서버리스 환경에서 객체 스토리지를 이용해 강한 일관성과 트랜잭션을 제공하는 키-값 데이터베이스 GlassDB의 설계 여정과 알고리즘, 성능, 트레이드오프를 소개합니다.
클라우드에서 상태 없음(stateless) 애플리케이션과 상태 있음(stateful) 애플리케이션 사이의 간극이 늘 답답했다. 주요 클라우드 프로바이더 어디서나 “서버리스” 함수 형태로 상태 없는 애플리케이션은 쉽게 띄우고 거의 잊고 지낼 수 있는데, 요청 간 데이터를 지속시키는 일만큼은 다음 세 가지 중 둘만 고르는 게임 같았다: 저렴함, 강한 일관성, 이식성.
클라이언트 단 하나의 솔루션 만으로 이식성과 트랜잭션 부재 문제를 스스로 해결할 수 있을까? 객체 스토리지(예: AWS S3)를 이용하면 될 거라고 생각했다. 객체 스토리지는 강한 일관성을 제공하고, 어디에나 있고, 싸다.
물론 “서버리스 데이터베이스”를 쓰고, DynamoDB (AWS), Cosmos DB (Azure), Firestore (GCP) 사이에 얇은 변환 레이어만 만들 수도 있다. 그러면 굳이 거의 바닥부터 새 데이터베이스를 다시 만드는 게 말이 되나? 실용적인 관점에서는 아니다. 하지만 이렇게 생각해보자. 나는 데이터베이스 설계에 대해 엄청 많이 배웠고, 그래서 그 자체로 가치가 있었고, 이 여정이 여러분에게도 유익할 거라 생각한다.
얘기가 길어지기 전에, 여기에 소스 코드가 있다.
몇 년 전, HTTP 요청을 처리하는 함수 를 배포하기 위해 AWS Lambda나 Google Cloud Run 같은 서버리스 솔루션을 손쉽게 띄울 수 있다는 걸 깨닫고부터 생각이 시작됐다. 호스트 OS 업데이트, Kubernetes 클러스터, VM, 그 외 기반 인프라를 신경 쓸 필요가 전혀 없다. 서버리스 과금은 요청당(pay-per-request)이고 공짜 구간도 넉넉해서, 내가 혼자 쓰는 서비스 대부분은 거의 비용이 들지 않았다.
딜은 단순하다. 당신은 코드를 제공하고, 클라우드 제공자는 그걸 실행해 준다. 돈 거의 안 쓰고, 유지보수도 안 하고, 그 대가로 동작하는 웹 서비스를 얻는다. 좋아 보이지 않는가?
이 구조는 요청 간 데이터를 지속시킬 필요가 없을 때까진 괜찮았다. 모든 데이터베이스 옵션에는 단점이 있었다. Google SQL for Postgres는 쓰든 안 쓰든 비용이 들고, 업그레이드는 수동이어서 다운타임이 필요했다. Spanner는 강한 일관성을 제공하지만 매우 비쌌고(당시엔 공유 인스턴스가 없었다) 이식성이 떨어졌다. Datastore (지금은 Firestore가 대체) 는 싸지만 트랜잭션에 제약(쓰기 전에 읽기) 이 있고, 역시 구글 클라우드 밖으론 이식성이 없었다. AWS도 비슷했다. RDS는 이식 가능하지만 비싸고 관리가 필요했고, DynamoDB는 관리 부담이 없고 싸지만 다른 클라우드로 이식할 수 없고 결국적(eventual) 일관성이다.
나는 다시 한 번 바퀴를 재발명해 보기로 했다. 공부를 핑계로 이런 생각을 했다. 이미 큰 파일은 객체 스토리지(Google Cloud Storage와 AWS S3)에 저장하고 있다. 이들의 강한 일관성 특성을 “악용해서” 트랜잭션 데이터베이스로 만들 수 있지 않을까? GCS는 느리지만, 엄청나게 스케일이 된다. 게다가 “얼마나 느리면 너무 느린 거지?”라는 질문도 있었다. 100KiB 객체 읽기/쓰기 성능을 테스트해 보니, 90번째 퍼센타일은 대략 다음과 같았다.
로컬 SQLite보다는 훨씬 느리다(10배 정도), 하지만 많은 시나리오에서 쓸 만한 수준이고, 여러 writer와도 잘 작동한다. 사실, 원하는 만큼 많은 writer 를 둘 수 있다.
또 다른 질문은, 언제부터 이런 구성이 Google Cloud SQL 같은 기존 매니지드 데이터베이스보다 더 비싸지느냐였다. 가장 저렴한 매니지드 Postgres 인스턴스는 한 달에 8.57달러 정도다. 같은 비용을 쓰려면(읽기 10k당 $0.004, 쓰기 10k당 $0.05라 치면) 평균 초당 0.66번 쓰기 또는 초당 8.3번 읽기를 해야 한다. 가장 작은 전용 인스턴스를 기준으로 하면, 이 값은 초당 2.7번 쓰기 또는 34번 읽기로 올라간다.
부하가 드물거나(bursty) 가끔 몰리는 정도라면, 지금까지는 이 구성이 충분히 합리적이다.
비용 요소를 대략 확인한 뒤 다음 단계는 가장 단순한 동작하는 솔루션을 만들어 보는 것이었다. 성능은 일단 완전히 무시했다. 내 모토는 “먼저 되게 만들고, 그다음에 예쁘게 만들자”였다. 당시 더 잘 알고 있었던 Google Cloud를 기준으로 GCS부터 시작했다.
첫 번째 설계 선택은 아키텍처였다. 가장 단순한 아키텍처는 서버 컴포넌트가 전혀 없는 구조다. 클라이언트 라이브러리와 객체 스토리지 만으로 어디까지 갈 수 있는지 보고 싶었다.

같은 맥락에서, 가장 단순한 데이터베이스는 SQLite다. 각 트랜잭션을 클라이언트에서 로컬로 실행하고, 트랜잭션 자체 와 객체 스토리지로의 업로드가 모두 성공했을 때만 OK를 반환하게 만들 수 있다. 서로 다른 두 클라이언트 사이의 레이스 컨디션을 피하려면 락을 쓰거나, OCC(Optimistic Concurrency Control, 낙관적 동시성 제어)를 구현하면 된다. OCC의 경우 트랜잭션에서 읽을 때와 커밋할 때 사이에 동시 업데이트가 일어나지 않았는지를 확인한다.
나는 두 번째 옵션을 택했다. 구현하기 훨씬 쉬웠기 때문 이다.
이를 위해 필요한 API는 읽기와 조건부 쓰기 두 가지였고, 둘 다 GCS가 제공한다. 이 원시적인(primitive) 프리미티브로도 데이터베이스를 만들 수 있다. SQLite 데이터베이스 전체를 하나의 객체로 직렬화한 뒤, 각 트랜잭션마다 다음을 수행한다.
2번 단계는 원자적이다. 그 사이에 다른 클라이언트가 객체를 수정하지 않았을 때만 성공한다. 이 점이 알고리즘이 동작하는 핵심이다.
물론, 이건 느리다. 매 트랜잭션마다 전체 데이터베이스를 통째로 내려받고 올려야 한다. DB가 기가바이트 단위면 꽤나 곤란하다. 또한 각 클라이언트는 트랜잭션마다 충돌이 날 게 거의 확실하므로, 재시도가 더해진다. 서로 다른 테이블을 접근하더라도 전역 객체 하나를 같이 업데이트해야 하므로 병렬성이 없다.
더 안 좋은 점은, GCS는 공식적으로 하나의 객체당 초당 한 번의 업데이트만 허용한다는 것이다. 즉, 최대 초당 1 트랜잭션만 처리 가능하므로 성능이 바닥난다. 실제로는 rate limiting이 토큰을 분 단위로 체크하고 초기화하는 식으로 구현돼 있어, 짧은 버스트는 좀 더 빠르게 허용해 주되 이후에 페널티가 붙는 식이다. 그 결과 성능이 매우 일정치 않다. 한 객체를 꾸준히 두들기기 시작하는 순간, 지연 시간이 수십 ms에서 수십 초까지 널뛰게 된다.
단일 객체 접근 방식이 여기까지밖에 가지 못한다면, 이제 부하를 여러 객체로 분산해야 했다. 이렇게 되면 해결해야 할 주된 문제는 여러 객체에 걸친 ACID 트랜잭션 구현이다. 같은 객체 에 대한 업데이트는 강한 일관성이 보장된다. 즉, 어떤 위치에서든 쓰기가 끝난 후 시작되는 모든 읽기는 그 최신 쓰기 내용을 즉시 볼 수 있다. 하지만 이건 어디까지나 단일 객체 에만 적용된다. 여러 객체를 한꺼번에 복사하거나 이름을 바꾸는 연산은 원자적이지 않다. 게다가 각 객체의 버전 번호는 서로 무관해서, 전체 쓰기에 대한 전역 순서(global ordering)도 없다.
다행히 이런 문제 공간을 다양한 트레이드오프와 함께 해결하기 위한 분산 트랜잭션 알고리즘에 대한 방대한 문헌이 있다. 이 시점에서의 설계 공간을 요약하면 다음과 같았다.
이 제약은, 쓰기 연산 수를 최소화하면서도 “정확성(correctness)”을 유지하는 알고리즘을 찾아야 한다는 뜻이었다. 잠시 후 다시 돌아오겠지만, 그 전에 “정확성”이란 말로 내가 뭘 의미하는지부터 짚고 가자.
정확성을 생각하다 보니 자연스럽게 대학 때 데이터베이스 수업에서 들었던 ACID 특성, 특히 격리성(isolation)이 떠올랐다. 하지만 그 (오래된) 지식과, 논문과 웹의 자료를 잘 연결해 이해하는 게 쉽지 않았다. 핵심 문제는 아마, 전통적 관계형 데이터베이스와 공유 메모리 시스템 연구 사이에서 용어와 개념이 겹친다는 점일 것이다. 예전에는 별개로 다뤄졌던 개념들이 분산 시스템에서는 동시에 유용해지면서, 양쪽에서 용어를 빌어 쓰기 시작했다.
ACID(Atomicity, Consistency, Isolation, Durability)에 대해서는, 모두가 원자성(Atomicity) (트랜잭션은 전부 적용되거나 아예 적용되지 않는다)과 지속성(Durability) (커밋 후에는 시스템 크래시 이후에도 효과가 남는다)에는 대체로 동의한다. 하지만 나머지 둘은 그렇지 않다. SQL 표준에 정의된 격리 수준(isolation level) 은 부정확할 뿐 아니라 90년대에 멈춰 있다. 이 문제는 1995년부터 알려져 있었고, 그 틈을 타 DB 벤더들이 굉장히 좁고 오해의 소지가 있는 해석을 밀어 넣을 여지가 생겼다. Oracle이 스냅샷 격리(snapshot isolation) 구현을 어떤 법률적인 말장난으로 “serializable”이라고 주장한 게 대표적이다.1 게다가 격리 수준은 단일 호스트 데이터베이스에 초점을 맞추기 때문에, 복제(replication) 로 인해 새로 등장하는 이상 현상(anomaly)을 제대로 반영하지 못한다. 이런 이상 현상을 표현하려면 더 강력한 표현력이 필요하다.
여기에 더해, 일관성(consistency) 이란 말도 SQL 표준과 분산 시스템 문헌에서 서로 다른 의미로 쓰인다. ACID에서 C 는 전통적으로 “사용자가 정의한 제약(예: 외래 키, 유니크 제약)을 만족시킨다”를 의미해 왔다. 반면 CAP과 PACELC 정리에서의 C 는 읽기가 가장 최근 쓰기 값을 받을 수 있는가 를 의미한다.
게다가 논문과 블로그에서는 “격리 수준(isolation level)”이란 말을 굉장히 느슨하게 쓰기도 한다. 때로는 “일관성 수준(consistency level)”을 말하려는 것이고, 때로는 격리와 일관성 보장을 합쳐서 말하기도 한다. 데이터베이스를 설계하려면 우선 나 자신부터 개념을 정리할 필요가 있었다.
이렇게 개념 정리를 하던 중, Jepsen의 다이어그램을 계속 마주치게 됐다. Jepsen은 Bailis의 접근을 따라 모든 것을 “일관성”의 크기가 점점 커지는 단일 계층 구조로 통합한다. 아주 좋은 단순화이긴 하지만, 사실 그 계층 구조는 두 개의 계층 을 하나로 녹여 놓은 것이라는 점을 명확히 언급하지 않는다. 하나는 일관성(consistency) 계층, 다른 하나는 격리성(isolation) 계층이다. 격리는 트랜잭션이 동시 실행될 때 시스템이 어떻게 동작해야 하는지에 대한 규칙을 제공하고, 일관성은 쓰기가 완료된 후 언제부터 읽기가 그 값을 볼 수 있어야 하는지를 정의한다. Daniel Abadi의 설명 덕분에, 데이터베이스는 두 계층 모두에 대해 보장을 제공할 수 있고, 우리가 때로 “격리 수준(isolation level)”, 때로 “일관성 모델(consistency model)”이라고 부르는 것들이 사실 이 둘의 조합이라는 점을 이해하게 됐다. 이 때문에 용어가 아주 혼란스러워진다.

수정한 다이어그램에서는 이 구분을 더 강조했다. 화살표는 포함 관계 보장을 나타낸다(예: Linearizable는 Sequential에 추가 보장 을 더한 것이다). 점선은 “격리 수준”이 격리와 일관성 보장의 조합으로 정의된다는 점을 나타낸다. Strict Serializable이 가장 강한 수준인데, 모든 보장을 암묵적으로 포함하기 때문이다.
요약하면, 어떤 보장 모델이란 허용하지 않는 이상 현상(anomaly)의 종류 로 정의된다. 막는 이상 현상이 많을수록 더 강한 모델이다. 이상 현상은 트랜잭션이 동시에 수행될 때 예상치 못한 결과가 나오는 것이다. 격리 수준이 허용하는 이상 현상이 많을수록, 개발자는 이 현상이 애플리케이션 로직에서 버그로 드러나지 않도록 더 많은 주의를 기울여야 한다. 예를 들어 더티 리드(dirty read)는 Read Uncommitted 격리 수준에서 허용되는데, 커밋되지 않은 다른 트랜잭션이 수정한 값을 읽을 수 있는 경우를 말한다. 이 때문에 나중에 롤백되는 트랜잭션도 다른 트랜잭션에 영향을 줄 수 있다.
격리성 이상 현상은 트랜잭션이 서로 독립적으로 실행되는 것 같은 환상을 깨고, 일관성 이상 현상은 시스템이 마치 단일 머신인 것 같은 환상(예: 복제 지연이 보이지 않는다는 환상)을 깬다.
격리 수준은 굉장히 추상적으로 느껴졌는데, 실제로 널리 쓰이는 데이터베이스들이 이 계층 구조에서 어느 위치에 있는지 보니 좀 더 감이 잡혔다. 두 가지는 분명했다. 첫째, DB 벤더들은 자기 데이터베이스가 “충분히 일관적”이며 “그런 이상 현상은 실제로는 드물다”고 설명하기 위해 큰 노력을 기울인다. 둘째, 수준 간 편차가 매우 크다.

예를 들어 Postgres는 기본으로 Read Committed를 제공하는데, 이는 같은 프로세스의 한 트랜잭션이 어떤 행을 업데이트한 뒤, 다음 트랜잭션이 여전히 예전 값을 읽을 수 있다는 뜻이다. 두 트랜잭션이 별개라고는 해도, 특히 데이터베이스가 단일 레플리카로 호스팅될 때 대부분 개발자에게는 꽤 놀라운 결과다. 하지만 Postgres는 Sequentially Consistent이기도 하므로, 트랜잭션 순서가 모두에게 동일 하다는 보장은 있다. 다만 그 순서가 실제 시간(real time) 순서를 반드시 따르지는 않는다.
격리 측면에서 최강자는 Spanner다. Strict Serializable을 제공하는데, 이는 전 세계적으로 트랜잭션이 마치 직렬(serial)로 실행된 것처럼 보이고, 전역적으로 실제 시간 순서를 따른다 는 의미다. 가장 정확한(correct) 모델이다. FaunaDB 역시 다른 메커니즘으로 Strict Serializable을 달성한다.2
예상하듯, Cassandra는 진정한 NoSQL 데이터베이스답게 약한, 결국적(eventual) 일관성 모델을 제공한다. 가용성을 최우선으로 하기 때문이다. 흥미로운 중간 지점에는 CockroachDB가 있다. Spanner와 매우 비슷하지만, 더 공격적인 낙관적 동시성 제어를 위해 때때로 트랜잭션이 오래된(stale) 데이터를 읽는 것을 허용한다.3
더 약한 격리 수준은 데이터베이스 구현에서 더 많은 최적화를 허용하지만, 그만큼 더 많은 종류의 이상 현상 을 허용한다. 보통 더 빠른 대신, 애플리케이션 개발자가 버그를 막기 위해 더 많은 로직을 직접 구현해야 한다. 성능과 정확성 사이의 균형추는 NoSQL 시기(“빠른 게 최고”)에서 2012년 Spanner 논문 이후 NewSQL 시기로 넘어오면서, “정확한 게 더 낫다” 쪽으로 기울었다. Bailis의 ACID rain 같은 논문과 실무 경험은, 약한 일관성 데이터베이스로 올바른 애플리케이션을 설계하는 일이 훨씬 더 어렵다는 것 을 보여줬다. 개발에 더 많은 노력과 시간이 들고, 이해하기도 더 어렵다. 그렇다면, 강한 일관성이 충분히 빠르다면 굳이 왜 약한 쪽을 택할까? 어차피 개발자 시간은 기계 시간보다 비싸다.
내게 답은 분명했다. 이상적인 격리 수준은, 애플리케이션에 대해 속도가 너무 느려지기 직전까지 가능한 한 가장 높은 수준이다.
이 배경을 토대로, 나는 다음과 같은 기본적인 트랜잭션 알고리즘을 떠올렸다.
- 필요한 걸 읽는다
- 필요한 걸 쓴다
- 커밋 시: 아무것도 하지 않는다
- 중단(abort) 시: 쓴 것들을 하나씩 되돌린다
이 알고리즘은 분명히 원자성(Atomicity) 도 제공하지 못하고, Read Committed처럼 아주 기초적인 격리성도 제공하지 못한다. 키를 하나씩 커밋하기 때문에, 동시 트랜잭션이 커밋되기 전에 새로운 값을 읽을 수 있기 때문이다. 하지만 이 방식은 Linearizable 일관성을 제공한다. S3와 GCS가 보장하는 강한 일관성 덕분이다. 이들에 따르면, 성공적인 쓰기 이후에 시작되는 모든 읽기는 항상 그 최신 쓰기 내용을 반환한다. 노력 없이도 격리는 없지만 강한 일관성 을 갖게 된 셈이다.

이제 과제는, 성능을 어느 정도 유지하면서 더 강한 격리 보장을 도입하는 것이다.
트랜잭션 알고리즘 선택이라는 토끼굴로 더 깊이 들어가기 전에, 잠시 뒤로 물러서서 어떤 인터페이스를 제공하고 싶은지를 정할 필요가 있었다. 가장 단순한 데이터베이스는 좋은 점이 하나 있었다. SQLite 덕분에 알아보기 쉬운 SQL 인터페이스를 바로 제공할 수 있다는 점이다. 하지만 데이터를 버킷 안 여러 객체로 쪼개기로 한 시점부터, 그건 훨씬 더 어려운 일이 됐다.
아이디어를 얻기 위해 이리저리 살펴보니, 많은 현대적 데이터베이스가 코어에서는 트랜잭션 키-값 저장소라는 점을 알게 됐다. FoundationDB 같은 것들은 거기서 멈춘다. 어떤 의미에서는 정말로 키-값 저장소일 뿐이다. 반면 CockroachDB 같은 것들은 한 발 더 나아가 그 위에 Postgres 호환 SQL 레이어를 얹는다.
또 다른 영감의 원천은 Ben Johnson의 BoltDB였다. Go로 작성된, 매우 우아한 트랜잭션 임베디드 키-값 저장소다. 내 GlassDB 예제에서 BoltDB의 흔적을 볼 수 있다.
func compareAndSwap(ctx context.Context, key, oldval, newval []byte) (bool, error) {
coll := db.Collection([]byte("my-collection"))
swapped := false
err := db.Tx(ctx, func(tx *glassdb.Tx) error {
b, err := tx.Read(coll, key)
if err != nil {
return err
}
if bytes.Equal(b, oldval) {
swapped = true
return tx.Write(coll, key, newval)
}
return nil
})
return swapped, err
}이 코드는 컬렉션 의 키에 대한 간단한 compare-and-swap을 구현한 것이다. 컬렉션은 단순히 같은 프리픽스를 공유하는 키들의 집합이다. db.Tx 메서드는 이 연산들을 하나의 트랜잭션으로 감싸서, GlassDB가 트랜잭션을 투명하게 재시도할 수 있게 해 준다.
사용법 자체를 길게 설명하지는 않겠다. 궁금하다면 저장소와 관련 레퍼런스 문서를 참고하라. 여기서 보여주고 싶었던 건, 트랜잭션 안에는 임의의 코드를 넣을 수 있고, 그 안에서 수행되는 데이터베이스 읽기/쓰기 가 트랜잭션으로 묶인다는 점이다.
앞서 말했듯, 목표는 가능한 한 강한 격리 수준을 보장하면서도, 어느 정도 쓸 만한 성능을 유지하는 알고리즘을 고르는 것이었다. 맨 먼저 떠오른 건 Spanner처럼 Strict Two Phase Locking (S2PL)을 쓰는 것이었다. 이 방법만으로도 serializable 격리성을 보장한다. 여기에 GCS의 linearizable 일관성을 결합하면, 격리 수준의 최정점인 strict serializability를 얻을 수 있다.
알고리즘 자체는 꽤 직관적이다.
나의 접근 방식은 먼저 동작하게 만들고, 그다음 빠르게 만드는 것이었다.
위 알고리즘을 동작시키려면, 락과 원자적 커밋이 필요했다.
GCS 객체는 콘텐츠와 메타데이터 두 부분으로 구성되며, 둘은 독립적이다. 메타데이터에는 사용자가 제어하는 key-value들, 그리고 매번 쓰기(또는 메타데이터 변경) 시 자동으로 바뀌는 버전 번호가 들어 있다. 이 점 덕분에 객체의 메타데이터를 업데이트해 “락 걸림(locked)” 상태를 표시하기가 쉽다. 알고리즘은 기본적으로 compare-and-swap이다.
락 해제는 반대로 “locked=false”에 대한 compare-and-swap을 수행하면 된다.
이 알고리즘은 꽤 단순하다. 읽기와 쓰기 락을 구분하지 않고, 애플리케이션이 크래시 나면 영원히 풀리지 않는 락이 생길 수도 있다. 크래시에 대해서는 뒤에서 다시 이야기하겠지만, 그 전에 읽기 락을 추가해야 한다.
직관적인 규칙 몇 가지도 추가한다.
커밋은 순식간에 일어난 것처럼 보여야 한다. 트랜잭션은 커밋되었거나, 아니거나 둘 중 하나여야 한다. 그 중간 상태는 없어야 한다. 여러 키를 업데이트하는 트랜잭션에서는 이를 어떻게 구현할까? 모든 업데이트를 동시에 실현하려면 어떻게 해야 할까? 키를 하나씩 업데이트하면서 락을 풀다 보면, 중간에 프로세스가 크래시 났을 때 불일치 상태가 생길 수 있음은 분명하다.
한 가지 방법은 트랜잭션 로그 를 사용하는 것이다. 트랜잭션은 실제로 키를 업데이트하기 전에, 어떤 업데이트를 할지 로그에 저장해 둔다. 이렇게 하면 크래시 후에 재실행(replay) 이 가능해진다. 로그가 커밋되면 트랜잭션은 커밋된 것으로 간주되고, 크래시 이후 일을 이어받는 프로세스는 이 로그를 읽어 쓰기 커밋을 마무리할 수 있다.
내 구현 방식은, 트랜잭션이 커밋될 때 그 트랜잭션이 쓸 값들을 모두 트랜잭션 로그에 포함시키는 것이었다. 트랜잭션은 커밋 직전까지 실제 키 값은 건드리지 않고, 로그가 성공적으로 쓰인 후에야 키를 언락하면서 값을 업데이트한다.
분산 락에는 타임아웃이 필요하다. 어떤 프로세스가 트랜잭션을 열고 몇 개의 키에 락을 잡은 뒤 크래시 나면, 그 키들은 접근 불가능해진다. 크래시가 일시적이라 해도 모든 클라이언트가 충돌 이후에 꽤 빠르게 복귀할 것이라 기대하는 건 비현실적이다.
이를 해결하려면 락에 TTL을 도입해야 한다. 키에 락을 잡을 때, 트랜잭션은 커밋까지 걸리는 시간도 함께 추적한다. 타임아웃이 지나면, 트랜잭션은 자신이 아직 pending 상태임을 나타내는 트랜잭션 로그를 새로 생성(또는 갱신)하고, 그 안에 락 갱신 기한(타임스탬프)을 적어 둔다. 경쟁 중인 트랜잭션이 어떤 락이 아직 유효한지 확인하려면, 해당 트랜잭션 로그를 읽기만 하면 된다. 타임스탬프가 너무 과거라면, 혹은 타임아웃 동안 로그가 전혀 보이지 않는다면, 그 락은 “만료(expired)”된 것으로 간주한다.
하지만, 단순히 락을 관찰하다가 한동안 활동이 없으면 가져와 버리는 알고리즘은 잘못된 것이다. 이유는 이렇다. 트랜잭션이 잠시 멈춰 있는 상황에서, 검증(verify) 단계를 마친 뒤 트랜잭션 로그를 쓰기 전에 멈춰 버리면, 이 트랜잭션 입장에서는 자신이 아직 커밋해도 되는지, 아니면 이미 어떤 락을 빼앗겼는지 확인할 길이 없기 때문이다.

이 문제는 커밋 직전에 더 많은 체크를 넣는다고 해결되지 않는다. 지연이 바로 그 트랜잭션 로그 쓰기 도중에 일어날 수도 있기 때문이다. 그 시점의 쓰기는 막을 수 없다.
이를 해결하는 방법 중 하나는, 트랜잭션 로그 자체 를 동기화 지점으로 사용하는 것이다. 어떤 트랜잭션 (2)이 만료된 락을 (1)로부터 빼앗고자 할 때, (1)의 트랜잭션 로그에 조건부 쓰기를 시도해, (1)이 aborted 상태임을 기록하려 한다. 만약 이 쓰기가 성공한다면(즉, 그 사이 로그가 바뀌지 않았다면) (1)은 공식적으로 abort된 것이고, 그가 보유하던 모든 락은 무효가 된다. 쓰기가 실패했다면(예: 트랜잭션이 이미 성공적으로 커밋했거나, 락을 갱신했기 때문), (2)는 더 기다려야 한다.
트랜잭션 로그에 대한 변경이 원자적으로 수행되고 잘못된 덮어쓰기가 일어나지 않도록만 보장하면, 동시 변경이 있더라도 각 트랜잭션의 의도와 상태를 항상 올바르게 전달할 수 있다.
위 예시에서 (2)가 (1)의 트랜잭션 로그 쓰기에 성공했다면, (1)이 커밋을 위해 같은 로그에 쓰려는 시도는 실패하게 된다. (1)이 가진 조건은 이전 버전에 맞춰져 있기 때문이다. 이 시점에서 (1)은 abort하게 된다.
트랜잭션에서 키 생성과 삭제를 처리하는 방식은, 가짜 키(pseudo-key)를 사용하는 것이다. 컬렉션마다 하나의 가짜 키가 있고, 그 키는 해당 컬렉션에 존재하는 “키 목록”을 나타낸다. 컬렉션을 순회(iteration)하거나 키를 추가/삭제할 때의 일관성을 보장하기 위해, 트랜잭션은 영향받는 각 컬렉션에 대해 다음과 같이 해당 가짜 키에 락을 건다.
이 메커니즘 덕분에, 키를 단순히 수정만 할 때는 컬렉션을 언락 상태로 둘 수 있다. 키 추가/삭제와 다르게, 수정은 대부분의 경우일 테니까.
지금까지 살펴본 알고리즘은 강한 격리성과 일관성을 제공하지만, 과연 빠를까? 객체 스토리지 자체가 특히 빠르지 않다는 점을 감안하면, 처리량을 최대화하려면 서로 다른 키를 다루는 트랜잭션이 서로에게 영향을 주지 않도록 하는 게 중요했다. 이는 전역 락이나 단일 트랜잭션 로그 같은 건 쓸 수 없다는 뜻이다. 그런 구조는 트랜잭션 전체에서 경합을 유발한다. 또, 객체 스토리지는 수평 확장을 전제로 설계돼 있으므로 최대한 병렬성을 높이고 싶었다.
성능을 높이려는 과정에서도 다음 제약을 잊어서는 안 된다.
트랜잭션이 서로에게 미치는 영향을 줄이는 가장 쉬운 방법은, 공용 로그 객체 하나 대신 트랜잭션마다 서로 다른 로그 객체를 쓰는 것이다. 클라이언트는 각 트랜잭션에 임의의 ID를 할당하고, 그 ID를 로그 객체 경로의 일부로 사용한다. 그러면 각 클라이언트는 다른 누구와도 통신하지 않고도 트랜잭션 로그를 찾을 수 있다. ID만 알면 그 경로는 결정적이기 때문이다.
하지만 키를 어떤 트랜잭션에 매핑할까? 답은 객체 메타데이터에 있다. 락을 잡을 때, 우리는 락을 잡은 트랜잭션 ID를 메타데이터에 기록한다. 그러면 읽는 쪽은 메타데이터만 읽어서, 키가 여전히 락이 걸려 있는지, 누가 락을 잡고 있는지, 그 트랜잭션 상태가 어떤지를 알 수 있다. 키를 검사할 때 고려해야 할 경우는 세 가지다.
“빠르다”는 말은 항상 상대적이고 맥락적이다. 무엇과 비교해서 빠른가? 어떤 조건에서인가? 어떤 사용 사례를 희생하더라도, 어떤 사용 사례에서 이득을 보고 싶은가? 내 핵심 선택은, 낮은 데이터 경합(low contention) 워크로드에 최적화하는 것이었다. 동일 키에 대한 동시 쓰기가 드물다면, 서로 충돌하지 않는 트랜잭션을 더 빠르게 처리하는 대신, 충돌하는 트랜잭션은 좀 느리게 처리해도 괜찮다. 이 생각은 낙관적 락(optimistic locking)으로 이어진다. 여기서 트랜잭션은 락을 잡지 않고 데이터 자원을 사용한다. 다른 트랜잭션이 같은 데이터를 수정했는지는 커밋 시 확인한다. 이는 객체 스토리지가 강점을 가지는 지점(지연 시간보다는 처리량)과도 잘 맞는다.
알고리즘은 다음과 같이 동작한다.
낙관적 락은 락을 피하지만, 묵시적으로 트랜잭션이 검증과 커밋을 순차적으로 하나씩만 수행해야 한다는 제약을 요구한다. 검증과 커밋은 원자적으로 실행돼야 하기 때문이다. 그렇지 않으면, 쓰기 손실(lost write) 위험이 생긴다.

이 문제를 피하면서 기본 알고리즘이 제공하는 격리 수준을 유지하기 위해, 나는 약간 변형된 낙관적 락을 사용했다. 즉, 락을 쓰는 낙관적 락이다. 다른 점은, 트랜잭션이 검증 단계 에 도달하기 전까지는 락을 잡지 않고 실행된다는 것이다. 검증 단계에 도달하면, 모든 키에 대해 락을 병렬로 획득하고, 충돌 여부를 안전하게 확인한 뒤, 그 후에야 트랜잭션 로그를 커밋하거나 재시도한다.

이 방식은 전역 동기화 지점을 피한다. 두 트랜잭션이 서로 다른 키를 건드린다면, 서로 같은 객체를 놓고 경쟁하지 않으므로 병렬로 진행할 수 있고, 락은 가능한 짧은 시간 동안만 유지된다.
3-2 단계에서 재시도하는 경우, 락은 해제하지 않는 점에 주목하자. 이 부작용으로, 트랜잭션은 최대 한 번만 재시도된다. 두 번째 실행은 이미 락을 쥔 상태에서 이뤄지므로 사실상 비관적 락(pessimistic locking)으로 변한다. 그 사이에 다른 트랜잭션이 해당 키들에 대해 커밋할 수 없다.
이미 우리는 높은 처리량과 낮은 경합을 가정한 워크로드에 최적화하고 있다. 이 시나리오에서 읽기 전용(read-only) 트랜잭션은 대부분 아무 방해 없이 실행될 것이다. 그렇다면, 읽기 전용 트랜잭션에 한해서는 표준 낙관적 동시성 제어 알고리즘을 락 없이 그대로 쓸 수 있을까? 기억해야 할 점은, 트랜잭션의 검증 단계 는 업데이트 손실을 막기 위해 순차적으로 실행해야 한다는 것이다. 일반적인 읽기-쓰기 트랜잭션의 경우, 현재 트랜잭션이 다른 트랜잭션의 검증/커밋에 영향을 줄 수도 있고, 반대로 다른 트랜잭션이 현재 트랜잭션에 영향을 줄 수도 있다. 하지만 읽기 전용 트랜잭션은 쓰기를 하지 않으므로, 첫 번째 문제는 고려할 필요가 없다. 즉, 다른 트랜잭션의 검증/커밋에 영향을 주지 않는다. 남는 문제는, 읽기 전용 트랜잭션이 키를 읽는 동안(첫 읽기부터 마지막 읽기 사이) 다른 트랜잭션이 키를 수정하지 않았음을 보장하는 것뿐이다.
이는 비교적 단순하게 구현할 수 있다.
2단계에서, 우리는 객체 버전만이 아니라 메타데이터 버전도 함께 확인한다는 점에 주목하자. 실제로는, 메타데이터가 바뀐 경우에도 재시도를 피할 수 있는 몇 가지 예외가 있다. 예를 들어 키가 읽기 락으로 잠겼다 풀린 경우나, 어떤 트랜잭션이 락을 잡았지만 결국 abort한 경우다.
불운한 트랜잭션이 무한히 재시도되는 것을 막기 위해, 첫 재시도 이후에는 일반 알고리즘으로 되돌아가 읽기 락을 잡고 writer를 막는다. 이 방식은 결국 진행(progress)을 보장한다.
첫 시도에서 성공했다면, 이 트랜잭션은 값도, 락 상태도 실제로는 바꾸지 않았으므로, 트랜잭션 로그를 쓸 필요도 없다. 즉, 해피 패스에서는 키당 한 번의 값 읽기와 한 번의 메타데이터 읽기만 발생하고, 쓰기는 없다.
이 접근법은 다중 버전 동시성 제어(MVCC)를 구현하는 Spanner의 방식과는 다르다. MVCC는 일관된 데이터베이스 스냅샷에서 읽을 수 있게 함으로써 읽기를 훨씬 빠르게 만든다. 이를 올바르게 구현하는 일은 쉽지 않다. 데이터베이스의 linearizable 일관성이 전 세계 모든 트랜잭션의 실제 시간 순서와 호환되는 버전을 선택하는 데 달려 있기 때문이다. 그보다 오래된 버전을 읽으면 더 약한 일관성 모델로 떨어진다. Spanner는 이를 어려운 방법으로 해결한다. 원자적 시계와 제한된 시간 불확실성을 이용하는 것이다.
우리는 여러 버전의 객체를 유지하지 않고, 원자적 시계도 없고, 트랜잭션 코디네이터도 없다. 따라서 나는 충돌이 발생하자마자 2단계 락(two-phase locking)으로 되돌아가 strict serializability 격리 수준을 유지하는 쪽을 택했다.
읽기와 쓰기를 모두 단일 키에만 하는 트랜잭션은, 객체 스토리지의 compare-and-swap(CAS) 연산을 그대로 활용해 최적화할 수 있다. 알고리즘은 다음과 같다.
충돌 시에는 기본 알고리즘으로 트랜잭션을 재시도해, 경합이 높을 때도 굶주림(starvation)이 일어나지 않도록 한다.
마지막으로 이야기하고 싶은 최적화는 로컬 캐시다. 클라이언트가 어떤 키에 대해 유일한 writer라면, 캐시는 읽기 연산을 제거하는 데 도움이 된다. 예를 들어 아래와 같은 연속된 트랜잭션 100개는, 다른 트랜잭션이 그 키를 건드리지 않더라도 같은 키를 100번 읽게 된다.
for i := 0; i < 100; i++ {
db.Tx(ctx, func(tx *glassdb.Tx) error {
b, _ := tx.Read(coll, key)
return tx.Write(coll, key, string(b) + "a")
})
}그래서 나는 가장 최근 트랜잭션이 커밋한 값을 메모리에 유지하는 로컬 LRU 캐시를 도입했다. 캐시는 전체 사용 가능한 메모리를 다 잡아먹지 않도록 크기를 제한하고 설정 가능하게 했다.
동작 방식은 단순하다. 트랜잭션에서 읽기를 수행할 때마다 캐시를 먼저 확인한다. 캐시에 값이 있으면 그 값을 사용한다. 검증 단계에서 그 값이 오래된 것으로 판명되면, 해당 키를 stale로 표시하고 트랜잭션을 재시도한다. 재시도 시에는 캐시 항목이 무효화되므로, 트랜잭션은 객체 스토리지에서 최신 값을 읽어 온다.
이제 이 물건의 성능은 어떨까? 자세한 내용은 glassdb 저장소에 있지만, 요약하면, 경합이 적은 워크로드에서는 트랜잭션 수가 늘어날수록 처리량이 어느 정도 선형적으로 증가한다.
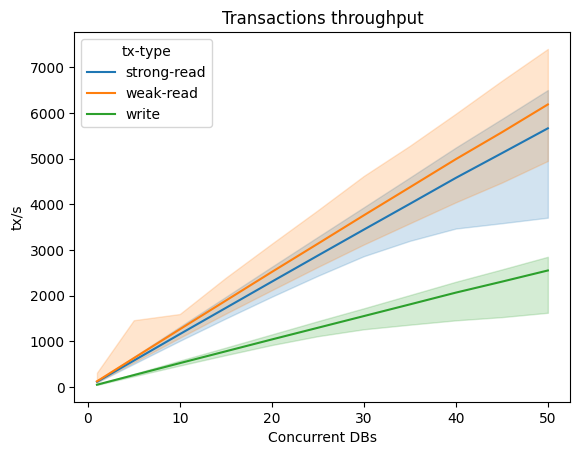
위 그래프는 세 가지 유형의 트랜잭션에서, 굵은 선은 초당 트랜잭션 수의 중앙값을, 옅은 밴드는 10번째와 90번째 퍼센타일을 포함하는 범위를 나타낸다. 데이터셋은 5만 개의 키로 구성돼 있고, 각 클라이언트는 10개의 트랜잭션을 병렬로 실행한다(10%는 2개의 키를 읽고 쓰기, 60%는 2개 키 읽기, 30%는 단일 키에 대해 weak read4).
트랜잭션이 키를 무작위로 선택하기 때문에, 동시성이 높아질수록 충돌 확률이 높아져 고퍼센타일이 더 크게 영향을 받는 것을 볼 수 있다.
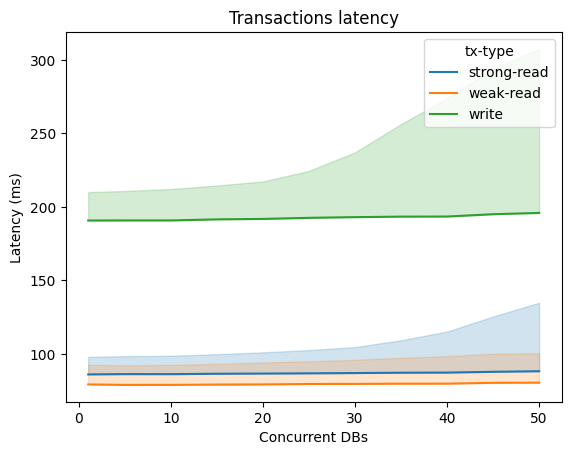
반면 지연 시간은(이 솔루션의 강점은 아니지만) 대부분의 데이터베이스보다 높지만, 경합 수준이 크게 높아지지 않는 한 동시성이 높아져도 비교적 평탄한 모습을 보인다.
글이 꽤 길어졌고, 사실 모든 걸 다 다루지도 못했다. 소스 코드, 테스트, 정확성 검증, 프로파일링, 기타 여러 최적화 이야기도 하고 싶었지만, 여기서는 설계의 가장 중요한 측면에 집중했다. 이 여정을 통해 내가 배운 핵심 교훈들을 어느 정도 전할 수 있었고, 데이터베이스 설계와 분류에서 자주 쓰이지만 실은 그렇게까지 어렵지 않은 용어들을 조금은 덜 신비롭게 느끼게 했기를 바란다.
소스 코드를 살펴보고 싶다면 트랜잭션 알고리즘부터 시작해 보라. 주석은 많지 않지만, Go로 쓰였으니 이해하기 어렵진 않을 것이다 :)
추가로 한 가지 더. S3는 잊은 게 아니다. 처음에는 여러 클라우드 제공자에 걸쳐 동일한 솔루션을 제공하는 일이 얼마나 쉬운지 강조했었다. 실제로 그렇게 됐을까? 솔직히 말하면, 아직은 아니다. 정확히는, GCS에서 이걸 제대로 동작시키는 데 너무 많은 시간을 써서, 다른 클라우드로 포팅할 시간이 나지 않았다. 게다가 구글 클라우드가 AWS S3보다 더 풍부한 형태의 조건부 업데이트를 제공한다는 점도 드러났다. 이식성이 생각보다 간단하지 않다.
뭐, 괜찮다. 나는 뭔가를 배웠고, 뭔가를 해결했다. 나머지는 다음 릴리스를 기다려도 된다.
피드백은 Hacker News에서.
더 자세한 내용은 Fauna 블로그의 Introduction to Isolation Levels를 참고하라.↩︎
Fauna architectural overview도 참고할 만하다.↩︎
CockroachDB의 일관성에 대한 블로그 글과 Jepsen 보고서를 보라.↩︎
weak read란, 사용자가 지정한 범위 내에서 오래된 값(스테일 값)을 읽을 수 있도록 허용하는 읽기다. 예를 들어, staleness bound가 10초인 weak read는 키의 최신 값이나, 캐시에 있는 10초 이내의 과거 값까지는 읽어도 되지만, 그보다 더 오래된 값은 읽을 수 없다.↩︎