StarRocks의 비용 기반 옵티마이저(CBO)가 분산 환경에서 조인을 빠르게 만들기 위해 사용하는 논리 최적화, 조인 재정렬, 분산 조인 계획, 런타임 필터 등을 심층적으로 살펴봅니다.
![]()
![]()
한 줄 추가 정보
게시일: 2026년 1월 20일 9:18:43 PM
✍🏼 저자 소개:
Seaven He, StarRocks Committer, Celerdata 엔지니어
조인은 OLAP에서 가장 어려운 부분입니다. 많은 시스템이 대규모에서 조인을 효율적으로 실행하지 못하기 때문에, 팀은 대신 데이터를 넓은 와이드 테이블로 비정규화하여 저장 공간을 10배로 늘리고, 복잡한 스트림 처리 파이프라인을 감당하며, 대규모 백필(backfill)을 유발하는 고통스럽고 느리며 비용이 큰 스키마 진화를 처리하게 됩니다.
StarRocks는 반대 접근을 택합니다. 데이터를 정규화된 상태로 유지하되, 조인을 즉시(on the fly) 수행할 만큼 충분히 빠르게 만드는 것입니다. 과제는 **플랜(plan)**입니다. 분산 시스템에서는 조인 탐색 공간(search space)이 매우 크며, 좋은 플랜은 성능이 수십~수백 배(orders of magnitude)까지도 달라질 수 있습니다.
이 딥다이브에서는 StarRocks의 비용 기반 옵티마이저(Cost-Based Optimizer)가 이를 가능하게 만드는 방식을 4가지 파트로 설명합니다. 조인 기본과 최적화 과제, 논리 조인 최적화, 조인 재정렬, 분산 조인 계획입니다. 마지막으로 NAVER, Demandbase, Shopee의 실제 사례를 통해, 효율적인 조인 실행이 어떻게 실질적인 비즈니스 가치를 제공하는지 살펴봅니다.
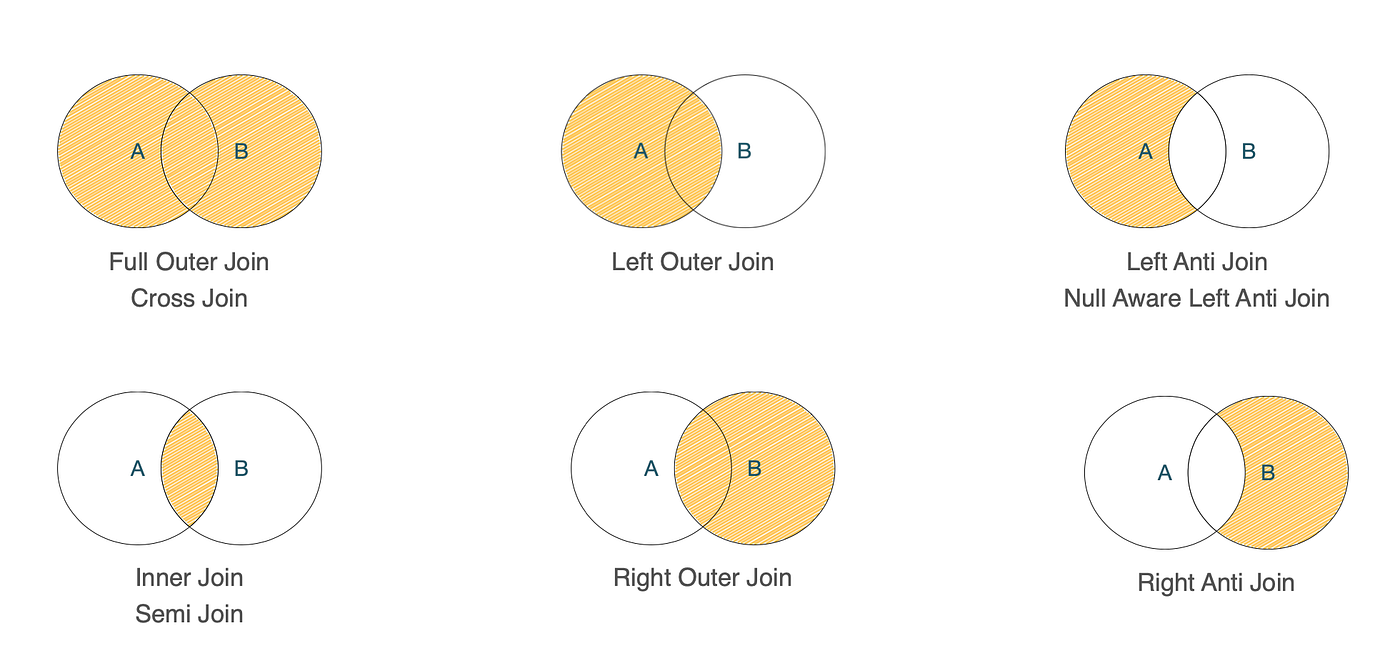
위 다이어그램은 몇 가지 대표적인 조인 유형을 보여줍니다.
NULL 값을 채워 반환합니다. 전체(Full)는 양쪽 테이블 모두, 좌(Left)는 왼쪽 테이블 유지, 우(Right)는 오른쪽 테이블 유지입니다.NOT IN 또는 NOT EXISTS 서브쿼리의 플랜에서 나타납니다.조인 성능 최적화는 일반적으로 두 가지 영역으로 나뉩니다.
이 글은 두 번째 측면에 초점을 둡니다. 배경을 만들기 위해, 조인 최적화의 핵심 과제를 먼저 살펴보겠습니다.
과제 1: 여러 조인 구현 전략(Implementation Strategies)
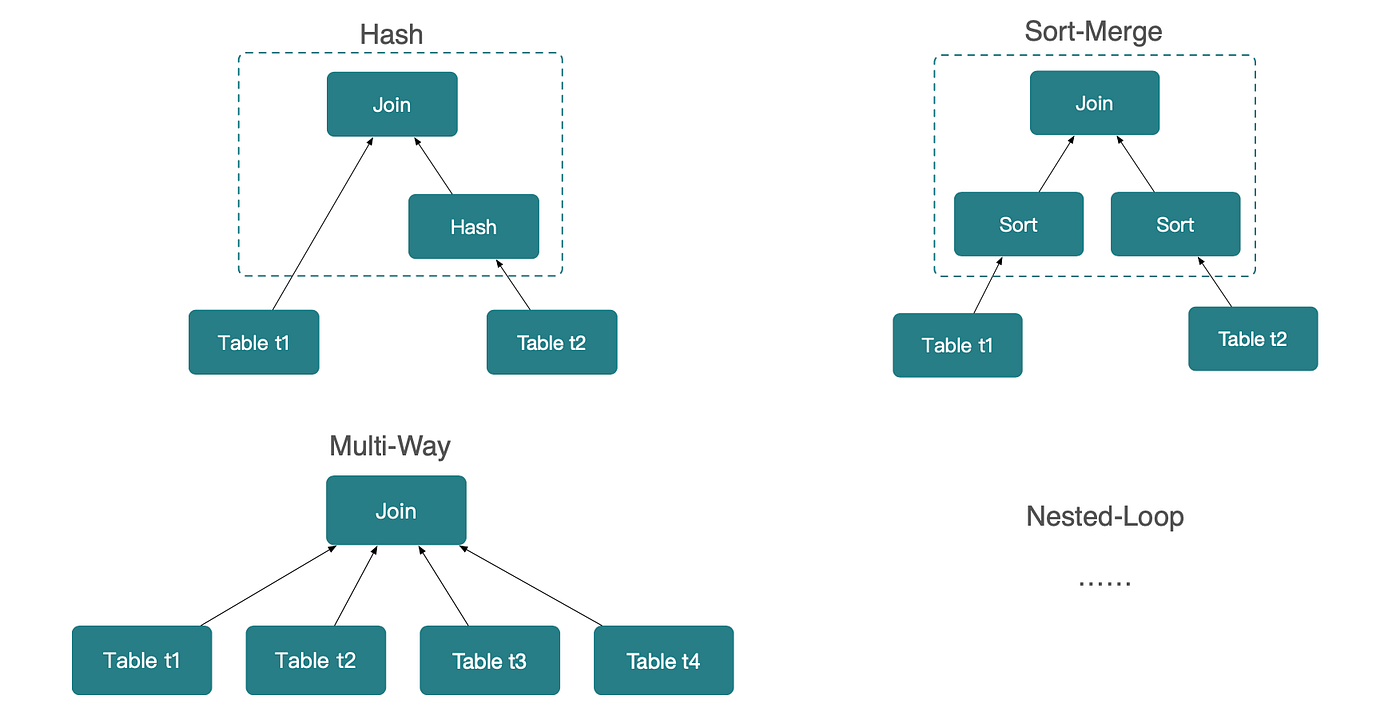
위에서 보듯, 서로 다른 조인 알고리즘은 상황에 따라 성능이 크게 달라집니다. 예를 들어 Sort-Merge Join은 이미 정렬된 데이터에 대해 Hash Join보다 훨씬 효율적일 수 있습니다. 하지만 데이터가 보통 해시 파티셔닝되는 분산 DB에서는 Hash Join이 Sort-Merge Join보다 훨씬 좋은 성능을 내는 경우가 많습니다. 따라서 DB는 워크로드와 데이터 특성에 기반해 가장 적절한 조인 전략을 선택해야 합니다.
과제 2: 다중 테이블 조인에서의 조인 순서 선택(Join Order)
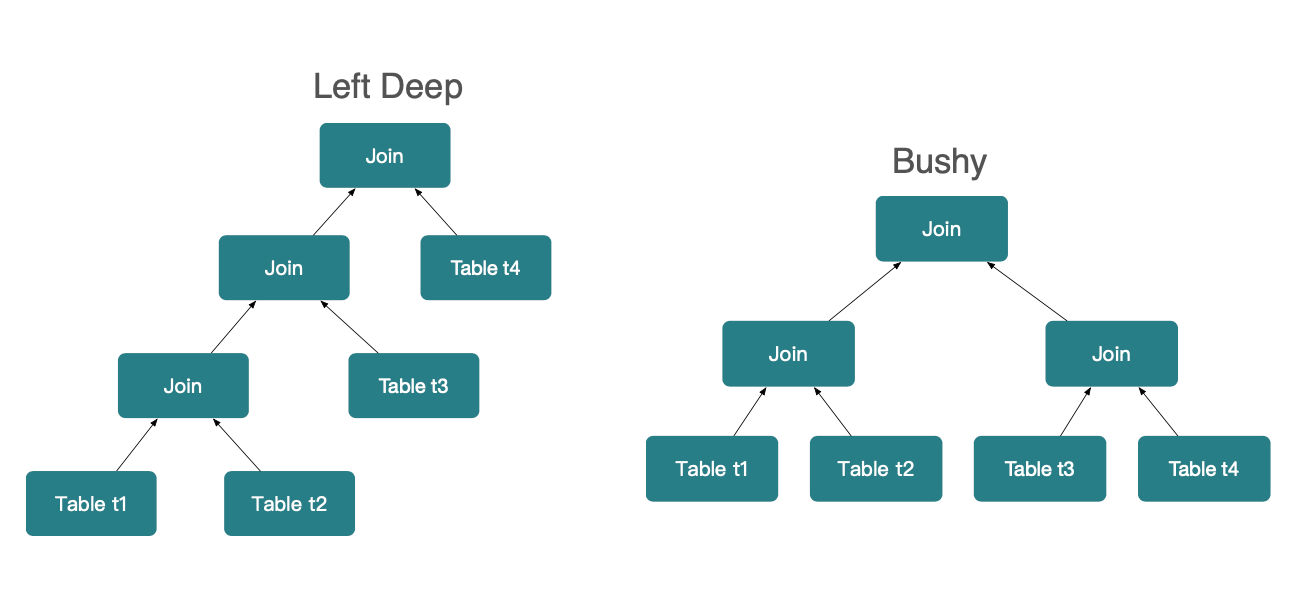
다중 테이블 조인에서는 선택도(selectivity)가 높은 조인을 먼저 수행하면 전체 성능이 크게 개선될 수 있습니다. 그러나 최적 조인 순서를 찾는 것은 결코 단순하지 않습니다.
위 그림처럼 Left-deep 조인 트리 모델에서는 _N_개 테이블의 가능한 조인 순서 수가 대략 2^n-1 수준입니다. Bushy 조인 트리 모델에서는 조합 수가 더 폭발적으로 증가하여 2^(n-1) * C(n-1)에 달합니다. 옵티마이저 입장에서는 최적 조인 순서를 찾기 위한 탐색 시간과 비용이 지수적으로(exponentially) 증가하므로, 조인 순서 결정은 쿼리 최적화에서 가장 어려운 문제 중 하나입니다.
과제 3: 조인 효과(Selectivity) 추정의 어려움
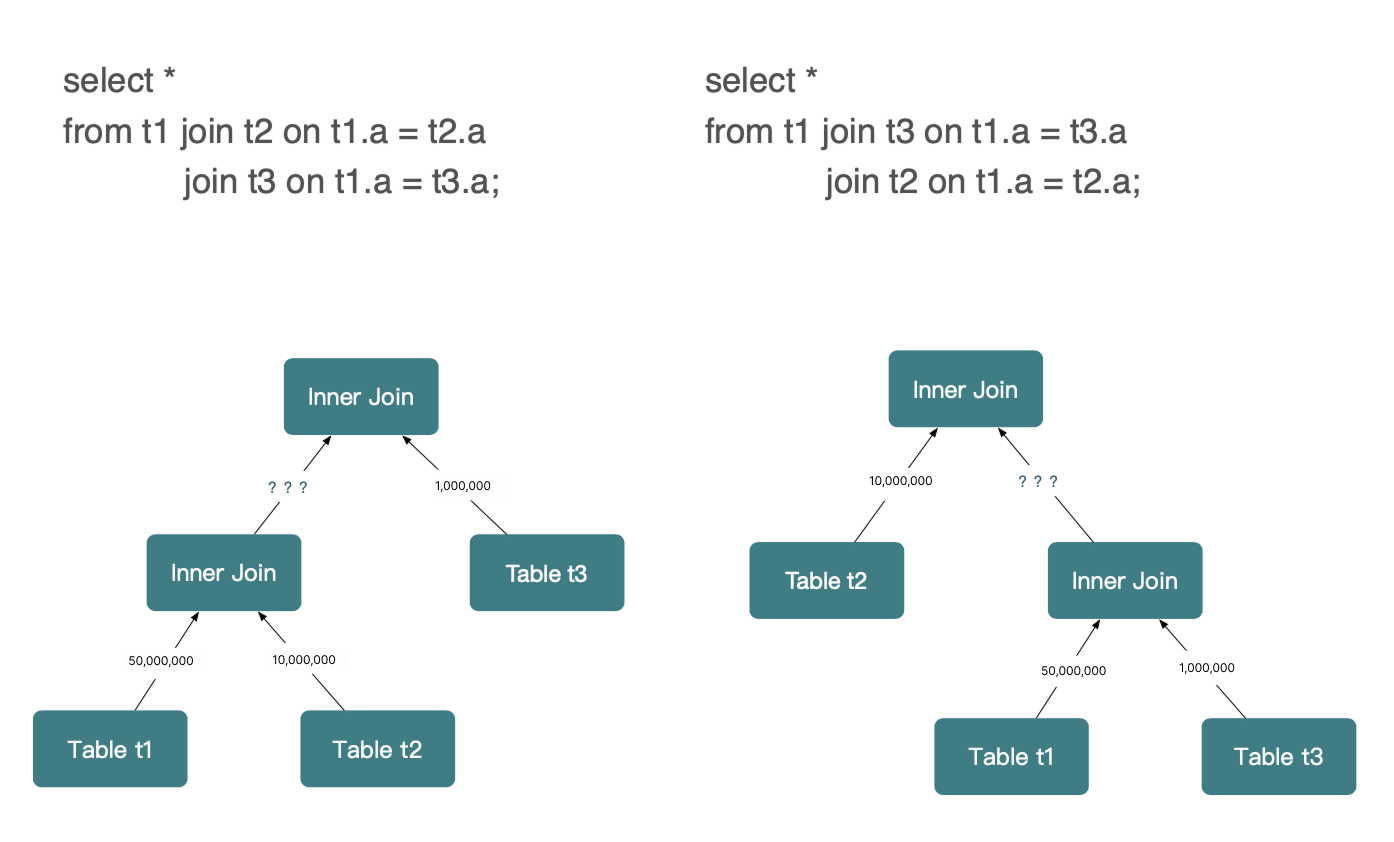
쿼리 실행 전에 DB가 조인의 실제 실행 동작을 정확히 예측하기는 매우 어렵습니다. 흔한 가정은 작은 테이블과 큰 테이블을 조인하는 것이 큰 테이블 둘을 조인하는 것보다 더 선택적이라는 것이지만, 항상 맞지는 않습니다.
실제로는 1:N 관계가 흔하며, 더 복잡한 쿼리에서는 조인이 필터, 집계, 기타 연산자와 함께 결합됩니다. 데이터가 여러 변환을 거치면 옵티마이저가 조인 입력 크기와 선택도를 정확히 추정하는 능력은 크게 떨어집니다.
과제 4: 단일 노드에서 최적인 플랜이 분산 시스템에서 최적이 아닐 수 있음
Press enter or click to view image in full size
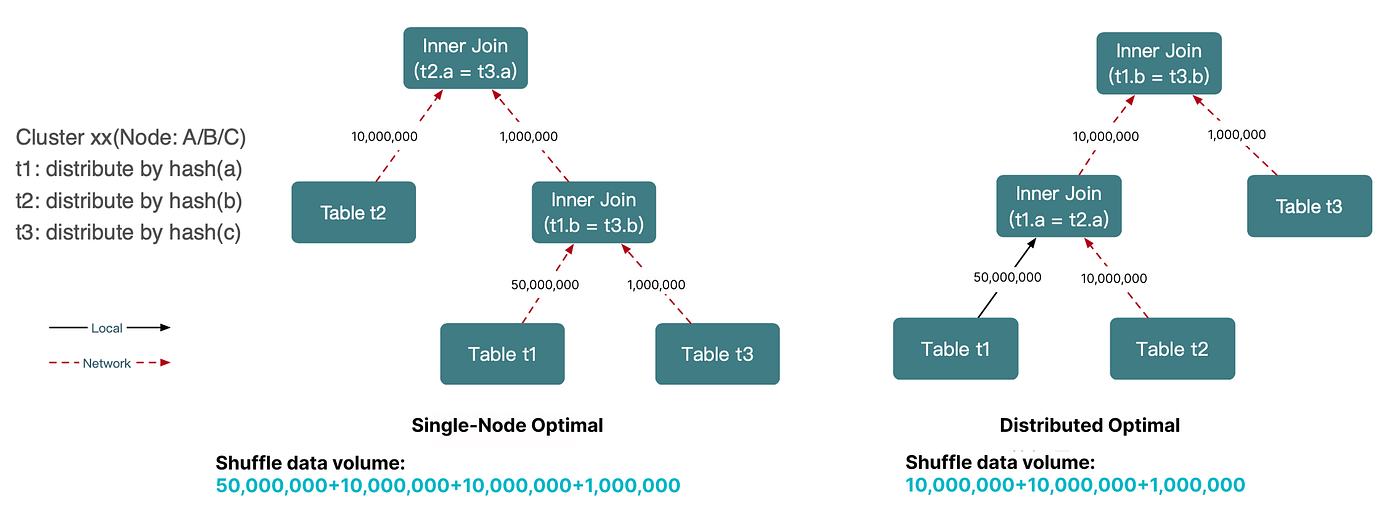
분산 시스템에서는 필요한 레코드가 조인 계산에 참여할 수 있도록, 데이터가 노드 간에 리셔플(reshuffle) 또는 브로드캐스트(broadcast) 되어야 하는 경우가 많습니다. 분산 조인도 예외가 아닙니다.
여기서 핵심적인 복잡성이 생깁니다. 단일 노드 DB에서 최적인 실행 계획은 데이터 분포와 네트워크 전송 비용을 무시하기 때문에 분산 환경에서는 오히려 성능이 나쁠 수 있습니다.
따라서 분산 DB에서 조인 실행 전략을 계획할 때 옵티마이저는 로컬 실행 효율뿐 아니라 데이터 배치와 통신 오버헤드를 명시적으로 고려해야 합니다.
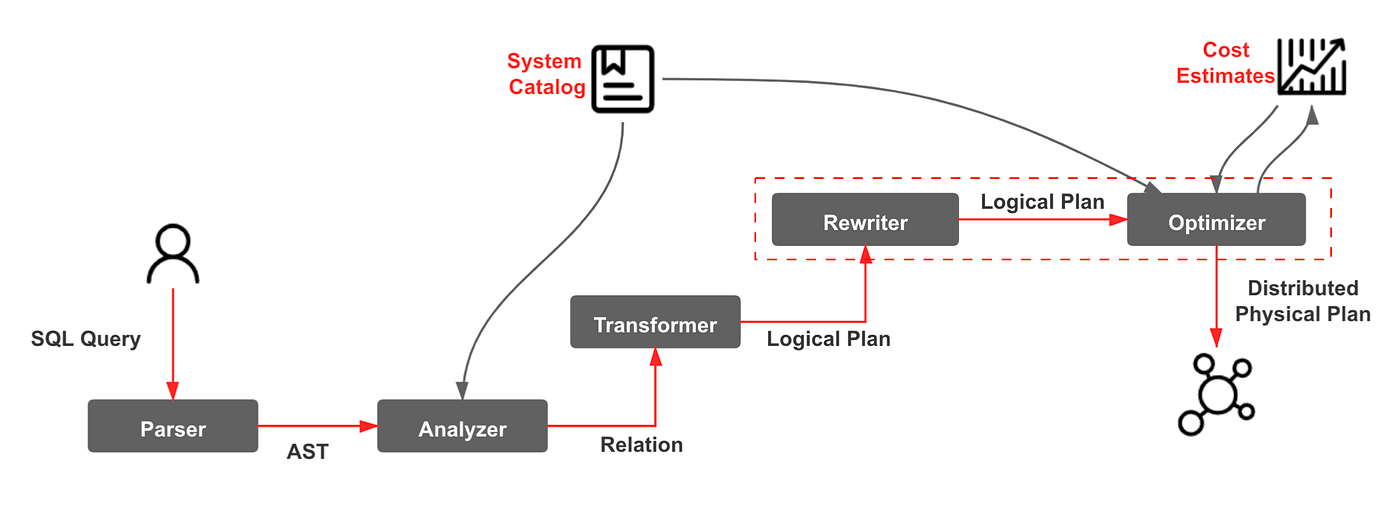
StarRocks에서 SQL 최적화는 주로 쿼리 옵티마이저가 담당하며, Rewrite와 Optimize 단계에 집중되어 있습니다.
현재 StarRocks는 조인 알고리즘으로 주로 Hash Join을 사용합니다. 기본적으로 오른쪽 테이블을 사용해 해시 테이블을 빌드합니다. 이 설계 선택을 바탕으로, 다음 5가지 핵심 최적화 원칙을 정리할 수 있습니다.
이 섹션에서는 StarRocks가 논리(logical) 레벨에서 조인을 최적화하기 위해 사용하는 휴리스틱 규칙(heuristic rules) 세트를 소개합니다.
첫 번째 최적화 그룹은 앞서 언급한 1번 원칙을 직접 따릅니다. 즉 의미(semantics)가 허용하는 경우, 비효율적인 조인 유형을 더 효율적인 유형으로 변환합니다.
StarRocks는 현재 3가지 주요 변환 규칙을 적용합니다.
규칙 1: 크로스 조인을 이너 조인으로 변환
다음 조건을 만족하면 Cross Join을 Inner Join으로 재작성할 수 있습니다.
예:
-- 변환 전
SELECT * FROM t1, t2 WHERE t1.v1 = t2.v1
-- 변환 후
-- WHERE t1.v1 = t2.v1 는 조인 술어
SELECT * FROM t1 INNER JOIN t2 ON t1.v1 = t2.v1;
규칙 2: 외부 조인을 이너 조인으로 변환
다음 조건을 만족하면 Left/Right Outer Join을 Inner Join으로 재작성할 수 있습니다.
예:
-- 변환 전
SELECT * FROM t1 LEFT OUTER JOIN t2 ON t1.v1 = t2.v1 WHERE t2.v1 > 0;
-- 변환 후
-- t2.v1 > 0 는 t2에 대한 strict 술어
SELECT * FROM t1 INNER JOIN t2 ON t1.v1 = t2.v1 WHERE t2.v1 > 0;
⚠️ 중요: 외부 조인에서는 ON 절의 술어가 필터링이 아니라 NULL 확장(null extension) 에 참여합니다. 따라서 이 규칙은 ON 절 내부의 조인 술어에는 적용되지 않습니다.
SELECT * FROM t1 LEFT OUTER JOIN t2 ON t1.v1 = t2.v1 AND t2.v1 > 1;
이 쿼리는 다음과 동일한 의미가 아닙니다.
SELECT * FROM t1 INNER JOIN t2 ON t1.v1 = t2.v1 AND t2.v1 > 1;
여기서 엄격(strict, null-rejecting) 술어 개념이 등장합니다. StarRocks에서는 NULL 값을 걸러내는 술어를 strict 술어로 봅니다(예: a > 0). 반대로 NULL 값을 제거하지 않는 술어는 non-strict 술어로 분류합니다(예: a IS NULL). 대부분의 술어는 strict 범주에 속하며, non-strict 술어는 주로 IS NULL, IF, CASE WHEN, 또는 특정 함수 기반 표현식에서 발생합니다.
StarRocks는 술어가 strict인지 판단하기 위해 간단하지만 효과적인 방법을 사용합니다. 참조되는 모든 컬럼을 NULL로 치환한 다음 표현식을 단순화합니다. 결과가 TRUE로 평가되면 WHERE 절이 NULL 입력 행을 필터링하지 않으므로 non-strict입니다. 반대로 결과가 FALSE 또는 NULL이면 strict 술어입니다.

규칙 3: 전체 외부 조인을 좌/우 외부 조인으로 변환
다음 조건을 만족하면 Full Outer Join을 Left Outer Join 또는 Right Outer Join으로 재작성할 수 있습니다.
예:
-- 변환 전
SELECT * FROM t1 FULL OUTER JOIN t2 ON t1.v1 = t2.v1 WHERE t1.v1 > 0;
-- 변환 후
-- t1.v1 > 0 는 왼쪽 테이블에 대한 strict 술어
SELECT * FROM t1 LEFT OUTER JOIN t2 ON t1.v1 = t2.v1 WHERE t1.v1 > 0;
술어 푸시다운은 가장 중요하고 널리 쓰이는 조인 최적화 기법 중 하나입니다. 핵심 목적은 조인 입력을 가능한 한 일찍 필터링하여 조인에 참여하는 데이터 양을 줄이고 전체 성능을 개선하는 것입니다.
WHERE 절의 술어는 다음 조건을 만족할 때 푸시다운을 적용할 수 있으며, 그 과정에서 조인 타입 변환이 가능해질 수도 있습니다.
WHERE 술어가 조인 입력 중 하나에 바인딩 가능.예:
Select *
From t1 Left Outer Join t2 On t1.v1 = t2.v1
Left Outer Join t3 On t2.v2 = t3.v2
Where t1.v1 = 1 And t2.v1 = 2 And t3.v2 = 3;
술어 푸시다운 과정은 다음과 같습니다.
Step 1:
(t1.v1 = 1 AND t2.v1 = 2)와 (t3.v2 = 3)을 각각 푸시다운합니다. 조인 타입 변환 규칙을 만족하므로 (t1 LEFT OUTER JOIN t2) LEFT OUTER JOIN t3는 (t1 LEFT OUTER JOIN t2) INNER JOIN t3로 재작성할 수 있습니다.
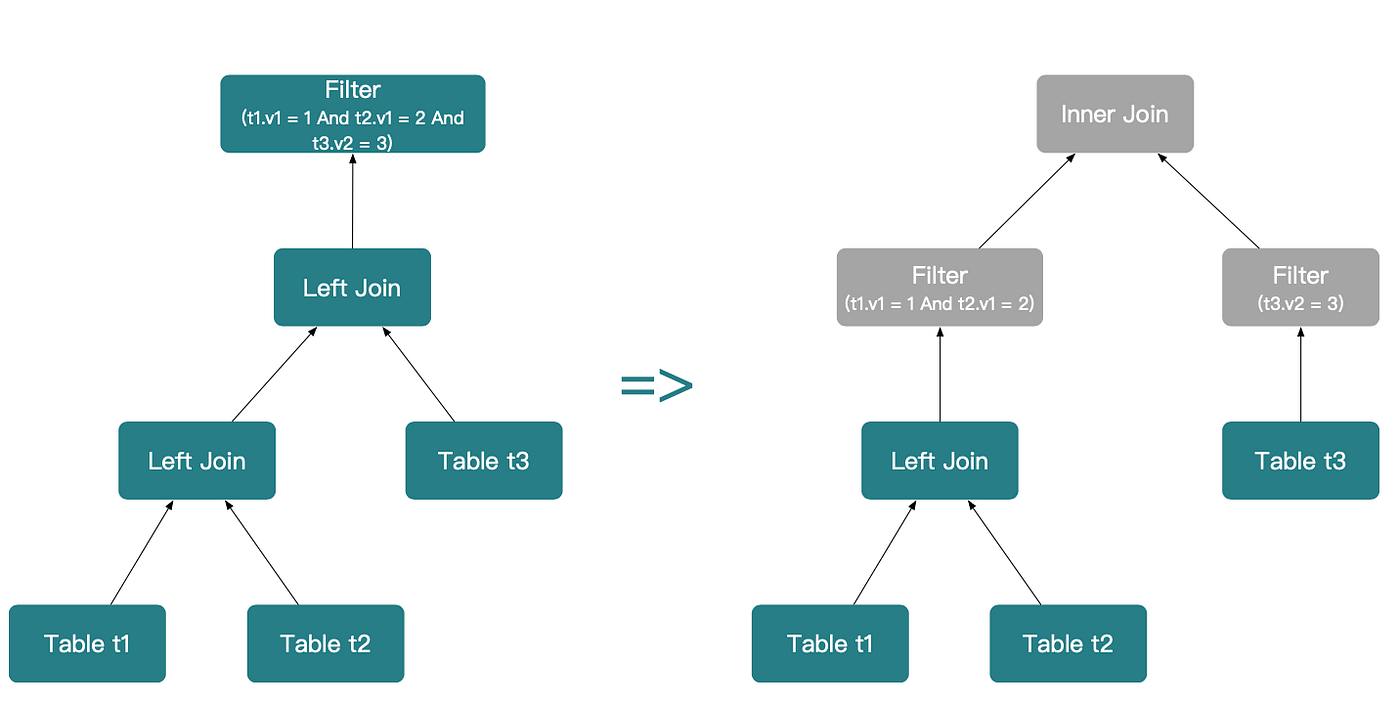
Step 2:
(t1.v1 = 1)과 (t2.v1 = 2)를 계속 푸시다운합니다. 이 시점에서 t1 LEFT OUTER JOIN t2는 t1 INNER JOIN t2로 추가 변환될 수 있습니다.
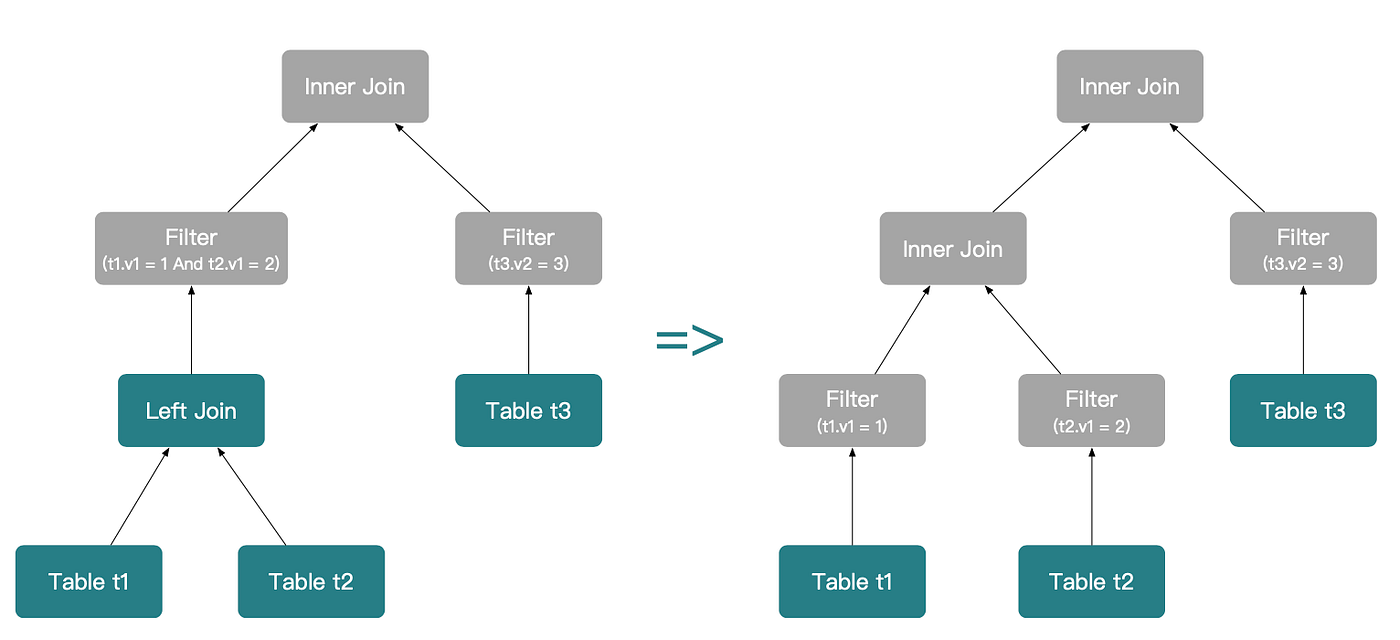
ON 절 조인 술어의 푸시다운 규칙은 WHERE 절과 다르다는 점이 중요합니다. 여기서는 두 경우를 구분합니다. 이너 조인과 기타 조인 타입입니다.
Case 1: Inner Join
이너 조인의 경우 ON 절 조인 술어 푸시다운은 WHERE 절 술어 푸시다운과 동일한 규칙을 따릅니다. 이미 위에서 다뤘으므로 반복하지 않습니다.
Case 2: Outer / Semi / Anti Joins
Outer/Semi/Anti Join에서는 ON 절 조인 술어 푸시다운이 다음 제약을 만족해야 하며, 푸시다운 과정에서 조인 타입 변환은 허용되지 않습니다.
다음 예를 보겠습니다.
Select *
From t1 Left Outer Join t2 On t1.v1 = t2.v1 And t1.v1 = 1 And t2.v1 = 2
Left Outer Join t3 On t2.v2 = t3.v2 And t3.v2 = 3;
술어 푸시다운은 다음처럼 진행됩니다.
Step 1:
조인 술어 (t3.v2 = 3)를 푸시다운합니다. 이는 t1 LEFT JOIN t2 LEFT JOIN t3의 오른쪽 입력에 바인딩될 수 있습니다. 이 단계에서는 LEFT OUTER JOIN을 INNER JOIN으로 변환할 수 없습니다.
Press enter or click to view image in full size
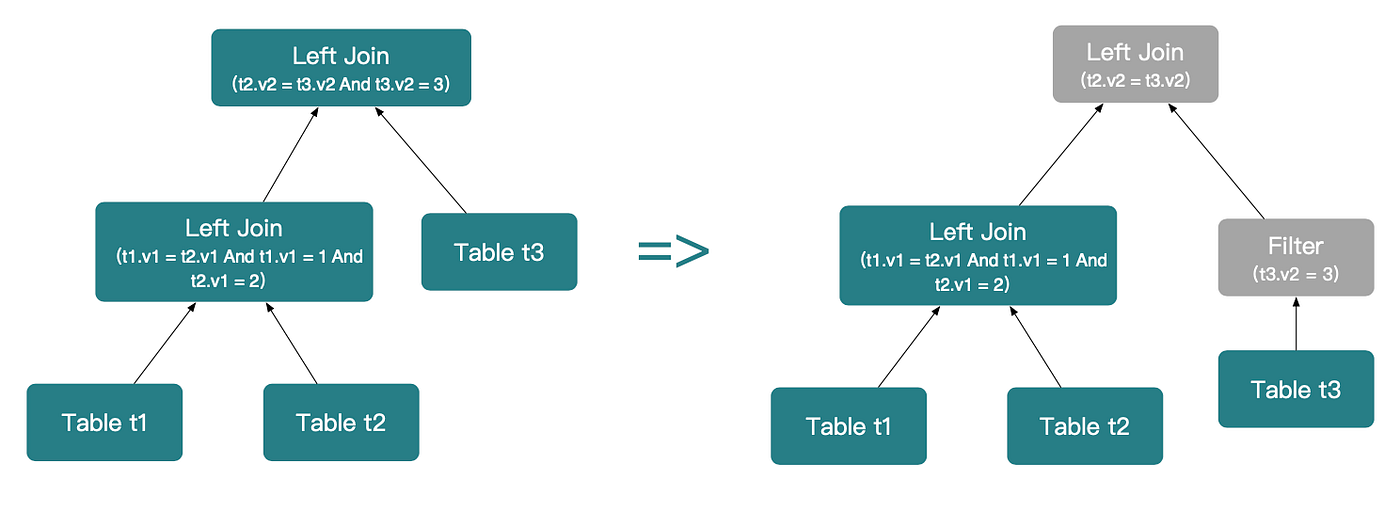
Step 2:
조인 술어 (t2.v1 = 2)를 푸시다운합니다. 이는 t1 LEFT JOIN t2의 오른쪽 입력에 바인딩될 수 있습니다.
하지만 (t1.v1 = 1)은 왼쪽 입력에 바인딩됩니다. 이를 푸시다운하면 t1의 행이 필터링되어 LEFT OUTER JOIN의 의미를 위반합니다. 따라서 이 술어는 푸시다운할 수 없습니다.
Press enter or click to view image in full size

앞서의 술어 푸시다운 규칙에서는 논리곱(AND) 의미의 술어만 푸시다운할 수 있습니다. 예를 들어 t1.v1 = 1 AND t2.v1 = 2 AND t3.v2 = 3에서는 각 하위 술어가 AND로 연결되어 있어 푸시다운이 쉽습니다. 하지만 t1.v1 = 1 OR t2.v1 = 2 OR t3.v2 = 3 같은 논리합(OR) 의미의 술어는 직접 푸시다운할 수 없습니다.
실제 쿼리에서는 OR 술어가 자주 등장합니다. 이를 해결하기 위해 StarRocks는 술어 추출(predicate extraction, 컬럼 값 도출/유도) 이라는 최적화를 도입했습니다. 이 기법은 컬럼 값 범위에 대해 합집합/교집합 연산을 수행하여 OR 술어로부터 AND 형태의 술어를 도출합니다. 이렇게 도출된 AND 술어는 푸시다운하여 조인 입력 크기를 줄일 수 있습니다.
예:
-- 술어 추출 전
SELECT *
FROM t1 JOIN t2 ON t1.v1 = t2.v1
WHERE (t2.v1 = 2 AND t1.v2 = 3)OR (t2.v1 > 5 AND t1.v2 = 4);
(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)에 대해 컬럼 값 도출을 수행하면 옵티마이저는 다음 술어를 추출할 수 있습니다.
t2.v1 >= 2t1.v2 IN (3, 4)그러면 쿼리는 다음과 같이 재작성될 수 있습니다.
SELECT *
FROM t1 JOIN t2 ON t1.v1 = t2.v1
WHERE (t2.v1 = 2 AND t1.v2 = 3)OR (t2.v1 > 5 AND t1.v2 = 4)AND t2.v1 >= 2
AND t1.v2 IN (3, 4);
추출된 술어는 원래 술어 범위의 상위집합(superset)이 될 수 있습니다. 따라서 원래 술어를 안전하게 대체할 수 없으며, 대신 원래 술어에 추가로 적용되어야 합니다.
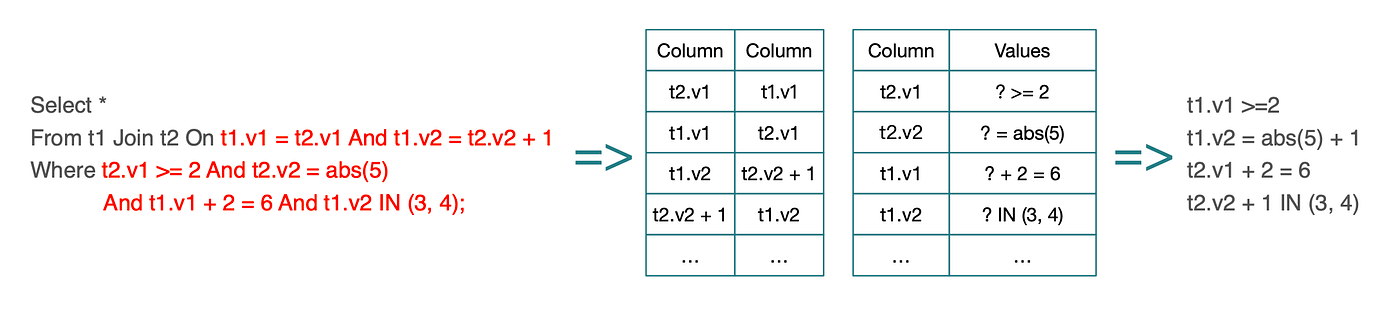
술어 추출 외에도 중요한 술어 수준 최적화가 하나 더 있는데, 바로 등가 도출(equivalence derivation) 입니다. 이 기법은 조인 동등 조건(join equality conditions) 을 활용해, 한쪽에 적용된 술어에서 다른 쪽의 값 제약을 추론합니다.
구체적으로, 조인 조건에 기반해 왼쪽 테이블 컬럼의 값 범위로부터 오른쪽 테이블 컬럼의 값 범위를 도출할 수 있고, 그 반대도 가능합니다.
예:
-- 원본 SQL
SELECT *
FROM t1 JOIN t2 ON t1.v1 = t2.v1
WHERE (t2.v1 = 2 AND t1.v2 = 3)
OR (t2.v1 > 5 AND t1.v2 = 4);
(t2.v1 = 2 AND t1.v2 = 3) OR (t2.v1 > 5 AND t1.v2 = 4)에 대해 술어 추출을 수행하면 옵티마이저는 다음 술어를 도출할 수 있습니다.
t2.v1 >= 2t1.v2 IN (3, 4)결과:
SELECT *
FROM t1 JOIN t2 ON t1.v1 = t2.v1
WHERE (t2.v1 = 2 AND t1.v2 = 3)
OR (t2.v1 > 5 AND t1.v2 = 4)
AND t2.v1 >= 2
AND t1.v2 IN (3, 4);
다음으로 조인 술어 (t1.v1 = t2.v1)와 t2.v1 >= 2를 함께 사용하면 등가 도출로 추가 술어를 추론할 수 있습니다.
t1.v1 >= 2따라서 쿼리는 다음처럼 더 재작성될 수 있습니다.
SELECT *
FROM t1 JOIN t2 ON t1.v1 = t2.v1
WHERE (t2.v1 = 2 AND t1.v2 = 3)
OR (t2.v1 > 5 AND t1.v2 = 4)
AND t2.v1 >= 2
AND t1.v2 IN (3, 4)
AND t1.v1 >= 2;
적용 범위와 제약
등가 도출의 적용 범위는 술어 추출보다 제한적입니다. 술어 추출은 임의의 술어에 적용할 수 있는 반면, 등가 도출은 술어 푸시다운처럼 조인 타입에 따라 제약이 달라집니다. 앞과 마찬가지로 WHERE 술어와 ON 절 조인 술어를 구분합니다.
WHERE 술어의 경우:
ON 절 조인 술어의 경우:
WHERE 술어와 동일하게 추가 제약이 없습니다.왜 Outer/Semi 조인에서 등가 도출이 단방향인가?
이유는 간단합니다. Left Outer Join을 생각해보면, 술어 푸시다운 규칙에서처럼 오른쪽 테이블의 술어만 푸시다운 가능하며, 왼쪽 테이블 술어는 푸시다운할 수 없습니다(의미 위반).
같은 이유로, 오른쪽 테이블에서 도출된 술어를 왼쪽 테이블에 적용하는 것도 이 제약을 따라야 합니다. 실제로 보존되는 쪽(preserved side)에 대한 도출 술어는 조기 필터링에 도움이 되지 않고 평가 오버헤드만 추가할 수 있습니다. 따라서 StarRocks는 Outer/Semi 조인에서 등가 도출을 의도적으로 단방향으로 제한합니다.
구현 세부사항
StarRocks는 등가 도출을 위해 내부적으로 두 개의 맵(map)을 유지합니다.
이 두 맵을 교차 조회 및 추론해 추가적인 등가 술어를 도출합니다. 전체 메커니즘은 아래 그림과 같습니다.
술어뿐 아니라 LIMIT 절도 조인을 통해 푸시다운할 수 있습니다. 쿼리에 Outer Join 또는 Cross Join이 포함된 경우, 출력 행 수가 안정적으로 보장되는 자식 연산자 쪽으로 LIMIT를 푸시다운할 수 있습니다.
예를 들어 Left Outer Join에서는 출력 행 수가 최소한 왼쪽 입력 행 수와 같거나 더 큽니다. 따라서 LIMIT는 왼쪽 테이블로 푸시다운될 수 있습니다(오른쪽 조인도 대칭적으로 동일).
-- 푸시다운 전
SELECT *
FROM t1 LEFT OUTER JOIN t2 ON t1.v1 = t2.v1
LIMIT 100;
-- 푸시다운 후
SELECT *
FROM (SELECT * FROM t1 LIMIT 100) t
LEFT OUTER JOIN t2 ON t.v1 = t2.v1
LIMIT 100;
Cross Join은 데카르트 곱을 만들며 출력 카디널리티는 rows(left) × rows(right)입니다. Full Outer Join은 최소 rows(left) + rows(right)를 생성합니다.
이 조인 타입들에서는 LIMIT를 양쪽 입력 모두에 독립적으로 푸시다운할 수 있습니다.
-- 푸시다운 전
SELECT *
FROM t1 JOIN t2
LIMIT 100;
-- 푸시다운 후
SELECT *
FROM (SELECT * FROM t1 LIMIT 100) x1
JOIN (SELECT * FROM t2 LIMIT 100)
LIMIT 100;
조인 재정렬(join reordering)은 다중 테이블 조인의 실행 순서를 결정합니다. 옵티마이저는 선택도가 높은 조인을 가능한 한 먼저 실행해 중간 결과 크기를 줄이고 전체 성능을 개선하는 것을 목표로 합니다.
StarRocks에서 조인 재정렬은 주로 연속된 Inner Join 또는 Cross Join 시퀀스에 대해 동작합니다. 아래 그림처럼, StarRocks는 연속된 Inner/Cross Join 시퀀스를 Multi Join Node로 그룹화합니다. Multi Join Node는 조인 재정렬의 기본 단위이며, 플랜에 여러 노드가 있으면 각각에 대해 독립적으로 재정렬을 수행합니다.
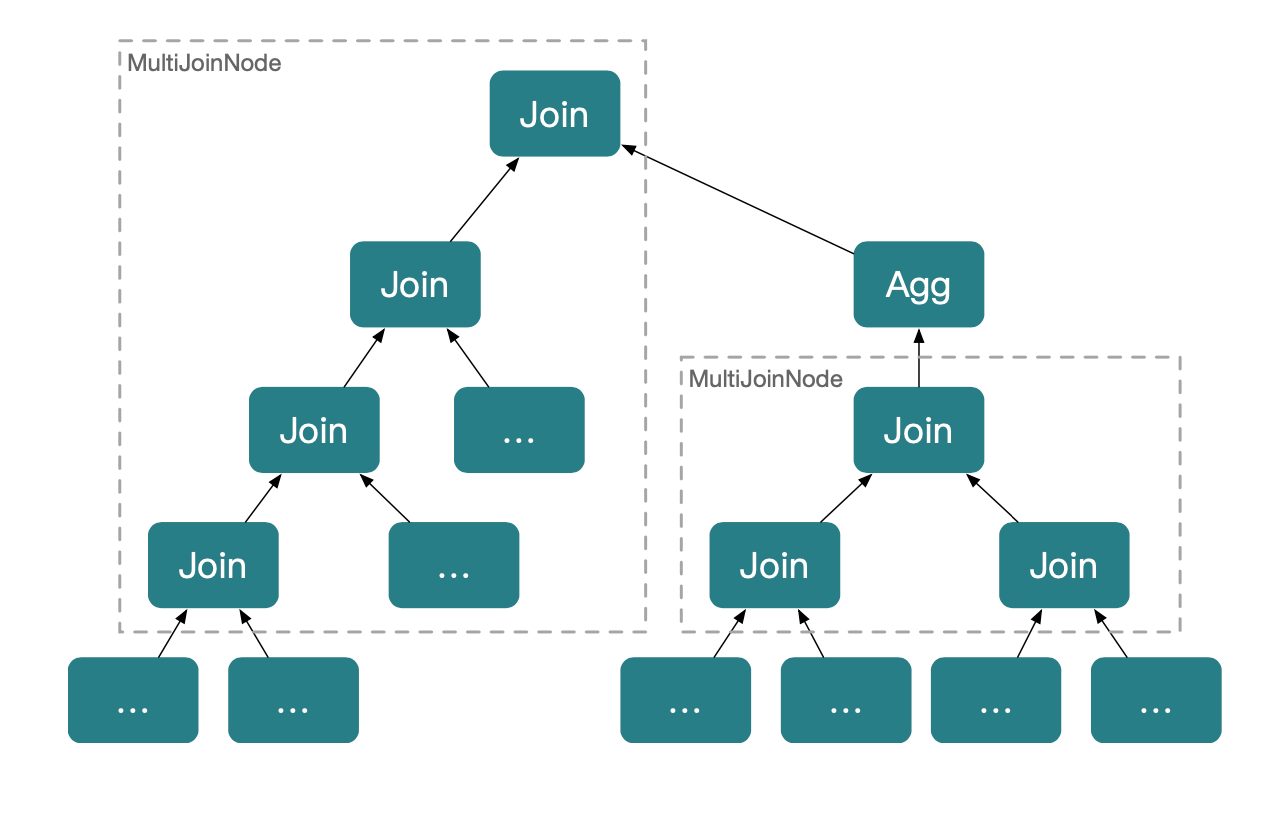
업계에는 다양한 조인 재정렬 알고리즘이 있으며, 서로 다른 최적화 모델을 기반으로 합니다.
StarRocks는 현재 Left-Deep, Exhaustive, Greedy, DPsub 등의 조인 재정렬 전략을 구현하고 있습니다. 다음 섹션에서는 StarRocks의 Exhaustive 및 Greedy 구현 상세에 집중합니다.
완전 탐색 조인 재정렬 알고리즘은 가능한 모든 조인 순서를 체계적으로 열거(enumerate)하는 방식입니다. 실제로는 두 가지 기본 규칙을 통해 거의 전체 조인 순열 공간을 커버합니다.
규칙 1: 조인의 교환법칙(Commutativity)
두 릴레이션 간 조인은 입력을 스왑하여 재정렬할 수 있습니다: A JOIN B → B JOIN A
이 변환에서는 조인 타입도 이에 맞게 조정되어야 합니다. 예를 들어 LEFT OUTER JOIN은 피연산자 스왑 후 RIGHT OUTER JOIN이 됩니다.
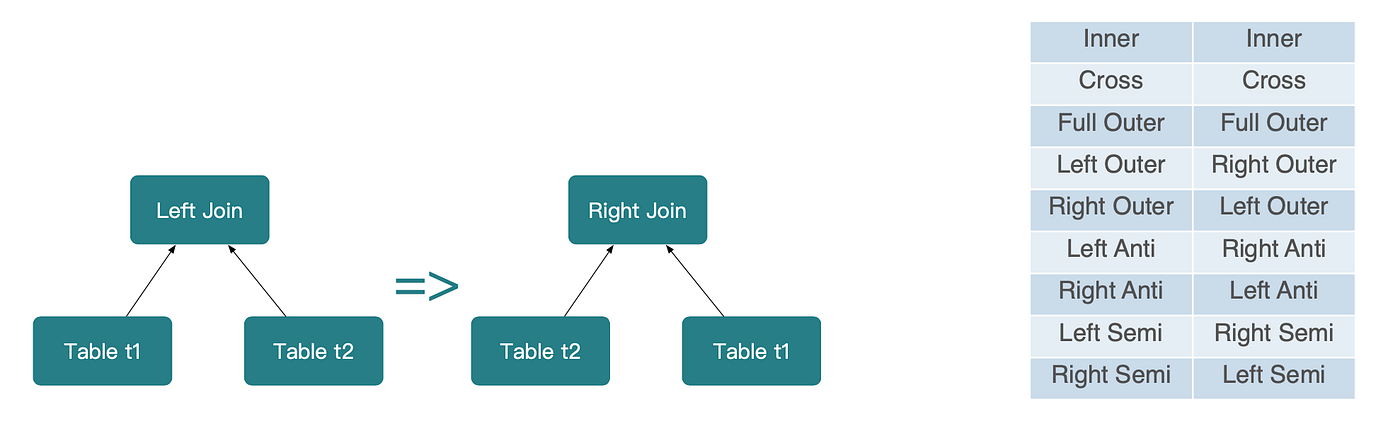
규칙 2: 조인의 결합법칙(Associativity)
조인 결합법칙은 3개 릴레이션 사이의 조인 순서를 재배치할 수 있게 합니다: (A JOIN B) JOIN C → A JOIN (B JOIN C)
StarRocks에서는 조인 타입에 따라 결합법칙을 다르게 처리합니다. 구체적으로 다음을 구분합니다.
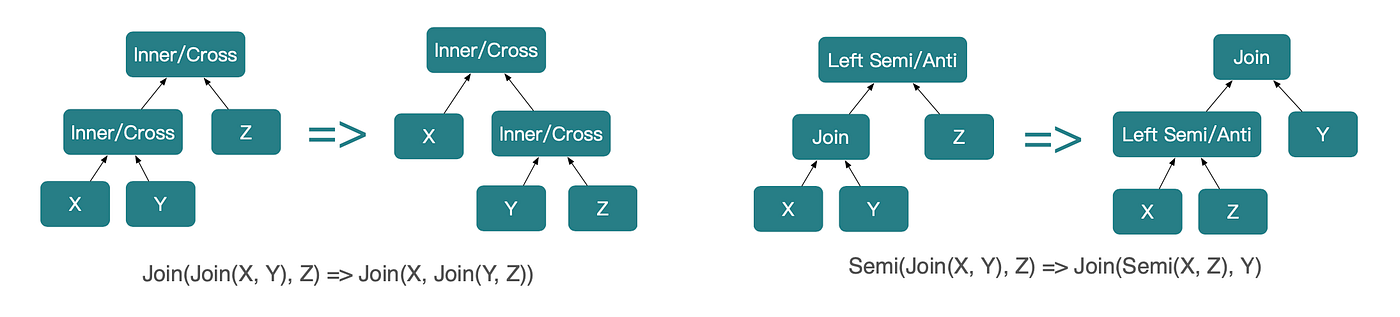
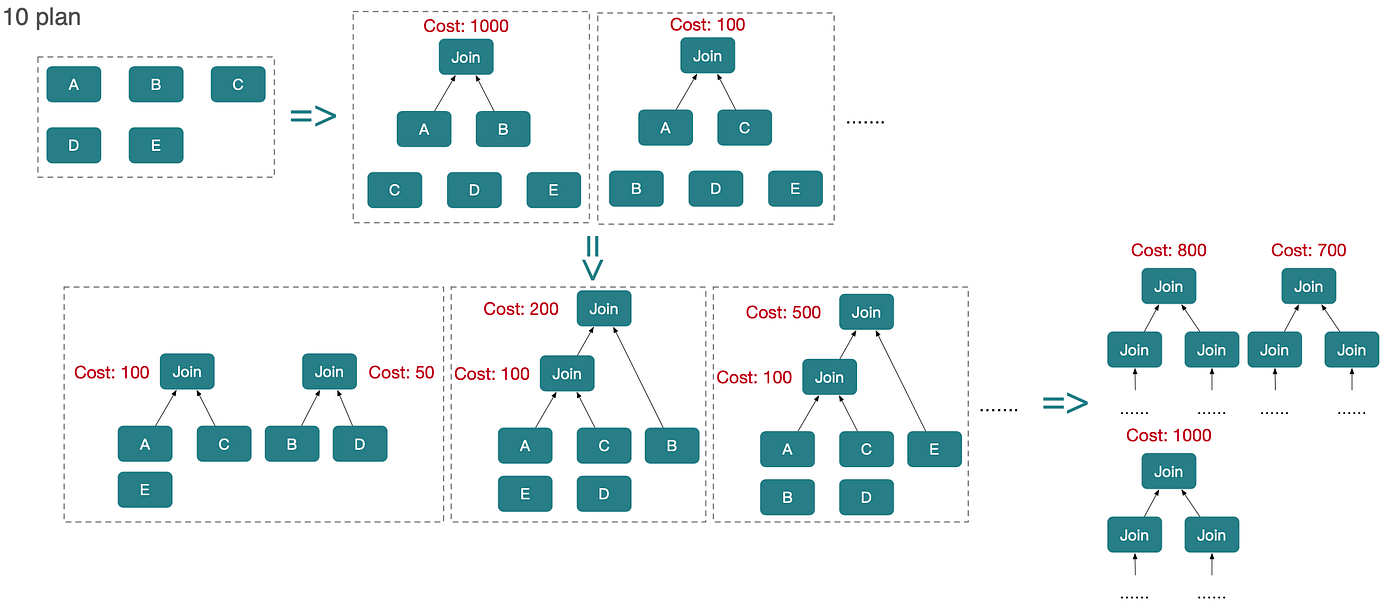
StarRocks의 그리디 조인 재정렬 전략은 주로 멀티-시퀀스 그리디 알고리즘에서 아이디어를 얻었고, 작은 하지만 중요한 개선이 있습니다. 각 반복 단계(iteration level)에서 단 하나의 최선 결과만 유지하는 대신, StarRocks는 상위 10개 후보 플랜(전역 최적이 아닐 수도 있음)을 유지합니다. 이 후보들은 다음 반복 단계로 전달되며, 최종적으로 그리디 최적화 플랜 10개를 생성합니다.
그리디 알고리즘의 한계 때문에 전역 최적 플랜을 보장하지는 않습니다. 하지만 각 단계에서 여러 고품질 후보를 보존함으로써 준최적 또는 최적 해를 찾을 가능성을 크게 높입니다.
Press enter or click to view image in full size
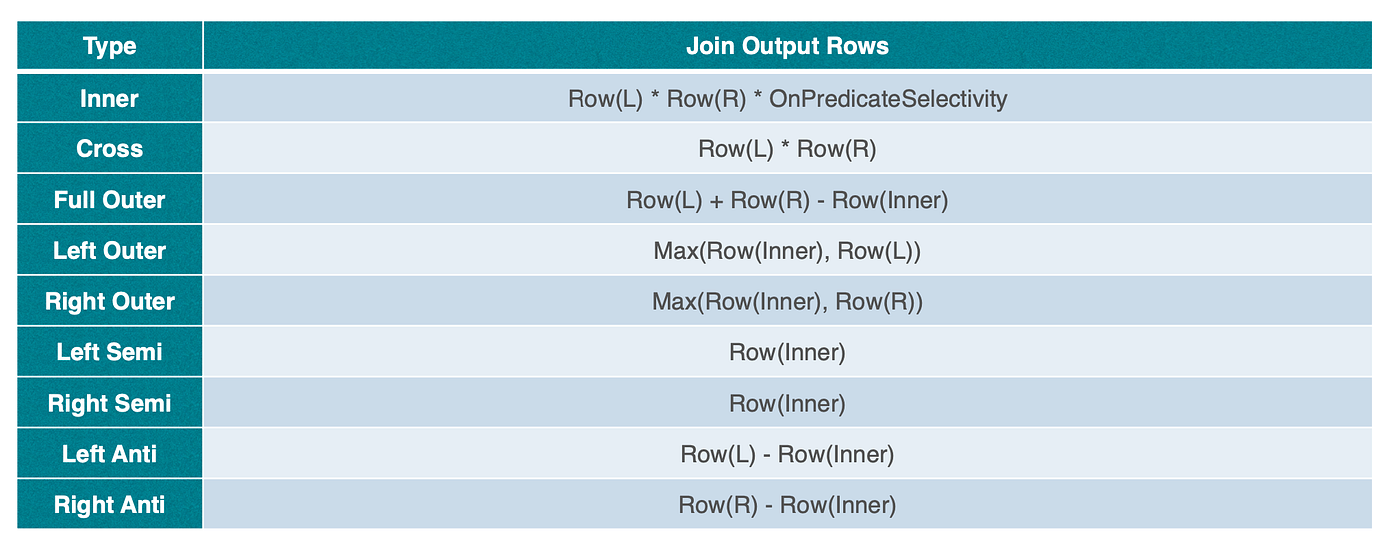
StarRocks는 조인 재정렬 알고리즘으로 _N_개의 후보 플랜을 생성한 뒤, 조인 비용을 추정하는 비용 모델로 이를 평가합니다. 전체 비용은 다음과 같이 계산됩니다: Join Cost = CPU × (Row(L) + Row(R)) + Memory × Row(R)
여기서 Row(L)과 Row(R)은 각각 조인의 왼쪽/오른쪽 자식의 추정 출력 행 수입니다. 이 수식은 두 입력을 처리하는 CPU 비용과, 해시 조인에서 오른쪽으로 해시 테이블을 빌드하는 메모리 비용을 반영합니다. 아래 그림은 StarRocks가 조인 출력 행 수를 더 자세히 추정하는 방식을 보여줍니다.
조인 재정렬 알고리즘마다 탐색 공간 크기와 시간 복잡도가 다르기 때문에, StarRocks는 실행 시간 및 복잡도 특성을 벤치마킹하여 아래와 같이 정리했습니다.

관측된 실행 비용을 바탕으로, StarRocks는 조인 재정렬 알고리즘 사용에 실용적인 제한을 둡니다.
여기에 더해 StarRocks는 조인 교환법칙을 이용해 추가 플랜도 더 탐색합니다.

조인 쿼리의 논리 최적화를 살펴봤으니, 이제 분산 DB로서 StarRocks가 분산 환경에서 조인 실행을 어떻게 최적화하는지, 분산 조인 계획(distributed join planning)에 초점을 맞춰 살펴보겠습니다.
StarRocks는 MPP(Massively Parallel Processing) 실행 프레임워크 위에 구축되어 있습니다. 전체 아키텍처는 아래 그림과 같습니다. 간단한 조인 쿼리를 예로 들면, StarRocks에서 A JOIN B 실행은 보통 다음 흐름으로 진행됩니다.
그림에서 보듯, 쿼리 실행에는 여러 머신 집합이 관여합니다. A를 읽는 노드, B를 읽는 노드, 조인을 수행하는 노드는 반드시 동일하지 않습니다. 그 결과 실행에는 필연적으로 네트워크 전송과 데이터 교환이 포함됩니다.
이러한 네트워크 작업은 큰 오버헤드를 유발합니다. 따라서 StarRocks에서 분산 조인 실행을 최적화하는 핵심 목표는 네트워크 비용을 최소화하는 한편, 플랜을 더 지능적으로 분할·분산하여 병렬 실행의 이점을 최대한 활용하는 것입니다.
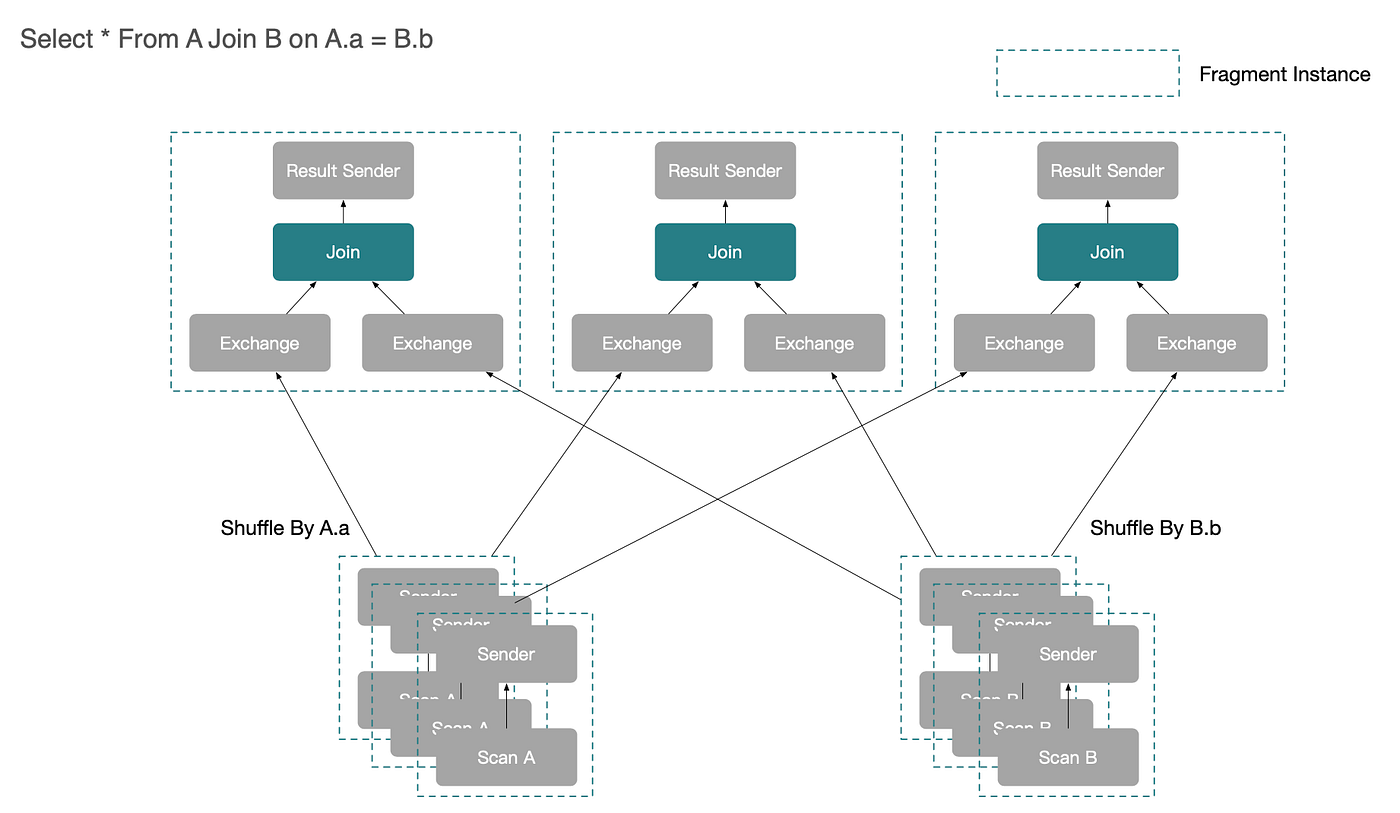
먼저 StarRocks가 생성할 수 있는 분산 실행 계획을 소개하겠습니다. 간단한 조인 쿼리를 예로 듭니다.
Select * From A Join B on A.a = B.b
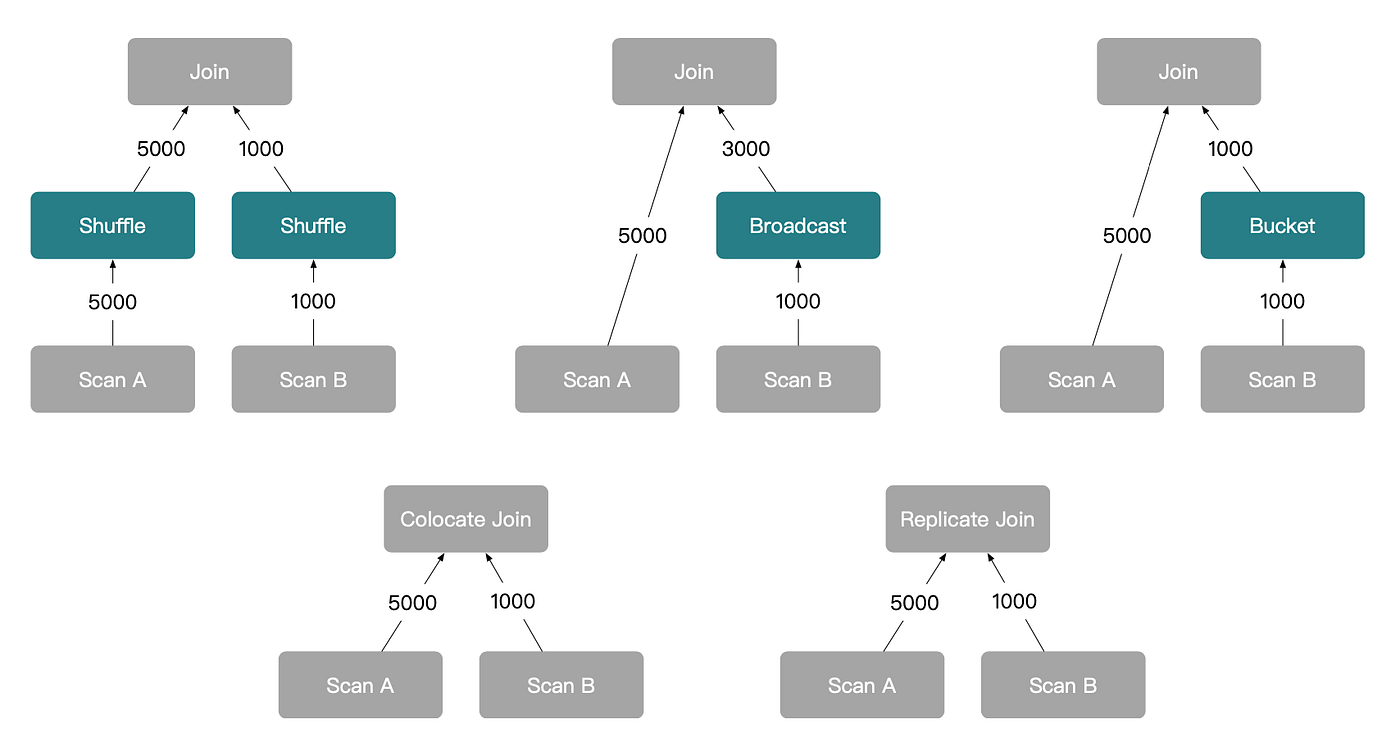
실제로 StarRocks는 5가지 기본 분산 조인 플랜 타입을 생성할 수 있습니다.
StarRocks는 분포 속성(distribution property) 추론(inference) 을 통해 분산 조인 플랜을 도출합니다. 셔플 조인 예시 SELECT * FROM A JOIN B ON A.a = B.b에서 조인 연산자는 셔플 요구사항을 상단에서 하단으로(top-down) A와 B에 전파합니다. 스캔 노드가 요구되는 분포를 만족하지 못하면 StarRocks는 셔플을 도입하는 Enforce 연산자를 삽입합니다. 최종 실행 계획에서는 이 셔플이 네트워크 데이터 전송을 담당하는 Exchange 노드로 변환됩니다.
다른 분산 조인 전략도 같은 방식으로 도출됩니다. 조인 연산자가 입력 연산자에 서로 다른 분포 속성을 요청하고, 옵티마이저가 그에 대응하는 분산 실행 계획을 생성합니다.
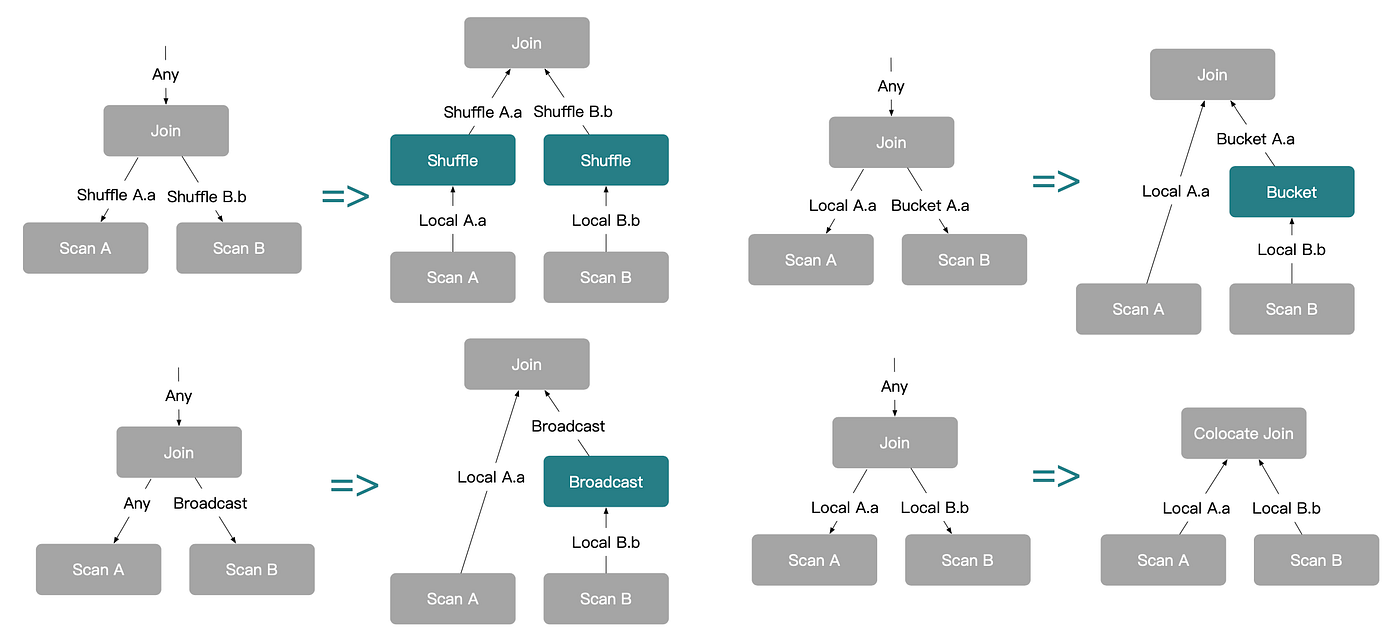
실제 워크로드에서 사용자 쿼리는 단순한 A JOIN B보다 훨씬 복잡하며, 보통 3개 이상의 테이블을 포함합니다. 이런 쿼리에 대해 StarRocks는 앞서 소개한 기본 조인 전략에서 파생된, 더 풍부한 분산 실행 계획을 생성합니다.
예:
Select * From A Join B on A.a = B.b Join C on A.a = C.c
Shuffle Join과 Broadcast Join 조합을 사용하면 StarRocks는 아래와 같이 여러 분산 플랜을 도출할 수 있습니다.
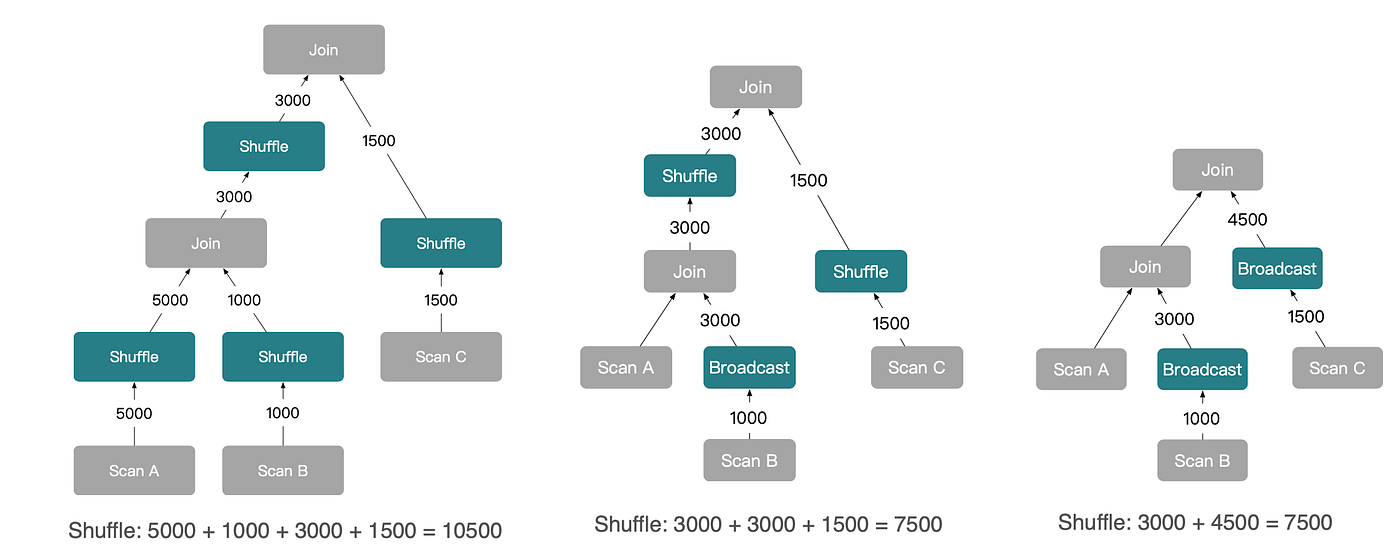
Colocate Join과 Bucket Shuffle Join까지 고려하면 더 많은 실행 계획이 가능해집니다.
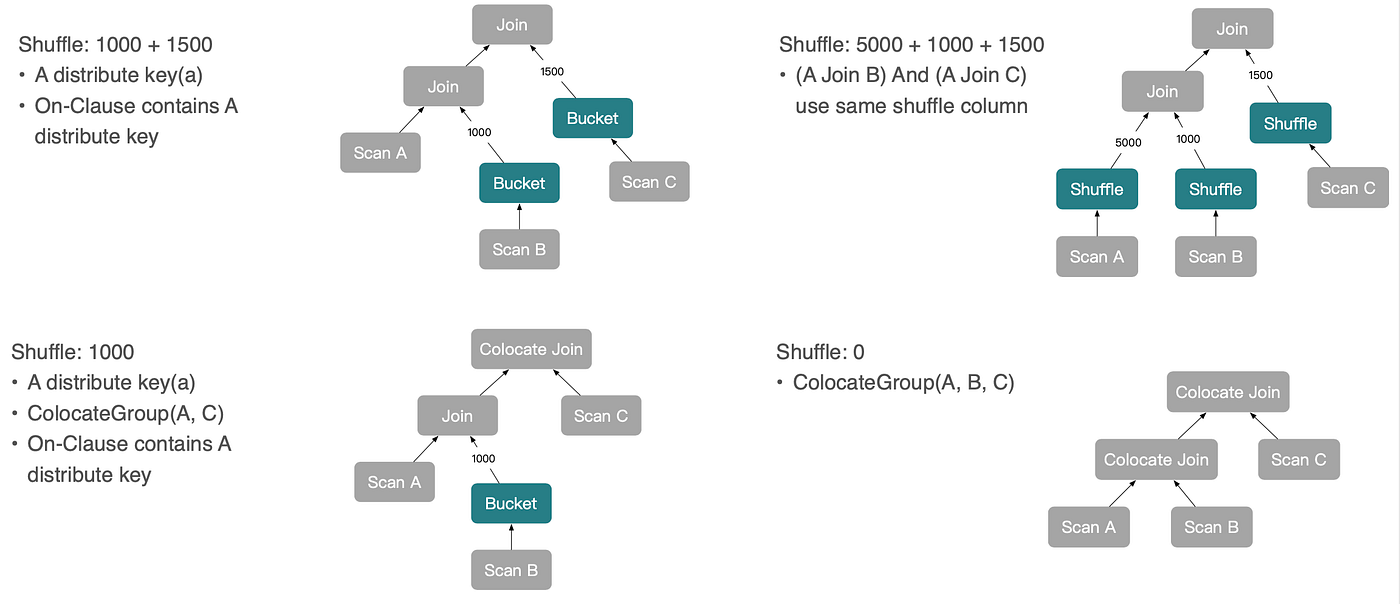
복잡도가 증가하더라도, 근본적인 도출 로직은 동일합니다. 분포 속성이 플랜 트리를 따라 아래로 전파되면서, 옵티마이저가 분산 조인 전략의 다양한 조합을 추론할 수 있게 됩니다.
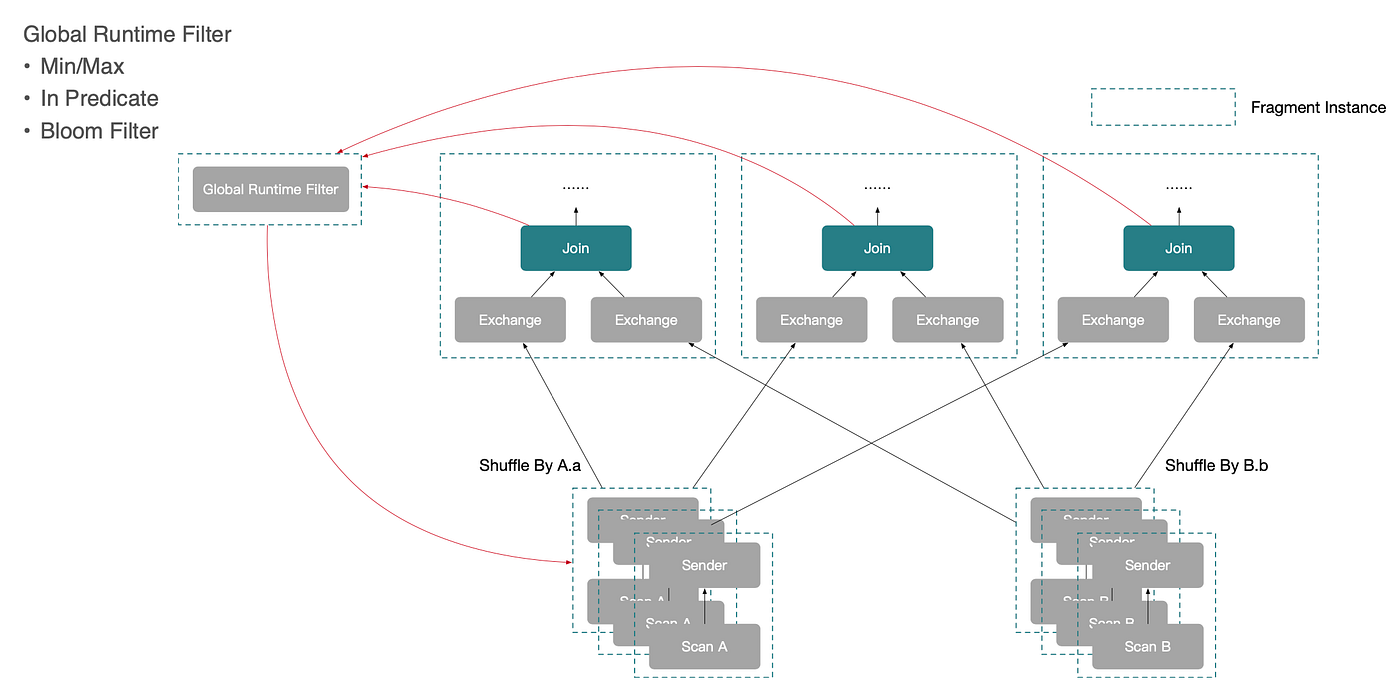
분산 실행 계획 탐색을 넘어, StarRocks는 조인 연산자의 실행 특성을 활용해 글로벌 런타임 필터(Global Runtime Filters) 를 구축함으로써 조인 성능을 추가로 최적화합니다.
StarRocks에서 Hash Join의 실행 흐름은 다음과 같습니다.
글로벌 런타임 필터는 Step 2와 Step 3 사이에 적용됩니다. 오른쪽에서 해시 테이블을 만든 후, StarRocks는 관측된 데이터로부터 런타임 필터 술어를 생성해 왼쪽 테이블의 스캔 노드로 푸시다운합니다(왼쪽 데이터를 읽기 전에). 이를 통해 왼쪽 테이블은 관련 없는 행을 조기에 걸러낼 수 있고, 조인 입력 크기를 크게 줄일 수 있습니다.
현재 StarRocks의 글로벌 런타임 필터는 다음 필터링 기법을 지원합니다: Min/Max 필터, IN 술어, Bloom 필터. 아래 다이어그램은 실제 동작 방식을 보여줍니다.
이 글에서는 StarRocks의 조인 쿼리 최적화에 대한 실전 경험과 진행 중인 작업을 살펴봤습니다. 소개한 모든 기법은 글 전반에 걸쳐 제시한 핵심 최적화 원칙과 긴밀히 연결되어 있습니다. 실전에서 SQL을 최적화할 때 사용자도 StarRocks가 제공하는 기능과 함께 다음 가이드를 적용하여 더 나은 성능을 얻을 수 있습니다.
Demandbase는 StarRocks의 On-the-Fly JOIN 기능을 활용해 기존 ClickHouse 클러스터를 성공적으로 대체했습니다. 성능을 최적화하는 동시에 여러 영역에서 비용을 크게 절감했습니다.
사례 읽기: Demandbase, ClickHouse를 끄고 비정규화를 버리다
NAVER는 비정규화 없이도 다중 테이블 조인에 대해 확장 가능한 실시간 분석을 가능하게 하면서 StarRocks로 데이터 인프라를 현대화했습니다. 이 사례는 프로덕션 규모의 분석 워크로드를 지원하는 데 있어 효율적인 온더플라이 조인 실행이 얼마나 중요한지 보여줍니다.
사례 읽기: NAVER에서 JOIN이 데이터 인프라 접근 방식을 바꾼 방법
Data Go는 Shopee의 비즈니스 사용자가 여러 테이블에서 노코드로 쿼리를 구성하는 플랫폼입니다. Presto는 복잡한 조인 성능과 높은 리소스 사용량에서 어려움을 겪었습니다. Shopee가 다중 테이블 조인을 위해 StarRocks로 전환했을 때, 외부 Hive 데이터에서 Presto 대비 3×–10× 성능 향상 과 CPU 사용량 약 60% 감소를 관측했습니다.
사례 읽기: Shopee가 StarRocks로 쿼리 성능을 3배로 끌어올린 방법
기술 세부사항을 더 깊이 파고들거나 질문이 있나요? StarRocks Slack에 참여해 대화를 이어가세요!
StarRocks Slack 커뮤니티 참여
노트를 공유하고, 질문하고, 세계적 기업에서 일하는 수천 명의 동료들로부터 피드백을 받아보세요.
무료로 시작하기!

![]()
StarRocks는 Apache License, Version 2.0에 따라 라이선스된 소프트웨어입니다.
Copyright © StarRocks Project a Series of LF Projects, LLC. 웹사이트 이용약관, 상표 정책 및 기타 프로젝트 정책은 https://lfprojects.org를 참고하세요.
Cookie Settings