정수 배열의 합을 가능한 한 느리게 계산하는 접근 패턴을 메모리 계층의 함정을 이용해 단계적으로 만들어 본다.
정수 데이터 배열이 주어졌을 때, 정수들을 합산하는 가장 느린 방법은 무엇일까요? 왼쪽에서 오른쪽으로 더하는 것일까요, 무작위로 더하는 것일까요, 아니면 다른 무언가일까요? 이 글에서는 메모리 계층의 함정을 이용해 숫자를 가능한 한 느리게 합산하는 데이터 접근 패턴을 처음부터 단계적으로 만들어 보겠습니다.
uint32_t* data = ...;
// sequential
data[0] + data[1] + data[2] + ...
// random
data[67] + data[69420] + data[42] + ...
// the slowest
data[A] + data[B] + data[C] + ...
스포일러: 무작위 접근 패턴보다 30% 이상 더 나쁘게 만들 수 있습니다.
몇 가지 규칙이 있습니다:
positions를 만드는 데 걸리는 시간은 포함하지 않습니다.data는 무작위로 채워지고 우리는 positions의 내용만 바꿀 수 있습니다:constexpr int ELEMENT_COUNT = (1 << 16) * (PAGE_SIZE / sizeof(uint32_t)); // 2^26
/* data contains integers that we want to sum up
* positions is the access pattern that we use to sum up the integers
* Overflow is expected, but we don’t really care about the actual sum, do we?
*/
uint32_t accumulator(uint32_t const* data, uint32_t const* positions) {
uint32_t total = 0;
for (uint32_t i = 0; i < ELEMENT_COUNT; ++i) {
uint32_t pos = positions[i];
total += data[pos];
}
return total;
}
rdtsc 사이클 카운트를 기준으로 합니다.추가로 몇 가지 메모가 있습니다:
Reveal machine specs Hide code
❯ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Address sizes: 42 bits physical, 48 bits virtual
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Vendor ID: GenuineIntel
Model name: Intel® Core™ Ultra 7 268V
CPU family: 6
Model: 189
Thread(s) per core: 1
Core(s) per socket: 8
Socket(s): 1
Stepping: 1
CPU(s) scaling MHz: 50%
CPU max MHz: 2200.0000
CPU min MHz: 400.0000
BogoMIPS: 6604.80
Flags: …
Virtualization features:
Virtualization: VT-x
Caches (sum of all):
L1d: 320 KiB (8 instances)
L1i: 512 KiB (8 instances)
L2: 14 MiB (5 instances)
L3: 12 MiB (1 instance)
NUMA:
…
Vulnerabilities:
…
전체 코드는 여기에서 볼 수 있으며, g++ -std=c++2a -O3 slowest.cc && taskset -c 3 sudo ./a.out로 실행합니다. slowest.cc를 직접 열어 보고 코드를 실행해 보시길 강력히 권합니다.
우리의 일은 가능한 한 가장 느린 실행 시간을 만들어 내는 positions의 순열을 찾는 것입니다. 가장 단순한 접근 패턴부터 시작해 봅시다:
void linear(uint32_t const* data, uint32_t* positions) {
for (uint32_t i = 0; i < ELEMENT_COUNT; ++i) {
positions[i] = i;
}
}
이것이 아마 가장 빠른 순열일 것이며, 133M (132752394) 사이클이 걸립니다. CPU는 순차 접근에 매우 강하게 최적화되어 있으므로, 이는 예상 가능한 결과입니다.
반면 positions의 순열을 무작위화할 수도 있습니다.
void fisher_yates_shuffle(uint32_t const* data, uint32_t* positions) {
linear(data, positions);
uint32_t remaining = ELEMENT_COUNT;
for (uint32_t i = 0; i < ELEMENT_COUNT; ++i) {
uint32_t random = rand() % remaining;
uint32_t tmp = positions[i];
positions[i] = positions[i + random];
positions[i + random] = tmp;
--remaining;
}
}
이제 CPU는 다음에 어떤 데이터를 접근할지 예측할 수 없으므로, 무작위 접근은 1.57B (1572108618) 사이클이 걸립니다. 이는 선형 접근보다 10배 이상 나쁩니다. 더 나쁘게 만들 수 있을까요? 물론입니다. 간단한 퇴보 사례부터 시작해서 최악의 순열을 차근차근 만들어 봅시다.
먼저, 연속해서 접근하는 모든 원소가 항상 캐시 라인 하나만큼 떨어져 있도록 positions를 설정해 봅시다. 캐시 라인은 캐시에 저장되는 데이터의 단위입니다:
void separated_by_a_cacheline(uint32_t const* data, uint32_t* positions) {
constexpr int element_count_per_cacheline =
CACHELINE_SIZE / sizeof(uint32_t);
constexpr int cacheline_count = ELEMENT_COUNT / element_count_per_cacheline;
static_assert(ELEMENT_COUNT % element_count_per_cacheline == 0);
int current = 0;
for (int element_index = 0; element_index < element_count_per_cacheline;
++element_index) {
for (int cacheline_index = 0; cacheline_index < cacheline_count;
++cacheline_index) {
positions[current] =
cacheline_index * element_count_per_cacheline + element_index;
++current;
}
}
}
이 패턴이 형편없는 이유는, 각 접근이 64바이트 캐시 라인에서 4바이트 정수 하나만 사용하고 바로 다음으로 넘어가기 때문입니다. 다시 같은 캐시 라인으로 돌아왔을 때쯤이면, 재사용 가치가 있는 그 캐시 라인은 이미 축출되어 있을 가능성이 큽니다. 그 결과 성능은 끔찍해져서 719M (718804156) 사이클이 걸리며, 이미 선형 스캔보다 4배 더 오래 걸립니다.
캐시 라인 간격으로 떨어진 원소들에 접근할 때에도, 하드웨어 프리페처는 data 안의 단순한 스트리밍 패턴을 인식하고 로드 요청이 오기 전에 미래의 캐시 라인을 가져오기 시작할 수 있습니다. 하지만 많은 Intel 하드웨어 데이터 프리페처는 4 KiB 페이지 경계를 넘어 프리페치하지 않습니다. 그래서 이런 도움은 한 페이지에서 다음 페이지로 자연스럽게 이어지지 않습니다. 제 추측으로는, 페이지 경계를 넘는다는 것은 또 다른 가상 주소에서 물리 주소로의 변환이 필요하다는 뜻이고, 인접한 가상 페이지가 인접한 물리 페이지에 매핑된다는 보장도 없으므로, 페이지를 넘는 추측성 프리페치는 더 위험하고 일반적으로도 덜 유용하기 때문입니다.
그러니 접근 간격을 캐시 라인 하나가 아니라 페이지 전체 하나로 벌려 봅시다. 각 페이지는 4096바이트이고, 코드는 다음과 같습니다:
void separated_by_a_page(uint32_t const* data, uint32_t* positions) {
constexpr int element_count_per_page = PAGE_SIZE / sizeof(uint32_t);
constexpr int page_count = ELEMENT_COUNT / element_count_per_page;
static_assert(ELEMENT_COUNT % element_count_per_page == 0);
int current = 0;
for (int element_index = 0; element_index < element_count_per_page;
++element_index) {
for (int page_index = 0; page_index < page_count; ++page_index) {
positions[current] =
page_index * element_count_per_page + element_index;
++current;
}
}
}
사이클 수는 1.41B (1411153154)로 크게 퇴보합니다. 위에서는 HW 프리페처를 방해하는 이야기를 했지만, 여기에 또 다른 메모리 효과가 작동합니다. 대부분의 가정용 머신에서 쓰이는 캐시 배치 정책은 세트 연관성입니다. 이는 주어진 캐시 라인이 여러 슬롯/웨이를 가진 특정 세트에만 들어갈 수 있다는 뜻입니다.
❯ lscpu -C
NAME ONE-SIZE ALL-SIZE WAYS TYPE LEVEL SETS PHY-LINE COHERENCY-SIZE
L1d 48K 320K 12 Data 1 64 1 64
L1i 64K 512K 16 Instruction 1 64 1 64
L2 2.5M 14M 10 Unified 2 4096 1 64
L3 12M 12M 12 Unified 3 16384 1 64
제 머신에서는 CPU 코어 하나당 L1d 캐시가 48KB이고, 각 세트에는 12개의 슬롯(웨이), 그리고 L1d 캐시 안에는 64개의 세트가 있습니다. 세트가 64개이므로, 주소 A의 데이터와 주소 A + 4096바이트 (64세트 * 64바이트 캐시 라인)의 데이터는 같은 L1d 세트에 매핑되고, 이 둘은 사용 가능한 12개 슬롯 중 하나를 놓고 경쟁해야 합니다. 그리고 우리는 페이지 단위 스트라이드(4096바이트)로 움직이고 있으므로, 각 내부 루프는 64개 세트 전체에 고르게 퍼지지 않고 같은 세트만 계속 두드립니다. 이것이 중요한 이유는 그 한 세트에는 슬롯이 12개밖에 없기 때문입니다. 경쟁하는 활성 캐시 라인이 12개를 넘으면 CPU는 라인을 반복적으로 축출하고 다시 불러와야 하며, 이로 인해 conflict miss가 발생합니다. 캐시 용량은 기술적으로 48KB이지만, 이 접근 패턴에서는 실질적인 L1d 용량이 768B (12 ways * 64B)에 불과합니다.
이제 한 걸음 물러서서 접근 패턴의 더 큰 형태를 생각해 봅시다:
page 0, cacheline 0, elem 0
page 1, cacheline 0, elem 0
page 2, cacheline 0, elem 0
…
page 65534, cacheline 0, elem 0
page 65535, cacheline 0, elem 0
page 0, cacheline 0, elem 1
page 1, cacheline 0, elem 1
page 2, cacheline 0, elem 1
...
65536개의 캐시 라인에 접근한 뒤에야 다시 같은 캐시 라인으로 돌아옵니다. 이런 경우 캐시 라인 재사용 거리(cache line reuse distance)가 65536이라고 말합니다. 같은 캐시 라인을 다시 접근하기 전에 65536번의 접근이 일어나기 때문입니다. 그런데 각 페이지를 접근한 뒤 바로 같은 캐시 라인을 다시 접근하지 않도록 하면 더 나쁘게 만들 수 있습니다:
void separated_by_a_page_and_cacheline(uint32_t const* data,
uint32_t* positions) {
constexpr int elements_per_cacheline = CACHELINE_SIZE / sizeof(uint32_t);
constexpr int elements_per_page = PAGE_SIZE / sizeof(uint32_t);
constexpr int cacheline_per_page = PAGE_SIZE / CACHELINE_SIZE;
constexpr int page_count = ELEMENT_COUNT / elements_per_page;
static_assert(ELEMENT_COUNT % elements_per_page == 0);
int current = 0;
for (int element_index_in_cacheline = 0;
element_index_in_cacheline < elements_per_cacheline;
++element_index_in_cacheline) {
for (int cacheline_index_in_page = 0;
cacheline_index_in_page < cacheline_per_page;
++cacheline_index_in_page) {
for (int page_index = 0; page_index < page_count; ++page_index) {
positions[current++] =
page_index * elements_per_page +
cacheline_index_in_page * elements_per_cacheline +
element_index_in_cacheline;
}
}
}
}
이제 캐시 재사용 거리는 4B (65536 pages * 4096 page size / 64 cacheline size)가 되고, 새로운 접근 패턴은 다음과 같습니다:
page 0, cacheline 0, elem 0
page 1, cacheline 0, elem 0
page 2, cacheline 0, elem 0
…
page 65534, cacheline 0, elem 0
page 65535, cacheline 0, elem 0
page 0, cacheline 1, elem 0
page 1, cacheline 1, elem 0
page 2, cacheline 1, elem 0
...
하지만 separated_by_a_page_and_cacheline를 실행해 보면 사이클 수는 여전히 1.41B (1408519172)로 똑같습니다. 캐시 라인 재사용 거리가 커졌으니 퇴보가 있어야 할 것 같은데, 이상한 일입니다.
❯ lstopo
Machine (31GB total)
Package L#0
NUMANode L#0 (P#0 31GB)
L3 L#0 (12MB)
L2 L#0 (2560KB) + L1d L#0 (48KB) + L1i L#0 (64KB) + Core L#0 + PU L#0 (P#0)
L2 L#1 (2560KB) + L1d L#1 (48KB) + L1i L#1 (64KB) + Core L#1 + PU L#1 (P#1)
L2 L#2 (2560KB) + L1d L#2 (48KB) + L1i L#2 (64KB) + Core L#2 + PU L#2 (P#2)
L2 L#3 (2560KB) + L1d L#3 (48KB) + L1i L#3 (64KB) + Core L#3 + PU L#3 (P#3)
L2 L#4 (4096KB)
L1d L#4 (32KB) + L1i L#4 (64KB) + Core L#4 + PU L#4 (P#4)
L1d L#5 (32KB) + L1i L#5 (64KB) + Core L#5 + PU L#5 (P#5)
L1d L#6 (32KB) + L1i L#6 (64KB) + Core L#6 + PU L#6 (P#6)
L1d L#7 (32KB) + L1i L#7 (64KB) + Core L#7 + PU L#7 (P#7)
HostBridge
PCI 00:02.0 (VGA)
PCI 00:0b.0 (ProcessingAccelerator)
PCI 00:14.3 (Network)
Net “wlp0s20f3”
PCIBridge
PCI 04:00.0 (NVMExp)
Block(Disk) “nvme0n1”
캐시 라인 재사용 거리가 4M (PAGE_COUNT * PAGE_SIZE / CACHELINE_SIZE)로 더 커졌음에도, 우리는 코어 3을 사용하고 있으며, L2 L#3 (2560KB) + L1d L#3 (48KB) + …라는 줄은 이 코어에 2.5MB의 L2 캐시와 48KB의 L1 캐시가 있음을 보여 줍니다. 65536개 페이지를 순회하고 나면 우리는 4MB의 데이터를 접근한 셈입니다. 이는 이 코어의 사설 L1/L2 용량보다 큽니다. 따라서 다음에 필요한 캐시 라인이 여전히 사설 캐시에 남아 있을 가능성은 낮습니다. L3에는 여전히 있을 수도 있지만, L3는 더 느리고 그 자체의 연관성 및 교체 동작의 영향을 받습니다. 이 경우, 캐시 라인 재사용 거리가 대략 4만 미만일 때만 ((2560+48)*1024/64) 사설 캐시 재사용을 기대하는 것이 맞습니다.
현재 접근 패턴은 연속된 페이지를 접근합니다. 접근 스트라이드를 페이지 하나 간격으로 두는 대신, N 페이지 간격으로 벌려 봅시다.
template <int page_stride>
void separated_by_stride_pages_and_cacheline(uint32_t const* data,
uint32_t* positions) {
constexpr int elements_per_cacheline = CACHELINE_SIZE / sizeof(uint32_t);
constexpr int elements_per_page = PAGE_SIZE / sizeof(uint32_t);
constexpr int cacheline_per_page = PAGE_SIZE / CACHELINE_SIZE;
constexpr int page_count = ELEMENT_COUNT / elements_per_page;
static_assert(ELEMENT_COUNT % elements_per_page == 0);
static_assert(page_stride > 0);
int current = 0;
for (int element_index_in_cacheline = 0;
element_index_in_cacheline < elements_per_cacheline;
++element_index_in_cacheline) {
for (int cacheline_index_in_page = 0;
cacheline_index_in_page < cacheline_per_page;
++cacheline_index_in_page) {
for (int page_start = 0;
page_start < page_stride && page_start < page_count;
++page_start) {
for (int page_index = page_start; page_index < page_count;
page_index += page_stride) {
positions[current++] =
page_index * elements_per_page +
cacheline_index_in_page * elements_per_cacheline +
element_index_in_cacheline;
}
}
}
}
}
이제 접근 패턴은 다음과 같습니다:
page 0, cacheline 0, elem 0
page N, cacheline 0, elem 0
page 2N, cacheline 0, elem 0
…
page 0, cacheline 1, elem 0
page N, cacheline 1, elem 0
page 2N, cacheline 1, elem 0
…
page 1, cacheline 0, elem 0
page N + 1, cacheline 0, elem 0
page 2N + 1, cacheline 0, elem 0
…
그리고 특정 N 하나만 실행하는 대신, 페이지 스트라이드에 따른 사이클 수 그래프를 그려 봅시다:
이 스윕에서는 8페이지 스트라이드가 최악의 결과를 보이며, 무작위 접근보다도 더 나빠 보입니다. -DSTRIDE=8로 따로 실행하면 사이클 수는 2.06B (2058425640)입니다. 그래프에는 이 밖에도 여러 흥미로운 메모리 접근 효과가 나타나지만, 오늘은 그것들까지 다루지는 않겠습니다. 스트라이드 8에서 피크가 생기는 한 가지 유력한 이유는 주소 변환입니다. 이 스트라이드에서는 페이지 워크 중 사용되는 페이지 테이블 엔트리의 데이터 지역성도 사라지기 때문입니다:
어떤 주소의 데이터에 접근할 때, 실제로는 그 가상 메모리 주소에 해당하는 데이터를 접근하려는 것입니다. 메모리 관리 장치(MMU)는 가상 메모리 주소를 물리 메모리 주소로 변환하는 일을 맡습니다. 대부분의 운영체제 입문 수업에서 다루는 내용이므로, 여기서 자세히 설명하지는 않겠습니다. 여기서 우리가 관심 있는 것은 MMU가 사용하는 특정 자료구조인 페이지 테이블 엔트리(PTE)입니다. 이 구조는 가상 페이지에 대응하는 물리 페이지 프레임 번호와 함께 플래그 및 기타 메타데이터를 저장합니다. 이 PTE는 8바이트이므로 캐시 라인 하나에 PTE 8개가 들어갑니다. 8페이지 스트라이드에서는 제 생각에 지배적인 효과가 이것입니다. 즉, 이제는 접근할 때마다 데이터를 가져오기 위한 새로운 캐시 라인 하나만 가져오는 것이 아니라, 페이지 매핑을 처리하기 위한 또 다른 캐시 라인도 가져오게 됩니다. 이렇게 해서 우리는 무작위 접근보다도 더 느리게 숫자를 합산하는 데 성공했습니다.
하지만 아직 끝이 아닙니다. 캐시는 포화시켰습니다. HW 프리페처도 망가뜨렸습니다. 캐시 라인 재사용도 끊었습니다. 그리고 MMU도 거의 한계까지 몰아붙여 매 접근마다 “워크”하게 만들었습니다. 이제 마지막으로 할 일은 DRAM 컨트롤러를 괴롭히는 것입니다.
일반적인 DRAM은 채널, 랭크, 칩, 뱅크, 행, 열로 구성됩니다. 아래 DIMM(램 스틱이라고 생각하면 됩니다) 그림은 설명을 위한 예시입니다. 각 DIMM은 하나 이상의 랭크를 가질 수 있고, 각 랭크는 여러 개의 칩으로 이루어집니다.

Figure 1: DRAM image, Credits: sabrent
위에 보인 DIMM은 두 개의 랭크를 포함하고 있으며, 각 랭크는 8개의 x8 DRAM 칩으로 이루어져 있습니다. 메모리 컨트롤러가 랭크에 접근할 때, 이 8개의 칩은 모두 병렬로 동작합니다. 각 칩이 DIMM의 64비트 데이터 버스에 8비트의 데이터를 제공합니다. 따라서 64비트 워드는 하나의 칩에 저장되는 것이 아니라 8개의 칩에 분산되어 저장됩니다.
이 글의 목적상 우리는 뱅크라고 부르는 것만 신경 쓰면 됩니다. 각 칩은 여러 개의 뱅크를 가지고, 각 뱅크는 여러 개의 행을 가지며, 이 행은 연속된 데이터 비트들의 묶음입니다. DRAM에서 특정 주소의 데이터에 접근할 때, DRAM 메모리 컨트롤러는 해당 데이터를 포함하는 특정 행을 “활성화”하고 그 행을 row buffer 영역으로 복사합니다. 그리고 그 버퍼에서 우리가 관심 있는 열에 해당하는 8비트 데이터를 꺼냅니다.
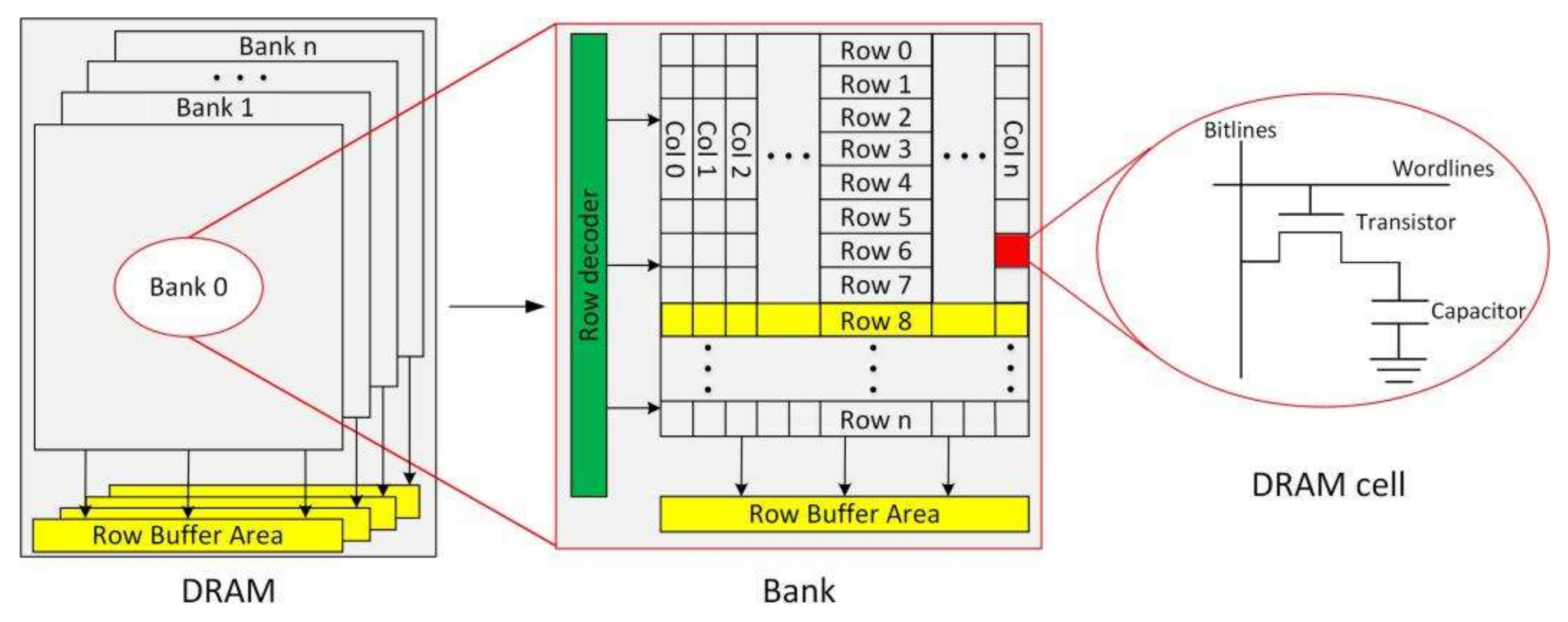
Figure 2: Accessing data in a DRAM, credits: https://www.mdpi.com/2079-9292/10/4/438
뱅크가 다른 행의 데이터에 접근하려면, 먼저 precharge 연산으로 현재 열려 있는 행을 비활성화한 뒤 새로운 행을 활성화해야 합니다. 따라서 같은 뱅크 안에서 행을 번갈아 반복적으로 바꾸면 row buffer conflict가 생기고, 그 결과 DRAM 컨트롤러가 데이터 요청에 응답하는 능력이 느려집니다. 반대로 뱅크에서 이미 활성화된 행이 우리가 원하는 바로 그 행이라면 row buffer hit가 됩니다. 랭크는 여러 뱅크를 포함하므로, 서로 다른 뱅크의 행들은 동시에 활성화될 수 있습니다. 그런데 우리는 그런 것을 원하지 않습니다. Branch Education에는 DRAM에 관한 훌륭한 YouTube 영상이 있습니다. 아래 그림은 row buffer hit와 row buffer miss의 지연 시간 차이를 근사해서 보여 줍니다.
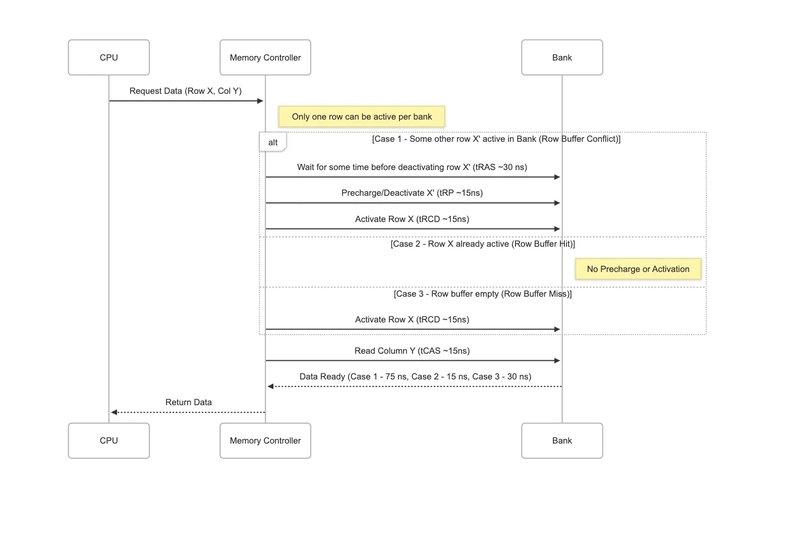
Figure 3: DRAM access time, credits: sachin tolay
더 느린 실행 시간을 얻으려면, 다음 뱅크로 넘어가기 전에 같은 뱅크에 들어 있는 모든 정수를 먼저 더해야 합니다. 여러 뱅크의 데이터에 동시에 접근하면 DRAM 메모리 컨트롤러는 서로 다른 요청들 사이에서 작업을 겹쳐 처리할 기회를 얻게 되는데, 우리는 그런 것을 원하지 않습니다. 각 뱅크 안에서는 모든 요청이 row buffer conflict/miss가 되기를 바랍니다.
전략은 다음과 같습니다. 페이지 테이블을 사용해 가상 페이지 번호를 물리 프레임 번호(PFN)로 변환하되, 물리 주소를 만들기 위해 페이지 오프셋은 유지합니다. 그다음 DRAM 주소 매핑에 따라 물리 주소를 해독해 채널, 랭크, 뱅크 그룹, 뱅크, 행, 열을 식별합니다. 최악의 접근 패턴을 만들기 위해, 같은 뱅크 안의 서로 다른 행들을 반복적으로 접근하여 거의 모든 요청에서 precharge와 activation이 일어나도록 만들고, row buffer locality와 bank-level parallelism은 최소화합니다.
하지만 물리 주소가 채널, 랭크, 뱅크, 행으로 어떻게 매핑되는지는 문서화되어 있지 않고 플랫폼마다 다릅니다. CPU, 메모리 종류, BIOS/펌웨어 설정, 채널/랭크 구성, 주소 해싱에 따라 달라질 수 있습니다. DRAMA나 Sudoku 같은 도구를 쓸 수도 있겠지만, 제 머신에서는 제대로 동작시키지 못해서 대략적으로 접근할 수밖에 없었습니다. DRAMA 논문과 몇 가지 로컬 실험을 바탕으로 저는 다음 설정을 사용했습니다:
constexpr uint32_t DRAM_BANK_GROUP_COUNT = 4;
constexpr uint32_t DRAM_BANK_COUNT_PER_GROUP = 4;
constexpr uint32_t DRAM_ROW_SHIFT = 18; // empirically tested between 15 to 19
DramLocation physical_address_to_dram_location(uint64_t physical_address,
uint32_t page_index) {
auto get_bit = [&](uint32_t index) {
return (physical_address >> index) & 1;
};
uint64_t bg0 = get_bit(7) ^ get_bit(14);
uint64_t bg1 = get_bit(15) ^ get_bit(19);
uint64_t bg = bg1 * 2 + bg0;
uint64_t ba0 = get_bit(17) ^ get_bit(21);
uint64_t ba1 = get_bit(18) ^ get_bit(22);
uint64_t ba = ba1 * 2 + ba0;
return {
.bank_index = bg * DRAM_BANK_COUNT_PER_GROUP + ba,
.rank = 0, // assume rank is 0
.channel = 0, // assume we only have 1 channel
.row_index = physical_address >> DRAM_ROW_SHIFT,
.page_index = page_index,
};
}
이 모든 것을 반영하고 나면, 사이클 수는 2.08B (2082308014)로 일관되게, 하지만 크게는 아니게 더 높아집니다. 뱅크 그룹 해시, 뱅크 해시, 그리고 추정한 row shift가 틀렸을 수 있다는 점 외에도, 우리는 8페이지 스트라이드로 데이터를 접근하고 있기 때문에 대략 32KB 간격으로 접근하게 되며, 이들은 어차피 같은 DRAM 행에 있지 않을 가능성이 큽니다. 따라서 이 접근 패턴은 우리가 바라는 만큼 많은 row conflict를 일으키지 못합니다. 여기서 우리가 활용할 수 있는 것은 한 번에 하나의 뱅크만 사용하는 정도뿐인데, Intel이 뱅크를 해싱하는 방식 때문에 여전히 여러 뱅크를 동시에 사용하게 되고, 이 메모리 허점을 완전히 이용할 수는 없습니다. 그래도 DRAM 접근 패턴을 악용한다는 아이디어 자체는 흥미롭다고 생각해서 여기에 남겨 두었습니다.
모든 테스트를 한 번에 실행하면, 코드의 출력 예시는 다음과 같습니다:
~/Developer/rough/slowest main* ⇡
❯ g++ -DSTRIDE=8 -std=c++2a -O3 slowest.cc && taskset -c 3 sudo ./a.out
linear: 132752394
fisher_yates_shuffle: 1572108618
separated_by_a_cacheline: 718804156
separated_by_a_page: 1411153154
separated_by_a_page_and_cacheline: 1408519172
stride=8 separated_by_stride_pages_and_cacheline: 2058425640
separated_by_stride_bank_conflicts_and_cacheline: 2082308014
가장 느린 접근 패턴을 떠올릴 때 가장 먼저 생각나는 답은 아마 무작위 접근일 것입니다. 하지만 접근을 무작위화하는 것이 왜 느린지를 이해함으로써, 우리는 그보다도 더 느린 접근 패턴을 만들어 냈습니다. 우리는 캐시 라인, 페이지, 그리고 리프 페이지 테이블 엔트리 단위로 떨어진 데이터를 접근하고, 남은 접근들은 DRAM 뱅크/행 충돌 쪽으로 치우치도록 시도했습니다. 그 결과 하드웨어 캐싱과 프리페칭 메커니즘의 효율이 크게 떨어졌고, 33%의 추가적인 성능 저하를 만들었습니다. 저는 이게 꽤 멋지다고 생각합니다.
마무리 메모: