수십억 건의 위치 데이터를 처리하는 클라우드 플랫폼이 기존 Aurora+PostGIS 대신 자체 저장 엔진을 설계해 성능을 유지하면서도 비용을 98% 절감한 과정과 설계 선택을 설명합니다.

프로그래밍의 첫 번째 규칙이 뭘까요? 아마 “자기 자신을 반복하지 말 것(DRY)”이라든가, “잘 돌아가면 건드리지 말 것”일 겁니다. 아니면 이런 것도 있겠죠. “직접 데이터베이스를 쓰지 말 것!” … 꽤 그럴듯합니다.
데이터베이스를 직접 만드는 일은 악몽에 가깝습니다. 원자성, 일관성, 고립성, 지속성(ACID) 요구사항부터 샤딩, 장애 복구, 운영까지——어느 것 하나 쉬운 게 없습니다.
다행히 수십 년에 걸쳐 다듬어진 훌륭한 데이터베이스들이 이미 존재하고, 그것도 공짜로 쓸 수 있습니다. 그런데 우리는 대체 왜, 제정신인가 싶을 정도로 이걸 처음부터 직접 만들기로 했을까요?
우리는 동시에 수만 명의 사람과 차량을 추적하는 클라우드 플랫폼을 운영하고 있습니다. 들어오는 모든 위치 업데이트는 저장되고, 히스토리 API를 통해 다시 조회할 수 있습니다.
동시에 접속한 차량 수와 이들이 위치를 전송하는 빈도는 시간에 따라 크게 달라지지만, 대략 동시 접속 13,000대, 각 차량이 초당 한 번 정도 업데이트를 보내는 상황은 꽤 일반적입니다.
고객들이 이 데이터를 사용하는 방식은 매우 다양합니다. 어떤 사용 사례는 아주 대략적인 수준이면 충분합니다. 예를 들어, 렌터카 회사가 하루 동안 고객이 이동한 경로의 윤곽만 보여주고 싶을 때가 그렇습니다. 이런 요구라면 한 시간짜리 이동 경로도 30~100개의 위치 점만 저장해도 충분하고, 저장 전에 위치 데이터를 강하게 집계·압축해도 문제가 없습니다.
하지만 그렇게 할 수 없는 경우가 훨씬 많습니다. 예를 들어, 사고 직전 몇 초 동안의 상황을 정확히 리플레이하고 싶어 하는 배송 회사들이 있습니다. 또는 아주 정밀한 온사이트 위치 추적기를 사용하는 광산에서는, 특정 작업자가 특정 출입 제한 구역에——심지어 0.5m 정도 차이까지 고려해서——들어갔는지 보고서를 만들고 싶어 합니다.
그래서, 각 고객에게 어느 정도의 세밀함이 필요한지 미리 알 수 없기 때문에 우리는 들어오는 모든 위치 업데이트를 전부 그대로 저장합니다. 차량 13,000대 기준으로 한 달에 약 35억 건의 업데이트가 생기며, 이 숫자는 앞으로 더 늘어날 겁니다. 지금까지 우리는 지리 공간 데이터를 저장하기 위해 AWS Aurora에 PostGIS 확장을 붙여 사용해 왔습니다. 그런데 Aurora 비용만 한 달에 10,000달러가 넘습니다. 그리고 앞으로는 더 비싸질 게 분명합니다.
문제는 Aurora 가격만이 아닙니다. Aurora는 부하를 꽤 잘 버티는 편이지만, 많은 고객이 우리 소프트웨어의 온프레미스 버전도 사용하고 있습니다. 온프레미스 환경에서는 고객이 직접 데이터베이스 클러스터를 운영해야 하는데, 이 정도 볼륨의 업데이트를 감당하다 보면 쉽게 과부하에 걸립니다.
안타깝게도 그런 데이터베이스는 존재하지 않습니다. (혹시 있는데 우리가 리서치에서 놓쳤다면, 꼭 알려주세요.)
Mongo, H2, Redis 같은 많은 데이터베이스들이 포인트나 영역 같은 공간 데이터 타입을 지원합니다. 또 “공간 데이터베이스(Spatial Database)”라고 불리는 것들도 있긴 한데, 이들은 전부 기존 DB 위에서 동작하는 확장(extension)들입니다. PostgreSQL 위에 구축된 PostGIS가 가장 유명하고, Geomesa처럼 다른 스토리지 엔진 위에서 강력한 공간 쿼리를 제공하는 프로젝트들도 있습니다.
그러나 우리가 필요한 건 그게 아닙니다.
우리의 요구사항은 다음과 같습니다.
극단적으로 높은 쓰기 성능
노드 하나당 초당 최대 30,000건의 위치 업데이트를 처리할 수 있어야 합니다. 다만 디스크에 쓰기 전에 버퍼링을 할 수 있기 때문에, 실제 IOPS는 훨씬 낮게 유지할 수 있습니다.
사실상 무한대에 가까운 병렬성
여러 노드가 동시에, 개수 제한 없이 데이터를 쓸 수 있어야 합니다.
아주 작은 디스크 사용량
데이터 볼륨이 워낙 크기 때문에, 디스크에 저장되는 데이터가 최대한 작아야 합니다.
이런 요구를 만족시키려면 일부는 포기해야 합니다. 우리가 감수하기로 한 부분은 다음과 같습니다.
디스크에서 읽을 때는 중간 정도의 성능이면 충분
우리 서버는 인메모리 아키텍처를 중심으로 설계되어 있습니다. 실시간 스트림에 대한 쿼리와 필터는 메모리 상의 데이터를 대상으로 수행되기 때문에 매우 빠르게 동작합니다.
디스크에서 읽는 경우는 새 서버가 올라올 때, 클라이언트가 히스토리 API를 사용할 때, 또는 (곧 제공될) 디지털 트윈 인터페이스에서 사용자가 시간을 되감기(rewind)할 때 정도입니다. 이 디스크 읽기들이 좋은 사용자 경험을 제공할 만큼은 빨라야 하지만, 호출 빈도는 상대적으로 낮고, 트래픽 양도 많지 않습니다.
낮은 일관성 보장
일정 정도 데이터 유실은 허용합니다. 우리는 디스크에 쓰기 전에 대략 1초 분량의 업데이트를 버퍼에 쌓습니다. 드물게 서버가 다운되고 다른 서버가 이를 인수하는 상황이 생겨도, 현재 버퍼에 들어 있던 1초 분량의 위치 업데이트를 잃는 정도는 괜찮다고 보고 있습니다.
우리가 주로 영구 저장해야 하는 엔티티는 “object(객체)”입니다. 차량, 사람, 센서, 기계 등 무엇이든 객체가 될 수 있습니다. 객체는 id 레이블, 위치, 그리고 연료 잔량이나 현재 승객 id 같은 임의의 key/value 데이터를 갖습니다. 위치 정보는 경도, 위도, 정확도, 속도, 방향(heading), 고도, 고도 정확도로 구성되고, 각 업데이트는 이 중 일부 필드만 변경될 수도 있습니다.
이 외에도 영역(area), 작업(task, 어떤 객체가 수행해야 하는 일), 그리고 우리의 Hivekit 서버가 들어오는 데이터에 기반해 실행하는 작은 공간 로직 조각들인 instruction(명령)도 저장해야 합니다.
우리는 서버 코어와 같은 실행 파일 안에서 동작하는, 특수 목적의 인프로세스 저장 엔진을 만들었습니다. 이 엔진은 최소한의, 델타 기반 바이너리 포맷으로 데이터를 기록합니다. 개별 엔트리는 다음과 같은 모습입니다.
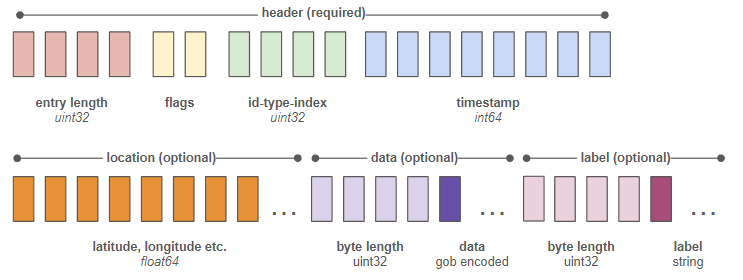
각 블록은 1바이트를 의미합니다. “flags”라고 표시된 두 바이트는 yes/no 스위치들의 집합으로, "latitude 있음", "longitude 있음", "data 있음" 등을 나타냅니다. 이 플래그들을 통해 파서는 해당 엔트리의 나머지 바이트들에서 무엇을 읽어야 할지를 알게 됩니다.
우리는 200번의 쓰기마다 객체의 전체 상태를 한 번 저장합니다. 그 사이에 있는 엔트리들에는 델타만 저장합니다. 이렇게 하면, 시간과 id, 위도, 경도를 모두 포함한 단일 위치 업데이트 하나가 단 34바이트면 충분합니다. 즉, 1GB의 디스크 공간에 약 3천만 건의 위치 업데이트를 넣을 수 있다는 의미입니다.
또한 별도의 인덱스 파일을 유지해, 각 엔트리의 정적인 문자열 id와 타입(객체, 영역 등)을 고정 길이 4바이트짜리 고유 식별자로 변환합니다. 이 고정 길이 식별자가 항상 각 엔트리의 바이트 인덱스 6~9에 위치한다는 사실을 알고 있기 때문에, 특정 객체의 히스토리를 가져오는 작업이 매우 빠르게 이루어집니다.
이 저장 엔진은 우리 서버 바이너리의 일부이기 때문에, 이를 운영하는 데 드는 비용은 달라지지 않았습니다. 달라진 건 데이터베이스 비용입니다. 1만 달러가 넘던 Aurora 인스턴스들을 월 200달러짜리 Elastic Block Storage(EBS) 볼륨 하나로 대체했습니다. 우리는 3,000 IOPS를 가진 Provisioned IOPS SSD(io2)를 사용하고 있으며, 업데이트를 모아서 노드·realm당 1초에 한 번씩만 쓰도록 배치 처리하고 있습니다.
EBS는 자동 백업과 복구, 높은 가용성을 기본 제공하기 때문에, Aurora가 제공하던 신뢰성 보장을 잃었다고 느끼지 않습니다. 현재 우리는 한 달에 약 100GB 정도의 데이터를 생성합니다. 하지만 고객들이 10일보다 오래된 데이터를 조회하는 경우는 드물기 때문에, 30GB를 초과하는 부분은 모두 AWS Glacier로 옮기기 시작했고, 그만큼 EBS 비용을 더 줄였습니다.
하지만 변화는 비용뿐만이 아닙니다. 파일 시스템을 통해 로컬 EBS에 쓰는 작업은 Aurora에 쓰는 것보다 훨씬 빠르고 오버헤드도 적습니다. 쿼리 속도 역시 크게 향상되었습니다. 쿼리가 정확히 1:1로 대응되는 것은 아니라 수치화가 쉽진 않지만, 예를 들면 어떤 realm의 히스토리에서 특정 시점을 재구성하는 시간이 대략 2초 정도에서 약 13ms로 줄었습니다.
물론 엄밀히 말하면 공정한 비교는 아닙니다. 결국 Postgres는 표현력이 풍부한 쿼리 언어를 갖춘 범용 데이터베이스이고, 우리가 만든 것은 기능이 매우 제한된, 바이너리 파일 피드를 커서로 스트리밍하는 수준에 불과하니까요. 하지만 바로 그 점이 중요합니다. 우리가 필요한 기능만 정확히 제공하고, 그 과정에서 어떤 기능도 잃지 않았다는 것입니다.
Hivekit의 API와 기능에 대해 더 알고 싶다면 https://hivekit.io/developers/를 참고하세요.