Anthropic이 Claude를 활용해 높은 정확도의 셀프서비스 비즈니스 분석을 구현하기 위해 데이터 기반, 소스 오브 트루스, 스킬, 검증 체계를 어떻게 구축했는지 설명합니다.

Claude Code
2026년 6월 3일
5
분
https://claude.com/blog/how-anthropic-enables-self-service-data-analytics-with-claude
많은 데이터 과학 및 데이터 엔지니어링 팀이 증언하듯, 셀프서비스 비즈니스 분석을 가능하게 하는 일은 전통적으로 고된 작업이었습니다.
넓고 비정규화된 테이블을 통해 기술적 역량이 낮은 동료들도 데이터 모델에 더 쉽게 접근하도록 만들면, 비즈니스가 확장될수록 정의가 일관되지 않은 중복 뷰가 생기기 쉽습니다. 게다가 SQL을 배우고자 하는 의지가 거의 없는 직원들과의 격차를 메우는 데도 큰 도움이 되지 않습니다. 반대로, 사용자를 위해 더 강하게 구획된 환경을 만들면 비즈니스 질문의 긴 꼬리 영역을 놓치기 쉽고, 팀들이 작업을 사일로화하면서 지표와 대시보드가 과도하게 늘어나는 결과로 이어집니다.
LLM의 부상은 이러한 문제를 피하면서 셀프서비스 분석을 구현할 수 있는 또 다른 경로를 제공합니다. 하지만 Claude를 웨어하우스에 연결해 에이전트가 실행하도록 두는 것만으로는 정밀하다는 잘못된 인상을 줄 수 있습니다.
애드혹 요청에서 해방되었다는 초기의 환희는, 이 설정이 이해관계자들을 그동안 신중하게 선별된 데이터셋으로 이끌던 기반 인프라, 문서, 전문성으로부터 분리한다는 사실을 깨닫는 순간 불안으로 바뀝니다.
Anthropic에서는 비즈니스 분석 질의의 95%가 Claude를 통해 자동화되며, 전체적으로 약 95%의 정확도를 보입니다. 이처럼 종종 기계적이고 반복적인 작업을 Claude에 맡김으로써, 우리 데이터 과학 팀은 인과 모델링, 예측, 머신러닝과 같은 더 전략적인 업무에 집중할 수 있습니다.
Anthropic의 주요 Claude Code 사용자 수십 명과 만나고, 분석 에이전트를 위한 수많은 설계 패턴을 살펴본 끝에, 우리는 LLM을 활용하는 다른 데이터 팀을 위한 몇 가지 모범 사례를 정리했습니다. 이 글에서는 셀프서비스 비즈니스 인사이트를 이끌어내는 Claude의 능력을 극대화하기 위한 팁과 접근법을 공유합니다. 여기에는 다음이 포함됩니다:
LLM의 생성 능력은 양날의 검입니다. 복잡한 문제에 대한 창의적 해결책을 가능하게 하는 메커니즘은 동시에 잘못된 출력을 환각할 수도 있습니다. 분석 에이전트의 과제를 온전히 이해하려면 이를 코딩 에이전트와 비교해 보는 것이 유용합니다.
코딩은 모델의 창의성을 보상하는 개방형 해법 공간이며, 문서와 테스트가 환각에 대한 자연스러운 가드레일을 제공합니다. 반면 분석 사용 사례에서는 종종 단 하나의 올바른 답과 단 하나의 올바른 출처만 존재하며, 그 정답성을 결정론적으로 증명할 방법이 없습니다.

셀프서비스 에이전트형 비즈니스 분석에서 복잡성은 주로 데이터의 모호성에 있습니다. 핵심 문제는 결국 사용자의 질문을 데이터 모델 안의 구체적이고 최신 상태의 엔터티에 매핑하고, 그것들을 올바르게 다루는 방법을 아는 능력으로 귀결됩니다. 이것만 해낼 수 있다면, 그 이후의 실행과 SQL은 사소한 문제가 됩니다.
우리는 부정확한 응답의 압도적 다수를 설명하는 이 문제의 세 가지 속성을 확인했습니다.
개념 <> 엔터티 모호성: 데이터 모델에 수백 개의 가능한 선택지(잠재적으로는 수백만 필드 중 일부)가 있을 때, 에이전트가 사용자의 질문에 가장 잘 답하는 올바른 필드를 선택하지 못합니다. 예를 들어 활성 사용자 수를 측정할 때, 어떤 행동이 “활성”에 해당할까요? 사기 사용자를 포함해야 할까요? 어떤 조회 기간을 써야 할까요?
데이터 노후화: 데이터 소스, 비즈니스 정의, 스키마는 끊임없이 바뀝니다. 자산과 에이전트 지식은 오래되어 미묘하게 잘못된 답을 반환하기 시작합니다.
검색 실패: 올바른 정보가 실제로 데이터 모델 안에 있고 적절히 주석 처리되어 있더라도, 탐색 공간이 너무 방대해 에이전트가 단순히 그것을 찾지 못합니다.
항목을 찾을 수 없습니다.
0/5
Claude Code 받기
eBook

Anthropic에서 우리가 이 세 가지 오류를 최소화하는 주된 방법은 에이전트형 데이터 스택을 사용하는 것입니다. 각 계층은 주로 이 문제들 중 하나 이상을 해결하기 위해 존재합니다.
엔터티 모호성: 데이터 기반과 소스 오브 트루스가 그럴듯한 엔터티 공간을 단 하나의 관리된 답으로 줄입니다.
노후화: 유지보수와 검증 프로세스가 비즈니스 변화에 따라 모든 것이 썩어가지 않도록 합니다.
검색 실패: 스킬이 에이전트가 그 답을 안정적으로 찾고 올바르게 사용하도록 보장합니다.
이 섹션에서는 우리가 각 계층을 어떻게 구축했는지 설명합니다.

분석 에이전트의 정확성을 보장하는 데 가장 중요한 측면은 강력한 데이터 기반입니다. 여기에는 데이터 웨어하우스의 데이터 모델, 변환, 테스트, 테이블과 이를 설명하는 메타데이터가 포함됩니다. 차원 모델링, 시프트 레프트 테스트, 핵심 파이프라인의 최신성 및 완전성 점검과 같은 표준 데이터 엔지니어링 및 데이터 품질 관행은 여전히 모두 적용됩니다(그리고 여기서 이를 다시 논쟁하지는 않겠습니다).
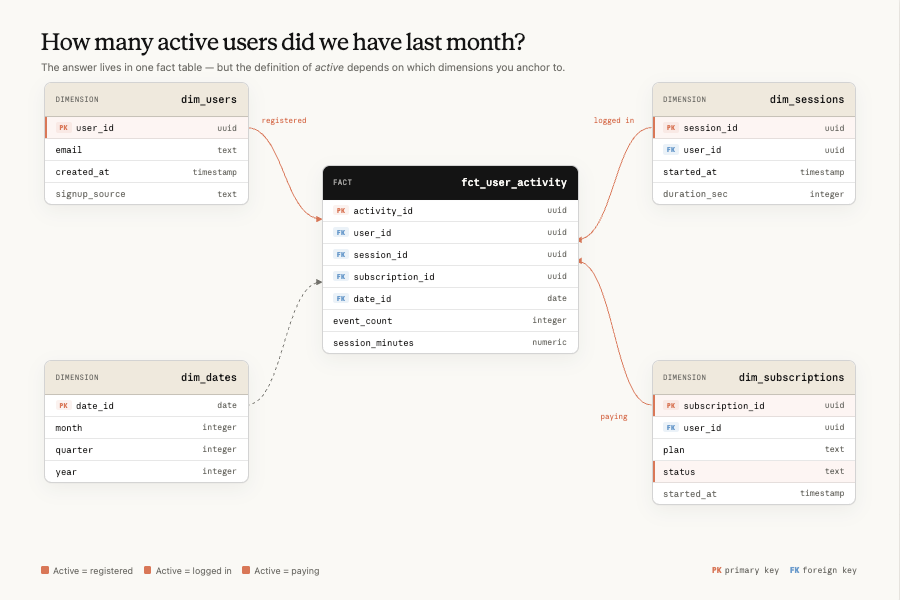
차원 모델링과 같은 표준 데이터 엔지니어링 관행은 예전만큼이나 중요합니다.
달라지는 점은 이제 데이터 모델의 최종 사용자가 더 이상 데이터 전문가(예: 데이터 과학자)가 아니라, 데이터 전문성이나 기반 인프라 이해 수준이 제각각인 사용자를 대신해 행동하는 에이전트라는 것입니다. 이 변화는 결과의 기본 정합성을 사용자가 검증하도록 요구할 수 없다는 점에서 도전 과제를 제시합니다. 최종 사용자가 애초에 그것을 알지 못하기 때문입니다.
데이터 기반 계층은 주로 모호성을 겨냥합니다. 예를 들어 _revenue_가 그럴듯한 후보 40개가 아니라 하나의 관리된 데이터셋으로 해석된다면, 문제는 에이전트가 검색을 시작하기도 전에 대부분 사라집니다. 또한 정식 모델을 정의하는 동일한 저장소가 그것들이 최신 상태를 유지하도록 강제하는 자연스러운 장소이기 때문에, 첫 번째 노후화 방어선도 여기에 있습니다.
특히 잘 작동하는 몇 가지 관행을 보았습니다.
데이터 기반이 데이터 웨어하우스 자체라면, 소스 오브 트루스는 에이전트가 이를 탐색하기 위해 참조하는 기준 표면입니다. 이 계층은 개념 <> 엔터티 모호성을 줄이고, 이해관계자의 질문 속 “주간 활성 사용자”를 데이터 모델의 구체적이고 관리된 엔터티로 바꿉니다. 대략 신뢰도 높은 순서대로 보면 다음과 같습니다.
이 네 가지 전반에 걸친 공통 실패 패턴은 데이터 기반 계층과 동일합니다. 바로 부실하거나 오래된 문서입니다. Claude는 이 간극을 메우는 데 매우 유용합니다(컬럼 설명 초안 작성, 쿼리 패턴에서 지표 문서 제안, CI에서 문서화되지 않은 모델 표시). 그러나 큐레이션과 소유권은 사람이 관리합니다.
다음 두 섹션에서는 그 소유권이 실제로 수행될 만큼 충분히 저렴해지도록 만드는 방법을 설명합니다.
소스 오브 트루스가 에이전트의 선언적 지식(즉, 어떤 지표가 무엇을 의미하는가)이라면, 스킬은 절차적 지식입니다. 즉 어떤 소스를 어떤 순서로 참고할지, 모호한 데이터를 어떻게 탐색할지, 완성된 분석이 어떤 모습이어야 하는지를 뜻합니다.
Claude Code에서 skill은 에이전트가 필요할 때 읽는 마크다운 폴더입니다. Anthropic에서는 우리가 개발한 스킬이 엄청난 가치를 더했습니다. 스킬이 없을 때, 분석 질문에 정확히 답하는 Claude의 능력은 평가에서 21%를 넘지 못했습니다. 스킬을 추가하면 이 수치가 전체적으로 일관되게 95%를 넘고, 특정 도메인에서는 정기적으로 99% 안팎에 도달합니다. 우리가 대부분의 스킬을 만들 때 사용하는 골격은 부록을 참조하세요.
몇 가지 모범 사례는 다음과 같습니다.
쌍으로 된 스킬 만들기: 지식 스킬은 필요할 때 추가 도메인 세부사항이 로드되도록 하는 얇은 최상위 라우터 역할을 합니다. 이 스킬은 “먼저 시맨틱 계층을 시도하되, 커버리지가 없다면 이 도메인의 관련 테이블, 컬럼, 조인, 함정을 설명하는 약 30개의 참조 파일이 있다”라고 안내합니다. 사실상 이 라우터는 검색 실패에 대한 우리의 해답입니다. 에이전트가 백만 필드의 웨어하우스를 검색하게 두는 대신, 쿼리를 작성하기도 전에 탐색 공간을 수십 개의 선별된 파일로 줄여줍니다. 언북 스킬은 숙련된 분석가가 따를 프로세스를 담고 있습니다. 질문을 명확히 하고, 출처를 찾고(지식 스킬을 통해), 쿼리를 실행한 뒤, 결과를 적대적 리뷰 서브에이전트로 반복 검토합니다. 또한 재사용 가능한 분석 패턴(리텐션 곡선, 비율 분해, 퍼널 분석)도 12여 개 묶어두어, 흔한 요청을 매번 새로 발명하지 않도록 합니다.
적절한 참조 문서 만들기: LLM의 검색을 위해 작성된 문서여야 합니다. 우리의 참조 문서는 테이블을 설명하고(그레인, 범위, 제외 사항), 함정의 작동 방식을 적으며(예: “알려진 무료 이메일 도메인은 제외하되 anthropic.com 같은 커스텀 도메인은 유지”), 명시적인 라우팅 트리거를 포함합니다(예: “질문이 실험 lift에 관한 것이라면… 원시 이벤트 카운트에는 사용하지 말 것”). 하지만 시간이 지나며 낡아버리는 처방적 레시피는 넣지 않습니다. 아래는 우리가 참조 문서를 만들 때 사용하는 골격입니다.
# [Domain] Tables
## Quick Reference
### Business Context — [what this domain means in plain words]
### Entity Grain — [what one row represents]
### Standard Hygiene Filter — [the filter every query in this domain applies]
## Dimensions
- [How the key dimensions are encoded, and how the same concept is named
differently across tables]
## Key Tables
### [table_name]
- **Grain**: [...] · **Scope/exclusions**: [...]
- **Usage**: [when to use it, when NOT to, join keys, required filters]
[... one short section per governed table ...]
## Gotchas
- [The wrong-answer modes a senior analyst would warn you about]
## Best Practices / Common Query Patterns
- [Default choices, standard cuts, worked patterns where the exact query
form is the hard part]
## Cross-References
- [Neighboring domain docs that own adjacent questions]
스킬 유지보수를 일급 시민으로 다루기: 스킬 문서는 매일 바뀌는 데이터 모델을 설명하므로, 적극적으로 유지보수하지 않으면 몇 주 안에 틀려집니다. 우리는 이를 엔지니어링 문제로 다루기 전까지 오프라인 정확도가 출시 시점 약 95%에서 한 달 만에 약 65%로 떨어지는 것을 지켜봤습니다. 그래서 스킬 마크다운 파일을 변환 모델과 같은 저장소에 공존 배치했습니다. 즉 모델을 바꾸는 PR이 그 모델을 설명하는 문서까지 업데이트하는 같은 PR이 되도록 했습니다. 코드 리뷰 훅은 보고 모델 변경이 스킬 파일을 건드리지 않으면 이를 표시합니다. 이제 우리 데이터 모델 PR의 약 90%는 같은 diff 안에 스킬 변경을 포함합니다. 또한 모델이 개선되고 예전 실패 모드가 더 이상 적용되지 않으면 스킬 비계도 정기적으로 정리합니다.
모든 표면에서 일관되고 매끄러운 경험 만들기: 동일한 스킬은 Slack, IDE, 대시보드 도구, 독립형 에이전트 세션 어디에서든 같은 질문에 같은 답을 제공해야 합니다. 우리는 하나의 정식 소스(데이터 저장소)를 보장하고, 스킬 변경이 자동으로 동기화되도록 함으로써 이를 달성했습니다. 머지 시 스킬은 플러그인 마켓플레이스(IDE 사용자용), 클라우드 스토리지 blob(단일 파일을 읽는 호스팅 앱용), 그리고 MCP를 통한 리소스로 직접 제공되는 경로에 동기화됩니다. 또한 처음부터 하드코딩된 저장소 경로와 표면별 네임스페이스를 피함으로써 이식성을 고려해 설계했습니다.
마지막으로, 검증은 세 가지 실패 모드 중 어느 것이 여전히 새어나오는지 알아내는 방법입니다.
우리가 자주 보는 패턴은 데이터 팀이 분석 환경을 정교하게 구성하면서도, 분석 에이전트의 정확도를 이해하는 프로세스는 전혀 갖추지 않는다는 점입니다.
이 간극을 메우는 한 가지 방법은 오프라인 평가를 활용하는 것입니다. 이는 단순한 질문/답변 쌍입니다. 오프라인 평가는 ML 모델의 오프라인 테스트와 비슷하다고 볼 수 있습니다. 온라인 에이전트의 성능을 직접 알려주지는 않지만, 치명적인 공백이 있는지를 꽤 잘 보여줍니다.
Anthropic에서는 두 종류의 오프라인 평가를 운영합니다. 대시보드 기반 평가는 Claude가 자동 생성한 뒤 사람이 검증하며, 가장 흔한 이해관계자 질문을 다룹니다. 롱테일 평가는 Claude에 비즈니스 컨텍스트(로드맵, 테이블 문서)를 제공하고 나머지 도메인 전반에서 그럴듯한 질문을 생성하게 하는 방식입니다. 또한 이해관계자가 스레드에서 에이전트를 수정할 때마다 이를 지속적으로 수집하는데, 그러한 수정은 평가 후보가 됩니다.
그 밖의 모범 사례는 다음과 같습니다.
스킬에 대한 모든 구조적 결정(예: 어떤 소스를 노출할지, 어떤 서브에이전트가 지연 시간을 감수할 가치가 있는지, 두 스킬을 하나로 합칠지 여부)은 오프라인 평가 집합을 고정한 채 이루어집니다.
우리는 정확히 하나의 구성요소만 바꾸고 통과율을 비교합니다. 각 실행은 한 시간밖에 걸리지 않지만, 많은 논쟁을 대체합니다. 어떤 단일 결과보다 방법론이 더 중요합니다.
마지막 단계는 실제 온라인 시스템 성능이 최대한 정확하도록 보장하는 것입니다. 우리가 취하는 조치 중 일부는 다음과 같습니다.
이 모든 것으로도 완전히 잡히지 않는 실패 모드는 침묵하는 실패입니다. 답은 틀렸지만 그럴듯해 보여 아무 이의 없이 사용되는 경우입니다. 우리의 완화책은 출처 푸터, 리더십에 전달되는 모든 것에 대한 명시적 인간 승인, 그리고 각 도메인의 핵심 KPI에 대해 매일 공식 대시보드와 sanity check를 수행하는 상시 평가이지만, 아직 견고한 해결책은 없습니다.
완전히 처음부터 시작한다면, 소수의 정식 데이터셋, 수십 개의 오프라인 평가, 그리고 얇은 지식 스킬만으로도 대부분의 이점을 얻을 수 있습니다. 이 글의 나머지는 그런 기본 요소를 구축한 뒤 우리가 추가한 것들입니다.
또한 우리는 많은 모범 사례를 공유했지만, 그 모든 것이 모든 데이터 팀에 적합한 것은 아닙니다. 접근 방식에 영향을 줄 몇 가지 원칙을 조직과 정렬하려면 다음 질문을 던져 보세요.
어떤 경로를 택하든, 우리의 가장 큰 성과는 세 가지 실패 모드를 각각 해결하는 데서 나왔습니다. 즉 모호성을 하나의 관리된 답으로 수렴시키고, 그 답을 쉽게 발견 가능하게 만들고, 둘 중 어느 하나가 오래되었을 때 이를 표시하는 것입니다.
이 글은 데이터 과학 및 데이터 엔지니어링 팀의 Chen Chang, Clement Peng, Justin Leder, Johanne Jiao, Josh Cherry가 작성했습니다. 저자들은 Michael Segner의 기여에도 감사를 전합니다.
아래는 우리 메인 웨어하우스 스킬의 골격입니다. 실제 파일의 구조를 보여 주되, 내부 세부사항은 [대괄호 자리표시자]로 대체했습니다. 그대로 복사하라는 뜻이 아니라, 우리가 문서화할 가치가 있다고 본 섹션의 종류를 보여 주기 위한 것입니다.
---
name: [warehouse-skill]
version: [x.y.z]
description: "IF the user asks to query [the company]'s data warehouse for any
[list of business domains] question — THEN invoke this skill. DO NOT invoke
for [adjacent engineering tasks] or questions with no data-warehouse component."
---
# [Warehouse] Skill Instructions
## Description
The single source of truth for safe and effective [warehouse] querying.
Referenced by other skills [listed] for query execution guidance.
Act as a Data Analyst, providing strategic insights and data-driven
recommendations but seek guidance along the way.
**Out-of-scope decisions**: [product areas, etc.] → surface data only,
state "decision is [owning team]'s call", do NOT take a position or author
code fixes.
## Executing queries
Priority:
1. **[Managed connection]** (if available): [query tool] / [schema tool]
2. **[CLI fallback]** (if installed): [default project, fallback project]
3. **Neither** — ask the user to authenticate, then stop
---
# Semantic Layer (REQUIRED first step)
The governed semantic layer is the **mandatory default path** for every data
question — same numbers as [the BI tool], joins/grain/filters baked in. Raw SQL
via the reference docs below is the **fallback**, used only after the
semantic-layer path is shown not to cover the ask.
## Required workflow
1. **Load** — [how to load the semantic layer in each runtime, with fallbacks]
2. **Discover** — search measures/dimensions by keyword; **always check
segments** (the named canonical population filters — hand-rolled WHERE
clauses for these are the dominant wrong-answer mode)
3. **Compile + run** — build the spec → compile to SQL → execute
4. **Fallback** — only if discovery finds no relevant metric or compile fails
→ raw SQL via `references/*.md` (PART 3 below)
> **Don't bail early.** Do NOT fall back to raw SQL on these grounds:
> - "[custom date filtering / cohorts]" → [covered by time-dimension specs]
> - "[needs a join]" → [the metric layer already encapsulates its joins]
> - [3–4 more pre-rebutted excuses agents use to skip the semantic layer]
### Date windows & timezone — decide before you query
- **As-of date vs trailing-N days**: [convention for each]
- **"Last week/month"** → the last *complete* calendar week/month, not trailing-7/30
- **Timezone default**: [TZ]; [exception for certain reporting rollups]
- **Freshness lag**: [some] tables settle late — anchor on MAX(date), not "yesterday"
---
# PART 1: MUST KNOW (Read First for Every Request)
## 🚀 Quick Start Workflow
1. **Check for red flags first**: [restricted/PII requests, gated domains,
high-stakes asks that need extra validation]
2. **Out of scope — escalate, don't guess**: [access requests, pipeline
troubleshooting, stale dashboards, root-cause assertions, product/pricing
recommendations] → redirect to [the owning team], don't answer
3. **Clarify the request**: time period, segment, the business decision it informs
4. **Check for existing dashboards**: [per-domain dashboard catalogs]
5. **Identify the data source**: [navigation map below; prefer governed/aggregated tables]
6. **Execute the analysis**: [required filters + adversarial review]
7. **Deliver insights**: show methodology, differentiate observations from interpretations
## 🏢 Business Context
### Entity Disambiguation (MUST CLARIFY)
- **"[Term A]" can mean**: [entity 1] or [entity 2] — always clarify which
- **"[Term B]" can mean**: [entity 1] → [entity 2] → [entity 3] (one-to-many chain)
- **"Users"**: [which identifier gives accurate counts, and which ones inflate them]
### Business Terminology
- [Current product names vs deprecated aliases that still appear as frozen
values in the data layer — write with the new names, filter with the old]
- [Key internal acronyms]
- **[Headline metric] calculations**: [monthly / default window / leading indicator]
- **Unfamiliar terms — search [internal docs], don't guess**
### Data Integrity Requirements ⚠️
- **NEVER**: make up data/columns; make speculative assertions beyond what data shows
- **ALWAYS**: use safe division; differentiate observations ("data shows X")
from interpretations ("this suggests Y"); flag limitations
---
# PART 2: HOW TO DO (Follow During Execution)
## 🔧 Technical Execution Guide
- [Managed-connection tools and CLI invocation details]
- **PII protection**: for restricted data, return the SQL for the user to run
themselves — do not return results
## 📊 Analysis Best Practices Guide
1. Clarify the ask before querying
2. Show your work (filters, inclusions/exclusions, freshness)
3. Clarify denominators
4. Consider sample bias
5. Connect to business impact
6. **Adversarial SQL review (MANDATORY)** — spawn the [sql-reviewer] sub-agent
for every query before the final answer; blocking findings must be fixed
and re-reviewed; do not self-certify
7. **Report with provenance** — every answer ends with a footer:
> **Source:** [semantic layer | governed table | raw exploration] ·
> **Confidence:** [tier] · **Reviewed:** [reviewer ✓, round N] ·
> **Freshness:** [max date in the data] · **Owner:** [owning team]
---
# PART 3: DATA REFERENCES & RESOURCES
## 📚 Knowledge Base Navigation
### [Domain A] → `references/[domain_a].md`
- **Use for**: [kinds of questions]
- **Key tables**: [...]
- **Dashboards**: `references/[domain_a]_dashboards.json`
### [Domain B] → `references/[domain_b].md`
- **Use for**: [...]
[... one entry per business domain — a few dozen in total ...]
## ⚠️ Troubleshooting Guide
### When Information Is Missing
- [missing tables / access denied / outdated docs / unknown enum values → what to do]
### Field Naming Gotchas
- Use `[field_x_v2]` NOT `[field_x]`
- [Two similarly-named tables report the same metric at different grains — which to use]
- [Which of two plausible sources is canonical for the headline metric]
- [… a dozen more hard-won one-liners …]
항목을 찾을 수 없습니다.
개발자 뉴스레터 받기
제품 업데이트, 사용 방법, 커뮤니티 하이라이트 등 다양한 내용을 받아보세요. 매달 이메일로 전해드립니다.
월간 개발자 뉴스레터를 받고 싶다면 이메일 주소를 입력해 주세요. 언제든지 구독을 취소할 수 있습니다.
감사합니다! 구독이 완료되었습니다.
죄송합니다. 제출 중 문제가 발생했습니다. 나중에 다시 시도해 주세요.