페타바이트 규모의 OpenTelemetry 트레이싱 워크로드를 대상으로 OTel Collector와 Rotel을 비교 벤치마크하고, Rotel이 동일 하드웨어에서 4배 가까운 처리량을 달성하기까지의 최적화 과정과 ClickHouse와의 통합 방법을 다룬다.
오늘 글은 고성능·고효율 OpenTelemetry 수집을 위한 오픈소스 Rust 프로젝트 Rotel을 유지보수하는 Streamfold의 Mike Heffner, Ray Jenkins의 기고입니다.
페타바이트 규모의 옵저버빌리티 플랫폼을 운영하려면, 자원 효율성에 대해 지속적이고 의도적인 주의가 필요합니다. 코어당 성능이나 메모리 사용량이 조금만 개선되어도 인프라 비용을 크게 줄일 수 있습니다.
이 글은 우리가 덴버에서 열린 ClickHouse 밋업에서 했던 발표에서 출발했습니다. 우리는 대규모 시스템에서 고성능을 목표로 설계된 OpenTelemetry 데이터 플레인인 Rotel에 대해 발표했습니다.
ClickHouse는 높은 압축률과 비용 효율성 때문에 대규모 OpenTelemetry 워크로드에서 점점 더 많이 선택되고 있습니다. 반면, 파이프라인에서 가장 비싼 구성요소로 OTel Collector가 자주 지목됩니다.
최근 ClickHouse는 내부 플랫폼인 LogHouse에서 OTel을 운영한 경험을 기반으로, 대규모 환경에서 효율성이 왜 중요한지 다룬 글을 공개했습니다.
그 글에서 특히 눈에 띈 부분이 있었습니다.
"OTel Collectors: Use over 800 CPU cores to ship 2 million logs per second."
코어당 대략 2.5k 로그/초의 처리량이라는 뜻인데, 평균적인 로그 라인 기준으로 8코어 박스에서 초당 약 10MB 정도밖에 안 됩니다. 이는 현대 하드웨어가 충분히 감당할 수 있는 수준보다 훨씬 낮습니다. ClickHouse는 코어당 초당 12.5k 이상의 OTel 이벤트를 처리할 수 있어, 수집보다 5배 이상 빠르게 저장 처리가 가능합니다. 결국 병목은 스토리지가 아니라 인제스트 쪽이라는 의미입니다. 우리는 ClickHouse 내부 플랫폼과 동일한 환경을 재현할 수는 없지만, 최신 OpenTelemetry 파이프라인을 벤치마크해 볼 가치는 있다고 생각했습니다. 그래서 발표에서 다음 질문을 중심으로 실험을 구성했습니다. OpenTelemetry 데이터를 ClickHouse로 보낼 때, 서로 다른 데이터 플레인은 얼마나 성능이 다를까?
이 글에서는 Kafka를 통해 트레이스 스팬을 스트리밍하고 ClickHouse에 적재하는 합성(synthetic) 트레이싱 파이프라인을 사용해 OpenTelemetry Collector와 Rotel을 비교한 벤치마크를 설명합니다. OTel Collector로는 초당 110만 스팬까지 벤치마크했고, 이후 Rotel에 JSON 바이너리 직렬화, Tokio 태스크 관리에 대한 perf 분석, 향상된 LZ4 압축을 적용해 동일한 하드웨어에서 최대 초당 370만 스팬을 처리하도록 스케일링한 과정을 단계별로 살펴봅니다.
글 마지막에는 우리가 사용한 벤치마크 프레임워크와 도구도 정리했습니다.
하나의 명령으로, 대규모 OpenTelemetry를 위한 오픈소스 옵저버빌리티 스택을 바로 시작할 수 있습니다.
OTel Collector와 Rotel을 어떻게, 무엇을 기준으로 평가할 것인지 설명하기 전에 전반적인 방향을 먼저 짚겠습니다. 바로 테스트 결과가 궁금하다면, 아래로 넘어가셔도 됩니다.
우리는 트레이스 데이터가 대규모 시스템에서 빠르게 성장한다는 점에 주목해, 트레이스 스팬을 ClickHouse에 쓰는 작업에 벤치마크를 집중했습니다. 안정적인 스트리밍 파이프라인을 모델로 삼아, Kafka를 로그 스트리밍 계층으로 사용했습니다. 많은 수의 엣지 컬렉터가 데이터를 스트림에 발행하고, 상대적으로 적은 수의 컬렉터가 이를 소비해 효율적으로 배치 쓰기로 ClickHouse에 적재하는 시스템을 상정했습니다. 이 파이프라인에서 Rotel과 OTel Collector 모두 동일한 Kafka Protobuf 인코딩을 지원하기 때문에 상호 교체 가능합니다.

우리의 목표는 고정된 하드웨어에서 단일 컬렉터가 지속적으로 유지할 수 있는 최대 처리량을 찾는 것이었습니다. 스케일 업/아웃보다는 효율성에 초점을 맞췄습니다. 예산 범위 내에서 노드 하나를 어디까지 밀어붙일 수 있는지가 궁금했습니다. 특히 게이트웨이 컬렉터에 초점을 맞췄는데, 이 컴포넌트가 ClickHouse로 직접 데이터를 내보내며, ClickHouse는 큰 배치 단위로 인서트할 때 성능이 가장 좋기 때문입니다. 배치 효율을 극대화하려면 소수의, 더 큰 게이트웨이 컬렉터를 운영하는 편이 유리하므로, 이 부분을 최적화하고 측정 대상으로 삼았습니다.
포화 상태 감지하기
컬렉터가 처리할 수 있는 최대 용량에 도달했음을 나타내는 시그널로 다음 두 가지를 사용했습니다.
테스트 방식
각 테스트에서 포화 직전의 지점으로 파이프라인을 밀어붙이고, 그 상태를 15분간 유지하면서 다음 두 가지 지표를 기록했습니다.
트레이스 스팬은 환경마다 크기 편차가 크기 때문에, 총 대역폭을 함께 보면 보다 정규화된 처리량 척도로 쓸 수 있습니다. 파이프라인 설정상 단일 엣지 컬렉터가 최적화된 배치를 Kafka로 내보내도록 했기 때문에, 전체 메시지 개수는 줄이고 개별 메시지 크기는 키우는 방향으로 구성했습니다.
각 테스트에서 Rotel과 ClickHouse의 평균 CPU 사용률도 함께 수집했습니다.
벤치마크를 위해 OpenTelemetry Collector와 Rotel 양쪽에서 호환 가능한 단일 ClickHouse 데이터 스키마를 사용했습니다. 이 스키마는 ClickHouse와 ClickStack 옵저버빌리티 솔루션에서 OTel 메트릭, 로그, 트레이스를 수집할 때 권장되는 스키마입니다.
OTel 데이터 모델은 인프라와 애플리케이션 환경의 다양한 속성을 표현하기 위해 key/value 속성(attribute)에 강하게 의존합니다. 기존 ClickHouse 스키마에서는 이 필드를 Map 컬럼 타입으로 저장했지만, 최근 OTel Collector에 추가된 기능 플래그를 사용하면 새 JSON 컬럼 타입을 사용하도록 스키마를 바꿀 수 있습니다. JSON 컬럼 타입은 ClickHouse CPU 부하는 더 크지만, 훨씬 유연하고 표현력 있는 쿼리를 가능하게 해줍니다. 우리의 평가는 새 JSON 컬럼 타입을 사용하는 방향을 택했습니다. 사용한 전체 ClickHouse 트레이스 스키마는 여기에서 볼 수 있습니다.
셋업에서 중요한 요소는 ClickHouse의 Null 테이블 엔진입니다. 이 엔진 덕분에 벤치마크에서 디스크 I/O를 제거할 수 있었습니다. Null 엔진은 쓰기를 받아들이지만 즉시 폐기하므로, 스토리지 레이턴시 없이 인제스트 처리량을 측정하고 스키마의 유효성을 검증할 수 있었습니다. 파이프라인의 최대 처리량을 찾은 뒤에는, 실제 디스크 쓰기를 감당하도록 ClickHouse를 스케일링하는 작업에 집중하면 됩니다.
벤치마크에 필요한 데이터 볼륨을 telemetrygen CLI로는 충분히 밀어넣을 수 없었습니다. 대신, 예전에 OpenTelemetry와 기타 텔레메트리 파이프라인을 테스트하기 위해 만들어 둔 내부 로드 제너레이터를 사용했습니다. 프로젝트는 otel-loadgen GitHub 저장소에서 확인할 수 있습니다. 이 도구는 엔드 투 엔드 데이터 전달을 검증하는 추가 기능도 제공하는데, 이는 추후 글에서 다룰 예정입니다.
우리는 다양한 속성과 메타데이터를 가진 트레이스마다 약 100개의 스팬을 생성했습니다. 어떤 합성 부하 테스트와 마찬가지로, 이 데이터셋이 실제 운영 트래픽을 완전히 동일하게 반영하지는 않습니다.
모든 벤치마크는 AWS EC2 인스턴스에서 수행했습니다. 평가 파이프라인의 각 계층을 별도 인스턴스에서 구동했고, 모든 인스턴스는 동일한 가용 영역에 생성했습니다.
| 인스턴스 | vCPU | 메모리 (GiB) | |
|---|---|---|---|
| 로드 제너레이터 | m8i.8xlarge | 32 | 128 |
| 엣지 컬렉터 | m8i.4xlarge | 16 | 64 |
| Kafka | i3.xlarge | 4 | 30.5 |
| 게이트웨이 컬렉터 | m8i.2xlarge | 8 | 32 |
| ClickHouse | i3.4xlarge | 16 | 122 |

Kafka와 ClickHouse에는 인스턴스 스토리지 NVMe 드라이브에 데이터 볼륨을 마운트해 최대 디스크 처리량을 확보했습니다. OS는 Amazon Linux 2023을 사용했고, 각 컴포넌트는 Docker Compose로 실행했습니다.
이 벤치마크의 목적은 단일 게이트웨이 컬렉터 박스에 얼마나 높은 처리량을 밀어넣을 수 있는지 찾는 것이었습니다. 우리는 8코어, 32GB 메모리를 가진 m8i.2xlarge 인스턴스를 게이트웨이 컬렉터로 선택했습니다. 파이프라인의 다른 박스는 필요에 따라 확장했지만, 게이트웨이 컬렉터는 계속 m8i.2xlarge로 유지했습니다.
우리는 OpenTelemetry Collector를 엣지 컬렉터와 게이트웨이 컬렉터 양쪽에 사용해 벤치마크를 시작했습니다.

docker-compose 설정은 여기에서 볼 수 있습니다.
| OTel Collector | 트레이스 스팬 | 트레이스 스팬 / 코어 | ClickHouse Network In (압축) |
|---|---|---|---|
| 단일 Collector 프로세스 | 700 K/sec | 87.5 K/sec | 40 MB/s |
| Collector 프로세스 2개 | 1.1 M/sec | 137.5 K/sec | 69 MB/s |
Collector 단일 인스턴스를 실행했을 때, 초당 약 70만 스팬(40MB/s) 지점에서 갑작스러운 경계에 부딪혔습니다. 이 지점을 넘어서면, CPU 사용률은 약 50% 수준임에도 불구하고 Collector의 메모리 사용량이 꾸준히 증가하기 시작했습니다.
OpenTelemetry Kafka 리시버는 단일 goroutine에서 메시지를 처리하는데, 이것이 처리량을 제한하는 요인일 가능성이 높습니다. 메시지 크기 관련 파라미터를 포함해 Kafka 설정 몇 가지를 조정해 봤지만, 눈에 띄는 개선은 없었습니다. 대신 동일 박스에서 Collector 인스턴스 두 개를 띄우는 방식으로 수평 확장했습니다(Docker Compose 설정에서 scale: 2).
Collector 프로세스를 두 개 실행해 Kafka 파티션을 반반 나누어 소비하자, 포화 직전까지 유지 가능한 최대 처리량은 **초당 110만 트레이스 스팬(69MB/s)**이었습니다. 이 지점을 넘어가면, 전송 큐가 차기 시작하면서 메모리 사용량이 급격히 증가했습니다. 전송 큐가 완전히 가득 차면 Kafka 리시버는 계속 메시지를 읽지만, 곧바로 드롭해 버립니다. 즉, 컨슈머 랙은 증가하지 않지만 데이터는 유실되고 있는 상태였습니다!
게이트웨이 컬렉터의 CPU 사용률은 테스트 도중 83% 조금 넘는 수준까지 치솟았고, 이것이 한계 요인으로 보였습니다. ClickHouse CPU는 약 23%에 머물렀습니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 83.1% | 23.8% |


docker-compose 설정은 여기에서 볼 수 있습니다.
| Rotel | 트레이스 스팬 | 트레이스 스팬 / 코어 | ClickHouse Network In (압축) |
|---|---|---|---|
| Rotel 단일 프로세스 | 750 K/sec | 93.75 K/sec | 41 MB/sec |
| Rotel 프로세스 2개 | 1.45 M/sec | 181.3 K/sec | 76 MB/sec |
Rotel 역시 Kafka에서 메시지를 읽어오는 단일 리시버 루프를 사용하며, 이는 OTel Collector와 유사합니다. 그래서 우리는 직렬 처리 병목이 있을 것이라고 예상했고, Rotel 프로세스를 두 개 실행했을 때 인스턴스의 전체 CPU를 다 써서 스케일 아웃되는 것을 보고 이 가설이 초기에 확인된 것처럼 보였습니다.
Rotel 프로세스를 두 개 사용할 경우, **초당 145만 트레이스 스팬(76 MB/sec)**까지 밀어넣을 수 있었는데, 이는 OTel Collector 대비 전체 처리량이 약 1.3배 향상된 수치입니다. 초당 145만 스팬을 넘기면 Kafka 컨슈머 랙이 서서히 증가하기 시작했는데, 이는 Kafka에서 메시지를 충분히 빠르게 소비하지 못하고 있음을 의미합니다.
초당 145만 스팬 지점에서 게이트웨이 컬렉터 인스턴스의 CPU가 병목으로 떠올랐고, ClickHouse CPU는 약 60%까지 상승했습니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 91.3% | 60.4% |

우리는 계속해서 최적화 기회를 찾아 나갔고, 그 과정에서 JSON 컬럼 타입을 어떻게 전송하고 있는지에 주목하게 되었습니다.
Rotel은 clickhouse-rs라는 공식 Rust ClickHouse 크레이트를 변형해 사용합니다. clickhouse-rs는 HTTP 위에서 동작하는 RowBinary, 즉 행 지향 바이너리 직렬화 포맷을 사용해 ClickHouse에 데이터를 쓰고 읽습니다. 반면 OTel Collector의 Go 드라이버와 ClickHouse 내부 서버 간 통신은 컬럼 지향 네이티브 프로토콜을 사용합니다.
JSON 컬럼 타입을 사용할 때, clickhouse-rs 크레이트는 값들을 전송 전에 JSON 문자열로 직렬화할 것을 권장합니다. ClickHouse는 JSON 컬럼을 실제로는 문자열 그대로 저장하지 않기 때문에, 이 문자열화 작업은 오직 전송을 위한 단계지만, 그럼에도 오버헤드가 상당합니다. 클라이언트는 JSON을 직렬화해야 하고, 서버는 이를 다시 파싱해야 합니다. 이 과정에서 JSON 키와 문자열 값을 스캔하며 따옴표나 백슬래시 같은 문자를 이스케이프해야 하므로, 긴 문자열을 높은 처리량으로 다룰 때 비용이 커집니다.
ClickHouse Slack 커뮤니티의 도움을 받아, JSON 컬럼이 네이티브 RowBinary 포맷으로도 인코딩될 수 있다는 사실을 알게 되었습니다. JSON 컬럼은 키-값 쌍의 시퀀스로 인코딩됩니다. 문자열 키를 쓰고, 그 다음 값의 타입 태그를 쓰고, 마지막으로 실제 값을 그대로 씁니다. 이 방식은 JSON 직렬화 비용을 제거해, 구조화된 데이터를 직접 ClickHouse로 스트리밍할 수 있게 해줍니다.
예를 들어 다음과 같은 간단한 JSON 객체를 보겠습니다.
{
"a": 42,
"b": "dog",
"c": 98
}이에 대한 RowBinary 인코딩은 다음과 같습니다.
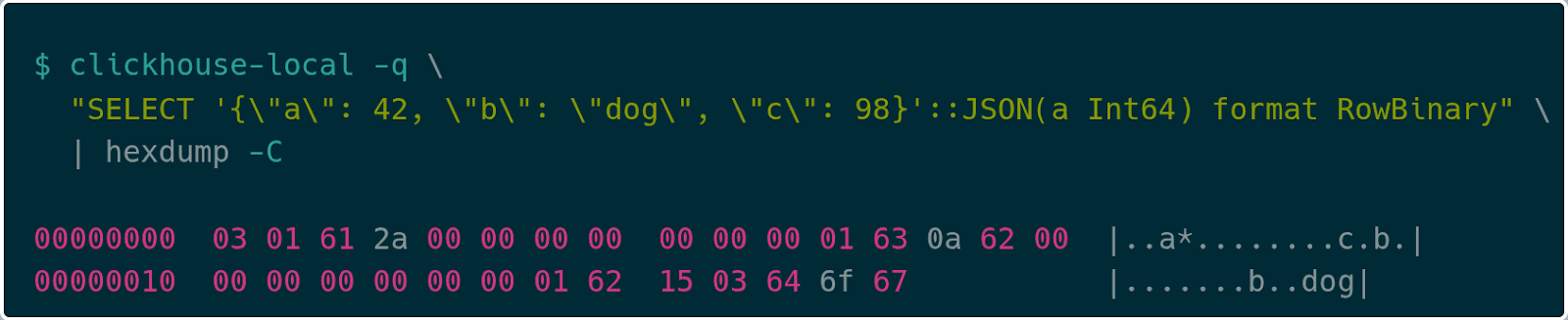
JSON RowBinary는 먼저 key/value 쌍의 개수를 가변 길이 정수(varint)로 인코딩합니다. 위 예에서는 03 쌍이고, 이어서 각 key/value 쌍의 인코딩이 나옵니다. 개별 key/value 쌍은 key 길이를 나타내는 varint(여기서는 01)로 시작하고, 그 뒤에 문자열 바이트, 마지막으로 값의 인코딩이 따라옵니다. 값의 타입이 JSON 타입 선언에서 미리 알려져 있으면(위 예에서 a가 그러합니다) 해당 타입을 직접 인코딩합니다. 예를 들어 값 42는 2a 00 00 00 00 00 00 00로 인코딩됩니다. 타입이 선언되지 않은 경우 Dynamic Type 인코딩을 사용합니다. 예를 들어 key c는 값이 Int64임을 나타내는 0a로 시작하고, 이어서 값 98 (62 00 00 00 00 00 00 00)이 옵니다. 마지막으로 key b는 값이 문자열 타입임을 나타내는 15 뒤에 문자열 길이 03, 그리고 문자열 "dog"가 따라옵니다.
이 방식은 훨씬 효율적이며, 클라이언트와 서버 양쪽에서 직렬화/역직렬화 시간을 줄여줍니다. 이 JSON 인코딩은 아직 clickhouse-rs 크레이트에 공식 지원되지는 않지만, 곧 지원을 기여할 계획입니다.
Rotel을 이 개선된 인코딩 방식을 사용하도록 업데이트한 뒤, 다시 테스트를 수행해 영향을 측정했습니다. 그 결과, 이전에 기록했던 초당 145만 스팬의 정점을 넘어서는 데에는 실패했지만, ClickHouse 서버 CPU 사용률이 약 10% 감소했고 게이트웨이 컬렉터의 CPU도 소폭 감소했습니다. 이 감소는 여러 번의 실행에서 일관되게 나타났기 때문에, 서버 쪽 역직렬화 비용이 실제로 줄어든 이득으로 보입니다.
이번 평가에 사용한 합성 부하에는 큰 문자열 값이 포함되어 있지 않고, 스팬당 속성 개수 역시 실제 운영 워크로드와 다를 수 있습니다. 클라이언트 측에서 눈에 띄는 성능 향상을 보지 못하긴 했지만, 더 많은 속성을 가진 스팬에서는 빠른 JSON 직렬화/역직렬화 경로의 효과가 훨씬 뚜렷하게 드러날 것으로 생각합니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 88.5% | 50.7% |

이 시점에서 우리는 게이트웨이 컬렉터에서 Rotel 인스턴스 두 개를 실행해야만, 호스트의 8 vCPU를 포화시키고 ClickHouse로 초당 145만 건의 이벤트를 밀어 넣을 수 있었습니다. Rotel Kafka 리시버는 단일 Tokio 태스크에서 돌아가며, 단순화하면 다음과 같은 형태입니다.

이 방식에는 두 가지 문제가 있습니다.
Tokio는 Rust 언어를 위한 비동기 런타임으로, 협력형(cooperative) 스케줄링에 의존합니다. 이는 태스크가 .await 지점이나 기타 양보 지점에서 자발적으로 런타임에 제어권을 돌려주리라는 전제 위에서 동작한다는 의미입니다. 이 계약의 중요성과 이를 어겼을 때 발생할 수 있는 심각한 문제는 인터넷에 많은 글로 소개되어 있습니다. 요약하자면, Tokio 태스크는 ".await 지점에서 너무 멀리 떨어져 있어서는 안 되며", 일반적인 규칙으로는 각 .await 사이에서 10~100 마이크로초 이상을 쓰지 말아야 합니다.
Rotel의 각종 exporter에서는, 나가는 요청 페이로드를 마샬링하고 압축하는 CPU 집중 작업을 별도의 스레드 풀에서 수행합니다. Kafka 리시버의 경우, 페이로드는 rust-rdkafka 라이브러리의 백그라운드 스레드에서 recv() 호출 전에 압축 해제됩니다. 최초 Kafka 리시버 구현에서는 들어오는 페이로드의 언마샬링 작업을 Tokio 비동기 태스크 안에 그대로 두었습니다. 이 언마샬링이 CPU 집약적이라는 점을 확인한 뒤, Kafka 리시버도 exporter와 동일한 스레드 풀을 사용해 블로킹 작업을 수행하도록 변경했습니다.
리팩터링 후 리시버의 메인 처리 루프는 대략 다음과 같은 형태가 되었습니다.
loop {
select! {
message = recv() => {
unmarshaling_futures.push(spawn_blocking(unmarshal(message)))
},
unmarshaled_res = unmarshaling_futures.next() => {
send_to_pipeline(unmarshaled_res)
}
}
}이제 게이트웨이 컬렉터에서 Rotel 단일 프로세스로 다시 테스트를 실행했습니다. 로드 제너레이터를 이전 최고치였던 초당 145만 트레이스 스팬으로 재시작했을 때, 이전과 동일한 처리량을 유지할 수 있었습니다. 그러나 우리는 CPU 부하가 40% 감소한 것을 보고 매우 놀랐습니다!
이전에는 8개 vCPU를 포화시키려면 Rotel 인스턴스 두 개가 필요했는데, 이는 Kafka 리시버가 직렬 처리 병목에 걸려 있었음을 시사하는 결과였습니다. 마샬링 작업을 별도 스레드로 옮겨 병렬성을 도입하면 이 병목이 해소되어야 합니다. 우리는, 병목이 사라진 단일 Rotel 인스턴스가 두 인스턴스와 비슷한 처리량에 비슷한 CPU 사용률을 보이리라고 예상했습니다.
그러나 CPU 부하가 크게 줄어든 것을 보고, 처리량을 더 올려 보았습니다. 결과적으로 초당 145만에서 360만 트레이스 스팬까지 2배 이상 처리량을 늘릴 수 있었습니다!
| Rotel | 트레이스 스팬 | 트레이스 스팬 / 코어 | ClickHouse Network In (압축) |
|---|---|---|---|
| Rotel 단일 프로세스 | 3.6 M/sec | 450 K/sec | 204 MB/sec |
초당 360만 트레이스 스팬 지점에서 다시 CPU 사용률이 약 93% 수준까지 포화되었습니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 93.7% | 55.7% |

성능 향상이 확인되자, 다음 단계는 CPU 효율성 개선의 실제 원인을 이해하는 것이었습니다. 이를 위해 Linux Perf와 플레임그래프를 사용해, 이전 빌드와 새로운 빌드를 정밀 분석하고 CPU 시간이 어디에서 소모되는지 시각화했습니다.
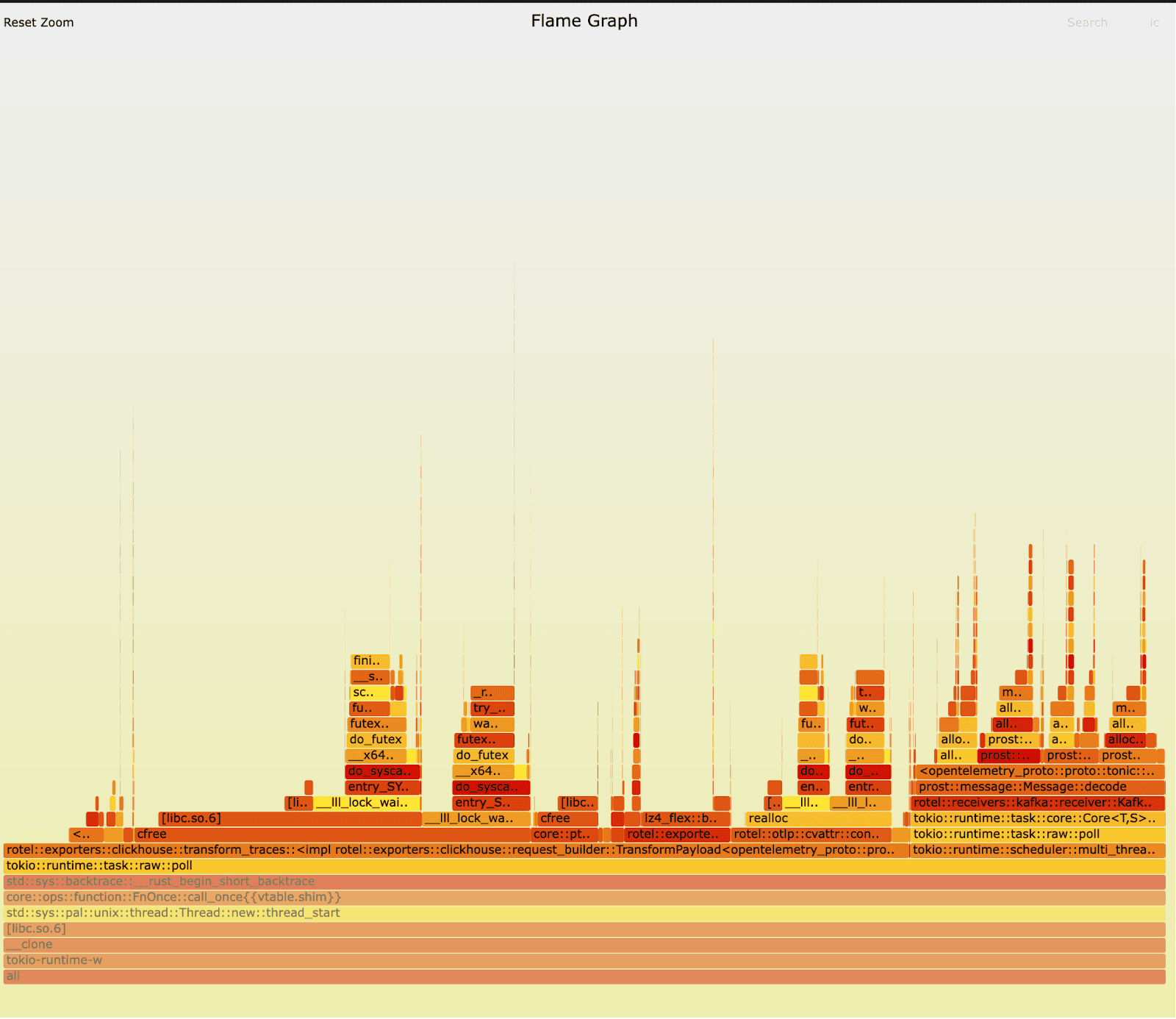
우리는 Rotel Kafka 리시버의 이전 버전과 새 버전에 대해 동일 테스트를 다시 실행하며 플레임그래프를 수집했습니다. 처음 플레임그래프를 봤을 때는, 딱 눈에 띄는 부분이 없어 보였습니다. 독자 여러분은 차이를 발견하실 수 있을까요? 두 버전 모두에서 ClickHouse로 내보내기 전 트레이스를 준비하고(export) 처리하는 부분이 런타임을 압도하고 있고, 리시버에서 메시지를 언마샬링하는 부분(언마샬링은 prost::message::Message::decode 루틴에서 발생합니다)에도 상당 시간을 쓰고 있습니다. 워크로드 특성상 수명이 짧은 객체가 대량 생성되기 때문에, 메모리 할당과 해제에도 많은 시간을 소비합니다.
이전 버전:
새 버전:
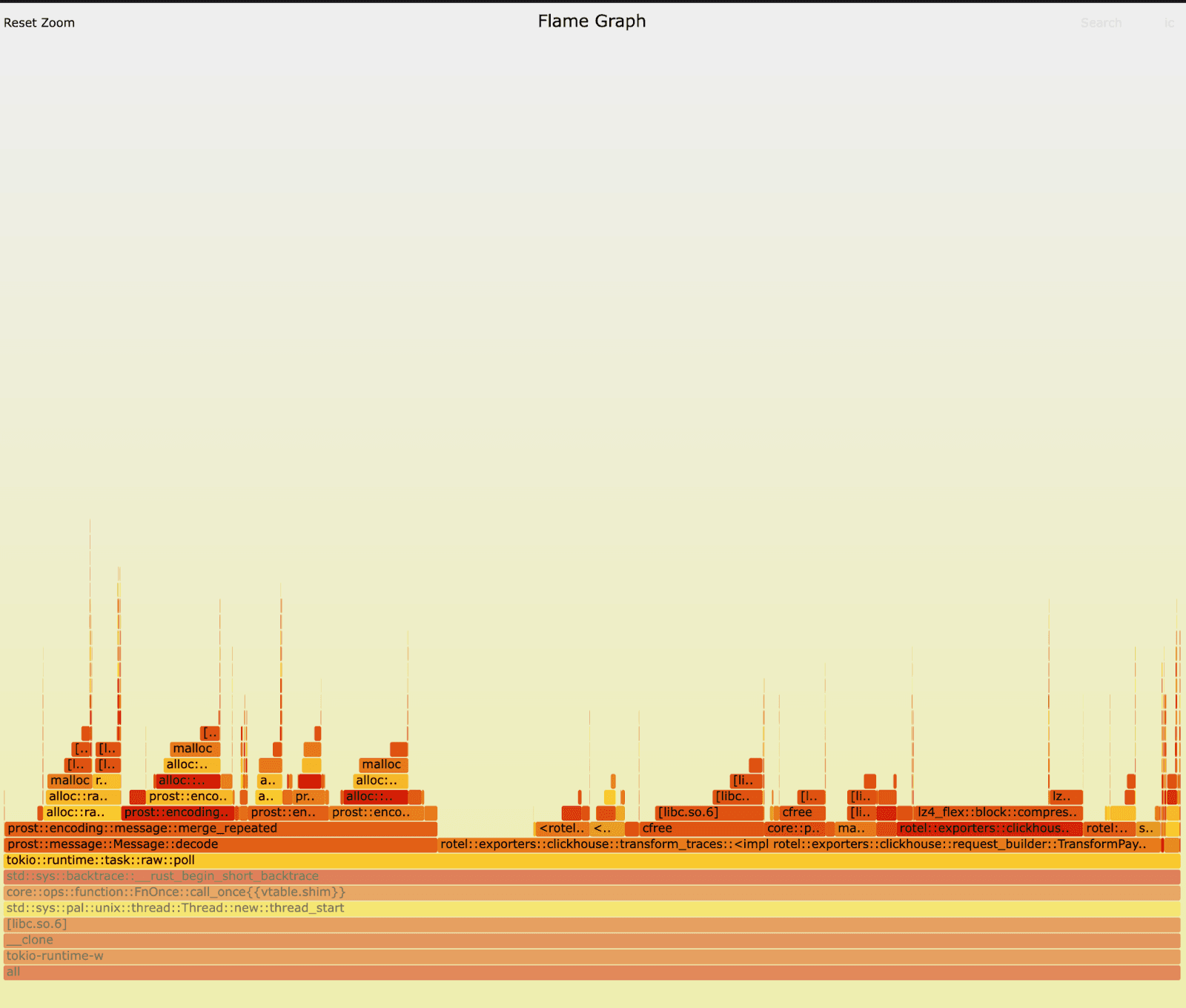
Linux perf stat 결과는 두 버전 사이의 극명한 차이를 보여주었습니다.
perf stat -c cycles,instructions,cache-misses,cache-references,context-switches,cpu-migrations
이전 버전:
95612663445 cycles
2264853636815 instructions # 0.90 insn per cycle
3615670230 cache-misses # 32.963 % of all cache refs
41867733351 cache-references
51224819 context-switches
1230 cpu-migrations
750.296446757 seconds time elapsed새 버전:
1150590256805 cycles
2287007890213 instructions # 1.91 insn per cycle
3598469068 cache-misses # 51.429 % of all cache refs
41163669589 cache-references
537675 context-switches
643 cpu-migrations
743.716966122 seconds time elapsed새 빌드는 사이클당 평균 1.9개의 명령(instruction)을 실행하며, 초당 컨텍스트 스위치는 862회 수준입니다. 명령 수준 병렬성(ILP) 측면에서 놀라운 수준은 아니지만 나쁘지 않습니다. 반면 이전 버전은 사이클당 0.9개의 명령만 실행했고, 초당 24,350회에 달하는 엄청난 컨텍스트 스위치를 기록했습니다. 새 버전과 비교하면 컨텍스트 스위치가 32.5배 감소한 수치입니다! 사실상 ILP를 거의 활용하지 못했고, 스레드가 계속 깨어났다 잠들기를 반복하는 상황이었습니다. 또한 새 버전은 초당 평균 1회의 CPU 마이그레이션만 기록해 캐시 친화도가 매우 좋은 반면, 이전 버전은 초당 24.5회의 마이그레이션, 즉 새 버전에 비해 24.5배 높은 마이그레이션을 보여주었는데, 이는 스케줄러가 스레드를 동일 코어에 유지하는 데 실패했음을 의미합니다.
새 버전은 병렬화 특성이 훨씬 나아져, 이전보다 처리량을 훨씬 더 높이는 데 기여했습니다. 하지만 코드 변경으로 한 일은 사실상, 일부 작업을 다른 스레드로 옮긴 것뿐이었습니다.
이전 버전의 성능 저하 원인을 Tokio 실행기 스레드의 블로킹 탓으로 돌릴 수도 있습니다. 이로 인해 폴링, 스핀 락, 워크 스틸링 시도가 늘어나 오버헤드가 증가했을 가능성이 있습니다. 그러나 perf report 결과를 더 들여다보자, 상황은 조금 더 미묘했습니다.
다시 perf record와 함께 테스트를 실행한 뒤, 이전과 새 Rotel Kafka 리시버에 대한 훨씬 더 자세한 프로파일을 확보했습니다. 새 버전은 꽤 건강하게 보였습니다. 대부분의 시간은 데이터 압축, ClickHouse로 내보내기 위해 OTLP를 행(row) 형태로 변환하는 작업, 메모리 할당과 해제에 사용되고 있었습니다.
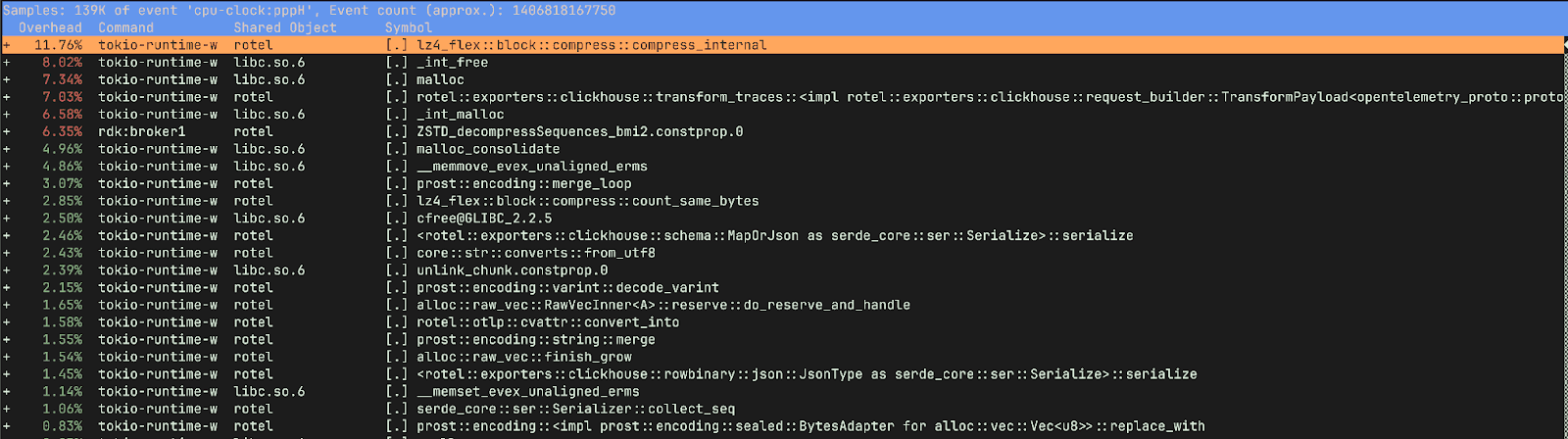
반면 이전 버전은 사뭇 다른 양상을 보였습니다. 전체 시간의 15%를 메모리 해제에 쓰고 있었고, ClickHouse로 데이터를 준비하고 압축하는 데는 9.75%만 사용했습니다(새 버전에서는 이 작업이 약 20%를 차지합니다). 또 _raw_spin_unlock_irqrestore, finish_task_switch.isra.0, __lll_lock_wait_private, __lll_lock_wake_private 같은 함수에 많은 시간을 쓰고 있었습니다.
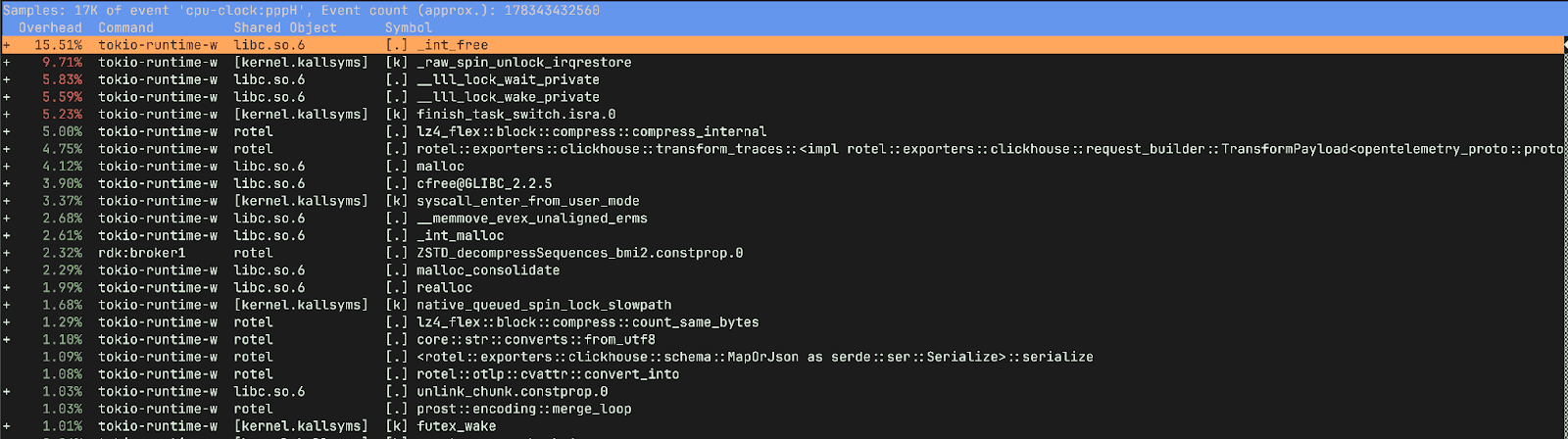
자식 호출까지 포함해 리포트를 보면, 락 대기 시간 대부분이 메모리를 해제하려고 할 때 발생하고 있음을 알 수 있습니다.
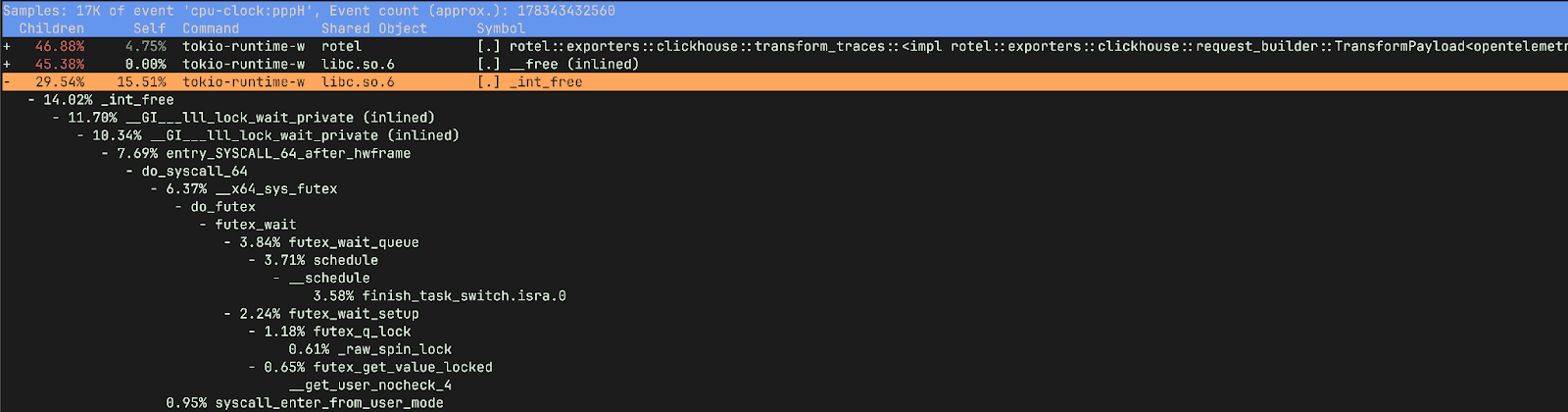
이 함수들은 무엇을 할까요?
_raw_spin_unlock_irqrestore는 인터럽트를 다시 활성화하고 스핀락을 해제해, 이전에 _raw_spin_lock_irqsave 호출 전의 인터럽트 컨텍스트로 복원하는 Linux 커널 함수입니다. 더 중요한 점은, _raw_spin_unlock_irqrestore는 태스크가 선점(preempt)되기 직전에 호출된다는 것입니다. 이 시점에 스케줄러가 컨텍스트 스위치를 수행할 수 있습니다. 한편 finish_task_switch.isra.0는 컨텍스트 스위치 이후의 정리 및 후처리를 수행하는 finish_task_switch 함수의 컴파일러 최적화 버전입니다. 이 함수들은 이전 버전에서 우리가 관찰한 컨텍스트 스위치 급증과 정확히 대응합니다.
__lll_lock_wait_private와 __lll_lock_wake_private는 glibc 내부의 로우레벨 함수로, 뮤텍스 같은 동기화 프리미티브 구현과 관련이 있습니다. 흥미로운 점은, 이 락 관련 함수들이 메모리를 해제하려는 시점에 나타난다는 것입니다.
이전 버전의 플레임그래프를 다시 보니, 이제는 문제가 꽤 명확해 보입니다. 이상적으로는 차등 플레임그래프(differential flame graph) 같은 도구를 써서 두 플레임그래프를 나란히 비교하면 차이를 더 쉽게 찾을 수 있었을 것입니다(쉽고 직관적인 플레임그래프 도구가 더 많았으면 하는 바람입니다). 다행히도 perf stat과 perf record만으로도 원인을 비교적 빨리 찾아낼 수 있었습니다. 실제 경합은 Kafka 리시버가 아니라 ClickHouse exporter의 마샬링 함수(TransformPayload)에 있었습니다.

이제 왜 변경 이후 CPU 사용률이 줄어들면서도 처리량이 늘어났는지 명확합니다. 이전 버전은 많은 일을 하고 있었지만, 우리가 바라던 종류의 일이 아니었습니다! 본질적으로 이전 버전은 메모리를 해제하기 위해 스핀락을 돌리고 있었던 셈입니다.
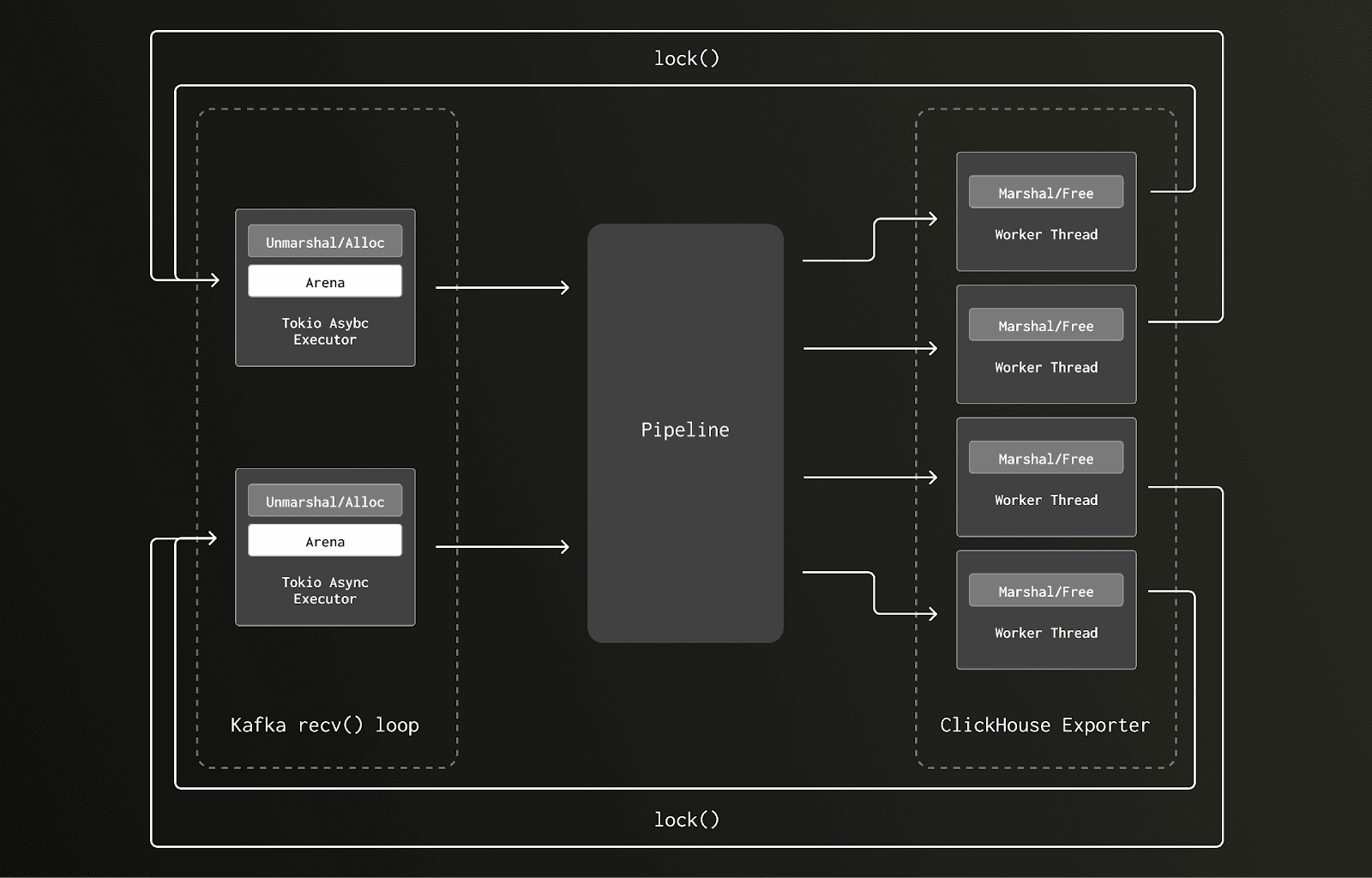
상황을 이해하려면 glibc 할당자가 어떻게 동작하는지 간단히 짚어 볼 필요가 있습니다. 메모리는 "arena"라 불리는 여러 영역으로 나뉘며, 각 arena에는 할당과 해제를 보호하는 뮤텍스 락이 하나씩 있습니다. 가능하면 스레드가 별도의 arena를 만들도록 해서 락 경합을 줄이는데, 스레드 풀의 크기가 커질수록 생성되는 arena 개수도 늘어납니다. 그러나 어떤 메모리 블록을 할당한 스레드와 다른 스레드가 그 블록을 해제하려 하면, 해제 스레드는 해당 arena의 락을 잡아야 하고, 이로 인해 다른 스레드가 대기하게 되어 경합이 발생합니다. 이전 버전에서는 Kafka 리시버의 언마샬링 루틴에서 트레이스 데이터를 처리할 메모리를 할당했는데, 이 루틴은 Tokio executor의 I/O 태스크에서 실행되었습니다. 이 작업은 게이트웨이 컬렉터 노드에서 코어당 하나씩 총 8개의 Tokio 비동기 실행 스레드 위에 스케줄링되었습니다. 이후 파이프라인 뒤쪽의 ClickHouse exporter 요청 마샬링 과정에서 이 메모리가 해제되었는데, 이 코드는 블로킹 태스크로 실행되며 10~수백 개의 스레드를 가진 훨씬 큰 스레드 풀 위에서 동작합니다.
2코어 박스에서 두 개의 Tokio 비동기 실행 스레드만 있는 상황에서, 데이터 흐름과 락 패턴을 단순화하면 다음과 같습니다.
새 버전에서는 CPU 바운드 Kafka 리시버 언마샬링 루틴에서 발생하는 메모리 할당도, 해제가 발생하는 ClickHouse exporter 쪽과 동일한 (더 큰) 스레드 풀에서 실행됩니다. 파이프라인 볼륨이 증가해 언마샬링/마샬링 작업이 많아질수록, 블로킹 스레드 풀도 함께 커집니다. 이에 따라 생성되는 arena의 개수도 늘어나고, 락 경합 가능성은 줄어듭니다.
이제 파이프라인은 다음과 같은 형태에 가깝습니다.
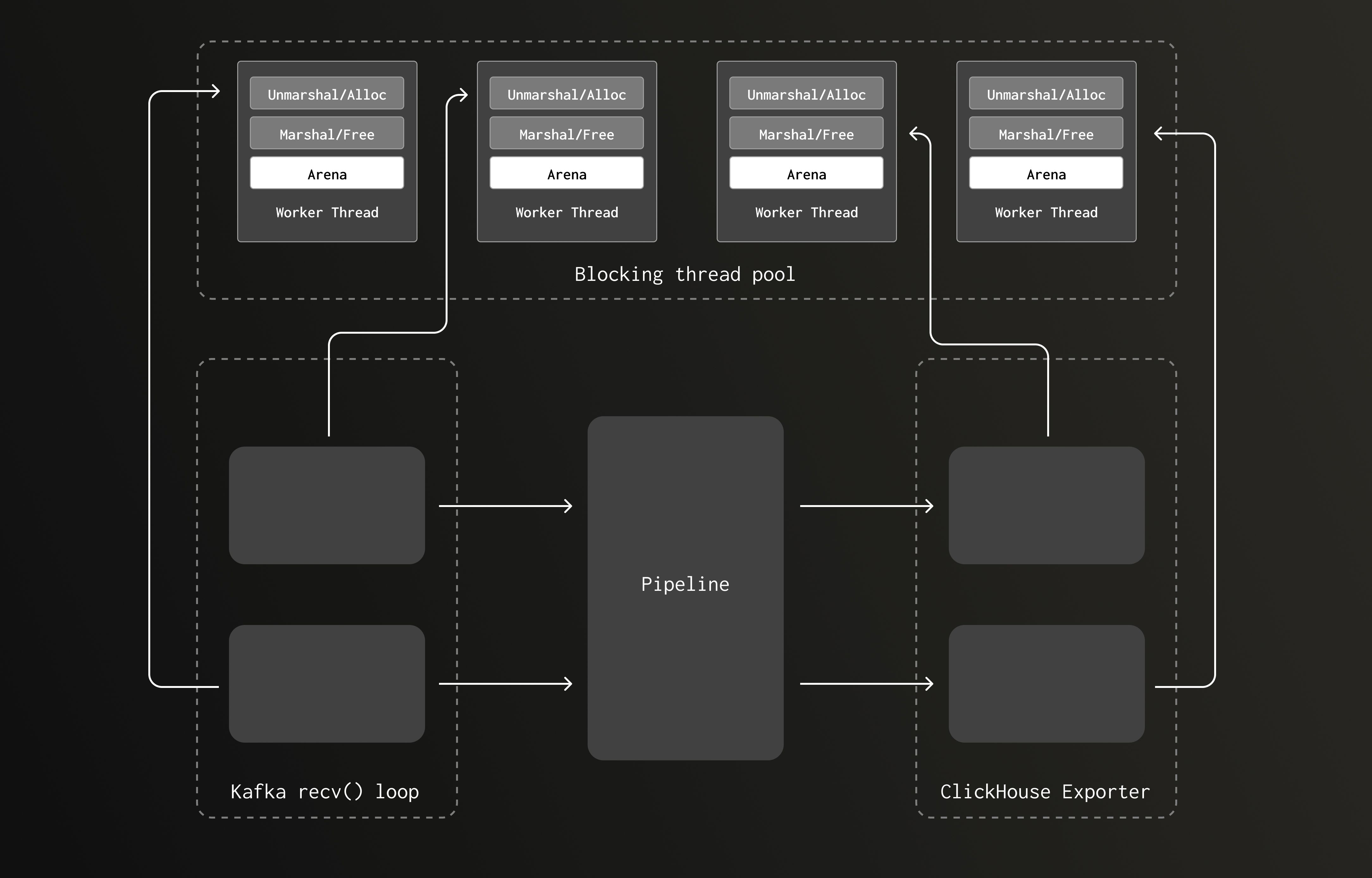
이 글의 초기 버전을 검토해 주신 한 분이 "이 현상이 jemalloc에서도 재현되는지 궁금하다"는 피드백을 주셨습니다. jemalloc은 멀티프로세서 시스템에서 스레드 기반 프로그램의 락 경합을 줄이도록 설계된 범용 malloc 구현입니다. Rotel에서 jemalloc을 테스트해 본 적이 있었지만, 당시에는 큰 성능 이득을 보지 못했습니다. 그러나 ClickHouse exporter 워크로드와 최근 Kafka 리시버 변경으로 인해, 이제는 메모리 할당에 상당한 압력이 걸리고 있었으므로, 이전/새 버전을 모두 jemalloc 위에서 돌려 보고 싶었습니다.
이전의 작업 스케줄링 모델을 사용하는 버전에 jemalloc을 적용해 보니, CPU 사용률이 93%에서 40%로 감소했습니다. 이는 언마샬링을 공유 스레드 풀로 옮겼을 때와 동일한 수준의 감소로, 우리의 분석을 뒷받침하는 결과였습니다.
다만 jemalloc은 이전 버전에서 CPU 사용량을 줄여 주긴 했지만, 최대 처리량 구간에서 Kafka 랙이 더 많이 발생했습니다. 게다가 jemalloc은 더 이상 적극적으로 유지보수되지 않고 있기 때문에, 기본 할당자로 채택할 계획은 없습니다. 대신 필요 시 사용자가 jemalloc이나 mimalloc 같은 커스텀 할당자를 선택할 수 있도록, feature flag 형태로 옵션을 제공하는 방안을 고려하고 있습니다.
Rotel은 ClickHouse로 전송하는 페이로드에 대해, over-the-wire 데이터 전송량을 줄이기 위해 권장되는 LZ4 압축 설정을 사용합니다. clickhouse-rs가 사용하는 것과 동일한 lz4_flex 크레이트를 사용하지만, 우리는 이를 직접 import했습니다. lz4-flex 기반의 압축 코드를 가져올 때, Cargo.toml의 feature 설정을 제대로 확인하지 못했던 것이 문제였습니다.
lz4-flex 크레이트는 unsafe 구현과 safe 구현을 모두 제공하며, unsafe 구현이 약간 더 나은 성능을 냅니다(Rust의 unsafe에 대해서는 여기를 참고하세요). lz4-flex에서는 unsafe이자 더 빠른 구현을 사용하려면 명시적으로 opt-in 해야 합니다.
clickhouse-rs 크레이트는 lz4-flex의 unsafe 변형을 활성화해 사용하고 있지만, 우리는 이를 놓쳤습니다. 해당 옵션을 켜자 약간의 추가 향상을 얻을 수 있었고, 게이트웨이 컬렉터의 처리량은 초당 360만에서 370만 트레이스 스팬, 209 MB/sec까지 올라갔습니다.
| Rotel | 트레이스 스팬 | 트레이스 스팬 / 코어 | ClickHouse Network In (압축) |
|---|---|---|---|
| Rotel 단일 프로세스 | 3.7 M/sec | 462.5 K/sec | 209 MB/sec |
게이트웨이 컬렉터의 CPU 사용률도 소폭 감소했습니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 90.8% | 57.8% |

Rotel에 대한 여러 최적화를 적용하고, ClickHouse의 Null 테이블 엔진을 대상으로 평가를 진행한 끝에 우리는 Rotel 단일 인스턴스의 처리량을 초기 초당 110만 트레이스 스팬에서 최종 초당 370만 트레이스 스팬, 그리고 코어당 초당 46만 2,500 트레이스 스팬까지 끌어올릴 수 있었습니다. 이는 OTel Collector를 테스트했을 때의 초기 110만 스팬/초 대비 거의 4배에 가까운 처리량입니다.
이제 마지막 단계인, 데이터를 ClickHouse에 영구 저장하고 디스크에 완전히 커밋하는 문제에 집중하기로 했습니다. ClickHouse를 스케일링하는 작업은, 들어오는 쓰기와 조회 쿼리 양쪽을 고려해 스키마를 최적화하는 일과 밀접하게 연결됩니다. 우리의 경우 기본 OTel 스키마를 사용하고 있었기 때문에, 주로 이전에 달성한 쓰기 부하를 감당할 수 있을 만큼 충분히 강력한 인스턴스를 선택하는 데 초점을 맞췄습니다.
이 거대한 쓰기 부하를 감당하기 위해 ClickHouse 인스턴스를 업그레이드했고, 최종적으로 다음과 같은 AWS 인스턴스를 선택했습니다. 디스크 사용률이 병목이 되는 것을 더 줄이기 위해, 네 개의 인스턴스 스토어 디스크를 RAID0으로 묶었습니다.
| i4i.16xlarge | 64 cores | 512 MB | 4 x 3,750 AWS Nitro SSD |
|---|
ClickHouse에 실제 디스크 쓰기를 수행하는 테스트에서는 Rotel의 async insert 기능을 끄고, 쓰기 성능을 높이기 위해 배치 크기를 크게 늘렸습니다. Rotel 설정에서 --clickhouse-exporter-async-inserts=false와 --batch-max-size=102400을 사용했고, 이를 통해 게이트웨이 컬렉터가 이전에 도달했던 초당 370만 트레이스 스팬 처리량까지 다시 도달할 수 있었습니다.
ClickHouse CPU는 압축된 트래픽이 최대 210MB/s까지 들어올 때 약 50% 수준이었습니다.
| Rotel | ClickHouse | |
|---|---|---|
| CPU | 86.2% | 52% |

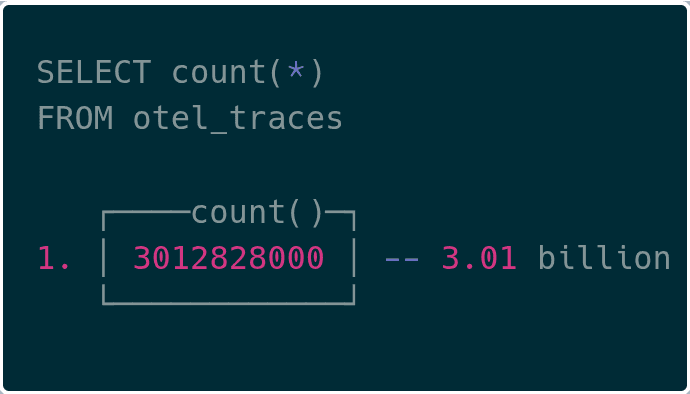
이제 ClickHouse 안에서 30억 개가 넘는 트레이스 스팬을 확인할 수 있었습니다!
ClickHouse가 내부 LogHouse 플랫폼을 페타바이트 규모로 운영하는 맥락에서는, 효율성이 선택이 아니라 필수가 됩니다. ClickHouse는 파이프라인 처리량을 20배까지 끌어올리는 동시에, 기존에 필요하던 리소스의 10%만으로도 동일한 일을 할 수 있게 만들었습니다. 이전 궤적을 그대로 따라갔다면, 운영 비용은 감당하기 어려운 수준이 되었을 것입니다. Netflix, OpenAI와 같은 다른 조직들도 비슷한 결론에 도달했습니다. 이 정도 규모에 이르면, 효율성은 비즈니스에 치명적으로 중요해진다는 것입니다. 우리가 OpenTelemetry 수집의 효율성을 개선하고 Rotel을 개발해 온 것도 바로 이런 맥락 속에서입니다.
이번 작업을 통해, 우리는 Rotel을 ClickHouse로 OpenTelemetry 트레이싱 데이터를 스트리밍하는 고처리량 파이프라인으로 최적화했습니다. 우리의 테스트에서 Rotel은 동일한 하드웨어에서 OpenTelemetry Collector보다 거의 네 배에 가까운 처리량을 달성했고, 이는 대규모 환경에서는 상당한 리소스 절감으로 연결될 수 있습니다. Rotel은 OpenTelemetry 트레이스, 메트릭, 로그를 모두 1급 citizen으로 지원하며, 이번 글에서는 트레이싱에 초점을 맞췄지만 앞으로 로그와 메트릭 워크로드에 대한 벤치마크 결과도 공유할 계획입니다.
또한, 이 정도 규모에서 운영할 때 어떤 기능이 가장 중요한지도 더 알고 싶습니다. 새로운 아이디어가 있거나, 여러분이 겪은 스케일링 도전 과제를 공유하고 싶다면, Discord 커뮤니티에 참여하거나 GitHub를 통해 기여해 주세요.
이번 작업을 진행하면서, 앞으로 더 깊이 탐구하고 싶은 주제는 다음과 같습니다.
이번 글에서는 짧게만 언급했지만, Rotel은 Kafka를 통한 스트리밍 시 auto-commit에 의존하지 않고, 엔드 투 엔드 메시지 ACK를 통한 적어도 한 번(at-least-once) 전달 보장을 지원합니다. 이 기능을 위해 파이프라인에 여러 변경이 필요했고, Rotel이 데이터를 드롭하지 않으면서도 중복 전달을 줄이도록 하기 위해 엄격한 테스트를 수행했습니다. 신뢰성 있는 전달이 정확히 무엇을 의미하는지, Rotel에서 이를 어떻게 구현했고, 검증을 위해 어떤 도구를 만들었는지 등을 깊이 있게 다루는 후속 글을 준비 중입니다.
Rotel의 ClickHouse 통합은 HTTP 상의 RowBinary 프로토콜을 사용하는 clickhouse-rs Rust 크레이트 위에서 구축되었습니다. 반면 OpenTelemetry Collector는 네이티브 ClickHouse 프로토콜로 통신하는 Go용 ClickHouse 드라이버를 사용합니다. 네이티브 프로토콜은 ClickHouse 간 내부 통신에도 사용되는 프로토콜로, 벤치마크에 따르면 RowBinary보다 20% 이상 빠른 성능을 보여줍니다. 또한 ClickHouse는 Apache Arrow 인메모리 포맷을 사용하는 Arrow Flight도 지원합니다. 우리는 행 지향 RowBinary에서 열 지향 포맷 중 하나로 옮기는 방안을 평가해 보려 합니다. 이를 통해 Rotel의 처리량을 한 단계 더 끌어올릴 수 있을지 테스트하고, 결과는 추후 공유할 계획입니다.
페이로드 역직렬화처럼 블로킹에 가까운 작업은 Tokio 성능에 큰 영향을 줄 수 있습니다. 이번 벤치마크를 진행하면서 그 영향이 얼마나 클 수 있는지 실감했고, 이와 관련된 다른 영향 요인도 더 찾아보고 싶습니다. 예를 들어 Rotel의 OTLP 리시버는 현재 tonic 크레이트가 제공하는 구조상, 연결 처리 비동기 태스크 안에서 비용이 큰 Protobuf 역직렬화를 인라인으로 수행하고 있습니다. 이 부분을 어떻게 잘 분리할지 탐색하려고 합니다. perf 도구로 한 초기 분석에 따르면, 이 부분에서도 큰 성능 개선 여지가 있어 보입니다.
Rust에는 가비지 컬렉터가 없지만, 고부하 환경에서는 메모리 할당/해제가 여전히 큰 성능 영향을 줍니다. Rotel에서는 파이프라인을 따라 짧은 수명의 객체들을 계속 생성/소멸시키고 있습니다. 공통적으로 사용하는 버퍼에 대해 메모리 자유 리스트(free list)를 도입해 할당자를 거치지 않도록 하면, 오버헤드를 상당히 줄일 수 있을 것입니다. 물론 구현은 까다롭고, 잘못하면 메모리 사용량이 폭발적으로 늘어날 위험도 있습니다. 이 부분 역시 tonic 크레이트 내부를 깊이 파고들어 변경이 필요할 수 있는 영역입니다.
이 글의 초고를 검토해 주신 Sujay Jayakar, Ben Sigelman, Rick Branson, Vlad Seliverstov, Rory Crispin, Achille Roussel께 감사드립니다.
이번 벤치마크를 준비하면서 OpenTelemetry를 지원하는 다른 데이터 플레인들도 포함하고자 했지만, 벤치마크 환경과 호환되지 않아 제외해야 했습니다. 이번 평가는 분산 트레이싱을 기준으로 진행했는데, 이는 OTel 도입의 큰 동인이며 데이터 볼륨도 빠르게 증가할 수 있기 때문입니다. 하지만 로그와 메트릭은 보다 전통적인 모니터링 텔레메트리여서, 많은 도구가 아직 트레이싱 지원이 제한적입니다. 이번 글에서 모두 다루지는 못했지만, 향후 로그와 메트릭을 대상으로 하는 벤치마크도 진행해 보고자 합니다.
Vector는 고성능 텔레메트리 파이프라인 구성을 위해 설계된 경량 도구입니다. 다양한 소스와 싱크를 광범위하게 지원해, 여러 서비스 및 프로젝트와 쉽게 통합할 수 있습니다. 현재는 DataDog가 개발을 이끌고 있으며, 자사의 observability pipelines 제품과도 연계됩니다.
Vector의 OpenTelemetry 지원은 비교적 최근에 도입된 것으로, 아직 많은 목적지와는 호환되지 않습니다. Vector 데이터 모델은 처음부터 트레이스를 네이티브하게 지원하지 않았고, 그 결과 OTel 트레이스 지원은 특히 제한적입니다. 이런 이유로, 우리는 Kafka와 ClickHouse 싱크 양쪽 모두에서 트레이싱 지원 부족 때문에 Vector를 벤치마크에 포함하지 못했습니다.
Fluent Bit은 Fluentd의 대안으로, C로 작성된 고성능 텔레메트리 에이전트입니다. Fluent Bit은 OpenTelemetry 데이터를 위한 입력과 출력을 모두 제공하고, 로그·메트릭·트레이스를 지원합니다. Kafka를 대상으로 입력과 출력을 모두 지원해, 신뢰할 수 있는 스트리밍 파이프라인을 구성할 수 있습니다. 그러나 우리의 평가 도중, OpenTelemetry 입력을 Kafka 출력 혹은 ClickHouse용 HTTP 출력에 연결할 때 메트릭과 트레이스는 아직 지원되지 않는다는 사실을 발견했습니다.
ClickHouse 문서에서는 exporter에서 자동 스키마 생성을 비활성화하고, 미리 스키마를 준비해 둘 것을 권장합니다. 하지만 스키마 마이그레이션이 OTel exporter에 같이 묶여 있기 때문에, 이를 어떻게 배포하는 것이 최선인지 명확하지 않습니다.
Rotel에서는 이런 DDL 관리를 별도 CLI 유틸리티로 분리해, 마이그레이션 배포를 쉽게 만들기로 했습니다. clickhouse-ddl 도구를 사용하면 Rotel과 OTel Collector 양쪽에서 호환 가능한 스키마를 생성할 수 있습니다.
이 도구는 Docker 컨테이너로도 제공되므로, OpenTelemetry 데이터를 인제스트하는 데 필요한 테이블을 쉽게 생성할 수 있습니다. 예를 들어 트레이스 스팬을 저장하는 데 필요한 테이블을 생성하려면 다음과 같이 실행합니다.
docker run streamfold/rotel-clickhouse-ddl create \
--endpoint https://abcd1234.us-east-1.aws.clickhouse.cloud:8443 \
--traces --enable-json우리처럼 벤치마크를 위한 Null 테이블 엔진을 사용해 마이그레이션을 생성할 수도 있습니다.
docker run streamfold/rotel-clickhouse-ddl create \
--endpoint https://abcd1234.us-east-1.aws.clickhouse.cloud:8443 \
--traces --enable-json \
--engine Null