클러스터형 인덱스의 기본값 선택이 왜 비효율적이며, 비클러스터형 인덱스에 미치는 성능 패널티와 그 대안인 인덱스 전용 스캔의 중요성을 설명합니다.
SQL Performance Explained을 읽어보신 분은 아시겠지만, 저는 클러스터형 인덱스가 대부분의 사람들이 생각하는 것만큼 유용하지 않다고 믿습니다. 그 이유는 좋은 클러스터링 키를 선택하는 것이 너무 어렵기 때문입니다. 실제로, 테이블에 한두 개 이상의 인덱스가 있다면 좋은—즉 "올바른"—클러스터 키를 선택하는 일은 거의 불가능합니다. 그래서 대부분은 그냥 기본값(Primary Key, 기본키)에 의존하게 되지만, 이는 거의 항상 최악의 선택이 됩니다.
이 글에서는 클러스터형 인덱스라는 개념과 그 단점에 대해 설명합니다. SQL Server를 예제로 사용하지만, MySQL/MariaDB의 InnoDB와 Oracle의 인덱스 조직 테이블에도 동일하게 적용되는 내용입니다.
클러스터형 인덱스의 개념은 전체 테이블을 B-tree 구조로 저장하는 것입니다. 테이블에 클러스터형 인덱스가 있다면, 즉 인덱스 자체가 테이블인 셈입니다. 클러스터형 인덱스도 다른 B-tree 인덱스와 마찬가지로 엄격한 행 순서를 가지며, 인덱스 정의에 따라 행이 정렬됩니다. 이때 인덱스 순서를 정의하는 컬럼을 클러스터링 키라고 부릅니다. 대안은 아무런 정렬 없이 데이터를 저장하는 힙(Heap) 테이블입니다.
클러스터형 인덱스의 장점은 빠른 범위 스캔을 지원한다는 점입니다. 동일하거나 유사한 클러스터링 키 값을 가진 행이 물리적으로 인접하게(클러스터되어) 저장되기 때문에 신속한 조회가 가능합니다.
클러스터형 인덱스가 중요한 점은 별도의 테이블 저장 공간이 없고, 클러스터형 인덱스가 곧 테이블이라는 것입니다. 따라서 테이블당 하나만 가질 수 있습니다.
클러스터형 인덱스와 대조되는 개념으로 비클러스터형 인덱스가 있습니다. 많은 사람들이 이름 때문에 클러스터형 인덱스의 자연스러운 상대라고 생각합니다. 클러스터형 인덱스는 항상 인덱스 전용 스캔(Index-Only Scan)으로 쿼리할 수 있지만, 비클러스터형 인덱스는 필요한 컬럼을 모두 포함하지 않으면 기본 테이블 저장소에서 빠진 컬럼을 추가로 읽어와야 합니다. 이 때 비클러스터형 인덱스의 각 행은 기본 테이블의 동일 행을 가리키는 참조(키 또는 물리적 주소)를 가지고 있어 추가적인 IO가 발생합니다. 이 추가적인 간접 참조는 모든 경우 발생하지는 않는데, 필요한 컬럼을 모두 비클러스터형 인덱스에 포함시키면 인덱스 전용 스캔이 가능해집니다.
인덱스 전용 스캔이 중요한 개념이지, 클러스터형 인덱스 자체가 핵심은 아닙니다.
이 글의 뒷부분에서는 클러스터형 인덱스의 두 가지 측면—테이블 저장소로서와 모든 컬럼을 가진 인덱스로서의 역할—을 다룰 것이며, 필요할 때 어떤 역할에 초점을 두는지 명확히 하겠습니다.
퍼포먼스를 생각할 때, 추가적인 간접 참조는 그리 바람직하지 않습니다. 여기서 중요한 포인트는 테이블이 물리적으로 어떻게 저장되는가(Heap 또는 클러스터형 인덱스)와 dereference 비용이 크게 달라진다는 것입니다.
아래 그림은 이 현상을 설명합니다. 예를 들어, 2012-05-23의 모든 SALES 행을 조회하는 쿼리를 실행할 때의 과정입니다. 첫 번째 그림은 SALE_DATE에 비클러스터형 인덱스와 힙 테이블(클러스터형 인덱스가 없는 경우)을 사용했습니다:
비클러스터형 인덱스에서 Index Seek (Non-Clustered)가 수행되고, 두 행 각각에 대해 힙 테이블을 직접 참조(RID Lookup)합니다. 이 때 비클러스터형 인덱스는 물리적 주소(RID)를 사용해 힙 테이블의 해당 행을 참조합니다. 최악의 경우, 각 행마다 추가적인 읽기가 한 번씩 발생합니다.
클러스터형 인덱스가 있는 같은 시나리오를 봅시다. 즉, SALE_ID(Primary Key)가 클러스터링 키인 클러스터형 인덱스가 있는 상태에서 비클러스터형 인덱스를 사용할 경우입니다.
비클러스터형 인덱스 자체의 정의는 바뀌지 않았지만, 클러스터형 인덱스의 존재만으로 비클러스터형 인덱스가 기본 테이블 저장소(=클러스터형 인덱스)를 참조하는 방식이 달라집니다. 힙 테이블과 달리, 클러스터형 인덱스는 행의 위치가 바뀔 수 있으므로 물리적 주소가 아닌 클러스터링 키(SALE_ID)를 참조로 사용합니다. 이제 기본 테이블 저장소(클러스터형 인덱스)에서 누락된 컬럼을 읽어오려면 각 행마다 전체 B-tree를 탐색해야 하므로, 힙과 비교해 한 행마다 더 많은 IO가 발생하게 됩니다.
이런 현상을 저는 "클러스터형 인덱스 패널티"라고 부릅니다. 이 패널티는 클러스터형 인덱스가 존재하는 테이블의 모든 비클러스터형 인덱스에 영향을 미칩니다.
Oracle의 인덱스 조직 테이블은 비클러스터형 인덱스(Secondary Index)마다 클러스터링 키와 함께 행의 물리적 주소(추정 ROWID)도 저장합니다. 해당 주소에 행이 있으면 B-tree 탐색 없이 IO를 절감할 수 있지만, 없으면 불필요한 IO가 추가로 발생합니다.
클러스터형 인덱스가 비클러스터형 인덱스에 상당한 부담을 준다는 점을 봤으니, 이제 그 영향이 어느 정도인지 궁금하실 겁니다. 이론적으로는, 힙의 RID Lookup이 한 번의 IO라면, 클러스터형의 Key Lookup (Clustered)는 여러 번의 IO가 필요하다고 할 수 있습니다. 하지만 실제로는 이를 데이터로 보여주는 것이 더 효과적이죠.
동일한 데이터 구조(저장 형태만 heap 또는 clustered로 다름)를 가진 두 테이블을 만들어 실험합니다. 아래는 테이블 생성 예시입니다. 대괄호 내부가 힙인지 클러스터형 인덱스인지 구분점입니다.
CREATE TABLE sales[nc] (
sale_id NUMERIC NOT NULL,
employee_id NUMERIC NOT NULL,
eur_value NUMERIC(16,2) NOT NULL,
SALE_DATE DATE NOT NULL
CONSTRAINT salesnc_pk
PRIMARY KEY [nonclustered] (sale_id),
);
CREATE INDEX sales[nc]2 ON sales[nc] (sale_date);
테스트를 위해 1,000만 행을 삽입했습니다.
다음 단계는 성능 영향을 측정할 쿼리입니다.
SELECT TOP 1 *
FROM salesnc
WHERE sale_date > '2012-05-23'
ORDER BY sale_date
이 쿼리는 비클러스터형 인덱스를 사용하여(SALE_DATE로 필터 및 정렬) 다양하게 행 수를 조절하며, 누락된 컬럼을 조회하여 인덱스 전용 스캔이 아닌 성능을 봅니다.
SET STATISTICS IO ON 명령으로 힙 테이블에서 실행하면 다음과 같습니다:
Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0,…
즉, 한 번의 쿼리에 논리적 읽기 4번—인덱스 3단계 + 힙에서 1회 읽기입니다. TOP 2로 바꾸면:
SELECT TOP 2 *
FROM salesnc
WHERE sale_date > '2012-05-23'
ORDER BY sale_date
Scan count 1, logical reads 5, physical reads 0, read-ahead reads 0,…
1행 더 읽으므로 논리적 읽기 1회 증가—즉, 인덱스 스캔은 변하지 않고, 힙 테이블 2행 각각 참조가 발생합니다.
이번엔 클러스터형 인덱스 테이블에서는:
SELECT TOP 1 *
FROM sales
WHERE sale_date > '2012-05-23'
ORDER BY sale_date
Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0,…
한 행당 무려 8회 읽기—힙의 두 배입니다!
다시 2행 조회하면:
SELECT TOP 2 *
FROM sales
WHERE sale_date > '2012-05-23'
ORDER BY sale_date
Scan count 1, logical reads 13, physical reads 0, read-ahead reads 0,…
5회 추가 IO가 발생했습니다.
1, 2, 5 ... 100행씩 조회하면서 데이터 수집:
| Rows Fetched | Logical Reads (Heap) | Logical Reads (Clustered) |
|---|---|---|
| 1 | 4 | 8 |
| 2 | 5 | 13 |
| 5 | 8 | 27 |
| 10 | 13 | 48 |
| 20 | 23 | 91 |
| 50 | 53 | 215 |
| 100 | 104 | 418 |
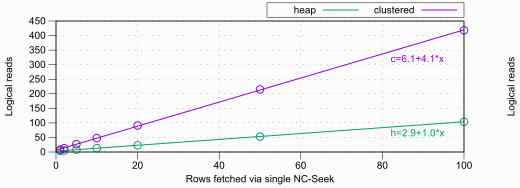
그래프에 선형식도 넣어보니, 힙은 거의 이론과 일치(3+1 per row)하고, 클러스터형은 행당 평균 4회 논리적 읽기가 나타납니다(1, 2행 조회시 기대값보다 다소 적음).
논리적 읽기는 캐시 등 환경에 독립적인, 재현 가능한 벤치마크지만 실제 성능 하락폭은 확정적으로 4배 느려지지는 않습니다. 실제로는 클러스터형 인덱스의 상위 B-tree 레벨이 캐시에 있으므로 그 영향이 완화됩니다.
실제 시간 측정을 위해, 10,000행부터 시작해 200,000행까지, 각각 heap과 clustered 테이블에서 시간 측정:
| Rows Fetched | Time (Heap) | Time (Clustered) |
|---|---|---|
| 10,000 | 31 | 78 |
| 20,000 | 47 | 130 |
| 50,000 | 109 | 297 |
| 100,000 | 203 | 624 |
| 200,000 | 390 | 1232 |
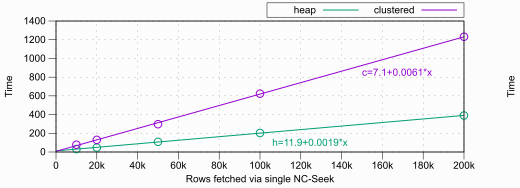
이 테스트 결과, 비클러스터형 인덱스에서 클러스터형 인덱스 패널티는 힙 테이블 대비 약 3배까지 나타납니다.
실제 환경에서는 캐시 상태에 따라 이 범위를 벗어날 수도 있습니다.
클러스터형 인덱스는 클러스터링 키로 직접 접근할 때 연속적인 행을 빠르게 조회할 수 있습니다. 즉, 클러스터링 키(보통 기본키)로 여러 행을 한 번에 조회할 때 빠릅니다. 하지만 Primary Key를 기준으로 =, >, <와 같은 질의를 얼마나 자주 쓰나요? 대부분의 경우 그런 쿼리에 테이블 구조를 최적화하고, 모든 비클러스터형 인덱스에 패널티를 주는 것은 비효율적입니다.
다행히 SQL Server는 어떤 컬럼도 클러스터링 키로 쓸 수 있습니다(고유하지 않아도 됨). 중요한 범위 스캔에 맞춰 선택이 가능합니다. 단, 클러스터링 키가 길거나 여러 컬럼이면 비클러스터형 인덱스가 모두 커지므로 주의해야 합니다. 고유하지 않은 키에 대해서는 SQL Server가 자동으로 추가 컬럼을 붙여 완전 고유하게 하는데, 이것도 인덱스 부풀림으로 이어집니다. 이로 인해 트리 깊이는 잘 안 변할 수 있지만, 캐시 적중률은 낮아질 수 있어 실제 작업 환경에서는 패널티가 더 커지거나 작아질 수 있습니다.
설령 범위 스캔에 최적인 클러스터링 키를 찾아도, 비클러스터형 인덱스에 주는 오버헤드가 이득을 상쇄할 수 있습니다. 테이블 전반의 영향을 추정하기 너무 어렵기 때문에(정말 까다롭습니다), 저는 가능하면 힙 테이블과 인덱스 전용 스캔을 추천합니다. 즉, 클러스터형 인덱스는 '패널티가 문제 안 되는 경우의 공간 최적화 용도' 정도로만 활용합니다.
MySQL/MariaDB의 InnoDB, Azure DB 등 일부 DB는 힙 테이블을 지원하지 않습니다.
또한, 일부 환경에서는 기본키 이외에 클러스터링 키를 허용하지 않습니다(MySQL/MariaDB InnoDB 및 Oracle 인덱스 조직 테이블 등).
InnoDB는 위 조건을 모두 해당하므로 대안이 사실상 없습니다(MyISAM은 대안이 아님).
마지막으로, 클러스터형 인덱스에만 집착하는 것이 얼마나 나쁜 생각인지를 보여주겠습니다.
SQL Server 테이블은 클러스터형 인덱스를 몇 개 가질 수 있나요?
SQL Server 성능교육에서 자주 묻는 질문인데, 대부분 첫 답은 "하나!"입니다. 왜 두 개를 못 가지냐고 하면, 대체로 대답을 못합니다. 이 글을 읽은 분은 아시겠지만, 클러스터형 인덱스는 인덱스이자 테이블 저장소입니다. 하나의 테이블 저장 공간만 가질 수 있으므로, 답은 '최대 1개'가 맞습니다.
그럼 모든 테이블에 클러스터형 인덱스가 필요합니까? 대부분 '글쎄요...'하거나 침묵합니다. 그러나 클러스터형 인덱스가 없으면 SQL Server는 힙 테이블을 쓰게 됩니다.
요약하자면, 답은 '최대 1개'입니다.
여기서 이제 클러스터형 인덱스가 만능이라고 생각하지 마시고, 인덱스 전용 스캔에 집중해 보세요. 질문을 바꾸겠습니다:
SQL Server 테이블에서 클러스터형 인덱스만큼 빠른 쿼리가 가능한 인덱스는 몇 개일까요?
이 질문은 클러스터형 인덱스 자체가 아닌, 그 기대효과에 초점을 둡니다. 핵심은 퍼포먼스(빠른 쿼리)인 것입니다.
클러스터형 인덱스가 빠른 이유는 모든 접근이 인덱스 전용 스캔이기 때문입니다. 즉, '몇 개의 인덱스가 인덱스 전용 스캔을 지원할 수 있냐'는 질문이 되고, 답은 '원하는 만큼 만들 수 있다'입니다. 필요한 컬럼을 모두 포함시킨 비클러스터형 인덱스를 추가하면 사용 시 클러스터형 인덱스만큼 빠릅니다. 바로 이를 위해 CREATE INDEX의 INCLUDE 키워드가 존재합니다!
인덱스 전용 스캔에 집중할 때의 이점은 다음과 같습니다:
INCLUDE 컬럼을 추가해도 해당 인덱스 외에 영향을 주지 않습니다. 타 인덱스에 패널티가 없습니다.이처럼 클러스터형 인덱스 패널티가 존재하기 때문에, 인덱스 전용 스캔 개념이 더욱 중요합니다. "실버불렛"이 있다면, 그것은 클러스터형 인덱스가 아니라 인덱스 전용 스캔일 것입니다.