Sentry의 백엔드 이벤트 저장 시스템을 혁신하며 도입된 새로운 검색 및 쿼리 인프라 Snuba와 그 설계 배경, ClickHouse 도입기, 구체적인 구현 방법을 자세히 설명합니다.
2018년 내내, 저희는 근본적인 이벤트 저장 시스템을 대대적으로 재구축하는 일에 매진했습니다. 그 결실로 제작된 결과물이 바로, Sentry 운영 환경을 지원하는 주요 이벤트 데이터 저장 및 쿼리 서비스인 Snuba입니다.
ClickHouse라는 오픈 소스 컬럼 기반 데이터베이스를 기반으로 한 Snuba는 현재 Sentry의 검색, 그래프, 이슈 상세 페이지, 룰 처리 쿼리, 그리고 가시성 강화에 언급된 모든 기능의 핵심 엔진입니다.
Sentry는 이미 Search, Tagstore(이벤트 태그용), TSDB(타임 시리즈 데이터베이스) 등의 추상화된 서비스 인터페이스 위에서 운영되고 있었습니다. 각 서비스는 표준 관계형 SQL(DB) 또는 Redis(TSDB)를 백엔드로 여러 해 동안 안정적으로 사용해왔죠.
문제는 Sentry의 고객과 엔지니어링 팀이 급격히 확장되면서 시작됐습니다. 사용할 이벤트 수가 하루가 다르게 늘어나고, 동시에 더 많은 엔지니어가 더 많은 기능을 개발하기를 원했습니다.
이벤트 볼륨이 증가함에 따라, 우리는 다양한 쿼리에 대해 빠른 응답을 얻기 위해 데이터를 대규모로 비정규화(denormalize)해야 했습니다. 예를 들어 Tagstore는 서로 다른 값을 저장하는 다섯 개의 테이블로 이뤄져 있었고, 여기에는 이슈별, 태그별 times_seen(등장 횟수)같은 값이 축적되어 있었습니다(예: 어떤 이슈에 browser.name: Chrome, times_seen: 10, browser.name: Safari, times_seen: 7). 이러한 비정규화된 카운터의 증가는 버퍼링하여 쌓아두고 한 번에 적용함으로써 쓰기 부담을 줄였죠.
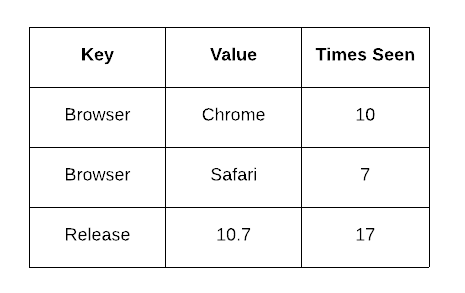
비정규화 카운터의 증가를 버퍼링해서 쓰기 부담을 낮춤.
이런 방식은 [새로운 차원의 쿼리 조건 추가](https://blog.sentry.io/introducing-sentry-9)(예: environment)가 필요해질 때까지 잘 작동했습니다. 그러나 기존 데이터 레이아웃을 리팩터링해서 새로운 차원으로 비정규화하는 작업은 수개월이 걸렸고, 전체 이벤트 데이터에 대한 백필(backfill)도 함께 필요했습니다.
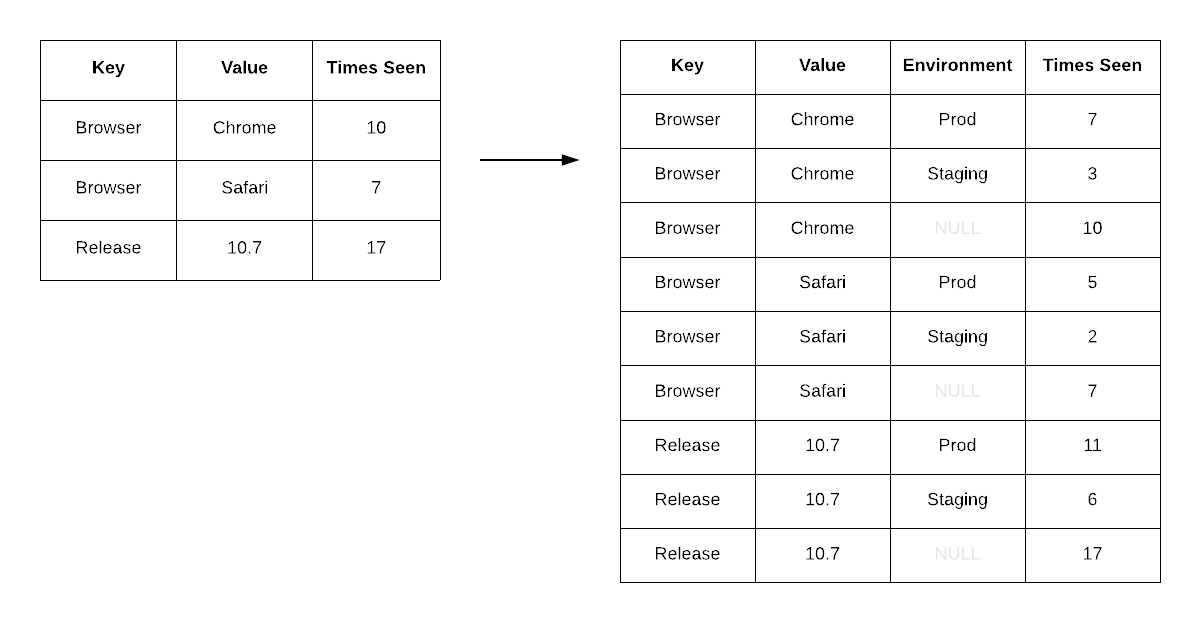
환경(environmnet) 차원을 추가하자 기존 데이터 레이아웃을 리팩터링해야 했고, 이는 다양한 문제를 초래했습니다.
이제는 OLAP(Online Analytical Processing) 방식의 플랫(flat) 이벤트 모델이 필요하다는 것이 분명해졌습니다. 비정규화 없이 ad-hoc 쿼리가 가능해야 하고, 또 사용자의 다양한 데이터 보기 요구에 따라 백엔드를 대대적으로 뜯어고칠 필요도 없어야 했죠.
당시 Facebook의 컬럼 스토어 Scuba가 비슷한 문제를 해결하는 선례로 떠올랐지만, 아쉽게도 Scuba는 오픈소스가 아니었습니다. 저희의 팀과 프로젝트명을 지어야 할 때, "scuba"만큼 완성도는 높지 않으니 Snuba (snorkel + scuba의 합성어)로 이름을 정했습니다.
좋은 질문입니다. 사실 단기적으로는 그렇게 했습니다.
태그 카운트를 집계/공급하는 주요 데이터셋("Tagstore")이 단일 Postgres 인스턴스에서 처리할 수 있는 변형 수를 넘어서기 시작했습니다. 여러 대의 서버로 확장하긴 했으나, 하드웨어만으로 해결하지 못하는 여러 문제가 쌓였습니다. 데이터에 새 차원이 발견될 때마다 추가 인프라 작업이 늘어나는 식의 한계가 있었고, dataset을 더 키우는 방향만으론 본질적인 문제를 해결할 수 없었습니다. Postgres에는 자신이 있지만, OLAP 시스템으로 이행해야 한다는 결정을 하게 됐죠.
OLAP으로 옮긴 주요 이유는 다음과 같습니다:
OLAP 분야의 다양한 데이터베이스를 검토했습니다: Impala, Druid, Pinot, Presto, Drill, BigQuery, Cloud Spanner, Spark Streaming 등. 각 시스템의 장단점은 시간이 지나며 바뀌었겠지만, 여러 시스템 위에서 Snuba의 프로토타이핑을 거친 끝에 최종적으로 ClickHouse를 선택했습니다.
ClickHouse가 선정된 이유는 다음과 같습니다:
Snuba는 ClickHouse로부터 Sentry를 추상화하는 2단계 서비스입니다. 어플리케이션 코드와 ClickHouse 외에도, Sentry 이벤트 데이터 플로우를 완성하기 위해 몇몇 지원 서비스를 함께 활용합니다.
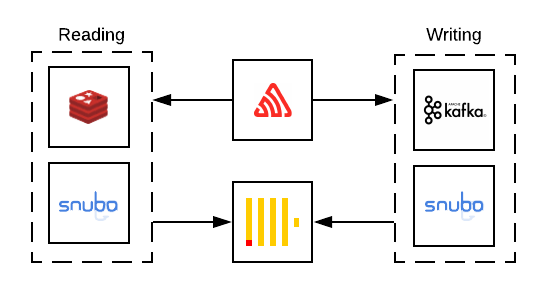
Sentry 데이터의 흐름
Snuba의 쿼리 서버는 Flask 기반 웹서비스로, 개발자에게 JSON 스키마 포맷의 고급 쿼리 인터페이스를 제공합니다. Snuba 클라이언트를 통해 ClickHouse SQL을 직접 쓰지 않아도 되어, 애플리케이션 개발자는 복잡함을 몰라도 됩니다. 예를 들어, 지난 24시간 동안 특정 프로젝트에 전송된 인기 태그를 뽑아오는 Snuba 쿼리는 다음과 같습니다.
{
"project": [1],
"aggregations": [
["count()", "", "count"]
],
"conditions": [
["project_id", "IN", [1]],
],
"groupby": ["tags_key"],
"granularity": 3600,
"from_date": "2019-02-14T20:10:02.059803",
"to_date": "2019-05-15T20:10:02.033713",
"orderby": "-count",
"limit": 1000
}이 쿼리는 다음과 같은 ClickHouse SQL 쿼리로 변환됩니다.
SELECT
arrayJoin(tags.key) AS tags_key,
count() AS count
FROM sentry_dist
PREWHERE project_id IN 1
WHERE (project_id IN 1)
AND (timestamp >= toDateTime('2019-02-14T20:10:02'))
AND (timestamp < toDateTime('2019-05-15T20:10:02'))
AND (deleted = 0)
GROUP BY tags_key
ORDER BY count DESC
LIMIT 0, 1000이런 고수준 Snuba 쿼리 인터페이스를 제공함으로써, 데이터 모델의 변경이 있더라도 Snuba 내부에서 처리하며 애플리케이션 개발자 쪽에서 쿼리를 계속 바꿔야 하는 부담을 제거했습니다.
또한, Redis를 활용하여 개별 쿼리 결과를 캐시함으로써 급증하거나 반복 빈도가 높은 쿼리를 하나의 ClickHouse 쿼리로 통합해서 ClickHouse 클러스터의 부하를 크게 줄였습니다.
Snuba로 데이터가 기록되는 과정은, Sentry에서 정규화·처리 과정을 거친 JSON 이벤트가 Kafka 토픽에 쌓이고, 이를 읽어와 배치 처리하여 각각을 ClickHouse의 단일 row로 매핑하는 방식입니다. ClickHouse에는 배치로 insert하는 것이 중요한데, 각 insert가 컬럼별 파일이 들어있는 새 폴더를 만들고 ZooKeeper에 새로운 레코드를 쓰기 때문입니다. ClickHouse의 백그라운드 쓰레드가 이러한 디렉터리를 머지하며, ZooKeeper와 디스크 파일이 많아지지 않도록 1초에 한 번 정도 쓰는 것을 권장합니다. 데이터는 작성된 시간-보존기간 단위로 파티션되어 있어, 기간이 지난 데이터는 손쉽게 삭제할 수 있습니다.
이 글은 지난 1년간 Search 및 Storage팀이 달성한 것의 짧은 개요일 뿐입니다. 앞으로도 Snuba를 어떻게 사전 런칭(dark launch)하고 기존 쿼리와 성능을 비교했는지, 쿼리별 성능 최적화 팁, 룰 기반 알림 쿼리 일관성 처리, 데이터 변형 방식 등 뒷얘기를 더 자세히 나눌 예정입니다.
그동안 새로운 Snuba 기반 기능들, 예컨대 이벤트 뷰 & Discover를 이용해 보세요.
끝으로 Snuba를 기획하고 다듬기 위해 헌신적으로 일한 Sentry 엔지니어분들(Brett Hoerner, Ted Kaemming, Alex Hofsteede, James Cunningham, Jason Shaw)께 진심으로 감사드립니다.