디스크에서 데이터를 직접 읽는 것이 메모리 캐시보다 실제로 더 빠를 수 있음을 실험으로 증명한다. io_uring 기반 파이프라인과 루프 언롤링/벡터화를 통해 병목을 분석하고, mmap 페이지 캐시의 지연 병목, NUMA 영향, 그리고 스케일링에 대한 시사점을 설명한다.
디스크에서 직접 데이터를 소싱하는 것이 메모리에 캐시하는 것보다 더 빠르다. 증거도 있다. 하드웨어는 더 넓어졌지만(폭이 증가) 더 빨라지지는 않았기에, 예전 방식으로는 목표 성능에 도달할 수 없다. 확장되는 것을 활용하고, 그렇지 않은 것을 피할 수 있는 새로운 도구가 필요하다.
1편에서 일부 컴퓨터 성능 요인은 지수적으로 확장되는 반면, 다른 것들은 수십 년째 정체되어 있음을 보였다. 그리고 아무 증명 없이 디스크에서 데이터를 소싱하는 것이 메모리에서 소싱하는 것보다 더 빠를 수 있다고 주장했다. 이제 그 증명을 보여준다.
컴퓨터 공학의 도그마는 “사용하지 않는 메모리는 파일시스템에서 뭔가를 캐시하는 데 써야 한다. 디스크는 느리고 메모리는 빠르니까”라는 것이다. 하지만 디스크 대역폭은 지수적으로 증가하는데 메모리 접근 지연(latency)은 정체되어 왔으므로, 이제는 이 말이 항상 참이 아니다.
데이터와, 그 데이터로 수행할 단순한 작업이 필요하다. 나는 자유의지(혹은 그 환상)를 발휘해 “10 세기(counting 10s)”라는 벤치마크를 만들었다. 0부터 20 사이의 의사난수 정수를 버퍼에 쓰고, 그중 값이 10인 정수의 개수를 센다. 암달의 법칙(Amdahl’s Law) 상황을 모사하기 위해 카운팅은 단일 스레드에서 전부 수행되도록 한다.
이 작업이 얼마나 빠르게 수행될 수 있을까? 상한은 메모리 대역폭이 될 것이다.
테스트 장비는 Supermicro H11SSL-i 보드에 AMD EPYC 7551P 32코어의 구형 서버, DDR4 2133 MHz 96GB, 그리고 eBay에서 모은 1.92TB Samsung PM983a PCIe 3.0 SSD 두 개다. 이 서버의 구성상 단일 스레드에서의 메모리 대역폭 상한은 3 채널 × 2133MT/s × 8B/T / 4 NUMA 도메인 ≈ 13GB/s로 계산된다. 좀 특이한 시스템이지만, 그래서 최적화할 맛이 더 난다!
디스크는 각 3.1GB/s 읽기 대역폭으로 스펙이 표기되어 있어 상한은 6.2GB/s이다. 4KB 스트라이프 크기의 raid0 볼륨을 만들고, 저널링 없이 ext4로 포맷한 뒤, 테스트 전 메타데이터 초기화를 모두 마쳤다.
sudo mdadm --create /dev/md0 --level=0 --raid-devices=2 --chunk=4K /dev/nvme1n1 /dev/nvme2n1
sudo mkfs.ext4 -F -L data -O ^has_journal -E lazy_itable_init=0 /dev/md0
sudo mount -o noatime /dev/md0 mnt
대부분의 벤치마크에서는 50GB 데이터셋을 사용했다. 시작할 때 테스트 시스템이 64GB인 줄 알았고, 그 관성이 계속 이어졌기 때문이다.
이를 C로 가장 단순하고 깔끔하게 작성하면 다음과 같다.
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
// count_10_loop
int main(int argc, char *argv[]) {
char* filename = argv[1];
size_t size_bytes = strtoull(argv[2], NULL, 10);
size_t total_ints = size_bytes / sizeof(int);
size_t count = 0;
int fd = open(filename, O_RDONLY);
int* data = (int*)mmap(NULL, size_bytes, PROT_READ, MAP_SHARED, fd, 0);
for (size_t i = 0; i < total_ints; ++i) {
if (data[i] == 10) count++;
}
printf("Found %ld 10s\n", count);
}
파일을 mmap()으로 매핑하면 읽을 수 있는 버퍼가 생긴다. 그런 다음 단순히 루프를 돌며 10의 개수를 센다.
벤치마크가 목적이므로 다음으로 넘어가기 전 타이밍 측정을 통합하자.
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <sys/time.h>
long get_time_us() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000L + tv.tv_usec;
}
// count_10_loop
int main(int argc, char *argv[]) {
char* filename = argv[1];
size_t size_bytes = strtoull(argv[2], NULL, 10);
size_t total_ints = size_bytes / sizeof(int);
size_t count = 0;
int fd = open(filename, O_RDONLY);
int* data = (int*)mmap(NULL, size_bytes, PROT_READ, MAP_SHARED, fd, 0);
long start = get_time_us();
for (size_t i = 0; i < total_ints; ++i) {
if (data[i] == 10) count++;
}
long elapsed = get_time_us() - start;
printf("simple loop found %ld 10s processed at %0.2f GB/s\n", count, (double)(size_bytes/1073741824)/((double)elapsed/1.0e6));
}
첫 실행에서는 디스크에서 읽게 된다. 디스크/파일시스템 읽기가 메모리 대역폭에 도달하기 전에 성능을 제한한다.
❯ sudo ./count_10_loop ./mnt/datafile.bin 53687091200
simple loop found 167802249 10s processed at 0.61 GB/s
예상대로 메모리 속도에는 한참 못 미친다. 모두가 알다시피 디스크는 느리니까. 시스템을 보면 첫 실행이 데이터를 메모리에 캐시했음을 확인할 수 있다.
두 번째 실행은 데이터가 이미 메모리에 있으므로 더 빨라질 것으로 기대한다. 모두가 알다시피 메모리는 빠르니까.
❯ sudo ./count_10_loop ./mnt/datafile.bin 53687091200
simple loop found 167802249 10s processed at 3.71 GB/s

빠르긴 하지만, 분명 메모리가 프로세서에 공급할 수 있는 속도보다 느리다. 어떤 병목에 걸린 걸까? 이 속도는 이 세대 CPU의 초당 명령어 처리 한계(2GHz × 1.5 IPC = 3G와 3GHz 부스트 × 1.5 IPC = 4.5G 사이의 명령어/초)와 상관이 있어 보인다.
perf로 CPU가 벡터 명령을 사용하는지 볼 수 있다. 아니라면 실제 연산이 병목이다.
Percent│ test %rbp,%rbp
│ ↓ je 84
│ lea (%rbx,%rbp,4),%rcx
│ mov %rbx,%rax
│ xor %ebp,%ebp
│ nop
│70: xor %edx,%edx
1.31 │ cmpl $0xa,(%rax)
42.38 │ sete %dl
45.72 │ add $0x4,%rax
0.01 │ add %rdx,%rbp
10.42 │ cmp %rax,%rcx
0.16 │ ↑ jne 70
│84: xor %eax,%eax
│ shr $0x14,%r12
│ → call get_time_us
│ pxor %xmm0,%xmm0
│ pxor %xmm1,%xmm1
확인됨. 비벡터화된 명령을 단일 스레드로 실행 중이고, 2GHz CPU에서 가능한 한 빠르게 돈다. 젠장. 첫 번째 비지수적 한계에 부딪혔다. 최신 CPU라도 이 기계어를 크게 개선해봐야 50% 향상 정도일 것이고, 여전히 메모리 대역폭 한계에는 한참 못 미친다.
좋은 소식은, 컴파일러를 도와주면 이 코드는 분명 벡터화될 수 있다는 것이다. 루프를 언롤하자!
컴파일러에게 이 코드가 벡터 명령을 써도 안전하다는 것을 아주 명확히 보여주자. 그러면 정수를 최대 8배 빠르게 처리할 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <stdint.h>
#include <sys/time.h>
long get_time_us() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000L + tv.tv_usec;
}
// count_10_unrolled
int main(int argc, char *argv[]) {
char* filename = argv[1];
size_t size_bytes = strtoull(argv[2], NULL, 10);
size_t total_ints = size_bytes / sizeof(int);
size_t count = 0;
int fd = open(filename, O_RDONLY);
void* buffer = mmap(NULL, size_bytes, PROT_READ, MAP_SHARED, fd, 0);
// Get the compiler to align the buffer
const int * __restrict data = (const int * __restrict)__builtin_assume_aligned(buffer, 4096);
uint64_t c0=0, c1=0, c2=0, c3=0,
c4=0, c5=0, c6=0, c7=0,
c8=0, c9=0, c10=0, c11=0,
c12=0, c13=0, c14=0, c15=0;
long start = get_time_us();
// Unrolling the compiler knows it can use a vector unit like AVX2 to process
for (size_t i = 0; i < total_ints; i += 16) {
// removed 'if' to get it to be branchless: each compares to 10, adds 0 or 1
c0 += (unsigned)(data[i+ 0] == 10);
c1 += (unsigned)(data[i+ 1] == 10);
c2 += (unsigned)(data[i+ 2] == 10);
c3 += (unsigned)(data[i+ 3] == 10);
c4 += (unsigned)(data[i+ 4] == 10);
c5 += (unsigned)(data[i+ 5] == 10);
c6 += (unsigned)(data[i+ 6] == 10);
c7 += (unsigned)(data[i+ 7] == 10);
c8 += (unsigned)(data[i+ 8] == 10);
c9 += (unsigned)(data[i+ 9] == 10);
c10 += (unsigned)(data[i+10] == 10);
c11 += (unsigned)(data[i+11] == 10);
c12 += (unsigned)(data[i+12] == 10);
c13 += (unsigned)(data[i+13] == 10);
c14 += (unsigned)(data[i+14] == 10);
c15 += (unsigned)(data[i+15] == 10);
}
// pairwise reduce to help some compilers schedule better
uint64_t s0 = c0 + c1, s1 = c2 + c3, s2 = c4 + c5, s3 = c6 + c7;
uint64_t s4 = c8 + c9, s5 = c10 + c11, s6 = c12 + c13, s7 = c14 + c15;
uint64_t t0 = s0 + s1, t1 = s2 + s3, t2 = s4 + s5, t3 = s6 + s7;
count = (t0 + t1) + (t2 + t3);
long elapsed = get_time_us() - start;
printf("unrolled loop found %ld 10s processed at %0.2f GB/s\n", count, (double)(size_bytes/1073741824)/((double)elapsed/1.0e6));
}
이제 perf로 벡터화된 명령이 쓰였는지 확인하자.
Percent│ movq %xmm0,%rcx
│ movdqa %xmm7,%xmm14
│ pxor %xmm0,%xmm0
│ nop
│ e8: movdqa %xmm6,%xmm4
0.30 │ movdqa %xmm6,%xmm3
0.12 │ movdqa %xmm6,%xmm2
0.35 │ add $0x1,%rdx
1.54 │ pcmpeqd (%rax),%xmm4
54.64 │ pcmpeqd 0x10(%rax),%xmm3
1.62 │ movdqa %xmm6,%xmm1
0.99 │ add $0x40,%rax
0.12 │ pcmpeqd -0x20(%rax),%xmm2
3.03 │ pcmpeqd -0x10(%rax),%xmm1
1.32 │ pand %xmm5,%xmm4
1.25 │ pand %xmm5,%xmm3
1.55 │ movdqa %xmm4,%xmm15
0.24 │ punpckhdq %xmm0,%xmm4
확인됨. 128비트 벡터 명령을 사용 중이며, 이론상 원본보다 최대 4배 빠를 수 있다.
참고: 128비트 벡터 명령이 쓰였지만, 나는 256비트를 기대했다. 더 파보니 1세대 EPYC에서 256비트 명령이 최적화가 덜 됐다는 주장들이 있었다. 컴파일러에 256비트를 강제하니 오히려 더 느렸다. 여기서는 컴파일러가 그 사실을 알고 있었던 듯하다.
페이지 캐시에 데이터가 있는 상태에서 언롤 버전을 벤치마크해보자.
❯ sudo ./count_10_unrolled ./mnt/datafile.bin 53687091200
unrolled loop found 167802249 10s processed at 5.51 GB/s
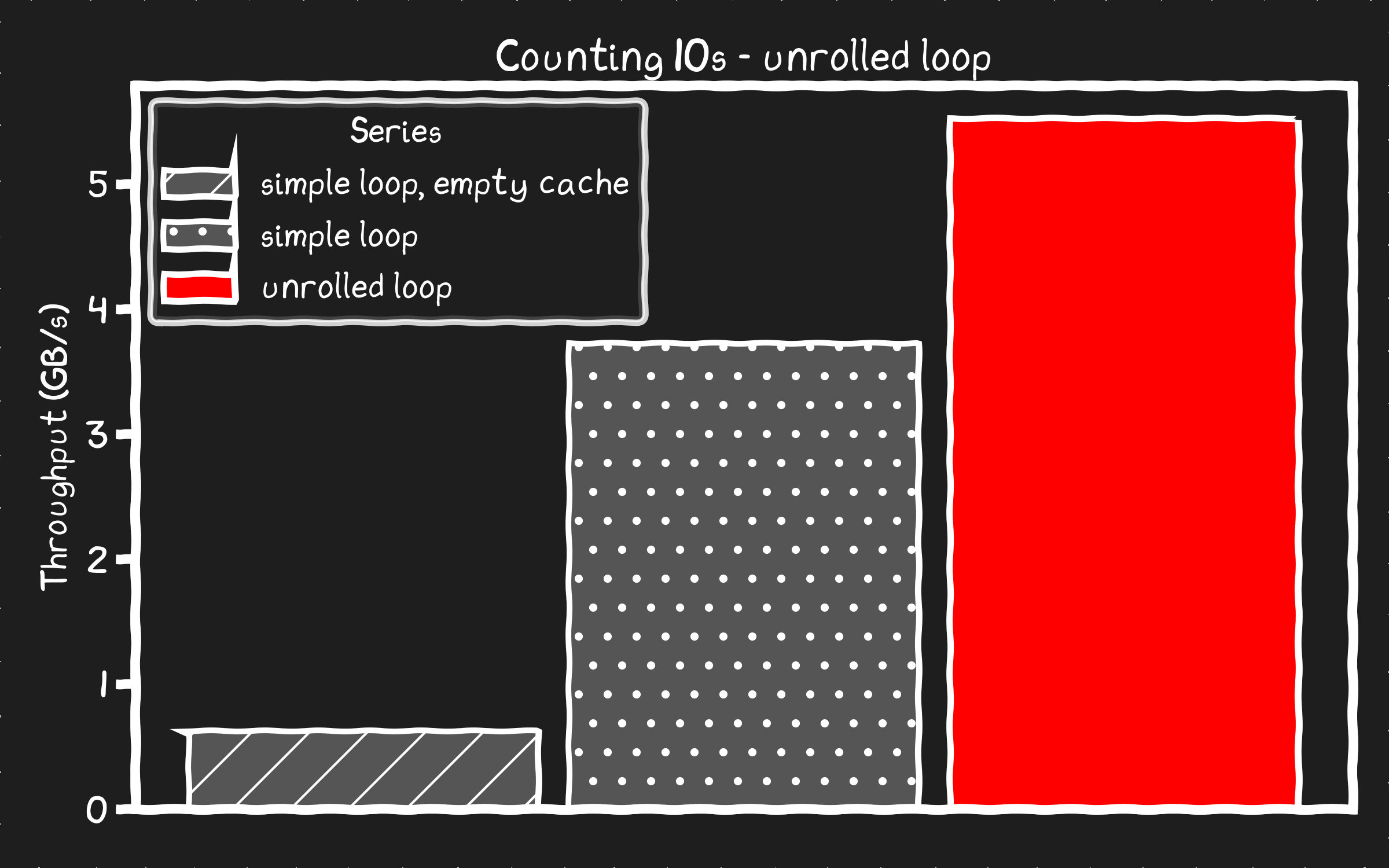
여전히 메모리 버스 속도 한계(13GB/s)에는 한참 못 미치지만, 오리지널보다 50% 빨라진 것은 성과다. 다른 병목이 분명 있다.
5.51GB/s? 스펙상 SSD는 6.2GB/s를 읽을 수 있다. 그런데 디스크에서 직접 읽은 첫 실행은 0.61GB/s에 그쳤다. 어떻게 디스크에서 직접 데이터를 소싱하면서 이 성능을 따라잡거나 넘을 수 있을까?
기본 mmap() 메커니즘을 생각해보자. 디스크에서 데이터를 투명하게 가져오기 위한 백그라운드 IO 파이프라인이다. 사용자 공간에서 빈 버퍼를 읽으면 폴트가 발생하고, 커널은 파일시스템에서 데이터를 읽어 처리하며, 디스크 IO를 큐잉한다. 불행히도 이 레거시 메커니즘은 진지한 고성능 IO를 위해 설계되지 않았다. 610MB/s는 SATA 디스크보다 빠르긴 하다. 반면 우리 디스크의 잠재력의 10%만 뽑아냈다. 다른 방법을 써야 함이 분명하다.
SSD가 자동으로 멀티 기가바이트 속도로 읽어주지는 않는다. 진지한 성능을 끌어내려면 IO 파이프라인에 공을 들여야 한다.
io_uring 기반 IO 엔진(일종의 사용자 공간 드라이버)을 만들어 이 속도를 달성했다. 메인 스레드는 데이터를 요청하고, IO 엔진이 IO를 처리하며, 메인 스레드는 데이터가 버퍼에 들어오면 카운팅을 수행한다. 요청/응답/버퍼를 관리하기 위해 여러 큐를 사용한다. IO 엔진은 워커 6개를 띄우고, 큐 깊이는 8192, 버퍼 크기는 16KB로 설정한다.
코드를 좀 더 깔끔히 다듬고 싶었지만, A) 정리할 시간이 없었고 B) 일부 복잡성은 불가피했다. IO 엔진 코드는 너무 길어 스크롤하기 힘들어 깃허브로 옮겼다 link
#include "io_engine.h"
#include <sys/mman.h>
#include <getopt.h>
#include <stdio.h>
#include <stdlib.h>
#include <fcntl.h>
#include <sys/mman.h>
#include <stdint.h>
#include <sys/time.h>
#define DEFAULT_WORKERS 6
#define DEFAULT_BLOCK_SIZE 16384
#define DEFAULT_QUEUE_DEPTH 8192
// Count the number of "10" (int format) in the buffer
static inline size_t count_tens_unrolled(void* data, size_t size_bytes) {
const size_t total = size_bytes / sizeof(int);
// Get the compiler to align the buffer
const int * __restrict p = (const int * __restrict)__builtin_assume_aligned(data, 4096);
uint64_t c0=0, c1=0, c2=0, c3=0,
c4=0, c5=0, c6=0, c7=0,
c8=0, c9=0, c10=0, c11=0,
c12=0, c13=0, c14=0, c15=0;
// Unrolling the compiler knows it can use a vector unit like AVX2 to process
for (size_t i = 0; i < total; i += 16) {
// removed 'if' to get it to be branchless: each compares to 10, adds 0 or 1
c0 += (unsigned)(p[i+ 0] == 10);
c1 += (unsigned)(p[i+ 1] == 10);
c2 += (unsigned)(p[i+ 2] == 10);
c3 += (unsigned)(p[i+ 3] == 10);
c4 += (unsigned)(p[i+ 4] == 10);
c5 += (unsigned)(p[i+ 5] == 10);
c6 += (unsigned)(p[i+ 6] == 10);
c7 += (unsigned)(p[i+ 7] == 10);
c8 += (unsigned)(p[i+ 8] == 10);
c9 += (unsigned)(p[i+ 9] == 10);
c10 += (unsigned)(p[i+10] == 10);
c11 += (unsigned)(p[i+11] == 10);
c12 += (unsigned)(p[i+12] == 10);
c13 += (unsigned)(p[i+13] == 10);
c14 += (unsigned)(p[i+14] == 10);
c15 += (unsigned)(p[i+15] == 10);
}
// pairwise reduce to help some compilers schedule better
uint64_t s0 = c0 + c1, s1 = c2 + c3, s2 = c4 + c5, s3 = c6 + c7;
uint64_t s4 = c8 + c9, s5 = c10 + c11, s6 = c12 + c13, s7 = c14 + c15;
uint64_t t0 = s0 + s1, t1 = s2 + s3, t2 = s4 + s5, t3 = s6 + s7;
return (t0 + t1) + (t2 + t3);
}
int main(int argc, char *argv[]) {
char* filename = argv[1];
size_t size_bytes = strtoull(argv[2], NULL, 10);
// Set up the io engine
ioengine_t* na = ioengine_alloc(filename, size_bytes, DEFAULT_QUEUE_DEPTH, DEFAULT_BLOCK_SIZE, DEFAULT_WORKERS);
sleep(1);
// Use the background workers to read file directly
size_t total_blocks = na->file_size / na->block_size;
uint64_t uid = 1;
size_t count = 0;
long start = get_time_us();
// Read all blocks
size_t blocks_queued = 0;
size_t blocks_read = 0;
int buffer_queued = 0;
while (blocks_read < total_blocks) {
//// Queue IO phase //////
// Do we have more blocks to queue up?
if (buffer_queued < na->num_io_buffers/2 && blocks_queued <= total_blocks) {
// Calculate how many blocks on average we want our workers to queue up
size_t free_buffers = (size_t)(na->num_io_buffers - buffer_queued - 4); // hold back a few buffers
size_t blocks_remaining = total_blocks - blocks_queued; // how many blocks have we not queued
size_t blocks_to_queue = free_buffers > blocks_remaining ? blocks_remaining : free_buffers;
int blocks_to_queue_per_worker = (int) (blocks_to_queue + na->num_workers - 1) / na->num_workers;
// Iterate through workers and assign work
for (int i = 0; i < na->num_workers; i++) {
worker_thread_data_t* worker = &na->workers[i];
// Try to queue N blocks to this worker
for (int j = 0; j < blocks_to_queue_per_worker; j++) {
if (blocks_queued == total_blocks) break;
int bgio_tail = worker->bgio_tail;
int bgio_head = worker->bgio_head;
int bgio_next = (bgio_tail + 1) % worker->num_max_bgio;
int next_bhead = (worker->buffer_head + 1) % worker->num_max_bgio;
if (bgio_next == bgio_head) break; // queue for send requests is full
if (next_bhead == worker->buffer_tail) break; // queue for recieving completed IO is full
// Queue this block with the worker. We have to track which buffer it's going to.
int buffer_idx = worker->buffer_start_idx + worker->buffer_head;
na->buffer_state[buffer_idx] = BUFFER_PREFETCHING;
worker->bgio_uids[bgio_tail] = (uid++)<<16; // unique id helps track IOs in io_uring, we encode 4 bytes later
worker->bgio_buffer_idx[bgio_tail] = buffer_idx;
worker->bgio_block_idx[bgio_tail] = blocks_queued++; // block sized index into file
worker->bgio_queued[bgio_tail] = -1; // Requested but not yet queued
int next_tail = (bgio_tail + 1) % worker->num_max_bgio;
worker->bgio_tail = next_tail;
// Log the buffer in an ordered queue for us to read
worker->complete_ring[worker->buffer_head] = buffer_idx;
worker->buffer_head = next_bhead;
buffer_queued++;
}
// Tell the worker to submit IOs as a group
worker->bgio_submit++;
}
}
//// Completion Phase //////
// Iterate through worker and check if they have complete IOs
for (int i = 0; i < na->num_workers; i++) {
worker_thread_data_t* worker = &na->workers[i];
int current = worker->buffer_tail;
// We know what IO's we're waiting on, but we have to poll
// to see if they are done.
for (int scan = 0; scan < worker->num_max_bgio; scan++) {
// Scan until we get to the end of the list
if (current == worker->buffer_head) break;
int buffer_idx = worker->complete_ring[current];
int state = na->buffer_state[buffer_idx];
if (state == BUFFER_PREFETCHED) {
// This buffer is completed - Process this buffer.
count += count_tens_unrolled(na->io_buffers[buffer_idx], na->block_size);
na->buffer_state[buffer_idx] = BUFFER_UNUSED;
blocks_read++;
buffer_queued--;
}
current = (current + 1) % worker->num_max_bgio;
}
// IO's might have been completed out of order, advance the tail when we can
current = worker->buffer_tail;
while (current != worker->buffer_head) {
int buffer_idx = worker->complete_ring[current];
int state = na->buffer_state[buffer_idx];
if (state != BUFFER_UNUSED) break;
current = (current + 1) % worker->num_max_bgio;
}
worker->buffer_tail = current;
worker->bgio_submit++; // probably unnecessary
}
}
long elapsed = get_time_us() - start;
printf("diskbased found %ld 10s processed at %0.2f GB/s\n", count, (double)(size_bytes/1073741824)/((double)elapsed/1.0e6));
// Cleanup I/O system
ioengine_free(na);
return 0;
}
이 추가 코드가 속도를 높여주길 바란다.
❯ sudo ./diskbased/benchmark ./mnt/datafile.bin 53687091200
diskbased found 167802249 10s processed at 5.81 GB/s
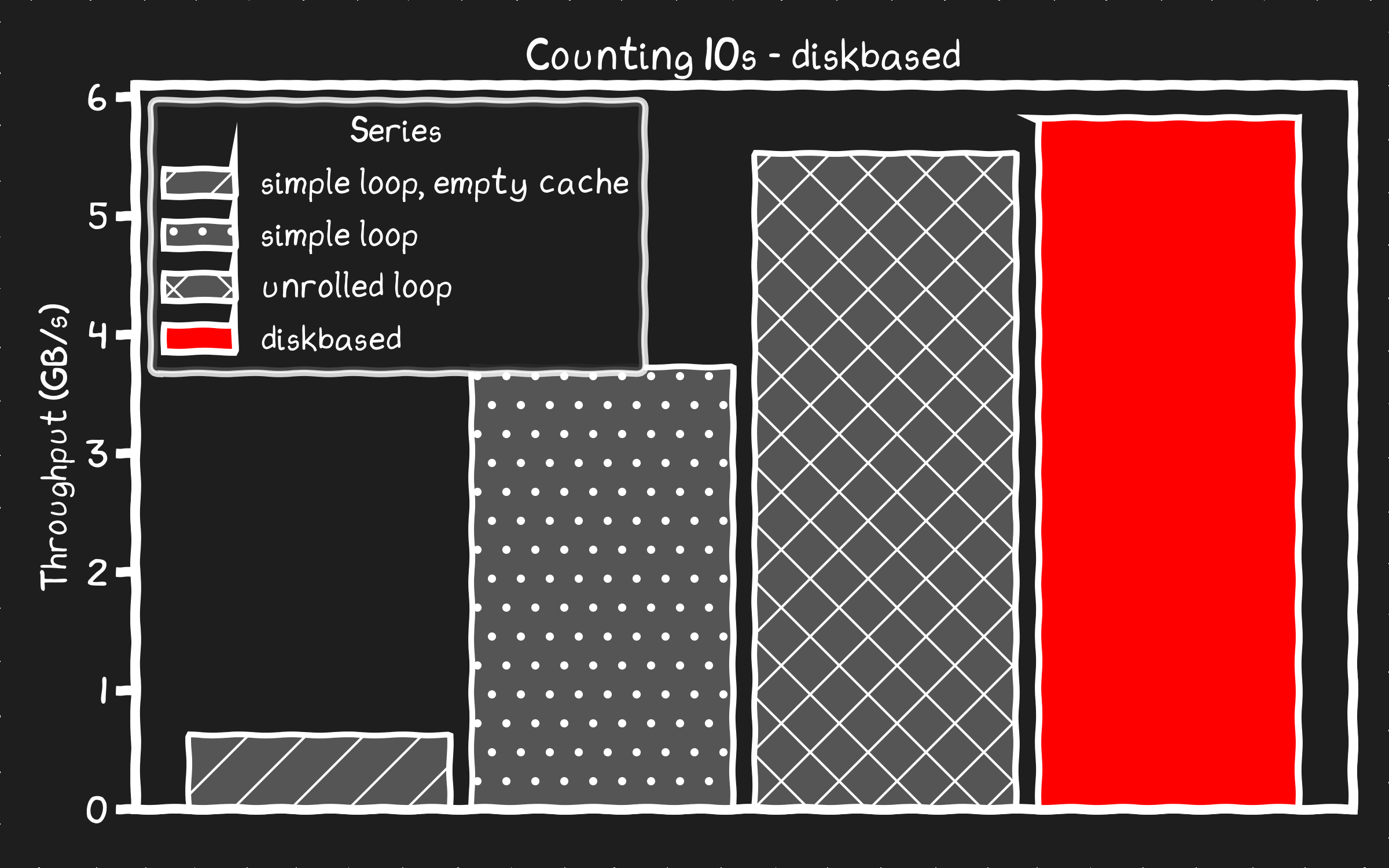
붐! 디스크가 메모리보다 빠르다! 수백 줄의 코드가 필요하지만, 이제는 메모리의 페이지 캐시에서 복사해오는 것보다 SSD에서 직접 데이터를 소싱하는 것이 더 빠르다.
물론 내 6GB/s 디스크 스트라이프가, 이 기이한 해크 시스템이라도, 메모리 버스보다 실제로 빠른 건 아니다. 그렇다면 무슨 일이 벌어진 걸까? 병목은 어디에 있을까? 분명 메모리의 페이지 캐시에서 데이터를 읽어오는 방식일 것이다.
mmap()을 read()로 바꿔서, 미리 할당한 버퍼로 디스크에서 읽어오면 어떨까. 그러면 페이지 캐시와 관련된 mmap() 오버헤드 없이, 메모리 상의 데이터로 카운팅을 측정할 수 있다.
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#include <stdint.h>
#include <string.h>
long get_time_us() {
struct timeval tv;
gettimeofday(&tv, NULL);
return tv.tv_sec * 1000000L + tv.tv_usec;
}
int main(int argc, char *argv[]) {
char* filename = argv[1];
size_t size_bytes = strtoull(argv[2], NULL, 10);
size_t total_ints = size_bytes / sizeof(int);
size_t count = 0;
int fd = open(filename, O_RDONLY|O_DIRECT);
void *buf;
posix_memalign(&buf, 4096, size_bytes);
int *data = buf;
size_t off = 0;
while (off < size_bytes) {
ssize_t n = read(fd, (char*)data + off, size_bytes - off);
off += (size_t)n; // YOLO: assume n > 0 until done
}
long start = get_time_us();
for (size_t i = 0; i < total_ints; ++i) {
if (data[i] == 10) count++;
}
long elapsed = get_time_us() - start;
printf("simple loop %ld 10s processed at %0.2f GB/s\n",
count,
(double)(size_bytes/1073741824)/((double)elapsed/1.0e6));
// Get the compiler to align the buffer
const int * __restrict p = (const int * __restrict)__builtin_assume_aligned((void*)data, 4096);
uint64_t c0=0, c1=0, c2=0, c3=0,
c4=0, c5=0, c6=0, c7=0,
c8=0, c9=0, c10=0, c11=0,
c12=0, c13=0, c14=0, c15=0;
start = get_time_us();
// Unrolling the compiler knows it can use a vector unit like AVX2 to process
for (size_t i = 0; i < total_ints; i += 16) {
// removed 'if' to get it to be branchless: each compares to 10, adds 0 or 1
c0 += (unsigned)(p[i+ 0] == 10);
c1 += (unsigned)(p[i+ 1] == 10);
c2 += (unsigned)(p[i+ 2] == 10);
c3 += (unsigned)(p[i+ 3] == 10);
c4 += (unsigned)(p[i+ 4] == 10);
c5 += (unsigned)(p[i+ 5] == 10);
c6 += (unsigned)(p[i+ 6] == 10);
c7 += (unsigned)(p[i+ 7] == 10);
c8 += (unsigned)(p[i+ 8] == 10);
c9 += (unsigned)(p[i+ 9] == 10);
c10 += (unsigned)(p[i+10] == 10);
c11 += (unsigned)(p[i+11] == 10);
c12 += (unsigned)(p[i+12] == 10);
c13 += (unsigned)(p[i+13] == 10);
c14 += (unsigned)(p[i+14] == 10);
c15 += (unsigned)(p[i+15] == 10);
}
// pairwise reduce to help some compilers schedule better
uint64_t s0 = c0 + c1, s1 = c2 + c3, s2 = c4 + c5, s3 = c6 + c7;
uint64_t s4 = c8 + c9, s5 = c10 + c11, s6 = c12 + c13, s7 = c14 + c15;
uint64_t t0 = s0 + s1, t1 = s2 + s3, t2 = s4 + s5, t3 = s6 + s7;
count = (t0 + t1) + (t2 + t3);
elapsed = get_time_us() - start;
printf("unrolled loop %ld 10s processed at %0.2f GB/s\n",
count,
(double)(size_bytes/1073741824)/((double)elapsed/1.0e6));
}
데이터셋을 NUMA 도메인 하나보다 작게 유지하고, NUMA 오버헤드를 막기 위해 하나의 NUMA 노드에 바인딩하면, 이론적으로 계산한 메모리 대역폭이 언롤 루프의 1차 병목임을(초기에 기대했던 그대로) 확인할 수 있다.
❯ sudo numactl --cpunodebind=0 ./in_ram mnt/datafile.bin 2147483648
simple loop 6709835 10s processed at 4.76 GB/s
unrolled loop 6709835 10s processed at 13.04 GB/s
하지만 이는 50GB 데이터셋을 썼던 다른 실행과 비교하기엔 유용하지 않다. 전체 50GB 데이터셋으로 실행하면 성능이 떨어진다. 데이터 상당 부분을 NUMA 도메인을 가로질러 접근해야 하므로 비용이 더 크다.
❯ sudo ./in_ram ./mnt/datafile.bin 53687091200
simple loop 167802249 10s processed at 3.76 GB/s
unrolled loop 167802249 10s processed at 7.90 GB/s
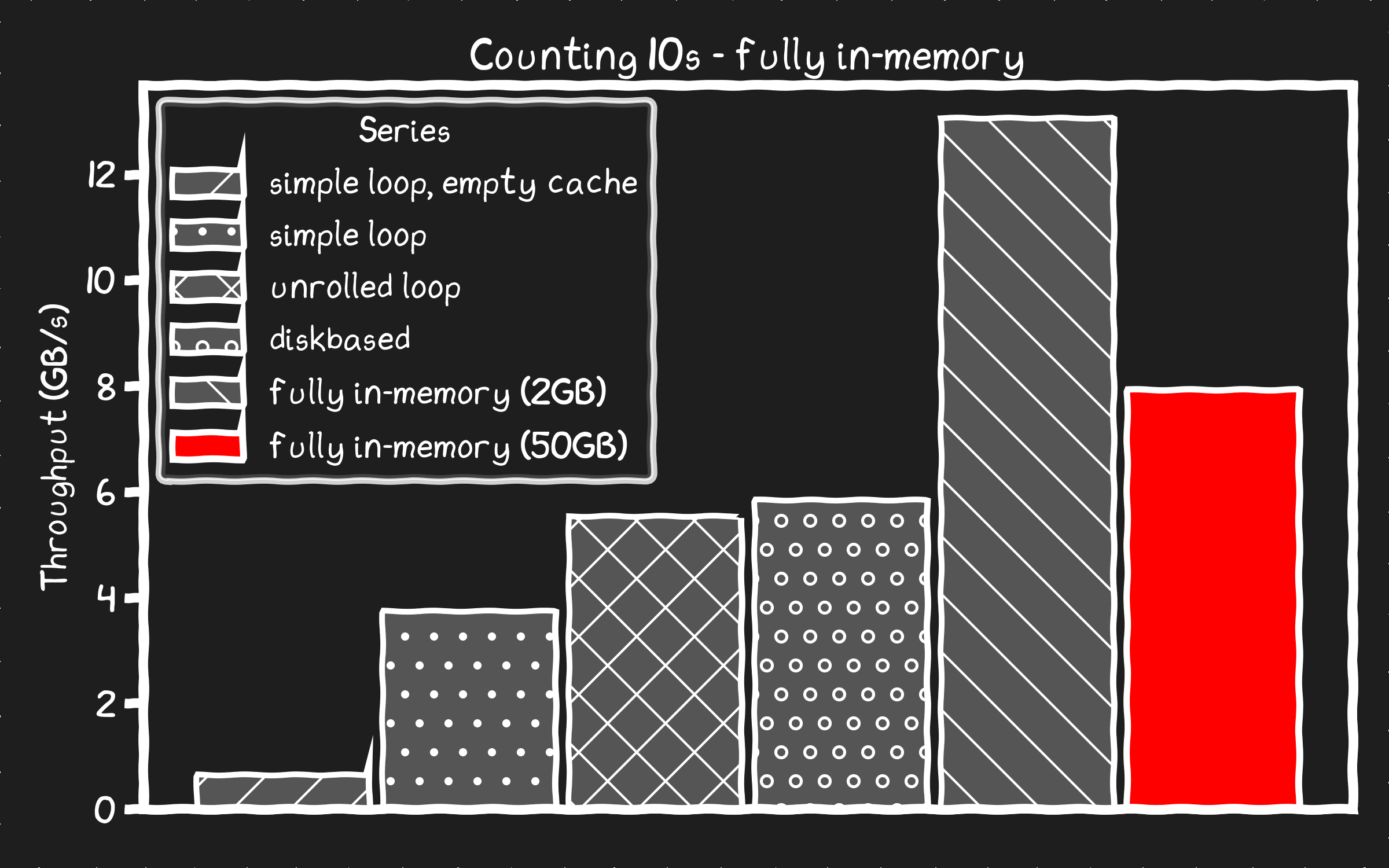
“완전히 인메모리(50GB)” 방식, 즉 측정 전에 메모리에 프리로드해 둔 경우와, “언롤 루프”처럼 단지 메모리에 캐시된 상태인 경우를 비교하면 40%의 오버헤드가 보인다. 9초 중 2.75초가 카운팅 대신 캐싱 시스템을 기다리는 데 쓰였다. 왜 이렇게 큰가?
mmap()
mmap() 호출은, 데이터가 이미 메모리에 있더라도, 프로세스에 빈 슬레이트와 같은 버퍼를 제공한다. 버퍼는 접근되는 페이지마다 페이지 캐시에서 채워진다. 이것은 복사가 아니라, OS가 캐시된 메모리를 프로세스에 매핑하는 것이다. 생각보다 비용이 크다. 최악의 경우 mmap()에서는 매 4KB 페이지 경계마다 카운팅이 멈추고, 커널이 폴트를 처리하며 페이지 캐시에서 데이터 페이지를 찾은 후, 해당 메모리를 프로세스에 삽입하도록 페이지 테이블을 갱신해야 한다. 근본적으로 이는 CPU 속도나 메모리 대역폭이 아니라 메모리 지연에 의해 제한되는 프로세스다. TLB 워크와 페이지 캐시를 추적하는 리스트 검색이 있을 수 있어, 4KB 페이지마다 잠재적으로 수십 번의 CPU 캐시 미스와 몇 마이크로초의 메모리 대기 시간이 발생할 수 있다.
direct IO
디스크에서 직접 읽는 우리의 접근은 파이프라인과 스트림을 사용하며, mmap()이 가진 메모리 지연 지배형 병목을 회피한다. 우리 사례에서는 디스크 대역폭이 제한 요인이지만, 파이프라이닝 덕분에 IO 지연의 큰 값이 카운팅의 크리티컬 패스에 크게 개입하지 않는다. 그 결과 더 높은 처리량이 가능하다.
스케일할 때 이 실험이 주는 함의를 생각해보자. 메모리에서 프로세스로 데이터를 가져오는 잘 검증된 솔루션이 디스크를 직접 사용하는 것보다 더 느리다. 이는 메모리가 디스크보다 느려서가 아니다. 메모리는 디스크보다 대역폭이 높다. 한 자릿수 배수 수준이지만 그럼에도 차이가 있다. 하지만 메모리의 지연은 디스크보다 수십 배 낮다. 그럼에도 메모리의 데이터를 접근하는 방식 이 문제의 주범이다. 메모리 연산이 저렴하고 지연이 낮다고 가정하는 동기식 접근인데, 접근이 누적되며 결국 메모리 지연을 기다리게 된다. 반면 디스크 방식은 대역폭을 활용하고 지연을 숨기도록 설계된 스트리밍 접근이다.
기존 장비 확장
디스크를 몇 개 더 추가하면 IO 대역폭을 단일 스레드 메모리 대역폭 한계인 13GB/s 이상으로 밀어올릴 수 있다. IO는 전체 데이터셋에 비해 상당히 작은 버퍼로 DMA된다. 이 버퍼의 크기는 데이터셋 크기가 아니라 CPU와 디스크의 처리량 능력에 맞춰 스케일된다. 버퍼를 단일 NUMA 도메인에 위치시켜 NUMA 간 버퍼 접근 오버헤드를 피할 수 있다. 이 시스템에 디스크를 더 추가하면, 인메모리 예제에서 전체 50GB 데이터셋일 때 보이는 7.90GB/s 한계 대신, 디스크 기반 솔루션으로 13GB/s 풀 속도로 카운트할 수도 있을지 모른다. 이런 시스템에서는 처리량이 데이터셋 크기에 영향을 받지 않는다. 인메모리 방식과 달리 NUMA 오버헤드가 있고, 결국 메모리가 부족해 확장이 멈추는 일이 없다.
메모리보다 빠른 것도 가능
제대로 된 최신 서버에서는 CPU가 L3 캐시로 직접 IO를 수행하게 할 수 있어, 메모리를 완전히 우회한다. PCIe 대역폭이 메모리 대역폭보다 높기 때문에, 이론상 버퍼를 CPU 캐시에 신중히 고정(pin)하면 메모리에서 얻을 수 있는 최대 대역폭보다 더 높은 최대 대역폭을 얻을 수도 있다. 실제로 이렇게 동작함을 내가 확인하진 않았지만, 가능하도록 만들 수 있고, 성능을 끌어올리기 위해 CPU 설계가 앞으로 기댈 수밖에 없는 방향이기도 하다.
메모리도 변화 중
이건 단지 디스크 vs 메모리 얘기만이 아니다. 유사한 기법과 원칙이 메모리에도 적용된다. 메모리 대역폭은 여전히 확장되지만 지연은 그렇지 않다. 즉, 메모리 성능을 활용하려면 메모리를 ‘랜덤 액세스 메모리’라기보다 ‘디스크에 가깝게’ 다뤄야 한다. 세대가 바뀔 때마다 성능이 함께 스케일하려면, 디스크에서 메모리로 데이터를 스트리밍하듯, 메모리에서 CPU 캐시로 데이터를 블록 단위로 스트리밍해야 한다. 그렇지 않으면 90년대 수준의 메모리 처리량에 갇힌다. 메모리에 데이터를 캐시하기 위한 커스텀 메커니즘을 쓰면, io_uring만큼 많은 코드 없이도 기본 mmap()에서 보인 메모리 지연 문제를 쉽게 피할 수 있다.
이런 구현에 공을 들이는 게 항상 그만한 가치가 있다고 말할 생각은 없다. mmap() 방식은 코딩 관점에서 정말 우아하다. 내가 io_uring 세팅을 위해 작성해야 했던 모든 코드와 비교하면 더욱 그렇다. 때로는 단순한 방법이 최선이다.
IO 6코어를 1코어의 컴퓨트에 바치는 게 항상 옳은가? 아마 아니다. 이번은 요점을 증명하기 위한 극단적인 상황이었다. 실제 상황에서는 트레이드오프를 따져보고, 당신의 유스케이스에 가장 적합한 방법을 선택해야 한다. 하드웨어의 강점과 약점을 올바르게 이해하면, 훨씬 적은 비용으로 훨씬 더 높은 성능을 얻을 수 있는 다양한 가능성이 열린다.
mmap()에서 보인 종류의 오버헤드는 사라지지 않을 것이고, 새 하드웨어가 해결해주지도 않을 것이다. 동시에 디스크 대역폭과 코어 수는 세대마다 확장되고 있다. 하지만 새 기술과 함께 성능이 스케일되게 하려면 추가적인 코드와 노력이 필요하다.
그렇다고 이런 것들을 가볍게 무시하진 말자. 물론 메모리 3TB짜리 서버를 전용으로 띄워 10K 클라이언트 연결을 서비스할 수도 있다. 클라우드에서 메모리는 GB당 한 달에 대략 $5쯤 한다. 그걸 감당할 수 있다면, 그러면 된다. 하지만 지구상의 반도체 공장과 발전소가, 앱 하나 만들겠다고 나선 모든 멍청한 바이브 코더들을 다 뒷받침할 수는 없다는 사실을 고려할 가치는 있다. 이 경고를 무시하는 자들에게는 언젠가 행성에 대한 업보 혹은 실리콘과 전기를 탐하는 복수심에 찬 AI 반신이 찾아갈 거라 생각한다. 어쨌든 내 양심은 편하다.
나쁜 소식은, 이런 영리함에는 추가 코드와 노력이 필요하다는 것이다.
좋은 소식은, 이제 이런 영리함에 필요한 추가 코드를 AI가 작성하고 테스트해줄 수 있다는 것이다.
더 좋은 소식은, 배울 의지가 있는 사람들에게는, AI가 시키는 대로 묻지 않으면 이런 일을 하지 않는다는 점이다.
스케일되는 것에 기대고, 스케일되지 않는 것은 피하라.
다음 편에서는 무엇이 밝혀질까?
Jared Hulbert
Hacker News에서 “음, 사실은” 류의 댓글러들을 위한 몇 가지 메모:
- 이것은 학술 논문이 아니며, 그렇게 주장하지도 않는다.
- NAND가 DRAM의 대체재라는 것을 증명하려는 의도가 없다.
- 이는 다만 현대 하드웨어의 한계와 트렌드, 그리고 성능 극대화를 위한 트레이드오프를 탐구하는 소박하고도 (바라건대) 재미있는 연습일 뿐이다.
- 앞서 말했듯, 당신이 이걸 무시하고 게으른 코드를 작성해도 새 하드웨어에서 15년 뒤에도 지금과 똑같이 빠를 것이다. 그런 선택을 하는 당신을 나는 응원한다. 제프 베이조스는 궤도 요트를 지어야 하고, 누군가는 그 비용을 내야 한다. 왜 당신이 아니겠는가?
- 나는 AI가 아니다. 나는 완벽히 쓰지 못하는 컴퓨터를 가진 인간이다.
소스 코드는 여기에서 확인할 수 있다.