본 글은 State Space Model(SSM)과 Transformer를 비교하며 각 모델의 특성, 장단점 및 최근 연구 동향과 실제 적용 이슈 등 심층적으로 다루고 있다.
이 블로그 글은 지난 1년 동안 여러 번 발표했던 강연에서 기반하여 작성되었습니다. 비교적 폭넓은 청중을 위한 높은 수준의 강의를 의도했으나, 시퀀스 모델을 연구하는 연구자들에게도 흥미로운 통찰, 의견, 직관이 담겨 있기를 바랍니다.
먼저, 제가 말하는 상태공간 모델이 무엇인지 정의하면서 시작하겠습니다. (이 구간은 글의 주요 내용을 이해하는 데 필수는 아니니 다음 섹션부터 읽어도 무방합니다.)
아래는 Mamba로 집대성된 일련의 논문들에서 발전되어 온 (구조화된) 상태공간 모델(SSM)을 정의하는 방정식입니다. SSM은 일종의 현대적 순환신경망(RNN)으로, 몇 가지 주요 특징이 있습니다. 수많은 기술적 발전 끝에 이 모델 계열이 작동하게 되었지만, 저는 각 요소별로 추상화하여 Transformer와 대등하게 언어 모델링이 가능하게 한 주요 핵심 요소를 먼저 소개하려고 합니다.
SSM의 특징은 은닉 상태 h_t가 입력 및 출력 x_t, y_t보다 크다는 점입니다. RNN 류에서 은닉상태는 모델이 보유할 유일한 컨텍스트 메모리이므로, 언어처럼 정보가 밀집한 데이터에서는 필요한 정보를 저장하려면 충분한 용량의 상태가 필요합니다.
SSM에서 입력 x_t가 1차원 스칼라라면 은닉 상태 h_t는 N-차원 벡터입니다. N은 상태 크기, 상태 차원, 상태 확장 계수 등의 하이퍼파라미터로 독립적으로 설정되며, SISO(single-input single-output) SSM이라 불리기도 합니다. 이 구조를 통해 기존 LSTM/GRU 같은 RNN들보다 N배 더 많은 정보를 저장할 수 있습니다.
충분히 큰 상태만으로는 부족하며, 원하는 정보를 정확하게 저장/활용할 수 있게 업데이트 함수가 충분히 표현력이 있어야 합니다.
이전의 "선형 시간 불변(Linear Time-Invariant)" SSM은 h_{t} = Ah_{t-1} + Bx_t와 같이 매 시점 갱신이 고정되었습니다. 이는 오디오처럼 압축률이 높은 데이터에는 잘 맞았으나, 언어 등 정보량이 시간대별로 가변적인 시퀀스에는 유연성이 부족합니다. Selective SSM(예:Mamba)은 전이 행렬이 시간 및 데이터에 따라 바뀌도록 하여 더 표현력 있게 만들었습니다. 이는 고전적인 RNN의 게이팅(gating) 메커니즘과 밀접한 연관이 있습니다.
이 영역이 최근 재현 모델 연구의 핵심 중 하나로, 전이행렬 A_t의 다양한 파라미터화가 가지는 이론적 표현력 및 모델의 상태 기억 범위를 탐구하고 있습니다.
커지고 표현력이 높아진 순환 상태는 중요하지만, 계산이 훨씬 어려워진다는 치명적 트레이드오프를 가집니다. Mamba는 반복 갱신의 정교한 파라미터화, 고전적 병렬 scan 알고리즘 활용 등으로 이 문제를 해결했습니다.
다수의 새 알고리즘 역시 공통적으로 아래 특성을 따릅니다:
위 세 가지 모두 새롭진 않습니다.
Mamba의 혁신은 이 모든 요소의 결합이 경험적 성능을 획기적으로 변화시키고, 언어 모델링에서 Transformer에 근접하게 했다는 점입니다.
이후 순환(recurrent) 모델의 이론 및 성능 개선을 겨냥한 연구가 급증했습니다. 모델마다 관점, 명칭, 이론적 틀도 다양합니다.
핵심 공통점은 거의 모든 모델이 유사한 SSM 방정식으로 귀결되며, 주요 차이는 A_t(선택성), 그리고 해당 학습 알고리즘(효율성) 구조에 있습니다. 저는 그래서 이 계열 전체를 상태공간 모델(또는 "현대적 순환 모델")이라 총칭하겠습니다. 물론 관련 아이디어만큼 다양한 명명도 가능하겠습니다!

이 그림은 Songlin Yang의 DeltaNet 논문에서 따왔으며, 다양한 현대적 순환 모델이 어떻게 이 프레임워크(Linear Attention 표기법 기준)로 수렴하는지 보여줍니다.
연구가 폭발적으로 늘었음에도 저는 이들 모두가 본질적으로 서로 매우 유사하고, 경험적 성능도 거의 비슷하며, 중요하게는 이 모델들은 서로와 훨씬 더 닮았지, 쿼드러플릭 어텐션(quadratic attention : 일반 Self-Attention)과는 거리가 있다고 봅니다. 남은 글에서는 SSM, Transformer 간 상위 구조의 트레이드오프를 살펴보려 합니다.
서로 다른 모델의 트레이드오프를 더 잘 이해하려면, **오토리그레시브 상태(autoregressive state)**에 무엇을 저장하고 어떻게 조작하는지를 보는 게 좋습니다.
사실 모든 오토리그레시브 모델—예컨대 LLM처럼 좌측에서 우측으로 순차적으로 데이터를 생성하는 모든 모델—은 메모리에 상태를 저장하고 매 스텝마다 이를 변환시킨다는 점에서 본질적으로 "상태공간 모델"입니다. (예, 매 단어 생성마다 상태 갱신)
Transformer의 핵심, (causal) self-attention은 모든 시퀀스 원소 쌍간 상호작용을 계산함으로써 정의되며, 계산비용이 시퀀스 길이에 대해 2차적(Quadratic) 으로 늘어난다는 점이 주된 단점입니다.
반면, SSM류 순환 구조는 반복 1회는 상수 시간에 계산되므로 전체 시퀀스 처리 비용이 _선형_으로 증가하며, 이는 주요 장점으로 여겨집니다.
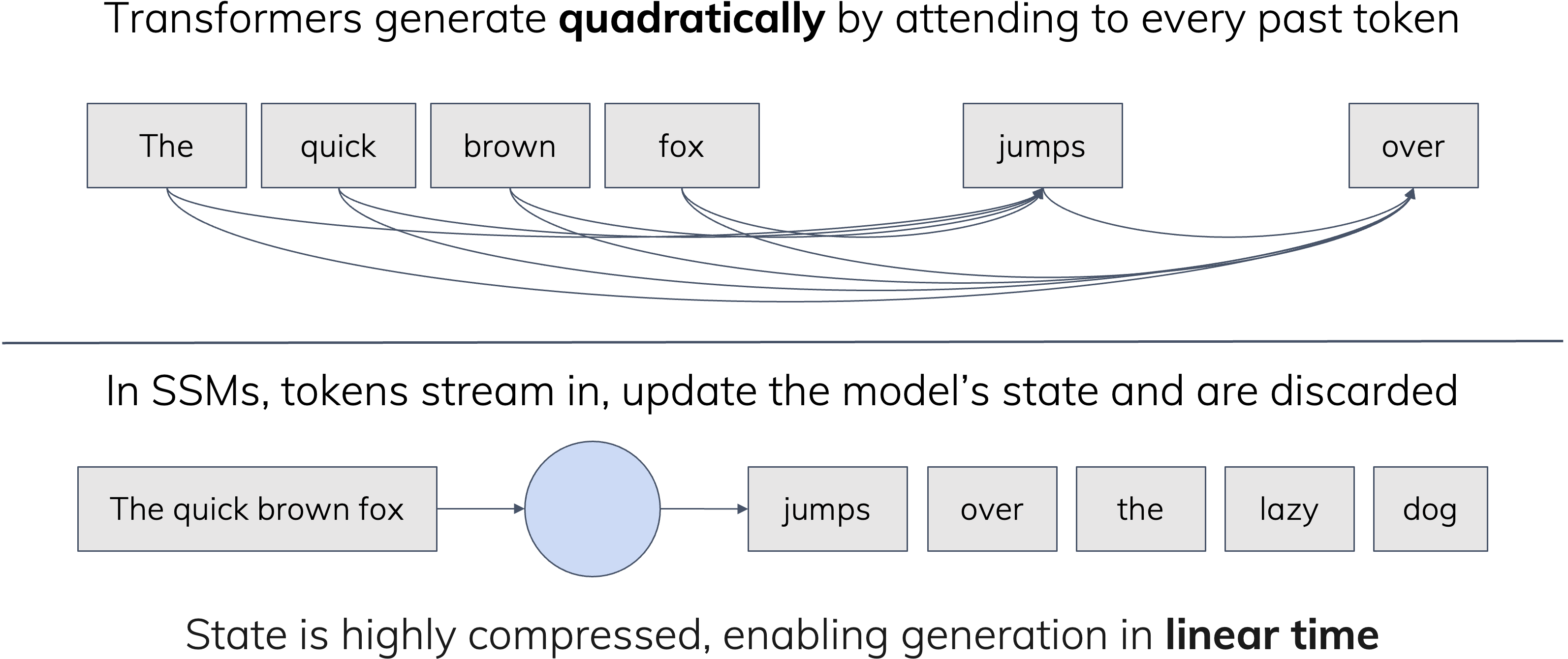
그러나 학습 비용보다는 추론 중 입력이 처리될 때 실제로 무슨 일이 벌어지는지를 생각해보는 게 더 유익합니다.
구체적 구현에 들어가지 않고서도, 이 두 모델은 오토리그레시브 상태 정의만으로 다음처럼 구분할 수 있습니다:
Transformer의 캐시는 좀 더 공식적으로 **KV Cache(Key-Value Cache)**라고 불립니다. 이 글에서는 구체 구현보다 원리를 드러내기 위해 "컨텍스트 캐시" 또는 "토큰 캐시"라 부릅니다.
덧붙이자면, LLM 연구자들과 대화할 때 SSM의 상태를 "KV 캐시의 한 형태"라고 부르는 경우가 많은데, 저는 KV 캐시를 일종의 state(상태)로 부르는 편이 더 직관적이고 정확하다고 생각합니다.
SSM은 더 효율적이면서도 다소 약한 Transformer의 대체처럼 보이기도 합니다. 그러나 효율성만이 전부가 아니며, 두 모델은 귀납적 편향(Inductive Bias), 즉 데이터를 처리하는 성향 자체가 다릅니다. 대표적 비유는 다음과 같습니다.
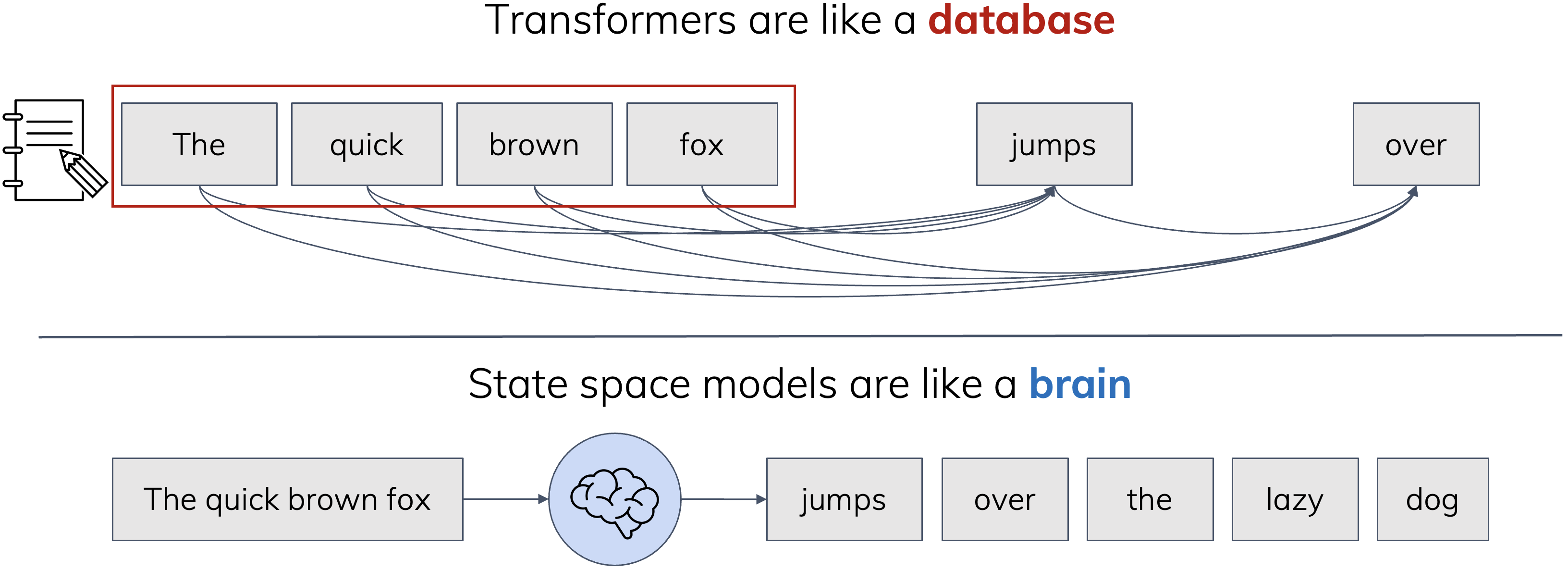
Transformer는 데이터베이스와 같습니다. 모든 관찰을 중요한 항목으로 취급해 저장해두고 필요할 때 참조합니다.
반면 SSM은 뇌와 같습니다. 유한한 크기의 기억 공간이 항상 활성되어 있으며, 실시간으로 새 입력을 처리하고 새 출력을 내보냅니다.
이 비유는 다소 거칠지만, 실제 관찰되는 행동(SSM은 전화번호부를 한 번에 외우고 불러줄 수 없음 등)을 설명합니다. SSM은 과거를 완벽하게 재현하지 못하지만, 사실 인간도 그렇습니다. 한편 Transformer에는 캐시 사이즈 이상의 컨텍스트 한계가, SSM류 순환 모델은 이론적으로 무한히 과거를 흐릿하게나마 기억(유지) 가능하다는 차이가 있죠.
최신의 컨텍스트 압축 기법들은 캐시를 요약해서 더 많은 정보를 처리하려고 시도합니다. 이 또한 정보 손실이 불가피하며, 점점 SSM과 닮아갑니다. 같은 맥락에서 SSM도 여러 번 데이터를 반복 처리하게 하여 회상 문제를 보완할 수 있습니다. 중요한 점은, 방법 자체의 한계가 절대적인 게 아니라, 사용 방식·시스템 레벨의 변화에 따라 유동적일 수 있단 점입니다.
"롱 컨텍스트"라는 용어는 명확히 정의되지 않았음에도 자주 사용됩니다. Transformer든 SSM이든 “롱 컨텍스트 능력”이 더 낫다는 식의 주장이 있지만, 서로 메모리의 _종류 자체_가 다릅니다. 앞서 비유처럼, 내 두뇌와 연구노트 중 누가 더 우월한지 단정하기 어렵듯, Transformer의 컨텍스트 캐시는 명확한 세부 정보 회상이 강점, SSM은 흐릿하더라도 장기 컨텍스트 유지에 유리합니다.
예를 들어 대형 SSM이 최신 길이 외삽(length extrapolation)로 잘 학습된다면, 인간 친구와의 대화처럼 꼼꼼한 요약기억을 통해 실제 연속적 관계 맥락 관리가 가능합니다. 이 브레인형 특질은 Transformer가 정확, 회상이 필요한 AI 작업에 강점을 가지는 것과 대비됩니다.

흥미로운 경험적 결과: 양쪽 모델을 결합하면 훨씬 능력이 높아질 수 있습니다! 인간 지능이 스크래치패드와 레퍼런스(참조물)로 증강되는 것처럼, SSM과 Attention 레이어를 교차 배치하는 전략이 실제 성능을 높입니다. 실제 대형 하이브리드 모델(NVIDIA Nemotron-H, Tencent T1/TurboS 등)이 이러한 구조로 SOTA를 갱신합니다. (재미 사실: 둘 다 제 생일에 발표됨 😂)
여기서의 성능은 Perplexity를 의미합니다. 모델 종류별 다운스트림 능력의 미묘한 차이(예, 알고리즘적 능력)도 있으나, Perplexity는 언어 모델링의 정의에 맞는 가장 근본적 지표입니다. FLOP-대-FLOP 기준이라면 SSM이 Transformer보다 언어를 더 잘 모델링한다고 믿습니다.
Attention is all you need? Transformer가 만능 구조이고, 데이터만 때려 넣으면 성능도 무한히 오른다는 인상이 있습니다.
신화
데이터를 Transformer에 때려넣기만 하면 된다 🙂
현실은 좀 더 복잡합니다. Attention은 놀랍고 거의 모든 모달리티(언어, 비전, 오디오 등)에 도입되었으나, 좀 더 세부적인 고려가 필요합니다.
현실
Attention은 적절한 추상화 레벨에서 사전 압축된 데이터에 가장 효과적이다
Transformer를 잘 쓰려면 _데이터가 상당히 가공되어야 한다_는 것이 제 주장입니다. 실제 사례로, 거의 모든 실 사용 파이프라인에서는 아래와 같이 전처리(encoder)가 있습니다:
이는 순전히 효율 때문만이 아니라, Transformer가 "적합한 표현 단위의 의미있는 정보"가 들어온 경우에만 강점을 발휘하기 때문이라는 더 근본적 이유가 있습니다.
토크나이즈(BPE 등)는 언어 모델링에서 거의 관습적으로 쓰이지만, 다양한 실패 사례(SolidGoldMagikarp, "How many R's in strawberry" 등)로 악명 높습니다.

대부분은 토크나이저가 "필요악"으로 효율상 포기할 수 없다고 봅니다. 하지만 저는 반드시 토크나이즈를 없애야 한다고 강하게 믿고 있습니다. 순수 딥러닝의 정신—즉, 핸드크래프트 피처 엔지니어링을 제거하고 데이터에서 학습하게 만드는 것—에 더 가깝고, 실제로 모델 스케일링, 다중언어/다중모달, 추론 등에서 큰 도약이 있을 거라고 보기 때문입니다.
자세한 논의는 병렬 포스팅 참조.
토크나이즈 없는(LM을 byte/character-level로 학습) 연구는 극히 드뭅니다.
다음 그림은 FineWeb-Edu 데이터(문맥 8192)에 대해 byte-level 모델(Mamba, sliding window/global attention)이 FLOP 일치 기준으로 비교된 결과입니다.
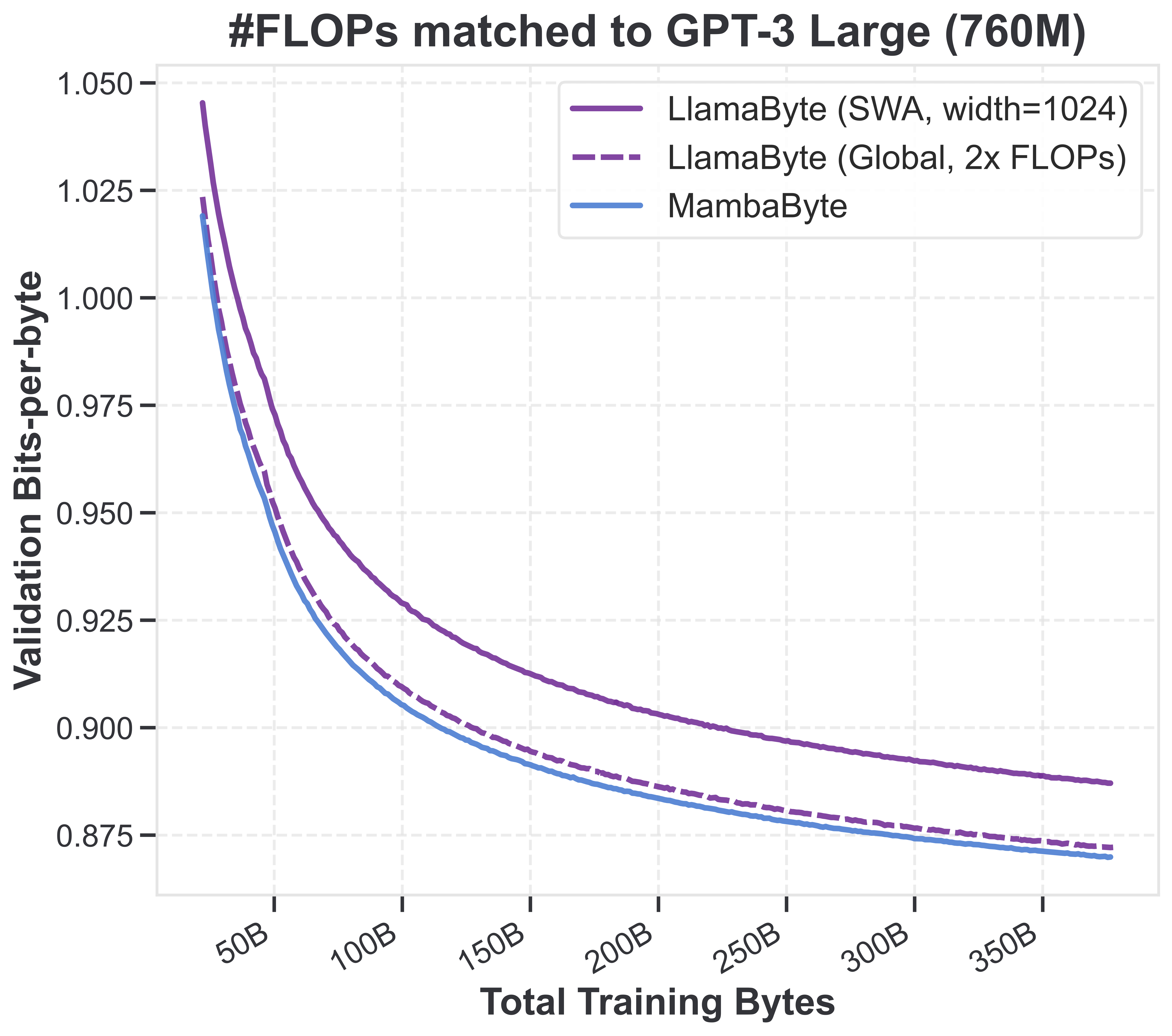
흥미롭게도 SSM이 FLOP-matched Transformer보다 훨씬 좋은 성능을 보이고, data-matched 기준에서도 전통적 Transformer를 꾸준히 앞섭니다. 동일 데이터, 동일 모델에 단지 토크나이즈만 바꾼 것만으로 이렇게 성능 격차가 발생합니다.
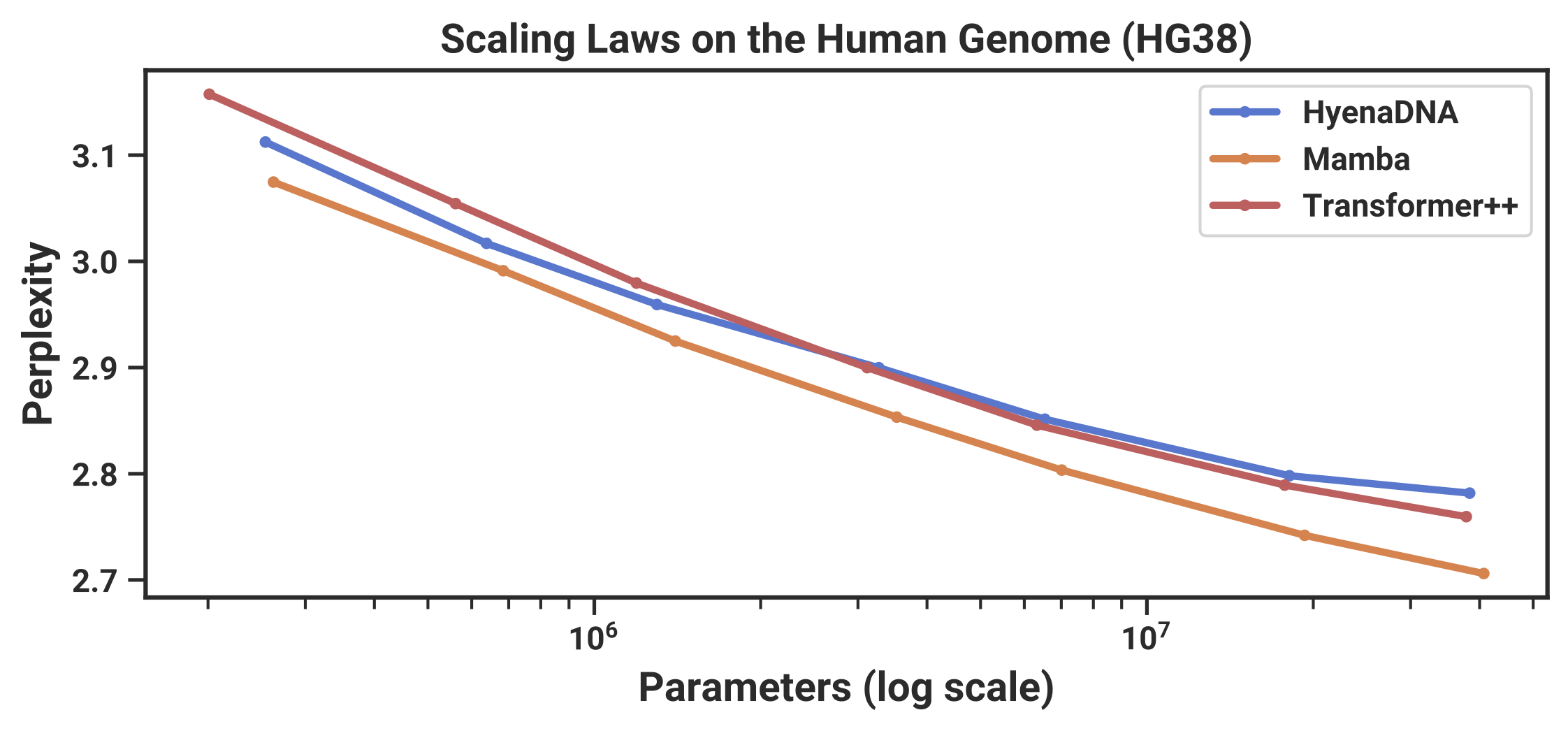
DNA(4글자 vocabulary)처럼 토크나이즈가 애매한 데이터에서 SSM이 Transformer를 훨씬 앞지르는 것도 대표적 예시입니다.
Transformer는 모든 과거 토큰을 명시적으로 캐시하므로, 각 토큰(의미)의 개별적 recall에 강한 귀납적 편향을 갖습니다.
"Soft Attention의 귀납적 편향은 Hard Attention(개별 토큰에 집중)이다."
정리하자면:
텍스트 언어처럼 의미 있는 subword를 분리해놓은 경우, attention은 매우 강력하며 반드시 필요합니다. 그러나 의미 없는 개별 단위(예: 문자, DNA 등)에는 SSM류가 우위에 있습니다. SSM은 이러한 입력을 더 의미 있는 abstraction으로 압축하는 데 적합합니다.
실제로 Mamba 등 SSM은 발표 이후 오디오/비전 등 다양한 모달리티에서 훨씬 많이 활용되고 있기도 합니다.참고:audio
모든 모델이 의미 있는 입력일 때 더 좋은 건 맞지만, Transformer가 특히 더 의존한다는 것이 제 주장입니다.
예를 들어 "n-gram 토크나이즈"처럼 suboptimal 토크나이즈 데이터라면, Transformer 성능이 더 많이 깨지고 SSM은 상대적으로 영향이 덜할 것으로 예측했습니다:
Transformer(나쁜 토큰) < SSM(나쁜 토큰) < SSM(좋은 토큰) <= Transformer(좋은 토큰)
실제 데이터는 매우 noisy하고, 인간은 노이즈에서도 잘 학습합니다. 정보 없는 filler token을 계속 삽입하는 thought-experiment를 상상해면,

Standard Attention이라면 가짜 토큰까지 전부 캐시하므로, 메모리/계산이 k배로 증가하고 비효율적입니다. SSM은 상태폭이 안 커집니다. 물론 k가 늘어나면 모든 모델이 토큰 처리량만큼은 증가할 테지만, "진짜 맞는 아키텍처"라면 정보량만 같다면 노이즈와 추가 토큰에 반응하지 않거나 아주 적은 오버헤드만 내야 합니다.
컨볼루션은 sampling rate가 명확할 때(영상/오디오)만 적합합니다. LLM에서는 입력 간 spacing이 임의적이라서 필연적으로 잘 안 맞습니다.
지금까지 논의를 통해, "Attention은 적절히 가공된 표현에 가장 효과적이다"는 주장을 다시 내세웁니다. 물론 oversimplification이지만, 어떤 의미에서는 맞다고 생각합니다.
오토리그레시브 상태만 놓고 봐도 명확:
강점: SSM은 효율적, 상태 기억형, 온라인 처리에 강하다.
약점: 세밀한 회상/검색 능력은 부족하다.
개념적으로, 압축된 상태 구조의 장단점은 동전의 양면입니다. 게다가, 압축이 실제 지능에 근본적일 수 있다는 가설도 흥미롭습니다. (자세한 논의: 링크)

실제 SSM이 적합한 시나리오도 많은데, 앞으로 언어에서도 그 압축적 귀납 편향이 핵심적 역할을 하는 케이스도 곧 공개될 예정입니다.
Transformer는 컨텍스트 내 개별 토큰에 fine-grained attention/조작이 필요한 과제에 거의 유일하게 완벽합니다.
강점: Transformer는 완벽한 회상(recall) 및 토큰 단위 세밀 조작이 가능하다.
그럼 약점은? 모두가 quadratic complexity(계산량 폭증)만 있다고 생각하지만, 더 중요한 건 구조적 귀납적 편향의 한계로 인해 세밀하지 않은(높은 수준 의미 메타데이터가 부족한) 입력에 약하다는 점입니다.
약점: Transformer는 주어진 토큰에 강하게 의존합니다.
즉, 데이터의 resolution, semantic content에 매우 민감합니다. 컨텍스트 캐시 구조상, 매 항목별로 개별 표현을 저장해두지 않으면 안 되니까요.
여러 attention 변종은 거의 모두 explicit token cache를 유지하는 한 동일한 약점을 공유합니다. 반면, low-rank/linear attention 등 token-level cache가 없는 형식은 약점이 옅어지고 SSM에 가까운 특성을 가질 것입니다. (그래서 "state space model, recurrent model"이란 용어를 더 선호하기도...)
현대 AI 발전의 동인은 결국 스케일링 법칙입니다. 즉, 충분히 많은 계산(flop)이 주어지면 성능은 꾸준히 오른다는 법칙이죠.

결국 우리의 목적은 compute를 능력으로 변환하는 최고의 블랙박스를 찾는 것입니다. 이 관점에서 핵심 질문은 단 하나:
내 모델은 compute를 현명하게 쓰고 있는가?
Transformer 혼자서는 최선이 아니라고, 저는 이제 더욱 확신하게 됐습니다.
실제론 “dollar-to-FLOP-to-capabilities”의 총합이 중요합니다. (dollar-to-flop: 가격대성능, flop-to-capabilities: 효율성) Transformer가 이 두 축의 곱을 최적으로 맞췄다는 의견도 있습니다만, 저는 여전히 flop-to-capabilities 자체에 진보가 더 큰 파급가능성이 있다고 생각합니다.
굳이 지금의 Transformer도 AGI에 충분하다는 시각도 있으나, 개선이 빠른 달성을 돕거나 더 지능적인 모델 진화에 필수적일 수 있습니다. Transformer 대체 모델 파를 대표하지만, 저 역시 Attention이 근본적 modeling primitive임엔 동의합니다. 하지만 Transformer만으론 최종 솔루션이 아니며, 갈 길이 남아 있습니다.

이 글을 통해 더 많은 사람과 내용을 나누고, 다음 아키텍처 발전 논의의 토대를 마련하고자 했습니다.
Tri Dao, Luca Perić에게 피드백을 감사드립니다.
@online{gu2025tradeoffs,
author = {Albert Gu},
title = {On the Tradeoffs of State Space Models and Transformers},
year = {2025},
url = {https://goombalab.github.io/blog/2025/tradeoffs/},
}