OxCaml의 언박싱 타입과 로컬 할당을 활용해 힙 할당을 거의 없애고 HTTP/1.1 파서를 고성능으로 구현한 httpz 웹서버 제작기와 성능 결과, 그리고 향후 io_uring/FFI 통합 방향을 정리한다.
URL: https://anil.recoil.org/notes/oxcaml-httpz
작년에 ICFP에서 OxCaml 튜토리얼 을 돕고 난 뒤부터, 우리 행성(planetary) 컴퓨팅 연구 인프라에서 실제로 OxCaml을 써 보고 싶은 마음이 계속 들끓었습니다. 우리가 생성해 온 페타바이트 규모의 TESSERA 임베딩 을 관리하는 데도 말이죠.
제가 이렇게 eager했던 이유는, OxCaml이 시스템 지향 프로그램에서 성능을 크게 끌어올려 주는 여러 언어 확장을 제공하면서도, OCaml의 익숙한 함수형 프로그래밍 스타일을 그대로 유지해 주기 때문입니다. 그리고 Rust와 달리 ‘일반’ 코드에서는 GC(가비지 컬렉터)를 그대로 쓸 수 있습니다. 최근엔 커다란 Python 스크립트를 유지보수하는 데도 진절머리가 나서, OCaml의 모듈성과 타입 안정성이 간절했습니다.
제가 새 기술을 배우는 전통적인 방법은 제 웹사이트 인프라 를 최신 유행으로 갈아엎는 것입니다. 작년에 제 실서비스 사이트를 OxCaml로 빌드하도록 바꾸긴 했지만, 새 확장들을 깊이 통합하진 못했습니다. 그래서 이번에는 OCaml에서 성능에 올인한 새 웹서버 httpz 를 만들고 있고, 그 이야기를 해 보려 합니다!
(이걸 시작하면서 질문을 정말 많이 던졌는데, Chris Casinghino, Max Slater, Richard Eisenberg, Yaron Minsky 그리고 Jane Street의 도구/컴파일러 팀 여러분께 큰 감사를 드립니다!)
httpz 는 고성능 HTTP/1.1 파서이며, OxCaml의 언박싱 타입(unboxed types) 과 로컬 할당(local allocations) 을 활용해 주요 힙 할당을 없애고, 마이너 힙 할당도 최소화하는 것을 목표로 합니다.
이게 왜 유용할까요? HTTP 연결의 전체 생명주기를 호출 스택(callstack)만으로 처리할 수 있다는 뜻입니다. 그러면 연결을 해제하는 일은 그 연결을 처리하는 함수에서 그냥 return 하는 것으로 끝납니다. 정상 상태(steady state)에서는 웹서버의 GC 활동이 거의 없어집니다. 게다가 direct style effects 와 결합하면 콜백 지옥(callback soup)처럼 보이지 않게 작성할 수도 있습니다.
저는 일단 HTTP/1.1에 특화하기로 했고, 입력은 단순한 32KB bytes 값으로 정했습니다. 이는 헤더 부분을 포함한 HTTP 요청을 나타냅니다(POST 요청의 바디 처리 자체는 상대적으로 단순하고, 이번 글에선 다루지 않습니다).
이런 입력 버퍼가 주어졌을 때, OxCaml과 일반(바닐라) OCaml을 비교해서 어떻게 더 빠르게 만들 수 있을까요?
가장 먼저 할 일은 파서에 사용할 핵심 타입들을 정하는 것입니다. OCaml의 런타임 메모리 표현에 익숙해질 필요가 있다면 Real World OCaml 을 참고하세요.
제가 보통 OCaml 코드에서 사용하는 방식은, 2012년에 원래 만들었던 cstruct 같은 라이브러리를 써서 bytes 버퍼에 대한 non-copying view를 관리하는 것입니다. Cstruct는 4워드짜리 레코드(박스 1 + 필드 3)로 정의됩니다:
type buffer = (char, Bigarray.int8_unsigned_elt, Bigarray.c_layout) Bigarray.Array1.t
type Cstruct.t = private {
buffer: buffer;
off : int;
len : int;
}아이디어는 레코드로 큰 버퍼에 대한 좁은 뷰(view)를 만들고, 이 작은 뷰들은 런타임의 마이너 힙에 살아도(그리고 빠르게 수거되어도) 괜찮다는 것입니다. OxCaml은 여기서 더 나아가, int16# 같은 새로운 문법으로 레지스터나 스택에 사는 작은 수(small numbers) 의 언박싱 버전을 제공합니다.
이제 Bigarray 대신 bytes를 쓰되 기본 아이디어는 동일합니다. httpz의 버퍼 최대 크기가 32KB이므로, 위치/길이에는 16비트 정수면 충분합니다!
type Httpz.t = #{ off : int16# ; len : int16# }여기에는 사실 두 가지 새 기능이 있습니다. 첫째는 #{} 문법으로 레코드를 언박싱할 수 있다는 점이고, 둘째는 내용 자체가 더 작은 폭(width)의 타입이라는 점입니다. Cstruct의 boxed 버전과 OxCaml의 새 버전 차이를 좀 더 자세히 봅시다.
저는 보통 utop에서 Obj 모듈로 이것저것 찔러보며 확인합니다. 하지만 OxCaml의 언박싱 레코드는 특별한 레이아웃(layout) 을 사용하기 때문에 그렇게 쉽지 않습니다:
# type t = #{ off : int16# ; len : int16# };;
type t = #{ off : int16#; len : int16#; }
# let x = #{ off=#1S; len=#2S };;
val x : t = #{off = <abstr>; len = <abstr>}
# Obj.repr x;;
Error: This expression has type t but an expression was expected of type
('a : value)
The layout of t is bits16 & bits16
because of the definition of t at line 1, characters 0-41.
But the layout of t must be a sublayout of value.실패하긴 했지만, 일반적인 OCaml의 flat value 표현 대신 “int16 쌍” 레이아웃이 나온다는 흥미로운 단서를 줍니다. 컴파일러를 써서 더 파고들어 봅시다.
다음으로 작은 테스트 프로그램을 만들고 컴파일러의 lambda 중간 언어 를 확인했습니다. 의존성을 피하려고 oxcaml 소스 코드를 체크아웃해서 컴파일러 내부를 직접 바인딩했습니다.
external add_int16 : int16# -> int16# -> int16# = "%int16#_add"
external int16_to_int : int16# -> int = "%int_of_int16#"
type span = #{ off : int16#; len : int16# }
let[@inline never] add_spans (x : span) (y : span) : span =
#{ off = add_int16 x.#off y.#off; len = add_int16 x.#len y.#len }
let () =
let x = Sys.opaque_identity #{ off = #1S; len = #2S } in
let y = Sys.opaque_identity #{ off = #100S; len = #200S } in
let z = add_spans x y in
Printf.printf "off=%d len=%d\n" (int16_to_int z.#off) (int16_to_int z.#len)이 코드는 최적화 장벽을 충분히 추가해서, 덧셈이 컴파일 타임에 상수 폴딩으로 사라지지 않게 합니다. ocaml -dlambda src.ml로 컴파일하면 타입체크 후의 중간 형태를 볼 수 있습니다:
(let
(add_spans/290 =
(function {nlocal = 0} x/292[#(int16, int16)] y/293[#(int16, int16)]
never_inline : #(int16, int16)
(funct-body add_spans ./x.ml(6)<ghost>:196-294
(before add_spans ./x.ml(7):229-294
(make_unboxed_product #(int16, int16)
(%int16#_add (unboxed_product_field 0 #(int16, int16) x/292)
(unboxed_product_field 0 #(int16, int16) y/293))
(%int16#_add (unboxed_product_field 1 #(int16, int16) x/292)
(unboxed_product_field 1 #(int16, int16) y/293)))))))중간 코드 전반에 걸쳐 언박싱이 깔끔하게 전파(propagate)되는 걸 볼 수 있습니다.
다음은 최적화된 네이티브 코드에서 어떤 모습인지 확인하는 것입니다. arm64 머신에서 ocamlopt -O3 -S를 사용해 모든 컴파일러 패스 이후의 어셈블리를 확인했고, 다음을 찾았습니다:
In the entry point:
orr x0, xzr, #1 ; x.#off = 1
orr x1, xzr, #2 ; x.#len = 2
movz x2, #100, lsl #0 ; y.#off = 100
movz x3, #200, lsl #0 ; y.#len = 200
bl _camlX__add_spans_0_1_code
_camlX__add_spans_0_1_code:
add x1, x1, x3 ; len: x.#len + y.#len
sbfm x1, x1, #0, #15 ; sign-extend to 16 bits (int16# semantics)
add x0, x0, x2 ; off: x.#off + y.#off
sbfm x0, x0, #0, #15 ; sign-extend to 16 bits
ret어셈블리에서 boxing이 없고, 힙 할당도 없으며, sbfm 명령 이 16비트 의미론을 부호 확장으로 유지해 준다는 것을 확인할 수 있습니다.
이게 단지 flambda2 컴파일러의 마법이 아닌지도 확인해 봅시다. 아래는 일반 OCaml로 만든 boxed 버전입니다:
type span = { off : int; len : int }
let[@inline never] add_spans (x : span) (y : span) : span =
{ off = x.off + y.off; len = x.len + y.len }
let () =
let x = Sys.opaque_identity { off = 1; len = 2 } in
let y = Sys.opaque_identity { off = 100; len = 200 } in
let z = add_spans x y in
Printf.printf "off=%d len=%d\n" z.off z.len이 boxed 버전을 ocamlopt -O3 -S로 컴파일하고 어셈블리를 보면 마이너 힙 활동이 훨씬 많습니다:
_camlY__add_spans_0_1_code:
sub sp, sp, #16
str x30, [sp, #8]
mov x2, x0
ldr x16, [x28, #0] ; load young_limit
sub x27, x27, #24 ; bump allocator: reserve 24 bytes (3 words)
cmp x27, x16 ; check if GC needed
b.cc L114 ; branch to GC if out of space
L113:
add x0, x27, #8 ; x0 = pointer to new block
orr x3, xzr, #2048 ; header word (tag 0, size 2)
str x3, [x0, #-8] ; write header
ldr x3, [x1, #0] ; load y.off from heap
ldr x4, [x2, #0] ; load x.off from heap
add x3, x4, x3 ; add them
sub x3, x3, #1 ; adjust for tagged int
str x3, [x0, #0] ; store result.off to heap
ldr x1, [x1, #8] ; load y.len from heap
ldr x2, [x2, #8] ; load x.len from heap
add x1, x2, x1 ; add them
sub x1, x1, #1 ; adjust for tagged int
str x1, [x0, #8] ; store result.len to heap
...
ret
L114:
bl _caml_call_gc ; GC call if neededOCaml의 마이너 힙은 매우 빠르지만, 레지스터로 값을 전달하고 직접 연산하는 것만큼 빠르진 않습니다. 언박싱 버전은 그걸 가능하게 해 줍니다!
위 벤치마크는 컴파일러 프리미티브에 직접 external 호출을 했지만, OxCaml은 이런 특수 타입들을 위한 일반 모듈을 노출하므로, 모듈을 열어서 평범한 정수 연산을 그대로 쓸 수 있습니다:
module I16 = Stdlib_stable.Int16_u
let[@inline always] i16 x = I16.of_int x
let[@inline always] to_int x = I16.to_int x
let pos : int16# = i16 0
let next : int16# = I16.add pos #1SOxCaml에는 정수 연산만 있는 게 아닙니다. 최근 몇 주 사이에 언박싱 문자 연산도 추가되어, OCaml int를 사용할 필요가 없어졌습니다(int도 언박싱이긴 하지만, char임을 알면 컴파일러가 8비트 연산을 더 효과적으로 최적화/패킹할 수 있을 거라 추측합니다).
httpz 파서는 이를 사용하려 하지만, untagged int 지원이 아직 완전히 끝나지 않았습니다 (Max Slater 가 포인터를 알려줘서 감사했습니다).
HTTP 날짜 타임스탬프 에서는 언박싱 float도 사용합니다.
이렇게 언박싱 레코드를 선언하면, 다른 언박싱 레코드 안에 완전히 중첩해 넣을 수도 있습니다. 예를 들어, 여러 필드를 가진 HTTP 요청 도 언박싱 상태를 유지합니다:
type request =
#{ meth : method_
; target : span (* 중첩된 언박싱 레코드 *)
; version : version
; body_off : int16#
; content_length : int64#
; is_chunked : bool
; keep_alive : bool
; expect_continue: bool
}따라서 함수의 반환값에 언박싱 튜플을 쓰면, 할당 없이 여러 값을 자연스럽게 반환할 수 있습니다:
let take_while predicate buf ~(pos : int16#) ~(len : int16#)
: #(span * int16#) =
let start = pos in
let mutable p = pos in
while (* ... *) do p <- I16.add p #1S done;
#(#{ off = start; len = I16.sub p start }, p)
let #(result_span, new_pos) = take_while is_token buf ~pos ~len일반 OCaml도 튜플 사용에서 어느 정도 언박싱을 하긴 했지만, 레코드에서는 그렇지 못해서(마이너 힙으로 떨어져서) 차이가 큽니다. 이 OxCaml 코드는 함수 호출 트레이스 동안 전부 스택에서 직접 전달됩니다.
또한 매개변수에 ‘함수 밖으로 새어나가지 않는다(escape하지 않는다)’는 제약을 걸어 스택 할당을 더 명시적으로 유도할 수 있습니다:
(* 버퍼는 빌려온 것이며, 어디에도 저장하지 않는다 *)
let[@inline] equal (local_ buf) (sp : span) (s : string) : bool =
let sp_len = I16.to_int sp.#len in
if sp_len <> String.length s then false
else Bigstring.memcmp_string buf ~pos:(I16.to_int sp.#off) s = 0함수가 로컬 값을 반환해야 한다면, 새 exclave_ 키워드를 사용합니다. 예를 들어 HTTP 요청 파싱 에서는 스택 할당된 헤더 리스트를 조회합니다:
val find : t list @ local -> Name.t -> t option @ local
let rec find_string (buf : bytes) (headers : t list @ local) name = exclave_
match headers with
| [] -> None
| hdr :: rest ->
let matches =
match hdr.name with
| Name.Other -> Span.equal_caseless buf hdr.name_span name
| known ->
let canonical = Name.lowercase known in
String.( = ) (String.lowercase name) canonical
in
if matches then Some hdr else find_string buf rest name
;;재귀 함수이기도 해서, 힙 할당을 피하면서도 자연스럽게 작성할 수 있는 형태입니다. 자세한 내용은 Gavin Gray 의 OxCaml 튜토리얼 슬라이드 를 참고하세요.
삶의 질(QoL) 개선으로, OxCaml은 루프에서 스택 할당된 가변 변수를 허용해 ref 값을 할당할 필요가 없어졌습니다. 덕분에 파싱 코드에서 로컬 가변성을 사용할 수 있습니다:
let parse_int64 (local_ buf) (sp : span) : int64# =
let mutable acc : int64# = #0L in
let mutable i = 0 in
let mutable valid = true in
while valid && i < I16.to_int sp.#len do
let c = Bytes.get buf (I16.to_int sp.#off + i) in
match c with
| '0' .. '9' ->
acc <- I64.add (I64.mul acc #10L) (I64.of_int (Char.code c - 48));
i <- i + 1
| _ -> valid <- false
done;
acc반면 기존 OCaml에서는 참조를 위해 마이너 힙 할당이 생길 수 있습니다:
let parse_int64 buf sp =
let acc = ref 0L in (* 힙에 할당되는 ref *)
let i = ref 0 in (* 힙에 할당되는 ref *)
let valid = ref true in (* 힙에 할당되는 ref *)
while !valid && !i < sp.len do
let c = Bytes.get buf (sp.off + !i) in
match c with
| '0' .. '9' ->
acc := Int64.add (Int64.mul !acc 10L) (Int64.of_int (Char.code c - 48));
i := !i + 1
| _ -> valid := false
done;
!accOxCaml에는 제가 통합을 시작한 다른 새 기능이 정말 많지만, 레이아웃을 신중하게 계획해야 합니다. 예를 들어, 할당 없는 option을 만들기 위해 or_null 을 쓰고 싶었지만, 값 추론 실패에 관한 긴 컴파일러 에러를 자주 만나서 결국 로컬 타입을 할당하는 쪽으로 갔습니다. OxCaml에 더 익숙해지면 나중에 더 조사해 볼 만한 부분입니다.
또 언박싱 레코드에서 가변 필드를 쓰다가 문제를 만났는데, 이는 문서에도 기재 되어 있습니다:
We plan to allow mutating unboxed records within boxed records (the design will differ from boxed record mutability, as unboxed types don’t have the same notion of identity).
또 지금은 OxCaml 확장을 걷어내고 일반 OCaml 문법으로 되돌리는 일이 어렵습니다. Chris Casinghino 가 --erase-jane-syntax 옵션이 있는 OxCaml의 ocamlformat 포크를 알려줬지만, 빌드 시스템에 통합할 작업이 필요하고, (언박싱 작은 리터럴 같은) 새 기능을 약간 늦게 따라가는 듯합니다. 당분간은 OxCaml만으로 집중해서 써 보고 어떻게 되는지 보려 합니다.
마지막으로, 도구(tooling)는 아직 유동적입니다. Arthur Wendling 과 Jon Ludlam 이 메인라인 도구에서 odoc가 동작하도록 빠르게 진척시키고 있지만, 오늘 당장 완전히 되는 수준은 아닙니다.
아키텍처를 시험하기 위한 작은 예제를 만들면서도, 파서의 대부분을 빠르게 실험하려고 Claude 코드를 많이 활용했습니다. 이를 위해 제 Claude OCaml 마켓플레이스 에서 프로젝트에 추가해 쓸 수 있는 OxCaml 전용 Claude 스킬 세트 를 합성했습니다. 스킬을 훑어보는 것 자체가 여러 기능을 익히는 좋은 방법이기도 합니다.
이 스킬들은 OxCaml 소스 트리를 요약하고 ICFP 2025 튜토리얼 을 참고해서 만들었고, 그 뒤 CC에게 예제 코드가 실제로 컴파일되는지 검증시켰습니다. 전부 자동화되어 있고, Jane Street에서 새 컴파일러가 떨어질 때마다 쉽게 갱신할 수 있습니다.
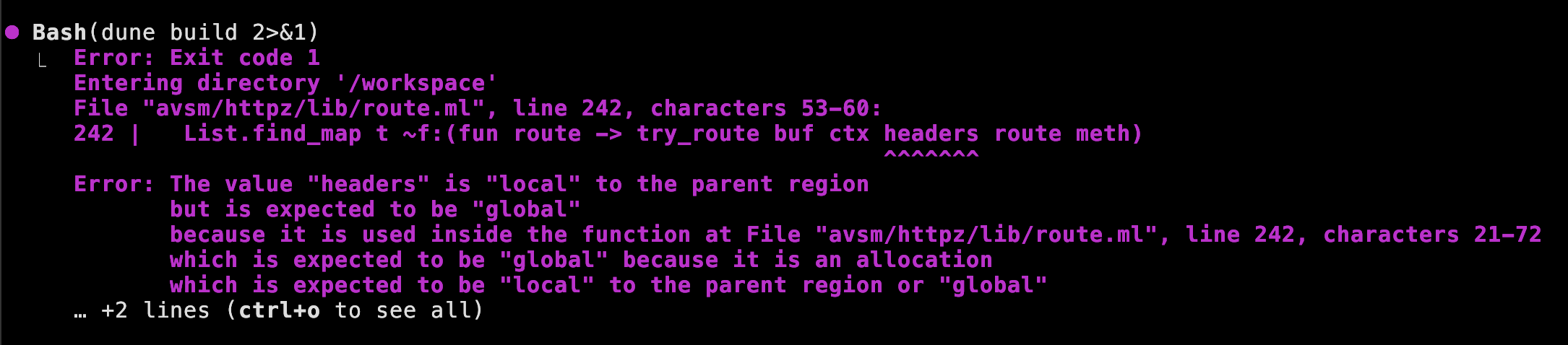
최신 드롭의 OxCaml 컴파일러 에러는 정말 설명이 자세해서, 코딩 에이전트가 새로운 타입을 파악하는 데 큰 도움이 됩니다.
결국 런타임 성능이 없으면 의미가 없습니다! 다행히도 HTTPz 파서는 (네트워크 벤치마크가 아니라 버퍼를 전달하는 합성 벤치마크에서) Core_bench로 측정했을 때 놀라운 성능을 보였습니다. 인상적인 점은 단순한 처리량(throughput) 자체도 있지만, 힙 활동이 크게 줄어 서비스의 예측 가능성과 tail latency가 크게 좋아졌다는 것입니다. 그리고 추가적인 타이핑 정보 덕분에 직선 구간(스트레이트라인) 성능은 더 좋아질 것이라 기대합니다(SIMD 지원 을 아직 보지도 않은 상태에서 말이죠).
| 지표 | httpz (OxCaml) | 전통적 파서 |
|---|---|---|
| 작은 요청(35B) | 154 ns | 300+ ns |
| 중간 요청(439B) | 1,150 ns | 2,000+ ns |
| 힙 할당 | 0 | 100-800 words |
| 처리량 | 6.5M req/sec | 3M req/sec |
그 다음 Eio로 이것을 붙여서 완전한 웹서버 를 만들었습니다. 잘 동작하고, 트래픽도 문제 없이 서빙합니다. 사실 여러분은 지금 이 페이지를 바로 그 웹서버로 보고 있습니다!
현재 Eio/OxCaml은 Eio가 Bigarray를 쓰기 때문에 데이터 복사가 발생합니다. 하지만 Thomas Leonard 와 Patrick Ferris 를 만나 이야기하면서, io-uring 레이어부터 위까지 전부 bytes를 쓰도록 제 로컬 eio를 갈아엎기로 합의했습니다. Sadiq Jaffer 에 따르면 그의 컴팩터는 자동으로 트리거되지 않아서, 4KB 임계값을 넘는 bytes는 mmap으로 할당되며 커널에 zero-copy receive로 넘기기 좋다고 합니다.
io_uring 통합을 멋지게 만들어 줄 핵심 OxCaml 기능은, 힙이 아니라 호출자의 OxCaml 스택에 직접 OCaml 값을 할당하는 새로운 FFI 함수입니다. 이는 io_uring 요청이 OCaml continuation으로 직접 라우팅되고, 스택에 준비된 버퍼와 함께 바로 깨워지는(woken up) 방식의 스킴을 만들 수 있음을 뜻합니다. 커널까지 진정한 zero-copy가 눈앞에 있고, 이는 Docker의 VPNKit 도 크게 가속할 수 있을 겁니다.
눈치 빠른 독자라면, 이 글의 OxCaml 레포 링크들이 Jane Street의 울타리 밖에서 실제 프로덕션 코드를 만지기 위해 제가 설정한 새 모노레포(monorepo) 를 가리킨다는 걸 알아챘을지도 모르겠습니다.
이건 다음 주에 더 블로그로 쓰겠지만, 지금은 실제 코드에서 OxCaml 확장이 무엇을 제공하는지 맛볼 수 있었길 바랍니다. 더 많은 성능 개선도 기대해 주세요. 그리고 Hannes Mehnert 의 ocaml-tls 를 OxCaml로 포팅한 네이티브 TLS도 곧 나올 예정이니 계속 지켜봐 주세요!