Transformers 라이브러리를 사용해 오토리그레시브 언어 생성에서 그리디 서치, 빔 서치, 샘플링(Top-K, Top-p) 등 다양한 디코딩 전략을 적용하는 방법을 살펴본다.
URL: https://huggingface.co/blog/how-to-generate
Title: How to generate text: using different decoding methods for language generation with Transformers

![]()
Note: 2023년 7월에 최신 참고문헌과 예시로 편집되었습니다.
최근 몇 년간, 수백만 개의 웹페이지로 학습된 대규모 트랜스포머 기반 언어 모델이 부상하면서 오픈 엔디드(open-ended) 언어 생성에 대한 관심이 크게 증가했습니다. 여기에는 OpenAI의 ChatGPT와 Meta의 LLaMA가 포함됩니다. 조건부 오픈 엔디드 언어 생성의 결과는 인상적이며, 새로운 작업으로의 일반화, 코드 처리, 비텍스트 데이터 입력 등의 능력을 보여주었습니다. 개선된 트랜스포머 아키텍처와 방대한 비지도 학습 데이터 외에도 더 나은 디코딩(decoding) 방법이 중요한 역할을 해왔습니다.
이 블로그 포스트는 다양한 디코딩 전략을 간단히 개관하고, 더 중요한 것은 인기 라이브러리인 transformers를 사용해 여러분이 아주 적은 노력으로 이를 구현하는 방법을 보여줍니다!
아래의 모든 기능은 오토리그레시브(auto-regressive) 언어 생성에 사용할 수 있습니다(여기에 복습 자료). 간단히 말해, 오토리그레시브 언어 생성은 단어 시퀀스의 확률 분포가 다음 단어의 조건부 분포들의 곱으로 분해될 수 있다는 가정에 기반합니다:
P(w 1:T∣W 0)=∏t=1 T P(w t∣w 1:t−1,W 0),with w 1:0=∅, P(w_{1:T} | W_0 ) = \prod_{t=1}^T P(w_{t} | w_{1: t-1}, W_0) \text{ ,with } w_{1: 0} = \emptyset,
여기서 W 0 W_0 는 초기 컨텍스트(context) 단어 시퀀스입니다. 단어 시퀀스의 길이 T T 는 보통 on-the-fly_로 결정되며, EOS 토큰이 P(w t∣w 1:t−1,W 0)P(w{t} | w_{1: t-1}, W_{0}) 에서 생성되는 시점 t=T t=T 에 해당합니다.
우리는 현재 가장 두드러진 디코딩 방법들—주로 그리디 서치(Greedy search), 빔 서치(Beam search), 샘플링(Sampling)—을 살펴보겠습니다.
먼저 transformers를 빠르게 설치하고 모델을 로드해봅시다. 데모로는 PyTorch의 GPT2를 사용하지만, API는 TensorFlow와 JAX에서도 1:1로 동일합니다.
!pip install -q transformers
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
torch_device = "cuda" if torch.cuda.is_available() else "cpu"
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 경고를 피하기 위해 EOS 토큰을 PAD 토큰으로 추가
model = AutoModelForCausalLM.from_pretrained("gpt2", pad_token_id=tokenizer.eos_token_id).to(torch_device)
그리디 서치는 가장 단순한 디코딩 방법입니다. 각 타임스텝 t t 마다 확률이 가장 높은 단어를 다음 단어로 선택합니다: w t=a r g m a x w P(w∣w 1:t−1)w_t = argmax_{w}P(w | w_{1:t-1}). 아래 스케치는 그리디 서치를 보여줍니다.
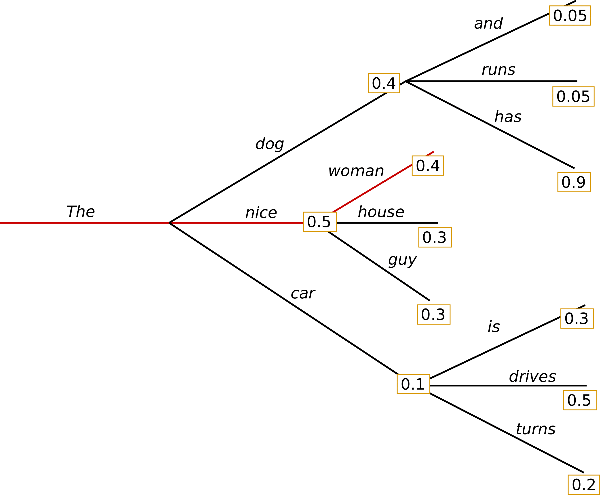
단어 "The",\text{"The"}에서 시작하여 알고리즘은 다음 단어로 확률이 가장 높은 "nice"\text{"nice"}를 탐욕적으로 선택하고, 계속 진행하여 최종적으로 ("The","nice","woman")(\text{"The"}, \text{"nice"}, \text{"woman"})을 생성하며, 전체 확률은 0.5×0.4=0.2 0.5 \times 0.4 = 0.2 입니다.
이제 GPT2를 사용해 컨텍스트 ("I","enjoy","walking","with","my","cute","dog")(\text{"I"}, \text{"enjoy"}, \text{"walking"}, \text{"with"}, \text{"my"}, \text{"cute"}, \text{"dog"})에 조건화된 단어 시퀀스를 생성해보겠습니다. transformers에서 그리디 서치를 어떻게 사용하는지 봅시다:
# 생성이 조건화될 컨텍스트 인코딩
model_inputs = tokenizer('I enjoy walking with my cute dog', return_tensors='pt').to(torch_device)
# 새 토큰 40개 생성
greedy_output = model.generate(**model_inputs, max_new_tokens=40)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(greedy_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with my dog. I'm not sure if I'll ever be able to walk with my dog.
I'm not sure
좋습니다! GPT2로 첫 번째 짧은 텍스트를 생성했습니다. 생성된 문장은 컨텍스트 뒤를 그럴듯하게 이어가지만, 모델이 빠르게 자기 반복을 시작합니다! 이는 일반적으로 언어 생성에서 매우 흔한 문제이며, 특히 그리디 및 빔 서치에서 더 두드러지는 것으로 보입니다. Vijayakumar et al., 2016과 Shao et al., 2017를 확인해보세요.
하지만 그리디 서치의 주요 단점은 위 스케치에서 볼 수 있듯이, 낮은 확률 단어 뒤에 숨어 있는 높은 확률의 단어들을 놓칠 수 있다는 점입니다.
조건부 확률이 0.9 0.9로 높은 단어 "has"\text{"has"}는 조건부 확률이 두 번째로 높은 "dog"\text{"dog"} 뒤에 숨어 있어, 그리디 서치는 "The","dog","has"\text{"The"}, \text{"dog"}, \text{"has"} 시퀀스를 놓칩니다.
다행히도, 이런 문제를 완화해줄 빔 서치가 있습니다!
빔 서치는 각 타임스텝에서 가장 가능성이 높은 가설(hypothesis) num_beams개를 유지함으로써, 숨어 있는 높은 확률의 단어 시퀀스를 놓칠 위험을 줄입니다. 그리고 최종적으로 전체 확률이 가장 높은 가설을 선택합니다. num_beams=2로 예시를 들어봅시다:
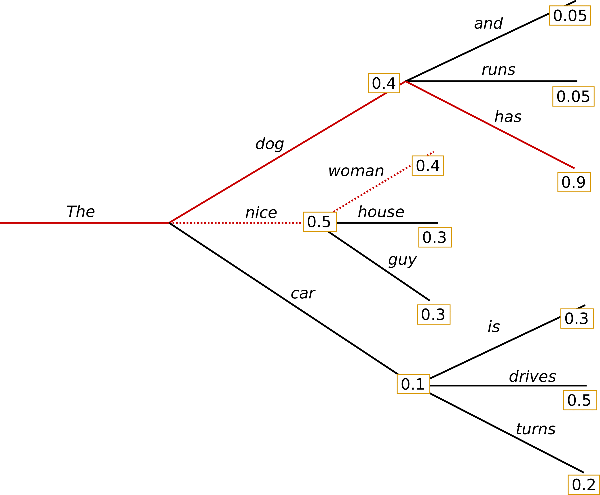
타임스텝 1에서, 빔 서치는 가장 가능성이 높은 ("The","nice")(\text{"The"}, \text{"nice"})뿐 아니라 두 번째로 가능성이 높은 ("The","dog")(\text{"The"}, \text{"dog"})도 추적합니다. 타임스텝 2에서, 빔 서치는 ("The","dog","has")(\text{"The"}, \text{"dog"}, \text{"has"})가 0.36 0.36의 확률로 ("The","nice","woman")(\text{"The"}, \text{"nice"}, \text{"woman"})의 0.2 0.2보다 더 높다는 것을 찾아냅니다. 훌륭합니다. 이 장난감 예제에서 가장 가능성이 높은 단어 시퀀스를 찾았습니다!
빔 서치는 항상 그리디 서치보다 더 높은 확률의 출력 시퀀스를 찾지만, 가장 가능성이 높은 출력을 반드시 찾는다고 보장되지는 않습니다.
이제 transformers에서 빔 서치를 사용하는 방법을 보겠습니다. num_beams > 1로 설정하고, 모든 빔 가설이 EOS 토큰에 도달하면 생성이 끝나도록 early_stopping=True를 설정합니다.
# 빔 서치와 early_stopping 활성화
beam_output = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I'm not sure if I'll ever be able to walk with him again. I'm not sure
결과가 더 유창해 보이긴 하지만, 여전히 같은 단어 시퀀스의 반복이 포함되어 있습니다. 이를 해결하는 방법 중 하나는 Paulus et al. (2017)와 Klein et al. (2017)에서 소개된 n-그램(n-gram) (즉 n개의 단어로 이루어진 단어 시퀀스) 페널티를 도입하는 것입니다. 가장 흔한 n-그램 페널티는 이미 등장한 _n-그램_을 다시 만들 수 있는 다음 단어들의 확률을 수동으로 0으로 설정해, 동일한 _n-그램_이 두 번 나타나지 않게 합니다.
no_repeat_ngram_size=2로 설정하여 어떤 _2-그램_도 두 번 나타나지 않게 해봅시다:
# no_repeat_ngram_size를 2로 설정
beam_output = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to
좋습니다. 훨씬 나아 보입니다! 반복이 더 이상 나타나지 않습니다. 다만 n-그램 페널티는 주의해서 사용해야 합니다. 예를 들어 뉴욕 _New York_에 대한 글을 생성할 때 2-그램 페널티를 사용하면 도시 이름이 전체 텍스트에서 한 번만 등장하게 될 수도 있습니다!
빔 서치의 또 다른 중요한 특징은, 생성이 끝난 후 상위 빔들을 비교하고 목적에 가장 잘 맞는 빔을 선택할 수 있다는 점입니다.
transformers에서는 num_return_sequences를 반환할 최고 점수 빔의 개수로 설정하면 됩니다. 단, num_return_sequences <= num_beams여야 합니다!
# num_return_sequences > 1로 설정
beam_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
num_beams=5,
no_repeat_ngram_size=2,
num_return_sequences=5,
early_stopping=True
)
print("Output:\n" + 100 * '-')
for i, beam_output in enumerate(beam_outputs):
print("{}: {}".format(i, tokenizer.decode(beam_output, skip_special_tokens=True)))
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time for me to
1: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with her again.
I've been thinking about this for a while now, and I think it's time for me to
2: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's a good idea to
3: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's time to take a
4: I enjoy walking with my cute dog, but I'm not sure if I'll ever be able to walk with him again.
I've been thinking about this for a while now, and I think it's a good idea.
보이는 것처럼, 다섯 개의 빔 가설은 서로 아주 조금만 다릅니다. 빔을 5개만 사용했다면 놀랄 일도 아닙니다.
오픈 엔디드 생성에서는 빔 서치가 최선의 선택이 아닐 수 있는 이유들이 제기되어 왔습니다:
빔 서치는 기계 번역이나 요약처럼 원하는 생성 길이가 어느 정도 예측 가능한 작업에서는 매우 잘 동작할 수 있습니다. Murray et al. (2018), Yang et al. (2018) 참고. 하지만 대화나 스토리 생성처럼 원하는 출력 길이가 크게 달라질 수 있는 오픈 엔디드 생성에서는 그렇지 않습니다.
빔 서치는 반복 생성에 심각하게 취약하다는 것을 보았습니다. 스토리 생성에서는 반복을 억제하면서도 동일한 _n-그램_의 순환적 반복을 막기 위한 적절한 트레이드오프를 찾으려면 많은 파인튜닝이 필요하기 때문에, _n-그램_이나 기타 페널티로 이를 제어하기가 특히 어렵습니다.
Ari Holtzman et al. (2019)에서 주장하듯, 고품질 인간 언어는 높은 확률의 다음 단어들만 따르는 분포를 따르지 않습니다. 즉 인간은 생성된 텍스트가 놀라움을 주길 원하며, 지루하고 예측 가능하길 원하지 않습니다. 저자들은 모델이 인간 텍스트에 부여하는 확률과 빔 서치의 동작을 비교해 이를 잘 보여줍니다.
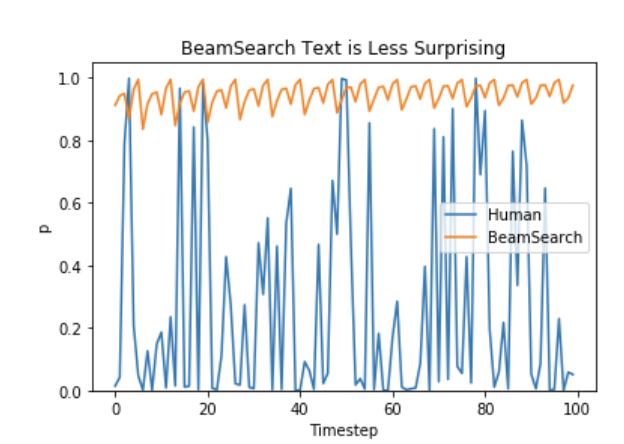
이제 지루함은 그만두고, 약간의 랜덤성을 도입해봅시다.
가장 기본적인 형태에서 샘플링은 조건부 확률 분포에 따라 다음 단어 w t w_t를 무작위로 선택하는 것을 의미합니다:
w t∼P(w∣w 1:t−1) w_t \sim P(w|w_{1:t-1})
위의 예시를 다시 사용하면, 아래 그래픽은 샘플링으로 언어를 생성할 때를 시각화합니다.
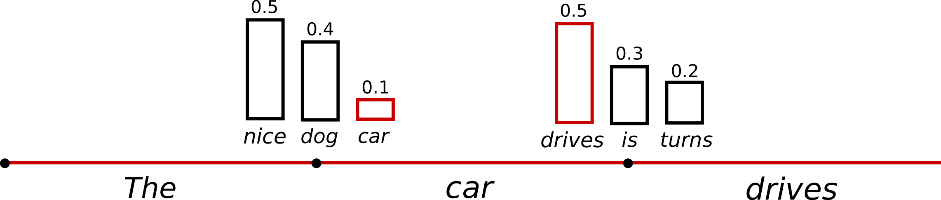
샘플링을 사용한 언어 생성은 더 이상 _결정적(deterministic)_이지 않다는 점이 분명해집니다. 단어 ("car")(\text{"car"})는 조건부 확률 분포 P(w∣"The")P(w | \text{"The"})에서 샘플링되고, 이어서 ("drives")(\text{"drives"})가 P(w∣"The","car")P(w | \text{"The"}, \text{"car"})에서 샘플링됩니다.
transformers에서는 do_sample=True로 설정하고, top_k=0으로 Top-K 샘플링(뒤에서 설명)을 비활성화합니다. 아래에서는 설명을 위해 랜덤 시드를 고정하겠습니다. 다른 결과를 보려면 set_seed 인자를 바꾸거나, 비결정성을 위해 제거해도 됩니다.
# 결과 재현을 위해 시드 설정 (다른 결과를 원하면 시드를 바꾸세요)
from transformers import set_seed
set_seed(42)
# 샘플링 활성화 및 top_k를 0으로 설정해 Top-K 비활성화
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this had me staying in an unusual room and not going on nights out with friends (which will always be wondered for a mere minute or so at this point).
흥미롭습니다! 텍스트는 괜찮아 보이지만, 자세히 보면 일관성이 떨어지고 사람이 쓴 글처럼 들리지 않습니다. 이것이 단어 시퀀스를 샘플링할 때의 큰 문제입니다. 모델이 종종 비일관적인 말도 안 되는 문장을 생성하곤 합니다. cf. Ari Holtzman et al. (2019).
한 가지 트릭은 softmax의 이른바 temperature를 낮춰 분포 P(w∣w 1:t−1)P(w|w_{1:t-1})를 더 날카롭게 만드는 것입니다(고확률 단어의 가능성은 증가시키고, 저확률 단어의 가능성은 감소). softmax 참고.
위 예시에 temperature를 적용한 그림은 다음과 같을 수 있습니다.
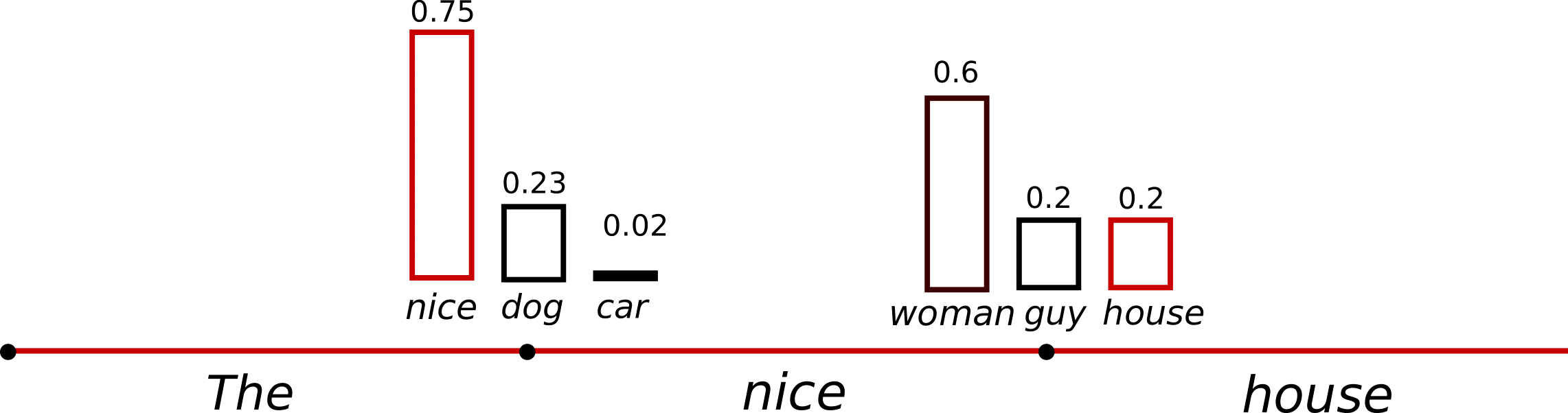
t=1 t=1에서의 조건부 다음 단어 분포가 훨씬 날카로워져 ("car")(\text{"car"})가 선택될 가능성이 거의 없어집니다.
라이브러리에서 temperature=0.6으로 분포를 ‘식히는’ 방법을 보겠습니다:
# 결과 재현을 위해 시드 설정 (다른 결과를 원하면 시드를 바꾸세요)
set_seed(42)
# temperature로 낮은 확률 후보에 대한 민감도 감소
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=0,
temperature=0.6,
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog, but I don't like to chew on it. I like to eat it and not chew on it. I like to be able to walk with my dog."
So how did you decide
OK. 이상한 n-그램이 줄었고 출력도 조금 더 일관적입니다! temperature를 적용하면 분포를 덜 랜덤하게 만들 수 있지만, temperature→0\to 0으로 가는 극한에서는 temperature 스케일 샘플링이 그리디 디코딩과 같아지며, 앞서 본 문제들을 다시 겪게 됩니다.
Fan et. al (2018)은 간단하지만 매우 강력한 샘플링 방식인 Top-K 샘플링을 제안했습니다. Top-K 샘플링에서는 다음 단어로 가장 가능성이 높은 _K_개의 단어만 남기고, 그 _K_개 단어들 사이에서 확률 질량을 재분배합니다. GPT2는 이 샘플링 방식을 채택했는데, 이것이 스토리 생성에서 성공할 수 있었던 이유 중 하나였습니다.
Top-K 샘플링을 더 잘 보여주기 위해 위 예시에서 두 샘플링 단계 모두에서 단어 범위를 3개에서 10개로 확장하겠습니다.
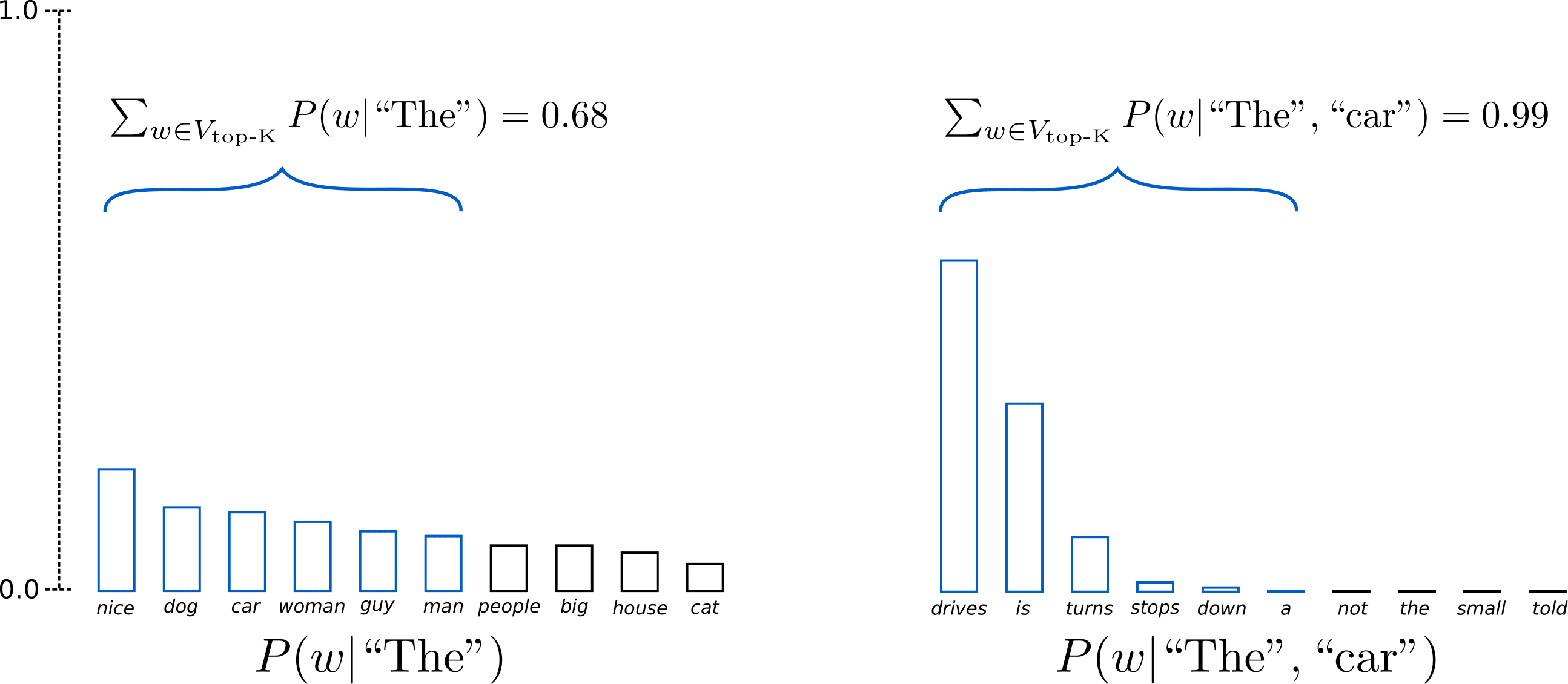
K=6 K = 6으로 설정하면, 두 샘플링 단계 모두에서 샘플링 풀을 6개 단어로 제한합니다. 첫 번째 단계에서는 V top-K V_{\text{top-K}}로 정의되는 6개 최상위 단어가 전체 확률 질량의 약 3분의 2 정도만을 포함하지만, 두 번째 단계에서는 거의 모든 확률 질량을 포함합니다. 그럼에도 두 번째 샘플링 단계에서 다소 이상한 후보들(“not",“the",“small",“told")(\text{not"}, \text{the"}, \text{small"}, \text{told"}))을 성공적으로 제거하는 것을 볼 수 있습니다.
라이브러리에서 top_k=50을 설정해 _Top-K_를 사용하는 방법을 보겠습니다:
# 결과 재현을 위해 시드 설정 (다른 결과를 원하면 시드를 바꾸세요)
set_seed(42)
# top_k를 50으로 설정
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this time it was hard for me to figure out what to do with it. (One reason I asked this for a few months back is that I had a
꽤 괜찮습니다! 지금까지 중 가장 사람이 쓴 것 같은 텍스트라고 할 수 있습니다. 다만 Top-K 샘플링의 한 가지 우려는 다음 단어 확률 분포 P(w∣w 1:t−1)P(w|w_{1:t-1})에서 필터링되는 단어의 수가 동적으로 바뀌지 않는다는 점입니다. 이는 어떤 단어는 매우 날카로운 분포(위 그래프의 오른쪽 분포)에서 샘플링되는 반면, 다른 단어는 훨씬 평평한 분포(위 그래프의 왼쪽 분포)에서 샘플링될 수 있어 문제가 될 수 있습니다.
t=1 t=1에서 _Top-K_는 ("people","big","house","cat")(\text{"people"}, \text{"big"}, \text{"house"}, \text{"cat"})처럼 꽤 그럴듯한 후보를 샘플링할 가능성을 제거합니다. 반면 t=2 t=2에서는 샘플 풀에 ("down","a")(\text{"down"}, \text{"a"})처럼 적절하지 않아 보이는 단어가 포함되기도 합니다. 따라서 고정된 크기 _K_로 샘플 풀을 제한하면, 날카로운 분포에서는 헛소리(gibberish)를 만들 위험이 있고, 평평한 분포에서는 창의성을 제한할 수 있습니다. 이 직관이 Ari Holtzman et al. (2019)이 Top-p 또는 nucleus 샘플링을 만들게 된 배경입니다.
Top-p 샘플링은 가장 가능성이 높은 _K_개 단어에서만 샘플링하는 대신, 누적 확률이 _p_를 넘는 가장 작은 단어 집합에서 샘플링합니다. 그리고 그 단어 집합 안에서 확률 질량을 재분배합니다. 이렇게 하면 단어 집합의 크기(즉 집합 안 단어 수)가 다음 단어 확률 분포에 따라 동적으로 늘거나 줄 수 있습니다. 말로만 하면 복잡하니 시각화해봅시다.
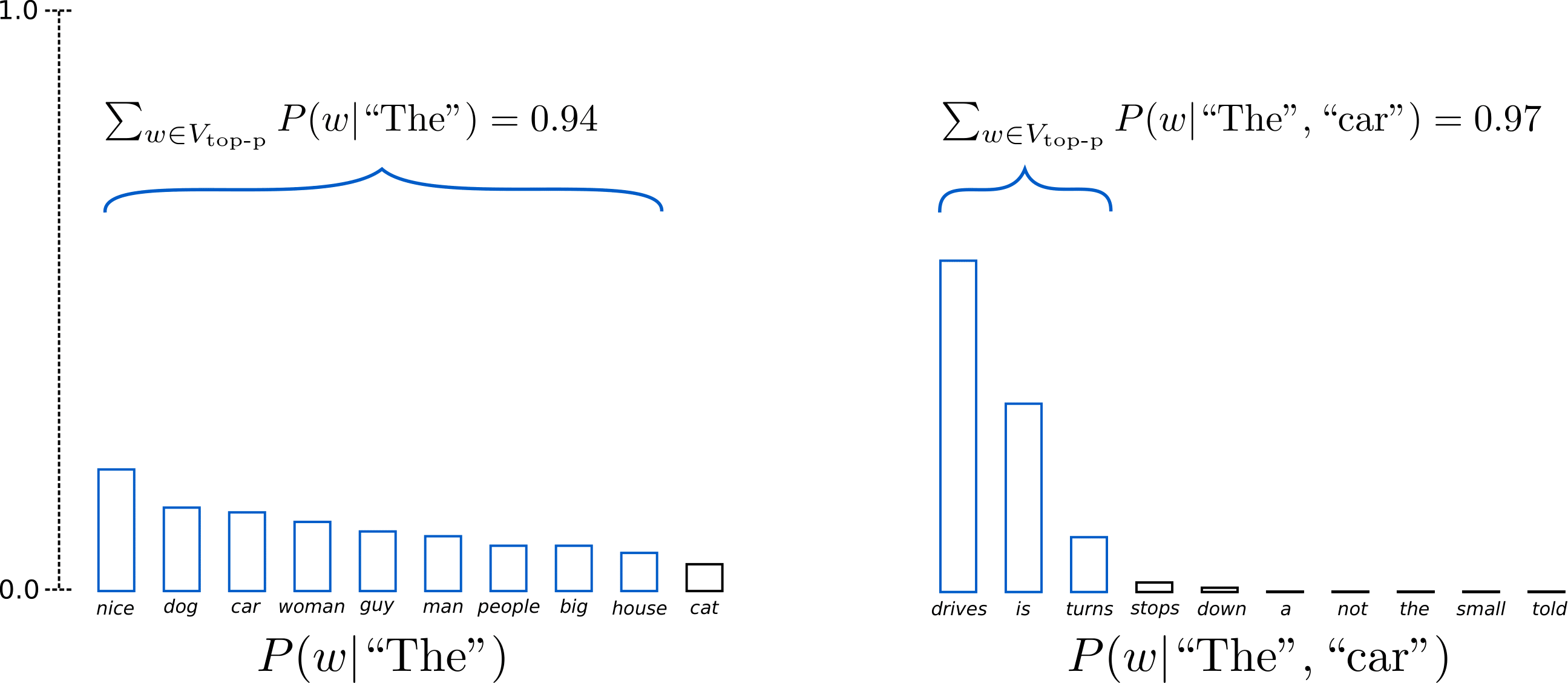
p=0.92 p=0.92로 설정하면, Top-p 샘플링은 확률 질량의 92%p=92%를 넘기기 위한 최소 단어 수를 선택하며, 이를 V top-p V_{\text{top-p}}로 정의합니다. 첫 번째 예시에서는 상위 9개 단어가 포함되지만, 두 번째 예시에서는 92%를 넘기 위해 상위 3개 단어만 선택하면 됩니다. 아주 간단하죠! 다음 단어가 덜 예측 가능한 경우(예: P(w∣"The”)P(w | \text{"The''}))에는 넓은 범위의 단어를 유지하고, 다음 단어가 더 예측 가능해 보이는 경우(예: P(w∣"The","car")P(w | \text{"The"}, \text{"car"}))에는 소수의 단어만 유지하는 것을 볼 수 있습니다.
이제 transformers에서 확인해볼 시간입니다! 0 < top_p < 1로 설정하면 Top-p 샘플링이 활성화됩니다:
# 결과 재현을 위해 시드 설정 (다른 결과를 원하면 시드를 바꾸세요)
set_seed(42)
# top_p=0.92로 설정하고 top_k=0으로 Top-K 비활성화
sample_output = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_p=0.92,
top_k=0
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(sample_output[0], skip_special_tokens=True))
Output:
----------------------------------------------------------------------------------------------------
I enjoy walking with my cute dog for the rest of the day, but this had me staying in an unusual room and not going on nights out with friends (which will always be my yearning for such a spacious screen on my desk
좋습니다. 사람이 쓴 것처럼 들릴 수도 있겠네요. 물론 아직 완벽하진 않지만요.
이론적으로는 _Top-p_가 _Top-K_보다 더 우아해 보이지만, 두 방법 모두 실제로 잘 작동합니다. _Top-p_는 _Top-K_와 함께 사용할 수도 있는데, 이는 매우 낮은 순위의 단어를 피하면서도 동적 선택을 어느 정도 허용할 수 있습니다.
마지막으로, 서로 독립적으로 샘플링된 여러 출력을 얻고 싶다면 num_return_sequences > 1을 다시 설정하면 됩니다:
# 결과 재현을 위해 시드 설정 (다른 결과를 원하면 시드를 바꾸세요)
set_seed(42)
# top_k=50, top_p=0.95, num_return_sequences=3 설정
sample_outputs = model.generate(
**model_inputs,
max_new_tokens=40,
do_sample=True,
top_k=50,
top_p=0.95,
num_return_sequences=3,
)
print("Output:\n" + 100 * '-')
for i, sample_output in enumerate(sample_outputs):
print("{}: {}".format(i, tokenizer.decode(sample_output, skip_special_tokens=True)))
Output:
----------------------------------------------------------------------------------------------------
0: I enjoy walking with my cute dog for the rest of the day, but this time it was hard for me to figure out what to do with it. When I finally looked at this for a few moments, I immediately thought, "
1: I enjoy walking with my cute dog. The only time I felt like walking was when I was working, so it was awesome for me. I didn't want to walk for days. I am really curious how she can walk with me
2: I enjoy walking with my cute dog (Chama-I-I-I-I-I), and I really enjoy running. I play in a little game I play with my brother in which I take pictures of our houses.
좋습니다. 이제 transformers로 모델에게 스토리를 쓰게 할 수 있는 도구들을 갖추었습니다!
오픈 엔디드 언어 생성에서는 그리디 및 빔 서치 같은 전통적인 ad-hoc 디코딩 방법보다 top-p 및 top-K 샘플링이 더 유창한 텍스트를 만들어내는 경향이 있습니다. _그리디_와 빔 서치의 명백한 결함—주로 반복적인 단어 시퀀스 생성—이 디코딩 방법 자체보다는 모델(특히 모델이 학습되는 방식) 때문에 발생한다는 증거도 있습니다. cf. Welleck et al. (2019). 또한 Welleck et al. (2020)에서 보였듯, top-K 및 top-p 샘플링도 반복적인 단어 시퀀스를 생성하는 문제를 겪는 것으로 보입니다.
Welleck et al. (2019)에서 저자들은 인간 평가에 따르면, 모델의 학습 목표를 적응시키는 경우 Top-p 샘플링보다 빔 서치가 더 유창한 텍스트를 생성할 수 있음을 보입니다.
오픈 엔디드 언어 생성은 빠르게 발전하는 연구 분야이며, 흔히 그렇듯 만능(one-size-fits-all) 방법은 없습니다. 따라서 자신의 특정 사용 사례에서 무엇이 가장 잘 작동하는지 확인해야 합니다.
다행히도 transfomers 🤗에서 모든 디코딩 방법을 직접 시험해볼 수 있습니다. 사용 가능한 방법들의 개요는 여기에서 확인할 수 있습니다.
이 블로그 포스트에 기여해준 모든 분들께 감사합니다: Alexander Rush, Julien Chaumand, Thomas Wolf, Victor Sanh, Sam Shleifer, Clément Delangue, Yacine Jernite, Oliver Åstrand, John de Wasseige.
generate는 매우 조합 가능한(composable) 메서드로 발전했으며, 이 글에서 다루지 않은 다양한 방향으로 결과 텍스트를 조작할 수 있는 플래그들을 제공합니다. 아래는 도움이 되는 페이지들입니다:
문서를 탐색하기가 어렵고 원하는 내용을 쉽게 찾기 힘들다면, 이 GitHub 이슈에 메시지를 남겨주세요. 여러분의 피드백은 우리의 미래 방향을 설정하는 데 매우 중요합니다! 🤗