V8와 HotSpot이 사용하는 어셈블리 기반 템플릿 인터프리터의 동기, 설계와 구현(디스패치·TOS 최적화·OSR/JIT 상호운용) 그리고 다른 인터프리터 스타일과의 벤치마크 비교를 다룬다.
11/8/2025 V8와 HotSpot에서 사용하는, 거의 논의되지 않는 인터프리터 스타일을 살펴본다.
가장 빠른 프로그래밍 언어 런타임이 최적화 JIT 컴파일러를 통해 속도를 얻는다는 것은 잘 알려져 있다. 대표적인 예로는 V8과 HotSpot이 있다.
이들의 기본(베이스라인) 바이트코드 인터프리터(즉 JIT이 개입하기 전 기본으로 코드를 실행하는 인터프리터)에 관해서는 덜 알려진 사실이 있다:
이들은 바이트코드 인터프리터를 C/C++ 같은 언어로 쓰지 않고, 실제로는 어셈블리(혹은 유사한 저수준 IR)로 작성한다.
더 알아보기 위해 V8과 HotSpot을 파봤고, 이후 HotSpot의 설계를 많이 참고해(코드를 읽기 가장 쉬웠기 때문) 이 스타일의 인터프리터를 직접 만들어 보았다.
HotSpot은 이 스타일의 인터프리터를 소스 코드와 문서에서 “template interpreter”라고 부르는데, 여기서도 그렇게 부르겠다. 다만 좀 더 정확한 이름은 “어셈블리 인터프리터”에 가까울 수도 있다.
핵심은 각 바이트코드 연산자(handler)에 대한 기계어를 생성하고, bytecode opcode -> 이를 실행할 기계어로 매핑하는 명령 디스패치 테이블을 만드는 데 있다.
이처럼 더 낮은 수준의 제어를 통해, 예컨대 중요/핫 변수들을 전용 레지스터에 유지한다든지, 스택을 시뮬레이션하지 않고 하드웨어 호출 스택을 사용하는 등의 흥미로운 일을 할 수 있다.
그래서 이 글에서는 왜 이런 스타일의 바이트코드 인터프리터가 존재하는지 설명하고, 구현 세부를 살펴본 다음, 보다 널리 알려진 다른 인터프리터 스타일과 벤치마크로 비교해 보겠다.
주로 HotSpot 기반의 스택형 인터프리터 설계를 다룬다.
또한 이 글에는 어셈블리, 특히 내가 가장 익숙한 아키텍처인 aarch64 어셈블리가 등장한다.
왜 굳이 어셈블리 같은 저수준 언어로 인터프리터를 내려가서 작성하려 할까? 첫 번째이자 분명한 이유는 성능이다.
일반적으로 컴파일러가 생성하는 기계어는 사람이 손으로 쓰는 것보다 빠르다.
하지만 LuaJIT의 저자인 Mike Pall은 LuaJIT의 인터프리터를 어셈블리로 다시 썼고, 그의 근거는 컴파일러가 인터프리터 메인 루프 최적화를 그리 잘하지 못한다는 점이었다.
보통 스택형 바이트코드 인터프리터는 익숙한 while 루프 + switch 문으로 구현된다:
const Opcode = enum(u8) {
// 두 정수 더하기
iadd = 0,
// 두 정수 빼기
isub = 1,
// 기타 연산...
};
const STACK_MAX = 1024;
var stack: [MAX]i32 = undefined;
var stack_top: [*]i32 = &stack[0];
while (true): (pc += 1) {
switch (bytecode[pc]) {
.add => {
const b = pop();
const a = pop();
push(a + b);
},
.sub => {
const b = pop();
const a = pop();
push(a - b);
},
// 그리고 다른 연산들...
}
}
하지만 인터프리터의 복잡도가 커질수록, 컴파일러의 눈에는 매우 복잡한 제어 흐름을 가진 거대한 하나의 루프로 보이게 된다.
이는 컴파일러가 다음과 같은 점에서 고전하게 만든다:
주의할 점은, 이 모든 이야기는 Mike Pall이 10년이 넘은 과거에 한 말이라는 것이다. 컴파일러 발전으로 이 성능 격차가 얼마나 줄었는지는 확실치 않다1.
그리고 Filip Pizlo(JSC의 LLInt 인터프리터 저자, 이것도 어셈블리로 작성됨)는 이렇게 말한다:
JSC의 인터프리터가 어셈블리로 작성된 이유는 성능 때문이 아니라 JIT과 ABI를 공유해야 했기 때문이다.
Mike는 틀렸다. 그 당시에도 C나 C++로도 좋은 인터프리터를 작성할 수 있었고, 다만 주의가 필요했을 뿐이다. 현대 컴파일러는 이걸 더 쉽게 만들어 준다. C/C++로 작성하지 않을 유일한 이유는 JIT과의 ABI 호환성 때문이다.
이는 고성능 언어 런타임이 인터프리터를 저수준 어셈블리 계열 언어로 작성하는 더 강력한 이유일 수 있다: 이렇게 하면 JIT과 잘 맞물려 동작시킬 수 있다.
JIT 컴파일을 가진 인터프리터가 고민해야 할 것 중 하나는, 어디에서 어떻게 JIT된 코드로 들어가고 나올 것인가다.
인터프리터가 JIT된 코드로 전환하기 가장 쉬운 지점은 함수 경계다: 그냥 컴파일된 코드를 호출하면 된다.
하지만 자주 호출되지는 않아서(“핫”으로 표시되지 않아) JIT되지 않은 함수가 매우 핫한 루프를 가지고 있다면 어떨까? 그 루프는 여전히 JIT의 혜택을 받아야 한다.
그래서 On-Stack Replacement (OSR)는 함수의 한가운데, 예컨대 핫 루프가 다음 이터레이션으로 넘어갈 때처럼, 최적화된 JIT 코드로 전환할 수 있게 해준다.
템플릿 인터프리터는 기계어를 정밀하게 제어하므로, 이 전환을 효율적으로 설계할 수 있다.
예를 들어 V8의 Ignition 인터프리터는 의도적으로 JIT 코드와 동일한 ABI를 공유하도록 설계되어, JIT 코드로 뛰어들기(jump)는 사실상 단 하나의 점프 명령으로 끝난다:
/* v8/src/builtins/x64/builtins-x64.cc */
void Generate_OSREntry(MacroAssembler* masm, Register entry_address) {
// 스택의 리턴 주소를 버리고 함수의 OSR 진입 지점으로 점프한다.
__ Drop(1);
__ jmp(entry_address, /*notrack=*/true);
}
반면 HotSpot은 이를 하지 않기 때문에, 현재 실행 중인 인터프리터 프레임을 컴파일된 프레임으로 변환해야 한다.
참고로 OSR은 반대로도 동작하여, 흔히 _디옵티마이제이션_에 사용되듯 JIT 컴파일된 코드에서 벗어날 때도 쓴다.
템플릿 인터프리터의 전체적인 개략은 대략 다음과 같다:
// `bytecode`는 바이트코드 명령 버퍼
fn run_bytecode(bytecode: []const u8) void {
// 바이트코드 op -> 그 op를 처리할 기계어의 주소
var dispatch_table: [OPS_COUNT]usize = std.mem.zeroes([OPS_COUNT]usize);
// `code_buffer`는 인터프리터가 실행할 기계어를 담는 실행 가능 메모리 영역
const code_buffer: ExecutableMemory = TemplateGenerator.generate(
&dispatch_table,
);
// 인터프리터를 실행!
var interpreter = TemplateInterpreter.new(
bytecode,
code_buffer,
&dispatch_table,
);
interpreter.run();
}
이는 VM 시작 시 각 바이트코드 op에 대한 기계어를 생성하는 HotSpot과 유사한 설계다.
반면 V8은 별도의 빌드 단계2를 두어, 각 바이트코드 핸들러를 TurboFan으로 생성해 embedded.S 파일로 만들고, V8이 이를 링크한다.
각 바이트코드 op에 대해 생성된 기계어의 구조는 다음과 같다:
<그 바이트코드 op를 실행하는 명령어들><다음 바이트코드 op로 디스패치하는 명령어들>먼저 2번에 집중해보자. 다음 바이트코드 op로 어떻게 디스패치할까?
바이트코드 버퍼에서 다음 바이트코드를 읽고, 그 바이트코드 op를 실행하는 코드의 주소를 찾은 뒤, 그 주소로 점프해야 한다.
_디스패치 테이블_을 사용하면 바이트코드 op 핸들러의 주소를 쉽게 찾을 수 있다. 이는 단순히 opcode로 인덱싱되는 배열로 표현할 수 있다:
var dispatch_table: [OPS_COUNT]usize = get_dispatch_table();
const addr_for_iadd_op = dispatch_table[Op.iadd];
이제 다음 명령으로 디스패치하는 어셈블리가 어떻게 생겼는지 보자. 읽기 쉽게 가짜 레지스터 이름을 쓰겠다:
rbcp -> 현재 바이트코드 명령을 가리키는 포인터를 담는 레지스터rdispatch -> 디스패치 테이블의 베이스 주소를 담는 레지스터; 다음 opcode를 x0에 로드
ldrb x0, [rbcp, #<step_amount>]!
; x0 = rdispatch[x0 << 3]
ldr x0, [rdispatch, x0, lsl #3]
; 점프
br x0
여기서 step_amount는 바이트코드 명령의 바이트 단위 크기다.
디스패치 코드는 단 3개의 명령이면 된다!
이제 각 바이트코드 op 핸들러가 생성하는 기계어가 어떻게 생겼는지 이야기해 보자.
대부분의 바이트코드 op는 상당히 사소하다. 많은 op가 CPU 명령과 1:1로 대응되기 때문이다(예: add 바이트코드 op는 CPU의 add 명령을 사용할 수 있다).
다음 질문: 값은 어디에 둘까?
스택형 인터프리터에서는 답이 비교적 분명하다: 실제 스택, 즉 하드웨어 스택을 쓰면 된다.
그렇게 할 때의 장점은 다음과 같다:
SP 레지스터가 있다.스택은 지역 변수들을 저장하기에도 편리하다.
레지스터 기반인 V8도 레지스터와 로컬을 스택에 저장한다4.
그래서 스위치 기반 바이트코드 인터프리터에서 iadd 바이트코드 op의 핸들러는 이렇게 생겼다:
.iadd => {
// 스택에서 `b`를 pop
const b = pop();
// 스택에서 `a`를 pop
const a = pop();
// `a + b`를 스택에 push
push(a + b);
},
우리의 템플릿 인터프리터에서는 어셈블리가 어떻게 될까?
이런 식으로 할 수 있다:
; a와 b를 pop하고 sp를 16바이트 올린다
; (스택은 아래로 자라고 위로 줄어든다는 점에 유의)
ldp x9, x10, [sp], #16
; 더하기
add x11, x10, x9
; sp를 8바이트 내리고 x11을 저장
str x11, [sp, #-8]!
이것도 괜찮지만, 실제로는 약간의 성능을 놓치고 있다.
가장 잘 보여주려면, 다음과 같은 바이트코드 시퀀스를 상상해 보자:
const_val_1
increment
이때의 흐름은 다음과 같다:
const_val_1: 스택에 1을 pushincrement: 스택 최상단을 pop, 1을 더하고 다시 push어셈블리는 이렇게 될 것이다:
;; const_val_1
; x9에 1 대입
mov x9, #1
; 스택에 push
str x9, [sp], #-8
<디스패치 코드>
;; increment
; 스택에서 pop
ldr x9, [sp, #8]!
; 1 더하기
add x9, x9, #1
; 다시 스택에 push
str x9, [sp], #-8
보면 x9의 값을 스택에 push한 뒤 즉시 다시 x9로 pop하고 있다… 완전히 중복이다!
이는 바이트코드 시퀀스에서 꽤 자주 나타나는 패턴이다. 피할 수 있을까?
이런 불필요한 스택 push/pop을 피하기 위해 할 수 있는 일이 있다.
스택 최상단을 나타내는 전용 레지스터를 하나 쓰자. 이는 HotSpot과 V85도 사용하는 기술이다(단 V8의 인터프리터는 레지스터 기반이라 방식은 다르다).
여기서는 aarch64이므로 x0를 택하겠다. 이는 함수 반환값을 담는 레지스터이기도 해서, 값들을 여기에 직접 넣고 곧바로 반환할 수도 있다.
그러면 위 어셈블리는 다음과 같이 바뀐다:
;; const_val_1
mov x0, #1
<디스패치 코드>
;; increment
add x0, x0, #1
상당히 타이트하고 좋다. _중복_된 스택 로드/스토어를 없앴을 뿐만 아니라, 이 경우에는 아예 스택 사용 자체를 제거했다.
물론 모든 바이트코드 시퀀스에 이렇게 적용되지는 않는다.
다음 두 바이트코드가 있다고 하자:
const_val_1
const_val_2
iadd
단순히 push(v)를 mov x0, v로 바꾸면, 앞의 두 const_val이 서로를 덮어쓴다:
;; const_val_1
mov x0, #1
<디스패치 코드>
;; const_val_2
mov x0, #2
최선의 해법은 첫 번째 const_val은 실제로 스택에 push하고, 두 번째 것만 전용 레지스터에 두는 것이다.
어떻게 할까?
HotSpot은 이렇게 해결한다.
각 바이트코드 op에 대해 다음을 기록한다:
x0 레지스터 안에 무엇이 있나?)x0 레지스터에 무엇을 넣나?)예를 들어 iadd 명령은 최상단에 _정수_가 오길 기대하고, 실행 후 스택에 _정수_를 남긴다. 이를 다음 표기로 표현하자:
int -> iadd -> int
이는 단순히 op의 매개변수(예: iadd는 스택에서 정수 2개를 pop)와는 약간 다르다. 여기서는 스택의 _최상단_에서 무슨 일이 일어나는지만 묘사한다.
또 다른 예로, const_val op는 입력이 없고 스택에 _정수_를 남긴다:
void -> const_val_N -> int
각 바이트코드 op에 대해 이를 각각 입력 “스택 최상단 상태(top-of-stack state)”와 출력 “스택 최상단 상태”라고 부르겠다. “top-of-stack”은 TOS로 줄여 쓰자. 코드로는 다음과 같다:
const TosState = enum(u8) {
void = 0,
int = 1,
};
이제 흥미로운 일을 할 수 있다. 어떤 바이트코드 명령을 실행할 때 TOS 상태가 기대와 다르면, 그 상태를 우리가 원하는 모양으로 만들기 위한 코드를 추가로 생성하면 된다.
예를 들어 보자:
const_val_1
const_val_2
두 번째 const_val을 실행할 때의 TOS 상태는 int인데, 두 번째 const_val은 void이길 기대한다.
어쩔까? 그냥 x0에 든 정수를 실제 스택에 내려놓자!
어셈블리는 이렇게 된다:
;; const_val_1
mov x0, #1
<디스패치 코드>
;; const_val_2
; x0를 스택에 저장
str x0, [sp, #-8]!
mov x0, #2
멋진 점은, TOS 상태가 _기대와 동일_하다면 str 명령을 건너뛸 수 있다는 것이다.
즉 바이트코드 명령은 TOS 상태에 따라 _여러 개의 진입점_을 갖게 된다.
이를 위해 디스패치 테이블을 2차원 배열로 바꾸자:
const dispatch_table: [TOS_COUNT][OPS_COUNT]usize = get_dispatch_table();
const addr = dispatch_table[TosState.int][Opcode.const_val_2];
그리고 const_val_2에 대해 생성되는 코드는 다음과 같다:
;; =dispatch_table[TosState.int][Opcode.const_val_2]
str x0, [sp, #-8]!
;; =dispatch_table[TosState.void][Opcode.const_val_2]
mov x0, #2
첫 줄의 주소가 dispatch_table[TosState.int][Opcode.iadd]에 저장되고, 둘째 줄의 주소가 dispatch_table[TosState.void][Opcode.iadd]에 저장된다는 것을 주석으로 표시했다.
템플릿 인터프리터가 스위치 기반이나 다이렉트 스레딩 접근보다 왜 _더 빠를 것 같다_는 이야기야 아무리 해도, 현대 CPU는 각종 최적화로 이뤄진 매우 복잡한 기계라서 일원론적으로 성능을 추론하기가 어렵다.
가장 설득력 있는 비교법은 실제로 벤치마크하는 것이다!
그래서 나는 Rust로 템플릿 인터프리터를 만들고, Claude에게 스위치 기반과 다이렉트 스레딩 인터프리터, 그리고 테일콜 인터프리터를 생성하게 한 뒤, 이들을 벤치마크했다.
결과는 다음과 같다:
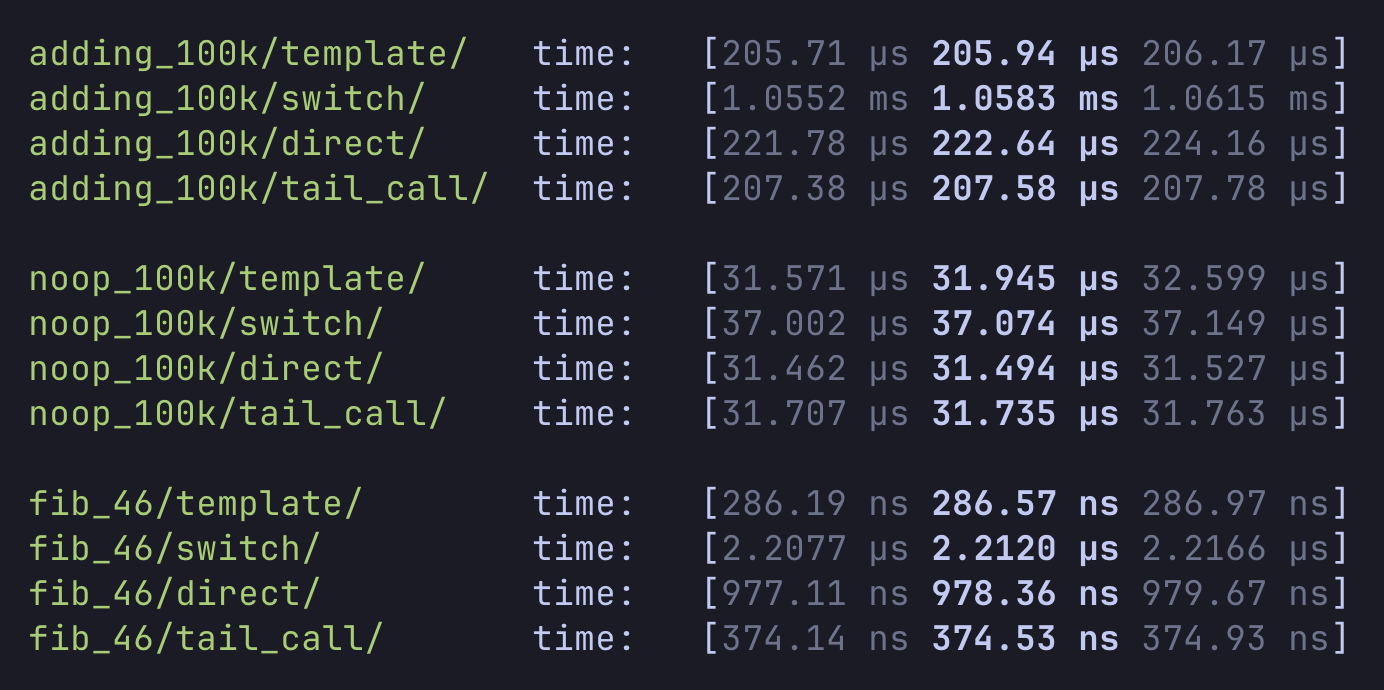
모두 세 가지 함수를 실행하며 서로 다른 지점을 벤치마크하도록 설계했다:
fibonacci(46) 실행: 산술과 분기를 조합한, 좀 더 “실제에 가까운” 프로그램결과에서 템플릿 인터프리터가 모든 경우에 더 빠름을 볼 수 있는데, 예상된 바다.
noop 벤치마크를 보면, 인터프리터들이 꽤 근접해 있어 명령 디스패치 오버헤드 측면에서는 서로 비슷함을 시사한다. 스위치와 다이렉트 스레딩 인터프리터의 컴파일러 출력을 보면, 디스패치 테이블과 pc 변수 같은 몇몇 핫 변수가 실제로 전용 레지스터에 고정(pinning)되었다. 다만 바이트코드 핸들러 함수들이 꽤 단순해서, 진짜 인터프리터를 대표한다고 보긴 어렵다.
fibonacci(46) 결과가 가장 큰 성능 격차를 보였는데, 템플릿 인터프리터가 다이렉트 스레딩 인터프리터보다 약 2.5배 빠르다. 이 코드는 로컬의 get/set을 많이 사용하며, 템플릿 인터프리터는 스택 최상단을 전용 레지스터에 유지하기 때문에 이에 더 적합했을 수 있다.
흥미롭게도 스위치 인터프리터는 더하기와 피보나치 벤치마크 모두에서 상대적으로 좋지 않았다. 이는 컴파일러가 다소 비최적의 코드를 생성했기 때문이라고 생각한다6.
또한 이 인터프리터들은 꽤 단순하며 산술과 제어 흐름만 처리한다. 객체, 함수 호출 등 많은 부분이 빠져 있다.
벤치마크에서 빠진 것 중 하나는 느린 경로(slow path)의 존재가 인터프리터 성능에 미치는 영향이다. 이론적으로는 컴파일러가 더 나쁜 코드를 생성하도록 만들 수 있다.
가장 흥미로운 결과는 테일콜 인터프리터가 템플릿 인터프리터와 꽤 경쟁력 있게 나왔다는 점이다. 주목할 점은 테일콜 인터프리터가 어셈보다 훨씬 작성하기 쉽다는 것이다.
네 인터프리터의 실제 코드를 보고 싶다면 레포를 확인하라.
이 인터프리터 스타일은 매우 흥미로웠고, HotSpot과 V8 코드를 읽으며 많은 즐거움을 얻었고, 그 과정에서 aarch64 어셈도 더 배웠다.
주요 단점은 구현 비용이 높다는 점이다. V8은 여러 CPU 아키텍처를 지원하는 기존의 최적화 JIT 컴파일러 위에 구축함으로써 이를 대부분 회피한다. HotSpot에서는 7개 CPU 아키텍처를 지원하는 코드가 약 25만 줄에 달한다7.
이 방식은 인터프리터에서 JIT로, 그리고 다시 되돌아오는 OSR 점프를 싸게 만들고 싶을 때에만 유용해 보인다.
컴파일러가 잘 최적화하는 인터프리터 스타일이자 구현 비용이 극적으로 낮은 스타일은, 인터프리터를 오직 테일콜만 쓰도록 설계하는 것이다. 오늘 내가 새로 만든다면 이 스타일을 선택하겠다.
Max Bernstein의 블로그(컴파일러/인터프리터에 관심 있다면 훌륭한 블로그)에도 감사한다. 그는 이 글에서 “템플릿 인터프리터” 개념을 소개했다!
HotSpot:
V8:
1↩︎
JIT을 끈 LuaJIT과(비활성화) switch/loop를 사용하는 Lua 5.1.5를 현대 clang으로 각각 컴파일해 간단히 벤치마크했다:
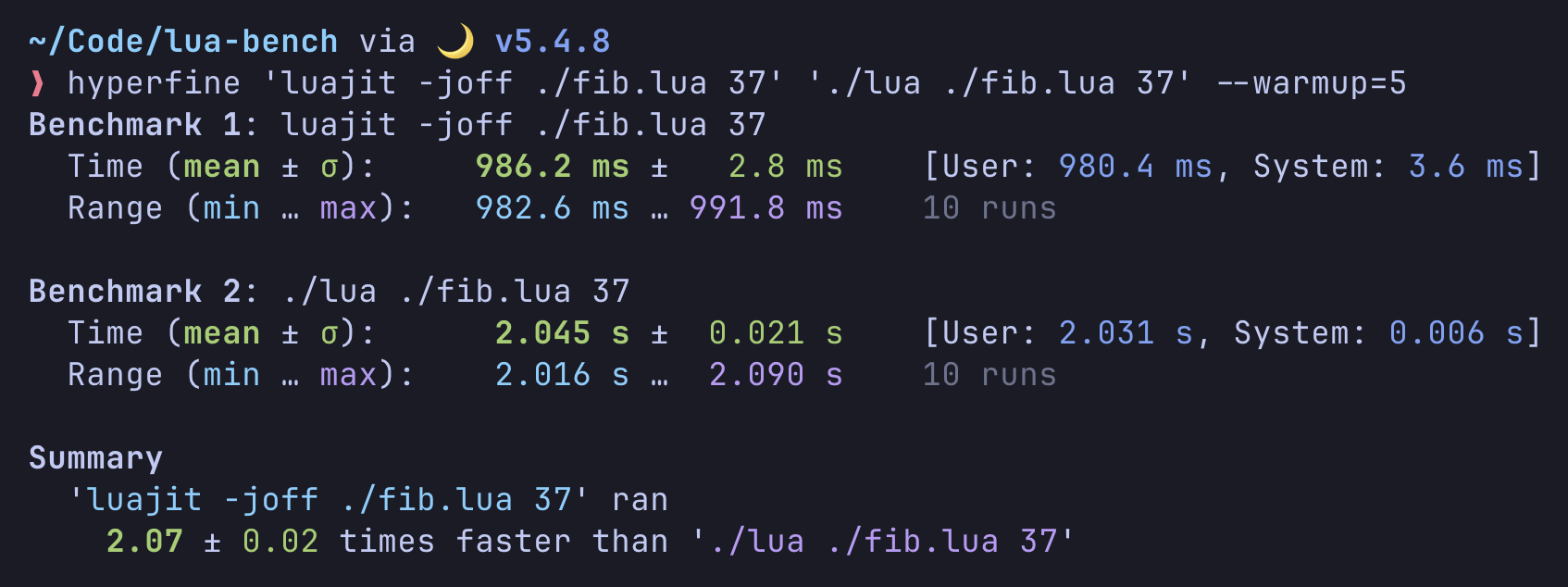
LuaJIT의 인터프리터가 약 2배 더 빨랐다. 이 차이가 어셈블리로 작성되었기 때문인지, 혹은 다른 구조적 차이 때문인지(예: LuaJIT은 더 많은 슈퍼 명령(super-instruction)을 가진 다른 바이트코드 명령 집합을 사용) 가늠하기는 어렵다.
같은 벤치마크에 대한(10년 이상 된 것으로 보이는) 결과는 3.6배 더 빨랐다고 보여준다. 이는 컴파일러가 발전하여 격차를 좁혔음을 시사할 수 있다. 그러나 동일한 코드를 찾지 못했고, 두 인터프리터를 더 오래된 clang 버전으로 컴파일해 다시 돌려봐야 하므로 과학적이라 보긴 어렵다.
3↩︎
정말 스택을 쓰기 싫다면, 리눅스에서 MAP_GROWSDOWN을 사용해 mmap된 메모리 영역으로 할 수도 있다. 하지만 macOS나 Windows에는 (내가 아는 한) 동등한 기능이 없어 이식성이 없다.
4↩︎
V8의 베이스라인 인터프리터는 Ignition이다. 그 바이트코드 포맷은 레지스터 기반이지만 고정된 레지스터 집합에 의존하지 않는다. 대신, 레지스터는 무한히 많을 수 있으며 모두 스택에 저장된다. 로컬도 스택에 저장된다. (출처)
5↩︎
Ignition의 바이트코드 포맷에서는 많은 명령이 암시적인 누산기(accumulator) 레지스터를 사용한다. 이는 스택 로드/스토어를 회피하려는 유사 최적화로 설계된 것으로 보인다.
6↩︎
스위치 인터프리터의 생성 코드를 보면, add opcode의 레이블이 LBB0_19로 붙어 있다.
예상대로 동작하긴 하지만, 생성된 코드 조각의 끝에서 스택에서 pop한 두 값을 더한 결과를 저장하는 대신, LBB0_21이라는 다른 레이블로 점프한다.
여기서 비로소 덧셈 결과를 저장하지만, 동시에 값 1을 두 개의 64비트 레지스터를 가진 벡터 레지스터에 넣고, 그 다음 또다시 LBB0_3으로 점프한다:
.LBB0_21:
str w11, [x8, x10, lsl #2]
dup v0.2d, x13 ; 이전에 1이 x13으로 이동됨
b .LBB0_3
LBB0_3에서는 다음을 본다:
.LBB0_3:
; q1 = interpreter.pc
ldr q1, [x0, #160]
add v0.2d, v1.2d, v0.2d
.LBB0_4:
mov x10, v0.d[1]
str q0, [x0, #160]
; 여기서 디스패치 코드 실행
.LBB0_5:
ldr x11, [x0, #8]
ldrb w12, [x11, x10]
adr x13, .LBB0_1
ldrb w14, [x9, x12]
add x13, x13, x14, lsl #2
br x13
즉 interpeter.pc를 q1(128비트 스칼라로 쓰이는 벡터 레지스터 1)에 로드한 뒤, v1과 v0를 더한다(사실상 pc + 1). 그리고 그 값을 프로그램 전반에서 pc 보관용으로 쓰는 x0에 저장하고, 인터프리터 구조체에도 다시 기록한다.
벡터 레지스터를 쓰는 의도는 잘 모르겠고, 괜히 분기가 추가된 것도 보인다.
7↩︎
openjdk/jdk 레포에서 다음 명령을 실행해 계산:
❯ cloc --by-file src/hotspot/cpu/**/*{cpp,hpp}
---------------------------------------------------------------------------------------
File blank comment code
---------------------------------------------------------------------------------------
src/hotspot/cpu/x86/assembler_x86.cpp 1879 722 14251
src/hotspot/cpu/aarch64/stubGenerator_aarch64.cpp 1693 2501 7831
src/hotspot/cpu/x86/macroAssembler_x86.cpp 1411 1118 7296
src/hotspot/cpu/x86/c2_MacroAssembler_x86.cpp 694 849 5518
src/hotspot/cpu/aarch64/macroAssembler_aarch64.cpp 880 1085 5200
src/hotspot/cpu/riscv/macroAssembler_riscv.cpp 922 905 4749
src/hotspot/cpu/s390/macroAssembler_s390.cpp 1002 1267 4506
src/hotspot/cpu/riscv/stubGenerator_riscv.cpp 995 1517 4400
src/hotspot/cpu/aarch64/assembler_aarch64.hpp 660 370 3343
src/hotspot/cpu/ppc/macroAssembler_ppc.cpp 718 794 3200
src/hotspot/cpu/ppc/stubGenerator_ppc.cpp 777 1251 3097
src/hotspot/cpu/riscv/assembler_riscv.hpp 670 353 3057
(725 omitted files...)
---------------------------------------------------------------------------------------
SUM: 53675 70764 256425
---------------------------------------------------------------------------------------