Netflix에서 이질적 처리 효과(HTE)를 탐지하고 측정하며 활용하는 방법을, 제품 실험과 혁신의 전 과정에 걸친 다섯 가지 사례로 소개합니다.

12분 읽기
2025년 11월 13일
Netflix의 HTE 및 실험에 관한 작업을CODE@MIT 2025! 에서 더 알아보세요.
Netflix에서는 우리가 하는 행동의 인과적 영향을 이해하는 데 큰 투자를 하고 있습니다. 이 영향은 종종 _이질적_입니다. 예를 들어 소프트웨어 업데이트는 레거시 펌웨어와 신규 펌웨어에 서로 다르게 영향을 미칠 수 있고, 홈 화면 리디자인은 한 국가에서는 가입을 더 많이 유도하지만 다른 국가에서는 그렇지 않을 수 있으며, 어떤 회원은 푸시 알림을 선호하는 반면 다른 회원은 이메일을 선호할 수 있습니다. 이러한 이질성을 포착하는 것은 회귀(regression)를 잡아내는 것부터 개인화된 느낌의 회원 경험을 제공하는 것까지, 여러 이유로 가치가 큽니다.
시간이 지나면서 우리는 이질적 처리 효과(HTE)를 탐지하고 측정하며 이에 따라 행동하는 능력을 다듬어 왔습니다. 이 글에서는 HTE가 Netflix에서 제품 실험과 혁신의 모든 단계에 어떻게 영향을 미치는지에 대한 다섯 가지 사례 연구를 공유합니다.
이번 주 MIT 디지털 실험 컨퍼런스(CODE@MIT)에서 이 중 두 가지 사례 연구를 발표하게 되어 특히 기쁩니다.
Netflix 앱은 수백만 대의 TV, 휴대폰, 태블릿 및 기타 기기에서 실행됩니다. 새로운 기능이나 버그 수정으로 이를 업데이트할 때, 우리는 모든 업데이트가 기대대로 작동하는지 확인하고 싶습니다. 우리는 A/B 테스트를 사용해 어떤 기기들이 업데이트에 좋지 않게 반응하는지 발견하는 데 도움을 받습니다. 하지만 회원들에게 A/B 테스트로 업데이트를 공유할 시점이면, 우리는 이미 광범위하게 테스트를 완료했고 잘 작동한다고 확신하고 있습니다. 그럼에도 문제가 발생할 때는 보통 소수의 기기 유형에만 영향을 미칩니다. 그렇다면 우리는 이 건초더미 속 바늘을 어떻게 찾을까요?
한 가지 접근은 Bonferroni correction 같은 보정을 적용해, 기기 유형별 크래시 수에서 처리군과 대조군 간 유의한 차이가 있는지 빈도주의 가설검정을 사용하는 것입니다. 이는 귀무가 참일 때 하나 이상의 유의한 테스트가 발생할 전체 확률이 명목 유의수준(보통 20번 중 1번)을 넘지 않도록 보장합니다.
우리의 맥락에서는 — 잦은 업데이트와 수천 개의 기기 유형이 존재하는 상황에서 — 이 보장은 그다지 유용하지 않습니다. 대부분의 앱 업데이트는 어떤 기기에서도 문제를 일으키지 않으며, 20번 중 1번 꼴로 거짓 경보가 발생한다면 신뢰가 빠르게 무너질 것입니다. 우리는 20번째 업데이트마다 거짓 경보를 보장하기보다, 경보가 발생했을 때 그것이 거짓일 확률이 낮도록 보장하는 편을 선호합니다. 이는 거짓 발견률(false discovery rate)(Benjamini & Hochberg 1995)에 대한 보장이며, 또한 귀무가설에 대한 베이지안 사후확률로도 이해할 수 있습니다(Efron et al. 2001, Efron 2005).
이 아이디어를 설명하기 위해, 서로 다른 두 A/B 테스트에서 z-점수 분포를 시뮬레이션했습니다. 첫 번째 A/B 테스트에는 1,000개의 고유한 기기 유형이 포함되어 있고(왼쪽), 두 번째 A/B 테스트에는 100,000개의 기기 유형이 포함되어 있습니다(오른쪽). 대부분의 기기 유형은 업데이트를 문제없이 실행하므로 z-점수는 표준 정규분포를 따릅니다. 소수의 기기는 나쁘게 반응할 수 있고, 그 결과 대체 분포를 따르는 큰 z-점수를 갖습니다. 두 A/B 테스트 모두에서, z-점수가 4 정도인 기기 유형 5개를 관측했으며 아래 두 패널에서 빨간색으로 표시되어 있습니다. 이 5개의 기기 유형은 귀무가설의 표준 정규분포에서 나온 것일까요, 아니면 대체분포에서 나온 것일까요?
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
두 A/B 테스트 모두에서 z-점수 4는 통계적으로 유의합니다. 그럼에도 테스트 통계량의 분포를 시각화하면, 총 기기 유형이 1,000개일 때 z = 4인 다섯 기기는 이상치(outlier)라는 직관을 많은 분들이 갖게 됩니다. 하지만 100,000개 기기 유형을 테스트할 때는, 빨간색의 다섯 기기 유형이 여전히 귀무분포의 일부일 가능성이 훨씬 커 보입니다. 샘플이 100,000개이면 z = 4인 다섯 개는 귀무의 종(bell) 곡선 안에 들어옵니다.
테스트 통계량의 경험적 분포를 시각화하는 것만으로도, 우리 소프트웨어 개발자들이 문제가 될 수 있는 이상치를 알아차리기에 충분한 경우가 많습니다. 즉, 종 곡선 밖으로 떨어지는 z-점수는 조사해 볼 만합니다. 베이즈 정리를 사용하면, 이 직관은 z = 4라는 관측이 주어졌을 때 귀무가설의 사후확률로도 정식화할 수 있으며, 이는 Efron et al. 2001에서 local 거짓 발견률이라고 부르는 것입니다. 우리 A/B 테스트 플랫폼은 이 확률을 추정해 기기 유형별로 개발자에게 보고하며, 진짜 문제에 대한 경보를 제공하는 동시에 진양성(true positive)이 드문 환경에서 거짓 양성(false positive)을 조사하느라 시간을 낭비하지 않도록 돕습니다.
Netflix의 데이터 사이언티스트들은 앱 업데이트의 안정성 확보부터 전체적인 회원 경험 개선까지, 매우 다양한 문제를 다룹니다. 우리 Member Data Science 팀의 주요 관심사 중 하나는 회원의 장기 만족도를 어떻게 측정하느냐입니다. 장기 만족도의 최상위 지표(top-line metric)는 구독 유지(subscriber retention)이지만, 우리는 이 북극성(North Star)을 향한 진전을 계속 신뢰할 수 있도록 하면서도, 제품 출시 의사결정을 위해 더 민감한 지표에 필연적으로 의존합니다.
이런 프록시(proxy)를 만들 때, 우리는 관찰 데이터 인과 추론(OCI)을 크게 의존해 지표 간 관계를 추론합니다(예: 시청과 유지 간 인과 관계 확립). 이러한 인과 관계는 하위 집단마다 다를 가능성이 큽니다. 예를 들어 시청은 모든 회원에게 중요하지만, 신규 회원이 스트리밍해서 즐길 타이틀을 찾도록 돕는 것은 특히 중요합니다. 이러한 HTE를 분해함으로써, 우리는 고객 기반의 미묘한 차이를 포착하는 프록시 지표를 구축할 수 있고, 그 결과 장기 영향에 대한 예측 정확도를 높일 수 있으며, 회원 기반의 다양한 니즈에 반응하는 혁신을 촉진할 수 있습니다.
이러한 인과 질문을 빠르게 탐색할 수 있도록, HTE는 Netflix 내부 OCI 플랫폼의 핵심 요소입니다. 이 플랫폼의 근간은 Augmented Inverse Propensity Weighting(AIPW) 추정량입니다. AIPW는 결과 회귀(outcome regression)와 성향(propensity) 모델을 결합해 이중 강건(doubly robust) 점수를 구성합니다. 구체적으로, 우리는 각 단위(unit)와 처리 수준별로 “의사-결과(pseudo-outcome)”를 구성합니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
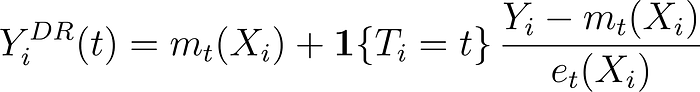
이는 실현된 결과 , 처치 이전 공변량 , 처치 가 주어졌을 때 조건부 결과 모델 과 성향 점수 모델 를 활용합니다.
모든 단위와 처치에 대해 이러한 의사-결과를 구성하므로, 관심 있는 하위 그룹(예: 신규 회원, 혹은 지역별 그룹)에서 의사-결과를 평균내는 것만으로도 조건부 평균 처리 효과(CATE)를 쉽게 계산할 수 있습니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
우리 OCI 플랫폼의 스크린샷
이 의사-결과를 만드는 데 들어가는 노력의 대부분은 결과 및 성향 모델을 만드는 데 있으므로, 이 접근은 1) 하위 그룹 차이에 대한 실행 가능한 인사이트를 확보하는 것과 2) 플랫폼의 연산 및 메모리 사용량을 최적화해 성능을 개선하는 것 사이에서 적절한 균형을 잡는 데 도움이 됩니다.
Carlos Velasco Rivera 그리고 Colin Gray
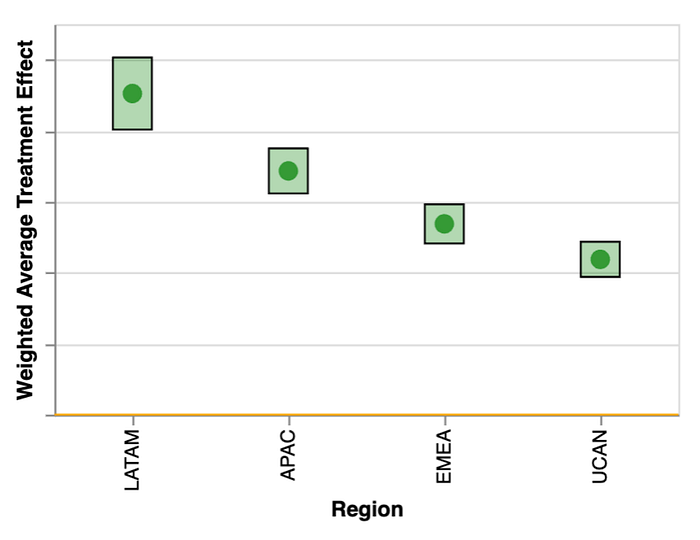
오랜 기간 동안 Netflix는 스트리밍의 대명사였습니다. 오늘날 우리는 게임, 라이브 스포츠, Netflix House 등 새로운 영역으로 확장하고 있습니다. 비즈니스 제공이 늘어날수록 잠재적 트레이드오프도 함께 생깁니다. 예를 들어 추천 알고리즘 변경이 사용자가 게임을 더 많이 하게 만들지만 영화를 덜 보게 만든다면 어떨까요? 또 다른 변경이 영화를 더 많이 보게 하지만 TV 쇼는 덜 보게 만든다면 어떨까요? 우리는 이러한 트레이드오프가 사용자 유형에 따라 의미 있게 달라진다는 것을 배웠고, HTE를 사용해 이런 상황에서 제품 혁신을 위한 의사결정에 도움을 받습니다.
이 트레이드오프의 균형을 맞추기 위해, 이상적으로는 구독 유지 같은 북극성 지표에 직접 의존하고 싶습니다. 하지만 이러한 지표는 종종 변화가 느리고 대부분의 실험에서 목표로 삼기에는 너무 둔감합니다. 대신 우리는 북극성과 상관되어 있으면서도 훨씬 정밀한 프록시 지표에 의존합니다. OCI 같은 도구로 후보 지표를 탐색하고, 과거 메타 분석으로 가장 강한 신호를 좁혀 나간 뒤, 우리는 서로 다른 프록시 지표가 북극성에 미치는 인과적 영향을 추정합니다. 이는 “환율(exchange rate)”을 제공해, 지표 간 특정 트레이드오프가 북극성의 기대 개선으로 이어지는지 여부를 판단할 수 있게 해줍니다.
이 글쓴이의 업데이트를 받으려면 Medium에 무료로 가입하세요.
더 빠른 로그인 위해 내 정보 기억하기
우리는 HTE를 사용해 이 아이디어를 한층 강화합니다. 보통 프록시 지표의 인과적 영향은 하위 그룹에 따라 크게 달라집니다. 예를 들어 어떤 회원은 게임 플레이를 특히 가치 있게 여기고, 다른 회원은 영화를 특히 가치 있게 여기며, 또 다른 회원은 매주 좋아하는 TV 쇼를 챙겨보는 것을 우선시할 수 있습니다. 그룹별 환율을 사용하면, 회원 기반의 이질적 선호를 반영하는 더 나은 의사결정을 할 수 있고, 동시에 이를 하나의 통합 추정치로 혼합(blending)하여 의사결정을 안내할 수 있습니다.
우리 프레임워크는 확장성이 매우 높습니다. 예를 들어 두 개의 하위 그룹과 두 지표 와 가 있다고 가정해 봅시다. OCI와 메타 분석을 포함한 다양한 인과 방법을 사용해, 각 하위 그룹에서 각 지표가 북극성에 미치는 HTE를 추정합니다. 마지막으로, 그 하위 그룹에 대해 처치가 전체적으로 이로운지 판단하는 데 도움이 되는 혼합 지표를 추정합니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
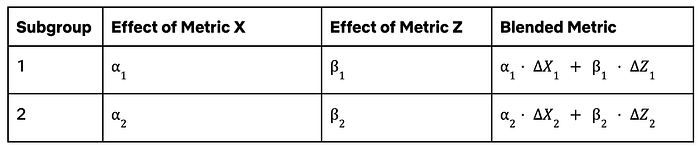
이 표를 가로로 확장하면 더 많은 프록시를, 세로로 확장하면 더 많은 하위 그룹을 쉽게 포함할 수 있습니다. 이러한 차이를 드러내는 것은 회원 기반의 이질성에 민감하고 장기적 성공에 지향점을 둔 더 나은 의사결정을 가능하게 합니다.
Tomoya Sasaki, Simon Ejdemyr, 그리고 Mihir Tendulkar
Tomoya는 11월 14일 금요일 오전 10:40 CODE@MIT에서 이 주제로 발표합니다.
실험이 결정되고 기능이 출시되면, 단기 실험 결과를 연환산된(annualized) 모집단 수준의 비즈니스 영향으로 변환해야 합니다. 이렇게 하는 데에는 두 가지 이점이 있습니다. (1) 달러 기반 비용-편익 분석: 팀이 기대 재무 수익과 구현 및 운영 비용을 저울질할 수 있습니다. (2) 실험 프로그램 전반에 걸친 일관된 누적 효과 추적: 서로 다른 모집단이나 지표를 목표로 하는 프로그램들 간에도 가능합니다. 이는 HTE가 세그먼트 및/또는 시장 간 차이를 드러낼 때 특히 중요하며, 이들은 서로 다른 성장 전략과 궤적을 가질 수 있습니다.
우리는 현재 및 미래 회원 코호트를 포함해 처치의 연환산 영향을 추정하는 자동화 도구를 개발했습니다. 이 프레임워크에서 첫 달 코호트는 12개월 동안 매출에 기여하고, 두 번째 달 코호트는 11개월 동안, …, 열두 번째 달 코호트는 1개월 동안 기여합니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
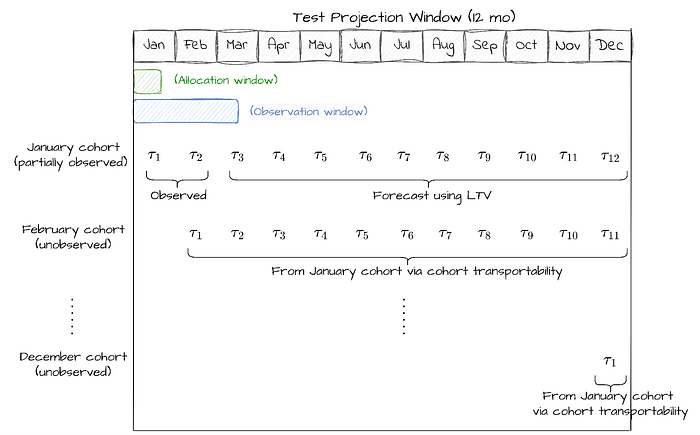
간단한 예로 방법론을 분해해 보겠습니다. 1개월(1월) 동안 사용자에게 A/B 테스트를 할당하고 다음 청구 기간(billing period) 동안 결과를 모니터링한다고 가정합니다. 그러면 우리는 한 개의 월별 코호트와 두 개의 청구 기간에서의 처리 효과를 관측합니다. 연환산 영향을 추정하기 위해, 우리는 1개월차와 2개월차(1과 2)의 관측된 처리 효과, 관측된 트래픽, 그리고 세 가지 미관측 수량에 의존합니다. (1) 첫 코호트의 나머지 10개 청구 기간에 대한 처리 효과, (2) 이후 11개 코호트의 트래픽, (3) 그리고 그 이후 코호트들의 처리 효과입니다.
우리 도구는 다음 접근으로 이 수량들을 추정합니다. 첫째, 관측된 코호트의 미관측 청구 기간에 대한 처리 효과를 얻기 위해, LTV(Lifetime Value) 예측 모델에 기반한 대리(surrogacy)를 통해 미래 잠재 결과를 모델링합니다. 둘째, 이후 각 코호트의 기간별 처리 효과가 첫 코호트의 것과 일치한다는 수송가능성(transportability) 가정을 적용합니다. 마지막으로, 이러한 효과를 합산해 연환산 영향을 구합니다. 우리 도구는 필요에 따라 모집단 성장 또는 감소를 모델링할 수 있어, 성장이나 계절성이 예상되는 시나리오도 수용합니다.
가정의 타당성을 높이고 정확도를 개선하기 위해, 우리는 이 알고리즘을 세그먼트별로 적용하는 것이 도움이 되는 경우가 많습니다. 즉, HTE를 세그먼트별 성장 전망과 함께 사용합니다. 이 접근은 더 세밀한 추정치를 산출할 수 있게 해주며, 서로 다른 모집단을 목표로 하는 실험 프로그램들 간 비교도 용이하게 합니다.
Shusei Eshima 그리고 Sambhav Jain
Shusei는 11월 14일 금요일 오후 2:50 CODE@MIT에서 이 주제로 발표합니다.
마지막으로, 우리는 개인화를 안내하는 데에도 HTE를 활용합니다. 즉, 모든 회원에게 관련성 있고 개인에게 맞는 느낌의 Netflix 경험을 제공하는 것입니다. 이러한 학습은 회원에게 가장 잘 맞는 경험이 무엇인지 알아보기 위해 우리가 수행하는 수많은 실험을 기반으로 합니다.
이런 실험에서는 여러 처리 arm(또는 “cell”)이 비슷하게 좋은 성과를 보이는 경우가 흔합니다. 예를 들어 네 개의 처리 cell이 있는 실험에서, Cell 2와 Cell 4가 대조군 대비 비슷하게 좋은 성과를 보인다고 관측할 수 있습니다. 그렇다면 Cell 4가 Cell 2보다 약간 더 좋아 보인다는 이유만으로 Cell 4를 선택해야 할까요?
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
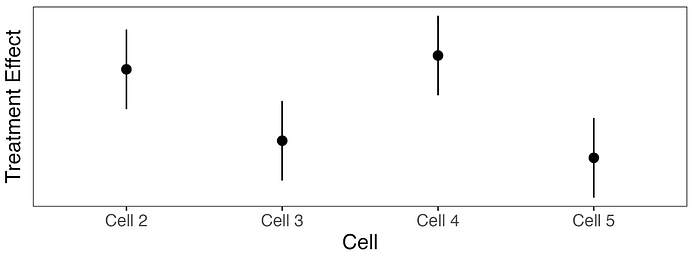
실험 결과를 자세히 살펴보면, Cell 2가 Cell 4보다 더 나은 결과를 만드는 세그먼트가 있을 수 있습니다. 우리는 이를 의미 있는(meaningful) HTE라고 부릅니다. 이는 개인화된 처치 정책이 단순히 글로벌 승자를 출시하는 것보다 더 나은 결과를 만들 수 있음을 뜻하기 때문입니다. 의미 있는 HTE를 식별하려면, 세그먼트를 (1) cell _간(across)_으로도 살펴봐야 하고(특정 세그먼트가 다른 cell에 노출될 경우 주요 지표에서 더 긍정적인 결과를 볼 수 있는지 확인), (2) 글로벌 승자 _내(within)_에서도 살펴봐야 합니다(전체적으로는 긍정적인 cell이라도 특정 세그먼트가 부정적으로 반응하는지 확인).
의미 있는 HTE를 확장 가능하게 찾는 과정에서 우리는 세 가지 핵심 과제에 직면합니다. (1) 세그먼트를 정의하는 일, (2) 개인화된 처치 규칙을 도출하는 일, (3) 이 규칙이 설명 가능하도록 보장하는 일이며, 이는 제품 개발과 혁신에 인사이트를 제공하는 데 중요합니다.
이 과제를 해결하기 위해 우리는 policy tree 문헌(Zhou et al., 2023)을 활용합니다. 또한 우리의 필요에 맞게 두 가지 핵심 혁신을 더했습니다. 첫째, 전통적인 이진 트리 대신 범주형 변수에 대해 m-ary 트리 탐색 알고리즘을 개발했습니다. 이 접근은 더 미묘한 회원 세그먼트를 포착할 수 있게 합니다. 둘째, 우리 실험에서 수백만 회원의 데이터를 분석할 수 있는 확장 가능한 정책 학습 알고리즘을 구현했습니다.
우리 방법은 두 단계로 이뤄집니다. 첫째, OCI 플랫폼과 마찬가지로 이중 강건 점수를 계산해 각 회원의 반사실(counterfactual) 결과를 추정합니다. 둘째, 이 점수를 동시에 최적화하고 우리의 성과 지표를 최대화하는 세그먼트를 식별하는 의사결정 트리를 구성합니다. 의사결정 트리의 구조는 결과로 도출되는 세그먼트와 개인화 규칙을 해석 가능하게 만들어, 이해관계자에게 인사이트를 전달할 수 있게 해줍니다.
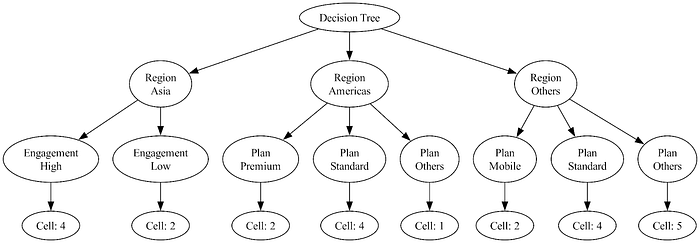
다음 두 그림은 우리의 접근을 보여줍니다. 먼저 “region”과 “plan” 변수가 세 개의 자식 노드로 분기하는 m-ary 트리의 예시를 보여줍니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
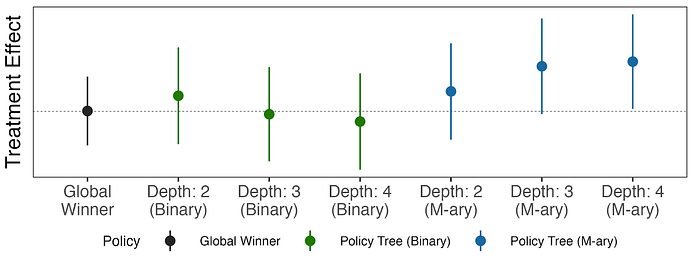
둘째, 개인화의 비즈니스 임팩트를 보여줍니다. 학습 데이터셋에서 정책을 학습시키고 테스트 데이터셋에서 평가함으로써, 다양한 깊이에서 이진 트리와 m-ary 트리를 비교합니다. 가장 왼쪽 추정치는 글로벌 승자에 해당하며, 모든 회원에게 단일 최선 cell을 할당합니다. m-ary 트리를 사용하면 글로벌 승자 대비 통계적으로 유의한 개선을 얻는 반면, 이진 트리는 그렇지 않습니다.
전체 크기로 이미지를 보려면 Enter를 누르거나 클릭하세요
이런 종류의 증거는 개인화의 비즈니스 임팩트를 명확히 보여주며, 어떤 처치를 개인화할 가치가 있는지, 그리고 언제 글로벌 승자를 롤아웃하는 것으로 충분한지에 대해 더 나은 의사결정을 내릴 수 있도록 돕습니다.
종합하면, 이 사례 연구들은 HTE를 제품 혁신의 전체 라이프사이클에 걸쳐 어떻게 사용하는지 보여줍니다. 출시 전 회귀를 잡아내는 것부터, 출시 의사결정, 그리고 궁극적으로 개인화를 구동하는 것까지입니다. 이러한 요소들은 실용적인 방식으로 서로 연결되는 모듈형 툴킷을 이루며, 예를 들어 다음과 같습니다.
이러한 모듈성은 우리의 highly aligned and loosely coupled 문화에 기반합니다. 서로 다른 버티컬이 로컬 문제를 해결하기 위한 구성요소를 만들지만, 우리는 이러한 요소를 결합해 대규모 의사결정 및 개인화를 위한 일관된 시스템으로 만들기 위해 노력합니다.
CODE@MIT에 참석하며 더 알아보고 싶으신가요? 부스에 들러 Netflix 데이터 사이언티스트들을 만나고, 최근 연구 출판물을 살펴보고, 채용 기회도 확인해 보세요.
Scott Seyfarth, Adrien Alexandre, Carlos Velasco Rivera, Colin Gray, Tomoya Sasaki, Shusei Eshima, Sambhav Jain, Simon Ejdemyr, Mihir Tendulkar, Matthew Wardrop, Winston Chou