path="/mnt/cluster_storage/training/", # Use a persistent/shared location
checkpoint_config=checkpoint_config,
)
설정을 모아 분산 학습을 시작합니다.
from ray.train.torch import TorchTrainer
global_batch_size = 1024
num_workers = 8
batch_size_per_worker = global_batch_size // num_workers
train_loop_config = {
"lr": 1e-3,
"epochs": 20,
"batch_size_per_worker": batch_size_per_worker,
}
trainer = TorchTrainer(
train_loop_per_worker=train_func_per_worker,
train_loop_config=train_loop_config,
scaling_config=scaling_config,
run_config=run_config,
)
print("Starting FSDP distributed training...")
result = trainer.fit()
학습이 끝나면 베스트 체크포인트에서 모델을 복원할 수 있습니다.
import torch
from torchvision.models import VisionTransformer
import os
ckpt = result.checkpoint
with ckpt.as_directory() as ckpt_dir:
model_path = os.path.join(ckpt_dir, "model.pt")
model = VisionTransformer(
image_size=32, patch_size=4,
num_layers=12, num_heads=8, hidden_dim=384, mlp_dim=768, num_classes=10,
)
state_dict = torch.load(model_path, map_location="cpu")
model.load_state_dict(state_dict)
이제 모든 조각을 합쳐 클러스터에서 모델을 학습해 보겠습니다.
import os
import tempfile
import torch
from torch import nn
from torchvision import datasets, transforms
from torchvision.models import VisionTransformer
from torch.utils.data import DataLoader
from filelock import FileLock
import ray
from ray.train import ScalingConfig, RunConfig, CheckpointConfig
from ray.train.torch import TorchTrainer
def get_dataloaders(batch_size):
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
with FileLock(os.path.expanduser("~/data.lock")):
train_data = datasets.CIFAR10(root="~/data", train=True, download=True, transform=transform)
valid_data = datasets.CIFAR10(root="~/data", train=False, download=True, transform=transform)
train_loader = DataLoader(train_data, batch_size=batch_size, shuffle=True)
valid_loader = DataLoader(valid_data, batch_size=batch_size)
return train_loader, valid_loader
def train_func_per_worker(config):
lr = config["lr"]
epochs = config["epochs"]
batch_size = config["batch_size_per_worker"]
ctx = ray.train.get_context()
world_size = ctx.get_world_size()
local_rank = ctx.get_world_rank()
if local_rank == 0:
print(f"FSDP Training on {world_size} workers")
train_loader, valid_loader = get_dataloaders(batch_size)
train_loader = ray.train.torch.prepare_data_loader(train_loader)
valid_loader = ray.train.torch.prepare_data_loader(valid_loader)
model = VisionTransformer(
image_size=32, patch_size=4,
num_layers=12, num_heads=8, hidden_dim=384, mlp_dim=768, num_classes=10,
)
# [FSDP] Key change from DDP:
model = ray.train.torch.prepare_model(model, parallel_strategy="fsdp")
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-2)
for epoch in range(epochs):
model.train()
train_loss, n = 0.0, 0
for X, y in train_loader:
pred = model(X)
loss = criterion(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * X.shape[0]
n += X.shape[0]
train_loss /= n
model.eval()
correct, total, valid_loss = 0, 0, 0.0
with torch.no_grad():
for X, y in valid_loader:
pred = model(X)
valid_loss += criterion(pred, y).item() * X.shape[0]
total += y.shape[0]
correct += (pred.argmax(dim=1) == y).sum().item()
valid_loss /= total
accuracy = correct / total
metrics = {
"epoch": epoch + 1,
"train_loss": train_loss,
"valid_loss": valid_loss,
"accuracy": accuracy
}
# Save a checkpoint every 5 epochs
if (epoch + 1) % 5 == 0:
with tempfile.TemporaryDirectory() as tmp_ckpt_dir:
torch.save(model.module.state_dict(),
os.path.join(tmp_ckpt_dir, "model.pt"))
ray.train.report(metrics, checkpoint=ray.train.Checkpoint.from_directory(tmp_ckpt_dir))
else:
ray.train.report(metrics)
scaling_config = ScalingConfig(num_workers=8, use_gpu=True, resources_per_worker={"CPU": 2, "GPU": 1})
checkpoint_config = CheckpointConfig(num_to_keep=2, checkpoint_score_attribute="accuracy", checkpoint_score_order="max")
run_config = RunConfig(name="cifar10_fsdp_example", storage_path="/mnt/cluster_storage/training/", checkpoint_config=checkpoint_config)
global_batch_size = 1024
batch_size_per_worker = global_batch_size // scaling_config.num_workers
train_loop_config = {"lr": 1e-3, "epochs": 20, "batch_size_per_worker": batch_size_per_worker}
trainer = TorchTrainer(
train_loop_per_worker=train_func_per_worker,
train_loop_config=train_loop_config,
scaling_config=scaling_config,
run_config=run_config,
)
result = trainer.fit()
학습이 돌아가는 동안 Ray 대시보드에서 진행 상황을 확인할 수 있습니다. 이제 8개 GPU가 모두 학습에 사용되는 것을 볼 수 있습니다.
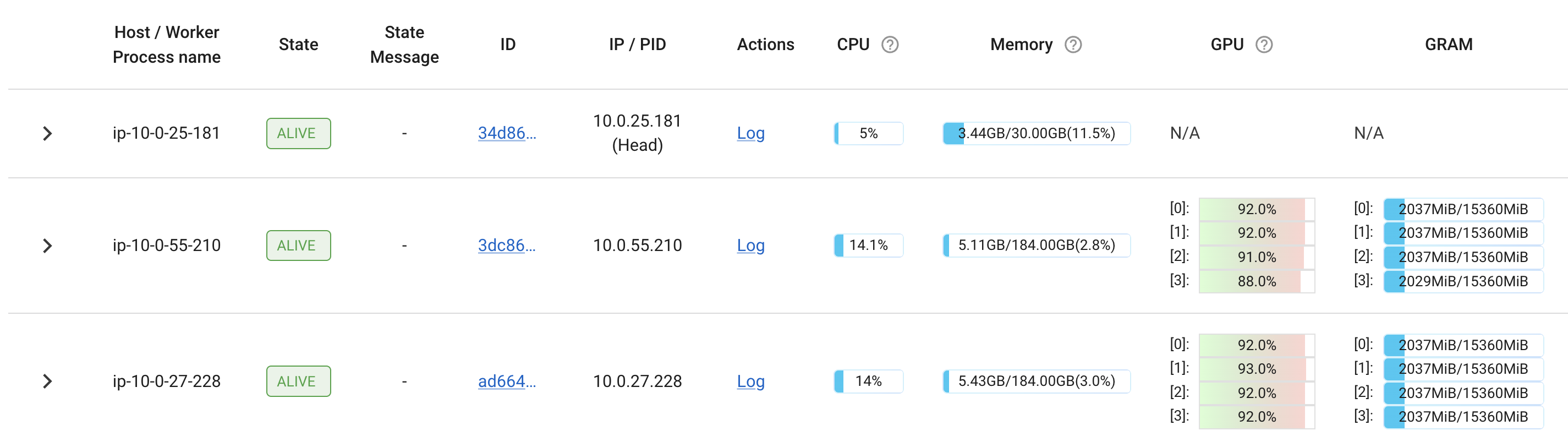
분산 학습을 바닥부터 구현하는 것은, 특히 여러 GPU 설정과 워커 간 통신을 오케스트레이션하는 부분 때문에 복잡하고 어렵게 느껴지곤 합니다. 하지만 Ray Train 같은 현대 오픈소스 프레임워크와 PyTorch의 FSDP 같은 강력한 기능 덕분에, 확장 가능하고 효율적인 분산 딥러닝의 진입 장벽이 크게 낮아졌습니다. 이 글에서는 Ray Train으로 오케스트레이션을 하고 PyTorch FSDP로 메모리/통신을 효율적으로 관리하면서 여러 GPU에서 모델을 파인튜닝하는 분산 학습 파이프라인을 단계별로 구축해 보았습니다.
Ray의 고수준 추상화를 활용하면, 커스텀 분산 학습에서 흔히 필요한 보일러플레이트를 상당 부분 제거하고, 실험 추적, 장애 내성, 자동 체크포인팅 같은 유용한 기능을 얻을 수 있습니다. 또한 Ray의 스케일링 설정으로 몇 개든 수십 개든 클러스터의 모든 자원을 활용할 수 있고, 대시보드는 자원 사용과 학습 진행을 실시간으로 명확하게 보여줍니다.
이 글에서는 주로 여러 GPU로 확장하기 위한 Data Parallelism(DP)을 다뤘습니다. 하지만 훨씬 더 큰 모델/데이터셋처럼 더 까다로운 작업을 위해서는 추가로 더 고급 기법들이 있습니다. Pipeline Parallelism, Tensor Parallelism, Sequence Parallelism 같은 전략은 프론티어급 스케일링에서 핵심 구성요소가 되었습니다. 이들은 레이어/파라미터/연산 단위를 분할하여 GPU 클러스터 전반에 걸친 효율적인 학습을 가능하게 합니다.
하이브리드 샤딩, 혼합 정밀도, 모델 오프로딩, 비동기 최적화 같은 새로운 실무 관행은 가능성의 경계를 더 밀어 붙이며, 자원/메모리 효율을 유지한 채 더 큰 규모로 실험할 수 있도록 돕습니다. 언젠가(제가 더 배우게 되면 :)) 미래의 글에서 이런 고급 기법도 더 자세히 다뤄 보겠습니다.
Anyscale and Ray
Distributed Training
LLM and Advance Deep Learning
Ray and PyTorch