PostgreSQL에서 VACUUM이 테이블(힙)과 인덱스(B-트리)에 대해 무엇을 해주고 무엇을 해주지 못하는지, 그리고 인덱스 블로트를 진단·해결하는 방법(REINDEX, pg_squeeze, VACUUM FULL)을 실험과 함께 설명한다.
URL: https://boringsql.com/posts/vacuum-is-lie/
Title: VACUUM Is a Lie (About Your Indexes)
대부분의 PostgreSQL 개발자를 괴롭히는 흔한 오해가 있다. VACUUM을 튜닝하거나 VACUUM을 돌리기만 하면 데이터베이스는 계속 건강할 거라는 믿음이다. 데드 튜플은 청소되고, 트랜잭션 ID는 재활용되며, 공간은 회수되고, 데이터베이스는 영원히 행복하게 살 것처럼 말이다.
하지만 사람들이 잘 모르는 더러운 “비밀”이 몇 가지 있다. 그중 첫 번째는 VACUUM이 인덱스에 대해서는 당신에게 거짓말을 하고 있다는 것이다.
PostgreSQL에서 어떤 행을 DELETE 하면, 그 행은 단지 ‘데드 튜플(dead tuple)’로 표시될 뿐이다. 새로운 트랜잭션에서는 보이지 않지만 물리적으로는 여전히 존재한다. 그 행을 참조하는 모든 트랜잭션이 끝난 뒤에야 VACUUM이 와서 실제로 그것들을 제거할 수 있으며, 그때 힙(테이블) 공간에서 공간이 회수된다.
이게 테이블과 인덱스에서 서로 다르게 중요한 이유를 이해하려면, PostgreSQL이 데이터를 실제로 어떻게 저장하는지 떠올려야 한다.
테이블 데이터는 힙(heap)에 살며, 힙은 8KB 페이지들의 집합이고 행은 들어갈 수 있는 곳 어디에나 저장된다. 본질적인 순서는 없다. INSERT를 하면 PostgreSQL은 충분한 여유 공간이 있는 페이지를 찾아 행을 끼워 넣는다. 행을 삭제하면 빈틈이 생긴다. 다른 행을 INSERT하면 그 빈틈을 채울 수도 있고(또는 아닐 수도 있고), 전혀 다른 곳에 들어갈 수도 있다.
그래서 ORDER BY 없이 SELECT * FROM users를 하면 처음엔 행이 어떤 “순서”로 반환되는 것처럼 보일 수 있지만, 업데이트가 몇 번 일어나면 마치 랜덤 순서처럼 보이기도 하고 그 순서는 시간에 따라 바뀔 수 있다. 힙은 테트리스 같다. 행은 가능한 공간에 떨어져 들어가고, 삭제되면 구멍이 남는다.
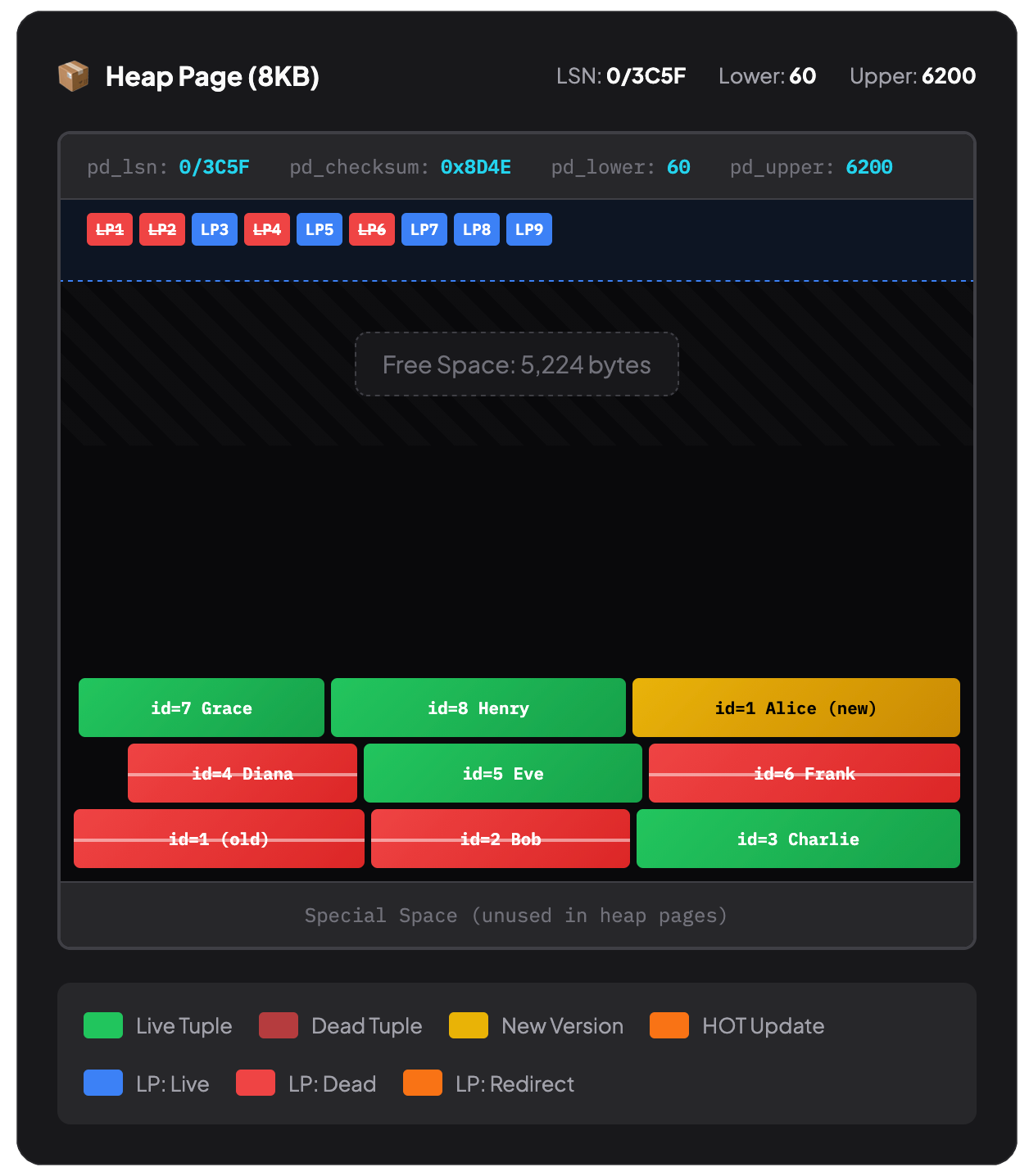
VACUUM이 실행되면 데드 튜플을 제거하고 각 페이지 안에서 남은 행들을 압축(compact)한다. 어떤 페이지가 완전히 비면 PostgreSQL은 그 페이지를 통째로 회수할 수도 있다.
그리고 인덱스도 겉으로는 같은 8KB 페이지들의 컬렉션이지만, 성격이 다르다. B-트리 인덱스는 정렬된 순서를 유지해야 한다. 그게 존재 이유이며 WHERE id = 12345가 빠른 이유다. PostgreSQL은 가능한 모든 행을 스캔하는 대신 트리를 이진 탐색처럼 내려갈 수 있다. 자세한 내용은 B-Tree 인덱스의 기본과 왜 빠른지를 참고하라.
하지만 인덱스를 빠르게 만드는 설계가, 동시에 가장 큰 제약이기도 하다. PostgreSQL은 테이블 행을 가능한 공간에 넣을 수 있지만, 인덱스 페이지 안의 엔트리들을 “최대한 꽉 차도록” 옮겨 담을 수는 없다.
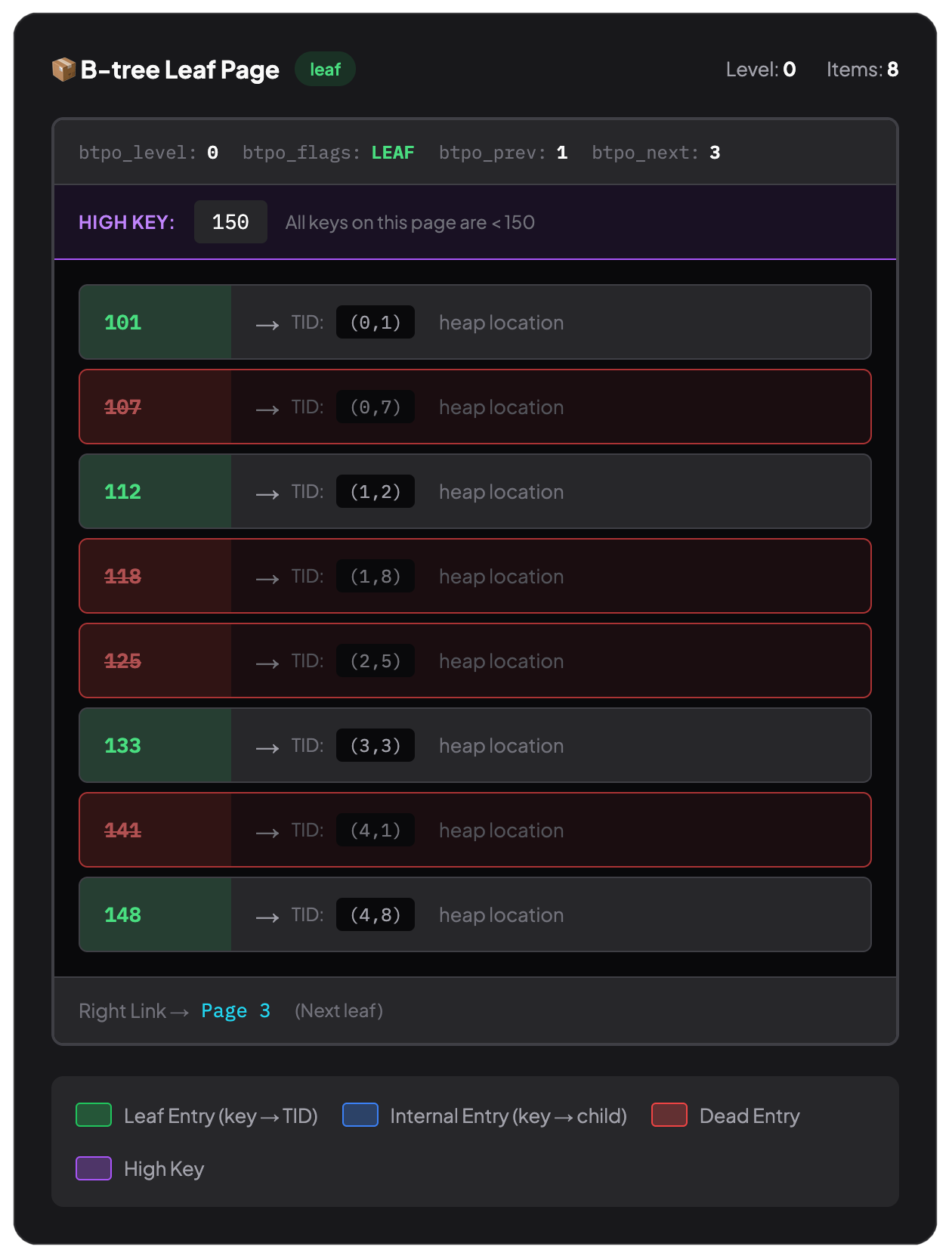
VACUUM은 죽은 인덱스 엔트리를 제거할 수는 있다. 하지만 B-트리를 재구성(restructure)하지는 않는다. VACUUM이 힙을 처리할 때는 페이지 내에서 행을 압축하고 빈 페이지를 회수할 수 있다. 힙은 정렬 제약이 없어서 행이 어디 있어도 된다. 하지만 B-트리 페이지는? 구조에 묶여 있다. VACUUM은 데드 인덱스 엔트리를 지울 수는 있다.
많은 개발자는 VACUUM이 힙 페이지든 인덱스 페이지든 모든 페이지를 똑같이 다룬다고 가정한다. VACUUM은 죽은 엔트리를 제거해야 하는 거 아닌가?
맞다. 하지만 여기서 VACUUM이 하지 못하는 것이 있다. B-트리를 재구성하지 않는다.
VACUUM이 실제로 하는 일
VACUUM이 할 수 없는 일:
힙은 테트리스라서 빈틈을 채울 수 있다. B-트리는 정렬된 책장이다. VACUUM은 책을 빼낼 수는 있지만 남은 책들을 옆으로 밀어 정리할 수는 없다. 스캔할 때마다 빈 칸을 지나가게 된다.
직접 해보자. 테이블을 만들고, 채우고, 대부분을 삭제한 뒤 어떤 일이 일어나는지 보자.
CREATE EXTENSION IF NOT EXISTS pgstattuple;
CREATE TABLE demo (id integer PRIMARY KEY, data text);
-- insert 100,000 rows
INSERT INTO demo (id, data)
SELECT g, 'Row number ' || g || ' with some extra data'
FROM generate_series(1, 100000) g;
ANALYZE demo;
이 시점에서 인덱스는 건강하다. 기준선을 잡자:
SELECT
relname,
pg_size_pretty(pg_relation_size(oid)) as file_size,
pg_size_pretty((pgstattuple(oid)).tuple_len) as actual_data
FROM pg_class
WHERE relname IN ('demo', 'demo_pkey');
relname | file_size | actual_data
-----------+-----------+-------------
demo | 7472 kB | 6434 kB
demo_pkey | 2208 kB | 1563 kB
이제 데이터의 80%를, 그것도 중간 구간에서 제거해 보자:
DELETE FROM demo WHERE id BETWEEN 10001 AND 90000;
목표는 현실에서 흔한 패턴을 시뮬레이션하는 것이다. 예를 들면 데이터 보관(리텐션) 정책, 대량 정리 작업, 혹은 망한 데이터 마이그레이션의 후처리 같은 것.
VACUUM demo;
SELECT
relname,
pg_size_pretty(pg_relation_size(oid)) as file_size,
pg_size_pretty((pgstattuple(oid)).tuple_len) as actual_data
FROM pg_class
WHERE relname IN ('demo', 'demo_pkey');
relname | file_size | actual_data
-----------+-----------+-------------
demo | 7472 kB | 1278 kB
demo_pkey | 2208 kB | 313 kB
테이블은 크게 줄었지만 인덱스는 그대로다. 이제 20,000개의 행을 100,000개를 처리하도록 만들어진 구조로 인덱싱하고 있는 셈이다.
하지만 중요한 점이 하나 있다. actual_data는 ~1.3MB로 줄었는데(남은 20,000개 행을 반영), 인덱스의 file_size는 여전히 2208kB다. VACUUM은 데드 튜플 데이터를 청소했지만, OS에 공간을 돌려주거나 인덱스 구조를 압축하지는 않는다. PostgreSQL 내부에서 “재사용 가능”으로 페이지를 표시할 뿐이다.
EDIT: 원래 글에서는 VACUUM을 실행하지 않았을 때의 테이블 크기가 있었는데, 블로그 글 작성 과정에서 내가 빼먹었다. 이를 발견하고(그리고 내 글을 분석하느라 꽤 시간을 썼을) Scaling PostgreSQL의 Creston Jamison에게 큰 감사를 전한다.
이 실험은 꽤 극단적인 케이스지만, 문제를 보여 주기에는 충분하다.
리프(leaf) 페이지에는 몇 가지 상태가 있다:
가득 찬 페이지(>80% 밀도): 페이지에 인덱스 엔트리가 많아 공간을 효율적으로 사용한다. 8KB 페이지를 읽을 때마다 유용한 데이터가 많이 나온다. 최적의 상태.
부분 페이지(40~80% 밀도): 약간의 낭비 공간이 있지만 여전히 효율적이다. 트리의 가장자리나 가벼운 churn(삽입/삭제 반복) 후에 흔하다. 걱정할 수준은 아니다.
희소 페이지(<40% 밀도): 대부분 비어 있다. 8KB 페이지를 읽어도 엔트리가 몇 개밖에 없다. I/O 비용은 가득 찬 페이지와 같은데 얻는 건 훨씬 적다.
빈 페이지(0% 밀도): 살아있는 엔트리가 0개지만, 페이지는 여전히 트리 구조 안에 존재한다. 순수한 오버헤드다. 범위 스캔(range scan) 중에 이 페이지를 읽고도 유용한 정보를 전혀 못 얻을 수 있다.
fillfactor가 이 문제에 도움이 되지 않을까 궁금할 수 있다. fillfactor는 힙과 리프 페이지 모두에 적용할 수 있는 설정으로, PostgreSQL이 페이지를 저장할 때 얼마나 꽉 채울지를 제어한다. **B-트리 인덱스의 기본값은 90%**다. 즉 각 리프 페이지에 10%의 여유 공간을 남겨 미래의 INSERT를 대비한다.
CREATE INDEX demo_index ON demo(id) WITH (fillfactor = 70);
fillfactor를 낮게(예: 70%) 설정하면 여유 공간이 더 생기므로, 인덱스 “중간”에 삽입해야 하는 경우 페이지 스플릿(page split)을 줄이는 데 도움이 될 수 있다. 예컨대 인덱스 컬럼에 랜덤하게 값이 들어오는 테이블이나, 인덱스 컬럼이 자주 업데이트되는 경우가 그렇다.
하지만 앞의 저장 구조 섹션을 잘 따라왔으면, 이것이 블로트 문제를 해결하지 못한다는 것을 알 수 있다. 오히려 반대다. fillfactor를 낮추고 나서 대부분의 행을 삭제하면, 시작부터 더 많은 페이지를 쓰게 되고 부분 페이지보다 희소 페이지가 더 많이 생길 가능성이 커진다.
리프 페이지 fillfactor는 업데이트/삽입 최적화에 관한 것이다. 삭제나 인덱스 컬럼 업데이트로 인한 블로트의 해결책은 아니다.
PostgreSQL의 쿼리 플래너는 인덱스 페이지 수를 포함한 물리 통계를 기반으로 비용을 추정한다.
EXPLAIN ANALYZE SELECT * FROM demo WHERE id BETWEEN 10001 AND 90000;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Index Scan using demo_pkey on demo (cost=0.29..29.29 rows=200 width=41) (actual time=0.111..0.112 rows=0 loops=1)
Index Cond: ((id >= 10001) AND (id <= 90000))
Planning Time: 1.701 ms
Execution Time: 0.240 ms
(4 rows)
실행은 거의 즉시 끝나지만, 내부에서는 다른 일이 일어난다. 플래너는 200행을 예상했지만 실제는 0행이었다. 존재하지 않는 데이터를 기대하며 B-트리 구조를 탐색했다. 단일 쿼리, 웜 캐시라면 사소하다. 하지만 운영 환경에서 수천 개의 쿼리와 콜드 페이지가 섞이면, 아무것도 얻지 못하는 I/O 비용을 계속 지불하게 된다. 반복해서.
더 파고들면 더 큰 문제가 보인다.
SELECT relname, reltuples::bigint as row_estimate, relpages as page_estimate
FROM pg_class
WHERE relname IN ('demo', 'demo_pkey');
relname | row_estimate | page_estimate
-----------+--------------+---------------
demo | 20000 | 934
demo_pkey | 20000 | 276
relpages 값은 물리 파일 크기를 8KB 페이지 크기로 나눈 값이다. PostgreSQL은 VACUUM과 ANALYZE 중에 이것을 업데이트하지만, 이는 디스크 상의 실제 파일을 반영할 뿐 “안에 유용한 데이터가 얼마나 들어 있는지”를 나타내지는 않는다. 우리의 인덱스 파일은 대부분 페이지가 비어 있는데도 여전히 2.2MB(276페이지 × 8KB)다.
플래너는 20,000행에 276페이지를 보고, 페이지당 행 수가 매우 낮다고 계산한다. 그러면 플래너는 “이 인덱스는 너무 듬성듬성하니 시퀀셜 스캔을 하자”라고 결론 내릴 수도 있다. 이런.
“하지만 ANALYZE가 통계를 고쳐주지 않나요?”
맞기도 하고 아니기도 하다. ANALYZE는 행 수 추정치를 업데이트한다. 이제 100,000행이 아니라 20,000행이라고는 알게 된다. 하지만 relpages는 줄어들지 않는다. 그 값은 디스크 상의 물리 파일 크기를 반영하기 때문이다. ANALYZE로는 그걸 바꿀 수 없다.
즉 플래너는 행 수 추정은 정확해졌지만 페이지 추정은 크게 틀렸다. 실제 유용한 데이터는 약 57페이지 정도에만 빽빽하게 들어 있지만, 플래너는 그걸 모른다.
cost = random_page_cost × pages + cpu_index_tuple_cost × tuples
블로트된 인덱스에서는:
인덱스 내부 통계를 보면 문제를 더 깊게 볼 수 있다:
SELECT * FROM pgstatindex('demo_pkey');
-[ RECORD 1 ]------+--------
version | 4
tree_level | 1
index_size | 2260992
root_block_no | 3
internal_pages | 1
leaf_pages | 57
empty_pages | 0
deleted_pages | 217
avg_leaf_density | 86.37
leaf_fragmentation | 0
잠깐, 뭐라고? avg_leaf_density가 86%면 완벽히 건강해 보인다. 이게 함정이다. 인덱스가 속이 빈(hollow) 상태(중간에서 80%를 삭제했으니)라서, 57개의 리프 페이지는 잘 채워져 있지만 인덱스에는 여전히 217개의 deleted 페이지가 들어 있다.
그래서 avg_leaf_density만 보면 오해하게 된다. 사용 중인 페이지의 밀도는 좋아 보이지만, 인덱스 파일의 79%는 죽은 무게(dead weight)다.
인덱스 블로트를 가장 간단히 찾는 방법은 실제 크기와 기대 크기를 비교하는 것이다.
SELECT
c.relname as index_name,
pg_size_pretty(pg_relation_size(c.oid)) as actual_size,
pg_size_pretty((c.reltuples * 40)::bigint) as expected_size,
round((pg_relation_size(c.oid) / nullif(c.reltuples * 40, 0))::numeric, 1) as bloat_ratio
FROM pg_class c
JOIN pg_index i ON c.oid = i.indexrelid
WHERE c.relkind = 'i'
AND c.reltuples > 0
AND c.relname NOT LIKE 'pg_%'
AND pg_relation_size(c.oid) > 1024 * 1024 -- only indexes > 1 MB
ORDER BY bloat_ratio DESC NULLS LAST;
index_name | actual_size | expected_size | bloat_ratio
------------+-------------+---------------+-------------
demo_pkey | 2208 kB | 781 kB | 2.8
bloat_ratio가 2.8이라는 것은 인덱스가 기대보다 거의 3배 크다는 뜻이다. 1.8~2.0을 넘기면 조사할 가치가 있다.
1MB 이상 인덱스만 필터링한 이유는, 작은 인덱스의 블로트는 큰 문제가 아닌 경우가 많기 때문이다. 환경에 맞춰 임계값을 조정하라. 대형 데이터베이스라면 100MB 이상 인덱스만 신경 쓸 수도 있다.
하지만 여기에는 큰 경고가 있다. 앞에서 사용한 pgstatindex()는 인덱스 전체를 물리적으로 읽는다. 10GB 인덱스라면 10GB I/O가 발생한다. 운영 서버에서 모든 인덱스에 대해 무작정 돌리면 안 된다—무슨 일을 하는지 알고 있을 때만.
그럼 인덱스 블로트는 어떻게 실제로 고칠까? REINDEX가 가장 прям(직관적)한 해결책이다. 인덱스를 처음부터 다시 빌드하기 때문이다.
REINDEX INDEX CONCURRENTLY demo_pkey ;
그 후 인덱스 상태를 확인해 보자:
SELECT * FROM pgstatindex('demo_pkey');
-[ RECORD 1 ]------+-------
version | 4
tree_level | 1
index_size | 466944
root_block_no | 3
internal_pages | 1
leaf_pages | 55
empty_pages | 0
deleted_pages | 0
avg_leaf_density | 89.5
leaf_fragmentation | 0
그리고
SELECT
relname,
pg_size_pretty(pg_relation_size(oid)) as file_size,
pg_size_pretty((pgstattuple(oid)).tuple_len) as actual_data
FROM pg_class
WHERE relname IN ('demo', 'demo_pkey');
relname | file_size | actual_data
-----------+-----------+-------------
demo | 7472 kB | 1278 kB
demo_pkey | 456 kB | 313 kB
인덱스가 2.2MB에서 456KB로 줄었다—79% 감소다(놀랄 일은 아니다).
눈치챘겠지만 CONCURRENTLY를 사용해 ACCESS EXCLUSIVE 락을 피했다. 이는 PostgreSQL 12+부터 가능하다. 생략할 수도 있지만, 그렇게 하는 거의 유일한 이유는 계획된 점검 시간에 인덱스 재빌드 시간을 줄이려는 경우다.
위에서 관계(relation)의 file_size를 보면, 영향을 받은 인덱스의 디스크 공간은 회수했지만(REINDEX를 했으니), 테이블 공간은 운영체제로 반환되지 않았다.
여기서 pg_squeeze가 빛을 발한다. 트리거 기반 대안과 달리 pg_squeeze는 logical decoding을 사용하므로, 실행 중인 시스템에 미치는 영향이 더 적다. 또한 최소한의 락으로 테이블과 모든 인덱스를 온라인으로 재작성한다:
CREATE EXTENSION pg_squeeze;
SELECT squeeze.squeeze_table('public', 'demo');
배타 락은 마지막 스왑 단계에서만 필요하며, 그 지속 시간도 설정할 수 있다. 더 좋은 점은 pg_squeeze가 정기적인 자동 처리를 염두에 두고 설계되었다는 것이다. 테이블을 등록해 두고, 블로트 임계치를 넘으면 자동으로 유지보수를 하게 할 수 있다.
pg_squeeze는 테이블과 인덱스가 모두 블로트된 경우, 또는 자동화된 관리를 원할 때 적합하다. 인덱스만 손보면 되는 경우라면 REINDEX CONCURRENTLY가 더 단순하다.
더 오래된 도구로 pg_repack도 있다. 블로트 제거 도구들을 더 깊게 비교하려면 The Bloat Busters: pg_repack vs pg_squeeze 글을 보라.
VACUUM FULL은 테이블과 모든 인덱스를 통째로 다시 쓴다. 모든 문제를 해결하지만 큰 단점이 있다. ACCESS EXCLUSIVE 락이 필요해서, 수행 시간 내내 모든 읽기/쓰기를 완전히 막는다. 큰 테이블이라면 몇 시간의 다운타임이 될 수도 있다.
일반적으로 운영 환경에서는 피하라. 다운타임 없이 같은 결과를 얻으려면 pg_squeeze를 사용하라.
이제 눈에 보이는 모든 것에 REINDEX를 돌리기 전에, 인덱스 블로트가 언제 실제로 중요한지 이야기해 보자.
B-트리는 데이터에 따라 커졌다가 줄어든다. UUID, 해시 키처럼 인덱스 컬럼에 랜덤 삽입이 발생하면 페이지 스플릿이 계속 일어난다. 인덱스 효율이 가끔 떨어졌다가도 시스템 사용의 자연스러운 사이클 속에서 70~80% 정도에 정착할 수 있다. 그건 블로트가 아니라, 데이터에 맞는 자연스러운 형태를 트리가 찾아가는 것이다.
여기서 보여준 블로트—57개의 유용한 페이지가 217개의 deleted 페이지에 파묻힌 상태—는 극단적이다. 연속된(contiguous) 데이터의 80%를 삭제했기 때문에 생겼다. 일상적인 운영에서 이렇게까지 되지는 않는다.
즉시 조치가 필요한 경우:
bloat_ratio가 2.0을 넘고 계속 상승하지만 대부분은 패닉할 필요 없다. 주간 단위로 모니터링하고, 인덱스 블로트 비율이 경고 수준을 지속적으로 넘겨 증가한다면 트래픽이 낮은 시간대에 REINDEX CONCURRENTLY를 예약하라.
인덱스 블로트는, 정말 문제가 될 때까지는 응급 상황이 아니다. 신호를 알고, 도구를 준비하고, VACUUM의 침묵이 모든 게 괜찮다는 뜻이라고 속지 마라.
VACUUM은 PostgreSQL에 필수다. 실행하라. autovacuum이 일을 하게 놔둬라. 하지만 한계를 이해해야 한다: VACUUM은 데드 튜플을 청소하지, 인덱스 구조를 청소하지는 않는다.
PostgreSQL 유지보수의 진실은 이렇다. VACUUM은 힙 블로트는 꽤 잘 처리하지만, 인덱스 블로트는 명시적인 개입이 필요하다. 인덱스가 실제로 아픈 건지, 그냥 정상적으로 숨 쉬는 건지 구분하라—그리고 REINDEX를 꺼내야 할 때를 알라.
VACUUM은 힙 블로트를 처리한다. 인덱스 블로트는 당신의 문제다. 차이를 알아라.