트랜스포머 아키텍처의 핵심 구성요소(토크나이징, 임베딩, GELU, 소프트맥스, 레이어 정규화, 선형 투영, FFN, 어텐션, 멀티헤드 어텐션, 트랜스포머 블록)를 순수 NumPy로 GPT-2를 구현하며 설명하고, safetensors로 가중치를 로드해 그리디 디코딩으로 텍스트를 생성하는 과정을 다룬다.

트랜스포머 아키텍처는 2017년의 기념비적 논문 Attention is All You Need에서 소개되며 자연어 처리 분야에 혁신을 가져왔습니다. 전통적인 시퀀스 모델에서 벗어나, 트랜스포머는 핵심 구성 블록으로 셀프 어텐션(self-attention) 메커니즘(이후 더 자세히 다룹니다)을 사용하여, 놀라운 효율로 데이터의 장거리 의존성을 포착할 수 있습니다. 본질적으로 트랜스포머는 범용 계산 기판으로 볼 수 있는데, 학습 데이터에 따라 재구성되는 프로그래머블한 논리적 조직이며, 층을 쌓아 올리면 흥미로운 창발적 행동을 보이는 거대 모델을 만들 수 있습니다.
각 층은 두 가지 필수 서브레이어가 함께 작동하도록 구성됩니다. 하나는 멀티헤드 셀프 어텐션 메커니즘, 다른 하나는 위치별(position-wise) 피드포워드 네트워크입니다. 멀티헤드 어텐션은 입력 시퀀스의 서로 다른 부분에 동시에 주의를 기울일 수 있게 하여, 다양한 표현 관점에서 토큰 사이의 여러 관계를 포착합니다. 이어서 각 위치에 동일하게 적용되는 피드포워드 네트워크가 비선형성을 도입하고 모델이 복잡한 패턴을 학습할 수 있는 용량을 확장합니다.
어텐션 메커니즘은 모든 토큰을 병렬로 처리하므로, 트랜스포머는 순차 정보를 다루기 위한 혁신적인 접근이 필요합니다. 이 문제는 위치 인코딩(positional encoding)으로 해결되며, 입력층에서 토큰 임베딩에 더해지는 학습된 임베딩 또는 고정된 사인파 함수 형태를 사용합니다. 이러한 인코딩은 병렬 처리 과정에서 사라질 수 있는 토큰 위치에 대한 중요한 정보를 모델에 제공합니다.
트랜스포머의 강점은 처리 중 서로 다른 토큰의 중요도를 동적으로 가중할 수 있는 능력에서 나옵니다. 예를 들어 "I went to the bank to deposit money."라는 문장에서 "bank"라는 단어를 생각해 봅시다. 이 모호한 단어를 처리할 때 모델은 "deposit"과 "money" 같은 문맥 단서에 강하게 어텐드할 수 있으며, 이를 통해 "bank"를 강둑이 아니라 금융기관으로 올바르게 해석하도록 돕습니다. 이러한 문맥 인식 능력 덕분에 트랜스포머는 미묘한 언어 이해가 요구되는 과제에서 뛰어난 성능을 보입니다.
레이어 정규화(layer normalization)와 잔차 연결(residual connection) 또한 트랜스포머 아키텍처를 강화합니다. 레이어 정규화는 각 층 내부의 활성값을 정규화하여 학습 과정을 안정화하고, 잔차 연결은 학습 중 그래디언트 흐름을 위한 지름길을 만듭니다. 이 구성 요소들은 함께, 깊은 네트워크에서 흔히 발생하는 그래디언트 소실 문제를 완화하여, 트랜스포머가 깊어도 효과적으로 학습되도록 합니다.
주목할 만하게도, 연구자들은 층 수, 임베딩 차원, 학습 데이터를 늘려 트랜스포머 모델을 스케일업할수록, 이 아키텍처가 놀라운 창발적 능력을 보인다는 것을 발견했습니다. 더 큰 모델은 더 작은 모델에는 없는 능력—예컨대 퓨샷 학습, 추론, 그리고 명시적으로 학습하지 않은 개념에 대한 기초적 이해—을 보여줍니다. 이러한 스케일링 효과는 최근 인공지능 발전의 상당 부분을 견인해 왔습니다.
여기서 처음부터 구축할 디코더 전용(decoder-only) 트랜스포머 아키텍처는 동일한 디코더 블록을 여러 개 수직으로 쌓아 올린 형태입니다. 인코더와 디코더 구성 요소를 모두 갖춘 원래의 트랜스포머와 달리, 현대의 언어 모델은 보통 다음 토큰 예측(next-token prediction) 과제에 디코더 부분만 사용합니다. 이 아키텍처는 확장성이 매우 뛰어나, 수억 개에서 시작해 최첨단 모델에서는 이제 수십억 개의 파라미터까지 이릅니다.
이제 GPT-2 모델을 순수 NumPy로 구성 요소별로 구현해 보겠습니다. 전체 코드는 합쳐서 약 100줄 정도에 불과합니다. 전체 소스 코드는 GitHub에서 여기에서 확인할 수 있습니다.
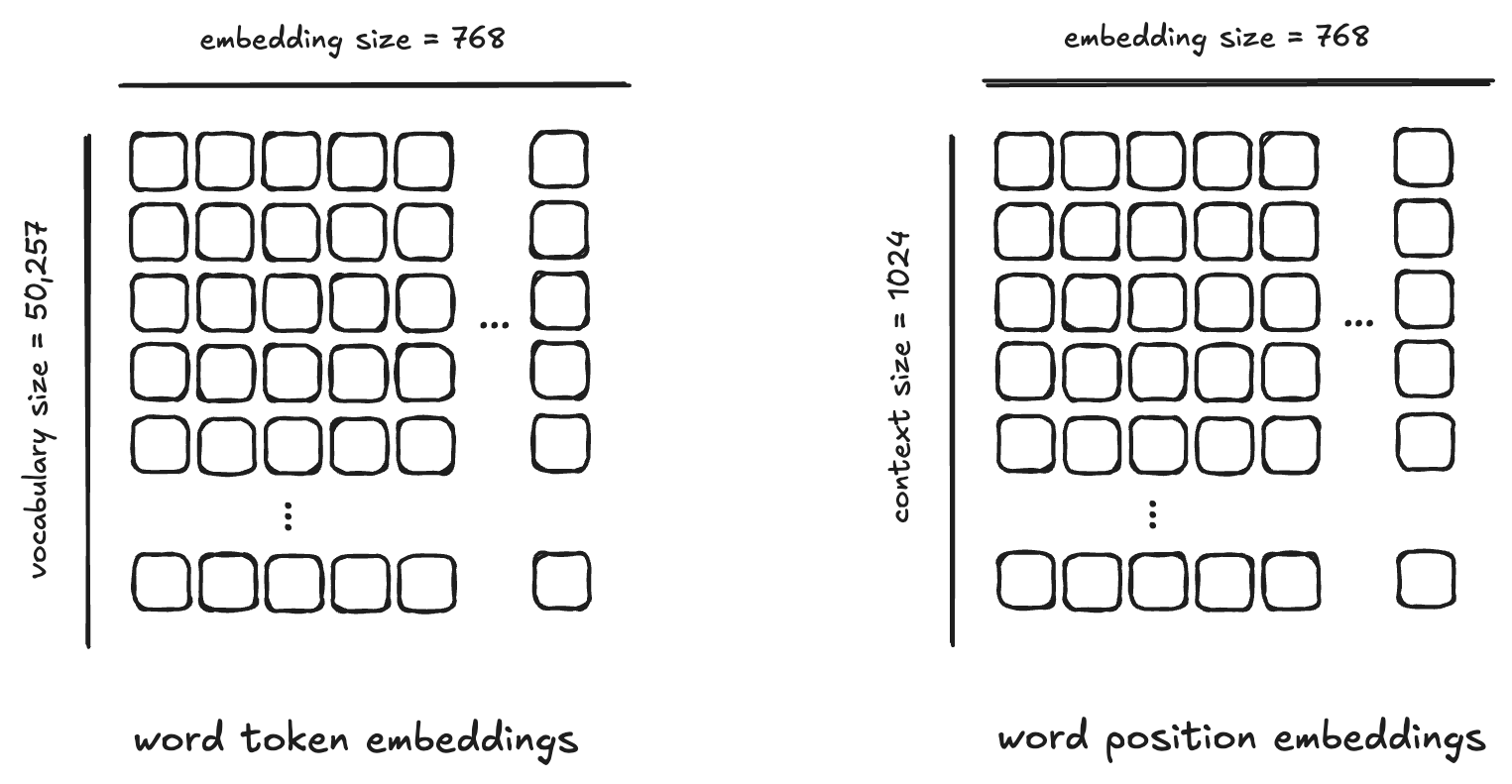
나중에 인터넷에서 다운로드할 신경망 가중치의 데이터 구조가 몇 가지 있습니다. 지금은 그저 다양한 차원의 배열들의 모음이라고만 알아두면 됩니다.
LinearParams - 선형 변환을 위한 가중치와 바이어스 파라미터를 가진 선형 레이어.LayerNormParams - 정규화를 위한 게인과 바이어스 파라미터를 가진 레이어 정규화 레이어.AttentionParams - 쿼리, 키, 값 및 출력 프로젝션 파라미터를 포함하는 멀티헤드 어텐션 레이어.BlockParams - 어텐션과 피드포워드 파라미터를 포함하는 트랜스포머 블록.ModelParams - 토큰 임베딩, 위치 임베딩, 트랜스포머 블록, 최종 레이어 정규화를 포함하는 전체 모델 파라미터.HParams - 레이어 수, 헤드 수, 임베딩 차원 등 모델 하이퍼파라미터.코드에서는 다음 약어를 사용합니다:
g - 감마(레이어 정규화의 스케일 파라미터)b - 베타(바이어스 파라미터)w - 가중치 행렬/배열wte - 단어/토큰 임베딩wpe - 단어 위치 임베딩ln - 레이어 정규화mlp - 다층 퍼셉트론fc - 완전연결 레이어qkv - 쿼리, 키, 값(어텐션 구성요소)attn - 어텐션proj - 프로젝션(선형 변환)Byte-Pair Encoding(줄여서 BPE)은 어휘 밖(out-of-vocabulary) 단어 문제를 해결하기 위해 단어를 서브워드(subword)라 불리는 더 작은 단위로 분해하는 토크나이제이션 알고리즘입니다. 원래는 데이터 압축 기법으로 개발되었지만, 단어를 문자 시퀀스로 취급하는 방식으로 자연어 처리에 적용되었습니다. BPE의 핵심 아이디어는 코퍼스에서 가장 자주 등장하는 인접 심볼 쌍을 반복적으로 병합하여 새로운 서브워드 단위를 만드는 것입니다. 이 과정은 코퍼스의 각 단어를 개별 문자로 분해하는 것으로 시작하며, 모든 고유 문자를 포함하는 초기 어휘를 형성합니다.
그 다음 BPE 알고리즘은 **반복적 병합(iterative merging)**을 수행합니다. 각 반복에서 코퍼스 전반의 모든 인접 심볼 쌍을 세고, 가장 높은 빈도의 쌍을 선택하여 새로운 심볼 또는 서브워드로 병합합니다. 이 병합 연산은 코퍼스 내 선택된 쌍의 모든 발생 위치에 적용되어, 단어의 토큰화 표현에서 그 사이의 공백을 사실상 제거합니다. 새로 생성된 서브워드는 어휘에 추가됩니다. 이 반복 과정은 어휘가 미리 정한 목표 크기에 도달하거나 더 이상 빈도가 높은 쌍을 찾을 수 없을 때까지 계속됩니다. 학습 중 수행된 병합 연산의 순서는 새로운(보지 못한) 단어를 토큰화하는 데 핵심입니다.
BPE 토크나이저가 학습되면(즉, 병합 순서가 결정되면) 새로운 텍스트를 토큰화하는 데 사용할 수 있습니다. 단어를 토큰화할 때 토크나이저는 먼저 단어 전체(초기 단어 경계 마커 포함)가 어휘에 존재하는지 확인합니다. 없으면 문자를 기준으로 분해한 다음, 학습된 병합 규칙을 학습된 순서대로 반복 적용합니다. 초기 문자 집합에 존재하지 않는 문자는 알 수 없는 토큰(예: <UNK>)으로 대체될 수 있습니다. BPE는 현대 언어 모델에서 널리 사용되며, 특히 희귀 단어와 중국어처럼 명확한 단어 경계가 없는 언어를 다루는 데 유용합니다. 이런 경우 초기 토큰화가 개별 문자에서 시작될 수 있습니다.
여기서는 BPE를 처음부터 구현하지는 않지만, 간단한 Python 구현은 여기에서 찾을 수 있습니다. 대신 원래 GPT-2 리포지토리의 기존 토크나이저를 로드하겠습니다.
encoder = get_encoder("", "model")
# encode a string into a list of tokens
tokens = encoder.encode("Hello world")
print(tokens) # [15496, 995]
여기서 토크나이저는 문자열 "Hello world"를 토큰 목록 [15496, 995]로 인코딩했는데, 이는 두 단어와 두 토큰에 해당합니다. 하지만 문자열 "Barack Obama"는 [10374, 441, 2486]로 인코딩되며, 이는 두 단어와 세 토큰에 해당합니다.

문자열 입력으로부터 먼저 토큰 목록으로 토큰화한 다음, params.wte 행렬에서 각 토큰의 토큰 임베딩을 조회합니다.
x = params.wte[inputs] + params.wpe[range(len(inputs))]
이 한 줄은 입력 시퀀스가 주요 트랜스포머 블록에서 처리되기 전에 준비하는 데 결정적으로 중요합니다. 입력의 각 토큰에 대해 두 가지 정보(위치와 토큰 자체)를 결합합니다. 모델 구성에는 두 개의 큰 임베딩 행렬—토큰 임베딩 행렬과 위치 임베딩 행렬—이 있습니다.
토큰 임베딩 (params.wte[inputs]):
inputs 파라미터는 입력 토큰 시퀀스를 정수(토큰 ID) 리스트로 나타낸 것입니다. 예를 들어 입력 텍스트 "Hello world"가 [15496, 995]로 토큰화되었다면 inputs는 [15496, 995]가 됩니다.
params.wte는 Word Token Embedding 행렬을 의미합니다. 이는 본질적으로 거대한 표(룩업 테이블)로, 각 행이 모델 어휘의 고유 토큰 ID에 대응하며, 그 행 자체는 벡터(예: 작은 GPT-2 모델의 경우 크기 768)입니다. 이 벡터는 해당 토큰에 대한 학습된 수치 표현, 즉 "임베딩"입니다.
params.wte[inputs] 연산은 조회를 수행합니다. inputs 리스트의 각 정수 ID를 가져와 params.wte 행렬에서 해당 임베딩 벡터를 반환합니다. 결과는 입력 시퀀스의 각 토큰에 대한 토큰 임베딩을 행으로 갖는 행렬입니다. 따라서 [15496, 995]의 경우, 토큰 15496의 임베딩과 토큰 995의 임베딩 두 행으로 이루어진 행렬을 얻게 됩니다.
위치 임베딩 (params.wpe[range(len(inputs))]):
트랜스포머는 셀프 어텐션을 통해 토큰을 병렬로 처리하기 때문에, 토큰의 순서를 본질적으로 알지 못합니다. 이 순차 정보를 제공하기 위해 위치 임베딩을 사용합니다. len(inputs)는 입력 시퀀스의 길이(예: [15496, 995]라면 2)를 계산합니다. range(len(inputs))는 0부터 시작하는 위치 인덱스 시퀀스를 생성하므로, 예제에서는 [0, 1]이 됩니다.
params.wpe는 Word Position Embedding 행렬을 의미합니다. wte와 비슷하게 룩업 테이블이지만, 행은 시퀀스의 위치(0, 1, 2, ... 최대 컨텍스트 길이까지)에 대응합니다. 각 행은 해당 위치를 나타내는 학습된 벡터입니다. GPT-2는 학습된 위치 임베딩을 사용하며, 이는 학습 중에 파라미터로서 학습되는 벡터라는 뜻입니다.
마지막으로 params.wpe[range(len(inputs))]는 위치 인덱스로 조회를 수행하여, 위치 0의 임베딩 벡터, 위치 1의 임베딩 벡터, ... 입력 길이만큼을 가져옵니다. 결과는 입력의 각 위치에 대한 위치 임베딩을 행으로 갖는 행렬입니다.
덧셈 (+):
토큰 임베딩 행렬(각 토큰이 무엇 인지)과 위치 임베딩 행렬(각 토큰이 시퀀스에서 어디 에 있는지)은 원소별로 단순히 더해집니다. 두 행렬은 같은 형태(시퀀스 길이 × 임베딩 차원)를 가집니다.
그 결과 행렬 x는 각 벡터가 토큰의 정체성과 위치를 모두 인코딩하도록 구성됩니다. 이 결합 표현은 이후 처리에서 트랜스포머 블록 스택에 입력되는 최종 입력입니다.
요약하면, x = params.wte[inputs] + params.wpe[range(len(inputs))]는 각 토큰의 학습된 벡터를 조회하고 해당 위치의 학습된 벡터를 더함으로써 입력 시퀀스의 초기 표현을 생성합니다. 이를 통해 이후 트랜스포머 레이어가 토큰을 처리하면서 순서도 인지할 수 있습니다.
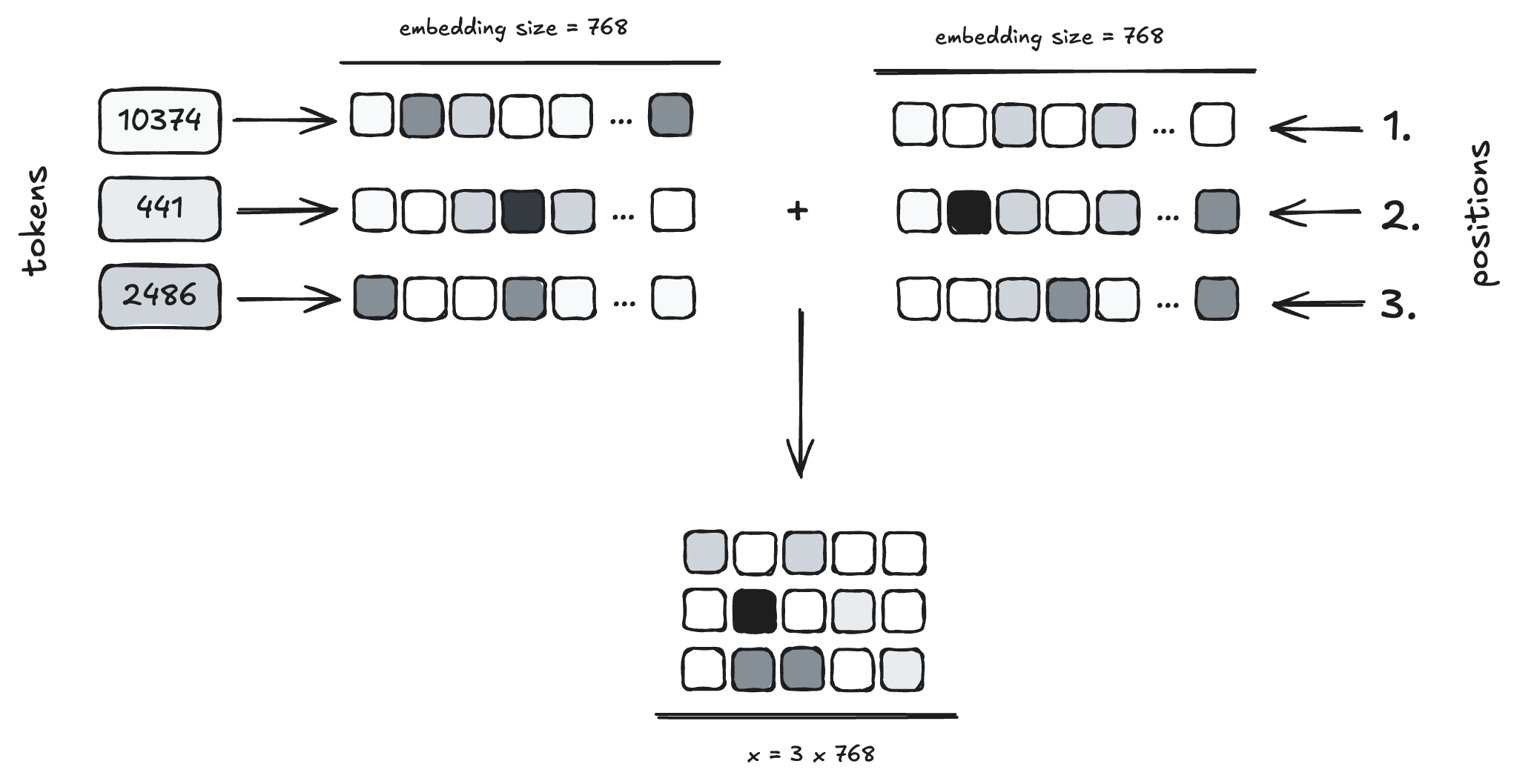
행렬의 크기는 [sequence_length, embedding_dimension]입니다. 코드에서는 시퀀스 길이를 N으로 표기합니다.
GELU(Gaussian Error Linear Unit)는 트랜스포머 아키텍처에서, 특히 각 블록의 피드포워드 네트워크(FFN) 내부에서 사용되는 활성화 함수입니다. 주요 역할은 모델에 비선형성을 도입하여 데이터에서 더 복잡한 패턴과 관계를 학습할 수 있도록 하는 것입니다. 비선형 활성화 함수가 없으면 여러 층을 쌓는 것은 하나의 선형 변환과 동등해져, 모델의 표현력이 크게 제한됩니다. 수학적으로는 다음과 같이 정의됩니다:
GELU(x)=0.5⋅x⋅(1+erf(x 2))
여기서 erf는 Guass error function입니다. 실제로는 오차 함수에 포함된 적분을 계산할 필요가 없도록, tanh 함수를 사용해 오차 함수를 근사하는 근사식을 사용합니다. Python에서는 이 근사식이 다음과 같이 구현됩니다:
# gelu:
# x : (N, 768)
# out : (N, 768)
def gelu(x: np.ndarray) -> np.ndarray:
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))
이는 스칼라 함수이며 입력에 대해 원소별로 적용된다는 점에 유의하세요.
GELU가 피드포워드 네트워크 내부의 비선형성을 처리하는 반면, 트랜스포머 아키텍처에는 원시 점수(raw score)를 의미 있는 확률 분포로 변환하는 방법도 필요합니다. 여기서 소프트맥스(softmax) 함수가 등장합니다. 소프트맥스는 트랜스포머 아키텍처에서 주로 두 곳—어텐션 메커니즘 내부와 최종 출력층—에서 사용되는 중요한 함수입니다. 목적은 원시 점수 벡터(로짓)를 확률 분포로 바꾸는 것입니다. 입력 벡터의 각 원소를 지수화하여 모두 양수가 되게 한 뒤, 그 합으로 나누어 정규화합니다. 결과는 모든 원소가 0과 1 사이이며, 전체 합이 1인 벡터가 됩니다.
softmax(x)i=e x i∑j e x j
어텐션 메커니즘(attention 함수)에서는, 소프트맥스가 쿼리와 키 간의 스케일드 점곱 점수에 적용됩니다. 이는 원시 유사도 점수를 어텐션 가중치로 변환하는데, 이 가중치는 값 벡터들에 대한 확률 분포를 나타내며—각 값이 얼마나 집중을 받아야 하는지—를 의미합니다.
모델의 최종 레이어(다음 토큰을 생성하기 직전)에서는, 소프트맥스가 보통 최종 선형 프로젝션이 만들어낸 로짓에 적용됩니다. 이를 통해 어휘의 각 단어에 대한 모델의 원시 출력 점수를 확률로 바꾸어, 점수를 해석하고 이 분포를 기반으로 다음 토큰을 샘플링할 수 있게 됩니다.
# softmax:
# x : (N, 64)
# out : (N, 64)
def softmax(x: np.ndarray) -> np.ndarray:
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)
활성화 함수와 확률 변환을 넘어, 신경망은 특히 트랜스포머처럼 깊은 아키텍처에서 학습을 안정화하는 방법이 필요합니다. 레이어 정규화(Layer Normalization, LayerNorm)는 이 중요한 역할을 합니다. 배치 차원에 걸쳐 정규화하는 배치 정규화(Batch Normalization)와 달리, 레이어 정규화는 각 데이터 샘플에 대해 특성(임베딩 차원) 방향으로 입력을 정규화합니다.
LayerNorm(x)=γ⋅x−μ σ 2+β
여기서 μ는 평균, σ 2는 입력의 분산이며, γ와 β는 학습 가능한 게인과 바이어스 파라미터입니다.
트랜스포머 블록에서는 레이어 정규화가 보통 멀티헤드 어텐션 서브레이어 이전 과 피드포워드 네트워크 서브레이어 이전 에 적용됩니다(이를 pre-LN이라고 합니다). 이는 단일 학습 예제에 대해 하나의 레이어 안에서 모든 활성값의 평균과 분산을 계산한 다음, 이 평균과 분산으로 활성값을 정규화합니다. 중요한 점은, 학습 가능한 게인(g)과 바이어스(b) 파라미터를 도입하여 네트워크가 정규화된 출력을 스케일 및 시프트할 수 있게 하여 표현 능력을 보존한다는 것입니다.
LayerNorm은 그래디언트 소실/폭주 같은 문제를 완화하고, 더 큰 학습률을 가능하게 하며, 파라미터 스케일과 초기화에 대한 민감도를 줄입니다. 각 레이어 내 활성값을 정규화함으로써 이후 레이어로 들어가는 입력이 일관된 스케일을 갖도록 보장하여, 더 매끄럽고 안정적인 학습 동역학을 이끕니다.
# layer_norm:
# x : (N, 768)
# g : (768,)
# b : (768,)
# out : (N, 768)
def layer_norm(
x: np.ndarray, g: np.ndarray, b: np.ndarray, eps: float = 1e-5
) -> np.ndarray:
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
return g * (x - mean) / np.sqrt(variance + eps) + b
정규화로 네트워크를 안정화한 뒤에는, 트랜스포머가 표현을 한 공간에서 다른 공간으로 변환하는 방법이 필요합니다. 여기서 선형 레이어가 등장합니다. 선형 레이어는 완전연결(fully connected) 또는 밀집(dense) 레이어라고도 하며, 신경망에서 가장 기본적인 구성 요소 중 하나입니다. 입력 데이터에 선형 변환을 적용합니다.
수학적으로는 output = input @ weights + bias를 계산하며, 여기서 @는 행렬 곱을 나타냅니다. input은 레이어로 들어오는 데이터, weights는 학습 가능한 파라미터 행렬, bias는 결과에 더해지는 학습 가능한 벡터입니다. 가중치 행렬은 입력 벡터를 원래 차원에서 새로운 차원(가중치 행렬의 형태로 정의됨)으로 사상(projection)하고, 바이어스는 출력의 이동을 허용합니다.
# linear:
# x : (N, 768)
# w : (768, 3072)
# b : (3072,)
# out : (N, 3072)
def linear(x: np.ndarray, w: np.ndarray, b: np.ndarray) -> np.ndarray:
return x @ w + b
정규화, 활성화, 선형 변환이라는 개별 빌딩 블록을 살펴보았으니, 이제 이 구성 요소들이 피드포워드 네트워크(FFN)에서 어떻게 결합되는지 보겠습니다. FFN은 위치별 피드포워드 네트워크라고도 하며, 각 트랜스포머 블록의 두 번째 주요 서브레이어입니다(멀티헤드 어텐션 서브레이어 다음).
FFN은 두 번의 선형 변환과 그 사이에 적용되는 비선형 활성화 함수(앞서 살펴본 GELU)로 구성됩니다. 첫 번째 선형 레이어는 보통 입력 차원을 확장하고(예: GPT-2에서는 768에서 3072로), GELU 활성화가 비선형성을 도입하며, 두 번째 선형 레이어가 결과를 다시 원래 입력 차원으로 투영합니다(예: 3072에서 768로).

이 FFN은 시퀀스의 각 위치에 독립적으로 적용됩니다. 어텐션 메커니즘이 토큰들이 서로 상호작용할 수 있게 하는 반면, FFN은 각 위치의 정보를 별도로 처리하여, 모델이 학습한 특징을 바탕으로 표현을 변환합니다. 이는 어텐션만으로는 포착하기 어려운 더 복잡한 함수를 학습할 수 있도록 모델의 표현 용량을 크게 늘립니다.
# ffn:
# x : (N, 768)
# c_fc_w : (768, 3072)
# c_fc_b : (3072,)
# c_proj_w : (3072, 768)
# c_proj_b : (768,)
# out : (N, 768)
def ffn(
x: np.ndarray,
c_fc_w: np.ndarray,
c_fc_b: np.ndarray,
c_proj_w: np.ndarray,
c_proj_b: np.ndarray,
) -> np.ndarray:
return linear(gelu(linear(x, w=c_fc_w, b=c_fc_b)), w=c_proj_w, b=c_proj_b)
어텐션은 트랜스포머 아키텍처의 핵심 아이디어입니다. 이는 인간의 시각적 주의에서 영감을 받은 메커니즘입니다. 우리가 이미지의 특정 부분이나 문장의 특정 단어에 집중하고 나머지는 무시하듯이, 어텐션은 모델이 특정 요소를 처리할 때 입력 데이터의 서로 다른 부분의 중요도를 동적으로 가중할 수 있게 합니다. 텍스트 같은 순차 데이터의 경우, 모델이 한 단어를 처리할 때 거리와 무관하게 시퀀스의 다른 관련 단어들에 "주의"를 기울여 문맥과 의미를 더 잘 이해할 수 있습니다. 이러한 선택적 집중은 오래된 시퀀스 모델보다 장거리 의존성과 관계를 더 효과적으로 포착하도록 돕습니다.
각 어텐션 계산의 중심에는 입력 시퀀스로부터 유도되는 세 가지 핵심 행렬이 있습니다:
과정은 입력 시퀀스 x가 세 개의 서로 다른 선형 레이어를 통과하여, 전체 입력 차원에 걸친 초기 Q, K, V 행렬을 생성하는 초기 프로젝션으로 시작합니다. 그런 다음 이 큰 행렬들을 임베딩 차원 방향으로 더 작은 조각으로 분할하여, 각 어텐션 "헤드"에 대한 별도의 Q, K, V 세트를 만듭니다. 형식적으로 셀프 어텐션은 다음과 같이 계산됩니다:
Attention(Q,K,V)=softmax(Q K T d k)⋅V
여기서:
Q, K, V는 쿼리, 키, 값 행렬이며,d_k는 키 벡터의 차원입니다.attention 함수는 각 멀티헤드 어텐션 레이어의 각 헤드에서 사용되는 핵심 스케일드 점곱 어텐션 메커니즘을 구현합니다. 이는 특정 토큰(쿼리 벡터로 표현됨)을 처리할 때 각 입력 토큰(값 벡터로 표현됨)이 얼마나 주목받아야 하는지를 계산합니다.
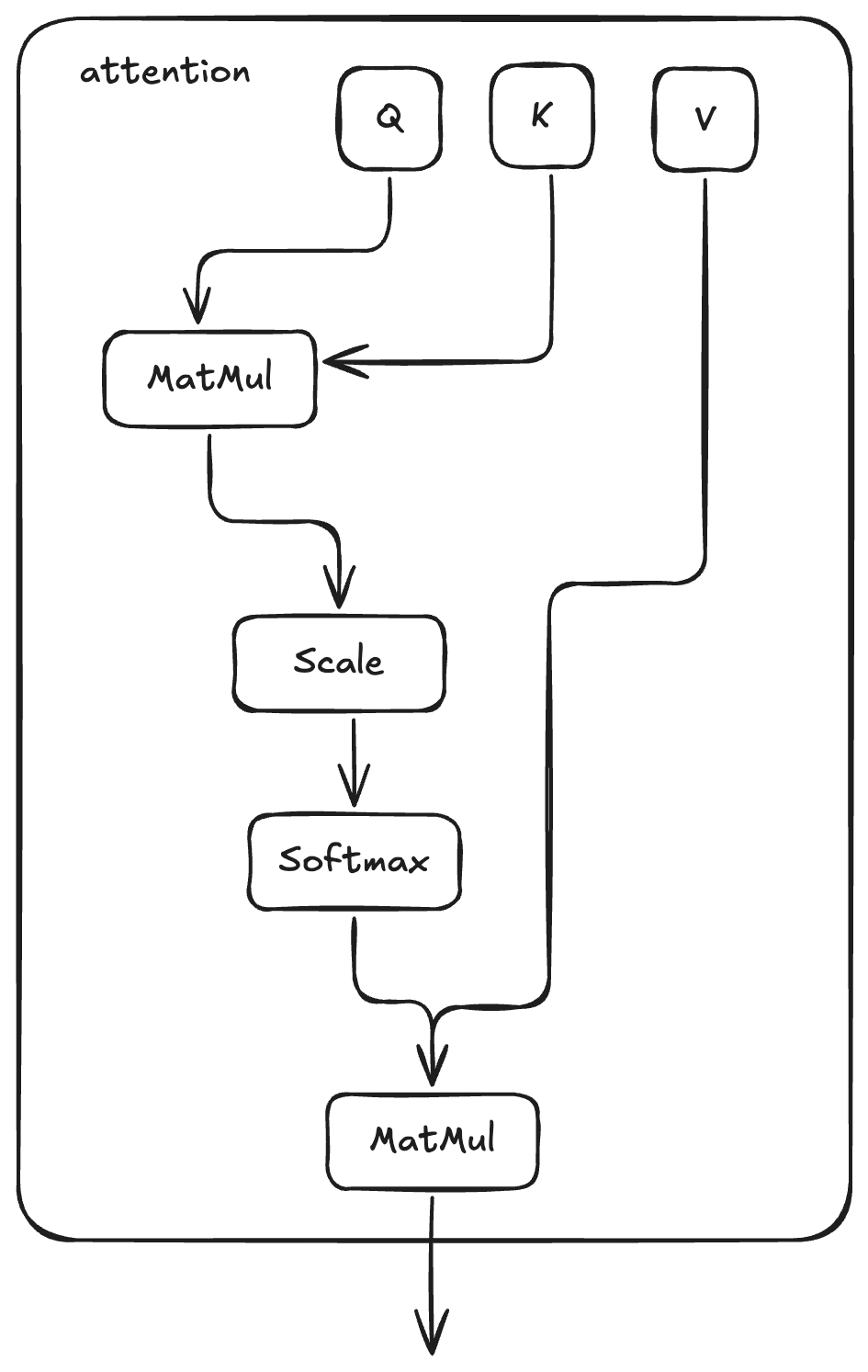
과정은 Q 행렬과 K 행렬 전치의 점곱(q @ k.T)을 계산하는 것으로 시작합니다. 이 단계는 각 쿼리와 모든 키 간의 원시 유사도 또는 적합도를 측정합니다. 그런 다음 이 원시 점수들을 키 벡터 차원의 제곱근(np.sqrt(q.shape[-1]))으로 나누어 스케일을 낮춥니다.
인과 마스크(causal mask)는 스케일된 점수에 더해지는 마스크입니다. 이는 미래 위치에 어텐드하는 것을 막아, 예측이 오직 이전 토큰에만 기반하도록 보장합니다. 마스크는 미래 토큰에 해당하는 점수에 매우 큰 음수 값을 할당하는 방식으로 동작합니다.
다음으로, 마스킹되고 스케일된 점수에 softmax가 적용됩니다. 이는 점수를 확률 분포(어텐션 가중치)로 변환하며, 각 가중치는 특정 키(및 그에 대응하는 값)가 해당 쿼리에 얼마나 중요한지를 나타냅니다.
마지막으로, 함수는 어텐션 가중치와 V 행렬의 행렬 곱(attention_weights @ v)을 계산합니다. 이는 어텐션 메커니즘의 출력, 즉 값 벡터의 가중 합을 산출하며, 가중치는 계산된 어텐션 확률입니다. 따라서 각 쿼리에 대한 결과 벡터는 입력 시퀀스 정보의 혼합이며, 쿼리-키 상호작용에 기반해 가장 관련 있는 부분을 강조합니다.
# attention:
# q : (N, 64)
# k : (N, 64)
# v : (N, 64)
# mask : (N, N)
# out : (N, 64)
def attention(
q: np.ndarray, k: np.ndarray, v: np.ndarray, mask: np.ndarray
) -> np.ndarray:
attention_scores = (q @ k.T) / np.sqrt(q.shape[-1]) + mask
attention_weights = softmax(attention_scores)
return attention_weights @ v
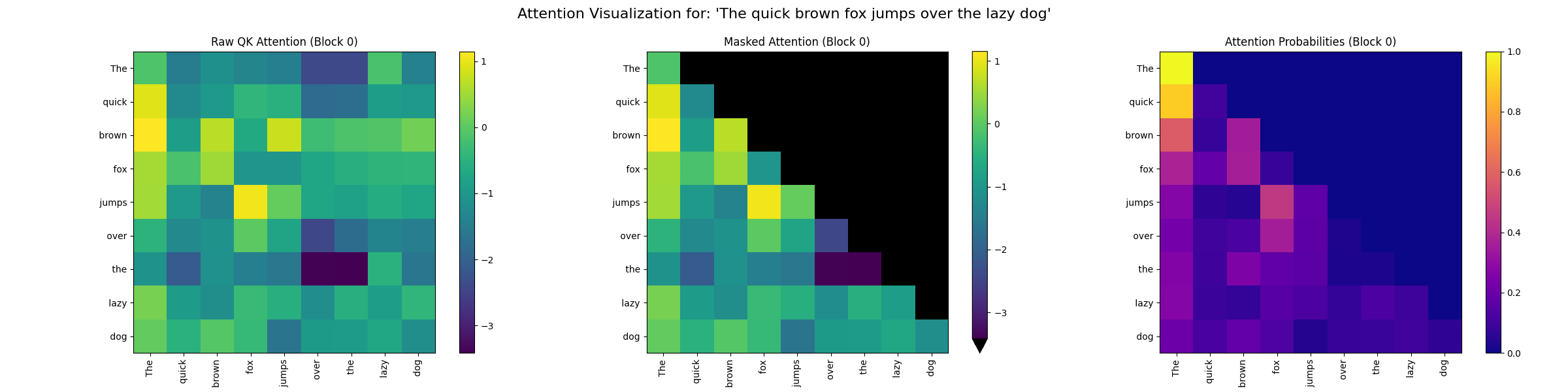
각 헤드의 어텐션 가중치를 플로팅하여 어텐션 메커니즘을 시각화할 수 있습니다. 예를 들어 구문 "The quick brown fox jumps over the lazy dog" 에 대해, 트랜스포머 스택의 첫 블록에서 어텐션 가중치를 플롯하면 각 헤드가 어떤 단어 쌍에 가장 많이 어텐드하는지 볼 수 있습니다. 여기서는 첫 번째 헤드가 "jumps" 와 "fox" 에 가장 많이 어텐드하는 것을 볼 수 있습니다.
기본 어텐션 메커니즘이 토큰 간 관계를 포착하는 방법을 제공한다면, 트랜스포머는 멀티헤드 어텐션으로 이를 한 단계 더 발전시킵니다. 이 향상은 모델이 서로 다른 유형의 관계를 동시에 포착할 수 있게 하여 표현력을 크게 확장합니다. 멀티헤드 어텐션(MHA)은 모델이 서로 다른 위치에서 서로 다른 표현 부분공간의 정보에 공동으로 어텐드할 수 있게 하는 핵심 구성 요소입니다. 단일 어텐션 계산을 수행하는 대신, MHA는 입력의 서로 다른 학습된 선형 변환에 대해 어텐션 메커니즘을 여러 번(여러 "헤드") 병렬로 실행합니다. 이를 통해 모델은 다양한 유형의 관계(예: 구문적, 의미적)를 동시에 포착할 수 있습니다.
각 헤드 내부에서는 스케일드 점곱 어텐션을 수행합니다. 어텐션 점수는 Q와 모든 K의 점곱을 통해 계산되며, 이는 현재 토큰과 다른 모든 토큰 사이의 관련도를 측정합니다. 이 점수는 스케일링(키 차원의 제곱근으로 나눔)된 뒤 소프트맥스를 거쳐 확률(어텐션 가중치)이 됩니다. 이 가중치는 각 V에 얼마나 집중할지를 나타냅니다.
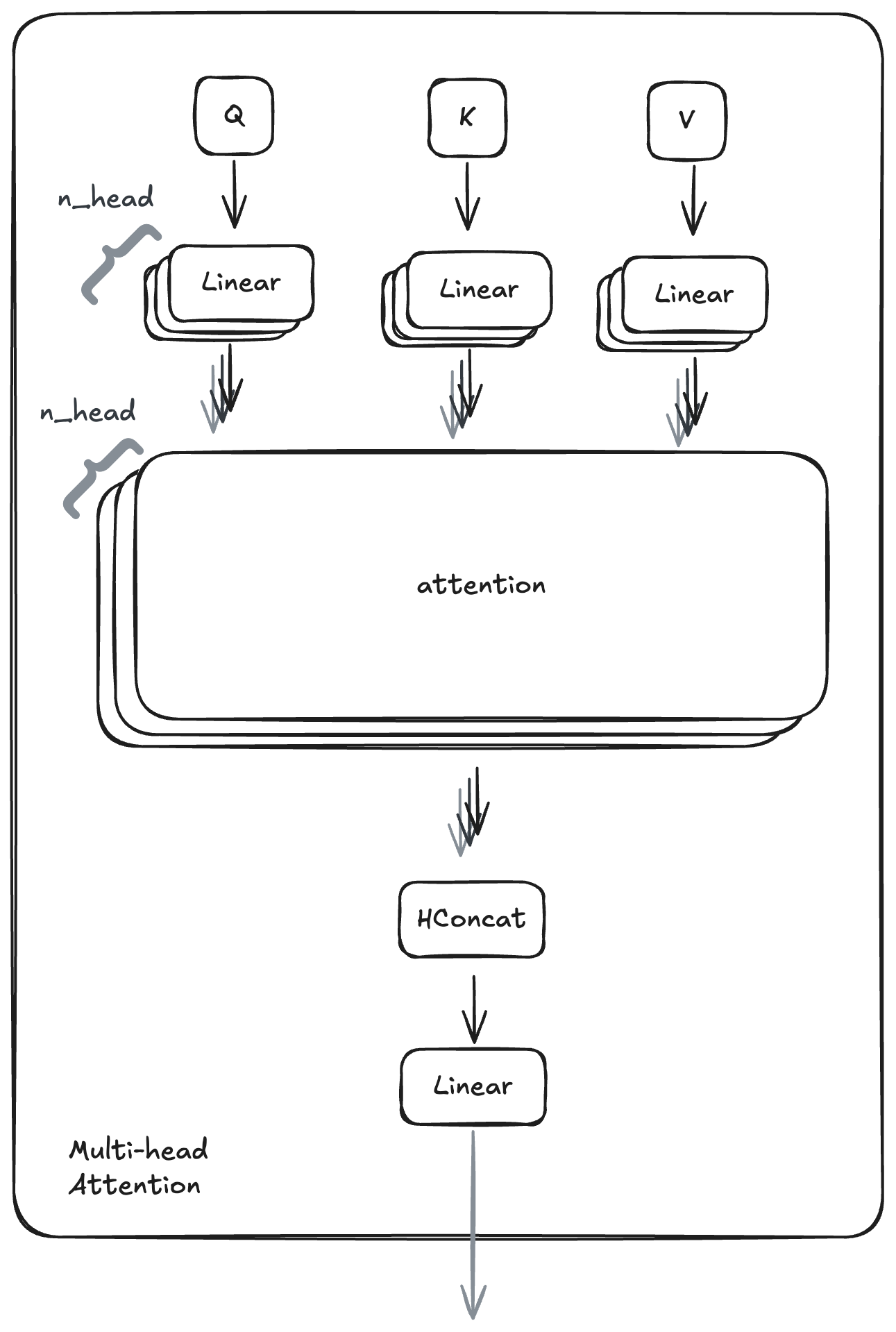
각 어텐션 헤드의 쿼리 행렬 크기(64)는 모델의 임베딩 차원(768)을 어텐션 헤드 수(12)로 나눈 값에서 유도됩니다. 모든 헤드의 출력을 다시 이어 붙이면 원래 임베딩 차원을 복구합니다:
768/n_head = 768/12 = 64
그 다음 어텐션 가중치는 해당하는 V 벡터와 곱해져 가중 합을 만들며, 이는 관련성이 가장 높은 토큰들로부터 정보를 혼합한 헤드의 출력 벡터를 생성합니다. 마지막으로 모든 어텐션 헤드의 출력 벡터를 다시 연결(concatenate)합니다. 이 결합 벡터는 마지막 선형 레이어를 통과하여 멀티헤드 어텐션 블록의 전체 출력을 생성합니다. 이러한 다면적 접근은 시퀀스를 여러 "관점"에서 동시에 바라봄으로써 더 풍부한 문맥 정보를 포착할 수 있게 합니다.
# mha:
# x : (N, 768)
# out : (N, 768)
def mha(
x: np.ndarray, c_attn: LinearParams, c_proj: LinearParams, n_head: int
) -> np.ndarray:
# qkv projection
# [N, 768] -> [N, 3*768]
x = linear(x, w=c_attn.w, b=c_attn.b)
# split into qkv
# [N, 3*768] -> [3, N, 768]
qkv = np.split(x, 3, axis=-1)
# split into heads
# [3, N, 768] -> [3, n_head, N, 64]
qkv_heads = [np.split(x, n_head, axis=-1) for x in qkv]
# apply causal mask to hide future inputs
# [N, N]
causal_mask = (1 - np.tri(x.shape[0], dtype=x.dtype)) * -1e10
# perform attention on each head
# [3, n_head, N, 64] -> [n_head, N, 64]
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)]
# merge heads
# [n_head, N, 64] -> [N, 768]
x = np.hstack(out_heads)
# out projection
# [N, 768] -> [N, 768]
return linear(x, w=c_proj.w, b=c_proj.b)
어텐션 메커니즘과 피드포워드 네트워크를 정의했으므로, 이제 이 구성 요소들이 완전한 트랜스포머 블록에 어떻게 통합되는지 살펴보겠습니다. 트랜스포머 블록은 GPT-2 아키텍처의 기본 반복 단위로, 멀티헤드 어텐션과 피드포워드 처리, 정규화, 잔차 연결을 결합한 계산 유닛이며 여러 번 쌓을 수 있습니다.
각 블록은 입력 벡터 시퀀스를 받아, 두 개의 주요 서브레이어를 통해 처리하되, 각 서브레이어 주변에 잔차 연결과 레이어 정규화를 포함합니다. 이 구조는 원래 입력의 보존(잔차 연결)과 새로운 표현으로의 변환(서브레이어)을 균형 있게 하여 정보 흐름을 만들어냅니다.
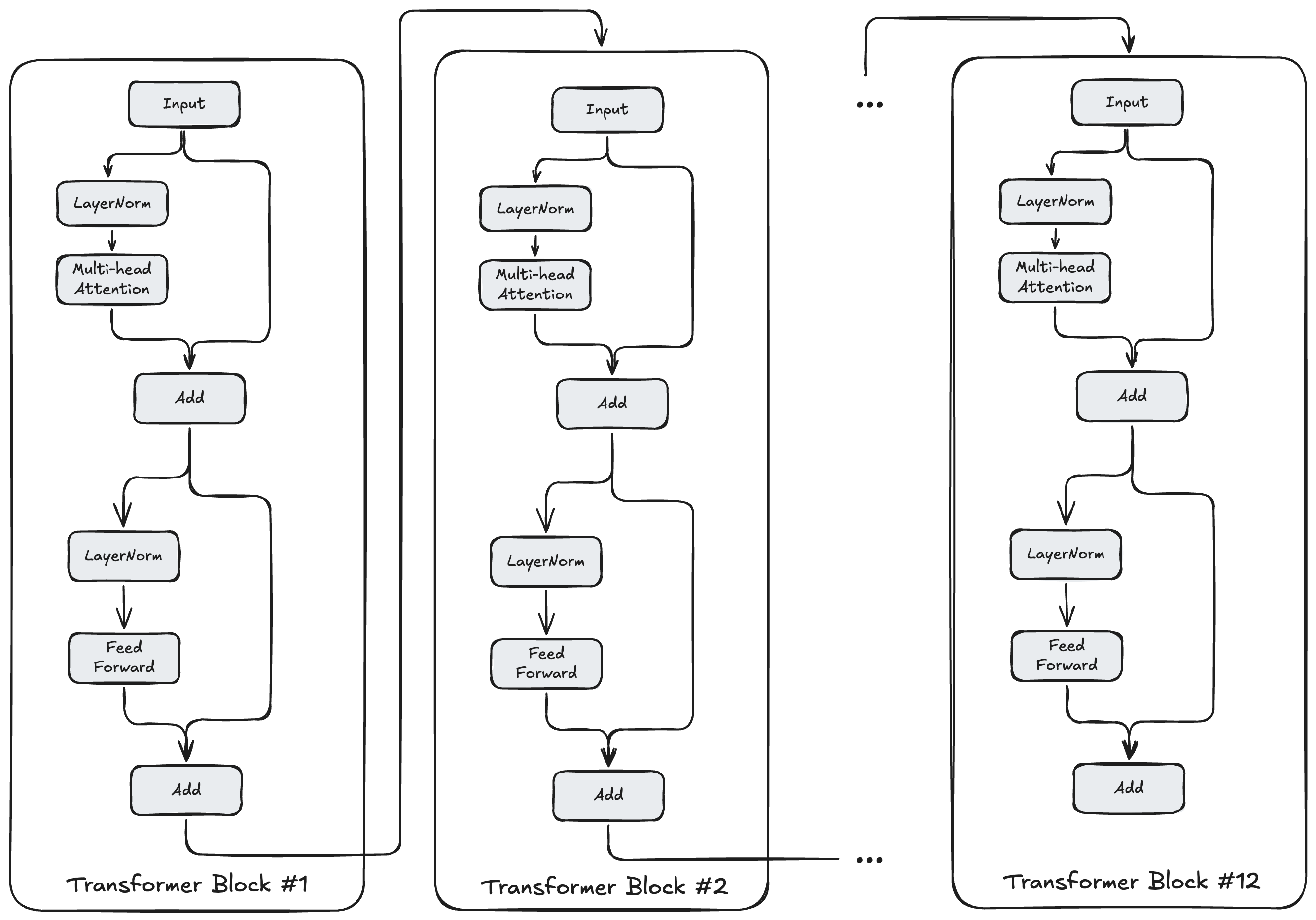
첫 번째 서브레이어는 방금 살펴본 멀티헤드 어텐션입니다. 입력이 MHA에 들어가기 전에 레이어 정규화를 거칩니다. 그 다음 MHA의 출력은 원래 입력에 더해져(잔차 연결) 어텐션으로부터 얻은 문맥과 원래 위치 표현을 결합합니다. 이 합은 두 번째 서브레이어로 전달됩니다.
두 번째 서브레이어는 앞서 설명한 피드포워드 네트워크입니다. 첫 번째 서브레이어와 마찬가지로, 입력(첫 번째 잔차 연결의 출력)은 먼저 레이어 정규화를 거칩니다. 정규화된 출력은 FFN에서 처리됩니다. 그 후 FFN의 출력은 또 다른 잔차 연결을 통해 입력에 더해집니다. 트랜스포머 블록의 최종 출력은 이 합이며, 스택에서 다음 동일한 트랜스포머 블록의 입력으로 사용됩니다.
# transformer_block:
# x : (N, 768)
# out : (N, 768)
def transformer_block(
x: np.ndarray,
mlp: MLPParams,
attn: AttentionParams,
ln_1: LayerNormParams,
ln_2: LayerNormParams,
n_head: int
) -> np.ndarray:
# First sub-block: Layer norm -> Attention -> Residual
a = layer_norm(x, g=ln_1.g, b=ln_1.b)
a = mha(a, c_attn=attn.c_attn, c_proj=attn.c_proj, n_head=n_head)
x = x + a
# Second sub-block: Layer norm -> FFN -> Residual
m = layer_norm(x, g=ln_2.g, b=ln_2.b)
m = ffn(
m,
c_fc_w=mlp.c_fc.w,
c_fc_b=mlp.c_fc.b,
c_proj_w=mlp.c_proj.w,
c_proj_b=mlp.c_proj.b,
)
x = x + m
return x
이제 개별 구성 요소와 트랜스포머 블록 구조를 살펴보았으니, 모든 것을 완전한 모델로 조립할 수 있습니다. 이 블록들은 여러 번(예: 가장 작은 GPT-2 모델에서는 12번) 쌓여, 정교한 언어 이해와 생성을 수행할 수 있는 깊은 네트워크를 만듭니다. 어텐션 메커니즘, 피드포워드 네트워크, 레이어 정규화, 잔차 연결의 결합은 순차 정보를 효과적으로 처리하고 복잡한 의존성을 포착하며, 깊이가 있어도 안정적으로 학습되는 아키텍처를 만듭니다.
gpt2 함수는 주어진 입력 토큰 ID 시퀀스에 대해 GPT-2 모델의 완전한 순전파(forward pass)를 나타냅니다. 이 함수는 앞서 정의한 모든 구성 요소를 통해 데이터의 흐름을 조정하여, 원시 토큰 ID를 문맥적 표현으로 변환한 뒤 궁극적으로 다음 토큰에 대한 예측으로 변환합니다.
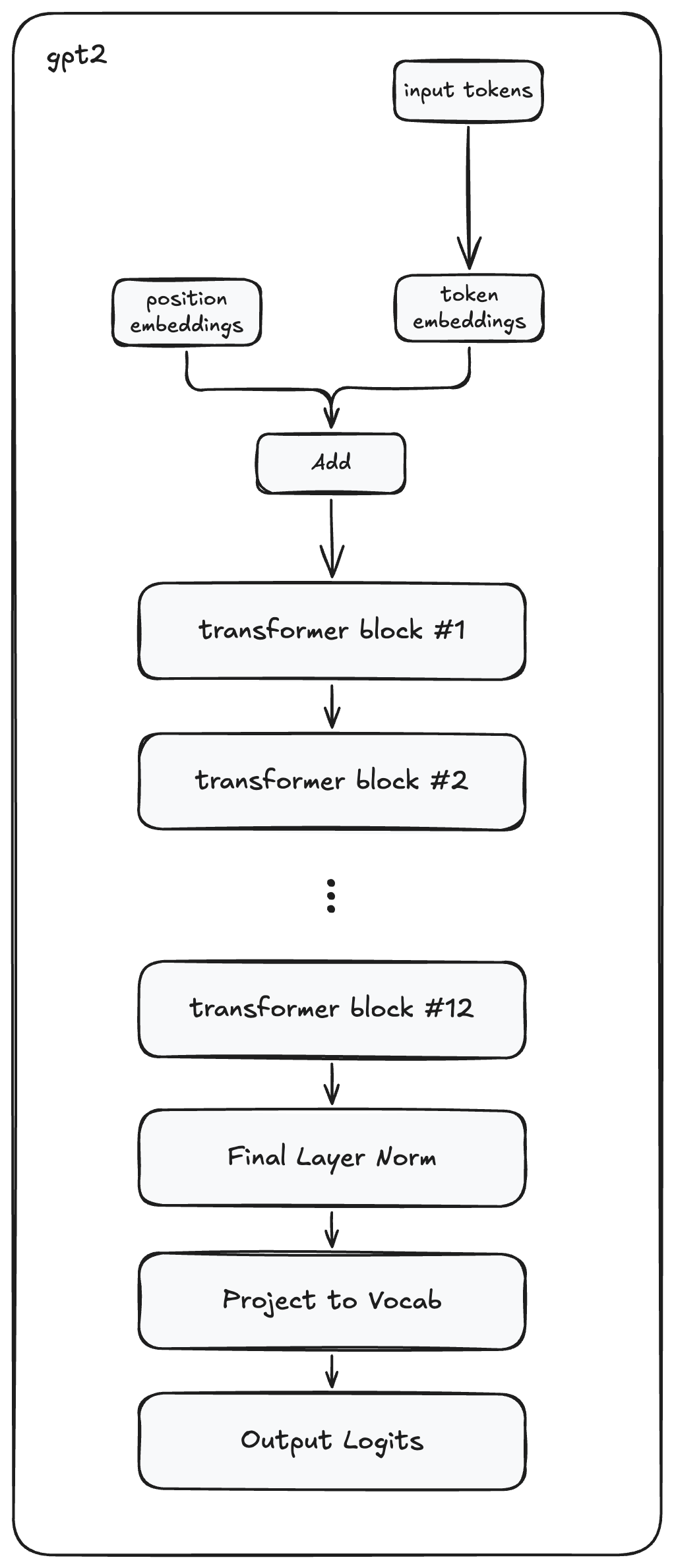
여정은 입력 토큰을 임베딩하는 것으로 시작합니다. 이는 입력 시퀀스의 각 토큰에 대해 토큰 임베딩(params.wte에서 조회)과 위치 임베딩(params.wpe에서 조회)을 더함으로써 달성됩니다. 이렇게 결합된 초기 임베딩은 각 토큰의 의미적 의미와 시퀀스 내 위치를 모두 포착하여, 이후 처리의 기반을 제공합니다.
이 임베딩 시퀀스는 트랜스포머 블록 스택을 통과합니다. 각 블록은 어텐션과 피드포워드 메커니즘을 통해 표현을 정교화하며, 점차 더 정교한 문맥적 이해를 구축합니다. 코드는 12-레이어 모델에 대해 이 스택을 명시적으로 구현하며, 한 블록의 출력이 다음 블록의 입력이 됩니다. 각 레이어를 거치며 모델은 데이터에서 점점 더 복잡한 패턴과 관계를 포착할 수 있습니다.
def gpt2(inputs: list[int], params: ModelParams, n_head: int) -> np.ndarray:
# Get token embeddings and position embeddings
x = params.wte[inputs] + params.wpe[range(len(inputs))]
# Apply transformer block stack ( 12 blocks total )
for i in range(12):
x = transformer_block(
x,
n_head=n_head,
mlp=params.blocks[i].mlp,
attn=params.blocks[i].attn,
ln_1=params.blocks[i].ln_1,
ln_2=params.blocks[i].ln_2,
)
# Apply final layer norm and project to vocabulary
x = layer_norm(x, g=params.ln_f.g, b=params.ln_f.b)
logits = x @ params.wte.T # Project to vocabulary
return logits
모든 트랜스포머 블록을 거친 뒤, 결과 시퀀스는 값을 안정화하기 위해 최종 레이어 정규화를 거칩니다. 이 정규화된 출력은 (작은 GPT-2의 경우) (N, 768) 형태이며, 시퀀스의 각 토큰에 대한 최종 문맥 임베딩을 나타냅니다. 이 임베딩을 어휘에 대한 예측으로 변환하기 위해, 모델은 토큰 임베딩 행렬의 전치(params.wte.T)를 사용해 프로젝션을 수행합니다. 이 영리한 가중치 공유 기법(입력 임베딩과 출력 프로젝션에 동일 임베딩 행렬을 사용)은 전체 파라미터 수를 줄입니다.
결과는 (N, 50257) 형태의 로짓 텐서(GPT-2의 경우)이며, 여기서 50,257은 어휘 크기입니다. 이 로짓은 시퀀스 각 위치에서 가능한 다음 토큰에 대한 정규화되지 않은 예측 점수입니다. 어휘의 모든 토큰이 점수를 받으며, 이 점수를 정렬해 어떤 토큰이 시퀀스를 이어갈 가능성이 가장 큰지 결정할 수 있습니다. 한 위치에서의 로짓 예시는 다음과 같습니다:
array([-114.83902718, -111.23177705, -116.58203861, ..., -118.4023539 ,
-118.92616557, -113.37047973], shape=(50257,))
자기회귀(autoregressive) 생성에서는 보통 현재 시퀀스의 끝 다음 토큰을 예측하는 것에만 관심이 있습니다. 마지막 위치에 해당하는 로짓을 선택한 뒤 argmax 같은 연산을 적용하면, 가장 가능성이 높은 다음 토큰을 찾을 수 있습니다:
next_token = np.argmax(logits[-1, :])
이 토큰 ID를 시퀀스에 추가하고, 이 과정을 반복하면 토큰을 하나씩 생성하며 텍스트를 만들 수 있습니다. 하지만 이 접근이 작동하려면, 사전학습된 가중치에서 로드된 적절히 초기화된 모델 파라미터가 필요하며, 이것이 다음 주제로 이어집니다.
GPT-2 같은 사전학습 모델을 활용하려면, 파라미터를 효과적으로 로드하고 정리해야 합니다. 이 섹션에서는 모델 가중치를 저장하는 안전하고 효율적인 방식인 safetensors 포맷을 사용하여, 이러한 파라미터를 어떻게 구조화하고 로드하는지 설명합니다. 이를 위해 HuggingFace에서 가중치를 로드하며, 가중치는 model.safetensors 파일에 저장되어 있습니다.
Safetensors는 텐서를 저장하기 위한 빠르고 안전한(즉, 임의 코드 실행이 필요한 Pickle을 사용하지 않는) 포맷입니다. 이 포맷은 단순한 키/값 구조를 사용합니다. 키는 텐서 이름(예: model.layers.0.attention.weight)을 나타내는 UTF-8 인코딩 문자열이고, 값은 shape 및 dtype 정보가 들어 있는 고정 헤더를 포함한 바이너리 텐서 데이터입니다. 또한 파일 시작 부분의 메타데이터 섹션에는 모든 텐서와 그 오프셋의 인덱스가 포함됩니다.
내부적으로 GPT-2의 모델 파라미터는 다음과 같은 키/값 포맷으로 저장됩니다:
{
"wpe.weight" : np.array([1024, 768]),
"wte.weight" : np.array([50257, 768]),
...
"h.0.attn.bias" : np.array([1, 1, 1024, 1024]),
"h.0.attn.c_attn.bias" : np.array([2304]),
"h.0.attn.c_attn.weight" : np.array([768, 2304]),
"h.0.attn.c_proj.bias" : np.array([768]),
"h.0.attn.c_proj.weight" : np.array([768, 768]),
"h.0.ln_1.bias" : np.array([768]),
"h.0.ln_1.weight" : np.array([768]),
"h.0.ln_2.bias" : np.array([768]),
"h.0.ln_2.weight" : np.array([768]),
"h.0.mlp.c_fc.bias" : np.array([3072]),
"h.0.mlp.c_fc.weight" : np.array([768, 3072]),
"h.0.mlp.c_proj.bias" : np.array([768]),
"h.0.mlp.c_proj.weight" : np.array([3072, 768]),
...
"ln_f.bias" : np.array([768]),
"ln_f.weight" : np.array([768])
}
각 항목은 특정 컴포넌트에 대한 학습된 파라미터를 담고 있는 shape 및 dtype을 가진 텐서이며, 이는 모델 학습 과정의 결과입니다.
LayerNormParams 데이터클래스는 레이어 정규화 파라미터를 나타내며, 각 레이어에 대한 스케일(g)과 바이어스(b)를 포함합니다.
@dataclass
class LayerNormParams:
g: np.ndarray # Gamma (scale)
b: np.ndarray # Beta (bias)
LinearParams 데이터클래스는 선형 프로젝션 파라미터를 나타내며, 가중치 행렬(w)과 바이어스 벡터(b)를 포함합니다.
@dataclass
class LinearParams:
w: np.ndarray # Weight matrix
b: np.ndarray # Bias vector
MLPParams 데이터클래스는 피드포워드 네트워크 파라미터를 나타내며, 두 개의 선형 레이어—첫 번째 선형 레이어(c_fc)와 두 번째 선형 레이어(c_proj)—를 포함합니다.
@dataclass
class MLPParams:
c_fc: LinearParams # First linear layer
c_proj: LinearParams # Second linear layer
AttentionParams 데이터클래스는 어텐션 파라미터를 나타내며, 쿼리-키-값 프로젝션(c_attn)과 출력 프로젝션(c_proj)을 포함합니다.
@dataclass
class AttentionParams:
c_attn: LinearParams # QKV projection
c_proj: LinearParams # Output projection
TransformerBlockParams 데이터클래스는 단일 트랜스포머 블록을 나타내며, 레이어 정규화(ln_1), 피드포워드 네트워크(mlp), 어텐션 메커니즘(attn), 두 번째 레이어 정규화(ln_2)를 포함합니다.
@dataclass
class TransformerBlockParams:
ln_1: LayerNormParams # First layer norm
ln_2: LayerNormParams # Second layer norm
mlp: MLPParams # MLP block
attn: AttentionParams # Attention block
ModelParams 데이터클래스는 전체 모델 파라미터를 나타내며, 토큰 임베딩 행렬(wte), 위치 임베딩 행렬(wpe), 트랜스포머 블록 리스트(blocks), 최종 레이어 정규화(ln_f)를 포함합니다.
@dataclass
class ModelParams:
wte: np.ndarray # Token embeddings
wpe: np.ndarray # Position embeddings
blocks: List[TransformerBlockParams] # Transformer blocks
ln_f: LayerNormParams # Final layer norm
HParams 데이터클래스는 모델의 하이퍼파라미터를 나타내며, 트랜스포머 레이어 수(n_layer), 어텐션 헤드 수(n_head), 컨텍스트 길이(n_ctx)를 포함합니다.
@dataclass
class HParams:
n_layer: int # Number of transformer layers
n_head: int # Number of attention heads
n_ctx: int # Context length
safe_open 함수를 사용하여 model.safetensors 파일에서 모델 파라미터를 로드할 수 있습니다. 이 파일은 Hugging Face Model Hub에서 다운로드할 수 있습니다.
tensors = {}
with safe_open(weights_path, framework="numpy") as f:
for key in f.keys():
tensors[key] = f.get_tensor(key)
# Build transformer blocks
blocks = []
for i in range(config["n_layer"]):
prefix = f"h.{i}"
block = TransformerBlockParams(
ln_1=LayerNormParams(
g=tensors[f"{prefix}.ln_1.weight"], b=tensors[f"{prefix}.ln_1.bias"]
),
ln_2=LayerNormParams(
g=tensors[f"{prefix}.ln_2.weight"], b=tensors[f"{prefix}.ln_2.bias"]
),
mlp=MLPParams(
c_fc=LinearParams(
w=tensors[f"{prefix}.mlp.c_fc.weight"],
b=tensors[f"{prefix}.mlp.c_fc.bias"],
),
c_proj=LinearParams(
w=tensors[f"{prefix}.mlp.c_proj.weight"],
b=tensors[f"{prefix}.mlp.c_proj.bias"],
),
),
attn=AttentionParams(
c_attn=LinearParams(
w=tensors[f"{prefix}.attn.c_attn.weight"],
b=tensors[f"{prefix}.attn.c_attn.bias"],
),
c_proj=LinearParams(
w=tensors[f"{prefix}.attn.c_proj.weight"],
b=tensors[f"{prefix}.attn.c_proj.bias"],
),
),
)
blocks.append(block)
# Build final model params
params = ModelParams(
wte=tensors["wte.weight"],
wpe=tensors["wpe.weight"],
blocks=blocks,
ln_f=LayerNormParams(g=tensors["ln_f.weight"], b=tensors["ln_f.bias"]),
)
모델 아키텍처를 정의하고 파라미터를 로드했으므로, 이제 모든 것을 결합해 텍스트를 생성할 준비가 되었습니다. 텍스트 생성의 가장 단순한 접근은 그리디 디코딩(greedy decoding)으로, 각 단계에서 모델이 예측한 확률이 가장 높은 토큰을 선택하는 방식입니다.
아래 generate 함수는 초기 프롬프트 인코딩부터 새 토큰을 반복적으로 생성하는 과정까지, 텍스트 생성 전체 과정을 캡슐화합니다. 이 함수는 우리가 살펴본 모든 구성 요소—토크나이제이션, 임베딩, 트랜스포머 블록, 어휘 프로젝션—가 어떻게 함께 작동하여 실제로 동작하는 언어 모델을 만드는지 보여줍니다.
def generate(prompt: str, n_tokens_to_generate: int = 40) -> str:
encoder = get_encoder("", "model")
params, hparams = load_gpt2_weights()
input_ids = encoder.encode(prompt)
generated_token_ids: list[int] = []
print(prompt, end="", flush=True)
current_ids = list(input_ids)
for _ in range(n_tokens_to_generate):
logits = gpt2(current_ids, params, n_head=hparams.n_head)
next_id = np.argmax(logits[-1, :])
next_id_int = int(next_id)
current_ids.append(next_id_int)
generated_token_ids.append(next_id_int)
token_text = encoder.decode([next_id_int])
print(token_text, end="", flush=True)
print()
return encoder.decode(generated_token_ids)
생성 과정은 BPE 토크나이저를 사용해 사용자의 프롬프트를 토큰 ID로 인코딩하는 것으로 시작합니다. 생성할 토큰을 추적하기 위해 빈 리스트를 초기화합니다. 그런 다음 루프에 들어가, 각 반복에서 다음을 수행합니다:
요청한 수의 토큰을 생성한 뒤, 생성된 토큰들의 전체 시퀀스를 다시 텍스트로 디코딩하여 반환합니다. 그리고 이것으로 GPT-2 모델의 순진한(naive) 버전을 구현하는 데 필요한 전부가 끝났습니다. 구현해야 하는 "커널" 연산은 대략 여섯 가지(softmax, gelu, layer_norm, linear, add, matmul, var, mean)뿐이고, 나머지는 데이터 구조를 다루기 위한 많은 부기(bookkeeping) 작업일 뿐입니다.
하지만 눈치채셨듯이, 이 모델은 매우 느리고 비효율적이며, 최신 CPU에서도 초당 약 2~3 토큰 정도에 불과합니다. MLIR과 PTX로 로워링(lowering)하는 과정에서 융합(fusion)과 병렬화(parallelization)의 기회가 많이 있으며, 다음 섹션에서 이를 살펴보겠습니다.