추론 효율성을 최우선 목표로 설계된 새로운 상태 공간 모델(SSM) Mamba-3의 핵심 아이디어, 아키텍처 변화, 실험 결과, 그리고 Triton/TileLang/CuTe DSL로 구현된 커널 공개를 소개합니다.

tl;dr
**Mamba-3는 추론 효율성을 1차 목표로 설계된 새로운 상태 공간 모델(SSM)**로, 학습 속도를 최적화했던 Mamba-2와는 다른 방향입니다. 핵심 업그레이드는 더 표현력 있는 재귀(recursion) 공식, 복소수 값 상태 추적, 그리고 디코딩을 느리게 만들지 않으면서 정확도를 끌어올리는 MIMO(다중 입력, 다중 출력) 변형입니다.
결과적으로 1.5B 스케일에서, Mamba-3 SISO는 모든 시퀀스 길이에 대해 prefill+decode 지연 시간에서 Mamba-2, Gated DeltaNet, 심지어 Llama-3.2-1B(Transformer)까지도 앞섭니다.
또한 팀은 Triton, TileLang, CuTe DSL을 혼합해 하드웨어 성능을 극대화한 커널을 오픈소스로 공개했습니다.
이 블로그는 Goomba Lab 블로그에도 크로스포스팅 되었으며, Carnegie Mellon University, Princeton University, Cartesia AI, Together AI 연구진의 협업으로 수행된 작업을 다룹니다.
2024년 중반 Mamba-2가 출시된 이후, 대부분의 아키텍처는 Mamba-1에서 Mamba-2로 전환했습니다. 왜일까요? Mamba-2는 상태 공간 모델(SSM)에서 가장 큰 병목이 학습 효율성이라고 보고, 이전 모델 대비 2−8× 더 빠른 학습을 제공하기 위해 기반 SSM 메커니즘을 단순화하는 쪽에 베팅했고, 그 결과 더 널리 채택되었습니다.
그 이후 LLM 환경은 변하기 시작했습니다. 사전학습이 여전히 매우 중요하긴 하지만, 사후학습(post-training)과 배포(deployment)에 더 많은 관심이 쏠리고 있으며, 둘 다 _극도로 추론 중심_입니다. 특히 코딩이나 수학을 위한 검증 가능한 보상 기반 강화학습(RLVR) 같은 사후학습 방법을 스케일링하려면 방대한 양의 생성 롤아웃이 필요하고, 가장 최근에는 Codex, Claude Code, 심지어 OpenClaw 같은 에이전트형 워크플로가 추론 수요를 폭발적으로 끌어올렸습니다.
추론의 중요성이 분명히 커지고 있음에도, 많은 선형(linear) 아키텍처( Mamba-2 포함)는 학습 우선 관점에서 개발되었습니다. 사전학습을 가속하기 위해 기반 SSM은 _점진적으로 단순화_되었고(예: 대각 전이를 항등행렬에 대한 스칼라 곱으로 축소), 이는 학습 속도를 가져왔지만 추론 단계는 “너무 단순해져” 완전히 메모리 바운드가 되었습니다 --- GPU가 계산을 하는 것이 아니라 대부분의 시간을 메모리 이동에 쓰게 된 것입니다.
추론의 새로운 시대에는 품질-효율 프런티어의 한계를 밀어붙이는 것이 중요합니다. 즉, 더 나은 모델이 더 빠르게 돌아가길 원합니다.
자연스러운 질문이 생깁니다:
추론을 염두에 두고 설계된 SSM은 어떤 모습일까?
무엇이 부족했을까? 선형 모델의 가장 큰 매력은 이름 그대로입니다. 상태 크기가 고정되어 있으므로, 계산이 시퀀스 길이에 대해 선형으로 스케일합니다. 하지만 공짜 점심은 없습니다. 효율적 계산을 가능하게 하는 동일한 고정 상태 크기가, 모델이 과거 정보를 모두 하나의 표현으로 압축하도록 강제합니다. 이는 과거 정보를 지속적으로 커지는 상태(KV 캐시)로 저장하는 Transformer와 정반대이며 --- 근본적인 차이입니다. 그렇다면 상태를 키울 수 없다면, 그 고정된 상태가 더 많은 일을 하도록 어떻게 만들 수 있을까요?
이전 설계들은 학습을 빠르게 만들기 위해 재귀와 전이 행렬을 단순화했습니다. 하지만 그 변화는 동역학의 풍부함을 줄였고, 디코딩을 메모리 바운드로 만들었습니다. 각 토큰 업데이트가 메모리 이동 대비 수행하는 계산이 너무 적었던 것입니다. 여기에는 우리가 조절할 수 있는 세 가지 레버가 있습니다: (1) 재귀 자체를 더 표현력 있게 만들기, (2) 더 풍부한 전이 행렬 사용하기, (3) 각 업데이트 내부에 더 많은 병렬(그리고 거의 공짜인) 작업 추가하기.
이 통찰을 바탕으로 우리는 Mamba-2를 다음의 세 가지 핵심 측면에서 개선했습니다:
이 세 가지 변화를 통해 Mamba-3는 유사한 추론 지연을 유지하면서 성능의 경계를 확장합니다.
특히 이 세 변화는 모두 보다 “고전적인” 제어 이론 및 상태 공간 모델 문헌에서 영감을 받았습니다.
본 연구는 선형 어텐션이나 테스트-타임 트레이닝 같은 재귀의 대안적 해석을 사용하는 많은 현대 선형 아키텍처 흐름과는 다른 방향이며, 그런 해석들은 이 개념들을 쉽게 포착하지 못합니다.
Mamba-2 레이어에서 무엇이 바뀌었을까요? 위에서 논의한 핵심 SSM에 대한 세 가지 방법론적 업그레이드 외에도, 아키텍처를 약간 개편하여 현대적 언어 모델의 관례와 더 맞추었습니다.
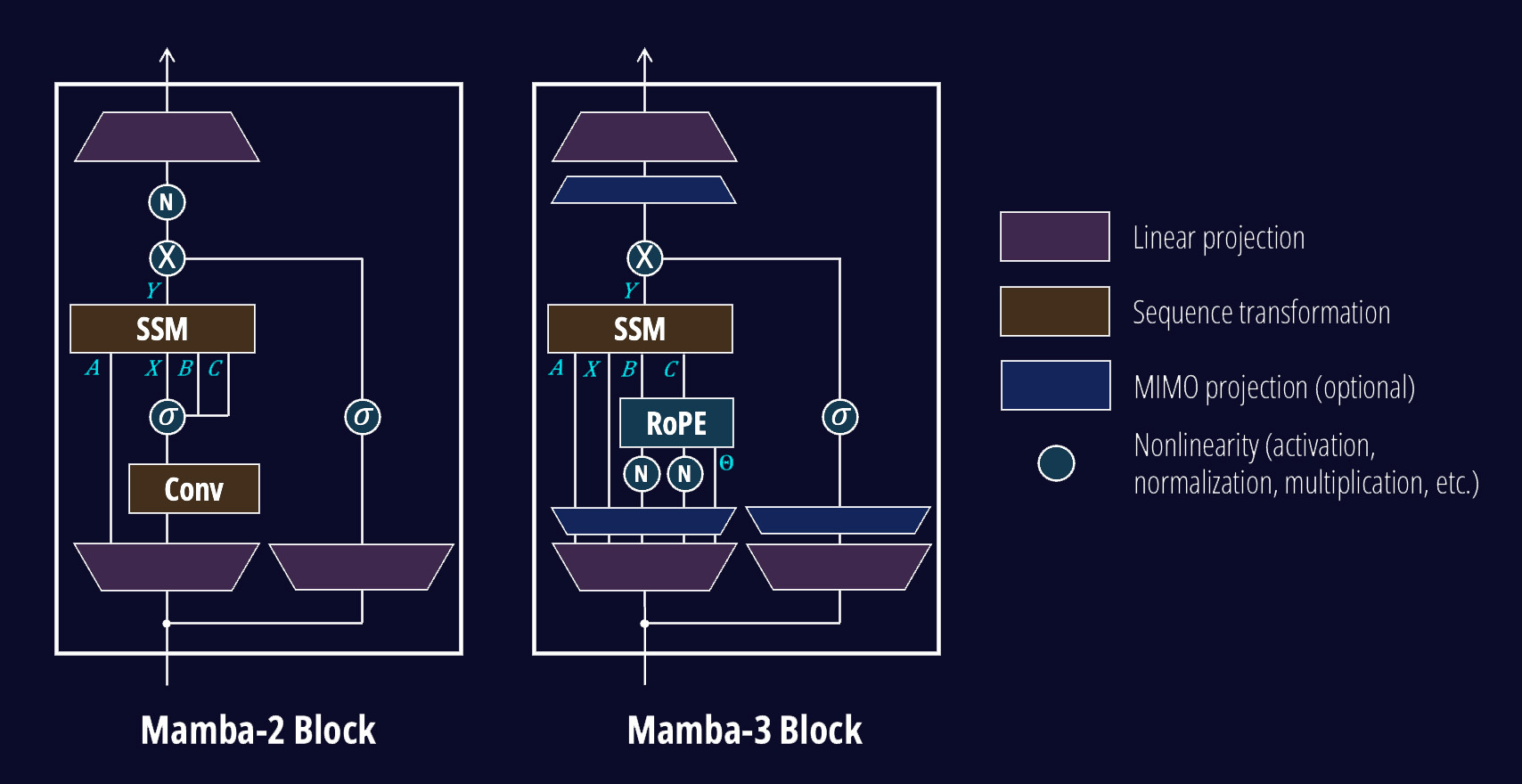
Mamba-3 architecture
도표를 보면 몇 가지 변화가 눈에 띕니다. 큰 틀에서,
Norms. SSM 용어로 QKNorm 또는 “BCNorm”을 추가했으며, 이는 경험적으로 Mamba-3 모델의 학습을 안정화합니다. 이 norm의 추가로 Mamba-3는 최신 Transformer 및 Gated DeltaNet(GDN) 모델과 같은 흐름을 따르게 됩니다. QKNorm이 들어가면 Mamba-2의 RMSNorm은 선택 사항이 됩니다. 다만 하이브리드 모델에서는 길이 외삽(length extrapolation) 능력에 도움이 되기 때문에 유지하는 것이 가치 있을 수 있음을 경험적으로 확인했습니다. 이에 대해서는 뒤에서 더 다룹니다.
Goodbye Short Conv. (1) BCNorm 이후 B와 C에 간단한 바이어스를 더하고 (2) 새로운 이산화 기반 재귀를 결합함으로써 Mamba-1/2의 성가신 짧은 인과 컨볼루션(short causal convolution)을 제거할 수 있었습니다. 새 재귀는 입력에서 은닉 상태로의 컨볼루션을 암묵적으로 적용하며, 이것이 왜 그런지에 대해서는 블로그 Part 2에서 보여드립니다.
Mamba-3의 변경은 SSM 재귀 내부에 컨볼루션 유사 구성요소를 추가하지만, 표준 짧은 컨볼루션처럼 SSM 재귀 외부에 배치된 것과 정확히 상호교환 가능한 것은 아닙니다.
후자는 Mamba-3와 함께 여전히 사용할 수 있지만, 사용하지 않기로 한 결정은 경험적 근거에 기반합니다. 표준 짧은 컨볼루션을 다시 추가하면:
왜 그럴까요? 이론적 메커니즘을 따로 연구하진 않았지만, 논문에서는 BC 바이어스와 지수-사다리꼴 재귀가 둘 다 유사한 컨볼루션 유사 메커니즘을 수행하며, 경험적으로 외부 짧은 컨볼루션과 같은 기능을 한다는 가설을 제시합니다.
짧은 컨볼루션은 오늘날 가장 성능이 좋은 선형 모델 다수의 핵심 구성요소가 되었습니다. 짧은 컨볼루션의 변형은 먼저 H3(Anthropic의 “smeared” induction heads 연구에서 영감을 받은 “shift SSM” 형태)와 RWKV-4(“token shift” 메커니즘) 같은 순환 아키텍처에서 사용되었고, 이후 Mamba-1이 현재 형태로 대중화했습니다.
이것이 널리 쓰이는 이유는, 기존 연구들이 짧은 컨볼루션이 경험적 성능을 높이고 이론적으로도 induction 스타일의 검색 능력을 뒷받침한다는 점을 반복적으로 보여줬기 때문입니다.
마지막으로 RoPE와 MIMO 프로젝션이라는 새로운 구성요소도 보일 것입니다. RoPE 모듈은 복소 전이를 회전으로 해석하여 복소수 값 SSM을 표현하며, 커널을 비용 크게 재구현할 필요를 없앱니다. MIMO 프로젝션은 MIMO SSM에 필요한 적절한 표현으로 B와 C 행렬을 확장합니다.
이 둘의 동기와 정확한 구현은 블로그 2부에서 더 자세히 다룹니다(거기엔 좋은 내용이 많습니다), 지금은 성능 및/또는 능력을 개선하는 데 각각 기여하는 독립적이고 근본적인 개선으로 생각하면 됩니다.
마지막으로 전체 아키텍처는 Transformer 및 기타 선형 모델의 표준 관례를 따라 MLP 레이어를 인터리브(interleave)합니다.
최종 Mamba-3 모델을 다른 인기 선형 대안들과 Transformer 베이스라인에 대해 평가했습니다.
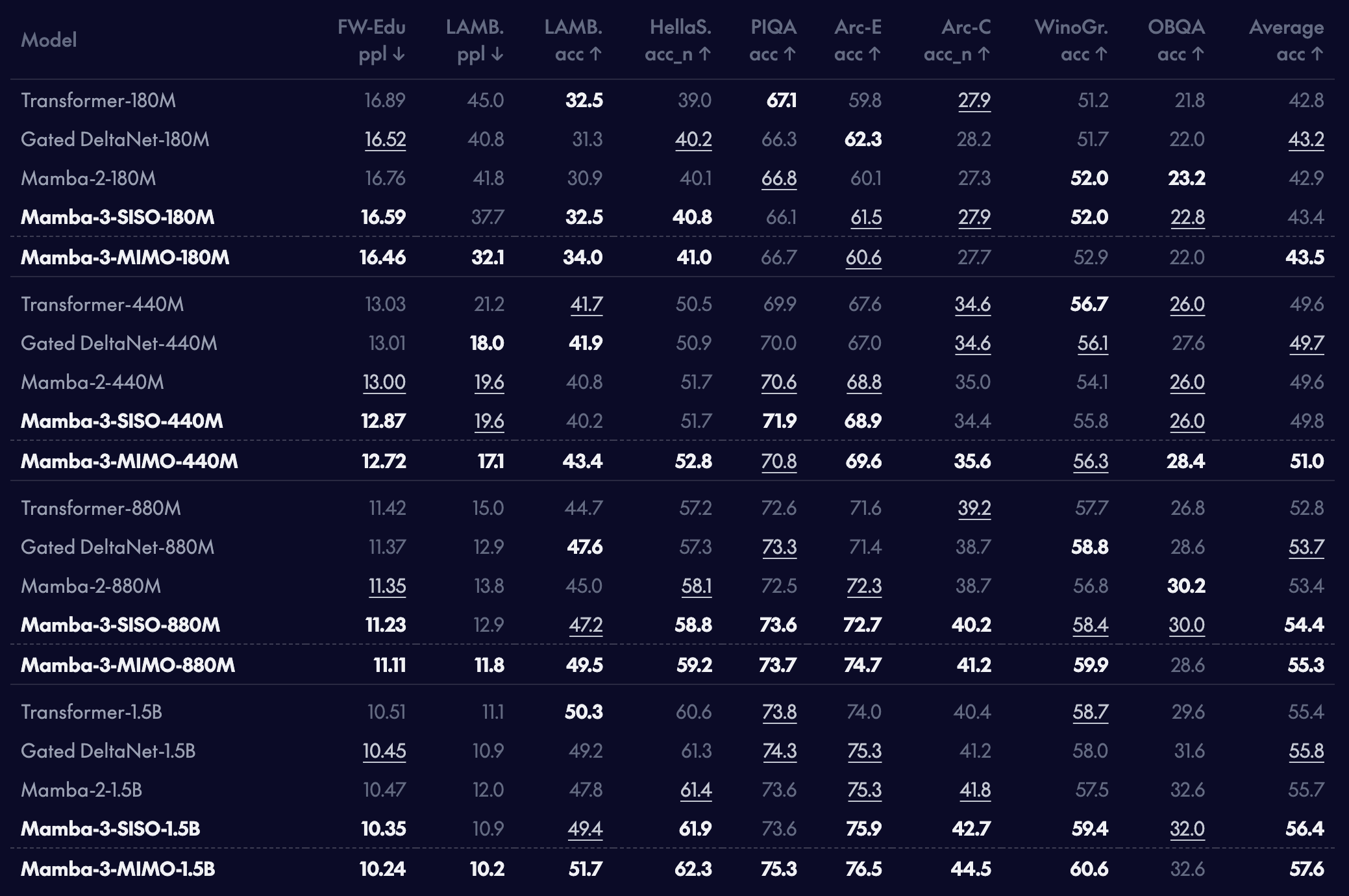
Downstream language modeling evaluations for pretrained models
새로운 Mamba-3 모델이 다양한 사전학습 모델 스케일에서 언어 모델링 성능 측면에서 기존 Mamba-2 모델과 GDN 같은 강력한 선형 어텐션 대안을 _능가_함을 확인했습니다. Mamba-3-SISO는 기존 선형 모델과 직접 비교 가능하며, 예를 들어 Mamba-2와 아키텍처 형태(모델 차원, 상태 크기 등)가 정확히 일치하고 학습 시간도 비슷합니다. Mamba-3의 MIMO 변형은 1B 스케일에서 일반 Mamba-3 대비 다운스트림 과제 정확도를 1 퍼센트 포인트 이상 더 끌어올립니다. 단, MIMO는 학습 시간이 더 길어지지만 디코딩 지연은 길어지지 않는다는 점이 있습니다!
2부에서 자세히 이야기하겠지만, 여기서는 미리 보기로 설명합니다.
이 이분법은 학습과 추론이 각각 컴퓨트 바운드 vs 메모리 바운드라는 성격 차이에서 비롯됩니다. 현재 선형 모델은 빠른 학습을 위해 GPU 텐서 코어를 많이 활용하도록 설계되어 왔지만(Mamba-2의 주요 기여 중 하나), 디코딩 시에는 각 타임스텝이 요구하는 연산이 너무 적어 하드웨어가 대부분의 시간 동안 놀게 됩니다.
따라서 각 타임스텝에 필요한 FLOPs를 늘리는 쪽으로 아키텍처를 설계하면, 놀고 있는 코어를 활용할 수 있어 추론 지연은 대체로 일정하게 유지됩니다 --- 하지만 학습에서는 그렇지 않습니다!
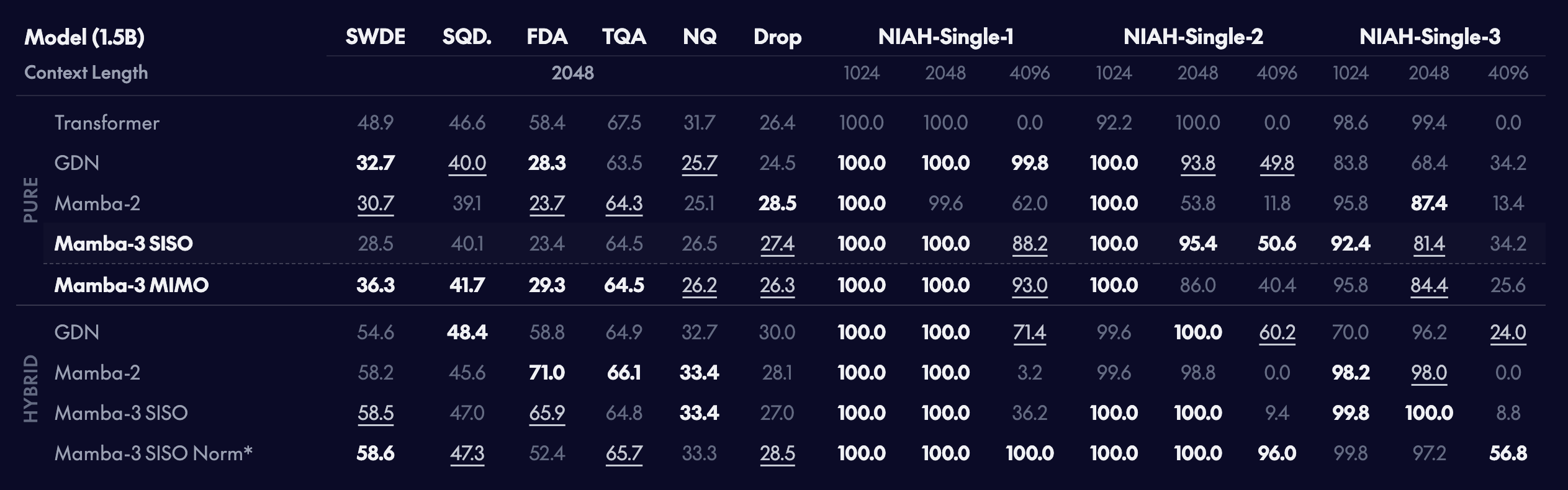
Real-world and synthetic retrieval tasks
고정 크기 상태를 쓰는 선형 모델은 검색 기반 과제에서 Transformer 대비 자연스럽게 성능이 떨어집니다. 예상대로 순수(pure) 모델끼리 비교하면 Transformer가 검색 과제에서 우수하지만, Mamba-3는 준-이차(sub-quadratic) 대안의 범주 안에서는 좋은 성능을 보입니다. 흥미롭게도 MIMO를 추가하면 상태 크기를 늘리지 않고도 검색 성능이 더 개선됩니다.
이러한 본질적 약점에도 불구하고 전반적 모델링 성능이 강하다는 점을 고려하면,
우리는 향후 선형 레이어가 주로 전역 self-attention 레이어와 결합되어 사용될 것이라고 예측합니다.*
적어도 언어 모델링에서는
선형 레이어의 일반적인 메모리 같은 성질과 self-attention의 KV 캐시가 제공하는 정확한 데이터베이스 같은 저장을 결합한 하이브리드 모델은, 경험적으로 순수 모델보다 더 높은 성능을 보이면서도 상당한 메모리 및 연산 절감을 가능케 하는 것으로 알려져 있습니다. 여기에서도 선형 레이어와 self-attention의 결합이 바닐라 Transformer 대비 더 나은 검색을 가능케 함을 확인했습니다.
다만 이러한 선형 모델이 self-attention과 상호작용하는 정확한 방식은 완전히 이해되지 않았습니다. 예를 들어 Mamba-3의 선택적 pre-output 프로젝션을 사용하면 합성 NIAH 과제에서 길이 일반화 성능이 개선되지만, in-context 현실 검색 과제에서는 약간의 비용이 발생함을 확인했습니다. 또한 반환되는 norm의 세부 사항(예: pre-gate vs post-gate 같은 배치, grouped vs regular 같은 타입)도 FDA 및 SWDE처럼 반구조화/비구조화 데이터가 섞인 과제의 정확도에 무시할 수 없는 영향을 미칩니다.
Mamba-3로 사람들이 무엇을 만들지 기대하고 있습니다. 이를 돕기 위해, 우리는 커널을 오픈소스로 공개하며, 속도 면에서 원래의 Mamba-2 Triton 커널과 동급입니다.
Prefill latency
| Model | n=512 | 1024 | 2048 | 4096 | 16384 |
|---|---|---|---|---|---|
| vLLM (Llama-3.2-1B) | 0.26 | 0.52 | 1.08 | 2.08 | 12.17 |
| Gated DeltaNet | 0.51 | 1.01 | 2.01 | 4.00 | 16.21 |
| Mamba-2 | 0.51 | 1.02 | 2.02 | 4.02 | 16.22 |
| Mamba-3 (SISO) | 0.51 | 1.01 | 2.02 | 4.01 | 16.22 |
| Mamba-3 (MIMO r=4) | 0.60 | 1.21 | 2.42 | 4.76 | 19.44 |
Prefill+decode latency
| Model | n=512 | 1024 | 2048 | 4096 | 16384 |
|---|---|---|---|---|---|
| vLLM (Llama-3.2-1B) | 4.45 | 9.60 | 20.37 | 58.64 | 976.50 |
| Gated DeltaNet | 4.56 | 9.11 | 18.22 | 36.41 | 145.87 |
| Mamba-2 | 4.66 | 9.32 | 18.62 | 37.22 | 149.02 |
| Mamba-3 (SISO) | 4.39 | 8.78 | 17.57 | 35.11 | 140.61 |
| Mamba-3 (MIMO r=4) | 4.74 | 9.48 | 18.96 | 37.85 | 151.81 |
단일 H100-SXM 80GB GPU에서 1.5B 모델에 대해, 시퀀스 길이별 prefill 및 prefill+decode(prefill과 decode 모두 동일 토큰 수) 지연 시간을 측정했습니다. 모든 시퀀스 길이에 대해 배치 크기 128을 사용했으며, 벽시계 시간(초)을 3회 반복 측정하여 보고합니다. 1.5B 스케일에서 모델을 비교하면, Mamba-3(SISO 변형)는 모든 시퀀스 길이에 걸쳐 _가장 빠른 prefill + decode 지연_을 달성하며, Mamba-2, Gated DeltaNet, 그리고 고도로 최적화된 vLLM 생태계를 갖춘 Transformer까지도 앞섭니다. 또한 Mamba-3 MIMO는 속도 면에서는 Mamba-2와 비슷하지만 성능은 훨씬 더 강력합니다.
Mamba-3 SISO의 Triton 기반 prefill은 Mamba-2와 거의 동일한 성능을 유지하며, 이는 새로운 이산화 및 데이터 의존 RoPE 임베딩이 추가 오버헤드를 유발하지 않음을 보여줍니다. 한편 Mamba-3 MIMO는 효율적인 TileLang 구현 덕분에 prefill에서 중간 정도의 감속만 발생합니다. 두 Mamba-3 변형의 강한 디코드 성능은 CuTe DSL 구현에 일부 기인하며, 이는 Mamba-3 구성요소의 단순성 덕분에 훨씬 수월해졌습니다.
사용 편의성을 해치지 않으면서 커널을 최대한 빠르게 만들기 위해 많은 시간을 들였습니다. 최종적으로 다음 스택을 사용했습니다: Triton, TileLang, CuTe DSL.
Triton의 사용은 꽤 쉬운 선택이었습니다. 이는 아키텍처 개발에서 사실상 표준이며(훌륭한 flash linear attention 저장소는 PyTorch와 Triton만으로 구성됨), 플랫폼 독립적 언어이면서 타일링 제어와 커널 퓨전을 통해 표준 PyTorch보다 더 나은 성능을 제공할 수 있기 때문입니다. Triton은 PTX (GPU 지향 어셈블리 언어) 인젝션과 Hopper GPU에서 전역 메모리에서 공유 메모리로의 대량 비동기 전송을 위한 Tensor Memory Accelerator 지원 같은 유용한 기능도 갖추고 있습니다.
MIMO prefill 커널은 대신 TileLang로 개발했습니다. 이 변형에 해당하는 추가 프로젝션은 GPU 메모리 계층 전반에서 전략적으로 조작하여 메모리 IO를 줄일 기회를 제공합니다. 하지만 Triton은 우리가 원하는 수준의 메모리 제어 세밀도를 제공하지 못했기 때문에, 공유 메모리 타일을 명시적으로 선언하고 제어하며 레지스터 프래그먼트를 만들 수 있는 TileLang을 선택했습니다. 이를 통해 더 효율적으로 메모리를 재사용하면서도, 충분히 고수준이라 커널을 빠르게 개발할 수 있었습니다.
추론과 디코드의 중요성을 계속 강조해왔기 때문에, 디코드 커널에는 CuTe DSL을 사용하기로 했습니다. Python 인터페이스를 통해 CUTLASS의 고수준 추상화를 사용하여 저수준 커널을 생성할 수 있습니다. 여기서는 사실상 CUDA 수준의 제어가 가능해, (이 경우 Hopper GPU라는) 하드웨어 사양에 맞춘 고성능 커널을 개발할 수 있습니다. 텐서 레이아웃과 워프 특수화(warp specialization)에 대한 정밀한 제어를 통해 GPU의 모든 기능을 활용하는 커널을 구축했습니다.
중요하게도, GPU 추상화 수준이 서로 다른 이러한 구현은 Mamba-3의 단순하고 가벼운 추가 요소와 그 영리한 구체화라는 기저 알고리즘 설계 덕분에 가능했습니다. 정확한 퓨전 구조 및 커널 DSL 같은 세부 사항은 전체 릴리스에서 더 깊게 다룹니다.
Part 1 끝까지 와주셔서 감사합니다! 이 글에서는 커널과 실험 결과 및 어블레이션에 관한 많은 세부 사항을 다루기엔 시간이 부족했지만, 걱정하지 마세요. 모든 내용은 논문에서 확인할 수 있고, 커널은 mamba-ssm에 오픈소스로 공개되어 있습니다!
다음으로, 시리즈의 두 번째(그리고 마지막) 글에서는 Mamba-3의 세 가지 핵심 개선과 그 SSM 기반을 깊이 있게 다루고, 우리가 특히 관심 있는 방향성을 제시합니다.
Gu, A. and Dao, T., 2024. 2. Transformers are SSMs: Generalized Models and Efficient Algorithms Through Structured State Space Duality[PDF]
Dao, T. and Gu, A., 2024. 3. Gated Delta Networks: Improving Mamba2 with Delta Rule[PDF]
Yang, S., Kautz, J. and Hatamizadeh, A., 2025. 4. Learning to (Learn at Test Time): RNNs with Expressive Hidden States[PDF]
Sun, Y., Li, X., Dalal, K., Xu, J., Vikram, A., Zhang, G., Dubois, Y., Chen, X., Wang, X., Koyejo, S., Hashimoto, T. and Guestrin, C., 2025. 5. Hungry Hungry Hippos: Towards Language Modeling with State Space Models[PDF]
Fu, D.Y., Dao, T., Saab, K.K., Thomas, A.W., Rudra, A. and Ré, C., 2023. 6. In-context Learning and Induction Heads
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., Ndousse, K., Amodei, D., Brown, T., Clark, J., Kaplan, J., McCandlish, S. and Olah, C., 2022. Transformer Circuits Thread. 7. RWKV: Reinventing RNNs for the Transformer Era[PDF]
Peng, B., Alcaide, E., Anthony, Q., Albalak, A., Arcadinho, S., Biderman, S., Cao, H., Cheng, X., Chung, M., Grella, M., GV, K.K., He, X., Hou, H., Lin, J., Kazienko, P., Kocon, J., Kong, J., Koptyra, B., Lau, H., Mantri, K.S.I., Mom, F., Saito, A., Song, G., Tang, X., Wang, B., Wind, J.S., Wozniak, S., Zhang, R., Zhang, Z., Zhao, Q., Zhou, P., Zhou, Q., Zhu, J. and Zhu, R., 2023. 8. Test-time regression: a unifying framework for designing sequence models with associative memory[PDF]
Wang, K.A., Shi, J. and Fox, E.B., 2025. 9. An Empirical Study of Mamba-based Language Models[PDF]
Waleffe, R., Byeon, W., Riach, D., Norick, B., Korthikanti, V., Dao, T., Gu, A., Hatamizadeh, A., Singh, S., Narayanan, D., Kulshreshtha, G., Singh, V., Casper, J., Kautz, J., Shoeybi, M. and Catanzaro, B., 2024.

8S
DeepSeek R1

네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
DeepSeek R1
8S
Audio Description
0:00
네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
8S
DeepSeek R1
네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
Performance & Scale
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
Infrastructure
Best for
더 빠른 처리 속도(전체 쿼리 지연 시간 감소)와 더 낮은 운영 비용
명확히 정의된, 단순하고 직선적인 작업의 실행
함수 호출, JSON 모드 또는 기타 구조화가 잘 된 작업
List Item #1
List Item #1
로렘 입숨 돌로르 시트 아멧, 콘섹테투르 아디피싱 엘리트, 세드 도 에이우스모드 템포르 인시디둔트 우트 라보레 엣 돌로레 마그나 알리쿠아. 우트 에님 아드 미님 베니암, 퀴스 노스트루드 엑서시타티온 울람코 라보리스 니시 우트 알리퀴프 엑스 에아 콤모도 콘세콰트.
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
단계별로 생각하고, 최종 답만 _<answer>_와 </answer> 태그 안에 넣으세요. 추론을 할 때는 다음 규칙에 따라 작성하세요: 추론할 때는 아랍어로만 답변해야 하며, 다른 언어는 허용되지 않습니다. 질문은 다음과 같습니다:
Natalia는 4월에 친구 48명에게 클립을 팔았고, 5월에는 그 절반만큼의 클립을 팔았습니다. 4월과 5월에 Natalia가 총 몇 개의 클립을 팔았나요?
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
8S
DeepSeek R1
네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
DeepSeek R1
8S
Audio Description
0:00
네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
8S
DeepSeek R1
네이티브 오디오와 실감 나는 물리 효과를 갖춘 프리미엄 시네마틱 비디오 생성.
Performance & Scale
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
Infrastructure
Best for
더 빠른 처리 속도(전체 쿼리 지연 시간 감소)와 더 낮은 운영 비용
명확히 정의된, 단순하고 직선적인 작업의 실행
함수 호출, JSON 모드 또는 기타 구조화가 잘 된 작업
List Item #1
List Item #1
로렘 입숨 돌로르 시트 아멧, 콘섹테투르 아디피싱 엘리트, 세드 도 에이우스모드 템포르 인시디둔트 우트 라보레 엣 돌로레 마그나 알리쿠아. 우트 에님 아드 미님 베니암, 퀴스 노스트루드 엑서시타티온 울람코 라보리스 니시 우트 알리퀴프 엑스 에아 콤모도 콘세콰트.
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
Build
포함된 혜택:
✔ 최대 $15K의 무료 플랫폼 크레딧*
✔ 3시간의 무료 현장(포워드 디플로이) 엔지니어링 시간.
Funding: $5M 미만
단계별로 생각하고, 최종 답만 _<answer>_와 </answer> 태그 안에 넣으세요. 추론을 할 때는 다음 규칙에 따라 작성하세요: 추론할 때는 아랍어로만 답변해야 하며, 다른 언어는 허용되지 않습니다. 질문은 다음과 같습니다:
Natalia는 4월에 친구 48명에게 클립을 팔았고, 5월에는 그 절반만큼의 클립을 팔았습니다. 4월과 5월에 Natalia가 총 몇 개의 클립을 팔았나요?
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧
XX
Title
본문 카피가 여기에 들어갑니다 로렘 입숨 돌로르 시트 아멧