x86 코드를 ARM 아키텍처에서 실행할 때 Rosetta 2가 유난히 빠른 이유와, 앞선 번역(AOT), 플래그 처리, 메모리 모델, 하드웨어 확장 등을 통한 성능 최적화 기법을 설명한다.
Rosetta 2는 다른 x86-on-ARM 에뮬레이터와 비교했을 때 놀라울 정도로 빠릅니다. 개인적인 호기심으로 이것이 어떻게 동작하는지 조금 살펴봤는데, 방식이 꽤 특이해서 메모를 정리해 보기로 했습니다.
제가 파악한 내용은 아직 다소 거친 편이며, 주로 앞선 번역(ahead-of-time, AOT)된 코드를 읽고, 그로부터 런타임을 추론한 것에 기반합니다. 만약 정정할 부분이 있거나, 제가 놓친 트릭을 발견하시면 알려 주세요.
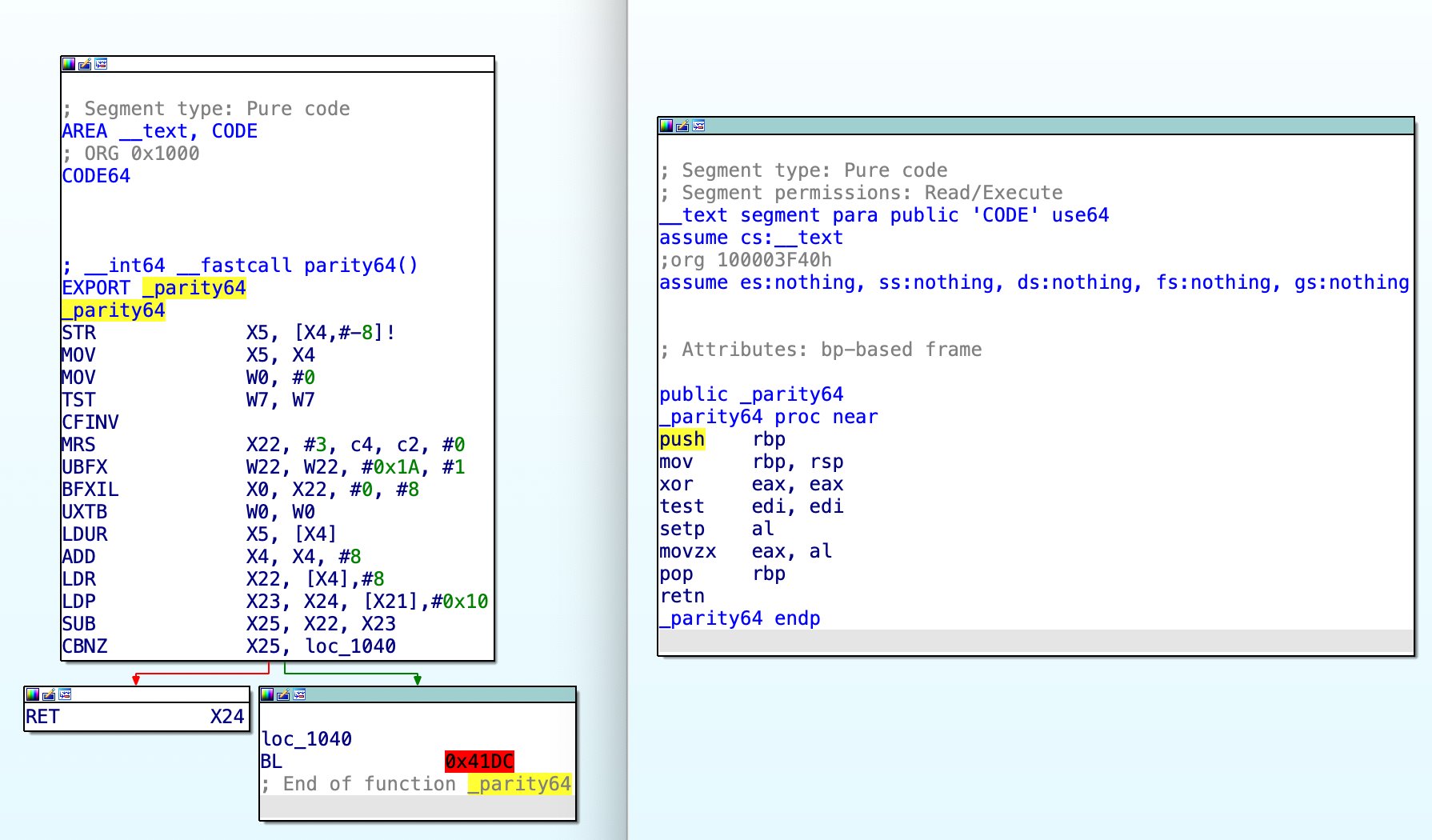
IDA Pro 스크린샷: Rosetta 2의 앞선 번역 코드와, 잘못 이름 붙여진 "parity64" 함수(실제로는 x86 parity-flag를 사용해 인자의 8비트 패리티를 계산)의 원래 x86 코드를 나란히 비교한 모습.
Rosetta 2는 바이너리의 전체 텍스트 세그먼트를 x86에서 ARM으로 미리 번역합니다. JIT(just-in-time) 번역도 지원하지만, 실제로는 비교적 드물게 사용되며, 이로써 컴파일의 직접적인 런타임 비용과, 명령/데이터 캐시 측면의 간접적인 비용을 모두 피합니다.
다른 인터프리터들은 보통 실행 순서대로 코드를 번역하는데, 이는 시작 시간을 더 빠르게 할 수 있지만, 코드 지역성(code locality)은 보존하지 못합니다.
정정: 이 글의 이전 버전에서는, 앞선 번역된 모든 명령이 유효한 진입점이라고 서술했습니다. 지금도 이론적으로는 거의 모든 앞선 번역 명령으로 점프하는 것이 가능하다고 생각하지만, 실제로 사용되는 룩업 테이블은 이를 허용하지 않습니다. 이는 룩업 테이블 크기를 작게 유지하기 위한 최적화라고 봅니다. 프로로그/에필로그 최적화도 글의 초기 버전 이후에 발견되었습니다.
각 x86 명령은 앞선 번역된 바이너리 안에서 (NOP은 예외로, 무시됨) 한 번만 하나 이상의 ARM 명령으로 번역됩니다. 간접 점프나 호출로 인해 명령 포인터가 텍스트 세그먼트 내의 임의의 오프로 설정되면, 런타임은 그에 대응하는 번역된 명령을 룩업하여 그리로 분기합니다.
이는 함수 시작 지점과, 그 외에는 참조되지 않는 기본 블록들까지 포함하는 x86→ARM 룩업 테이블을 사용합니다. 예를 들어 switch 문을 처리하는 중에 여기서 미스가 나면, JIT로 폴백할 수 있습니다.
정확한 예외 처리, 샘플링 프로파일링, 디버거 부착을 가능하게 하기 위해, Rosetta 2는 번역된 ARM 명령에서 원래 x86 주소로의 매핑을 유지하고, 각 명령 사이에서 상태(state)가 표준화된(canonical) 형태임을 보장합니다.
이는 거의 모든 명령 간(inter-instruction) 최적화를 사실상 막습니다. 알려진 예외는 두 가지입니다. 하나는 "unused-flags" 최적화로, 플래그를 설정하는 명령 이후 모든 경로에서 플래그가 덮어써지기 전까지 사용되지 않는다면 x86 플래그 값을 계산하지 않는 것입니다. 다른 하나는 함수 프로로그와 에필로그를 합치는 최적화로, push와 pop 명령을 묶고 스택 포인터 갱신을 지연시킵니다. ARM→x86 주소 매핑에서는 이것이 마치 단일 명령인 것처럼 보입니다.
명령 사이에서 상태를 표준화된 형태로 유지하는 것에는 몇 가지 트레이드오프가 있습니다:
반면 여기에 따른 장점은 상당합니다:
명령 캐시에 최적화하는 것이 별로 중요한 이득처럼 보이지 않을 수 있지만, 실제로는 에뮬레이터에서 꽤 중요한 편입니다. 서로 다른 명령 집합 사이를 번역할 때는 이미 코드 팽창(expansion factor)이 존재하기 때문입니다. 1바이트짜리 x86 push는 4바이트짜리 ARM 명령이 되고, 읽기-수정-쓰기 x86 명령 하나는 ARM 명령 세 개(또는 주소 지정 모드에 따라 더 많이)로 바뀝니다. 그리고 그것도 이상적인 ARM 명령이 제공되는 경우의 이야기입니다. 명령의 의미가 조금만 달라도, 요구되는 동작을 얻기 위해 더 많은 명령이 필요합니다.
이러한 제약을 고려하면, 목표는 일반적으로 "x86 명령 하나당 ARM 명령 하나"에 최대한 근접하는 것이고, 아래 섹션에서 설명하는 트릭들이 Rosetta가 이를 놀라울 정도로 자주 달성하게 도와줍니다. 이렇게 해서 코드 팽창률을 가능한 한 낮게 유지합니다. 예를 들어 sqlite3 바이너리의 명령 크기 팽창률은 대략 1.64배입니다(1.05MB의 x86 명령 vs 1.72MB의 ARM 명령).
(x86→ARM과 ARM→x86, 두 개의 룩업은 LC_AOT_METADATA에 있는 fragment list를 통해 찾습니다. 분기 대상 결과는 해시맵에 캐시됩니다. 이를 위해 여러 구조가 쓰일 수 있는데, 제가 본 한 바이너리에서는 성능이 중요한 x86→ARM 매핑에 2단계 이진 검색을 쓰고, 훨씬 더 크지만 성능 중요도가 낮은 ARM→x86 매핑에는 최상위 이진 검색 후 비트 패킹된 데이터를 선형 스캔하는 방식을 사용했습니다.)
x86의 RIP-relative 주소 지정을 에뮬레이트하기 위해, ADRP 명령 뒤에 ADD를 붙여 사용합니다. 이는 ±1GB 범위로 제한됩니다. Rosetta 2는 메모리 상에서 번역되지 않은 바이너리 뒤에 번역된 바이너리를 배치하므로, 대략 [번역 전 코드][데이터][번역된 코드][런타임 지원 코드] 형태가 됩니다. 이렇게 하면 ADRP가 필요에 따라 데이터와 번역 전 코드를 참조할 수 있습니다. 번역된 코드 바로 뒤에 런타임 지원 함수를 배치함으로써, 번역된 코드가 런타임으로 직접 호출을 할 수도 있게 됩니다.
성능이 좋은 모든 프로세서에는 리턴-주소-스택이 있어서, 브랜치 예측기가 return 명령을 올바르게 예측할 수 있습니다.
Rosetta 2는 이를 활용하기 위해, x86의 CALL과 RET 명령을 ARM의 BL과 RET 명령으로 다시 작성합니다(여기에 아키텍처적인 로드/스토어와 스택 포인터 조정도 함께). 이를 위해서는 호출 시 x86에서 기대되는 리턴 주소와 그에 해당하는 번역된 점프 대상을 특수 스택에 저장하고, 리턴 시 이를 검증하는 추가 부가 작업이 필요하지만, 그 덕분에 올바른 리턴 예측이 가능합니다.
이 트릭은 GameCube/Wii 에뮬레이터인 Dolphin에서도 사용됩니다.
x86과 ARM의 동작 차이(특히 플래그 의미 차이)에서 상당한 오버헤드가 발생합니다. Rosetta 2는 이러한 차이를 효율적으로 처리하기 위해 ARM의 flag-manipulation 확장(FEAT_FlagM, FEAT_FlagM2)을 사용합니다.
예를 들어 x86은 "borrow가 있는 뺄셈(subtract-with-borrow)"을 사용하지만, ARM은 "carry가 있는 뺄셈(subtract-with-carry)"을 사용합니다. 이는 덧셈과 달리, 뺄셈에서는 carry 플래그 의미가 반대로 되는 효과가 있습니다. CMP는 결과값이 없는 플래그 설정용 뺄셈이므로, 실제로는 덧셈보다 뺄셈에서 플래그를 사용하는 경우가 훨씬 일반적입니다. 그래서 Rosetta 2는 carry 플래그의 표준형(canonical form)으로 "반전된 값"을 선택합니다. CFINV(carry-flag-invert) 명령은 carry 플래그가 사용되거나 외부로 새어나갈 수 있는 ADD 이후에 carry를 반전하는 데, 그리고 add-with-carry 명령의 입력으로 carry 플래그를 쓸 때 이를 바로잡는 데 사용됩니다.
x86의 shift 명령 역시, 비트를 carry 플래그로 밀어 넣기 때문에 플래그 처리가 복잡합니다. Rosetta는 레지스터의 임의 비트를 임의의 플래그로 이동시키는 RMIF(rotate-mask-insert-flags) 명령을 사용해, 고정 시프트(등) 에뮬레이션을 비교적 효율적으로 수행합니다. 단, 시프트 양이 가변인 경우 플래그가 외부로 새어 나가면 여전히 비효율적인데, 시프트 양이 0인 경우 플래그를 수정해서는 안 되므로 조건 분기가 필요하기 때문입니다.
x86과 달리 ARM에는 8비트/16비트 연산이 없습니다. 이들은 보통 더 넓은 연산으로 쉽게 에뮬레이트할 수 있고(컴파일러가 실제로 그렇게 구현합니다), x86은 상위 비트를 보존해야 한다는 작은 함정만 있습니다. SETF8과 SETF16 명령은 이러한 더 좁은 폭의 명령이 플래그를 어떻게 설정하는지 에뮬레이션하는 데 도움을 줍니다.
이상은 모두 FEAT_FlagM으로부터 온 명령들입니다. FEAT_FlagM2의 명령은 AXFLAG와 XAFLAG로, 부동소수점 조건 플래그를 어떤 "외부 포맷(external format)"으로 변환하거나 그 반대로 변환합니다. 우연의 일치인지, 이 포맷은 바로 x86 형식이며, 따라서 이 명령은 부동소수점 플래그를 다룰 때 사용됩니다.
x86과 ARM은 모두 IEEE-754를 구현하므로, 가장 흔한 부동소수점 연산은 거의 동일합니다. 한 가지 예외는 NaN 값의 다양한 비트 패턴 처리 방식이고, 또 하나는 작은 값(tininess)을 반올림 전/후 어느 시점에 검출하느냐입니다. 대부분의 애플리케이션은 이 부분이 조금 틀려도 상관없지만, 일부는 그렇지 않습니다. 이를 정확히 맞추려면 모든 부동소수점 연산마다 비싼 검사가 필요합니다. 다행히도, 이는 하드웨어에서 처리됩니다.
ARMv8.7에는 표준 ARM 대체 부동소수점 동작 확장(FEAT_AFP)이 있지만, M1 설계는 v8.7 표준보다 먼저 나왔기 때문에 Rosetta 2는 비표준 구현을 사용합니다.
(우연의 일치로, 이 "대체(alternative)"가 정확히 x86과 일치합니다. ARM은 명령 설명에 "Javascript"라는 단어를 넣으면서도, x86을 지칭할 때는 두 가지 돌려 말하기 표현이 필요한 것이 꽤 웃깁니다.)
Apple M1에서 사용할 수 있는 비표준 ARM 확장 중, 하드웨어 TSO(total-store-ordering) 지원은 널리 알려져 있습니다. 이를 활성화하면, 일반 ARM 로드/스토어 명령도 x86 시스템의 로드/스토어와 동일한 순서 보장(total store ordering)을 갖습니다.
제가 아는 한 이는 ARM 표준의 일부는 아니지만, Apple 전용도 아닙니다. Nvidia Denver/Carmel과 Fujitsu A64fx 역시 TSO를 구현한 다른 64비트 ARM 프로세서입니다(이 세부 정보는 marcan에게 감사).
실제 실행되는 연산의 90%를 차지하는 명령은 손에 꼽을 정도이며, 그 상위권에는 덧셈과 뺄셈이 있습니다. ARM에서 이들은 옵션으로 4비트 NZCV 레지스터를 설정할 수 있습니다. 반면 x86에서 이들은 항상 여섯 개의 플래그 비트를 설정합니다: CF, ZF, SF, OF(이는 NZCV에 꽤 잘 대응함)와, PF(패리티 플래그), AF(adjust 플래그)입니다.
마지막 두 플래그를 소프트웨어로 에뮬레이션하는 것은 가능하며(Linux용 Rosetta 2는 실제로 그렇게 하는 듯합니다), 하지만 꽤 비쌉니다. 대부분의 소프트웨어는 이 값이 잘못되어도 눈치채지 못하겠지만, 일부는 그렇지 않습니다. Apple M1에는 문서화되지 않은 확장이 하나 있어서, 이를 활성화하면 ADDS, SUBS, CMP 같은 명령이 PF와 AF를 계산해 NZCV의 26, 27번 비트에 각각 저장합니다. 이로써 성능 손실 없이 정확한 에뮬레이션이 가능합니다.
결국, M1 자체가 엄청나게 빠른 칩입니다. 동급 x86 CPU보다 훨씬 더 폭넓은(wide) 설계 덕분에, Rosetta 2가 추가로 생성하는 명령이 있어도, 스루풋 한계에 걸리지 않고 버텨낼 수 있는 능력이 뛰어납니다. 어떤 경우(제 기억으로는 IDA Pro)에는 Rosetta 2에서 네이티브 ARM으로 옮겨도 체감 속도가 그리 크게 오르지 않을 정도입니다.
Rosetta 2에는 여전히 성능 개선 여지가 있다고 생각합니다. 더 많은 명령 간 최적화를 수행하면 될 것입니다. 하지만 이는 복잡도(특히 디버깅과 예외 처리 측면)와 번역 시간의 상당한 증가를 대가로 치러야 합니다.
엔지니어링은 적절한 트레이드오프를 선택하는 일이며, Rosetta 2는 이 부분을 아주 잘 해낸 것으로 보입니다. 다른 에뮬레이터들은 성능을 위해 명령 간 최적화가 필수일 수 있지만, Rosetta 2는 빠른 CPU를 신뢰하고, 캐시와 예측기를 존중하는 코드를 생성하며, 가장 지저분한 문제들을 하드웨어에서 해결하는 방식을 택했습니다.
저를 팔로우하시려면 @dougall@mastodon.social에서 보실 수 있습니다.
댓글을 읽다 보니, 원글에서 이 부분을 빠트린 것이 꽤 큰 누락이라는 걸 깨달았습니다. Rosetta 2는 SSE2 SIMD 명령 집합을 완전히 에뮬레이션합니다. 이 명령들은 이미 수년 전부터 컴파일러에서 기본으로 활성화되어 왔기 때문에, 호환성을 위해서는 필수였습니다. 하지만 Rosetta 2는 모든 일반적인 연산을 비교적 최적화된 NEON 연산 시퀀스로 번역합니다. 이는 이러한 명령을 활용하도록 최적화된 소프트웨어의 성능에 결정적입니다.
많은 에뮬레이터들이 SIMD→SIMD 번역 방식을 사용하지만, 일부는 SIMD를 스칼라 연산으로 풀어서 처리하거나, 각 SIMD 연산마다 런타임 지원 함수 호출로 넘기기도 합니다.
이는 앞에서 언급한 두 가지 명령 간 최적화 중 하나이지만, 별도 섹션으로 다룰 가치가 있습니다. Rosetta 2는 플래그가 사용되지 않고 외부로 새어 나가지 않을 때, 플래그 계산 자체를 생략합니다. 덕분에 flag-manipulation 명령이 있음에도 불구하고, 대다수의 x86 플래그 설정 명령은 플래그를 설정하지 않는 ARM 명령으로 번역되며, 별도의 수정(fix-up)도 필요 없습니다. 이로 인해 명령 수와 코드 크기가 상당히 줄어듭니다.
이는 특히 Linux VM에서의 Rosetta 2에 더 큰 의미를 가집니다. VM 안에서는 Rosetta가 Apple의 parity-flag 확장을 활성화할 수 없으므로, 패리티 값을 직접 계산해야 합니다(또는 adjust 플래그도 계산할 수도, 안 할 수도 있습니다). 이는 비교적 비용이 크기 때문에, 이를 피할 수 있는 경우가 많을수록 좋습니다.
제가 알고 있는 마지막 명령 간 최적화는 프로로그/에필로그 결합입니다. Rosetta 2는 스택 프레임을 설정/해제하는 명령 그룹을 찾아, 이를 병합하면서 로드와 스토어를 페어링하고, 스택 포인터 갱신을 지연시킵니다. 이는 x86 하드웨어 구현에서 흔히 볼 수 있는 "스택 엔진(stack engine)"과 동등합니다.
예를 들어, 다음과 같은 프로로그가:
push rbp
mov rbp, rsp
push rbx
push rax다음과 같이 바뀝니다:
stur x5, [x4,#-8]
sub x5, x4, #8
stp x0, x3, [x4,#-0x18]!이렇게 하면 스택 포인터를 수정하는 로드/스토어/산술 명령 수가 크게 줄어들어, 성능과 코드 크기가 모두 개선됩니다. 이러한 페어 로드/스토어는 Apple M1에서는 단일 연산으로 실행되는데, 제가 아는 한 이는 x86 CPU에서는 불가능한 동작이어서, Rosetta 2가 이 부분에서 이점을 갖습니다.
이 탐구는 Koh M. Nakagawa의 훌륭한 Project Champollion에서 설명된 방법과 정보를 기반으로 이루어졌습니다.
앞선 번역된 Rosetta 코드를 보려면, SIP를 비활성화하고, 새로운 x86 바이너리를 컴파일한 뒤, 고유한 이름을 붙여 실행하고, 그 다음에 otool -tv /var/db/oah///unique-name.aot을 실행해야 했던 것으로 기억합니다(또는 원하는 도구를 사용해도 됩니다. 그냥 Mach-O 바이너리일 뿐입니다). 이는 예전 버전의 macOS에서 했던 작업이라, 지금은 상황이 바뀌거나 개선되었을 수 있습니다.
Rosetta 2의 빠른 이유와는 직접적인 관련은 없지만, 언급할 만한 인상적인 호환성 기능이 몇 가지 있습니다.
Rosetta 2에는 x87의 80비트 부동소수점 수를 완전히 소프트웨어로 구현한(느리지만 완전한) 구현이 있습니다. 이를 통해 해당 명령을 사용하는 소프트웨어도 올바르게 동작할 수 있습니다. Windows on Arm은 64비트 float 연산을 사용해 이 문제에 대응하는데, 일반적으로는 잘 동작하지만, 정밀도 감소로 인해 드물게 문제가 발생하기도 합니다. 대부분의 소프트웨어는 x87을 사용하지 않거나, 오래된 하드웨어에서 실행되도록 설계되었기 때문에, 이 에뮬레이션이 느리더라도 실제 성능은 보통 괜찮게 나옵니다.
업데이트: 글의 이전 버전에서는 Windows on Arm이 x87을 처리하지 않는다고 썼는데, 댓글에서 kode54님이 이를 정정해 주셨습니다.
Rosetta 2는 Wine을 위해 전체 32비트 명령 집합도 지원하는 것으로 보입니다. 네이티브 32비트 macOS 애플리케이션 지원은 Apple Silicon 출시 전에 이미 제거되었지만, 32비트 x86 명령 집합 지원은 여전히 남아 있는 것으로 알려져 있습니다(직접 확인해 보지는 않았습니다).