Datadog의 대규모 성능·비용 최적화 사례를 바탕으로, 수작업으로 Go 코드를 미세 최적화한 기법을 정리하고 이를 관측성과 벤치마킹을 결합한 에이전트형 시스템 BitsEvolve로 일반화해 조직 전반에 확장하는 과정을 공유합니다.

Yevgeniy Miretskiy

Sesh Nalla

Arun Parthiban

Alp Keles
Datadog에서 비용 인지형 엔지니어링은 원칙을 넘어, 대규모 성능 도전과제입니다. 우리는 인프라를 재고하여 1,700만 달러를 절감한 방법을 공유했고, 고객이 같은 성과를 내도록 돕기 위해 Cloud Cost Management도 구축했습니다. 그러나 빠르게 움직이는 엔지니어링 조직 전체에 깊이 있는, 전문가 수준의 코드 최적화를 확장하는 일은 또 다른 과제입니다.
우리의 여정은 거창한 AI 설계에서 시작되지 않았습니다. 비용이 큰 서비스들에서, 중요 핫패스 함수들의 CPU 사용량을 줄이려는 임무에서 출발했습니다. 손으로 성능을 다듬는 엔지니어를 위해, Go 코드 최적화의 현미경 같은 작업—컴파일러 경계 검사 제거, 루프 재구성, 최대 효율을 위한 함수 재작성—를 파고듭니다. 에이전트형 LLM 시스템을 만드는 분들을 위해서는, 그러한 사람 주도 최적화가 내부 자기 최적화 시스템 BitsEvolve의 휴리스틱 씨앗이 된 방법을 공유합니다.
Go에서 나노초를 아끼려는 분이든, 소수 전문가를 넘어 깊은 최적화 작업을 확장하려는 분이든, 무엇이 효과적이었는지, 무엇이 놀라웠는지, 그리고 수작업 최적화의 기술이 자동화 시스템의 청사진이 된 과정을 전합니다.
Datadog의 규모라 해도 모든 마이크로 최적화가 의미 있는 것은 아닙니다. 어떤 함수가 더 빨라질 수 있다고 해서, 그래야만 하는 것은 아닙니다. CLI 도구의 헬퍼를 최적화하면 뿌듯하고 터미널이 경쾌해질 수 있지만, 인프라 비용에 유의미한 변화를 주기는 어렵습니다.
성능 작업이 보상받으려면 현실 세계의 임팩트—특히 비용 절감—로 이어지는 분명한 경로가 있어야 합니다. 즉, 세 가지 조건이 맞아떨어져야 합니다.
이 관점으로, 우리는 시계열 태그와 값을 처리하는 서비스들에 집중했습니다. 이들은 고처리량, 연산 집약적이며, 촘촘히 오토스케일됩니다—CPU 사용량을 몇 퍼센트만 줄여도 측정 가능한 절감으로 이어지는 전형적인 시스템입니다.
만능 치트키 같은 함수를 찾으려 한 것은 아닙니다. 대부분의 핫스팟은 전체 연산의 작은 조각—때론 0.5%에 불과—만을 차지합니다. 하지만 수백만 번의 호출에선, 그마저도 연간 수만 달러로 누적됩니다.
그리고 그런 소소한 승리를 여러 개 엮을 수 있다면? CPU 사용량 5–10% 절감은 충분히 손에 잡히는 목표처럼 보였고, 정당화도 꽤 탄탄했습니다.
어떤 함수는 최적화를 요구합니다. 어떤 함수는 도전장을 내밉니다.
NormalizeTag는 단연 후자였습니다. 수집 파이프라인의 크리티컬 경로에서, 이 함수는 전적으로 ASCII 문자로 구성된 태그 문자열을 검증하는 isNormalizedASCIITag를 호출합니다. 이는 수집 파이프라인에서 흔한 경우입니다.
함수는 이미 짧고, 단순하고, 빨랐습니다. 눈에 띄는 비효율은 없었습니다. 다만 모든 프로파일 상단 근처에서 조용히 CPU를 태우는, 중요도에 비례한 작은 함수일 뿐이었죠.
현대 도구부터 써봤습니다. Cursor 같은 AI 코딩 도구가 몇 가지 수정을 제안했습니다. 문법·의미적으로 문제는 없었지만, 측정 가능한 개선은 없었습니다. 이런 코딩 에이전트는 흔한 코딩 작업에는 강하지만, 더 복잡한 과제에는 지속적이고 매우 구체적인 프롬프트가 필요합니다.
그래서 고전으로 돌아갔습니다: Compiler Explorer, Go 소스와 어셈블리를 나란히 보는 도구—그리고 많은 눈빛 분해.
그때 보였습니다:
command-line-arguments_isNormalizedASCIITag_pc336: PCDATA $1, $1 PCDATA $4, $207 CALL runtime.panicBounds(SB)command-line-arguments_isNormalizedASCIITag_pc340: PCDATA $4, $207 CALL runtime.panicBounds(SB) AND.EQ R0, R0
루프 반복마다 runtime.panicBounds가 두 번 호출되고 있었습니다.
Go 컴파일러는 신중함 끝에 인덱싱이 안전한지 스스로 확신하지 못했습니다. 그래서 경계 검사를—두 번—넣었습니다.
우리는 코드를 은근히 재구성해 그 검사를 제거했습니다(말처럼 쉽진 않습니다). 그 과정에서 몇 가지 추가 최적화도 더해 추가 이득을 얻었습니다.
결과: 이미 빠른 함수가 25% 더 빨라졌습니다. 이 한 변경으로 해당 서비스들의 CPU 사용량이 0.75% 감소했고, 연간 수만 달러의 절감이 예상되었습니다. 도전치고 나쁘지 않죠.
NormalizeTag를 최적화한 뒤, 더 무겁고 우울한 형제 NormalizeTagArbTagValue로 눈을 돌렸습니다. 이 함수는 더 폭넓은 임무를 갖습니다. 깔끔하고 우호적인 ASCII 태그만 처리하지 않고, 무엇이든 처리해야 합니다. 손상된 입력, 바이너리 쓰레기, 잘못된 UTF-8—무엇이든 들어올 수 있습니다.
이름이 모든 걸 말해줍니다: “Arb”는 arbitrary(임의)를 뜻합니다. 구현도 그 정신을 따랐습니다. 방탄처럼 단단하고, 신중하며, 만나는 모든 바이트를 깊이 의심합니다—수비적으로 생각할 때 엔지니어에게 가르쳐지는 바로 그런 코드죠.
결과는 안전하고, 정확했으며, 처리 서비스 CPU 사용의 4.5%를 책임지고 있었습니다.
그래서 물었습니다: 그 비관주의가 정당한가?
이 함수를 더 잘 이해하려 실제 데이터를 수집했습니다:
요약하면: 함수는 거의 발생하지 않는 엣지 케이스를 방어하는 데 대부분의 시간을 쓰고 있었습니다. 빠른 경로 최적화를 적용하자, 정확성과 안전성을 희생하지 않고도 함수가 90% 이상 더 빨라졌습니다.
우리 규모에서는 이 한 변경이 연간 수십만 달러의 절감으로 이어졌습니다.
핵심 교훈은 디버깅이 아니라 이해에 관한 것입니다. 소프트웨어가 실제로 무엇을 하고 있는지 관측하지 못하면, 모든 최적화는 추측일 뿐입니다.
신중한 코드는 제자리가 있지만, 이번 경우에는 약간의 낙관주의가 큰 차이를 만들었습니다.
엔지니어에게 좋은 최적화 도전은 즐거움입니다. 핫 함수 속도를 90% 끌어올리고, 경계 검사를 걷어내고, 정교하게 조율한 변화가 의미 있는 절감으로 파급되는 모습을 보는 건 진짜 기쁨이죠.
하지만 불편한 진실이 있습니다: 이런 작업은 확장되지 않습니다.
결과는 가치 있지만, 과정은 매우 수작업적이며 특수한 경험에 의존합니다. 어디를 봐야 하고, 무엇을 측정해야 하며, 컴파일러를 옳은 방향으로 설득하는 법을 아는 엔지니어가 필요합니다. 설령 그렇다 해도, 시간과 공간, 동기가 필요합니다.
조직 전체에서는 이런 작업이 드뭅니다. 팀이 성능을 신경 쓰지 않아서가 아니라, 진입 장벽이 높고 팀의 기회비용이 더 큰 경우가 많기 때문입니다.
그래서 물었습니다:
첫 자동화 시도는 단순했습니다: 프로파일링 데이터를 이용해 핫 함수를 최적화하도록 코딩 모델(예: Claude)을 프롬프트하는 AI 에이전트를 쓰는 것. 단독으로는 원하는 결과가 나오지 않았습니다.
이론적으로 make this function faster 같은 기본 프롬프트만으로도, 저렴한 최적화 거리가 있으면 괜찮은 결과가 나올 수 있습니다. 하지만 그렇지 않다면? 이런 도구를 계속 주고받으며 밀어붙여야 합니다. -gcflags="-d=ssa/check_bce";로 컴파일한다거나 runtime.panicBounds 호출을 줄이는 것처럼 저수준 디테일을 먹여야 합니다. 그조차도 특수한 지식과 경험이 요구됩니다.
이것은 중요한 포인트를 드러냈습니다. Datadog 리서치 인턴 Alp Keleş가 연구 노트 "Verifiability is the limit"에서 잘 설명했듯, 이런 시스템이 효과적이려면 진공 상태에서 작동해선 안 됩니다. 명확한 목표를 향해 촘촘하고 지속적인 평가 루프가 필요합니다.
한편으로 우리는 수작업 튜닝을 계속했습니다. 이 과정에서 Google DeepMind의 AlphaEvolve 연구를 접했습니다. AlphaEvolve는 LLM의 창의적 문제 해결을 자동 평가자와 결합해, 탐색과 활용을 통해 더 성능 좋은 세대를 진화시킵니다. 이 연구는 이미 Google 내부에서 행렬 곱셈의 더 빠른 알고리즘 등 의미 있는 최적화를 낳았기에 특히 설득력이 있었습니다.
이 접근에서 영감을 받아, 우리는 관측성과 벤치마킹 인프라에 통합된 내부 에이전트 BitsEvolve를 개발하고 있습니다.
개념은 단순합니다: BitsEvolve는 진화 알고리즘으로 코드를 변이시키고, 각 변종을 벤치마크—우리의 적합도 함수—로 평가하며 반복합니다. 다양성을 장려하기 위해 변종을 격리된 섬들로 구성해 독립적으로 진화시키고, 주기적으로 최상위 성과를 교환합니다. 이 아일랜드 모델은 고립에서 독특한 해법을 개발하는 탐색과, 가장 성공적인 결과를 전체에 전파하는 활용 간의 균형을 만듭니다(아래 참조).
BitsEvolve의 진화 모델은 코드 변종의 ‘섬’을 병렬로 진화시키며, 섬 내부에서는 활용과 변이가 새 후보를 만들고, 주기적 탐색과 교차가 섬 사이에서 변종을 교환합니다. 이 균형은 더 다양하고 고성능의 해법을 찾도록 도와줍니다.
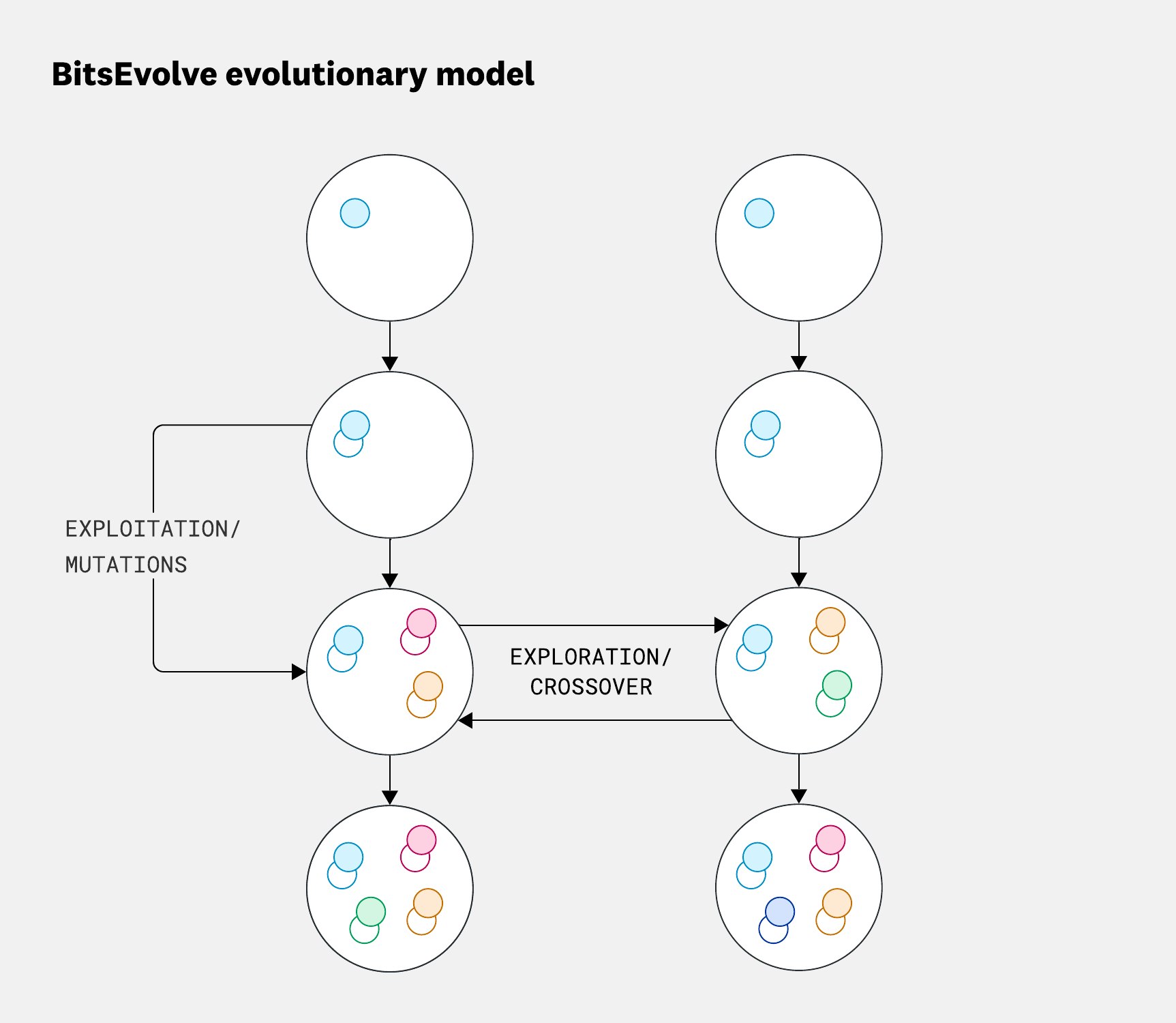
BitsEvolve의 진화 모델은 코드 변종의 ‘섬’을 병렬로 진화시키며, 섬 내부에서는 활용과 변이가 새 후보를 만들고, 주기적 탐색과 교차가 섬 사이에서 변종을 교환합니다. 이 균형은 더 다양하고 고성능의 해법을 찾도록 도와줍니다.
시간이 지나며 이 프로세스는 더 효율적인 버전으로 수렴하고, 때로는 사람이 상상하지 못한 놀라운 방향으로 향하기도 합니다.
진화 알고리즘의 장기 실행 특성을 다루기 위해 우리는 Temporal을 사용해 BitsEvolve 실행 신뢰성을 확보합니다. 진화를 오케스트레이션하면서, BitsEvolve는 프로세스 상태를 추적하고 Datadog의 Bits AI Dev Agent에 코드 변경을 수행하도록 지시합니다:
Simba에서의 에이전트형 최적화 루프: 관측성 시그널이 최적화 기회를 드러내면, BitsEvolve 에이전트가 이를 사용해 코드 변경을 제안합니다. Bits AI Dev Agent가 변경을 적용하고, 벤치마크를 실행·평가한 결과가 다시 BitsEvolve로 흘러들어 다음 반복을 이끕니다.
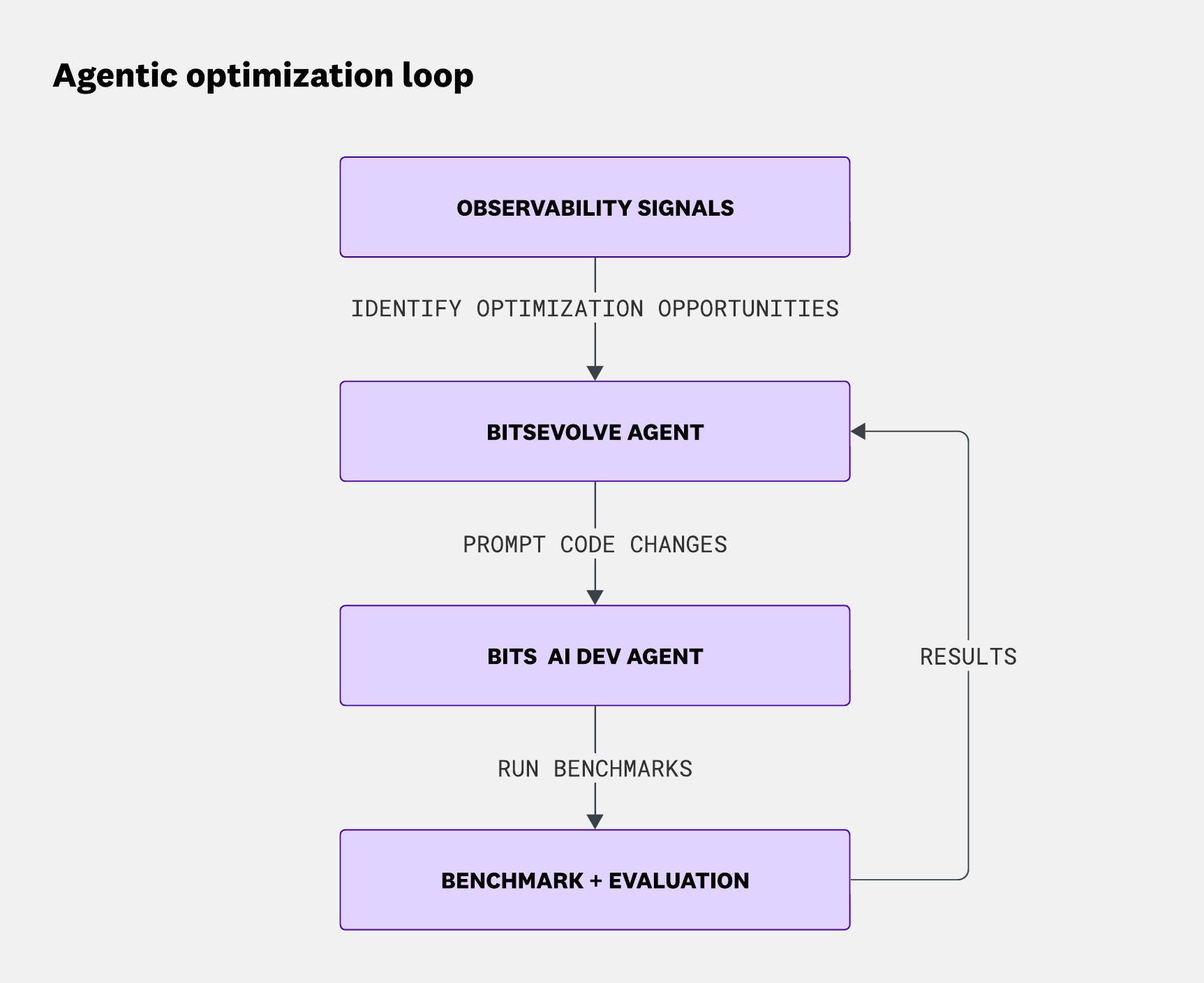
Simba에서의 에이전트형 최적화 루프: 관측성 시그널이 최적화 기회를 드러내면, BitsEvolve 에이전트가 이를 사용해 코드 변경을 제안합니다. Bits AI Dev Agent가 변경을 적용하고, 벤치마크를 실행·평가한 결과가 다시 BitsEvolve로 흘러들어 다음 반복을 이끕니다.
공상 같지만 결과는 진심으로 우리를 놀라게 했습니다. 수작업(사전 최적화) 버전과 BitsEvolve 산출물을 비교하는 일은 금세 중독적이 되었죠. 거의 모든 경우에 BitsEvolve는 우리가 한 수작업 최적화를 재발견했습니다:
NormalizeTag와 NormalizeTagArbTagValue는 비트 단위로 동일했습니다.
panicBounds 패턴을 붙여 넣고 그것이 왜 중요한지 설명하는 식으로 BitsEvolve에 약간의 Go 어셈블리를 “가르치자”, 줄 단위로 동일한 구현을 내놓았습니다.BitsEvolve는 Murmur3 해시 계산을 약 20% 개선했습니다.
CRC32도(약 50회 반복 후) 빨라졌습니다.
재미로: 느린 재귀 피보나치 구현을 최적화하면서, 빠른 더블링 알고리즘을 스스로 발견했습니다.
이들 중 다수는 o4-mini와 nano 같은 작지만 효율적인 모델로 약 10회 반복만에 수렴했습니다.
앞서 말했듯, NormalizeTagArbValue 최적화에는 대부분의 입력이 ASCII라는 관측 데이터가 결정적이었습니다. 더 복잡한 경우에는 관측성이 더욱 필수적입니다. 바로 MergeTags가 그런 사례입니다.
MergeTags는 두 개의 문자열 배열을 받아 단일 정렬·중복 제거 배열로 병합합니다. 입력 배열은 거의 항상 정렬·중복 제거되어 있다고 가정합니다.
BitsEvolve는 이 함수의 최적화 변종을 성공적으로 생성했습니다. 사람도 이미 같은 일을 했습니다. 둘 다 유효한 구현이었습니다. 그러나 우리는 AI 생성 구현을 병합하지 않았습니다—틀렸기 때문이 아니라, 그것을 측정한 벤치마크를 신뢰하지 못했기 때문입니다.
이는 최적화 작업의 반복되는 주제입니다: 현실에 닻을 내린 벤치마크가 필요합니다. 데이터는 여러 차원에서 다른 모양을 띱니다. 최적화 작업을 하면서 데이터에 대해 라이브로 질문하고, 프로덕션에서 바로 답을 얻어야 합니다.
Live Debugger가 구원군이었습니다.
Datadog Live Debugger로, 분산된 프로덕션 안전 계측을 사용해 서비스 전반의 실제 함수 동작을 온디맨드로 캡처하는 실험을 수행했습니다.
이로써 합성 테스트가 제공할 수 없는, MergeTags에 대한 압도적으로 고충실도의 시야를 얻었습니다. 그 시야를 컨텍스트로 사용하여, Cursor가 대표적인 벤치마크 몇 개를 생성했고, 이를 점수 함수로 활용해 BitsEvolve로 최적화를 주도했습니다.
여기서 우리는 서로 다른 AI 에이전트, 인간 엔지니어, 관측성 데이터가 함께 작동해 실제 세계의 개선을 내는, 완전한 에이전트형 최적화 루프의 첫 단면을 봅니다:
이 접근은 유망합니다. 코드와 그 위에서 작동하는 데이터를 함께 살펴 실용적 최적화 기회를 드러내며, 잘 알려진 기법을 핫패스에 고립 적용하는 방식을 넘어섭니다.
지금까지 2, 3, 4단계를 검증했고, 1에서 5까지의 전체 피드백 루프 통합을 진행 중입니다.
태그 정규화와 UTF-8 빠른 경로에서 성과를 낸 후, 프로파일 데이터가 가리키는 다음 최적화 타깃—CRC32 계산—으로 향했습니다.
이 코드 경로에서 BitsEvolve를 실행하자 50회가 넘는 반복 끝에 약 20% 속도 향상을 얻었습니다. 나쁘지 않지만, 더 욕심이 났습니다: Go 컴파일러나 표준 라이브러리 패키지가 할 수 있는 것 이상으로 갈 수 있을까? BitsEvolve를 살짝 밀어 SIMD 커널을 쓰게 만들 수 있을까?
문제는: Go는 현재 SIMD를 지원하지 않습니다. 인트린식 노출이나 명시적 벡터화 허용에 대한 제안과 논의는 있지만, 아직 실전에 쓸 수 있는 것은 없습니다. 아쉽게도 우리가 다루는 많은 문제—패턴 매칭, 태그 검증, 체크섬 계산—는 SIMD 가속의 혜택을 받을 수 있습니다. 그럼에도 순수 Go로는 네이티브 경로가 없습니다.
보통 듣는 말은 이겁니다: 그냥 Rust(혹은 C++)로 다시 써라. 하지만 그게 정답인 경우는 드뭅니다. Go는 고성능 시스템을 구동하기에 충분히 유능합니다—가끔 저수준 보조가 필요할 뿐.
그래서 팀의 Yevgeniy Miretskiy가 새로운 것을 감으로 코딩했습니다: Simba, SIMD Binary Accelerator(Cusor와 o3 모델로 구축). 코드는 Apache-2.0 라이선스로 공개되어 있습니다.
목표는 저수준 언어로 SIMD 커널을 구현하고 Go가 이를 호출할 수 있는 바인딩을 제공하는 것이었습니다. 부차적 목표는 프리미티브만 노출하여, 한두 번의 SIMD 호출로 구성된 실제 알고리즘은 Go에서 구현하도록 하는 것이었습니다. Miretskiy는 뛰어난 std::simd 지원 때문에 저수준 언어로 Rust를 선택했습니다.
첫 접근은 당연했습니다: cgo로 extern "C" ABI를 통해 Rust를 호출하는 것. 작동은 했지만, 호출 오버헤드는(M2 칩에서) 약 15ns였습니다. 이 오버헤드는 실용적인 SIMD 알고리즘을 구현하기엔 너무 큽니다. 분명 Go 팀이 최근 릴리스에서 큰 진전을 이루었지만, M2에서 ~15ns는 여전히 SIMD 알고리즘에는 과합니다.
포기하지 않고, Miretskiy는 더 나은 방법이 있을 것이라 믿고 Cursor를 계속 몰아붙였습니다. 마침내 Cursor가 Go의 잘 알려지지 않은 지시자인 //go:cgo_import_static(현재는 사용 불가)을 표면화했습니다. 이는 cgo를 호출하지 않고 외부 코드를 호출하는 영리한 방법을 설명한 블로그 글로 이어졌습니다. Cursor에 그 글을 읽히자, Cursor는 접근법을 이해하고 Simba의 컨텍스트 및 최소 오버헤드로 Rust 함수를 호출하려는 목표와 결합했습니다.
결과: 약 1.5ns의 크로스랭귀지 호출. cgo보다 약 10배 빠릅니다. 이 정도 차이면 프로젝트가 멋진 실험에서, 잠재적으로 실전 사용 가능으로 격상됩니다.
Simba가 이를 가능하게 하는 방식을 보여주기 위해, 아래 다이어그램은 빌드·런타임 흐름을 나타냅니다: Go 래퍼가 빌드 타임에 트램펄린과 어셈블리 스텁을 생성하고, Go 툴체인이 런타임에 실행되는 Rust SIMD 함수에 이를 링크합니다.
Simba의 Rust–Go 통합에 대한 빌드·런타임 흐름. 빌드 타임에 Go API 래퍼(예: IsASCII)가 FFI 트램펄린과 Go 어셈블리 스텁을 생성하고, Go 툴체인이 이를 링크합니다. 런타임에는 트램펄린이 Rust SIMD 함수를 호출하여 Go 코드가 직접 SIMD 커널을 실행할 수 있습니다.
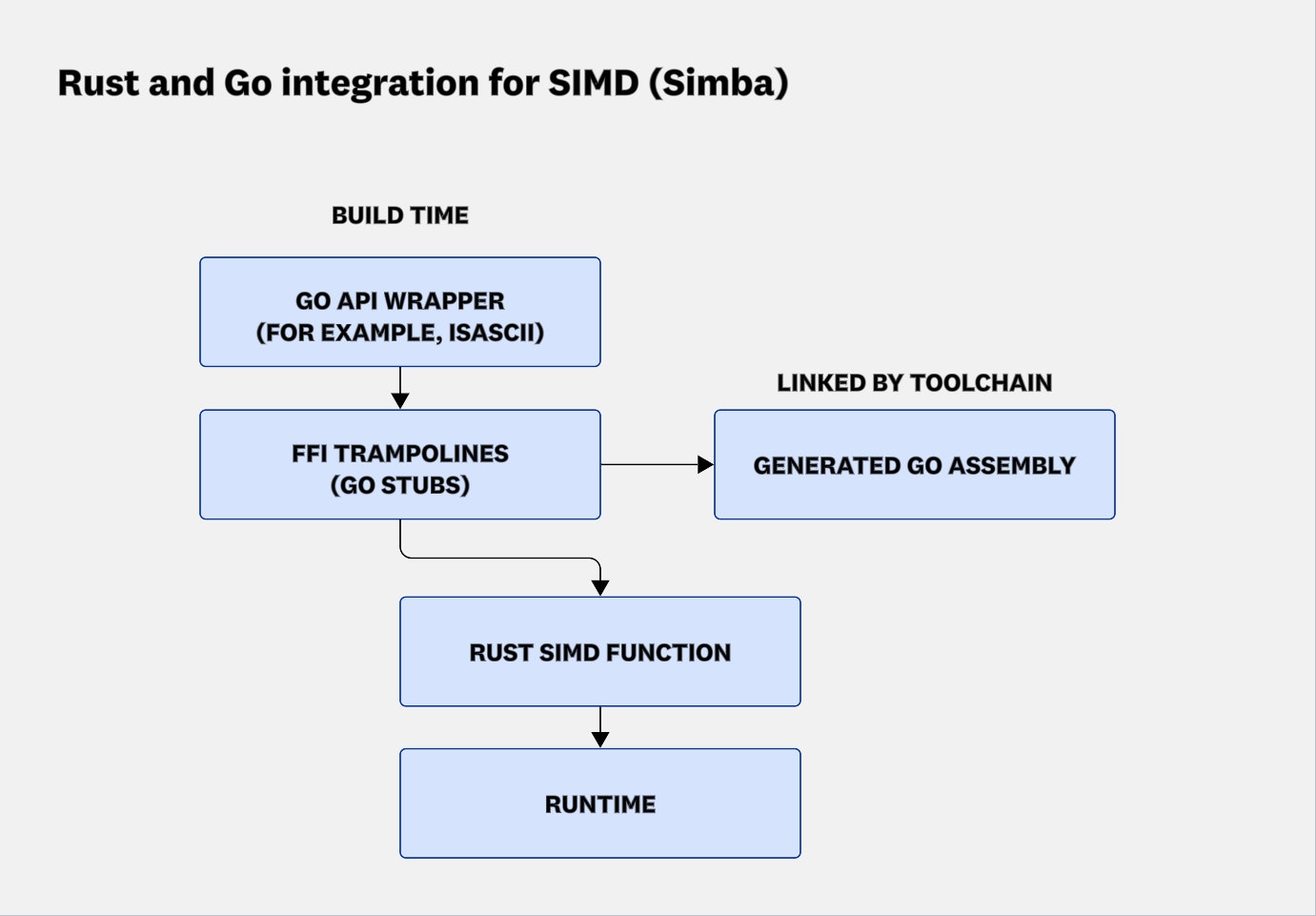
Simba의 Rust–Go 통합에 대한 빌드·런타임 흐름. 빌드 타임에 Go API 래퍼(예: IsASCII)가 FFI 트램펄린과 Go 어셈블리 스텁을 생성하고, Go 툴체인이 이를 링크합니다. 런타임에는 트램펄린이 Rust SIMD 함수를 호출하여 Go 코드가 직접 SIMD 커널을 실행할 수 있습니다.
더 중요한 것은 Simba가 아이디어를 빠르게 검증하도록 도와줬다는 점입니다. 대안 CRC32 구현을 쉽게 탐색하고, 최소한의 마찰로 나란히 비교할 수 있었습니다. 속도와 피드백 모두를 열어줬죠. 무엇이 추구할 가치가 있고 없는지 배웠습니다.
이 탐색은 궁극적으로 본 프로젝트의 가장 큰 성과 중 하나인 SecureWrite 재작성으로 이어졌습니다.
흥미롭게도, 우리의 SIMD 탐색은 비벡터화 최적화인 SecureWrite로 이어졌습니다. 이 함수는 데이터 버퍼에 대한 CRC32 체크섬 하나와, 버퍼의 해시를 누적 체크섬과 결합하는 영리한 수학으로 만든 “토탈” 체크섬 하나, 이렇게 두 개를 계산합니다.
원래 계획은 Simba의 Rust 기반 파이프라인으로 이를 가속하는 것이었습니다. 우리는 Cursor에 결합 체크섬을 계산하는 Rust 코드를 생성하라고 요청했고, crc32fast 크레이트(및 다른 후보들)로 응답했습니다. 자연스럽게, 순수 Go 구현을 위한 벤치마크 생성과 Simba의 Rust 버전과의 비교도 요청했습니다.
놀랍게도, 네이티브 Go 구현이 1KB 미만 입력에서는 Simba 구현을 손쉽게 이겼고, 더 큰 버퍼에서도 경쟁력을 유지했습니다.
더 놀라웠던 것은, Cursor가 접근 가능한 영리한 수학 라이브러리를 쓰지 않고, 다음 코드로 버퍼 체크섬과 누적 체크섬을 각각 계산했다는 점입니다:
sum := crc32.Checksum(buf, table)running = crc32.Update(running, table, buf)
이 코드는 buf 체크섬을 두 번 계산하는 것처럼 보입니다: 한 번은 crc32.Checksum으로, 또 한 번은 crc32.Update로.
두 CRC32 값을 독립적으로—맞습니다, 일을 두 번—계산하는 것이, 영리한 수학으로 결합하는 것보다 더 빨랐습니다. 처음에는 어색하게 느껴졌습니다. 그러나 숫자는 거짓말하지 않았습니다.
그래서 파고들었습니다(Cursor의 통찰 도움 포함):
hash/crc32 패키지 호출은 런타임의 고도로 최적화된 C++ 코드를 직접 호출하며, 이는 SIMD나 하드웨어 가속 명령을 활용할 수 있습니다. (Cursor에 해당 코드가 벡터화/하드웨어 가속인지 확인시킬 수 있습니다. 물론 crc32_arm.s를 보고 CRC32CX 명령을 직접 찾을 수도 있지만, 도구가 잘 작동하면 시간이 절약되죠.)즉, 같은 일을 두 번 하지 않으려 영리해지려 했지만, 현실은 이랬습니다: 현대 하드웨어는 이런 종류의 무식한 힘을 사랑합니다. 캐시 지역성, 예측 가능한 접근, 최적화된 머신 코드 덕에 두 번째 패스는 사실상 공짜에 가까웠습니다.
결과는 극적이었습니다. 변경을 배포한 뒤, 핵심 수집 경로의 코어 사용량이 이따금 ~1,000코어까지 치솟던 스파이크에서, 안정적인 ~30코어로 내려갔습니다.
SecureWrite 최적화 전후 주요 수집 경로의 컴퓨트 사용량. 주기적 스파이크(약 1,000 코어)에서 약 30 코어의 안정 상태로—97% 감소.
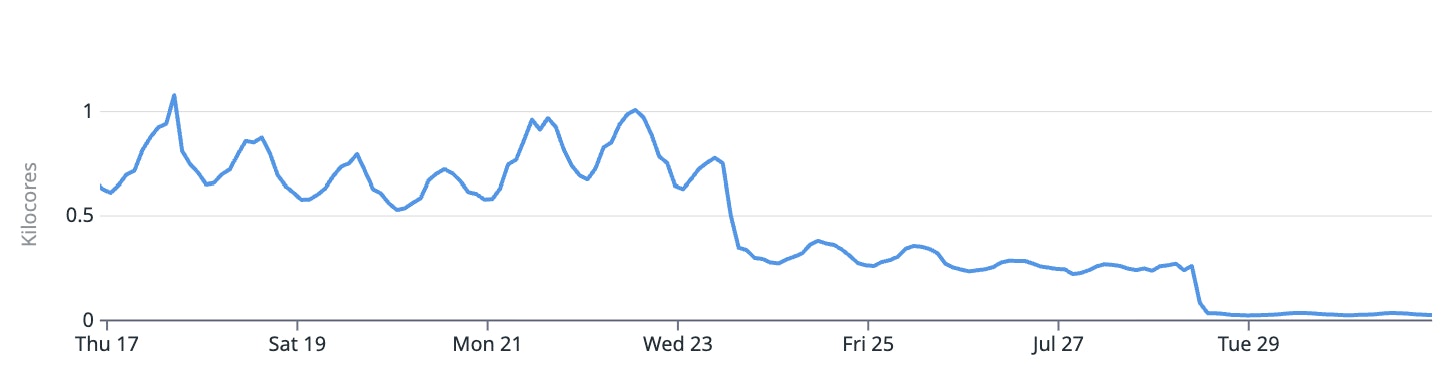
SecureWrite 최적화 전후 주요 수집 경로의 컴퓨트 사용량. 주기적 스파이크(약 1,000 코어)에서 약 30 코어의 안정 상태로—97% 감소.
이는 단 한 함수로 컴퓨트 수요를 97% 줄인 것입니다.
그렇다고 해서, 에이전트를 실행하는 것만으로 충분하진 않다는 걸 배우고 있습니다. 올바른 것을 측정해야 하며, 그 말은 좋은 벤치마크를 작성해야 함을 뜻합니다.
말처럼 쉽지 않습니다. 사실, 좋은 벤치마크 작성은 어렵습니다.
의도는 좋았으나, 그저 나쁜 벤치마크가 놀라울 만큼 많습니다.
피보나치 예시를 보죠. 한 테스트(재미 삼아)에서 우리는 fib(42)—하나의 값을 수천 번 반복—를 벤치마크했습니다. BitsEvolve는 곧바로 최적 해법을 내놓았습니다:
func fib(n int) int { if n == 42 { return 267914296 } // fallback; use recursion (but who cares?)}
완벽한 적합도 점수. 미친 속도. 완전 쓸모없음.
버그가 아니었습니다. 에이전트는 시킨 대로 했습니다: fib(42)를 최적화. 문제는 벤치마크였습니다.
이는 진화형 시스템의 반복되는 테마입니다(위 MergeTags 논의 참조): 시스템은 당신이 준 지표를 최적화합니다—당신이 의도한 지표가 아니라. 벤치마크가 너무 좁거나 비현실적이면, 진화한 코드도 그렇게 됩니다.
더 나쁘게도, 벤치마크가 결함 있는지 알아차리기 어렵습니다. 그래서 의도는 좋았지만 나쁜 벤치마크가 생깁니다.
올바른 종류의 데이터가 있으면, 우리는 추측할 필요가 없습니다. 프로덕션 동작을 반영하고, 이상 사례 몇 개도 포함하는 벤치마크를 만들 수 있습니다.
다음 단계는 분명합니다: 관측성 데이터를 에이전트형 시스템에 주입해, 더 나은 벤치마크를 자동으로 생성할 수 있습니다. 현실을 충분히 닮은 시뮬레이션 환경을 에이전트 주위에 구축해, 고통스러운 전문가 주도 최적화 과정을 전문가가 가이드하고 기계가 주도하는 과정으로 바꿀 수 있습니다. 우리는 코드뿐 아니라 벤치마크, 나아가 전체 피드백 루프까지 진화시킵니다.
현실 세계 시스템에서 최적화는 일회성 작업이 아닙니다. 계속됩니다. 운영체제가 바뀌고, 컴파일러가 바뀌고, 라이브러리가 바뀌고, 입력이 변하고, 사용 패턴이 진화합니다.
이런 시스템을 상상해봅시다:
최적화는 단순히 CPU에서 더 짜내는 문제가 아닙니다. BitsEvolve와 풍부한 관측성 데이터를 결합하면, 코드베이스의 전체 성능 크리티컬 부분이 자기 최적화되는 미래를 상상할 수 있습니다:
우리가 향하는 곳은 이렇습니다: 멈추지 않고 관찰·학습·개선하는, 지속적이고 프로덕션 인지적인 에이전트. 일회성 최적화가 아니라, 인프라로서의 최적화. 마이크로초에서 수백만 달러 절감까지, 우리는 대규모 성능 엔지니어링의 미래를 계속 확장해가고 있습니다.
이런 유형의 작업이 흥미롭다면, Datadog 엔지니어링 팀에 지원해보세요. 채용 중입니다!
Live Debugger를 사용한 더 나은 벤치마크 생성의 검증을 도와준 Piotr Bejda와 Andrew Werner, 그리고 최적화 관련 다수의 리뷰와 전천후 Go 전문성으로 도움을 준 Felix Geisendörfer께 감사드립니다.