pg_query.rs 포크에서 Protobuf (역)직렬화를 제거하고 bindgen 기반의 C↔Rust 직접 바인딩으로 전환해 파싱은 5배, 디파싱은 10배 가까이 가속한 과정과 구현 세부를 설명한다.
2026년 1월 22일
Lev Kokotov
PgDog는 PostgreSQL을 수평 확장하기 위한 프록시입니다. 내부적으로는 plaintext libpg_query 를 사용해 SQL 쿼리를 파싱하고 이해합니다. PgDog는 Rust로 작성되어 있기 때문에, 코어 C 라이브러리와 연동하기 위해 Rust 바인딩을 사용합니다. 이 바인딩은 여러 프로그래밍 언어에서 동일하게 동작하도록 Protobuf (역)직렬화를 사용합니다. 예를 들어 널리 쓰이는 Ruby의 pg_query gem이 그렇습니다.
Protobuf는 빠르지만, Protobuf를 쓰지 않는 편이 더 빠릅니다. 우리는 _pg_query.rs_를 포크한 뒤 Protobuf를 제거하고 bindgen 및 Claude가 생성한 래퍼를 이용해 C↔Rust(그리고 다시 C) 직접 바인딩으로 교체했습니다. 그 결과 쿼리 파싱은 5배, 디파싱(Postgres AST를 SQL 문자열로 변환)은 10배의 성능 개선을 얻었습니다.
아래 결과는 우리 포크를 클론한 뒤 벤치마크 테스트를 실행하면 재현할 수 있습니다.
| 함수 | 초당 쿼리 수 |
|---|---|
plaintext pg_query::parse (Protobuf) | 613 |
plaintext pg_query::parse_raw (C→Rust 직접 변환) | 3357 (5.45배 더 빠름) |
plaintext pg_query::deparse (Protobuf) | 759 |
plaintext pg_query::deparse_raw (Rust→C 직접 변환) | 7319 (9.64배 더 빠름) |
첫 단계는 언제나 프로파일링입니다. 우리는 Firefox 프로파일러와 잘 통합되는 samply를 사용합니다. Samply는 샘플링 프로파일러로, 각 함수에서 CPU 명령을 실행하는 데 얼마나 많은 시간이 쓰이는지 측정합니다. 초당 수천 번 애플리케이션의 콜 스택을 검사하는 방식으로 동작합니다. 특정 함수(또는 일반적으로 span이라고 부르는 단위) 안에서 더 많은 시간이 소비될수록, 그 코드는 더 느리다는 뜻입니다. 이렇게 해서 우리는 다음을 발견했습니다.
pg_query_parse_protobuf:
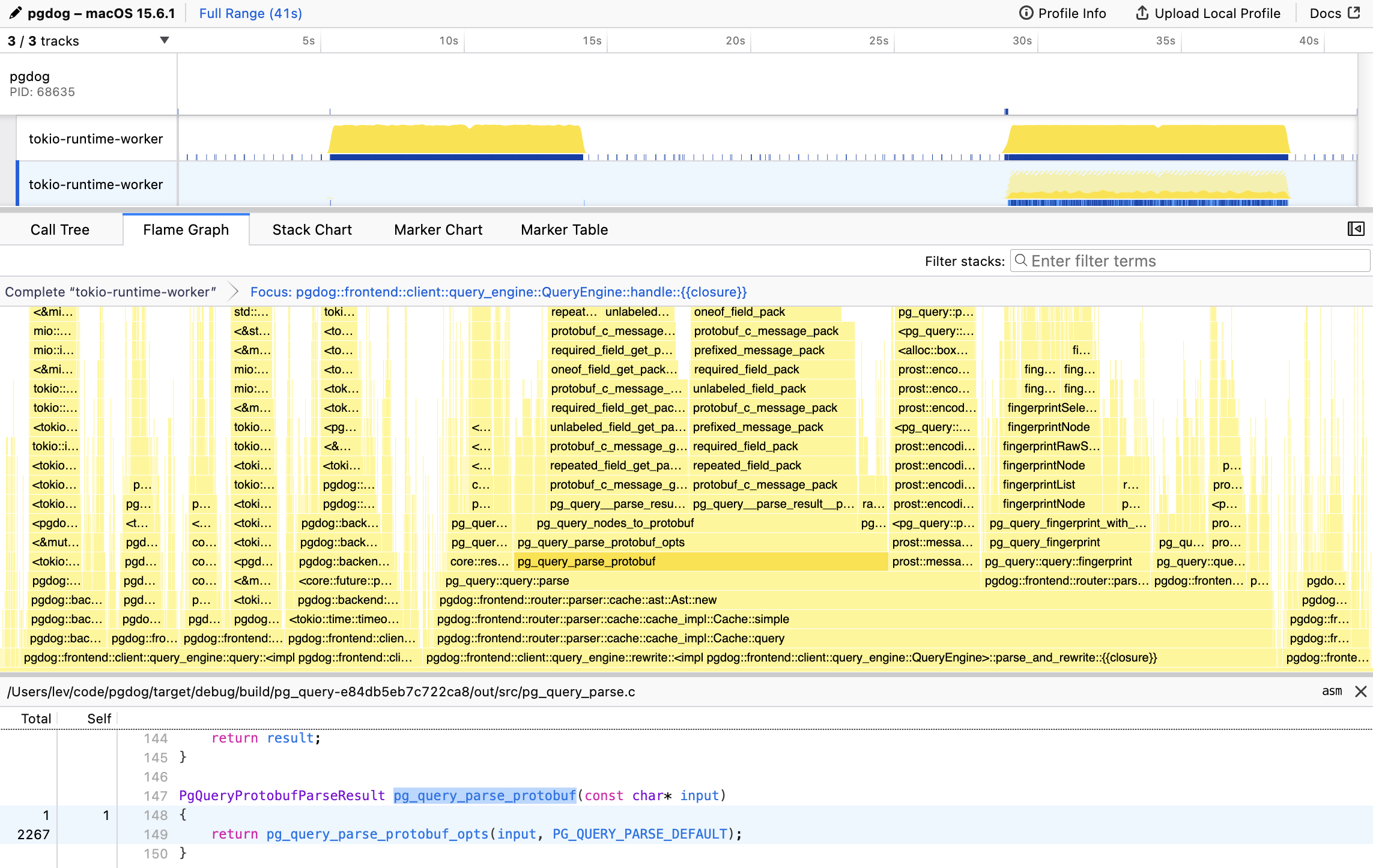
이 함수는 모든 pg_query 바인딩이 사용하는 plaintext libpg_query C 라이브러리의 엔트리포인트입니다. 실제 Postgres 파서를 감싸는 함수인 ```plaintext
pg_query_raw_parse
#### 캐싱은 대체로 잘 동작한다
캐싱은 메모리와 CPU 사용량 간의 트레이드오프이며(최근 DRAM 수급 이슈가 있긴 하지만) 메모리는 상대적으로 저렴합니다. 캐시는 뮤텍스로 보호되며 LRU 알고리즘을 사용하고, 해시맵으로 백업됩니다[1](https://pgdog.dev/blog/replace-protobuf-with-rust#fn:1). 쿼리 텍스트가 키이고, AST(추상 구문 트리)가 값입니다. 이는 대부분의 앱이 prepared statement를 사용한다는 전제를 둡니다. 쿼리 텍스트는 실제 값 대신 플레이스홀더를 포함하므로 재사용이 가능합니다. 예를 들어:
SELECT * FROM users WHERE id = $1;
여기서 ```plaintext
id
``` 파라미터는 호출마다 바뀔 수 있지만 prepared statement 자체는 바뀌지 않으므로, 정적인 AST를 메모리에 캐시할 수 있습니다.
이 방식은 꽤 잘 동작하지만, 결국 몇 가지 문제를 만났습니다.
1. 일부 ORM은 버그로 인해 수천 개의 유니크한 문장을 생성할 수 있습니다. 예를 들어 ```plaintext
value = ANY($1)
``` 대신 ```plaintext
value IN ($1, $2, $3)
``` 같은 형태를 만들어 캐시 미스가 많이 발생합니다.
2. 애플리케이션이 prepared statement를 지원하지 않는 오래된 PostgreSQL 클라이언트 드라이버를 사용하기도 합니다. 예: Python의 ```plaintext
psycopg2
``` 패키지
Protobuf가 병목이 되는 상황이었고, 우리는 조치를 취해야 했습니다. 그래서 요즘 많은 엔지니어들처럼, LLM에게 그냥 해달라고 요청했습니다.
#### 빡빡한 제약 조건
이 섹션을 시작하기 전에 말해두자면, PgDog의 소스 코드 대부분은 사람이 작성했습니다. AI가 커넥션 풀러, 로드 밸런서, 데이터베이스 샤더를 한 방에 만들어낼 수준은 아닙니다. 하지만 범위가 매우 구체적이고 잘 정의되어 있으며 무엇보다도 *기계적으로 검증 가능한* 작업으로 한정하면, AI가 꽤 잘해낼 수 있습니다.
우리가 시작한 프롬프트는 꽤 직관적이었습니다.
> _libpg\_query는 PostgreSQL 파서를 API로 감싼 라이브러리다. pg\_query.rs는 libpg\_query를 감싼 Rust 래퍼이며 Protobuf (역)직렬화를 사용한다. Protobuf를 bindgen이 생성한 Rust 구조체로 대체해 Postgres AST에 직접 매핑하라._
그리고 우리와 머신이 이틀 동안 주고받은 끝에, 실제로 동작했습니다. 우리는 C 타입과 구조체를 Rust 구조체로(그리고 그 반대로) 수동 매핑하는 재귀적 Rust 코드 6,000줄을 얻었습니다. [```plaintext parse ```](https://docs.rs/pg_query/latest/pg_query/fn.parse.html), [```plaintext deparse ```](https://docs.rs/pg_query/latest/pg_query/fn.deparse.html)(새 쿼리 리라이트 엔진에서 사용하며, 이는 다른 글에서 다루겠습니다), [```plaintext fingerprint ```](https://docs.rs/pg_query/latest/pg_query/fn.fingerprint.html), [```plaintext scan ```](https://docs.rs/pg_query/latest/pg_query/fn.scan.html) 네 가지 메서드에 대해 전환을 완료했습니다. 이 네 메서드는 PgDog에서 샤딩을 동작시키기 위해 많이 사용되며, 우리는 즉시 _pgbench_ 벤치마크에서 25% 개선을 확인했습니다[2](https://pgdog.dev/blog/replace-protobuf-with-rust#fn:2).
명확히 하자면, 이게 가능했던 데에는 이미 여러 유리한 조건이 있었습니다. 첫째, _pg\_query_에는 _protoc_(그리고 Protobuf의 Rust 구현인 Prost)이 바인딩을 생성할 수 있도록 Protobuf 스펙이 존재합니다. 덕분에 Claude는 C에서 뽑아와야 할 구조체의 포괄적인 목록과 기대 데이터 타입을 얻을 수 있었습니다.
둘째, _pg\_query.rs_는 이미 bindgen을 사용하고 있었기 때문에, bindgen 출력에 AST 구조체가 포함되도록 몇몇 호출을 복사/붙여넣기만 하면 됐습니다.
마지막으로, 그리고 가장 중요한 점은, _pg\_query.rs_에 이미 동작하는 ```plaintext
parse
``` 및 ```plaintext
deparse
``` 구현이 있었다는 것입니다. 따라서 우리는 AI가 생성한 코드의 출력이 기존 구현과 같은지 테스트할 수 있었습니다. 이 과정은 완전히 자동화되고 검증 가능했습니다. ```plaintext
parse
```를 사용하는 각 테스트 케이스마다 ```plaintext
parse_raw
``` 호출을 추가한 다음, 두 결과를 비교했습니다. 단 1바이트라도 다르면 Claude Code는 다시 돌아가 재시도해야 했습니다.
#### 구현
Rust와 C 사이의 변환 코드는 Rust 구조체를 C 구조체로 감싸는 ```plaintext
unsafe
``` Rust 함수들을 사용합니다. 이렇게 만든 C 구조체를 Postgres/```plaintext
libpg_query
``` C API에 전달하면, 실제 AST를 구성하는 작업은 C 쪽에서 수행합니다.
결과는 재귀 알고리즘으로 다시 Rust로 변환됩니다. AST의 각 노드마다 해당 노드를 변환하는 전용 컨버터 함수가 있으며, ```plaintext
unsafe
``` C 포인터를 받아 안전한 Rust 구조체를 반환합니다. 이름 그대로 AST는 트리이며, 배열에 저장됩니다.
unsafe fn convert_list_to_raw_stmts( list: *mut bindings_raw::List ) -> Vecprotobuf::RawStmt { // C→Rust 변환. }
리스트의 각 노드에 대해 구현은 ```plaintext
convert_node
```를 호출하고, 이 함수는 SQL 문법에서 사용 가능한 수백 개의 토큰을 처리합니다.
unsafe fn convert_node( node_ptr: *mut bindings_raw::Node ) -> Optionprotobuf::Node { // 사실상 Rust로 작성한 C 같은 코드이므로, null 체크는 필수! if node_ptr.is_null() { return None; }
match (*node_ptr).type_ {
// SELECT 문 루트 노드.
bindings_raw::NodeTag_T_SelectStmt => {
let stmt = node_ptr as *mut bindings_raw::SelectStmt;
Some(protobuf::node::Node::SelectStmt(Box::new(convert_select_stmt(&*stmt))))
}
// INSERT 문 루트 노드.
bindings_raw::NodeTag_T_InsertStmt => {
let stmt = node_ptr as *mut bindings_raw::InsertStmt;
Some(protobuf::node::Node::InsertStmt(Box::new(convert_insert_stmt(&*stmt))))
}
// ... 수백 개의 노드가 더 있음.
}
}
다른 노드를 포함하는 노드의 경우, 알고리즘이 리프(자식이 없는 노드)에 도달해 종료할 때까지 ```plaintext
convert_node
```를 다시 재귀 호출합니다. 숫자(예: ```plaintext
5
```)나 텍스트(예: ```plaintext
'hello world'
```)처럼 스칼라를 포함하는 노드의 경우에는 해당 타입을 Rust의 대응 타입(예: ```plaintext
i32
``` 또는 ```plaintext
String
```)으로 복사합니다.
최종 결과는 [```plaintext protobuf::ParseResult ```](https://docs.rs/pg_query/latest/pg_query/protobuf/struct.ParseResult.html)입니다. 이는 _pg\_query_ API Protobuf 스펙에서 Prost가 생성한 Rust 구조체이지만, Prost의 디시리얼라이저가 아니라 네이티브 Rust 코드가 채워 넣습니다. 기존 구조체를 재사용하면 오류 가능성이 상당히 줄어듭니다. 테스트에서 파생된 ```plaintext
PartialEq
``` 트레이트를 이용해 ```plaintext
parse
```와 ```plaintext
parse_raw
```의 출력이 동일한지 비교해, 둘이 완전히 같음을 보장할 수 있습니다.
재귀 알고리즘은 잘못 작성하면 스택 오버플로를 유발할 수 있어 업계에서 평판이 애매한 편이지만, 매우 빠릅니다. 재귀는 추가 메모리 할당이 필요 없는데, 작업 공간인 스택이 프로그램 시작 시 만들어지기 때문입니다. 또한 동일 함수의 다음 호출에 대한 명령어가 이미 CPU L1/L2/L3 캐시에 올라와 있을 가능성이 높아 캐시 지역성도 훌륭합니다. 마지막으로, 그리고 어쩌면 더 중요하게도, 반복(iterative) 구현보다 읽고 이해하기가 쉬워 디버깅에서 인간에게 도움이 됩니다.
만약을 대비해 반복 알고리즘도 생성해 보았지만, 결과적으로 Prost보다 느렸습니다. 주된 원인(추정)은 불필요한 메모리 할당, 이미 변환된 노드를 찾기 위한 해시맵 조회, 그리고 트리를 여러 번 순회하는 데서 오는 오버헤드였습니다. 반면 재귀 방식은 각 AST 노드를 정확히 한 번만 처리하고, 스택 포인터로 트리에서의 위치를 추적합니다. 반복 알고리즘을 더 잘 동작하게 만드는 아이디어가 있다면 [알려주세요](https://discord.gg/CcBZkjSJdd)!
### 마무리 생각
PgDog에서 Postgres 파서를 사용하는 오버헤드를 줄이는 것은 우리에게 큰 차이를 만듭니다. 네트워크 프록시로서 지연 시간, 메모리 사용량, CPU 사이클에 대한 예산이 낮기 때문입니다. 결국 우리는 진짜 데이터베이스가 아니니까요…아직은요! 이 변경은 두 가지 측면에서 성능을 개선합니다. CPU를 덜 쓰고, 해야 하는 작업 자체도 줄어드니 PgDog는 더 빠르고 운영 비용도 더 저렴해집니다.
이런 내용이 흥미롭다면 [연락주세요](https://pgdog.dev/cdn-cgi/l/email-protection#e28a8ba29285868d85cc868794). 우리는 PostgreSQL의 다음 수평 확장 이터레이션을 함께 성장시키고 구축할 Founding Software Engineer를 찾고 있습니다.
1. 참고로 Rust의 hashmap 구현은 [SipHash](https://en.wikipedia.org/wiki/SipHash)를 사용합니다. 빠르고 DDoS에 강하지만, 그 이야기는 다음에.[↩](https://pgdog.dev/blog/replace-protobuf-with-rust#fnref:1)
2. [#699](https://github.com/pgdogdev/pgdog/pull/699)[↩](https://pgdog.dev/blog/replace-protobuf-with-rust#fnref:2)
[PgDog](https://pgdog.dev/)
PostgreSQL을 위한 수평 확장 레이어.
#### 리소스
* [문서](https://docs.pgdog.dev/)
* [GitHub](https://github.com/pgdogdev/pgdog)
* [블로그](https://pgdog.dev/blog/)
#### 연락처
* [데모 예약](https://calendly.com/lev-pgdog/30min)
* [문의](https://pgdog.dev/cdn-cgi/l/email-protection#a0c8c9e0d0c7c4cfc78ec4c5d6)
* [커뮤니티](https://discord.gg/CcBZkjSJdd)
© 2026 PgDog, Inc. All rights reserved.
