GPT-2부터 DeepSeek V3/R1, Gemma 3·3n, Mistral Small 3.1, Llama 4, Qwen3, SmolLM3, Kimi K2, gpt-oss까지 2024-2025년 오픈 모델의 핵심 아키텍처 변화를 MLA·GQA·MHA, MoE, 슬라이딩 윈도우 어텐션, RMSNorm과 Pre/Post-Norm, QK-Norm, NoPE, 토크나이저·KV 캐시 등 관점에서 그림과 함께 정리하고 비교합니다.
원래 GPT 아키텍처가 개발된 지 7년이 지났습니다. 2019년의 GPT-2를 돌아보고 2024-2025년의 DeepSeek-V3와 Llama 4를 바라보면, 겉보기에는 이 모델들이 여전히 구조적으로 꽤 비슷하다는 점에 놀랄 수 있습니다.
물론, 위치 임베딩은 절대적(absolute)에서 회전형(RoPE)으로 진화했고, 다중 헤드 어텐션(MHA)은 주로 그룹드-쿼리 어텐션(GQA)으로 대체되었으며, 더 효율적인 SwiGLU가 GELU 같은 활성화 함수를 대체했습니다. 하지만 이런 사소한 다듬기를 넘어, 정말로 획기적인 변화가 있었을까요, 아니면 같은 아키텍처적 토대를 계속 연마하고 있을 뿐일까요?
LLM의 성능(좋거나 혹은 그다지 좋지 않거나)에 기여하는 핵심 재료를 가리기 위해 모델들을 비교하는 것은 악명높게 어렵습니다. 데이터셋, 학습 기법, 하이퍼파라미터가 제각각이고 충분히 문서화되지 않는 경우가 많기 때문입니다.
그럼에도 2025년에 LLM 개발자들이 무엇을 하고 있는지 보기 위해, 아키텍처 자체의 구조적 변화를 살펴보는 일에는 여전히 큰 가치가 있다고 생각합니다. (그 일부가 아래 그림 1에 보입니다.)

그림 1: 이 글에서 다루는 아키텍처의 일부.
그래서 이 글에서는 벤치마크 성능이나 학습 알고리즘을 논하는 대신, 오늘날의 대표적인 오픈 모델들을 규정하는 아키텍처적 발전에 초점을 맞추겠습니다.
(기억하시겠지만, 얼마 전 저는 멀티모달 LLM에 대해 썼습니다. 이번 글에서는 최근 모델들의 텍스트 능력에 집중하고, 멀티모달 능력 논의는 다음 기회로 미루겠습니다.)
팁: 이 글은 꽤 포괄적이므로, Substack 페이지 왼쪽에 마우스를 올려 목차를 여는 내비게이션 바를 사용하는 것을 추천합니다.
아마 여러 번 들으셨듯이, DeepSeek R1은 2025년 1월 공개 당시 큰 반향을 일으켰습니다. DeepSeek R1은 2024년 12월에 소개된 DeepSeek V3 아키텍처 위에 구축된 추론(reasoning) 모델입니다.
이 글의 초점이 2025년에 공개된 아키텍처이기는 하지만, DeepSeek V3는 R1의 2025년 출시 이후에야 널리 주목과 채택을 받았기 때문에 포함하는 것이 타당하다고 봅니다.
DeepSeek R1의 학습에 특히 관심이 있다면, 올해 초에 쓴 제 글도 도움이 될 수 있습니다:
이 섹션에서는 DeepSeek V3에 도입되어 계산 효율을 높였고 다른 많은 LLM과 구분되는 두 가지 핵심 아키텍처 기술에 집중하겠습니다.
Multi-Head Latent Attention(MLA)을 논하기 전에, 왜 이것을 쓰는지 동기를 위해 간단한 배경을 짚고 넘어가겠습니다. 최근 몇 년간 MHA의 연산/파라미터 효율을 개선한 표준 대체재가 된 Grouped-Query Attention(GQA)부터 시작하겠습니다.
간단히 GQA를 요약하면, MHA에서는 각 헤드가 자신만의 key와 value를 갖지만, GQA는 메모리 사용량을 줄이기 위해 여러 헤드를 묶어 동일한 key와 value 투영을 공유합니다.
예를 들어 아래 그림 2처럼 key-value 그룹이 2개이고 어텐션 헤드가 4개라면, 헤드 1과 2는 하나의 key-value 세트를 공유하고, 헤드 3과 4는 또 다른 세트를 공유합니다. 이렇게 하면 key와 value의 총 연산 수가 줄어 KV 캐시에 저장·조회해야 할 양이 감소하고, 메모리 사용량이 줄어 효율이 향상됩니다(절제 실험에 따르면 모델링 성능에 유의미한 손실 없이).

그림 2: MHA와 GQA 비교. 여기서 그룹 크기는 2이며, 하나의 key-value 쌍이 2개의 쿼리 사이에서 공유됩니다.
GQA의 핵심 아이디어는 여러 쿼리 헤드에 걸쳐 key와 value 헤드를 공유함으로써 key와 value 헤드의 수를 줄이는 것입니다. 이는 (1) 모델 파라미터 수를 낮추고 (2) 추론 중 KV 캐시에서 key/value 텐서를 저장·읽는 메모리 대역폭 사용량을 줄여 효율을 높입니다.
(GQA가 코드에서 어떻게 보이는지 궁금하다면, KV 캐시 없는 버전은 제 GPT-2에서 Llama 3 변환 가이드, KV 캐시 버전은 여기를 참고하세요.)
GQA는 주로 MHA의 계산 효율 개선을 위한 우회로이지만, 원조 GQA 논문과 Llama 2 논문 등의 절제 실험에 따르면 모델링 성능은 표준 MHA와 견줄 만합니다.
이제 Multi-Head Latent Attention(MLA)은 메모리 절감을 위한 또 다른 전략으로, 특히 KV 캐시와 궁합이 좋습니다. GQA처럼 key와 value 헤드를 공유하는 대신, MLA는 KV 캐시에 저장하기 전에 key와 value 텐서를 더 낮은 차원으로 압축합니다.
추론 시에는 아래 그림 3처럼 이 압축된 텐서를 다시 원래 크기로 투영해 사용합니다. 행렬 곱셈이 하나 추가되지만 메모리 사용량은 줄어듭니다.

그림 3: DeepSeek V3와 R1에서 사용한 MLA와 일반 MHA 비교.
(참고로, 쿼리도 학습 중에는 압축되지만, 추론 중에는 압축하지 않습니다.)
덧붙이면, MLA는 DeepSeek V3에서 처음 나온 것이 아닙니다. DeepSeek-V2 전작에서도 사용(심지어 도입)되었습니다. 또한 V2 논문에는 DeepSeek 팀이 GQA 대신 MLA를 선택한 이유를 설명해 줄 흥미로운 절제 실험들이 포함되어 있습니다(아래 그림 4 참고).

그림 4: DeepSeek-V2 논문에서 발췌·주석 추가, https://arxiv.org/abs/2405.04434
그림 4에서 보듯이, GQA는 MHA보다 성능이 떨어지는 반면 MLA는 MHA보다 더 나은 모델링 성능을 제공합니다. 아마 이것이 DeepSeek 팀이 GQA 대신 MLA를 선택한 이유일 것입니다. (MLA와 GQA의 "토큰당 KV 캐시" 절감량 비교도 있었으면 흥미로웠을 텐데요!)
정리하면, MLA는 KV 캐시 메모리 사용을 줄이는 영리한 요령이며, 모델링 성능 면에서도 MHA를 약간 상회합니다. 이제 다음 아키텍처 구성요소로 넘어가겠습니다.
DeepSeek에서 또 하나 강조할 만한 주요 아키텍처 구성요소는 Mixture-of-Experts(MoE) 레이어입니다. MoE는 DeepSeek의 발명은 아니지만, 올해 재조명되었고 이 글에서 다룰 몇몇 아키텍처도 채택하고 있습니다.
이미 MoE에 익숙하시겠지만, 간단히 복습해 보겠습니다.
MoE의 핵심 아이디어는 트랜스포머 블록의 FeedForward 모듈을 여러 개의 전문가(expert) 레이어로 대체하는 것입니다. 각 전문가 레이어 또한 FeedForward 모듈입니다. 즉, 아래 그림 5처럼 하나의 FeedForward 블록을 여러 개의 FeedForward 블록으로 교체합니다.

그림 5: 표준 FeedForward 블록(좌)과 DeepSeek V3/R1의 Mixture-of-Experts(MoE) 모듈(우) 비교.
트랜스포머 블록 안의 FeedForward 블록(위 그림에서 진회색)은 보통 모델 전체 파라미터의 큰 비중을 차지합니다. (참고로 트랜스포머 블록, 즉 FeedForward 블록은 LLM에서 여러 번 반복됩니다. DeepSeek-V3의 경우 61회.)
따라서 하나의 FeedForward 블록을 MoE 구성으로 여러 개의 FeedForward 블록으로 바꾸면 모델의 총 파라미터 수가 크게 증가합니다. 하지만 핵심 요령은 매 토큰마다 모든 전문가를 사용("활성화")하지 않는다는 것입니다. 대신 라우터가 토큰별로 소수의 전문가만 선택합니다. (지면 관계상, 라우터는 다음에 더 자세히 다루겠습니다.)
한 번에 일부 전문가만 활성화되기에, MoE 모듈은 항상 전체 파라미터를 사용하는 밀집(dense) 모듈과 달리 희소(sparse) 모듈로 불립니다. 그러나 MoE로 인해 모델의 총 파라미터 수 자체는 크게 늘어나므로 LLM의 용량(학습 중 지식을 더 많이 담을 수 있는 능력)은 증가합니다. 반면 추론 시에는 모든 파라미터를 동시에 쓰지 않기에 효율은 유지됩니다.
예를 들어, DeepSeek-V3는 MoE 모듈마다 256명의 전문가를 갖고 전체 파라미터는 671 billion입니다. 하지만 추론 시에는 매번 9명의 전문가(1명의 공유 전문가 + 라우터가 선택한 8명)만 활성화됩니다. 즉, 한 스텝 추론에 사용되는 파라미터는 전체 671 billion이 아닌 37 billion뿐입니다.
DeepSeek-V3의 MoE 설계에서 주목할만한 특징은 공유 전문가(shared expert)의 사용입니다. 공유 전문가는 모든 토큰에 대해 항상 활성화되는 전문가입니다. 이 아이디어는 DeepSeek 2024 MoE와 2022 DeepSpeedMoE 논문에서 이미 소개되었습니다.

그림 6: "DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models"에서 발췌·주석 추가, https://arxiv.org/abs/2401.06066
공유 전문가의 이점은 DeepSpeedMoE 논문에서 먼저 언급되었으며, 공유 전문가가 없는 경우보다 전반적인 모델링 성능이 향상됨을 보였습니다. 이는 빈번하거나 반복되는 패턴을 다수의 개별 전문가가 중복 학습하지 않아도 되어, 각 전문가가 더 특화된 패턴 학습에 역량을 할애할 수 있기 때문일 가능성이 큽니다.
정리하자면, DeepSeek-V3는 671-billion 파라미터의 거대한 모델로, 공개 당시 405B Llama 3를 포함한 다른 오픈 가중치 모델을 능가했습니다. 더 크지만, 토큰마다 MoE 구조 덕분에 소수(단 37B)의 파라미터만 활성화되어 추론 시 훨씬 효율적입니다.
또 다른 주요 차별점은 DeepSeek-V3가 GQA 대신 Multi-Head Latent Attention(MLA)을 사용한다는 것입니다. 둘 다 특히 KV 캐시를 사용할 때 표준 MHA보다 추론 효율이 좋습니다. MLA는 구현이 더 복잡하지만, DeepSeek-V2 논문에서의 연구는 MLA가 GQA보다 더 나은 모델링 성능을 제공함을 보였습니다.
비영리 Allen Institute for AI의 OLMo 시리즈는 학습 데이터와 코드의 투명성, 그리고 비교적 자세한 기술 보고서로 주목할 만합니다.
OLMo 모델이 벤치마크나 리더보드 최상단에 올라 있는 경우는 드물지만, 깔끔하고 투명성 덕분에 LLM 개발의 훌륭한 청사진 역할을 합니다.
또한 투명성으로 유명하지만 성능도 나쁘지 않습니다. 실제로 1월 공개 당시(아직 Llama 4, Gemma 3, Qwen 3 이전에는) OLMo 2는 아래 그림 7처럼 연산 대비 성능의 파레토 전선에 있었습니다.
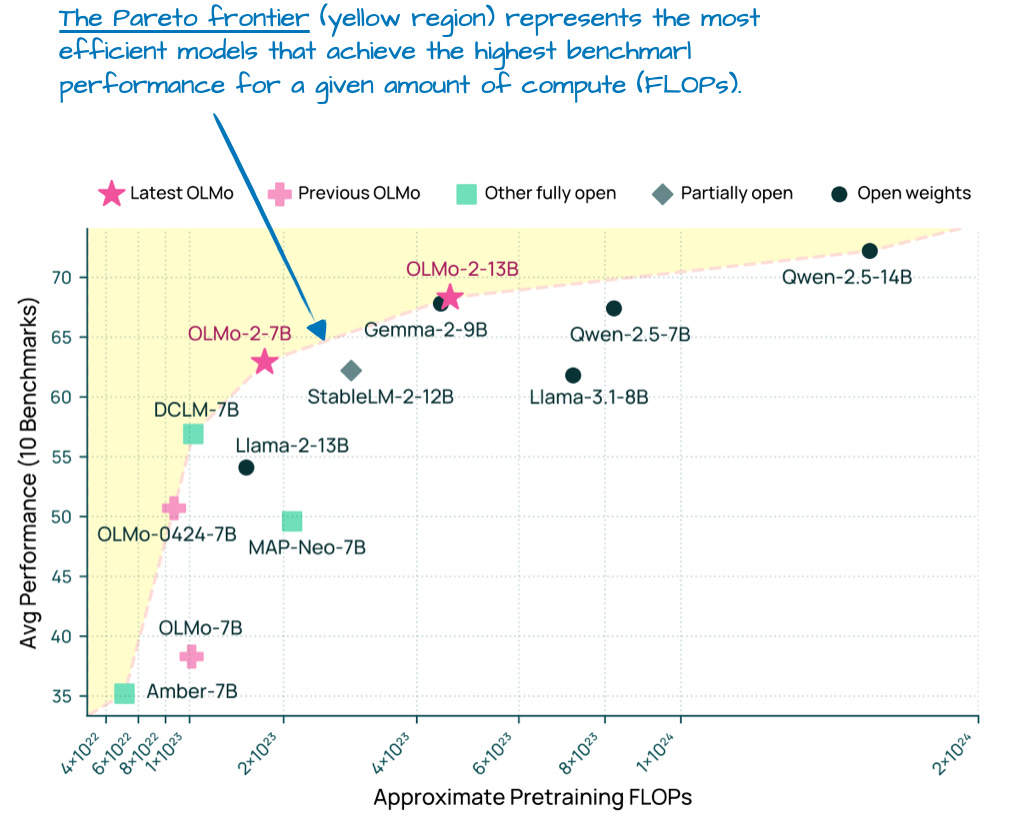
그림 7: 여러 LLM의 모델링 벤치마크 성능(높을수록 좋음) vs 사전학습 비용(FLOPs; 낮을수록 좋음). OLMo 2 논문에서 발췌·주석 추가, https://arxiv.org/abs/2501.00656
앞서 언급했듯, 글의 길이를 관리하기 위해 여기서는 LLM의 아키텍처 세부(학습·데이터 제외)에만 집중합니다. 그렇다면 OLMo 2에서 흥미로운 아키텍처 설계 선택은 무엇이었을까요? 주로 정규화(normalization)에 관한 것으로, RMSNorm 레이어의 위치와 QK-Norm의 도입입니다. 아래에서 논의하겠습니다.
또 하나 언급할 점은 OLMo 2가 여전히 MLA나 GQA 대신 전통적인 Multi-Head Attention(MHA)을 사용한다는 것입니다.
전반적으로 OLMo 2는 다른 동시대 LLM처럼 원조 GPT 아키텍처를 대체로 따릅니다. 하지만 주목할 만한 차이점이 있습니다. 정규화 레이어부터 시작해 봅시다.
Llama, Gemma, 대부분의 다른 LLM과 마찬가지로 OLMo 2는 LayerNorm에서 RMSNorm으로 전환했습니다.
하지만 RMSNorm은 이제 익숙한 주제이므로(사실상 학습 가능한 파라미터가 더 적은 간소화된 LayerNorm) 여기서는 논의를 생략하겠습니다. (자세한 구현 코드는 제 GPT-2에서 Llama 변환 가이드에서 볼 수 있습니다.)
다만 RMSNorm의 배치 위치는 논할 가치가 있습니다. 원조 트랜스포머(“Attention is all you need”)에서는 트랜스포머 블록 안의 두 개 정규화 레이어를 각각 어텐션 모듈과 FeedForward 모듈 _뒤_에 배치했습니다.
이를 Post-LN 또는 Post-Norm이라고 부릅니다.
그 이후 GPT를 포함한 대부분의 LLM은 정규화 레이어를 어텐션과 FeedForward 모듈 _앞_에 배치했는데, 이를 Pre-LN 또는 Pre-Norm이라 합니다. 아래 그림은 Post-Norm과 Pre-Norm을 비교합니다.

그림 8: Post-Norm, Pre-Norm, 그리고 OLMo 2식 Post-Norm 비교.
2020년 Xiong 등은 Pre-LN이 초기화 시 그래디언트가 더 안정적임을 보였습니다. 또한 Pre-LN은 학습률 웜업 없이도 잘 동작하는데, 이는 Post-LN에는 매우 중요한 도구입니다.
이를 언급하는 이유는 OLMo 2가 LayerNorm 대신 RMSNorm을 쓰지만 형태상 Post-LN(여기서는 Post-Norm)을 채택했기 때문입니다.
OLMo 2에서는 정규화 레이어를 어텐션과 FeedForward 레이어의 앞이 아닌 뒤에 배치합니다(위 그림 참고). 다만 원조 트랜스포머와 달리 정규화 레이어가 여전히 스킵 연결(잔차 연결) 내부에 위치합니다.
그렇다면 왜 정규화 레이어 위치를 옮겼을까요? 그 이유는 아래 그림에서 보이듯 학습 안정성에 도움이 되었기 때문입니다.

그림 9: Pre-Norm(GPT-2, Llama 3 등)과 OLMo 2식 Post-Norm의 학습 안정성 비교. OLMo 2 논문에서 발췌·주석 추가, https://arxiv.org/abs/2501.00656
아쉬운 점은 이 그림이 레이어 재배치와 QK-Norm을 함께 보여줘, 정규화 레이어 재배치만의 기여도를 따로 보기 어렵다는 것입니다.
앞선 섹션에서 QK-Norm이 언급되었고, 이후 다룰 Gemma 2와 Gemma 3도 QK-Norm을 사용하므로 간단히 설명하겠습니다.
QK-Norm은 본질적으로 또 하나의 RMSNorm 레이어입니다. Multi-Head Attention(MHA) 모듈 내부에서 쿼리(q)와 키(k)에 RoPE를 적용하기 전에 이를 적용합니다. 이를 보여주기 위해, 제가 Qwen3 from-scratch 구현을 위해 작성한 Grouped-Query Attention(GQA) 층의 일부를 아래에 발췌합니다(GQA에서의 QK-Norm 적용은 OLMo의 MHA와 유사합니다).
class GroupedQueryAttention(nn.Module):
def __init__(
self, d_in, num_heads, num_kv_groups,
head_dim=None, qk_norm=False, dtype=None
):
# ...
if qk_norm:
self.q_norm = RMSNorm(head_dim, eps=1e-6)
self.k_norm = RMSNorm(head_dim, eps=1e-6)
else:
self.q_norm = self.k_norm = None
def forward(self, x, mask, cos, sin):
b, num_tokens, _ = x.shape
# Apply projections
queries = self.W_query(x)
keys = self.W_key(x)
values = self.W_value(x)
# ...
# Optional normalization
if self.q_norm:
queries = self.q_norm(queries)
if self.k_norm:
keys = self.k_norm(keys)
# Apply RoPE
queries = apply_rope(queries, cos, sin)
keys = apply_rope(keys, cos, sin)
# Expand K and V to match number of heads
keys = keys.repeat_interleave(self.group_size, dim=1)
values = values.repeat_interleave(self.group_size, dim=1)
# Attention
attn_scores = queries @ keys.transpose(2, 3)
# ...
앞서 언급했듯, Post-Norm과 함께 QK-Norm은 학습을 안정화합니다. QK-Norm은 OLMo 2의 발명은 아니고 2023년 Scaling Vision Transformers 논문으로 거슬러 올라갑니다.
요약하면, OLMo 2의 주목할 아키텍처 설계 결정은 주로 RMSNorm 배치입니다. 어텐션과 FeedForward 앞이 아닌 뒤에 RMSNorm을 두는 것(일종의 Post-Norm), 그리고 어텐션 내부에서 쿼리와 키에 RMSNorm을 추가하는 것(QK-Norm). 이 둘이 함께 학습 손실을 안정화합니다.
아래 그림은 OLMo 2와 Llama 3를 나란히 비교한 것으로, 전반적 아키텍처는 상당히 유사하지만 OLMo 2는 여전히 GQA 대신 전통적인 MHA를 쓰는 점이 다릅니다. (다만, 3개월 뒤 OLMo 2 팀은 GQA를 사용하는 32B 변종을 공개했습니다.)

그림 10: Llama 3와 OLMo 2의 아키텍처 비교.
Google의 Gemma 모델은 항상 매우 좋았고, Llama 시리즈처럼 인기 있는 모델들과 비교하면 다소 과소평가되었다고 생각합니다.
Gemma의 차별점 중 하나는 다국어 지원을 위해 비교적 큰 어휘 규모와, 27B 크기에 더 집중한다는 점입니다(8B나 70B 대비). 물론 Gemma 2는 1B, 4B, 12B 같은 작은 크기들도 있습니다.
27B는 아주 좋은 스위트 스폿입니다. 8B보다 훨씬 더 유능하지만 70B만큼 리소스를 많이 쓰지 않고, 제 맥 미니에서도 무리 없이 잘 돌아갑니다.
그렇다면 Gemma 3에서 흥미로운 점은 무엇일까요? 앞서 논했듯, DeepSeek-V3/R1 같은 다른 모델들은 고정된 모델 크기에서 추론 시 메모리 요구량을 줄이기 위해 MoE를 사용합니다(이 접근은 뒤에서 다룰 여러 모델에도 쓰입니다).
Gemma 3는 계산 비용을 줄이기 위해 다른 "요령"을 씁니다. 바로 슬라이딩 윈도우 어텐션입니다.
슬라이딩 윈도우 어텐션은 (원래 2020년 LongFormer 논문에서 소개되어 Gemma 2에서도 이미 사용) KV 캐시 메모리 요구량을 크게 줄일 수 있었고, 아래 그림처럼 그 절감량이 제시됩니다.

그림 11: 슬라이딩 윈도우 어텐션을 통한 KV 캐시 메모리 절감(Gemma 3 논문 발췌·주석, https://arxiv.org/abs/2503.19786).
그렇다면 슬라이딩 윈도우 어텐션이란 무엇일까요? 일반적인 자기어텐션을 각 시퀀스 요소가 모든 다른 요소에 접근 가능한 글로벌 어텐션으로 생각한다면, 슬라이딩 윈도우 어텐션은 현재 쿼리 위치 주변의 문맥 크기를 제한하므로 로컬 어텐션이라 볼 수 있습니다. 아래 그림에 설명되어 있습니다.
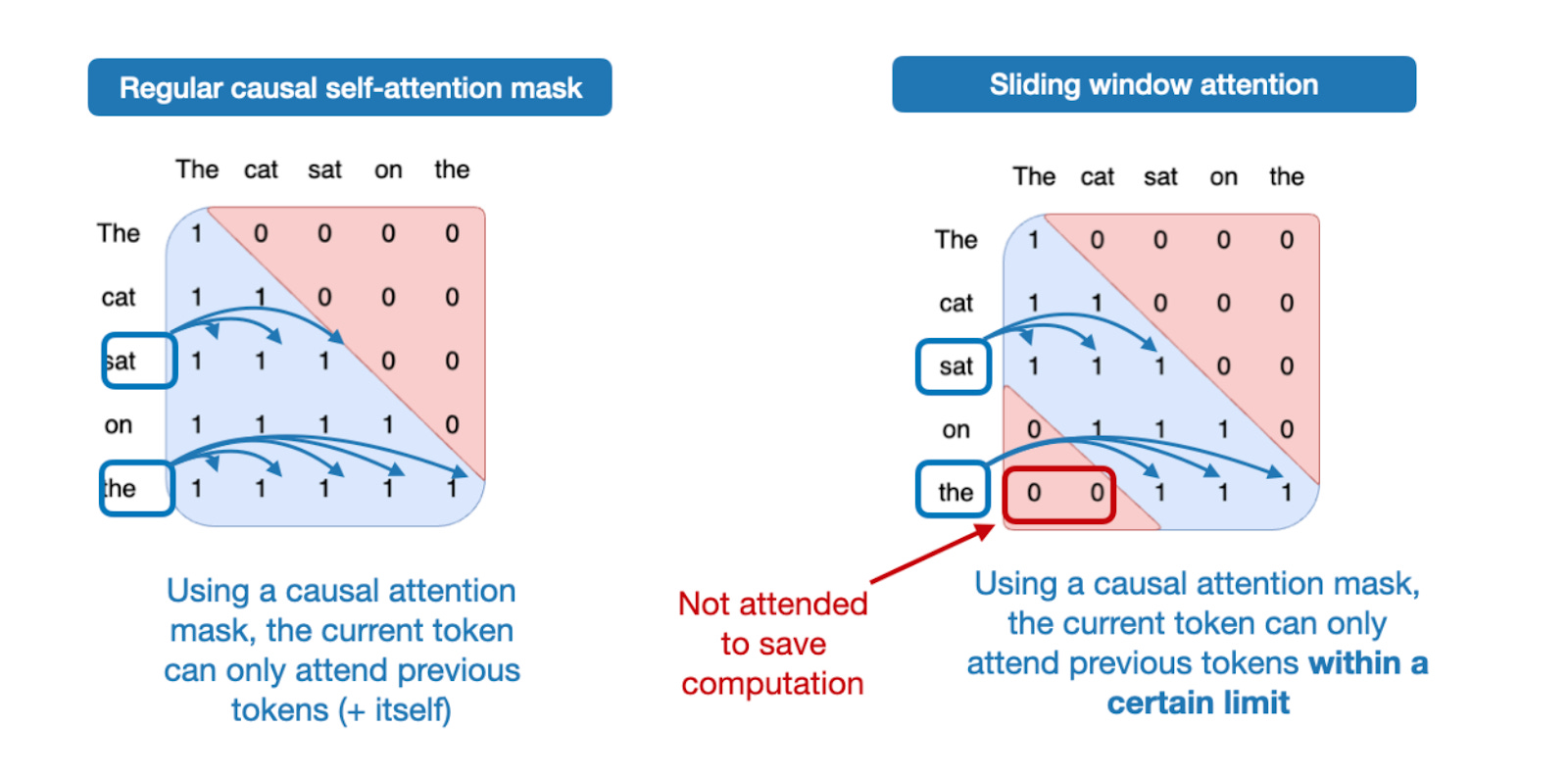
그림 12: 일반 어텐션(좌)과 슬라이딩 윈도우 어텐션(우) 비교.
슬라이딩 윈도우 어텐션은 MHA와 GQA 모두와 함께 사용할 수 있습니다. Gemma 3는 GQA를 사용합니다.
앞서 말했듯 슬라이딩 윈도우 어텐션은 로컬 창이 현재 쿼리 위치를 둘러싸며 함께 움직이기 때문에 로컬 어텐션이라고도 합니다. 반면 일반 어텐션은 각 토큰이 다른 모든 토큰에 접근 가능한 글로벌 어텐션입니다.
앞서 간략히 언급했듯, 전작 Gemma 2도 슬라이딩 윈도우 어텐션을 사용했습니다. Gemma 3의 차이는 글로벌(일반)과 로컬(슬라이딩) 어텐션 간의 비율을 조정했다는 점입니다.
예를 들어 Gemma 2는 슬라이딩 윈도우(로컬)와 글로벌 어텐션을 1:1로 혼합합니다. 각 토큰은 주변 4k 토큰의 문맥을 볼 수 있습니다.
Gemma 2는 모든 레이어 중 격 레이어마다 슬라이딩 윈도우를 사용했지만, Gemma 3는 이제 5:1 비율을 채택합니다. 즉, 슬라이딩 윈도우(로컬) 어텐션 5개마다 글로벌 어텐션 레이어 1개만 둡니다. 게다가 슬라이딩 윈도우 크기를 Gemma 2의 4096에서 Gemma 3에서는 1024로 줄였습니다. 이는 모델의 초점을 보다 효율적인 로컬 계산으로 옮기는 변화입니다.
절제 실험에 따르면, 슬라이딩 윈도우 어텐션 사용은 모델링 성능에 미치는 영향이 미미합니다(아래 그림 참고).

그림 13: 슬라이딩 윈도우 어텐션이 LLM이 생성한 출력의 퍼플렉서티에 거의 영향을 주지 않음을 보이는 그림(Gemma 3 논문 발췌·주석, https://arxiv.org/abs/2503.19786).
슬라이딩 윈도우 어텐션은 Gemma 3의 가장 주목할 아키텍처 측면이지만, 앞선 OLMo 2 섹션의 연장선으로 정규화 레이어의 배치도 간단히 짚고 넘어가겠습니다.
강조할 만한 작은 포인트는 Gemma 3가 GQA 모듈 주변에 Pre-Norm과 Post-Norm의 두 형태로 RMSNorm을 모두 사용한다는 것입니다.
이는 Gemma 2와 유사하지만, (1) 원조 트랜스포머(“Attention is all you need”)의 Post-Norm, (2) GPT-2가 대중화하고 이후 많은 아키텍처가 사용한 Pre-Norm, (3) 앞서 본 OLMo 2의 Post-Norm 변형과는 배치가 다르다는 점에서 주목할 가치가 있습니다.

그림 14: OLMo2와 Gemma 3의 아키텍처 비교; Gemma 3의 추가 정규화 레이어에 주목.
이 정규화 레이어 배치는 Pre-Norm과 Post-Norm의 장점을 모두 취하는 직관적 접근이라고 생각합니다. 제 의견으로는 약간의 추가 정규화는 해가 될 것이 없습니다. 설령 중복으로 비효율이 약간 생긴다 해도, RMSNorm의 비용은 전체 대비 매우 작아 체감 영향은 거의 없을 것입니다.
Gemma 3는 뛰어난 오픈 가중치 LLM이며, 제 생각에는 오픈소스 커뮤니티에서 다소 과소평가되어 있습니다. 가장 흥미로운 부분은 효율 향상을 위해 슬라이딩 윈도우 어텐션을 사용했다는 점입니다(향후 MoE와 결합하면 더 흥미로울 것입니다).
또한 Gemma 3는 정규화 레이어 배치가 독특하여, 어텐션과 FeedForward 모듈의 앞뒤 모두에 RMSNorm을 배치합니다.
Gemma 3 출시 몇 달 후, Google은 Gemma 3n을 공개했습니다. Gemma 3n은 폰에서의 실행을 목표로 소형 디바이스 효율을 위해 최적화된 Gemma 3 모델입니다.
Gemma 3n에서 효율을 높이기 위한 변경 중 하나가 이른바 Per-Layer Embedding(PLE) 파라미터 레이어입니다. 핵심 아이디어는 모델 파라미터 중 일부만 GPU 메모리에 유지하고, 텍스트·오디오·비전 모달리티 등 토큰·레이어 특이 임베딩은 필요할 때 CPU나 SSD에서 스트리밍하는 것입니다.
아래 그림은 PLE 메모리 절감을 보여주며, 표준 Gemma 3 모델의 파라미터가 5.44 billion이라고 표시합니다. 이는 아마 Gemma 3의 4-billion 변종을 가리키는 듯합니다.

그림 15: PLE 메모리 절감을 보여주는 Google의 Gemma 3n 블로그 발췌·주석(https://developers.googleblog.com/en/introducing-gemma-3n/).
5.44 vs. 4 billion의 차이는 Google이 LLM 파라미터 수를 보고하는 흥미로운 관행 때문입니다. 보통 임베딩 파라미터를 제외해 모델을 더 작아 보이게 하지만, 이번처럼 모델을 더 커 보이게 할 필요가 있을 때는 임베딩을 포함합니다. 이 점은 Google만의 일은 아니고, 업계 전반에서 흔한 관행이 되었습니다.
또 하나 흥미로운 요령은 MatFormer 개념(마트료시카 트랜스포머)입니다. 예를 들어 Gemma 3n은 하나의 공유 LLM(트랜스포머) 아키텍처를 작은 독립 모델들로 슬라이스해 사용할 수 있습니다. 각 슬라이스는 독자적으로 동작하도록 학습되므로, 추론 시 큰 모델 전체가 아닌 필요한 부분만 실행할 수 있습니다.
Mistral Small 3.1 24B는 Gemma 3 직후인 3월에 공개되었는데, 더 빠르면서도 여러 벤치마크(수학 제외)에서 Gemma 3 27B를 능가한 점이 주목됩니다.
Mistral Small 3.1이 Gemma 3보다 지연 시간이 낮은 이유는 커스텀 토크나이저, KV 캐시와 레이어 수 축소 덕분일 가능성이 큽니다. 그 외에는 아래 그림처럼 표준적인 아키텍처입니다.

그림 16: Gemma 3 27B와 Mistral 3.1 Small 24B의 아키텍처 비교.
흥미롭게도, 초기 Mistral 모델은 슬라이딩 윈도우 어텐션을 사용했지만 Mistral Small 3.1에서는 이를 포기한 듯합니다. Gemma 3는 슬라이딩 윈도우가 있는 GQA를 쓰지만 Mistral은 일반 GQA를 써서, 더 최적화된 코드(예: FlashAttention)를 사용해 추가 추론 계산 절감을 얻었을 수도 있습니다. 제 추측으로는, 슬라이딩 윈도우 어텐션은 메모리 사용량을 줄이지만, Mistral Small 3.1이 초점을 맞추는 추론 지연 시간을 반드시 줄이지는 않을 수 있습니다.
이 글 앞부분에서 길게 논한 Mixture-of-Experts(MoE)가 다시 빛을 발합니다. Llama 4도 MoE 접근을 채택했고, 아래 그림처럼 전반적으로 DeepSeek-V3와 매우 유사한 표준 아키텍처를 따릅니다. (Llama 4는 Gemma, Mistral처럼 네이티브 멀티모달을 포함하지만, 이 글은 언어 모델링에만 초점을 둡니다.)

그림 17: DeepSeek V3(671-billion 파라미터)와 Llama 4 Maverick(400-billion 파라미터)의 아키텍처 비교.
Llama 4 Maverick 아키텍처는 전체적으로 DeepSeek-V3와 매우 비슷해 보이나, 강조할 차이점이 몇 가지 있습니다.
첫째, Llama 4는 전작들과 유사하게 GQA를 사용하는 반면, DeepSeek-V3는 이 글 서두에서 논한 Multi-Head Latent Attention을 사용합니다. 두 모델 모두 아주 큰 아키텍처로, 총 파라미터 수는 DeepSeek-V3가 약 68% 더 큽니다. 그러나 활성 파라미터 기준으로는 DeepSeek-V3가 37 billion으로 Llama 4 Maverick(17B)의 2배 이상입니다.
Llama 4 Maverick은 DeepSeek-V3(활성 전문가 9명, hidden 2,048) 대비 더 전통적인 MoE 설정을 택해, 더 적지만 더 큰 전문가(활성 2명, hidden 8,192)를 사용합니다. 또한 DeepSeek는 (처음 3개를 제외한) 매 트랜스포머 블록마다 MoE 레이어를 사용하는 반면, Llama 4는 매 블록을 번갈아 MoE와 밀집 모듈로 교대합니다.
아키텍처 간 작은 차이가 많아 최종 성능에 미치는 정확한 영향을 단정하기는 어렵습니다. 다만 2025년에 MoE 아키텍처의 인기가 크게 상승했다는 점이 핵심입니다.
Qwen 팀은 일관되게 고품질의 오픈 가중치 LLM을 내놓고 있습니다. NeurIPS 2023 LLM 효율 대회를 공동 조언했을 때, 상위 입상 솔루션이 모두 Qwen2 기반이었던 것으로 기억합니다.
이제 Qwen3도 각 크기 클래스에서 리더보드를 장악한 히트 시리즈입니다. 밀집(dense) 모델은 0.6B, 1.7B, 4B, 8B, 14B, 32B의 7종이 있고, MoE 모델은 30B-A3B, 235B-A22B의 2종이 있습니다.
(덧붙여, "Qwen3"에 공백이 없는 것은 오타가 아닙니다. Qwen 개발자들이 택한 표기를 그대로 따릅니다.)
먼저 밀집 아키텍처를 논의하겠습니다. 이 글을 쓰는 시점에서 0.6B 모델은 최신 세대 오픈 가중치 모델 중 가장 작은 축일 것입니다. 제 경험상 작은 크기 대비 성능이 매우 좋습니다. 로컬 실행을 고려한다면 토큰/초 처리량이 좋고 메모리 발자국도 작습니다. 더 나아가 작은 크기 덕분에 (교육 목적으로) 로컬에서 학습하기도 쉽습니다.
그래서 Qwen3 0.6B는 제게 대부분의 용도에서 Llama 3 1B를 대체했습니다. 두 아키텍처 비교는 아래에 있습니다.

그림 18: Qwen3 0.6B와 Llama 3 1B의 아키텍처 비교; Qwen3는 레이어 수가 더 많은 깊은 아키텍처, Llama 3는 어텐션 헤드가 더 많은 넓은 아키텍처.
외부 LLM 라이브러리 의존성 없이 읽기 쉬운 Qwen3 구현에 관심이 있다면, 최근에 순수 PyTorch로 Qwen3를 처음부터 구현했습니다.
위 그림의 계산 성능 수치는 제가 A100 GPU에서 실행한 from-scratch PyTorch 구현을 기반으로 합니다. 보시다시피 Qwen3는 전반적으로 더 작은 아키텍처이고 히든 차원과 어텐션 헤드 수도 더 적어 메모리 발자국이 작습니다. 그러나 트랜스포머 블록이 더 많아 런타임이 느립니다(토큰/초 생성 속도 낮음).
앞서 언급했듯 Qwen3는 30B-A3B와 235B-A22B의 두 가지 MoE 변종도 제공합니다. 왜 Qwen3 같은 아키텍처는 밀집과 MoE(희소) 변종을 함께 제공할까요?
글 서두에서 언급했듯, MoE 변종은 큰 기본 모델의 추론 비용을 줄이는 데 도움을 줍니다. 밀집과 MoE 버전을 모두 제공하면 사용자는 목표와 제약에 따라 선택할 수 있습니다.
밀집 모델은 보통 다양한 하드웨어에서 파인튜닝·배포·최적화가 더 단순합니다.
반면 MoE 모델은 추론 스케일링에 최적화되어 있습니다. 고정된 추론 예산에서, 파라미터(즉, 학습 중 지식 흡수 능력)를 더 크게 가져가면서도 추론 비용을 비례해 늘리지 않을 수 있습니다.
두 유형을 함께 공개함으로써 Qwen3 시리즈는 더 넓은 활용 사례를 지원합니다. 밀집 모델은 견고함·단순함·파인튜닝 용이성, MoE 모델은 대규모 서빙 효율성을 제공합니다.
이 섹션을 마무리하며, 활성 파라미터가 거의 2배(37B)인 DeepSeek-V3와 Qwen3 235B-A22B(여기서 A22B는 "22B 활성 파라미터"를 의미)를 비교해 보겠습니다.

그림 19: DeepSeek-V3와 Qwen3 235B-A22B의 아키텍처 비교.
위 그림에서 보듯 DeepSeek-V3와 Qwen3 235B-A22B의 아키텍처는 놀라울 만큼 유사합니다. 주목할 점은 Qwen3가 공유 전문가 사용을 중단했다는 것입니다(이전 Qwen2.5-MoE는 공유 전문가를 사용했음).
안타깝게도 Qwen3 팀은 공유 전문가를 포기한 이유를 밝히지 않았습니다. 제 추측으로는, 전문가 수를 Qwen2.5-MoE의 2명에서 Qwen3의 8명으로 늘렸을 때 학습 안정성에 공유 전문가가 굳이 필요하지 않았을 수 있습니다. 그러면 8+1이 아닌 8명만 쓰면서 추가 계산/메모리 비용을 절약할 수 있겠지요. (다만 이것이 DeepSeek-V3가 여전히 공유 전문가를 유지하는 이유를 설명해 주지는 않습니다.)
업데이트. Junyang Lin, Qwen3 개발자 중 한 명의 답변은 다음과 같습니다.
그 당시 공유 전문가에서 충분히 의미 있는 향상을 찾지 못했고, 공유 전문가가 추론 최적화에 야기할 수 있는 문제를 우려했습니다. 정답이 딱 있는 사안은 아닙니다.
SmolLM3는 이 글의 다른 LLM들만큼 널리 알려진 모델은 아닐지 모르지만, 3-billion이라는 편리한 크기에서 상당히 좋은 모델링 성능을 제공하여 포함할 만하다고 생각했습니다. 이는 아래 그림처럼 Qwen3 1.7B와 4B 사이에 위치합니다.
게다가 OLMo처럼 학습 세부도 많이 공개했는데, 이는 드물고 늘 환영할 일입니다!

그림 20: SmolLM3 발표 글(https://huggingface.co/blog/smollm3)에서 발췌·주석. Qwen3 1.7B/4B, Llama 3 3B, Gemma 3 4B 대비 SmolLM3의 승률 비교.
아키텍처 비교 그림에서 보듯 SmolLM3의 아키텍처는 꽤 표준적입니다. 가장 흥미로운 점은 NoPE(No Positional Embeddings)의 사용일 것입니다.
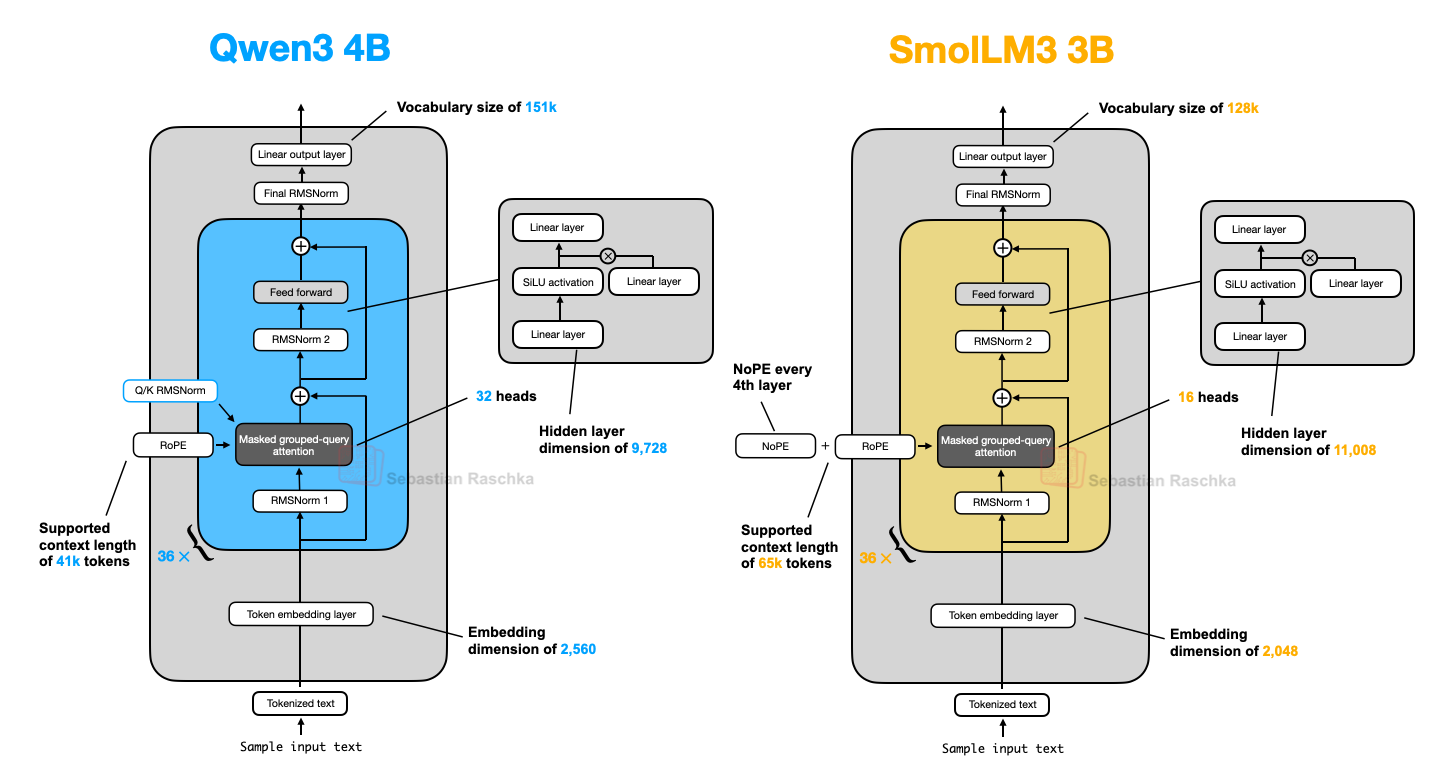
그림 21: Qwen3 4B와 SmolLM3 3B의 아키텍처 비교.
NoPE는 LLM 맥락에서 2023년 논문(The Impact of Positional Encoding on Length Generalization in Transformers)으로 거슬러 올라가며, 명시적 위치 정보 주입(초기 GPT 아키텍처의 절대적 위치 임베딩, 혹은 요즘의 RoPE 등)을 제거하는 아이디어입니다.
트랜스포머 기반 LLM에서는 자기어텐션이 토큰을 순서와 무관하게 취급하기 때문에, 보통 위치 인코딩이 필요합니다. 절대적 위치 임베딩은 토큰 임베딩에 추가 임베딩을 더해 이 문제를 해결합니다.

그림 22: 절대적 위치 임베딩을 설명하는 제 저서 Build A Large Language Model (From Scratch)의 수정 그림(https://www.amazon.com/Build-Large-Language-Model-Scratch/dp/1633437167).
한편 RoPE는 토큰 위치에 따라 쿼리와 키 벡터를 회전시켜 이를 해결합니다.
하지만 NoPE에서는 이런 위치 신호를 일절 추가하지 않습니다. 고정도, 학습도, 상대적도 아닙니다. 아무것도요.
그럼에도 인과(causal) 어텐션 마스크 덕분에 모델은 어떤 토큰이 앞에 오는지 압니다. 이 마스크는 각 토큰이 미래 토큰에 주의를 기울이지 못하게 합니다. 결과적으로 위치 t의 토큰은 위치 ≤ t의 토큰만 볼 수 있어, 오토리그레시브 순서가 보존됩니다.
즉, 명시적 위치 정보는 추가하지 않지만, 모델 구조에 암묵적 방향성이 내재되어 있고, LLM은 정규의 경사하강법 학습 중 필요하다면 이를 최적화 목표에 활용하도록 학습할 수 있습니다(자세한 내용은 NoPE 논문의 정리를 보세요).
종합하면, NoPE 논문은 위치 정보 주입이 불필요할 뿐 아니라, 길이 일반화가 더 좋다고 보고합니다. 즉, 시퀀스 길이가 길어질수록 LLM의 응답 성능 저하가 덜합니다(아래 그림 참고).

그림 23: NoPE에서 더 나은 길이 일반화를 보여주는 그림(NoPE 논문 발췌·주석, https://arxiv.org/abs/2305.19466).
위 실험은 약 1억 파라미터의 비교적 작은 GPT 스타일 모델과 작은 컨텍스트 크기에서 수행되었음을 유념하십시오. 이 발견이 더 크고 현대적인 LLM에도 잘 일반화되는지는 명확하지 않습니다.
이러한 이유로 SmolLM3 팀은 아마도 NoPE(정확히는 RoPE 생략)를 매 4번째 레이어에만 적용했을 것입니다.
Kimi 2는 놀라울 정도로 뛰어난 성능의 오픈 가중치 모델로 AI 커뮤니티에 큰 반향을 일으켰습니다. 벤치마크에 따르면 Google Gemini, Anthropic Claude, OpenAI ChatGPT 같은 최고 수준의 상용 모델과 동급입니다.
주목할 점은 비교적 새로운 Muon 옵티마이저를 AdamW 대신 사용했다는 것입니다. 제가 아는 한 이 규모의 프로덕션 모델에서 AdamW 대신 Muon을 사용한 것은 처음입니다(이전에는 16B까지 스케일만 보였습니다). 그 결과 학습 손실 곡선이 매우 좋아졌고, 이는 앞서 언급한 벤치마크에서 최상위에 오르는 데 기여했을 것입니다.
사람들은 스파이크가 없어서 손실이 유달리 매끈하다고 논평했지만, 제 생각에 그것이 특별히 매끈한 것은 아닙니다(예: 아래 그림의 OLMo 2 손실 곡선 참고; 또한 학습 안정성 지표로는 그래디언트의 L2 노름을 추적하는 편이 더 낫습니다). 다만 손실 곡선이 매우 잘 감쇠한다는 점이 주목할 만합니다.
하지만 서두에서 언급했듯, 학습 방법론 이야기는 다음에 하겠습니다.

그림 24: Kimi K2 발표 블로그(https://moonshotai.github.io/Kimi-K2/)와 OLMo 2 논문(https://arxiv.org/abs/2305.19466)에서 발췌·주석.
모델 자체는 1 trillion 파라미터 규모로, 실로 인상적입니다.
이 글을 쓰는 시점에서(아직 Llama 4 Behemoth 미공개, 상용 LLM 제외, Google의 1.6 trillion Switch Transformer는 다른 세대의 인코더-디코더 아키텍처) 이 세대 최대 LLM일 수 있습니다.
또한 Kimi 2는 이 글 초반에 다룬 DeepSeek-V3 아키텍처를 그대로 사용하되 더 크게 확장했습니다(아래 그림 참고).

그림 25: DeepSeek V3와 Kimi K2의 아키텍처 비교.
위 그림에서 보듯 Kimi 2.5는 기본적으로 DeepSeek V3와 동일하지만, MoE에서 더 많은 전문가를 쓰고 MLA에서 더 적은 헤드를 사용합니다.
Kimi 2는 갑자기 나온 모델이 아닙니다. 앞서 Kimi k1.5: Scaling Reinforcement Learning with LLMs 논문에서 논의된 Kimi 1.5도 인상적이었습니다. 다만 1월 22일 DeepSeek R1 논문이 같은 날 공개되는 불운이 있었고, 제 아는 한 Kimi 1.5의 가중치는 공개되지 않았습니다.
아마 Kimi K2 팀은 이 교훈을 살려 DeepSeek R2 공개 전 오픈 가중치로 Kimi K2를 공개했을 것입니다. 이 글을 쓰는 시점에서 Kimi K2는 가장 인상적인 오픈 가중치 모델입니다.
OpenAI는 제가 이 글을 쓴 지 약 일주일 뒤, 2019년 GPT-2 이후 처음으로 오픈 가중치 모델 gpt-oss-120b와 gpt-oss-20b를 공개했습니다. OpenAI의 오픈 가중치 모델이 워낙 오래 기다려졌던 만큼, 이 글에 업데이트로 포함합니다. 이 섹션은 간단히 요약하고, gpt-oss에 대해서는 더 자세한 전용 글을 별도로 작성했습니다.
흥미로운 포인트를 요약하기 전에, 아래 그림 26에서 두 모델(gpt-oss-20b, gpt-oss-120b)의 개요를 먼저 보겠습니다.
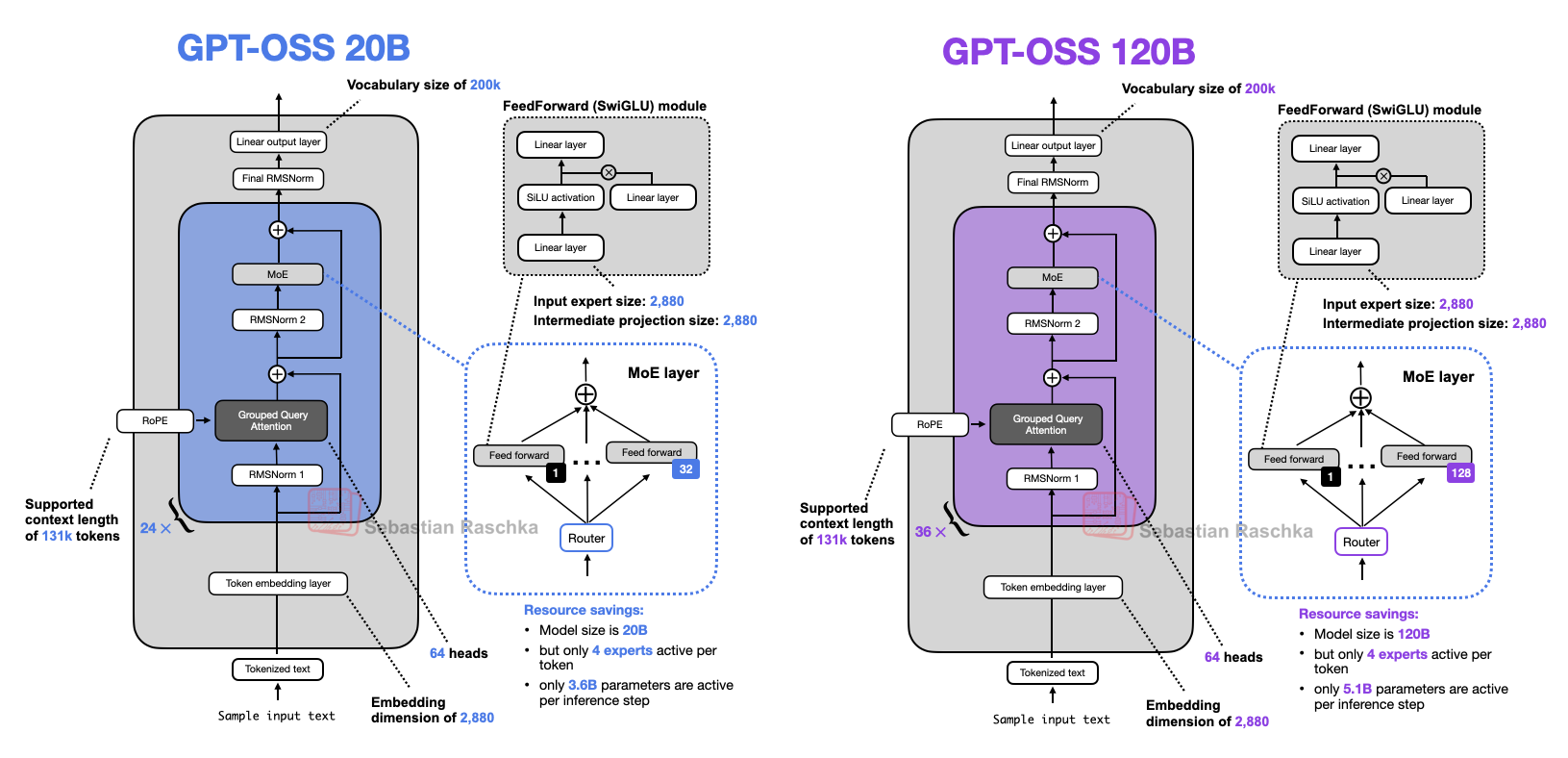
그림 26: 두 gpt-oss 모델의 아키텍처 개요.
그림 26을 보면, 앞서 다룬 다른 아키텍처에서 본 익숙한 구성요소가 모두 보입니다. 예를 들어, 아래 그림 27은 더 작은 gpt-oss를 활성 파라미터 수가 유사한 Qwen3 30B-A3B(둘 다 MoE, gpt-oss는 3.6B, Qwen3 30B-A3B는 3.3B) 옆에 놓고 비교합니다.
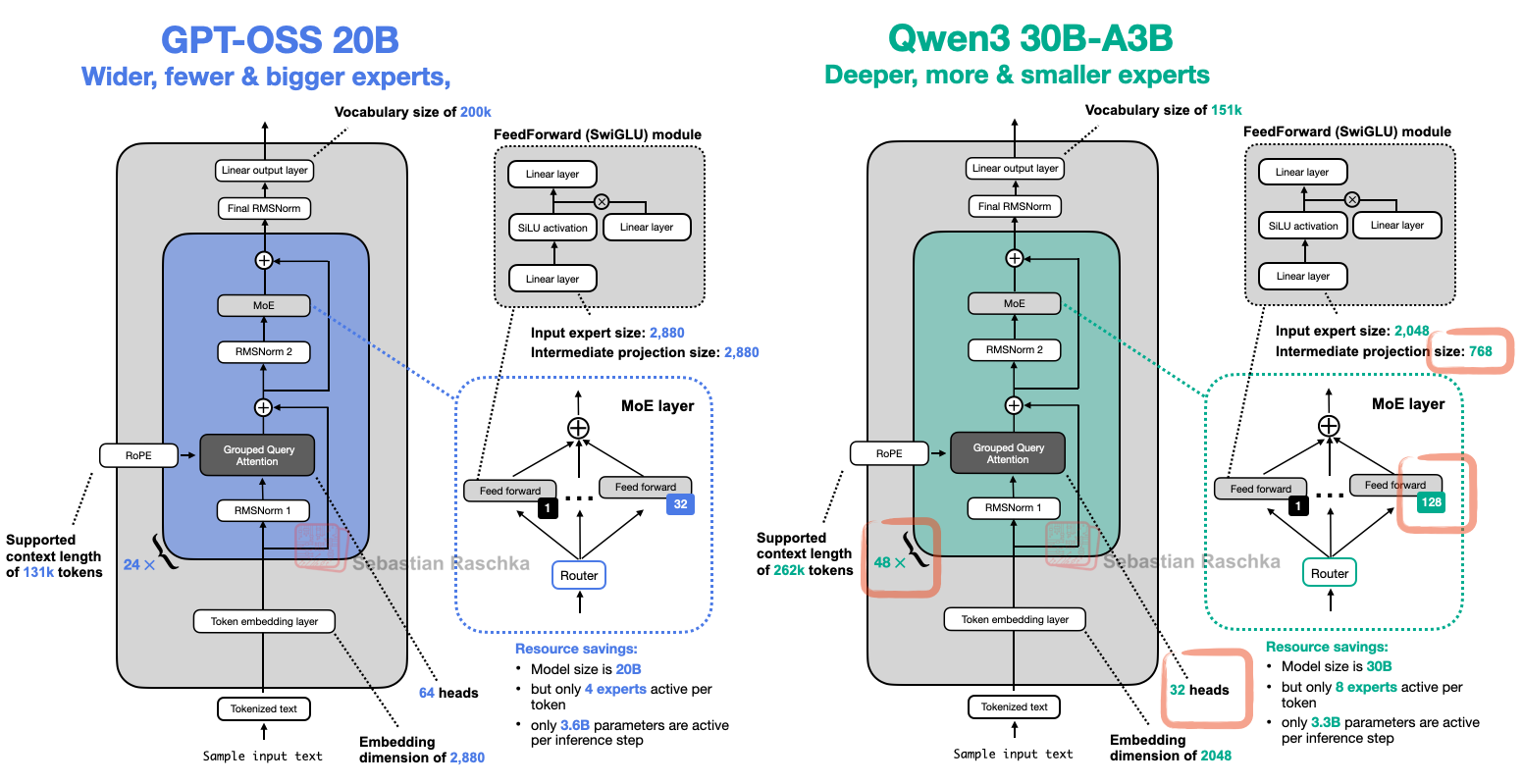
그림 27: gpt-oss와 Qwen3의 아키텍처 비교.
그림 27에는 나오지 않았지만, gpt-oss는 슬라이딩 윈도우 어텐션을 사용합니다(Gemma 3와 유사하지만 5:1이 아니라 격 레이어마다 적용).
그림 27이 gpt-oss와 Qwen3가 유사한 구성요소를 쓴다는 점을 보여주지만, 자세히 보면 Qwen3는 트랜스포머 블록이 24개가 아닌 48개인 더 깊은 아키텍처입니다.
반면 gpt-oss는 훨씬 더 넓은 아키텍처입니다.
또한 gpt-oss는 어텐션 헤드 수가 2배이지만, 이것이 모델의 "너비"를 직접 늘리지는 않습니다. 너비는 임베딩 차원으로 결정됩니다.
고정 파라미터 수에서, 깊은 설계와 넓은 설계 중 어느 쪽이 유리할까요? 경험칙으로, 깊은 모델은 더 유연하지만 폭발·소실 그래디언트로 학습이 더 어려울 수 있습니다(RMSNorm과 잔차 연결이 이를 완화하려고 존재합니다).
넓은 아키텍처는 메모리 비용은 더 들지만, 병렬화가 좋아 추론 속도(토큰/초)가 빠릅니다.
모델링 성능 면에서는, 파라미터 크기와 데이터셋을 고정한 일대일 비교는 제가 아는 한 많지 않습니다. 예외적으로 Gemma 2 논문 표 9에서는 9B 파라미터 아키텍처에서 넓은 구성이 깊은 구성보다 약간 낫다고 보고합니다. 4개 벤치마크 평균에서 넓은 모델은 52.0, 깊은 모델은 50.8을 기록했습니다.
그림 27에서 또 주목할 점은 gpt-oss가 놀랄 만큼 적은 수의 전문가(128이 아닌 32)를 가지고, 토큰당 활성 전문가도 8이 아닌 4만 사용한다는 것입니다. 다만 각 전문가는 Qwen3의 전문가보다 훨씬 큽니다.
이는 최근 경향이 더 많고 작은 모델(전문가)을 선호하는 것과 상반되어 흥미롭습니다. 총 파라미터가 일정할 때의 변화는 아래 그림 28(DeepSeekMoE 논문 발췌)에서 잘 표현됩니다.
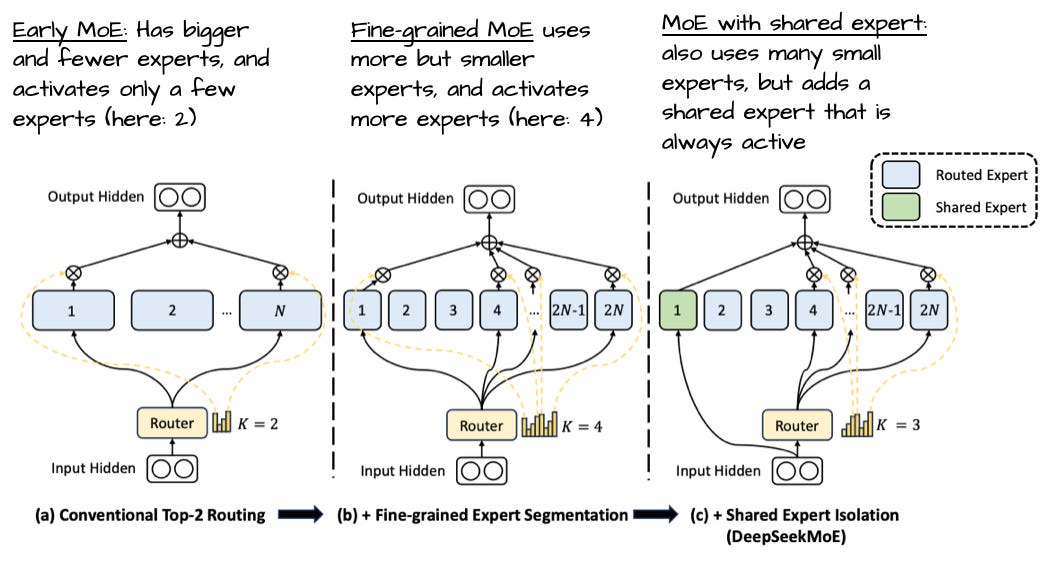
그림 28: "DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models"에서 발췌·주석, https://arxiv.org/abs/2401.06066
주목할 점은, DeepSeek의 모델과 달리 gpt-oss와 Qwen3는 공유 전문가를 사용하지 않는다는 것입니다.
gpt-oss와 Qwen3 모두 그룹드 쿼리 어텐션을 사용합니다. 주요 차이는 앞서 말했듯 gpt-oss가 격 레이어에 슬라이딩 윈도우 어텐션으로 컨텍스트 크기를 제한한다는 점입니다.
그런데 제 눈을 끈 흥미로운 디테일이 하나 있습니다. gpt-oss는 어텐션 가중치에 바이어스 유닛을 사용하는 듯합니다(아래 그림 29 참고).
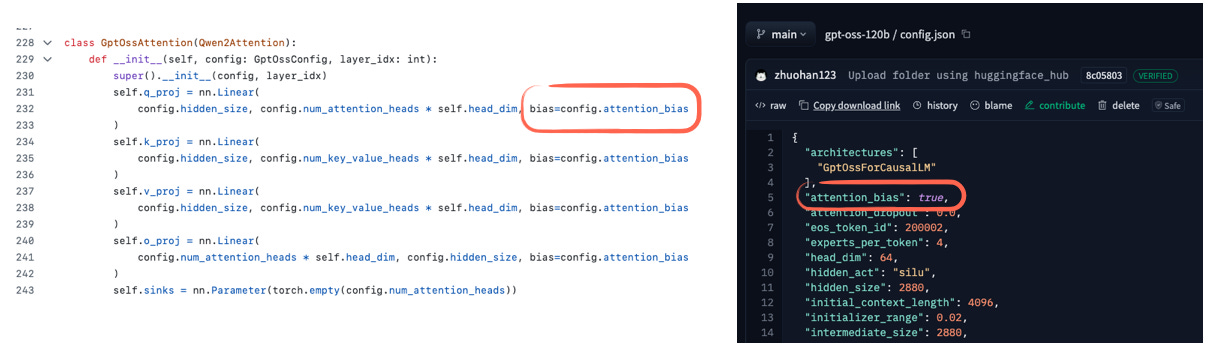
그림 29: gpt-oss 모델은 어텐션 레이어에 바이어스 유닛을 사용합니다. 코드 예시는 여기 참조.
GPT-2 시대 이후로 바이어스 유닛을 사용하는 경우를 거의 못 봤고, 일반적으로 중복적이라고 여겨집니다. 실제로 최근 논문은 적어도 key 변환(k_proj)에 대해서는 수학적으로 중복임을 보입니다. 또한 실험 결과로도 바이어스 유닛 유무에 따른 차이가 거의 없음을 보입니다(아래 그림 30 참고).
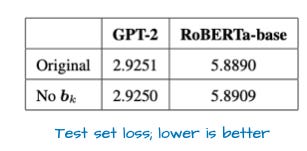
그림 30: 바이어스 유닛 유무로 처음부터 학습한 모델의 평균 테스트 손실(https://arxiv.org/pdf/2302.08626).
또 하나 눈에 띄는 디테일은 그림 30의 코드 스크린샷에 있는 sinks 정의입니다. 일반 모델에서 어텐션 싱크(attention sinks)는 긴 컨텍스트에서 어텐션을 안정화하기 위해 시퀀스 시작에 두는 특별한 "항상 주목되는" 토큰입니다. 즉, 컨텍스트가 매우 길어져도 시퀀스 초반의 이 토큰은 여전히 주목되어, 전체 시퀀스에 유용한 정보를 저장하도록 학습될 수 있습니다(원래 Efficient Streaming Language Models with Attention Sinks에서 제안된 것으로 기억합니다).
gpt-oss 구현에서는 _어텐션 싱크_가 입력 시퀀스의 실제 토큰이 아닙니다. 대신, 헤드별로 학습되는 바이어스 로짓을 어텐션 점수에 덧붙입니다(그림 31). 목적은 동일하지만, 토큰화된 입력을 변경하지 않아도 됩니다.
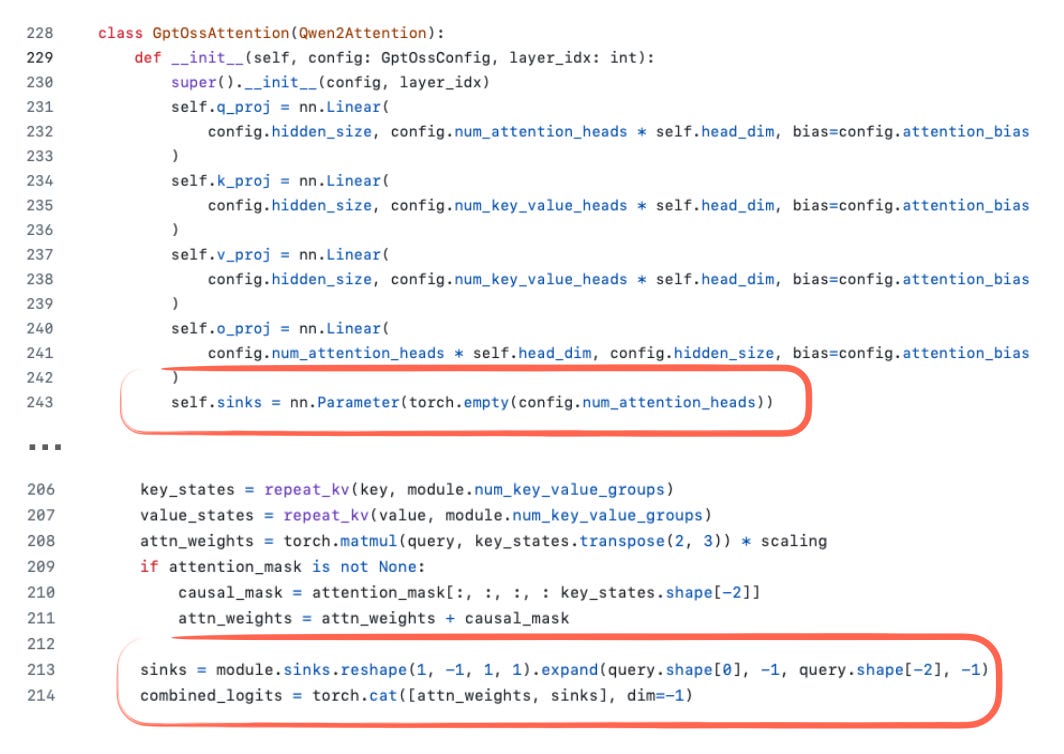
그림 31: gpt-oss에서의 어텐션 싱크 사용; Hugging Face 코드 기반 여기.
gpt-oss에 대한 더 자세한 내용과 GPT-2와의 비교는 제 다른 gpt-oss 글을 참고하세요:
수년이 지나도 LLM 공개는 여전히 흥미롭습니다. 다음은 무엇일지 벌써 궁금합니다!
이 매거진은 개인적인 열정 프로젝트이며, 여러분의 지원이 연재를 지속하는 데 큰 힘이 됩니다. 기여하고 싶다면 다음과 같은 좋은 방법이 있습니다.
읽어주셔서 감사드리며, 독립 연구를 응원해 주셔서 고맙습니다!