이 글에서는 Instructor를 통해 Chain of Density 요약법을 구현하고, GPT-3.5 모델을 미세조정하여 GPT-4 수준의 반복 요약 능력을 갖추는 과정을 소개합니다. 이 방법을 통해 요약 지연 시간을 20배, 비용을 50배까지 줄이면서도 엔터티 밀도를 유지할 수 있었습니다.
반복적인 Chain Of Density 기법을 Instructor로 단일 미세조정 모델에 어떻게 증류할 수 있는지 알아보세요.
이 글에서는 Instructor를 활용해 원래의 Chain Of Density 방법을 구현하는 과정을 안내하고, 이후 GPT-3.5 모델을 미세조정하여 GPT-4의 반복 요약 성능에 근접시키는 방법을 소개합니다. 이러한 접근법을 통해 지연 시간을 20배, 비용을 50배 줄이고, 엔터티(정보 단위) 밀도도 유지할 수 있었습니다.
최종적으로 Instructor의 우수한 툴링을 활용해 미세조정된 GPT-3.5 모델을 얻게 되며, 논문 [Adams et al. (2023)]의 Chain of Density 기법 수준의 효과적인 요약을 생성할 수 있습니다. 모든 코드는 리포지터리의 examples/chain-of-density 폴더에서 확인할 수 있습니다.
생성된 모든 데이터는 Hugging Face의 여기에 업로드되어 있습니다. 실험을 재현하고 싶을 때 사용하세요. 또한 Colab 예제로 생성값도 직접 확인할 수 있습니다.
AI로 긴 텍스트를 요약하는 것은 종종 불안정한 방법에 의존하게 됩니다. Chain Of Density 프롬프트 기법은 AI 기반 텍스트 요약 성능을 개선하며, 인간 요약보다 뛰어난 성능을 보여줍니다.
처음엔 AI가 요약을 생성하고, 이후 여러 번 반복해 부족한 엔터티(기사 내 정보)를 점진적으로 추가하며 길이는 일정하게 유지합니다. 이렇게 하여, 정보 밀도가 높고 유익한 요약–Chain of Density–가 완성됩니다.
이 기법은 From Sparse to Dense: GPT-4 Summarization with Chain of Density Prompting 논문에서 처음 소개됐으며, 인간 요약보다 꾸준히 더 나은 결과를 보여주었습니다.
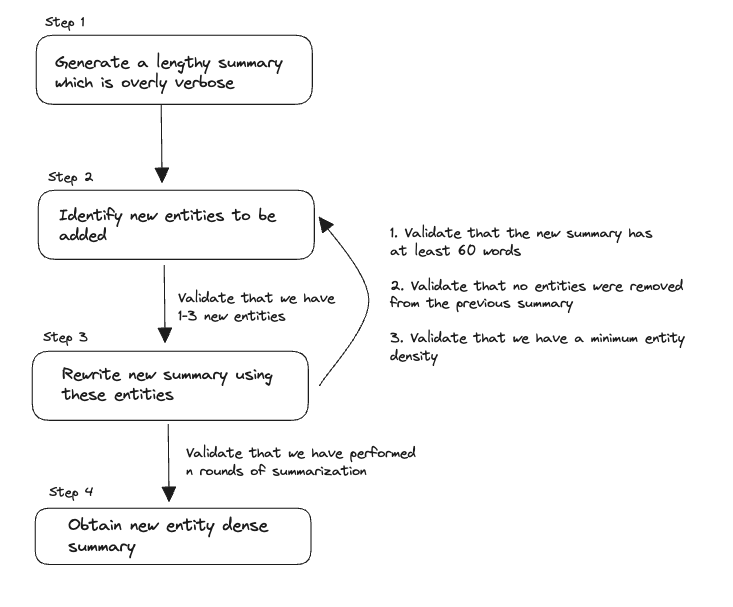
저희 구현에서는 요약을 새롭게 쓸 때 프롬프트가 아니라 validator로 최소 길이를 검증합니다. 또한 5번 대신 3번만 반복해 최종 엔터티 밀도가 다소 낮아집니다.
원래 과정을 더 작은 API 호출로 쪼개면 검증 로직을 각 스텝에 쉽게 도입할 수 있습니다.
원본 Chain of Density 프롬프트
Article: {{ARTICLE}}
당신은 위 기사에 대해 점점 더 간결하면서 엔터티 밀도가 높은 요약을 생성합니다.
다음의 2단계를 5번 반복하세요.
Step 1. 기사에서, 이전 요약에 없었던 1~3개의 정보가 풍부한 엔터티(";"로 구분)를 식별하세요.
Step 2. 이전 요약에 있는 엔터티와 이번에 추가된 새로운 엔터티 모두를 담아, 길이는 동일하지만 더 압축된 요약을 작성하세요.
Missing Entity란:
- 주제에 관련 있음
- 구체적이며(5단어 이내), 간결
- 이전 요약에 없었던 정보
- 기사 내에 실제 존재함
- 기사 어디에 있든 상관 없음
가이드라인:
- 첫 요약은 길고(4-5문장, 약 80단어), 정보는 거의 없고 비구체적이어야 함(엔터티만 제외). 과하게 장황한 문장과 군더더기를 써서 80단어 가까이 만드세요.
- 모든 단어에 의미를 부여해 요약을 다시 쓰고 엔터티 공간을 확보하세요.
- "이 글은 ~에 대해 다룹니다"처럼 의미 없는 구절을 압축하거나 제거하세요.
- 점점 더 밀도가 높고, 간결하면서, 기사 없이도 이해할 수 있게 해야 함
- 새로운 엔터티는 요약 어디에나 넣을 수 있음
- 이전 요약의 엔터티는 절대 삭제하지 말 것. 공간이 부족하면 추가 엔터티 수를 줄일 것
항상 동일한 단어 수로 요약 작성
답변은 JSON으로. JSON 리스트(5개 원소)로 각 딕셔너리 키는 "Missing_Entities", "Denser_Summary"입니다.
아래의 예시처럼 필요한 python 패키지를 설치하세요.
pip install instructor aiohttp rich
OpenAI 함수 호출 시 사용할 데이터 모델부터 설명합니다. 원본 프롬프트에서 이 클래스의 설명을 가져옵니다. 이 주석(docs)은 LLM이 결과를 생성할 때 직접 사용되니 매우 중요합니다.
예시 (후에 미세조정에 쓰임):
class GeneratedSummary(BaseModel):
"""
기사 원문에서 가능한 많은 엔터티를 포함한, 매우 간결한 요약을 나타냄.
엔터티란, 이름이 부여된 실세계의 개체(예: 사람, 국가, 제품, 책 제목 등)
가이드라인
- 모든 단어를 아껴 쓰세요
- 요약은 밀도 높고 간결하며, 기사 없이도 이해 가능해야 함
- "이 글은 ~에 대해" 같은 군더더기 구절은 압축/삭제
"""
summary: str = Field(
...,
description="기사의 의미를 최대한 간결하게 담은 최종 요약",
)
이 모델은 최종적으로 아래와 같이 OpenAI 함수 호출로 변환됩니다. (JSON 예시는 생략합니다.)
모델 설명이 상세할수록 더 정확한 결과를 얻는 경향이 있습니다. 또한 Pydantic 기반이므로 결과를 python에서 검증/파싱해 원하는 형태와 일치하도록 할 수 있습니다.
예시로, 초기 장황한 요약을 만들 데이터 모델:
class InitialSummary(BaseModel):
"""
이 요약은 길고(4-5문장, 약 80단어), 정보는 거의 없으며, 엔터티 외에는 구체적인 내용이 최소화되어야 함.
"""
summary: str = Field(
...,
description="군더더기와 군말(예: 이 글은 ~을 다룬다)을 써서 80단어 근처로 만든 장황한 요약",
)
추가로 반복 요약 과정에서 사용할 클래스 예시입니다.
class RewrittenSummary(BaseModel):
"""
이전 요약에 있던 엔터티에 더해 새롭게 추가된 Missing Entities까지 모두 포함, 길이는 동일한 더 압축된 요약
가이드라인
- 모든 단어를 아낌; 흐름 개선 및 엔터티 공간 확보
- 이전 요약 엔터티는 빼지 않음(공간이 부족하면 새 엔터티 수를 줄임)
- 요약은 밀도 높고 자체적으로 이해 가능해야 함
- "이 글은 ~" 같은 군더더기는 압축/삭제
- Missing Entities는 어디든 등장 가능
엔터티란, 이름이 붙은 실세계 개체
"""
summary: str = Field(
...,
description="80단어 전후의 동일 길이, 모든 엔터티(기존+신규) 포함, 기사 없어도 이해 가능한 요약"
)
absent: List[str] = Field(
..., default_factory=list, description="이전 요약에는 있었으나 이번에는 빠진 엔터티"
)
missing: List[str] = Field(
default_factory=list, description="이번 요약에 새롭게 포함되어야 할, 기사 내 1-3개의 정보성 엔터티"
)
Instructor에서 Pydantic Validator 사용법, 자세한 내용은 좋은 LLM 검증은 곧 좋은 검증 글을 참고하세요.
예를 들어, missing은 1~3개, absent는 항상 빈 리스트, 요약은 최소 엔터티 밀도를 지키도록 검증 로직을 넣을 수 있습니다.
예시:
import nltk
import spacy
nlp = spacy.load("en_core_web_sm")
@field_validator("summary")
def min_length(cls, v: str):
tokens = nltk.word_tokenize(v)
num_tokens = len(tokens)
if num_tokens < 60:
raise ValueError("요약이 너무 짧음. 80단어 내외로 생성해주세요.")
return v
@field_validator("missing")
def has_missing_entities(cls, missing_entities: List[str]):
if len(missing_entities) == 0:
raise ValueError("이전 요약에 없는 신규 엔터티 1~3개를 반드시 식별하세요.")
return missing_entities
@field_validator("absent")
def has_no_absent_entities(cls, absent_entities: List[str]):
if len(absent_entities) > 0:
raise ValueError(f"다음 엔터티를 새 요약에서 빼지 마세요: {','.join(absent_entities)}")
return absent_entities
@field_validator("summary")
def min_entity_density(cls, v: str):
tokens = nltk.word_tokenize(v)
num_tokens = len(tokens)
doc = nlp(v)
num_entities = len(doc.ents)
density = num_entities / num_tokens
if density < 0.08:
raise ValueError("엔터티 밀도가 너무 낮음. 새 엔터티를 더 추가하세요.")
return v
이제 모델도 있고, 흐름도 정했으니 실제 Chain Of Density 요약을 수행하는 함수를 만들어 보죠.
from openai import OpenAI
import instructor
client = instructor.from_openai(OpenAI())
def summarize_article(article: str, summary_steps: int = 3):
summary_chain = []
# 1. 초기 장황 요약 생성
summary: InitialSummary = client.chat.completions.create(
model="gpt-4-0613",
response_model=InitialSummary,
messages=[
{
"role": "system",
"content": "4-5문장 길고, 구체적이지 않은 장황 요약을 써라 (~80단어)",
},
{"role": "user", "content": f"Here is the Article: {article}"},
{
"role": "user",
"content": "요약은 80단어쯤 됩니다.",
},
],
max_retries=2,
)
prev_summary = None
summary_chain.append(summary.summary)
for i in range(summary_steps):
missing_entity_message = (
[] if prev_summary is None else [
{"role": "user",
"content": f"Please include these Missing Entities: {','.join(prev_summary.missing)}",},])
new_summary: RewrittenSummary = client.chat.completions.create(
model="gpt-4-0613",
messages=[
{"role": "system",
"content": """
||점점 더 간결, 엔터티 밀도가 높아지도록 요약||
1. 기사에서 이전 요약에 없던 정보성 엔터티 1-3개 식별
2. 기존+신규 엔터티 모두 포함, 길이는 동일하지만 더 압축적인 새로운 요약
가이드라인: 군더더기 압축, 이전 엔터티 누락 금지, 새 엔터티 추가
"""},
{"role": "user", "content": f"Here is the Article: {article}"},
{"role": "user", "content": f"Here is the previous summary: {summary_chain[-1]}"},
*missing_entity_message,
],
max_retries=3,
max_tokens=1000,
response_model=RewrittenSummary,
)
summary_chain.append(new_summary.summary)
prev_summary = new_summary
return summary_chain
이 함수는 동일 토큰 수를 유지하며 엔터티 수가 3배가 되는 결과를 보여줍니다. 스타일도 훨씬 자연스럽습니다.
첫 반복
이 글은 매니 파키아오와 플로이드 메이웨더의 기대되는 복싱 경기를 중심으로 한다. 매니 파키아오가 향후 대결을 준비하며 자신의 각오를 밝히고, 경기의 재정, 스포츠적 의미, 파키아오의 결의와 전략도 언급된다. 전체적으로 다가오는 빅매치를 부각시키는 분위기다.
최종 반복
필리핀 복서 매니 파키아오는 5월 2일 MGM 그랜드에서 무패의 미국 선수 플로이드 메이웨더와 3억 달러(약 3900억 원)가 걸린 '운명의 대결'을 앞두고 있다. 언더독임에도 파키아오는 10년을 기다린 팬들에게 이 경기가 역대 최고의 스포츠 이벤트가 될 것이라 자신감을 내비쳤으며 확실한 결전을 다짐했다.
이번엔 GPT-3.5 모델을 미세조정하여 GPT-4 수준으로 상향하는 방법을 살펴보고, 성능도 비교합니다.
테스트시 데이터 누출 방지를 위해 griffin/chain-of-density의 기사 120개를 무작위 추출, train.csv와 test.csv로 분리해 Hugging Face에 업로드했습니다. 이제 Instructor의 Instructions 모듈을 써서 미세조정용 .jsonl 파일을 수월하게 만들 수 있습니다.
from typing import List
from chain_of_density import summarize_article
import csv
import logging
import instructor
from pydantic import BaseModel
from openai import OpenAI
client = instructor.from_openai(OpenAI())
logging.basicConfig(level=logging.INFO)
instructions = instructor.Instructions(
name="Chain Of Density",
finetune_format="messages",
log_handlers=[logging.FileHandler("generated.jsonl")],
openai_client=client,
)
class GeneratedSummary(BaseModel):
"""
기사 원문에서 최대한 많은 엔터티를 포함한 매우 간결 요약
"""
summary: str = Field(..., description="기사 의미를 최대로 압축한 요약",)
@instructions.distil
def distil_summarization(text: str) -> GeneratedSummary:
summary_chain: List[str] = summarize_article(text)
return GeneratedSummary(summary=summary_chain[-1])
with open("train.csv", "r") as file:
reader = csv.reader(file)
next(reader) # 헤더 스킵
for article, summary in reader:
distil_summarization(article)
레이트 리밋
처음엔 작은 데이터셋으로 테스트하며 실행하세요. tenacity로 에러를, OPENAI_API_KEY 환경변수로 키를 반드시 설정하세요.
스크립트 실행 후 generated.jsonl 파일이 생성됩니다. 이제 아래 명령으로 미세조정 시작!
instructor jobs create-from-file generated.jsonl
미세조정 튜토리얼과 다양한 하이퍼파라미터는 Finetuning CLI 문서를 참고하세요.
모델 생성 후, 함수 데코레이터에 미세조정 모델명을 아래와 같이 적용해 사용하면 됩니다.
@instructions.distil(model='gpt-3.5-turbo:finetuned-123', mode="dispatch")
def distil_summarization(text: str) -> GeneratedSummary:
summary_chain: List[str] = summarize_article(text)
return GeneratedSummary(summary=summary_chain[-1])
이제 커스텀 미세조정 모델을 실제 서비스에 활용할 수 있습니다. Instructor의 데이터모델링~증류~미세조정이 얼마나 편리한지도 직접 확인할 수 있습니다.
미세조정에 쓰지 않은 20개 기사로 아래 세 모델을 비교합니다.
3.5 Finetuned (n)
GPT-4 (COD)GPT-3.5 (Vanilla)| 모델 | 평균 지연(초) | 평균 엔터티밀도 |
|---|---|---|
| 3.5 Finetuned (20) | 2.1 | 0.15 |
| 3.5 Finetuned (50) | 2.1 | 0.14 |
| 3.5 Finetuned (76) | 2.1 | 0.14 |
| GPT-3.5 (Vanilla) | 16.8 | 0.12 |
| GPT-4 (COD) | 49.5 | 0.15 |
미세조정 데이터셋을 만들 때, 엔터티 밀도 0.15 이상만 포함했고, 엔터티 밀도가 가장 높은 요약을 최종값으로 삼았습니다. 각 요약은 최소 0.12 밀도를 갖도록 하고, 미달시 최대 3회 재생성했습니다. 이 방식은 비용이 훨씬 많이 들 수 있습니다(예시당 2.5배 이상)
이렇게 해서 75개의 예시를 만드는 데 총 63.46달러가 들었습니다. 즉, 요약 하나 생성에 약 0.85달러입니다.
OpenAI Usage Dashboard를 기준으로, 요약 20개 생성 비용을 산출하면 아래와 같습니다.
| 모델 | 학습비($) | 추론비($) | 토큰수 | 합계($) |
|---|---|---|---|---|
| GPT-3.5 (Vanilla) | - | 0.20 | 51,162 | 0.2 |
| 3.5 Finetuned (20) | 0.7 | 0.20 | 56,573 | 0.8 |
| 3.5 Finetuned (50) | 1.4 | 0.17 | 49,057 | 1.3 |
| 3.5 Finetuned (76) | 1.8 | 0.17 | 51,583 | 2.5 |
| GPT-4 (COD) | - | 12.9 | 409,062 | 12.9 |
GPT-4의 요약 1개 추론비는 약 0.65달러, 반면 미세조정 모델은 0.0091달러로 약 72배 저렴합니다.
흥미롭게도 작은 예시/적은 epoch으로 미세조정한 모델이 더 높은 성능을 보였습니다. 이는 에폭이 충분하지 않았거나, 다양한 샘플에 노출돼 다른 추상적 스타일을 따라하다 밀도가 낮아졌기 때문일 수 있습니다.
이 반복 방법을 미세조정으로 전환하면 20~40배 더 빠른 속도 향상과 전체 성능 개선, 그리고 효율성을 동시에 누릴 수 있습니다.
데이터모델링부터 증류(모델 경량화), 미세조정까지 Instructor가 과정 전반을 쉬워지게 만듭니다. 더 궁금하다면 깃허브에서 직접 instructor를 체험해보세요. 별점도 잊지 말고요!