ClickHouse를 사용해 고카디널리티 BEAM 메트릭을 수집·저장하고, 실제 쿼리 예시로 활용 가능성을 살펴본다.
At Knock에서는 관측 가능성(observability)에 진심입니다. 안 그런 사람이 어디 있겠어요! 또한 ClickHouse의 열렬한 팬이기도 합니다. 이 글은 우리가 여러 이유로 ClickHouse를 사용해 상세하고 고카디널리티(high-cardinality)인 BEAM 메트릭을 수집하기 시작한 과정을 개괄적으로 정리한 것입니다.
우리는 모든 메트릭(그리고 모니터링, 그리고 로깅까지!)에 Datadog를 사용합니다. AWS 메트릭, 데이터베이스 메트릭, Kubernetes, 애플리케이션—전부 Datadog로 들어갑니다. 우리는 이 도구를 다루는 법을 알고 있고 대체로 만족스럽다고 느낍니다. 하지만 그에 대한 비용을 지불하죠. 이게 딱히 새삼스러운 주장도 아닙니다. Datadog는 ✨비쌉니다✨.
우리가 가장 많은 비용을 지불하는 항목은 분명 커스텀 메트릭입니다. 즉, 메트릭 이름과 태그 값 조합이 유일한 경우를 의미하죠. 전형적인 예시는 다음과 같습니다.
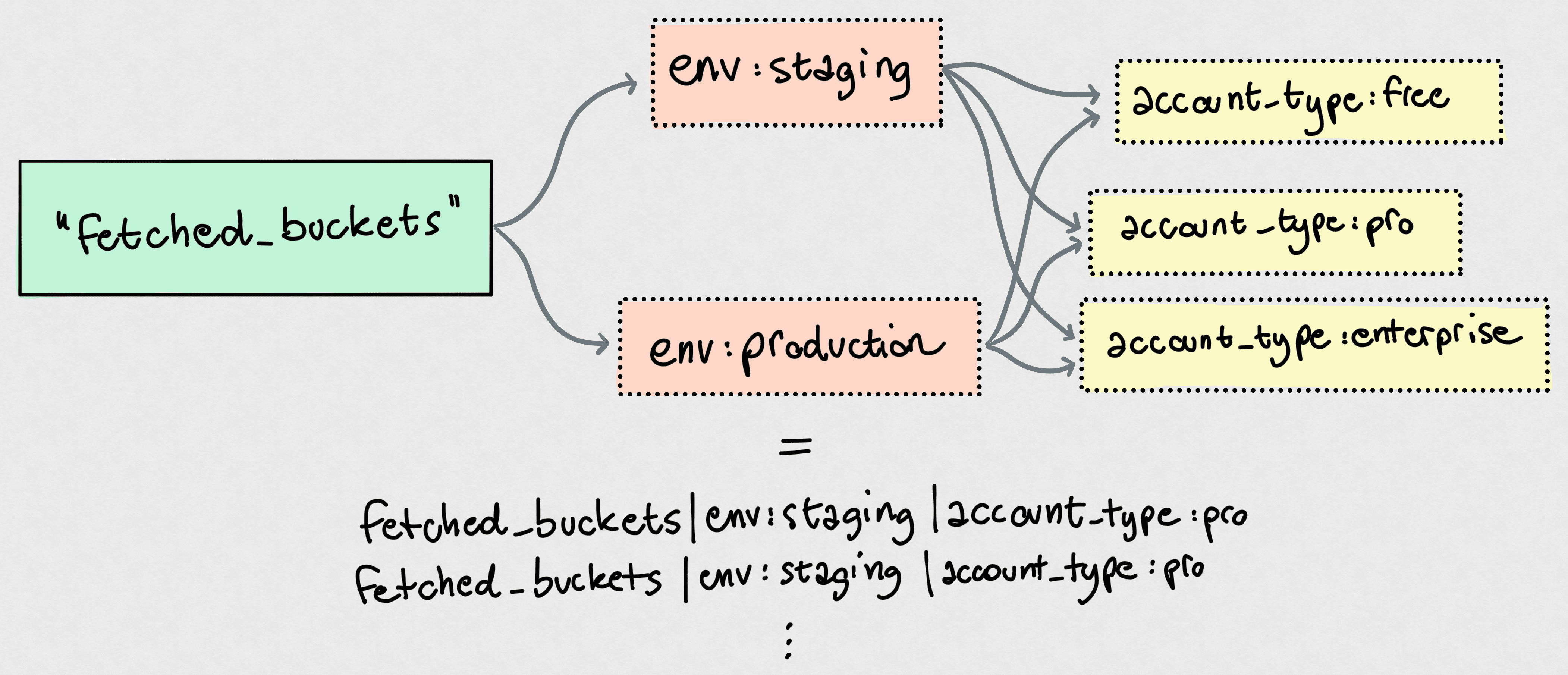
이건 단 하나의 카운터 메트릭 fetched_buckets일 뿐입니다. 하지만 태그 카디널리티 때문에 다음이 생깁니다.
env 값 2개account_type 값 3개즉 2 × 3 = 6개의 유일한 커스텀 메트릭이 됩니다! 어떻게 커지는지 쉽게 감이 오죠. 예를 들어, 어떤 스토리지 버킷에서 가져왔는지 나타내기 위해 backend 태그를 추가하고 값이 2개라고 해봅시다. 그러면 사실상 6에 또 2를 곱하게 되어, 커스텀 메트릭이 12개가 됩니다. 정말 순식간에 폭발하죠.
문제를 일으키는 건 사실 이런 “저카디널리티” 메트릭이 아닙니다. 이런 방식으로도 결국 수천 개의 메트릭이 생기겠지만, Datadog 같은 서비스에서는 지극히 정상적인 범위입니다.
진짜 문제는 고카디널리티 메트릭입니다. 예를 들어, Kubernetes 노드에서 실행되는 Datadog 에이전트는 메트릭에 온갖 태그를 잔뜩 붙이는데, 그중에는 메트릭이 어디서 왔는지(어떤 클러스터 노드인지)를 나타내는 kube_node 태그도 있습니다. 노드가 많거나 노드를 스케일 업/다운하면, 모든 메트릭의 카디널리티가 올라갑니다.
우리에게 특히 문제를 크게 만들었던 원인 중 하나는 pod_name 태그였습니다. Kubernetes에서 어떤 파드에서 나온 메트릭인지 표시하려고 일부 메트릭에 pod_name 태그를 붙입니다. 애플리케이션 레벨 메트릭은 보통 이런 수준의 세분화로 큰 이득을 보지 않지만, 확실히 이득을 보는 메트릭 묶음이 있습니다. 바로 BEAM 관련 메트릭입니다. 각 파드는 자체 Erlang 노드를 실행합니다. Erlang 노드별로 나누지 않고 실행 중인 프로세스 총합만 아는 건 의미가 없습니다. 예컨대 클러스터에 80만 개 프로세스가 돈다는 걸 안다고 해도, 어떤 파드가 폭주해서 그 숫자의 큰 부분을 차지하는지 절대 알 수 없죠.
딜레마는? 어느 시점이든 파드가 100개 돌아간다면, BEAM 메트릭은 전부 100배가 됩니다. 그리고 진짜 폭발은 배포할 때마다 반복된다는 점입니다! 새 버전의 코드는 새 Docker 이미지로 이어지고, 그건 새 파드 이름으로 이어지며, pod_name이 붙은 각 메트릭마다 유일한 조합이 100개 더 생긴다는 뜻입니다. 쾅.
하지만 이런 데이터는 이런 시스템을 운영하는 플랫폼 팀에겐 대단히 중요합니다. 인시던트 중에는 특히 결정적이고, 트렌드와 패턴을 찾고, 시스템이 무엇을 하고 있는지 이해하는 데 필수죠. 우리는 이걸 포기하고 싶지 않습니다. 오히려 더 원합니다.
예를 들어, 최근에는 일부 노드가 과열(running hot)되는 문제를 다뤄야 했습니다. BEAM의 런타임 인스펙션 기능은 환상적입니다. 문제가 있는 박스에 접속해서 IEx를 띄우고 recon을 사용해 마음껏 뒤졌습니다. 다음 같은 걸 _라이브_로 돌아가는 시스템에서 실행해서 내부를 들여다볼 수 있다니, 이보다 더 좋을 수가 없죠.
biggest_offenders = :recon.proc_window(:reductions, 5, _ms = 1000)
# Now just get all the info + stacktrace to get some more context on these processes:
Enum.map(biggest_offenders, fn {pid, _reductions, _some_info} ->
{pid, Process.info(pid)}
end)
이건 정말 값지지만, 시스템을 상시로 모니터링하는 해법은 아닙니다. 예를 들어 “어느 시점이든 메모리를 가장 많이 먹는 프로세스 5개”에 대한 히스토리 데이터를 우리는 갖고 있지 않습니다.
ClickHouse는 정말 빠른 컬럼 지향(columnar) OLAP 데이터베이스입니다. 믿음직한 일꾼 같은 존재고, 우리는 세그멘테이션이나 감사 로그, 애널리틱스 같은 제품 기능을 구동하는 데 사용합니다. ClickHouse 덕분에 최근 아주 쉽게 출시할 수 있었던 기능은 email.info였는데, 이메일 제공업체 성능을 분석해 보여주는 페이지입니다. 기본적으로 ClickHouse가 제공업체 전송 데이터를 씹어 먹고 그 결과로 애널리틱스를 뱉어내게 한 거죠. 겉보기엔 대단치 않을 수도 있지만, “이걸 해볼까?”에서 실제 라이브 페이지까지 가는 과정이 너무 쉬워서 저는 어안이 벙벙했습니다.
BEAM 애널리틱스로 돌아오면, 처음부터 우리를 ClickHouse로 끌어들인 멋진 동료 Victor가 여기서 판도라의 상자를 열어버렸습니다. 이 고카디널리티, 대용량 내부 텔레메트리 데이터를 ClickHouse에 저장하면 어떨까?
이건 말이 너무 됩니다. 어떤 메트릭(메모리 사용량, reductions, mailbox 길이)에 대해 top-n 프로세스를 주기적으로 샘플링하고, 그에 대한 정보 묶음을 ClickHouse 테이블에 덤프하면 됩니다. 우리는 internal_telemetry라는 새 데이터베이스를 만들고 작업을 시작했습니다. “작업을 시작했다”는 표현이 실제보다 훨씬 거창한데요. 전체는 몇 시간 만에 끝났습니다.
여기서는 테이블 구조를 오래 고민하진 않았습니다. 이건 내부 데이터고, 쿼리하는 사람은 오직 우리 뿐이라 쿼리 성능이 최우선 요소는 아니었거든요.
첫 번째 이터레이션에서 이렇게 정리했습니다.
CREATE TABLE top_processes (
metric LowCardinality(String),
deployment LowCardinality(String),
pod_name LowCardinality(String),
timestamp DateTime64(3, 'UTC'),
pid String,
registered_name String DEFAULT '',
current_function String DEFAULT '',
initial_call String DEFAULT '',
reductions UInt64,
message_queue_len UInt32,
memory UInt64,
label String,
memory_details Map(String, UInt128)
)
ENGINE = MergeTree
PARTITION BY toMonday(timestamp)
ORDER BY (metric, deployment, pod_name, timestamp)
TTL toDate(timestamp) + toIntervalDay(30)
SETTINGS ttl_only_drop_parts = 1;
몇 가지 메모:
metric은 우리가 이 프로세스를 어떤 메트릭을 통해 “발견했는지”를 나타냅니다. 예를 들어 metric = 'memory'라면, 이 행은 시스템 스캔 시점에 메모리 사용량 기준 top-n 프로세스 중 하나였다는 뜻입니다.deployment는 우리의 Kubernetes deployment입니다.TTL을 훨씬 길게 늘릴 수 있습니다.memory_details는 맵으로 두어서, 나중에 스키마 변경 없이도 쉽게 항목을 추가할 수 있게 했습니다. 적절한 타협점처럼 느껴졌습니다.나머지 컬럼은 설명이 필요 없을 정도로 자명할 겁니다.
정렬 키(ORDER BY)는 ClickHouse 쿼리의 핵심 중 하나입니다. ClickHouse가 데이터를 빠르게 찾고 가능한 한 적게 스캔하도록 해주죠. 경험칙으로는 카디널리티가 낮은 것에서 높은 것으로(점진적으로 증가하도록) 잡는 건데, 여기서 우리가 정확히 그렇게 했습니다. 우리가 예상하는 쿼리 패턴은 대부분 다음과 같습니다.
timestamp로 정렬.이런 정렬 키는 쿼리에서 일부를 _생략_할 수 없다는 뜻이 아닙니다. 다만 그렇게 하면 최적화가 덜 되고 스캔량이 늘어난다는 뜻이죠. 만약 언젠가 모든 pod_name에 대해 모든 metric을 조회하는 일이 생긴다면, 그 쿼리 패턴에 최적화된 별도 테이블로 이 데이터를 써 주는 머티리얼라이즈드 뷰를 쉽게 배포할 수 있습니다. 저장소는 저렴하니까요.
솔직히 이 섹션을 넣어야 하나 고민했습니다. Erlang/Elixir를 하는 분들에겐 새로울 게 하나도 없거든요!
우리는 훌륭한 telemetry_poller를 사용해서 몇 초마다 시스템 상태를 수집하고 덤프하고 있을 뿐입니다. child spec은 이렇게 생겼습니다.
@doc """
Returns a child spec for a `telemetry_poller` that periodically
logs top processes.
"""
def child_spec([] = _opts) do
Supervisor.child_spec(
{:telemetry_poller,
measurements: [{__MODULE__, :measure_and_persist, []}],
period: to_timeout(second: 5),
init_delay: to_timeout(second: 5),
name: :top_processes_poller},
id: __MODULE__
)
end
전혀 대단한 건 없습니다. measure_and_persist/0도 아마 예상하시는 그대로일 겁니다.
@doc """
Collects top process data and writes it to ClickHouse.
"""
def measure_and_persist do
now = DateTime.utc_now()
pod_name = System.get_env("HOSTNAME", "unknown")
deployment = System.get_env("DEPLOYMENT", "<redacted>")
rows =
Enum.flat_map(@metrics, fn metric ->
metric
|> :recon.proc_count(@top_n)
|> Enum.map(fn {pid, _value, _recon_info} ->
build_row(pid, metric, now, pod_name, deployment)
end)
|> Enum.reject(&is_nil/1)
end)
if rows != [] do
InternalTelemetryRepo.insert_all(TopProcess, rows)
end
:ok
end
우리는 ClickHouse 드라이버로 Ch를 쓰고, Ecto와 통합하기 위해 ecto_ch를 사용합니다.
이 데이터 캡처를 위한 인프라는 여기까지가 전부입니다. build_row/5는 포매팅 몇 가지와 Process.info/2 호출 묶음일 뿐입니다. 끝!
프로덕션에 올린 지 이제 10일 됐습니다. 우리의 top-n은 20입니다. 즉, reductions, message queue length, memory라는 세 가지 메트릭에 대해 top-20 프로세스를 샘플링합니다. 5초마다 샘플링하고요. 이 테이블의 총 처리량은 다음과 같습니다.
좋은 old ClickHouse에게는 누워서 떡 먹기죠. 라이브 테이블의 몇 가지 통계는 이렇습니다.
top_processes에 행이 약 607M개 있습니다. ClickHouse 입장에선 껌값이죠.이제 재미있는 부분입니다. 쿼리! 지난 며칠 동안 우리가 실행해볼 수 있었던 재미있는 쿼리 몇 개만 봅시다.
지난 24시간 동안, 메모리 기준 top-n 프로세스에 가장 자주 등장하는 프로세스를 찾습니다. 가끔 한 번 튀는 게 아니라, 지속적으로 메모리를 많이 먹는 프로세스를 찾는 데 도움이 됩니다.
SELECT
concat('`', registered_name, '`') AS name,
count() AS appearances,
formatReadableSize(avg(memory)) AS avg_memory,
formatReadableSize(max(memory)) AS max_memory
FROM top_processes
WHERE
metric = 'memory'
AND deployment = {deployment:LowCardinality(String)}
AND registered_name != ''
AND timestamp >= now() - INTERVAL 24 HOUR
GROUP BY registered_name
ORDER BY appearances DESC
LIMIT 10
FORMAT MARKDOWN
| name | appearances | avg_memory | max_memory |
|---|---|---|---|
tzdata_release_updater | 362659 | 8.25 MiB | 8.55 MiB |
Elixir.Sentry.Sources | 362659 | 13.18 MiB | 13.18 MiB |
code_server | 362659 | 26.52 MiB | 51.77 MiB |
application_controller | 362659 | 10.23 MiB | 10.29 MiB |
ldclient_event_process_server_default | 362657 | 54.69 MiB | 283.01 MiB |
Elixir.<redacted>.K8sServer | 352357 | 10.03 MiB | 12.00 MiB |
ldclient_event_server_default | 349761 | 12.82 MiB | 39.39 MiB |
<redacted> | 286100 | 5.10 MiB | 7.88 MiB |
<redacted> | 275572 | 4.65 MiB | 11.58 MiB |
<redacted> | 242255 | 5.70 MiB | 12.80 MiB |
감만 드리자면, 이 쿼리는 0.238s에 실행됐고, 7,389,364행(데이터 516.95 MB)을 스캔했습니다 🤯.
이 쿼리는 특정 deployment에서, 가장 많은 메모리를 쓰는 프로세스가 다른 파드들의 최상위 메모리 잡아먹는 프로세스보다 더 많이 쓰는 파드가 있는지 찾는 데 유용합니다.
SELECT
toStartOfMinute(timestamp) AS minute,
pod_name,
max(memory) peak_memory
FROM top_processes
WHERE metric = 'memory'
AND deployment = {deployment:LowCardinality(String)}
AND timestamp >= now() - INTERVAL 3 HOUR
GROUP BY minute, pod_name
ORDER BY minute;
ClickHouse Cloud는 괜찮은 차트 기능을 제공하고, 이런 유형의 쿼리는 “눈에 띄는 것”을 아주 쉽게 보여주는 차트를 만들어 줍니다. 시간에 따라 파드별로(폭주 프로세스가 없는 상황에서) 보면 이렇게 보입니다.
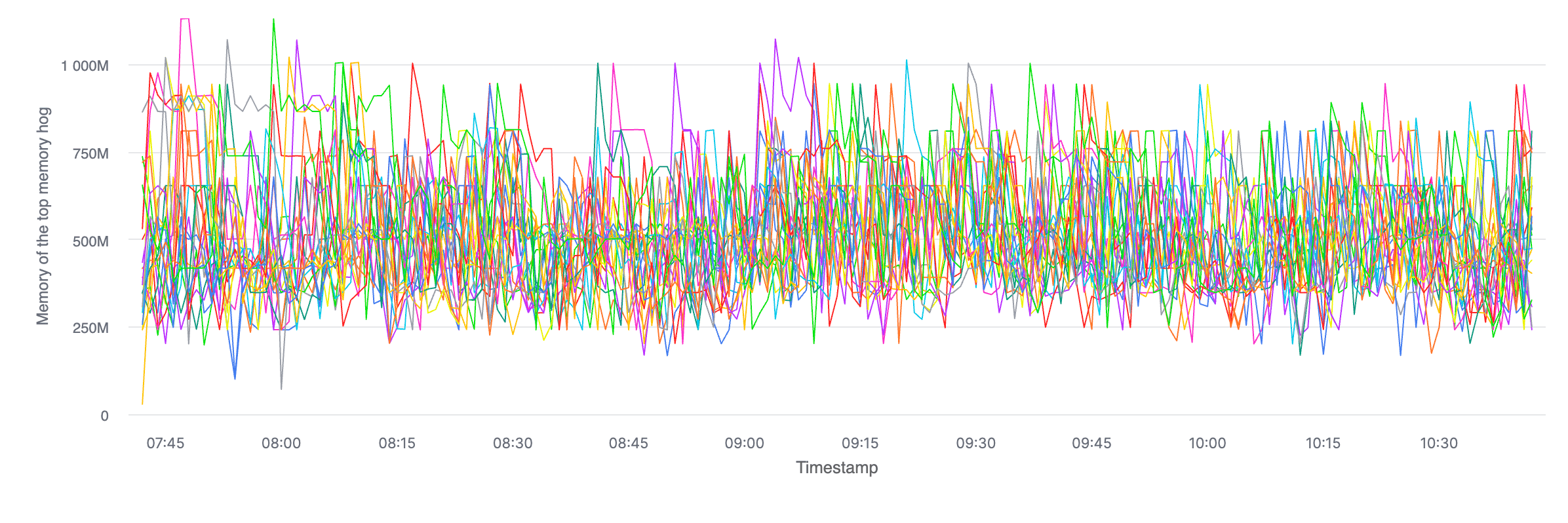
그리고 이것도 공유하지 않을 수가 없네요. 쿼리 캐시를 어떤 것도 쓰지 않게 강제(SETTINGS use_query_cache = false)했는데도, 이 쿼리는 42 밀리초 만에 결과가 나왔고, 1,131,629행(데이터 21.51 MB)을 읽었습니다. 볼 때마다 질리지가 않습니다.
이런 용도로 ClickHouse를 쓰는 게 엄청나게 획기적인 건 아니라는 점은 알고 있습니다. ClickHouse는 주로 _애널리틱스 데이터베이스_로 판매되고, OpenTelemetry 데이터를 저장하고 쿼리하기 위한 ClickStack이라는 제품까지 있을 정도입니다. 이건 정말 ClickHouse의 주특기죠.
제가 이 글에서 설명한 건, 제가 보기엔 완벽한 유스 케이스라는 점뿐입니다. BEAM은 런타임에서(혹은 “self”-inspect로) 검사하기가 쉬워서, 이 모든 게 아주 단순해집니다.
정리하자면, 우리는 다음을 이야기했습니다.
이 글에서는 비용 관점의 루프를 명시적으로 닫지는 않았는데, 최소한 이 규모에서는 ClickHouse의 저장소 비용이 무시할 만한 수준이기 때문입니다. 글을 쓰는 시점에 ClickHouse는 us-east-*에서 대략 USD$25/TB/mo 정도를 청구합니다. 오늘 저장 중인 내부 메트릭의 크기가 100배로 늘어난다 해도 데이터는 0.5TB에 불과하고, 단일 ChatGPT Plus 구독보다도 적은 비용을 내게 됩니다. 물론 egress와 compute 비용도 고려해야 하지만, 그건 데이터를 _쿼리_할 때만 의미가 있습니다. 플랫폼 팀 엔지니어 5명이 가끔씩만 이 데이터를 본다면, 사실상 그 비용은 0이라고 봐도 됩니다.
마지막으로, 사실상 이 아이디어 전체를 만들어낸 동료 Victor에게 다시 한 번 감사 인사를 전하고 싶습니다.
읽어주셔서 감사합니다!