행렬 곱셈 벤치마크와 분기 예측 디버깅, 캐시 라인 공유 오버헤드 측정, OProfile 사용 팁, 등록/비등록 및 ECC 메모리 설명, libNUMA 소개, 그리고 참고 문헌을 포함한 부록.
메모리에 대해 모든 프로그래머가 알아야 할 것
LWN 구독을 고려해 주세요 LWN.net은 구독으로 운영됩니다. 이 콘텐츠가 유익했고 더 많은 콘텐츠를 보고 싶다면, 구독으로 LWN이 계속 성장하도록 도와주세요. 가입 및 지속적인 운영을 위한 방법은 이 페이지(https://lwn.net/Promo/nst-nag1/subscribe)를 방문해 주세요.
[편집자 주: 아래는 Ulrich Drepper의 ‘What every programmer should know about memory’(https://lwn.net/Articles/250967/)에서 발췌한 부록과 참고 문헌입니다.]
섹션 6.2.1의 행렬 곱셈 벤치마크 프로그램 전체 코드이다. 사용된 인트린식의 상세는 Intel 레퍼런스 매뉴얼을 참고하라.
#include <stdlib.h>
#include <stdio.h>
#include <emmintrin.h>
#define N 1000
double res[N][N] __attribute__ ((aligned (64)));
double mul1[N][N] __attribute__ ((aligned (64)));
double mul2[N][N] __attribute__ ((aligned (64)));
#define SM (CLS / sizeof (double))
int main (void) { // ... Initialize mul1 and mul2
int i, i2, j, j2, k, k2; double *restrict rres; double *restrict rmul1; double *restrict rmul2; for (i = 0; i < N; i += SM) for (j = 0; j < N; j += SM) for (k = 0; k < N; k += SM) for (i2 = 0, rres = &res[i][j], rmul1 = &mul1[i][k]; i2 < SM; ++i2, rres += N, rmul1 += N) { _mm_prefetch (&rmul1[8], _MM_HINT_NTA); for (k2 = 0, rmul2 = &mul2[k][j]; k2 < SM; ++k2, rmul2 += N) { __m128d m1d = _mm_load_sd (&rmul1[k2]); m1d = _mm_unpacklo_pd (m1d, m1d); for (j2 = 0; j2 < SM; j2 += 2) { __m128d m2 = _mm_load_pd (&rmul2[j2]); __m128d r2 = _mm_load_pd (&rres[j2]); _mm_store_pd (&rres[j2], _mm_add_pd (_mm_mul_pd (m2, m1d), r2)); } } }
// ... use res matrix
return 0; }루프 구조는 섹션 6.2.1의 최종 형태와 거의 동일하다. 큰 변화 한 가지는 rmul1[k2] 값을 로드하는 일을 가장 안쪽 루프 바깥으로 뺐다는 점이다. 이는 두 요소가 동일한 값을 갖는 벡터를 만들어야 하기 때문이다. 이를 _mm_unpacklo_pd() 인트린식이 수행한다.
또 하나 주목할 점은 세 배열을 명시적으로 정렬(aligned)하여, 동일한 캐시 라인에 있기를 기대하는 값들이 실제로 같은 캐시 라인에 놓이도록 한 것이다.
섹션 6.2.2에서 권장한 likely/unlikely 정의를 사용한다면, 가정이 실제로 맞는지 확인하기 위한 디버그 모드를 갖추는 것은 쉽다 {적어도 GNU 툴체인에서는.}. 매크로 정의를 다음과 같이 바꿀 수 있다:
#ifndef DEBUGPRED
# define unlikely(expr) __builtin_expect (!!(expr), 0)
# define likely(expr) __builtin_expect (!!(expr), 1)
#else
asm (".section predict_data, \"aw\"; .previous\n"
".section predict_line, \"a\"; .previous\n"
".section predict_file, \"a\"; .previous");
# ifdef __x86_64__
# define debugpred__(e, E) \
({ long int _e = !!(e); \
asm volatile (".pushsection predict_data\n" \
"..predictcnt%=: .quad 0; .quad 0\n" \
".section predict_line; .quad %c1\n" \
".section predict_file; .quad %c2; .popsection\n" \
"addq $1,..predictcnt%=(,%0,8)" \
: : "r" (_e == E), "i" (__LINE__), "i" (__FILE__)); \
__builtin_expect (_e, E); \
})
# elif defined __i386__
# define debugpred__(e, E) \
({ long int _e = !!(e); \
asm volatile (".pushsection predict_data\n" \
"..predictcnt%=: .long 0; .long 0\n" \
".section predict_line; .long %c1\n" \
".section predict_file; .long %c2; .popsection\n" \
"incl ..predictcnt%=(,%0,4)" \
: : "r" (_e == E), "i" (__LINE__), "i" (__FILE__)); \
__builtin_expect (_e, E); \
})
# else
# error "debugpred__ definition missing"
# endif
# define unlikely(expt) debugpred__ ((expr), 0)
# define likely(expr) debugpred__ ((expr), 1)
#endif이 매크로들은 ELF 파일을 만들 때 GNU 어셈블러와 링커가 제공하는 많은 기능을 활용한다. DEBUGPRED 경우의 첫 asm 문은 세 개의 추가 섹션을 정의한다. 이는 주로 섹션이 어떻게 생성되어야 하는지에 대한 정보를 어셈블러에 제공한다. 모든 섹션은 런타임에 접근 가능하며 predict_data 섹션은 쓰기 가능하다. 모든 섹션 이름이 유효한 C 식별자여야 한다는 점이 중요하다. 곧 그 이유가 분명해질 것이다.
likely/unlikely의 새 정의는 아키텍처별 debugpred__ 매크로를 참조한다. 이 매크로의 작업은 다음과 같다.
.pushsection과 .popsection 의사 연산은 어셈블러 매뉴얼에 설명되어 있다. 관심 있는 독자는 매뉴얼과 약간의 시행착오를 통해 이 정의의 세부 사항을 탐구하길 바란다.
이 매크로들은 올바른/잘못된 분기 예측 정보를 자동으로, 투명하게 수집한다. 남은 것은 결과를 얻는 방법이다. 가장 간단한 방법은 객체에 소멸자를 정의하고 그 안에서 결과를 출력하는 것이다. 다음과 같은 함수를 정의하면 된다:
extern long int __start_predict_data;
extern long int __stop_predict_data;
extern long int __start_predict_line;
extern const char *__start_predict_file;
static void __attribute__ ((destructor)) predprint(void) { long int *s = &__start_predict_data; long int *e = &__stop_predict_data; long int *sl = &__start_predict_line; const char **sf = &__start_predict_file; while (s < e) { printf("%s:%ld: incorrect=%ld, correct=%ld%s\n", *sf, *sl, s[0], s[1], s[0] > s[1] ? " <==== WARNING" : ""); ++sl; ++sf; s += 2; } }여기서 섹션 이름이 유효한 C 식별자여야 한다는 사실의 의미가 나타난다. GNU 링커는 (필요하다면) 섹션에 대해 두 개의 심볼을 자동으로 정의한다. __start_XYZ 심볼은 섹션 XYZ의 시작을, __stop_XYZ 심볼은 섹션 XYZ 뒤의 첫 바이트 위치를 나타낸다. 이 심볼들은 런타임에 섹션 내용을 순회(iterate)할 수 있게 해준다. 주의할 점은, 섹션의 내용이 링크 시점에 링커가 사용하는 모든 파일에서 올 수 있으므로 컴파일러와 어셈블러는 섹션 크기를 알 수 없다는 것이다. 이 마법 같은 링커 생성 심볼이 있어야만 섹션 내용을 순회할 수 있다.
코드는 하나의 섹션만 순회하는 것이 아니라, 세 개의 섹션을 함께 다룬다. predict_data 섹션에 두 워드를 추가할 때마다 predict_line과 predict_file에도 각각 한 워드를 추가한다는 사실을 알고 있으므로, 이 두 섹션의 경계를 따로 확인할 필요가 없다. 단지 포인터를 함께 옮겨가며 동일하게 증가시키면 된다.
코드는 프로그램에 등장하는 각 예측마다 한 줄을 출력한다. 그중에서 예측이 틀린 경우를 강조한다. 물론 변경할 수 있고, 디버그 모드를 ‘틀린 예측이 맞은 예측보다 많은 항목만’ 표시하도록 제한할 수도 있다. 그러한 항목들이 변경 후보가 된다. 매크로 안에서 분기 예측이 이루어지고 그 매크로가 여러 곳에서 사용되는 경우처럼, 상황을 복잡하게 만드는 세부 사항도 있다. 최종 판단을 내리기 전에 모든 매크로 사용을 함께 고려해야 한다.
마지막으로 두 가지 주석: 이 디버깅에 필요한 데이터는 적지 않으며, DSO의 경우 비용이 많이 든다(특히 predict_file 섹션의 재배치가 필요). 따라서 디버깅 모드는 프로덕션 바이너리에서는 활성화하지 말아야 한다. 마지막으로, 각 실행 파일과 DSO는 각각의 출력을 만든다는 점을 기억해야 한다. 데이터 분석 시 이를 유념하라.
이 섹션은 동일 캐시 라인의 변수들을 사용할 때의 오버헤드와, 서로 다른 캐시 라인의 변수를 사용할 때의 오버헤드를 비교 측정하는 테스트 프로그램을 담고 있다.
#include <error.h>
#include <pthread.h>
#include <stdlib.h>
#define N (atomic ? 10000000 : 500000000)
static int atomic;
static unsigned nthreads;
static unsigned disp;
static long **reads;
static pthread_barrier_t b;
static void *
tf(void *arg)
{
long *p = arg;
if (atomic)
for (int n = 0; n < N; ++n)
__sync_add_and_fetch(p, 1);
else
for (int n = 0; n < N; ++n)
{
*p += 1;
asm volatile("" : : "m" (*p));
}
return NULL;
}
int
main(int argc, char *argv[])
{
if (argc < 2)
disp = 0;
else
disp = atol(argv[1]);
if (argc < 3)
nthreads = 2;
else
nthreads = atol(argv[2]) ?: 1;
if (argc < 4)
atomic = 1;
else
atomic = atol(argv[3]);
pthread_barrier_init(&b, NULL, nthreads);
void *p;
posix_memalign(&p, 64, (nthreads * disp ?: 1) * sizeof(long));
long *mem = p;
pthread_t th[nthreads];
pthread_attr_t a;
pthread_attr_init(&a);
cpu_set_t c;
for (unsigned i = 1; i < nthreads; ++i)
{
CPU_ZERO(&c);
CPU_SET(i, &c);
pthread_attr_setaffinity_np(&a, sizeof(c), &c);
mem[i * disp] = 0;
pthread_create(&th[i], &a, tf, &mem[i * disp]);
}
CPU_ZERO(&c);
CPU_SET(0, &c);
pthread_setaffinity_np(pthread_self(), sizeof(c), &c);
mem[0] = 0;
tf(&mem[0]);
if ((disp == 0 && mem[0] != nthreads * N)
|| (disp != 0 && mem[0] != N))
error(1,0,"mem[0] wrong: %ld instead of %d",
mem[0], disp == 0 ? nthreads * N : N);
for (unsigned i = 1; i < nthreads; ++i)
{
pthread_join(th[i], NULL);
if (disp != 0 && mem[i * disp] != N)
error(1,0,"mem[%u] wrong: %ld instead of %d", i, mem[i * disp], N);
}
return 0;
}이 코드는 캐시 라인 오버헤드 같은 효과를 측정하는 프로그램을 어떻게 작성할 수 있는지 보여주기 위한 예시로 제공된다. 흥미로운 부분은 tf의 루프 본문이다. 컴파일러가 아는 __sync_add_and_fetch 인트린식은 원자적 덧셈 명령을 생성한다. 두 번째 루프에서는 증가 결과를 “소비”해야 한다(인라인 asm 문을 통해). 이 asm은 실제 코드를 생성하지 않지만, 컴파일러가 증가 연산을 루프 밖으로 끌어올리는 것을 방지한다.
또 하나 흥미로운 부분은 스레드를 특정 프로세서에 고정(pinning)한다는 점이다. 이 코드는 프로세서가 0부터 3까지 번호가 매겨져 있다고 가정한다. 이는 보통 논리 프로세서가 네 개 이상인 머신에서 사실이다. 사용 가능한 프로세서 번호를 알아내려면 libNUMA의 인터페이스를 사용할 수도 있겠지만, 이 테스트 프로그램은 의존성을 추가하지 않고 널리 사용 가능해야 한다. 어느 쪽으로든 쉽게 보완할 수 있다.
다음 내용은 oprofile 사용법에 대한 튜토리얼이 아니다. 그 주제로 쓰인 문서가 따로 있다. 여기서는 프로그램을 바라보며 문제 지점을 찾는 데 도움이 되는 몇 가지 상위 수준의 힌트를 제공한다. 그 전에 최소한의 소개가 필요하다.
Oprofile은 수집 단계와 분석 단계, 두 단계로 동작한다. 수집은 커널이 수행한다. 측정은 CPU의 성능 카운터를 사용하므로 사용자 수준에서 수행할 수 없다. 이러한 카운터는 MSR 접근이 필요하고, 이는 권한을 요구한다.
각 최신 프로세서는 고유한 성능 카운터 집합을 제공한다. 어떤 아키텍처에서는 모든 프로세서 구현체가 제공하는 카운터의 부분 집합이 있고, 나머지는 버전마다 다르다. 이는 oprofile 사용에 대한 일반적인 조언을 하기 어렵게 만든다. 이러한 세부를 감추는 상위 추상화는 (아직) 없다.
프로세서 버전은 한 번에 추적할 수 있는 이벤트 수와 조합도 결정한다. 이는 그림을 더 복잡하게 만든다.
필요한 성능 카운터의 세부 사항을 알고 있다면, opcontrol 프로그램을 사용해 카운트할 이벤트를 선택할 수 있다. 각 이벤트에 대해 “오버런 수”(CPU가 인터럽트되어 이벤트를 기록하기 전에 발생해야 하는 이벤트 수), 사용자 수준과/또는 커널에서 이벤트를 카운트할지 여부, 마지막으로 “유닛 마스크”(성능 카운터의 하위 기능을 선택)를 지정해야 한다.
x86/x86-64에서 CPU 사이클을 세려면 다음 명령을 사용한다:
opcontrol --event CPU_CLK_UNHALTED:30000:0:1:1
숫자 30000은 오버런 수다. 시스템 동작과 수집 데이터에 영향을 주므로 적절한 값을 선택하는 것이 중요하다. 모든 이벤트 발생마다 데이터를 받도록 요청하는 것은 나쁜 생각이다. 많은 이벤트의 경우, 머신은 이벤트 오버런에 대한 데이터 수집 작업만 하느라 거의 멈추게 된다. 그래서 oprofile은 최소 값을 강제한다. 최소 값은 이벤트마다 다른데, 이는 서로 다른 이벤트가 일반 코드에서 트리거될 확률이 서로 다르기 때문이다.
매우 높은 숫자를 선택하면 프로파일의 해상도가 낮아진다. 각 오버런 시점에, oprofile은 그 순간 실행 중인 명령의 주소를 기록한다. x86과 PowerPC에서는 경우에 따라 백트레이스를 기록할 수도 있다 {언젠가 모든 아키텍처에 백트레이스 지원이 제공되길 바란다.}. 해상도가 거칠면, 핫스팟이 대표적인 히트 수를 얻지 못할 수 있다. 이는 전부 확률의 문제이며, 그래서 oprofile은 확률적 프로파일러라고 불린다. 오버런 수가 낮을수록 시스템 지연은 커지지만 해상도는 높아진다.
프로덕션 용도가 아닌 시스템에서 특정 프로그램을 프로파일링하려면, 가능한 가장 낮은 오버런 값을 사용하는 것이 보통 가장 유용하다. 각 이벤트의 정확한 값은 다음으로 조회할 수 있다:
opcontrol --list-events
프로파일링 대상 프로그램이 다른 프로세스와 상호작용하고, 그 상호작용에 지연으로 문제가 생긴다면 이 방법이 문제를 유발할 수 있다. 또한 인터럽트가 자주 발생하면 만족시킬 수 없는 실시간 요구가 있는 프로세스도 문제가 될 수 있다. 이 경우 중간 지점을 찾아야 한다. 시스템 전체를 장시간 프로파일링할 때도 마찬가지다. 낮은 오버런 수는 큰 지연을 의미한다. 어떤 경우든, oprofile은 다른 모든 프로파일링 메커니즘과 마찬가지로 불확실성과 부정확성을 도입한다.
프로파일링은 opcontrol --start로 시작하고 opcontrol --stop으로 중지할 수 있다. oprofile이 활성화되어 있는 동안 데이터가 수집된다. 데이터는 먼저 커널에 모였다가, 배치로 사용자 수준 데몬에 전달되어 해독되고 파일시스템에 기록된다. opcontrol --dump로 커널에 버퍼링된 모든 정보를 사용자 수준으로 내보내도록 요청할 수 있다.
수집된 데이터에는 서로 다른 성능 카운터에서 온 이벤트가 포함될 수 있다. 사용자가 별도 실행 사이에 저장된 데이터를 지우도록 선택하지 않는 한, 숫자는 모두 병렬로 유지된다. 서로 다른 시점의 동일 이벤트 데이터를 누적할 수 있다. 이벤트가 서로 다른 프로파일링 실행에서 관찰되면, 사용자가 그렇게 선택했다면 수가 합산된다.
사용자 수준 수집 부분은 데이터를 디멀티플렉싱한다. 각 파일에 대한 데이터가 별도로 저장된다. 개별 실행 파일이 사용하는 DSO를 구분하는 것도 가능하며, 심지어 개별 스레드의 데이터도 가능하다. 이렇게 생성된 데이터는 oparchive를 사용해 보관할 수 있다. 이 명령이 만든 파일을 다른 머신으로 옮겨 그곳에서 분석할 수 있다.
opreport 프로그램으로 프로파일링 결과로부터 리포트를 생성할 수 있다. opannotate를 사용하면 다양한 이벤트가 어디에서 발생했는지—어떤 명령에서, 데이터가 가능하다면 어떤 소스 라인에서—를 볼 수 있다. 핫스팟을 찾기 쉽다. CPU 사이클을 세면 가장 많은 시간을 보낸 곳(캐시 미스 포함)을 지목하고, 은퇴(retired)된 명령 수를 세면 가장 많은 명령이 실행된 곳을 찾을 수 있다—둘 사이에는 큰 차이가 있다.
한 주소에서의 단일 히트는 보통 의미가 없다. 통계적 프로파일링의 부작용으로, 몇 번만 실행되거나 심지어 한 번만 실행되는 명령에도 히트가 귀속될 수 있다. 이런 경우에는 반복을 통해 결과를 검증해야 한다.
oprofile 세션은 다음처럼 단순할 수 있다:
$ opcontrol -i cachebench
$ opcontrol -e INST_RETIRED:6000:0:0:1 --start
$ ./cachebench ...
$ opcontrol -h
이 명령들(실제 프로그램 포함)은 root로 실행된다는 점에 주의하라. 여기서는 단순화를 위해 root로 실행했지만, 프로그램은 아무 사용자나 실행할 수 있고, oprofile은 이를 포착한다. 다음 단계는 데이터 분석이다. opreport로 보면 다음과 같다:
CPU: Core 2, speed 1596 MHz (estimated)
Counted INST_RETIRED.ANY_P events (number of instructions retired) with a unit mask of
0x00 (No unit mask) count 6000
INST_RETIRED:6000|
samples| %|
------------------
116452 100.000 cachebench
즉, 이벤트를 많이 수집했다. 이제 opannotate로 데이터를 더 자세히 볼 수 있다. 프로그램의 어디에서 이벤트가 많이 기록되었는지 확인할 수 있다. opannotate --source 출력의 일부는 다음과 같다:
:static void
:inc (struct l *l, unsigned n)
:{
: while (n-- > 0) /* inc total: 13980 11.7926 */
: {
5 0.0042 : ++l->pad[0].l;
13974 11.7875 : l = l->n;
1 8.4e-04 : asm volatile ("" :: "r" (l));
: }
:}
이는 테스트의 내부 함수로, 시간이 많이 소요되는 부분이다. 루프의 세 줄에 샘플이 분산되어 있음을 볼 수 있다. 주요 이유는 기록된 명령 포인터에 대해 샘플링이 항상 100% 정확하지 않기 때문이다. CPU는 명령을 순서 밖으로(out-of-order) 실행한다. 정확한 실행 순서를 재구성해 올바른 명령 포인터를 만드는 것은 어렵다. 최신 CPU 버전은 일부 선택된 이벤트에 대해 이를 시도하지만, 일반적으로 노력 대비 효용이 없거나 아예 불가능하다. 대부분의 경우 큰 문제가 아니다. 샘플이 정규 분포로 퍼져 있더라도, 프로그래머는 무슨 일이 일어나는지 판단할 수 있어야 한다.
코드 분석을 시작할 때, 프로그램에서 시간이 가장 많이 소비되는 곳을 먼저 보는 것은 당연하다. 그 코드는 가능한 한 최적화되어야 한다. 하지만 그 다음은? 프로그램이 ‘불필요하게’ 시간을 쓰는 곳은 어디인가? 이 질문에 답하는 것은 그리 쉽지 않다.
이런 상황에서의 문제 중 하나는 절대값이 진짜 이야기를 해주지 않는다는 것이다. 프로그램의 한 루프가 대부분의 시간을 요구할 수 있고, 그 자체로는 문제없다. CPU 사용량이 높은 이유는 여러 가지일 수 있다. 그러나 더 흔한 경우는 CPU 사용량이 프로그램 전체에 비교적 고르게 분산되어 있다는 것이다. 이 경우 절대값은 많은 위치를 지목하게 되고, 이는 유용하지 않다.
많은 상황에서 두 이벤트의 비율을 보는 것이 도움이 된다. 예를 들어, 한 함수에서의 잘못 예측된 분기 수는 그 함수가 얼마나 자주 실행되었는지 기준 없이 보면 의미가 없을 수 있다. 물론 절대값은 프로그램 성능과 관련이 있다. 하지만 호출당 오예측 비율은 함수의 코드 품질을 더 잘 보여준다. Intel의 x86/x86-64 최적화 매뉴얼[intelopt]은 조사해야 할 비율들을 제시한다(인용 문서의 부록 B.7, Core 2 이벤트). 메모리 처리와 관련된 몇 가지 비율은 다음과 같다.
Instruction Fetch Stall: CYCLES_L1I_MEM_STALLED / CPU_CLK_UNHALTED.CORE — 캐시 또는 ITLB 미스로 인해 명령 디코더가 새 데이터를 기다리는 사이클의 비율.
ITLB Miss Rate: ITLB_MISS_RETIRED / INST_RETIRED.ANY — 명령당 ITLB 미스. 이 비율이 높으면 코드가 너무 많은 페이지에 흩어져 있음을 뜻한다.
L1I Miss Rate: L1I_MISSES / INST_RETIRED.ANY — 명령당 L1i 미스. 실행 흐름이 예측 불가능하거나 코드 크기가 너무 크다. 전자의 경우 간접 점프를 피하는 것이 도움이 될 수 있고, 후자의 경우 블록 재배치나 인라이닝 회피가 도움이 될 수 있다.
L2 Instruction Miss Rate: L2_IFETCH.SELF.I_STATE / INST_RETIRED.ANY — 명령당 코드에 대한 L2 미스. 0보다 크면 L1i 미스보다 더 심각한 코드 지역성 문제가 있음을 나타낸다.
Load Rate: L1D_CACHE_LD.MESI / CPU_CLK_UNHALTED.CORE — 사이클당 읽기 연산 수. Core 2 코어는 한 사이클에 하나의 로드를 처리할 수 있다. 비율이 높으면 실행이 메모리 읽기에 구속되어 있음을 의미한다.
Store Order Block: STORE_BLOCK.ORDER / CPU_CLK_UNHALTED.CORE — 캐시 미스로 인해 이전 저장에 막히는 저장의 비율.
L1d Rate Blocking Loads: LOAD_BLOCK.L1D / CPU_CLK_UNHALTED.CORE — 자원 부족으로 차단되는 L1d 로드. 보통 동시 L1d 접근이 너무 많음을 의미한다.
L1D Miss Rate: L1D_REPL / INST_RETIRED.ANY — 명령당 L1d 미스. 비율이 높으면 프리페치가 효과적이지 않아 L2 사용이 너무 잦음을 의미한다.
L2 Data Miss Rate: L2_LINES_IN.SELF.ANY / INST_RETIRED.ANY — 명령당 데이터에 대한 L2 미스. 값이 유의하게 0보다 크면 하드웨어/소프트웨어 프리페칭이 비효율적임을 뜻한다. 더 많은(혹은 더 이른) 소프트웨어 프리페치가 필요하다.
L2 Demand Miss Rate: L2_LINES_IN.SELF.DEMAND / INST_RETIRED.ANY — 하드웨어 프리페처가 전혀 사용되지 않은 명령당 데이터 L2 미스. 즉, 프리페칭이 시작조차 되지 않았다.
Useful NTA Prefetch Rate: SSE_PRE_MISS.NTA / SSS_PRE_EXEC.NTA — 전체 비-일시적(non-temporal) 프리페치 수 대비 유용한 비-일시적 프리페치 비율. 낮으면 값들이 이미 캐시에 많다는 뜻. 다른 프리페치 유형에도 동일한 방식으로 비율을 계산할 수 있다.
Late NTA Prefetch Rate: LOAD_HIT_PRE / SSS_PRE_EXEC.NTA — 전체 비-일시적 프리페치 수 대비, 프리페치가 진행 중인 데이터에 대한 로드 요청 비율. 높으면 소프트웨어 프리페치 명령을 너무 늦게 발행했다는 뜻. 다른 프리페치 유형에도 동일하게 계산 가능하다.
이러한 모든 비율에 대해, 프로그램은 oprofile에 두 이벤트 모두를 측정하도록 지시한 상태로 실행되어야 한다. 이렇게 해야 두 카운트가 비교 가능하다. 나누기 전에, 서로 다른 오버런 값이 반영되었는지 확인해야 한다. 가장 쉬운 방법은 각 이벤트 카운터에 해당 오버런 값을 곱하는 것이다.
이 비율들은 전체 프로그램, 실행 파일/DSO 수준, 심지어 함수 수준에서도 의미가 있다. 프로그램을 더 깊이 들여다볼수록 값에는 더 많은 오차가 포함된다.
비율을 해석하려면 기준선(baseline) 값이 필요하다. 이는 생각만큼 쉽지 않다. 코드 유형에 따라 특성이 다르고, 어떤 프로그램에서 나쁜 비율 값이 다른 프로그램에서는 정상일 수 있다.
효율적 프로그래밍에 필수 지식은 아니지만, 사용 가능한 메모리 유형에 관한 기술적 세부를 더 설명하는 것이 유익할 수 있다. 특히 여기서는 “등록(registered)”과 “비등록(unregistered)”, 그리고 ECC와 비-ECC DRAM의 차이에 관심이 있다.
“registered”와 “buffered”라는 용어는 DRAM 모듈에 버퍼라는 추가 구성 요소가 있는 DRAM 유형을 설명할 때 동의어로 사용된다. 모든 DDR 메모리 유형은 등록형과 비등록형이 있을 수 있다. 비등록 모듈의 경우, 메모리 컨트롤러는 모듈의 모든 칩에 직접 연결된다. 그림 11.1은 이 구성을 보여준다.
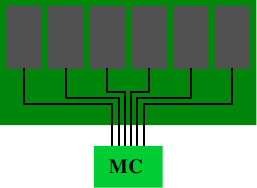
그림 11.1: 비등록 DRAM 모듈
전기적으로 이는 꽤 까다롭다. 메모리 컨트롤러는 모듈의 모든 메모리 칩의 정전용량(그림에는 6개만 보이지만 실제는 더 많다)을 처리할 수 있어야 한다. 메모리 컨트롤러(MC)에 한계가 있거나 많은 메모리 모듈을 사용하려는 경우, 이 구성은 이상적이지 않다.
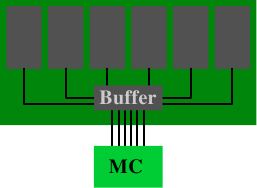
그림 11.2: 등록 DRAM 모듈
버퍼드(또는 등록형) 메모리는 상황을 바꾼다. DRAM 모듈의 RAM 칩을 메모리에 직접 연결하는 대신 버퍼에 연결하고, 이 버퍼가 메모리 컨트롤러에 연결된다. 이는 전기적 연결의 복잡도를 크게 줄인다. 메모리 컨트롤러가 DRAM 모듈을 구동할 수 있는 능력은 절감된 연결 수에 비례하여 증가한다.
이러한 장점에도 불구하고 왜 모든 DRAM 모듈이 버퍼드가 아닌가? 이유는 여러 가지다. 분명히 버퍼드 모듈은 좀 더 복잡하고, 따라서 더 비싸다. 하지만 비용만이 요인은 아니다. 버퍼는 RAM 칩의 신호를 약간 지연시키는데, 모든 신호가 버퍼링되도록 충분히 큰 지연이어야 한다. 결과적으로 DRAM 모듈의 대기 시간이 증가한다. 마지막으로 언급할 요인은 추가 전기 구성 요소가 에너지 비용을 증가시킨다는 것이다. 버퍼는 버스 주파수로 동작해야 하므로 이 구성 요소의 에너지 소모가 상당할 수 있다.
DDR2/DDR3 모듈 사용의 다른 요인들과 함께, 보통 한 뱅크(bank)당 두 개를 넘는 DRAM 모듈을 둘 수 없다. 메모리 컨트롤러의 핀 수가 뱅크 수(범용 하드웨어에서 둘) 제한의 원인이다. 대부분의 메모리 컨트롤러는 DRAM 모듈 네 개까지 구동할 수 있으므로, 비등록 모듈이면 충분하다. 메모리 요구가 큰 서버 환경에서는 상황이 다를 수 있다.
일부 서버 환경의 다른 측면은 오류를 용납할 수 없다는 것이다. RAM 셀의 축전기에 저장되는 전하가 매우 작기 때문에 오류가 발생할 수 있다. 사람들은 흔히 우주 방사선을 농담처럼 말하지만, 실제로 가능한 원인이다. 알파 붕괴 등 다른 자연 현상도 더해져, RAM 셀의 내용이 0에서 1로(또는 그 반대로) 바뀌는 오류가 발생한다. 메모리를 많이 사용할수록 이러한 사건의 확률은 높아진다.
이러한 오류가 용납되지 않는다면 ECC(Error Correction Code) DRAM을 사용할 수 있다. 오류 정정 코드(ECC)는 하드웨어가 잘못된 셀 내용을 인식하고, 경우에 따라 오류를 교정할 수 있게 한다. 예전에는 패리티 체크가 오류만을 인식했고, 오류가 감지되면 머신을 중지해야 했다. ECC에서는 소수의 잘못된 비트를 자동으로 교정할 수 있다. 하지만 오류 수가 너무 많으면 메모리 접근을 올바르게 수행할 수 없고, 머신은 여전히 중지될 수 있다. 하지만 이는 정상적으로 동작하는 DRAM 모듈에서는 꽤 드문 경우다. 같은 모듈에서 여러 오류가 동시에 발생해야 하기 때문이다.
엄밀히 말하면 “ECC 메모리”라는 표현은 정확하지 않다. 오류 검사와 정정을 수행하는 것은 메모리가 아니라 메모리 컨트롤러다. DRAM 모듈은 단지 더 많은 저장 공간을 제공하고, 실제 데이터와 함께 추가 비-데이터 비트를 전송할 뿐이다. 보통 ECC 메모리는 8 데이터 비트마다 1개의 추가 비트를 저장한다. 왜 8비트가 사용되는지는 뒤에서 설명한다.
메모리 주소에 데이터를 쓸 때, 메모리 컨트롤러는 새 내용의 ECC를 즉석에서 계산하고, 계산된 ECC와 데이터를 메모리 버스로 보낸다. 읽을 때는 데이터와 ECC를 받아 데이터의 ECC를 계산하고, DRAM 모듈에서 전달된 ECC와 비교한다. 두 ECC가 일치하면 이상이 없다. 일치하지 않으면 메모리 컨트롤러는 오류를 교정하려 시도한다. 교정이 불가능하면 오류를 기록하고, 머신을 중지시킬 수도 있다.
| SEC | SEC/DED | |
|---|---|---|
| 데이터 비트 W | ECC 비트 E | 오버헤드 |
| 4 | 3 | 75.0% |
| 8 | 4 | 50.0% |
| 16 | 5 | 31.3% |
| 32 | 6 | 18.8% |
| 64 | 7 | 10.9% |
표 11.1: ECC와 데이터 비트의 관계
오류 교정에는 여러 기술이 사용되지만, DRAM의 ECC에는 보통 해밍(Hamming) 코드가 사용된다. 해밍 코드는 원래 4 데이터 비트를 인코딩해 하나의 비트 반전 오류(SEC, Single Error Correction)를 인식하고 교정할 수 있게 했다. 이 메커니즘은 더 많은 데이터 비트로 쉽게 확장할 수 있다. 데이터 비트 수 W와 오류 코드 비트 수 E의 관계는 다음 등식으로 표현된다.
E = ⌈log2(W+E+1)⌉
이 등식을 반복적으로 풀면 표 11.1의 두 번째 열 값이 나온다. 여기에 간단한 패리티 비트를 하나 더 추가하면 두 비트 반전 오류를 인식할 수 있다. 이를 SEC/DED(Single Error Correction/Double Error Detection)라 부른다. 이 추가 비트를 더하면 표 11.1의 네 번째 열 값이 된다. W=64에서의 오버헤드는 충분히 낮고, (64, 8)은 8의 배수이므로 ECC에 자연스러운 선택이다. 대부분의 모듈에서 RAM 칩 하나는 8비트를 제공하므로, 다른 조합은 덜 효율적이다.
7 6 5 4 3 2 1
ECC Word D D D P D P P
P 1 Parity D—D—D—P
P 2 Parity D D——D P—
P 4 Parity D D D P———
그림 11.3: 해밍 생성 행렬 구성 원리
W=4, E=3인 경우로 해밍 코드 계산을 쉽게 보여줄 수 있다. 인코딩된 워드의 전략적 위치에 패리티 비트를 계산해 넣는다. 그림 11.3은 원리를 보여준다. 2의 거듭제곱에 해당하는 비트 위치에 패리티 비트를 추가한다. 첫 번째 패리티 비트 P1의 패리티 합에는 매 두 번째 비트가 포함된다. 두 번째 패리티 비트 P2의 패리티 합에는 데이터 비트 1, 3, 4(여기서는 3, 6, 7로 인코딩됨)가 포함된다. P4도 유사하게 계산한다.
패리티 비트의 계산은 행렬 곱셈을 사용해 더 우아하게 기술할 수 있다. G=[I|A] 행렬을 구성하는데, I는 항등 행렬이고 A는 그림 11.3에서 얻은 패리티 생성 행렬이다.
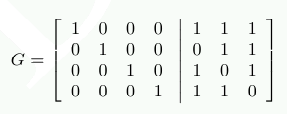
A의 각 열은 P1, P2, P4 계산에 사용되는 비트로 구성된다. 이제 각 입력 데이터 항목을 4차원 벡터 d로 나타내면 r=d⋅G를 계산해 7차원 벡터 r을 얻는다. ECC DDR의 경우 저장되는 데이터가 이것이다.
디코딩을 위해서는 H=[A^T|I] 행렬을 구성한다. 여기서 A^T는 G 계산에서 사용한 패리티 생성 행렬 A의 전치다. 즉:
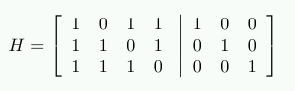
H⋅r의 결과는 저장된 데이터가 손상되었는지 보여준다. 손상이 없다면 곱의 결과는 3차원 영벡터 (0 0 0)^T가 된다. 그렇지 않다면, 곱의 값을 2진수로 해석해 나온 숫자가 반전된 비트의 열 번호를 나타낸다.
예를 들어 d=(1 0 0 1)이라 하자. 그러면
r = (1001001)
가 된다. H와의 곱을 통해 테스트하면 다음과 같다:
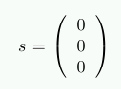
이제 저장 데이터에 손상이 있어 r'=(1 0 1 1 0 0 1)을 읽어왔다고 하자. 이 경우 결과는 다음과 같다:
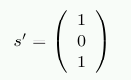
이 벡터는 영벡터가 아니며, 숫자로 해석하면 s'의 값은 5다. 이는 r'에서 반전된 비트의 번호(비트는 1부터 센다)다. 메모리 컨트롤러는 이 비트를 교정할 수 있고, 프로그램은 문제를 알아차리지 못한다.
DED 부분을 위한 추가 비트를 처리하는 것도 약간만 더 복잡할 뿐이다. 더 많은 노력을 들이면 두 비트 이상의 반전도 교정 가능한 코드를 만들 수 있다. 이것이 필요한지는 확률과 위험이 결정한다. 어떤 메모리 제조사는 256MB RAM당 750시간마다 오류가 한 번 발생할 수 있다고 말한다. 메모리 용량이 두 배가 되면 시간은 75% 줄어든다. 메모리가 충분히 크면 짧은 시간 안에 오류를 경험할 확률이 유의미해지고, ECC RAM이 필수가 된다. 심지어 SEC/DED 구현만으로는 충분하지 않을 수도 있다.
더 많은 오류 교정 기능을 구현하는 대신, 서버 마더보드는 주어진 시간 프레임 동안 모든 메모리를 자동으로 읽어들이는 기능을 제공한다. 즉, 프로세서가 실제로 메모리를 요청했는지와 무관하게, 메모리 컨트롤러가 데이터를 읽고, ECC 검사에 실패하면 교정된 데이터를 메모리에 다시 쓴다. 전체 메모리를 읽고 다시 쓰는 데 필요한 시간 동안 두 개 미만의 메모리 오류를 겪을 확률이 수용 가능하다면, SEC/DED는 충분히 합리적인 해결책이다.
등록 DRAM과 마찬가지로 묻지 않을 수 없다. 왜 ECC DRAM이 표준이 아닌가? 답은 등록 RAM 때와 같다. 추가 RAM 칩은 비용을 증가시키고, 패리티 계산은 지연을 늘린다. 비등록, 비-ECC 메모리가 상당히 더 빠를 수 있다. 등록형과 ECC DRAM의 문제들이 유사하기 때문에, 보통은 등록형 ECC DRAM만 보이고, 등록형 비-ECC DRAM은 보기 어렵다.
메모리 오류를 극복하는 또 다른 방법도 있다. 일부 제조사는 흔히 “메모리 RAID”라고 잘못 불리는 기능을 제공하는데, 데이터가 여러 DRAM 모듈(또는 최소한 RAM 칩)에 중복으로 분산 저장된다. 이 기능을 제공하는 마더보드는 비등록 DRAM 모듈을 사용할 수 있지만, 메모리 버스의 트래픽 증가가 ECC와 비-ECC DRAM 모듈의 접근 시간 차이를 상쇄할 가능성이 크다.
스레드를 최적으로 스케줄링하고, 메모리를 적절히 할당하는 데 프로그래머가 필요한 정보의 상당 부분은 제공되지만, 이 정보를 얻어내기는 번거롭다. 기존의 NUMA 지원 라이브러리(libnuma, RHEL/Fedora에서는 numactl 패키지)는 충분한 기능을 제공하지 못한다.
이에 대한 응답으로, 저자는 NUMA에 필요한 모든 기능을 제공하는 새로운 라이브러리를 제안했다. 메모리와 캐시 계층 처리의 중첩(overlap) 때문에, 이 라이브러리는 NUMA가 아닌 시스템에서도 멀티스레드/멀티코어 프로세서 환경—사실상 현재 이용 가능한 거의 모든 머신—에서 유용하다.
이 새 라이브러리의 기능은 이 문서의 조언을 따르기 위해 시급히 필요하다. 이것이 여기서 언급하는 유일한 이유다. 이 라이브러리는(이 글을 쓰는 시점에서) 완성되지 않았고, 리뷰도 받지 않았으며, 다듬어지지도 않았고, (널리) 배포되지도 않았다. 향후 크게 바뀔 수 있다. 현재는 http://people.redhat.com/drepper/libNUMA.tar.bz2 에서 받을 수 있다.
이 라이브러리의 인터페이스는 /sys 파일시스템이 내보내는 정보에 크게 의존한다. 이 파일시스템이 마운트되어 있지 않으면 많은 함수가 단순히 실패하거나 부정확한 정보를 제공할 것이다. 프로세스가 chroot jail에서 실행될 때 특히 이를 기억해야 한다.
라이브러리의 인터페이스 헤더에는 현재 다음 정의들이 포함되어 있다:
typedef memnode_set_t;
#define MEMNODE_ZERO_S(setsize, memnodesetp)
#define MEMNODE_SET_S(node, setsize, memnodesetp)
#define MEMNODE_CLR_S(node, setsize, memnodesetp)
#define MEMNODE_ISSET_S(node, setsize, memnodesetp)
#define MEMNODE_COUNT_S(setsize, memnodesetp)
#define MEMNODE_EQUAL_S(setsize, memnodesetp1, memnodesetp2)
#define MEMNODE_AND_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_OR_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_XOR_S(setsize, destset, srcset1, srcset2)
#define MEMNODE_ALLOC_SIZE(count)
#define MEMNODE_ALLOC(count)
#define MEMNODE_FREE(memnodeset)
int NUMA_cpu_system_count(void);
int NUMA_cpu_system_mask(size_t destsize, cpu_set_t *dest);
int NUMA_cpu_self_count(void);
int NUMA_cpu_self_mask(size_t destsize, cpu_set_t *dest);
int NUMA_cpu_self_current_idx(void);
int NUMA_cpu_self_current_mask(size_t destsize, cpu_set_t *dest);
ssize_t NUMA_cpu_level_mask(size_t destsize, cpu_set_t *dest,
size_t srcsize, const cpu_set_t *src,
unsigned int level);
int NUMA_memnode_system_count(void);
int NUMA_memnode_system_mask(size_t destsize, memnode_set_t *dest);
int NUMA_memnode_self_mask(size_t destsize, memnode_set_t *dest);
int NUMA_memnode_self_current_idx(void);
int NUMA_memnode_self_current_mask(size_t destsize, memnode_set_t *dest);
int NUMA_cpu_to_memnode(size_t cpusetsize, const cpu_set_t *cpuset,
size_t __memnodesize, memnode_set_t *memnodeset);
int NUMA_memnode_to_cpu(size_t memnodesize, const memnode_set_t *memnodeset,
size_t cpusetsize, cpu_set_t *cpuset);
int NUMA_mem_get_node_idx(void *addr);
int NUMA_mem_get_node_mask(void *addr, size_t size,
size_t destsize, memnode_set_t *dest);MEMNODE_* 매크로는 섹션 6.4.3에서 소개한 CPU_* 매크로와 형태와 기능이 유사하다. _S가 아닌 변형은 없고, 모두 크기(size) 매개변수를 요구한다. memnode_set_t 타입은 cpu_set_t의 대응물인데, 이번에는 메모리 노드용이다. 메모리 노드 수가 CPU 수와 아무 관련이 없을 수 있다는 점에 주의하라. 한 메모리 노드 당 여러 CPU가 있을 수 있고, 심지어 CPU가 전혀 없을 수도 있다. 따라서 동적 할당하는 메모리 노드 비트셋의 크기를 CPU 수로 결정해서는 안 된다.
대신 NUMA_memnode_system_count 인터페이스를 사용해야 한다. 이는 현재 등록된 노드 수를 반환한다. 이 숫자는 시간이 지나며 늘거나 줄 수 있다. 하지만 대부분의 경우 일정하게 유지되므로, 메모리 노드 비트셋 크기를 정하는 데 좋은 값이다. 할당은 CPU_* 매크로와 유사하게 MEMNODE_ALLOC_SIZE, MEMNODE_ALLOC, MEMNODE_FREE로 수행한다.
CPU_* 매크로와의 마지막 유사점으로, 이 라이브러리는 메모리 노드 비트셋을 비교(동등성)하고 논리 연산을 수행하는 매크로도 제공한다.
NUMA_cpu_* 함수들은 CPU 셋을 다루는 기능을 제공한다. 일부 인터페이스는 기존 기능을 새 이름으로 제공하는 것일 뿐이다. NUMA_cpu_system_count는 시스템의 CPU 수를 반환하고, NUMA_CPU_system_mask 변형은 적절한 비트를 세팅한 비트 마스크를 반환한다—이 기능은 다른 방법으로는 제공되지 않는다.
NUMA_cpu_self_count와 NUMA_cpu_self_mask는 현재 스레드가 실행될 수 있도록 허용된 CPU들에 대한 정보를 반환한다. NUMA_cpu_self_current_idx는 현재 사용 중인 CPU의 인덱스를 반환한다. 이 정보는 커널의 스케줄링 결정으로 인해 반환 시점에 이미 오래되었을 수 있다. 항상 부정확할 수 있음을 감안해야 한다. NUMA_cpu_self_current_mask는 같은 정보를 비트셋에 적절한 비트를 세팅하는 방식으로 반환한다.
NUMA_memnode_system_count는 앞서 소개했다. NUMA_memnode_system_mask는 비트셋을 채워주는 등가 함수다. NUMA_memnode_self_mask는 스레드가 현재 실행될 수 있는 CPU 중 어느 하나에 직접 연결된 메모리 노드들에 따라 비트셋을 채운다.
더 전문화된 정보는 NUMA_memnode_self_current_idx와 NUMA_memnode_self_current_mask가 반환한다. 반환되는 정보는 스레드가 현재 실행 중인 프로세서에 연결된 메모리 노드다. NUMA_cpu_self_current_* 함수와 마찬가지로, 이 정보는 함수가 반환할 때 이미 오래되었을 수 있으며, 힌트로만 사용할 수 있다.
NUMA_cpu_to_memnode 함수는 CPU 집합을 직접 연결된 메모리 노드 집합으로 매핑하는 데 사용할 수 있다. CPU 셋에서 단일 비트만 세팅되어 있다면, 각 CPU가 속한 메모리 노드를 알 수 있다. 현재 리눅스에는 단일 CPU가 두 개 이상의 메모리 노드에 속하는 것을 지원하지 않지만, 이론적으로는 미래에 바뀔 수 있다. 반대 방향의 매핑은 NUMA_memnode_to_cpu로 할 수 있다.
이미 메모리가 할당되어 있는 경우, 그것이 어디에 할당되었는지 아는 것이 유용할 때가 있다. NUMA_mem_get_node_idx와 NUMA_mem_get_node_mask는 이를 알아내게 해준다. 전자는 지정한 주소가 속한 페이지가 할당된(또는 아직 할당되지 않았다면 현재 정책에 따라 할당될) 메모리 노드의 인덱스를 반환한다. 후자는 전체 주소 범위에 대해 작업할 수 있고, 결과를 비트셋으로 반환한다. 반환값은 사용된 서로 다른 메모리 노드의 개수다.
이 섹션의 나머지에서는 이러한 인터페이스의 사용 예를 몇 가지 본다. 모든 경우에, 에러 처리와 cpu_set_t와 memnode_set_t가 감당할 수 없을 만큼 CPU/메모리 노드 수가 큰 경우는 생략한다. 코드를 견고하게 만드는 것은 독자의 몫으로 남겨둔다.
헬퍼 스레드 등 특정 CPU의 스레드에서 스케줄링되면 이득을 보는 스레드를 스케줄링하려면, 다음과 같은 코드 시퀀스를 사용할 수 있다.
cpu_set_t cur;
CPU_ZERO(&cur);
CPU_SET(cpunr, &cur);
cpu_set_t hyperths;
NUMA_cpu_level_mask(sizeof(hyperths), &hyperths, sizeof(cur), &cur, 1);
CPU_CLR(cpunr, &hyperths);코드는 먼저 cpunr로 지정한 CPU에 대한 비트셋을 만든다. 이 비트셋을, 다섯 번째 인자로 하이퍼스레드를 찾는다는 의미의 1을 넣어 NUMA_cpu_level_mask에 전달한다. 결과는 hyperths 비트셋에 반환된다. 마지막으로 원래 CPU에 해당하는 비트를 지우면 된다.
두 스레드를 두 하이퍼스레드에 스케줄링하지 않되, 캐시 공유 혜택을 보고 싶다면 프로세서의 다른 코어들을 찾아야 한다. 다음 코드 시퀀스가 그 작업을 수행한다.
cpu_set_t cur;
CPU_ZERO(&cur);
CPU_SET(cpunr, &cur);
cpu_set_t hyperths;
int nhts = NUMA_cpu_level_mask(sizeof(hyperths), &hyperths, sizeof(cur), &cur, 1);
cpu_set_t coreths;
int ncs = NUMA_cpu_level_mask(sizeof(coreths), &coreths, sizeof(cur), &cur, 2);
CPU_XOR(&coreths, &coreths, &hyperths);
ncs -= nhts;코드의 첫 부분은 하이퍼스레드를 찾는 코드와 동일하다. 이는 우연이 아니다. 지정한 CPU의 하이퍼스레드를 다른 코어들과 구분해야 하기 때문이다. 두 번째 부분에서는 이번에는 레벨 2로 NUMA_cpu_level_mask를 다시 호출한다. 남은 일은 결과에서 지정한 CPU의 모든 하이퍼스레드를 제거하는 것이다. nhts와 ncs 변수는 각 비트셋에서 세팅된 비트의 개수를 추적하는 데 사용된다.
결과 마스크는 다른 스레드를 스케줄링하는 데 사용할 수 있다. 다른 스레드를 명시적으로 스케줄링할 필요가 없다면, 사용할 코어에 대한 결정은 OS에 맡겨도 된다. 그렇지 않다면 다음 코드를 반복적으로 실행할 수 있다:
while (ncs > 0) {
size_t idx = 0;
while (! CPU_ISSET(idx, &ncs))
++idx;
CPU_ZERO(&cur);
CPU_SET(idx, &cur);
nhts = NUMA_cpu_level_mask(sizeof(hyperths), &hyperths, sizeof(cur), &cur, 1);
CPU_XOR(&coreths, &coreths, hyperths);
ncs -= nhts;
... schedule thread on CPU idx ... }루프는 각 반복에서 남아 있는 사용 코어들로부터 하나의 CPU 번호를 고른다. 그런 다음 이 CPU의 모든 하이퍼스레드를 계산한다. 결과 비트셋을 사용 가능 코어의 비트셋에서(CPU_XOR로) 빼준다. XOR이 아무것도 제거하지 않는다면 뭔가 크게 잘못된 것이다. ncs를 갱신한 뒤, 스케줄링 결정을 내리고 다음 라운드에 들어간다. 마지막에는 프로그램의 요구에 따라 idx, cur, hyperths 중 아무 것이나 사용해 스레드를 스케줄링할 수 있다. 종종 OS에 최대한의 자유를 주는 것이 좋으므로, 하이퍼스레드 집합인 hyperths를 사용해 OS가 최적의 하이퍼스레드를 선택하게 하는 편이 낫다.
[amdccnuma] Performance guidelines for amd athlon™ 64 and amd opteron™ ccnuma multiprocessor systems. Advanced Micro Devices, 2006. http://www.amd.com/us-en/assets/content_type/white_papers_and_tech_docs/40555.pdf
[arstechtwo] Stokes, Jon “Hannibal”. Ars Technica RAM Guide, Part II: Asynchronous and Synchronous DRAM. http://arstechnica.com/paedia/r/ram_guide/ram_guide.part2-1.html, 2004.
[continuous] Anderson, Jennifer M., Lance M. Berc, Jeffrey Dean, Sanjay Ghemawat, Monika R. Henzinger, Shun-Tak A. Leung, Richard L. Sites, Mark T. Vandevoorde, Carl A. Waldspurger and William E. Weihl. Continuous profiling: Where have all the cycles gone. Proceedings of the 16th ACM Symposium of Operating Systems Principles, pages 1–14. 1997. http://citeseer.ist.psu.edu/anderson97continuous.html
[dcas] Doherty, Simon, David L. Detlefs, Lindsay Grove, Christine H. Flood, Victor Luchangco, Paul A. Martin, Mark Moir, Nir Shavit and Jr. Guy L. Steele. DCAS is not a Silver Bullet for Nonblocking Algorithm Design. SPAA '04: Proceedings of the Sixteenth Annual ACM Symposium on Parallelism in Algorithms and Architectures, pages 216–224. New York, NY, USA, 2004. ACM Press. http://research.sun.com/scalable/pubs/SPAA04.pdf
[ddrtwo] Dowler, M. Introduction to DDR-2: The DDR Memory Replacement. http://www.pcstats.com/articleview.cfm?articleID=1573, 2004.
[directcacheaccess] Huggahalli, Ram, Ravi Iyer and Scott Tetrick. Direct Cache Access for High Bandwidth Network I/O. 2005. http://www.stanford.edu/group/comparch/papers/huggahalli05.pdf
[dwarves] Melo, Arnaldo Carvalho de. The 7 dwarves: debugging information beyond gdb. Proceedings of the Linux Symposium. 2007. https://ols2006.108.redhat.com/2007/Reprints/melo-Reprint.pdf
[futexes] Drepper, Ulrich. Futexes Are Tricky. 2005. http://people.redhat.com/drepper/futex.pdf
[goldberg] Goldberg, David. What Every Computer Scientist Should Know About Floating-Point Arithmetic. ACM Computing Surveys, 23(1):5–48, 1991. http://citeseer.ist.psu.edu/goldberg91what.html
[highperfdram] Cuppu, Vinodh, Bruce Jacob, Brian Davis and Trevor Mudge. High-Performance DRAMs in Workstation Environments. IEEE Transactions on Computers, 50(11):1133–1153, 2001. http://citeseer.ist.psu.edu/476689.html
[htimpact] Margo, William, Paul Petersen and Sanjiv Shah. Hyper-Threading Technology: Impact on Compute-Intensive Workloads. Intel Technology Journal, 6(1), 2002. ftp://download.intel.com/technology/itj/2002/volume06issue01/art06_computeintensive/vol6iss1_art06.pdf
[intelopt] Intel 64 and IA-32 Architectures Optimization Reference Manual. Intel Corporation, 2007. http://www.intel.com/design/processor/manuals/248966.pdf
[lockfree] Fober, Dominique, Yann Orlarey and Stephane Letz. Lock-Free Techniques for Concurrent Access to Shared Objects. In GMEM, editor, Actes des journées d'informatique musicale JIM2002, Marseille, pages 143–150. 2002. http://www.grame.fr/pub/fober-JIM2002.pdf
[micronddr] Double Data Rate (DDR) SDRAM MT46V. Micron Technology, 2003.
[mytls] Drepper, Ulrich. ELF Handling For Thread-Local Storage. Technical report, Red Hat, Inc., 2003. http://people.redhat.com/drepper/tls.pdf
[nonselsec] Drepper, Ulrich. Security Enhancements in Red Hat Enterprise Linux. 2004. http://people.redhat.com/drepper/nonselsec.pdf
[oooreorder] McNamara, Caolán. Controlling symbol ordering. 2007. http://blogs.linux.ie/caolan/2007/04/24/controlling-symbol-ordering/
[sramwiki] Wikipedia. Static random access memory. 2006. http://en.wikipedia.org/wiki/Static_Random_Access_Memory
[transactmem] Herlihy, Maurice and J. Eliot B. Moss. Transactional memory: Architectural support for lock-free data structures. Proceedings of 20th International Symposium on Computer Architecture. 1993. http://citeseer.ist.psu.edu/herlihy93transactional.html
[vectorops] Gebis, Joe and David Patterson. Embracing and Extending 20th-Century Instruction Set Architectures. Computer, 40(4):68–75, 2007.
| 이 글의 색인 항목 |
|---|
| GuestArticles |