몇 가지 설정만 조정해도 SQLite를 서버 환경에서 높은 동시 처리량과 안정성으로 운용할 수 있다. WAL, busy_timeout, 트랜잭션 모드, 연결 풀 분리, 배치 쓰기, STRICT 테이블, 운영/백업(Litestream)까지 실전 튜닝 포인트를 정리한다.
URL: https://kerkour.com/sqlite-for-servers
Title: 서버를 위한 SQLite 최적화
SQLite는 종종 “장난감 데이터베이스”로 오해받습니다. 기본 설정이 임베디드 용도에 최적화되어 있어서, 대부분의 사람들이 서버에 적용해보면 성능이 나쁘고 악명 높은 SQLITE_BUSY 에러를 만나기 때문입니다.
하지만 몇 가지 노브만 조정하면, 4 vCPU를 가진 약 40€짜리 범용 가상 서버에서(자세한 내용과 코드는 부록 참고) 에러 0으로 동시 처리 기준 대략 초당 8,300 writes와 초당 168,000 reads까지 SQLite를 설정할 수 있다고 말하면 어떨까요?
서버 애플리케이션이 요청당 평균 8개의 DB 읽기 쿼리를 수행한다고 가정하면, 이론상 초당 약 21,000개의 요청, 혹은 하루에 약 1,814,300,000개의 요청을 처리할 수 있습니다. 월 40€(대역폭 포함)라면 나쁘지 않죠! (실제로는 그렇게 못 할 수도 있습니다. 서버 대역폭이 병목이 될 가능성이 큽니다.)
그리고 이건 GC 튜닝, 캐싱과 CDN 이야기를 하기 전입니다.
추가로 수치를 더 보고 싶다면, Expensify의 2018년 글을 보세요: Scaling SQLite to 4M QPS on a single server.
TL;DR?
PRAGMA journal_mode = WAL;
PRAGMA busy_timeout = 5000;
PRAGMA synchronous = NORMAL;
PRAGMA cache_size = 1000000000;
PRAGMA foreign_keys = true;
PRAGMA temp_store = memory;
BEGIN IMMEDIATE 트랜잭션을 사용하세요.
writeDB.SetMaxOpenConns(1)
readDB.SetMaxOpenConns(max(4, runtime.NumCPU()))
STRICT 테이블을 사용하세요.
SQLite는 가장 널리 배포되고 사용되는 데이터베이스 엔진입니다. 정말 어디에나 있습니다. 휴대폰과 컴퓨터(설치된 애플리케이션 수에 따라)에 수백 개의 SQLite 데이터베이스가 있을 가능성이 크고, 자동차에도 몇 개가 있으며, 여러분이 지난 휴가 때 탔던 비행기에도 있을 수 있습니다.
이것은 SQLite의 신뢰성을 부정할 수 없다는 증거이며, SQLite에 데이터를 맡겨도 안전하다는 마음의 평화를 줍니다.
클라우드 제공자들이 “모든 소프트웨어 조각을 과도하게 엔지니어링해야 한다”는 서사를 밀어붙이는 건 이제 끝나야 합니다!
여기 AWS에서 워드프레스를 호스팅하기 위한 “레퍼런스 아키텍처”가 있습니다:

...

서버에서 SQLite를 쓰고 싶은 가장 큰 이유 3가지는 신뢰성, 성능, 단순성입니다(순서는 상관없습니다).
신뢰성(Reliability): DB에 대한 네트워크 호출을 제거하면 DNS 오류, 네트워크 장애 같은 수많은 실패 케이스가 사라집니다.
성능(Performance): 네트워크 DB의 읽기 지연이 밀리초(ms) 단위라면, SQLite의 읽기 지연은 마이크로초(µs) 단위입니다.
단순성(Simplicity): 성능과 신뢰성은 단순성으로 이어집니다. SQLite를 쓰면 단일 머신에서 엄청나게 스케일할 수 있고, 클러스터 관리(k8s 등)를 둘러싼 모든 서커스를 제거할 수 있습니다. 더 좋은 건 보안이 크게 향상된다는 점입니다. 더 이상 외부에 노출된 DB나 전송 중 암호화 설정 실수 같은 문제가 없습니다… 특히 오픈소스 및 온프레미스 프로젝트에서는, 사용자들이 시스템 관리자나 보안 엔지니어가 아니더라도 앱을 셀프 호스팅하길 원할 수 있으니 매우 중요합니다.
그리고 묻기 전에 말하자면, 네, SQLite는 전문 검색(Full-text search) 모듈, JSON 함수와 연산자, 그리고 벡터 검색 확장도 있습니다.
SQLITE_BUSY 에러SQLITE_BUSY(언어에 따라 database is locked)는 서버에서 SQLite를 처음 쓰기 시작할 때 가장 자주 만나게 될 에러입니다. 그래서 의미와 발생 이유를 이해하는 것이 중요합니다.
현재 SQLite는 한 번에 오직 1개의 writer만 DB에 쓸 수 있도록 허용합니다. 이를 위해 SQLite 엔진은 쓰기 작업 동안 DB를 잠급니다.
따라서 SQLITE_BUSY의 의미는 단순합니다: “DB에 대한 락을 얻으려고 했지만, 다른 연결/프로세스가 충돌하는 락을 잡고 있어서 실패했다.”
서로 다른 스레드/프로세스가 동시에 DB에 쓰려고 하면 SQLite는 잠깐 기다렸다가 재시도합니다. busy_timeout(뒤에서 설명) 밀리초 동안 재시도한 후에도 안 되면 SQLite는 SQLITE_BUSY 에러를 반환합니다.
말은 이쯤 하고, 코드로 들어가 봅시다!
SQLite는 기본적으로 모바일 앱이나 임베디드 장치 같은 클라이언트 애플리케이션에 최적화되어 있지만, 올바른 설정을 적용하면 서버에서도 훌륭하게 만들 수 있습니다.
PRAGMA 명령은 연결을 연 직후 간단히 db.Exec(또는 유사한 호출)로 실행해야 합니다.
PRAGMA journal_mode = WAL;
WAL 저널 모드는 Write-Ahead Log를 제공하며, 기본 모드와 달리 reader가 writer를 막지 않고 writer도 reader를 막지 않기 때문에 동시성이 더 좋아집니다(기본 모드에서는 reader가 writer를 막고 그 반대도 마찬가지).
PRAGMA synchronous = NORMAL;
“synchronous가 NORMAL이면 SQLite DB 엔진은 여전히 가장 중요한 순간에는 sync를 수행하지만, FULL 모드보다 덜 자주 수행합니다. WAL 모드는 synchronous=NORMAL이어도 손상(corruption)으로부터 안전합니다.”
WAL 모드에서 최고의 성능을 제공합니다.
PRAGMA cache_size = 1000000000;
SQLite 캐시를 늘립니다.
cache_size pragma로 캐시 크기를 바꾸면, 변경은 현재 세션에만 유지됩니다. DB를 닫았다가 다시 열면 캐시 크기는 기본값으로 돌아갑니다.
PRAGMA foreign_keys = true;
역사적 이유로 SQLite는 기본적으로 외래 키를 강제하지 않습니다. 직접 활성화해야 합니다.
PRAGMA busy_timeout = 5000;
앞서 봤듯이 더 큰 busy_timeout을 설정하면 SQLITE_BUSY 에러를 방지하는 데 도움이 됩니다.
저는 API 같은 사용자 대면 애플리케이션에는 5000(5초)을, 큐나 M2M API 같은 백엔드 애플리케이션에는 15000(15초) 또는 그 이상을 선호합니다.
이건 SQLite의 가장 큰 함정(footgun) 중 하나일 수 있습니다.
기본적으로 SQLite는 트랜잭션을 DEFERRED 모드로 시작합니다. 즉 읽기 전용으로 간주됩니다. 그리고 write/update/delete가 포함된 쿼리가 실행되는 순간, DB 락이 필요한 쓰기 트랜잭션으로 “실시간(in-flight)” 업그레이드됩니다.
문제는 트랜잭션을 시작한 후에 업그레이드하면, 이미 다른 연결이 DB를 잠그고 있는 경우 SQLite가 앞서 말한 busy_timeout을 존중하지 않고 즉시 SQLITE_BUSY 에러를 반환한다는 점입니다.
그래서 BEGIN만 쓰지 말고, 트랜잭션 시작을 BEGIN IMMEDIATE로 해야 합니다. 트랜잭션 시작 시점에 DB가 잠겨 있으면 SQLite는 busy_timeout을 존중합니다.
이는 Go에서는 mydb.db?_txlock=immediate로 풀 수준에서 설정할 수 있고, Django 5.1+에서는 "transaction_mode": "IMMEDIATE"로 설정할 수 있습니다.
마지막으로 SQLITE_BUSY 에러를 완전히 없애기 위한 단계는, 쓰기 쿼리에는 연결 1개만 사용하고 뮤텍스로 보호하는 것입니다. Go에서는 db.SetMaxOpenConns(1)로 달성할 수 있습니다. 그러면 쓰기 락은 뮤텍스로 관리되고, 쓰기는 SQLite 내장 재시도 및 busy_timeout 메커니즘에 의존하는 대신 애플리케이션 측에서 큐잉됩니다.
여기서 멈추면 읽기 성능이 나빠질 수 있습니다. 읽기 쿼리가 쓰기 쿼리와 단일 DB 연결을 두고 경쟁하기 때문입니다. 하지만 앞서 본 것처럼 WAL 저널 모드에서는, DB가 쓰기 락 상태여도 SQLite는 무한한(reader 수 제한 없는) reader를 허용합니다.
요령은 DB 커넥션 풀을 2개 두는 것입니다: 쓰기용 풀은 SetMaxOpenConns(1)로, 읽기용 풀은 CPU 수에 맞춰 확장합니다.
writeDB, err := sql.Open("sqlite3", connectionUrl)
if err != nil {
// ...
}
writeDB.SetMaxOpenConns(1)
readDB, err := sql.Open("sqlite3", connectionUrl)
if err != nil {
// ...
}
readDB.SetMaxOpenConns(max(4, runtime.NumCPU()))
저는 개인적으로 이 복잡함을 커스텀 DB 구조체로 숨기는데, Select/Get 메서드는 ReadDB 풀을 사용하고 Exec/ExecSelect/Transaction 메서드는 WriteDB 풀을 사용하게 합니다.
type DB struct {
writeDB *sqlx.DB
readDB *sqlx.DB
}
func (db *DB) Exec(ctx context.Context, query string, args ...any) (sql.Result, error) {
return db.writeDB.ExecContext(ctx, query, args...)
}
func (db *DB) Select(ctx context.Context, dest any, query string, args ...any) error {
return db.readDB.SelectContext(ctx, dest, query, args...)
}
// ...
애플리케이션이 허용하는 경우, 여러 쓰기를 하나의 트랜잭션에 배치하세요.
err = Db.Transaction(func (tx *Tx) (err error) {
for _, event := range events {
err = tx.Exec("...", ...)
if err != nil {
return err
}
return nil
}
})
SQLite는 위에서 언급한 범용 서버에서 insert를 배치로 처리하면 초당 ~250,000+ writes까지도 쉽게 도달할 수 있습니다.
하드웨어에서 SQLite 쓰기 성능의 한계에 도달하면, DB를 여러 개의 더 작은 조각으로 나누는 것이 좋습니다.
예를 들어, 제가 현재 작업 중인 서버 애플리케이션은 DB를 3개 사용합니다:
myservice.db: 사용자 및 비즈니스 데이터를 담는 메인 DB. 읽기 ~75% / 쓰기 25%.myservice_queue.db: 백그라운드 잡용 큐 DB. 읽기 2% / 쓰기 ~98%.(큐에서 잡을 뽑는 것조차 UPDATE가 필요합니다.)myservice_events.db: 이벤트를 저장하는 DB(이벤트 테이블은 언제나 있습니다). 쓰기 ~90% / 읽기 10%.이벤트 DB가 가장 쓰기 집약적이어서, 저는 20ms마다 또는 메모리 내 이벤트 버퍼가 10,000 레코드에 도달할 때마다 단일 트랜잭션으로 이벤트 삽입을 배치 처리합니다.
STRICT 테이블 사용하기SQLite는 기본적으로 “약한 타입(weakly typed)”입니다. INT 컬럼에 문자열을 넣어도 불평하지 않고 그냥 받아줍니다.
이건 나쁩니다.
3.37 버전부터 SQLite는 테이블에 대한 STRICT 모드를 지원하며, 강한 타이핑을 강제합니다.
CREATE TABLE example (
id BLOB NOT NULL PRIMARY KEY,
created_at INTEGER NOT NULL,
something INT NOT NULL
) STRICT;
Litestream은 SQLite 사용을 “가능하게” 만들 뿐 아니라, “아주 좋은 아이디어”로 만들어주는 비밀 병기입니다.
Litestream은 “SQLite를 위한 스트리밍 복제(Streaming replication)”를 제공합니다. 이는 무슨 뜻일까요?
Litestream은 백그라운드에서 DB의 WAL을 복제해 S3 호환 서버에 저장하는 데몬입니다. 비동기 포인트-인-타임 복구와 실시간 백업을 가능하게 하고, 장애 시에도 데이터 손실 없이 DB를 복원할 수 있게 해줍니다. 이 모든 것이 S3 비용으로 월 몇 센트 수준입니다.

동작 방식은 여기에서 자세히 볼 수 있습니다.
SQLite 저자들은 일부 네트워크 파일시스템이 결함 있는 락 메커니즘을 갖고 있어, 여러 프로세스가 접근할 경우 DB 손상이 발생할 수 있으므로 네트워크 파일시스템 위에서 SQLite를 사용하는 것을 권장하지 않습니다.
하지만 이 시나리오는 여러 프로세스/머신이 다중 머신 네트워크 파일시스템(NFS)에 동시에 접근할 때만 발생할 수 있습니다. AWS EBS나 Scaleway Block Storage처럼 네트워크 볼륨에 연결되어 있지만 단일 머신 파일시스템을 사용하는 경우에는, 커널이 성능과 올바른 락킹을 처리합니다.
따라서 여기에는 두 가지 선택지가 있습니다.
첫째, 베어메탈 서버에서 RAID 구성의 여러 디스크를 사용해 신뢰성과 가용성을 확보하며 SQLite를 사용합니다.
둘째, 클라우드에서 SQLite를 쓴다면, AWS EBS나 Scaleway Block Storage처럼 오직 1대 머신만 접근 가능한 네트워크 볼륨 위에 단일 머신 파일시스템(ext4)으로 SQLite DB를 두는 것을 권장합니다. 충분한 IOPS도 확보하세요. 이러한 네트워크 볼륨은 로컬 SSD보다 신뢰성과 가용성이 더 좋습니다. 서버에서 가장 자주 고장 나는 부품이 디스크이기 때문입니다.
참고로 2017년 이후 AWS EFS 네트워크 파일시스템은 NFS v4 락을 지원하여 여러 서버가 SQLite에 안전하게 접근할 수 있게 되었지만, 네트워크 락은 성능이 좋지 않습니다(마이크로초가 아니라 밀리초 락을 생각하세요). 정말 다른 선택지가 없을 때만 고려해야 합니다.
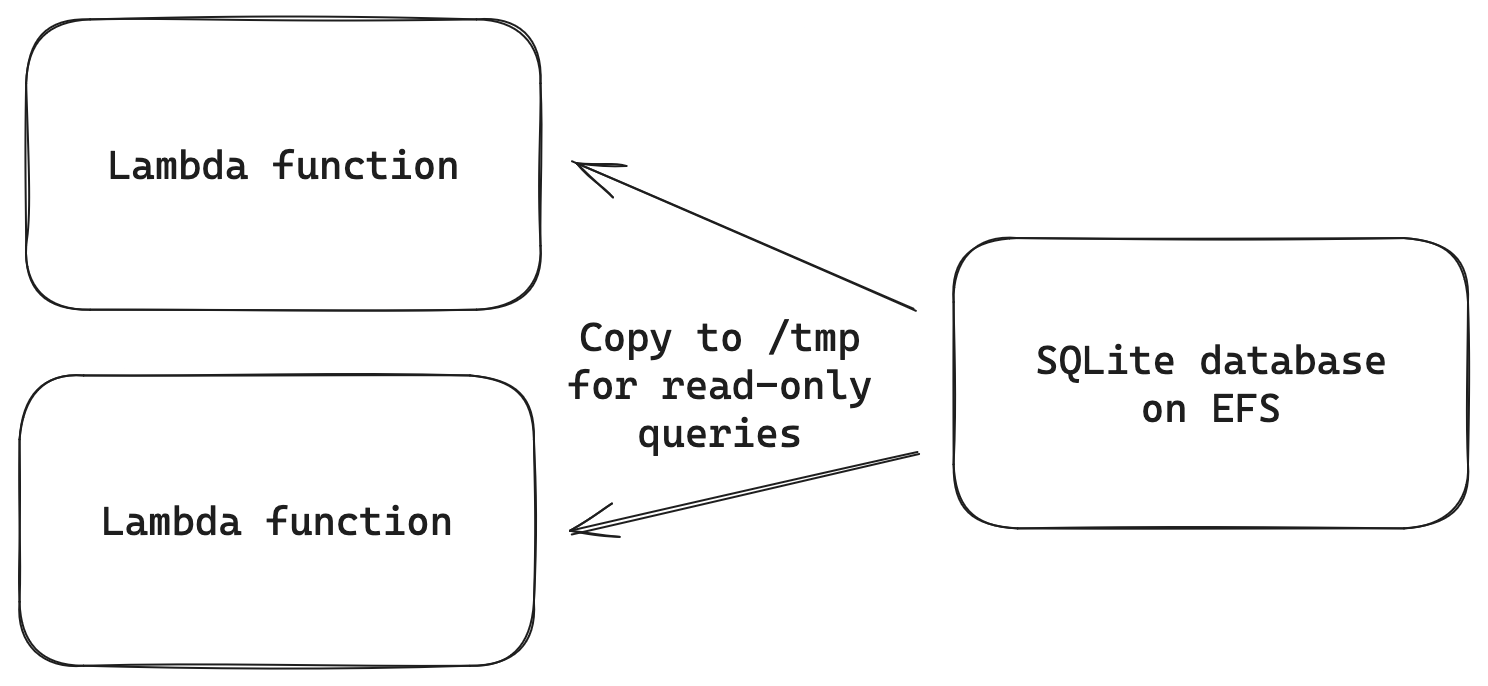
또한 이론상 EFS를 Lambda 서버리스 함수와 함께 사용할 수도 있습니다. 이를 위해 현실적인 선택지는 2가지입니다.
첫째, DB가 읽기 전용이고 업데이트가 매우 드물다면(한 달에 한 번 정도) DB를 코드와 함께 lambda.zip 번들에 구워 넣을(bake) 수 있습니다.
둘째, DB가 읽기 전용이지만 자주(매시간/매일) 업데이트된다면, 다른 해결책은 기본 DB를 EFS 볼륨에 두고, 시작 시점에 Lambda의 /tmp 디렉터리로 복사하여 훨씬 나은 성능(밀리초 대신 마이크로초)을 얻는 것입니다.
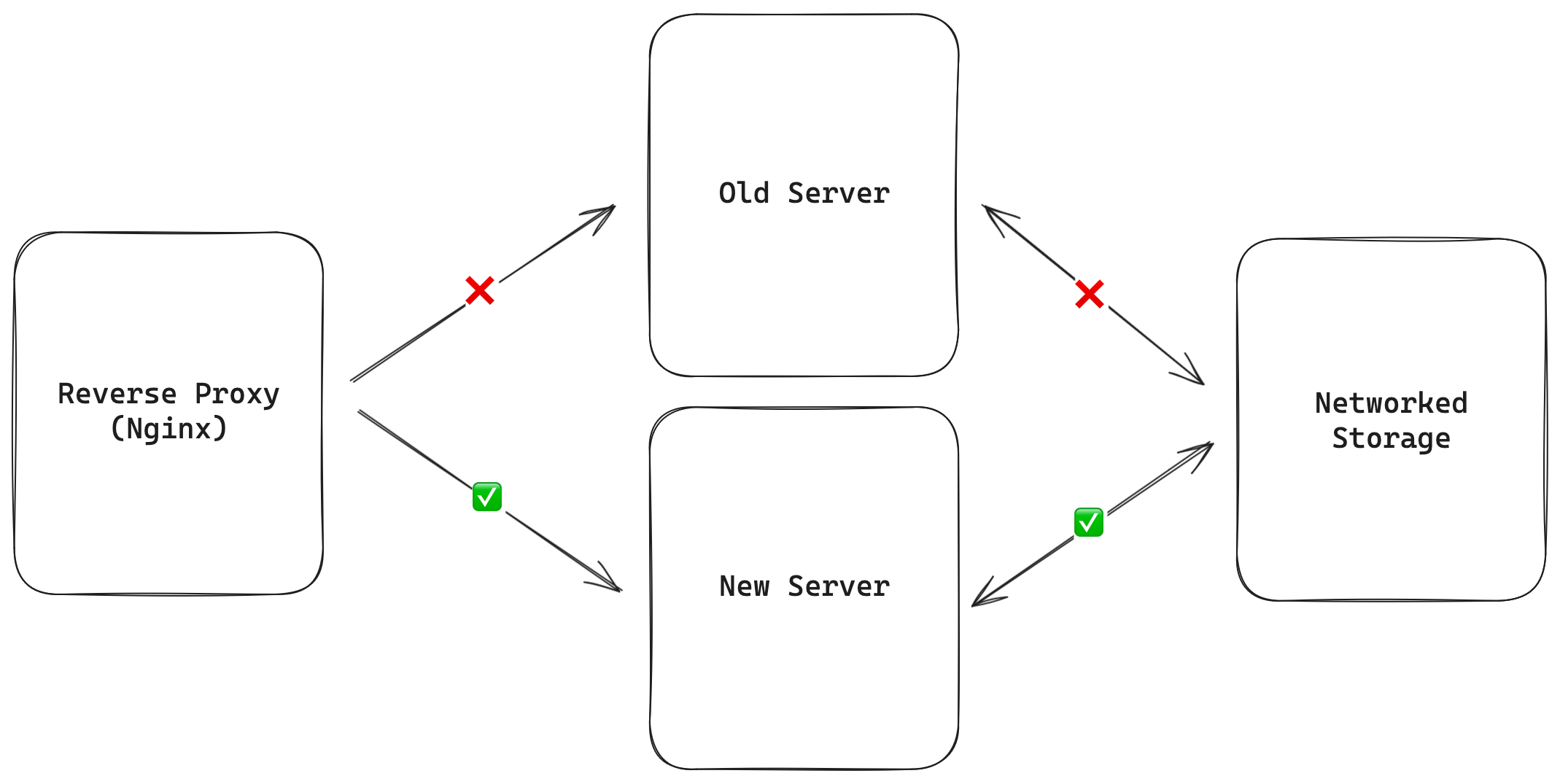
Pingoo 같은 리버스 프록시/로드 밸런서를 사용하세요. 백엔드 서버가 내려가도 요청을 재시도해줍니다.
대중적 믿음과 달리, 몇 초 동안 스토리지 볼륨을 구 서버에서 분리(detach)해 신 서버에 붙이는 동안(reverse proxy가 연결을 유지하도록) 리버스 프록시의 도움을 받으면 DB를 호스팅하는 머신도 다운타임 없이 업그레이드할 수 있습니다.
리버스 프록시가 들어오는 연결을 붙잡고 있는 상태에서, 이 모든 과정을 5초 이내로 수행할 수 있습니다.
그런데 머신이 예기치 않게 죽거나, 데이터센터가 불타는 상황은 어떻게 할까요?
여기만큼은 까다로워집니다. 아래 내용은 순수한 추측이며(아직) 구현해보지는 않았습니다.
5분 미만 다운타임의 페일오버 스크립트를 구현하는 것이 가능할 것입니다.
이를 위해서는 서로 다른 데이터센터(이상적으로는 서로 다른 제공자)에 2대의 서버가 필요합니다.
모니터링 시스템이 기본(primary) 서버가 X분 동안 다운되었다고 감지하면:
끝입니다.
이제 숫자를 계산해봅시다. 99.99% 가용성을 주장하려면 연간 허용 다운타임은 52.60분입니다. 페일오버에 5분이 걸린다면, 1년에 10번이나 머신이 죽어도(!) 99.99% 라벨을 유지할 수 있습니다.
현실적으로는 현대의 머신은 올바르게 관리된다면 훨씬 더 신뢰할 수 있고, 깨진 릴리스를 배포하지만 않는다면 99.999%(“파이브 나인”) 신뢰성도 쉽게 달성할 수 있습니다.
어쨌든, SQLite의 단순성은 오늘날 대부분 애플리케이션이 쓰는 카프카스러운 아키텍처와 비교할 때 너무나 많은 장애를 예방해주기 때문에, 5분 페일오버는 작은 리스크라고 생각합니다.
SQLite에서 동시 쓰기 성능을 개선하기 위한 3개의 프로젝트가 진행 중입니다:
BEGIN CONCURRENT: 쓰기 시 DB 전체가 아니라 영향받는 페이지들만 락을 걸도록 함.WAL2: WAL 모드를 개선.이 기능들이 메인 브랜치에 합쳐질지, 언제 합쳐질지는 불확실합니다. 모든 개발자가 알듯이 동시성은 어렵고, SQLite 저자들은 이런 기능들이 데이터 손상 문제를 절대 유발하지 않는다는 확신이 필요합니다.
SQLite 3.35부터 ALTER TABLE DROP COLUMN이 가능하지만, 테이블이 크면 일반적으로 느립니다.
TIMESTAMP 타입이 없다는 것은, Unix 타임스탬프를 INT로 쓰거나 ISO-8601/RFC-3339 타임스탬프를 TEXT로 사용해야 한다는 뜻입니다.
저는 개인적으로 성능이 가장 좋은 커스텀 Time 타입과 함께 Unix 밀리초 타임스탬프를 사용합니다.
type Time int64
func (t *Time) Scan(val any) (err error) {
switch v := val.(type) {
case int64:
*t = Time(v)
return nil
default:
return fmt.Errorf("Time.Scan: Unsupported type: %T", v)
}
}
func (t *Time) Value() (driver.Value, error) {
return *t, nil
}
SQLite는 PostgreSQL과 달리 인덱스에 대한 통계를 유지하지 않기 때문에, 인덱싱된 필드에 WHERE 절을 쓰더라도 COUNT 쿼리가 느립니다. SQLite는 매칭되는 모든 레코드를 스캔해야 합니다.
한 가지 해결책은 INSERT와 DELETE에 트리거(trigger)를 걸어서 별도 테이블에 누적 카운트를 업데이트하고, 카운트가 필요할 때는 그 별도 테이블에서 최신 값을 조회하는 것입니다.
2024년 3월 업데이트: Distributed SQLite: Paradigm shift or hype?
마무리하기 전에, SQLite를 분산 DB로 만들려는 흥미로운 프로젝트들에 대해 조금 이야기하고 싶습니다.
근본 아이디어는 대략 모든 프로젝트에서 같습니다: 쓰기용 단일 DB를 두고, 그것을 “무한한” 수의 읽기 전용 레플리카로 복제하는 것입니다.
이렇게 하면 읽기 스케일링뿐 아니라, 더 중요하게는 전 세계에 읽기 레플리카를 분산 배치할 수 있습니다.
단일 리전에 메인 DB를 두고, 엣지(edge)로 복제해 초고속 읽기를 제공합니다. 웹 앱의 전 세계 응답 시간을 50ms로 만든다고 생각해보세요.

2022년에 Ben Johnson은 이렇게 선언했습니다: I’m All-In on Server-Side SQLite. 2024년에는 저도 그렇습니다!
몇 달 뒤 실제 프로덕션 부하에서 얼마나 잘 동작하는지 계속 업데이트하겠습니다 :)
아래 결과는 모두 cryptsetup으로 암호화된 디스크에서 수행했습니다:
$ cryptsetup luksFormat --type luks2 --cipher aes-xts-plain64 --hash sha512 --iter-time 3000 --key-size 256 --pbkdf argon2id /dev/sdb
Scaleway Stardust1-s (공유 vCPU 1개, RAM 1GB) + 15K IOPS 블록 스토리지:
elapsed 10.027475918s
----------------------
272811 reads
27206.348061 reads/s
----------------------
20278 writes
2022.243700 writes/s
Scaleway PLAY2-MICRO (공유 vCPU 4개, RAM 8GB) + 15K IOPS 블록 스토리지:
elapsed 10.023892746s
----------------------
1681936 reads
167792.796932 reads/s
----------------------
82953 writes
8275.527492 writes/s
Scaleway POP2-2C-8G (전용 vCPU 2개, RAM 8GB) + 15K IOPS 블록 스토리지:
elapsed: 10.006010993s
----------------------
1000497 reads
99989.596324 reads/s
----------------------
69477 writes
6943.526251 writes/s
Go 버전: 1.22.0
사용법:
$ mkdir sql && cd sqlitebench
$ go mod init sqlitebench
# 아래 파일을 main.go에 복사
$ go mod tidy
$ go run main.go
package main
import (
"database/sql"
"database/sql/driver"
"fmt"
"log"
"net/url"
"os"
"runtime"
"sync"
"sync/atomic"
"time"
"github.com/google/uuid"
_ "github.com/mattn/go-sqlite3"
)
// Time is used to store timestamps as INT in SQLite
type Time int64
func (t *Time) Scan(val any) (err error) {
switch v := val.(type) {
case int64:
*t = Time(v)
return nil
case string:
tt, err := time.Parse(time.RFC3339, v)
if err != nil {
return err
}
*t = Time(tt.UnixMilli())
return nil
default:
return fmt.Errorf("Time.Scan: Unsupported type: %T", v)
}
}
func (t *Time) Value() (driver.Value, error) {
return *t, nil
}
type entity struct {
ID uuid.UUID
Timestamp Time
Counter int64
}
func setupSqlite(db *sql.DB) (err error) {
pragmas := []string{
// "journal_mode = WAL",
// "busy_timeout = 5000",
// "synchronous = NORMAL",
// "cache_size = 1000000000", // 1GB
// "foreign_keys = true",
"temp_store = memory",
// "mmap_size = 3000000000",
}
for _, pragma := range pragmas {
_, err = db.Exec("PRAGMA " + pragma)
if err != nil {
return
}
}
return nil
}
func main() {
cleanup()
defer cleanup()
uuid.EnableRandPool()
connectionUrlParams := make(url.Values)
connectionUrlParams.Add("_txlock", "immediate")
connectionUrlParams.Add("_journal_mode", "WAL")
connectionUrlParams.Add("_busy_timeout", "5000")
connectionUrlParams.Add("_synchronous", "NORMAL")
connectionUrlParams.Add("_cache_size", "1000000000")
connectionUrlParams.Add("_foreign_keys", "true")
connectionUrl := "file:test.db?" + connectionUrlParams.Encode()
writeDB, err := sql.Open("sqlite3", connectionUrl)
if err != nil {
log.Fatal(err)
}
defer writeDB.Close()
writeDB.SetMaxOpenConns(1)
err = setupSqlite(writeDB)
if err != nil {
log.Fatal(err)
}
readDB, err := sql.Open("sqlite3", connectionUrl)
if err != nil {
log.Fatal(err)
}
defer readDB.Close()
readDB.SetMaxOpenConns(max(4, runtime.NumCPU()))
err = setupSqlite(readDB)
if err != nil {
log.Fatal(err)
}
_, err = writeDB.Exec(`CREATE TABLE test (
id BLOB NOT NULL PRIMARY KEY,
timestamp INTEGER NOT NULL,
counter INT NOT NULL
) STRICT`)
if err != nil {
log.Fatal(err)
}
log.Println("Inserting 5,000,000 rows")
err = setupDB(writeDB)
if err != nil {
log.Fatal(err)
}
var recordIdToFind uuid.UUID
row := readDB.QueryRow("SELECT id FROM test ORDER BY id DESC LIMIT 1")
if row.Err() != nil {
log.Fatal(row.Err())
}
row.Scan(&recordIdToFind)
log.Println("Starting benchmark")
concurrentReaders := 500
concurrentWriters := 1
var wg sync.WaitGroup
var reads atomic.Int64
var writes atomic.Int64
ticker := time.NewTicker(10 * time.Second)
start := time.Now()
wg.Add(concurrentReaders)
for c := 0; c < concurrentReaders; c += 1 {
go func() {
// we use a goroutine-local counter to avoid the performance impact of updating a shared atomic counter
var readsLocal int64
for {
var record entity
if len(ticker.C) > 0 {
break
}
row := readDB.QueryRow("SELECT * FROM test WHERE id = ?", recordIdToFind)
if row.Err() != nil {
log.Fatal(row.Err())
}
row.Scan(&record.ID, &record.Timestamp, &record.Counter)
readsLocal += 1
}
reads.Add(readsLocal)
wg.Done()
}()
}
wg.Add(concurrentWriters)
for c := 0; c < concurrentWriters; c += 1 {
go func() {
timestamp := start.UnixMilli()
// we use a goroutine-local counter to avoid the performance impact of updating a shared atomic counter
var writesLocal int64
for {
if len(ticker.C) > 0 {
break
}
recordID := uuid.Must(uuid.NewV7())
_, err = writeDB.Exec(`INSERT INTO test
(id, timestamp, counter) VALUES (?, ?, ?)`, recordID[:], timestamp, writesLocal)
if err != nil {
log.Fatal(err)
}
writesLocal += 1
}
writes.Add(writesLocal)
wg.Done()
}()
}
wg.Wait()
elapsed := time.Since(start)
log.Println("Benchmark stopped:", elapsed)
fmt.Println("----------------------")
log.Printf("%d reads\n", reads.Load())
throughputRead := float64(reads.Load()) / float64(elapsed.Seconds())
log.Printf("%f reads/s\n", throughputRead)
fmt.Println("----------------------")
log.Printf("%d writes\n", writes.Load())
throughputWrite := float64(writes.Load()) / float64(elapsed.Seconds())
log.Printf("%f writes/s\n", throughputWrite)
}
func cleanup() {
os.RemoveAll("./test.db")
os.RemoveAll("./test.db-shm")
os.RemoveAll("./test.db-wal")
}
func setupDB(db *sql.DB) (err error) {
tx, err := db.Begin()
if err != nil {
log.Fatal(err)
}
defer tx.Rollback()
timestamp := time.Now().UTC().UnixMilli()
for i := range 5_000_000 {
recordID := uuid.Must(uuid.NewV7())
_, err = tx.Exec(`INSERT INTO test
(id, timestamp, counter) VALUES (?, ?, ?)`, recordID[:], timestamp, i)
if err != nil {
return err
}
// insert by batches of 500,000 rows
if i%500_000 == 0 {
err = tx.Commit()
if err != nil {
tx.Rollback()
return err
}
tx, err = db.Begin()
if err != nil {
return err
}
}
}
err = tx.Commit()
if err != nil {
return err
}
_, err = db.Exec("VACUUM")
if err != nil {
return err
}
_, err = db.Exec("ANALYZE")
if err != nil {
log.Fatal(err)
}
return nil
}