Block이 데이터 거버넌스, 소유권, 메트릭 정의, 조직 정렬을 재구성해 신뢰할 수 있는 AI 기반 분석 플랫폼을 구축한 방법을 소개합니다.
데이터는 의사결정을 움직입니다. 하지만 신뢰할 수 있을 때만 그렇습니다.
Block 전반을 살펴보았을 때, 같은 메트릭이 수십 가지 방식으로 계산되고 있었고, 분석가들은 서로의 작업을 모른 채 중복 수행하고 있었으며, AI 에이전트는 보기에는 맞아 보이지만 누구도 신뢰할 수 없는 수치를 만들어내는 SQL을 태연하게 생성하고 있었습니다. 우리에게는 툴링 문제가 있었습니다. 하지만 그 아래에는 데이터 전략 문제가 있었습니다.
이 글은 Block가 데이터와 맺는 관계 전체를 어떻게 전면 개편했는지에 대한 이야기입니다. 거버넌스, 소유권, 메트릭 정의, 그리고 조직 정렬까지 포함합니다. 우리는 데이터 메시 프레임워크의 변형을 도입하고, 거버넌스가 적용된 시맨틱 레이어를 구축했으며, 안전하고 정확한 AI 기반 분석을 조정하기 위해 맞춤형 MCP servers를 만들었습니다. 그 결과, Block의 어떤 데이터 사용자든 AI 에이전트를 통해 비즈니스 질문에서 신뢰할 수 있는 답변으로 이동할 수 있는 시스템이 만들어졌습니다. 거버넌스가 적용된 메트릭에 대해서는 SQL 검토 없이도 메트릭 정확도 100%를 달성할 수 있고, 또는 검증된 컨텍스트 소스에서 동적으로 SQL을 생성할 수 있습니다.
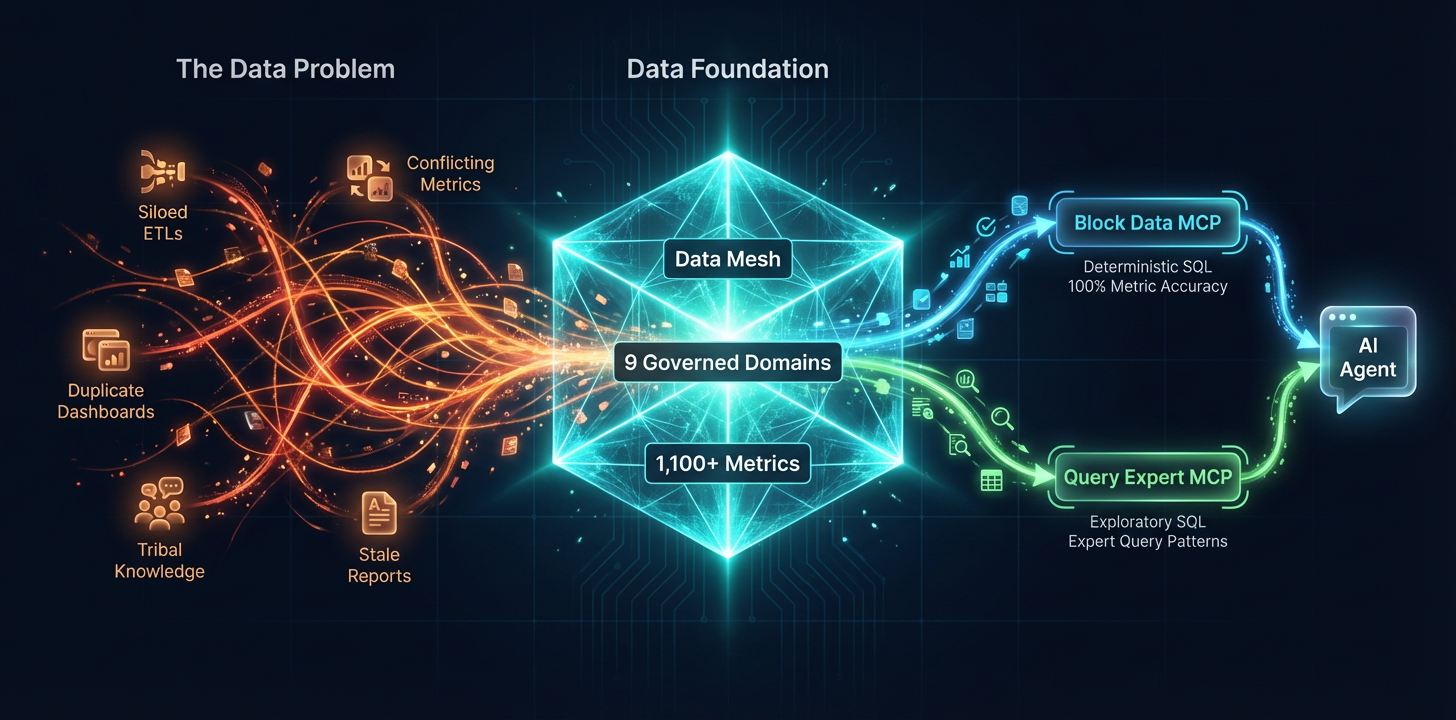
그 기반이 마련되자 자동화가 가능해졌습니다. 결정적이고 거버넌스가 적용된 SQL을 위한 경로를 구축함으로써, 온콜 프로세스를 자동화하고, 리더십이 맞춤형 데이터 질문에 즉시 답을 얻을 수 있게 하며, 사용자가 필요한 데이터를 찾는 일을 막힘 없이 진행하도록 하고, AI 에이전트가 완전 자동화 루프를 통해 새로운 메트릭과 컨텍스트를 추가하도록 할 수 있었습니다.
우리가 거기에 어떻게 도달했는지, 그리고 그 과정에서 무엇을 배웠는지 소개하겠습니다.
코드를 작성하기 전에, 우리는 네 가지 핵심 결정을 내렸습니다.
첫째, 구체적인 비즈니스 애플리케이션에 기준점을 두었습니다. 우리의 최종 목표는 Block의 어떤 데이터 사용자든 AI 에이전트를 통해 비즈니스 질문에서 신뢰할 수 있는 답변으로 이동할 수 있게 하는 것이었습니다. 하지만 우리는 범용 솔루션부터 만들지 않았습니다. 대신 Finance와 Sales 리더십이 실제로 반복적으로 묻는 40개의 현실적인 비즈니스 질문을 식별하는 것부터 시작했습니다. 예를 들어 "지난 분기 Cash App의 월간 활성 사용자 성장률은 얼마였는가?" 또는 "지역별로 Square GPV는 전년 대비 어떻게 비교되는가?" 같은 질문입니다. 이렇게 정의된 질문 집합은 우리가 측정할 수 있는 결승선을 제공했습니다.
둘째, 타협 없는 성공 기준을 세웠습니다: 메트릭 정확도 100%. 95%도 아니고, "첫 번째 초안으로는 충분히 가깝다"도 아니었습니다. CFO가 숫자를 요청하면, 그 숫자는 반드시 source of truth와 정확히 일치해야 합니다. 이 단 하나의 결정이 우리를, 유연성을 위해 정밀성을 희생하는 대부분의 AI 분석 프로젝트와는 근본적으로 다른 아키텍처 경로로 이끌었습니다. 우리는 먼저 정밀성에 최적화하고, 그 옆에 유연성을 더했습니다.
셋째, Block에서 데이터를 다룰 때 핵심 문제는 시작하는 방법이라는 점을 확인했습니다: 대규모 조직에서는 수십만 개의 데이터 테이블, 데이터 지원을 위한 여러 slack 채널, 그리고 google docs, github, slack, 그리고 사람들의 머릿속에 흩어져 있는 수많은 모범 사례가 존재합니다. 데이터 문제는 먼저 콜드 스타트 문제입니다. 어디로 가야 하는가, 누구와 협업해야 하는가, 어떤 테이블을 사용해야 하는가? 우리는 에이전트가 진정한 일급 동료가 될 수 있도록, 데이터 구조, 데이터 전문가, 그리고 데이터에 숨겨진 모호성을 이해하는 데 컨텍스트 레이어를 최적화했습니다.
넷째, 우리는 크로스펑셔널 타이거 팀을 구성했습니다. 핵심 그룹은 작았습니다. Tech Lead 1명, Data Engineers 2명, Data Scientists 3명, AI Engineer 1명이었습니다. 이 팀은 6주 만에 동작하는 개념 증명을 만들었습니다. 프로젝트가 확장되면서 Data Governance, Platform Engineering, Product, 그리고 비즈니스 이해관계자 파트너를 참여시켰습니다. 크로스펑셔널한 동의는 프로젝트를 POC에서 회사 전반의 플랫폼으로 확장하는 데 있어 가장 중요한 단일 요인으로 드러났습니다. 거버넌스 팀이 논의에 참여하지 않았다면, 우리는 또 하나의 사일로를 만들었을 것입니다. 비즈니스 이해관계자가 없었다면, 우리는 잘못된 질문에 최적화했을 것입니다.
우리의 첫 시도는 두 가지 기능을 결합한 단일 MCP 서버를 만드는 것이었습니다. 하나는 사전 정의되고 검증된 메트릭을 조회하기 위한 거버넌스형 시맨틱 레이어(Block Metrics Store)였고, 다른 하나는 개방형 데이터 탐색을 위한 자연어-대-SQL 엔진(Query Expert)였습니다. 문서상으로는 타당해 보였습니다. 하나의 도구, 하나의 인터페이스, 사용자가 질문할 하나의 장소. 하지만 실제로는 누구도 완전히 만족하지 못했습니다.
비즈니스 사용자, 특히 재무 및 경영진 이해관계자는 도구에 정확하고 신뢰할 수 있는 답을 기대하며 접근했습니다. 그들은 "지난 분기의 총매출은 얼마였는가?"라고 묻고, 다시 의심할 필요 없이 이사회 자료에 넣을 수 있는 숫자를 원했습니다. 시스템이 가끔 그 질문을 거버넌스 메트릭 경로 대신 자연어 SQL 경로로 라우팅하면, 그들은 거의 맞지만 정확하지는 않은 답을 받았습니다. 성공 기준이 정확도 100%일 때는 "거의 맞음"으로는 충분하지 않습니다. 그들의 피드백은 분명했습니다: "이건 신뢰할 수 없어요."
기술 사용자, 주로 분석가와 데이터 과학자들은 정반대의 불만을 가졌습니다. 그들은 폭넓음을 원하며 도구를 사용했습니다. 거버넌스형 시맨틱 레이어는 특히 초기에는 사용 가능한 메트릭의 일부만 다루었고, 분석가들은 지금까지 정의된 범위를 넘어설 필요가 있었습니다. 그들의 피드백 역시 분명했습니다: "이건 충분히 유연하지 않아요."
우리는 근본적으로 다른 두 가지 사용자 의도를 하나의 인터페이스로 제공하려 했고, 그 결과 한쪽 청중에게는 신뢰할 수 없고 다른 쪽에는 제약적으로 느껴지는 도구가 되었습니다.
해결책은 관심사를 완전히 분리하는 것이었습니다. 우리는 단일 MCP를 두 개의 별도 도구로 나누었습니다.
Block Data MCP는 Block Metrics Store로 구동되며, 결정적 정확성에 최적화되어 있습니다. 사용자가 메트릭을 요청하면, 시스템은 시맨틱 레이어에서 사전 승인된 SQL 로직을 가져와 LLM에 노출하지 않은 채 그 SQL을 실행합니다. LLM은 실행되는 SQL을 수정할 수 없습니다. 질문이 어떻게 표현되든 답은 항상 동일합니다.
Query Expert MCP는 탐색적 유연성에 최적화되어 있습니다. 이 도구는 과거 데이터 과학자들의 쿼리 패턴, 데이터 컨텍스트, 테이블 스키마를 RAG 아키텍처로 큐레이션하여 LLM이 검색, 검증, SQL 생성을 수행하게 합니다. 결과는 덜 결정적이지만 훨씬 더 유연합니다.
이 분리는 각 사용자 그룹에 정확히 필요한 것을 제공했습니다. 비즈니스 사용자는 무조건 신뢰할 수 있는 도구를 얻었습니다. 기술 사용자는 자신의 작업 방식에 맞는 도구를 얻었습니다. 그리고 사용자는 사용 사례에 따라 두 MCP 사이를 오갈 수 있게 되었습니다.
관심사를 분리한 뒤, 아키텍처는 공통 데이터 인프라를 공유하면서 서로 다른 사용자 의도를 지원하는 두 개의 별도 MCP 서버로 명확해졌습니다.
| Persona | Traditional Usage | AI-Enhanced Usage |
|---|---|---|
| Business Users(e.g., Executive Leadership, Operations) | 임시 보고 질문에 대해 분석가에게 의존한다. 비즈니스 인사이트를 위해 대시보드를 검색한다. | AI 도구에서 자연어 질문을 해 맞춤형 분석을 얻는다. 데이터 소비 워크플로를 자동화한다. |
| Technical Users(e.g., Data Scientists, Data Engineers, Product Managers, Engineers) | SQL 중심의 임시 요청을 처리한다. 데이터셋을 찾기 위해 데이터 확산 속을 탐색한다. | AI 도구를 사용해 SQL 작성을 자동화하고, 전문성을 바탕으로 검증한다. 비즈니스 질문에 대한 source of truth 테이블, 데이터 컨텍스트, 데이터 전문가를 식별하도록 AI에 요청한다. |
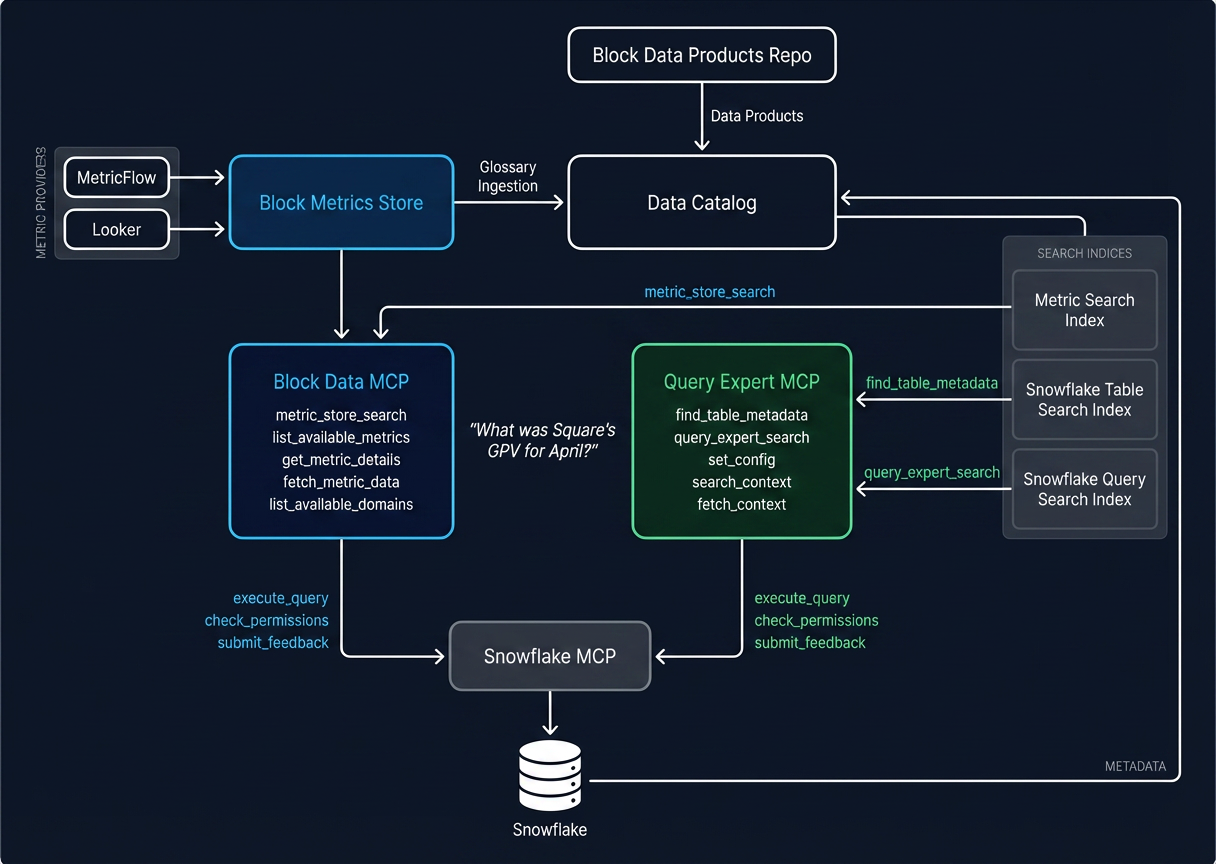
Block Data MCP는 특정 대상을 위해 설계되었습니다. 비즈니스 사용자, 프로덕트 매니저, 경영진, 그리고 SQL을 알 필요 없이 신뢰할 수 있는 메트릭에 접근하려는 모든 사람입니다. 이 도구의 핵심 엔진은 Block Metrics Store로, Metricflow로 구동되는 거버넌스형 시맨틱 레이어이며, Block 전반의 메트릭 정의를 위한 중앙 source of truth 역할을 합니다. 자연어로 질문하는 재무 리더는 도구를 직접 사용하는 분석가와 동일한 거버넌스 파이프라인을 거치게 됩니다.
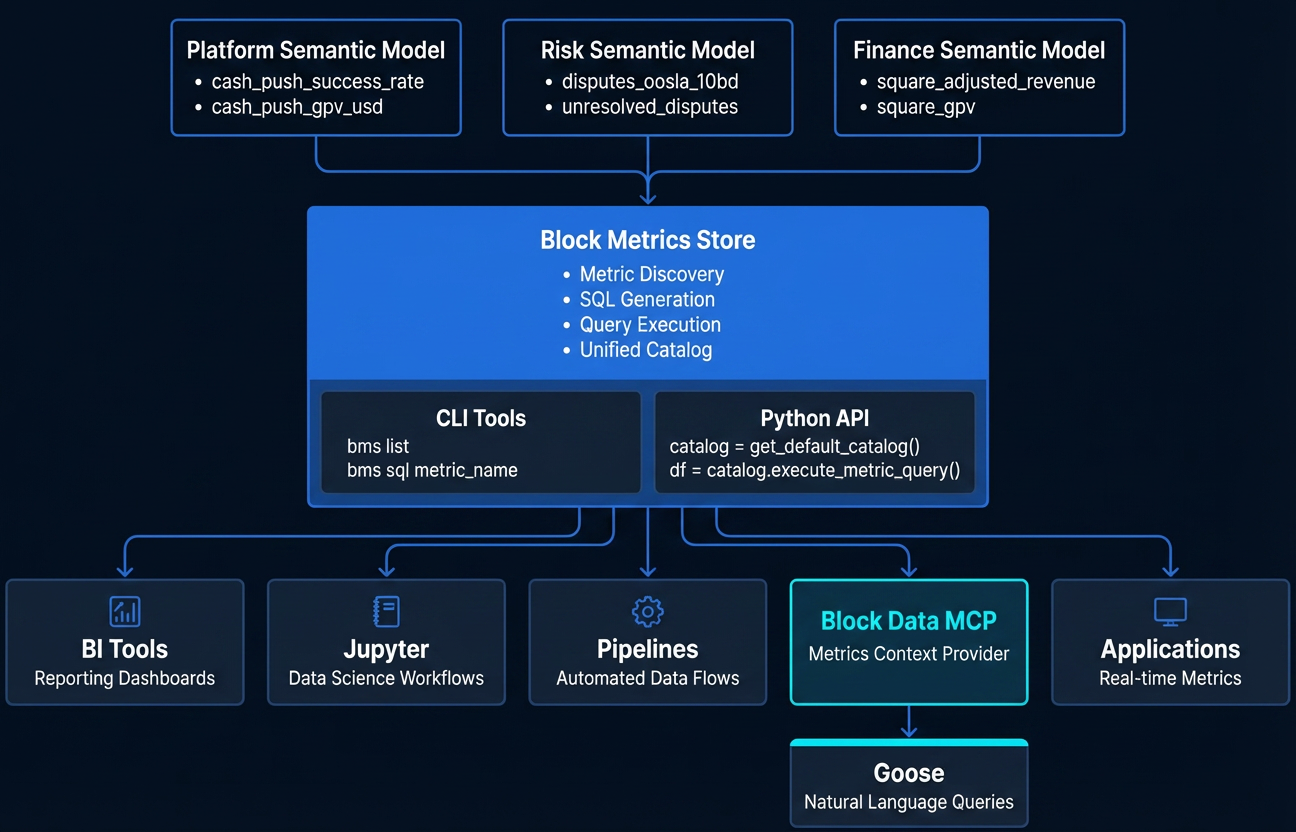
현재 Block Metrics Store에는 회사 전반의 데이터 스튜어드가 기여한 1,100개 이상의 거버넌스 메트릭이 포함되어 있습니다. 여기에는 Square, Cash App, Afterpay, TIDAL, Bitkey 등 Block의 모든 브랜드에 걸친 revenue, GPV, 활성 사용자, 유지율 등이 포함됩니다. 각 메트릭은 중앙 GitHub 저장소에서 코드로 정의됩니다. 메트릭 정의에는 SQL 로직, 차원 속성, 그리고 풍부한 거버넌스 메타데이터가 포함됩니다. 누가 소유하는지(비즈니스 및 기술 소유자), 어떤 거버넌스 수준을 달성했는지, 어떤 브랜드에 속하는지, 어떤 오디언스 티어를 대상으로 하는지, 그리고 정확성을 확인하는 데 사용한 검증 소스 링크 등이 여기에 해당합니다. 아래는 단순화한 예시입니다:
1metric:
2 name: cash_app_total_inflows_usd
3 label: Total Inflows
4 description: "The total amount of USD from all Inflow transactions..."
5 type: SIMPLE
6 config:
7 meta:
8 business_owner: quantitative-finance
9 technical_owner: cash-bie
10 support_slack_channel: "#money_movement_data"
11 governance_level: verified
12 brand: cash_app
13 audience_tier: tier_1
14 use_case: inflows_framework, earnings
MCP 자체는 AI 에이전트가 호출할 수 있는 구조화된 도구 집합으로 구축되어 있습니다. 키워드로 메트릭 검색, 메트릭 세부정보 조회(거버넌스 수준, 소유자, 사용 가능한 차원 포함), 필터와 차원별 분해를 적용한 데이터 조회, 기존 대시보드와 보고서 탐색, 사용자 권한 확인, 피드백 제출 등을 수행합니다. 여기서 핵심 아키텍처 선택은 설계에 의한 제약입니다. AI 에이전트에게 데이터 웨어하우스에 대한 개방형 접근을 주는 대신, MCP는 검증된 작업의 메뉴 역할을 합니다. 모든 MCP 도구는 메타데이터와 쿼리 결과만 제공하므로, LLM이 SQL을 수정하면서도 결과가 검증되었다고 주장하는 일을 방지합니다.
거버넌스는 3단계 시스템으로 시행됩니다.
이 계층형 접근법은 팀이 gatekeeping 없이도 새로운 메트릭을 preliminary 수준에서 빠르게 온보딩할 수 있게 하면서, 특정 메트릭에 대한 신뢰 수준을 소비자에게 투명하게 보여줍니다. 시스템은 단지 숫자가 무엇인지뿐 아니라, 그 숫자를 얼마나 신뢰해야 하는지도 알려줍니다.
모든 질문이 사전 정의된 메트릭에 매핑되지는 않습니다. 새로운 데이터셋을 탐색하거나, 이상 현상을 조사하거나, 일회성 분석을 구축하는 분석가에게는 테이블을 발견하고, 전문가 쿼리 패턴에서 배우고, 맞춤형 SQL을 작성할 자유가 필요합니다. 이것이 Query Expert MCP의 역할입니다.
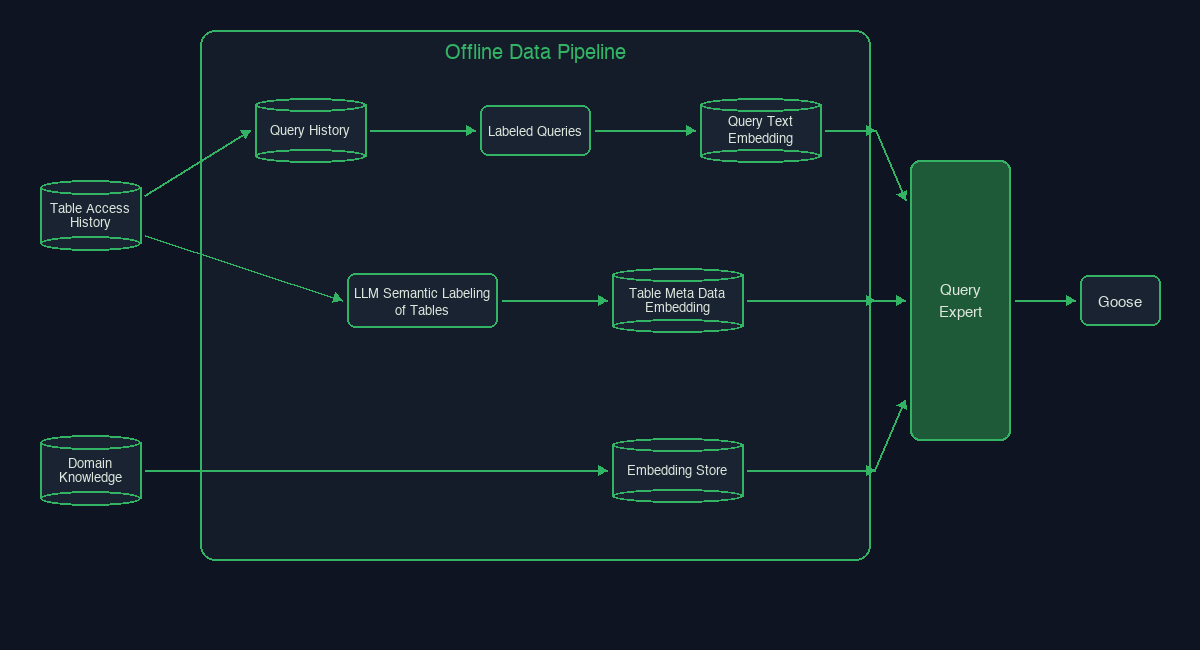
우리는 Query Expert를 데이터 과학자의 흐름을 모방하는 RAG 아키텍처로 구축했습니다.
사용자가 질문을 하면, MCP는 AI 에이전트를 구조화된 워크플로로 안내합니다. 사용자의 의도를 이해하고, 브랜드 및 도메인별 컨텍스트(용어집, 인구통계, 비즈니스 규칙)를 검색하고, 관련 테이블과 그 메타데이터(컬럼 스키마, 소유자, 일반적인 조인 패턴 포함)를 검색하고, 데이터를 가장 잘 아는 사람들이 작성한 과거 쿼리를 찾은 다음, 실행 전에 전체 "Query Expert Report"와 함께 쿼리를 합성합니다. 이 보고서에는 제안된 SQL, 유사한 쿼리를 작성하는 전문가 사용자 목록, 그리고 추가로 탐색할 관련 테이블이 포함됩니다. 이를 통해 사람이 루프 안에서 SQL과, 정확성 검증을 위해 상담할 수 있는 데이터 전문가를 검토할 수 있습니다.
Query Expert의 결과는 Metrics Store보다 본질적으로 덜 결정적입니다. LLM은 쿼리를 구성하고 조정하는 데 더 큰 자유를 가집니다. 하지만 이는 의도된 트레이드오프입니다. Query Expert는 다른 사용자 의도를 지원하며, 이 도구를 사용하는 사용자는 자신이 거버넌스 메트릭을 가져오는 것이 아니라 탐색적 영역에 들어와 있음을 이해합니다.
Query Expert는 신뢰할 수 있고 최신의 도메인 컨텍스트를 드러내기 위해 설계된 세 가지 지식 소스 위에 구축되어 있습니다. 이전에는 이런 지식이 Slack 채널, 문서, 또는 분석가의 머릿속에 존재했습니다.
Data Knowledge 데이터 팀은 데이터 도메인별 지식을 생성해 벡터 데이터베이스에 추가할 수 있고, 에이전트는 이를 의미적으로 검색해 활용합니다. 데이터 지식은 revenue 계산 시 세금을 포함할지 제외할지 같은 매우 구체적인 지식 저장소부터, 일반적인 약어를 데이터 필드 및 흔한 인구통계 용어와 연결하는 넓은 범위의 공통 데이터 관행까지 다양합니다. 이전에는 흩어져 있었거나 품질이 고르지 않았던 지식이 이제는 쉽게 발견할 수 있도록 중앙집중화되었습니다.
Table Knowledge Block에는 10만 개가 넘는 analytics 테이블이 있습니다. 대개는 질문에 답하기 위한 올바른 데이터셋을 찾는 일 자체가 분석 프로젝트를 시작할 때 가장 어려운 부분입니다. 이를 해결하기 위해 우리는 Block에서 많이 사용되는 테이블을 모두 찾아 약 1만 개로 수를 줄였고, Slack 이력, GitHub lineage, 문서, 샘플 쿼리를 바탕으로 테이블에 시맨틱 설명을 추가했습니다.
1table_name: CASH_APP.ANALYTICS.DIM_CUSTOMERS
2table_type: Analytics
3table_description: >
4 300-500 words describing what this table contains, its data lineage, common business questions answered, common query patterns
5primary_key: CUSTOMER_ID
6column_schema:
7 - CUSTOMER_ID:
8 - data_type: INT
9 - description: The unique identifier of a cash app customer. This is the primary key of the dataset.
10 - SIGNUP_AT:
11 - data_type: TIMESTAMP
12 - description: The timestamp of when the customer signed up for cash app. This is used for cohort analysis and anchoring on when the user first onboarded to Cash App. Often used as the first top of funnel event.
Queries Query Expert라는 이름은 데이터를 어떻게 쿼리해야 하는지 아는 전문가를 찾는다는 데서 비롯되었습니다. 이를 위해 우리는 모든 Data Scientists의 최근 쿼리 이력에서 무작위 샘플을 가져와 각 개인을 중심으로 지식 코퍼스를 구축합니다. 누군가 데이터 질문을 하면, MCP는 모든 분석가 패턴을 검색한 뒤, 가장 관련성 높은 분석가의 쿼리 이력으로 범위를 좁혀 따라야 할 쿼리 전문가를 찾습니다.
매달 Block에서는 4억 건이 넘는 쿼리가 실행됩니다. 쿼리 이력을 채굴하는 일은, 가드레일이 적용된 샘플이라 하더라도, 신호보다 잡음이 더 많을 수 있습니다. 이것이 우리가 Labeled Queries를 만든 이유입니다. 데이터 과학자는 자신의 쿼리에 주석을 추가하는 것만으로 이 쿼리를 벡터 데이터베이스에 로드할 수 있습니다. 이런 쿼리는 고품질 시맨틱 임베딩을 생성하고, 특정 비즈니스 지식을 어떻게 쿼리해야 하는지에 대한 ground truth로서 정확성 검토를 거칩니다. 이 쿼리들은 별도의 sidecar 벡터 데이터베이스에서 처리되며, 무작위 쿼리 이력 샘플로 폴백하기 전에 먼저 검색됩니다. 가장 유용한 점은, 이 쿼리들이 LLM이 생성한 모든 쿼리를 검증해 표준 SQL 로직이 지켜지도록 하고, text-to-SQL 생성의 재현성을 열어준다는 것입니다.
1select date_trunc('month', signup_at::DATE) AS signup_month
2 ,case when signup_source = 'APP' then 'Mobile' else 'Web' end as signup_source
3 , count(distinct customer_id) AS unique_signups
4from cash_app.analytics.dim_customers
5where signup_at::DATE BETWEEN '2025-01-01' and '2025-12-31'
6and is_test_account = FALSE
7and is_risk_flagged = FALSE
8group by 1,2
9/* query_expert: The unique number of cash app signups by month and source. Common segmentation of web vs. mobile by signup_source used by marketing. Always remove test accounts and accounts flagged by risk when counting unique signups. */
10;
컨텍스트를 최신 상태로 유지하기
비즈니스가 변하면 데이터도 변합니다. 테이블의 의미와 그것이 해결하는 문제는 빠르게 구식이 될 수 있습니다. 우리는 새로운 컬럼이 테이블에 추가되거나, 새로운 테이블이 생성되거나, 더 이상 사용되지 않는 테이블이 생기는 등 결정적 변화에 따라 벡터 데이터베이스를 업데이트하는 일별 ETL을 운영합니다. 또한 관련성이 높은 쿼리를 labeled로 태깅하고 Slack 채널을 스크래핑해 지식 저장소를 갱신하는 에이전트 기반 자동화도 운영합니다. 이러한 자동화에 투자함으로써 최신 지식을 사용할 수 있게 보장합니다.
일부 내부 사용자는 역할에 따라 Block Data MCP만 사용하거나 Query Expert MCP만 사용합니다. 하지만 많은 사용자가 둘 다 사용합니다. 두 MCP 서버는 동일한 AI 에이전트 세션에서 함께 활성화될 수 있습니다. 에이전트 지침은 거버넌스 메트릭으로 매핑될 수 있는 질문에 대해서는 먼저 Block Data MCP를 확인하고, 보다 넓은 탐색이 필요한 경우 Query Expert MCP로 폴백하도록 안내합니다. 즉, 사용자는 같은 세션 안에서 신뢰 가능한 revenue 메트릭 요청(Block Data MCP 경유)으로 대화를 시작한 뒤, 그 기반 데이터에 대한 ad-hoc 조사(Query Expert MCP 경유)로 이어갈 수 있습니다.
두 도구는 동일한 Snowflake 권한 레이어(RBAC)를 공유하므로, 사용자는 어떤 경로를 택하든 자신에게 접근 권한이 있는 데이터만 볼 수 있습니다. 그리고 두 도구는 서로에게 피드백을 제공합니다. Query Expert를 통해 검증된 쿼리는 Metrics Store의 새로운 메트릭 정의에 정보를 제공할 수 있고, Block Data MCP 사용 중 드러난 공백은 새로운 거버넌스 메트릭의 우선순위 설정으로 이어집니다.
앞에서 설명한 아키텍처는, Block가 데이터를 조직하고, 거버넌스를 적용하고, 소유권을 정의하는 방식을 근본적으로 재구성하지 않았다면 작동할 수 없었습니다. 이 섹션은 바로 그 작업에 대한 이야기입니다. MCP 서버를 구축하는 것만큼 화려하지는 않지만, MCP 서버가 실제로 유용한 결과를 내는 이유입니다.
이 프로젝트 이전에는 Block의 데이터 팀이 종종 사일로 안에서 일했습니다. 개별 팀은 자체 ETL 파이프라인을 유지하고, 자체 대시보드를 만들고, 자체 메트릭을 정의했습니다. 같은 비즈니스 개념도 어느 팀에 묻느냐에 따라 여러 정의를 가질 수 있었습니다. 이는 대기업에서 흔한 패턴이며, 데이터의 소비자가 사람뿐일 때는 관리 가능합니다. 숙련된 분석가는 자료에 숫자를 넣기 전에 "어느 revenue 수치인지"를 먼저 묻는 법을 알고 있습니다.
하지만 이렇게 분절된 환경 앞에 AI 에이전트를 두면 문제는 더욱 커집니다. 에이전트는 어떤 정의가 정본인지 모릅니다. 어떤 대시보드가 오래되었는지도 모릅니다. 이름이 비슷한 두 테이블이 서로 다른 목적을 가진다는 사실도 모릅니다. 그 아래에 일관된 데이터 전략이 없다면, 아무리 잘 설계된 MCP 서버라도 일관되지 않은 답을 내놓게 됩니다.
우리는 곧, 거버넌스 프레임워크 없이 누구나 Metrics Store에 메트릭을 추가하게 하면 결국 출발점으로 되돌아간다는 사실을 깨달았습니다. 중복 메트릭, 충돌하는 정의, 그리고 데이터 일관성 부재 말입니다.
이를 해결하기 위해, 우리는 데이터 메시 프레임워크의 개념을 차용해 Block의 모든 데이터를 최상위 Data Domain 핵심 집합으로 조직했습니다. Customer Support, Financial, Internal, Product, Operations, Risk, Marketing, Sales입니다.
이 도메인 구조는 네 가지 핵심 원칙을 따릅니다.
핵심 설계 결정 하나는, 도메인이 Block의 조직 구조가 아니라 데이터의 기능을 설명한다는 점이었습니다. 회사가 조직개편을 해도 도메인은 안정적으로 유지됩니다. "Financial" 도메인은 어느 VP 산하에 있든 항상 재무 데이터입니다. 이는 Block의 구체적 필요에 맞게 약간 조정한 DAMA 프레임워크에서 영감을 받았습니다.
도메인을 정립한 뒤에는, 메트릭 정확성을 보장할 만큼 엄격하면서도 팀이 실제로 채택할 수 있을 만큼 유연하고 가벼운 거버넌스 프레임워크가 필요했습니다. 너무 무거우면 팀은 시스템을 우회할 것입니다. 너무 가벼우면 전체 아키텍처가 의존하는 신뢰 보장을 잃게 됩니다.
우리가 구축한 거버넌스 프레임워크는 몇 가지 핵심 메커니즘을 중심으로 합니다.
메트릭 소유권. Block Metrics Store의 모든 메트릭에는 지정된 비즈니스 소유자(메트릭의 의미와 정확성을 책임지는 팀)와 기술 소유자(구현과 코드 로직을 책임지는 팀)가 있습니다. 이 이중 소유권은 메트릭이 비즈니스와 엔지니어링 관점 모두에서 검토되도록 보장합니다.
CODEOWNERS. Metrics Store는 중앙 GitHub 저장소이며, 메트릭 정의는 표준 코드 리뷰를 통해 관리됩니다. 메트릭 정의 변경은 GitHub CODEOWNERS를 통해 소유 팀의 승인이 필요합니다. 이는 메트릭 변경이 프로덕션 코드와 동일한 수준의 엄격한 검토를 거치도록 만듭니다.
거버넌스 티어. 아키텍처 섹션에서 설명했듯, 모든 메트릭은 거버넌스 수준(Preliminary, Verified, Certified)을 지니며, 이를 통해 신뢰성을 투명하게 드러냅니다. 팀은 메트릭을 preliminary 수준에서 빠르게 온보딩하고 검증이 완료되면 상위 단계로 승격할 수 있습니다. 이는 신뢰 신호를 손상시키지 않으면서 시스템의 접근성을 유지합니다.
오디언스 티어. 메트릭은 의도된 오디언스에 따라 태그됩니다. Tier 1(외부, 투자자 및 규제기관과 공유), Tier 2(전사 보고), Tier 3(조직 전반), Tier 4(탐색적 또는 팀별)입니다. 이는 소비자가 특정 메트릭과 관련된 중요도를 이해하는 데 도움을 주고, 가장 엄격한 검토가 필요한 메트릭에 가장 강력한 검증이 이루어지도록 합니다.
그 결과, 거버넌스는 별도의 프로세스로 위에 덧씌워진 것이 아니라 데이터 자체에 내장된 시스템이 되었습니다. 사용자가 Block Data MCP를 통해 메트릭을 조회하면, 거버넌스 메타데이터가 결과와 함께 이동합니다. 누가 소유하는지, 어떻게 검증되었는지, 어떤 오디언스를 위해 설계되었는지를 볼 수 있습니다. 신뢰는 가정되는 것이 아니라 입증됩니다.
아키텍처와 데이터 전략을 마련한 뒤, 우리는 이 시스템이 실제로 고위험의 현실 환경에서 작동한다는 것을 증명해야 했습니다. 그래서 finance를 선택했습니다.
Finance Copilot는 우리의 첫 번째 전면 파일럿이었습니다. 목표는 Block의 분절된 재무 데이터 생태계를 통합된 AI 기반 인터페이스로 바꾸어, 재무 리더십이 자연어 질문을 하고 이사회 자료, 실적 발표 준비, 임원 보고에 사용할 수 있을 만큼 신뢰할 수 있는 답을 얻도록 하는 것이었습니다. 목표는 Finance Copilot 메트릭과 source of truth 사이의 분산이 0이 되는 것이었습니다.
우리는 Block의 finance 및 strategy 리더십이 실제로 반복적으로 묻는 40개의 비즈니스 질문을 수집하는 것부터 시작했습니다. 여기에는 단순한 메트릭 조회부터 차원별 분해, 기간 비교, 브랜드 간 분석이 필요한 질문까지 포함되었습니다. 우리는 이를 복잡도별로 분류하고, 개발 목표이자 평가 프레임워크로 사용했습니다.
각 질문에 대해 우리는 구조화된 프로세스를 따랐습니다.
파일럿이 끝날 무렵, 우리는 재무 도메인을 위해 Block Metrics Store에 우선순위 메트릭 59개를 추가했고, Block Data MCP를 통해 메트릭을 사용할 수 있는 질문에 대해서는 정확도 100%를 달성했습니다. Finance Copilot는 내부 AI 플랫폼 내 전용 공간과 함께 출시되었고, 이를 통해 finance 리더십은 구조화된 재무 메트릭(Block Data MCP 경유)과 비정형 IR 문서(Glean MCP 위에 구축한 별도 document intelligence 컴포넌트 경유)에 모두 거버넌스된 방식으로 접근할 수 있게 되었습니다.
2025년 9월부터 2026년 3월까지, Query Expert 사용 직원 수는 월 700명에서 2.1K명으로 증가했으며, 이는 회사의 33% 이상에 해당합니다. Query Expert는 데이터 컨텍스트, 테이블 정보, 최적의 쿼리 관행을 규모 있게 제공함으로써 제도적 데이터 지식을 모든 직원에게 확산합니다. 가치는 새로운 SQL 생성에서 나오기도 하지만, 데이터 발견의 병목을 풀고, 데이터의 미묘한 차이를 이해하고, 상담할 데이터 도메인 전문가를 찾게 해주는 데에서도 나옵니다.
팀들은 데이터 질문을 하는 만큼이나 데이터 자체에 대해 질문하기 위해 Query Expert를 사용하고 있습니다. 이는 기술 사용자와 비기술 사용자가 데이터를 더 효과적으로 발견하고, 검증하고, 활용하도록 돕습니다.
"commerce 데이터를 더 배우려면 누구와 협업할 수 있나요?"
"cash app으로 들어가는 Square tip payout 금액을 찾기에는 어떤 테이블이 가장 좋은가요?"
"이 쿼리를 모범 사례에 따라 검증해 줄 수 있나요? Select …"
대다수 사용자는 자연어 SQL 생성을 위해 Query Expert를 사용하고 있습니다. 이를 통해 중급에서 전문가 수준의 SQL 작성자는 질문에서 인사이트까지 가는 속도를 크게 높일 수 있었습니다.
2025년 3분기에 출시된 이후, 두 도구의 도입은 Block 전반에서 빠르게 증가했습니다.
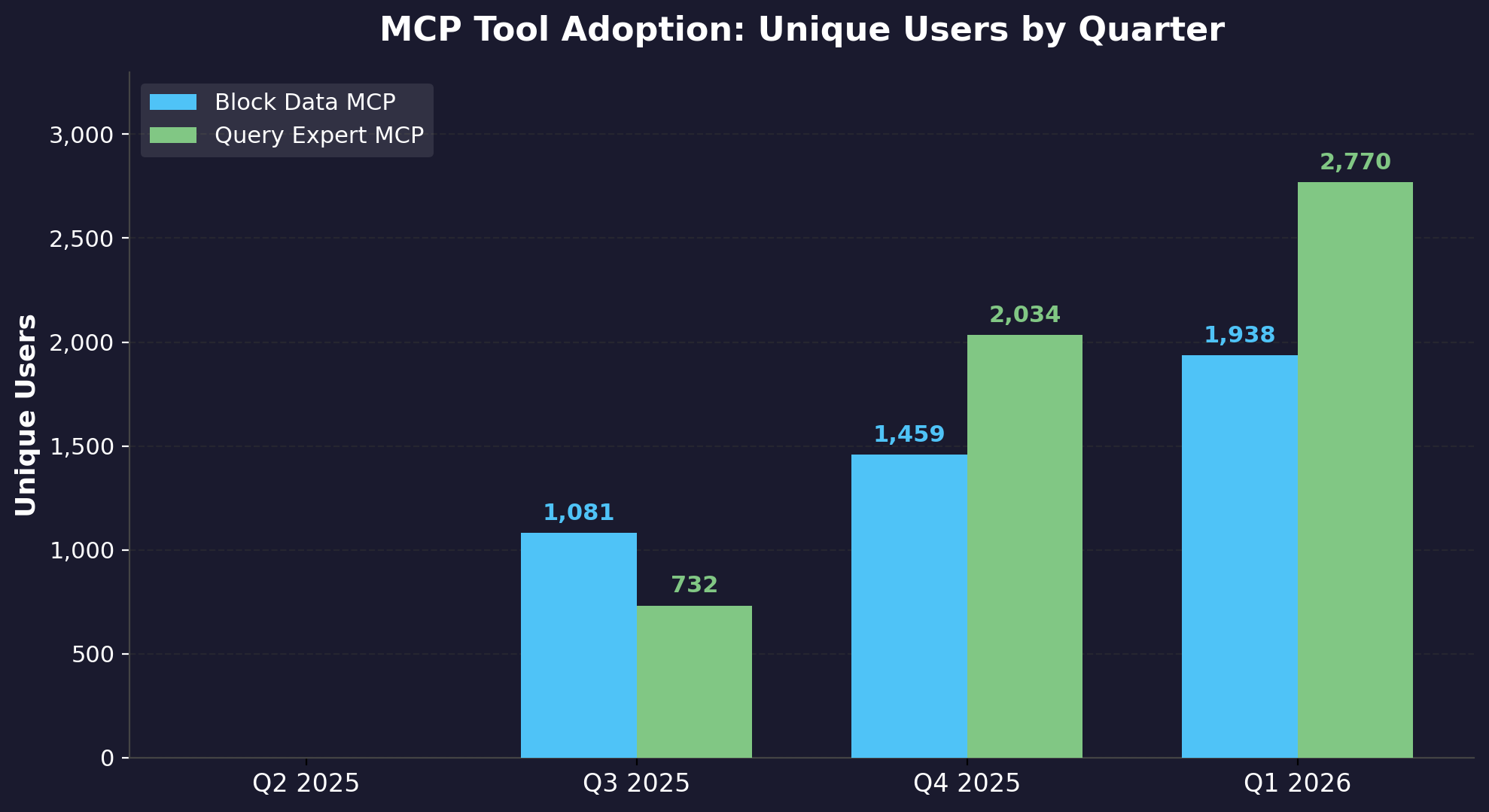
2025년 2분기 사용자 0명에서 2026년 1분기에는 각 도구별 분기별 고유 사용자 수가 1,800명을 넘기까지, 플랫폼은 빠른 자연 확산을 경험했습니다. Block Data MCP는 고유 사용자 1,812명, Query Expert MCP는 1,899명에 도달했으며, 두 도구를 합치면 비즈니스 및 기술 사용자 전반에 걸친 광범위한 도입을 보여줍니다.
2026년 1분기 기준, Block 전반의 데이터 스튜어드는 모든 주요 브랜드와 데이터 도메인에 걸쳐 Block Metrics Store에 1,100개 이상의 거버넌스 메트릭을 기여했습니다.
효율성 향상을 정량화하기 위해, 우리는 MCP 도구를 사용할 때와 사용하지 않을 때 분석가가 질문에 답하는 데 얼마나 오래 걸리는지 비교하는 블라인드 실험을 수행했습니다. 그 결과 분석가 시간 87% 감소가 나타났습니다. Finance Copilot 파일럿에서, 전통적인 분석가 워크플로로 40개의 핵심 비즈니스 질문에 답하는 데는 7.6시간이 걸렸습니다. Block Data MCP를 사용했을 때는, 같은 40개 질문에 1시간이 채 되지 않아 정확도 100%로 답할 수 있었습니다.
또 하나의 영향 사례는 거버넌스된 데이터 기반이 에이전트 기반 자동화를 어떻게 가능하게 했는가입니다. 결정적 SQL과 코드 저장소의 강력한 CI/CD 덕분에, 우리는 사용자 피드백을 프로덕션 준비가 된 코드로 전환하는 종단간 AI 자동화 루프를 구축할 수 있었습니다. 사용자는 Block Data MCP와 Query Expert MCP를 통해 직접 피드백을 제출합니다. 자동화된 워크플로는 이 피드백을 구조화된 Linear 티켓으로 변환하고, 컨텍스트 수집과 리서치를 수행하며, 구현 계획을 생성하고, 코드를 작성하고, pull request를 만듭니다. 엔지니어는 그저 검토하고 머지하면 됩니다.
이 시스템을 사용해, 우리는 단 세 시간의 인간 노력만으로 40개의 티켓 백로그를 처리했으며, 이는 시간 기준으로 85% 절감에 해당합니다. 이전에는 티켓 하나를 처리하는 데 엔지니어 평균 2시간이 걸렸지만, 에이전트 기반 자동화 루프에서는 AI Agent가 30분 동안 작업하는 동안 인간의 노력은 대략 5분 정도만 필요했습니다.
여기서 핵심 가능 요소는 AI 에이전트 자체가 아니었습니다. 그 아래에 있는 거버넌스된 데이터 기반이었습니다. 메트릭 정의가 엄격한 스키마를 따르고, CI/CD 테스트가 정확성을 검증하며, CODEOWNERS가 리뷰를 강제하기 때문에, AI 에이전트는 분명한 가드레일 안에서 작업할 수 있었습니다. 자동화는 좋은 데이터 거버넌스의 부산물이지, 그것을 대체하는 것이 아닙니다.
이 글에서 설명한 아키텍처는 분석 문제를 해결하기 위해 구축되었습니다. 하지만 기반이 마련되자, 그것은 다른 사용 사례가 그 위에 구축될 수 있는 플랫폼이 되었습니다. 데이터 메시는 일관된 도메인 소유권과 거버넌스를 제공합니다. Block Metrics Store는 결정적이고 신뢰할 수 있는 데이터 조회를 제공합니다. 그리고 MCP 인터페이스는 AI 에이전트가 이 모든 것과 상호작용하는 표준 방식을 제공합니다. 이 세 가지는 함께, 질문에서 신뢰할 수 있는 답변으로 나아가야 하는 모든 워크플로를 위한 재사용 가능한 토대를 형성합니다. 추가적인 자동화 사용 사례로는 생성형 UI 대시보드 구성, 데이터 도메인별로 조직된 자동화 ETL, 에이전트 기반 온콜 트리아지가 있습니다.
초기 데이터 도메인 파일럿은 대상 오디언스에 대해 이 모델이 작동한다는 것을 입증했습니다. 다음 과제는 핵심 개발 팀이 모든 새 도메인을 일일이 붙잡아주지 않고도 이를 반복 가능하게 만드는 것이었습니다. 이를 위해 우리는 배운 모든 것을 Data Domain AI Playbook으로 체계화했습니다. 이는 어떤 데이터 도메인 팀이든 따라 시스템에 데이터를 온보딩할 수 있는 8단계 가이드입니다.
우리 스택의 세부사항보다 그것을 형성한 원칙이 더 중요합니다. 몇 가지 핵심 교훈은 다음과 같습니다.
AI 기반 분석을 구축할 때 가장 어려운 부분은 그 아래의 데이터입니다. 기반을 올바르게 갖추면 에이전트 기반 AI 구현은 훨씬 쉬워집니다.
원래 타이거 팀에서 적극적인 역할을 해준 Joanna Qiu, Query Expert 작업을 담당한 Justin Battles, BI 도구 통합 작업을 담당한 Matthew White, 데이터 도메인 steering committee 작업을 담당한 Kelsey Perkins와 Ragz Rojkhird, MCP 평가 프레임워크 작업을 담당한 Daniel Gole과 Will Dumesnil, 내부 MCP 인프라의 핵심 작업을 수행한 Anusha Gururaj Jamkhandi와 Kalvin Chau, Block 내 데이터 도메인에 대한 팀 교육과 인지도 제고를 도운 Priya Anantharaman, 그리고 Query Expert 핵심 DS 워킹 그룹에서 작업한 Jixin Wang, Conny Chen, Fan Zhang에게 감사드립니다. 또한 이 프로젝트를 위해 리소싱을 지원해 준 매니저들, 특히 Jackie Brosamer, Peter Weir, Paul Luong, Michael Wexler에게 깊이 감사드립니다.