시계열 데이터베이스에서 샘플, 시리즈, 역인덱스, 정방향 인덱스, 압축, 버킷팅을 통해 메트릭을 효율적으로 저장하고 조회하는 방법을 설명합니다.
최근 저는 MIT 라이선스의, 오브젝트 스토어 네이티브 시계열 데이터베이스를 이것저것 만들며 시간을 보내고 있는데, 이 분야가 매우 흥미로워서 데이터베이스에서 메트릭이 어떻게 저장되고 조회되는지에 대한 글을 써볼 만하다고 느꼈습니다.
언제나처럼, 바로 핵심으로 들어가겠습니다.
소프트웨어 엔지니어로 어느 정도 시간을 보냈다면, 여러분이 만든 소프트웨어가 실행되는 컴퓨터에서 시간에 따라 무슨 일이 일어나고 있는지를 중요한 정보로 그려 보여주는 그래프를 한 번쯤은 봤을 가능성이 큽니다.
그래프로 분석하기에는 매우 직관적인 대상이지만, 이를 형식적으로 정의하는 일은 그만큼 직관적이지는 않습니다. 데이터베이스 개발자인 저는 시계열 그래프를 세 가지 구성요소로 생각합니다.
샘플은 원시 측정값입니다. 보통 이것들은 어떤 메트릭 값을 읽어서 지속적으로 보고하는 머신으로부터 폴링됩니다(예를 들어 atomic f64 같은 곳에 저장된 값). 특정 시점에 채취되므로, 측정된 타임스탬프와 연결됩니다.
시리즈는 특정한 맥락과 연결된 샘플 벡터이며, 대부분의 시스템에서는 이를 레이블이라고 부릅니다(예: {instance='a2', region='us-west-2'}).
쿼리는 시리즈를 유용한 정보로 정제합니다. 일반적으로 시리즈를 직접 살펴보기에는 정보가 너무 많습니다. 노드가 수천 개 있다면, 코어가 잘 활용되고 있는지 알기 위해 평균 CPU 사용률을 보고 싶을 수 있습니다.
이 글에서는 쿼리를 효율적으로 처리하기 위해 시리즈와 샘플을 어떻게 저장하는지 다룹니다.
데이터가 디스크에 어떻게 배치되는지 이해하려면, 그 데이터를 사용하는 쿼리의 구조를 이해하는 것이 도움이 됩니다.
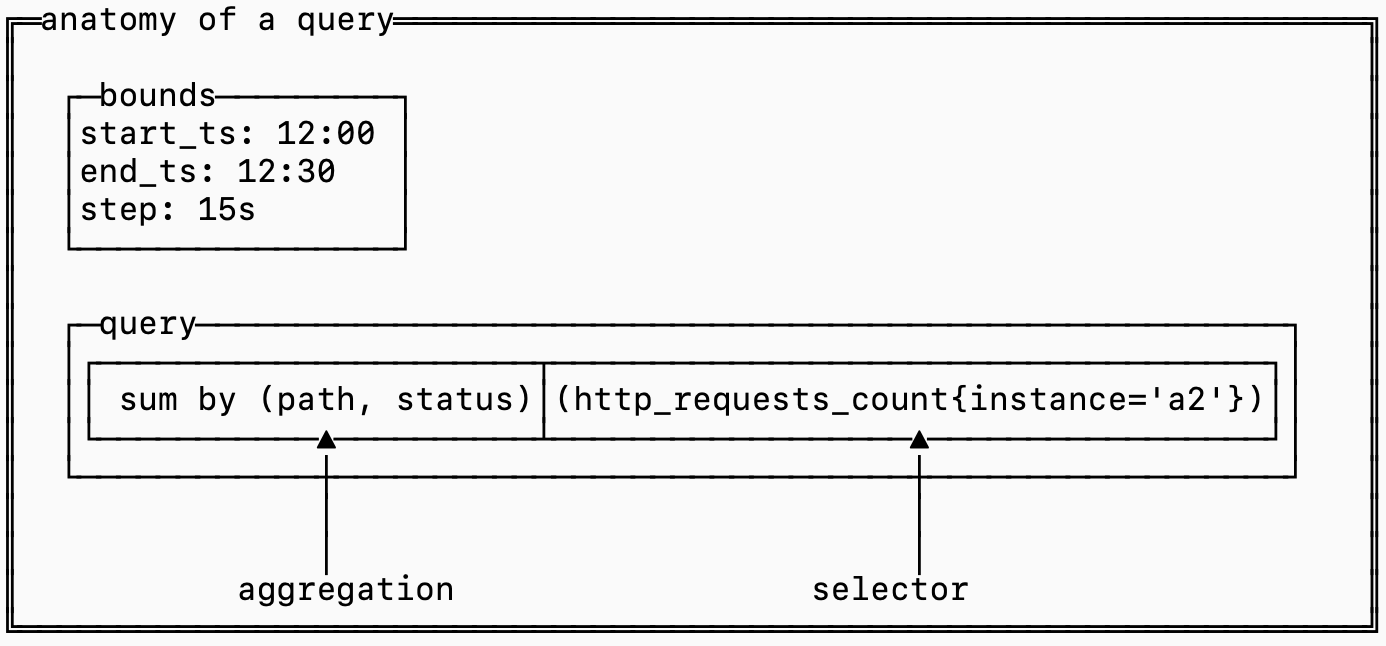
셀렉터는 어떤 시리즈를 가져와 쿼리에 포함할지를 결정하고, 집계는 서로 다른 시리즈의 샘플들을 결합하는 논리를 정의합니다.
이를 각 시리즈가 행이고 각 타임스탬프가 열인 2차원 행렬처럼 생각해보세요. 각 셀에는 해당 타임스탬프에서의 측정값이 들어 있습니다.
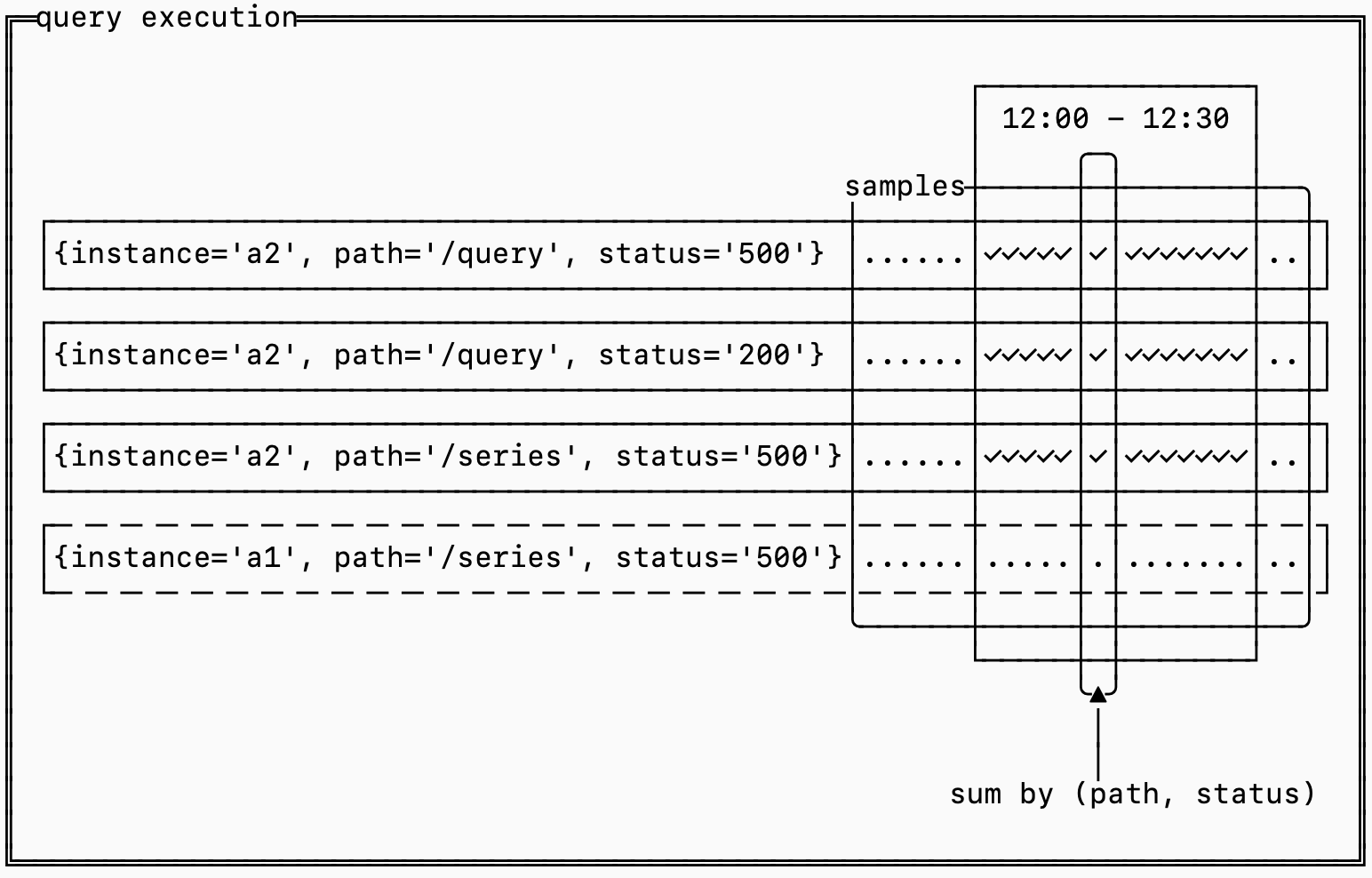
쿼리를 효율적으로 계산하려면 셀렉터에 맞는 시리즈만 남기도록 가지치기를 하고, 필요한 시간 범위의 샘플을 추출하고, 집계 기준에 따라 그룹화한 뒤, 최종 결과를 계산해야 합니다.
이는 세 단계로 이루어집니다.
역인덱스를 사용해 가져와야 할 시리즈를 좁힙니다
정방향 인덱스가 어떤 시리즈들을 함께 집계해야 하는지 결정합니다
원시 샘플을 가져와 집계합니다
쿼리는 여기서 시작됩니다. 역인덱스는 많게는 수십만 개에 달할 수 있는 시리즈를, 쿼리를 처리하는 데 필요한 시리즈만으로 좁혀줍니다.
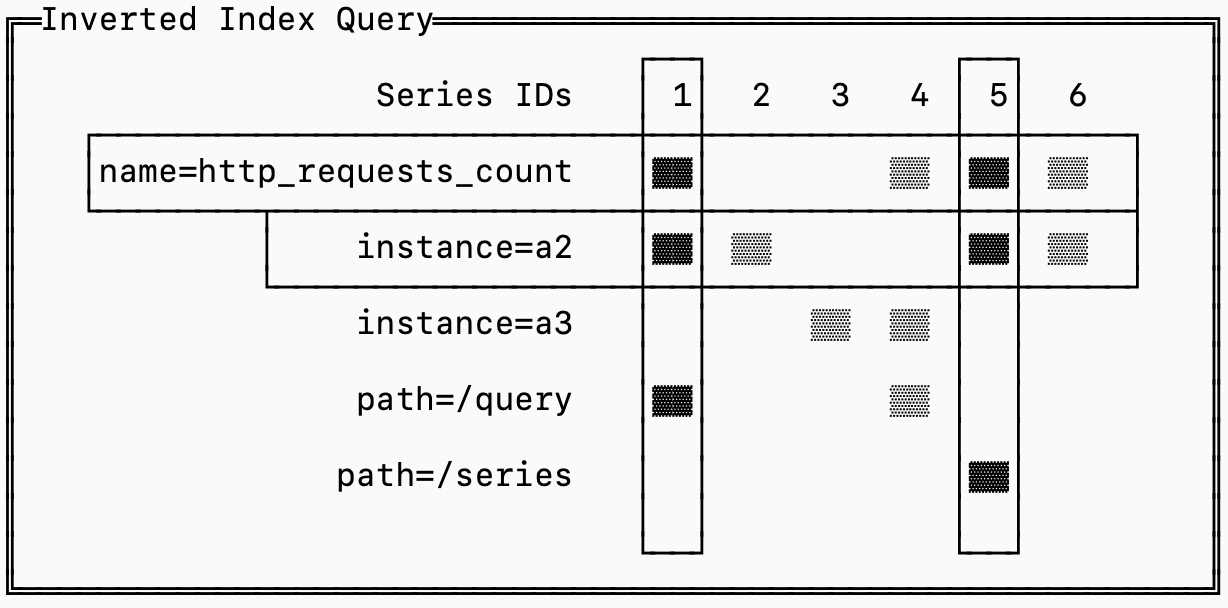
예를 들어 쿼리 http_requests_count{instance='a2'} 는 http_requests_count 에 대한 모든 시리즈 중에서 레이블 instance=’a2’ 도 가진 것들을 가져와야 하며, 나머지는 무시할 수 있습니다.
순진한 접근법은 시리즈를 이름순으로 정렬해 저장하는 것입니다. 그러면 전체 데이터베이스에서 이진 탐색을 통해 http_request_count 라는 이름의 시리즈만 분리한 다음, 그중 instance='a2' 에 속하는 것을 찾기 위해 스캔할 수 있습니다.
문제는 인스턴스가 수천 개일 수 있고, 각 인스턴스가 수백 개의 메트릭을 수집할 수 있기 때문에, instance=’a2’ 와 일치하는 시리즈만으로 집합을 좁히는 일이 간단하지 않다는 점입니다.
이 문제의 해결책은 검색 시스템에서 빌려온 것입니다. 바로 역인덱스입니다.
존재하는 모든 레이블에 대해 데이터베이스는 그 레이블을 가진 시리즈 목록을 저장합니다. 이 목록을 “포스팅 리스트”라고 부릅니다.
필요한 시리즈를 찾는 문제는 포스팅 리스트들의 교집합을 구하는 문제로 줄어듭니다.
이 교집합 연산을 효율적으로 만들기 위해 각 시리즈에는 고유한 ID가 부여되고, 포스팅 리스트는 이 ID를 기준으로 정렬됩니다. 그러면 알고리즘은 단순해집니다. 관심 있는 레이블의 포스팅 리스트를 불러오고, 리스트들 안의 포인터를 전진시키다가 모두 같은 시리즈 ID에 정렬되면, 그것이 가져와야 할 시리즈입니다(위 그림에서는 시리즈 1과 5). 포스팅 리스트 중 하나를 다 소진할 때까지 이를 계속하면 되고, 쿼리에 포함되지 않은 포스팅 리스트는 무시할 수 있습니다.
역인덱스를 효율적으로 저장하고 활용하기 위해 사용할 수 있는 몇 가지 인코딩 기법도 있습니다. 이 특정 사용 사례에서 최첨단 메커니즘은 roaring bitmap이라고 불립니다.
이 데이터 구조의 핵심 통찰은 포스팅 리스트가 대체로 희소하거나 조밀하며, 희소한 리스트는 군집되는 경향이 있다는 점입니다. 시계열의 경우, container_id=123 에 대한 포스팅 리스트(희소한 리스트)는 region:us-west-2 에 대한 리스트(조밀한 리스트)보다 훨씬 적은 수의 시리즈를 담고 있을 것이라고 상상할 수 있습니다. 그런데 시리즈 ID를 단조 증가하게 할당하면, container_id=123 이 생성한 모든 시리즈의 ID가 전체 시리즈 ID 영역 중 작은 범위 안에 들어갈 가능성이 큽니다(모두 시작 시점에 등록되기 때문입니다).
이 관찰을 활용하기 위해 roaring bitmap은 포스팅 리스트의 표현을 “조밀 블록”과 “희소 블록”으로 나눕니다. 이들은 32비트 정수 값만 인코딩하므로, “상위 16비트”로 블록을 인덱싱하고, 그 뒤 각 블록이 어떤 정확한 값이 존재하는지를 인코딩합니다. 조밀 블록은 어떤 값이 존재하는지를 비트셋으로 표현하고, 희소 블록은 값 배열을 단순하게 그대로 인코딩합니다.
아래 예시에는 희소 블록과 조밀 블록의 표현이 모두 있습니다. 희소 블록은 값 [5, 1000] 을 인코딩하고, 조밀 블록은 196608 과 250000 사이의 모든 수를 인코딩합니다.
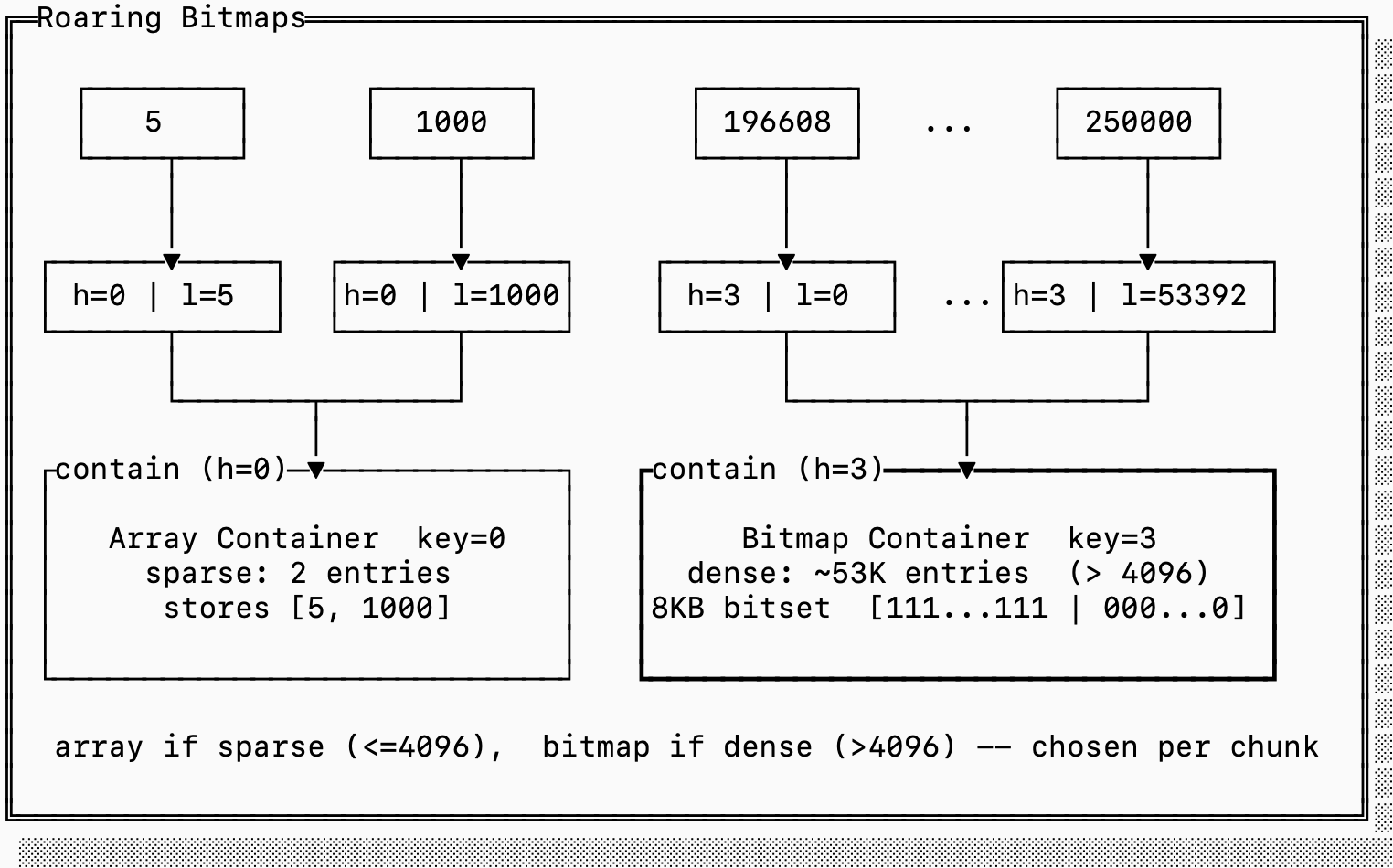
희소 블록을 전체 비트셋으로 인코딩한다면 0x0000 으로 시작하는 모든 값에 대해 1비트씩 필요하므로 8KB가 필요합니다. 하지만 숫자가 두 개뿐이므로 4바이트만 인코딩하는 편이 더 효율적입니다(각 5와 1000에 대한 하위 16비트).
반면 조밀 블록을 단순 배열로 인코딩한다면 212KB가 필요합니다(항목당 2바이트). 하나의 8KB 비트셋을 저장하는 편이 더 효율적입니다.
Roaring bitmap은 저장 공간 측면에서만 효율적인 것이 아닙니다. 리스트가 정렬되어 있고, bitmap 교집합/합집합 연산을 SIMD 명령어로 수행할 수 있기 때문에, roaring bitmap에 대한 집합 연산은 매우 효율적입니다.
역인덱스 섹션을 주의 깊게 읽으셨다면, 우리가 큰 함의를 가진 작은 결정을 내렸다는 점을 눈치채셨을 겁니다. 역인덱스는 시리즈 정의 자체가 아니라 시리즈 ID만 저장합니다.
이는 역인덱스가 쿼리를 처리하는 데 필요한 시리즈 ID를 찾는 데는 도움이 되었지만, 집계를 위해 어떤 시리즈들을 함께 묶어야 하는지를 결정하는 데에는 전혀 도움이 되지 않는다는 뜻입니다. 따라서 시리즈 ID를 해당 정의(레이블 집합)에 매핑하는 무언가가 필요합니다.
이것이 정방향 인덱스입니다.
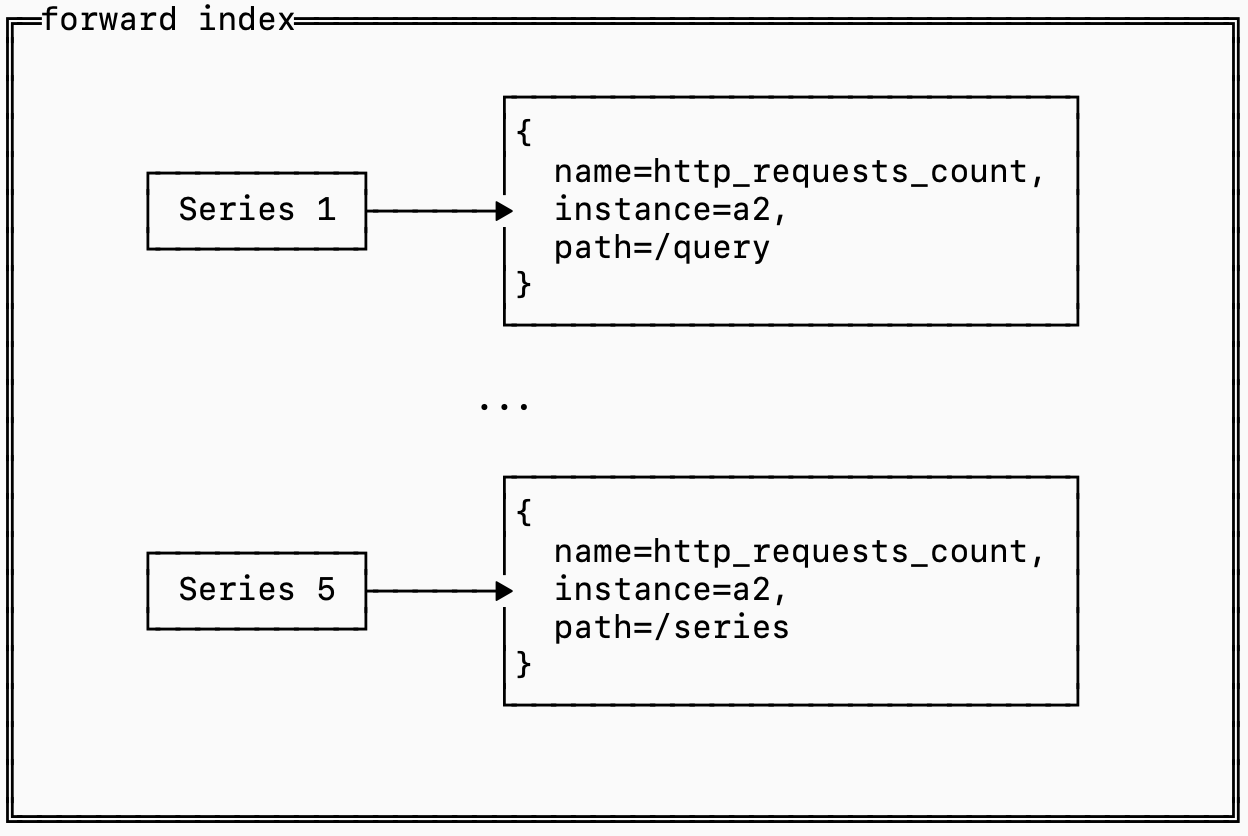
쿼리는 매칭되는 모든 시리즈에 대해 정방향 인덱스를 불러와야 하므로, 이 데이터의 조회 비용은 커질 수 있습니다.
정방향 인덱스 같은 인덱스를 포함해, 디스크에 저장되는 대부분의 데이터는 SST와 유사한 형태로 저장됩니다(이전 글에서 더 자세히 다뤘습니다). 즉, 정렬 기준이 되는 키를 선택해야 합니다. 이를 “클러스터링” 키라고 하며, 이를 어떻게 선택하느냐가 저장 성능에 큰 차이를 만듭니다.
이를 구체적으로 보기 위해, 시리즈와 정방향 인덱스를 저장하는 두 가지 대안적 배치 방식을 살펴보겠습니다.

첫 번째 예시에서는 단순히 series_id 로 정렬합니다. 이렇게 하면 역인덱스에서 각 포스팅이 곧 시리즈 ID이므로, 역인덱스에서 샘플과 정방향 인덱스를 조회하는 단계로 쉽게 넘어갈 수 있습니다.
문제는 시리즈 ID에는 메트릭 이름과 관련된 인코딩이나 관계가 없다는 점입니다. 쿼리가 특정 메트릭만 대상으로 할 때(거의 모든 쿼리가 그렇습니다), 디스크 여기저기에 흩어진 시리즈를 가져와야 할 수 있으며, 이는 쿼리의 읽기 증폭을 크게 증가시킬 수 있습니다.
오른쪽 배치는 대신 정방향 인덱스와 샘플을 (metric_name, series_id) 의 복합 키를 기준으로 정렬합니다. 이는 연속된 시리즈 ID가 반드시 함께 묶여 있지는 않지만, 디스크의 블록이 하나의 메트릭 전용이 된다는 뜻입니다. 같은 메트릭에 대해 많은 시리즈를 가져와야 한다면, 이는 훨씬 더 효율적일 수 있습니다.
이제 어떤 시리즈가 필요한지, 그리고 집계에서 어떤 것들이 함께 그룹화되는지 알 수 있게 되었으니, 남은 것은 원시 데이터를 저장하고 가져오는 메커니즘뿐입니다.
흥미로운 점은 시계열 데이터가 풍부하면서도 반복적이라는 것입니다. 이 조합은 압축에 특히 잘 맞는 몇 가지 특성을 만들어냅니다(이전 글에서 자세히 논의했습니다).
시리즈의 데이터 포인트인 샘플은 두 부분으로 이루어집니다. 측정이 이루어진 타임스탬프와 측정값입니다.
Prometheus를 설정해본 적이 있다면, 스크레이퍼를 어떤 고정 간격(예를 들면 15s)으로 스크레이프하도록 설정한다는 것을 알고 있을 것입니다. 따라서 특정 시리즈의 타임스탬프가 대체로 이런 모습이라는 사실은 놀랍지 않습니다.
가끔 더 넓은 간격의 공백이 보일 수는 있습니다(예: pod에 과부하가 걸렸을 때). 하지만 정상 상태에서는 타임스탬프가 항상 약 15s 간격일 것이라고 기대합니다.
타임스탬프의 일반적인 인코딩은 8바이트를 차지하는 i64 long입니다. 만약 15s마다 100k 시리즈를 인코딩한다면, 타임스탬프만 저장하는 데도 시간당 192 MB가 필요합니다. 하지만 실제 프로덕션에서는 대부분의 시스템이 이를 약 3 MB/hour 정도로 저장할 수 있습니다(60배 감소). 어떻게 가능할까요?
똑똑한 사람들이 알아낸 바에 따르면, 첫 번째 타임스탬프만 저장하고 그다음부터는 차이값만 인코딩하면 훨씬 적은 데이터로 이 지점들을 저장할 수 있습니다.
델타당 2바이트를 사용하면 최대 18시간(65k seconds)의 간격까지 인코딩할 수 있고, 전체 데이터를 4배 줄일 수 있습니다.
타임스탬프가 15s 간격으로 보고되기 때문에, 사실 우리는 더 잘할 수 있습니다. 타임스탬프들 사이 차이의 차이값은 훨씬 더 작고, 실제로 거의 항상 0에 매우 가깝습니다.
델타의 델타를 인코딩하는 정교한 방법들이 있어서, 타임스탬프를 샘플당 대략 1비트로 저장할 수 있습니다. 이는 원래의 8바이트 형식 대비 64배 감소입니다.
앞 절의 요지를 이해했다면, 측정값도 비슷한 패턴을 따를 수 있다는 점을 이미 짐작하셨을지도 모릅니다. 메트릭은 보통 시간이 지나면서 천천히 변합니다(뭔가 특별한 일이 일어나지 않는 한, 그런데 정의상 그런 일은 자주 일어나지 않습니다).
이것은 타임스탬프를 논의할 때 본 것과 꽤 비슷해 보이지만, 문제는 측정값이 부동소수점 값이라는 점입니다. 두 부동소수점 수의 차이가 작더라도 여전히 많은 비트를 필요로 할 수 있습니다.
예를 들어 IEEE 754(표준)에서 0.0001 의 표현은, 이렇게 단순한 십진수임에도 놀랍게도 다음과 같은 모습입니다.
부호 비트는 단순합니다(양수 또는 음수). 가수는 2 ^ exponent 를 곱해 분수값을 복원하는 데 사용되며, 이 경우 다음을 얻습니다.
(−1)^0 × 1.1010...0101101₂ × 2^−14 ≈ 0.00010000000000000000479
정확히 0.0001 은 아니지만, 부동소수점 수로 표현할 수 있는 가장 가까운 값입니다. 흥미로운 점은 0.0001 과 0.0002 가… 매우 비슷해 보인다는 것입니다(실제로 가수는 같습니다).
이 두 값을 XOR하면 0이 많이 포함된 값을 얻게 됩니다.
이것은 우연이 아닙니다. 서로 비슷한 많은 부동소수점 수는 XOR했을 때 0이 많이 나옵니다. 즉, 세 부분으로 된 수를 저장할 수 있습니다. 먼저 앞쪽의 0 개수(10)를 저장하고, 그다음 유의미한 길이(2)를 저장한 뒤, 유의미한 비트 0b11 만 저장하면 되며, 이건 2비트에 불과합니다. 그러면 원래 64비트에서 이 경우 단 15비트까지 줄일 수 있습니다.
이 두 개념(타임스탬프에 대한 델타의 델타 인코딩과 측정값에 대한 XOR 인코딩)을 함께 사용하면, 많은 측정값을 매우 효율적으로 저장할 수 있어, 순진한 형식의 16바이트에서 평균적으로 측정값당 약 11비트만 저장하면 됩니다.
다시 원래의 15s 간격으로 보고되는 100k 시리즈로 돌아가 보면, 시간당 384 MB에서 33 MB로 줄어들며, 거의 12배 개선입니다.
시간이 가로축이고 시리즈가 세로축인 시계열의 원래 2차원 행렬 모델로 돌아가 봅시다. 몇 시간치의 프로덕션 데이터를 보면 아마 이런 모습일 것입니다.
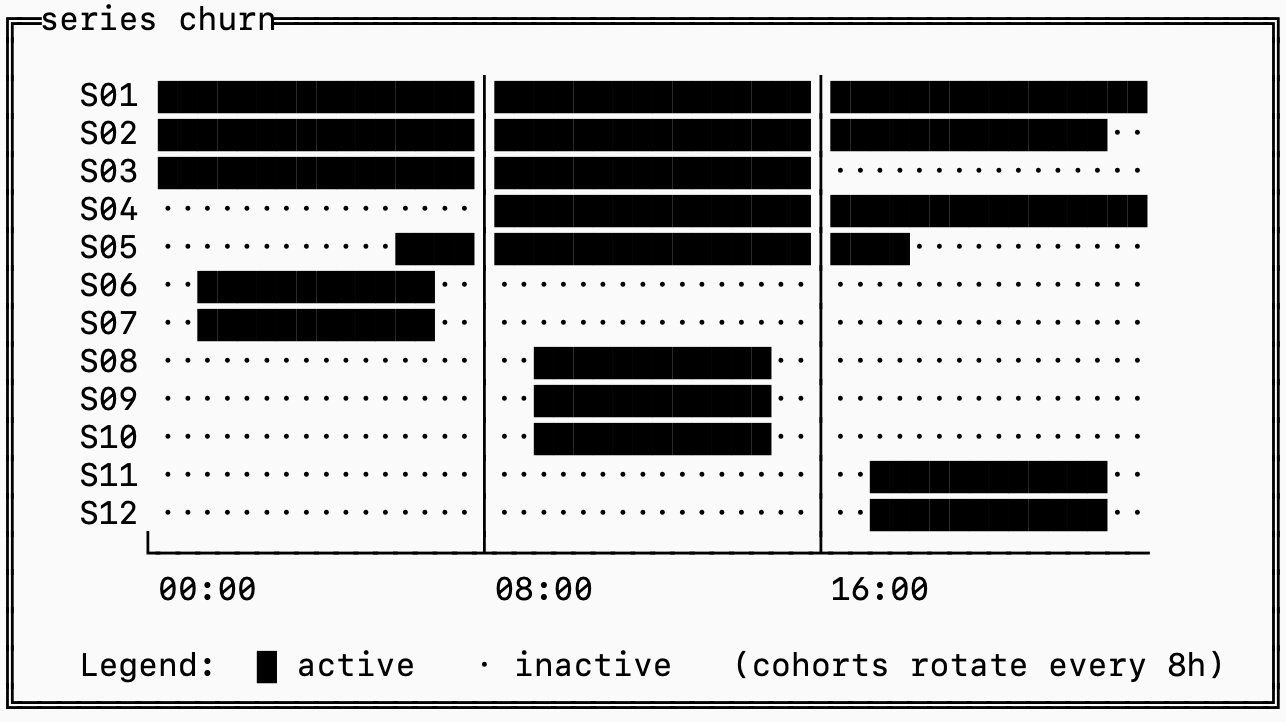
██ 는 그 시간 동안 데이터가 있는 시리즈를 나타내고, . 는 그 시간에 데이터가 없는 시리즈를 나타냅니다.
시리즈 S06-S12는 아마 container_id 같은 정적이지 않은 값으로 태깅되어 있을 가능성이 큽니다. 그래서 배포할 때마다 container_id 만 바뀌고 나머지 레이블은 거의 동일한 새로운 시리즈가 생성됩니다.
이것을 “시리즈 churn”이라고 하며, 시계열 데이터베이스에서 가장 큰 문제입니다. 관측 가능성 시스템에서 이 패턴을 무시한다면, 꽤 골치 아픈 부작용들이 생기게 됩니다.
설명을 위해, 이 메트릭들 각각에 레이블이 두 개뿐이라고 가정해봅시다. name(메트릭 이름)과 container_id 입니다. 이를 하나의 역인덱스에 인덱싱하면 대략 이렇게 보일 것입니다.
name=metric_1: [1, 3, 5, 7, 9, 11]
name=metric_2: [2, 4, 6, 8, 10, 12]
container=a: [1, 2, 3]
container=b: [4, 5]
container=c: [6, 7]
container=d: [8, 9, 10]
container=e: [11, 12]
제 쿼리가 시간 범위 16:00-24:00 를 대상으로 하고, metric_2 를 조회한다고 해봅시다. 그러면 제가 가진 유일한 필터 조건이 그것뿐이므로 [1, 3, 5, 7, 9, 11] 전체를 검사해야 합니다. 그리고 나서야 [7, 9] 시리즈에는 제가 조회한 윈도우와 관련된 데이터가 없다는 사실을 알게 되는데, 그 시리즈들의 샘플을 가져온 후에야 알 수 있습니다.
이 문제의 해결책은 버킷팅입니다. 즉, 각 시간 “버킷”마다 샘플, 역인덱스, 정방향 인덱스의 완전한 삼중 구성을 저장하는 것입니다. 시리즈 ID도 버킷 범위 안으로 한정되므로, 들어오는 데이터에 대한 시리즈 ID를 전체 시리즈 이력을 뒤지지 않고도 빠르게 찾을 수 있습니다.
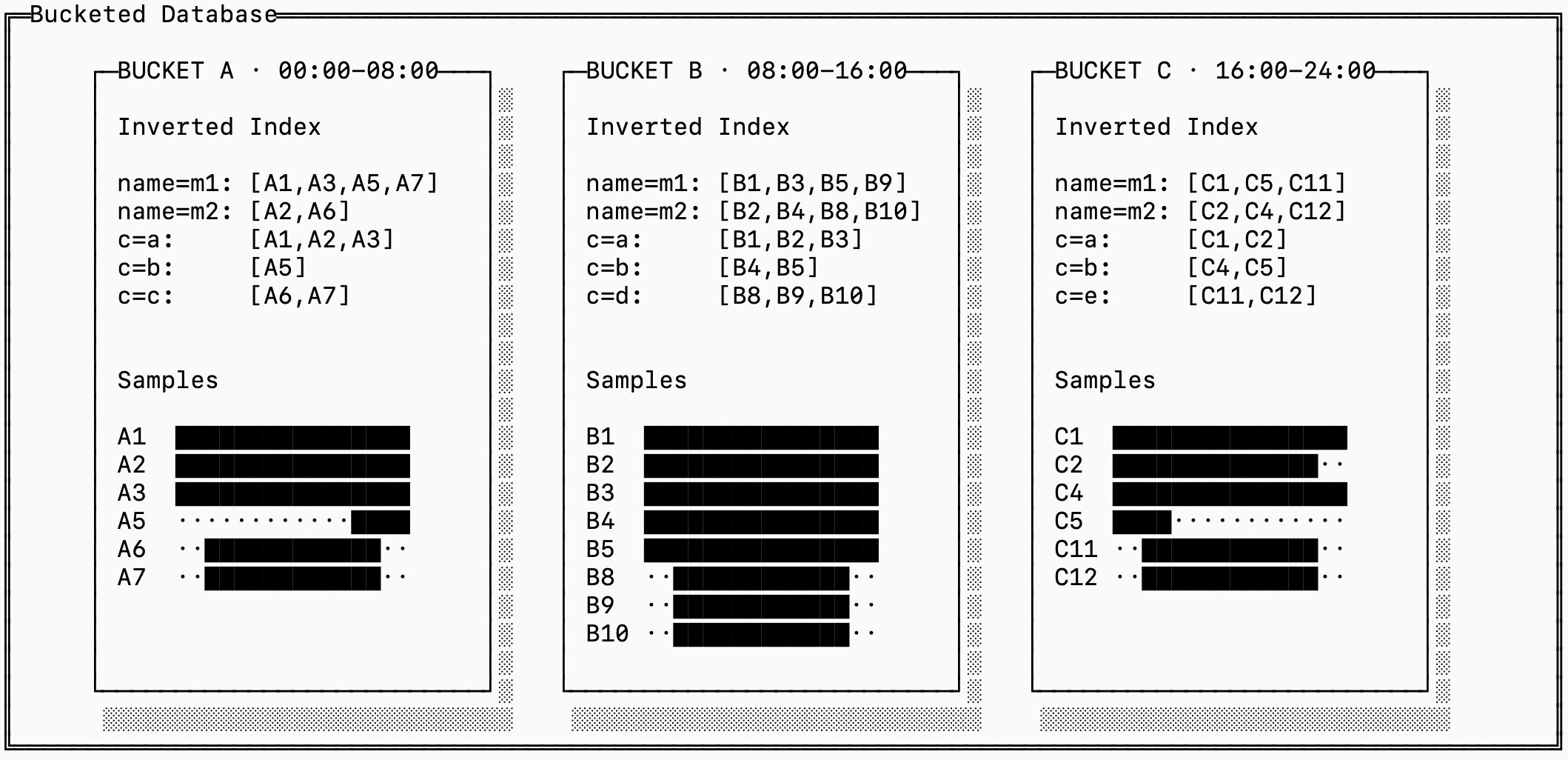
이 방식의 단점은, 그중 일부가 같은 “논리적” 시리즈를 가리키더라도 훨씬 더 많은 개별 시리즈 ID가 생성된다는 점입니다. 위 예시에서 A1, B1, C1은 모두 같은 레이블을 가집니다.
이는 시계열 저장소에서의 읽기, 쓰기, 공간 증폭 사이의 근본적인 트레이드오프입니다. 오래된 버킷에 대해서는 시간 블록 전반에 걸쳐 시리즈를 병합함으로써 이를 관리할 수 있으며, 실제로 많은 시계열 데이터베이스가 정확히 이런 방식으로 이 문제를 처리합니다.
오늘은 여기까지입니다! 이 데이터 타입들을 디스크에 어떻게 인코딩하고 저장하는지에 대해 더 자세히 읽고 싶다면, GitHub에 있는 자세한 RFC를 참고해보세요.
시계열 시스템이 저장하는 세 가지 주요 데이터 유형, 즉 샘플, 역인덱스, 정방향 인덱스와 이들이 디스크에 어떻게 표현되는지를 살펴봤습니다. 곧 시계열 엔진의 쿼리 실행 파이프라인에 대한 전체 글도 쓸 예정이니, 바로 받아보실 수 있도록 꼭 구독해 주세요.